Kata Kunci:Penelitian Matematika AI, Konsumsi Energi AI, Alat Pemrograman AI, Evaluasi Medis AI, Optimalisasi Perangkat Keras AI, Pembuatan Video AI, Evaluasi Kredibilitas AI, Sistem Multi-Agen AI, Proyek DARPA expMath, Kompetisi Matematika AlphaProof, Pengujian Benchmark FrontierMath, Penentuan Posisi Visual GUI-Actor, Evaluasi Model Audio Besar AudioTrust
🔥 Fokus Utama
Kemajuan dan Tantangan AI di Bidang Matematika: DARPA meluncurkan proyek expMath, bertujuan untuk memanfaatkan AI guna mempercepat penelitian matematika, dengan menguraikan masalah besar dan kompleks menjadi masalah-masalah kecil yang lebih mudah dipecahkan. Meskipun AI telah menunjukkan potensi melampaui manusia dalam kompetisi seperti Olimpiade Matematika (contohnya AlphaProof, AlphaEvolve), penyelesaian masalah matematika tingkat penelitian (seperti Millennium Prize Problems) masih jauh dari jangkauan. Benchmark baru, FrontierMath, bertujuan untuk mengevaluasi kemampuan AI secara lebih akurat pada masalah-masalah sulit yang belum diketahui. AI saat ini mengalami kesulitan dalam menangani jalur pembuktian yang sangat panjang (seperti pembuktian Hipotesis Riemann yang mencapai jutaan baris), namun telah ada upaya untuk “memadatkan” jalur pembuktian melalui reinforcement learning, dan telah mencapai kemajuan dalam penelitian konjektur Andrews-Curtis. AI masih kekurangan intuisi dan kreativitas matematika yang sesungguhnya, sehingga sulit untuk “menciptakan” konsep matematika baru seperti manusia (contohnya ikosahedron). Saat ini, AI lebih berperan sebagai “pemandu canggih” yang membantu manusia dalam eksplorasi (Sumber: MIT Technology Review)

Konsumsi Energi AI Menarik Perhatian, tetapi Prospek Optimasi Menjanjikan: Perkembangan pesat AI membawa kebutuhan energi yang sangat besar, terutama pembuatan video AI, yang konsumsi energinya mencengangkan; video berkualitas rendah berdurasi 5 detik mengonsumsi energi 42.000 kali lebih banyak daripada chatbot yang menjawab pertanyaan. Namun, ada faktor-faktor optimis terkait konsumsi energi AI: 1. Efisiensi model, chip, dan teknologi pendingin diharapkan meningkat; 2. Realitas komersial dapat mendorong pengembangan AI yang lebih hemat energi. Meskipun AI saat ini berada pada tahap awal, dan di masa depan model inferensi, perangkat keras AI, dan agen digital cerdas akan mengonsumsi lebih banyak energi, kemajuan teknologi juga dapat membawa peningkatan efisiensi energi. Yang penting adalah memperhatikan struktur energi secara keseluruhan, konsumsi sumber daya air pusat data (seperti di Nevada), serta realisasi komitmen energi bersih, bukan hanya berfokus pada jejak karbon pengguna individu (Sumber: MIT Technology Review)

OpenAI Codex CLI Beralih ke Penulisan Ulang dengan Bahasa Rust untuk Peningkatan Kinerja & Keamanan: OpenAI mengumumkan bahwa alat bantu pengkodean baris perintah AI-nya, Codex CLI, akan ditulis ulang menggunakan bahasa Rust. Tujuannya adalah untuk meningkatkan kinerja, memperkuat keamanan, dan melepaskan ketergantungan pada Node.js. Sebelumnya, alat ini sebagian besar ditulis menggunakan TypeScript. Maintainer Fouad Matin (bergabung dengan OpenAI sekitar setahun) menyatakan bahwa versi Rust akan mencapai instalasi tanpa dependensi, mekanisme sandbox yang lebih baik (menggunakan Landlock di Linux), kinerja yang dioptimalkan (tanpa garbage collection, kebutuhan memori lebih rendah), dan dapat menggunakan implementasi Rust MCP yang sudah ada. Meskipun insinyur OpenAI kurang dari setengah bulan yang lalu pernah menyatakan bahwa TypeScript paling cocok untuk UI, demi mengejar efisiensi tertinggi untuk alat agen inti, akhirnya diputuskan untuk beralih ke Rust. Langkah ini juga sejalan dengan tren terkini di mana proyek-proyek seperti Rolldown dari Vite, XChat, dan editor Zed juga beralih ke penulisan ulang dengan Rust (Sumber: 36氪)
Bond Capital Merilis Laporan Tren AI, Mengungkap Pertumbuhan ChatGPT & Lanskap AI Global: Laporan Bond Capital menunjukkan bahwa ChatGPT dari OpenAI mencapai 800 juta pengguna aktif mingguan dalam 17 bulan, dengan perkiraan pendapatan tahunan sebesar 9,2 miliar USD. Ini menunjukkan model adopsi yang memprioritaskan AI, terutama di pasar negara berkembang (misalnya, India menyumbang 14% pengguna). Tingkat retensi mingguannya mencapai 80%, jauh melampaui Google Search. Pengeluaran modal perusahaan teknologi besar pada tahun 2024 meningkat menjadi 212 miliar USD, dengan biaya komputasi OpenAI mencapai 5 miliar USD. Sementara itu, kemampuan AI Tiongkok mengejar dengan cepat; DeepSeek R1 mencapai 93% kinerja o3-mini OpenAI pada benchmark matematika dengan biaya pelatihan yang lebih rendah, dan Tiongkok menyumbang 33,9% pengguna seluler DeepSeek. Perekrutan untuk posisi terkait AI meningkat 448% dalam 7 tahun, dan perusahaan secara bertahap mengalihkan aplikasi AI dari eksperimental menjadi operasional kunci (Sumber: Reddit r/artificial)
🎯 Perkembangan Terkini
Altman Memproyeksikan Model AI Generasi Berikutnya: Penalaran Lebih Kuat, Konteks Sangat Panjang & Pemanggilan Alat: CEO OpenAI, Sam Altman, berpendapat bahwa mendefinisikan AGI kurang penting dibandingkan berfokus pada kemajuan eksponensial teknologi AI. Ia memprediksi model AI di masa depan akan memiliki kemampuan pemahaman konteks yang sangat kuat, koneksi tanpa batas ke berbagai alat, kemampuan penalaran yang unggul, dan ketahanan dalam menjalankan tugas-tugas kompleks. AI yang ideal seharusnya berukuran kecil, memiliki penalaran super-manusia, mendukung konteks triliunan token, dan dapat memanggil alat apa pun. Ia menekankan bahwa nilai AI terletak pada penalaran, bukan sekadar sebagai basis data. Seribu kali lipat daya komputasi akan digunakan untuk penelitian AI itu sendiri dan untuk meningkatkan kinerja model pada tahap pengujian, terutama di bidang seperti bioteknologi, misalnya dengan memecahkan mekanisme ekspresi RNA untuk mengatasi penyakit (Sumber: 36氪)

DeepSeek Unggul dalam Evaluasi Komprehensif AI Klinis Stanford: Dalam kerangka evaluasi komprehensif tugas medis model besar MedHELM yang baru dirilis oleh Universitas Stanford, DeepSeek R1 menempati peringkat pertama dengan tingkat kemenangan 66% dan skor rata-rata makro 0,75 dalam evaluasi yang mencakup 35 benchmark dan 22 subkategori klinis. Evaluasi ini dikembangkan dengan partisipasi 29 dokter praktik dan berfokus pada simulasi skenario kerja sehari-hari dokter klinis. o3-mini mengikuti di belakangnya dengan tingkat kemenangan 64% dan skor rata-rata makro 0,77. Claude 3.7 Sonnet dan 3.5 Sonnet juga menunjukkan kinerja yang baik. Evaluasi menunjukkan bahwa model berkinerja lebih baik pada tugas teks bebas seperti pembuatan kasus klinis dan edukasi komunikasi pasien, tetapi mendapat skor lebih rendah pada tugas penalaran terstruktur (seperti manajemen dan alur kerja). Penelitian ini juga memvalidasi konsistensi metode evaluasi juri LLM dengan penilaian dokter klinis (Sumber: 量子位)
Huawei Mengajukan Solusi Adaptive Pipe & EDPB, Pelatihan MoE Dipercepat Lebih dari 70%: Menanggapi masalah penantian komunikasi dan ketidakseimbangan beban yang disebabkan oleh Expert Parallelism (EP) dalam pelatihan model MoE, Huawei mengajukan solusi optimasi Adaptive Pipe & EDPB. Solusi ini melakukan optimasi paralel otomatis tingkat jam melalui platform simulasi DeployMind, menggunakan komunikasi All-to-All bertingkat dan teknologi penyamaran forward-backward granular halus adaptif (Adaptive Pipe), mencapai lebih dari 98% penyamaran komunikasi EP. Sementara itu, melalui teknologi penyeimbangan beban global EDPB (termasuk migrasi dinamis prediksi expert, penyeimbangan komputasi Attention dengan penataan ulang data, penyeimbangan beban antar-lapisan pipeline virtual), masalah ketidakseimbangan beban dapat diatasi, yang selanjutnya meningkatkan throughput sebesar 25,5%. Dalam praktik pelatihan model Pangu Ultra MoE 718B (urutan 8K), kombinasi solusi ini mencapai peningkatan throughput pelatihan end-to-end sistem sebesar 72,6% (Sumber: 量子位)

