
关键词:主权AI, FSD, Kimi, 韩国主权AI计划, Tesla FSD V14.2, 月之暗面K3模型
🔥 聚焦
韩国启动 1.4 亿美元“主权 AI”计划以构建本土生态 : 韩国科学部联合 SKT、LG、Naver 等 5 家巨头,投入约 1.4 亿美元训练不受外部控制的本土大模型。目前已发布多款开源模型,包括 SKT 的 A(.)X-K1(519B)和 LG 的 K-EXAONE(236B)。该计划强调“从零训练”和“商业开放”,旨在通过提供算力与数据支持,防止欧洲式数字主权流失,使韩国成为全球 AI 版图中的重要一极。此举被社区视为应对 OpenAI 等美系模型垄断的标志性事件(来源: huggingface, ClementDelangue, aiamblichus)

Tesla FSD V14.2 完成首次无干预横跨美国挑战 : 驾驶者 David Moss 使用特斯拉 FSD V14.2,从洛杉矶行驶 2732 英里到达南卡罗来纳州,全程耗时 2 天 20 小时,实现了 0 干预、0 接管的重大突破。Karpathy 对此表示,这曾是 Autopilot 团队初创时的终极目标,标志着端到端神经网络在处理复杂长途场景上已达到成熟期。社区认为这证明了视觉方案在自动驾驶领域的领导地位,但也引发了对未来交通监管适配性的热议(来源: karpathy, BorisMPower, chaitu)

月之暗面(Kimi)获 5 亿美元融资,All in 推理模型 K3 : 月之暗面完成新一轮融资,估值达 43 亿美元,现金储备超 100 亿人民币。创始人杨植麟表示,2026 年将大幅提升人才激励,平均激励达上一年的 200%。战略重心已从投流转向底层能力,K3 模型将通过垂直整合训练技术与 Agent 产品力,追求智力上限而非单纯用户数。此举反映了国产大模型厂商在 DeepSeek 冲击后,集体转向技术驱动与海外商业化的共识(来源: Reddit, 36氪)

硅谷人才战升级:Meta 20 亿美元收购 Manus 抢夺 Agent 核心 : Meta 以超 20 亿美元收购智能体公司 Manus,并为顶级人才开出 1 亿美元起步的“爆炸式 Offer”。目前,大量华人精英如 Alexandr Wang、赵晟佳等站上硅谷 AI 关键岗位。行业重心正从单纯的“刷榜”转向“工程兑现”,即谁能将模型转化为可执行的系统(Agent)。这种从基础研究向产品集权的转型,导致了 FAIR 等传统研究实验室的权力更迭与人才流动(来源: TheRundownAI, 36氪)

