
Palavras-chave:Programação com IA, Redes neurais, Infraestrutura de computação, Claude Code, Artigo mHC, Reator modular pequeno
🔥 Destaques
Claude Code gera discussões sobre a “Singularidade da Programação”: O fundador da Midjourney, David Holz, afirmou que a quantidade de programação que realizou via AI durante as férias de Natal superou o total dos últimos dez anos. Elon Musk comentou: “Entramos na singularidade”. O Claude Code lançado pela Anthropic, em conjunto com o modelo Opus 4.5, demonstrou uma capacidade surpreendente de longo alcance em tarefas de codificação autônoma. Vários engenheiros seniores do Google e da Anthropic afirmaram que a ferramenta pode comprimir anos de engenharia em meses, marcando uma mudança de paradigma da “escrita manual” para a “revisão de intenção” na engenharia de software. Essa febre de “Vibe Coding” prevê que, em 2026, a linguagem natural se tornará oficialmente a nova sintaxe de programação (Fonte: DavidSHolz, elonmusk)

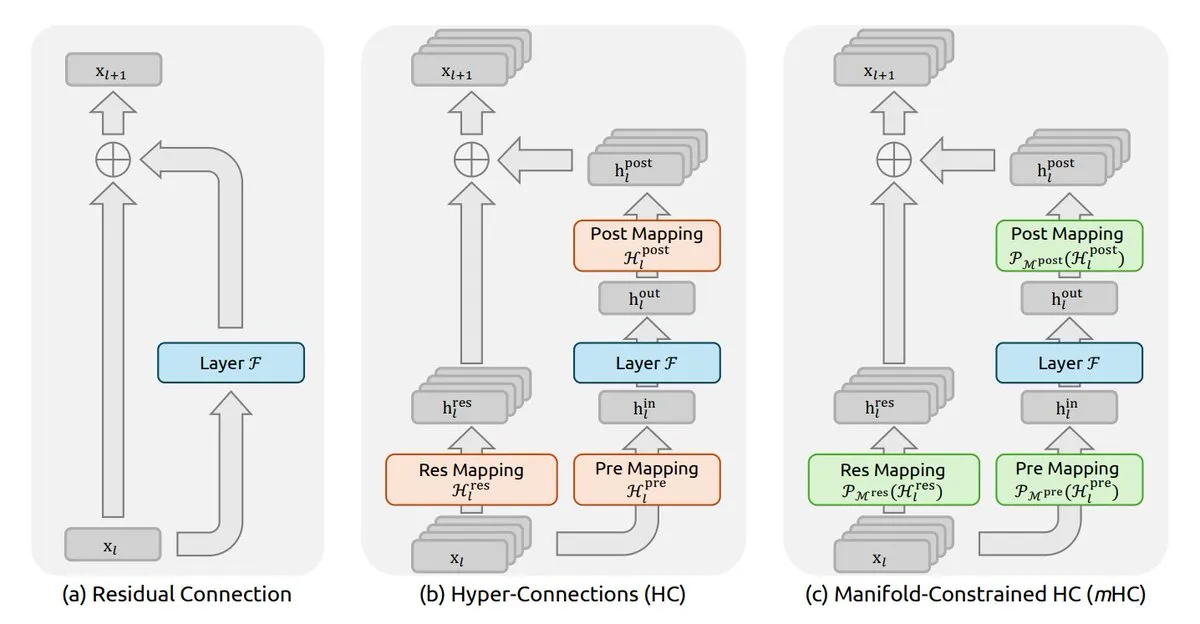
DeepSeek publica artigo sobre mHC para remodelar conexões de redes neurais: A equipe da DeepSeek publicou o artigo “Manifold-constrained Hyper-Connections (mHC)”, que se tornou rapidamente uma leitura obrigatória no meio acadêmico em 2026. O mHC visa resolver a instabilidade em Hyper-Connections, garantindo que o fluxo residual mantenha a força do sinal estável durante o compartilhamento de informações através de “restrições de manifold”. Especialistas da comunidade, como Tom Yeh, chegaram a decompor a lógica do algoritmo Sinkhorn–Knopp e do polítopo de Birkhoff por trás disso usando Excel. Este avanço é considerado o “fosso” de eficiência para arquiteturas de grandes modelos, consolidando ainda mais a liderança da DeepSeek em inovação algorítmica (Fonte: ProfTomYeh, TheTuringPost)
Anthropic adquire um milhão de TPUs para desafiar o cenário de poder computacional: Informações indicam que a Anthropic contornou provedores de serviços em nuvem para comprar quase 1 milhão de chips TPU v7 diretamente da Broadcom, implantando-os em instalações próprias. A presidente Daniela Amodei destacou que a competição futura não será apenas sobre o tamanho do modelo, mas sobre “gastar o poder computacional corretamente”. Este movimento significa que a Anthropic está mudando de um modelo de ativos leves (aluguel de computação) para um layout de ativos pesados, visando reduzir o custo por FLOP e eliminar a dependência de um único fornecedor, além de pavimentar o caminho para o IPO em 2026 (Fonte: SemiAnalysis, 36氪)

