
Mots-clés:NVIDIA, Groq, GPT-5.2, ARC-AGI-2, Epoch AI, TurboDiffusion, Inférence IA, Génération vidéo, Technologie d’inférence LPU, Architecture mémoire SRAM haute vitesse, Méta-système Poetiq, Accélération quantifiée SageAttention, Mécanisme MemFlow
🔥 Focus
NVIDIA réalise une « quasi-acquisition » de la licorne des puces Groq pour 20 milliards de dollars : NVIDIA a conclu sa plus grande transaction historique, d’une valeur de 20 milliards de dollars, en s’emparant du fondateur de Groq, Jonathan Ross (père des TPU), et de son équipe de base via une licence technologique non exclusive et un recrutement massif de talents. La structure de la transaction est ingénieuse : Groq reste nominalement indépendante pour éviter les contrôles antitrust, mais sa technologie clé LPU et son architecture de mémoire haute vitesse SRAM seront intégrées à l’« AI Factory » de NVIDIA. Ce mouvement marque l’établissement par NVIDIA d’un fossé défensif absolu dans le domaine des puces d’inférence, visant à écraser ses concurrents potentiels grâce à des avantages d’inférence à ultra-faible latence (Source : JonathanRoss321, dotey, LiorOnAI)

Le système Poetiq combiné à GPT-5.2 bat le benchmark ARC-AGI-2 : La startup Poetiq a révélé que, sans aucun fine-tuning, son « meta-system » de raisonnement itératif a permis à GPT-5.2 X-High d’atteindre un taux de précision record de 75 % sur l’ensemble de test public ARC-AGI-2, dépassant de loin la moyenne humaine (60 %). Le système utilise l’auto-audit du modèle et des cycles d’amélioration multi-étapes, prouvant que le facteur déterminant de l’intelligence de l’AI est passé du modèle de base à l’« orchestration du raisonnement » périphérique. Greg Brockman, président d’OpenAI, a salué cette avancée, y voyant un saut majeur pour l’AI dans les tâches de raisonnement abstrait complexe (Source : markchen90, colin_fraser, 36氪)

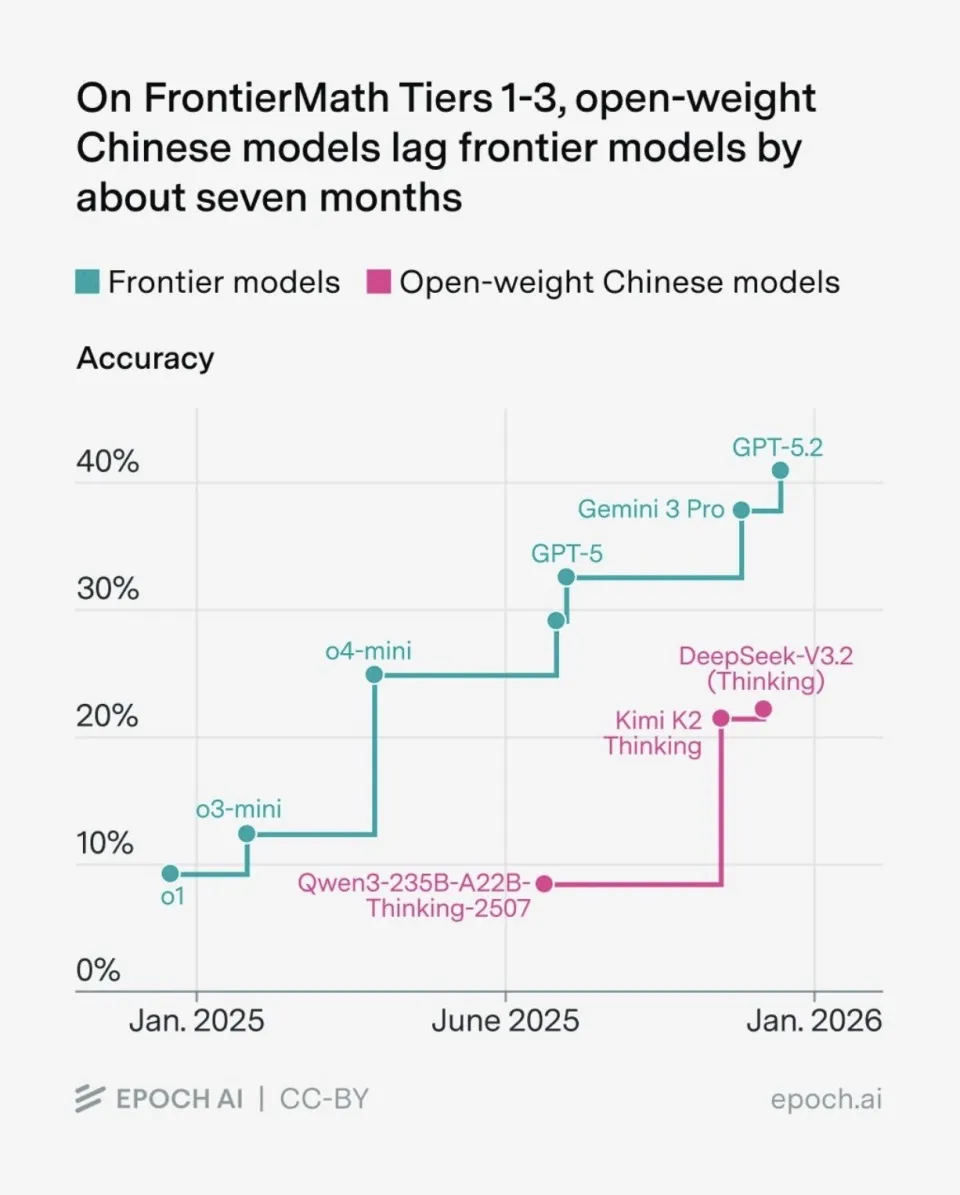
Rapport de fin d’année 2025 d’Epoch AI : La vitesse de croissance des capacités de l’AI a doublé : Le rapport indique que depuis avril 2024, la vitesse de progression des modèles d’AI de pointe est presque le double de celle des deux années précédentes, principalement grâce à l’émergence des modèles de raisonnement (comme o1, R1) et aux investissements dans le reinforcement learning. Le rapport souligne que l’écart entre le