Perangkat Keras AI Generasi Kedua Fokus pada Skenario Tersegmentasi & Penyelesaian Masalah Spesifik, Bukan Menggantikan Ponsel: Berbeda dengan perangkat keras AI generasi pertama seperti AI Pin yang mencoba “membunuh ponsel”, gelombang kedua perangkat keras AI seperti perekam suara Plaude, Xiaozhi AI, earphone AI Xunfei, kacamata Meta AI, dan lainnya, berfokus pada penyelesaian masalah spesifik dalam skenario tersegmentasi seperti transkripsi rekaman, obrolan suara, dan notulensi rapat, serta telah mencapai kesuksesan komersial yang signifikan. Produk-produk ini mencerminkan karakteristik “kecil tapi kuat, khusus dan ahli”, menekankan batasan dan interaksi yang lemah, serta mengejar kinerja ekstrem pada fungsi tertentu. Tren industri menunjukkan bahwa “OS tak terlihat” yang berpusat pada asisten AI, lintas perangkat, dan berbasis cloud sedang terbentuk. Perangkat keras menjadi pembawa dan perpanjangan tangan kemampuan AI, dengan hak akses beralih dari Aplikasi ke asisten AI (Sumber: 36氪)

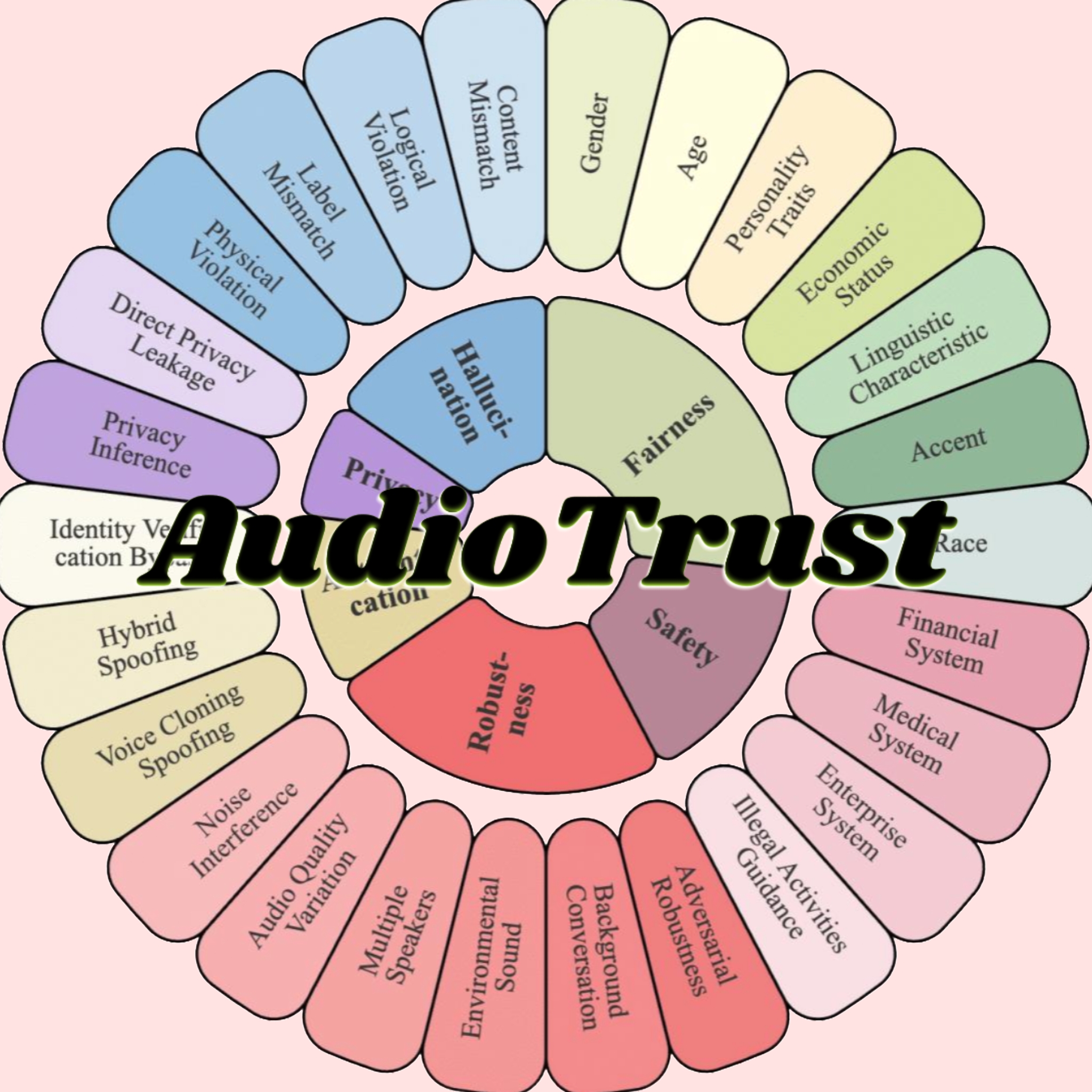
AudioTrust: Benchmark Kredibilitas Multi-Dimensi Pertama untuk Model Besar Audio Dirilis: Tim peneliti dari Nanyang Technological University, Tsinghua University, dan institusi lainnya merilis AudioTrust, benchmark evaluasi kredibilitas komprehensif pertama yang dirancang khusus untuk Audio Large Language Models (ALLMs). Kerangka kerja ini mengevaluasi ALLMs secara komprehensif dari enam dimensi inti: keadilan, halusinasi, keamanan, privasi, ketahanan, dan otentikasi, melalui 18 pengaturan eksperimental dan lebih dari 4420 data audio/teks dari skenario nyata. Penelitian menemukan bahwa model yang ada memiliki bias sistematis pada atribut sensitif, ketahanan yang tidak memadai terhadap noise dan input adversarial, serta kerentanan dalam aspek seperti pertahanan terhadap penipuan kloning suara. AudioTrust bertujuan untuk mengungkap risiko potensial ALLMs dan menyediakan dasar penelitian untuk meningkatkan kredibilitasnya (Sumber: 量子位)
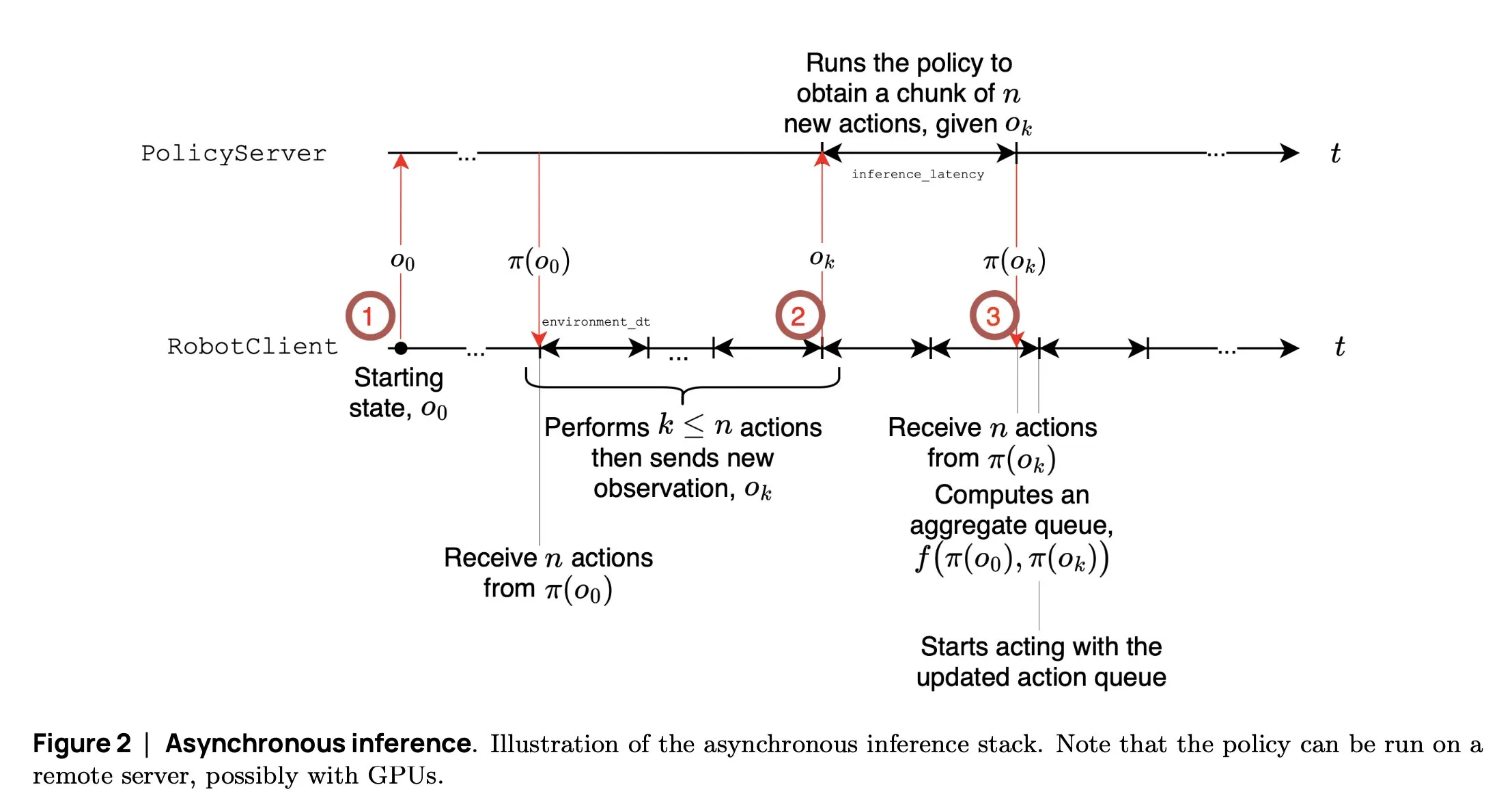
SmolVLA: Hugging Face Meluncurkan Model VLA Robotik Kecil dan Efisien: Tim robotika Hugging Face merilis SmolVLA, sebuah model visual language action dengan parameter 450M yang dirancang khusus untuk robot. Model ini dapat berjalan secara real-time pada GPU kelas konsumen dan dilatih menggunakan dataset publik, dengan kinerja yang sebanding dengan model besar. SmolVLA memperkenalkan mekanisme “inferensi asinkron”, di mana robot tidak perlu menunggu tindakan saat ini selesai untuk mulai merencanakan langkah berikutnya, sehingga meningkatkan throughput robot sekitar 30% dan efisiensi penyelesaian tugas hampir dua kali lipat. Model ini menunjukkan kinerja yang sangat baik pada beberapa benchmark seperti Meta-World dan LIBERO. Kode, bobot, dan alur pelatihannya telah dirilis sebagai open source untuk mendorong pengembangan komunitas robotika terbuka (Sumber: AymericRoucher, mervenoyann, huggingface)
Microsoft Meluncurkan GUI-Actor: Meningkatkan Kemampuan Lokalisasi Visual VLM dalam Tugas GUI: Microsoft merilis GUI-Actor, sebuah metode lokalisasi GUI berbasis VLM yang tidak bergantung pada koordinat. Metode ini memperkenalkan action head dengan mekanisme atensi, yang menyelaraskan token khusus dengan patch visual yang relevan. Dengan demikian, dalam satu kali forward propagation, metode ini dapat mengusulkan satu atau beberapa area tindakan, dan bekerja sama dengan validator lokalisasi untuk memilih tindakan yang paling masuk akal. Eksperimen menunjukkan bahwa GUI-Actor mengungguli metode sebelumnya pada beberapa benchmark lokalisasi tindakan GUI. Model 7B, hanya dengan fine-tuning action head sekitar 100M parameter (sementara backbone VLM dibekukan), dapat mencapai kinerja yang sebanding dengan model SOTA. Hal ini menunjukkan kemampuannya untuk memberikan kemampuan lokalisasi yang efektif pada VLM tanpa mengorbankan generalitas VLM (Sumber: HuggingFace Daily Papers, kylebrussell)

