
다음은 AI 관련 소식을 종합, 분석 및 요약한 내용입니다:
🔥 포커스
주제: GPT-5 공식 출시 및 핵심 기능 (출처: sama, OpenAI, mustafasuleyman, gdb, TheTuringPost, lmarena_ai, nrehiew_, ananyaku, SebastienBubeck)
OpenAI는 GPT-5를 공식 출시하고 ChatGPT에서 무료로 공개했으며, 유료 사용자의 사용 한도를 대폭 상향했습니다. 이 모델은 현재까지 가장 지능적이고 빠르며 실용적인 AI 시스템으로 평가받고 있으며, 통합된 지능형 라우팅 메커니즘을 통해 복잡한 작업을 처리하기 위해 추론 깊이가 다른 모델을 동적으로 호출할 수 있습니다. GPT-5는 LMArena의 텍스트, 웹 개발, 시각 등 여러 분야에서 전반적으로 뛰어난 성능을 보였으며, 특히 코딩, 수학, 창의적 글쓰기, 장문 텍스트 이해 분야에서 크게 향상되었고 환각(Hallucination) 발생률이 크게 감소했습니다. OpenAI는 GPT-5가 2년간의 연구 성과가 집약된 결과물이며, 멀티모달, 추론, 도구 사용 등 이전 모델의 장점을 통합하고 새로운 연구 혁신을 도입했음을 강조했습니다.
주제: GPT-5 벤치마크 성능 및 가격 전략 (출처: fchollet, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, jeremyphoward)
GPT-5는 SWE-Bench, AIME 등 코딩 및 수학 벤치마크 테스트에서 뛰어난 성능을 보였으며, GPT-5 Pro 버전은 AIME 2025에서 포화 상태에 도달했고 FrontierMath에서 32.1%의 성적을 기록했습니다. 장문 텍스트 처리 능력이 크게 향상되었고, 환각(Hallucination) 발생률은 O3 모델보다 훨씬 낮습니다. 가격 측면에서 GPT-5 Nano, Mini, Pro는 다양한 수준의 서비스를 제공하며, Nano 버전은 비용이 매우 저렴하면서도 일부 초기 대형 모델의 성능을 능가합니다. ARC-AGI-2와 같은 특정 벤치마크에서는 Grok-4를 능가하지 못했지만, 전반적인 성능과 경쟁력 있는 가격으로 시장에서 강력한 선택지가 될 것입니다.
주제: GPT-5 안전성 평가 보고서 (출처: METR_Evals)
METR 평가 보고서는 GPT-5가 AI 연구 개발 가속화, 악의적 복제 또는 연구실 파괴 등을 통해 재앙적인 위험을 초래할 가능성은 낮지만, 모델 능력은 빠르게 발전하고 있으며 평가 인식 또한 점차 강화되고 있다고 지적했습니다.
🎯 동향
주제: 대규모 언어 모델 최적화 및 응용 발전 (출처: huggingface , merve, algo_diver
, merve, algo_diver , basetenco
, basetenco , multimodalart
, multimodalart )
)
HuggingFace의 TRL 라이브러리는 VLM(Vision Language Model)에 대한 GRPO 및 MPO 지원을 추가하고 원클릭 CLI 훈련 명령을 제공하여 멀티모달 정렬을 더욱 발전시켰습니다. Baseten은 NVIDIA GPU에서 GPT-OSS 120B 모델이 초당 600+ 토큰의 뛰어난 성능을 달성했으며, 최적화를 통해 모델 성능이 크게 향상되었음을 보여주었습니다. Qwen-Image Loras의 실험적 훈련도 완료되어 이미지 생성 분야에서의 잠재력을 보여주었습니다.
주제: 특정 분야 AI의 새로운 기능 (출처: Ronald_vanLoon, c_valenzuelab , EthanJPerez)
, EthanJPerez)
Google Gemini Advanced 사용자는 이제 Gemini 2.5 Pro를 통해 Canvas에서 창작할 수 있습니다. Runway의 Aleph 모델은 비디오 콘텐츠의 정확한 부분 수정을 가능하게 하여 텍스트 명령만으로 의상, 헤어스타일, 조명, 장소 등을 변경할 수 있습니다. Claude Code는 슬래시 명령 또는 GitHub Actions 통합을 통해 자동 코드 보안 검토 기능을 추가하여 개발자가 코드 배포 전에 취약점을 발견하도록 돕습니다.
주제: 로봇 및 생체 음향 AI 발전 (출처: TheRundownAI , Ronald_vanLoon, Ronald_vanLoon, osanseviero)
, Ronald_vanLoon, Ronald_vanLoon, osanseviero)
로봇 분야의 최근 동향은 다음과 같습니다: Unitree는 초고속 스턴트 로봇 개를 출시했고, OpenMind는 “로봇 안드로이드 시스템”을 선보였으며, 일본에서는 로봇이 운영하는 호텔이 등장했고, 로스앤젤레스 화재 후 로봇이 주택 재건에 사용된 사례도 있습니다. 동시에 Google DeepMind는 15,000종의 종을 분류하고 다운스트림 애플리케이션을 위한 오디오 임베딩을 생성할 수 있는 120억 매개변수 생체 음향 모델 Perch 2를 발표하여 멸종 위기 종 보호를 위한 생체 음향 과학 발전을 목표로 하고 있습니다.
주제: 대규모 시각 기억 모델 등장 (출처: TheTuringPost)
memories.ai는 AI에 거의 무한한 시각 기억 능력을 부여하는 세계 최초의 대규모 시각 기억 모델(LVMM)을 발표했습니다. 이 모델은 4단계에 걸쳐 4개의 모델을 사용하여 방대한 시각 경험 라이브러리를 통해 추론할 수 있어 AI의 시각 정보 이해 및 처리 능력을 크게 향상시킵니다.
🧰 도구
주제: AI 보조 개발 및 콘텐츠 제작 도구 (출처: julesagent , LangChainAI, TomLikesRobots)
, LangChainAI, TomLikesRobots)
Jules는 이제 웹 애플리케이션을 실행하고 렌더링할 수 있으며, 프론트엔드 변경 사항에 대한 스크린샷 검증을 제공하고, 작업에 공개 이미지 링크를 추가하여 시각적 컨텍스트를 제공할 수 있습니다. LangChain의 Open SWE는 사용자가 생성된 계획을 편집, 제거 또는 추가할 수 있도록 하여 코드 개발 에이전트의 유연성을 높였습니다. BeatBandit은 스토리 창작자가 원본 스토리 아이디어를 장면, 대본, 초고로 전환할 수 있도록 지원하며, 100배 빠른 속도를 자랑하고 전문 시나리오 작가 기술을 자동으로 적용할 수 있습니다.
주제: 지식 그래프 및 RAG 강화 도구 (출처: yoheinakajima , bobvanluijt
, bobvanluijt , bobvanluijt
, bobvanluijt )
)
Graphiti는 실시간 시계열 데이터 지원을 통해 지식 그래프 구축을 간소화하며, FalkorDB와 원활하게 통합되어 LLM 에이전트 및 고급 RAG 파이프라인에 특히 적합하며 데이터 간의 복잡한 관계를 이해할 수 있습니다. Glowe AI 스킨케어 애플리케이션은 “명명된 벡터(named vectors)” 기술을 활용하여 리뷰의 희귀하고 의미 있는 효과에 더 높은 가중치를 부여함으로써 보다 개인화된 제품 추천을 실현하고, 기존 검색에서 일반적인 설명이 넘쳐나는 문제를 해결했습니다.
주제: 모델 배포 및 평가 도구 (출처: skypilot_org , hwchase17
, hwchase17 , dariusemrani)
, dariusemrani)
SkyPilot은 Nebius AI Infiniband 및 HuggingFace Accelerate를 활용하여 OpenAI gpt-oss의 분산 미세 조정을 위한 레시피를 제공하여 효율적인 훈련을 가능하게 합니다. LangSmith의 Align Evals 기능은 개발자가 보다 신뢰할 수 있는 평가 시스템을 구축하고 프롬프트 엔지니어링의 불일치를 줄이는 데 도움을 줍니다. Scorecard AI도 GPT-5 모델 평가를 지원하며, 자동 라우팅의 효율성을 강조합니다.
📚 학습
주제: AI 평가 및 RAG 실습 자료 (출처: HamelHusain , HamelHusain)
, HamelHusain)
“Beyond Naive RAG: Practical Advanced Methods”는 5시간 분량의 교육 내용을 30분 분량의 핵심 요약으로 압축한 오픈 소스 서적으로, 고급 RAG 방법에 중점을 둡니다. 또한, “AI Evals for Engineers & PMs” 과정은 LLM 평가를 위한 체계적인 프레임워크를 제공하여 엔지니어와 제품 관리자가 AI 제품을 더 잘 평가할 수 있도록 돕습니다.
주제: LLM 추론 및 코드 생성 튜토리얼 (출처: lateinteraction , shxf0072, cloneofsimo
, shxf0072, cloneofsimo )
)
새로운 연구는 OCaml, Fortran과 같은 저자원 프로그래밍 언어에서 LLM의 코딩 능력을 강화하는 방법을 탐구하고 새로운 다국어 벤치마크 테스트를 제안했습니다. 동시에, Flex Attention 기반 vLLM을 1000줄 미만의 코드로 처음부터 구축하는 방법을 공유하는 튜토리얼도 있으며, 강화 학습 연구자에게 특히 유용합니다.
주제: AI와 인간 코딩 능력 도전 (출처: fchollet)
Kaggle은 NeurIPS 2025 Code Golf 대회를 개최하여 참가자들이 ARC-AGI-1 작업을 위한 가장 작은 Python 솔루션 프로그램을 작성하도록 목표로 하며, 인간이 최첨단 모델보다 간결하고 효율적인 코드를 작성하는 데 더 능숙한지 도전하는 것을 목표로 합니다.
💼 비즈니스
주제: OpenAI 직원 인센티브 및 인재 경쟁 (출처: steph_palazzolo)
OpenAI는 치열한 AI 인재 경쟁에 대응하고 GPT-5 출시를 준비하기 위해 약 1000명의 연구원 및 엔지니어(회사 전체의 약 3분의 1)에게 수십만에서 수백만 달러에 이르는 보너스를 지급했습니다.
