
키워드:NVIDIA AI, 로봇 학습, 강화 학습, 구현된 지능, DeepSeek 모델, Lambda GPU 클라우드, 로봇 보행 시뮬레이션 기술, NVIDIA AI 강화 학습 연구, 로봇 제어에서의 DeepSeek 모델 적용, 구현된 지능 기술 발전, Lambda GPU 클라우드 추론 능력
다음은 제공된 뉴스와 소셜 미디어 토론을 심층 분석, 요약 및 정리한 내용입니다.
🔥 포커스
NVIDIA AI, 로봇의 보행 학습 지원 : NVIDIA AI 연구팀은 강화 학습 로봇 보행에 대한 획기적인 연구를 발표했습니다. 딥러닝과 시뮬레이션 기술을 통해 로봇이 복잡한 보행 패턴을 더 효과적으로 학습하고 적응할 수 있도록 했습니다. 이 연구는 Lambda GPU 클라우드에서 DeepSeek 모델의 추론 능력을 활용했으며, 관련 논문을 발표하여 AI가 로봇 제어 및 시뮬레이션 분야에서 이룬 최신 발전을 보여주었습니다. 이는 구현된 지능(embodied AI)과 범용 로봇 기술의 발전을 가속화하고, 미래 현실 세계의 로봇 애플리케이션을 위한 기반을 마련할 것으로 기대됩니다. (출처: )

🎯 동향
OpenAI, 감정 조절 가능한 ChatGPT 출시 : OpenAI는 사용자가 ChatGPT의 ‘열정’ 수준을 직접 조절할 수 있도록 했습니다. 이 새로운 기능은 더욱 개인화되고 적응성 높은 사용자 경험을 제공하여 AI 출력의 어조와 스타일이 사용자 요구에 더 잘 부합하도록 하는 것을 목표로 합니다. 이는 AI 모델이 감정 및 표현 제어 측면에서 새로운 발걸음을 내디딘 것이며, AI 상호작용에 대한 사용자의 세밀한 제어 능력을 강화합니다. (출처: Reddit r/artificial)