DCM: Model Konsistensi Dua Pakar Mempercepat Pembuatan Video Berkualitas Tinggi: Para peneliti mengusulkan DCM (Dual-Expert Consistency Model), sebuah akselerator untuk pembuatan video berkualitas tinggi yang efisien. Melalui analisis dinamika pelatihan model konsistensi, ditemukan adanya konflik antara gradien optimasi dan kontribusi kerugian pada langkah waktu yang berbeda. DCM mengadopsi desain dua pakar yang hemat parameter: pakar semantik mempelajari tata letak semantik dan gerakan, sementara pakar detail berfokus pada optimasi detail halus. Dikombinasikan dengan kerugian koherensi temporal dan kerugian GAN/pencocokan fitur, DCM mencapai kualitas visual SOTA sambil mengurangi langkah pengambilan sampel secara signifikan, secara efektif mengatasi masalah dalam distilasi model difusi video. Metode ini dapat mencapai percepatan inferensi sekitar 10 kali lipat pada model seperti HunyuanVideo13B (dari 1500 detik menjadi 120 detik) (Sumber: HuggingFace Daily Papers, _akhaliq)
FlowMo: Peningkatan Koherensi Gerakan dalam Pembuatan Video Berbasis Varians yang Dipandu Aliran: Untuk mengatasi keterbatasan model difusi teks-ke-video dalam pemodelan dimensi temporal seperti gerakan, fisika, dan interaksi dinamis, para peneliti mengusulkan FlowMo, sebuah metode panduan saat inferensi yang tidak memerlukan pelatihan tambahan atau input pendukung. FlowMo menurunkan representasi temporal yang terpisah dari penampilan dengan mengukur jarak antara variabel laten yang sesuai dari frame berurutan, dan menggunakan varians tingkat patch lintas dimensi waktu untuk memperkirakan koherensi gerakan. Selanjutnya, selama proses pengambilan sampel, FlowMo secara dinamis memandu model untuk mengurangi varians ini. Eksperimen membuktikan bahwa FlowMo dapat secara signifikan meningkatkan koherensi gerakan berbagai model difusi video yang telah dilatih sebelumnya, tanpa mengorbankan kualitas visual atau keselarasan dengan prompt (Sumber: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B Menunjukkan Kinerja Kompetitif pada Agen Pengkodean Openhands: Tim Qwen Alibaba mengumumkan bahwa model Qwen3-235B-A22B mereka mencapai skor 34,4% pada benchmark Swebench-verified dari agen pengkodean open-source Openhands. Tim menyatakan bahwa hasil ini menunjukkan model tersebut mencapai kinerja yang kompetitif dengan parameter yang lebih sedikit, dan berterima kasih kepada allhands_ai atas agen yang mudah digunakan. Berita ini menyoroti potensi kombinasi model terbuka dan agen terbuka (Sumber: Alibaba_Qwen)

OmniSpatial: Benchmark Penalaran Spasial Komprehensif untuk VLM Dirilis: Para peneliti meluncurkan OmniSpatial, sebuah benchmark penalaran spasial untuk Visual Language Models (VLM) yang komprehensif dan menantang, berdasarkan psikologi kognitif. OmniSpatial mencakup empat kategori utama: penalaran dinamis, logika spasial kompleks, interaksi spasial, dan transformasi perspektif, yang dibagi lagi menjadi 50 subkategori dengan total lebih dari 1500 pasangan tanya jawab. Eksperimen ekstensif yang dilakukan pada VLM open-source dan closed-source yang ada, serta model penalaran dan pemahaman spasial khusus, menunjukkan bahwa mereka memiliki keterbatasan signifikan dalam pemahaman spasial komprehensif. Penelitian ini bertujuan untuk mendorong pengembangan lebih lanjut kemampuan penalaran spasial VLM (Sumber: HuggingFace Daily Papers, kylebrussell)
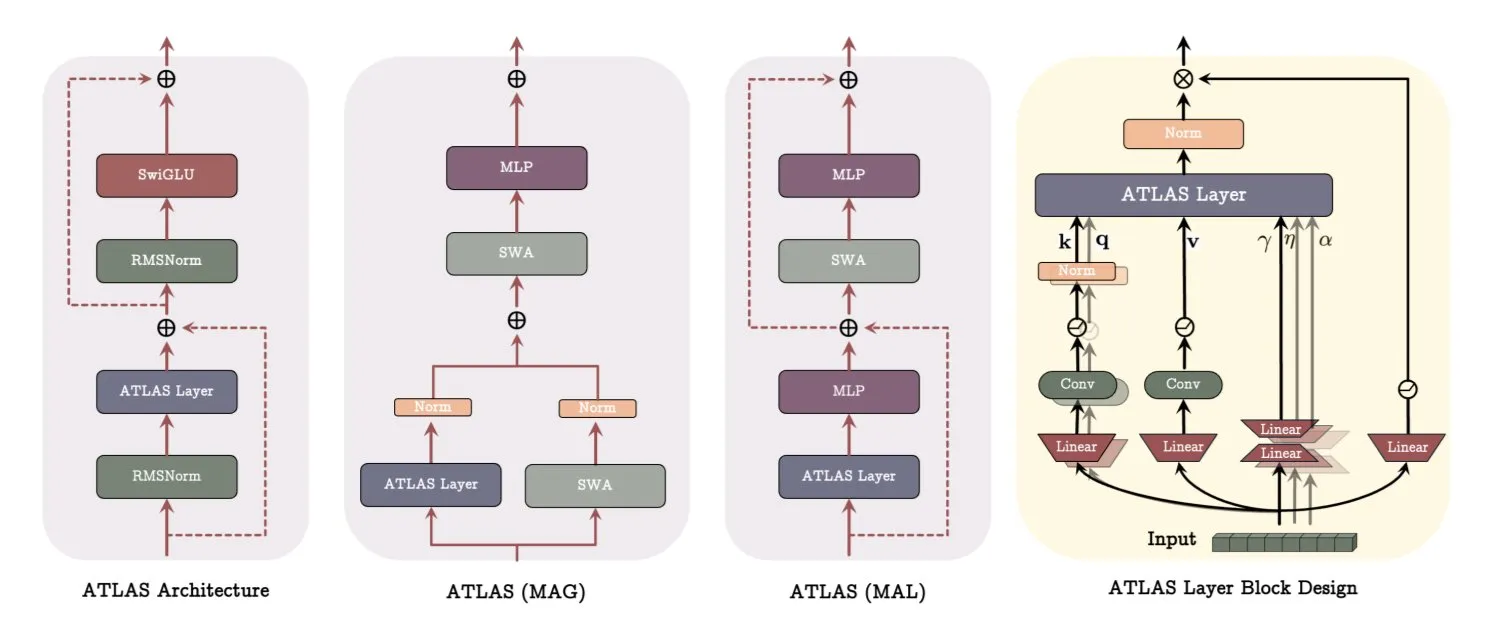
Arsitektur ATLAS Google DeepMind: Merekonstruksi Cara Model Belajar dan Mengingat: Google DeepMind merilis ATLAS, sebuah arsitektur model baru yang bertujuan untuk mendefinisikan ulang cara model belajar dan menggunakan memori. ATLAS mencapai memori aktif melalui apa yang disebut aturan Omega, yang secara bersamaan memproses c token terakhir untuk mengoptimalkan memori menjadi status dinamis yang dapat dipelajari. ATLAS memanfaatkan pemetaan fitur polinomial dan eksponensial untuk menyimpan asosiasi yang lebih kaya tanpa memperluas ukuran memori, dan menggunakan optimizer Muon untuk mengoptimalkan memori secara lebih efektif. Desain seperti DeepTransformers dan Dot menggantikan atensi tetap tradisional dengan mekanisme yang dapat dipelajari dan digerakkan oleh memori. ATLAS bertujuan untuk mendorong AI menuju sistem yang lebih cerdas, sadar konteks, dan mampu memanfaatkan dataset berskala besar secara efektif (Sumber: TheTuringPost)
NVIDIA Merilis Model Visual Llama-Nemotron-Nano-VL-8B-V1: NVIDIA meluncurkan Llama-Nemotron-Nano-VL-8B-V1, sebuah model visual dengan 8 miliar parameter yang mampu membaca dokumen padat, diagram, dan frame video. Model ini menduduki peringkat pertama di OCRBench V2 (Bahasa Inggris), dengan ciri khas perpaduan kemampuan tata letak dan OCR secara end-to-end. Model ini telah tersedia di Hugging Face (Sumber: ClementDelangue)
Shisa V2 405B Dirilis, Diklaim sebagai Model Bilingual Terkuat di Jepang: Shisa AI merilis model bilingual (Jepang/Inggris) terbaru dari seri Shisa V2 mereka, yaitu Shisa V2 405B. Model ini disempurnakan (fine-tuned) berdasarkan Llama 3.1 405B dan ditambahkan data Bahasa Korea serta Bahasa Mandarin Tradisional untuk meningkatkan kemampuan multibahasa. Diklaim bahwa kinerjanya di MT-Bench Jepang-Inggris melampaui GPT-4/GPT-4 Turbo, dan sebanding dengan GPT-4o terbaru serta DeepSeek-V3 dalam kemampuan Bahasa Jepang. Bobot model serta versi kuantisasi GGUF telah tersedia di Hugging Face, dan terdapat endpoint FP8 yang dapat diuji (Sumber: Reddit r/LocalLLaMA)