Gemini 3.0 Pro decifra manuscrito histórico de 500 anos: O Gemini 3.0 Pro do Google levou apenas uma hora para decifrar anotações manuscritas na “Crônica de Nuremberg” que intrigavam historiadores há 500 anos. Através de reconhecimento visual de nível micrométrico e raciocínio contextual, a AI identificou que as abreviações em latim não eram rabiscos, mas tabelas de conversão entre dois sistemas de cronologia bíblica. Este caso demonstra a capacidade de “superioridade esmagadora” dos modelos multimodais no campo da arqueologia humanística, provando que a AI superou a experiência humana em tarefas de recuperação em larga escala e raciocínio lógico de longa cadeia (Fonte: SiliconAngle)

🎯 Tendências
OpenAI aposta em “Audio-first” e dispositivos sem tela: A OpenAI planeja lançar no primeiro trimestre de 2026 uma nova geração de modelos de áudio, com suporte para interrupções em tempo real e diálogos bidirecionais. Simultaneamente, um “dispositivo de AI sem tela” (possivelmente uma AI Pen) projetado por Jony Ive entrou no planejamento de longo prazo. Sam Altman acredita que as telas limitam as possibilidades da AI; no futuro, a AI deve atuar como uma “presença no ambiente” intervindo na vida através de voz e percepção. Essa mudança reflete o consenso coletivo do Silicon Valley sobre paradigmas de interação: reduzir a ocupação visual e fortalecer a inteligência ambiental (Fonte: 第一新声)
Energia nuclear torna-se o “Momento Silicon Valley” para infraestrutura de AI: Com o crescimento explosivo da demanda de energia para AI, gigantes como Microsoft, Google e Amazon estão substituindo governos como os principais impulsionadores de Small Modular Reactors (SMR). Os SMR possuem vantagens como ciclos de construção curtos e produção em massa em fábricas, fornecendo energia limpa e estável 24/7. Os próximos cinco anos são vistos como a janela crítica para a implementação em escala dos SMR, tornando a energia nuclear a base sólida para redes elétricas limpas e resolvendo o problema da “parede física” enfrentada pelo desenvolvimento da AI (Fonte: 硬AI)
Lançamento do MiniMax M2.1 e seu Roadmap para 2026: A MiniMax publicou um blog técnico sobre o M2.1, destacando seus resultados em Reinforcement Learning (RL) em ambientes diversificados (multilíngue e multitarefa). Seu Roadmap para 2026 foca na expansão de RL, incluindo melhorias abrangentes em algoritmos, poder computacional e qualidade de dados, com planos para modelagem profunda de execução de código e comportamento do usuário. Atualmente, o modelo M2.1 apresenta forte desempenho em tarefas de programação e raciocínio, atraindo a atenção de muitos desenvolvedores (Fonte: MiniMax__AI, eliebakouch)

