
Schlüsselwörter:Souveräne KI, FSD, Kimi, Südkoreas Souveräne-KI-Initiative, Tesla FSD V14.2, Dark Side of the Moon K3-Modell
🔥 Fokus
Südkorea startet 140-Millionen-Dollar-Plan für „Sovereign AI“ zum Aufbau eines lokalen Ökosystems : Das südkoreanische Wissenschaftsministerium investiert gemeinsam mit fünf Giganten wie SKT, LG und Naver rund 140 Millionen US-Dollar in das Training lokaler Large Models, die keiner externen Kontrolle unterliegen. Bisher wurden mehrere Open-Source-Modelle veröffentlicht, darunter A(.)X-K1 (519B) von SKT und K-EXAONE (236B) von LG. Der Plan betont „Training from Scratch“ und „kommerzielle Offenheit“ und zielt darauf ab, durch die Bereitstellung von Rechenleistung und Datenunterstützung den Verlust digitaler Souveränität nach europäischem Vorbild zu verhindern und Südkorea zu einem wichtigen Akteur auf der globalen AI-Landkarte zu machen. Dieser Schritt wird in der Community als wegweisendes Ereignis gegen das Monopol US-amerikanischer Modelle wie OpenAI gewertet (Quelle: huggingface, ClementDelangue, aiamblichus)

Tesla FSD V14.2 schließt erste interventionsfreie Herausforderung quer durch die USA ab : Der Fahrer David Moss nutzte Tesla FSD V14.2 für eine Fahrt von 2.732 Meilen von Los Angeles nach South Carolina. Die gesamte Fahrt dauerte 2 Tage und 20 Stunden und markierte einen bedeutenden Durchbruch mit 0 Interventionen und 0 Übernahmen. Karpathy kommentierte, dass dies das ultimative Ziel des Autopilot-Teams bei dessen Gründung war und signalisiert, dass End-to-End Neural Networks die Reifephase für komplexe Langstreckenszenarien erreicht haben. Die Community sieht darin einen Beweis für die führende Rolle von Vision-Lösungen im Bereich des autonomen Fahrens, was jedoch auch Diskussionen über die regulatorische Anpassungsfähigkeit des zukünftigen Verkehrs auslöste (Quelle: karpathy, BorisMPower, chaitu)