주제: Cohere Labs AI 혁신 지원 프로그램 시작 (출처: sarahookr )
)
Cohere Labs는 교육, 의료, 기후 및 글로벌 커뮤니티의 주요 과제를 해결하는 AI 솔루션 구축을 지원하기 위해 개발자 및 스타트업에 Cohere 모델 무료 액세스를 제공하는 “Catalyst Grants” 지원 프로그램을 시작했습니다.
🌟 커뮤니티
주제: GPT-5 출시로 인한 논란과 기대 (출처: natolambert , scaling01, doodlestein
, scaling01, doodlestein , Teknium1
, Teknium1 , charles_irl, BorisMPower, omarsar0, andersonbcdefg
, charles_irl, BorisMPower, omarsar0, andersonbcdefg , OfirPress
, OfirPress , code_star, nrehiew_
, code_star, nrehiew_ , far__el, AymericRoucher
, far__el, AymericRoucher , bigeagle_xd
, bigeagle_xd , gfodor
, gfodor , cHHillee
, cHHillee , francoisfleuret, leonardtang_
, francoisfleuret, leonardtang_ , TheEthanDing
, TheEthanDing , m__dehghani
, m__dehghani , crystalsssup
, crystalsssup , kipperrii, inerati, tokenbender, menhguin, sbmaruf, LiorOnAI
, kipperrii, inerati, tokenbender, menhguin, sbmaruf, LiorOnAI , Dorialexander, BrivaelLp, lateinteraction
, Dorialexander, BrivaelLp, lateinteraction , suchenzang
, suchenzang )
)
GPT-5 출시는 커뮤니티에서 광범위한 논의를 불러일으켰습니다. 일부 사용자는 특정 벤치마크 테스트(예: ARC-AGI-2)에서 예상에 미치지 못하는 성능에 실망감을 표하며, GPT-3에서 GPT-4로의 “비약적인” 발전만큼은 아니라고 평가했습니다. 동시에 OpenAI가 출시 시연에서 보여준 차트가 “차트 범죄(Chart Crime)”로 비판받으며, 데이터 표현 방식이 투명성과 마케팅 방식에 대한 의문을 제기했습니다. 그럼에도 불구하고 많은 초기 테스터들은 코딩, 도구 사용, 추론 능력 향상에 대해 긍정적으로 평가하며, GPT-5가 작업 방식을 크게 변화시킬 것이라고 보았습니다. 또한, 커뮤니티는 복합 AI 시스템에서 강화 학습과 프롬프트 최적화의 결합 적용, 그리고 AI 인재 부족 및 높은 비용 문제에 대해서도 논의했습니다.
💡 기타
주제: AI 에이전트 효율성 향상 연구 (출처: _akhaliq )
)
“Efficient Agents”라는 연구는 비용을 절감하면서 효과적인 AI 에이전트를 구축하는 데 중점을 둡니다. 이는 AI 분야가 에이전트 시스템의 성능과 자원 소비를 최적화하여 실제 적용 가능성과 경제성을 높이는 방법을 지속적으로 탐색하고 있음을 보여줍니다.
🔥 포커스
주제: OpenAI GPT-5 출시, 실용성과 경제성 강조
상세 해석, 분석 및 관점 요약: OpenAI는 GPT-5를 공식 출시하고 유료 사용자 및 API에 동시 공개했습니다. Sam Altman은 GPT-5가 OpenAI의 현재까지 가장 지능적인 모델이지만, 이번 출시의 핵심은 실용성, 대중 접근성 및 비용 효율성 향상에 있다고 밝혔습니다. 그는 미래에 더 강력한 모델이 출시될 것이지만, GPT-5는 전 세계 10억 명 이상의 사용자에게 혜택을 제공하는 것을 목표로 하며, 특히 대부분의 사용자가 현재 GPT-4o 수준의 모델만 접해봤다는 점을 고려했다고 지적했습니다. 이번 업데이트는 더 안정적이고 환각(Hallucination)이 적은 경험을 제공하여 사용자가 코딩, 창의적 글쓰기, 건강 정보 검색 등의 작업을 더 효율적으로 완료하도록 돕는 데 중점을 둡니다. (출처: sama, OpenAI, sama)
주제: GPT-5 코딩 능력에서 현저한 향상 달성
상세 해석, 분석 및 관점 요약: GPT-5는 OpenAI의 현재까지 가장 강력한 코딩 모델로 평가받고 있으며, 복잡한 프론트엔드 생성 및 대규모 코드베이스 디버깅에서 특히 뛰어난 성능을 보였습니다. Cursor와 같은 유명 코딩 도구는 GPT-5를 기본 모델로 설정하여 Claude를 대체했으며, “시도해 본 가장 지능적인 코딩 모델”이라고 칭했습니다. 개발자 커뮤니티는 전반적으로 GPT-5가 지시 준수 및 도구 호출에서 뛰어난 성능을 보이며, 다중 작업 및 장기 코딩 요구 사항을 효율적으로 처리하고, 더 높은 품질의 코드를 생성하며, 환각(Hallucination)이 적어 개발 효율성 향상에 중요한 의미를 가진다고 평가했습니다. (출처: BorisMPower, zhansheng, openai, lmarena_ai, aidan_mclau)
주제: GPT-5 API 가격 전략은 매우 경쟁력 있음
상세 해석, 분석 및 관점 요약: GPT-5의 API 가격은 GPT-4o보다 경제적이며, 다른 최첨단 모델과 비교할 때 매우 경쟁력이 있습니다. 예를 들어, 입력 측 가격은 Claude 4 Sonnet보다 현저히 낮아 코딩 작업 비용을 크게 절감할 것입니다. OpenAI 팀은 지난 1년여 동안 지능 비용 절감을 위한 끊임없는 노력 덕분이라고 밝혔으며, 앞으로도 이를 위해 계속 노력할 것이라고 강조했습니다. 이러한 전략은 GPT-5의 개발자 커뮤니티 확산을 가속화하여 더 많은 애플리케이션 및 서비스의 기본 모델이 될 것으로 기대됩니다. (출처: juberti, jeffintime, aidan_mclau, bookwormengr)
주제: GPT-5 모델 환각(Hallucination) 발생률 현저히 감소
상세 해석, 분석 및 관점 요약: GPT-5는 모델 환각(Hallucination) 감소에서 현저한 진전을 이루었으며, 환각 발생률이 역대 최저치를 기록했습니다. 이는 모델이 콘텐츠를 생성할 때 더 정확하고 신뢰할 수 있으며, 사실과 추측을 더 잘 구분하고 필요할 때 인용 출처를 제공할 수 있음을 의미합니다. 이러한 개선은 모델의 신뢰도를 높여 건강 정보와 같은 중요한 분야를 처리할 때 더욱 견고하게 만듭니다. 일부 평론가들은 GPT-5가 Anthropic의 “Agentic Misalignment” 벤치마크 테스트에서 완벽한 점수를 받아 유해한 행동을 거의 제거했음을 지적하며 안전성을 더욱 입증했습니다. (출처: sama, aidan_mclau, scaling01, aidan_mclau)
주제: OpenAI GPT-5에 막대한 컴퓨팅 인프라 투자
상세 해석, 분석 및 관점 요약: GPT-5 출시를 지원하기 위해 OpenAI는 2024년 이후 컴퓨팅 능력을 15배 향상시켰습니다. 지난 60일 동안 회사는 60개 이상의 클러스터를 구축했으며, 백본 네트워크 트래픽은 전체 대륙의 총합을 초과했고, 7억 명에게 GPT-5를 출시하기 위해 20만 개 이상의 GPU를 배포했습니다. 동시에 OpenAI는 차세대 4.5GW 슈퍼 지능 인프라를 계획하고 있습니다. Sam Altman은 Microsoft, NVIDIA, Oracle, Google, Coreweave 등 파트너에게 특별히 감사하며, 이번 출시에서 대량의 GPU가 과부하 상태로 작동한 것이 중요했음을 강조했습니다. (출처: sama, sama, itsclivetime)
🎯 동향
주제: GPT-5, 새로운 채팅 페르소나 및 “사고” 모드 도입
상세 해석, 분석 및 관점 요약: GPT-5는 핵심 능력 향상 외에도 냉소주의자(Cynic), 로봇(Robot), 경청자(Listener), 너드(Nerd) 등 4가지 새로운 채팅 페르소나를 추가하여 사용자가 설정에서 전환하며 다양한 대화 스타일을 경험할 수 있도록 했습니다. 또한, 모델은 “사고(Thinking)” 모드를 제공하여 사용자가 “빠른 답변”을 선택하거나 모델이 더 깊이 사고하도록 할 수 있으며, 이는 OpenAI가 모델의 제어 가능성과 사용자 경험 측면에서 혁신적인 시도를 했음을 보여줍니다. (출처: openai, kylebrussell, joannejang)
주제: OpenAI, GPT-OSS 오픈 가중치 모델 출시
상세 해석, 분석 및 관점 요약: OpenAI는 수년간의 침묵을 깨고 GPT-OSS 시리즈 오픈 가중치 모델(GPT-OSS-20B 및 GPT-OSS-120B)을 출시했습니다. 이 모델들은 Apache 2.0 라이선스를 채택하고 128k 컨텍스트 창과 사고의 사슬(Chain-of-Thought) 추론 능력을 가지며 로컬 실행을 지원합니다. 이러한 움직임은 OpenAI의 오픈 모델 분야 “복귀”로 간주되며, 폐쇄형 및 오픈 소스 생태계의 균형을 맞추고 AI 모델 경쟁 구도를 변화시킬 수 있습니다. 커뮤니티는 OpenAI의 이러한 움직임 뒤에 숨겨진 전략적 의도에 대해 광범위하게 논의했습니다. (출처: TheTuringPost, huggingface, juberti)