NVIDIA, Nemotron 3 하이브리드 Mamba Transformer 모델 발표 : NVIDIA AI는 Nemotron 3를 출시했습니다. 이 모델은 Mamba, Transformer, MoE(전문가 혼합) 아키텍처를 결합한 하이브리드 모델 스택으로, 긴 컨텍스트와 에이전트 AI를 위해 특별히 설계되었습니다. 이 모델은 복잡하고 긴 시퀀스 작업을 처리할 때 AI의 성능과 효율성을 향상시키는 것을 목표로 하며, 미래 AI 모델이 더 강력한 기능을 위해 다중 아키텍처 융합에 더 중점을 둘 것임을 시사합니다. (출처: Reddit r/artificial)
MiraTTS: 빠르고 사실적인 로컬 텍스트 음성 변환 모델 발표 : MiraTTS는 새로운 텍스트 음성 변환(TTS) 모델로, 매우 빠른 생성 속도, 고음질, 낮은 VRAM 점유율로 두각을 나타냅니다. 이 모델은 1초 안에 100초 분량의 48kHz 오디오를 생성할 수 있으며, 음성 복제를 지원하고, 6GB의 VRAM만으로 소비자용 GPU에서 실행 가능합니다. MiraTTS의 출시는 기존 TTS 모델의 로컬화, 사실감, 속도 측면의 문제점을 해결하며, 개인 사용자 및 개발자에게 효율적이고 고품질의 음성 합성 솔루션을 제공합니다. (출처: Reddit r/ArtificialInteligence)
MiniMax M2.1 모델, 디자인 및 시각적 품질에서 상당한 진전 달성 : MiniMax M2.1 모델은 디자인 및 시각적 품질 측면에서 중대한 돌파구를 마련했으며, M2.5 버전에서 추가적인 개선을 계획하고 있습니다. 이러한 진전은 MiniMax가 사용자 경험과 시각적 출력의 정교함에 지속적으로 집중하고 있음을 보여주며, 특히 멀티모달 분야에서 더 높은 수준의 AI 생성 콘텐츠를 제공하기 위해 노력하고 있음을 나타냅니다. (출처: MiniMax__AI)
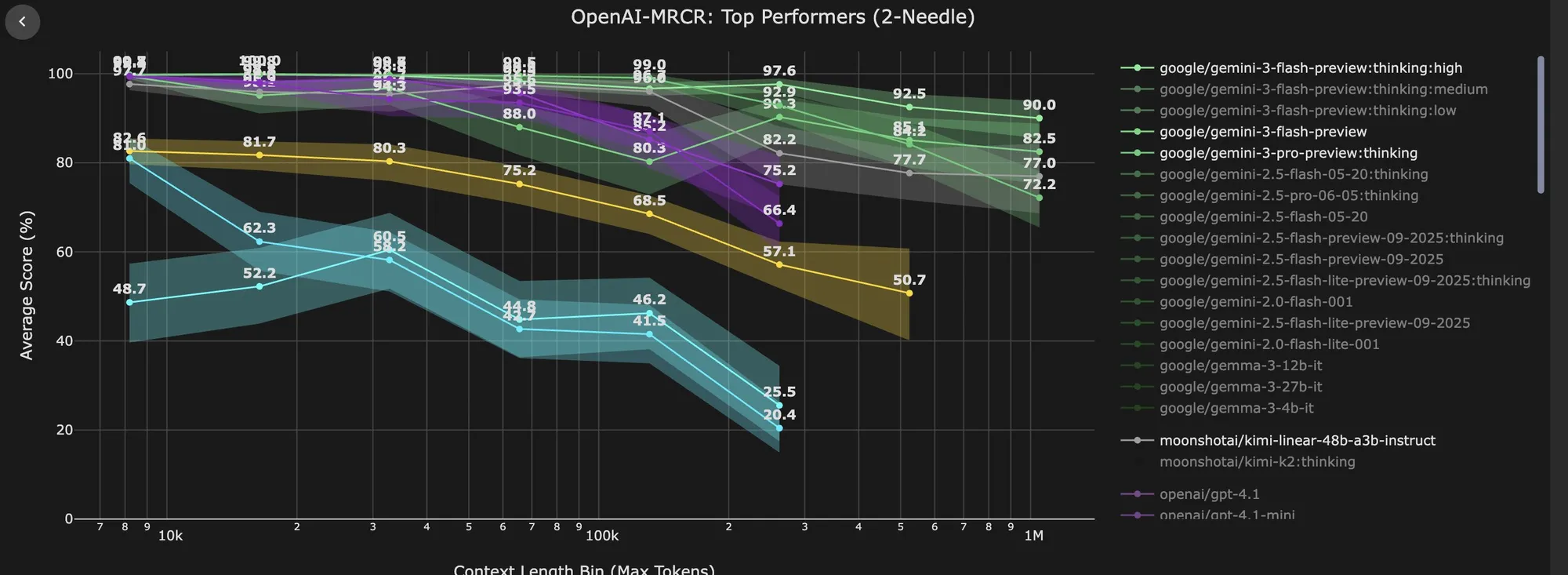
