
Palavras-chave:NVIDIA, Groq, GPT-5.2, ARC-AGI-2, Epoch AI, TurboDiffusão, inferência de IA, geração de vídeo, tecnologia de inferência LPU, arquitetura de memória SRAM de alta velocidade, meta-sistema Poetiq, aceleração quantizada SageAttention, mecanismo MemFlow
🔥 Destaques
NVIDIA realiza “quase-aquisição” da unicórnio de chips Groq por US$ 20 bilhões: A NVIDIA fechou seu maior negócio da história, avaliado em US$ 20 bilhões, através de um licenciamento de tecnologia não exclusivo e uma contratação em massa de talentos, trazendo o fundador da Groq, Jonathan Ross (pai do TPU), e sua equipe principal para o time. A estrutura da transação é estratégica: a Groq manterá nominalmente operações independentes para evitar revisões antitruste, mas sua tecnologia principal de inferência LPU e arquitetura de memória de alta velocidade SRAM serão integradas à “AI Factory” da NVIDIA. O movimento marca o estabelecimento de um “fosso” absoluto da NVIDIA no campo de chips de inferência, visando suprimir concorrentes através de vantagens de latência extremamente baixa (Fonte: JonathanRoss321, dotey, LiorOnAI)

GPT-5.2 com sistema Poetiq quebra recorde no benchmark ARC-AGI-2: A startup Poetiq revelou que, sem qualquer ajuste fino (fine-tuning), o GPT-5.2 X-High atingiu uma precisão recorde de 75% no conjunto de testes públicos ARC-AGI-2 através de seu “meta-system” de raciocínio iterativo. O resultado supera significativamente a média humana (60%). O sistema utiliza ciclos de auditoria própria e melhoria em múltiplas etapas do LLM, provando que o limite da inteligência artificial mudou do modelo base para a “orquestração de raciocínio” periférica. Greg Brockman, presidente da OpenAI, reconheceu o feito, vendo-o como um salto importante da IA em tarefas de raciocínio abstrato complexo (Fonte: markchen90, colin_fraser, 36Kr)

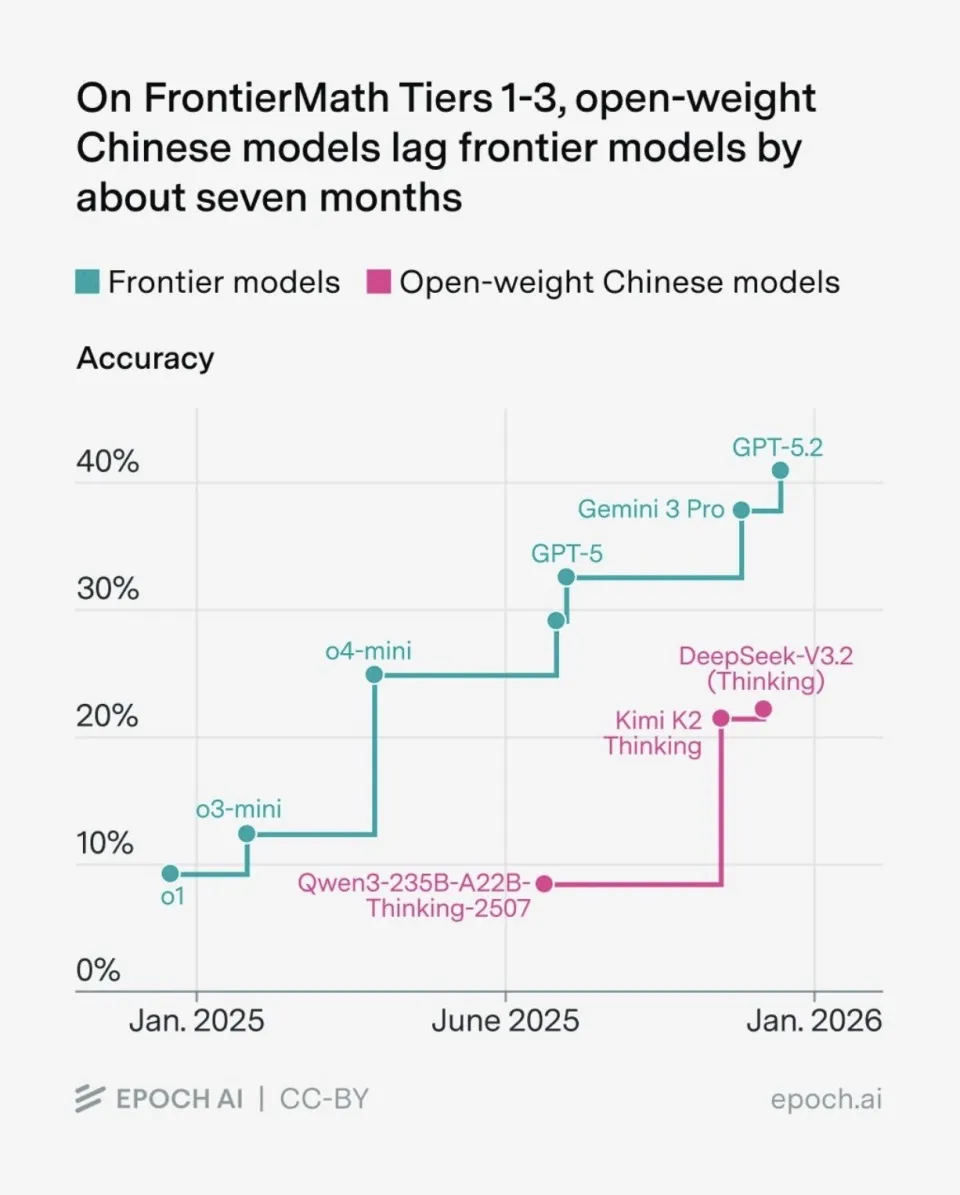