Moonshot AI (Kimi) erhält 500 Millionen Dollar Finanzierung, All-in auf Reasoning-Modell K3 : Moonshot AI hat eine neue Finanzierungsrunde abgeschlossen, wodurch die Bewertung auf 4,3 Milliarden US-Dollar steigt und die Barreserven 10 Milliarden RMB übersteigen. Gründer Yang Zhilin erklärte, dass die Anreize für Talente im Jahr 2026 massiv erhöht werden, mit einer durchschnittlichen Steigerung auf 200 % des Vorjahres. Der strategische Schwerpunkt hat sich vom Traffic-Einkauf auf grundlegende Fähigkeiten verlagert. Das K3-Modell wird durch die vertikale Integration von Trainingstechnologien und Agent-Produktstärke eher die Grenzen der Intelligenz als die reine Nutzerzahl anstreben. Dieser Schritt spiegelt den Konsens chinesischer Modellhersteller wider, nach dem DeepSeek-Schock kollektiv auf technologiegetriebene Ansätze und globale Kommerzialisierung umzuschwenken (Quelle: Reddit, 36氪)

Talentkrieg im Silicon Valley eskaliert: Meta übernimmt Manus für 2 Milliarden Dollar, um Agent-Kernkompetenzen zu sichern : Meta hat das Agent-Unternehmen Manus für über 2 Milliarden US-Dollar übernommen und bietet Top-Talenten „explosive Offers“ ab 100 Millionen US-Dollar an. Derzeit besetzen zahlreiche chinesische Eliten wie Alexandr Wang und Zhao Shengjia Schlüsselpositionen im Bereich AI im Silicon Valley. Der Branchenschwerpunkt verlagert sich vom reinen „Benchmark-Ranking“ hin zur „Engineering-Umsetzung“, also der Frage, wer Modelle in ausführbare Systeme (Agent) verwandeln kann. Dieser Übergang von der Grundlagenforschung zur Produktzentrierung führt zu Machtverschiebungen und Talentabwanderungen in traditionellen Forschungslaboren wie FAIR (Quelle: TheRundownAI, 36氪)

🎯 Trends
Qwen-Image-2512 veröffentlicht: Deutliche Verbesserung bei Realismus und Text-Rendering : Alibaba hat das Dezember-Update des multimodalen Modells Qwen-Image veröffentlicht. Der Fokus lag auf der Optimierung von Hautdetails, natürlichen Texturen und der Textwiedergabe in Bildern, wodurch der „AI-Look“ deutlich reduziert wurde. Das Modell ist zeitgleich auf Hugging Face und Replicate erschienen und unterstützt komplexere visuelle Verständnisaufgaben. Die Community lobt die Leistung bei realistischen Porträts und der Erkennung von Bildern mit langem Text, was es zu einem starken Konkurrenten im Open-Source-Bereich für Multimodalität macht (Quelle: huggingface, Alibaba_Qwen)
