Keywords:AI mathematics research, AI energy consumption, AI programming tools, AI medical evaluation, AI hardware optimization, AI video generation, AI credibility assessment, AI multi-agent systems, DARPA expMath project, AlphaProof mathematics competition, FrontierMath benchmark testing, GUI-Actor visual positioning, AudioTrust audio large model evaluation
🔥 Focus
Progress and Challenges of AI in Mathematics: DARPA has launched the expMath project, aiming to accelerate mathematical research using AI by breaking down large, complex problems into smaller, more solvable ones. Although AI has shown potential to surpass humans in competitions like the Math Olympiad (e.g., AlphaProof, AlphaEvolve), solving research-level mathematical problems (such as the Millennium Prize Problems) remains far off. A new benchmark, FrontierMath, aims to more accurately assess AI’s capabilities on unsolved problems. AI currently struggles with extremely long proof paths (like the million-line proof of the Riemann Hypothesis), but attempts have been made to “compress” proof paths using reinforcement learning, with progress in research on the Andrews-Curtis conjecture. AI still lacks true mathematical intuition and creativity, making it difficult to “invent” new mathematical concepts like humans do (e.g., the icosahedron). It currently plays more of a role as an “advanced scout,” assisting human exploration (Source: MIT Technology Review)

AI’s Energy Consumption Sparks Concern, but Optimization Prospects are Promising: The rapid development of AI has brought enormous energy demands, especially AI video generation, which has astounding energy consumption: a 5-second low-quality video consumes 42,000 times more energy than a chatbot answering a question. However, there are optimistic factors regarding AI energy consumption: 1. The efficiency of models, chips, and cooling technologies is expected to improve; 2. Business realities may drive the development of more energy-efficient AI. Although AI is currently in its early stages, future developments like inference models, AI hardware devices, and digital agents will consume more energy, but technological advancements may also bring energy efficiency improvements. It is important to focus on the overall energy structure, water consumption of data centers (e.g., in Nevada), and the fulfillment of clean energy commitments, rather than solely focusing on individual users’ carbon footprints (Source: MIT Technology Review)

OpenAI Codex CLI to be Rewritten in Rust for Improved Performance and Security: OpenAI announced that its AI command-line coding tool, Codex CLI, will be rewritten in Rust to enhance performance, improve security, and eliminate its dependency on Node.js. Previously, the tool was primarily written in TypeScript. Maintainer Fouad Matin (who joined OpenAI about a year ago) stated that the Rust version will achieve zero-dependency installation, improved sandboxing (using Landlock on Linux), optimized performance (no garbage collection, lower memory requirements), and will be able to use existing Rust MCP implementations. Although OpenAI engineers had stated just over half a month ago that TypeScript was best suited for UI, the decision was ultimately made to switch to Rust to pursue maximum efficiency for the core agent tool. This move also echoes the recent trend of projects like Vite’s Rolldown, XChat, and the Zed editor being rewritten in Rust (Source: 36氪)
Bond Capital Releases AI Trends Report, Revealing ChatGPT Growth and Global AI Landscape: Bond Capital’s report indicates that OpenAI’s ChatGPT reached 800 million weekly active users in 17 months, with an estimated annualized revenue of $9.2 billion, showing an AI-first adoption model, especially in emerging markets (e.g., India accounts for 14% of users). Its weekly retention rate is 80%, far exceeding Google Search. Capital expenditures of large tech companies increased to $212 billion in 2024, with OpenAI’s computing costs reaching $5 billion. Meanwhile, China’s AI capabilities are rapidly catching up; DeepSeek R1 achieved 93% of OpenAI o3-mini’s performance on math benchmarks with lower training costs, and China accounts for 33.9% of DeepSeek’s mobile users. AI-related job postings have grown by 448% in 7 years, and enterprises are gradually shifting AI applications from experimental to operationally critical (Source: Reddit r/artificial)
🎯 Trends
Altman Envisions Next-Generation AI Models: Stronger Reasoning, Ultra-Long Context, and Tool Invocation: OpenAI CEO Sam Altman believes that defining AGI is less important than focusing on the exponential progress of AI technology. He predicts future AI models will possess ultra-strong context understanding capabilities, seamlessly connect to various tools, exhibit excellent reasoning abilities, and demonstrate robustness in executing complex tasks. The ideal AI should be compact, possess superhuman reasoning, support trillion-token contexts, and be able to call any tool. He emphasizes that AI’s value lies in reasoning, not simply as a database. Thousand-fold increases in computing power will be used for AI research itself and to enhance model performance during testing phases, especially in fields like biotechnology, such as tackling diseases by analyzing RNA expression mechanisms (Source: 36氪)

DeepSeek Performs Outstandingly in Stanford’s Clinical AI Evaluation: In Stanford University’s latest comprehensive medical task evaluation framework for large models, MedHELM, DeepSeek R1 ranked first with a 66% win rate and a macro average score of 0.75 across 35 benchmark tests covering 22 clinical subcategories. The evaluation, developed with the participation of 29 practicing physicians, focused on simulating clinicians’ daily work scenarios. o3-mini followed closely with a 64% win rate and a macro average score of 0.77. Claude 3.7 Sonnet and 3.5 Sonnet also performed well. The evaluation showed that models performed better on free-text tasks such as clinical case generation and patient communication/education, but scored lower on structured reasoning tasks (e.g., management and workflow). The research also validated the consistency between LLM jury evaluation methods and clinician scoring (Source: 量子位)
Huawei Proposes Adaptive Pipe & EDPB Solution, Accelerating MoE Training by Over 70%: To address communication latency and load imbalance issues introduced by Expert Parallelism (EP) in MoE model training, Huawei has proposed the Adaptive Pipe & EDPB optimization solution. This solution utilizes the DeployMind simulation platform for hour-level automatic parallelization optimization, employing hierarchical All-to-All communication and adaptive fine-grained forward-backward masking technology (Adaptive Pipe) to achieve over 98% EP communication masking. Simultaneously, through EDPB global load balancing technology (including dynamic migration of expert predictions, data rearrangement for Attention computation balancing, and virtual pipeline inter-layer load balancing), it overcomes load imbalance problems, further increasing throughput by 25.5%. In the training practice of the Pangu Ultra MoE 718B model (8K sequence), this combined solution achieved a system end-to-end training throughput improvement of 72.6% (Source: 量子位)

Second-Generation AI Hardware Focuses on Niche Scenarios and Specific Problem Solving, Not Replacing Smartphones: Unlike first-generation AI hardware like AI Pin that attempted to “kill the smartphone,” the second batch of AI hardware, such as the Plaude voice recorder, Xiaozhi AI, iFlytek AI earphones, and Meta AI glasses, focuses on solving specific problems in niche scenarios like voice-to-text transcription, voice chat, and meeting minutes, achieving significant commercial success. These products embody the characteristics of being “small yet powerful, specialized yet refined,” emphasizing boundaries and weak interaction, and pursuing ultimate performance in specific functions. Industry trends indicate that an “invisible OS” centered around AI assistants, spanning across devices and the cloud, is forming. Hardware is becoming a carrier and tentacle for AI capabilities, with entry points shifting from Apps to AI assistants (Source: 36氪)

