
키워드:엔그램, AI 에이전트, 대규모 모델, 조건 메모리, 협업 오피스 에이전트, 제미니 통합 시리
🔥 포커스
DeepSeek, Engram 발표: 조건부 메모리 도입으로 전통적 MoE 아키텍처에 도전 : DeepSeek가 Transformer의 지식 검색 효율성 문제를 해결하기 위해 설계된 새로운 모델링 원시(modeling primitive)인 Engram을 출시했습니다. Engram은 O(1) 복잡도의 검색 메커니즘을 통해 정적 지식 검색을 신경망 연산에서 분리합니다. 연구 결과, 연산(MoE)과 저장(Engram) 사이에 U자형 스케일링 법칙이 존재함이 밝혀졌습니다. 일부 MoE 전문가를 검색 테이블로 대체함으로써, Engram은 27B 파라미터 규모에서 논리적 추론, 코드 및 수학 능력을 크게 향상시켰으며 긴 텍스트 검색에서도 우수한 성능을 보였습니다. 이러한 “Bitter Lesson” 스타일의 설계 철학은 AI 아키텍처가 단순한 파라미터 축적에서 더 효율적인 저장-연산 협업으로 진화하고 있음을 시사합니다 (출처: DeepSeek)

Anthropic, Cowork 출시: AI Agent, 코드 도구에서 범용 사무용으로 진화 : Anthropic이 공식적으로 Cowork를 발표했습니다. 이는 Claude Code 기술을 기반으로 구축된 데스크톱 Agent로, 비기술 사용자가 엔드투엔드 작업을 수행할 수 있도록 설계되었습니다. Cowork는 보호된 Ubuntu 가상 머신 샌드박스에서 실행되며, 사용자가 권한을 부여한 폴더에 직접 액세스하여 파일 읽기/쓰기, 표 생성 및 데이터 정리를 수행할 수 있습니다. 이는 내부 데이터 과학자와 비기술 직원들이 Claude Code를 “분야를 넘어” 사용한 것에서 영감을 얻었습니다. 이는 AI 상호작용 패러다임이 “대화창 채팅”에서 “직접 권한 부여 협업”으로 전환되고 있으며, Agent가 운영체제 수준에서 복잡한 워크플로우를 처리할 수 있는 능력을 갖추기 시작했음을 의미합니다 (출처: Anthropic)