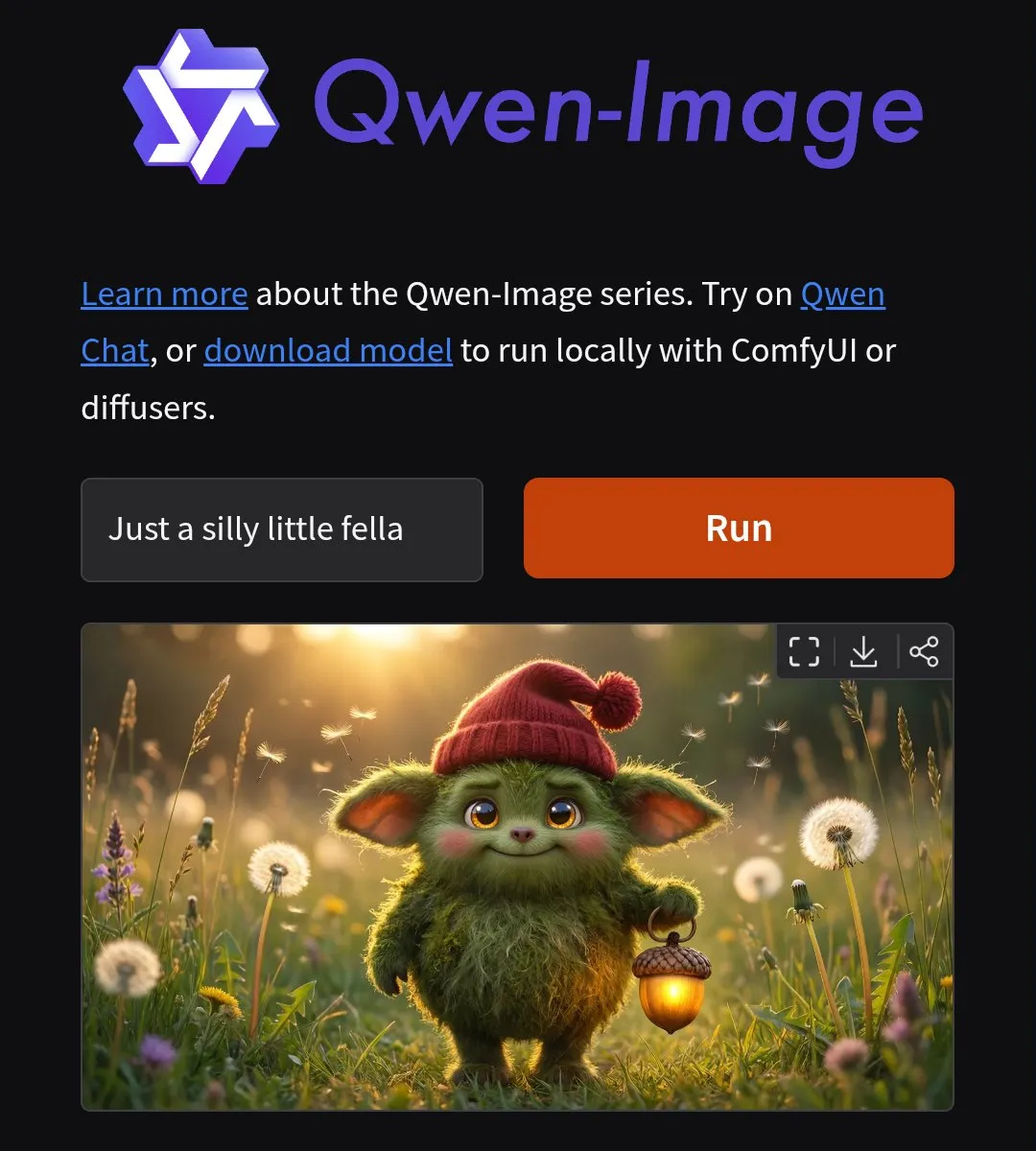
GLM-4.7 und MiniMax M2.1 kämpfen um den Spitzenplatz in Open-Source-Modell-Benchmarks : Im neuesten GDPval-AA-Ranking wurde GLM-4.7 mit einem ELO-Score von 1224 zum Spitzenreiter bei Open-Source-Weights. Gleichzeitig glänzte MiniMax M2.1 bei der Befolgung von Anweisungen und der Forschungsunterstützung. Entwicklertests zeigen, dass GLM-4.7 beim Refactoring von Python-Backends und der Pflege langer Kontexte besser als Qwen abschneidet, bei komplexem Architekturdesign jedoch noch generisch wirkt. Die schnelle Iteration dieser beiden Modelle markiert, dass chinesische Open-Source-Modelle in den Bereichen Programmierung und logisches Denken bereits mit Top-Modellen wie Sonnet konkurrieren können (Quelle: huggingface, Reddit)
DeepSeek-Bibliotheken tief optimiert: 30 % Leistungssteigerung und Anpassung an B200-Chips : Community-Entwickler haben begonnen, DeepSeek-bezogene Bibliotheken einzeln zu optimieren. Durch technische Mittel wie CuTeDSL wurde auf NVIDIA B200-Chips eine Steigerung der Laufgeschwindigkeit um 20 % bis 30 % erreicht. Diese hardwarespezifische Feinabstimmung deutet darauf hin, dass die AI-Branche in die Phase „Effizienz ist König“ eintritt, in der bei begrenzter Rechenleistung die Inferenzleistung durch Low-Level-Engineering maximiert wird (Quelle: QuixiAI)

Neuralink kündigt Start der Hochvolumenproduktion von Brain-Computer Interfaces für 2026 an : Elon Musk verriet, dass Neuralink bis 2026 eine vollständige Automatisierung der Operationen erreichen wird, bei der Roboter die Implantation des Brain-Computer Interface übernehmen. Die neue Technologie ermöglicht es, Elektrodenfäden durch die Dura Mater zu führen, ohne diese entfernen zu müssen, was das Operationsrisiko erheblich senkt. Ziel ist es, Brain-Computer Interfaces von experimenteller Medizin in den Massenmarkt zu bringen, um eine Hochbreitbandverbindung zwischen Mensch und AI zu realisieren (Quelle: teortaxesTex)