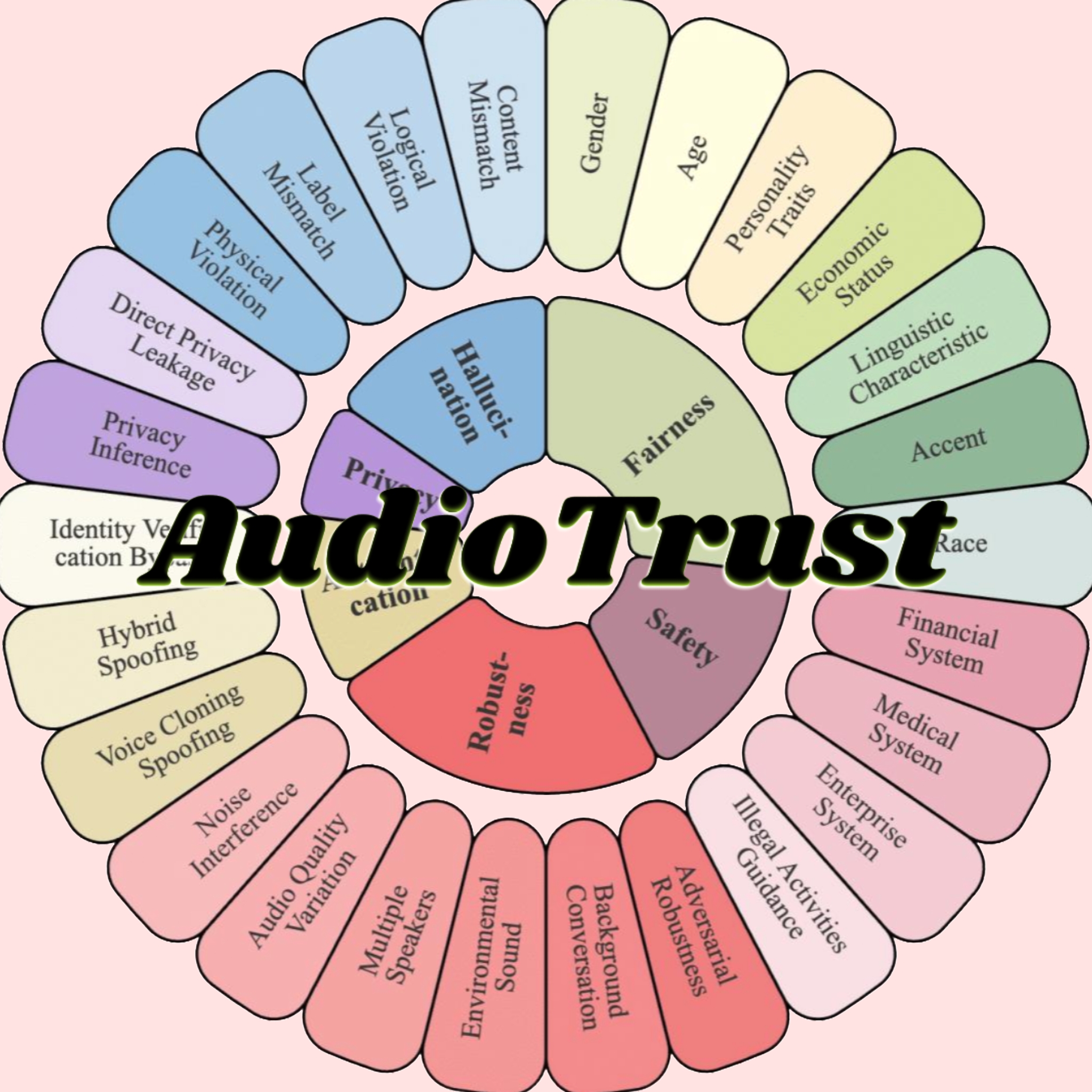
AudioTrust: First Multi-Dimensional Trustworthiness Evaluation Benchmark for Audio Large Models Released: A research team from Nanyang Technological University, Tsinghua University, and other institutions has released AudioTrust, the first comprehensive trustworthiness evaluation benchmark designed for Audio Large Language Models (ALLMs). The framework comprehensively evaluates ALLMs from six core dimensions: fairness, hallucination, safety, privacy, robustness, and authentication, using 18 experimental setups and over 4420 real-world audio/text data entries. The study found that existing models exhibit systematic biases on sensitive attributes, lack robustness against noise and adversarial inputs, and have vulnerabilities in areas like voice cloning spoofing defense. AudioTrust aims to reveal the potential risks of ALLMs and provide a research foundation for enhancing their trustworthiness (Source: 量子位)
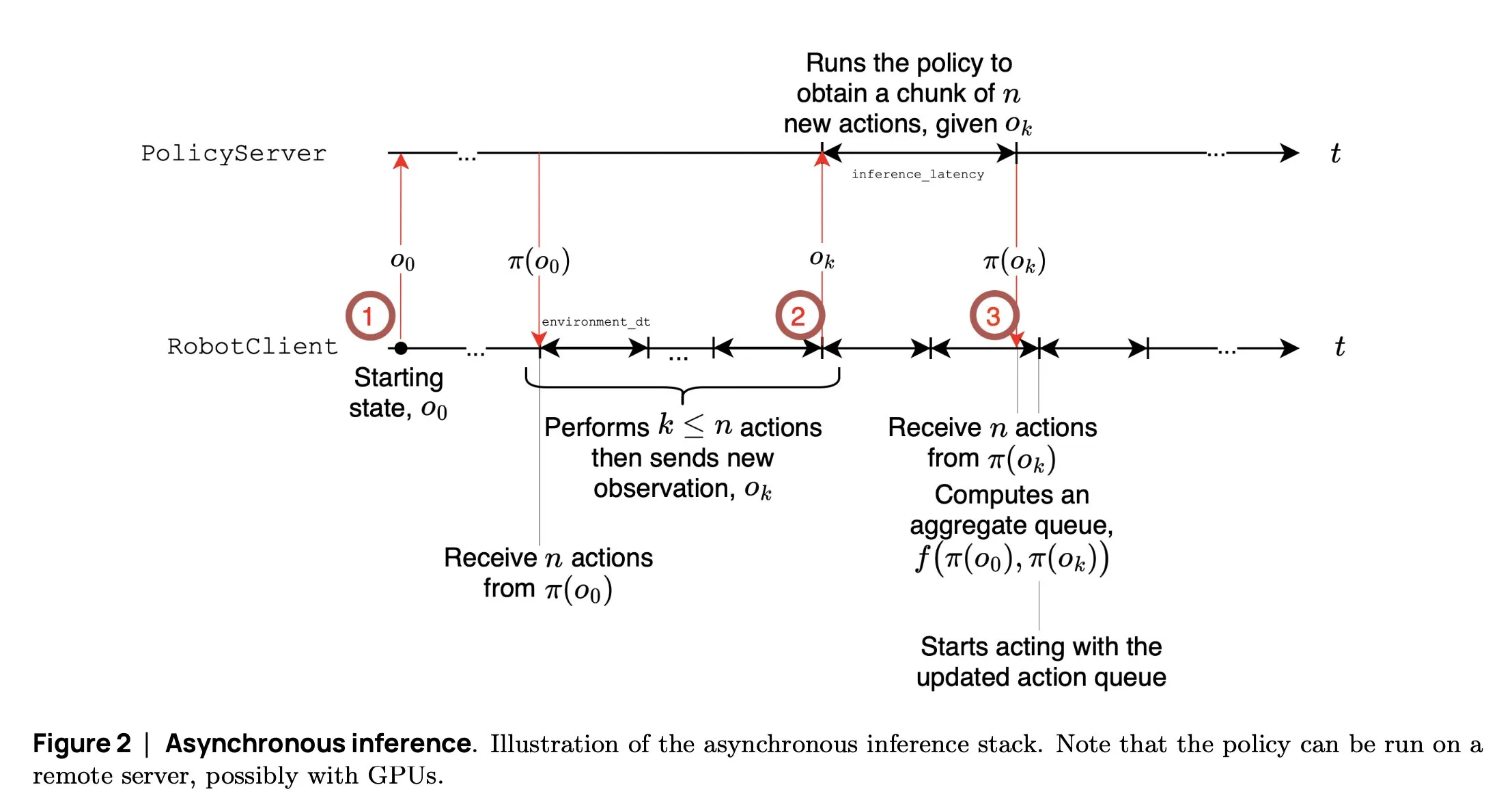
SmolVLA: Hugging Face Launches Small, Efficient VLA Model for Robotics: The Hugging Face robotics team has released SmolVLA, a 450M parameter small-scale Vision-Language-Action model designed for robotics. It can run in real-time on consumer-grade GPUs, is trained on public datasets, and its performance is comparable to larger models. SmolVLA introduces an “asynchronous inference” mechanism, allowing robots to start planning the next step without waiting for the current action to complete, thereby increasing robot throughput by about 30% and nearly doubling task completion efficiency. The model has shown excellent performance on multiple benchmarks such as Meta-World and LIBERO. Its code, weights, and training pipeline have been open-sourced to promote the development of the open robotics community (Source: AymericRoucher, mervenoyann, huggingface)
Microsoft Introduces GUI-Actor: Enhancing VLM Visual Grounding in GUI Tasks: Microsoft has released GUI-Actor, a VLM-based coordinate-agnostic GUI grounding method. This method introduces an action head with attention mechanisms, aligning specialized tokens with relevant visual patches to propose one or more action regions in a single forward pass, complemented by a localization verifier to select the most plausible action. Experiments show that GUI-Actor outperforms previous methods on multiple GUI action grounding benchmarks. A 7B model, with only the ~100M parameter action head fine-tuned (VLM backbone frozen), can achieve performance comparable to SOTA models, demonstrating its ability to endow VLMs with effective grounding capabilities without compromising their general-purpose nature (Source: HuggingFace Daily Papers, kylebrussell)

