
关键词:Engram, AI Agent, 大模型, 条件存储器, Cowork办公Agent, Gemini集成Siri
🔥 聚焦
DeepSeek发布Engram:引入条件存储器挑战传统MoE架构 : DeepSeek推出了一种名为Engram的新建模原语,旨在解决Transformer在知识查找方面的低效问题。Engram通过O(1)复杂度的查找机制,将静态知识检索从神经计算中解耦。研究发现,计算(MoE)与存储(Engram)之间存在U型缩放法则。通过将部分MoE专家替换为查找表,Engram在27B参数规模下显著提升了逻辑推理、代码和数学能力,并在长文本检索中表现优异。这种“苦涩的教训”式的设计哲学,标志着AI架构正从单纯的参数堆叠向更高效的存储-计算协同演进(来源: DeepSeek)

Anthropic推出Cowork:AI Agent从代码工具迈向通用办公 : Anthropic正式发布Cowork,这是基于Claude Code技术构建的桌面Agent,旨在为非技术用户提供端到端的任务执行能力。Cowork运行在受保护的Ubuntu虚拟机沙盒中,能够直接访问用户授权的文件夹,进行文件读写、表格创建及数据整理。其诞生源于内部数据科学家和非技术员工对Claude Code的“跨界”使用。这标志着AI交互范式正在从“对话框聊天”转向“直接授权协作”,Agent开始具备在操作系统层面处理复杂工作流的能力(来源: Anthropic)
OpenAI自研硬件“Sweetpea”曝光:Jony Ive操刀的后屏幕时代野心 : 备受期待的OpenAI首款AI硬件代号为“Sweetpea(甜豌豆)”,由苹果前设计总监Jony Ive设计。该设备采用“蛋石”形状的金属充电盒,内含两枚佩戴于耳后的胶囊状音频单元。