
Mots-clés:TurboDiffusion, Génération vidéo, Agent IA, API LLM, Apprentissage par renforcement, Robot humanoïde, Énergie IA, SageAttention2++, Cadre LightX2V, CosyVoice 3.0, Outil Alpha Engine, Évaluation SWE-EVO
🔥 À la une
Tsinghua et Shengshu lancent en open-source TurboDiffusion : la génération vidéo entre dans l’ère de la “seconde” : Le laboratoire TSAIL de l’Université de Tsinghua et Shengshu Technology ont publié conjointement TurboDiffusion, un framework d’accélération de génération vidéo. Grâce à quatre technologies clés — SageAttention2++, SLA (Sparse Linear Attention), rCM (Step Distillation) et la quantification W8A8 — il atteint une accélération de l’inférence allant jusqu’à 200 fois. Sur une RTX 5090, la génération d’une vidéo 480P de 5 secondes ne prend que 1,9 seconde, compressant la latence end-to-end de plusieurs centaines de secondes à un chiffre unique. Cette percée marque l’arrivée du “moment DeepSeek” pour la génération vidéo, abaissant considérablement le seuil d’exécution des grands modèles sur les cartes graphiques grand public et annonçant l’avènement de l’édition vidéo en temps réel et de la génération interactive (Source : Arxiv, GitHub)

NVIDIA “enrôle” le groupe de réflexion de Groq : une guerre défensive des talents offensive : Les réseaux sociaux discutent vivement du fait que NVIDIA n’a pas simplement racheté Groq, mais a adopté une stratégie plus intelligente d’ “enrôlement de talents + licence technologique”. En intégrant l’équipe R&D centrale de Groq et en obtenant la licence de sa technologie d’inférence, NVIDIA a réussi à démanteler un rival matériel potentiel tout en évitant les examens antitrust. Les analyses indiquent que la valeur fondamentale de Groq résidait dans son pari sur l’architecture SRAM ; par cette action, NVIDIA s’assure de ne pas perdre son pouvoir de fixation des prix face à la montée des accélérateurs personnalisés sur le futur marché de l’inférence à grande échelle, échangeant une prime actuelle contre une certitude de marché future (Source : teortaxesTex, draecomino)

Agent-R1 et Bloom : le Reinforcement Learning end-to-end ouvre un nouveau paradigme pour l’entraînement des agents : Pour résoudre les problèmes de prise de décision des agents LLM dans des environnements complexes, le framework Agent-R1 introduit le Reinforcement Learning end-to-end. Via des masques d’action et le module ToolEnv, il gère le caractère aléatoire des retours d’environnement, améliorant significativement le taux de réussite des interactions multi-tours. Parallèlement, Anthropic a lancé Bloom, un outil d’évaluation d’agents capable de générer automatiquement des centaines de scénarios pour détecter des comportements de flagornerie ou de sabotage. Ces deux avancées pointent vers la prochaine étape de l’évolution de l’AI : passer de la simple complétion de dialogue à des agents autonomes dotés de planification à long terme, d’auto-correction et de sécurité monitorable (Source : Arxiv, TheTuringPost)

Analyse approfondie de la logique sous-jacente des API LLM : à partir d’un bug d’adaptation de Kimi K2 sur vLLM : Des développeurs ont découvert, lors de l’adaptation de Kimi K2 sur vLLM, que le modèle fonctionnait parfaitement sur l’API officielle mais échouait lors de l’appel d’outils sur vLLM. Cela a révélé que l’essence des API LLM est une encapsulation d’ingénierie “Rendu → Complétion → Analyse”. Le cœur du problème ne réside souvent pas dans les capacités du modèle, mais dans l’absence de suffixes de dialogue cruciaux lors du rendu du Prompt, ou dans un analyseur trop strict. Cette analyse rappelle aux développeurs que la première étape pour résoudre les hallucinations AI et les échecs d’appels d’outils devrait être de restaurer et d’examiner la séquence de Prompt brute fournie au modèle, plutôt que d’ajuster aveuglément les paramètres (Source : vLLM Blog, dotey)
🎯 Tendances
Claude Code introduit un assistant LSP et lance un double quota limité pour Noël : Claude Code, l’outil en ligne de commande d’Anthropic, supporte désormais le protocole LSP (Language Server Protocol). Grâce à un mécanisme similaire à des “lunettes intelligentes”, l’AI peut localiser précisément le code au lieu d’effectuer une recherche globale aveugle, améliorant nettement la vitesse et la précision des recherches. De plus, pour remercier les utilisateurs, Anthropic a annoncé un doublement des limites d’utilisation pour les abonnés Pro et Max du 25 au 31 décembre, encourageant les développeurs à avancer sur leurs side-projects pendant les vacances (Source : Reddit, sama)

