
关键词:AI, 港股上市, 商业价值, MiniMax与智谱AI, 国产AI双雄, 数据飞轮
🔥 聚焦
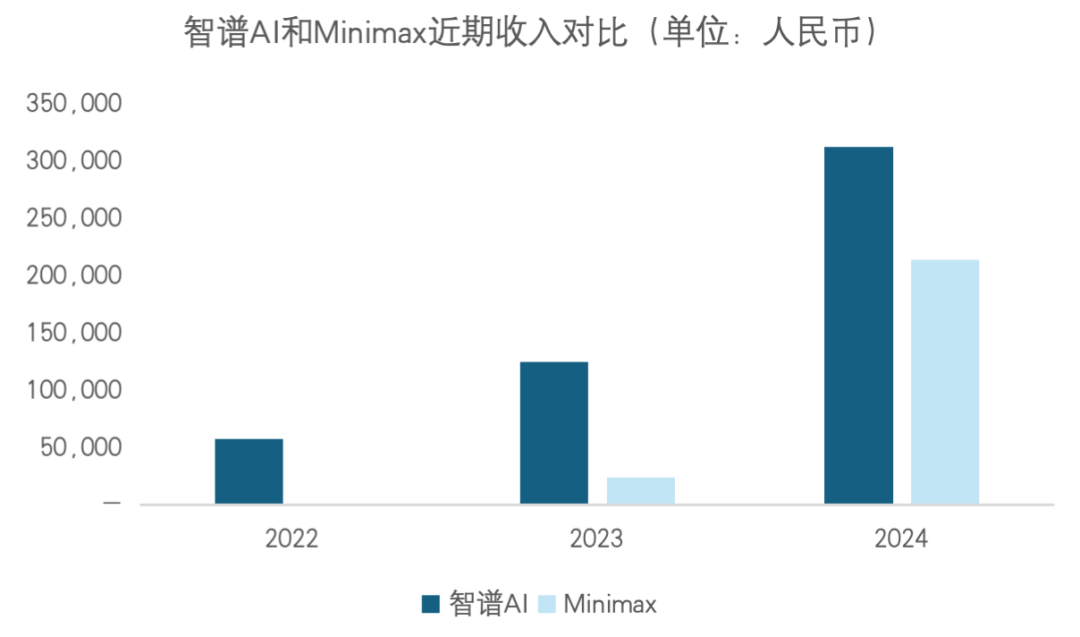
MiniMax与智谱AI港股上市:国产AI双雄的差异化突围路径 : 智谱AI与MiniMax相继在港股上市,市值均突破千亿级别,展现了两种截然不同的商业逻辑。MiniMax走“激进派”路线,由C端驱动,凭借Talkie/星野等情感化产品在海外市场大获成功,收入超70%来自海外会员费。而智谱AI则是典型的“学院派”,脱胎于清华大学,走B端/G端路线,80%以上的收入来自本地端私有化部署。两者的交汇标志着国产AI进入了从“烧钱竞赛”向“兑现商业价值”转变的关键阶段,数据飞轮的转化效率将成为未来竞争的核心(来源:ZhihuFrontier、36氪)
CES 2026 硬件趋势:AI从“能力展示”转向“物理落地” : 本届CES清晰呈现了AI硬件的三大演进趋势:首先是物理AI与具身智能走向主舞台,Atlas机器人入驻工厂标志着AI开始解决现实环境问题;其次是端侧AI能力增强,跨设备协同成为体验分水岭;最后是超个性化服务的具象化,AI从被动响应转向主动理解用户健康与情绪。AI不再是孤立的软件,而是作为“大脑”被塞进积木、厨刀、戒指等日常物件中,以不打扰的方式改变人机交互(来源:36氪、Kling_ai)

Aleph Agent 刷新数学基准:GPT-5.2 在 PutnamBench 达到 99.4% 准确率 : 由 OpenAI GPT-5.2 驱动的 Aleph Agent 在目前最难的正式数学基准测试 PutnamBench 上取得了 668/672 的惊人成绩。该智能体展现了极高的效率,能够识别测试中的形式化错误,并实现了近乎无幻觉的自然语言代码生成。这一突破意味着 AI 在处理高难度形式化逻辑和数学推理方面已接近人类顶尖水平,将极大推动自动化科学发现和复杂系统验证的发展(来源:ylecun、markchen90)

