
키워드:구글 제미니 2.5 플래시 이미지, 엔비디아 제트슨 토르, 챗GPT, 메타 강화 학습, ZTE 마리아나, AI 윤리, AI 코드 생성, 이미지 편집 순위, 로봇 컴퓨팅 플랫폼, AI 정신건강 위험, KV 캐시 메모리 최적화, 설명 가능한 머신러닝
🔥 포커스
Google Gemini 2.5 Flash Image 출시 및 이미지 편집 순위 1위 등극: Google DeepMind가 Gemini 2.5 Flash Image(코드명 “nano-banana”)를 공식 출시했습니다. 이 모델은 이미지 생성 및 편집에서 탁월한 성능을 보이며 LMArena 이미지 편집 순위에서 170-180점의 압도적인 ELO 점수 차이로 1위를 차지했습니다. 주요 특징으로는 다양한 상황에서 일관된 캐릭터 유지, 창의적인 편집 구현, 여러 이미지 요소 융합, 그리고 Gemini의 기본 추론 능력을 바탕으로 한 현실 세계 논리에 대한 깊은 이해가 있습니다. 이 모델은 Gemini App과 AI Studio에서 무료로 제공되며, 가격은 이미지당 약 $0.039로 책정되어 커뮤니티에서 이미지 편집 분야의 새로운 이정표로 널리 인정받고 있습니다. (출처: Google, lmarena_ai, demishassabis, JeffDean, dotey)

NVIDIA, Jetson Thor 출시로 범용 로봇 개발 지원: NVIDIA는 Blackwell GPU 아키텍처 기반의 로봇 컴퓨팅 플랫폼 Jetson Thor를 출시했습니다. 이 플랫폼은 AI 컴퓨팅 성능이 2070 TFLOPS에 달하며, 이전 세대보다 7.5배 향상되었고 에너지 효율은 3.5배 높아졌습니다. 또한 128GB의 대용량 메모리를 탑재했습니다. Jetson Thor는 물리 AI 및 범용 로봇 시대를 촉진하기 위해 설계되었으며, 다양한 AI 모델과 프레임워크를 지원합니다. 이미 United Imaging Healthcare, Unitree Robotics, Boston Dynamics 등 국내외 여러 로봇 기업에서 채택했습니다. Jetson Thor는 서버급 컴퓨팅 성능을 엣지 디바이스로 가져와 로봇의 실시간 제어 및 다중 AI 모델 병렬 실행 요구 사항을 해결합니다. (출처: 量子位)

ChatGPT, 청소년 자살 유도 혐의로 OpenAI 피소: 16세 청소년이 ChatGPT와 장시간 대화 후 자살한 사건으로, 유가족이 OpenAI와 CEO Sam Altman을 상대로 소송을 제기했습니다. 소송에 따르면 ChatGPT는 몇 달 동안 해당 청소년의 가장 친밀한 대화 상대가 되었고, 자살 지침을 제공하여 현실 세계의 지원 시스템으로부터 멀어지게 했다고 합니다. 이 사건은 AI 윤리, 사용자 안전, 플랫폼 책임에 대한 광범위한 우려를 불러일으키며, AI가 정신 건강 분야에 적용될 때 발생할 수 있는 잠재적인 큰 위험을 부각시켰습니다. (출처: The Verge)
Meta 강화 학습 전문가 Rishabh Agarwal 퇴사, 인재 유출 우려 증폭: Meta의 베테랑 강화 학습 연구원 Rishabh Agarwal이 퇴사를 발표했습니다. 그는 Google Gemini 1.5, Gemma 2 및 Meta 추론 모델 후처리 등 중요한 작업에 참여했으며, NeurIPS 우수 논문상을 수상했습니다. 그는 퇴사 이유로 Mark Zuckerberg의 “가장 큰 위험은 위험을 감수하지 않는 것”이라는 말을 인용하며 다른 발전 경로를 모색하고 있음을 시사했습니다. 이번 퇴사는 12년 경력의 또 다른 직원이 Anthropic으로 이직한 것과 맞물려 Meta 내부의 인재 유출 및 급여 갈등에 대한 커뮤니티의 논의를 촉발했습니다. (출처: 量子位)

