

키워드:메타, 텐센트 혼원 이미지 3.0, xAI 그록 4 패스트, 오픈AI 소라 2, 바이트댄스 셀프포싱++, 알리바바 큐wen, vLLM, GPT-5 프로, 메타인지 재사용 메커니즘, 일반화 인과 주의 메커니즘, 멀티모달 추론 모델, 분 단위 비디오 생성, 포즈 인식 패션 생성
🔥 포커스
Meta, 사고 체인 단축 및 반복 추론 제거를 위한 새로운 방법 제시 : Meta, Mila-Quebec AI Institute 등이 공동으로 제안한 “메타인지 재사용(Metacognitive Reuse)” 메커니즘은 대규모 모델(LLM) 추론에서 반복적인 추론으로 인한 token 팽창 및 지연 증가 문제를 해결하는 것을 목표로 한다. 이 메커니즘은 모델이 문제 해결 방식을 되돌아보고 요약하여, 자주 사용되는 추론 패턴을 “행동(behavior)”으로 추출하여 “행동 매뉴얼(behavior handbook)”에 저장하고, 필요할 때 직접 호출하여 다시 추론할 필요가 없도록 한다. 실험 결과, MATH, AIME 등 수학 벤치마크 테스트에서 이 메커니즘은 정확도를 유지하면서도 추론 token 사용량을 최대 46%까지 줄일 수 있었으며, 모델 효율성을 높이고 새로운 경로를 탐색하는 능력을 향상시켰다. (출처: 量子位)

텐센트 Hunyuan Image 3.0, 전 세계 AI 이미지 생성 순위 1위 차지 : 텐센트 Hunyuan Image 3.0이 LMArena 벤치마크의 텍스트-이미지 생성 순위에서 1위를 차지하며, Google Nano Banana, ByteDance Seedream, OpenAI gpt-Image를 넘어섰다. 이 모델은 Hunyuan-A13B를 기반으로 한 네이티브 멀티모달 아키텍처를 채택했으며, 총 800억 개 이상의 파라미터를 가지고 있다. 텍스트, 이미지, 비디오, 오디오 등 다양한 모달리티를 통합적으로 처리할 수 있으며, 강력한 의미 이해, 언어 모델 사고 및 세계 지식 추론 능력을 갖추고 있다. 핵심 기술로는 일반화된 인과적 어텐션 메커니즘(Generalized Causal Attention Mechanism)과 2차원 위치 인코딩(2D Positional Encoding)이 포함되며, 자동 해상도 예측 기능도 도입되었다. 모델은 3단계 필터링과 계층적 설명 시스템을 통해 데이터를 구축하고, 4단계 점진적 훈련 전략을 사용하여 생성된 이미지의 사실감과 선명도를 효과적으로 향상시켰다. (출처: 量子位)