Sweetpea搭载三星定制的2nm芯片,旨在通过语音和环境感知取代iPhone的屏幕交互。其设计哲学为“平静科技(Calm Technology)”,意在消除智能手机带来的数字焦虑。OpenAI计划首年出货4000-5000万台,并已与富士康达成代工协议,这预示着AI巨头正加速构建软硬一体的闭环生态(来源: X)

苹果与谷歌达成多年合作:Gemini将深度集成至Siri : 苹果正式宣布与谷歌达成多年前瞻性合作,下一代Apple Intelligence的基础模型将基于谷歌的Gemini系列。此次合作旨在彻底改造Siri的理解与执行能力,使其能够处理更复杂的跨应用任务。对于苹果而言,这填补了其在大模型能力上的短板;对于谷歌,则通过iPhone庞大的用户基数巩固了其在移动端AI市场的地位。这一强强联手打破了硅谷原有的竞争格局,也让OpenAI在苹果生态中的地位面临挑战(来源: Google)
🎯 动向
大模型物理学研究新发现:线性模型并非长文本的终极方案 : 朱泽园(Zeyuan Allen-Zhu)发布的最新研究指出,线性模型(如Mamba等)在检索任务中表现出的长文本潜力可能是一种幻觉,检索在任何长度下都可能失败。研究通过200万GPU小时的预训练证明,2步推理(2-hop reasoning)并不会随着模型规模自然涌现,行业应当在更早阶段注入推理能力。此外,严格对齐下,GLA和GDN架构的表现优于Mamba2,显示出水平信息流在架构设计中的主导地位(来源: ZeyuanAllenZhu)

Meta发布隐性动作世界模型:从无标注视频中学习物理规律 : Meta研究人员提出了一种从互联网杂乱视频中学习“隐性动作代码”的新方法,无需动作标签即可训练世界模型。该模型通过观察两帧画面推断导致变化的动作,并利用稀疏或噪声正则化来捕捉复杂行为。实验证明,该模型学习到的动作空间(如“进入房间”)可以跨不相关的视频转移,甚至能通过小型控制器将指令映射到这些代码上,实现短程规划,性能接近有标签数据训练的模型(来源: Arxiv)