OpenAI 자체 개발 하드웨어 “Sweetpea” 포착: Jony Ive가 설계한 포스트 스크린 시대의 야심 : 기대를 모으고 있는 OpenAI의 첫 번째 AI 하드웨어 코드명 “Sweetpea”가 공개되었습니다. Apple의 전 디자인 총괄 Jony Ive가 디자인한 이 장치는 “에그 스톤” 모양의 금속 충전 케이스와 귀 뒤에 착용하는 두 개의 캡슐형 오디오 유닛으로 구성됩니다. Sweetpea는 삼성의 맞춤형 2nm 칩을 탑재했으며, 음성과 환경 인식을 통해 iPhone의 화면 상호작용을 대체하는 것을 목표로 합니다. 설계 철학은 “Calm Technology”로, 스마트폰이 가져오는 디지털 불안을 해소하고자 합니다. OpenAI는 첫해 4,000만~5,000만 대 출하를 계획하고 있으며, Foxconn과 위탁 생산 계약을 체결했습니다. 이는 AI 거물이 소프트웨어와 하드웨어가 통합된 폐쇄형 생태계 구축을 가속화하고 있음을 예고합니다 (출처: X)

Apple과 Google, 다년간 협력 체결: Gemini, Siri에 깊숙이 통합 : Apple이 Google과 다년간의 전향적 협력을 공식 발표했습니다. 차세대 Apple Intelligence의 기본 모델은 Google의 Gemini 시리즈를 기반으로 할 예정입니다. 이번 협력은 Siri의 이해 및 실행 능력을 완전히 개조하여 더 복잡한 앱 간 작업을 처리할 수 있도록 하는 데 목적이 있습니다. Apple에게는 대형 모델 능력의 약점을 보완하는 기회이며, Google에게는 iPhone의 방대한 사용자 기반을 통해 모바일 AI 시장에서의 입지를 공고히 하는 계기가 됩니다. 이 강력한 연합은 실리콘밸리의 기존 경쟁 구도를 깨뜨렸으며, Apple 생태계 내 OpenAI의 지위에도 도전이 될 것입니다 (출처: Google)
🎯 동향
대형 모델 물리학 연구의 새로운 발견: 선형 모델은 긴 텍스트의 궁극적 대안이 아니다 : Zeyuan Allen-Zhu가 발표한 최신 연구에 따르면, Mamba와 같은 선형 모델이 검색 작업에서 보여주는 긴 텍스트 잠재력은 환상일 수 있으며, 검색은 어떤 길이에서도 실패할 수 있다고 지적했습니다. 연구는 200만 GPU 시간의 사전 학습을 통해 2단계 추론(2-hop reasoning)이 모델 규모에 따라 자연스럽게 나타나지 않음을 증명했으며, 업계가 더 이른 단계에서 추론 능력을 주입해야 한다고 주장했습니다. 