🎯 动向
Qwen-Image-2512 发布:显著提升写实感与文字渲染 : 阿里发布多模态模型 Qwen-Image 12 月升级版,重点优化了人物皮肤细节、自然纹理及图片中的文字渲染能力,显著降低了“AI 感”。该模型已同步上线 Hugging Face 和 Replicate,支持更复杂的视觉理解任务。社区反馈其在处理写实人像和长文本图片识别上表现优异,被视为开源多模态领域的强力竞争者(来源: huggingface, Alibaba_Qwen)
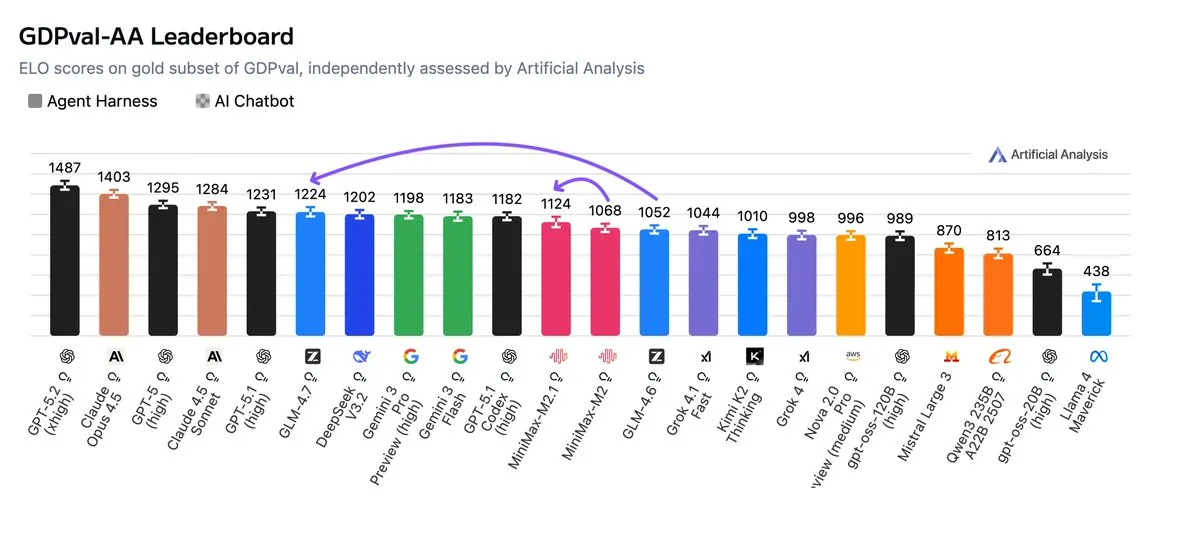
GLM-4.7 与 MiniMax M2.1 争夺开源模型基准测试首位 : 在最新的 GDPval-AA 排行榜中,GLM-4.7 凭借 1224 的 ELO 分数成为开源权重领导者。与此同时,MiniMax M2.1 在遵循指令和研究辅助方面表现出色。开发者实测显示,GLM-4.7 在 Python 后端重构和长上下文维护上优于 Qwen,但在复杂架构设计上仍显通用。这两款模型的快速迭代标志着国产开源模型在编程与逻辑推理领域已能与 Sonnet 等顶尖模型分庭抗礼(来源: huggingface, Reddit)
DeepSeek 库深度优化:性能提升 30% 并适配 B200 芯片 : 社区开发者开始针对 DeepSeek 相关库进行逐一优化,通过 CuTeDSL 等技术手段,在 NVIDIA B200 芯片上实现了 20%-30% 的运行速度提升。这种针对特定硬件的精细化调优,预示着 AI 行业正进入“效率为王”的阶段,即在算力受限的情况下,通过底层工程优化压榨模型推理性能(来源: QuixiAI)

Neuralink 宣布 2026 年启动脑机接口高产量生产 : 马斯克透露 Neuralink 将在 2026 年实现手术全自动化,通过机器人完成脑机接口植入。新技术允许电极丝穿过硬脑膜而无需切除,极大降低了手术风险。此举旨在将脑机接口从实验性医疗推向大规模消费市场,实现人类与 AI 的高带宽连接,被 teortaxesTex 评价为“马斯克正在工业化又一个前沿领域”(来源: teortaxesTex)
谷歌三年逆袭策略盘点:从“红色警报”到全面反攻 : 谷歌通过合并 Google Brain 与 DeepMind 成立新 Google DeepMind,确立了哈萨比斯的统帅地位,并召回 Noam Shazeer 等老兵,彻底打破了以往“追求完美才发布”的官僚主义。目前谷歌在模型(Gemini 3)、芯片(TPU)和应用侧全面加速,迫使 OpenAI 同样进入“红色警报”状态。这一反转展示了巨头在组织重塑后的恐怖爆发力(来源: 36氪)

