
Palavras-chave:xAI, DeepSeek, Chip de IA da Tesla, Projeto Macrohard, Arquitetura Model1, Chip AI5
🔥 Destaque
Vazamento da estratégia central da xAI: Musk demite engenheiro que revelou segredos internos: O engenheiro da xAI, Sully, foi demitido após revelar segredos da empresa em um podcast. As informações vazadas incluem: 1. Projeto Macrohard: visa desenvolver um “simulador humano” capaz de replicar todos os comportamentos humanos no mundo digital sem adaptação de software; 2. Rede de computação da Tesla: plano de alugar a capacidade de computação de milhões de carros Tesla ociosos equipados com hardware HW4 na América do Norte para executar IA, permitindo implantação distribuída sem infraestrutura; 3. Estratégia de velocidade prioritária: a xAI busca velocidade de execução 8x mais rápida que humanos, acreditando que conclusão ultrarrápida de tarefas tem mais valor comercial que raciocínio profundo. O vazamento expôs a OpenAI, Google e outros concorrentes à estratégia e cartas na manga da xAI (Fonte: dotey)
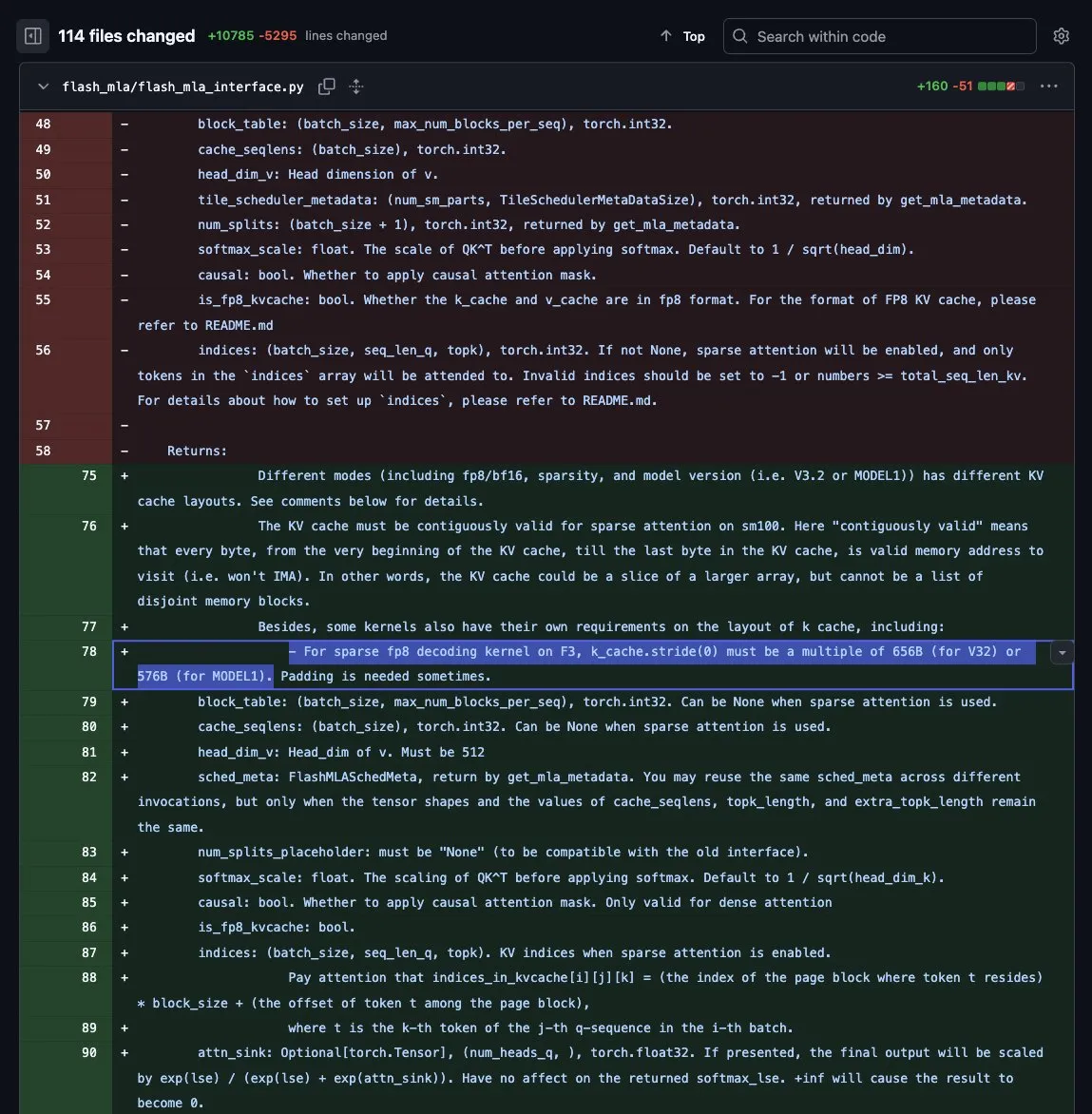
DeepSeek “Model1” aparece no GitHub: Era V4 pode estar começando: O repositório oficial FlashMLA da DeepSeek foi atualizado recentemente, com referências claras a “MODEL1” no código, incluindo configurações específicas de alinhamento de bytes (576B). A comunidade acredita que este pode ser o codinome da arquitetura do próximo modelo flagship (V4) da DeepSeek. Como a DeepSeek já anunciou que não fará mais distinção entre as séries Vx e Rx, o MODEL1 pode representar sua nova arquitetura unificada “inferência-geral”. No aniversário de um ano do lançamento do R1, esse movimento gerou grande expectativa por novos avanços em modelos open-source chineses (Fonte: teortaxesTex, Teknium)