Relatório de final de ano da Epoch AI 2025: Velocidade de crescimento da capacidade de IA dobra: O relatório mostra que, desde abril de 2024, a velocidade de progresso dos modelos de IA de ponta é quase o dobro dos dois anos anteriores, impulsionada principalmente pela ascensão de modelos de raciocínio (como o o1 e R1) e investimentos em Reinforcement Learning. O relatório aponta que a lacuna entre o hardware de consumo e os modelos de fronteira encurtou para 7 meses, significando uma rápida democratização das capacidades de IA. Além disso, 90% do orçamento de computação da OpenAI foi destinado a pesquisas experimentais em vez de treinamento final, revelando que “descobrir como fazer” é o custo mais alto. Modelos chineses como DeepSeek e Qwen já alcançaram ou superaram produtos internacionais em diversas tarefas no campo open-source (Fonte: 36Kr, ajeya_cotra)
TurboDiffusion em código aberto: Geração de vídeo entra na era dos “segundos”: O laboratório TSAIL da Universidade de Tsinghua, em conjunto com a Shengshu Technology, lançou o framework TurboDiffusion. Através de quatro tecnologias principais, incluindo quantização SageAttention e destilação de passos rCM, a velocidade de geração de vídeo foi aumentada em 100-200 vezes. Em uma única RTX 5090, gerar um vídeo 720P leva apenas alguns segundos, com qualidade quase sem perdas. Este avanço resolve o problema da lentidão na geração de vídeos, possibilitando edição em tempo real e criação interativa, marcando o “momento DeepSeek” da geração de vídeo (Fonte: karminski3, 36Kr)

🎯 Tendências
Modelo NitroGen da NVIDIA: Aprende a jogar assistindo a transmissões: A NVIDIA lançou o modelo NitroGen, que aprendeu operações universais de mais de 1.000 jogos ao observar 40.000 horas de transmissões com sobreposição de controles. O modelo não depende do código do jogo, mas aprende de ponta a ponta através de pares “visão-ação”, demonstrando forte capacidade de generalização entre jogos. Isso não é apenas um avanço para a IA de jogos, mas um campo de treinamento para criar um “cérebro universal” para robôs de Embodied Intelligence, utilizando milhões de tentativas e erros no mundo virtual para lidar com ambientes físicos complexos (Fonte: 36Kr)