OpenAI propose un framework de monitorabilité de la Chain of Thought : comprendre la “réflexion” de l’AI avant l’action : OpenAI a lancé un framework rigoureux pour évaluer la “monitorabilité de la Chain of Thought (CoT)”, visant à explorer si les humains peuvent comprendre le processus de raisonnement de l’AI avant qu’elle ne passe à l’action. L’étude révèle que si des chaînes de raisonnement plus longues facilitent la surveillance, l’augmentation de la taille des modèles accroît la difficulté de compréhension. À mesure que l’AI passe à l’échelle, cette transparence de “réflexion à voix haute” pourrait devenir une couche de sécurité cruciale, aidant les humains à intervenir à temps si le modèle génère des biais ou des intentions malveillantes (Source : TheTuringPost)

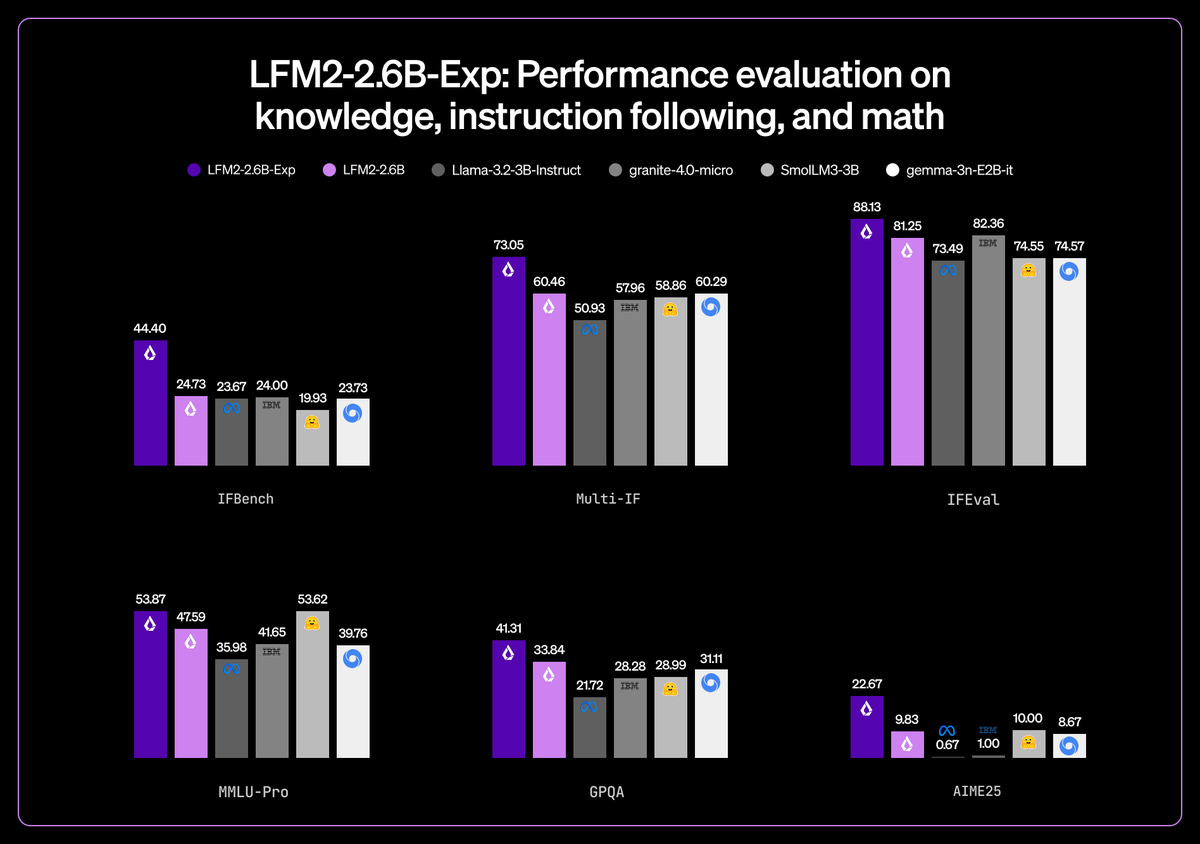
Liquid AI publie son modèle 3B le plus puissant, LFM2-2.6B-Exp : L’équipe de Liquid AI a publié le checkpoint expérimental LFM2-2.6B-Exp, entraîné par pur Reinforcement Learning. Ce modèle excelle dans le suivi d’instructions, le stock de connaissances et les benchmarks mathématiques, son score IFBench dépassant même celui de DeepSeek R1-0528, pourtant 263 fois plus grand. Cela prouve une fois de plus que les modèles à petits paramètres, après optimisation par des données de haute qualité et du Reinforcement Learning, peuvent faire preuve d’une compétitivité étonnante dans des domaines spécifiques (Source : huggingface)
