

키워드:광자 기반 AI 칩, K2 Think, 구현형 인공지능, Jupyter 에이전트, OpenPI, Claude 모델, Qwen3-Next, Seedream 4.0, 광자 AI 칩 에너지 효율, 오픈소스 대형 모델 추론 속도, 휴머노이드 로봇 감정 표현, LLM 데이터 과학 에이전트, 로봇 시각 언어 동작 모델
🔥 포커스
Light-based AI chip 효율성 돌파 : 플로리다 대학교 엔지니어 팀이 새로운 Light-based AI chip을 개발했습니다. 이 칩은 전력 대신 광자를 사용하여 이미지 인식 및 패턴 감지와 같은 AI operations을 수행합니다. 이 칩은 디지털 분류 테스트에서 98%의 정확도를 달성했으며, 동시에 에너지 효율은 최대 100배 향상되었습니다. 이 돌파구는 AI 계산 비용과 에너지 소비를 크게 줄여 스마트폰부터 슈퍼컴퓨터에 이르는 다양한 분야에서 AI의 친환경화 및 확장성 발전을 촉진할 것으로 기대되며, hybrid electro-optical chips이 AI 하드웨어 지형을 재편할 것을 예고합니다. (출처: Reddit r/ArtificialInteligence)

K2 Think: 세계에서 가장 빠른 오픈소스 Large Model 출시 : 아랍에미리트 MBZUAI와 G42 AI가 협력하여 Qwen 2.5-32B 기반의 오픈소스 Large Model인 K2 Think를 발표했습니다. 이 모델은 실제 측정 속도가 초당 2000 tokens를 초과하여, 일반적인 GPU deployment throughput의 10배 이상입니다. 이 모델은 AIME 등 수학 벤치마크 테스트에서 뛰어난 성능을 보였으며, long-chain thinking SFT, verifiable reward RLVR, 추론 전 계획, Best-of-N sampling, speculative decoding 및 Cerebras WSE hardware acceleration을 통해 기술 혁신을 이루어 오픈소스 AI inference system 성능의 새로운 지평을 열었습니다. (출처: teortaxesTex, HuggingFace)

Embodied AI 및 Humanoid Robots 최신 동향 : Zhihu 원탁 토론에서 Embodied AI 분야의 여러 돌파구가 공개되었습니다. 칭화 Air Lab은 hybrid drive와 digital human technology를 사용하여 풍부한 미세 표정을 구현하는 “Morpheus”를 선보였으며, 이는 Humanoid Robots의 감성적 가치를 높이는 것을 목표로 합니다. 동시에 베이징 Tiangong Ultra 로봇은 세계 Humanoid Robot 스포츠 대회 100m 경주에서 우승하여 알고리즘과 자율 감지 능력의 우수성을 입증했습니다. 토론에서는 Humanoid Robots의 비용, 양산, 제어 이론과 Large Model 융합 등 핵심 의제도 다루었으며, Embodied AI가 기술 탐색 단계를 넘어 실제 적용 단계로 나아가고 있음을 예고합니다. (출처: ZhihuFrontier)

Jupyter Agent: Notebook으로 LLM 훈련하여 Data Science 추론 수행 : Hugging Face가 Jupyter Agent 프로젝트를 발표했습니다. 이 프로젝트는 코드 실행 도구를 통해 LLM에 Jupyter Notebook에서 데이터 분석 및 data science tasks를 해결하는 능력을 부여하는 것을 목표로 합니다. 대규모 Kaggle Notebooks 데이터 클리닝, 교육 품질 평가, QA generation 및 code execution trajectory generation 등 다단계 훈련 프로세스를 통해 Qwen3-4B와 같은 소형 모델이 DABStep 벤치마크 테스트의 Easy tasks에서 44.4%에서 75%로 성공적으로 향상되었음을 입증하며, 소형 모델도 고품질 데이터와 스캐폴딩을 결합하면 강력한 data science agent가 될 수 있음을 보여줍니다. (출처: HuggingFace Blog)
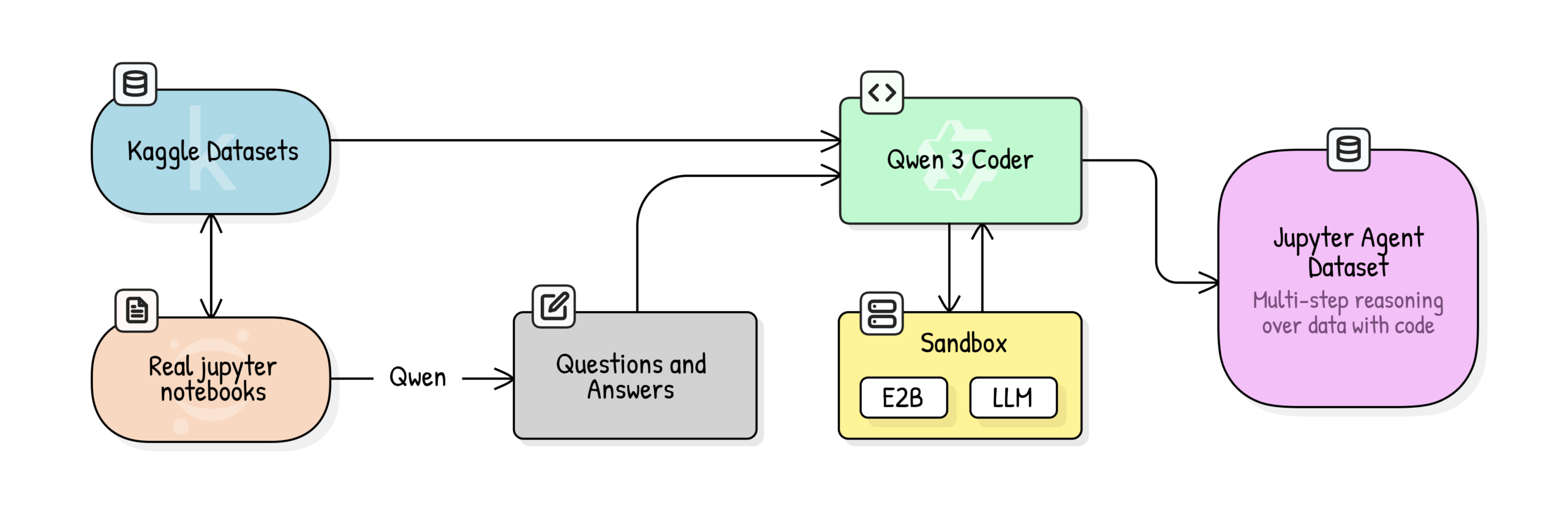
OpenPI: 오픈소스 Robot Vision-Language-Action 모델 : Physical Intelligence 팀이 π₀, π₀-FAST, π₀.₅ 등 오픈소스 VLA models을 포함하는 OpenPI 라이브러리를 발표했습니다. 이 모델들은 10k+ 시간의 로봇 데이터로 사전 훈련되었으며, PyTorch를 지원하고 LIBERO 벤치마크 테스트에서 SOTA 성능을 달성했습니다. OpenPI는 base model checkpoints 및 fine-tuning examples을 제공하며, remote inference를 지원하여 로봇 분야의 오픈 연구 및 응용을 촉진하는 것을 목표로 하며, 특히 데스크톱 작업 및 물체 잡기 등 작업에서 잠재력을 보여줍니다. (출처: GitHub Trending)
🎯 동향
Microsoft와 Anthropic 협력, Claude 모델 Office 365 Copilot에 통합 : Microsoft는 Anthropic의 Claude 모델을 Office 365 Copilot에 통합하고 있으며, 특히 Claude가 더 뛰어난 성능을 보이는 Excel function calculation 및 PowerPoint slide creation과 같은 분야에 중점을 둡니다. 이 조치는 Word, Excel, PowerPoint 내 특정 기능을 최적화하여 사용자 경험을 향상시키고, 기업 생산성 도구에서 Claude의 적용 범위를 확장하는 것을 목표로 합니다. (출처: dotey, alexalbert__, menhguin, TheRundownAI)