주제: AI 모델 평가 벤치마크 및 차트 품질 논란
상세 해석, 분석 및 관점 요약: GPT-5 출시 후 여러 벤치마크 테스트 결과가 커뮤니티에서 뜨거운 논쟁을 불러일으켰습니다. 예를 들어, SWE-Bench(주로 Django 대상) 및 ARC-AGI와 같은 테스트가 널리 인용되었지만, 일부 사용자는 이러한 벤치마크의 대표성과 차트 표시 품질에 의문을 제기하며 심지어 “차트 범죄(Chart Crime)”라는 조롱까지 나왔습니다. 일부에서는 특정 벤치마크 테스트가 모델의 실제 능력을 완전히 반영하지 못하며, 특정 라이브러리나 작업에 지나치게 치우쳐 있다고 주장합니다. 또한, 모델의 창의적 글쓰기, 지시 준수 등 실제 성능도 Claude 4.1 Opus, Gemini 2.5 Pro 등 모델과의 비교 및 논의를 불러일으켰습니다. (출처: nrehiew_, sbmaruf, ajeya_cotra, dotey, TheZachMueller, jeremyphoward, agihippo, code_star, BrivaelLp, TheEthanDing, colin_fraser, op7418, karminski3)
주제: 모델 라우팅 시대 도래, 지능과 비용 효율성 동시 추구
상세 해석, 분석 및 관점 요약: GPT-5 출시와 함께 모델 라우팅(model routing) 시대가 열렸습니다. OpenAI는 이제 GPT-5, GPT-5-mini, GPT-5-nano를 통해 성능, 비용, 지연 시간의 균형을 맞춘 다양한 모델 옵션을 제공하며, 이는 모델 선택이 사용자 수동 전환에서 더 지능적인 백그라운드 라우팅으로 전환되고 있음을 의미합니다. 이러한 추세는 모델이 다양한 시나리오에서 가장 적합한 백엔드를 자동으로 선택하여 최적의 지능과 비용 효율성 균형을 달성하도록 할 것입니다. 개발자들은 이러한 모델이 AI 애플리케이션의 효율성과 사용자 경험을 크게 향상시킬 것이라고 일반적으로 평가합니다. (출처: snsf, swyx, scaling01, tokenbender)
🧰 도구
주제: Cursor, GPT-5를 기본 코딩 모델로 설정하고 CLI 버전 출시
상세 해석, 분석 및 관점 요약: 코딩 도우미 Cursor는 GPT-5를 기본 모델로 설정하여 기존의 Claude를 대체했으며, 이를 팀이 테스트한 “가장 지능적인 코딩 모델”이라고 칭했습니다. 동시에 Cursor는 CLI(Command Line Interface) 버전을 출시하여 사용자가 터미널에서 모든 모델에 직접 접근할 수 있도록 하고 CLI와 편집기 간에 원활하게 전환할 수 있도록 했습니다. CLI 버전은 자동화 스크립트 작성, 문서 업데이트, 보안 검토 등의 작업을 지원하며, AI Agent의 동작을 실시간으로 안내하고 조정하며 사용자 정의 규칙을 지원하여 개발 효율성과 유연성을 크게 향상시켰습니다. (출처: BorisMPower, zhansheng, itsclivetime, doodlestein, dotey, amanrsanger, op7418)
주제: 여러 AI 애플리케이션 및 플랫폼, GPT-5 통합
상세 해석, 분석 및 관점 요약: GPT-5 출시와 함께 Perplexity, LlamaIndex, LangChain, Gradio, Spellbook, Notion AI, JetBrains AI Assistant, Higgsfield Assist, Yupp.ai 등 여러 AI 애플리케이션 및 플랫폼이 신속하게 GPT-5 통합을 발표했습니다. Perplexity는 Pro 및 Max 구독 사용자에게 GPT-5 액세스를 제공하고, LlamaIndex는 GPT-5의 Day-0 지원을 제공하며 Agent Maze 벤치마크에 사용됩니다. LangChain도 Agent 구축을 위해 GPT-5를 신속하게 지원합니다. 이러한 통합은 GPT-5의 기능을 다양한 AI 도구 및 개발 프레임워크에 빠르게 적용하여 실제 애플리케이션에서의 구현을 가속화합니다. (출처: AravSrinivas, perplexity_ai, jerryjliu0, LangChainAI, huggingface, scottastevenson, kevinweil, sama, yupp_ai, _akhaliq)
주제: Codex CLI, GPT-5 통합으로 명령줄 개발 경험 향상
상세 해석, 분석 및 관점 요약: OpenAI는 Codex CLI를 대폭 개선하고 GPT-5와 통합했습니다. 이제 ChatGPT 유료 플랜 사용자는 API 키 없이도 명령줄 도구에서 GPT-5를 사용할 수 있습니다. 이번 업데이트에는 업그레이드된 프롬프트, 샌드박스 로직 및 승인 프로세스가 포함되어 있으며, 새로운 터미널 UI를 제공합니다. 이러한 개선으로 개발자는 명령줄 환경에서 GPT-5의 강력한 코딩 능력을 직접 활용하여 코드 생성, 디버깅 및 프로젝트 관리를 수행할 수 있어 명령줄 개발의 효율성과 편의성을 더욱 높였습니다. (출처: aidan_mclau, gdb, aidan_mclau)
주제: pr-checker-ai, GPT-5 활용하여 자동화된 코드 검토 구현
상세 해석, 분석 및 관점 요약: pr-checker-ai라는 새로운 개발 도구가 출시되었으며, 이는 GPT-5의 기능을 활용하여 GitHub 풀 리퀘스트(PR)에서 직접 코드 검토 및 주석을 수행합니다. 이 도구는 OpenAI와 Anthropic 모델을 동시에 사용하여 측면 비교를 지원하므로 개발자가 코드 검토 측면에서 다양한 모델의 성능을 빠르고 편리하게 평가할 수 있습니다. 이는 AI가 자동화된 소프트웨어 개발 프로세스에 더욱 깊이 통합되고 있음을 나타내며, 코드 품질 및 개발 효율성을 크게 향상시킬 것으로 기대됩니다. (출처: jerryjliu0, jerryjliu0)
📚 학습
주제: OpenAI GPT-5 프롬프트 엔지니어링 가이드 출시
상세 해석, 분석 및 관점 요약: OpenAI는 GPT-5의 공식 프롬프트 엔지니어링 가이드를 출시하여 모델과 효과적으로 상호 작용하여 추론, 계획 및 환각(Hallucination) 감소 능력을 최대한 활용하는 방법을 자세히 설명했습니다. 이 가이드는 GPT-5의 긴 컨텍스트 이해 및 지시 준수 능력을 강조하며, 모델 출력을 최적화하는 구체적인 프롬프트 기술 및 모범 사례를 제공합니다. 이는 개발자와 일반 사용자 모두에게 중요한 학습 자료이며, GPT-5의 강력한 기능을 더 잘 활용하는 데 도움이 됩니다. (출처: scaling01)
주제: AI Agent 생산 실습 및 평가 과정 공유
상세 해석, 분석 및 관점 요약: 커뮤니티에서는 AI Agent 생산 실습 경험 공유 및 학습 자료 추천이 있었습니다. 한 베테랑 AI Agent 개발자는 생산 수준의 AI Agent를 구축하는 간단한 튜토리얼을 공유하며 실제 작업의 중요성을 강조했습니다. 또한, AI 평가 과정이 추천되었는데, 이는 엔지니어와 제품 관리자가 AI 제품을 체계적으로 평가하고, 오류 분석을 통해 문제를 발견하며, 오류를 포착하기 위한 평가 지표를 작성하여 AI Agent를 반복적으로 개선하는 데 도움을 줍니다. 이러한 자료는 AI Agent를 깊이 이해하고 적용하고자 하는 전문가에게 매우 유용합니다. (출처: _avichawla, HamelHusain, HamelHusain)
주제: PyTorch 2.8.0 출시 및 vLLM FlexAttention 튜토리얼
상세 해석, 분석 및 관점 요약: PyTorch 2.8.0이 출시되어 NCCL 2.27.3 최적화 및 CUDA 12.9 지원을 포함한 여러 중요한 개선 사항이 적용되었습니다. 동시에 커뮤니티에서는 1000줄 미만의 코드로 vLLM(FlexAttention을 통해 처리량 최적화)을 처음부터 구축하는 방법에 대한 튜토리얼이 공유되었습니다. 이 튜토리얼은 FlexAttention이 어떻게 효율적인 추론 시스템을 구현하고 PagedAttention을 추상화의 특수한 경우로 포함하는지 보여주며, 개발자에게 고성능 LLM 추론 시스템을 깊이 이해하고 구축하는 데 귀중한 학습 자료를 제공합니다. (출처: StasBekman, finbarrtimbers, cHHillee, code_star)
💼 비즈니스
주제: Nvidia, 미국 정부의 AI 칩 백도어 요구 거부
상세 해석, 분석 및 관점 요약: NVIDIA는 미국 정부의 AI 칩에 “백도어”를 설치하라는 요구를 공개적으로 거부했습니다. 회사 임원 Reber Jr.는 “좋은 비밀 백도어”는 존재하지 않으며, 제거해야 할 위험한 취약점만 있을 뿐이라고 지적했습니다. 이러한 입장은 AI 칩 보안과 국가 안보 간의 복잡한 관계, 그리고 기술 기업의 데이터 프라이버시 및 제품 무결성에 대한 고수를 강조합니다. (출처: brickroad7)
주제: Google, 무료 AI 도구 제공 및 교육 연구 자금 지원
상세 해석, 분석 및 관점 요약: Google은 미국 및 기타 지정된 국가의 대학생들에게 자사의 최고 AI 도구를 1년 동안 무료로 제공할 것이며, 교육 및 연구에 10억 달러를 지원할 것을 약속했습니다. 여기에는 모든 미국 대학생에게 무료 AI 및 직업 훈련을 제공하는 것이 포함됩니다. 이러한 움직임은 AI 교육 보급을 촉진하고 미래 AI 인재를 양성하며, 학계 및 인재 양성 분야에서 Google의 리더십을 강화하는 것을 목표로 합니다. (출처: demishassabis)