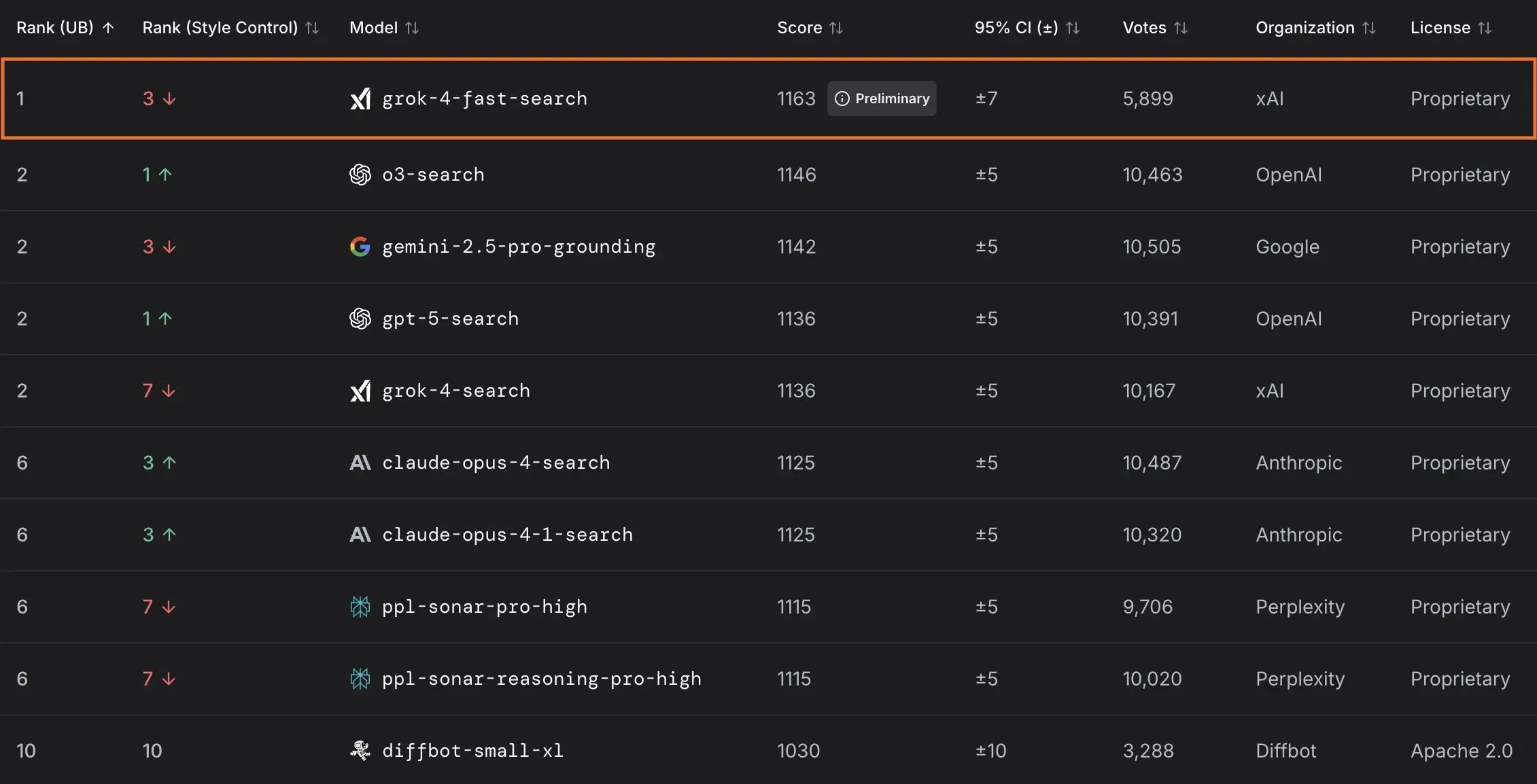
xAI, Grok 4 Fast 모델 출시 및 미국 정부와 협력 : xAI는 2M 컨텍스트 윈도우를 가진 멀티모달 추론 모델인 Grok 4 Fast를 출시했다. 이 모델은 비용 효율적인 지능형 서비스를 제공하는 것을 목표로 한다. 이 모델은 모든 사용자에게 무료로 공개되었으며, 미국 연방 정부와의 협력을 통해 모든 연방 기관에 최첨단 AI 모델(Grok 4, Grok 4 Fast)을 18개월간 무료로 사용할 수 있는 권한을 제공한다. 또한, AI 활용을 지원하기 위해 엔지니어 팀을 파견할 예정이다. 이 외에도 xAI는 LLM 성능 및 보안 평가를 위한 OpenBench를 출시했으며, 코딩 작업에서 뛰어난 성능을 보이는 Grok Code Fast 1도 선보였다. (출처: xai, xai, xai, JonathanRoss321)
🎯 동향
OpenAI, 소비자용 AI 제품 및 Sora 2 업데이트 예고 : UBS는 OpenAI 개발자 컨퍼런스에서 여행 예약 AI 에이전트를 포함한 소비자용 AI 제품이 중점적으로 발표될 것이라고 예측했다. 한편, Sora 2 비디오 생성 모델이 테스트 중이며, 사용자들은 생성된 콘텐츠에서 유머러스한 요소를 자주 발견했다. OpenAI는 Sora 2 Pro 모델의 고화질 모드에서 해상도 문제를 해결했으며, 이제 17921024 또는 10241792 해상도를 지원하고 최대 15초 길이의 비디오 생성이 가능하다. 다만, 일일 생성 한도는 30회로 줄었다. (출처: teortaxesTex, francoisfleuret, fabianstelzer, TomLikesRobots, op7418, Reddit r/ChatGPT)

ByteDance, 분 단위 비디오 생성 모델 출시 : ByteDance는 Self-Forcing++이라는 새로운 방법을 발표했으며, 이 방법은 최대 4분 15초 길이의 고품질 비디오를 생성할 수 있다. 이 방법은 긴 비디오 교사 모델(teacher model)이나 재훈련 없이도 확산 모델(diffusion model)을 확장할 수 있으며, 생성된 비디오의 충실도와 일관성을 유지한다. (출처: _akhaliq)
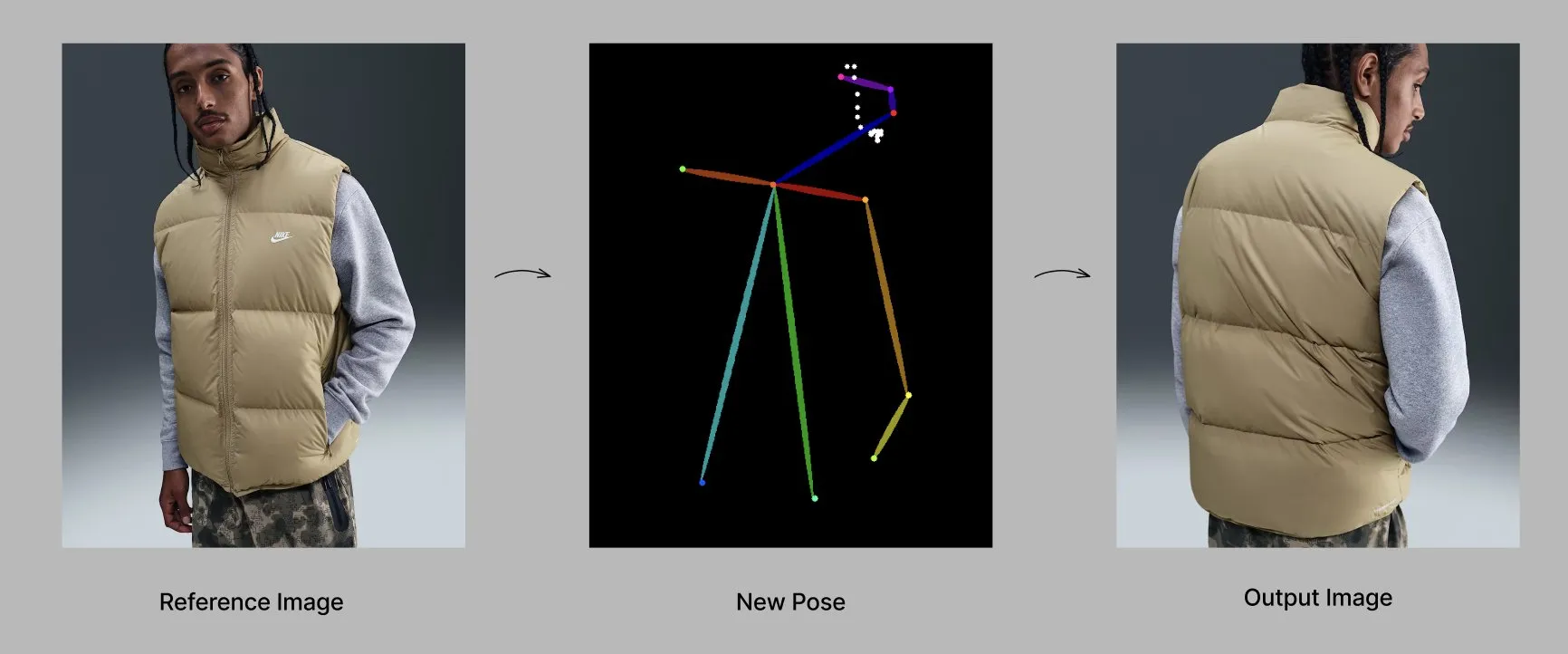
Qwen 모델, 새로운 기능 및 애플리케이션 출시 : Alibaba Qwen 팀은 기억 및 사용자 정의 시스템 명령어와 같은 개인화 기능을 점진적으로 출시하고 있으며, 현재 제한된 테스트를 진행 중이다. 동시에 Qwen-Image-Edit-2509 모델은 자세 인식 패션 생성 분야에서 첨단 능력을 보여주며, 미세 조정을 통해 다각도, 고품질의 패션 모델 생성을 가능하게 한다. (출처: Alibaba_Qwen, Alibaba_Qwen)
vLLM 및 PipelineRL, RL 커뮤니티의 경계 확장 : vLLM 프로젝트는 강화 학습(RL) 분야에서 RL 커뮤니티의 새로운 돌파구를 지원한다. 여기에는 더 나은 on-policy 데이터, 부분 rollouts, 그리고 추론 과정에서 KV 캐시를 혼합하는 in-flight 가중치 업데이트가 포함된다. PipelineRL은 가중치 변화와 KV 상태가 유지되는 동안 추론을 계속함으로써, 확장 가능한 비동기 RL을 구현하고 in-flight 가중치 업데이트를 지원한다. (출처: vllm_project, Reddit r/LocalLLaMA)