🧰 工具
Claude Code 开启“Vibe Coding”编程新范式 : 开发者社区对 Anthropic 推出的 Claude Code 反应热烈,认为其在 ASCII 艺术可视化、分层架构理解及自动 Debug 方面表现惊人。用户通过“Vibe Coding”(氛围编程)在移动端或床头即可完成复杂 Web 应用开发。尽管存在 2X 额度限制,但其带来的生产力飞跃让许多开发者选择退订 Cursor,转而构建基于 MCP 的自定义工作流(来源: brivael, omarsar0, Reddit)
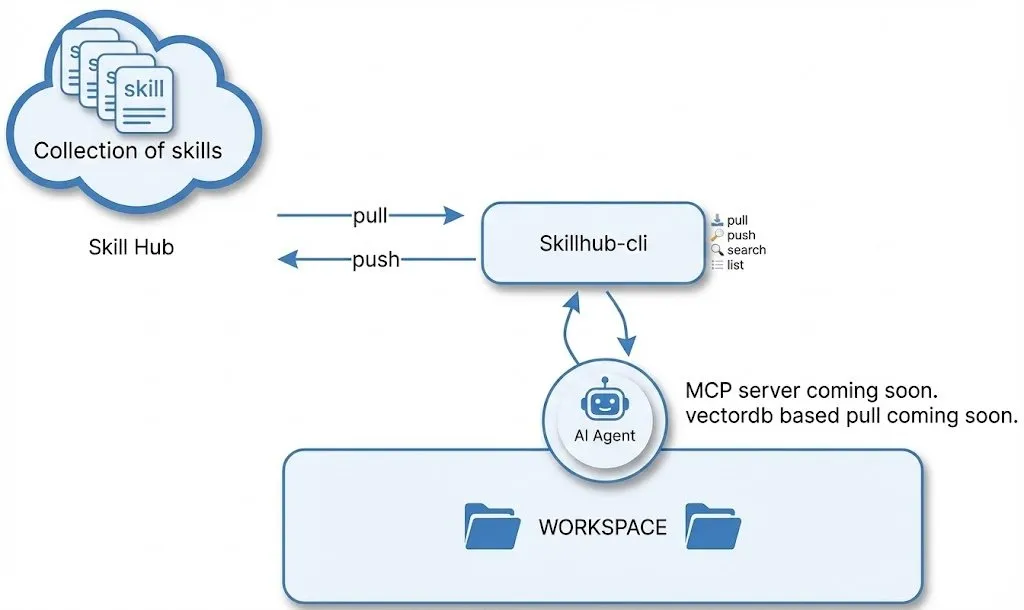
SkillHub:AI 智能体工作流的“Homebrew”注册表 : SkillHub 允许开发者保存、拉取并重用成功的 AI 任务工作流。它解决了每次启动新项目都要重写 Prompt 的痛点,支持跨模型、跨平台使用。这种“工作流商店”的模式被视为 Agent 规模化落地的关键基础设施,让复杂的 AI 技能可以像软件包一样分发(来源: QuixiAI)
Pommel:解决 Claude Code 上下文消耗的本地语义搜索工具 : Pommel 是一款开源的本地语义代码搜索工具,通过维护本地向量数据库(sqlite-vec),帮助 AI 智能体精准定位代码段。它避免了 Claude Code 在理解项目时盲目读取大量无关文件,从而节省高达 50% 的上下文窗口,目前支持 Python、Go、Java 等主流语言(来源: Reddit)
EmbeddingAdapters:跨模型向量空间转换库 : 该 Python 库提供预训练适配器,支持将本地小模型(如 MiniLM)生成的向量翻译为 OpenAI 或 Gemini 等高维向量空间。这使得开发者无需重新嵌入整个语料库即可迁移向量数据库,并能在断网或受限环境下实现高效的本地 RAG 检索(来源: Reddit)
Manus 发布 Slack 连接器,转化对话为行动知识 : Manus 推出 Slack Connector,旨在将碎片化的 Slack 聊天记录转化为可搜索、可执行的结构化知识库。这解决了团队知识在聊天流中流失的问题,标志着 Agent 正在深度切入企业内部协作场景,从“对话助手”进化为“知识管理中枢”(来源: hidecloud)
📚 学习
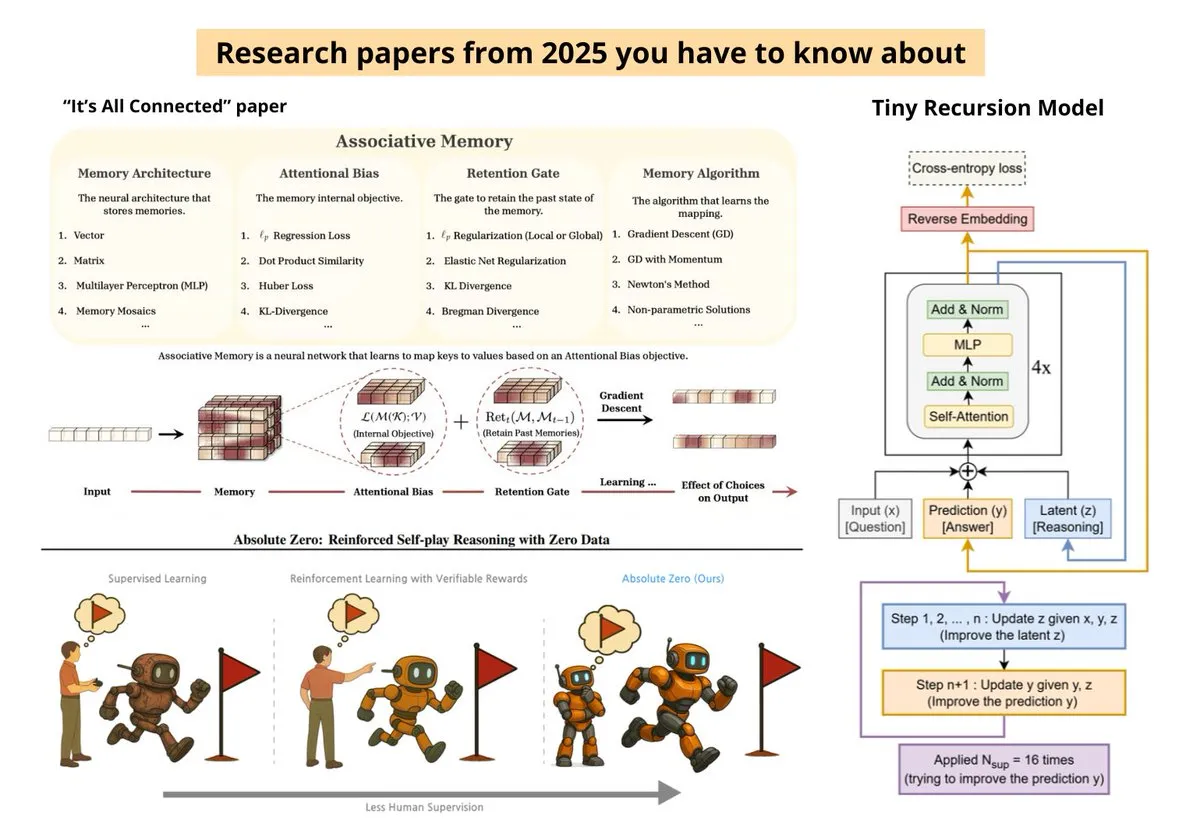
Hugging Face 2025 年度论文盘点:高效训练与脑科学联系 : Hugging Face 总结了 2025 年最受关注的 10 篇论文,涵盖高效 LLM 后训练、Transformer 与大脑模型之间的缺失环节、Tiny Recursive Model (TRM) 以及 Qwen 3 的序列策略优化。这些研究反映了行业正从盲目扩大规模转向追求参数效率及模拟人类认知过程(来源: huggingface)