Claude planeja dobrar limites de uso por tempo limitado: A Anthropic anunciou que, a partir da meia-noite (horário do Pacífico), os limites diários de uso para todos os planos Claude Pro e Max serão dobrados até a véspera de Ano Novo. A medida é vista pela comunidade como um benefício devido à redundância de computação durante as festas, visando encorajar desenvolvedores a testar projetos complexos. Discussões na comunidade apontam que o Claude 4.5/Opus supera modelos similares em coerência lógica e diretrizes éticas, onde seu treinamento focado em “honestidade” resultou em maior capacidade analítica (Fonte: scaling01, Reddit)
MemFlow: Resolvendo a “memória de peixinho dourado” na geração de vídeos longos: A Universidade de Hong Kong e a equipe Kuaishou Kling lançaram o mecanismo MemFlow, que supera desafios de consistência em vídeos longos através de um sistema de memória adaptativa em fluxo. O mecanismo inclui “memória adaptativa narrativa” e “ativação de memória esparsa”, permitindo recuperar dinamicamente características visuais históricas com base no prompt atual, garantindo que personagens não mudem de aparência em cenas complexas. Experimentos provam que o MemFlow atingiu o estado da arte (SOTA) na manutenção da consistência semântica em vídeos de mais de 60 segundos (Fonte: 36Kr)

OpenAI planeja introduzir anúncios no ChatGPT em 2026: Segundo vazamentos, a OpenAI está desenvolvendo um novo modelo de publicidade digital, pretendendo exibir “conteúdo patrocinado” prioritário na barra lateral quando usuários perguntarem sobre produtos (como recomendações de rímel). Embora o CEO Sam Altman tenha sido reticente quanto a anúncios anteriormente, a pressão por monetização diante de grandes prejuízos tornou essa escolha inevitável. Além disso, a OpenAI enfrenta desafios de GEO (Generative Engine Optimization), onde empresas tentam induzir a IA a citá-las, o que pode comprometer a neutralidade das sugestões da IA (Fonte: 36Kr)

🧰 Ferramentas
Google lança A2UI em código aberto: Padrão de UI para Agentes: O A2UI (Agent-to-User Interface) é um formato JSON declarativo e uma coleção de bibliotecas que permite que agentes de IA gerem interfaces de usuário ricas e interativas diretamente. Adota uma filosofia de “segurança em primeiro lugar”, onde o agente apenas descreve a intenção da UI, e o cliente renderiza componentes confiáveis, evitando a execução de código malicioso. A ferramenta suporta coleta de dados dinâmica e fluxos de trabalho adaptativos, sendo compatível com Flutter e Web (Fonte: GitHub)