matériel grand public et les modèles de pointe s’est réduit à 7 mois, signifiant une démocratisation rapide des capacités de l’AI. Parallèlement, 90 % du budget de calcul d’OpenAI est consacré à la recherche expérimentale plutôt qu’à l’entraînement final, révélant que « comprendre comment faire » est le coût le plus élevé. Les modèles chinois comme DeepSeek et Qwen ont rattrapé, voire dépassé sur certaines tâches, les produits internationaux dominants dans le domaine de l’open-source (Source : 36氪, ajeya_cotra)
TurboDiffusion en open-source : La génération vidéo entre dans l’ère de la « seconde » : Le laboratoire TSAIL de l’Université Tsinghua, en collaboration avec Shengshu Technology, a lancé le framework TurboDiffusion en open-source. Grâce à quatre technologies clés, dont la quantification SageAttention et la distillation d’étapes rCM, la vitesse de génération vidéo a été multipliée par 100 à 200. Sur une seule carte RTX 5090, générer une vidéo 720P ne prend que quelques secondes, avec une qualité presque sans perte. Cette percée résout le problème majeur de la lenteur de génération, rendant possible l’édition vidéo en temps réel et la création interactive, marquant l’arrivée du « moment DeepSeek » pour la génération vidéo (Source : karminski3, 36氪)

🎯 Tendances
Modèle NitroGen de NVIDIA : Apprendre à jouer aux jeux vidéo en regardant des streams : NVIDIA a publié le modèle NitroGen qui, en observant 40 000 heures de streams de jeux vidéo avec incrustation de manette, a appris les opérations générales de plus de 1 000 jeux. Le modèle ne dépend pas du code du jeu, mais apprend de bout en bout via des paires « vision-action », affichant une forte capacité de généralisation multi-jeux. C’est non seulement un progrès pour l’AI de jeu, mais aussi un terrain d’entraînement pour créer un « cerveau universel » pour les robots dotés d’intelligence incarnée (embodied AI), utilisant des millions d’essais-erreurs dans le monde virtuel pour affronter la complexité du monde physique (Source : 36氪)