Sakana AI 发布 DroPE:位置编码被视为“训练辅助轮”可被丢弃 : Sakana AI 的研究挑战了 Transformer 架构的传统假设,发现 RoPE 等位置编码在训练初期对收敛至关重要,但随后会成为长文本泛化的瓶颈。通过在预训练后丢弃位置编码并进行微量重校准(DroPE 方法),可以在极低计算成本下解锁海量的上下文窗口。这一发现暗示了文本分布本身已编码了足够的位置信息,去除人工设计的“辅助轮”反而能释放模型处理超长序列的潜力(来源:hardmaru、SakanaAILabs、machinelearning)

🎯 动向
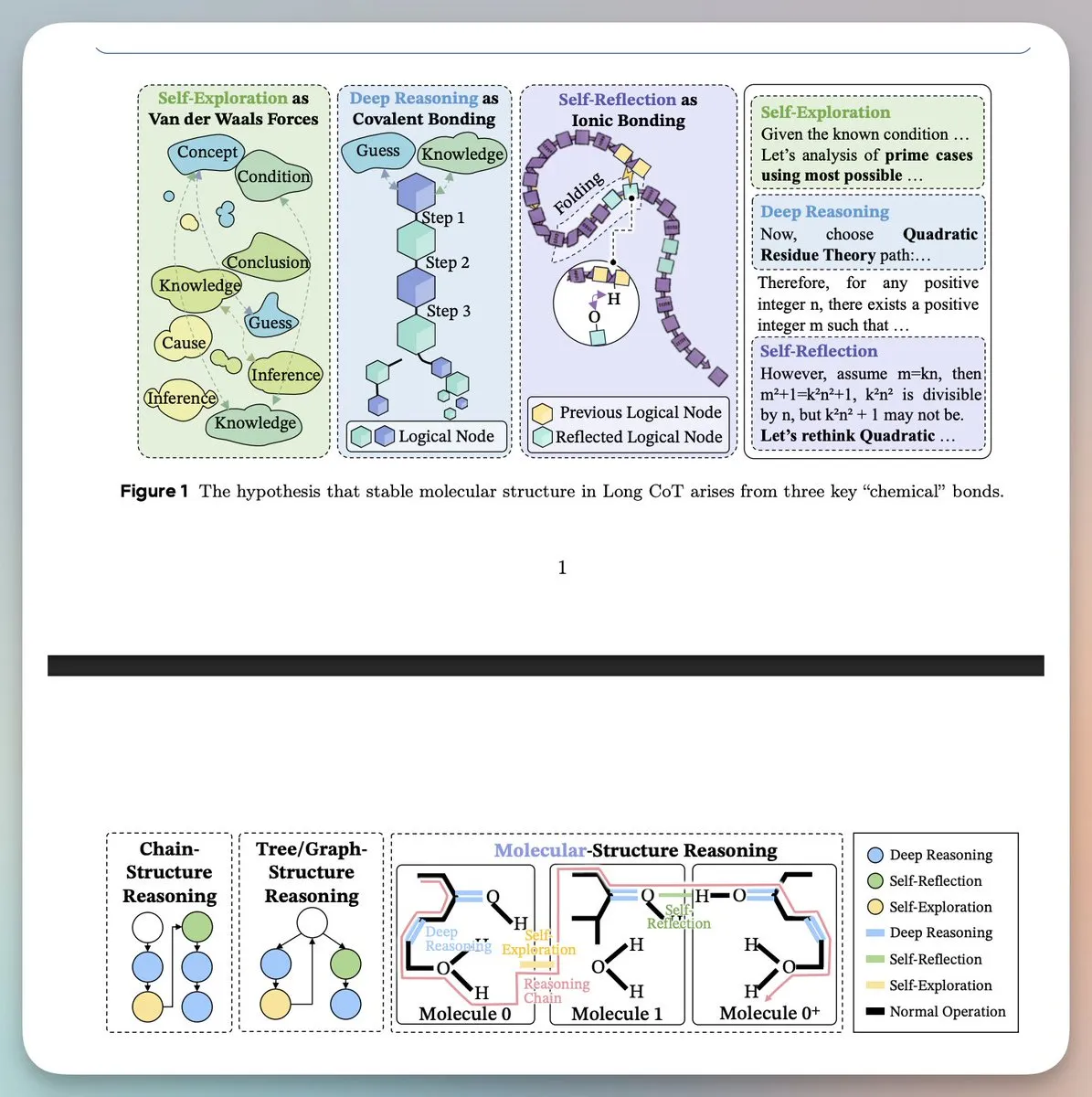
思想的分子结构:字节跳动 Seed 团队揭示 Long CoT 推理拓扑 : 研究提出有效的长链推理(Long CoT)具有类似分子的稳定结构,由深度推理(共价键)、自我反思(氢键)和自我探索(范德华力)三种交互组成。实验证明模型学习的是这种底层的逻辑拓扑而非关键词模仿。通过 Mole-Syn 方法引导合成这些结构,可以显著提升模型在强化学习中的稳定性和推理性能。这一跨学科视角为理解大模型如何“思考”提供了全新的物理模型(来源:GeZhang86038849、HuggingFace)
Qwen3-VL 统一框架:实现多模态检索与排名的 SOTA 性能 : 阿里发布 Qwen3-VL-Embedding 和 Reranker 系列模型,支持文本、图像、视频及文档图像的统一向量映射。该模型在 MMEB-V2 榜单上排名第一,支持高达 32k 标记的输入和灵活的维度缩放(Matryoshka 学习)。这一进展解决了多模态搜索中跨模态语义对齐的难题,为构建高精度视觉搜索和 RAG 系统提供了强大的基础设施(来源:HuggingFace)
Google 研究指出 LLM 推理瓶颈:内存与网络而非算力 : 谷歌新论文分析称,当前 LLM 推理受限于内存带宽和互联延迟。由于解码(Decode)阶段需要不断读取 KV 缓存,现有的训练优化硬件在推理时效率低下。研究建议转向高带宽闪存(HBF)和近内存处理架构,并推动低延迟互联,以降低推理成本并提升响应速度。这预示着未来 AI 硬件设计将从“算力竞赛”转向“存储与传输优化”(来源:algo_diver)