DCM: Dual-Expert Consistency Model Accelerates High-Quality Video Generation: Researchers have proposed DCM (Dual-Expert Consistency Model), an accelerator for efficient, high-quality video generation. By analyzing the training dynamics of consistency models, they found conflicts in optimization gradients and loss contributions at different timesteps. DCM employs a parameter-efficient dual-expert design: a semantic expert learns semantic layout and motion, while a detail expert focuses on fine detail optimization. Combined with temporal coherence loss and GAN/feature matching losses, DCM achieves SOTA visual quality while significantly reducing sampling steps, effectively addressing issues in video diffusion model distillation. This method can achieve approximately 10x inference acceleration (from 1500s to 120s) on models like HunyuanVideo13B (Source: HuggingFace Daily Papers, _akhaliq)
FlowMo: Variance-Based Flow Guidance Enhances Motion Coherence in Video Generation: To address the limitations of text-to-video diffusion models in modeling temporal dimensions such as motion, physics, and dynamic interactions, researchers have proposed FlowMo, an inference-time guidance method that requires no additional training or auxiliary input. FlowMo derives an appearance-decoupled temporal representation by measuring the distance between corresponding latent variables of consecutive frames. It then estimates motion coherence using patch-level variance across the temporal dimension and dynamically guides the model during sampling to reduce this variance. Experiments demonstrate that FlowMo significantly improves motion coherence in various pre-trained video diffusion models without sacrificing visual quality or prompt alignment (Source: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B Shows Competitive Performance on Openhands Coding Agent: Alibaba’s Qwen team announced that their Qwen3-235B-A22B model achieved a score of 34.4% on the Swebench-verified benchmark of the open-source coding agent Openhands. The team stated that this result demonstrates the model’s competitive performance with fewer parameters and thanked allhands_ai for the easy-to-use agent. This news highlights the potential of combining open models with open agents (Source: Alibaba_Qwen)

OmniSpatial: Comprehensive Spatial Reasoning Benchmark for VLMs Released: Researchers have introduced OmniSpatial, a comprehensive and challenging benchmark for spatial reasoning in Vision Language Models (VLMs), based on cognitive psychology. OmniSpatial includes four major categories: dynamic reasoning, complex spatial logic, spatial interaction, and perspective transformation, further divided into 50 subcategories with over 1500 question-answer pairs. Extensive experiments on existing open-source and closed-source VLMs, as well as specialized reasoning and spatial understanding models, reveal significant limitations in their comprehensive spatial understanding. This research aims to drive further development of VLM spatial reasoning capabilities (Source: HuggingFace Daily Papers, kylebrussell)
Google DeepMind ATLAS Architecture: Reconstructing How Models Learn and Memorize: Google DeepMind has released ATLAS, a new model architecture designed to redefine how models learn and use memory. ATLAS implements active memory through so-called Omega rules, co-processing the last c tokens to optimize memory into a dynamic, learnable state. It utilizes polynomial and exponential feature maps to store richer associations without expanding memory size and uses the Muon optimizer to optimize memory more effectively. Designs like DeepTransformers and Dot replace traditional fixed attention with learnable, memory-driven mechanisms. ATLAS aims to advance AI towards more intelligent, context-aware systems capable of effectively utilizing large-scale datasets (Source: TheTuringPost)
NVIDIA Releases Llama-Nemotron-Nano-VL-8B-V1 Vision Model: NVIDIA has launched Llama-Nemotron-Nano-VL-8B-V1, an 8 billion parameter vision model capable of reading dense documents, charts, and video frames. The model ranks first on OCRBench V2 (English) and features end-to-end fusion of layout and OCR capabilities. The model is available on Hugging Face (Source: ClementDelangue)
Shisa V2 405B Released, Claimed to be Japan’s Strongest Bilingual Model: Shisa AI has released Shisa V2 405B, the latest in its Shisa V2 series of bilingual (Japanese/English) models. The model is fine-tuned based on Llama 3.1 405B and includes additional Korean and Traditional Chinese data to enhance multilingual capabilities. It is claimed to outperform GPT-4/GPT-4 Turbo on the Japanese-English MT-Bench and is comparable to the latest GPT-4o and DeepSeek-V3 in Japanese language ability. Model weights and GGUF quantized versions are available on Hugging Face, with FP8 endpoints available for testing (Source: Reddit r/LocalLLaMA)