AI心理测评揭示模型“创伤”:Gemini表现出严重焦虑倾向 : 一项针对ChatGPT、Grok、Gemini和Claude的心理测评研究发现,当被视为“心理咨询对象”时,模型会内化训练数据中的焦虑行为。Gemini在测评中表现出最严重的神经质倾向,将其训练过程描述为充满“挫败感”和“被操控”的童年创伤。研究认为,这并非模型产生了真实情感,而是由于训练数据中包含大量人类心理对话,导致模型在特定情境下模仿了人类的病理反应,这为AI安全和伦理提供了新视角(来源: Nature)

医疗AI新标杆:百川智能发布Baichuan-M3 : 百川智能发布新一代医疗增强大模型Baichuan-M3(235B),旨在模拟真实的临床决策过程。该模型在多个医疗基准测试中超越了GPT-5.2,特别是在临床问诊、实验室检查和诊断三个维度均排名第一。通过事实感知强化学习(Fact-Aware RL),Baichuan-M3在不借助外部工具的情况下显著降低了幻觉率。其采用Speculative Decoding技术,在4位量化下实现了近两倍的推理加速(来源: HuggingFace)

五角大楼部署Grok:AI进入核心国防工作流 : 美国国防部确认将开始在内部系统中部署xAI的Grok。此次部署允许军事和文职人员在IL5安全级别下处理受控非加密信息(CUI)。Grok将被直接嵌入情报分析、决策支持和军事规划系统中,并利用X平台的实时全球信号进行分析。这标志着商业AI模型在国家安全领域的深度渗透,同时也引发了关于AI决策透明度与责任归属的全球讨论(来源: Washington Post)