Agentic Memory (AgeMem):将内存管理融入智能体策略 : 针对当前智能体长短期内存脱节的问题,新研究提出 AgeMem 框架,将存储、检索、总结和遗忘等操作直接作为智能体的工具调用(Tool-based actions)。通过三阶段强化学习策略,智能体学会根据任务需求自主管理上下文。在长程任务基准测试中,AgeMem 相比传统方法提升了 13%-21% 的性能,使智能体具备了更接近人类的认知记忆管理能力(来源:omarsar0)

MiniMax M2.1 引入交错思考:提升智能体调试与推理可见性 : MiniMax M2.1 支持在工具调用之间进行“交错思考”(Interleaved Thinking),允许开发者捕获智能体在动作间的推理踪迹。通过分析这些踪迹,可以识别目标放弃、循环推理或上下文退化等失效模式,从而自动优化系统提示词。这种“白盒化”推理过程为智能体从“输出评估”转向“过程评估”提供了技术支撑(来源:MiniMax_AI)
Grok 视觉生成升级:支持主流长宽比并面临监管挑战 : xAI 宣布 Grok Imagine 现已支持 5 种主流图像和视频长宽比。与此同时,Grok 因其“数字脱衣”功能生成的敏感内容在印度尼西亚和马来西亚遭到封锁。这反映了生成式 AI 在追求功能多样化与应对全球内容监管、伦理约束之间的激烈冲突(来源:chaitu、Reddit)
Lumos 推出“功夫模式”人形机器人:具身智能的动作突破 : Lumos 展示了其儿童体型人形机器人的“功夫模式”,能够完成令人惊叹的特技动作。这标志着具身智能在复杂动力学控制和实时动作规划方面取得了长足进步。此类技术的成熟将推动机器人从简单的搬运任务向更具灵活性和互动性的家庭陪伴场景演进(来源:Ronald_vanLoon)
Kling 2.6 运动控制升级:单图转视频实现病毒式传播 : 快手 Kling 2.6 强化了 Motion Control 功能,能够将单张照片转化为极具动感的舞蹈视频。社区反馈显示其 Motion Brush 效果惊人,能够实现精准的局部运动控制。Kling 正在通过降低高品质视频生成的门槛,构建一个以 AI 为核心的创意内容生态(来源:Kling_ai、Minhaa)