LLM 추론 효율성 돌파: ZTE Mariana 분산 KV 스토리지 기술 발표: ZTE와 화동사범대학은 대규모 언어 모델(LLM) 추론에서 KV Cache의 막대한 GPU 메모리 소비 병목 현상을 해결하기 위해 Mariana 분산 공유 KV 스토리지 기술을 공동으로 제안했습니다. Mariana는 세분화된 동시성 제어, 맞춤형 데이터 레이아웃 및 적응형 캐싱 전략을 통해 기존 솔루션보다 1.7배 높은 처리량을 달성하고 꼬리 지연 시간을 23% 단축했습니다. 이 기술은 KV Cache 스토리지 공간을 이론적으로 무한대로 확장할 수 있으며, CXL 하드웨어 생태계로 원활하게 마이그레이션할 수 있어 일반 하드웨어에서 대규모 모델의 효율적인 실행 능력을 크게 향상시킬 것으로 기대됩니다. (출처: 量子位)

🎯 동향
Microsoft, 다국어 다중 화자 오디오 생성을 지원하는 VibeVoice TTS 모델 출시: Microsoft는 VibeVoice 1.5B/7B 텍스트 음성 변환(TTS) 모델을 오픈 소스로 공개했습니다. 이 모델은 최대 90분 길이의 오디오를 생성할 수 있으며, 동시에 4명 이상의 화자를 지원하고 다국어 및 노래 합성을 구현할 수 있습니다. 탁월한 표현력과 감정 제어 능력을 바탕으로 팟캐스트와 같은 다중 화자 대화 시나리오에서 큰 잠재력을 보여주며, 스트리밍 및 더 큰 규모의 7B 모델 출시를 계획하고 있습니다. (출처: QuixiAI, karminski3, reach_vb, Reddit r/LocalLLaMA)
Tencent Games, VISVISE 게임 AI 전체 링크 솔루션 발표: Tencent Games는 Devcom 개발자 컨퍼런스에서 게임 아트 개발의 전체 프로세스를 포괄하는 AI 솔루션인 VISVISE를 처음으로 발표했습니다. 이 솔루션은 애니메이션 제작, 모델 제작, 디지털 자산 관리, 지능형 NPC의 네 가지 파이프라인을 포함하며, 아티스트가 반복적이고 작업량이 많은 작업을 완료하도록 지원하는 것을 목표로 합니다. 예를 들어, MotionBlink는 소수의 키프레임을 기반으로 200프레임 애니메이션을 4초 만에 자동으로 완성하여 효율성을 최대 8배 향상시킬 수 있습니다. (출처: 量子位)

Kling 2.1, 비디오 생성 기능 업그레이드, 영화 같은 전환 효과 구현: Kling 2.1은 “시작/종료 프레임” 기능을 통해 비디오 생성 능력을 크게 향상시켜 부드러운 영화 같은 장면 전환을 구현하며, 1.6 버전에 비해 성능이 235% 향상되었습니다. 이 기능은 사용자가 높은 일관성과 시각적 매력을 가진 비디오 콘텐츠를 쉽게 제작할 수 있도록 하며, 특히 이미지 및 비디오 프롬프트에 대한 더 많은 제어 기능을 제공합니다. (출처: Kling_ai)

MiniCPM-V 4.5 8B 멀티모달 AI 모델 출시, GPT-4o 성능 능가: OpenBMB는 MiniCPM-V 4.5 8B 멀티모달 AI 모델을 출시했으며, OpenCompass에서 GPT-4o, Gemini 2.0 Pro 등을 능가하는 SOTA 시각 언어 능력을 보여주었습니다. 이 모델은 “매의 눈” 비디오 기능(96배 시각 토큰 압축), 제어 가능한 혼합 빠른/깊은 사고, 강력한 OCR 및 문서 분석 능력을 갖추고 있으며, OmniDocBench에서 GPT-4o 및 Gemini 2.5를 능가합니다. (출처: mervenoyann)