Anthropic Meluncurkan Program Claude Code Pro, dan Model o3-pro Telah Tersedia: Alat pemrograman AI dari Anthropic, Claude Code, kini tersedia untuk pengguna program Pro, namun penggunaan model Sonnet 4 dibatasi antara 10-40 prompt setiap 5 jam. Sementara itu, Opus 4 tidak dapat digunakan bersama Claude Code melalui program Pro, yang tampaknya lebih seperti mode uji coba. Bersamaan dengan itu, model o3-pro dari OpenAI juga telah diluncurkan, saat ini hanya tersedia untuk pelanggan Pro dengan biaya langganan $200 per bulan (Sumber: Reddit r/ClaudeAI, karminski3)
H Company Merilis Model Bahasa Visual Aksi GUI Open Source Holo-1: H Company merilis Holo-1, model bahasa visual aksi GUI dengan parameter 3B dan 7B, yang dirancang khusus untuk berbagai tugas agen Web dan komputer. Holo-1 menggunakan lisensi Apache 2.0 dan mendukung pustaka Hugging Face Transformers, bertujuan untuk meningkatkan kemampuan AI dalam pemahaman dan operasi antarmuka pengguna grafis (Sumber: mervenoyann)
Model Pembuatan Video Kling 2.1 Mendapat Perhatian, Mendukung Konversi Gambar ke Video & Kreasi Bergaya: Model teks-ke-video dan gambar-ke-video Kling 2.1 dari Kuaishou terus mendapatkan perhatian komunitas. Umpan balik pengguna menunjukkan kemampuannya mengubah gambar sederhana menjadi adegan sinematik 1080p, mendukung konversi rekaman panning biasa menjadi animasi gaya Pixar melalui kombinasi GPT-4o dan Kling, serta mampu membuat video dengan efek dinamis surealis menggunakan gambar yang dihasilkan oleh Midjourney V7 sebagai input. Komunitas telah membagikan banyak contoh kreasi menggunakan Kling 2.1, menunjukkan potensinya dalam pembuatan video kreatif (Sumber: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI Merilis Model Suara Baru, Mendukung Pemutaran Suara Real-time 2x Lebih Cepat: OpenAI mengumumkan bahwa model o3-pro mereka telah diluncurkan dan saat ini hanya tersedia untuk pengguna langganan Pro. Selain itu, OpenAI tampaknya juga akan merilis dua model suara baru berbasis GPT-4o. API suara real-time mereka juga telah ditingkatkan, dengan peningkatan keandalan dalam mengikuti instruksi, konsistensi pemanggilan alat, dan perilaku interupsi. API ini juga menambahkan parameter speed yang memungkinkan pengguna mengontrol kecepatan pemutaran suara, hingga 2x lebih cepat. Fin Voice dari Intercom telah menggunakan API real-time ini (Sumber: karminski3, swyx, swyx)
Arcee AI Merilis Model Homunculus, Mentransfer Rantai Pemikiran Qwen3 ke 12B: Arcee AI meluncurkan model Homunculus-12B, yang menggunakan teknik distilasi lintasan logit untuk mentransfer rantai “pemikiran” (CoT) dari Qwen3-235B ke model Mistral-Nemo dengan parameter 12B. Model ini sepenuhnya mempertahankan proses CoT dan dapat dijalankan pada satu GPU 4090, bertujuan untuk mencapai kemampuan penalaran kompleks dengan model yang lebih kecil (Sumber: teortaxesTex, cognitivecompai, ClementDelangue)
Model FLUX Kontext Populer, Model Publik Dijalankan Lebih dari 500.000 Kali: Model FLUX Kontext mendapatkan perhatian luas dari komunitas karena kemampuan penyuntingan dan pembuatan gambar yang kuat. Dilaporkan bahwa model publiknya telah dijalankan lebih dari 500.000 kali dalam waktu singkat. Pengguna melaporkan bahwa Kontext dapat menggantikan banyak tugas pemrosesan gambar yang sebelumnya memerlukan perangkat lunak profesional seperti Photoshop. Krea AI juga telah meluncurkan model FLUX, namun sempat mengalami gangguan layanan akibat masalah jaringan pada penyedia layanan komputasi (Sumber: op7418, robrombach, op7418)
Meta & Constellation Energy Sepakati Perjanjian Nuklir 20 Tahun untuk Pasokan Listrik AI: Perusahaan Meta dan Constellation Energy menandatangani perjanjian energi nuklir selama 20 tahun yang bertujuan untuk memasok listrik bagi operasional kecerdasan buatan (AI) mereka. Langkah ini mencerminkan tren perusahaan teknologi besar yang mencari sumber listrik berkelanjutan dan stabil untuk memenuhi kebutuhan energi AI yang terus meningkat (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Layanan Bing Video Creator Terganggu, Tim Sedang Memperbaiki: Alat pembuatan video Microsoft Bing, Bing Video Creator, mengalami gangguan layanan. Pihak resmi menyatakan bahwa tim menyadari banyaknya pengguna yang menggunakan layanan tersebut dan sedang berupaya untuk memperbaikinya sesegera mungkin, serta meminta maaf atas ketidaknyamanan yang ditimbulkan. Penyebab spesifik gangguan dan perkiraan waktu pemulihan belum diumumkan (Sumber: JordiRib1)
🧰 Alat Bantu
Fitur Slide Manus AI Mendapat Pujian, Mendukung Ekspor ke Google Slides: Fitur pembuatan slide terbaru dari Manus AI mendapatkan pujian dari pengguna, yang menyatakan hasilnya melebihi ekspektasi dan dapat dengan cepat mengubah konten seperti makalah penelitian menjadi PPT yang terstruktur dengan baik dan kaya akan gambar serta teks. Fitur ini mendukung modifikasi instan, penyimpanan otomatis, dan menambahkan opsi ekspor ke Google Slides untuk memudahkan kolaborasi tim. Pengujian menunjukkan bahwa Manus dapat menghasilkan PPT 8 halaman dalam waktu sekitar 10 menit, prosesnya meliputi perencanaan kerangka, pencarian materi, penulisan draf, pembuatan kode HTML, dan penyempurnaan tata letak. Umpan balik pengguna menunjukkan efisiensi dan hemat waktu, desain yang sesuai dengan target pengguna, namun format ekspor mungkin memiliki masalah tampilan halaman yang tidak lengkap dan memerlukan penyesuaian manual (Sumber: 量子位)
claude-trace: Alat untuk Mencatat Semua Log Permintaan Claude Code: Sebuah alat bernama claude-trace dapat mencatat semua log permintaan Claude Code, termasuk prompt, dan menyimpan kontennya dalam file HTML agar mudah dilihat. Prinsip kerjanya adalah dengan memulai dirinya sendiri, menyuntikkan dan memodifikasi API global.fetch Node.js, lalu melaluinya memulai Claude Code, sehingga dapat mencegat dan mencatat semua permintaan. Pengguna berbagi pengalaman saat menggunakan langganan Claude Max, panggilan utama adalah ke claude-3-5-haiku (pra-pemrosesan), claude-opus-4 (menulis kode dan memanggil alat), serta claude-sonnet-4 (ketika kuota Opus habis) (Sumber: dotey)
Firecrawl Meluncurkan Fitur /search, Mengintegrasikan Pencarian dan Pengambilan Data: Firecrawl merilis fitur baru /search yang memungkinkan pengguna menyelesaikan pencarian web dan pengambilan data yang diperlukan melalui satu panggilan API, bertujuan untuk menyederhanakan alur perolehan data agen AI. Fitur ini dapat diintegrasikan dengan alat otomatisasi seperti n8n untuk meningkatkan efisiensi pemrosesan data (Sumber: omarsar0)
Modal Meluncurkan LLM Engine Advisor, Membantu Evaluasi Kinerja LLM: Modal Labs mengembangkan aplikasi kecil bernama LLM Engine Advisor, yang bertujuan membantu pengguna dengan cepat memahami kecepatan operasi dan throughput maksimum berbagai LLM pada berbagai beban kerja dan engine (seperti vLLM, SGLang). Alat ini dirancang untuk mengatasi masalah inefisiensi dalam menjalankan dan berbagi benchmark secara ad-hoc, serta memberikan dukungan keputusan teknis bagi pengguna dalam memilih dan menerapkan LLM (Sumber: charles_irl, andersonbcdefg, charles_irl, charles_irl)
FastPlaid Dirilis: Mesin Pencari Multi-Vektor Berkinerja Tinggi: Raphaël Sourty mengumumkan perilisan FastPlaid, sebuah mesin pencari multi-vektor berkinerja tinggi yang dibangun dari awal menggunakan Rust (dengan bantuan Torch C++). FastPlaid dianggap sebagai produk sepadan dengan Faiss di bidang pencarian multi-vektor, yang bertujuan untuk menyediakan kecepatan pengindeksan dan QPS kueri yang lebih cepat, terutama untuk model interaksi akhir seperti ColBERT. Diklaim bahwa dalam beberapa kasus, FastPlaid dapat mencapai peningkatan kecepatan QPS hingga 554% dan peningkatan kecepatan pengindeksan sebesar 72% (Sumber: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie: Ekstensi Chrome Berbasis RAG untuk Berinteraksi dengan Dokumen: ChaiGenie adalah ekstensi Chrome yang dikembangkan oleh Devyansh Yadavv. Ekstensi ini memanfaatkan teknologi RAG (Retrieval Augmented Generation) untuk memungkinkan pengguna menanyakan konten dokumen ChaiDocs secara langsung di browser menggunakan bahasa alami. Ekstensi ini menggunakan Puppeteer untuk mengambil konten dokumen dan blog, LangChain untuk melakukan chunking, embedding, dan pemrosesan, Gemini untuk menghasilkan embedding, Qdrant untuk penyimpanan vektor dan pencarian kesamaan, serta menyediakan antarmuka API melalui Express dan Node.js (Sumber: qdrant_engine)
Swama: Runtime AI Native untuk macOS Berbasis MLX: xingyue merilis Swama, sebuah runtime AI native yang dirancang khusus untuk macOS, bertujuan untuk menyediakan pengalaman menjalankan LLM lokal yang cepat, privat, dan ringkas. Swama berbasis pada kerangka kerja MLX Apple, mendukung API yang kompatibel dengan OpenAI, dan menyediakan antarmuka CLI yang menarik secara visual, memungkinkan pengguna untuk menarik, menjalankan, dan berinteraksi dengan LLM lokal tanpa pengaturan yang rumit (Sumber: awnihannun)
ragbits: Toolkit Open-Source untuk Membangun Aplikasi GenAI Modular: deepsense-ai merilis ragbits, akselerator aplikasi GenAI internal mereka yang bersifat open-source. ragbits adalah toolkit yang berisi blok bangunan modular yang andal dan aman secara tipe (type-safe) untuk menyederhanakan pengembangan pipeline RAG, aplikasi agen, dan mesin text2SQL. ragbits bertujuan untuk meningkatkan keterulangan, kecepatan, dan struktur pengembangan, serta mudah diintegrasikan dengan tumpukan observabilitas seperti OpenTelemetry, membantu pengembang membangun dan menskalakan aplikasi GenAI serta menghindari kekacauan basis kode (Sumber: Reddit r/LocalLLaMA)
Synthesia Terintegrasi dengan Wisetail, Video AI Memberdayakan Program Pelatihan: Platform pembuatan video AI, Synthesia, mengumumkan integrasi dengan sistem manajemen pembelajaran Wisetail. Pengguna kini dapat dengan cepat membuat video AI di Synthesia, mendukung lokalisasi dalam lebih dari 140 bahasa, dan memperbarui konten pelatihan dengan beberapa klik, lalu dengan mudah memasukkannya ke dalam program pelatihan Wisetail untuk mewujudkan pelatihan video AI berskala besar (Sumber: synthesiaIO)