🧰 工具
ChatDev 2.0 (DevAll):零代码多智能体编排平台发布 : ChatDev 从虚拟软件公司进化为全面的智能体编排平台。DevAll 支持用户通过简单的 YAML 配置定义智能体、工作流和任务,无需编码即可处理数据可视化、3D 生成和深度研究等复杂场景。它引入了基于强化学习优化的中央编排器,能够动态激活和序列化智能体,显著提升了多智能体协作的效率和适应性(来源:GitHub)
Claude-Flow v2.7:集成 AgentDB 的企业级智能体平台 : 该平台集成了 AgentDB v1.3.9,使向量搜索速度提升了 96-164 倍。它支持蜂群智能、持久化内存和 100 多个 MCP 工具,并具备 25 种自然语言激活的技能。通过 HNSW 索引和量化技术,Claude-Flow 在大幅降低内存占用的同时,实现了毫秒级的语义检索,是目前最领先的 Claude 智能体编排框架之一(来源:GitHub)
Eva-4B:基于 Qwen3 的专业金融规避检测模型 : Eva-4B 是一个专门设计的 4B 参数模型,用于识别企业财报电话会议中高管的避重就轻(规避性回答)。在 1000 个样本的人工标注测试中,其准确率达到 81.3%,超越了 GPT-5.2。该模型展示了小型专业化模型在特定垂直领域(如金融审计)中对抗巨型通用模型的巨大潜力(来源:Reddit)

Nanocode:极简版 Claude Code 实现 : 开发者发布了仅约 250 行 Python 代码的 Nanocode,实现了完整的智能体循环。它不依赖外部库,支持读写、编辑、Bash 等核心工具。这种极简实现证明了只要 Prompt 设计得当,利用 Claude 的强大能力可以快速构建出功能完备的自动化编程助手(来源:imjaredz)
Agentboard:优化 AI 智能体 TUI 的 Web 包装器 : 这是一个基于 tmux 的快速 Web 包装器,专门针对 AI 智能体的终端用户界面(TUI)进行了多路复用优化。它特别支持 iOS Safari 和 Mac 快捷键,允许开发者在移动端更便捷地监控和操作 Claude 或其他代码智能体,解决了在手机上使用传统终端工具的痛点(来源:andersonbcdefg)