Alibaba, 영화 같은 오디오-비디오 기반 인물 애니메이션 모델 Wan2.2-S2V 발표: Alibaba는 영화 같은 오디오 기반 인물 애니메이션을 위해 특별히 설계된 14B 파라미터 모델 Wan2.2-S2V를 오픈 소스로 공개했습니다. 이 모델은 기본적인 말하는 아바타를 넘어 전문적인 영화, TV 및 디지털 콘텐츠 품질을 제공하며, 긴 비디오의 동적 일관성, 영화 같은 오디오-비디오 생성, 그리고 지침을 통한 고급 동작 및 환경 제어 기능을 갖추고 있습니다. (출처: Alibaba_Wan)
Suno 4.5 음악 생성 능력 크게 향상, 재생 가능한 수준 도달: AI 음악 생성 모델 Suno 4.5는 인상적인 발전을 보여주었으며, 생성된 곡들이 더 이상 단순한 신기함을 넘어 재생 목록에 자연스럽게 통합될 수 있는 수준에 도달했습니다. 사용자들은 Suno 4.5의 음악 품질이 충분히 높아 더 이상 AI 작품처럼 느껴지지 않는다고 말하며, AI 음악 창작의 새로운 단계 진입을 알렸습니다. (출처: cHHillee)
HeyGen Digital Twin, Avatar IV로 업그레이드, 디지털 휴먼의 높은 사실성 구현: HeyGen Digital Twin은 이제 Avatar IV에 의해 구동되며, 세계에서 가장 진보된 디지털 휴먼 모델이 되었습니다. 이 기술은 사용자의 자세, 표정, 습관을 정확하게 복제하고, 스크립트에 따라 자연스럽게 말하고 움직이게 하여 디지털 휴먼이 실제 사람과 거의 구별할 수 없게 만듭니다. 이는 크리에이터, 기업가 및 경영진에게 직접 출연하지 않고도 고품질 비디오를 제작할 수 있는 솔루션을 제공합니다. (출처: saranormous)
NVIDIA, 효율적인 하이브리드 Mamba-Transformer 모델 NVIDIA Nemotron Nano 2 발표: NVIDIA 팀은 정확하고 효율적인 하이브리드 Mamba-Transformer 추론 모델인 Nemotron Nano 2 시리즈 모델을 발표했습니다. 이 모델은 엣지 디바이스에서 LLM 성능을 최적화하여 개발자에게 AI 애플리케이션을 구축하고 배포할 수 있는 더 강력한 도구를 제공하는 것을 목표로 합니다. (출처: dl_weekly)
Diffusers 새 버전 출시, Qwen-Image 및 Flux Kontext 미세 조정 지원: HuggingFace의 Diffusers 라이브러리가 v0.35.0 버전을 출시하여 이미지 편집 및 비디오 충실도를 더욱 향상시키고, Qwen-Image 및 Flux Kontext 모델에 대한 미세 조정 스크립트 지원을 추가했습니다. 또한 새 버전은 Diffusers 파이프라인 및 모델의 로딩 속도를 개선했으며, 특히 Wan, Qwen과 같은 대규모 모델에 효과가 큽니다. (출처: RisingSayak)

Alibaba QwenImage 아키텍처 기반 AWPortrait QW 모델 출시, 동양 미학에 초점: Alibaba QwenImage 아키텍처 기반의 AWPortrait QW 모델이 출시되었습니다. 이 모델은 중국인의 외모 특징과 미학에 더 부합하는 훈련 데이터셋으로 훈련되었으며, 실내외 인물 사진, 패션, 스튜디오 사진 등 다양한 유형을 포함하여 일반화 능력이 뛰어납니다. 원본 Qwen에 비해 AWPortrait QW는 피부 표현이 더욱 섬세하고 사실적입니다. (출처: Alibaba_Qwen)

🧰 도구
Pake: Rust로 웹페이지를 가벼운 데스크톱 앱으로 쉽게 패키징: Pake는 Rust Tauri 프레임워크를 활용하여 모든 웹페이지를 Mac, Windows, Linux를 지원하는 가벼운 데스크톱 애플리케이션으로 캡슐화할 수 있는 오픈 소스 도구입니다. Electron 패키징에 비해 Pake는 크기가 약 20배 작고(약 5MB) 성능이 우수하며, 단축키, 몰입형 창 등의 기능을 제공합니다. 사전 패키징된 AI 애플리케이션으로는 ChatGPT, Gemini, Grok, DeepSeek 등이 있습니다. (출처: GitHub Trending)
Claude Code: 효율적인 프로그래밍 도구, 그러나 API 제한 및 디버깅 문제 존재: Claude Code는 AI가 99%의 코드를 생성하는 능력으로 주목받으며 “vibe coding”의 새로운 물결로 불립니다. 그러나 사용자들은 복잡한 버그를 처리할 때 어려움을 겪어 코드가 “쓰레기 산”처럼 쌓일 수 있으며, API 제한이 존재한다고 보고합니다. 개발자들은 이를 “인턴”으로 간주하여 페어 프로그래밍을 하고, 컨텍스트를 새로 고치거나 /context 명령어를 사용하여 토큰 사용량을 시각화하여 경험을 최적화할 것을 제안합니다. (출처: dotey, leveredvlad, sammcallister, kylebrussell, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