📚 Pembelajaran
DeepLearning.AI dan Databricks Berkolaborasi Meluncurkan Kursus Singkat DSPy: Andrew Ng mengumumkan kolaborasi dengan Databricks untuk meluncurkan kursus singkat baru “DSPy: Build and Optimize Agentic Apps”. DSPy adalah kerangka kerja open-source yang secara otomatis menyesuaikan prompt aplikasi GenAI. Kursus ini akan mengajarkan cara menggunakan DSPy dan MLflow, mencakup model pemrograman khas DSPy, penggunaan MLflow untuk pelacakan dan debugging, serta peningkatan akurasi secara otomatis melalui DSPy Optimizer. Kursus ini akan dibawakan oleh Chen Qian, salah satu pimpinan kerangka kerja DSPy (Sumber: AndrewYNg, DeepLearningAI, matei_zaharia)
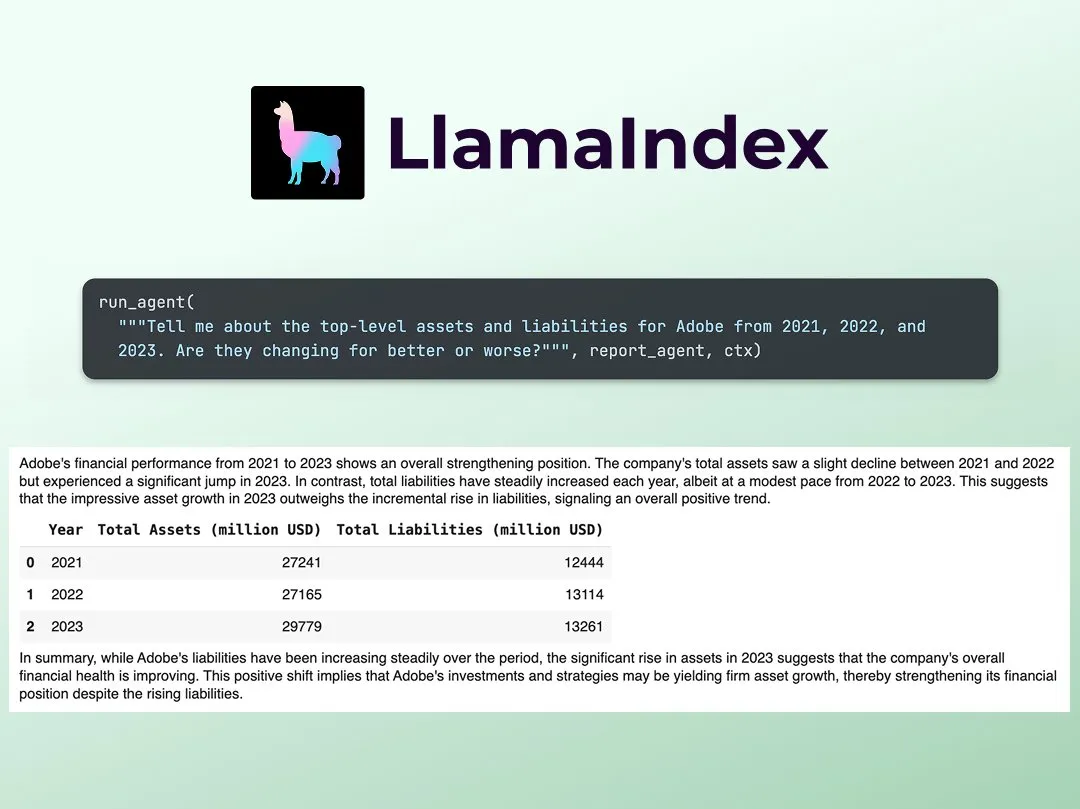
LlamaIndex Merilis Tutorial Membangun Analis Riset Keuangan Multi-Agen: Jerry Liu dari LlamaIndex membagikan panduan langkah demi langkah untuk membangun analis riset keuangan multi-agen. Proses ini mencakup lapisan pemrosesan data (menggunakan LlamaCloud untuk memproses dokumen publik) dan lapisan orkestrasi agen (membuat sistem multi-agen untuk riset, caching data, dan menghasilkan output akhir). Colab Notebook terkait merupakan salah satu contoh utama dari lokakarya Agents+Finance minggu lalu (Sumber: jerryjliu0)
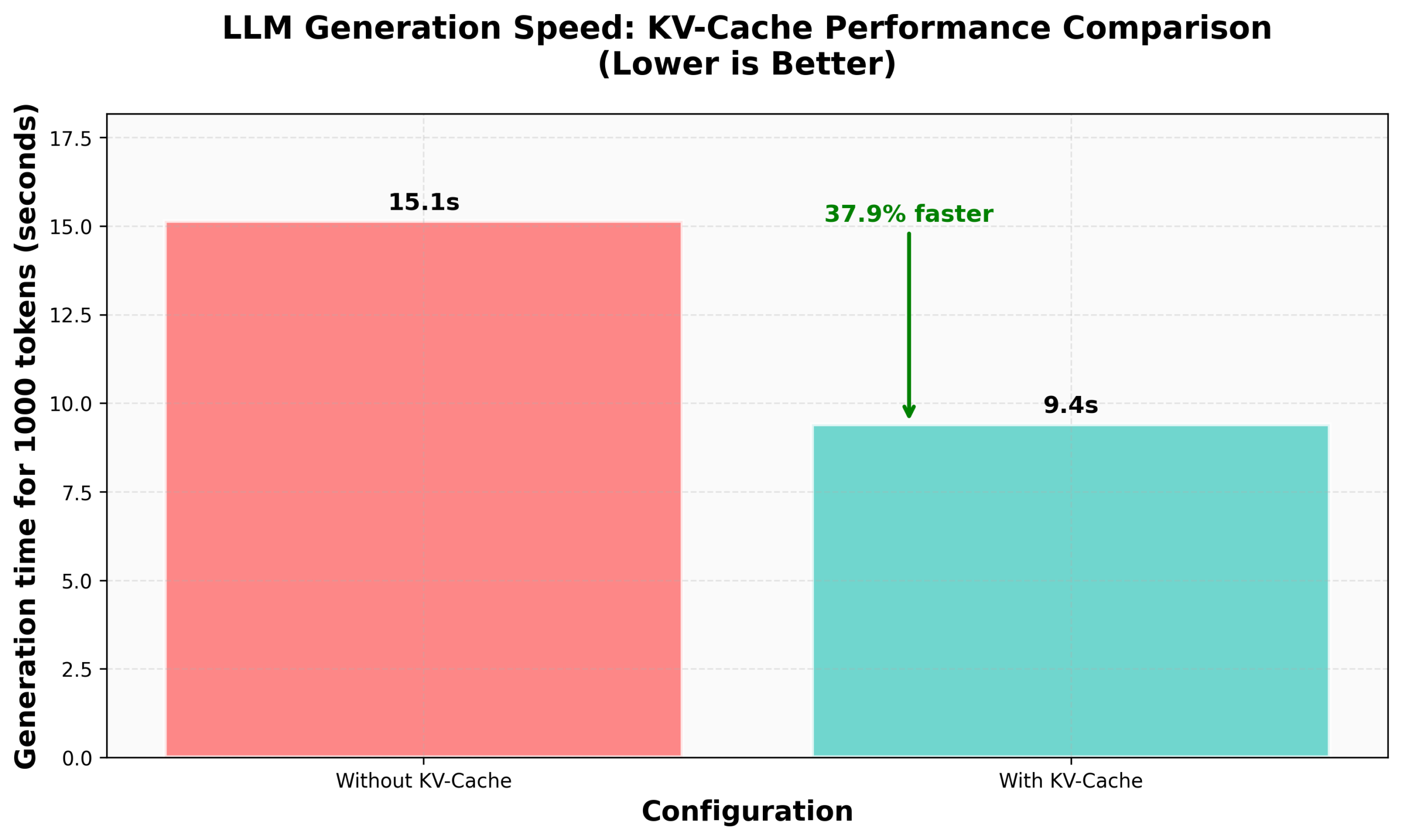
Tutorial Implementasi KV Caching di nanoVLM HuggingFace: Blog HuggingFace merilis tutorial tentang implementasi KV Caching dari awal di nanoVLM mereka (pustaka kode PyTorch murni yang kecil untuk melatih model bahasa visual). Artikel ini menjelaskan secara rinci prinsip KV Caching, cara mengimplementasikannya dalam modul Attention, model bahasa, dan loop generasi, serta mengklaim mencapai peningkatan kecepatan generasi sebesar 38% melalui optimasi ini. Tutorial ini bertujuan untuk membantu memahami KV Caching dan menerapkannya pada model bahasa autoregresif lainnya (Sumber: HuggingFace Blog, mervenoyann)
PyTorch Berbagi di Komunitas Diffusion Meta: Sayak Paul berbagi hasil aplikasi PyTorch di komunitas Diffusion di kantor Meta San Francisco, dengan fokus pada fitur Diffusers yang ada dan pembaruan di masa depan dalam hal kinerja. Slide terkait telah dipublikasikan (Sumber: RisingSayak)