Googles dreijährige Aufholstrategie im Überblick: Vom „Code Red“ zum umfassenden Gegenangriff : Durch die Fusion von Google Brain und DeepMind zu Google DeepMind wurde Hassabis als Anführer etabliert und Veteranen wie Noam Shazeer zurückgeholt, um die bisherige Bürokratie des „Veröffentlichung nur bei Perfektion“ zu durchbrechen. Derzeit beschleunigt Google in den Bereichen Modelle (Gemini 3), Chips (TPU) und Anwendungen an allen Fronten, was OpenAI ebenfalls in einen „Code Red“-Zustand versetzt. Diese Wende zeigt die enorme Schlagkraft eines Giganten nach einer organisatorischen Neugestaltung (Quelle: 36氪)

🧰 Tools
Claude Code eröffnet neues Programmierparadigma „Vibe Coding“ : Die Entwickler-Community reagiert begeistert auf Claude Code von Anthropic und lobt dessen Leistung bei ASCII-Art-Visualisierung, dem Verständnis hierarchischer Architekturen und automatischem Debugging. Nutzer können durch „Vibe Coding“ komplexe Web-Anwendungen mobil oder vom Bett aus entwickeln. Trotz eines 2X-Token-Limits entscheiden sich viele Entwickler aufgrund des Produktivitätssprungs gegen Cursor und bauen stattdessen eigene MCP-basierte Workflows (Quelle: brivael, omarsar0, Reddit)
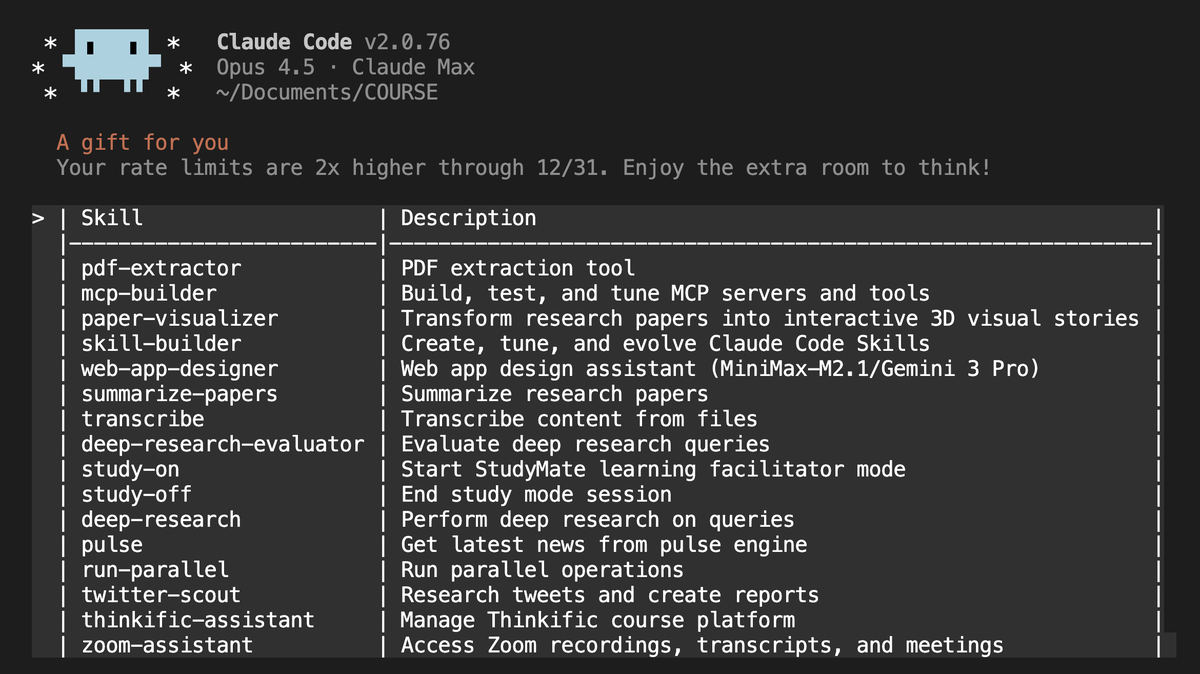
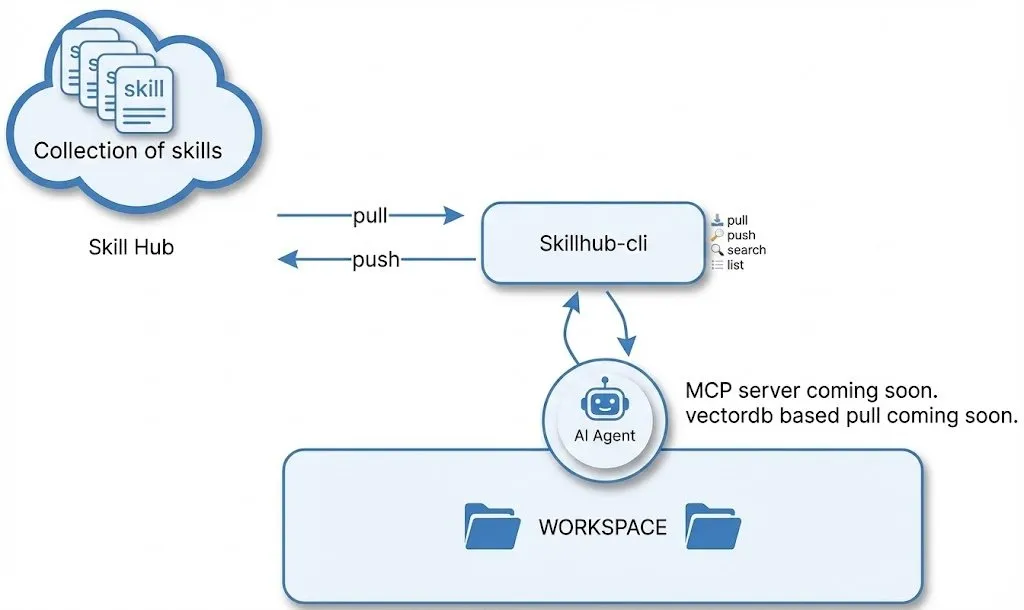
SkillHub: Ein „Homebrew“-Register für AI Agent Workflows : SkillHub ermöglicht es Entwicklern, erfolgreiche AI-Task-Workflows zu speichern, zu laden und wiederzuverwenden. Es löst das Problem, bei jedem neuen Projekt Prompts neu schreiben zu müssen, und unterstützt die modell- und plattformübergreifende Nutzung. Dieses Modell eines „Workflow-Stores“ wird als wichtige Infrastruktur für die Skalierung von Agents angesehen, wodurch komplexe AI-Fähigkeiten wie Softwarepakete verteilt werden können (Quelle: QuixiAI)
Pommel: Lokales semantisches Suchtool zur Lösung des Kontextverbrauchs von Claude Code : Pommel ist ein Open-Source-Tool für die lokale semantische Codesuche, das AI-Agents durch eine lokale Vektordatenbank (sqlite-vec) hilft, Codeabschnitte präzise zu lokalisieren. Es verhindert, dass Claude Code beim Verständnis eines Projekts blind große Mengen irrelevanter Dateien liest, wodurch bis zu 50 % des Kontextfensters eingespart werden können. Unterstützt werden derzeit Sprachen wie Python, Go und Java (Quelle: Reddit)