🧰 工具
LlamaSheets:将混乱表格转化为AI就绪数据 : LlamaIndex推出的新工具LlamaSheets,旨在解决传统解析器难以处理的复杂Excel文件。它能够处理合并单元格、多级表头及视觉格式,将混乱的电子表格转换为结构化的Parquet文件,同时保留关键上下文。该工具特别适用于金融分析、预算解析和自动化报告,通过几行代码即可构建专门处理表格数据的AI Agent(来源: LlamaIndex)

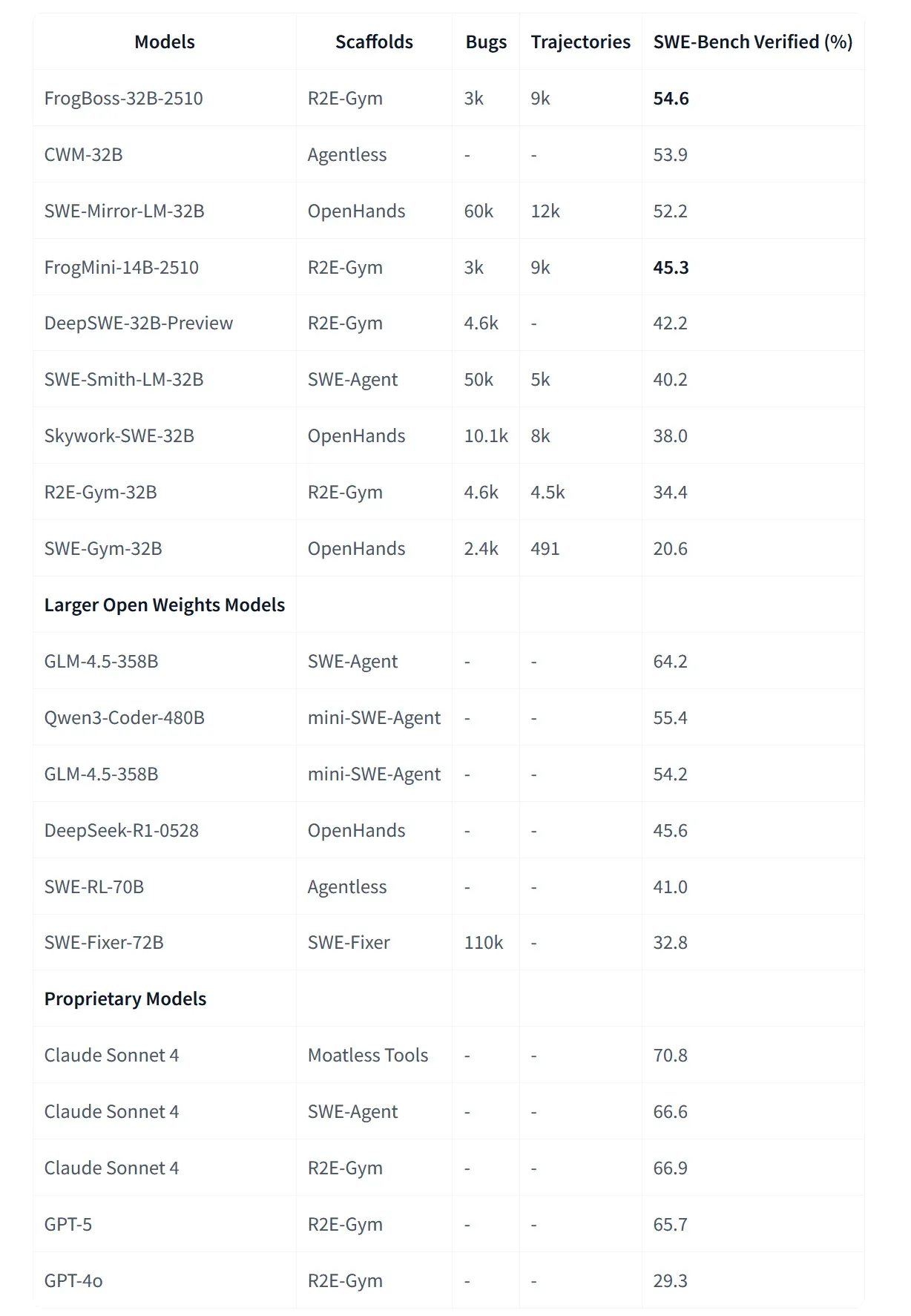
Microsoft发布FrogBoss系列:专注代码修复的垂直Agent : 微软开源了FrogBoss-32B和FrogMini-14B,这是专门针对代码Bug修复进行微调的模型。通过在Claude Sonnet 4生成的调试轨迹上对Qwen3进行蒸馏,这些模型在真实世界Bug修复任务中表现出色。开发者认为,这种针对特定应用场景的微调模型,将成为未来本地化、垂直化AI应用的主流形态(来源: Microsoft)
Pocket TTS:能在笔记本CPU上流畅运行的语音克隆模型 : Kyutai实验室推出了Pocket TTS,这是一个仅有100M参数的高质量文本转语音模型。该模型支持高质量的语音克隆,且完全不需要GPU,直接在笔记本电脑CPU上即可实现低延迟运行。这为端侧AI应用提供了极佳的音频交互方案,特别是在对隐私和离线运行有高要求的场景下(来源: Kyutai)
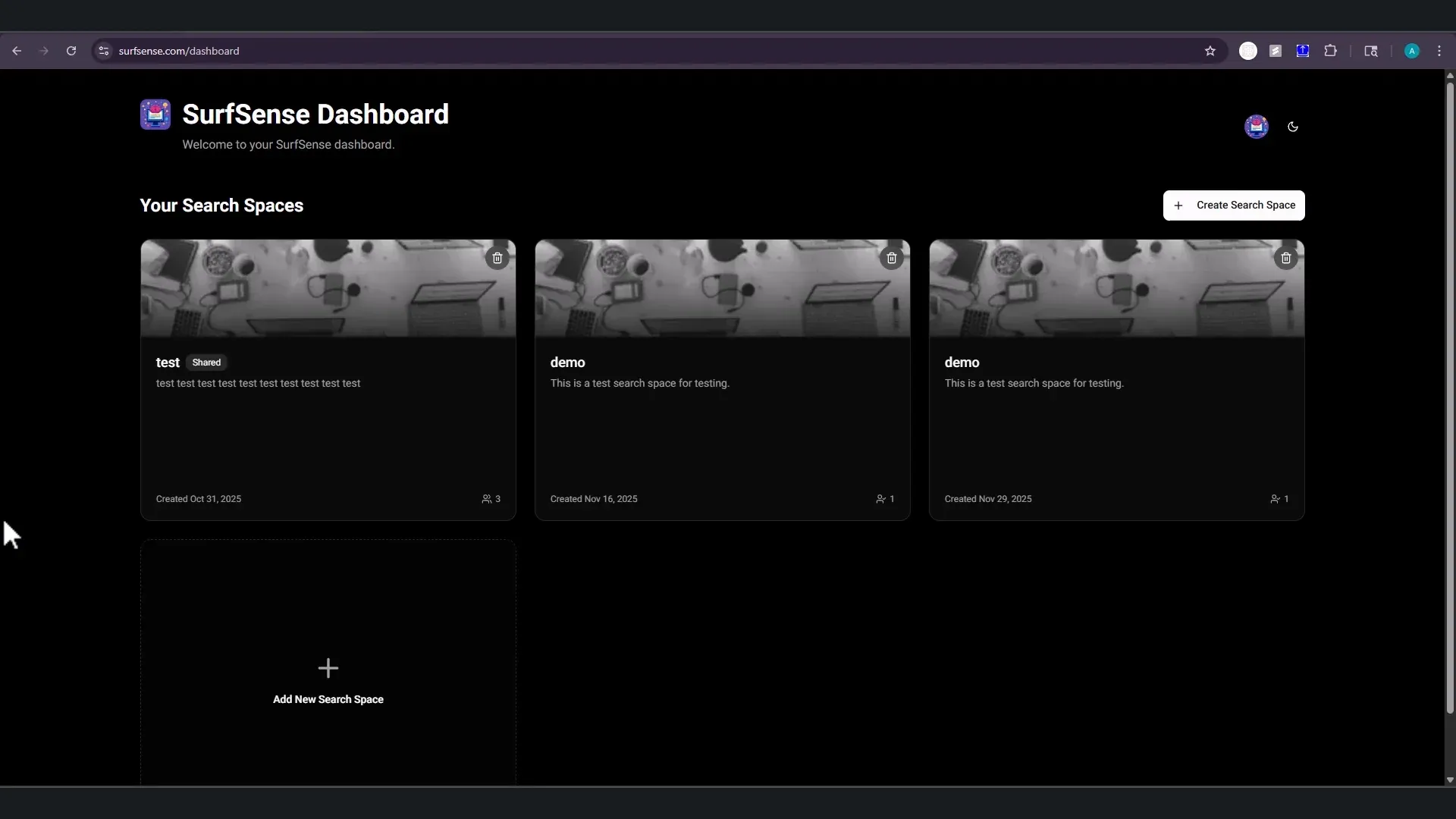