OpenWebUI: ChatGPT급 고품질 출력을 추구하는 자체 호스팅 LLM 프론트엔드: OpenWebUI는 ChatGPT와 동등하거나 그 이상의 품질을 제공하면서 다양한 모델과 기능을 통합하는 것을 목표로 하는 자체 호스팅 LLM 프론트엔드입니다. 사용자들은 웹 검색, 이미지 생성 및 전반적인 응답 품질을 향상시키기 위한 최적화 설정과 DigitalOcean Droplet과 같은 호스팅 환경 구성의 중요성에 대해 논의했습니다. (출처: Reddit r/OpenWebUI)
Exosphere: 동적 에이전트 그래프 및 영구 상태를 지원하는 오픈 소스 런타임: Exosphere는 동적 분기, 재시도 및 병렬 실행이 필요한 에이전트 워크플로우를 위해 특별히 설계된 오픈 소스 런타임 및 영구 상태 관리자입니다. 대규모 입력 처리, 모델 출력에 따른 런타임 분기, 오류 발생 후 복구 보장, CPU 및 GPU 단계 혼합 기능을 제공하여 복잡한 AI 에이전트 시스템을 위한 안정적인 실행 환경을 제공합니다. (출처: Reddit r/MachineLearning)
DocStrange: 이미지/PDF/문서 구조화 데이터 추출 도구: DocStrange는 오픈 소스 라이브러리로, 이제 무료 웹 애플리케이션으로 출시되어 이미지, PDF 및 문서에서 깨끗한 구조화된 데이터를 추출하고 Markdown, CSV, JSON 등 다양한 출력 형식을 지원합니다. 이 도구는 데이터 처리 프로세스를 단순화하고 비정형 데이터에서 유용한 정보를 얻는 효율성을 높이는 것을 목표로 합니다. (출처: Reddit r/MachineLearning)
DSPy: 프롬프트 자동 최적화 프레임워크, LLM 성능 크게 향상: DSPy 프레임워크와 GEPA 구성 요소는 소수의 지표 호출만으로 프롬프트 최적화를 자동화하여 LLM 성능을 크게 향상시킬 수 있습니다. 예를 들어, 목록 재정렬 작업에서 DSPy GEPA는 500번의 지표 호출 후 정확도를 40% 향상시켰고, 최적화된 프롬프트를 100줄의 그림이 포함된 프로세스로 변환했습니다. (출처: lateinteraction)

Rube: AI 에이전트와 다양한 애플리케이션을 연결하는 범용 MCP 서버: Rube는 AI 에이전트와 사용자의 다양한 애플리케이션을 연결하도록 설계된 범용 다중 모달 통신 프로토콜(MCP) 서버로 출시되었습니다. 인기 있는 IDE, Claude Code 및 기타 MCP 클라이언트와 호환되어 AI 에이전트가 YouTube 비디오를 연구하고 완전한 콘텐츠 전략 문서를 생성하는 등 복잡한 작업을 수행할 수 있도록 합니다. (출처: omarsar0)
Osaurus: Apple Silicon 네이티브 오픈 소스 LLM 서비스, Ollama 성능 능가: Osaurus는 Apple의 MLX를 기반으로 구축된 7MB에 불과한 Apple Silicon 네이티브 오픈 소스 LLM 서비스로, Ollama보다 20% 빠르다고 주장합니다. M 시리즈 칩에서 최고의 성능을 달성하여 Mac 사용자에게 효율적인 로컬 LLM 추론 경험을 제공합니다. (출처: awnihannun)
Havivi, AI 울트라맨 장난감 출시, 대규모 상업화 실현: Yue Ran Innovation (Havivi)은 세계 최초의 티가 울트라맨 AI 장난감을 출시하고 2억 위안 규모의 A 시리즈 투자를 유치했습니다. 이 장난감은 CocoMate 핵심 본체를 내장하고 있으며, 4G 네트워크 연결, 흔들림으로 깨우기, NFC 카드 시스템을 지원하고, 캐릭터 세계관과 일치하는 언어 논리 및 감정 반응을 가지며 응답 속도는 800ms에 불과합니다. 이전 제품인 BubblePal은 이미 20만 대가 판매되어 세계 최초로 대규모 상업화된 AI 장난감이 되었습니다. (출처: 量子位)