Gemini 3 Flash, 긴 컨텍스트 처리 능력에서 뛰어난 성능 발휘 : Gemini 3 Flash는 긴 컨텍스트 처리에서 탁월한 성능을 보여주었으며, 특히 OpenAI의 MRCR 벤치마크 테스트에서 100만 컨텍스트 길이에서 90%의 정확도를 달성하여, 대부분의 모델이 256k 컨텍스트 길이에서 보이는 성능을 능가했습니다. 이러한 획기적인 성과는 Google이 긴 컨텍스트 기술에 깊이 투자한 덕분이며, LLM이 초장문 텍스트 정보를 이해하고 활용하는 데 있어 엄청난 잠재력을 가지고 있음을 시사합니다. (출처: gabriberton)
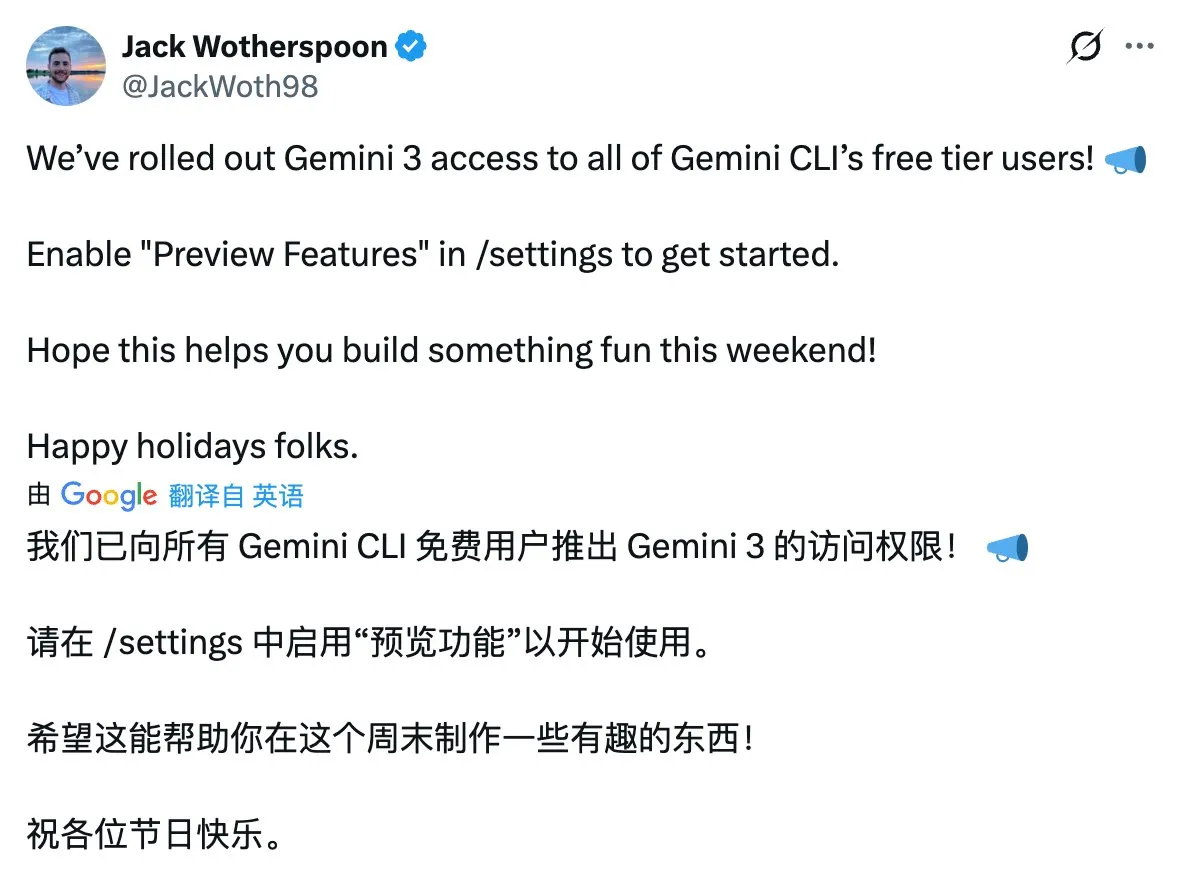
Gemini CLI, 무료 사용자에게 Gemini 3 접근 권한 개방 : Gemini 명령줄 인터페이스(CLI)는 모든 무료 사용자에게 Gemini 3 모델의 접근 권한을 개방했으며, 사용자는 설정에서 ‘미리 보기 기능’을 활성화하기만 하면 경험할 수 있습니다. 이러한 조치는 개발자와 일반 사용자가 최첨단 AI 모델에 접근하는 장벽을 크게 낮추고, Gemini 생태계의 발전과 혁신적인 애플리케이션을 촉진할 것입니다. (출처: op7418)
일본 정부, AI 발전을 위해 조 엔 규모 투자 계획 : 일본 정부는 다카이치 총무대신을 통해 AI 기본 계획 초안을 발표했으며, 신뢰할 수 있는 AI의 민관 협력을 추진하기 위해 1조 엔 이상을 투자할 계획입니다. Sakana AI 등 일본 AI 기업들이 적극적으로 참여하여, 일본을 AI 활용 선진국으로 만들기 위해 함께 노력할 것입니다. 이러한 움직임은 일본 정부가 AI 발전에 대한 중요성과 결의를 보여주는 것이며, 대규모 투자와 산학연 협력을 통해 AI 분야에서 국가 경쟁력을 높이는 것을 목표로 합니다. (출처: SakanaAILabs)
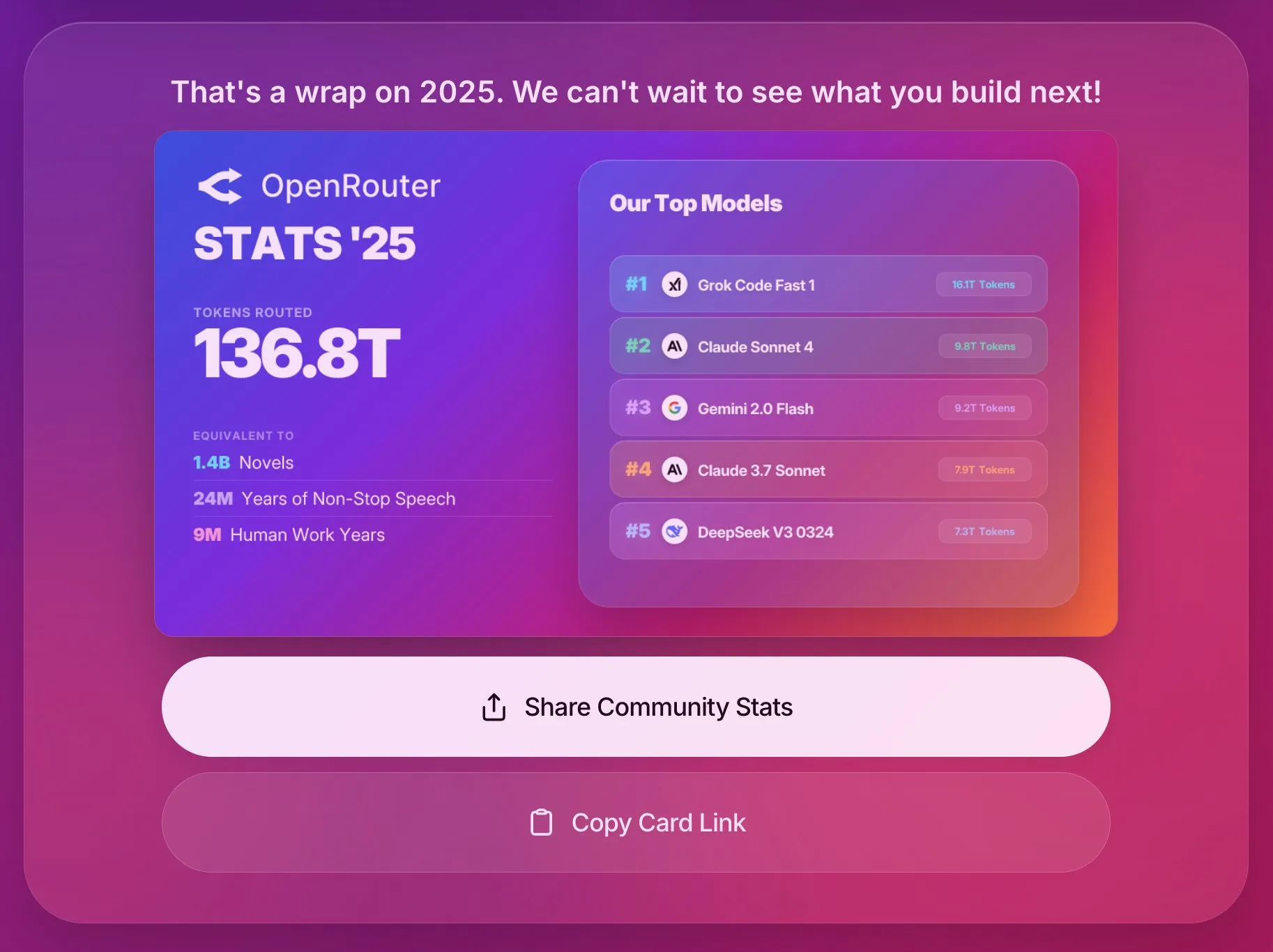