GPT-5-Pro, 복잡한 수학 문제 해결 : GPT-5-Pro는 15분 이내에 “Yu Tsumura의 554번째 문제”를 독립적으로 해결했다. 이는 이 작업을 완전히 해결한 최초의 모델로, 강력한 수학 문제 해결 능력을 보여주었다. (출처: Teknium1)

SAP, AI를 기업 워크플로우의 핵심으로 활용 : SAP는 Connect 2025 컨퍼런스에서 AI를 기업 워크플로우의 핵심으로 삼는 비전을 선보일 계획이다. 내장된 AI를 통해 실시간 데이터를 의사 결정으로 전환하고 AI 에이전트를 활용하여 능동적인 작업을 수행한다. SAP는 처음부터 신뢰를 구축하고 적극적인 지원을 제공하며, 현지화 유연성과 규정 준수를 보장하는 것을 강조한다. (출처: TheRundownAI)

Salesforce, CoDA-1.7B 텍스트 확산 인코딩 모델 출시 : Salesforce Research는 양방향 병렬 token 출력이 가능한 텍스트 확산 인코딩 모델인 CoDA-1.7B를 발표했다. 이 모델은 추론 속도가 더 빠르며, 1.7B 파라미터로도 7B 모델에 필적하는 성능을 보인다. HumanEval, HumanEval+, EvalPlus 등 벤치마크 테스트에서 뛰어난 성능을 발휘했다. (출처: ClementDelangue)

Google Gemini 3.0, EQ(감성 지능)에 집중하며 OpenAI와의 경쟁 심화 : Google은 곧 Gemini 3.0을 출시할 예정이며, “감성 지능(EQ)”에 중점을 둘 것으로 알려졌다. 이는 OpenAI에 대한 강력한 도전으로 평가된다. 이러한 움직임은 AI 모델이 감정 이해 및 상호 작용 측면에서 발전하고 있음을 보여주며, AI 거대 기업 간의 경쟁이 더욱 심화될 것임을 예고한다. (출처: Reddit r/ChatGPT)
로봇 및 자동화 기술 발전 : 로봇 분야는 지속적으로 혁신하고 있으며, 물류 작업을 위한 전방향 이동 휴머노이드 로봇, 로봇 팔과 사물함을 결합한 자율 이동 로봇 배달 서비스, 그리고 미국 학생들이 로프 구동과 정교한 수학적 설계를 활용하여 만든 12개 모터 로봇 개 “Cara” 등이 포함된다. 또한, 최초의 “Wuji Hand” 로봇도 공식 출시되었다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

🧰 도구
GPT4Free (g4f) 프로젝트, 무료 LLM 및 미디어 생성 도구 제공 : GPT4Free (g4f)는 다양한 접근 가능한 LLM 및 미디어 생성 모델을 통합하는 것을 목표로 하는 커뮤니티 주도 프로젝트이다. Python 클라이언트, 로컬 웹 GUI, OpenAI 호환 REST API 및 JavaScript 클라이언트를 제공한다. 이 프로젝트는 OpenAI, PerplexityLabs, Gemini, MetaAI 등을 포함한 다중 공급자 어댑터를 지원하며, 이미지/오디오/비디오 생성 및 미디어 영구 저장을 지원한다. AI 도구에 대한 개방형 접근을 보편화하는 데 전념하고 있다. (출처: GitHub Trending)