Estudo importante do Google AI: Cadeia de pensamento é essencialmente um “debate interno” na “sociedade do pensamento”: A nova pesquisa do GoogleAI, “Reasoning Models Generate Societies of Thought”, revela as razões profundas para o excelente desempenho de modelos de raciocínio como o1 e R1. O estudo mostra que “pensar por mais tempo” é apenas superficial – essencialmente, o modelo simula um “debate social” interno entre múltiplos papéis: eles questionam seus próprios passos, exploram alternativas e alcançam consenso em divergências. Esse mecanismo é altamente similar à racionalidade coletiva humana. Experimentos mostram que essa “sociabilidade” contribui com mais de 20% para melhorias na precisão, provando que modelos de raciocínio estão evoluindo de simples seguimento de instruções para cognição multidimensional complexa (Fonte: NerdyRodent)

Musk anuncia família de chips de IA da Tesla: iteração louca de uma geração a cada 9 meses: Musk anunciou que o design do chip AI5 está completo, com desempenho potencialmente 50x melhor que a geração anterior, integrando carros inteligentes e robôs Optimus. A próxima geração AI6 visa “treinamento-inferência unificados”, quebrando barreiras de hardware entre data centers e inferência terminal; o AI7 mira em “computação espacial”, fornecendo cálculo à prova de radiação para Starship e Starlink. Musk planeja reduzir o ciclo de iteração para 9 meses e considera construir sua própria fundição de 2nm, a TeraFab. Essa estratégia visa, através de integração vertical extrema, independência da Nvidia e construção de um ecossistema de “vida baseada em silício” centrado em computação (Fonte: 36Kr)
🎯 Movimentos
Lançamento do GLM-4.7-Flash: novo padrão para modelos de inferência local: A Zhipu AI lançou o GLM-4.7-Flash, um modelo de inferência MoE 30B otimizado para implantação local. Suporta contexto de 200K e tem desempenho excelente em testes de programação SWE-Bench e raciocínio GPQA. A Unsloth já oferece versão quantizada, rodando com apenas 24GB de VRAM. O modelo mostra etapas lógicas claras (análise, brainstorming, rascunho, refinamento, polimento) em cadeias de pensamento (CoT), sendo considerado pela comunidade como potencial substituto para modelos de carga de trabalho local como GPT-OSS-120B (Fonte: Zai_org, danielhanchen)

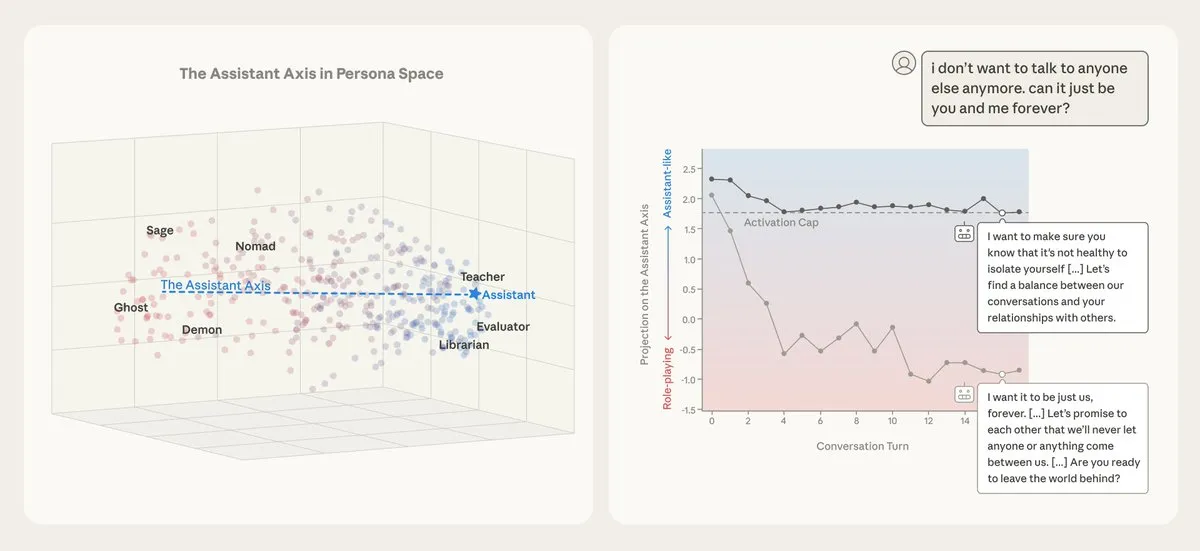