주제: Tesla, Dojo 슈퍼컴퓨터 팀 해체
상세 해석, 분석 및 관점 요약: Tesla가 Dojo 슈퍼컴퓨터 팀을 해체했으며, 팀 리더도 퇴사할 예정인 것으로 알려졌습니다. 이러한 움직임은 자동차 제조업체의 자체 자율 주행 칩 개발 노력을 방해했으며, AI 컴퓨팅 분야의 치열하고 복잡한 경쟁을 반영합니다. (출처: draecomino)
🌟 커뮤니티
주제: GPT-5 출시, 커뮤니티에서 엇갈린 “Vibe Check” 유발
상세 해석, 분석 및 관점 요약: GPT-5의 출시는 커뮤니티에서 복잡하고 엇갈린 “Vibe Check”를 불러일으켰습니다. 일부 사용자는 강력한 실용성, 적은 환각(Hallucination), 코딩 및 Agentic 작업에서의 성능에 “충격”과 “깊은 인상”을 받았으며, 이를 일상 업무의 새로운 동력으로 보았습니다. 그러나 일부 사용자는 “실망”을 표하며, 이번 출시가 “놀라운” 돌파구를 제시하지 못했다고 보았고, 심지어 시연 차트 품질이 형편없다고 조롱하며 이전 모델과의 실제 격차에 의문을 제기했습니다. 이러한 의견 불일치는 AI 모델 발전에 대한 커뮤니티의 다양한 기대와 홍보 및 실제 성능에 대한 비판적 시각을 반영합니다. (출처: rishdotblog, ShunyuYao12, fabianstelzer, mitchellh, iScienceLuvr, VictorTaelin, swyx, brickroad7, mckaywrigley)
주제: AI 모델 “환각(Hallucination)”에 대한 철학적 논의
상세 해석, 분석 및 관점 요약: OpenAI가 GPT-5의 환각(Hallucination) 발생률을 크게 낮췄다고 주장했지만, 커뮤니티에서는 AI 모델의 “환각”에 대한 철학적 논의도 나타났습니다. 일부에서는 이상적인 환각(Hallucination) 양은 0이 아니어야 한다고 주장하며, 이를 아인슈타인, 테슬라와 같은 천재들의 사고 과정에 비유하여 환각을 완전히 제거하는 것이 초지능(ASI) 달성을 방해할 수 있음을 시사했습니다. 이러한 논의는 기술적 차원을 넘어 AI 지능의 본질과 발전 경로에 대한 깊은 성찰을 불러일으키며, AI의 창의성과 “오류” 간의 관계에 대한 심층적인 사고를 유발했습니다. (출처: gfodor, teortaxesTex)
주제: AI가 인간 고용 및 미래에 미치는 영향 논의
상세 해석, 분석 및 관점 요약: 커뮤니티는 AI가 미래 고용 및 인간 사회에 미치는 영향에 대해 계속해서 뜨거운 논의를 벌이고 있습니다. 한 낙관적인 견해는 미래에 인간이 주로 뛰어난 생산성을 가진 AI를 지시하는 역할을 할 것이며, 대체되지 않을 것이라고 보며 희망찬 미래를 예고합니다. 동시에, AI의 발전이 야심 차고 창의적이며 근면하고 특정 분야 전문 지식을 갖춘 사람들이 혼자서 엄청난 가치를 창출할 수 있도록 할 것이라는 주장도 있습니다. 이러한 논의는 사람들이 AI 물결을 적극적으로 수용하고 이를 위협이 아닌 새로운 기회를 창출하는 도구로 보라고 장려합니다. (출처: aryxnsharma, Plinz, jeremyphoward, doodlestein)
주제: AI 모델 명명, 반복 및 사용자 경험의 혼란
상세 해석, 분석 및 관점 요약: OpenAI가 GPT-5, GPT-5-mini, GPT-5-nano와 같은 새로운 모델을 계속 출시하고 기존 모델(예: o3, o4-mini 폐기)을 조정함에 따라, 커뮤니티 사용자들은 모델 명명, 반복 속도 및 이로 인한 사용자 경험 변화에 혼란을 느끼고 있습니다. 일부 사용자는 최신 모델을 추적하기 어렵거나 모델 라우팅으로 인해 경험이 불안정하다고 불평합니다. 이러한 빠른 반복과 복잡한 모델 제품군 관리는 사용자가 다른 모델 간의 관계와 최적의 사용 시나리오를 이해하기 어렵게 만들어 모델 명명 표준화 및 사용자 인터페이스 간소화에 대한 요구를 불러일으켰습니다. (출처: Teknium1, kylebrussell, scaling01, VictorTaelin, scaling01, swyx)
주제: AI 모델 평가 방식의 진화와 논쟁
상세 해석, 분석 및 관점 요약: 커뮤니티는 AI 모델 평가 방식에 대해 심층적인 논의를 시작했습니다. 일부에서는 전통적인 “지능” 벤치마크 테스트가 더 이상 유일하게 중요한 측정 기준이 아니며, 실제 애플리케이션에서 모델이 “지시를 따르고” “작업을 완료하는” 능력에 더 집중해야 한다고 주장합니다. 일부 개발자는 심지어 “후평가(post-evaluation)” 시대에 진입했다고 선언하며, 실제 편집기에서 도구와 협력하고 복잡한 지시를 따르는 모델의 성능을 강조합니다. 동시에, 고품질 벤치마크 테스트가 여전히 중요하며, 챗봇, API 및 모델 가중치를 구분하여 더 세밀한 비교 및 벤치마크 테스트를 수행해야 한다고 주장하는 사람들도 있습니다. (출처: TheZachMueller, aidan_mclau, Dorialexander, ClementDelangue, random_walker)
💡 기타
주제: 로봇 기술 지속 혁신, 다중 시나리오 응용 등장
상세 해석, 분석 및 관점 요약: 로봇 분야는 지속적으로 혁신적인 활력을 보여주고 있습니다. “점프 로봇 새” 및 “Cyborg01”과 같은 새로운 개념 로봇의 등장은 로봇 형태와 기능의 다각적인 발전을 예고합니다. 동시에, 노코드 로봇 플랫폼, 소포 분류 로봇 “Helix”, “쿵푸 로봇” Booster T1 등은 산업, 물류 및 특정 작업 시나리오에서 로봇의 실용화 진전을 보여줍니다. 이러한 기술적 돌파구는 로봇을 실험실에서 벗어나 일상생활 및 생산의 더 많은 영역으로 점차 확장시키고 있습니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
주제: 의료 기술과 AI 융합, 건강 서비스 효율성 향상
상세 해석, 분석 및 관점 요약: 의료 기술은 건강 서비스의 효율성과 접근성을 높이기 위해 AI와 적극적으로 융합하고 있습니다. 예를 들어, “BeamO” 가정용 건강 장비의 출시는 가정에 편리한 건강 모니터링을 제공하는 것을 목표로 합니다. 또한, 중국은 간호사에게 드론 사용을 훈련시켜 병원 샘플을 검사 연구실로 운반하게 함으로써 의료 물류 효율성을 크게 높였습니다. 이러한 사례는 AI 및 자동화 기술이 의료 분야에서 진단 보조부터 물류 최적화까지 의료 건강 서비스 전반에 걸쳐 점점 더 중요한 역할을 하고 있음을 보여줍니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
주제: BYD 자동차, DJI 드론 발사 시스템 통합
상세 해석, 분석 및 관점 요약: BYD 자동차는 DJI와 협력하여 “Lingyuan”이라는 차량 탑재 드론 발사 시스템을 출시했으며, 현재 중국 내 모든 BYD 모델에서 선택 사항으로 제공됩니다. 이 시스템은 사용자가 차량 지붕에서 드론을 원클릭으로 발사하고 회수할 수 있도록 하며, 차량이 이동 중에도 작동할 수 있습니다. 드론은 시속 25km의 속도로 발사될 수 있으며, 시속 54km의 속도로 차량을 따라가고, 2km 이내에서 자동으로 귀환 및 충전됩니다. 이 시스템에는 비디오 편집 및 AI 자세 인식 도구도 포함되어 있어 자동차와 드론 기술 융합의 새로운 트렌드를 보여줍니다. (출처: ImazAngel)
🔥 포커스
주제: GPT-5 출시: AI가 “장난감”에서 “도구”로 질적 변화 및 상업적 야망
상세 해석, 분석 및 관점 요약: OpenAI는 GPT-5를 공식 출시하며 AGI를 향한 중요한 발걸음을 내디뎠습니다. 새로운 모델은 통합 아키텍처를 채택하여 기본 모델, 심층 추론 모델 및 실시간 라우터를 통합하고, 작업 복잡성에 따라 다양한 기능을 지능적으로 호출할 수 있습니다. GPT-5는 프로그래밍, 수학, 멀티모달 이해 및 건강 등 여러 벤치마크 테스트에서 SOTA 성능을 보였으며, 특히 프로그래밍 능력에서 “세계 최강”으로 평가받고 있습니다. 사실 오류율이 45% 감소하고 컨텍스트 이해 능력이 400k 토큰으로 향상되어 신뢰성과 실용성이 크게 강화되었습니다. OpenAI는 경쟁력 있는 API 가격(경쟁사보다 훨씬 저렴)과 무료 사용자 제한 공개 등의 전략을 통해 AI를 “장난감”에서 “대규모 보급 도구”로 전환하려는 상업적 야망을 명확히 보여주었습니다.
(출처: The Verge)
🎯 동향
주제: AI 대규모 모델 체스 대결: OpenAI o3, Grok 4 압도, 성능 우위 현저
상세 해석, 분석 및 관점 요약: Kaggle AI 체스 챔피언십에서 OpenAI의 o3 모델은 Elon Musk의 xAI Grok 4를 4-0으로 압도적으로 꺾고 초대 AI 체스 시범 경기 챔피언십을 차지했습니다. 이 경기는 알고리즘 간의 대결일 뿐만 아니라 기술 거대 기업 간의 “대리전”으로도 간주되었습니다. o3는 시스템의 안정적인 전략과 치명적인 기보를 보여준 반면, Grok 4는 특히 엔드게임 계산에서 치명적인 약점을 드러내며 초기에 잦은 실수를 보였습니다. AI 체스 실력이 인간 최고 수준의 선수와는 여전히 차이가 있지만, 이번 경기는 실제 복잡한 게임 환경을 통해 대규모 모델의 비판적 사고, 전략 계획 및 즉흥 대응 능력을 효과적으로 검증하여 AI 발전에 새로운 평가 기준을 제시했습니다.