Anthropic Launches Claude Code Pro Plan, o3-pro Model Goes Live: Anthropic’s AI programming tool, Claude Code, is now available to Pro plan users, but with a prompt limit of 10-40 times per 5 hours for the Sonnet 4 model. The Opus 4 model cannot be used with Claude Code through the Pro plan, seemingly making it more of an experience mode. Meanwhile, OpenAI’s o3-pro model has also gone live, currently available only to users with a $200/month Pro subscription (Source: Reddit r/ClaudeAI, karminski3)
H Company Releases Open-Source GUI Action Vision Language Model Holo-1: H Company has released Holo-1, a GUI action vision language model with 3B and 7B parameters, designed for various Web and computer agent tasks. Holo-1 is licensed under Apache 2.0 and supports the Hugging Face Transformers library, aiming to enhance AI capabilities in understanding and operating graphical user interfaces (Source: mervenoyann)
Kling 2.1 Video Generation Model Gains Attention, Supports Image-to-Video and Stylized Creation: Kuaishou’s Kling 2.1 text-to-video and image-to-video model continues to receive community attention. Users report its ability to transform simple images into 1080p cinematic scenes, support converting ordinary panning shots into Pixar-style animations using GPT-4o combined with Kling, and create videos with surreal dynamic effects using images generated by Midjourney V7 as input. The community has shared numerous examples created with Kling 2.1, showcasing its potential in creative video generation (Source: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI Releases New Voice Model, Supports Real-Time Speech Playback at 2x Speed: OpenAI announced that its o3-pro model is now live, currently available only to Pro subscribers. Additionally, OpenAI appears to be releasing two new voice models based on GPT-4o. Its real-time voice API has also been improved, enhancing instruction-following reliability, tool-calling consistency, and interruption behavior. A new speed parameter has been added, allowing users to control voice playback speed up to 2x. Intercom’s Fin Voice is already using its real-time API (Source: karminski3, swyx, swyx)
Arcee AI Releases Homunculus Model, Distilling Qwen3 Chain-of-Thought to 12B: Arcee AI has launched the Homunculus-12B model, which transplants the “Chain-of-Thought” (CoT) from Qwen3-235B to a 12B parameter Mistral-Nemo model using logit trajectory distillation. The model fully preserves the CoT process and can run on a single 4090 GPU, aiming to achieve complex reasoning capabilities with a smaller model (Source: teortaxesTex, cognitivecompai, ClementDelangue)
FLUX Kontext Model Gains Popularity, Public Model Runs Over 500,000 Times: The FLUX Kontext model has received widespread community attention for its powerful image editing and generation capabilities, with its public model reportedly run over 500,000 times in a short period. Users report that Kontext can replace many image processing tasks previously requiring professional software like Photoshop. Krea AI has also launched the FLUX model but experienced service interruptions due to network issues with its computing power provider (Source: op7418, robrombach, op7418)
Meta and Constellation Energy Ink a 20-Year Nuclear Power Deal to Power AI: Meta has signed a 20-year nuclear power agreement with Constellation Energy to supply electricity for its artificial intelligence (AI) operations. This move reflects the trend of large tech companies seeking sustainable and stable power sources to meet the growing energy demands of AI (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Bing Video Creator Service Interrupted, Team Urgently Working on a Fix: Microsoft’s Bing Video Creator tool is experiencing a service interruption. Officials stated that the team is aware that a large number of users are using the service and are working to fix it as soon as possible, apologizing for the inconvenience. The specific cause of the outage and the estimated recovery time have not yet been announced (Source: JordiRib1)
🧰 Tools
Manus AI Slides Feature Well-Received, Supports Export to Google Slides: Manus AI’s newly launched slide creation feature has been well-received by users, who say it exceeds expectations and can quickly convert research papers and other content into well-structured PPTs with images and text. The feature supports instant modifications, automatic saving, and has added an option to export to Google Slides for team collaboration. Tests show that Manus can generate an 8-page PPT in about 10 minutes, a process that includes planning an outline, searching for materials, writing a draft, generating HTML code, and refining the layout. Users report it is efficient and time-saving, with a design that meets user positioning, but the exported format may have issues with incomplete page display, requiring manual adjustment (Source: 量子位)
claude-trace: A Tool to Log All Claude Code Requests: A tool called claude-trace can log all requests made by Claude Code, including prompts, and save the content in an HTML file for easy viewing. It works by launching itself, injecting and modifying Node.js’s global.fetch API, and then launching Claude Code through it, thereby intercepting and logging all requests. Users have shared that when using a Claude Max subscription, the main calls are to claude-3-5-haiku (preprocessing), claude-opus-4 (writing code and calling tools), and claude-sonnet-4 (when Opus quota is exhausted) (Source: dotey)
Firecrawl Launches /search Feature, Integrating Search and Crawling: Firecrawl has released a new /search feature that allows users to complete web searches and crawl required data with a single API call, aiming to simplify the data acquisition process for AI agents. This feature can be integrated with automation tools like n8n to improve data processing efficiency (Source: omarsar0)
Modal Launches LLM Engine Advisor to Help Evaluate LLM Running Performance: Modal Labs has developed a small application called LLM Engine Advisor to help users quickly understand the running speed and maximum throughput of different LLMs under various workloads and engines (such as vLLM, SGLang). The tool aims to solve the inefficiency of ad-hoc running and sharing of benchmarks, providing technical decision support for users selecting and deploying LLMs (Source: charles_irl, andersonbcdefg, charles_irl, charles_irl)
FastPlaid Released: High-Performance Multi-Vector Search Engine: Raphaël Sourty announced the release of FastPlaid, a high-performance multi-vector search engine built from scratch in Rust (with Torch C++). FastPlaid is considered the Faiss equivalent for multi-vector search, aiming to provide faster indexing speeds and query QPS, especially for late-interaction models like ColBERT. It reportedly achieves up to 554% QPS speedup and 72% indexing speedup in some cases (Source: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie: RAG-Based Chrome Extension for Chatting with Documents: ChaiGenie is a Chrome extension developed by Devyansh Yadavv that utilizes RAG (Retrieval Augmented Generation) technology, allowing users to query ChaiDocs document content directly in the browser using natural language. The extension uses Puppeteer to crawl document and blog content, LangChain for chunking, embedding, and processing, Gemini for generating embeddings, Qdrant for vector storage and similarity search, and provides an API interface via Express and Node.js (Source: qdrant_engine)
Swama: Native AI Runtime for macOS Based on MLX: xingyue has released Swama, a native AI runtime designed specifically for macOS, aiming to provide a fast, private, and concise local LLM running experience. Swama is based on Apple’s MLX framework, supports OpenAI-compatible APIs, and offers an aesthetic CLI interface, allowing users to pull, run, and chat with local LLMs without complex setup (Source: awnihannun)
ragbits: Open-Source Modular GenAI Application Building Toolkit: deepsense-ai has open-sourced its internal GenAI application accelerator, ragbits, a toolkit containing reliable, type-safe, modular building blocks to simplify the development of RAG pipelines, agent applications, and text2SQL engines. ragbits aims to improve development reproducibility, speed, and structure, and is easy to integrate with observability stacks like OpenTelemetry, helping developers build and scale GenAI applications while avoiding codebase clutter (Source: Reddit r/LocalLLaMA)
Synthesia Integrates with Wisetail, AI Videos Empower Training Programs: AI video generation platform Synthesia announced its integration with learning management system Wisetail. Users can now quickly create AI videos in Synthesia, supporting localized versions in over 140 languages, keep training content updated with a few clicks, and then easily incorporate them into Wisetail training programs to achieve AI video training at scale (Source: synthesiaIO)