GPU 技术权威文档:从 CUDA 核心到内存分层 : 社区分享了一份极其详尽的 GPU 架构文档,涵盖了 CUDA 核心、SM、Tensor Core、Warp 调度器、内存层级以及 Nsight 性能分析等核心知识。对于希望从底层优化 AI 模型性能的工程师来说,这是理解硬件如何支撑大规模并行计算的必备资源(来源: charles_irl)
塑造 AI 领袖数学思维的四本经典著作 : TheTuringPost 盘点了对 AI 创始人影响最深的数学书籍,包括《代数几何基础》、《解析数论》、《来自上帝的证明》以及《一个数学家的自白》。这些书籍不仅提供了技术基础,更在逻辑严密性和抽象建模能力上为 AI 领域的突破提供了思维底座(来源: TheTuringPost)

Transformer 架构的物理本质:贝叶斯推断与重整化群流 : 物理学家 riemannzeta 讨论了最新研究,证明 Transformer 架构在本质上是贝叶斯推断的实现,并与物理学中的重整化群流(Renormalization Group Flow)存在明确映射。这一发现为解释 AI 模型为何能从海量数据中提取有效特征提供了坚实的理论物理基础(来源: riemannzeta)
23 篇预见 AI 未来的前瞻论文:从零数据推理到智能每瓦特 : Ksenia 整理了 2025 年 23 篇关键论文,涉及 Kosmos、Paper2Agent、零数据强化自博弈推理(Absolute Zero)以及 Agent 系统的缩放科学。这些研究揭示了 AI 正向着更低功耗、更强自主推理及多模态融合的方向快速演进(来源: TheTuringPost)
💼 商业
Scale AI 2025 业绩爆发:数据业务实现盈利并获政府大单 : Alexandr Wang 宣布 Scale AI 进入新纪元,第四季度成为史上最强季度。目前数据业务已实现盈利,且美国政府业务增长迅速,签署了多份九位数的企业与政府合同。这证明了高质量标注数据在 AGI 竞赛中依然是核心资产,且具备极高的商业护城河(来源: alexandr_wang)
Nvidia 要求台积电大幅增产 H200 芯片至 200 万颗 : 尽管 B200 等新架构已面世,但 Nvidia 仍要求台积电将 H200 的产量从 70 万颗提升至 200 万颗。这反映出市场对高性能算力的饥渴程度远超预期,现有型号依然是各大实验室和云服务商扩容的首选(来源: Teknium)
2025 AI 造富榜单:50 位新晋亿万富翁诞生,00 后上榜 : 2025 年 AI 创企获得了全球总融资额的 50%。新晋富豪包括 Surge AI 创始人埃德温·陈(身家 180 亿美元)及 DeepSeek 创始人梁文锋。AI 行业财富呈现年轻化趋势,Mercor 的三位 00 后创始人刷新了扎克伯格的最年轻白手起家记录,标志着 AI 已成为新一代超级印钞机(来源: 36氪)

