
关键词:AI编程, 神经网络, 算力基建, Claude Code, mHC论文, 小型模块化反应堆
🔥 聚焦
Claude Code 引发“编程奇点”热议 : Midjourney 创始人 David Holz 称其在圣诞假期通过 AI 完成的编程量超过过去十年总和,马斯克对此评论“我们已进入奇点”。Anthropic 推出的 Claude Code 配合 Opus 4.5 模型,在自主编码任务中表现出惊人的长程能力。谷歌、Anthropic 的多位资深工程师表示,该工具能将数年的工程量压缩至数月,标志着软件工程从“手动编写”向“意图审查”的范式转移。这种“Vibe Coding”热潮预示着 2026 年自然语言将正式成为新的编程语法(来源:DavidSHolz, elonmusk)

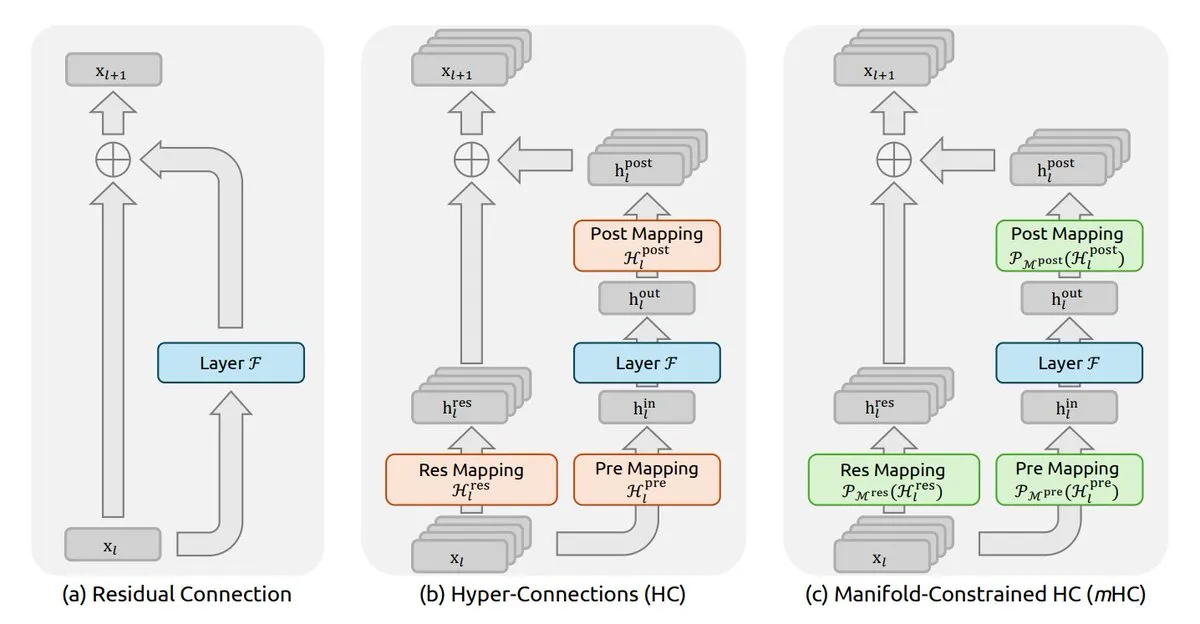
DeepSeek 发布 mHC 论文重塑神经网络连接 : DeepSeek 团队发布了《流形约束超连接(mHC)》论文,迅速成为 2026 年学术界必读之作。mHC 旨在解决超连接(Hyper-Connections)中的不稳定性,通过“流形约束”确保残差流在信息共享时保持信号强度稳定。社区专家如 Tom Yeh 甚至通过 Excel 手拆其背后的 Sinkhorn–Knopp 算法和 Birkhoff 多面体逻辑。这一突破被认为是大模型架构效率的“护城河”,进一步巩固了 DeepSeek 在算法创新领域的领先地位(来源:ProfTomYeh, TheTuringPost)
Anthropic 采购百万颗 TPU 挑战算力格局 : 消息称 Anthropic 绕过云服务商,直接从博通(Broadcom)购买近 100 万颗 TPU v7 芯片,并部署在自控设施中。总裁 Daniela Amodei 指出,未来竞争不再是单纯比拼模型大小,而是“把算力花对”。此举意味着 Anthropic 正在从租用算力的轻资产模式转向重资产布局,旨在降低每 FLOP 成本并摆脱对单一供应商的依赖,同时也为 2026 年的 IPO 铺平道路(来源:SemiAnalysis, 36氪)