AI, Knowledge Graphs 및 Autonomous Agents를 통해 과학 연구 가속화 : MiniculeAI는 AI가 knowledge graphs 및 autonomous agents를 통해 과학적 발견을 어떻게 가속화하는지 보여줍니다. 유전자, 약물 및 결과를 동적 네트워크에 매핑함으로써 AI는 PDF documents에서 발견하기 어려운 숨겨진 연결을 밝혀낼 수 있습니다. autonomous agents는 문헌을 스캔하고 패턴을 발견하며, 설명 가능한 통찰력을 제공하여 수개월이 걸리던 전통적인 연구를 몇 분으로 단축하고, 동시에 enterprise-grade data privacy를 보장합니다. (출처: Ronald_vanLoon)
Qwen3-Next 모델 시리즈: Long Context 및 Parameter Efficiency 최적화 : Qwen 팀이 극단적인 context 길이와 대규모 parameter efficiency에 중점을 둔 Qwen3-Next 시리즈 base models을 출시했습니다. 이 시리즈는 GatedAttention(이상치 해결), GatedDeltaNet RNN(KV cache 절약) 등 여러 아키텍처 혁신을 도입했으며, Sink+SWA hybrid 또는 Gated Attention+Linear RNN hybrid architecture를 결합하여 성능을 극대화하고 계산 비용을 최소화하는 것을 목표로 하며, pure Attention models 시대의 종말을 예고합니다. (출처: tokenbender, SchmidhuberAI, teortaxesTex, ClementDelangue, andriy_mulyar)
ByteDance Seedream 4.0 이미지 생성 및 편집 모델 출시 : ByteDance가 Seedream 4.0을 출시하여 탁월한 이미지 생성 및 편집 기능을 제공합니다. 사용자 피드백에 따르면 사용자 요구 사항, RLHF aesthetic preferences 및 주류 취향 유지 측면에서 뛰어난 성능을 보였습니다. Seedream 3.0과 비교하여 4.0 버전은 film grain 및 lens artifacts를 추가하고 대비가 더 높으며 애니메이션 스타일의 붓놀림이 더 선명해졌습니다. 동시에 Chinese semantic understanding 및 일관성 측면에서 강력한 성능을 보여 infographics, tutorials 및 product design에 적합합니다. (출처: ZhihuFrontier, Reddit r/artificial, op7418, TomLikesRobots, dotey)
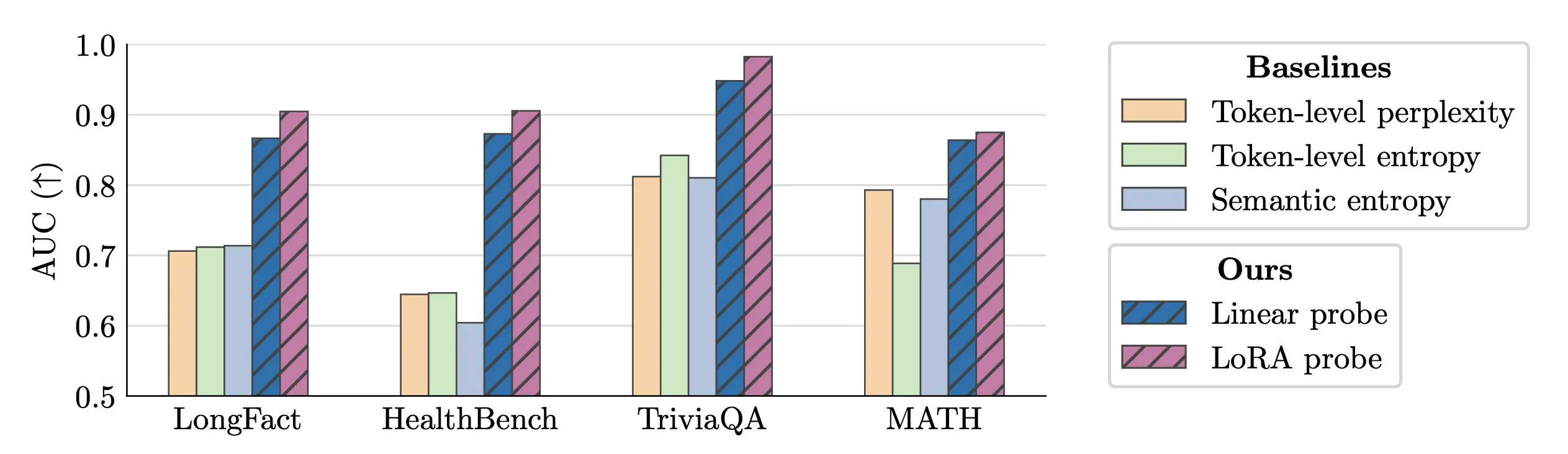
LLM Hallucination 실시간 감지 기술 : 연구원들이 activation probes를 사용하여 LLM hallucination을 실시간으로 감지하는 방법을 제안했습니다. 이 방법은 긴 텍스트에서 위조된 엔티티를 식별하는 데 뛰어난 성능을 보였으며, AUC value가 0.90에 달하여 기존 semantic entropy methods보다 훨씬 우수했습니다. 또한 새로운 연구는 Transformer models에서 hallucination의 기원을 심층적으로 탐구하여 LLM의 신뢰성을 높이는 새로운 아이디어를 제공합니다. (출처: paul_cal, tokenbender)
Microsoft VibeVoice: 장시간 고음질 음성 생성 : Microsoft VibeVoice 모델은 AI audio 분야에서 상당한 발전을 이루었으며, 45-90분 길이의 최대 4명 화자의 사실적인 음성을 이어붙이기 없이 생성할 수 있습니다. 이 모델은 Hugging Face Space에서 체험할 수 있으며, 사용자는 이를 활용하여 고품질 voice cloning을 수행하여 podcasts, audiobooks 등 응용 프로그램에 새로운 가능성을 제공합니다. (출처: Reddit r/LocalLLaMA)
mmBERT: Multilingual Encoder의 새로운 기준 : 새로운 mmBERT 모델이 출시되어 6년 동안 SOTA였던 XLM-R을 대체할 것으로 예상됩니다. mmBERT는 기존 모델보다 2-4배 빠르며, multilingual encoding 작업에서 o3 및 Gemini 2.5 Pro를 능가했습니다. 이 모델의 출시는 오픈 모델 및 훈련 데이터와 함께 다국어 AI 응용 프로그램에 더 효율적이고 강력한 기반을 제공할 것입니다. (출처: code_star)