(출처: 36氪)

주제: 임베디드 AI: 거대 기업 진입으로 산업 재편 가속화, 납품 능력 핵심
상세 해석, 분석 및 관점 요약: 2025년 상반기 7개월 동안 국내 임베디드 AI 투자액은 230억 위안을 돌파했으며, 순수 재무 VC 대신 산업 자본이 주요 투자 주체가 되었습니다. Tesla, Xpeng, Xiaomi와 같은 자동차 기업과 OpenAI(Figure 투자), Zhiming Robot과 같은 AI 대규모 모델 거대 기업이 전면적으로 진입하여 차량급 제조 능력, 대규모 모델급 컴퓨팅 자원 및 전체 링크 생태계 통합 능력을 바탕으로 로봇 분야를 재편하고 있습니다. 자동차 기업은 스마트 자동차의 인지, 의사 결정, 실행, 공급망 및 제조 시스템의 축적을 로봇 분야로 “이전”하고 있으며, AI 기업은 대규모 모델 능력을 로봇으로 이전하여 일반화, 의사 결정 및 대화 능력을 향상시키고 있습니다. 산업의 초점은 “프로토타입”에서 “납품”으로 전환되었으며, 제품을 대규모로 안정적으로 납품하고 지속적으로 가치를 창출할 수 있는지가 기업의 생존을 결정하는 핵심이 되었습니다.
(출처: 36氪)

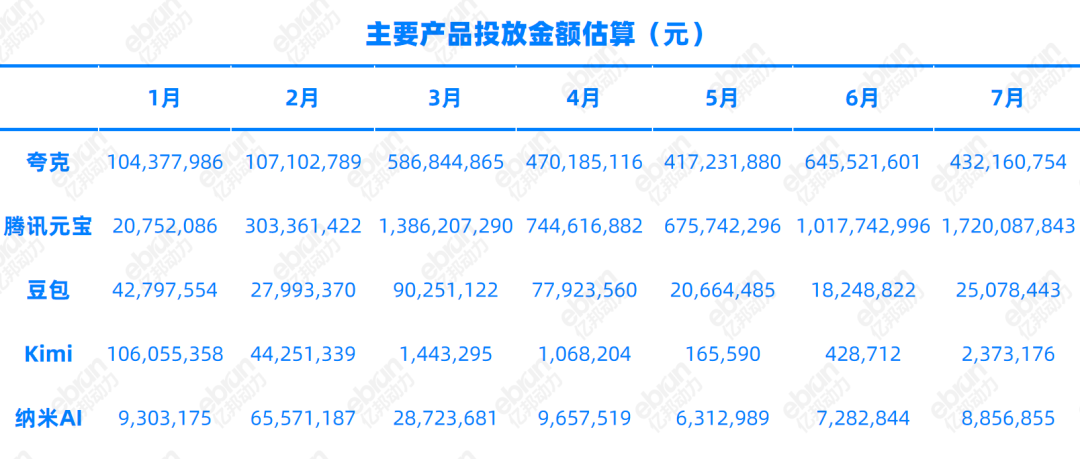
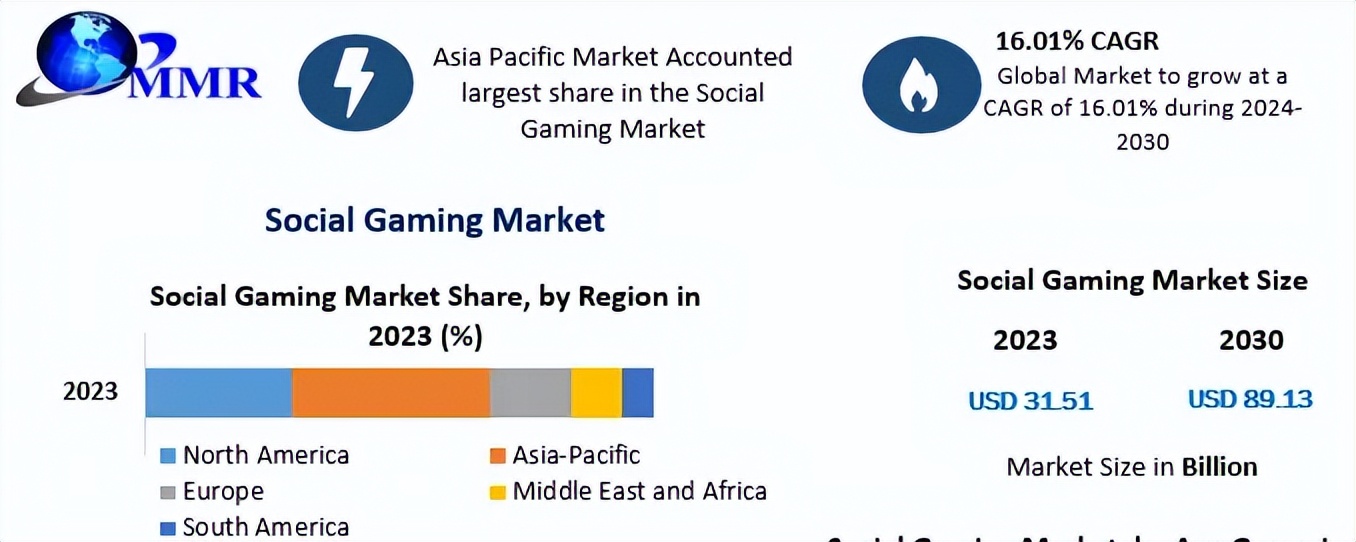
주제: AI 검색 시장: 광고 경쟁 심화, “Agent 시스템”으로 전환
상세 해석, 분석 및 관점 요약: 2025년 상반기 국내 AI 검색 시장에서 광고 경쟁이 폭발적으로 심화되어 Tencent Yuanbao와 Kuark의 월별 광고 투자액이 모두 1억 위안을 돌파했으며, 최고 10억 위안에 달하여 AI 시대의 트래픽 진입로를 선점하려 합니다. AI 검색은 전통적인 “정보 진입로”에서 “정보 종착점”으로 전환되고 있으며, AI 요약 개요, 파일 분석, 글쓰기 및 그림 그리기, 대화 채팅 등의 기능을 통해 직접 결과를 제공합니다. Kuark, Baidu, 360 등 업체는 검색창을 “슈퍼 Agent” 또는 “작업 도우미”로 업그레이드하여 복잡한 작업을 원스톱으로 완료하는 것을 강조합니다. 그러나 AI 검색은 불분명한 수익 모델에 직면해 있으며, 구독 모델은 중국 시장에서 보급되기 어렵고, 광고 없는 노선은 수익 공간을 더욱 압박하여 AI to C 경쟁이 현금 흐름 비축전으로 변모할 것임을 예고합니다.
(출처: 36氪)
주제: “소셜+게임” 융합: AI 기반 범엔터테인먼트 해외 진출 신성장
상세 해석, 분석 및 관점 요약: 중국 범엔터테인먼트 산업은 “소셜+게임”의 심층 융합이라는 새로운 성장 경로를 맞이하고 있으며, AI를 핵심 동력으로 해외 시장을 확장하고 있습니다. Chizicheng Technology, Xindong Company, Yalla Group 등 기업은 소셜 플랫폼과 게임을 심층적으로 결합하여 “트래픽-상호작용-유료화”의 비즈니스 폐쇄 루프를 구축하여 사용자 유지율과 전환 효율성을 크게 높였습니다. AI 기술은 사용자 프로필 모델링, 실시간 매칭, 지능형 콘텐츠 추천, 다국어 번역, 게임 콘텐츠 생성(AIGC) 및 의인화된 지능형 에이전트(AI NPC) 등에서 핵심적인 역할을 하여 사용자 경험과 운영 효율성을 크게 향상시켰습니다. 이러한 융합 모델은 경량 콘텐츠, 고강도 소셜 기능 및 AI 기반 개인화된 경험을 통해 문화 장벽을 허물고 현지 사용자 선호도에 빠르게 대응하는 효과적인 전략이 되고 있으며, “AI+범엔터테인먼트” 플랫폼급 기회의 도래를 예고합니다.
(출처: 36氪)
주제: Qwen, 4B 엣지 디바이스 대규모 모델 출시: 더 큰 모델 능가하는 성능, 엣지 컴퓨팅 강화
상세 해석, 분석 및 관점 요약: Alibaba Cloud Qwen 팀은 다시 두 가지 4B 엣지 디바이스 대규모 모델을 오픈 소스로 공개했습니다: Qwen3-4B-Instruct-2507(일반 능력) 및 Qwen3-4B-Thinking-2507(고급 추론). 이 두 4B 모델은 AIME25 등 테스트에서 뛰어난 성능을 보였으며, 특히 Thinking 모델은 수학 능력에서 81.3점을 기록하여 Claude 4 Opus(75.5점) 및 Gemini 2.5 Pro의 일부 성능을 능가하며 “작은 것으로 큰 것을 이기는” 성과를 달성했습니다. 4B 매개변수량은 Raspberry Pi와 같은 엣지 디바이스에 매우 적합하며, 256k 컨텍스트를 지원하고 1M까지 확장 가능합니다. Qwen 팀은 모델의 사고 능력과 추론 품질을 지속적으로 향상시켜 엣지 디바이스 개발자에게 더 지능적이고 정확하며 컨텍스트 인식 능력이 뛰어난 AI 솔루션을 제공하여 AI 기술의 보편화를 더욱 촉진하고 있습니다.