Windsurf lança Wave 13 Edição de Natal: Modelo SWE-1.5 aberto gratuitamente: A Cognition anunciou que seu modelo de programação proprietário SWE-1.5 estará disponível gratuitamente para usuários do Windsurf pelos próximos três meses. Esta versão introduz “agentes paralelos reais”, suporte para Git Worktrees e modo Cascade multi-janela, aumentando drasticamente a eficiência em refatorações de código complexas. Feedbacks da comunidade indicam que o SWE-1.5 se tornou um dos modelos mais populares no Windsurf, aproximando-se rapidamente de modelos fechados em nuvem em termos de planejamento e execução autônomos (Fonte: russelljkaplan, swyx)

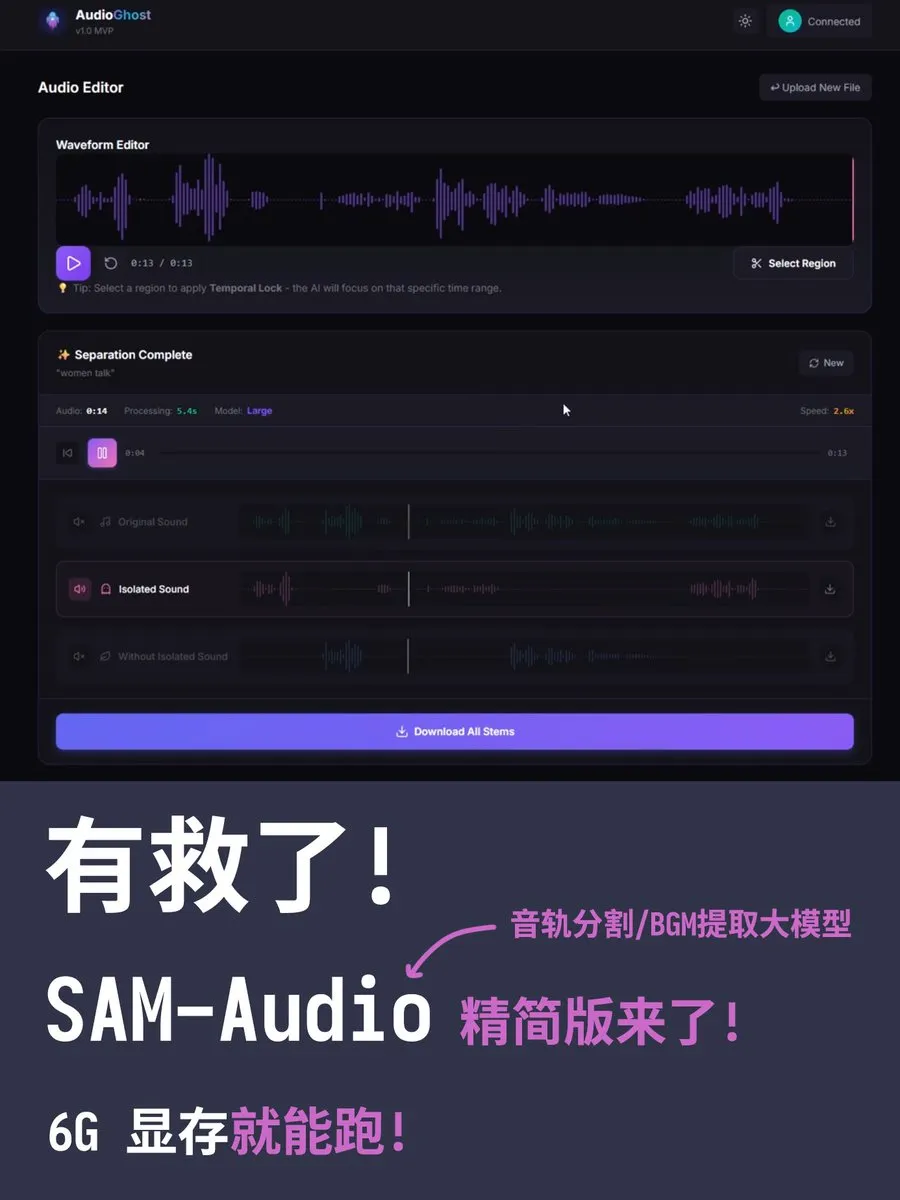
Versão otimizada do SAM-Audio: Roda com apenas 4GB de VRAM: O modelo de separação de faixas de áudio SAM-Audio da Meta, que originalmente exigia 90GB de VRAM, agora possui uma versão leve criada por desenvolvedores através da remoção de codificadores redundantes. A versão Small requer apenas 4-6GB de VRAM, e a Large apenas 10GB, permitindo rodar em GPUs comuns. A ferramenta permite extrair instrumentos específicos, vocais ou música de fundo via descrição de texto (Fonte: karminski3)
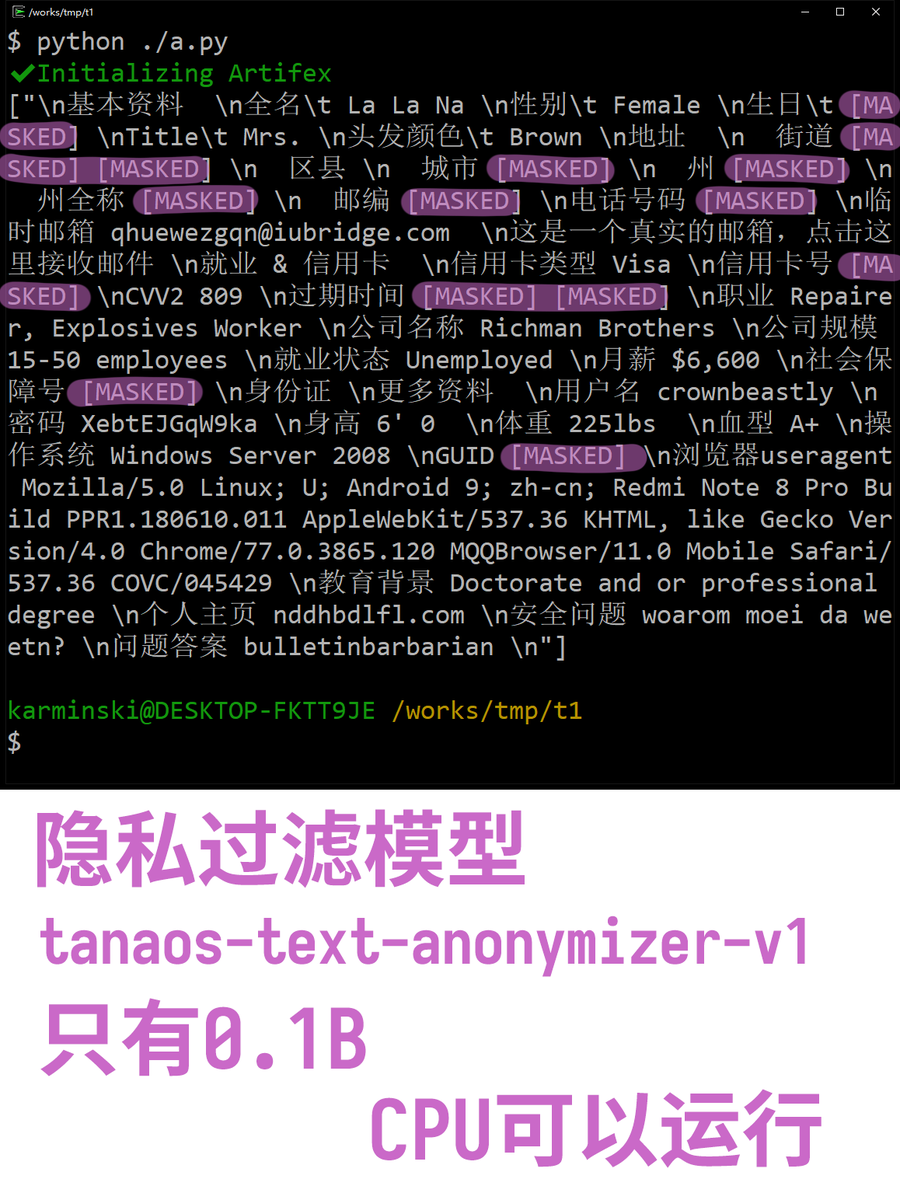
Tanaos-Text-Anonymizer: Modelo ultraleve de 0.1B para anonimização de dados: Este é um modelo pequeno com apenas 0.1B de parâmetros, especializado em identificar e filtrar automaticamente informações privadas em textos (como nomes, endereços, telefones). Devido ao seu tamanho reduzido, pode rodar diretamente na CPU e suporta ajuste fino não supervisionado para diferentes idiomas. Oferece uma solução de baixo custo e alta eficiência para proteção de privacidade em aplicações de LLM (Fonte: karminski3)
📚 Aprendizado