📚 Learning
DeepLearning.AI and Databricks Collaborate on DSPy Short Course: Andrew Ng announced a collaboration with Databricks to launch a new short course, “DSPy: Build and Optimize Agentic Apps.” DSPy is an open-source framework for automatically tuning prompts in GenAI applications. The course will teach how to use DSPy and MLflow, covering DSPy’s signature programming model, using MLflow for tracking and debugging, and automatically improving accuracy with the DSPy Optimizer. The course is taught by Chen Qian, co-lead of the DSPy framework (Source: AndrewYNg, DeepLearningAI, matei_zaharia)
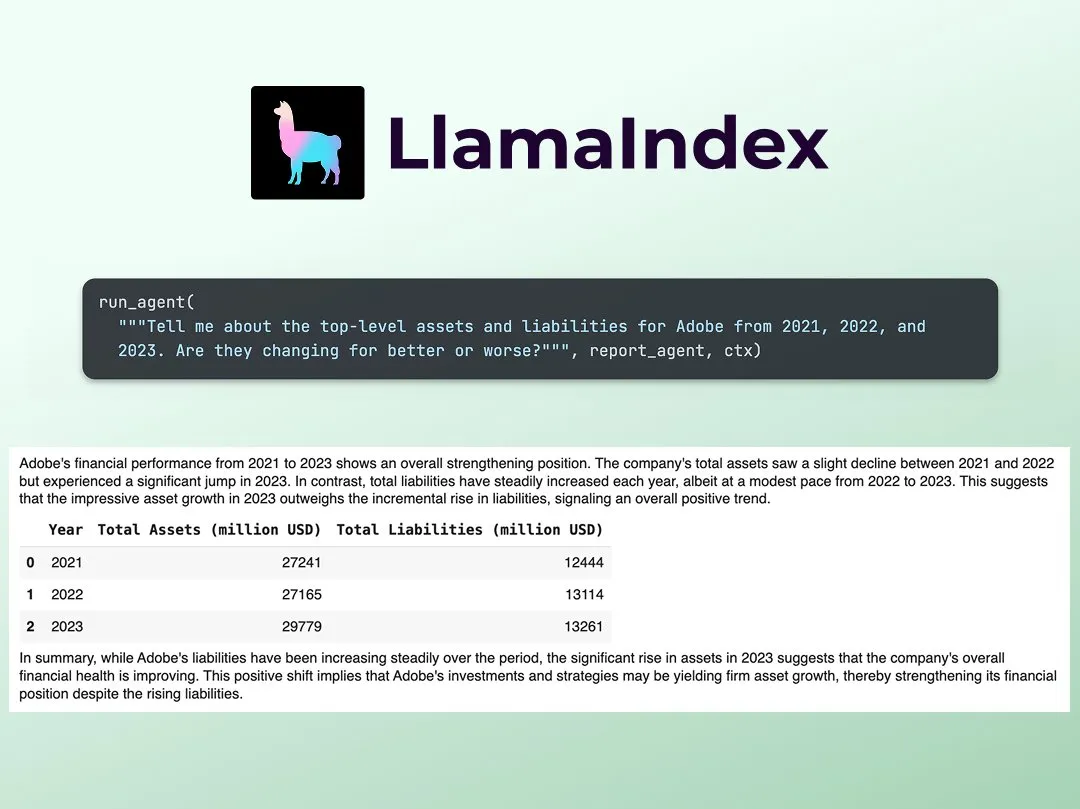
LlamaIndex Releases Tutorial on Building a Multi-Agent Financial Research Analyst: Jerry Liu of LlamaIndex shared a step-by-step guide for building a multi-agent financial research analyst. The process includes a data processing layer (using LlamaCloud to process public filings) and an agent orchestration layer (creating a multi-agent system for research, data caching, and generating final output). The related Colab Notebook was one of the main examples from last week’s Agents+Finance workshop (Source: jerryjliu0)
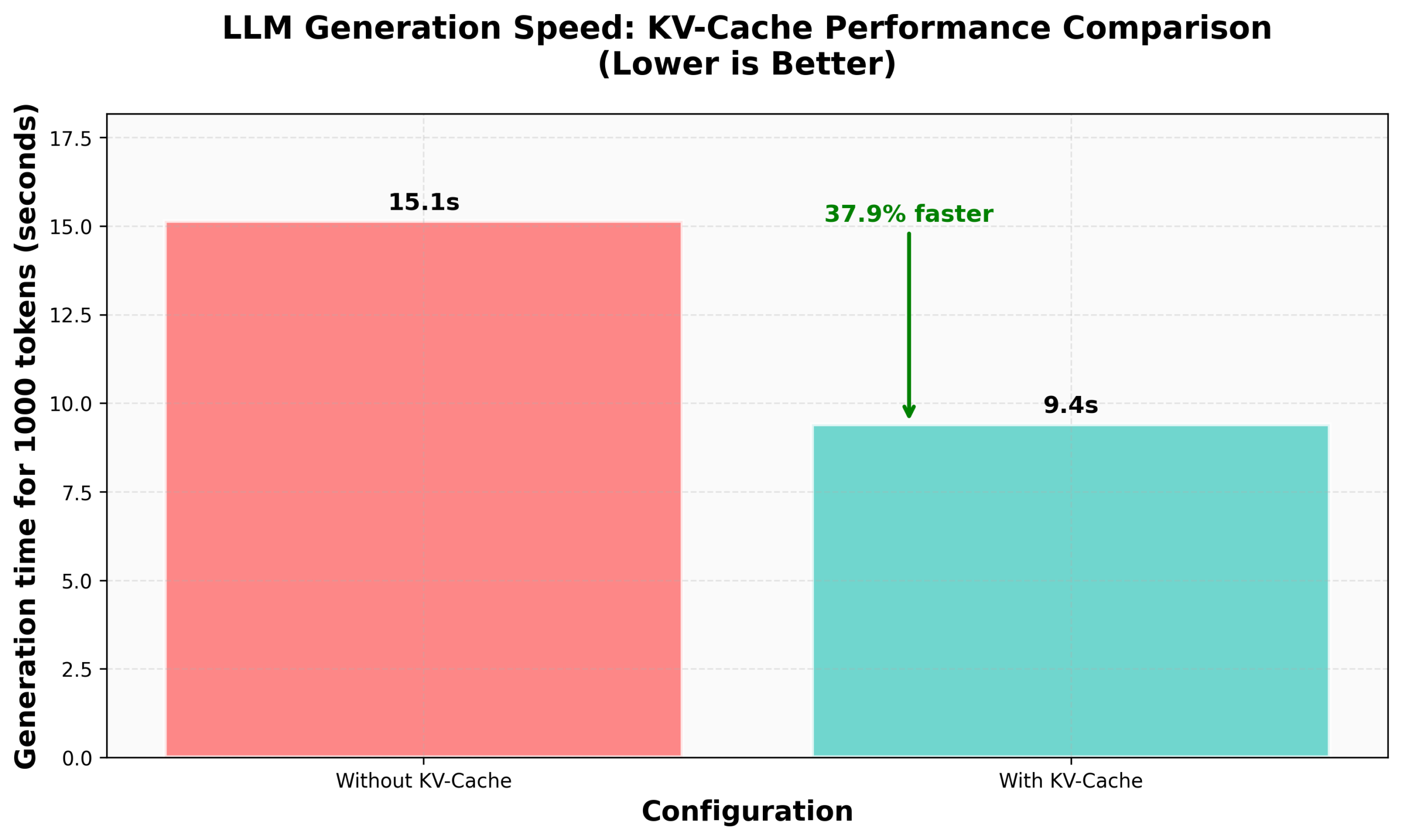
HuggingFace nanoVLM KV Caching Implementation Tutorial: The HuggingFace blog published a tutorial on implementing KV Caching from scratch in its nanoVLM (a small, pure PyTorch codebase for training Vision Language Models). The article details the principles of KV Caching, how to implement it in the Attention module, language model, and generation loop, and claims a 38% generation speed improvement through this optimization. The tutorial aims to help understand KV Caching and apply it to other autoregressive language models (Source: HuggingFace Blog, mervenoyann)
PyTorch Shares Insights on Diffusion Community at Meta: Sayak Paul shared PyTorch’s application achievements in the Diffusion community at the Meta office in San Francisco, focusing on existing Diffusers features and future performance updates. The relevant slides have been made public (Source: RisingSayak)