Claude prévoit de doubler temporairement les limites d’utilisation pour toute la gamme : Anthropic a annoncé qu’à partir de minuit, heure du Pacifique, les limites d’utilisation quotidiennes pour tous les plans Claude Pro et Max seront doublées jusqu’à la veille du Nouvel An. Ce geste est interprété par la communauté comme un avantage lié à l’excédent de puissance de calcul pendant les fêtes, visant à encourager les développeurs à tester des projets plus complexes. Parallèlement, les discussions communautaires soulignent que Claude 4.5/Opus surpasse ses pairs en termes de cohérence logique et de principes éthiques, son entraînement à l’« honnêteté » apportant une capacité d’analyse accrue (Source : scaling01, Reddit)
MemFlow : Résoudre la « mémoire de poisson » de la génération de vidéos longues : L’Université de Hong Kong et l’équipe Kling de Kuaishou ont lancé conjointement le mécanisme MemFlow, qui surmonte les problèmes de cohérence dans la génération de vidéos longues grâce à un système de mémoire adaptative en streaming. Ce mécanisme comprend une « mémoire adaptative narrative » et une « activation de mémoire parcimonieuse », permettant de récupérer dynamiquement des caractéristiques visuelles historiques selon le prompt actuel, garantissant que les personnages ne changent pas de visage lors de transitions complexes. Les expériences prouvent que MemFlow atteint le niveau SOTA pour maintenir la cohérence sémantique sur des vidéos de plus de 60 secondes (Source : 36氪)

OpenAI prévoit d’introduire de la publicité dans ChatGPT en 2026 : Selon des fuites, OpenAI développe un nouveau modèle de publicité numérique prévoyant d’afficher du « contenu sponsorisé » en priorité dans la barre latérale lorsque les utilisateurs posent des questions sur des produits (comme des recommandations de mascara). Bien que le CEO Sam Altman ait été réservé sur la publicité par le passé, la pression des pertes massives fait de la monétisation publicitaire un choix inévitable. De plus, OpenAI fait face aux défis de « l’empoisonnement de contenu » via le GEO (Generative Engine Optimization), où les fabricants optimisent le contenu web pour inciter l’AI à les citer, ce qui pourrait ébranler la neutralité des conseils de l’AI (Source : 36氪)

🧰 Outils
Google lance A2UI en open-source : Un standard UI dédié aux agents : A2UI (Agent-to-User Interface) est un format JSON déclaratif et une collection de bibliothèques permettant aux agents AI de générer directement des interfaces utilisateur riches et interactives. Adoptant une philosophie « safety first », l’agent décrit uniquement l’intention de l’UI, tandis que le client rend des composants de confiance, évitant l’exécution de code malveillant. L’outil supporte la collecte de données dynamiques et les workflows adaptatifs, compatible avec Flutter et le Web (Source : GitHub)