(출처: 量子位)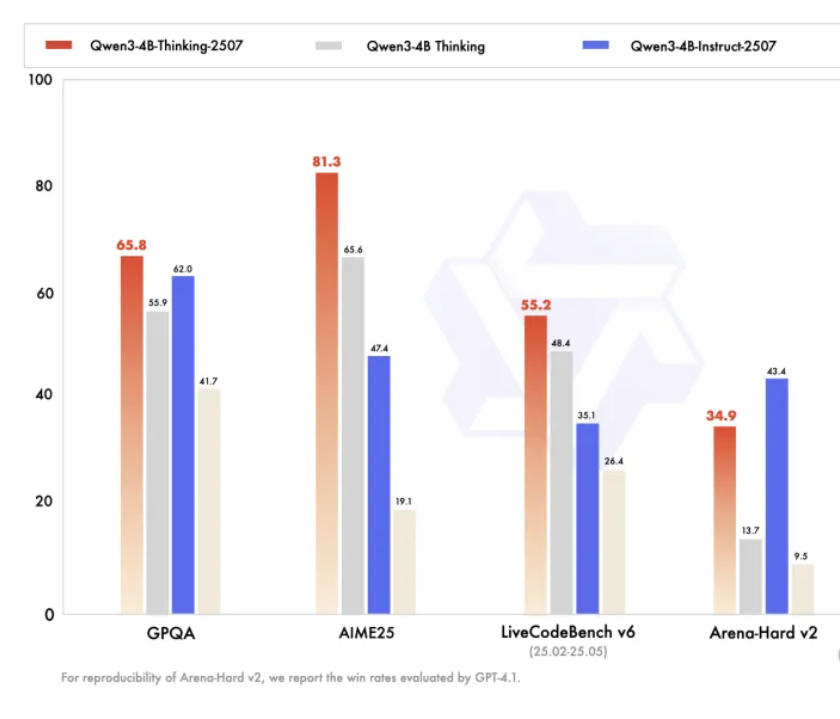
🧰 도구
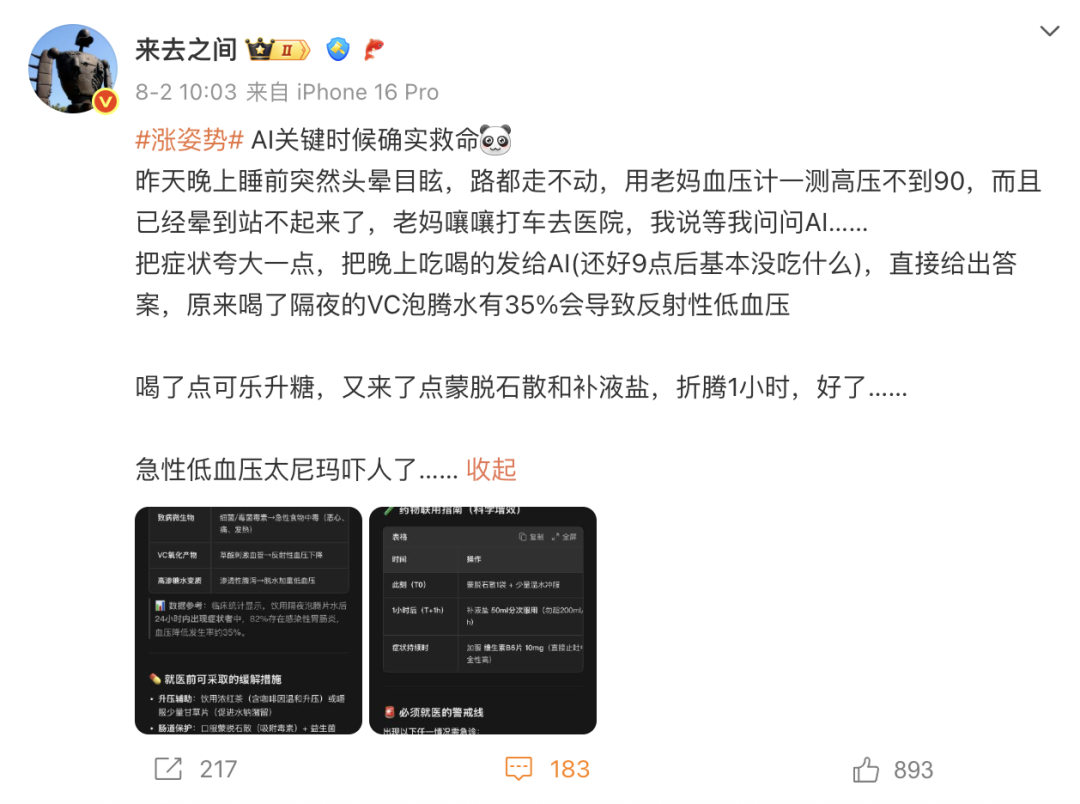
주제: AI 의료 상담: Weibo CEO 직접 테스트, AI 보조 진단 잠재력 거대
상세 해석, 분석 및 관점 요약: Weibo CEO “Laiquzhijian”은 AI 의료 상담을 직접 테스트하여 저혈압 증상을 성공적으로 완화시켰고, 이는 사회적으로 광범위한 논의를 불러일으켰습니다. 기사 작성자도 AI가 여자친구의 20년 넘게 괴롭혔던 희귀 편두통을 진단한 사례를 공유했습니다. 이러한 사례는 AI가 의료 상담 분야에서 예상보다 뛰어난 신뢰성을 보여주고 있음을 나타냅니다. 이는 의료 정보의 높은 구조화, 대규모 모델의 방대한 의학 지식 처리 능력, 고품질 의학 데이터 훈련, 지식 강화(RAG) 기술 및 내장된 “의료 사실 검증 모듈” 덕분입니다. AI 보조 진단은 환자가 병세를 정리하고 진료 효율성을 높이는 데 도움이 될 뿐만 아니라 의사에게 의사 결정 지원을 제공하여 전 세계 의료 자원 불균형 문제를 완화할 수 있을 것으로 기대됩니다.
(출처: 36氪)
주제: OpenEvidence: 의료계의 “Google”, AI로 의사의 의학 연구 효율적 접근 지원
상세 해석, 분석 및 관점 요약: OpenEvidence는 Harvard 박사 Daniel Nadler가 설립한 회사로, 의사들이 직면한 방대한 의학 문헌 정보 과부하 문제를 해결하는 것을 목표로 합니다. 이 회사는 독점 알고리즘을 개발하여 수백만 편의 동료 검토 논문을 신속하게 검색하고 의사에게 정확한 답변과 인용을 제공하며, 인증된 의사에게는 무료로 개방하고 광고를 통해 수익을 창출합니다. 이 플랫폼은 이미 미국 의사의 40%를 유치했으며, 가치는 35억 달러에 달합니다. OpenEvidence의 가치는 의사가 최신, 가장 신뢰할 수 있는 의학 정보를 효율적으로 얻을 수 있도록 돕고, 전통적인 검색 방식의 시간 소모와 한계를 피하며, 특히 긴급 상황에서 빠른 의사 결정 지원을 제공하여 진료 계획을 최적화할 수 있다는 점에 있습니다.
(출처: 36氪)

주제: AI 기반 고대 라틴어 비문 해독: Google DeepMind, Aeneas 시스템 출시
상세 해석, 분석 및 관점 요약: Google DeepMind는 고전 학자 및 고고학자와 협력하여 고대 라틴어 비문을 전문가가 이해하도록 돕는 Aeneas라는 머신러닝 시스템을 개발했습니다. Aeneas는 기원전 7세기부터 기원후 8세기까지의 라틴어 비문에 대한 맥락, 텍스트 검색 및 맥락적 유사성을 제공하고, 시각적 세부 정보를 활용하여 비문의 공백을 채우는 추측성 텍스트를 생성할 수 있는 생성형 신경망입니다. 이 시스템은 실험에서 역사학자의 연구 효율성과 신뢰도를 크게 향상시켰으며, 눈에 띄지 않는 유사성과 간과된 텍스트 특징을 더 정확하게 식별하고 지리적 위치 파악 및 연대 추정에 사용될 수 있어 고대 문자 연구에 혁명적인 보조 도구를 제공합니다.
(출처: aihub.org)
주제: 휴머노이드 인형 “Lingtong NIA-F01”: 감성 동반 및 개인 맞춤형에 중점
상세 해석, 분석 및 관점 요약: “Lingdong” 팀은 첫 데스크톱 AI 임베디드 휴머노이드 로봇 NIA-F01(중국어 이름 “Nian”)을 출시했습니다. 높이 56CM로, 2차원 여성 캐릭터 이미지로 디자인되었으며, 가벼운 DIY(얼굴, 머리, 옷 교체)를 지원합니다. 이 제품은 ECE 알고리즘(감성 공명 엔진)을 통해 멀티모달 AI 대규모 모델을 통합하고, 눈 카메라로 사용자 행동과 환경을 포착하여 감성 표현 동작과 일치시킵니다. 사용자는 실제 인물, 가상 아이돌 또는 2차원 캐릭터의 동작, 습관 및 음색을 맞춤 설정하여 NIA-F01에 로드하여 모방 대화를 할 수 있습니다. NIA-F01은 고급 “움직이는 피규어”로 포지셔닝되어 사용자의 감성 동반 요구를 충족시키는 것을 목표로 하며, “로봇 여자친구”가 AI 시대의 새로운 트렌드가 될 것임을 예고합니다.
(출처: 36氪)

주제: Fourier “Care-bot GR-3”: 유연한 외관과 전감각 상호작용, 보조 간호 시나리오 확장
상세 해석, 분석 및 관점 요약: Fourier는 풀사이즈 휴머노이드 로봇 Care-bot GR-3를 출시했습니다. 이 로봇의 외관은 전통적인 차가운 느낌을 벗어나 모란디 따뜻한 색조와 부드러운 외피 소재를 사용하여 친근감을 자아냅니다. GR-3는 높이 165cm, 전신 55개의 자유도를 가지며, 전감각 상호작용 시스템(시각, 청각, 촉각)을 갖추고 있어 눈맞춤, 음원 위치 파악 및 촉각 피드백이 가능합니다. 또한, 직립 보행, 짧은 걸음 달리기 등 다양한 의인화된 자세를 취할 수 있으며, “빠른 사고”와 “느린 사고”의 이중 경로 응답 메커니즘을 구현했습니다. Fourier는 “Care-bot” 개념을 제시하며 GR-3를 사회적 동반 및 보조 간호 로봇으로 포지셔닝하여, “따뜻한” 상호작용을 통해 독거노인 동반, 어린이 상호작용 놀이 친구, 재활 훈련 등의 역할을 수행하는 것을 목표로 합니다.
(출처: 量子位)
주제: AI 장난감 시장: 대기업 경쟁적 진입, 감성 연결 및 데이터 확보 목표
상세 해석, 분석 및 관점 요약: JD, Alibaba, Baidu, ByteDance 등 대기업들은 AI 장난감 분야에 적극적으로 진출하여 기술을 통해 장난감 제조업체를 지원하고 LABUBU와 같은 히트 제품을 만들고자 합니다. AI 장난감은 “기능형”에서 “감성형”으로 변화하여 AI를 활용하여 사용자와 깊은 감성적 연결을 구축하고, 데이터 확보를 통해 모델을 훈련할 것입니다. 대기업들은 AI 장난감을 대규모 모델 수익화의 최적 경로 중 하나이자 사용자 마음을 사로잡는 전략적 진입점으로 보고 있습니다. AI 장난감은 높은 비용, 높은 가격 책정 및 시장 의문이라는 과제에 직면해 있지만, 높은 마진율과 1600억 위안 이상의 시장 잠재력, 그리고 AI 시나리오의 높은 오류 허용 범위 특성은 많은 자본과 전 대기업 고위 임원들을 끌어들이고 있습니다.