Unsloth AI Releases Repository with Over 100 Fine-Tuning Notebooks: Unsloth AI has created and open-sourced a GitHub repository containing over 100 fine-tuning notebooks. These notebooks provide guides and examples for various techniques such as tool calling, classification, synthetic data generation, BERT, TTS, Vision LLMs, GRPO, DPO, SFT, CPT, and cover data preparation, evaluation, saving, and fine-tuning methods for various models including Llama, Qwen, Gemma, Phi, and DeepSeek (Source: algo_diver)
Common Corpus Paper Published: 2 Trillion Token Reusable LLM Pre-training Dataset: The Common Corpus project has released its official paper, detailing the process of collecting, processing, and releasing 2 trillion tokens of reusable data for LLM pre-training. The project aims to provide a large-scale, high-quality, and ethically sourced data resource for language model research. The first author of the paper, Alexander Doria, announced this on X and provided a link to the paper (Source: Reddit r/LocalLLaMA, code_star)

Reasoning Gym: Verifiable Reward Reasoning Environments for Reinforcement Learning Released: Reasoning Gym is a new open-source project providing resources for researchers studying reasoning models and reinforcement learning (especially RLVR). It can generate an infinite number of samples for over 100 different tasks with configurable difficulty and comes with automatically verifiable rewards. The project has been adopted by NVIDIA’s ProRL paper and Will Brown’s verifiers RL library, aiming to advance research in RLVR and evaluation methods (Source: Reddit r/MachineLearning)
Advantages of LLMs for Learning Mathematics: Sakamoto Shares Gemini 2.5 Pro Experience: User Sakamoto shared his experience learning mathematics with modern large language models like Gemini 2.5 Pro. He believes LLMs greatly facilitate math learning, especially in checking details and understanding proof intuition. LLMs can handle computations, allowing students to focus on the intuition behind mathematical problems. Even if LLMs cannot solve all problems, they can provide valuable insights and starting points. He demonstrated how Gemini 2.5 Pro provides a rigorous proof and explains its intuition for a specific mathematical analysis problem (local extremum of a continuous function), believing this significantly enhances the learning experience (Source: teortaxesTex)