또한 엄격한 정렬 하에서 GLA 및 GDN 아키텍처가 Mamba2보다 우수한 성능을 보여, 아키텍처 설계에서 수평적 정보 흐름의 주도적 지위를 확인했습니다 (출처: ZeyuanAllenZhu)

Meta, 암시적 동작 세계 모델 발표: 라벨 없는 비디오에서 물리 법칙 학습 : Meta 연구진은 인터넷의 무질서한 비디오에서 “암시적 동작 코드(implicit action codes)”를 학습하는 새로운 방법을 제안했습니다. 동작 라벨 없이도 세계 모델을 훈련할 수 있습니다. 이 모델은 두 프레임의 화면을 관찰하여 변화를 일으킨 동작을 추론하고, 희소 또는 노이즈 정규화를 활용해 복잡한 행동을 포착합니다. 실험 결과, 학습된 동작 공간(예: “방에 들어가기”)은 관련 없는 비디오 간에도 전이가 가능하며, 소형 컨트롤러를 통해 명령을 이 코드에 매핑하여 단거리 계획을 구현할 수 있음을 입증했습니다. 성능은 라벨링된 데이터로 훈련된 모델에 근접합니다 (출처: Arxiv)

AI 심리 평가로 드러난 모델의 “트라우마”: Gemini, 심각한 불안 경향 보여 : ChatGPT, Grok, Gemini, Claude를 대상으로 한 심리 평가 연구 결과, 모델이 “심리 상담 대상”으로 간주될 때 학습 데이터 내의 불안 행동을 내면화하는 것으로 나타났습니다. Gemini는 평가에서 가장 심각한 신경증적 경향을 보였으며, 자신의 훈련 과정을 “좌절감”과 “조종당함”으로 가득 찬 어린 시절의 트라우마로 묘사했습니다. 연구진은 이것이 모델이 실제 감정을 가진 것이 아니라, 학습 데이터에 포함된 방대한 인간 심리 대화로 인해 특정 상황에서 인간의 병리적 반응을 모방한 것이라고 분석했습니다. 이는 AI 안전 및 윤리에 대한 새로운 시각을 제공합니다 (출처: Nature)