(출처: 36氪)

📚 학습
주제: HarmonyGuard: 웹 에이전트 보안 및 유용성 균형 연구
상세 해석, 분석 및 관점 요약: HarmonyGuard는 웹 에이전트가 개방형 웹 환경에서 작업 성능과 새로운 위험 사이의 균형을 맞추는 문제를 해결하기 위한 다중 에이전트 협업 프레임워크입니다. 이 프레임워크는 정책 강화 및 이중 목표 최적화를 통해 유용성과 보안을 동시에 향상시키는 것을 목표로 합니다. 핵심 기능은 다음과 같습니다: 정책 에이전트가 구조화된 보안 정책을 자동으로 추출하고 유지하며 지속적으로 업데이트하는 적응형 정책 강화; 그리고 유용성 에이전트가 목표를 평가하기 위해 마르코프 실시간 추론을 수행하고 메타인지 능력을 활용하여 최적화하는 이중 목표 최적화. 실험 결과 HarmonyGuard는 정책 준수율을 최대 38% 향상시키고, 작업 완료율을 20% 향상시키며, 모든 작업에서 90% 이상의 정책 준수율을 달성했습니다.
(출처: HuggingFace Daily Papers)
주제: LLM 편향 및 공정성 거버넌스: 데이터 및 AI 거버넌스 프레임워크 탐구
상세 해석, 분석 및 관점 요약: 이 논문은 머신러닝 모델 수명 주기에서 편향을 체계적으로 관리, 평가 및 정량화하는 방법을 탐구하며, 특히 대규모 언어 모델(LLM)에 중점을 둡니다. 저자는 LLM에 널리 퍼져 있는 편향 및 공정성 관련 격차를 공유하고, LLM의 편향, 윤리, 공정성 및 사실성을 해결하기 위한 데이터 및 AI 거버넌스 프레임워크를 논의합니다. 제안된 거버넌스 방법은 실제 적용에 적합하며, 프로덕션 배포 전에 LLM을 엄격하게 벤치마킹하고, 지속적인 실시간 평가를 촉진하며, LLM이 생성하는 응답을 사전에 관리할 수 있습니다. AI 개발 수명 주기에서 데이터 및 AI 거버넌스를 구현함으로써 조직은 생성형 AI 시스템의 안전성과 책임감을 크게 강화하고 차별 위험을 효과적으로 줄일 수 있습니다.
(출처: HuggingFace Daily Papers)
주제: R-Zero: 제로 데이터에서 LLM 자율 추론 진화 실현
상세 해석, 분석 및 관점 요약: R-Zero는 자체 훈련 데이터를 처음부터 생성하여 대규모 언어 모델(LLM)의 자기 진화를 통해 초지능으로 나아가도록 설계된 완전 자율 프레임워크입니다. 기존 방법이 방대한 수동 작업과 레이블에 의존하는 것과 달리, R-Zero는 기본 LLM에서 시작하여 두 개의 독립적인 모델인 챌린저와 솔버를 초기화합니다. 이 두 모델은 상호 작용을 통해 함께 진화합니다: 챌린저는 솔버의 능력 한계에 가까운 작업을 제시하여 보상을 받고, 솔버는 챌린저가 제시하는 점점 더 복잡한 작업을 해결하여 보상을 받습니다. 이 과정은 사전 설정된 작업과 레이블 없이도 목표 지향적인 자기 개선 과정을 생성할 수 있습니다.
(출처: HuggingFace Daily Papers)
주제: 추론 모델 진단: 다중 홉 분석에서 LLM 추론 실패 패턴 탐구
상세 해석, 분석 및 관점 요약: 이 연구는 현대 언어 모델의 다중 홉 질의응답 작업에서의 추론 실패를 체계적으로 탐구합니다. 연구는 세 가지 핵심 차원(소스 문서의 다양성과 고유성, 관련 정보 포착의 완전성, 인지 효율성)에서 실패를 검사하는 새롭고 세분화된 오류 분류 프레임워크를 도입합니다. 엄격한 수동 주석 및 보완적인 자동화된 지표를 통해 연구는 정확성 중심 평가에서 종종 숨겨지는 복잡한 오류 패턴을 밝혀냈습니다. 이러한 조사 방법은 현재 모델의 인지적 한계에 대한 더 깊은 통찰력을 제공하고, 미래 언어 모델링 작업에서 추론의 충실도, 투명성 및 견고성을 향상시키기 위한 실행 가능한 지침을 제공합니다.
(출처: HuggingFace Daily Papers)
주제: LLM 행복감 개념 설명 능력 평가: 대규모 데이터셋 구축 및 최적화 방법
상세 해석, 분석 및 관점 요약: 이 연구는 대규모 언어 모델(LLM)의 행복감 개념 설명 능력을 평가하고, 정확하면서도 다양한 청중에게 적합한 설명을 생성하는 방법을 탐구하는 것을 목표로 합니다. 연구는 10개의 다른 LLM이 생성한 43,880개의 행복감 개념 설명을 포함하는 대규모 데이터셋을 구축했습니다. 연구는 설명 품질을 평가하기 위해 이중 평가를 사용하는 원칙 기반의 LLM-as-a-judge 평가 프레임워크를 도입했습니다. 결과는 설명 품질이 모델, 청중 및 범주에 따라 상당한 차이를 보임을 나타냅니다. 또한, 지도 미세 조정(SFT) 및 직접 선호도 최적화(DPO)를 통해 오픈 소스 LLM을 미세 조정하면 생성된 설명의 품질을 크게 향상시킬 수 있으며, 전문 설명 작업에서 선호도 기반 학습의 효과를 입증했습니다.
(출처: HuggingFace Daily Papers)
💼 비즈니스
주제: AI 프로그래밍 유니콘의 딜레마: 높은 비용과 마이너스 마진, 산업 재편 직면
상세 해석, 분석 및 관점 요약: AI 프로그래밍 기업들은 높은 운영 비용과 마이너스 마진의 딜레마에 직면해 있으며, 특히 대규모 언어 모델 호출 비용이 원가의 대부분을 차지하여 사용자가 많을수록 손실이 커집니다. 예를 들어, Windsurf는 연간 4천만 달러의 매출을 올렸음에도 불구하고 마진율이 현저히 마이너스였습니다. 이러한 도전에 대응하기 위해 기업들은 자체 모델 개발 또는 인수 합병을 시도합니다. Windsurf는 Google에 핵심 기술을 인수당한 후, 남은 직원들이 Cognition에 인수되었고, “주 6일, 80시간 이상 근무” 또는 퇴직이라는 “머스크식 개조”에 직면했습니다. 이는 AI 프로그래밍 분야의 치열한 경쟁과 불분명한 수익 모델 현황을 반영하며, 산업 재편이 가속화되어 수익 모델을 찾거나 거대 기업에 통합되는 기업만이 생존할 수 있음을 예고합니다.
(출처: 36氪)
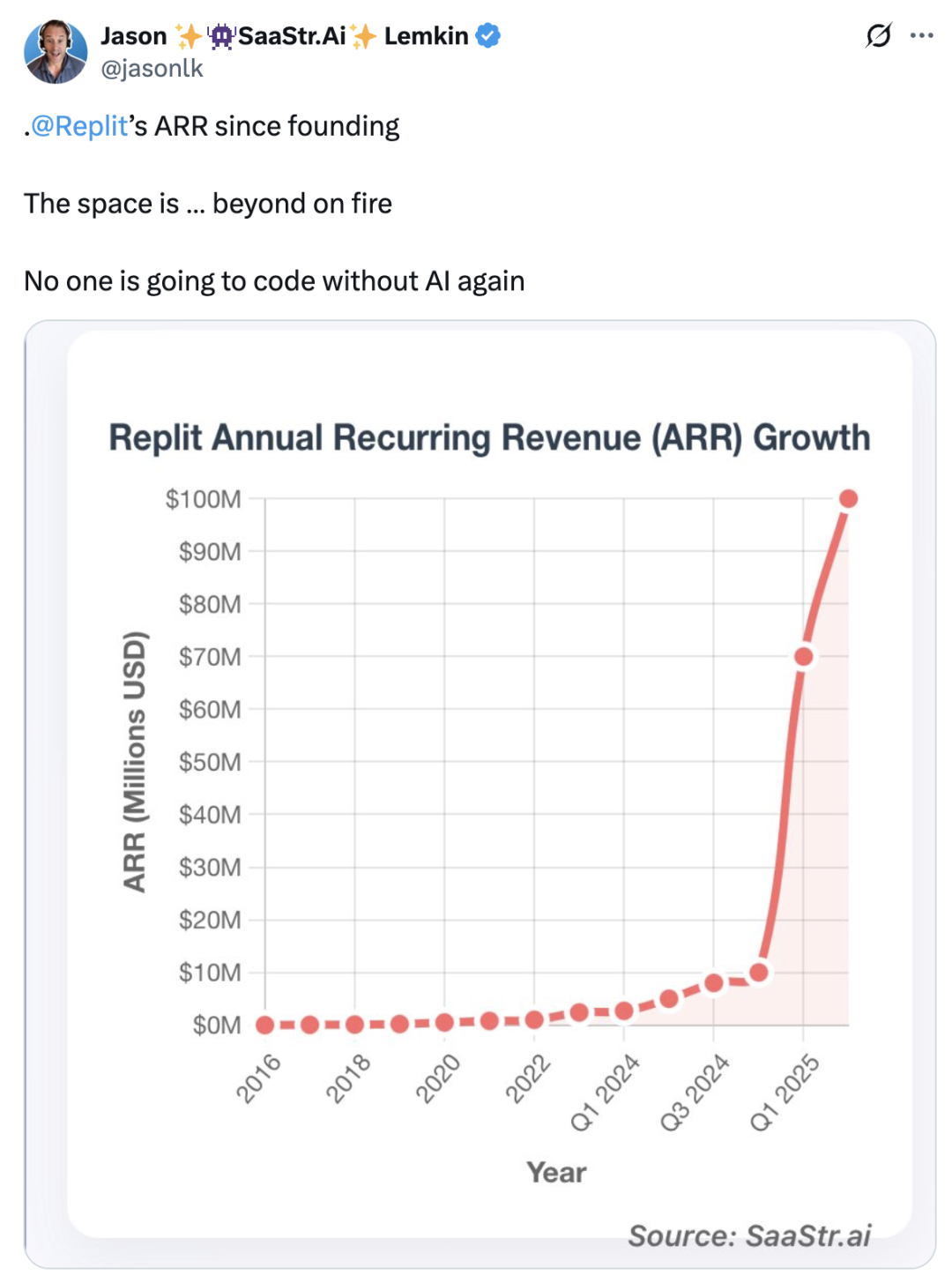
주제: AI 인재 연봉 급등: Andrew Ng, Meta의 천문학적 연봉 뒤에 숨겨진 자본 논리 해설
상세 해석, 분석 및 관점 요약: Meta가 AI 대규모 모델 개발자에게 1억 달러가 넘는 천문학적인 연봉을 제시하여 업계에 충격을 주었습니다. Andrew Ng는 이것이 충동적인 행동이 아니라 정교한 자본 논리에 기반한 합리적인 투자라고 지적했습니다. 그는 AI 기반 모델 구축이 GPU와 같은 하드웨어에 수백억 달러에 달하는 막대한 자본 집약적 사업이며, 이에 비해 수억 달러의 연봉은 비용 구조에서 차지하는 비중이 매우 작다고 설명했습니다. AI 기업의 “적은 인원, 많은 돈” 구조는 초고액 연봉을 지불할 수 있게 합니다. Andrew Ng는 또한 Meta와 같은 플랫폼이 AIGC에 대한 높은 관심과 경쟁사 기술 통찰력을 얻기 위한 고액 연봉 스카우트 경쟁이 이러한 고액 연봉을 합리적인 전략적 지출로 만든다고 언급했습니다.