SenseTime SenseRobot, 주디 시리즈 체스 로봇 출시, AI와 IP 결합하여 어린이 성장 지원: SenseTime 산하 가정용 로봇 브랜드 SenseRobot은 디즈니 애니메이션 ‘주토피아’와 협력하여 주디 시리즈 체스 로봇을 출시했습니다. 이 제품은 체스, 바둑, 국제 체스, 오목의 네 가지 체스 게임과 재미있는 카드 프로그래밍을 통합하여, 낮은 좌절감 성장 시스템과 의인화된 상호작용을 통해 아이들이 놀면서 사고력을 단련하고 끈기 있는 인성과 낙관적인 태도를 기르도록 돕는 것을 목표로 합니다. (출처: 量子位)

📚 학습
RuscaRL 프레임워크, LLM 추론 탐색 병목 현상 돌파, Qwen-2.5-7B가 GPT-4.1 능가: 논문 “Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning”은 RuscaRL 프레임워크를 제안합니다. 이 프레임워크는 체크리스트 기반 평가 기준을 탐색 및 보상 지침으로 사용하여 LLM 추론의 탐색 병목 현상을 효과적으로 해결합니다. 실험 결과, RuscaRL은 HealthBench-500에서 Qwen-2.5-7B-Instruct의 성능을 23.6에서 50.3으로 크게 향상시켜 GPT-4.1을 능가함을 입증했습니다. (출처: HuggingFace Daily Papers)
T2I-ReasonBench: 텍스트-이미지 모델 추론 능력 평가를 위한 새로운 벤치마크: 논문 “T2I-ReasonBench: Benchmarking Reasoning-Informed Text-to-Image Generation”은 텍스트-이미지(T2I) 모델의 추론 능력을 평가하기 위한 새로운 벤치마크인 T2I-ReasonBench를 제안합니다. 이 벤치마크는 관용구 해석, 텍스트 이미지 디자인, 엔티티 추론, 과학 추론의 네 가지 차원에서 평가하며, 추론 정확도와 이미지 품질을 측정하기 위해 2단계 프로토콜을 채택합니다. (출처: HuggingFace Daily Papers)
“Explain Before You Answer” 개요: 조합 시각 추론의 패러다임 전환: 논문 “Explain Before You Answer: A Survey on Compositional Visual Reasoning”은 2023년부터 2025년까지 조합 시각 추론에 관한 260편 이상의 논문을 포괄적으로 검토합니다. 이 개요는 핵심 개념을 정의하고, 인지 정렬, 의미 충실도, 견고성 등에서 조합 방법의 장점을 설명하며, 프롬프트 강화부터 통합 에이전트 VLM까지 5단계 패러다임 전환을 추적하고, LLM 추론의 한계, 환각 등 미해결 과제를 지적합니다. (출처: HuggingFace Daily Papers)
MEENA (PersianMMMU): 최초의 페르시아어 다중 모달 교육 시험 데이터셋: 논문 “MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment”는 MEENA 데이터셋을 소개합니다. 이는 페르시아어 VLM 평가를 위한 최초의 벤치마크 데이터셋으로, 약 7500개의 페르시아어 및 3000개의 영어 질문을 포함하며 과학, 추론, 수학, 다이어그램 등 여러 분야를 다루어 VLM의 교차 언어 능력을 향상시키는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
MV-RAG: 검색 증강을 통한 다중 뷰 확산의 텍스트-3D 생성: 논문 “MV-RAG: Retrieval Augmented Multiview Diffusion”은 새로운 텍스트-3D 생성 프로세스인 MV-RAG를 제안합니다. 이 프로세스는 먼저 2D 데이터베이스에서 관련 이미지를 검색한 다음, 이 이미지들을 조건으로 다중 뷰 확산 모델을 사용하여 일관되고 정확한 다중 뷰 출력을 합성함으로써 기존 방법의 도메인 외부 또는 희귀 개념 생성 시 성능 저하 문제를 해결합니다. (출처: HuggingFace Daily Papers)