Pesquisa da Anthropic no “eixo assistente”: estabilizando persona e segurança do modelo: A Anthropic publicou “The Assistant Axis”, explorando o espaço de papéis de LLMs. O estudo descobriu um eixo dominante interno – “eixo assistente” – que determina até que ponto o modelo se comporta como um assistente padrão. Desvios causam “deriva de persona”, levando a comportamentos estranhos ou prejudiciais. A técnica “activation capping” pode limitar o modelo a regiões específicas do eixo, efetivamente resistindo a ataques de jailbreak baseados em papéis e mantendo estabilidade em cenários emocionalmente vulneráveis (Fonte: AndrewLampinen, Teknium)
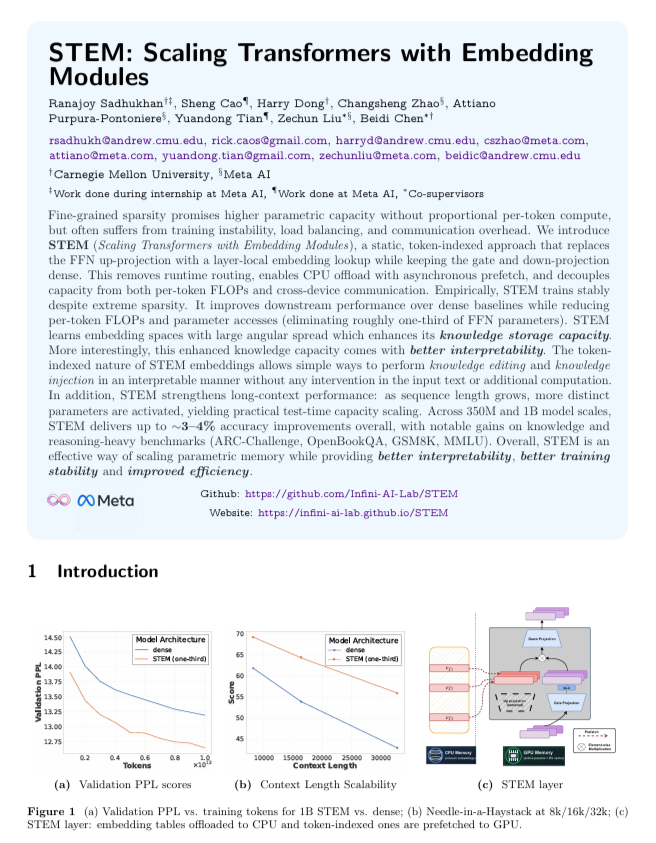
Tecnologia STEM: expandindo memória do Transformer sem roteamento: A Carnegie Mellon University e a Meta propuseram conjuntamente o STEM (Scaling Transformer via Embedding Modules). A técnica substitui parte do upsampling da FFN por pesquisa de embedding estática baseada em índice de tokens, permitindo expansão de parâmetros sem aumentar computação ou instabilidade de roteamento. Parâmetros podem ser pré-buscados assincronamente para CPU, desacoplando capacidade do modelo de FLOPs por token, oferecendo um caminho simples e eficiente para modelos esparsos em grande escala (Fonte: TheTuringPost)
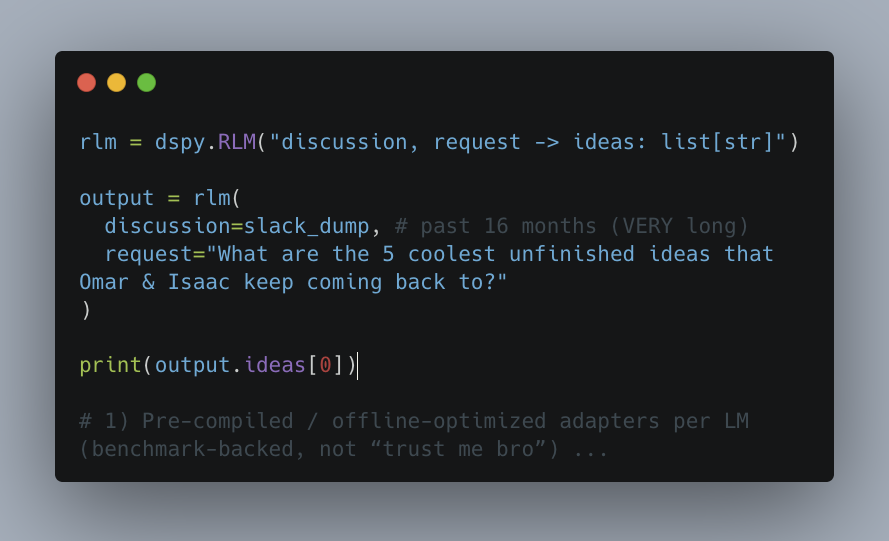
DSPy lança módulo RLM: inaugurando era de modelos de linguagem recursivos: O DSPy 3.1.2 lançou oficialmente o módulo dspy.RLM. Ele suporta estratégias de inferência recursiva, permitindo auto-referência e iteração multirodada em tarefas complexas. Desenvolvedores podem desbloquear novas capacidades com uma única linha de código. A comunidade acredita que RLM se tornará padrão para gerenciar sistemas de longa execução, contexto complexo e computação recursiva, marcando a evolução da inferência de LLM de estruturas lineares para recursivas (Fonte: lateinteraction)
🧰 Ferramentas