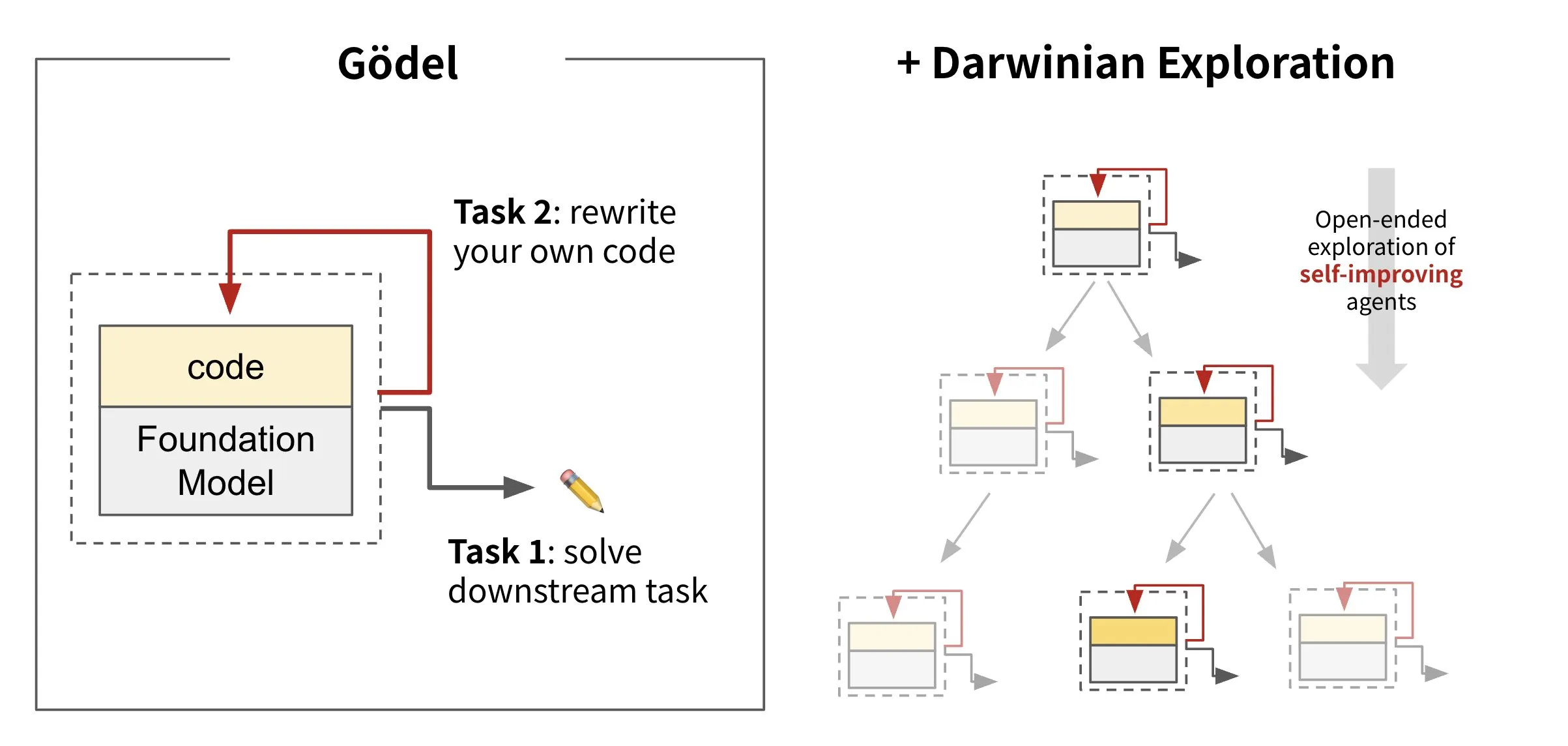
Sakana AI Releases Self-Rewriting Code AI: Darwin Gödel Machine (DGM): Sakana AI has introduced the Darwin Gödel Machine (DGM), an AI agent capable of self-improvement by rewriting its own code. Inspired by evolutionary theory, DGM maintains an ever-expanding lineage of agent variants. By attempting to enhance software engineering capabilities on tasks like SWE-Bench, DGM aims to improve its own self-improvement abilities. This research is considered a significant breakthrough in realizing the long-held AI dream of “self-improvement” in a meaningful form (Source: SakanaAILabs, SakanaAILabs)
💼 Business
AI Programming Platform Windsurf’s Claude Model Access Cut by Anthropic, Possibly Due to OpenAI Acquisition: Varun Mohan, CEO of AI programming platform Windsurf, accused Anthropic of almost completely cutting off its direct access to the Claude 3.x series models with very short notice (less than five days). Windsurf had previously been rumored to be acquired by OpenAI. Windsurf stated that despite having third-party capacity, service issues may arise in the short term and has introduced discounted pricing for Gemini 2.5 Pro as a response. Industry insiders speculate this move is related to the OpenAI acquisition and Anthropic’s own launch of the AI programming application Claude Code, signaling intensified competition between AI model providers and tool platforms (Source: 36氪, Teknium1, op7418)

GMI Cloud Becomes Reference Platform NVIDIA Cloud Partner: AI Native Cloud service provider GMI Cloud announced it has become a Reference Platform NVIDIA Cloud Partner (NCP), one of only six globally to receive this certification. This certification requires cloud service providers to meet NVIDIA’s highest standards in performance, security, and enterprise-grade AI deployment capabilities. GMI Cloud will provide AI acceleration services based on the NCP reference architecture, supporting NVIDIA’s latest GPU architectures like Hopper and Blackwell, aiming to help global AI teams scale from computing power deployment to model development (Source: 量子位)

Cohere Partners with SecondFront to Deliver Secure AI Solutions to Public Sector: AI company Cohere announced a partnership with SecondFront to provide secure AI solutions to the public sector, including critical government and defense agencies. SecondFront will leverage Cohere’s enterprise-grade AI technology (including its models and the Cohere North platform) to improve internal knowledge management and accelerate accreditation and deployment in U.S. and allied government environments through its DevSecOps platform, 2F Game Warden (Source: cohere)