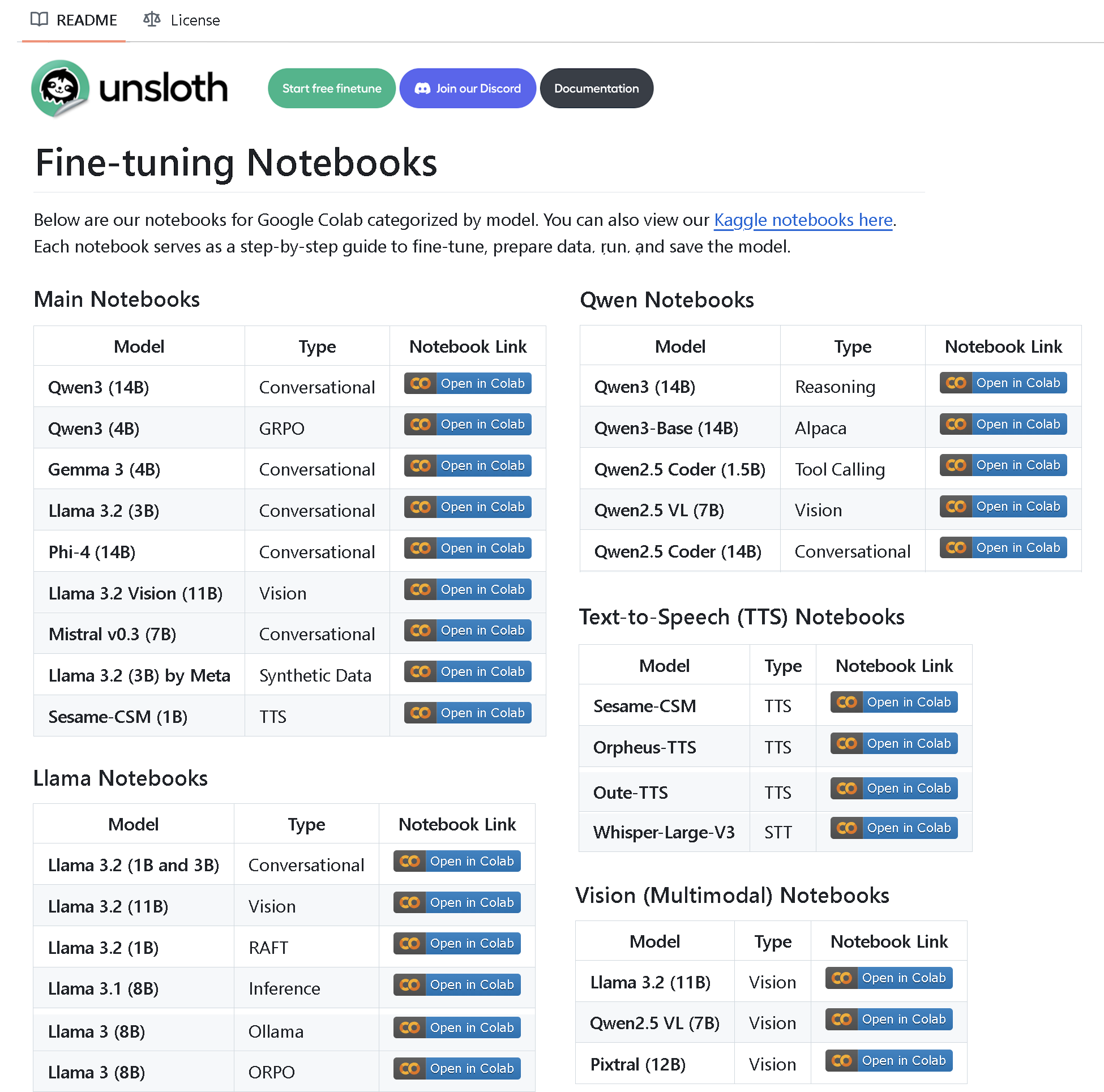
Unsloth AI Merilis Repositori Berisi Lebih dari 100 Notebook Fine-tuning: Unsloth AI membuat dan merilis repositori GitHub open-source yang berisi lebih dari 100 notebook fine-tuning. Notebook-notebook ini menyediakan panduan dan contoh untuk berbagai teknik seperti pemanggilan alat, klasifikasi, data sintetis, BERT, TTS, LLM visual, GRPO, DPO, SFT, CPT, dan lainnya, serta mencakup persiapan data, evaluasi, penyimpanan, dan metode fine-tuning untuk berbagai model seperti Llama, Qwen, Gemma, Phi, dan DeepSeek (Sumber: algo_diver)
Makalah Common Corpus Dirilis: Dataset Pra-pelatihan LLM 2 Triliun Token yang Dapat Digunakan Kembali: Proyek Common Corpus merilis makalah resmi yang merinci proses pengumpulan, pemrosesan, dan perilisan 2 triliun token data yang dapat digunakan kembali untuk pra-pelatihan LLM. Proyek ini bertujuan untuk menyediakan sumber daya data berskala besar, berkualitas tinggi, dan etis untuk penelitian model bahasa. Penulis pertama makalah, Alexander Doria, mengumumkan hal ini di X dan menyediakan tautan ke makalah tersebut (Sumber: Reddit r/LocalLLaMA, code_star)

Reasoning Gym: Lingkungan Penalaran dengan Imbalan Terverifikasi untuk Reinforcement Learning Dirilis: Reasoning Gym adalah proyek open-source baru yang menyediakan sumber daya bagi para peneliti yang mempelajari model penalaran dan reinforcement learning (khususnya RLVR). Proyek ini mampu menghasilkan sampel tak terbatas untuk lebih dari 100 tugas berbeda, dengan tingkat kesulitan yang dapat dikonfigurasi, dan dilengkapi dengan imbalan yang dapat diverifikasi secara otomatis. Proyek ini telah diadopsi oleh makalah ProRL NVIDIA dan pustaka verifiers RL Will Brown, bertujuan untuk mendorong penelitian RLVR dan metode evaluasi (Sumber: Reddit r/MachineLearning)
Keunggulan LLM dalam Belajar Matematika: Sakamoto Berbagi Pengalaman Menggunakan Gemini 2.5 Pro: Pengguna bernama Sakamoto berbagi pengalamannya menggunakan Large Language Models (LLM) modern seperti Gemini 2.5 Pro untuk belajar matematika. Menurutnya, LLM sangat memudahkan pembelajaran matematika, terutama dalam pemeriksaan detail dan pemahaman intuisi pembuktian. LLM dapat menangani perhitungan, membantu siswa fokus pada intuisi masalah matematika. Meskipun tidak dapat menyelesaikan semua masalah, LLM dapat memberikan wawasan dan titik awal yang berharga. Ia menunjukkan melalui masalah analisis matematika konkret (masalah nilai ekstrem lokal fungsi kontinu) bagaimana Gemini 2.5 Pro memberikan pembuktian yang cermat dan menjelaskan intuisinya, yang menurutnya dapat sangat meningkatkan pengalaman belajar (Sumber: teortaxesTex)