EmbeddingAdapters: Bibliothek zur modellübergreifenden Vektorraum-Konvertierung : Diese Python-Bibliothek bietet vortrainierte Adapter, um Vektoren, die von kleinen lokalen Modellen (wie MiniLM) generiert wurden, in hochdimensionale Vektorräume wie die von OpenAI oder Gemini zu übersetzen. Dies ermöglicht es Entwicklern, Vektordatenbanken zu migrieren, ohne den gesamten Korpus neu einzubetten, und erlaubt effizientes lokales RAG-Retrieval in Offline-Umgebungen (Quelle: Reddit)
Manus veröffentlicht Slack-Connector zur Umwandlung von Dialogen in handlungsrelevantes Wissen : Manus hat einen Slack Connector eingeführt, der darauf abzielt, fragmentierte Slack-Chatverläufe in eine durchsuchbare, ausführbare und strukturierte Wissensdatenbank zu verwandeln. Dies löst das Problem des Wissensverlusts in Chat-Streams und markiert die Entwicklung von Agents hin zu Wissensmanagement-Zentralen in Unternehmen (Quelle: hidecloud)
📚 Lernen
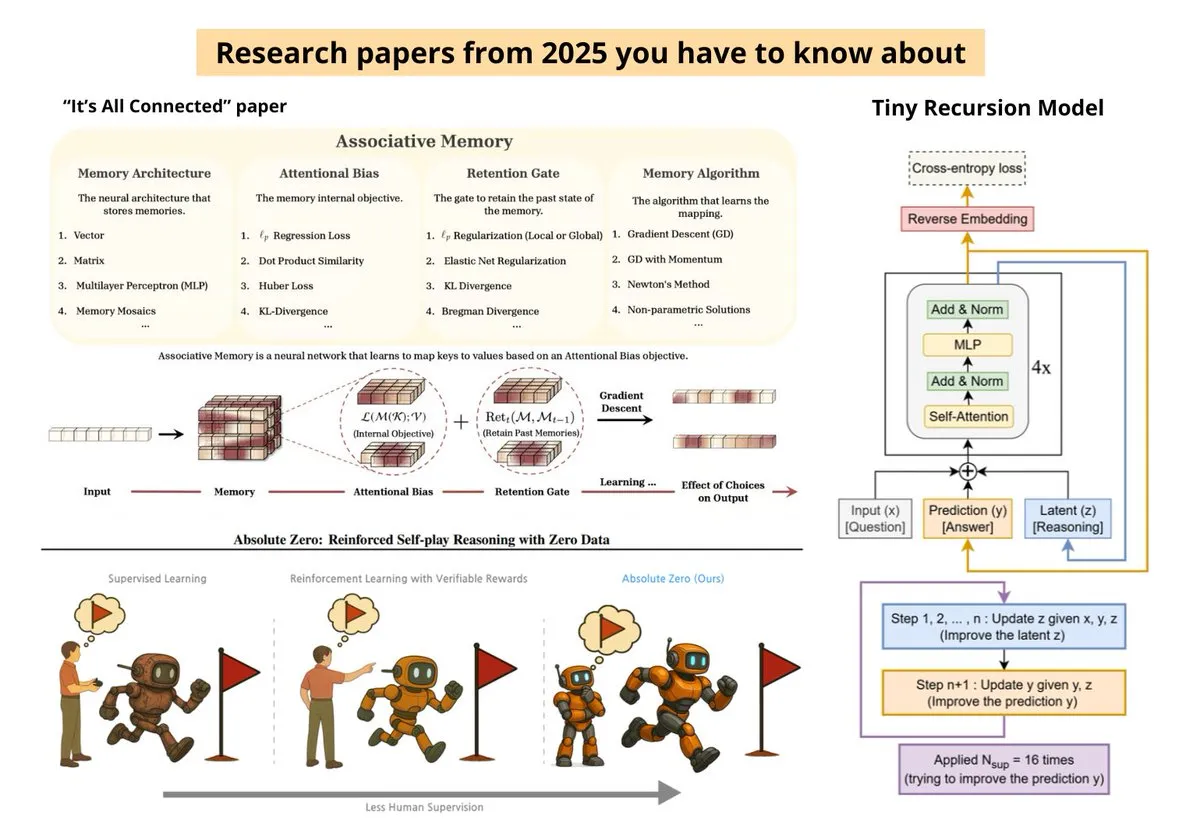
Hugging Face 2025 Paper-Review: Effizientes Training und Verbindung zur Neurowissenschaft : Hugging Face fasst die 10 meistbeachteten Paper des Jahres 2025 zusammen, darunter effizientes LLM Post-Training, die fehlende Verbindung zwischen Transformer und Gehirnmodellen, das Tiny Recursive Model (TRM) sowie die Optimierung der Sequenzstrategie von Qwen 3. Diese Studien spiegeln den Trend weg von blinder Skalierung hin zu Parametereffizienz und der Simulation menschlicher kognitiver Prozesse wider (Quelle: huggingface)

Autoritative Dokumentation zur GPU-Technologie: Von CUDA-Kernen bis zur Speicherhierarchie : Die Community teilt ein extrem detailliertes Dokument zur GPU-Architektur, das Kernwissen zu CUDA-Kernen, SM, Tensor Cores, Warp-Schedulern, Speicherhierarchien und Nsight-Performance-Analyse abdeckt. Für Ingenieure, die AI-Modelle auf unterster Ebene optimieren wollen, ist dies eine unverzichtbare Ressource (Quelle: charles_irl)