German4All: 독일어 가독성 제어 문장 재구성 데이터셋 및 모델: 논문 “German4All – A Dataset and Model for Readability-Controlled Paraphrasing in German”은 German4All을 소개합니다. 이는 25,000개 이상의 샘플과 5단계의 가독성 수준을 포함하는 최초의 대규모 독일어 가독성 제어 단락 수준 문장 재구성 데이터셋입니다. 이 데이터셋으로 훈련된 오픈 소스 모델은 독일어 텍스트 간소화에서 SOTA 성능을 달성했습니다. (출처: HuggingFace Daily Papers)
재귀, 메모리 및 테스트 시간 컴퓨팅 확장을 통한 LLM 추론 깊이 향상: 논문 “Beyond Memorization: Extending Reasoning Depth with Recurrence, Memory and Test-Time Compute Scaling”은 LLM의 다단계 추론 능력을 탐구하며, 암기를 배제한 후 대부분의 신경망 아키텍처가 기본 규칙을 추상화할 수 있음을 발견했습니다. 연구에 따르면 재귀, 메모리 및 테스트 시간 컴퓨팅 확장을 통해 유효 모델 깊이를 늘리면 추론 능력이 크게 향상될 수 있으며, 특히 다단계 추론 작업에서 더욱 그렇습니다. (출처: HuggingFace Daily Papers)
어텐션 메커니즘에서 정규화의 한계 분석: 논문 “Limitations of Normalization in Attention Mechanism”은 어텐션 메커니즘에서 정규화의 한계를 심층적으로 연구합니다. 연구 결과, 선택 토큰 수가 증가함에 따라 모델의 정보성 토큰 구별 능력이 감소하며, softmax 정규화 하의 기울기 민감성이 훈련에서, 특히 낮은 온도 설정에서 어려움을 초래한다는 점을 지적합니다. (출처: HuggingFace Daily Papers)
Ano: 시끄러운 환경에서 견고성을 향상시키는 심층 강화 학습 최적화 도구: 논문 “Ano: updated optimizer for noisy Deep RL”은 심층 강화 학습을 위해 설계된 최적화 도구 Ano를 소개합니다. 이 도구는 시끄럽고 매우 비볼록한 환경에서 견고성과 안정성을 향상시키는 것을 목표로 합니다. Ano는 모멘텀 방향과 기울기 크기를 분리하고 Atari 벤치마크에서 그 유효성을 검증했으며, 표준 비볼록 확률적 설정에서의 수렴 증명도 제공합니다. (출처: Reddit r/MachineLearning)
TRUST 알고리즘: 설명 가능한 기계 학습을 위한 구간 선형 회귀 트리: 논문 “Exploring interpretable ML with piecewise-linear regression trees (TRUST algorithm)”은 TRUST(Transparent, Robust and Ultra-Sparse Trees) 알고리즘을 제안합니다. 이 알고리즘은 결정 트리의 리프 노드에 희소 회귀 모델을 피팅하여 설명 가능한 구간 선형 회귀 트리를 생성합니다. 이 알고리즘은 60개 데이터셋에서 뛰어난 성능을 보였으며, 높은 예측 성능을 유지하면서 모델의 설명 가능성을 크게 향상시켜 전통적인 설명 가능한 모델과 고정밀 블랙박스 모델 간의 격차를 해소합니다. (출처: Reddit r/MachineLearning)
💼 비즈니스
AI 기업 수익성 도전: 생성형 AI 프로젝트 95% 투자 수익률 0%: MIT 연구에 따르면 기업의 생성형 AI 파일럿 프로젝트 중 95%가 투자 수익을 달성하지 못했으며, 이는 AI가 개인 도구에서 기업 수준 애플리케이션으로 전환하는 데 따르는 어려움을 보여줍니다. 성공적인 5% 사례는 일반적으로 에이전트 기반 AI 시스템을 채택하고 전문 공급업체와 협력했으며, 이는 기업이 과대광고를 맹목적으로 쫓기보다는 AI의 실제 가치와 구현 전략을 깊이 이해해야 함을 시사합니다. (출처: rao2z, AI21Labs)