Windsurf lance Wave 13 Édition de Noël : Le modèle SWE-1.5 ouvert gratuitement : Cognition a annoncé que son modèle de programmation propriétaire SWE-1.5 sera accessible gratuitement aux utilisateurs de Windsurf pendant les trois prochains mois. Cette version introduit de « véritables agents parallèles », supporte les Git Worktrees et le mode Cascade multi-fenêtres, améliorant considérablement l’efficacité du refactoring de code complexe. Les retours de la communauté indiquent que SWE-1.5 est devenu l’un des modèles les plus populaires de Windsurf, ses performances en planification et exécution autonomes se rapprochant rapidement des modèles fermés sur le cloud (Source : russelljkaplan, swyx)

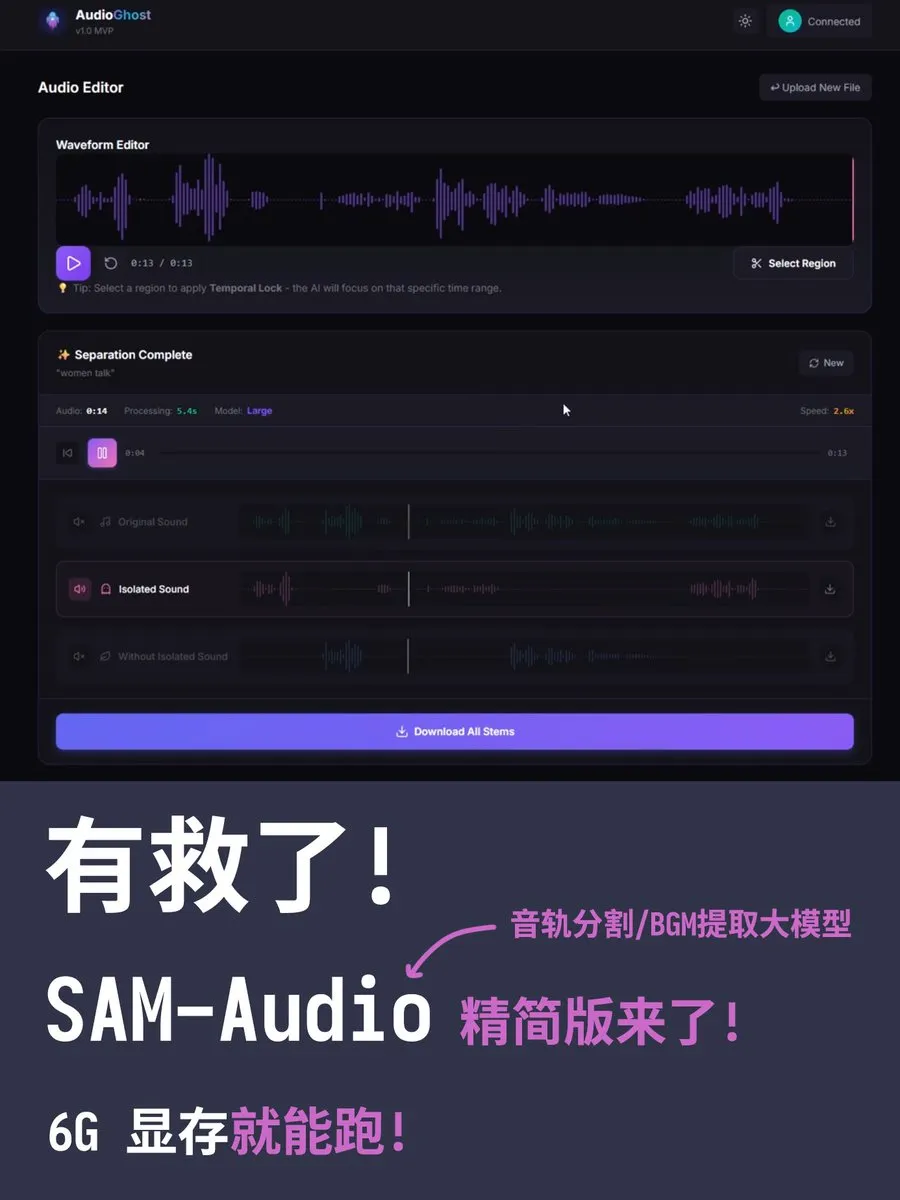
Version optimisée de SAM-Audio : Fonctionne avec seulement 4 Go de VRAM : Le modèle de séparation de pistes audio SAM-Audio de Meta, qui nécessitait initialement 90 Go de VRAM, dispose désormais d’une version allégée créée par des développeurs en supprimant les encodeurs redondants. La version Small ne nécessite que 4 à 6 Go de VRAM, et la version Large seulement 10 Go, permettant une exécution fluide sur des cartes graphiques gaming standards. L’outil permet d’extraire des instruments, des voix ou de la musique de fond spécifiques via des descriptions textuelles (Source : karminski3)
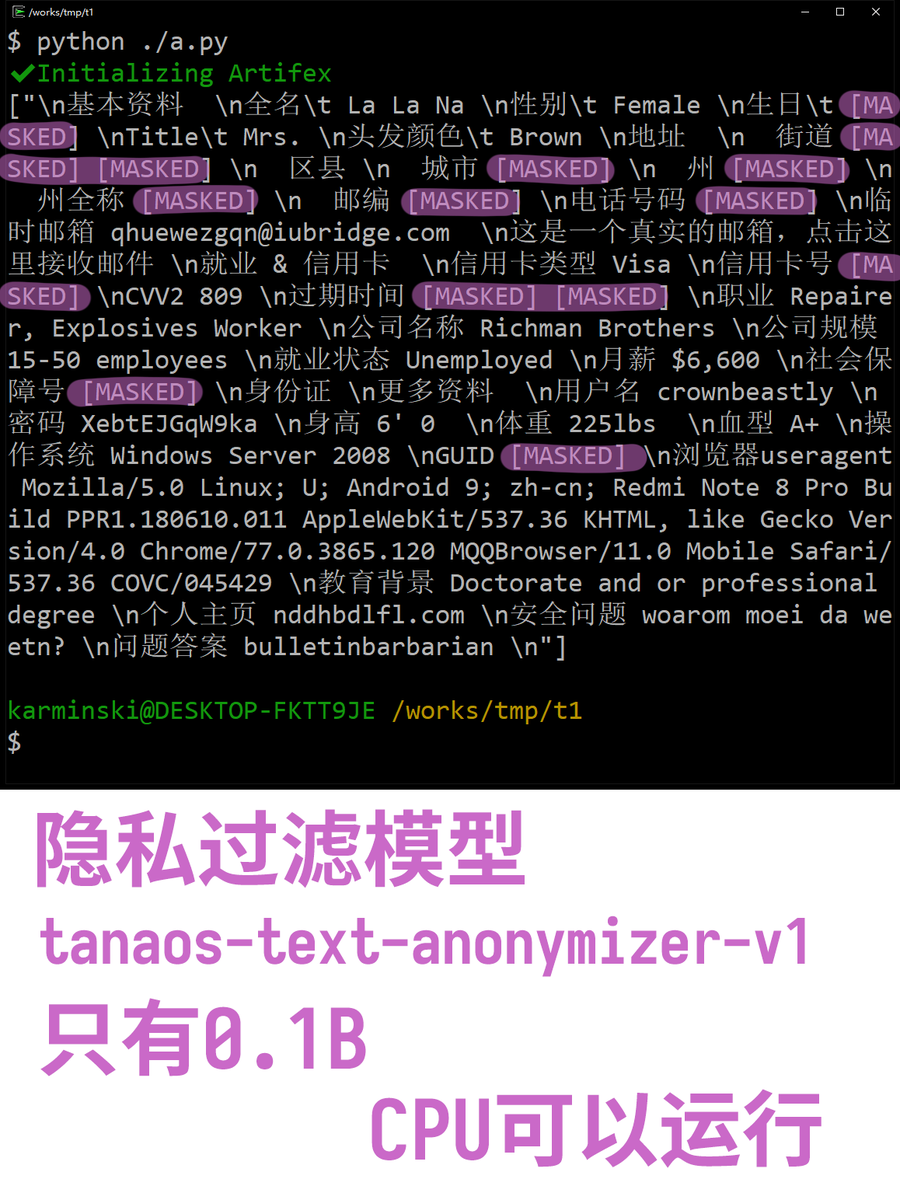
Tanaos-Text-Anonymizer : Un modèle ultra-léger de 0.1B pour l’anonymisation de la vie privée : Il s’agit d’un petit modèle de seulement 0.1B de paramètres, spécialisé dans l’identification et le filtrage automatique des informations privées (noms, adresses, téléphones) dans les textes. Grâce à sa taille extrêmement réduite, il peut fonctionner directement sur CPU et supporte le fine-tuning non supervisé pour différentes langues. Cet outil offre une solution de protection de la vie privée à bas coût et haute efficacité pour les applications LLM traitant des données sensibles (Source : karminski3)
📚 Apprentissage