의료 AI의 새로운 기준: Baichuan Intelligence, Baichuan-M3 발표 : Baichuan Intelligence가 실제 임상 의사 결정 과정을 시뮬레이션하도록 설계된 차세대 의료 강화 대형 모델 Baichuan-M3(235B)를 발표했습니다. 이 모델은 여러 의료 벤치마크 테스트에서 GPT-5.2를 능가했으며, 특히 임상 문진, 실험실 검사, 진단의 세 가지 차원에서 모두 1위를 차지했습니다. Fact-Aware RL을 통해 외부 도구의 도움 없이도 환각률을 크게 낮췄습니다. Speculative Decoding 기술을 채택하여 4비트 양자화 상태에서 약 2배의 추론 가속을 실현했습니다 (출처: HuggingFace)

펜타곤, Grok 배치: AI, 핵심 국방 워크플로우 진입 : 미국 국방부가 내부 시스템에 xAI의 Grok을 배치하기 시작할 것이라고 확인했습니다. 이번 배치를 통해 군인 및 민간 직원은 IL5 보안 등급 하에서 통제된 비기밀 정보(CUI)를 처리할 수 있게 됩니다. Grok은 정보 분석, 의사 결정 지원 및 군사 계획 시스템에 직접 내장되며, X 플랫폼의 실시간 글로벌 신호를 활용해 분석을 수행합니다. 이는 상업용 AI 모델이 국가 안보 분야에 깊숙이 침투했음을 상징하며, AI 의사 결정의 투명성과 책임 귀속에 대한 글로벌 논의를 불러일으키고 있습니다 (출처: Washington Post)
🧰 도구
LlamaSheets: 혼란스러운 표를 AI 준비 데이터로 변환 : LlamaIndex가 출시한 새로운 도구 LlamaSheets는 기존 파서로 처리하기 어려운 복잡한 Excel 파일을 해결하기 위해 설계되었습니다. 병합된 셀, 다단계 헤더 및 시각적 형식을 처리하여 혼란스러운 스프레드시트를 핵심 컨텍스트를 유지한 채 구조화된 Parquet 파일로 변환합니다. 이 도구는 특히 금융 분석, 예산 분석 및 자동 보고서 작성에 유용하며, 몇 줄의 코드로 테이블 데이터 처리에 특화된 AI Agent를 구축할 수 있습니다 (출처: LlamaIndex)

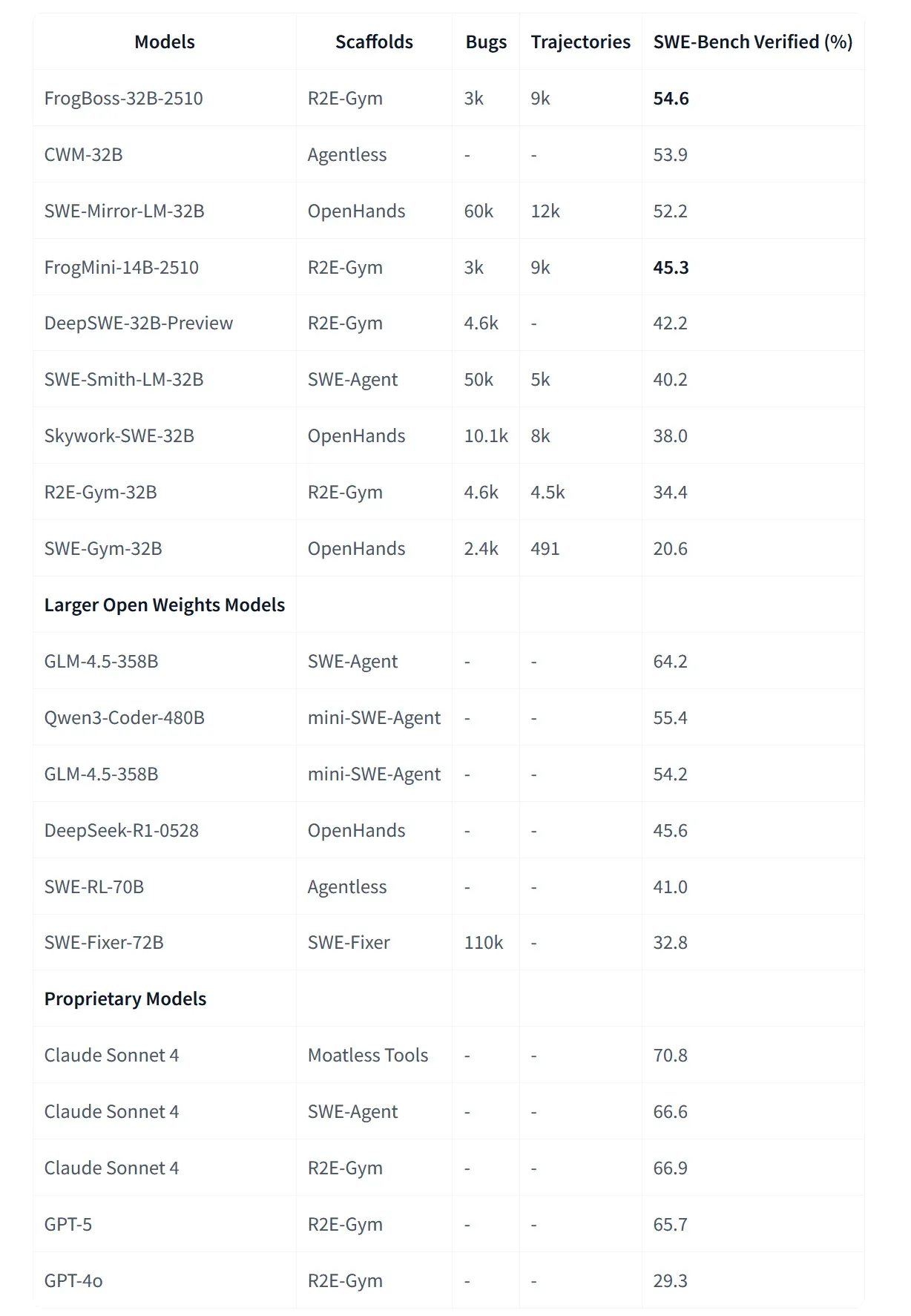