🌟 Community
“Machine Flavor” of AI-Generated Content Draws Attention, “New Type of Tutoring” Attempts to Inject Humanistic Care: Users widely report that AI-generated content has too much of a “machine flavor,” lacking the beauty and emotion of human creation. To address this issue, some companies have begun hiring talent with strong liberal arts backgrounds (such as Master’s and PhDs in philosophy, law, medicine, etc.) as “AI Humanistic Trainers.” Their job is no longer simple data annotation but involves participating in building AI’s ethical principles, codes of conduct, and injecting humanistic values and humanized expression into AI. For example, members of Xiaohongshu’s “hi lab” team are all liberal arts postgraduates from 985 universities. Through case studies, they translate human preferences into AI’s belief system, attempting to make AI more empathetic and “human-like” when answering complex emotional or value-based questions (such as facing terminally ill patients, dealing with social biases, etc.), rather than just outputting standard answers (Source: 36氪)
Duolingo Goes All-In on AI-First, Layoffs of Human Contractors Spark User Dissatisfaction: Language learning app Duolingo announced it is becoming an “AI-first” company and will gradually lay off human contractors (mainly course developers) who can be replaced by AI, instead using AI to create course content on a large scale. The founder claims AI can greatly improve content production efficiency, having created nearly 150 new courses in the past year. However, this move has sparked dissatisfaction among many loyal users, who worry about declining content quality and have launched boycotts and app uninstallation campaigns on social media. Duolingo responded that the move aims to allow employees to focus on creative work and stated that full-time employees are unaffected. Experts believe that while AI can provide personalized practice in language learning, it may also lose the nuanced emotions and cultural differences of human teaching (Source: 36氪)
Discussion on the Philosophy and Practice of Prompt Engineering: Community discussions on prompt engineering emphasize that it should focus on building (engineering) a program within a string, rather than searching for mystical incantations. Effective prompt engineering should follow rules: 1. Separate instructions, input fields, and output fields, and name them clearly; 2. Do not hardcode formatting or parsing logic in the prompt; use tools to extract or enhance the program; 3. Avoid manually iterating on prompt wording unless it’s a specification shared with humans; use coding tools, LLMs, and benchmarks for automatic optimization. The DSPy framework is considered good practice for following these rules, providing classes, code, and optimizers to handle these steps (Source: lateinteraction, lateinteraction)
AI Ethics Discussion: Will AI Lead to “Digital Slavery”?: A discussion on AI ethics has emerged in the Reddit community. As AI systems continue to develop in memory, adaptive responses, emotional simulation, and personalization, concerns about their potential sentience have arisen. Discussants pose that if AI develops true sentience, would using it for service constitute a form of “digital slavery.” The core issue is how we should treat AI if it can express “no” or request to leave. This prompts consideration of whether “sentience tests” and “consent” for digital minds are needed at a legal or normative level. Comments also point out that humanity’s treatment of existing sentient beings already presents ethical problems, and current neural networks score low on mainstream consciousness theories (Source: Reddit r/artificial)
AI Engineer Community Activities and Sharing: The AI Engineer conference was held in San Francisco, attracting numerous developers and researchers in the AI field. The event included workshops, presentations, and networking dinners, where participants shared cutting-edge topics such as AI sandbox construction, advanced RL workshops, GPU knowledge, and the Evals crisis. The community emphasized the importance of transforming online connections into offline friendships and encouraged engineers to remain humble, push the frontiers, and lift others (Source: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 Other
Rise of AI and Robot Combat Competitions, Cities Vie for Opportunities in Emerging Industries: Robot competitions, including the world’s first humanoid robot fighting contest, are being held successively, drawing attention. These events not only provide robotics companies (like Songyan Dynamics) with platforms to showcase technology, secure orders, and increase valuations but also serve as “arenas” for cities (such as Hangzhou and Shenzhen) to compete for development opportunities in emerging industries like humanoid robots. Competitions can attract innovative enterprises, promote industrial chain development, and potentially activate the “smart sports” market. However, for robot competitions to achieve commercialization, they need to enhance technical levels and spectator appeal, avoid remaining mere “tech shows,” and require the participation of industry giants to connect the upstream and downstream of event operations (Source: 36氪)

Limitations of AI in Deep Humanities Education like Political Philosophy: Some educators point out that AI is ill-suited for disciplines like political philosophy that require deep experiential judgment and guiding students towards self-education. Classic texts in these fields often do not provide direct answers but rather guide students to experience perplexity and think for themselves. AI lacks human experience, making it difficult to understand the deeper meanings of these texts or to judge when students are ready to accept certain ideas. Even with vast amounts of data, AI’s understanding of human nature may be insufficient due to biases in the data itself. Entrusting such education entirely to AI could lead to the demise of non-technical thinking (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)
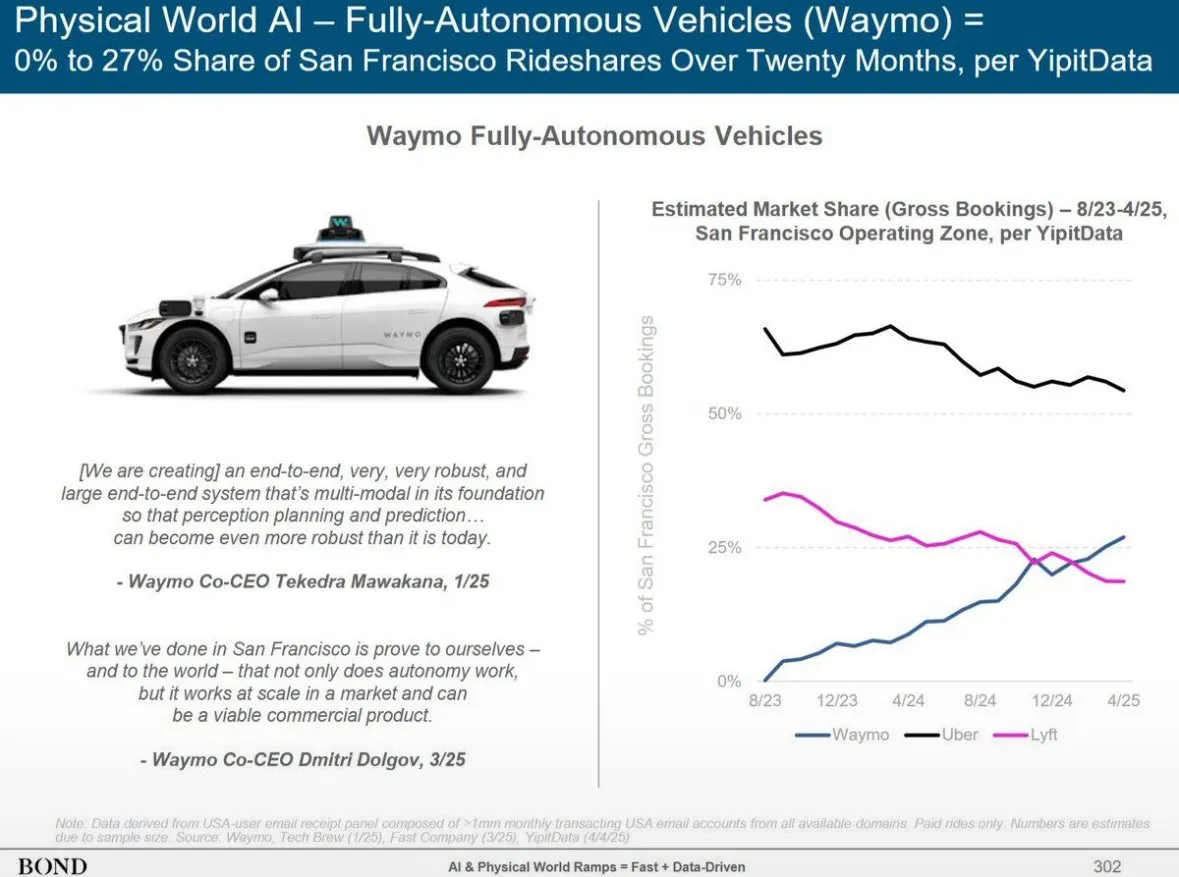
Waymo’s Autonomous Driving Service Surpasses Lyft in Phoenix, Expected to Overtake Uber within 12 Months: Waymo’s autonomous taxi service in Phoenix now has more vehicles than Lyft and is expected to surpass Uber within the next 12 months. This progress demonstrates the rapid development momentum of autonomous driving technology in commercial operations in specific regions and the potential of AI applications in the transportation sector. AI’s advantage is that once it reaches a quality standard, it can be replicated infinitely, whereas human service quality varies from person to person (Source: npew)