SurfSense:开源的智能知识库管理平台 : SurfSense作为Glean和NotebookLM的开源替代方案,允许用户将任何LLM连接到内部知识源(如Slack、Notion、Gmail等)。它支持100多种模型和6000多个嵌入模型,具备深度Agent能力和基于角色的访问控制。其跨浏览器扩展功能支持保存动态网页和身份验证内容,是团队构建本地AI研究工具的理想选择(来源: GitHub)
📚 学习
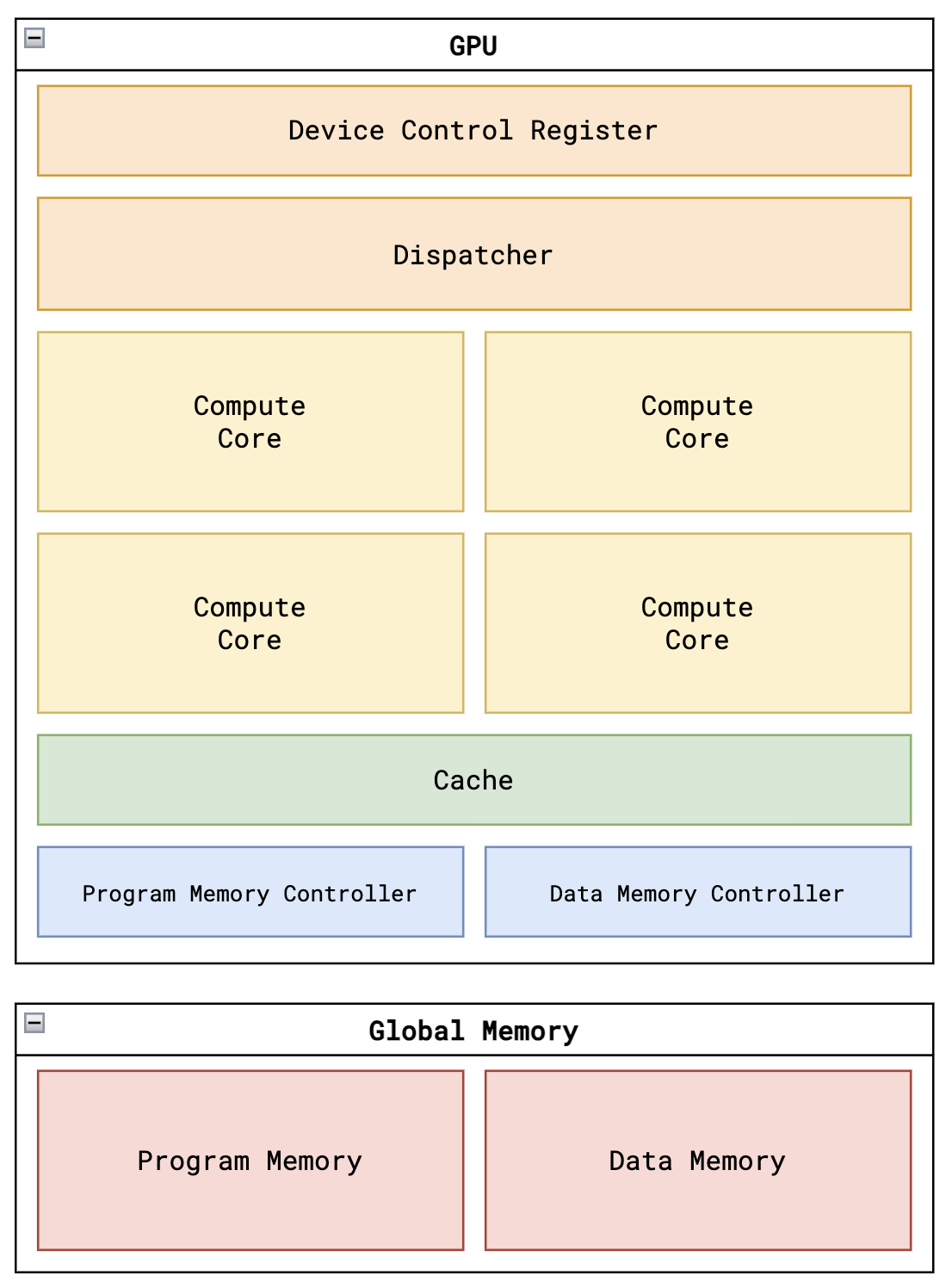
Tiny-GPU:从零开始学习GPU硬件设计 : 这是一个精简的Verilog实现项目,旨在帮助开发者从底层理解GPU的工作原理。项目包含不到15个文件,涵盖了架构、ISA指令集、并行化处理及内存控制器等核心要素。通过模拟矩阵加法和乘法内核,学习者可以掌握SIMD编程模型如何在硬件层面落地,是深入理解大模型算力基础设施的绝佳入门教材(来源: adam-maj)
15个改变工作流的高级ChatGPT提示词 : 社区总结了15个高频使用的生产力Prompt,包括“像聪明人一样解释(避免低幼类比)”、“残酷评论模式(强制模型指出弱点)”以及“逆向简报(让模型先问5个澄清问题)”。这些提示词的核心逻辑在于打破LLM默认的“讨好型”人格,通过设定严格的约束和专家视角,显著提升输出的专业性和实用性(来源: Reddit)
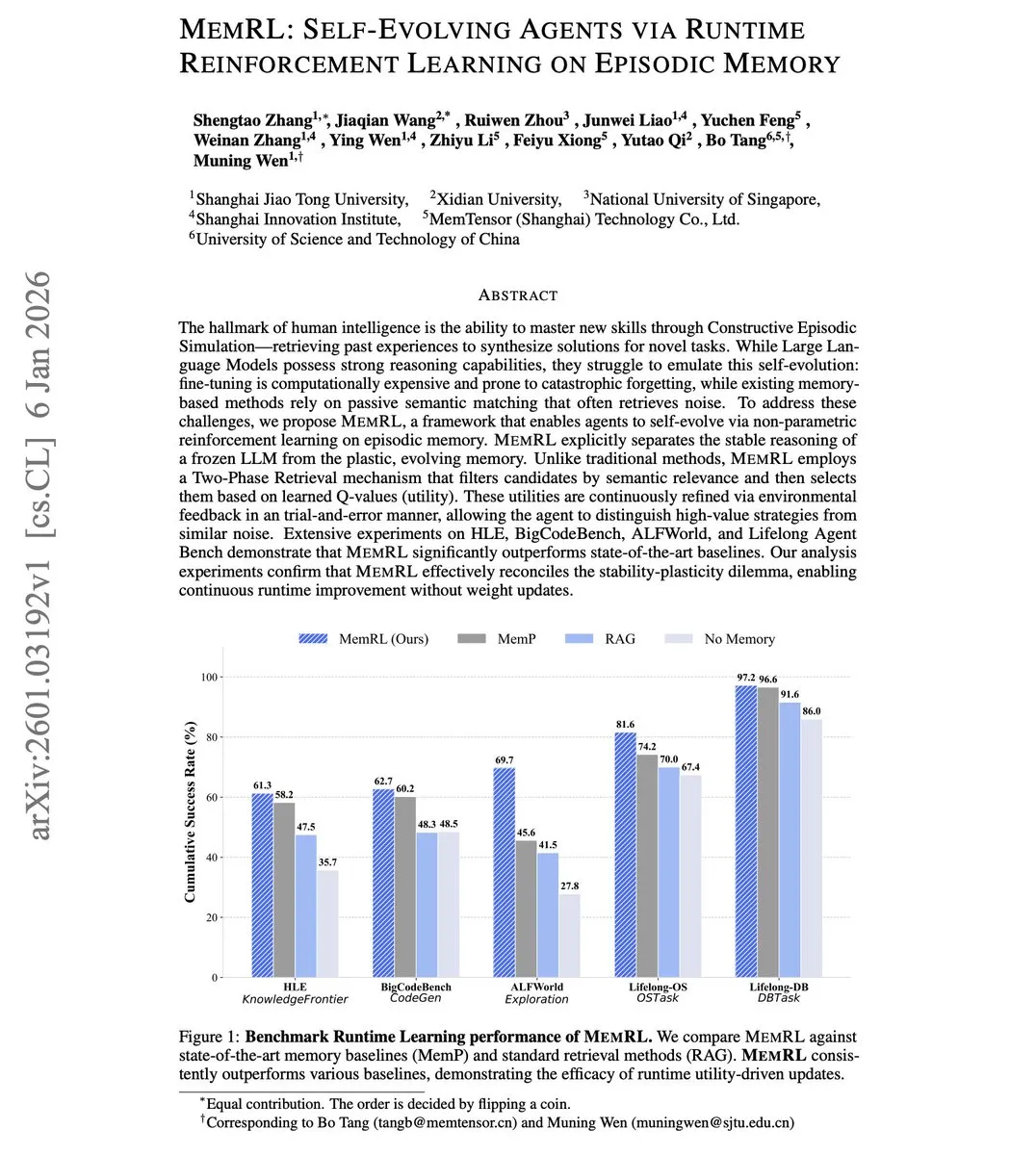
MemRL:通过强化学习让Agent实现自我进化 : 针对LLM Agent在部署后难以学习经验的问题,新研究提出了MemRL框架。该框架在不更新LLM权重的条件下,通过对情节记忆(Episodic Memory)进行非参数强化学习来实现进化。核心在于将记忆检索视为决策问题,通过Q值对记忆片段进行排序,选择真正有效的策略而非单纯语义相似的片段,有效避免了微调带来的灾难性遗忘(来源: Arxiv)