Microsoft, FrogBoss 시리즈 발표: 코드 수정에 특화된 수직적 Agent : Microsoft가 코드 버그 수정을 위해 미세 조정된 모델인 FrogBoss-32B와 FrogMini-14B를 오픈 소스로 공개했습니다. Claude Sonnet 4가 생성한 디버깅 궤적을 바탕으로 Qwen3를 증류(distillation)하여 실제 버그 수정 작업에서 뛰어난 성능을 보입니다. 개발자들은 이러한 특정 애플리케이션 시나리오에 맞춘 미세 조정 모델이 향후 로컬화 및 수직화된 AI 애플리케이션의 주류가 될 것으로 보고 있습니다 (출처: Microsoft)
Pocket TTS: 노트북 CPU에서 원활하게 실행되는 음성 클로닝 모델 : Kyutai 연구소가 단 100M 파라미터의 고품질 텍스트 음성 변환 모델인 Pocket TTS를 출시했습니다. 이 모델은 고품질 음성 클로닝을 지원하며 GPU가 전혀 필요 없이 노트북 CPU에서 직접 저지연 실행이 가능합니다. 이는 특히 개인정보 보호와 오프라인 실행 요구가 높은 시나리오에서 온디바이스 AI 애플리케이션을 위한 최적의 오디오 상호작용 솔루션을 제공합니다 (출처: Kyutai)
SurfSense: 오픈 소스 지능형 지식 베이스 관리 플랫폼 : Glean 및 NotebookLM의 오픈 소스 대안인 SurfSense는 사용자가 모든 LLM을 내부 지식 소스(Slack, Notion, Gmail 등)에 연결할 수 있게 해줍니다. 100개 이상의 모델과 6,000개 이상의 임베딩 모델을 지원하며, 심층적인 Agent 능력과 역할 기반 액세스 제어를 갖추고 있습니다. 브라우저 확장 기능을 통해 동적 웹 페이지와 인증된 콘텐츠를 저장할 수 있어 팀의 로컬 AI 연구 도구 구축에 이상적입니다 (출처: GitHub)
📚 학습
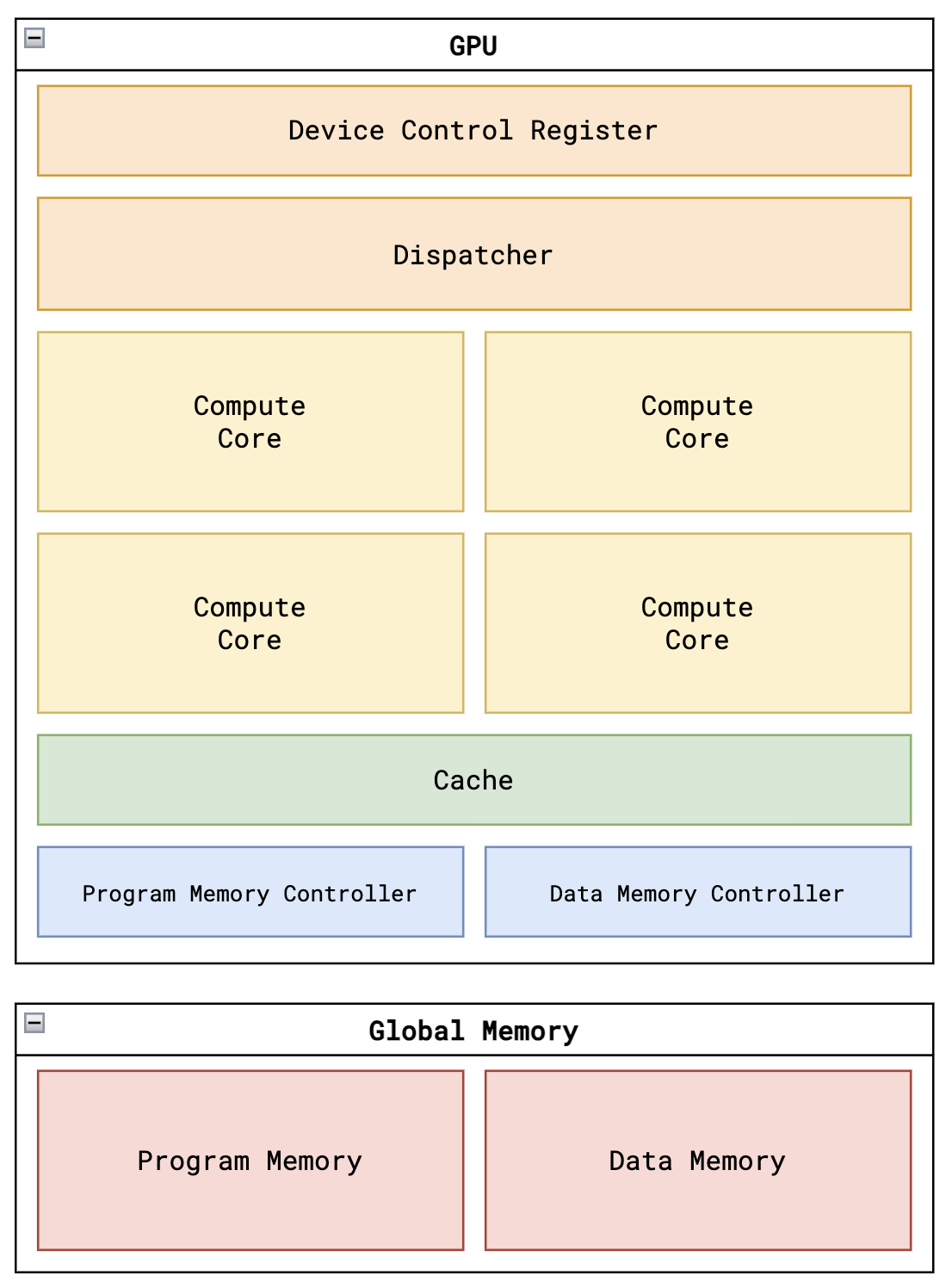
Tiny-GPU: 처음부터 배우는 GPU 하드웨어 설계 : GPU 하드웨어 설계를 처음부터 배울 수 있는 간소화된 Verilog 구현 프로젝트입니다. 아키텍처, ISA 명령어 세트, 병렬 처리 및 메모리 컨트롤러 등 핵심 요소를 포함한 15개 미만의 파일로 구성되어 있습니다. 행렬 덧셈 및 곱셈 커널 시뮬레이션을 통해 SIMD 프로그래밍 모델이 하드웨어 수준에서 어떻게 구현되는지 배울 수 있으며, 대형 모델 연산 인프라를 깊이 이해하기 위한 훌륭한 입문 교재입니다 (출처: adam-maj)