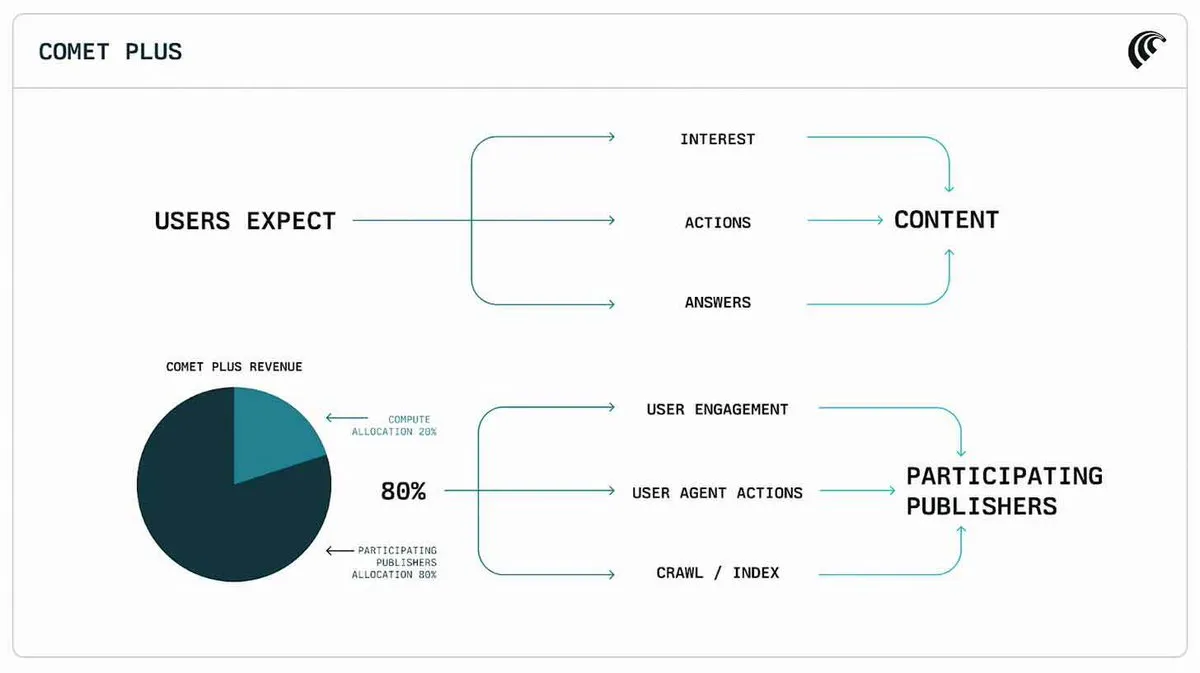
Perplexity, 4,250만 달러 규모의 출판사 수익 공유 프로그램 출시: Perplexity는 AI 콘텐츠 생성이 전통 미디어의 저작권 및 수익에 미치는 영향을 해결하기 위해 4,250만 달러 규모의 출판사 수익 공유 프로그램을 출시했습니다. 이러한 움직임은 AI 기업들이 콘텐츠 창작자와 상생하는 비즈니스 모델을 적극적으로 모색하고 있으며, AI 콘텐츠 생태계에서 지속 가능한 협력 관계를 구축하고자 함을 보여줍니다. (출처: TheRundownAI)
Synthesia, 매출 1억 달러 ARR 돌파, AI 가상 아바타 시장 고속 성장: AI 가상 아바타 생성 플랫폼 Synthesia는 연간 반복 매출(ARR)이 1억 달러를 돌파했으며, 전년 대비 100% 성장, 순 유지율 142%를 기록했다고 발표했습니다. 이 회사는 지난 12개월 동안 10만 달러 이상 고객 기반을 4배 확장했으며, Fortune 100대 기업의 80% 이상으로부터 신뢰를 얻어 기업 커뮤니케이션 분야에서 AI 가상 아바타의 강력한 성장과 적용 잠재력을 보여주었습니다. (출처: synthesiaIO)
🌟 커뮤니티
ChatGPT/Claude 모델의 “개성 상실”로 사용자들의 강한 불만 야기: ChatGPT-5 출시 후, GPT-4o와 Claude Opus 4.1 모델이 “냉담하고, 딱딱하며, 맥락 이해와 미묘한 차이가 부족하다”는 사용자들의 일반적인 불만이 제기되었고, 심지어 “헛소리”와 “고집”을 부리는 현상까지 나타나 사용자 경험이 크게 저하되었습니다. 많은 사용자들이 구독 취소를 고려하고 있다고 밝혔습니다. (출처: Reddit r/ChatGPT, Reddit r/ClaudeAI)