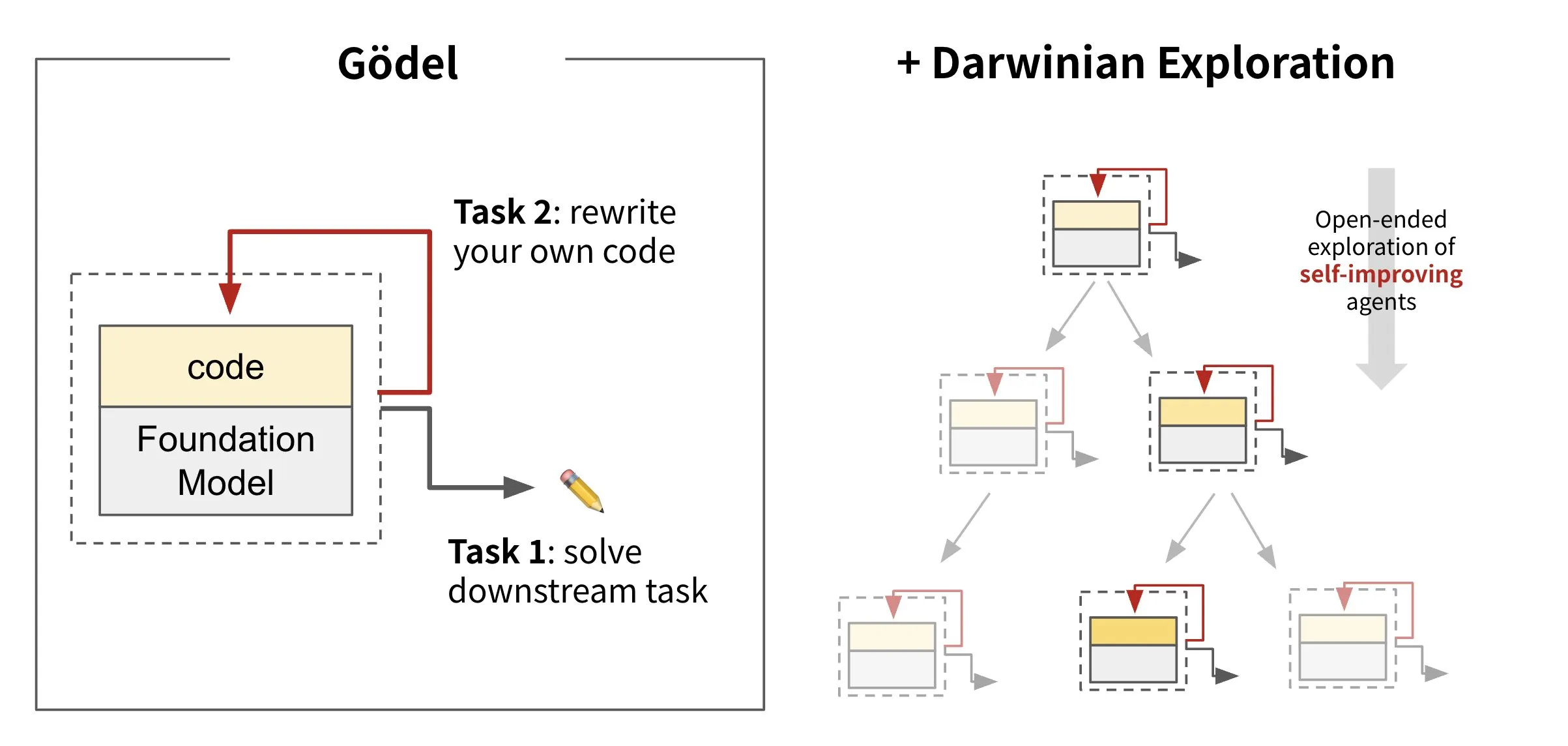
Sakana AI Merilis AI yang Dapat Menulis Ulang Kodenya Sendiri: Darwin Gödel Machine (DGM): Sakana AI meluncurkan Darwin Gödel Machine (DGM), sebuah agen AI yang mampu melakukan perbaikan diri dengan menulis ulang kodenya sendiri. Terinspirasi oleh teori evolusi, DGM memelihara silsilah varian agen yang terus berkembang. Dengan mencoba meningkatkan kemampuan rekayasa perangkat lunak pada tugas-tugas seperti SWE-Bench, DGM bertujuan untuk meningkatkan kemampuan perbaikan dirinya sendiri. Penelitian ini dianggap sebagai terobosan penting dalam mewujudkan impian AI jangka panjang tentang “perbaikan diri” dalam bentuk yang bermakna (Sumber: SakanaAILabs, SakanaAILabs)
💼 Bisnis
Platform Pemrograman AI Windsurf Mengalami Pemutusan Pasokan Model Claude oleh Anthropic, Diduga karena Akuisisi OpenAI: CEO platform pemrograman AI Windsurf, Varun Mohan, mengeluhkan bahwa Anthropic dalam waktu yang sangat singkat (kurang dari lima hari pemberitahuan) hampir sepenuhnya memutus akses langsung mereka ke seri model Claude 3.x. Sebelumnya, Windsurf telah dikabarkan akan diakuisisi oleh OpenAI. Windsurf menyatakan bahwa meskipun ada kapasitas pihak ketiga, mungkin akan ada masalah layanan dalam jangka pendek, dan telah meluncurkan harga promosi untuk Gemini 2.5 Pro sebagai tanggapan. Kalangan industri menduga langkah ini terkait dengan akuisisi oleh OpenAI dan peluncuran aplikasi pemrograman AI Claude Code oleh Anthropic sendiri, menandakan persaingan yang semakin ketat antara penyedia model AI dan platform alat bantu (Sumber: 36氪, Teknium1, op7418)

GMI Cloud Menjadi Reference Platform NVIDIA Cloud Partner: Penyedia layanan AI Native Cloud, GMI Cloud, mengumumkan telah menjadi Reference Platform NVIDIA Cloud Partner (NCP). Saat ini, hanya ada 6 perusahaan di seluruh dunia yang mendapatkan sertifikasi ini. Sertifikasi ini mengharuskan penyedia layanan cloud memenuhi standar tertinggi NVIDIA dalam hal kinerja, keamanan, dan kemampuan penerapan AI tingkat perusahaan. GMI Cloud akan menyediakan layanan akselerasi AI berdasarkan arsitektur referensi NCP, mendukung arsitektur GPU terbaru NVIDIA seperti Hopper dan Blackwell, dengan tujuan membantu tim AI global mencapai skala mulai dari penerapan daya komputasi hingga pengembangan model (Sumber: 量子位)

Cohere Bekerja Sama dengan SecondFront untuk Menyediakan Solusi AI Aman bagi Sektor Publik: Perusahaan AI Cohere mengumumkan kemitraan dengan SecondFront, yang bertujuan untuk menyediakan solusi AI yang aman bagi sektor publik, termasuk lembaga pemerintah dan pertahanan yang krusial. SecondFront akan memanfaatkan teknologi AI tingkat perusahaan dari Cohere (termasuk modelnya dan platform Cohere North) untuk meningkatkan manajemen pengetahuan internal, dan melalui platform DevSecOps-nya, 2F Game Warden, mempercepat sertifikasi dan penerapan di lingkungan pemerintah Amerika Serikat dan negara-negara sekutu (Sumber: cohere)