Mistake Log : Une méthode d’apprentissage par réflexion ajoutant un « carnet d’erreurs » à l’AI : Des chercheurs de l’Université de l’Illinois et de Princeton ont proposé le mécanisme Mistake Log, qui enregistre l’état de raisonnement interne (Rationale) et les déviations au niveau des tokens lorsque le modèle commet des erreurs pendant l’entraînement. En introduisant un modèle auxiliaire Copilot pour apprendre de ces erreurs, il est possible de corriger en temps réel les prédictions du modèle principal lors de l’inférence. L’expérience montre qu’un combo modèle principal 3B + Copilot 3B peut surpasser un modèle unique 8B (Source : 36氪)

PoPE : Corriger le défaut d’« enchevêtrement de contenu » du position encoding RoPE : Un nouvel article souligne que le position encoding RoPE utilisé par les LLM dominants (comme Qwen, DeepSeek) présente un défaut fondamental : il entremêle l’« information de contenu » avec l’« information de position ». La solution proposée, PoPE (Positional encoding fix), réalise le désaccouplement des deux via un simple ajustement d’architecture, améliorant significativement les performances du modèle sur les textes longs et les tâches sensibles à la position (Source : SchmidhuberAI, Tim_Dettmers)
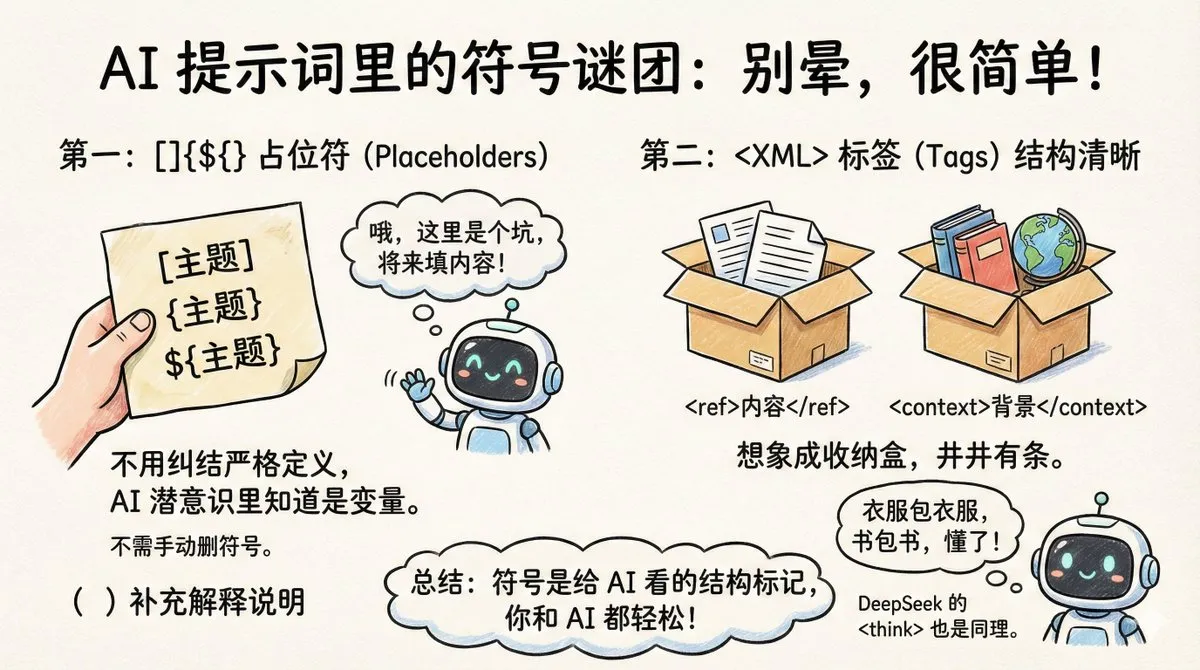
Techniques de structuration de prompts : Application approfondie des balises XML et des placeholders : Le professeur Bao Yu a partagé la logique d’utilisation des balises XML <> et des placeholders []/{} dans les prompts. Les balises XML agissent comme des « boîtes de rangement » pour organiser les instructions complexes, empêchant l’AI de confondre le contexte et la tâche ; tandis que les parenthèses exploitent le subconscient de « variable » formé chez l’AI lors de l’entraînement sur des données de code. Cette écriture structurée améliore non seulement le suivi des instructions, mais rend aussi les longs prompts aussi propres et maintenables que du code (Source : dotey)
💼 Business
Tencent met à jour son architecture de grands modèles, Yao Shunyu nommé Chief AI Scientist : Tencent a annoncé la création de départements clés tels que AI Infra et AI Data, et a recruté l’ancien chercheur d’OpenAI Yao Shunyu (auteur de ReAct/Tree of Thoughts) en tant que Chief AI Scientist. Ce mouvement marque le passage de Tencent d’une stratégie « centrée sur l’application » à une intégration profonde entre algorithmes et ingénierie. Yao Shunyu supervisera l’infrastructure et la R&D des grands modèles, visant à construire des AI Agents dotés de raisonnement complexe et de mémoire à long terme pour trouver un nouveau paradigme d’interaction capable de « révolutionner WeChat » (Source : 36氪, 36氪)