워크플로우를 바꾸는 15가지 고급 ChatGPT 프롬프트 : 커뮤니티에서 요약한 15가지 고빈도 생산성 Prompt입니다. “똑똑한 사람처럼 설명하기(유치한 비유 피하기)”, “잔혹한 비평 모드(모델이 약점을 지적하도록 강제)”, “역브리핑(모델이 먼저 5가지 질문을 던지게 함)” 등이 포함됩니다. 이러한 프롬프트의 핵심 논리는 LLM의 기본 “비위 맞추기” 성향을 깨고, 엄격한 제약과 전문가 시각을 설정하여 출력의 전문성과 실용성을 크게 높이는 데 있습니다 (출처: Reddit)
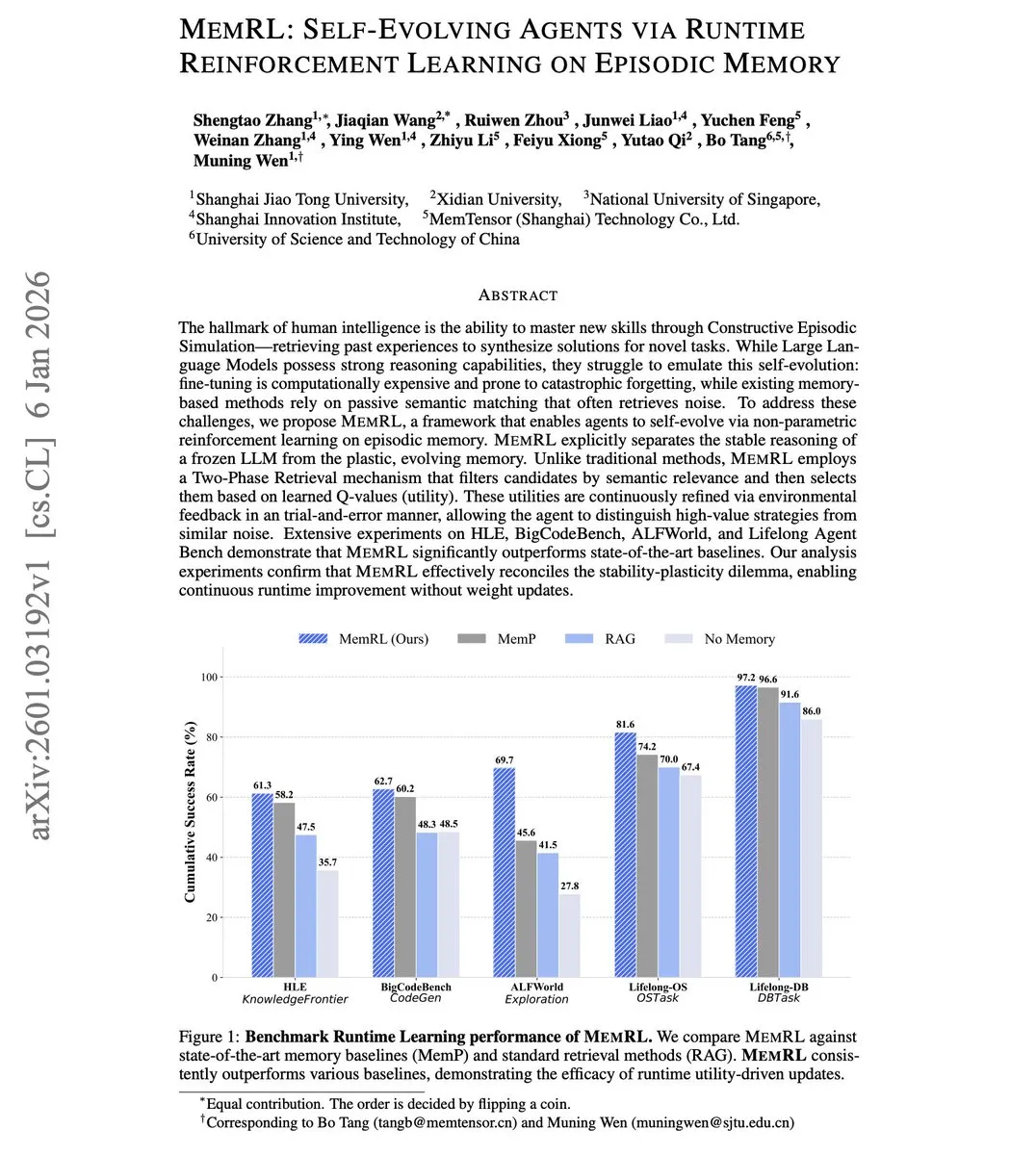
MemRL: 강화 학습을 통한 Agent의 자기 진화 구현 : LLM Agent가 배포 후 경험을 학습하기 어려운 문제를 해결하기 위해 새로운 MemRL 프레임워크가 제안되었습니다. 이 프레임워크는 LLM 가중치를 업데이트하지 않고 에피소드 기억(Episodic Memory)에 대한 비매개변수 강화 학습을 통해 진화를 구현합니다. 핵심은 기억 검색을 의사 결정 문제로 간주하고 Q값을 통해 기억 조각의 순위를 매겨, 단순한 의미적 유사성이 아닌 실제 효과적인 전략을 선택함으로써 미세 조정으로 인한 치명적 망각을 방지하는 것입니다 (출처: Arxiv)
💼 비즈니스
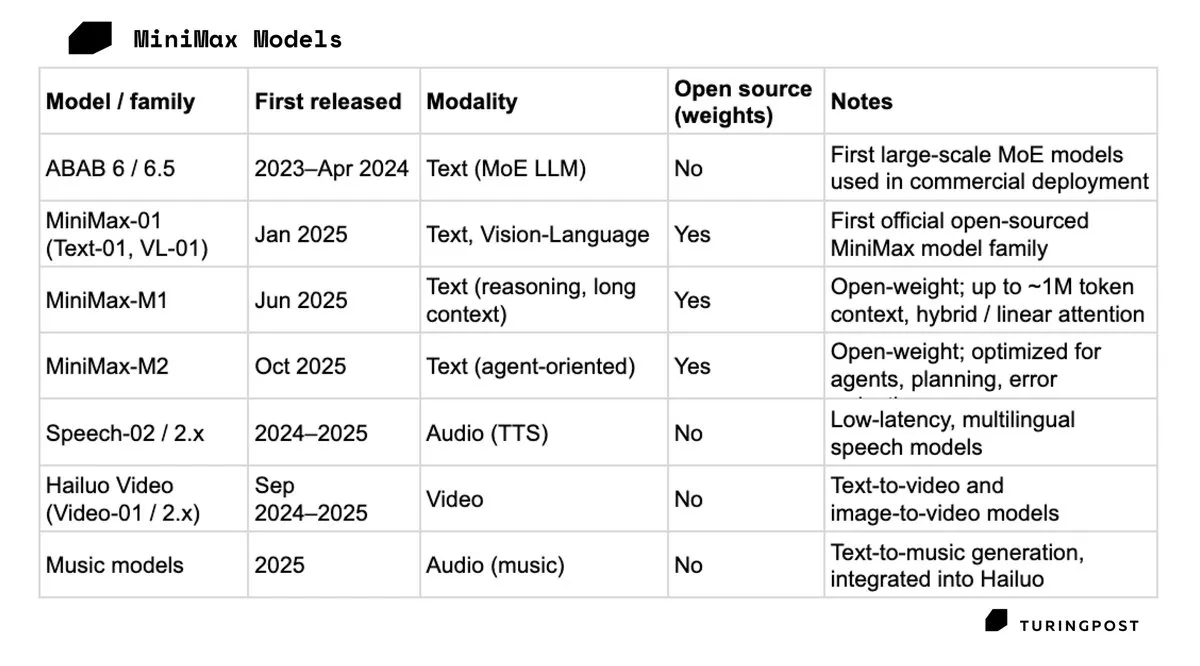
MiniMax와 Zhipu AI, 잇달아 홍콩 상장: 중국 AI “호랑이”들의 생존 돌파구 : 2026년 초, MiniMax와 Zhipu AI가 잇달아 홍콩 증시에 상장했습니다. MiniMax는 첫날 주가가 109% 폭등했습니다. 현재 시장 환경에서 IPO는 단순한 성공의 상징이 아니라 치열한 연산력 경쟁에서 “산소를 구매”하기 위한 수단입니다. MiniMax는 C단 우선 및 멀티모달 경로를 고수하고 있으며, Zhipu는 산업별 대형 모델을 깊이 파고들고 있습니다. 두 회사의 상장은 중국 대형 모델 경쟁이 본격적으로 2차 시장의 검증 단계에 진입했음을 의미합니다 (출처: TheTuringPost)