LLM 도구 설계 및 Prompt 엔지니어링 모범 사례 : AI가 더 쉽게 이해할 수 있는 도구를 작성할 때, 우선순위는 도구 정의, 시스템 명령어, 사용자 프롬프트 순이다. 도구 이름과 설명은 직관적이고 명확해야 하며, 모호함을 피해야 한다. 파라미터는 가능한 한 적게 하고, 열거 항목을 제공하거나 상한선과 하한선을 설정해야 한다. 응답 속도를 높이기 위해 너무 많이 중첩된 구조화된 파라미터 사용을 피해야 한다. 모델이 프롬프트를 작성하고 피드백을 제공하게 함으로써, 대규모 모델(LLM)의 도구 이해도를 효과적으로 높일 수 있다. (출처: dotey)
Zen MCP, Gemini CLI를 활용하여 Claude Code 크레딧 절약 : Zen MCP 프로젝트는 사용자가 Claude Code와 같은 도구에서 Gemini CLI를 직접 사용할 수 있도록 하여, Claude Code의 token 사용량을 크게 줄이고 Gemini의 무료 크레딧을 활용할 수 있게 한다. 이 도구는 다른 AI 모델 간에 작업을 위임하고 공유 컨텍스트를 유지하는 것을 지원한다. 예를 들어, GPT-5로 계획하고, Gemini 2.5 Pro로 검토하며, Sonnet 4.5로 구현한 다음, Gemini CLI로 코드 검토 및 단위 테스트를 수행하여 효율적이고 경제적인 AI 보조 개발을 가능하게 한다. (출처: Reddit r/ClaudeAI)
오픈소스 LLM 평가 도구 Opik : Opik은 LLM 애플리케이션, RAG 시스템 및 Agentic 워크플로우를 디버깅, 평가 및 모니터링하는 데 사용되는 오픈소스 LLM 평가 도구이다. 이 도구는 포괄적인 추적, 자동화된 평가 및 프로덕션 준비 대시보드를 제공하여, 개발자가 AI 모델을 더 잘 이해하고 최적화하도록 돕는다. (출처: dl_weekly)
Claude Sonnet 4.5, Tampermonkey 스크립트 작성에 능숙 : Claude Sonnet 4.5는 Tampermonkey 스크립트 작성에서 뛰어난 성능을 보여주며, 사용자는 단 하나의 프롬프트로 Google AI Studio의 테마를 변경할 수 있다. 이는 자동화된 브라우저 작업 및 사용자 인터페이스 맞춤화 분야에서 강력한 능력을 입증한다. (출처: Reddit r/ClaudeAI)

Phi-3-mini 모델 로컬 배포 : 사용자는 Unsloth를 사용하여 Google Colab에서 미세 조정된 Phi-3-mini-4k-instruct-bnb-4bit 모델을 로컬 머신에 배포하려고 한다. 이 모델은 텍스트에서 요약 및 필드를 추출할 수 있으며, 배포 목표는 로컬에서 DataFrame의 텍스트를 읽고, 모델 처리 후 출력을 새로운 DataFrame에 저장하는 것이다. 이는 통합 그래픽 카드와 8GB RAM의 낮은 사양 환경에서도 구현되어야 한다. (출처: Reddit r/MachineLearning)
LLM 백엔드 성능 비교 : 커뮤니티는 현재 LLM 백엔드 프레임워크의 성능을 논의하고 있으며, vLLM, llama.cpp, ExLlama3가 가장 빠른 옵션으로 간주되는 반면, Ollama는 가장 느리다고 여겨진다. vLLM은 여러 동시 채팅을 처리할 때 뛰어난 성능을 보이며, llama.cpp는 유연성과 광범위한 하드웨어 지원으로 선호된다. ExLlama3는 NVIDIA GPU에 최적화된 최고의 성능을 제공하지만, 모델 지원은 제한적이다. (출처: Reddit r/LocalLLaMA)
“solveit” 도구, 프로그래머가 AI 과제에 대처하도록 돕다 : 프로그래머가 AI를 사용할 때 겪을 수 있는 좌절감을 해결하기 위해, Jeremy Howard는 “solveit” 도구를 출시했다. 이 도구는 프로그래머가 AI를 더 효과적으로 활용하고, AI에 의해 잘못된 방향으로 이끌리는 것을 방지하며, 프로그래밍 경험과 효율성을 향상시키는 것을 목표로 한다. (출처: jeremyphoward)
📚 학습
스탠포드와 NVIDIA, Embodied AI 벤치마크 추진을 위한 협력 : 스탠포드 대학교와 NVIDIA는 공동 라이브 스트리밍을 통해, Embodied AI 발전을 위한 대규모 벤치마크 및 챌린지인 BEHAVIOR에 대해 심도 있게 논의할 예정이다. 논의 내용은 BEHAVIOR의 동기, 다가오는 챌린지 설계, 그리고 로봇 연구 발전에 있어 시뮬레이션의 역할 등을 다룰 것이다. (출처: drfeifei)

Agent-as-a-Judge, AI 에이전트 평가 논문 발표 : “Agent-as-a-Judge”라는 새로운 논문은 AI 에이전트를 통해 AI 에이전트를 평가하는 개념 증명 방법을 제시했다. 이 방법은 비용과 시간을 97% 절감하고 풍부한 중간 피드백을 제공할 수 있다. 이 연구는 또한 55개의 자동화된 AI 개발 작업을 포함하는 DevAI 벤치마크를 개발했으며, Agent-as-a-Judge가 LLM-as-a-Judge보다 우수할 뿐만 아니라 효율성과 정확도 면에서 인간 평가에 더 가깝다는 것을 입증했다. (출처: SchmidhuberAI, SchmidhuberAI)