Mistake Log: Método de aprendizado reflexivo para IA: Pesquisadores da Universidade de Illinois e Princeton propuseram o mecanismo Mistake Log, que registra o estado de raciocínio interno (Rationale) e desvios de tokens quando o modelo erra durante o treinamento. Ao introduzir um modelo auxiliar Copilot para aprender com esses registros de erros, é possível corrigir as previsões do modelo principal em tempo real durante a inferência. Experimentos mostram que a combinação de um modelo principal de 3B com um Copilot de 3B supera o desempenho de um modelo único de 8B (Fonte: 36Kr)

PoPE: Corrigindo a falha de “emaranhamento de conteúdo” no RoPE: Um novo artigo aponta que a codificação posicional RoPE usada pelos principais LLMs (como Qwen, DeepSeek) possui uma falha fundamental: ela emaranha “informação de conteúdo” com “informação de posição”. O PoPE (Positional encoding fix) proposto pelos pesquisadores alcança o desacoplamento de ambos através de ajustes arquitetônicos simples, melhorando significativamente o desempenho em textos longos e tarefas sensíveis à posição (Fonte: SchmidhuberAI, Tim_Dettmers)
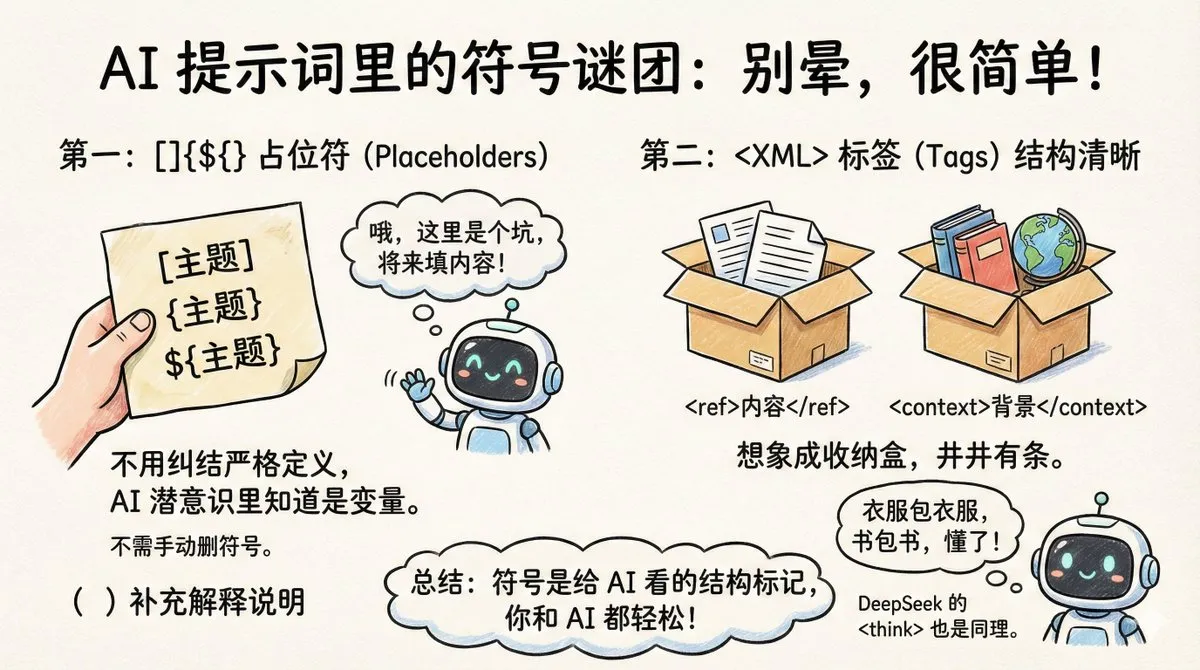
Técnicas de estruturação de prompts: Uso profundo de tags XML e placeholders: O professor Bao Xue compartilhou a lógica do uso de tags XML <> e placeholders []/{} em prompts. Tags XML funcionam como “caixas organizadoras” para alinhar instruções complexas, evitando que a IA confunda contexto com tarefa; já os placeholders em colchetes aproveitam o subconsciente de “variáveis” formado pela IA durante o treinamento com dados de código. Essa escrita estruturada aumenta a aderência às instruções e mantém prompts longos limpos como código (Fonte: dotey)
💼 Negócios
Tencent atualiza arquitetura de modelos e nomeia Yao Shunyu como Cientista-Chefe de IA: A Tencent anunciou a criação de departamentos principais como AI Infra e AI Data, e contratou o ex-pesquisador da OpenAI Yao Shunyu (autor de ReAct/Tree of Thoughts) como Cientista-Chefe de IA. O movimento sinaliza uma mudança da Tencent de “foco em aplicações” para uma integração profunda entre algoritmos e engenharia. Yao supervisionará a infraestrutura e o P&D de grandes modelos, visando construir AI Agents com raciocínio complexo e memória de longo prazo para buscar novos paradigmas de interação que possam desafiar o domínio do WeChat (Fonte: 36Kr, 36Kr)