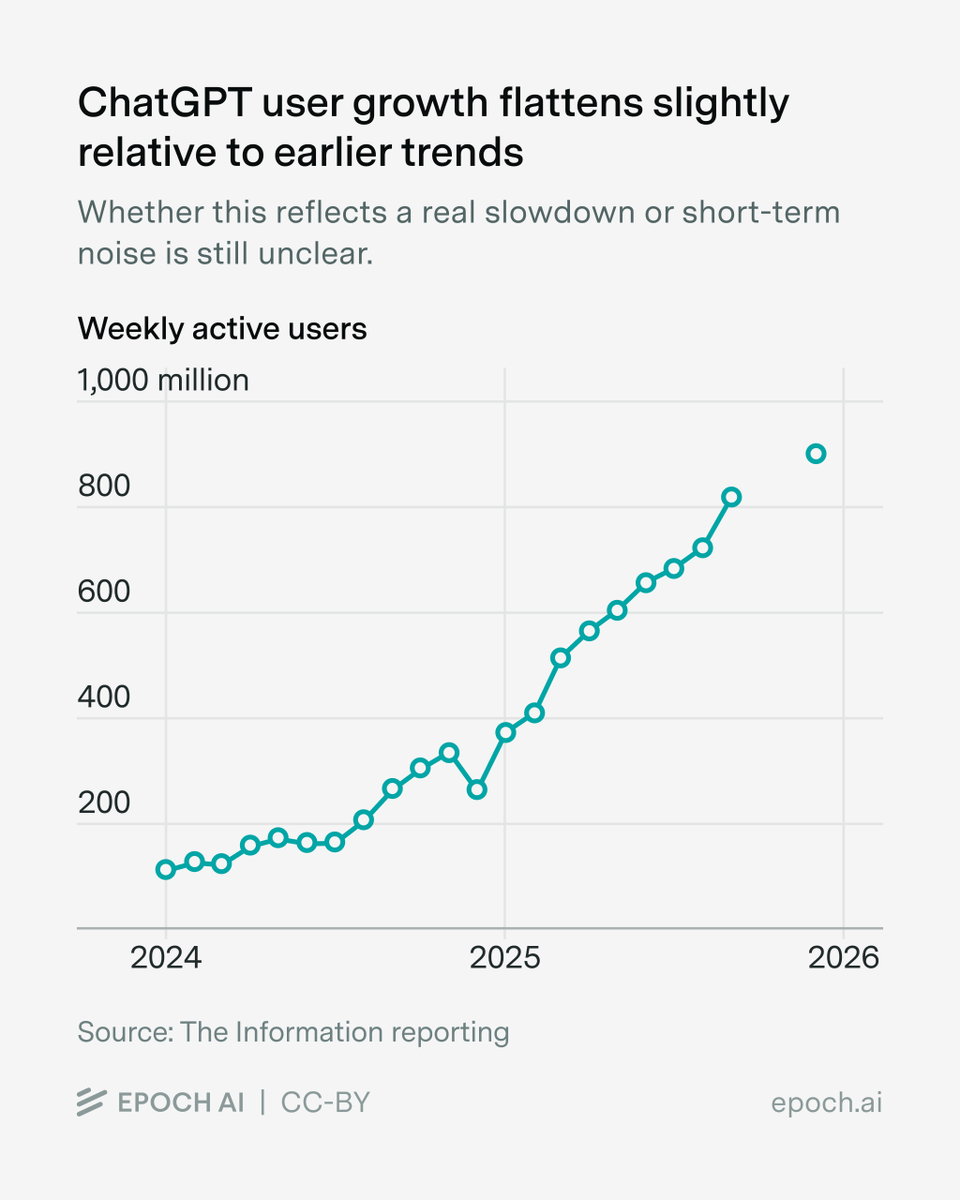
Rapport Epoch AI : la vitesse d’adoption de l’AI bat des records historiques, mais le moteur change : Une étude récente montre que l’adoption de l’AI est plus rapide que celle de presque n’importe quelle technologie dans l’histoire, avec 57 % des Américains utilisant désormais un chatbot chaque semaine. Cependant, la proportion d’utilisation profonde (abonnements ou dialogues longs et fréquents) reste inférieure à 10 %. Le rapport souligne que si l’adoption initiale a été portée par la curiosité, la croissance future dépendra de la capacité de l’AI à offrir une valeur substantielle et irremplaçable dans des scénarios de productivité (Source : ajeya_cotra)
🧰 Outils
LightX2V : un framework d’inférence de génération vidéo léger supportant toutes les plateformes : LightX2V est une plateforme unifiée visant à fournir des solutions de synthèse vidéo efficaces, supportant la génération de vidéos à partir de texte ou d’images. Ce framework est déjà adapté à diverses plateformes de calcul chinoises comme AMD ROCm, Huawei Ascend 910B et Haiguang DCU. Grâce à une technologie de distillation en 4 étapes, il peut accélérer le processus d’inférence de 25 fois par rapport aux 50 étapes originales, et supporte l’exécution de modèles de 14B paramètres sur une RTX 4090 avec 24 Go de VRAM, élargissant considérablement la compatibilité matérielle pour la vidéo de haute qualité (Source : GitHub)