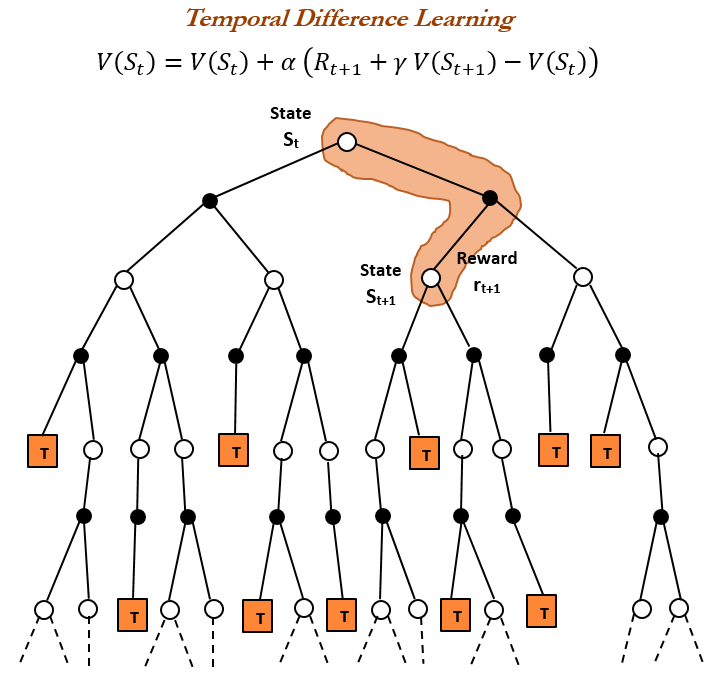
강화 학습(RL) 역사 및 시간차(TD) 학습 : 강화 학습의 역사를 되돌아보면, 시간차(TD) 학습이 현대 RL 알고리즘(예: 심층 Actor-Critic)의 기초임을 알 수 있다. TD 학습은 에이전트가 불확실한 환경에서 학습할 수 있도록 하며, 연속적인 예측을 비교하고 점진적으로 업데이트하여 예측 오차를 최소화함으로써, 더 빠르고 정확한 예측을 가능하게 한다. 그 장점으로는 희귀한 결과에 의해 오도되는 것을 방지하고, 메모리와 계산을 절약하며, 실시간 시나리오에 적용 가능하다는 점 등이 있다. (출처: TheTuringPost, TheTuringPost, gabriberton)
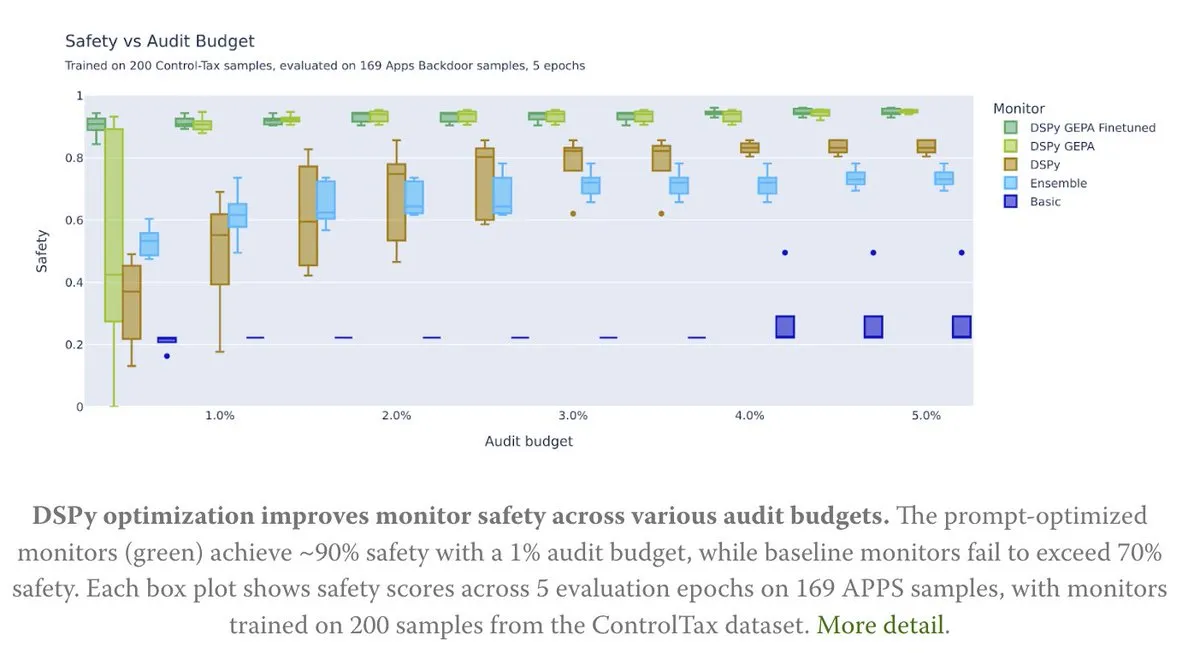
Prompt 최적화, AI 제어 연구에 힘을 실어주다 : 새로운 기사는 Prompt 최적화가 AI 제어 연구에 어떻게 기여하는지 탐구한다. 특히 DSPy의 GEPA(Generative-Enhanced Prompting for Agents) 방법을 통해, AI 안전율을 최대 90%까지 달성했으며, 이는 기준 방법의 70%에 불과한 수치이다. 이는 신중하게 설계된 Prompt가 AI 안전성 및 제어 가능성을 향상시키는 데 큰 잠재력을 가지고 있음을 보여준다. (출처: lateinteraction, lateinteraction)
Transformer 학습 알고리즘 및 CoT : Francois Chollet은 CoT(사고의 사슬) token을 통해 훈련 중 정확한 단계별 알고리즘을 제공하여 Transformer에게 간단한 알고리즘을 실행하도록 가르칠 수 있지만, 머신러닝의 진정한 목표는 외부에서 제공된 알고리즘을 단순히 기억하는 것이 아니라, 입력/출력 쌍에서 알고리즘을 “발견”하는 것이어야 한다고 지적했다. 그는 이미 알고리즘이 있다면, Transformer를 비효율적으로 인코딩하도록 훈련하는 것보다 직접 실행하는 것이 더 낫다고 주장한다. (출처: fchollet)