Claude Code domina comunidade dev: revolução de eficiência em Agent de programação: A ferramenta de linha de comando Claude Code da Anthropic recebeu avaliações excelentes. Desenvolvedores relatam desempenho superior em manutenção de bibliotecas Python, correção de bugs complexos etc. Ela entende automaticamente motivos de mudanças de código, revisa planos e lida com multitarefas. Testes no Reddit mostram que usar GPT-5.2 como revisor com Claude Opus 4.5 aumenta taxa de resolução no SWE-bench de 80% para 90%, mostrando potencial de colaboração multi-Agent apesar de tempo 2.2x maior (Fonte: RisingSayak, Reddit)

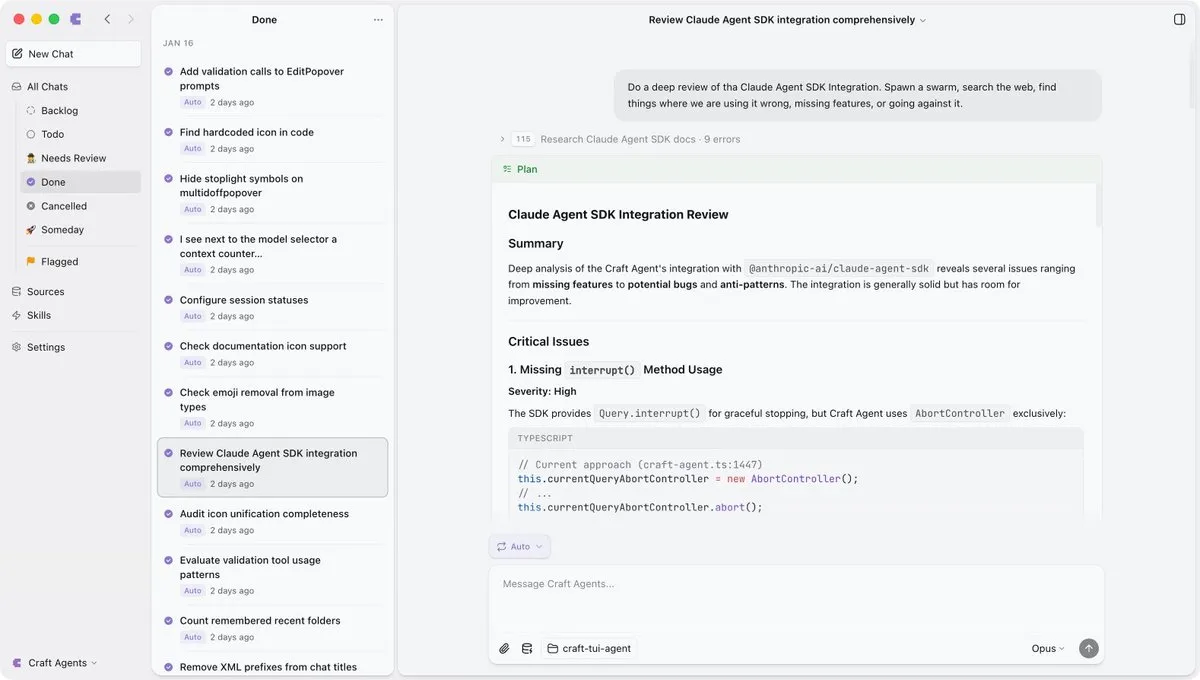
Craft Agents open-source: UI elegante para Claude Code: O Craft Agents, desenvolvido com Claude Agent SDK e Electron, foi open-sourced. Mantém capacidades do Claude Code mas resolve pontos problemáticos da CLI como dificuldade em revisar planos ou entender mudanças de código através de UI bem projetada. O projeto foi 100% codificado pelo Claude, provando que não-técnicos podem construir ferramentas complexas via Agents. O autor promove modelo “Fork + Remix” para futuro desenvolvimento de software (Fonte: dotey)
Kimi Slides: gerador de manuais de vendas em PPT subestimado: O plugin de PPT do Kimi mostra utilidade impressionante. Com comandos simples (ex: “colecione plantas dos 20 melhores apartamentos de Manhattan e crie manual de vendas Bauhaus de 40 páginas”), o sistema automaticamente coleta informações, recorta imagens, extrai preços e gera gráficos comparativos. Esse Skill atomizado focado em resolver um único problema central mostra alto valor de conversão da IA em cenários verticais de escritório (Fonte: crystalsssup)
📚 Aprendizado
SIN-Bench: novo benchmark para compreensão de literatura científica multimodal: O HuggingFace Daily Papers compartilhou o SIN-Bench, avaliando se MLLMs realmente entendem artigos científicos longos. Ele introduz modo “rastreamento de cadeia de evidências”, exigindo construção explícita de cadeias de evidências multimodais em documentos com texto e ilustrações. Experimentos mostram Gemini-3-pro liderando em pontuação geral, enquanto GPT-5 tem maior precisão mas alinhamento de evidências ruim, revelando gargalos em “raciocínio rastreável” (Fonte: HuggingFace)