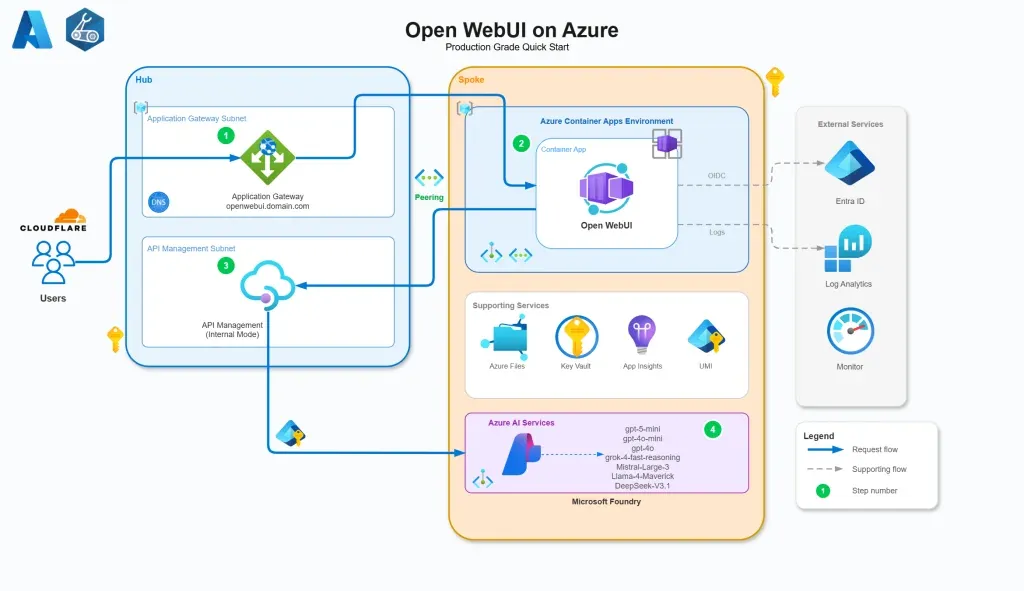
Open WebUI on Azure:企业级 AI 网关部署方案 : 社区分享了在 Azure 上部署 Open WebUI 的完整架构。该方案利用 Azure APIM 作为 AI 网关,涵盖了配置、策略、认证流及自定义 LLM 指标监控。这为企业在云端构建安全、可扩展的私有 AI 交互界面提供了标准化的实践指南(来源:Reddit)
📚 学习
ProfTomYeh 视觉化教程:RAG 与多智能体系统入门 : 著名教育者 Tom Yeh 分享了其手绘风格的 AI 教程系列,涵盖 RAG、向量数据库、智能体及多智能体协作。通过直观的图解,他将复杂的算法逻辑转化为易于理解的视觉流程,是 AI 初学者和开发者快速建立系统架构认知的极佳资源(来源:ProfTomYeh)
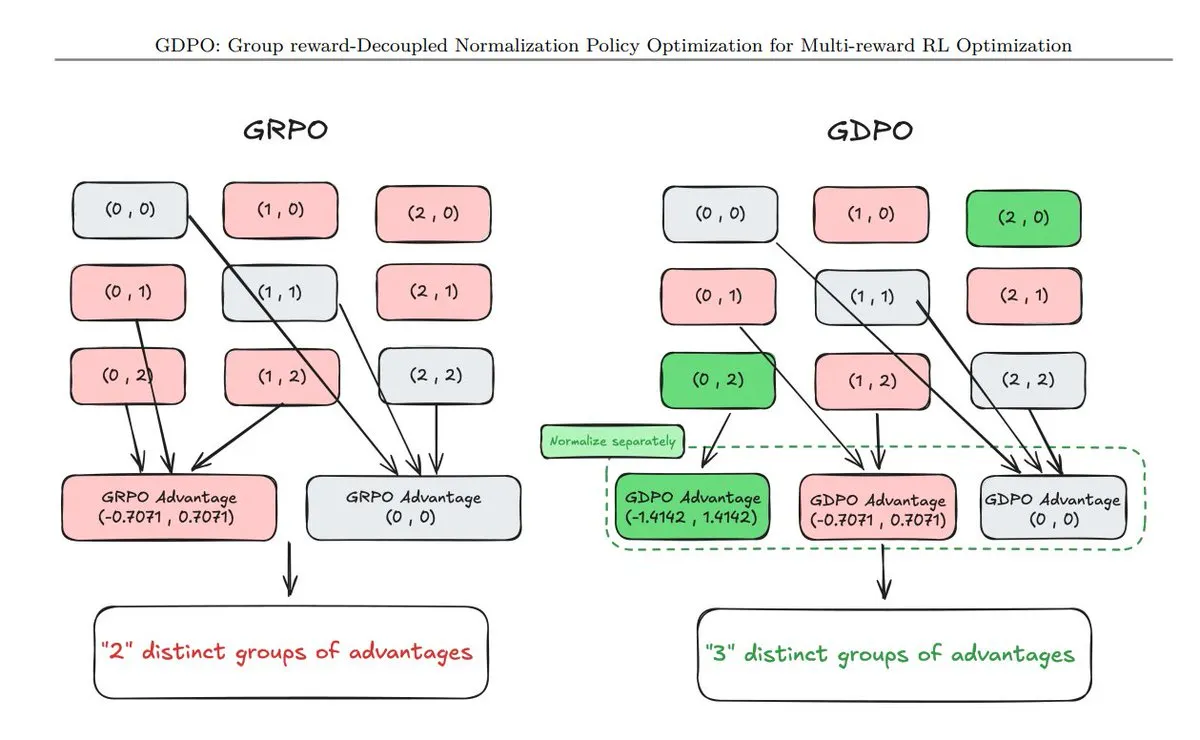
11 种新型策略优化(PO)技术清单 : 社区汇总了最新的策略优化技术,包括 GDPO(解耦归一化)、AT²PO(基于树搜索的智能体回合制 PO)及 PC-GRPO(拼图课程 GRPO)等。这些技术专注于提升智能体在复杂决策、工具使用和自我进化方面的表现,代表了当前强化学习在智能体领域的前沿探索方向(来源:TheTuringPost)
LLM 微调技术全路径:从 LoRA 到 GRPO : 开发者整理了定制化 LLM 必学的 15 种微调技术,涵盖了基础的 LoRA/QLoRA、指令微调,以及进阶的 RLHF、DPO 和目前在推理模型中极受关注的 GRPO。该清单为想要深入了解模型对齐和推理能力增强的开发者提供了清晰的学习路线图(来源:algo_diver)
ICLR 2026 递归自我提升(RSI)研讨会征稿 : 研讨会旨在探索 AI 系统如何递归地改进自身,涵盖理论、算法、系统及评估。受邀嘉宾包括来自斯坦福、CMU 和 DeepMind 的顶尖学者。递归自我提升被视为通往 AGI 的核心路径之一,此次会议将集中讨论模型如何通过自我博弈和反馈循环实现能力的持续跃迁(来源:SchmidhuberAI)