Vier klassische Werke, die das mathematische Denken von AI-Leadern prägen : TheTuringPost listet mathematische Bücher auf, die AI-Gründer am stärksten beeinflusst haben, darunter „Foundations of Algebraic Geometry“, „Analytic Number Theory“, „Proofs from THE BOOK“ und „A Mathematician’s Apology“. Diese Bücher bieten nicht nur technische Grundlagen, sondern auch das logische Fundament für Durchbrüche im AI-Bereich (Quelle: TheTuringPost)

Die physikalische Natur der Transformer-Architektur: Bayesian Inference und Renormalization Group Flow : Der Physiker riemannzeta diskutiert aktuelle Forschungen, die belegen, dass die Transformer-Architektur im Kern eine Implementierung von Bayesian Inference ist und eine klare Abbildung auf den Renormalization Group Flow in der Physik aufweist. Diese Entdeckung liefert eine solide theoretische Basis dafür, warum AI-Modelle effektive Merkmale aus riesigen Datenmengen extrahieren können (Quelle: riemannzeta)
23 zukunftsweisende Paper zur AI-Zukunft: Von Zero-Data Reasoning bis Intelligence per Watt : Ksenia hat 23 Schlüssel-Paper für 2025 zusammengestellt, die Themen wie Kosmos, Paper2Agent, Zero-Data Reinforcement Self-Play Reasoning (Absolute Zero) und die Scaling Science von Agent-Systemen behandeln. Diese Studien zeigen, dass sich AI in Richtung geringerem Stromverbrauch, stärkerem autonomen Denken und multimodaler Fusion entwickelt (Quelle: TheTuringPost)
💼 Business
Scale AI 2025 Performance-Explosion: Datengeschäft profitabel und Großaufträge der Regierung : Alexandr Wang verkündete den Beginn einer neuen Ära für Scale AI, wobei das vierte Quartal das stärkste der Geschichte war. Das Datengeschäft ist nun profitabel, und das US-Regierungsgeschäft wächst rasant mit mehreren neunstelligen Verträgen. Dies beweist, dass hochwertige Label-Daten im AGI-Wettlauf weiterhin ein Kernasset mit hohem Burggraben sind (Quelle: alexandr_wang)
Nvidia fordert TSMC auf, die Produktion von H200-Chips massiv auf 2 Millionen Einheiten zu steigern : Obwohl neue Architekturen wie B200 bereits auf dem Markt sind, hat Nvidia TSMC angewiesen, die Produktion von H200 von 700.000 auf 2 Millionen Einheiten zu erhöhen. Dies spiegelt den unerwartet hohen Hunger des Marktes nach Hochleistungs-Rechenleistung wider, wobei bestehende Modelle weiterhin die erste Wahl für Labore und Cloud-Anbieter sind (Quelle: Teknium)