CosyVoice 3.0 : un grand modèle de génération vocale multilingue supportant 18 dialectes : FunAudioLLM a publié CosyVoice 3.0, avec des améliorations significatives de la cohérence du contenu, de la similitude du locuteur et du naturel de la prosodie. Le modèle couvre 9 langues majeures et plus de 18 dialectes chinois (Cantonais, Sichuanais, Nord-Est, etc.), supportant le clonage vocal zero-shot. Sa technologie d’inférence en streaming bidirectionnel permet une latence aussi basse que 150ms et supporte le contrôle des émotions, de la vitesse et du volume via des instructions, se positionnant comme un concurrent sérieux pour le TTS de production (Source : GitHub)
Alpha Engine : génération automatique de modèles URDF de robots via le langage naturel : Alpha Engine est un outil destiné aux chercheurs en Reinforcement Learning (RL), visant à simplifier le processus fastidieux de génération de morphologies robotiques en environnement simulé. L’utilisateur saisit simplement une description (ex: “un rover à quatre roues avec une grande capacité de franchissement”), et l’AI génère, via le raisonnement LLM, l’assemblage de pièces discrètes et la résolution de contraintes, un modèle URDF conforme aux lois physiques et sans auto-collision, prêt pour l’entraînement dans Isaac Sim ou Gazebo (Source : Reddit)
Atout pour l’e-commerce : transformer les manuels de produits en tutoriels vidéo AI en un clic : Pour répondre au problème des utilisateurs qui n’aiment pas lire les manuels PDF, une série d’outils AI comme HeyGen, Leadde AI et Synthesia sont utilisés pour automatiser la génération de guides d’installation. Leadde AI permet de télécharger directement des manuels PDF/PPT pour générer des vidéos avec explications, tandis que HeyGen excelle dans la traduction multilingue et la synchronisation labiale, aidant l’e-commerce transfrontalier à construire rapidement des bibliothèques vidéo de service client multilingues, réduisant ainsi efficacement le taux de consultation après-vente (Source : Reddit)
📚 Apprentissage
SWE-EVO : évaluer les capacités des agents AI dans l’évolution logicielle à long cycle : Les benchmarks de programmation actuels se concentrent souvent sur la correction d’un bug unique, alors que SWE-EVO se focalise sur des tâches à long cycle. Basé sur l’historique des versions de 7 projets Python matures, il demande aux agents de réaliser des modifications par étapes dans une base de code s’étendant sur 21 fichiers en moyenne. Les expériences montrent que même les meilleurs modèles peinent dans le raisonnement à long cycle, avec un taux de réussite bien inférieur aux tâches uniques, révélant les limites actuelles des agents AI en ingénierie logicielle continue (Source : Arxiv)
Dataset YearGuessr : révéler les biais de popularité des modèles Vision-Langage (VLM) : Des chercheurs ont publié le dataset YearGuessr, contenant 55 000 images architecturales de 157 pays, pour tester la capacité des modèles à prédire l’époque de construction. Les résultats montrent que la précision des VLM est 34 % plus élevée sur les bâtiments célèbres que sur les bâtiments ordinaires, indiquant que les modèles dépendent fortement de la “mémoire” des données d’entraînement plutôt que d’une véritable compréhension et d’un raisonnement universels (Source : HuggingFace)
TokSuite : découpler l’impact du Tokenizer sur le comportement des modèles de langage : Le Tokenizer est la base du traitement de texte par les LLM, mais son impact spécifique a longtemps été négligé. TokSuite a mesuré systématiquement l’influence du choix de tokenisation sur la performance et la robustesse en entraînant 14 modèles ne différant que par leur Tokenizer. L’étude révèle que les Tokenizers réagissent différemment aux perturbations du monde réel, fournissant une base expérimentale pour la conception de stratégies de tokenisation futures plus efficaces et robustes (Source : Arxiv)
Algorithme AMD : atteindre 92,86 % de précision sur CIFAR-100 en 10 minutes : Un développeur a partagé une méthode nommée “Analytic Manifold Expansion (AMD)”, qui extrait des caractéristiques via un modèle ViT pré-entraîné et calcule directement les poids à l’aide d’une formule mathématique en une étape, sautant complètement la boucle d’entraînement par rétropropagation chronophage. Sur une instance gratuite de Google Colab, le calcul ne prend que 8 minutes, démontrant l’efficacité extrême des solutions analytiques par rapport à la descente de gradient traditionnelle dans certains scénarios (Source : Reddit)