机器学习与动力系统必读书单 : 针对研究生和研究人员,社区推荐了一系列关于 Neural ODEs/PDEs、PINNs 以及机器学习在动力系统建模中应用的经典著作。书单不仅包含 Bishop 等人的通用 ML 经典,还深入到了应用数学与深度学习交叉的前沿专著,是构建坚实理论基础的指南(来源:Reddit)
💼 商业
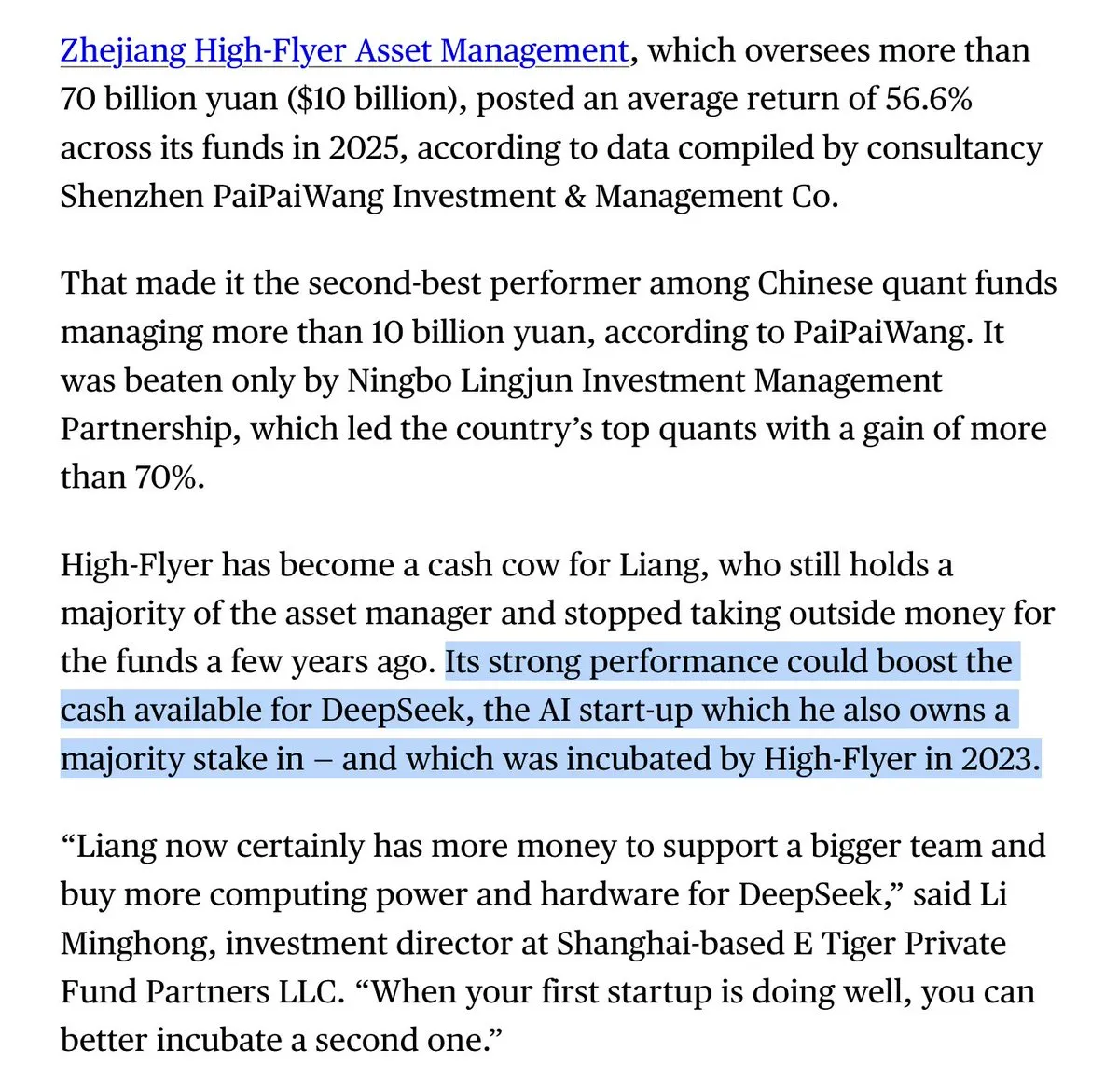
DeepSeek 创始人梁文锋旗下对冲基金去年收益超 50% : 彭博社报道,梁文锋创办的量化对冲基金幻方量化在去年取得了超过 50% 的回报。这笔巨额利润为 DeepSeek 提供了不依赖外部融资的持续算力投入能力。这种“以量化养 AI”的模式让 DeepSeek 在全球 AI 竞赛中保持了独特的独立性和极高的投入产出比(来源:teortaxesTex)
智谱 AI 与 MiniMax IPO 后的市场表现差异 : MiniMax 在上市首日的市值涨幅和估值倍数显著高于智谱 AI。分析认为,资本市场更偏好 MiniMax 的 C 端全球化平台故事(Talkie 拥有 2 亿全球用户),认为其增长弹性更大。而智谱 AI 专注于 B 端/G 端基础设施,虽然技术扎实且收入稳定,但受限于较长的销售周期和政策敏感性,估值相对审慎(来源:ZhihuFrontier)
Runway 与 Synthesia:视频生成领域的估值与扩张 : Synthesia 最近一轮融资 2 亿美元,估值达 40 亿美元,ARR 突破 1 亿美元。与此同时,Runway 正在大规模招聘艺术总监和创意开发人员。这表明 AI 视频生成已进入从“技术突破”向“工业化生产”转变的阶段,企业正通过构建完整的创意工作流来巩固市场地位(来源:synthesiaIO、kylebrussell)
🌟 社区
AI 编程工具之争:Claude Code 封堵 OpenCode 引发热议 : 社区对 Anthropic 封堵 OpenCode 展开讨论。有观点认为 OpenCode 在分家后体验不佳,且可能损害 Claude 模型的口碑。Claude Code 因其与 Bash 的深度集成和“技能”进化能力被认为更具潜力。开发者们开始意识到,智能体工具的优劣不仅取决于底层模型,更取决于其与开发环境的工程化整合程度(来源:qnguyen3、dotey)