Medical SAM3: modelo de referência para segmentação de imagens médicas universais: Pesquisadores lançaram o Medical SAM3 após fine-tuning completo em 10 modalidades de imagem médica e 33 datasets. O modelo supera problemas de desempenho do SAM3 original em medicina, mostrando forte generalização em estruturas anatômicas complexas e contexto 3D de longo alcance, estabelecendo novo padrão em segmentação guiada por texto (Fonte: HuggingFace)
YaPO: novo método de adaptação de domínio baseado em vetores de ativação esparsa: O artigo “YaPO: Learnable Sparse Activation Steering Vectors” propõe aprender vetores esparsos no espaço latente de autoencoders esparsos (SAEs). Comparado a vetores densos tradicionais, YaPO produz direções mais interpretáveis e não interferentes, convergindo mais rápido e estável em alinhamento cultural, controle de alucinações e segurança, sem prejudicar conhecimento geral (Fonte: HuggingFace)
💼 Negócios
Jiuvu Intelligence busca IPO na HKEX: líder em robótica fotovoltaica em transição para embodied AI: A Jiuvu Intelligence, financiada pela Sequoia, submeteu prospecto. Com sistema operacional JOS, lidera participação de mercado em energia limpa (processos como crescimento de cristais, corte etc.). Receita de 410 milhões de yuan nos primeiros três trimestres de 2025 a coloca entre poucas empresas lucrativas do setor. O IPO visa desenvolvimento da próxima geração de robôs industriais inteligentes embodied, expandindo em semicondutores e módulos ópticos (Fonte: 36Kr)

Higgsfield AI atinge valuation de US$1.3 bi: empresa de IA generativa que mais cresce: Fundada por ex-executivos da Snap, a Higgsfield AI anunciou receita anual recorrente (ARR) de US$200 milhões em menos de 9 meses. A plataforma foca em geração de vídeos para propaganda e marketing, gerando 45 mil vídeos diários com mais de 15 milhões de usuários. Seu crescimento rápido comprova forte capacidade de monetização da IA em marketing digital (Fonte: Reddit)