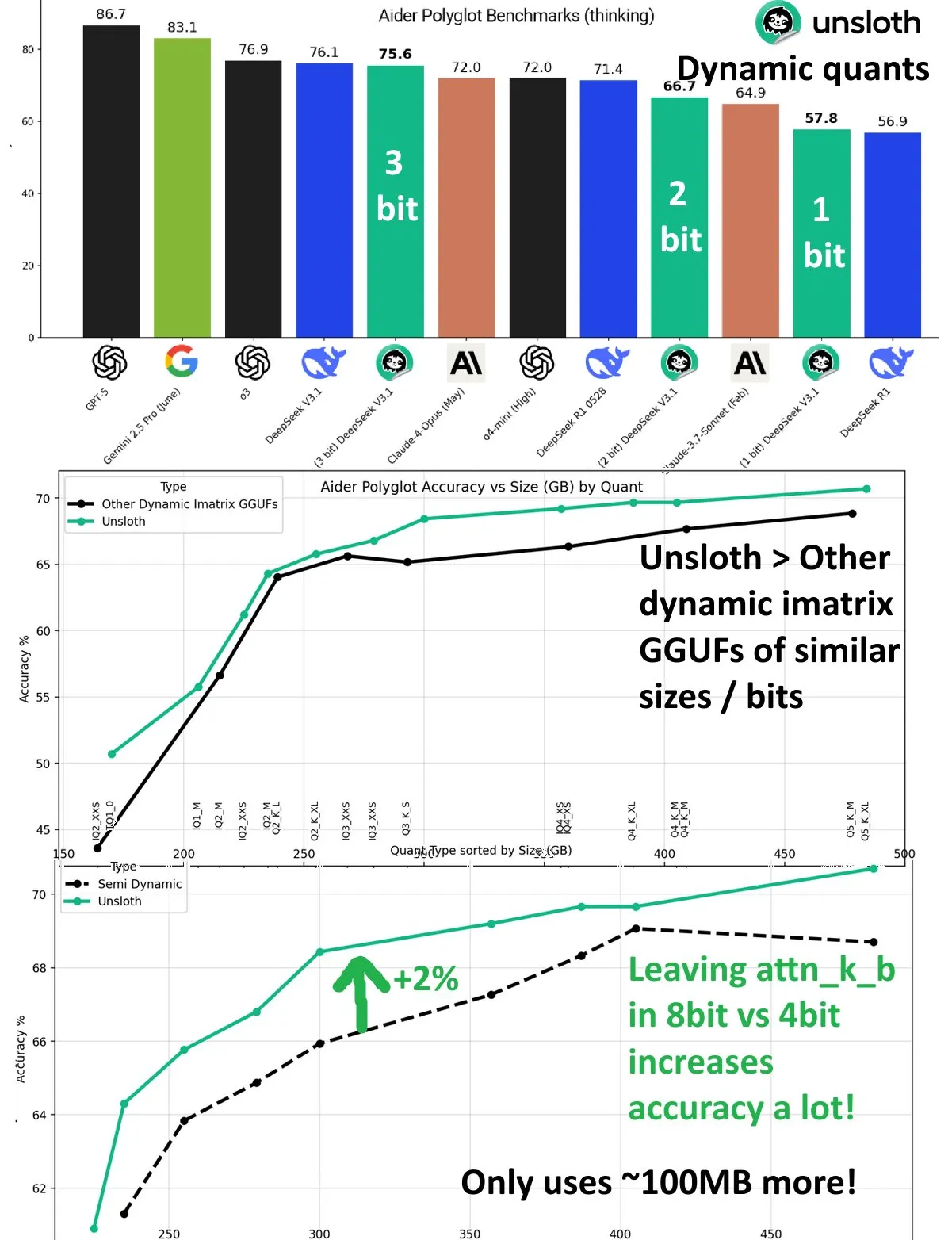
DeepSeek V3.1 Dynamic Quantization 성능 향상 : DeepSeek V3.1 모델은 UnslothAI의 Aider Polyglot 벤치마크 테스트에서 dynamic quantization 기술을 통해 상당한 성능 향상을 달성했습니다. 3-bit quantization은 비양자화 모델의 정확도에 근접했으며, inference 모드에서 1-bit dynamic quantization은 DeepSeek R1의 원래 성능을 능가했습니다. 연구에 따르면 attn_k_b layer를 8-bit precision으로 유지하면 추가로 2%의 정확도가 향상되어, 모델 기능을 유지하고 계산 비용을 줄이는 데 있어 효율적인 양자화의 잠재력을 보여줍니다. (출처: danielhanchen)
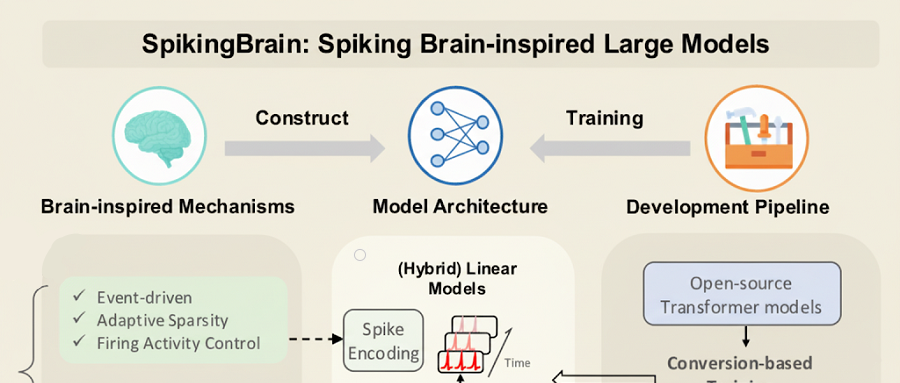
국산 GPU로 훈련된 국산 Large Model SpikingBrain-1.0 : 중국과학원 자동화연구소가 뇌 모방 스파이킹 Large Model “SpikingBrain-1.0”을 발표했습니다. 이 모델은 국산 Muxi GPU 클러스터에서 훈련 및 추론을 완료했으며, 에너지 효율은 기존 FP16 operations 대비 97.7% 감소했습니다. 이 모델은 주류 Large Model의 2%에 불과한 사전 훈련 데이터만으로 Qwen2.5-7B의 90% 성능을 달성했으며, 초장기 시퀀스 처리 작업에서 뛰어난 성능을 보여 TTFT 가속도가 최대 26.5배에 달하여, 국산 자율 제어 non-Transformer Large Model 생태계의 실현 가능성을 입증했습니다. (출처: 36氪)
Wenxin X1.1 출시: 사실성, 지시 준수 및 Agent 능력 대폭 향상 : Baidu의 심층 사고 모델 Wenxin Large Model X1.1이 업그레이드되어 출시되었으며, 사실성은 34.8%, 지시 준수는 12.5%, Agent 능력은 9.6% 향상되었습니다. 이 모델은 전반적인 효과가 DeepSeek R1-0528을 능가하며 GPT-5, Gemini 2.5 Pro에 필적하며, 복잡한 장기 작업에서 강력한 Agent 능력을 보여 작업을 자동으로 분할하고 도구를 호출할 수 있습니다. Baidu는 또한 ERNIE-4.5-21B-A3B-Thinking 오픈소스 모델 및 ERNIEKit 개발 키트를 출시하여 AI 응용 프로그램 진입 장벽을 더욱 낮췄습니다. (출처: 量子位)

Huawei 오픈소스 OpenPangu-Embedded-7B-v1.1: 빠르고 느린 사고 자유롭게 전환 : Huawei가 7B parameter의 오픈소스 모델인 OpenPangu-Embedded-7B-v1.1을 발표했습니다. 이 모델은 빠르고 느린 사고 모드를 자유롭게 전환할 수 있으며, 문제 난이도에 따라 자동으로 선택할 수 있는 기능을 최초로 구현했습니다. 점진적 fine-tuning 및 2단계 훈련 전략을 통해 모델은 일반, 수학, 코드 등 평가에서 정확도가 크게 향상되었으며, 정확도를 유지하면서 평균 Chain of Thought 길이가 거의 50% 단축되어 오픈소스 Large Model의 해당 능력 공백을 메우고 효율성과 정확도를 높였습니다. (출처: 量子位)

Tencent CodeBuddy Code: AI Programming L4 시대 진입 : Tencent가 AI CLI tool CodeBuddy Code를 발표하고 CodeBuddy IDE 공개 베타 테스트를 시작하여 AI programming을 L4급 “AI Software Engineer” 시대로 이끄는 것을 목표로 합니다. CodeBuddy Code는 npm 설치 기반으로, 자연어 기반 개발 및 운영 전 수명 주기를 지원하여 궁극적인 자동화를 실현합니다. 이 도구는 문서 기반 관리, context compression 및 MCP extension을 통해 기업용 AI programming의 기본 인프라가 되어 개발 효율성을 크게 향상시킵니다. (출처: 量子位)

OpenAI 핵심 과학자: 폴란드 두 거장, GPT-4 및 추론 돌파구 주도 : OpenAI 수석 과학자 Jakub Pachocki와 기술 연구원 Szymon Sidor는 Dota 프로젝트, GPT-4 pre-training 및 추론 돌파구 추진에 대한 핵심 기여로 Altman으로부터 높은 찬사를 받았습니다. 고등학교 동창에서 OpenAI에서 재회한 두 사람은 심층 사고와 실습 실험을 결합한 방식으로 OpenAI의 필수적인 인물이 되었으며, 2023년 내분 위기 속에서도 Altman의 복귀를 확고히 지지했습니다. (출처: 量子位)

백악관 AI 서밋, 인재, 보안 및 국가적 과제에 집중 : Melania Trump가 백악관에서 Google, IBM 및 Microsoft와 같은 기술 거물들을 초청하여 AI 분야의 인재 양성, 보안 보장 및 국가적 과제에 중점을 둔 AI 회의를 주재했습니다. 이 조치는 미국 정부가 AI 발전이 가져오는 기회와 도전에 대응하고 AI 분야에서 국가의 리더십을 확보하기 위해 AI 전략을 적극적으로 추진하고 있음을 보여줍니다. (출처: TheTuringPost, Reddit r/artificial)