AI-Reichtumsliste 2025: 50 neue Milliardäre geboren, Generation Z auf der Liste : Im Jahr 2025 erhielten AI-Startups 50 % des weltweiten Finanzierungsvolumens. Zu den neuen Superreichen gehören Surge AI-Gründer Edwin Chen (Vermögen 18 Mrd. USD) und DeepSeek-Gründer Liang Wenfeng. Der Reichtum in der AI-Branche wird jünger: Die drei Gründer von Mercor (Jahrgang 2000+) brachen Zuckerbergs Rekord als jüngste Selfmade-Milliardäre (Quelle: 36氪)

🌟 Community
„Vibe Coding“ und „Agentic Will“: Die neue Wasserscheide zwischen technischen und nicht-technischen Gruppen : Die Community diskutiert darüber, dass die Grenze zwischen „technisch“ und „nicht-technisch“ verschwimmt und durch den Unterschied zwischen „Willen zum Lernen und Bauen“ ersetzt wird. Fachleute, die dem Vorurteil verfallen, dass „AI-Code Müll ist“, werden an Wettbewerbsfähigkeit verlieren; während High-agency Nicht-Techniker durch „Vibe Coding“ direkt den Willen von Agents mobilisieren und zur neuen Innovationskraft werden (Quelle: matanSF, HamelHusain)
Extreme Ungleichheit durch AI-Automatisierung und Sorgen über „Kapital-Stellvertretung“ : Dwarkesh Patel weist darauf hin, dass in einer vollautomatisierten Welt die Ungleichheit geometrisch wachsen wird, da Kapital die Arbeit vollständig ersetzt. Wenn AI alle Aufgaben übernimmt, versagt der traditionelle Mechanismus „Arbeit gegen Lohn“, und Reichtum konzentriert sich bei frühen Kapitalbesitzern. Diese millionenfache Kluft zwischen Arm und Reich wird in einer Post-Scarcity-Ära schwer zu rechtfertigen sein (Quelle: dwarkesh_sp)
Umweltkosten der AI-Expansion: Sinkende Grundwasserspiegel in Indien und weltweit steigende Strompreise : In sozialen Medien werden die Nebenwirkungen von AI-Rechenzentren diskutiert. In einigen indischen Dörfern müssen Bauern bis zu 250 Meter tief graben, um Wasser zu finden, da Rechenzentren das Grundwasser zur Kühlung absaugen. Gleichzeitig berichten Bewohner in Chicago, dass ihre Stromrechnungen trotz sinkenden Verbrauchs um 11 % gestiegen sind, seit Rechenzentren eingezogen sind (Quelle: Reddit, Reddit)