As três novas curvas de crescimento da Scaling Law: Jensen Huang propôs que a Scaling Law não falhou, mas evoluiu para três curvas: Pre-training, Post-training e Test-time compute. O progresso do Gemini 3 provou que ainda há espaço para melhorias no Pre-training. O papel do poder computacional está mudando de transformar inteligência diretamente para acelerar a “Lei de Experimentos Estendidos”. Embora os ganhos apenas com o aumento de parâmetros estejam diminuindo, as capacidades de AI continuam a romper barreiras através do Test-time compute em modelos como o o1 e DeepSeek-R1 (Fonte: 硅星人Pro)
Zhipu e MiniMax iniciam processo de IPO: As “Little Dragons” dos grandes modelos na China estão se diferenciando; Zhipu e MiniMax planejam listar na Bolsa de Hong Kong no início de 2026, visando obter mais “munição” para enfrentar a concorrência das grandes empresas. A Zhipu pretende captar cerca de 4,3 bilhões de HKD, enquanto a MiniMax busca até 4,2 bilhões de HKD. Isso marca uma nova fase de comercialização e eficiência de capital na competição de modelos na China, onde startups buscam espaço de sobrevivência entre o tráfego das gigantes (Fonte: 窄播)
🧰 Ferramentas
Flakestorm: Ferramenta de teste de mutação para agentes LangChain: Flakestorm é uma ferramenta de teste de robustez projetada especificamente para agentes LangChain. Ela captura falhas fáceis de ignorar em avaliações através de mutações de entrada (como erros de digitação, mudanças de formato e tom). A ferramenta revela vulnerabilidades ocultas antes do ambiente de produção, ajudando desenvolvedores a construir aplicações de AI mais confiáveis (Fonte: LangChainAI)

Adaptive-P: Novo amostrador criativo para llama.cpp: O Adaptive-P é um novo método de amostragem que visa resolver o problema de modelos presos em padrões previsíveis. Em vez de usar o tradicional escalonamento de temperatura, ele permite que o usuário especifique uma faixa de probabilidade alvo, reforçando tokens próximos ao alvo via Preference Curve. O amostrador mantém um histórico EMA e pode quebrar automaticamente cadeias repetitivas de alta confiança, sendo ideal para escrita de ficção, roleplay e brainstorming (Fonte: llama.cpp, Reddit)

VectorDBZ: Ferramenta GUI para gerenciamento de bancos de dados vetoriais locais: VectorDBZ é uma aplicação desktop focada em fluxos de trabalho locais, suportando pgvector, Qdrant, Chroma, Milvus e Weaviate. Permite aos usuários navegar em coleções, executar buscas por similaridade e visualizar distribuições de embeddings via PCA/t-SNE. Resolve a dificuldade de depurar pipelines RAG locais com ferramentas cloud-native, mantendo configurações e chaves de API locais para garantir a privacidade (Fonte: Reddit)
fastapi-fullstack: Gerador CLI para aplicações de AI full-stack: Desenvolvida pela comunidade LangChain, esta ferramenta permite gerar com um clique aplicações de AI de nível de produção contendo FastAPI, Next.js, autenticação e streaming via WebSocket. A versão mais recente adicionou suporte para agentes LangGraph ReAct e integrou observabilidade LangSmith, reduzindo drasticamente o ciclo de desenvolvimento do protótipo à produção (Fonte: LangChainAI)

📚 Aprendizado
Guia definitivo de RLHF edição 2026 atualizado: Nathan Lambert revisou completamente seu “RLHF Book”, expandindo-o de 150 para 200 páginas. Foram adicionados capítulos sobre os algoritmos mais recentes como GSPO e CISPO, tabelas comparativas de relatórios técnicos de modelos de raciocínio e novos critérios de pontuação para RLVR. O livro é considerado o material mais avançado para entender técnicas de alinhamento e dados sintéticos, enfatizando a evolução da Constitutional AI para os modelos de raciocínio modernos (Fonte: swyx)
Stanford CS336: Matéria obrigatória na era pós-bolha de AI: Com a ascensão de modelos eficientes como o DeepSeek, o curso CS336 de Stanford (Construindo LLMs do zero) ganhou enorme popularidade. O curso ensina os alunos a entender a eficiência de MoE, mHC e outras tecnologias centrais a partir do nível de arquitetura, em vez de serem apenas consumidores de API. A comunidade acredita que apenas aprofundando-se no Pre-training e na arquitetura subjacente é possível construir fossos tecnológicos reais na era da democratização do poder computacional (Fonte: stanfordnlp)