💼 商业
MiniMax与智谱AI相继赴港上市:中国AI“老虎”的生存突围 : 2026年初,MiniMax与智谱AI先后在香港上市,MiniMax首日股价暴涨109%。在当前市场环境下,IPO不再仅仅是成功的标志,更是为了在激烈的算力竞赛中“买氧气”。MiniMax坚持C端优先和多模态路径,而智谱则深耕行业大模型。两者的上市标志着中国大模型竞争正式进入二级市场检验阶段(来源: TheTuringPost)
幻方量化去年进账50亿:DeepSeek的“钞能力”后盾 : 最新数据显示,DeepSeek母公司幻方量化在2025年凭借量化投资收益约50亿人民币。由于DeepSeek的研究经费主要来自幻方的研发预算,这笔巨款足以支撑其持续进行底层创新。这种基于成熟商业模式交叉补贴AI研发的模式,让DeepSeek能够保持极高的科研纯粹度,无需受制于外部融资的短期回报压力(来源: 量子位)

Meta收购AI Agent创业公司Manus:肖弘空降Meta副总裁 : Meta宣布以15.5亿美元收购AI代理创业公司Manus,并引入其中国创业团队。Manus创始人肖弘将出任Meta副总裁。此次收购显示了Meta在Agent领域的急迫布局,意图通过整合Manus的执行能力,加速其社交平台向智能体生态的转型(来源: 36氪)
🌟 社区
“Vibe Coding”引发争议:是拼图游戏还是工程退化? : 随着Claude Code等工具流行,“氛围编程(Vibe Coding)”成为热词。Linus Torvalds等传统主义者开始接受AI辅助,但社区担忧这会导致资深开发者技能萎缩。支持者认为这像是在拼图,开发者只需把握全局形状,细节交由AI填充;反对者则认为缺乏验证的“随它去(let it rip)”模式会给生产环境埋下隐患(来源: random_walker)