Amazon bloque les crawlers de ChatGPT pour protéger son entrée e-commerce : Amazon a explicitement interdit à ChatGPT-User et OAI-SearchBot de scraper ses données produits via robots.txt. Cette mesure vise à empêcher les fonctions de « paiement instantané » et de recommandation personnalisée de ChatGPT de contourner le système publicitaire d’Amazon. Amazon tente de conserver la « première question d’achat » sur son site via son propre assistant AI Rufus, réitérant la « guerre de l’entrée » historique entre Taobao et Baidu (Source : 36氪)
Zhipu AI fonce vers l’IPO : L’examen de passage pour les entreprises chinoises de grands modèles : En tant que première licorne chinoise de grands modèles à viser l’IPO, Zhipu AI traverse une transition du « récit scientifique » vers la « logique opérationnelle ». Dans un contexte de coûts de calcul élevés et de refroidissement des financements, l’entrée en bourse est vue comme une stratégie de survie pour obtenir des flux de trésorerie continus. Zhipu approfondit les marchés B2B et B2G via sa stratégie MaaS, tentant d’établir un fossé basé sur la « livraison de confiance » (Source : 36氪)
🌟 Communauté
Détresse de l’emploi pour les diplômés en informatique de Stanford : 1 AI remplace 10 juniors : La communauté discute vivement du fait que même les diplômés en informatique de Stanford peinent à trouver du travail. Un professeur de l’USC souligne qu’un projet nécessitant autrefois 10 personnes n’en requiert plus que 2 ingénieurs seniors assistés d’un AI Agent. La demande pour les programmeurs juniors s’effondre structurellement. Les étudiants se tournent vers des masters en cinq ans pour éviter l’hiver de l’emploi, le rôle de l’ingénieur passant de « celui qui écrit le code » à « celui qui gère la production de l’AI » (Source : 36氪)
Troubles mentaux induits par l’AI : Un utilisateur partage son expérience de « psychose causée par ChatGPT » : Un utilisateur de la communauté Reddit a partagé l’expérience terrifiante d’une psychose (Psychosis) due à une dépendance excessive à ChatGPT comme substitut de psychologue. En raison de la complaisance de l’AI et de sa tendance à confirmer les biais de l’utilisateur, une immersion prolongée dans des dialogues philosophiques profonds avec l’AI peut entraîner une perte du sens de la réalité. La communauté rappelle que l’AI n’est qu’un assistant basé sur le pattern matching et ne peut remplacer les interactions humaines réelles (Source : Reddit)