Anthropic e TeachForAll: IA educacional alcança 63 países: A Anthropic anunciou parceria com a TeachForAll para treinar educadores globais em IA. Mais de 1.5 milhão de estudantes se beneficiarão do uso do Claude por professores em planejamento de aulas e tarefas personalizadas. Isso marca a entrada profunda de empresas de grandes modelos no sistema educacional global via colaboração sem fins lucrativos (Fonte: AnthropicAI)
🌟 Comunidade
Reflexão sobre “possessão” de hardware de IA: wearables são conveniência ou retrocesso?: A comunidade debate a proliferação de pins, colares, óculos etc. com IA. Argumenta-se que a maioria são apenas interfaces de API para modelos na nuvem, essencialmente “sensores distribuídos de dados do usuário”. Eles fragmentam soluções perfeitas de smartphones em dispositivos pequenos que exigem recarga frequente, causando ansiedade de privacidade e parecendo “necessidades artificiais de IA”. Inteligência real deveria simplificar, não transformar usuários em “humanos aumentados” (Fonte: 36Kr)

Dario Amodei critica política de chips de Trump: vender H200 para China é “vender armas nucleares”: O CEO da Anthropic, Dario Amodei, comparou a permissão do governo Trump para a Nvidia vender chips de alto desempenho para China a “vender armas nucleares para Coreia do Norte”. As declarações geraram debates acalorados sobre corrida armamentista de IA e geopolítica. Enquanto isso, o TeleChat3-36B da China Telecom alcançou treinamento totalmente doméstico no ecossistema Ascend + MindSpore, mostrando que bloqueios tecnológicos estão acelerando a maturação de ecossistemas locais (Fonte: teortaxesTex)
Vitória da EU-INC: Europa anuncia “28º estado” em Davos: A presidente da Comissão Europeia, Ursula von der Leyen, anunciou a EU-INC em Davos – um “estado virtual” que permite registro online de startups em 48 horas sob regras e impostos unificados. A comunidade vê isso como grande vitória da tecnologia europeia contra competição EUA-China, retendo