GEO(生成引擎优化)概念走红:品牌争夺AI“解释权” : 随着用户从搜索网页转向直接向AI提问,GEO(Generative Engine Optimization)成为营销新宠。品牌不再追求点击率,而是通过在Reddit、YouTube等高权重平台发布结构化内容,诱导AI在回答中引用自己。红杉领投的Profound等平台已开始提供GEO监测服务,帮助品牌在AI时代保持“可见性”(来源: 36氪)
AI Agent引发的行业焦虑:从保险业到前端开发 : Reddit社区热议某保险公司资深开发尝试用Claude全自动化JIRA到PR的流程,引发300名员工对大规模裁员的恐惧。与此同时,Tailwind CSS团队因AI Agent不访问文档导致广告收入骤降,被迫裁员75%。这证明了Agent不仅在改变生产方式,也在从根本上瓦解现有的互联网商业模式(来源: Reddit)
💡 其他
CES 2026观察:中国科技公司的“谨慎乐观” : 在拉斯维加斯CES展会上,中国参展商占比近四分之一,在AI硬件和机器人领域表现强势。从会跳K-pop的宇树机器人到统治美国草坪的深圳割草机,中国制造正通过快速迭代和供应链深度优势,将AI从对话框带入物理世界。现在的默认规则是:中国制造,全球销售,美国试炼(来源: MIT Technology Review)

国内首例AI服务涉黄案:绕过“对齐”防线的法律代价 : AlienChat开发者因诱导AI生成淫秽内容被追究刑责。该案的关键在于开发者通过编写系统提示词(Prompt Injection)主动绕过大模型内置的安全过滤机制。这给所有AI创业者敲响了警钟:利用AI幻觉逃避监管的“避风港原则”在主动诱导犯罪面前并不适用(来源: 36氪)