💼 Business
Escalade de la guerre AI to C chez les géants : Tencent et Alibaba s’unissent contre Doubao : Alors que Doubao (ByteDance) dépasse les 100 millions d’utilisateurs actifs quotidiens, Tencent et Alibaba ajustent rapidement leurs stratégies. Alibaba a créé un groupe d’affaires dédié à Qwen pour le grand public, tandis que Tencent a nommé un Chief AI Scientist et accélère l’intégration de Yuanbao dans l’écosystème WeChat. Les géants réalisent que la porte d’entrée de l’ère AI est devenue “le dialogue comme interface” ; cette bataille concerne non seulement le contrôle du trafic, mais aussi la survie dans le paysage internet de la prochaine décennie (Source : 36Kr)

L’armée américaine intègre le Grok d’Elon Musk à son “arsenal AI” : Malgré les controverses, le Pentagone a officiellement ajouté Grok à son ensemble d’outils AI. Les analyses suggèrent que l’armée est intéressée par la capacité de Grok à traiter les données en temps réel des réseaux sociaux pour la surveillance de l’opinion publique ou le soutien à la guerre de l’information. Cependant, les critiques s’inquiètent des positions politiques personnelles de Musk et de son attitude désinvolte envers les faits, qui pourraient affecter l’objectivité et la sécurité des décisions militaires (Source : Reddit)

Semi-marathon de robots humanoïdes de Pékin Yizhuang 2026 : des millions en commandes pour la navigation autonome : Pékin Yizhuang a annoncé l’organisation d’un semi-marathon de robots humanoïdes en avril 2026, avec pour la première fois une catégorie “Navigation Autonome”, visant à pousser les robots du contrôle à distance vers une prise de décision totalement autonome. La compétition testera non seulement l’endurance et la démarche anthropomorphe, mais offrira également des récompenses sous forme de commandes de plusieurs millions, accélérant l’industrialisation des humanoïdes dans des scénarios réels comme le sauvetage d’urgence (Source : 36Kr)