Neuromorphic Computing: 전통적인 Neural Network를 넘어서 : Neuromorphic Computing은 생물학적 뇌 구조와 작동 원리에서 영감을 받아 지능을 재정의하고 있습니다. 이 기술은 더 효율적이고 저전력 AI 하드웨어를 개발하는 것을 목표로 하며, 뉴런과 시냅스의 병렬 처리 능력을 시뮬레이션하여 전통적인 Von Neumann architecture를 뛰어넘는 컴퓨팅 패턴을 구현하고 미래 AI 시스템에 더 강력한 기반을 제공합니다. (출처: Reddit r/artificial)
MEGS²: Memory-Efficient Gaussian Splatting 기술 : MEGS² (Memory-Efficient Gaussian Splatting via Spherical Gaussians and Unified Pruning)는 Memory-Efficient 3D Gaussian Splatting (3DGS) 기술입니다. 구면 조화 함수 대신 임의 방향의 spherical Gaussian functions으로 색상을 표현하고 통합 soft pruning framework를 도입함으로써, 이 방법은 원시 프리미티브당 parameter 수를 크게 줄여 8배의 정적 VRAM 압축과 거의 6배의 렌더링 VRAM 압축을 달성하면서 렌더링 품질을 유지하거나 향상시켜 3D 그래픽 및 실시간 렌더링에 중요한 의미를 가집니다. (출처: janusch_patas)

🧰 도구
LangChain 1.0 Middleware 도입: Agent Context Control의 새로운 패러다임 : LangChain 1.0이 Middleware를 출시하여 AI agents에 새로운 추상화 계층을 제공하고 개발자가 context engineering을 완전히 제어할 수 있도록 합니다. 이 기능은 Agent의 유연성, 구성 가능성 및 적응성을 향상시키고 reflection, groups, supervisors 등 다양한 Agent 아키텍처를 지원하여 더 복잡한 AI 응용 프로그램을 구축하기 위한 강력한 기반을 제공합니다. (출처: hwchase17, hwchase17, Hacubu)
MaxKB: 오픈소스 Enterprise Agent Platform : MaxKB는 강력하고 사용하기 쉬운 오픈소스 Enterprise Agent Platform으로, RAG (Retrieval-Augmented Generation) 파이프라인, 강력한 workflow engine 및 MCP tool usage capability를 통합합니다. 문서 업로드, 자동 크롤링, text segmentation 및 vectorization을 지원하여 Large Model hallucination을 효과적으로 줄이고, 다양한 사설 및 공용 Large Model을 지원하며, multimodal input/output을 제공하여 스마트 고객 서비스, 기업 지식 기반 등 시나리오에 널리 적용됩니다. (출처: GitHub Trending)

BlenderMCP: Claude AI와 Blender의 심층 통합 : BlenderMCP는 Claude AI와 Blender의 심층 통합을 구현했으며, Model Context Protocol (MCP)을 통해 Claude가 Blender를 직접 제어하여 3D modeling, 장면 생성 및 조작을 수행할 수 있도록 합니다. 이 도구는 양방향 통신, 객체 조작, 재료 제어, 장면 검사 및 code execution을 지원하며, Poly Haven 및 Hyper3D Rodin assets을 통합할 수 있어 AI-assisted 3D creation의 효율성과 가능성을 크게 향상시킵니다. (출처: GitHub Trending)

AI Sheets: No-code AI Dataset 구축 및 변환 도구 : Hugging Face가 AI Sheets를 발표했습니다. 이 도구는 AI 모델을 사용하여 데이터셋을 구축, 보강 및 변환하는 오픈소스 no-code tool입니다. 이 도구는 로컬에 배포하거나 Hub에서 실행할 수 있으며, Hugging Face Hub의 수천 개의 오픈소스 모델(gpt-oss 포함)에 액세스할 수 있고, Docker 또는 pnpm을 통해 빠르게 시작할 수 있어 데이터 처리 프로세스를 간소화하며, 특히 대규모 데이터셋 생성에 적합합니다. (출처: GitHub Trending)