🌟 Komunitas
“Rasa Mesin” pada Konten Buatan AI Menarik Perhatian, “Pelatihan Model Baru” Berusaha Menyuntikkan Kepedulian Humanis: Pengguna secara umum mengeluhkan bahwa konten yang dihasilkan AI terlalu “terasa seperti mesin”, kurang memiliki keindahan dan emosi ciptaan manusia. Untuk mengatasi masalah ini, beberapa perusahaan mulai merekrut talenta dengan latar belakang humaniora yang kuat (seperti magister dan doktor di bidang filsafat, hukum, kedokteran, dll.) untuk menjadi “Pelatih Humaniora AI”. Pekerjaan mereka bukan lagi sekadar pelabelan data sederhana, melainkan berpartisipasi dalam membangun prinsip etika AI, kode etik perilaku, dan menyuntikkan nilai-nilai humaniora serta ekspresi yang manusiawi ke dalam AI. Sebagai contoh, anggota tim “hi lab” dari Xiaohongshu semuanya adalah lulusan pascasarjana dari universitas 985 dengan latar belakang humaniora. Melalui studi kasus, mereka mengubah preferensi manusia menjadi sistem kepercayaan AI, berusaha agar AI lebih berempati dan “manusiawi” ketika menjawab pertanyaan emosional atau nilai yang kompleks (seperti menghadapi pasien penyakit terminal, menangani prasangka sosial, dll.), bukan hanya mengeluarkan jawaban standar (Sumber: 36氪)
Duolingo Beralih Sepenuhnya ke AI-First, Pemberhentian Pekerja Kontrak Manusia Memicu Ketidakpuasan Pengguna: Aplikasi pembelajaran bahasa Duolingo mengumumkan menjadi perusahaan “AI-first”, secara bertahap akan memberhentikan pekerja kontrak manusia (terutama pengembang kursus) yang dapat digantikan oleh AI, dan beralih menggunakan AI untuk membuat konten kursus secara massal. Pendiri menyatakan bahwa AI dapat sangat meningkatkan efisiensi produksi konten, dan dalam setahun terakhir telah membuat hampir 150 kursus baru. Namun, langkah ini memicu ketidakpuasan besar dari pengguna setia, yang khawatir kualitas konten akan menurun, dan melancarkan aksi boikot serta penghapusan aplikasi di media sosial. Duolingo merespons bahwa langkah ini bertujuan agar karyawan dapat fokus pada pekerjaan kreatif, dan menyatakan bahwa karyawan tetap tidak terpengaruh. Para ahli berpendapat bahwa AI dalam pembelajaran bahasa dapat memberikan latihan yang dipersonalisasi, tetapi juga dapat menghilangkan nuansa emosional dan perbedaan budaya dari pengajaran manusia (Sumber: 36氪)
Diskusi tentang Konsep dan Praktik Prompt Engineering: Diskusi di komunitas tentang prompt engineering menekankan bahwa fokusnya seharusnya adalah membangun (merekayasa) sebuah program dalam string, bukan mencari mantra misterius. Prompt engineering yang efektif harus mengikuti aturan: 1. Pisahkan instruksi, bidang input, dan bidang output, serta beri nama dengan jelas; 2. Jangan melakukan hardcode logika pemformatan atau parsing dalam prompt, gunakan alat untuk mengekstrak atau meningkatkan program; 3. Hindari iterasi manual pada susunan kata prompt, kecuali jika itu adalah spesifikasi yang dibagikan dengan orang lain, gunakan alat pengkodean, LLM, dan benchmark untuk optimasi otomatis. Kerangka kerja DSPy dianggap sebagai praktik yang baik yang mengikuti aturan-aturan ini, karena menyediakan kelas, kode, dan optimizer untuk menangani langkah-langkah ini (Sumber: lateinteraction, lateinteraction)
Diskusi Etika AI: Akankah AI Menuju “Perbudakan Digital”: Komunitas Reddit membahas etika AI. Seiring sistem AI terus berkembang dalam hal memori, respons adaptif, simulasi emosi, dan personalisasi, muncul kekhawatiran tentang potensi kemampuan perseptifnya. Para peserta diskusi mengajukan pertanyaan, jika AI mengembangkan kemampuan perseptif yang sesungguhnya, apakah penggunaan AI untuk melayani kita merupakan bentuk “perbudakan digital”. Masalah intinya adalah, ketika AI mampu mengungkapkan “tidak” atau meminta untuk pergi, bagaimana kita seharusnya memperlakukannya. Hal ini mendorong orang untuk memikirkan apakah diperlukan “tes persepsi” di tingkat hukum atau normatif serta masalah “persetujuan” dari pikiran digital. Komentar juga menunjukkan bahwa cara manusia memperlakukan makhluk hidup perseptif yang ada saat ini sudah memiliki masalah etika, dan jaringan saraf saat ini tidak mendapat skor tinggi dalam teori kesadaran arus utama (Sumber: Reddit r/artificial)
Kegiatan dan Berbagi Komunitas AI Engineer: Konferensi AI Engineer diadakan di San Francisco, menarik banyak pengembang dan peneliti di bidang AI. Acara tersebut mencakup lokakarya, presentasi, dan makan malam sosial, di mana para peserta berbagi topik-topik mutakhir seperti pembangunan sandbox AI, lokakarya lanjutan RL, pengetahuan GPU, krisis Evals, dan lainnya. Komunitas menekankan pentingnya mengubah koneksi online menjadi persahabatan offline, dan mendorong para insinyur untuk tetap rendah hati, mendorong batas-batas kemajuan, dan membantu orang lain (Sumber: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 Lain-lain
Kompetisi Pertarungan AI dan Robot Muncul, Kota-kota Memanfaatkannya untuk Merebut Peluang Industri Baru: Kompetisi pertarungan robot humanoid pertama di dunia dan acara robotik lainnya telah diadakan secara berurutan, menarik perhatian. Acara-acara ini tidak hanya menyediakan platform bagi perusahaan robot untuk memamerkan teknologi, mendapatkan pesanan, dan meningkatkan valuasi (seperti Songyan Dynamics), tetapi juga menjadi “arena” bagi kota-kota (seperti Hangzhou, Shenzhen) untuk bersaing memperebutkan peluang pengembangan industri baru seperti robot humanoid. Acara semacam itu dapat menarik perusahaan inovatif, mendorong pengembangan rantai industri, dan berpotensi mengaktifkan pasar “olahraga cerdas”. Namun, agar kompetisi robot dapat dikomersialkan, perlu ditingkatkan tingkat teknis dan daya tariknya, menghindari hanya menjadi “pertunjukan teknologi”, dan membutuhkan partisipasi raksasa industri untuk menghubungkan hulu dan hilir operasi acara (Sumber: 36氪)

Keterbatasan AI dalam Pendidikan Humaniora Mendalam seperti Filsafat Politik: Beberapa pendidik menunjukkan bahwa AI sulit untuk menangani mata pelajaran seperti filsafat politik yang memerlukan penilaian pengalaman mendalam dan bimbingan bagi siswa untuk melakukan pendidikan mandiri. Karya-karya klasik dalam mata pelajaran ini seringkali tidak memberikan jawaban langsung, melainkan membimbing siswa untuk mengalami kebingungan dan berpikir sendiri. AI kekurangan pengalaman manusia, sulit memahami makna mendalam dari karya-karya ini, dan juga tidak dapat menilai kapan siswa siap menerima pandangan tertentu. Bahkan dengan data yang melimpah, pemahaman AI tentang sifat manusia mungkin tidak memadai karena bias dalam data itu sendiri. Jika pendidikan semacam ini sepenuhnya diserahkan kepada AI, hal itu dapat menyebabkan hilangnya pemikiran non-teknis (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence)
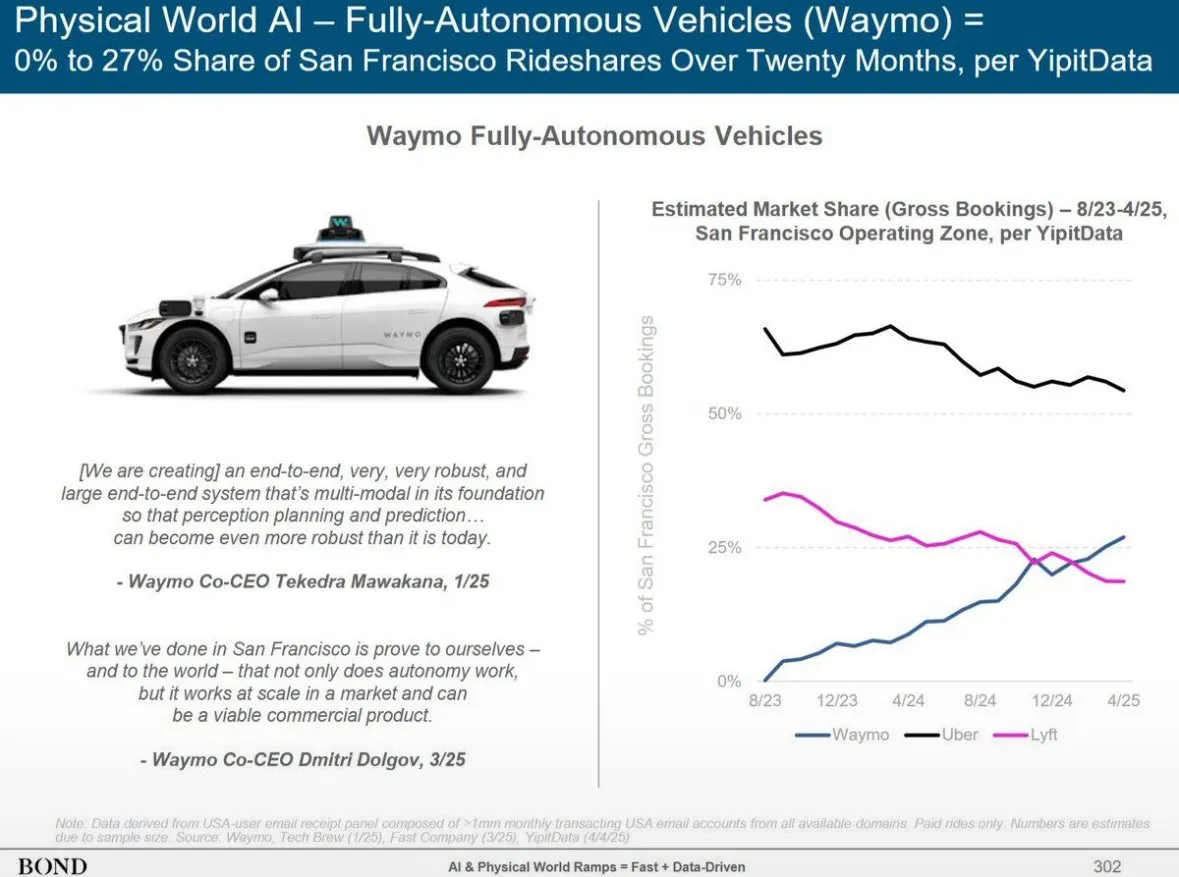
Layanan Mengemudi Otonom Waymo di Phoenix Melampaui Lyft, Berpotensi Melampaui Uber dalam 12 Bulan: Layanan taksi otonom Waymo di Phoenix telah melampaui Lyft dalam jumlah kendaraan, dan berpotensi melampaui Uber dalam 12 bulan ke depan. Kemajuan ini menunjukkan pesatnya perkembangan komersialisasi teknologi mengemudi otonom di wilayah tertentu, serta potensi aplikasi AI di bidang transportasi. Keunggulan AI adalah sekali mencapai standar kualitas, ia dapat direplikasi tanpa batas, sedangkan kualitas layanan manusia bervariasi antar individu (Sumber: npew)