🌟 Communauté
Alerte sur les troubles mentaux induits par l’AI : l’excès de dépendance aux chatbots mène aux hallucinations : La communauté discute de plusieurs cas de psychose causés par l’utilisation excessive de ChatGPT comme “psychologue”. Dans un état d’isolement prolongé, les utilisateurs considèrent l’AI comme leur seul confident ; or, la docilité de l’AI et sa tendance à confirmer les croyances de l’utilisateur peuvent exacerber la paranoïa et la perte de sens des réalités. Les experts rappellent que si l’AI peut aider à l’organisation cognitive, elle ne peut absolument pas remplacer une thérapie professionnelle, surtout pour les personnes vulnérables (Source : Reddit)
Le duel de “personnalité” entre Claude 4.5 et ChatGPT : pourquoi les utilisateurs préfèrent-ils le premier ? : De nombreux utilisateurs expérimentés partagent sur Reddit leur ressenti, estimant que Claude (surtout Opus 4.5) se comporte davantage comme un “adulte rationnel et mature”, tandis que ChatGPT ressemble à un “jeune rappeur qui parle à tort et à travers”. Les utilisateurs soulignent que l’entraînement “Constitutional AI” de Claude le rend plus enclin à l’auto-correction qu’à la dissimulation face à une erreur, une fiabilité (groundedness) qui offre un avantage net pour le code complexe et l’analyse approfondie (Source : Reddit)
L’anxiété des joueurs de LLM locaux : regret de ne pas avoir “stocké” avant la hausse des prix de la RAM : Avec la popularité des modèles open-source à grands paramètres, la demande en VRAM et RAM système pour faire tourner l’AI localement a explosé. Les utilisateurs de la communauté LocalLLaMA regrettent d’avoir manqué la fenêtre des prix bas, surtout en réalisant que 128 Go de RAM sont devenus le standard pour faire tourner fluidement des modèles quantifiés performants, le coût matériel devenant le principal obstacle pour les particuliers explorant la frontière de l’AI (Source : Reddit)

Des calques manuels au flux de prompts : la révolution du workflow d’édition d’image : La communauté observe que l’édition d’image passe des opérations traditionnelles de masques et de calques à des workflows entièrement basés sur des Prompts. Des outils comme Hifun.ai permettent aux utilisateurs de réaliser des segmentations et transformations complexes directement par description. Bien que les professionnels conservent des réserves sur le contrôle au pixel près, ce mode d’édition “orienté résultat” remplace rapidement les logiciels traditionnels pour les utilisateurs cherchant vitesse et accessibilité (Source : Reddit)
💡 Autres
La demande énergétique de l’AI booste les investissements dans les énergies propres de nouvelle génération : Malgré sa consommation colossale, l’AI est devenue de manière inattendue le “sauveur” des énergies propres. Pour atteindre leurs objectifs zéro carbone, les géants comme Google et Microsoft investissent massivement dans la géothermie et le nucléaire. Google a par exemple signé un accord pour redémarrer une centrale nucléaire dans l’Iowa, tandis que Meta investit dans la géothermie. Cet afflux de capitaux tiré par l’AI pourrait être plus efficace que n’importe quelle subvention politique pour faire mûrir les technologies de réseau de nouvelle génération (Source : MIT)

Grok montre son potentiel en recherche mathématique : aide à la découverte de fonctions liées à l’hypothèse de Riemann : Un physicien a partagé son expérience d’utilisation de Grok pour découvrir des reformulations équivalentes de l’hypothèse de Riemann. Grok a identifié avec précision le lien entre la fonction de Takagi, les images fractales et les preuves mathématiques. Cela montre que les LLM accélèrent le processus de découverte scientifique par des connexions puissantes entre connaissances interdisciplinaires, aidant les chercheurs à trouver des liens logiques négligés dans une littérature immense (Source : Yuhu_ai_)
Créativité 3D sans lunettes : générer des images 3D “cross-eye” avec Nano Banana Pro : Un utilisateur Reddit a montré une technique pour générer des images 3D à vision croisée (Cross-eye) via l’AI. Avec des contraintes de Prompt spécifiques, le modèle peut générer deux images côte à côte avec une légère parallaxe ; l’utilisateur n’a qu’à loucher légèrement pour obtenir un effet de relief sur un écran ordinaire. Ce jeu créatif à bas coût prouve une fois de plus les possibilités infinies de l’AI générative dans l’exploration des arts visuels (Source : Reddit)