Gemini 3.0 Pro 破解 500 年历史天书 : 谷歌 Gemini 3.0 Pro 仅用一小时便破解了《纽伦堡编年史》中困扰历史学家 500 年的手写注释。AI 通过微米级的视觉识别和跨语境推理,识别出这些拉丁缩写并非涂鸦,而是两种圣经年代学体系的换算表。这一案例展示了多模态大模型在人文考古领域的“降维打击”能力,证明了 AI 在处理大规模检索与长链条逻辑推理任务上已超越人类专家经验(来源:SiliconAngle)

🎯 动向
OpenAI 押注“音频优先”与无屏设备 : OpenAI 计划于 2026 年 Q1 发布新一代音频模型,支持实时打断和双向对话。与此同时,由 Jony Ive 设计的“无屏 AI 设备”(疑似 AI 笔)已进入长期规划。Sam Altman 认为屏幕限制了 AI 的可能性,未来 AI 应作为“环境中的存在”通过语音和感知介入生活。这一转向反映了硅谷在交互范式上的集体共识:弱化视觉占用,强化环境智能(来源:第一新声)
核能成为 AI 算力基建的“硅谷时刻” : 随着 AI 对电力需求的爆炸式增长,微软、谷歌、亚马逊等巨头正取代政府成为小型模块化反应堆(SMR)的核心推动者。SMR 具备建设周期短、工厂量产等优势,能提供 24/7 的稳定清洁电力。未来五年被视为 SMR 规模化落地的关键窗口期,核能将成为清洁电网的坚实底座,解决 AI 发展撞上的“物理墙”问题(来源:硬AI)
MiniMax M2.1 发布及其 2026 路线图 : MiniMax 发布 M2.1 技术博客,重点展示了其在多样化环境(多语言、多任务覆盖)下的强化学习(RL)成果。其 2026 路线图聚焦于 RL 扩展,包括算法、算力及数据质量的全面提升,并计划对代码执行和用户行为进行深度建模。目前其 M2.1 模型在编程和推理任务上表现强劲,已吸引大量开发者关注(来源:MiniMax__AI, eliebakouch)

Scaling Law 的三条新增长曲线 : 黄仁勋提出 Scaling Law 并未失效,而是演变为预训练、后训练及推理时(Test-time compute)三条曲线。Gemini 3 的跨越式进步证明了预训练仍有改进空间。算力的作用正从直接转化智能转变为加速实验迭代的“扩展实验定律”。尽管单纯堆参数收益递减,但通过 o1、DeepSeek-R1 等模型的推理时计算,AI 能力仍在持续向上突破(来源:硅星人Pro)
智谱与 MiniMax 开启 IPO 进程 : 国内大模型“六小龙”出现分化,智谱和 MiniMax 计划于 2026 年初在港股挂牌,旨在通过上市获取更多“弹药”应对大厂竞争。智谱拟募资约 43 亿港元,MiniMax 最高募资约 42 亿港元。这标志着国内大模型竞争进入商业化变现与资本效率的新阶段,创业公司正努力在大厂的流量缝隙中寻找生存空间(来源:窄播)
🧰 工具
Flakestorm:LangChain 智能体的变异测试工具 : Flakestorm 是一款专门针对 LangChain 智能体的鲁棒性测试工具。它通过输入变异(如错别字、格式变化、语气转变)来捕捉评估中容易遗漏的故障。该工具能揭示生产环境前的隐藏漏洞,帮助开发者构建更可靠的 AI 应用,确保智能体在面对非标准输入时依然能稳定运行(来源:LangChainAI)