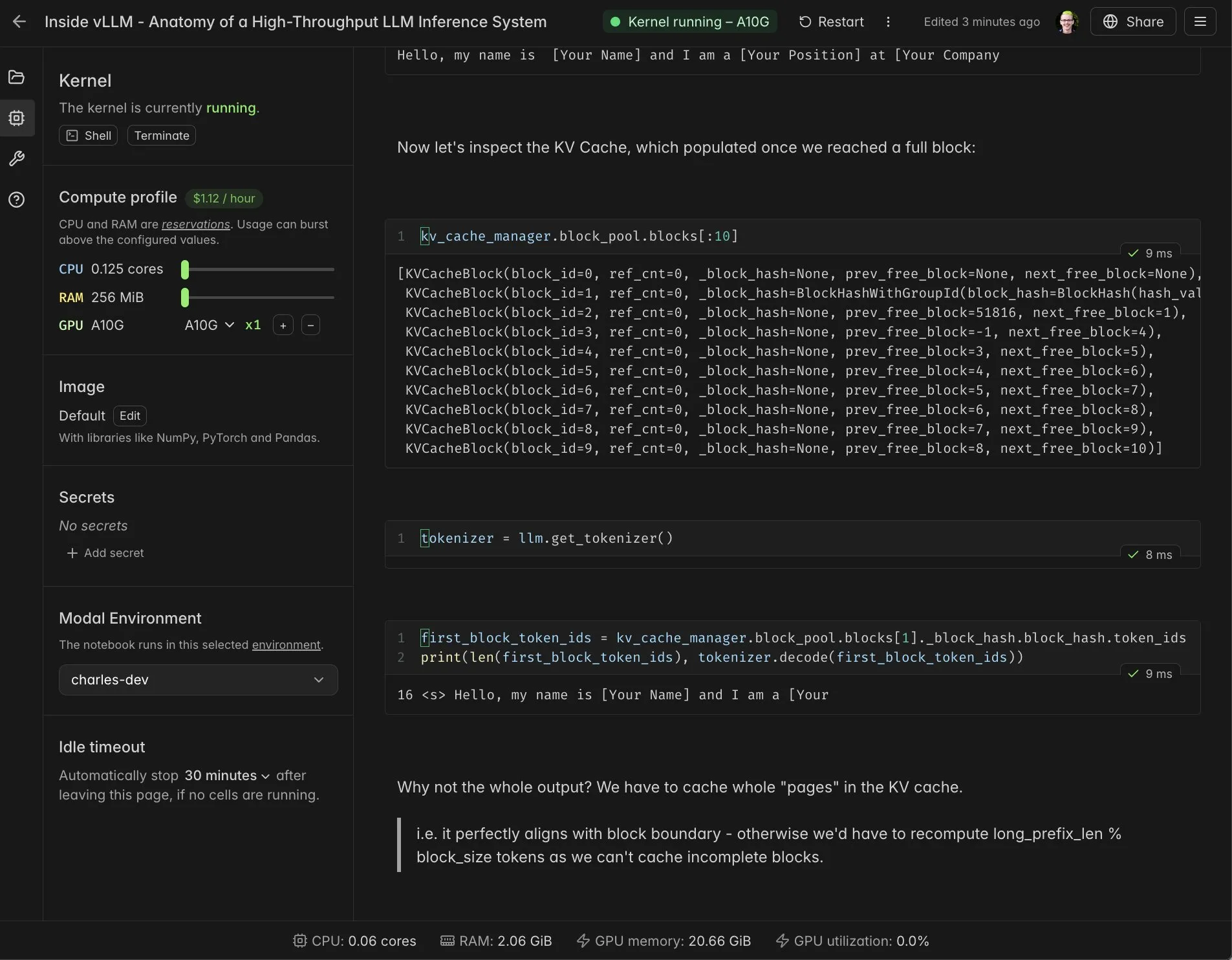
vLLM 실시간 Notebook과 Modal 통합 : Modal Notebooks가 vLLM과 통합되어 실시간으로 공유 가능한 대화형 환경을 제공하여 개발자가 vLLM의 내부 메커니즘을 심층적으로 이해할 수 있도록 돕습니다. 이 통합을 통해 사용자는 복잡한 통합을 구축할 필요 없이 클라우드에서 CUDA-compatible computing tasks를 쉽게 실행하고 공유할 수 있어 vLLM의 개발 및 학습 과정을 크게 간소화합니다. (출처: charles_irl, vllm_project, charles_irl, charles_irl, charles_irl, charles_irl)
Docker, Minions AI 지원: 로컬 Hybrid AI Workloads : Minions AI가 이제 공식적으로 Docker를 지원하여 사용자가 Docker model runner를 통해 로컬에서 hybrid AI workloads를 활용할 수 있도록 합니다. 이 협력을 통해 개발자는 로컬 환경에서 Minions AI를 더 편리하게 배포하고 관리할 수 있으며, Docker의 containerization 장점과 결합하여 AI 응용 프로그램 개발의 유연성과 효율성을 높입니다. (출처: shishirpatil_)
Replit Agent 3: 자율 소프트웨어 개발의 새로운 돌파구 : Replit이 Agent 3를 출시하며 소프트웨어 개발의 “full self-driving” 순간이라고 자칭했습니다. 이전 Agent보다 자율성이 10배 향상되었습니다. 이 Agent는 응용 프로그램을 더 깊이 prototype할 수 있으며, 다른 Agent가 막혔을 때도 계속 진행하여 소프트웨어 개발에서 시간이 많이 소요되는 testing, debugging 및 refactoring 단계를 해결하고 개발 효율성을 크게 높이는 것을 목표로 합니다. (출처: amasad, amasad, pirroh)
Qwen3-Coder: 고성능 오픈소스 Programming 모델 : Qwen3-Coder는 Windsurf 플랫폼에서 뛰어난 성능과 비용 효율성을 보여주며, 0.5 credits만으로 실행 가능하여 Claude 4 및 GPT-5 High(2배 credits)보다 경쟁력이 있습니다. 이 모델은 programming 작업에서 뛰어난 성능을 보이며, 오픈소스 모델로서 규제 대상 기업 및 공공 부문 조직에 공용 API에 의존할 필요 없는 강력한 AI programming 옵션을 제공하여 data sovereignty 및 가시성 문제를 해결하는 데 기여합니다. (출처: bookwormengr)
📚 학습
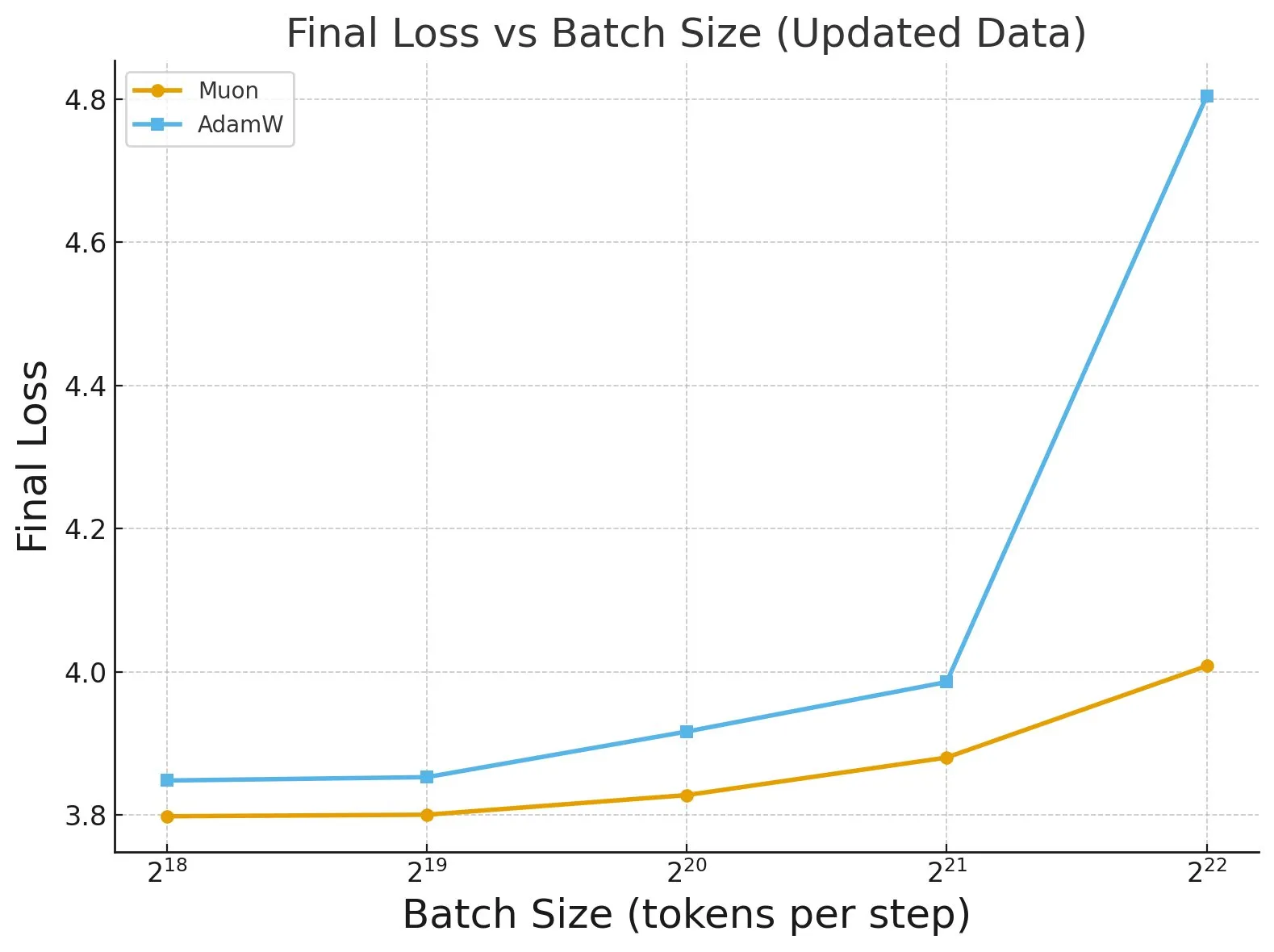
《Fantastic Pretraining Optimizers and Where to Find Them》 연구 : 4000개 이상의 모델을 대상으로 한 광범위한 연구에서 pre-training optimizers의 성능이 밝혀졌습니다. 연구 결과, 특정 optimizer(예: Muon)는 소규모 모델(<0.5B parameters)에서 최대 40%의 속도 향상을 달성할 수 있지만, 대규모 모델(1.2B parameters)에서는 10%만 향상되는 것으로 나타났습니다. 이는 optimizer를 평가할 때 insufficient baseline tuning 및 규모 제한에 주의해야 하며, batch size가 optimizer 성능 차이에 미치는 영향을 지적합니다. (출처: tokenbender, code_star)
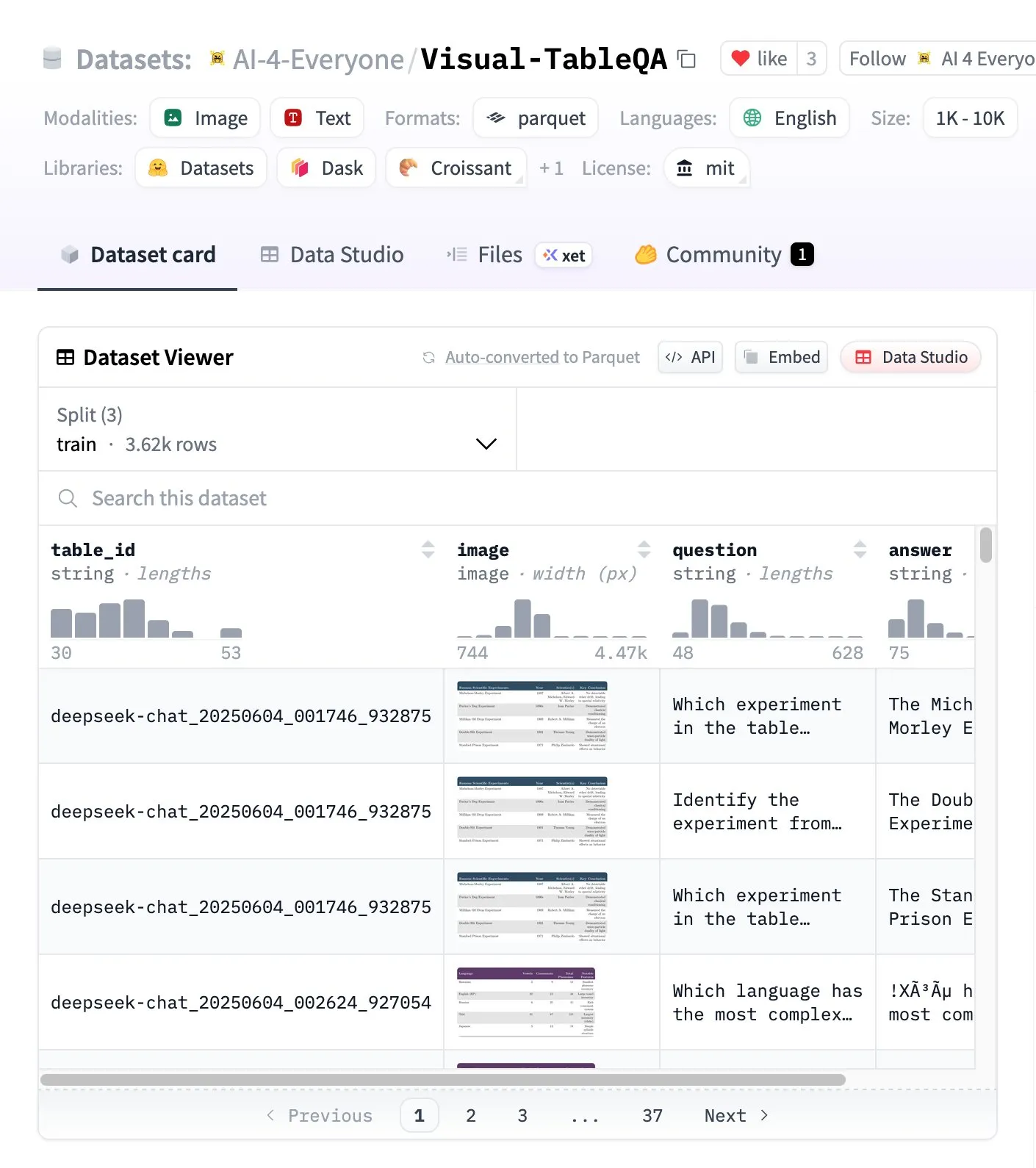
Visual-TableQA: 복잡한 Table Reasoning 벤치마크 : Hugging Face가 2.5K tables 및 6K QA pairs를 포함하는 복잡한 Table Reasoning 벤치마크인 Visual-TableQA를 발표했습니다. 이 벤치마크는 visual structure에 대한 multi-step reasoning에 중점을 두며, 92%의 수동 검증을 거쳤고 생성 비용은 100달러 미만입니다. 이는 복잡한 테이블 데이터를 이해하고 추론하는 모델의 능력을 평가하고 향상시키는 데 고품질 리소스를 제공합니다. (출처: huggingface)
AI Agents vs Agentic AI 개념 분석 : 커뮤니티에서는 AI Agents와 Agentic AI systems에 대한 일반적인 혼란이 존재합니다. AI Agents는 특정 작업을 수행하는 단일 자율 소프트웨어(LLM+tools)를 의미하며, 반응적이고 제한된 기억을 가집니다. Agentic AI는 다중 Agent 협업 시스템(multi-LLM+orchestration+shared memory)을 의미하며, 능동적이고 영구적인 기억을 가집니다. 이 둘의 차이를 이해하는 것은 아키텍처 결정에 매우 중요하며, 불필요하게 복잡한 시스템을 구축하는 것을 피할 수 있습니다. (출처: Reddit r/deeplearning)