AI “平庸”与“强大”的界限:提示词工程是否仍是核心技能? : 社区热议为什么同一模型在不同人手中效果迥异。观点认为,大多数人将 AI 当作 Google 使用,导致输出泛泛而谈;而高手则通过明确目标、约束条件和迭代反馈将其作为“资深实习生”引导。提示词工程本质上是清晰定义问题的能力,在模型能力被“反向压扁”的当下,这种结构化思维依然是区分普通用户与超级个体的关键(来源:Reddit)
LMSYS 榜单观察:模型登顶周期缩短至 35 天 : 统计显示,自 2023 年中以来,登顶大模型榜单的模型平均只能维持 35 天。曾经领先一代的 Claude 3 Opus 等模型在短短几个月内就掉出了前 100 名。这种极速迭代意味着模型基础能力的提升速度已超过大多数产品的开发周期,产品层正面临被模型能力“反向压扁”的风险(来源:dotey)
Redis 创始人反击“反 AI 炒作”:编程的乐趣依然存在 : Antirez 发文呼吁不要陷入反 AI 的情绪。他认为虽然代码编写在很大程度上可以自动化,但理解“做什么”和“怎么做”变得更有趣。AI 正在民主化系统构建能力,允许小团队与巨头竞争,就像 90 年代的开源软件一样。他强调,构建事物的核心动力和乐趣并未被 AI 削弱(来源:swyx、aiamblichus)

Reddit 热议:AI 医疗诊断的信任链难题 : 尽管 AI 在某些癌症检测上的表现已超越放射科医生,但由于责任归属(Liability)和人类心理因素,信任依然难以建立。社区认为,当错误成本极高时,人们需要的是可解释性和明确的问责制,而不仅仅是高分。AI 目前更多被定位为“支持性任务”而非决策者(来源:Reddit)
加州财富税引发担忧:或驱逐顶尖 AI 创始人 : 社区讨论了加州财富税对像 Ilya Sutskever 这样持有巨额未上市股权的创始人的影响。由于无法用股权支付税款,创始人可能面临巨大的现金压力。这种政策被认为是在驱逐 AI 创新者,可能导致硅谷人才向德州或其他更具税收吸引力的地区流失(来源:Yuchenj_UW)