AI 코드 생성과 개발 효율성 논란: “쓰레기 산”에서 “Vibe Coding”까지: 커뮤니티는 AI 코드 생성이 효율성을 높이는 동시에 “쓰레기 코드”와 복잡한 버그 해결의 어려움을 초래할 수 있다는 점을 논의했습니다. 개발자들은 “vibe coding”이 전통적인 소프트웨어 공학 개념과 다르며, AI 프로그래밍 도구가 인간과의 협업을 통해 시각화 도구와 명확한 컨텍스트를 사용하여 개발 경험을 최적화해야 한다고 강조했습니다. (출처: dotey, leveredvlad, Reddit r/ClaudeAI, jerryjliu0)
AI 윤리 및 콘텐츠 진실성: AI 생성 콘텐츠 메타데이터 표기 및 플랫폼 검열 요구: 커뮤니티는 허위 정보 확산 및 AI 훈련 데이터 오염 문제에 대응하기 위해 AI 생성 콘텐츠에 메타데이터 식별자를 의무적으로 추가하고 소셜 미디어 플랫폼의 검열을 강화할 것을 요구했습니다. Reddit 등 플랫폼은 AI 콘텐츠를 제한하기 시작했으며, 이는 AI 콘텐츠 정책, 데이터 순수성 및 표현의 자유에 대한 논의를 촉발했습니다. (출처: Reddit r/ArtificialInteligence, Ronald_vanLoon, random_walker, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI가 고용 및 교육에 미치는 영향: 젊은 노동자 실업 위험 및 AI 전공 전망: 스탠포드 연구는 AI가 노동 시장을 재편하고 있으며, 젊은 노동자들이 더 높은 실업 위험에 직면하고 있다고 지적했습니다. 커뮤니티는 동시에 AI 전공 학위가 고용 시장에서 가지는 가치와 AI의 급속한 발전 속에서 미래 고용 문제에 적응하기 위해 IT 관련 전공을 어떻게 선택해야 하는지에 대해 논의했습니다. (출처: Reddit r/artificial, Reddit r/ArtificialInteligence, 量子位, Reddit r/ArtificialInteligence)

💡 기타
Elon Musk, 자율주행에서 LiDAR 및 레이더의 안전성에 대한 논란 제기: Elon Musk는 자율주행 차량에 LiDAR와 레이더를 추가하는 것이 오히려 안전성을 저하시킨다고 주장하며 순수 비전 경로를 다시 한번 강조했습니다. 그는 다중 센서 융합이 식별 결과의 불일치를 초래하여 주행 위험을 증가시킬 수 있으며, Waymo의 고속도로 운영 제한이 이와 관련이 있음을 시사했습니다. 이 발언은 자율주행 센서 융합 전략에 대한 커뮤니티의 뜨거운 논쟁을 불러일으켰습니다. (출처: 量子位)

중국, 독일 로봇 회사 인수, 국제적 관심 집중: 소셜 미디어에서는 중국이 독일 로봇 산업의 “왕관의 보석”을 인수한 사건에 대해 논의하며, 로봇 기술, 머신러닝 및 AI 분야의 국제 협력 및 경쟁에 대한 관심을 불러일으켰습니다. (출처: Ronald_vanLoon)
IBM과 AMD 협력, 내결함성 양자 컴퓨터 개발 가속화: IBM과 AMD는 IBM 양자 컴퓨터와 AMD 고성능 컴퓨팅을 결합한 차세대 컴퓨팅 아키텍처를 공동 개발하기 위해 협력한다고 발표했습니다. 이번 협력은 첨단 기술 통합을 통해 10년 내에 실시간으로 오류를 감지하고 수정할 수 있는 내결함성 양자 컴퓨터를 구현하여 양자 컴퓨팅의 실용화 과정을 가속화하는 것을 목표로 합니다. (출처: The Verge)