Die Zukunft des NSFW-Verbots: Werden große Modellhersteller Erotikinhalte für immer sperren? : Die Reddit-Community diskutiert, ob Google, OpenAI und Co. in den nächsten 20 Jahren die Filter für NSFW-Inhalte lockern werden. Die Mehrheit glaubt, dass die großen Player aufgrund rechtlicher Risiken und des Markenrufs Distanz wahren werden, während Nischenbedarfe durch kleinere oder Open-Source-Modelle gedeckt werden. Diese „Inhalts-Isolation“ könnte zu einer deutlichen Marktsegmentierung führen (Quelle: Reddit)
💡 Sonstiges
AI erschafft neues Gefühlswort „Velvetmist“ und löst Resonanz aus : Der Nutzer noahjeadie kreierte mit ChatGPT das Wort „Velvetmist“, um ein Gefühl zwischen Ruhe und Illusionshaftigkeit zu beschreiben. Soziologen glauben, dass AI-gestützte Neologismen Menschen helfen können, ihre emotionale Granularität zu erhöhen und das psychische Wohlbefinden zu steigern, was zeigt, dass AI in die intimsten Bereiche menschlichen Ausdrucks vordringt (Quelle: MIT Technology Review)
Insider-Einblicke in Dating-App-Algorithmen: Wie Rankings Matches manipulieren : Ein populärer Post im Machine Learning-Subreddit analysiert die Sortierlogik von Apps wie Tinder. Kostenlose Nutzer sehen oft attraktive, aber schwer erreichbare Profile, während zahlende Nutzer eine Gewichtung der „gegenseitigen Match-Wahrscheinlichkeit“ erhalten. Algorithmen identifizieren sogar „potenzielle Zahler“ und geben ihnen kurzfristige Reichweitenvorteile (Quelle: Reddit)
Prognose für 2026: Das Jahr der Auslassungspunkte und die Rückkehr der „Präsenz“ : Yohei glaubt, dass 2026 das Jahr der „Auslassungspunkte“ sein wird, ein Symbol für kontinuierliche Entwicklung statt Bruch. Die Community prognostiziert, dass sich der AI-Fokus von „mehr Rechenleistung“ hin zu „besserer Präsenz (Presence)“ verlagern wird – also der Frage, wie AI verloren gegangenen Blickkontakt und emotionale Verbindung in der digitalen Kommunikation wiederherstellen kann (Quelle: yoheinakajima, Reddit)