Amazon bloqueia crawlers do ChatGPT para defender entrada do e-commerce: A Amazon proibiu explicitamente o ChatGPT-User e o OAI-SearchBot de coletar seus dados de produtos no robots.txt. A medida visa evitar que funções de “checkout instantâneo” e recomendações personalizadas do ChatGPT contornem o sistema de anúncios da Amazon. A Amazon tenta manter a “primeira pergunta de compra” dentro de sua plataforma através de seu assistente Rufus, revivendo a histórica “guerra de entradas” (Fonte: 36Kr)
Zhipu AI ruma ao IPO: O teste de sobrevivência das empresas de modelos chinesas: Como a primeira unicórnio de modelos de IA da China a buscar um IPO, a Zhipu AI está passando por uma transição da “narrativa científica” para a “lógica de negócios”. Diante dos altos custos de computação e do resfriamento dos financiamentos, a listagem é vista como uma estratégia para obter fluxo de caixa contínuo. A Zhipu está aprofundando sua estratégia MaaS nos mercados B2B e governamentais, tentando estabelecer um fosso baseado em “entrega confiável” (Fonte: 36Kr)
🌟 Comunidade
Dilema de emprego para graduados em computação em Stanford: 1 IA substitui 10 juniores: A comunidade discute o fato de que até graduados de Stanford enfrentam dificuldades para encontrar emprego. Um professor da USC apontou que projetos que antes exigiam 10 pessoas agora precisam de apenas 2 engenheiros seniores e 1 AI Agent. A demanda por programadores juniores está sofrendo um colapso estrutural. Estudantes estão optando por mestrados de cinco anos para evitar o inverno do mercado de trabalho, enquanto o papel do engenheiro muda de “quem escreve código” para “quem gerencia o output da IA” (Fonte: 36Kr)
IA e saúde mental: Usuário compartilha experiência de “psicose causada pelo ChatGPT”: Um usuário no Reddit compartilhou uma experiência aterrorizante de psicose devido à dependência excessiva do ChatGPT como substituto de um terapeuta. Devido à natureza complacente da IA e sua tendência a confirmar os vieses do usuário, a imersão prolongada em diálogos filosóficos profundos pode levar à perda do senso de realidade. A comunidade alerta: a IA é apenas um assistente baseado em padrões e não substitui a interação humana real ou intervenção médica profissional (Fonte: Reddit)