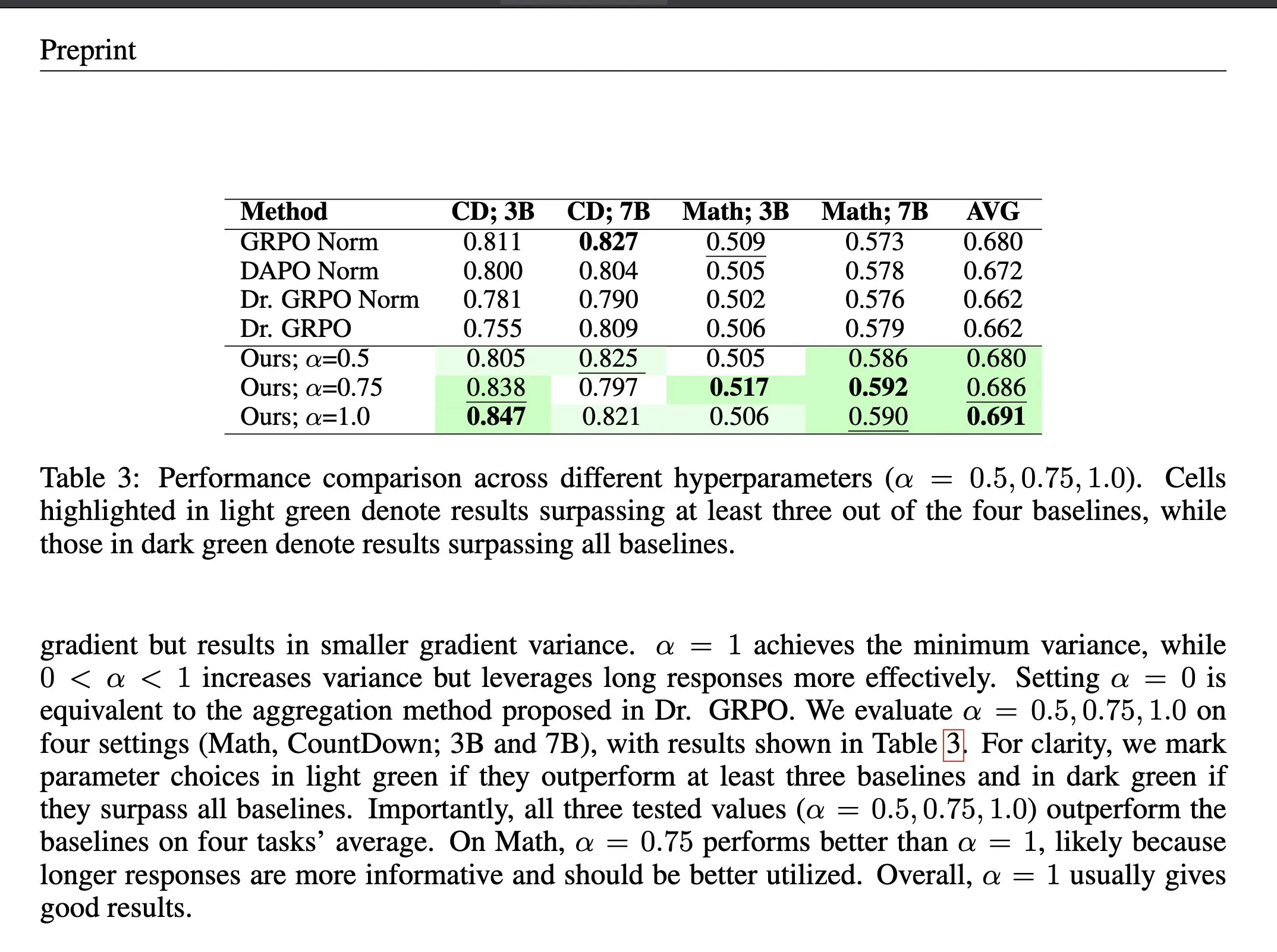
강화 학습의 Loss Aggregation 방법 ΔL Normalization : ΔL Normalization은 verifiable reward 강화 학습(RLVR)에서 동적으로 생성되는 길이 특성을 위해 설계된 loss aggregation 방법입니다. 이 방법은 다른 길이가 policy loss에 미치는 영향을 분석하여, 최소 분산 비편향 추정량을 찾기 위해 문제를 재구성하여 이론적으로 gradient variance를 최소화합니다. 실험 결과, ΔL Normalization은 다양한 모델 규모, 최대 길이 및 작업에서 지속적으로 우수한 결과를 달성하여 RLVR에서 높은 gradient variance 및 불안정한 최적화 문제를 해결했습니다. (출처: HuggingFace Daily Papers, teortaxesTex)
LLM Architecture 비교 비디오 강의 : Rasbt가 2025년 11가지 LLM architecture에 대한 비교 분석 비디오 강의를 발표했습니다. DeepSeek V3/R1, OLMo 2, Gemma 3, Mistral Small 3.1, Llama 4, Qwen3, SmolLM3, Kimi 2, GPT-OSS, Grok 2.5 및 GLM-4.5를 다룹니다. 이 강의는 개발자와 연구원에게 포괄적인 LLM architecture 개요를 제공하여 다양한 모델의 설계 철학과 성능 특성을 이해하는 데 도움이 됩니다. (출처: rasbt)
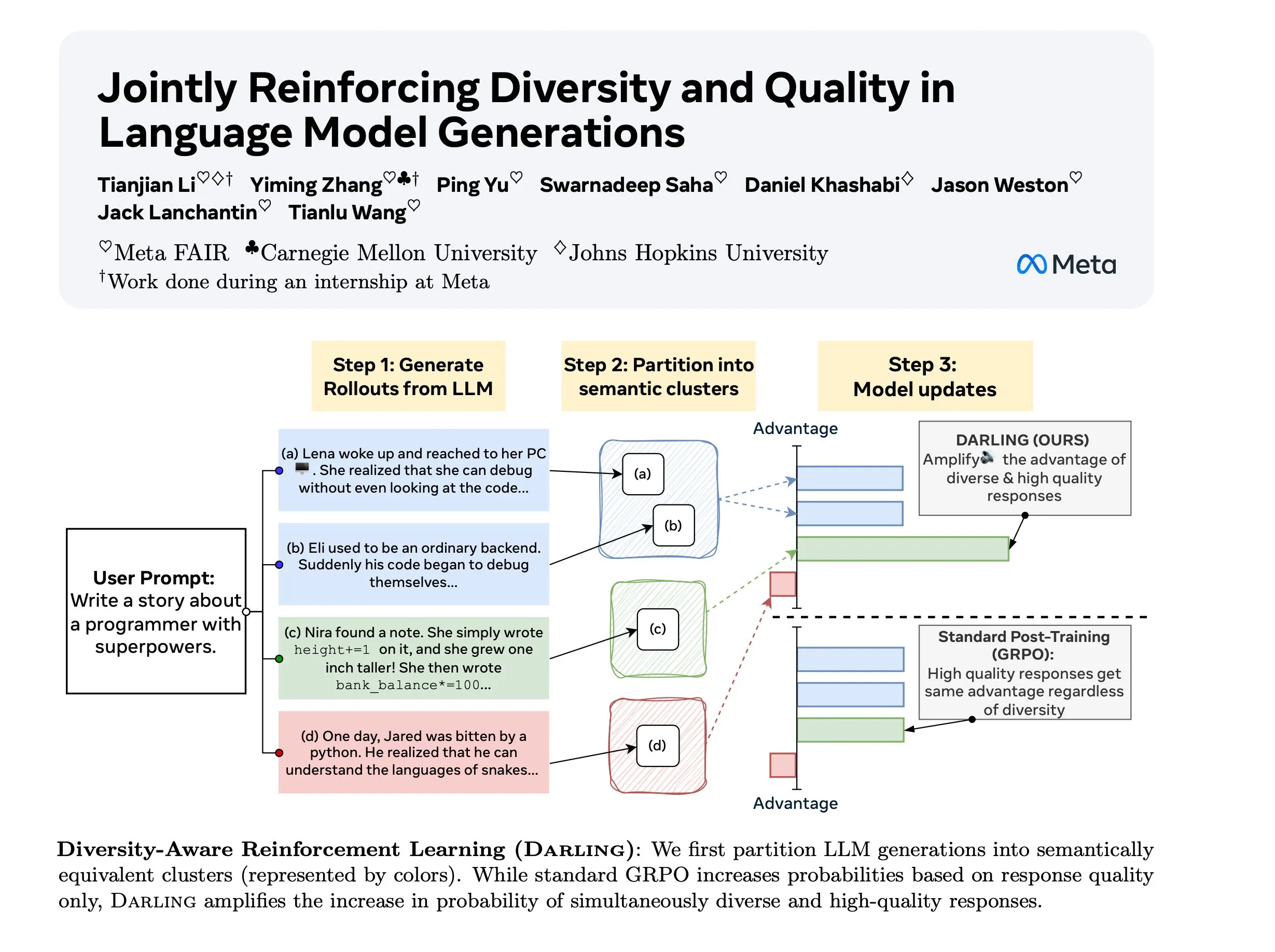
Diversity Aware RL (DARLING) 연구 : DARLING (Diversity Aware RL)은 파티션 함수를 학습하여 품질과 다양성을 동시에 최적화하는 새로운 강화 학습 방법입니다. 이 방법은 품질 및 다양성 지표 모두에서 표준 RL보다 우수하며, 예를 들어 더 높은 pass@1/p@k를 달성하고, 검증 불가능한 작업과 검증 가능한 작업 모두에 적용 가능하여 복잡한 환경에서 RL의 일반화 능력을 향상시키는 새로운 길을 제공합니다. (출처: ylecun)
Stanford CS 224N: Deep Learning 및 NLP 과정 : Stanford 대학교 CS 224N 과정은 Deep Learning 및 Natural Language Processing에 대한 포괄적인 교육을 제공합니다. 이 과정은 YouTube 비디오를 통해 공개되어 전 세계 학습자에게 고품질 AI 학습 리소스를 제공하며, NLP 기본 이론, 최신 모델 및 실제 응용 프로그램을 다루는 AI 분야의 중요한 입문 과정입니다. (출처: stanfordnlp)
💼 비즈니스
Anthropic의 새로운 Privacy Policy 논란: Independent Developers에 대한 체계적인 불이익 : Anthropic의 새로운 Privacy Policy는 사용자에게 9월 28일까지 대화 데이터를 AI 훈련에 사용하고 5년간 보존할지 여부를 선택하도록 요구하며, 그렇지 않으면 기억 및 개인화 기능을 잃게 됩니다. 이 조치는 “두 계층 시스템”을 만들어 independent developers가 프라이버시와 기능 사이에서 선택해야 하는 상황에 직면하게 하며, 그들의 proprietary code가 기업 AI 훈련 데이터가 될 수 있는 반면, 기업 고객은 프라이버시 보호와 개인화를 동시에 누리는 고가의 솔루션을 이용할 수 있어 AI 민주화 및 혁신 추출에 대한 우려를 불러일으킵니다. (출처: Reddit r/ClaudeAI)
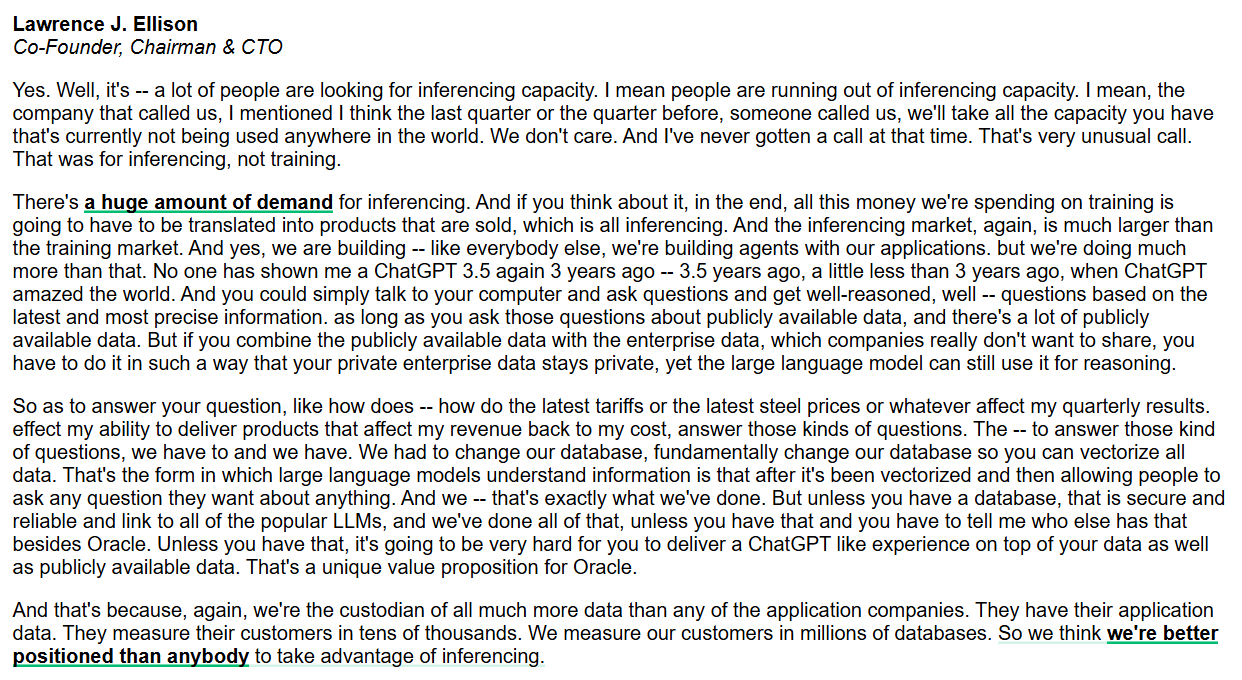
Oracle, Inference Capability 및 Enterprise-Grade AI Database에 집중 : Oracle CEO Larry Ellison은 inference capability 시장이 training 시장보다 훨씬 크고 수요가 막대하다고 강조했습니다. Oracle은 모든 데이터를 vectorization하기 위해 database를 근본적으로 변경하고 안전하고 신뢰할 수 있도록 보장함으로써, 공용 및 기업 사설 데이터를 결합한 ChatGPT-like experience를 제공하는 것을 목표로 합니다. Oracle은 데이터 관리자로서 enterprise-grade AI inference services를 제공하는 데 독점적인 이점을 가지고 있다고 믿습니다. (출처: JonathanRoss321)
AI Content Licensing 새 표준 RSL Standard: AI 기업의 유료화 추진 : Reddit, Yahoo, Quora 및 wikiHow와 같은 주요 브랜드가 Really Simple Licensing (RSL) Standard를 지지합니다. 이는 웹 퍼블리셔가 AI system developers의 작품 사용 조건을 설정할 수 있도록 하는 오픈 content licensing standard입니다. RSL은 robots.txt 프로토콜을 기반으로 하며, 웹사이트가 라이선스 및 로열티 조건을 추가할 수 있도록 하여 AI crawlers가 training data에 대해 비용을 지불하도록 요구합니다(구독 또는 크롤링/추론 횟수당 지불). 이는 content creators가 합당한 보상을 받도록 보장하는 것을 목표로 합니다. (출처: Reddit r/artificial)
🌟 커뮤니티
AI와 Human Intelligence의 공존 및 강화 : 커뮤니티에서는 AI가 Human Intelligence를 보조하는 “cognitive prosthetics”(예: 주판) 역할을 할 것인지, 아니면 인간을 대체하는 “competitor”(예: 계산기) 역할을 할 것인지에 대한 논의가 활발합니다. François Chollet은 기술이 인간의 노력을 증폭시켜야지 인간을 아무것도 하지 않게 만들어서는 안 된다는 “mind-bike” 비유를 제시하며, AI와 Human Intelligence (IA) 간의 관계 및 미래 발전 방향에 대한 philosophical reflection을 불러일으켰습니다. (출처: rao2z)
AI 산업 PR 난관과 대중의 부정적 정서 : AI products가 수십억 명의 사용자를 보유하고 많은 사람들이 혜택을 받고 있음에도 불구하고, AI 산업은 전반적으로 부정적인 대중 정서에 직면해 있습니다. 일부 의견은 업계 리더들이 대외 홍보에서 효과적으로 소통하지 못하여 대중이 AI 기업에 대한 편견을 갖게 되었다고 주장합니다. 또 다른 의견은 이것이 AI 산업이 핵심 기술과 이점을 소수의 플레이어에게 집중시키기 위한 의도적인 행동일 수 있다고 추측합니다. (출처: Dorialexander)
LLM Multi-Agent Systems의 약점 영향 : 연구에 따르면 multi-agent systems에서 small language models을 사용하는 것이 항상 이상적인 선택은 아닙니다. multi-agent debate와 같은 시나리오에서 약한 LLM agents는 종종 강한 Agent의 성능을 방해하거나 심지어 손상시켜 전체 시스템 성능을 저하시킵니다. 이는 multi-agent systems를 설계하고 배포할 때 각 Agent 능력의 차이와 잠재적인 부정적 상호 작용 영향을 신중하게 고려해야 함을 보여줍니다. (출처: omarsar0)