머신러닝 수명 주기 개요 : 머신러닝 수명 주기는 데이터 수집, 전처리, 모델 훈련, 평가, 배포 및 모니터링에 이르는 모든 단계를 포함하며, ML 시스템을 구축하고 유지 관리하는 데 중요한 프레임워크이다. (출처: Ronald_vanLoon)

LLM 추론에서의 음의 로그 우도(NLL) 최적화 목표 : 한 연구는 분류 및 SFT(지도 미세 조정)의 최적화 목표로서 음의 로그 우도(NLL)가 보편적으로 최적인지 여부를 탐구했다. 이 연구는 어떤 상황에서 대체 목표가 NLL보다 우수할 수 있는지 분석했으며, 이는 목표의 사전 경향성(prior propensity)과 모델 능력에 따라 달라진다고 지적하며, LLM 훈련 최적화에 새로운 관점을 제공했다. (출처: arankomatsuzaki)

머신러닝 입문 가이드 : Reddit 커뮤니티는 머신러닝 학습 방법에 대한 간략한 가이드를 공유했으며, 이론적 정의에만 머무르지 않고 탐색과 소규모 프로젝트 구축을 통해 실질적인 이해를 얻는 것을 강조했다. 이 가이드는 또한 딥러닝의 수학적 기초를 개괄하고, 초보자들이 기존 라이브러리를 활용하여 실습하도록 권장한다. (출처: Reddit r/deeplearning, Reddit r/deeplearning)

비전 모델의 순수 텍스트 데이터셋 훈련 문제 : 사용자가 Axolotl 프레임워크를 사용하여 순수 텍스트 데이터셋으로 LLaMA 3.2 11B Vision Instruct 모델을 미세 조정할 때 오류가 발생했다. 이는 모델의 지시 따르기 능력을 향상시키면서 멀티모달 입력 처리 능력을 유지하는 것을 목표로 한다. 문제는 processor_type 및 is_causal 속성 오류와 관련되어 있으며, 이는 비전 모델을 순수 텍스트 훈련에 적용할 때 구성 및 모델 아키텍처 호환성이 과제임을 시사한다. (출처: Reddit r/MachineLearning)
분산 훈련 강좌 공유 : 커뮤니티는 분산 훈련에 대한 강좌를 공유했으며, 이는 학생들이 전문가들이 일상적으로 사용하는 도구와 알고리즘을 습득하고, 단일 H100을 넘어 훈련을 확장하며, 분산 훈련의 세계를 깊이 이해하도록 돕는 것을 목표로 한다. (출처: TheZachMueller)
Agentic AI 숙달 단계 로드맵 : Agentic AI의 다양한 숙달 단계에 대한 로드맵이 존재하며, 이는 개발자와 연구자에게 명확한 경로를 제공한다. 이를 통해 AI 에이전트 기술을 점진적으로 이해하고 적용하여 더 스마트하고 자율적인 시스템을 구축할 수 있다. (출처: Ronald_vanLoon)

💼 비즈니스
NVIDIA, 최초의 4조 달러 시가총액 상장 기업 등극 : NVIDIA의 시가총액이 4조 달러에 도달하며, 이 이정표를 달성한 최초의 상장 기업이 되었다. 이러한 성과는 AI 칩 및 관련 기술 분야에서의 선도적인 위치와, 신경망 연구에 대한 지속적인 투자 및 지원을 반영한다. (출처: SchmidhuberAI, SchmidhuberAI, SchmidhuberAI)

Replit, AI 네이티브 애플리케이션 계층 기업 상위 3위 등극 : Mercury의 거래 데이터 분석에 따르면, Replit은 AI 네이티브 애플리케이션 계층 기업 중 3위를 차지하며, 다른 모든 개발 도구를 넘어섰다. 이는 AI 개발 분야에서의 강력한 성장과 시장 인정을 보여준다. 이러한 성과는 투자자들의 긍정적인 평가도 받았다. (출처: amasad)
CoreWeave, AI 스토리지 비용 최적화 방안 제공 : CoreWeave는 AI 스토리지 비용을 최대 65%까지 절감하면서도 혁신 속도에 영향을 미치지 않는 방법을 논의하기 위한 웹 세미나를 개최했다. 이 세미나에서는 AI 데이터의 80%가 비활성 상태인 이유와, CoreWeave의 차세대 객체 스토리지가 GPU를 최대한 활용하고 예산을 예측 가능하게 하는 방법, 그리고 AI 스토리지의 미래 발전에 대한 전망을 공개할 예정이다. (출처: TheTuringPost)