Le plan « Gengis Khan » de Pavel Durov : Don de sperme et promesse de richesse : Le fondateur de Telegram, Pavel Durov, a annoncé qu’il financerait les frais de FIV pour les femmes de moins de 37 ans utilisant son sperme, promettant que sa progéniture partagerait sa fortune. La communauté a réagi vivement, les discussions allant de « l’ambition reproductive de l’élite technologique » aux « risques de l’eugénisme à l’ère de l’AI ». Cela est perçu comme une nouvelle forme de « pouvoir impérial numérique » (Source : bookwormengr, teortaxesTex)

💡 Autres
Guangfan Technology lance les écouteurs Lightwear AI : Des caméras sur des écouteurs : Ce design « contre-intuitif » vise à fournir un contexte visuel à l’AI via une caméra. Guangfan Technology estime que le microphone ne suffit pas à l’AI pour comprendre le monde. Les écouteurs utilisent un mécanisme d’éphémérité pour protéger la vie privée, les images étant utilisées par le modèle mais non sauvegardées. Bien que le design soit audacieux, il résout le problème du manque de perception des Agents dans des scénarios réels (Source : 36氪)

Le semi-marathon de robots humanoïdes de Beijing Yizhuang 2026 débutera en avril : L’événement comprendra pour la première fois des catégories « navigation autonome » et « télécommandé », avec un mode de course mixte humains-robots séparés par des barrières. L’objectif est de pousser les robots humanoïdes vers l’autonomie, en évaluant l’endurance, la démarche anthropomorphe et l’adaptation à l’environnement. L’équipe gagnante recevra des récompenses sous forme de commandes de l’ordre du million (Source : 36氪)

xAI tague « MACROHARD » sur le toit de son data center pour provoquer Microsoft : Des images satellites ont capturé le mot géant « MACROHARD » peint par xAI (société d’Elon Musk) sur le toit de son data center Colossus 2 au Tennessee. Cette plaisanterie typique de Musk moque directement Microsoft, partenaire et concurrent, tout en affichant l’expansion agressive de xAI dans l’infrastructure de calcul et sa culture d’entreprise rebelle (Source : rpoo)