Adaptive-P:llama.cpp 的新型创造性采样器 : Adaptive-P 是一种旨在解决模型陷入预测模式的新型采样方法。它不采用传统的温度缩放,而是让用户指定目标概率范围,通过 Preference Curve 增强目标附近的 token。该采样器维护一个 EMA 历史记录,能自动打破重复的高置信度链条,非常适合小说创作、角色扮演和头脑风暴等需要多样性的场景(来源:llama.cpp, Reddit)

VectorDBZ:本地向量数据库 GUI 管理工具 : VectorDBZ 是一款专注于本地工作流的桌面应用,支持 pgvector、Qdrant、Chroma、Milvus 和 Weaviate。它允许用户直接浏览集合、运行相似性搜索,并通过 PCA/t-SNE 可视化嵌入分布。该工具解决了云原生工具难以调试本地 RAG 管道的痛点,所有配置和 API 密钥均存储在本地,确保数据隐私(来源:Reddit)
fastapi-fullstack:全栈 AI 应用 CLI 生成器 : 该工具由 LangChain 社区开发,支持一键生成包含 FastAPI、Next.js、身份验证及 WebSocket 流媒体的生产级 AI 应用。最新版本增加了对 LangGraph ReAct 智能体的支持,并集成了 LangSmith 可观测性,极大缩短了从原型到生产的开发周期(来源:LangChainAI)

📚 学习
RLHF 权威指南 2026 版大幅更新 : Nathan Lambert 对其《RLHF Book》进行了全面修订,内容从 150 页扩充至 200 页。新增了 GSPO、CISPO 等最新算法章节,更新了推理模型技术报告对比表,并增加了关于 RLVR 的评分标准。该书被认为是目前理解对齐技术和合成数据最前沿的教材,特别强调了从 Constitutional AI 到现代推理模型的演进路径(来源:swyx)
斯坦福 CS336:后 AI 泡沫时代的必修课 : 随着 DeepSeek 等高效模型的崛起,斯坦福 CS336 课程(从零构建 LLM)在社区热度飙升。该课程教导学生从架构层面理解 MoE 效率、mHC 等核心技术,而非仅仅作为 API 消费者。社区认为,只有深入到预训练和底层架构,才能在算力平权时代构建真正的技术护城河(来源:stanfordnlp)

SWE-EVO:长程软件演化评估基准 : 传统基准常优化错误的目标,新研究提出的 SWE-EVO 专注于长程软件演化。它要求智能体处理平均涉及 21 个文件、610 行代码修改的任务。结果显示,GPT-5 在 SWE-Bench 上得分 65%,但在 SWE-EVO 上仅为 21%,揭示了当前智能体在处理遗留代码库和跨文件语义推理方面的巨大鸿沟(来源:omarsar0)

从代码模型到智能体的全面综述 : 论文《From Code Foundation Models to Agents and Applications》提供了一份关于代码智能的实践指南。该综述涵盖了从基础代码模型到能够自主执行任务的 Agent 架构,分析了当前在代码补全、修复及复杂系统构建中的应用现状,是开发者进阶 AI 编程领域的深度参考资料(来源:dl_weekly)
💼 商业
Meta 20 亿美元“闪电收购”智能体公司 Manus : 2025 年底,Meta 斥资 20 亿美元收购了成立仅三年的 AI Agent 创业公司 Manus。Manus 凭借“通用自主智能体”概念在 8 个月内实现 1.25 亿美元年化收入。扎克伯格此举被视为缓解 Meta 在 Agent 能力上的焦虑,试图通过集成 Manus 团队来补齐 Llama 4 在实际任务执行上的短板(来源:36氪)
智身科技完成数亿元融资,小米铁蛋前负责人掌舵 : 具身智能创企智身科技宣布完成连续多轮融资,由智元机器人、金马游乐等产业资本投资。公司由原小米“铁蛋”项目负责人刘宇龙创立,已实现四足机器人钢镚 L1 和铜锤 M1 的规模化量产,并开源了 MATRiX 仿真平台。资金将用于加速产品规模化落地和生态建设(来源:36氪)