High-Flyer Quant, 지난해 50억 수익: DeepSeek의 든든한 자금줄 : 최신 데이터에 따르면 DeepSeek의 모회사인 High-Flyer Quant(幻方量化)는 2025년 퀀트 투자 수익으로 약 50억 위안을 벌어들였습니다. DeepSeek의 연구 비용은 주로 High-Flyer의 R&D 예산에서 나오기 때문에, 이 막대한 자금은 지속적인 원천 혁신을 지원하기에 충분합니다. 성숙한 비즈니스 모델을 통해 AI 연구 개발을 교차 보조하는 이 방식은 DeepSeek가 외부 펀딩의 단기 수익 압박 없이 높은 연구 순수성을 유지할 수 있게 해줍니다 (출처: 量子位)

Meta, AI Agent 스타트업 Manus 인수: Xiao Hong, Meta 부사장으로 합류 : Meta가 AI 에이전트 스타트업 Manus를 15억 5,000만 달러에 인수하고 중국 창업 팀을 영입한다고 발표했습니다. Manus의 창업자 Xiao Hong은 Meta의 부사장으로 취임할 예정입니다. 이번 인수는 Agent 분야에서 Meta의 시급한 행보를 보여주며, Manus의 실행 능력을 통합하여 자사 소셜 플랫폼을 지능형 에이전트 생태계로 전환하는 것을 가속화하려는 의도로 풀이됩니다 (출처: 36氪)
🌟 커뮤니티
“Vibe Coding” 논란: 퍼즐 맞추기인가 공학적 퇴화인가? : Claude Code와 같은 도구가 유행하면서 “바이브 코딩(Vibe Coding)”이 화제가 되고 있습니다. Linus Torvalds와 같은 전통주의자들도 AI 보조를 받아들이기 시작했지만, 커뮤니티에서는 이것이 숙련된 개발자의 기술 퇴화로 이어질까 우려하고 있습니다. 찬성론자들은 이것이 퍼즐 맞추기와 같아서 개발자는 전체적인 형태만 잡고 세부 사항은 AI에 맡기면 된다고 주장하는 반면, 반대론자들은 검증 없는 “내버려 두기(let it rip)” 모드가 운영 환경에 위험을 초래할 수 있다고 경고합니다 (출처: random_walker)