OpenRouter 2025년 연례 보고서, AI 모델 사용 트렌드 공개 : OpenRouter가 발표한 2025년 연례 통계 회고에 따르면, 플랫폼의 총 라우팅 Token 양은 136.78T에 달했으며, 이는 14억 권의 소설에 해당합니다. Grok Code Fast, Claude 4 Sonnet, Gemini 2.0 Flash가 가장 인기 있는 모델 상위 3위를 차지했습니다. 보고서는 또한 멀티모달 AI의 폭발적인 성장을 지적하며, 연간 1,730만 장의 이미지가 생성되었다고 밝혔습니다. 오픈소스 모델은 전체의 절반을 차지했으며, 총 255개에 달했습니다. 이러한 데이터는 텍스트, 멀티모달, 오픈소스 분야에서 AI 모델의 활발한 발전과 다양한 응용 트렌드를 반영합니다. (출처: dotey)
AI 비디오 움직임 제어 기술, 상당한 돌파구 마련 : Kling_ai 팀은 AI 비디오의 움직임 제어 분야에서 놀라운 진전을 이루었습니다. 그들의 도구는 복잡한 동작을 처리할 수 있으며, 기존 비디오 생성 모델로는 구현하기 어려웠던 체조 동작, 립싱크, 카메라 움직임 등을 가능하게 합니다. 이러한 돌파구는 AI 비디오 제작을 혁신하여, 더욱 사실적이고 표현력 있는 콘텐츠를 생성할 수 있게 하고, 영화, 게임, 가상 현실 등 다양한 분야에 새로운 기회를 가져올 것으로 기대됩니다. (출처: Kling_ai)
소형 언어 모델, 내부 ‘사고’ 과정을 통해 복잡한 추론 작업 해결 : MIT CSAIL 연구진은 새로운 훈련 방법을 개발했습니다. 이 방법은 소형 언어 모델이 내부 ‘사고’ 과정을 생성하여 복잡한 추론 작업을 수행할 수 있게 하며, 그 결과는 대형 모델과 견줄 만합니다. 이 방법은 인간의 사고 단계를 모방함으로써, 소형 모델의 추론 능력을 크게 향상시켰으며, 자원 제약이 있는 환경에서 고성능 AI를 배포할 수 있는 새로운 길을 제시합니다. (출처: dl_weekly)
AI 기반 ISP, iPhone 저조도 사진 품질 크게 향상 : 애플의 한 연구에 따르면, AI 기반 이미지 신호 프로세서(ISP)가 저조도 환경에서 iPhone 사진 품질을 크게 개선할 수 있습니다. 이 기술은 지능형 알고리즘을 통해 이미지 처리를 최적화하여, 노이즈를 줄이고 디테일을 향상시키며, 까다로운 조명 조건에서 모바일 사진 촬영 성능을 크게 향상시킬 것으로 기대됩니다. (출처: Reddit r/artificial)