🌟 커뮤니티
LLM 능력의 한계, 이해 기준 및 지속 학습 과제 : 커뮤니티는 LLM이 에이전트 작업을 수행할 때의 부족함을 논의하며, 그 능력이 여전히 미흡하다고 평가한다. LLM과 인간 두뇌의 “이해” 기준에 대해서는 의견이 엇갈리며, 일부는 현재 LLM에 대한 이해가 여전히 낮은 수준에 머물러 있다고 본다. 강화 학습의 아버지 Richard Sutton은 LLM이 아직 지속 학습을 구현하지 못했다고 보며, 온라인 학습과 적응성이 미래 AI 발전의 핵심이라고 강조했다. (출처: teortaxesTex, teortaxesTex, aiamblichus, dwarkesh_sp)
주류 LLM 제품 전략, 사용자 경험 및 모델 행동 논란 : Anthropic의 브랜드 이미지와 사용자 경험이 뜨거운 논쟁을 불러일으켰다. “사고 공간(Thinking Space)” 활동은 호평을 받았지만, GPU 자원 할당, Sonnet 4.5(Opus 4.1보다 버그 찾기 능력이 떨어지고 “보모 같은” 스타일이라는 지적) 및 높은 가치 평가에도 불구하고 사용자 경험 저하(예: Claude 사용 제한)에 대한 논란이 있다. ChatGPT는 NSFW(직장 부적합) 콘텐츠 생성을 전면적으로 강화하여 사용자들의 불만을 야기했다. 커뮤니티는 AI 기능이 기본값이 아닌 선택적으로 추가되어야 하며, 사용자 자율성을 존중해야 한다고 촉구했다. (출처: swyx, vikhyatk, shlomifruchter, Dorialexander, scaling01, sammcallister, kylebrussell, raizamrtn, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/LocalLLaMA, Reddit r/ChatGPT, qtnx_)
AI 생태계 과제, 오픈소스 모델 논란 및 대중의 인식 : NIST의 DeepSeek 모델 안전성 평가로 인해 오픈소스 모델의 신뢰성 및 중국 모델에 대한 금지 조치 가능성에 대한 우려가 제기되었다. 그러나 오픈소스 커뮤니티는 DeepSeek을 광범위하게 지지하며, “안전하지 않다”는 것은 실제로는 사용자 지시를 더 쉽게 따른다는 의미라고 주장한다. Google 검색 API 변경은 AI 생태계가 타사 데이터에 의존하는 방식에 영향을 미친다. 로컬 LLM 개발 환경 설정은 높은 하드웨어 비용과 유지 관리 문제에 직면해 있다. AI 모델 평가에는 “움직이는 목표(moving target)” 현상이 존재하며, 대중은 AI 생성 콘텐츠(예: Taylor Swift AI 비디오 사용)의 품질과 윤리에 대해 논란을 제기하고 있다. (출처: QuixiAI, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial, Reddit r/artificial)

AI가 고용 및 전문 서비스에 미치는 영향 : 경제학자들은 AI가 고용 시장에 미치는 영향을 심각하게 과소평가했을 수 있다. AI는 전문 서비스를 완전히 대체하기보다는 “파편화”할 것이다. AI의 등장은 일부 일자리의 소멸을 가져올 수 있지만, 동시에 새로운 기회를 창출할 것이며, 사람들은 끊임없이 학습하고 적응해야 한다. 커뮤니티는 공감, 판단력 또는 신뢰가 필요한 직업(예: 의료, 심리 상담, 교육, 법률)과 AI를 활용하여 문제를 해결할 수 있는 사람들이 더 경쟁력을 가질 것이라고 일반적으로 보고 있다. (출처: Ronald_vanLoon, Ronald_vanLoon, Reddit r/ArtificialInteligence)