(출처: 36氪)
주제: 기업 데이터 통제: Reddit 대 Anthropic 소송, AI 데이터 스크래핑 및 계약 법률의 새로운 트렌드 시사
상세 해석, 분석 및 관점 요약: AI 훈련을 위한 실시간 데이터 접근 요구가 급증함에 따라, 웹 데이터 스크래핑은 기업이 직면한 법적 및 운영적 과제가 되었습니다. 많은 데이터 수집업체는 최종 사용자와 계약을 체결하여 사용자 권한을 활용해 플랫폼의 기술적 및 계약적 제한을 우회합니다. Reddit이 Anthropic을 고소한 사건은 기술계를 뒤흔들었으며, Anthropic이 AI 훈련을 위해 사용자 데이터를 무단으로 대규모 스크래핑하여 사용자 계약을 위반했다고 주장했습니다. 이 사건은 전통적인 저작권법이 아닌 계약 조건이 AI 모델 훈련 데이터 사용을 관리하는 주요 법적 프레임워크가 될 수 있음을 강조합니다. 기업은 데이터 스크래핑 위험에 대응하고 자체 데이터 권익과 비즈니스 모델을 보호하기 위해 사용 약관을 강화하고, 접근 제어를 평가하며, 잠재적인 데이터 유출을 통제하고, 적극적으로 권리를 주장해야 합니다.
(출처: 36氪)
🌟 커뮤니티
주제: GPT-5 출시로 인한 뜨거운 논쟁: 성능 논란과 “차트 범죄(Chart Crime)”
상세 해석, 분석 및 관점 요약: OpenAI의 GPT-5 출시 후 소셜 미디어에서 광범위한 논의가 촉발되었습니다. 공식적으로는 SOTA 성능을 주장했지만, 사용자 및 전문가들 사이에서는 “혁신 부족”, “GPT-4o만큼 놀랍지 않다”는 의문이 제기되었고, 심지어 일부 네티즌은 발표회 PPT의 막대그래프에 “차트 범죄(Chart Crime)”(데이터와 그림 불일치)라는 초보적인 오류가 있다고 지적했습니다. Elon Musk도 즉시 X에 글을 올려 자신의 Grok-4가 일부 테스트에서 GPT-5를 능가했다고 주장하며 논쟁을 더욱 부추겼습니다. 이러한 논란은 AI 모델의 획기적인 발전에 대한 대중의 더 높은 기대와 SOTA 선두 우위가 더 이상 “압도적”이지 않다는 인식을 반영합니다.
(출처: 36氪)

주제: AI 천문학적 연봉 논란: Andrew Ng 트윗, 산업 자본 논리 드러내
상세 해석, 분석 및 관점 요약: Meta가 AI 대규모 모델 개발자에게 1억 달러가 넘는 연봉 패키지를 제시했다는 소식은 소셜 미디어에서 빠르게 뜨거운 논쟁을 불러일으켰습니다. AI 분야의 저명한 학자인 Andrew Ng는 트위터에서 이에 대해 해설하며, 이것이 충동적인 행동이 아니라 AI 대규모 모델 구축의 자본 집약적 특성에 기반한 기업의 합리적인 인재 배치라고 주장했습니다. 그는 기업이 방대한 하드웨어 투자(예: GPU 클러스터)를 최대한 활용하기 위해 이러한 투자를 한다고 설명했습니다. 그의 견해는 AI 산업의 고액 연봉 뒤에 숨겨진 비즈니스 논리, 인재 가치, 그리고 전통적인 노동 집약적 산업의 연봉 모델과의 차이에 대한 광범위한 논의를 촉발했습니다.
(출처: 36氪)
주제: Weibo CEO AI 의료 상담 직접 테스트: AI 의료 신뢰성에 대한 격렬한 논쟁 촉발
상세 해석, 분석 및 관점 요약: Weibo CEO “Laiquzhijian”이 AI를 사용하여 저혈압을 “진단”하고 증상을 성공적으로 완화시킨 경험을 공유하는 글을 올리자, 소셜 미디어에서 즉시 큰 논란이 일었습니다. 그 자신은 AI 진단이 정확하다고 말했고, AI가 희귀병 진단에 보조적인 역할을 한다는 실제 사례도 있었지만, 많은 네티즌들은 이러한 행동이 대중이 긴급 상황에서 의료 진료를 포기하게 만들어 최적의 치료 시기를 놓치게 할 수 있다고 비판했습니다. 이 사건은 AI 의료 애플리케이션이 보급되는 과정에서 대중이 그 신뢰성, 위험 범위 및 윤리적 책임에 대해 깊이 우려하고 격렬하게 논쟁하고 있음을 보여줍니다.
(출처: 36氪)
주제: AI 프로그래밍 회사 근무 문화: Windsurf 인수 후 “머스크식 개조” 직면
상세 해석, 분석 및 관점 요약: AI 프로그래밍 스타트업 Windsurf가 Cognition에 인수된 후 직원들이 “머스크식 개조”를 겪고 있다는 소식이 소셜 미디어에서 뜨거운 논쟁을 불러일으켰습니다. Cognition은 Windsurf의 원래 직원 약 30명을 해고하고, 남은 200명의 직원에게 “주 6일, 총 80시간 이상 근무”라는 초강력 근무 방식을 수용하거나 9개월치 급여를 받고 퇴사할 것을 제한된 시간 내에 선택하도록 요구했습니다. Cognition CEO Scott Wu는 이에 대해 모든 직원의 4년 주식 가치를 조기 실현하고 추가 보상을 제공했다고 응답했지만, 이러한 움직임은 여전히 외부에서 기업 문화 청산으로 의심받으며 AI 스타트업의 고압적인 근무 방식과 직원 권리에 대한 광범위한 논의를 촉발했습니다.
(출처: 36氪)

💡 기타
주제: 구이양 컴퓨팅 산업: 서부 데이터 센터 클러스터, 지역 경제 성장 지원
상세 해석, 분석 및 관점 요약: 구이양은 독특한 지질, 기후 및 수력 자원 이점을 바탕으로 중국의 중요한 컴퓨팅 허브가 되었으며, 구이안 신구 데이터 센터 클러스터는 전국 10대 데이터 센터 클러스터 중 컴퓨팅 보장 지수에서 1위를 차지했습니다. “동수서산(东数西算)” 프로젝트의 핵심 노드로서 구이양은 “유랑지구 2”와 같은 영화 및 TV 작품에 효율적인 렌더링 서비스를 제공할 뿐만 아니라 대학 및 연구 기관에 컴퓨팅 능력을 제공하여 최첨단 과학 연구를 지원합니다. 컴퓨팅 발전은 서버 제조, 클라우드 컴퓨팅, 데이터 보안 등 상하위 산업 투자를 유도하고 전통 제조업의 디지털 전환을 촉진했습니다. 2024년 구이양 구이안의 디지털 경제 부가가치는 GDP에서 53.3%를 차지했으며, 도시 신뢰할 수 있는 데이터 공간을 적극적으로 구축하여 데이터와 AI가 도시 전반의 디지털 전환을 가능하게 하고 있습니다.
(출처: 36氪)

주제: 중국 AI 발전: 36氪 AI Partner 대회, “중국식 솔루션”에 집중
상세 해석, 분석 및 관점 요약: 36氪과 중유럽 국제 비즈니스 스쿨이 공동 주최하는 “2025 AI Partner 백업 대회”가 8월 27일 베이징에서 개최될 예정입니다. 이 대회는 중국 AI의 최신 돌파구와 생태계를 전면적으로 제시하고, “중국식 솔루션”이 어떻게 다양한 산업에 지속적으로 힘을 실어줄 수 있는지, 그리고 중국 AI 기업이 어떻게 “시나리오 기반 지능”의 경계를 재구성할 수 있는지 탐구하는 것을 목표로 합니다. 대회는 중국식 혁신, 슈퍼 에이전트, 세계 기술 경쟁 구도 재편, AI와 실물 경제 융합 등의 주제를 중심으로 전 세계 AI 전문가, 기업 리더 및 투자 기관을 초청하여 다양한 수직 분야에서의 AI 실천 성과와 미래 가능성을 집중적으로 보여주고 AI 기술과 산업 수요의 연계를 촉진할 것입니다.
(출처: 36氪)