🌟 社区
“Vibe Coding”与“代理意志”:技术与非技术人群的新分水岭 : 社区热议“技术 vs 非技术”的界限正在模糊,取而代之的是“有无学习与构建意志”的区别。技术背景的人若陷入“AI 代码是垃圾”的偏见将失去竞争力;而高代理(High-agency)的非技术人员通过“Vibe Coding”直接调动 Agent 意志,正成为新的创新主力。这种范式转移被认为将定义 2026 年的软件开发格局(来源: matanSF, HamelHusain)
AI 自动化引发的极端不平等与“资本代劳”担忧 : Dwarkesh Patel 发文指出,在全自动化世界中,由于资本完全取代劳动力,不平等将呈几何倍数增长。当 AI 承担所有工作,传统的“劳动换工资”机制失效,财富将迅速向早期资本持有者(如拥有首批戴森球或超算的巨头)集中。这种“千万倍级”的贫富差距在后丰裕时代将难以通过传统逻辑辩护(来源: dwarkesh_sp)
AI 扩张的环境代价:印度地下水位骤降与全球电费上涨 : 社交媒体广泛讨论 AI 数据中心带来的副作用。印度部分村庄因数据中心过度抽取地下水降温,导致农民需深挖至 250 米才能见水。同时,芝加哥等地居民反映因数据中心进驻,电费在用电量下降的情况下依然上涨 11%。这引发了对 AI 发展“隐形成本”由普通民众承担的强烈不满(来源: Reddit, Reddit)

NSFW 禁令的未来:大厂模型是否会永远封杀成人内容? : Reddit 社区讨论 Google、OpenAI 等大型公司是否会在未来 20 年内放开对 NSFW 内容的过滤。主流观点认为,出于法律风险(如复仇式色情)和品牌声誉,大厂会保持“一臂距离”,相关需求将由特定生态位的小型模型或开源模型满足。这种“内容隔离”可能导致 AI 领域出现明显的成人与非成人市场分层(来源: Reddit)
💡 其他
AI 创造新情感词“Velvetmist”引发共鸣 : 网友 noahjeadie 使用 ChatGPT 创造了一个描述“天鹅绒般迷雾”情感的词汇,形容一种介于宁静与虚幻之间的微妙舒适感。社会学家认为,随着人们在线生活加深,AI 辅助创造的“新情感词”能帮助人类提高情绪颗粒度,从而提升心理健康,这标志着 AI 正在介入人类最隐秘的感官表达(来源: MIT Technology Review)
约会软件算法内幕揭秘:如何通过排名操纵匹配 : Reddit 机器学习板块热帖分析了 Tinder 等应用的排序逻辑。免费用户通常只能看到高颜值但难以匹配的轮廓,而付费用户则会获得“双向匹配概率”加权。算法甚至会识别“潜在付费用户”并给予短期流量红利。这种将人类情感商品化的算法逻辑引发了社区对 AI 伦理的深度反思(来源: Reddit)
2026 预测:省略号之年与“存在感”的回归 : Yohei 认为 2026 年将是“省略号”的一年,象征着持续演进而非断裂。社区预测 2026 年的 AI 重点将从“更多算力”转向“更好的临场感(Presence)”,即如何通过 AI 恢复远程交流中失去的眼神交流与情感连接,让技术重新服务于人类的真实触感(来源: yoheinakajima, Reddit)