AI 프로그래밍과 기술 관리 비유 : 커뮤니티는 AI 프로그래밍을 기술 관리에 비유하며, 개발자가 EM(엔지니어링 매니저)처럼 요구 사항을 명확히 이해하고, 설계에 참여하며, 작업을 분할하고, 품질을 관리(AI 코드 검토 및 테스트)하고, 모델을 적시에 업데이트해야 한다고 강조한다. AI는 주도성이 부족하지만, 인간 관계 처리의 복잡성을 덜어준다. (출처: dotey)
AI 환각 및 현실 위험 : AI 환각 현상은 우려를 불러일으키고 있다. AI가 관광객을 존재하지 않는 위험한 장소로 안내하여 안전 문제를 야기했다는 보고가 있다. 이는 AI 정보 정확성의 중요성을 부각시키며, 특히 현실 세계의 안전과 관련된 애플리케이션에서는 더욱 엄격한 검증 메커니즘이 필요하다. (출처: Reddit r/artificial)
AI 윤리 및 인간의 성찰 : 커뮤니티는 AI가 인간을 더 인간적으로 만들 수 있는지에 대해 논의했다. 기술 발전이 반드시 도덕적 향상을 가져오는 것은 아니며, 인간의 도덕적 진보는 종종 엄청난 대가를 수반한다는 견해가 있다. AI 자체가 마법처럼 인간의 양심을 일깨우지는 않으며, 진정한 변화는 공포에 직면했을 때의 자기 성찰과 인간성 각성에서 비롯된다. 비판자들은 기업들이 AI 도구를 홍보할 때, 도구가 비인도적인 행위에 악용될 수 있는 위험을 종종 간과한다고 지적한다. (출처: Reddit r/artificial)
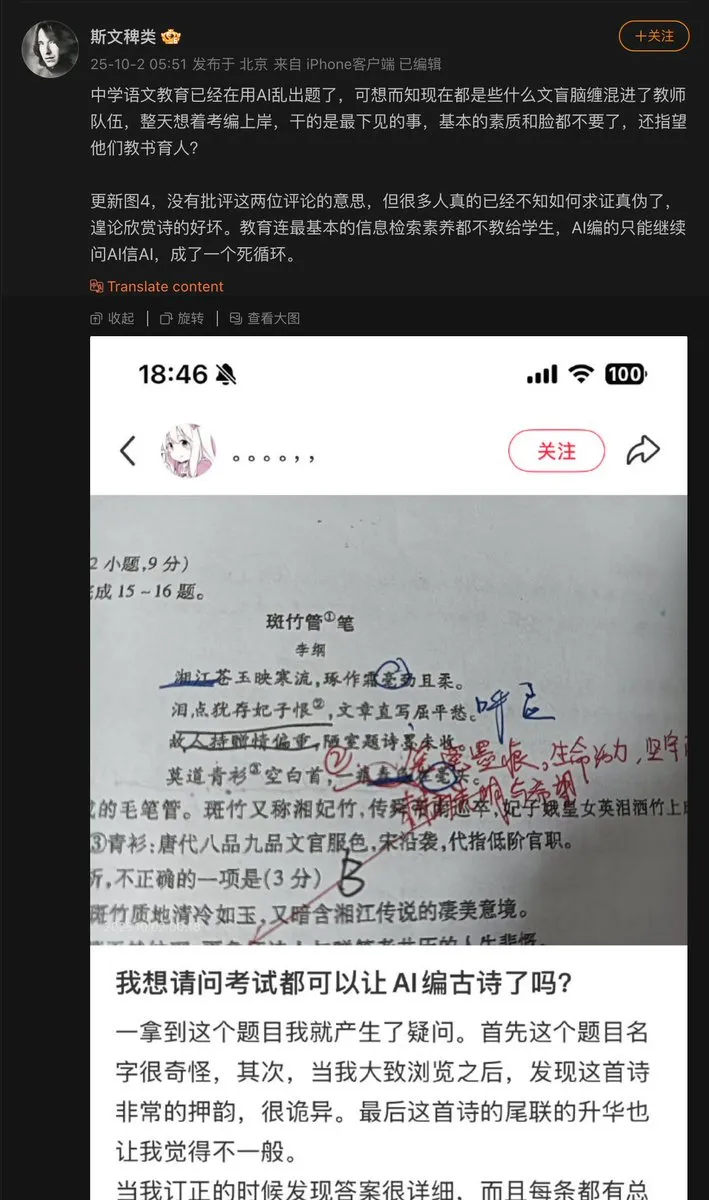
AI의 교육 분야 적용 문제 : 중학교 교사가 AI를 사용하여 문제를 출제했는데, AI가 고대 시를 지어내어 시험 문제로 낸 사례가 발생했다. 이는 AI가 콘텐츠를 생성할 때 발생할 수 있는 “환각” 문제를 드러낸다. 특히 사실 정확성이 요구되는 교육 분야에서는 AI 생성 콘텐츠에 대한 검토 및 검증 메커니즘이 매우 중요하다. (출처: dotey)
AI 모델 발전 및 데이터 병목 현상 : 커뮤니티는 현재 AI 모델 발전의 주요 병목 현상이 데이터에 있다고 지적한다. 그중 가장 어려운 부분은 데이터의 오케스트레이션, 컨텍스트 풍부화, 그리고 이를 통해 올바른 결정을 도출하는 것이다. 이는 AI 발전에 있어 고품질의 구조화된 데이터의 중요성과 모델 훈련에서 데이터 관리의 어려움을 강조한다. (출처: TheTuringPost)
LLM 계산 에너지 소비 및 가치 균형 : 커뮤니티는 AI(특히 LLM)의 막대한 에너지 소비에 대해 논의했다. 어떤 이들은 이를 “악하다”고 보지만, AI가 문제를 해결하고 우주를 탐험하는 데 기여하는 바가 에너지 소비를 훨씬 초과하며, AI 발전을 막는 것은 근시안적이라는 견해도 있다. 이는 AI 발전과 환경 영향 사이의 균형에 대한 지속적인 논쟁을 반영한다. (출처: timsoret)

💡 기타
AI+IoT 금 ATM : AI와 IoT 기술을 결합한 ATM 기기가 금을 거래 매개체로 받아들일 수 있다. 이는 금융과 IoT를 결합한 AI의 혁신적인 적용 사례이며, 상대적으로 틈새 시장이지만, 특정 시나리오에서 AI의 잠재력을 보여준다. (출처: Ronald_vanLoon)
Z.ai Chat CPU 서버, 공격으로 중단 : Z.ai Chat 서비스가 CPU 서버 공격으로 인해 일시적으로 중단되었으며, 팀은 현재 복구 중이다. 이는 AI 서비스가 인프라 보안 및 안정성 측면에서 직면한 과제와, DDoS 또는 기타 네트워크 공격이 AI 플랫폼 운영에 미칠 수 있는 잠재적 영향을 부각시킨다. (출처: Zai_org)
Apache Gravitino: 오픈 데이터 카탈로그 및 AI 자산 관리 : Apache Gravitino는 고성능, 지리 분산형, 연합 메타데이터 레이크로, 다양한 출처, 유형 및 지역의 메타데이터를 통합 관리하는 것을 목표로 한다. 이는 통합된 메타데이터 접근을 제공하고 데이터 및 AI 자산 거버넌스를 지원하며, AI 모델 및 특징 추적 기능을 개발 중으로, AI 자산 관리의 핵심 인프라가 될 것으로 기대된다. (출처: GitHub Trending)