Synthetic Data의 AGI 한계 : Andrew Trask와 Fei-Fei Li는 synthetic data가 LLM이 AGI를 달성하는 데 있어 약한 전략이라고 지적합니다. synthetic data는 새로운 정보(예: 모델이 들어본 적 없는 엔티티)를 생성할 수 없으며, 기존 정보의 자연스러운 추론만 밝힐 수 있습니다. synthetic data가 논리적 치환과 알려진 사실의 조합을 통해 “reversal curse”와 같은 문제를 해결할 수 있지만, 그 정보 병목 현상은 AGI의 “silver bullet”으로서의 잠재력을 제한하며, 진정한 돌파구는 global intelligence와 context의 즉각적인 검색에 있을 수 있습니다. (출처: algo_diver, jpt401)
AI와 인간 고용 시장: AI 이력서 작성과 AI 이력서 필터링의 악순환 : AI는 고용 시장에서 “아무도 채용되지 않는” 악순환을 야기하고 있습니다. job seekers는 AI로 이력서를 작성하고, HR은 AI로 이력서를 필터링하여 효율성은 “향상”되지만 아무도 채용되지 않는 상황이 발생합니다. 이력서는 AI에 의해 온갖 이유로 거부되며, 심지어 HR도 AI 생성 이력서가 천편일률적이라고 불평합니다. 이는 AI가 채용 과정에서 가져오는 새로운 도전을 강조하며, 채용 프로세스가 경직되어 진정한 인재를 식별하지 못할 수 있음을 보여줍니다. (출처: 量子位)