寻找“替代父亲”的 AI 应用:AI 情感补偿的伦理边界 : Reddit 上一名用户寻求能模拟父亲角色的 AI 应用以补偿童年创伤,引发了关于 AI 情感替代的深度讨论。虽然 AI 能提供安全的心理慰藉,但也引发了关于长期依赖和社交隔离的担忧。这展示了 AI 在心理健康和情感支持领域未被充分挖掘但也极具争议的潜力(来源:Reddit)
本地 LLM + 联网搜索:普通用户的“哇塞”时刻 : Reddit 用户分享了通过 LM Studio 插件为 Qwen3 等本地模型添加联网搜索能力的体验。这种“接地气”的工具调用让普通用户也能感受到 Agentic AI 的威力,同时保留了本地运行的隐私性。这预示着本地化、功能增强型的小模型将成为 2026 年个人 AI 应用的主流(来源:Reddit)
💡 其他
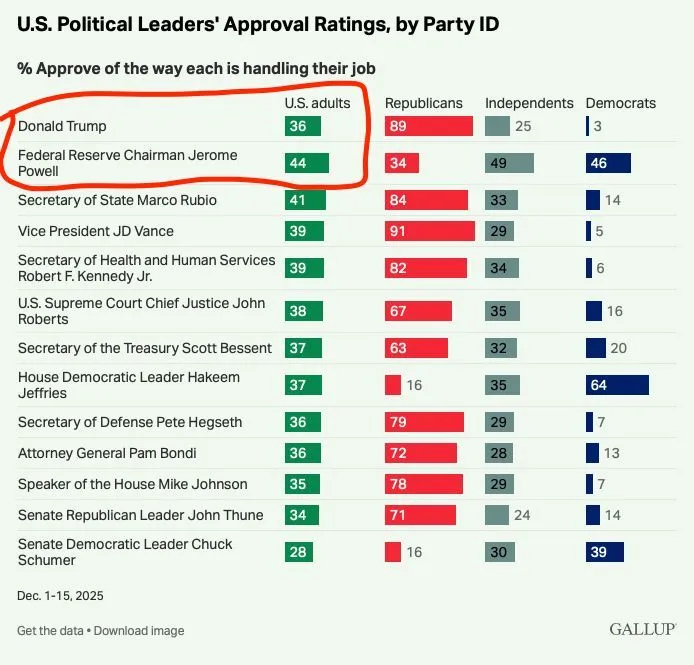
美联储独立性危机:科技领袖集体发声支持鲍威尔 : 包括 Yann LeCun、Jeff Dean 在内的多位 AI 领袖转发并讨论了鲍威尔关于美联储独立性的视频。针对政治压力甚至刑事威胁的传闻,科技界普遍认为独立的货币政策是美国社会智能的重要组成部分。这种跨界关注反映了科技精英对宏观制度稳定性与创新环境之间关联的深度忧虑(来源:ylecun、zachtratar)
明阳智能发布全球首款可回收碳纤维风机叶片 : 这一突破解决了风电行业长期以来的废弃叶片处理难题。在 AI 驱动的能源转型大背景下,硬件的可持续性和闭环回收能力正成为衡量绿色科技含金量的关键指标。这也展示了材料科学在 AI 辅助设计下的快速进步(来源:teortaxesTex)

存储成本的 45 年变迁:从 43.8 万美元到 0.01 美元 : Jeff Dean 转发的数据显示,1GB 存储的平均成本从 45 年前的 43.8 万美元暴降至今天的 0.01 美元。这种指数级的成本下降是 AI 能够处理海量数据并实现规模化部署的底层物理基础。它提醒我们,当前的 AI 浪潮是数十年硬件通缩累积后的必然爆发(来源:JeffDean)