Steam 베스트셀러 게임 절반, 생성형 AI를 수용한 개발자 작품 : Steam 플랫폼의 현재 베스트셀러 상위 10개 게임 중, 절반은 생성형 AI 기술을 채택한 개발자들이 제작한 것입니다. 이러한 현상은 생성형 AI가 게임 개발 분야에서 점점 더 중요한 역할을 하고 있음을 보여주며, 개발자들이 효율성을 높이고 콘텐츠를 혁신하며 궁극적으로 시장에서 성공을 거두는 데 도움을 주고 있습니다. 이는 게임 산업에서 AI의 광범위한 응용 가능성을 시사합니다. (출처: Reddit r/artificial)

Al Jazeera, 완전히 새로운 통합형 AI 모델 “The Core” 출시 : Al Jazeera는 새로운 통합형 AI 모델 “The Core”를 발표했습니다. 이 모델은 뉴스 콘텐츠의 생성, 분석 및 배포 효율성을 높이는 것을 목표로 하며, AI 기술을 통해 뉴스 생산의 모든 단계를 지원합니다. 여기에는 자동화된 보도, 콘텐츠 통합 및 개인화된 추천 등이 포함될 수 있으며, 빠르게 변화하는 뉴스 미디어 환경에 적응하기 위함입니다. (출처: Reddit r/artificial)

윈펑커지, AI+ 헬스케어 신제품 발표: AI 대규모 모델로 스마트 주방 및 건강 관리 지원 : 윈펑커지(云澎科技)는 솨이캉(帅康), 창웨이(创维)와 협력하여 “디지털 지능형 미래 주방 연구소”와 AI 헬스케어 대규모 모델이 탑재된 스마트 냉장고를 발표했습니다. AI 헬스케어 대규모 모델은 주방 디자인 및 운영 최적화를 목표로 하며, 스마트 냉장고는 “건강 도우미 샤오윈(小云)”을 통해 개인 맞춤형 건강 관리를 제공합니다. 이는 가정 건강 분야에서 AI의 심층적인 응용을 의미하며, 스마트 기기를 통해 맞춤형