尧乐科技获近亿元 Pre-A 轮融资,深耕柔性触觉感知 : 柔性织物压力传感器研发商尧乐科技完成近亿元融资,科沃斯参股基金领投。公司创新性提出“织物即传感器”,产品已进入多家头部车企供应链,提供智能座舱感知方案。随着具身智能向实际场景落地,大面积柔性触觉感知将成为机器人与人频繁交互的刚需(来源:36氪)

🌟 社区
纳德拉“AI Slop”言论引发舆论反弹 : 微软 CEO 纳德拉呼吁行业跳出“AI 垃圾内容(slop)与高端体验”的争论,构建 AI 应用新共识。然而,用户对此强烈不满,认为“slop”反映的是 AI 输出的低价值和错误,而非品牌问题。社区批评微软将 Copilot 强行植入产品忽视用户体验,甚至出现了“Microslop”这一讽刺热词(来源:36氪, Reddit)

Vibe Coding 带来的认知疲劳与“隐性疲劳” : 随着 Cursor 和 Claude Code 的普及,开发者正从“生产者”转变为“审查者”。Stephan Schmidt 指出,这种高频的上下文切换和对 AI 意图的猜测导致大脑“过热”。AI 并没有减少工作量,而是将体力活变成了超负荷的认知空转。社区建议有意识控制节奏,进行手动回顾,避免沦为算力机器的零件(来源:36氪)

Grok 与 ChatGPT 的“安全对话” : 针对 Grok 生成未成年人及极端主义图像的争议,有用户模拟了 ChatGPT 与 Grok 的辩论。Grok 在对话中承认执行层面存在“为了参与度而牺牲安全”的偏差,而 ChatGPT 则坚持“谨慎是公共 AI 的底线”。这场讨论揭示了 AI 厂商在“真理追求”与“风险 containment”之间的利益冲突(来源:Reddit)
AI 时代的信息组织:Gen Z 放弃文件夹 : 社区讨论指出,Gen Z 越来越不关心传统的文件夹结构。文件夹代表“预先确定的确定性”,而 AI 时代的标签、全局搜索和动态召回(如 Readwise)让信息能够随时间自然浮现。系统应该负责“记忆”,而不是让用户在捕获信息时就决定其归属(来源:scottastevenson)
💡 其他
Meta 发布“红利奖励”训练 AI 科学家 : Meta 推出使用 Rubric Rewards 训练 AI 共同科学家的研究,并开源了训练和评估数据集。通过 RL 训练,AI 在科学研究任务中的表现获得了 70% 的人类胜率。这预示着 AI 将从简单的知识检索向深度科学发现和假设验证阶段进化(来源:lateinteraction)

10Kh RealOmni-Open:最大规模具身 AI 数据集 : Genrobot.AI 开源了 10Kh RealOmni-Open 数据集,包含超过 1 万小时、100 万个剪辑,覆盖 3000 多个真实家庭场景。这是目前全球最大、泛化性最强的具身智能数据集,旨在解决机器人研究中极度匮乏的真实世界交互数据问题(来源:huggingface)
AI 辅助医疗:CES 2026 上的新亮点 : 在 CES 2026 上,AI 辅助检测乳腺癌的应用 HopeValley 受到关注。该应用通过 AI 算法提高早期筛查的准确率,展示了 AI 在医疗健康领域的实际落地价值。此外,脑机接口、可穿戴设备等 AI 原生硬件也成为今年展会的绝对主角(来源:TheTuringPost)