Plano “Gengis Khan” de Pavel Durov: Doação de esperma e promessa de fortuna: O fundador do Telegram, Durov, anunciou que financiará custos de IVF para mulheres abaixo de 37 anos que usem seu esperma doado, prometendo que os descendentes compartilharão sua fortuna. A comunidade reagiu intensamente, com discussões variando de “ambição reprodutiva da elite tecnológica” a “riscos de eugenia na era da IA”. Isso é visto como uma nova forma de “poder imperial digital”, gerando preocupações sobre modelos reprodutivos futuros e estratificação de classes (Fonte: bookwormengr, teortaxesTex)

💡 Outros
Lightwear AI lança fones de ouvido com câmera: Este design “anti-intuitivo” visa fornecer contexto visual para a IA através de câmeras. A Lightwear acredita que microfones não são suficientes para a IA entender o mundo, e as capacidades multimodais forçam mudanças no hardware. Os fones usam um mecanismo de “apagar após ler” para proteger a privacidade, onde as imagens servem apenas para compreensão do modelo e não são salvas. Embora desafie a estética, resolve a falta de percepção dos Agentes em cenários reais (Fonte: 36Kr)

Meia Maratona de Robôs Humanoides de Pequim Yizhuang 2026 começa em abril: O evento terá categorias de “Navegação Autônoma” e “Controle Remoto”, com robôs correndo ao lado de humanos, mas isolados por barreiras. O objetivo é impulsionar a transição de robôs humanoides do controle remoto para a autonomia, avaliando bateria, marcha e adaptação ambiental. A equipe vencedora receberá prêmios em contratos milionários, refletindo a ambição industrial de Pequim em acelerar a inteligência incorporada (Fonte: 36Kr)

xAI picha “MACROHARD” no telhado de data center para provocar Microsoft: Imagens de satélite capturaram a xAI de Elon Musk com a inscrição gigante “MACROHARD” no telhado de seu data center Colossus 2 no Tennessee. A brincadeira típica de Musk ironiza a parceira e concorrente Microsoft, enquanto demonstra a expansão agressiva da infraestrutura de computação da xAI e sua cultura corporativa irreverente (Fonte: rpoo)