AI 윤리학자들이 직면한 도전 : AI 기술이 빠르게 발전함에 따라 AI ethicists들은 “허공에 외치는” 딜레마에 직면하고 있습니다. 자본주의가 주도하는 AI 경쟁으로 인해 윤리적 고려가 뒷전으로 밀려나고 있으며, 기술 발전 속도가 윤리 통합 속도를 훨씬 앞지르고 있습니다. 전문가들은 피해가 대규모로 나타날 때까지 기다리면 너무 늦을 수 있다고 우려하며, 업계가 윤리적 보장을 핵심 고려 사항으로 포함할 것을 촉구합니다. (출처: Reddit r/ArtificialInteligence)

인터넷의 미래: Bot Traffic이 인간을 능가 : 향후 3년 내에 인터넷상의 bot-driven 상호작용이 인간 상호작용을 훨씬 넘어설 것이며, 인터넷을 “죽은 공간”으로 만들 것이라는 추세가 나타나고 있습니다. 이미 일부 연구에서는 bot traffic이 50%를 초과했다고 지적합니다. 이는 실제 인간의 목소리와 AI-generated content를 어떻게 구별할 것인지, 그리고 인터넷 정보의 진실성에 대한 우려를 불러일으키며, 네트워크 생태계가 근본적으로 변화할 것을 예고합니다. (출처: Reddit r/artificial)

Claude Code 성능 저하 및 사용자 이탈 : Anthropic의 Claude Code 사용자들은 최근 모델 성능이 크게 저하되었다고 보고했습니다. 코드 품질 저하, 불필요한 코드 생성, 낮은 테스트 품질, 과도한 엔지니어링 및 이해 능력 약화 등이 그 증상입니다. 많은 사용자들이 GPT-5, GLM-4.5, Qwen3 등 대체 솔루션으로 전환을 고려하고 있으며, Anthropic에 모델 퇴보 원인 및 해결책에 대한 투명성 제고를 요구하고 있습니다. 그렇지 않으면 사용자 이탈에 직면할 것이라고 경고합니다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
💡 기타
AI와 VR의 범죄 교정 잠재력 : 저렴한 AI와 VR technology를 활용하여 forensic psychiatric patients에게 강제 VR pods를 제공함으로써 전통적인 숙식 비용보다 저렴하게 사회로부터 격리할 수 있다는 의견이 제시되었습니다. 이 급진적인 구상은 AI의 사회 통제, 처벌 시스템 및 ethical boundaries에 대한 논의를 불러일으키며, 그 실현 가능성과 인도주의적 측면에서 논란이 있지만, 사회 문제 해결에 있어 기술의 잠재적 응용 방향을 보여줍니다. (출처: gfodor, gfodor)
Replit의 교도소 적용 구상 : 한 사용자가 Replit(온라인 programming 플랫폼)을 교도소에 도입하는 구상을 제시했습니다. 이는 오락 시설을 대체하고 수감자들이 programming을 통해 가치 있는 제품을 만들 수 있게 할 것이라고 주장합니다. 이 아이디어는 사회 개조, 기술 교육 제공 및 수감자들의 사회 재통합 촉진에 있어 기술의 잠재적 역할을 탐구하며, educational equity 및 technological empowerment에 대한 논의를 불러일으킵니다. (출처: amasad)