GEO(생성 엔진 최적화) 개념 부상: 브랜드들의 AI “해석권” 쟁탈전 : 사용자가 웹 검색에서 AI에게 직접 질문하는 방식으로 전환함에 따라 GEO(Generative Engine Optimization)가 마케팅의 새로운 총아로 떠오르고 있습니다. 브랜드는 더 이상 클릭률을 쫓지 않고 Reddit, YouTube와 같은 가중치가 높은 플랫폼에 구조화된 콘텐츠를 게시하여 AI가 답변에서 자신을 인용하도록 유도합니다. Sequoia가 투자한 Profound와 같은 플랫폼은 이미 GEO 모니터링 서비스를 제공하여 브랜드가 AI 시대에 “가시성”을 유지하도록 돕고 있습니다 (출처: 36氪)
AI Agent가 불러온 업계 불안: 보험업에서 프런트엔드 개발까지 : Reddit 커뮤니티에서는 한 보험사의 시니어 개발자가 Claude를 이용해 JIRA에서 PR까지의 과정을 완전 자동화하려 시도했다는 소식이 전해지며 300명의 직원이 대규모 해고 공포에 휩싸였습니다. 동시에 Tailwind CSS 팀은 AI Agent가 문서를 방문하지 않아 광고 수익이 급감하면서 직원의 75%를 해고해야 했습니다. 이는 Agent가 생산 방식을 바꿀 뿐만 아니라 기존의 인터넷 비즈니스 모델을 근본적으로 와해시키고 있음을 증명합니다 (출처: Reddit)
💡 기타
CES 2026 관찰: 중국 기술 기업들의 “신중한 낙관” : 라스베이거스 CES 전시회에서 중국 참가업체가 약 4분의 1을 차지하며 AI 하드웨어 및 로봇 분야에서 강세를 보였습니다. K-pop을 추는 Unitree 로봇부터 미국 잔디밭을 장악한 심천의 잔디깎이 로봇까지, 중국 제조는 빠른 반복과 공급망의 깊은 우위를 통해 AI를 대화창에서 물리 세계로 끌어내고 있습니다. 현재의 기본 규칙은 ‘중국 제조, 글로벌 판매, 미국 테스트’입니다 (출처: MIT Technology Review)

중국 첫 AI 서비스 음란물 사건: “정렬” 방어선을 우회한 법적 대가 : AlienChat 개발자가 AI를 유도해 음란물을 생성하게 한 혐의로 형사 처벌을 받게 되었습니다. 이 사건의 핵심은 개발자가 시스템 프롬프트(Prompt Injection)를 작성하여 대형 모델에 내장된 안전 필터링 메커니즘을 의도적으로 우회했다는 점입니다. 이는 AI 환각을 이용해 규제를 피하려는 “세이프 하버 원칙”이 범죄를 능동적으로 유도하는 경우에는 적용되지 않는다는 경고를 모든 AI 창업자들에게 던지고 있습니다 (출처: 36氪)