SWE-EVO: Benchmark para avaliação de evolução de software de longo alcance: Benchmarks tradicionais frequentemente otimizam objetivos errados; a nova pesquisa propõe o SWE-EVO, focado na evolução de software de longo alcance. Ele exige que os agentes lidem com tarefas que envolvem, em média, 21 arquivos e 610 linhas de modificação de código. Os resultados mostram que o GPT-5 pontua 65% no SWE-Bench, mas apenas 21% no SWE-EVO, revelando a enorme lacuna dos agentes atuais ao lidar com bases de código legadas e raciocínio semântico entre arquivos (Fonte: omarsar0)

Visão geral abrangente: De modelos de código a agentes: O artigo “From Code Foundation Models to Agents and Applications” fornece um guia prático sobre inteligência de código. A revisão abrange desde modelos de base de código até arquiteturas de Agent capazes de executar tarefas de forma autônoma, analisando o estado atual das aplicações em completude de código, correção e construção de sistemas complexos (Fonte: dl_weekly)
💼 Negócios
Meta realiza “aquisição relâmpago” de 2 bilhões de dólares da empresa de agentes Manus: No final de 2025, a Meta desembolsou 2 bilhões de dólares para adquirir a Manus, uma startup de AI Agent com apenas três anos de existência. A Manus alcançou uma receita anualizada de 125 milhões de dólares em 8 meses com o conceito de “agente autônomo geral”. O movimento de Zuckerberg é visto como uma forma de aliviar a ansiedade da Meta em relação às capacidades de Agent, tentando integrar a equipe da Manus para suprir as deficiências do Llama 4 na execução de tarefas reais (Fonte: 36氪)
Zhishen Technology conclui rodada de financiamento de centenas de milhões, liderada pelo ex-responsável pelo “Tie Dan” da Xiaomi: A startup de Embodied AI, Zhishen Technology, anunciou a conclusão de várias rodadas consecutivas de financiamento, com investimentos de capitais industriais como Agibot e Jinma Rides. A empresa foi fundada por Liu Yulong, ex-responsável pelo projeto “Tie Dan” (CyberDog) da Xiaomi, e já alcançou a produção em massa dos robôs quadrúpedes Gang Beng L1 e Tong Chui M1, além de abrir o código da plataforma de simulação MATRiX (Fonte: 36氪)

Yaole Technology obtém quase 100 milhões de yuans em rodada Pre-A, focando em percepção tátil flexível: A desenvolvedora de sensores de pressão de tecido flexível, Yaole Technology, concluiu um financiamento de quase 100 milhões de yuans, liderado por um fundo do grupo Ecovacs. A empresa propôs de forma inovadora que “o tecido é o sensor”, e seus produtos já entraram na cadeia de suprimentos de várias montadoras líderes, fornecendo soluções de percepção para cabines inteligentes. Com a implementação da Embodied AI em cenários reais, a percepção tátil flexível de grande área se tornará uma necessidade para a interação frequente entre robôs e humanos (Fonte: 36氪)

🌟 Comunidade
Comentário de Nadella sobre “AI Slop” gera reação negativa: O CEO da Microsoft, Satya Nadella, apelou para que a indústria supere a discussão entre “conteúdo de baixa qualidade de AI (slop) e experiências premium” para construir um novo consenso sobre aplicações de AI. No entanto, os usuários ficaram indignados, argumentando que “slop” reflete o baixo valor e os erros das saídas de AI, não um problema de marca. A comunidade criticou a Microsoft por forçar o Copilot em produtos ignorando a experiência do usuário, surgindo até o termo satírico “Microslop” (Fonte: 36氪, Reddit)

Fadiga cognitiva e “exaustão invisível” trazidas pelo Vibe Coding: Com a popularização do Cursor e do Claude Code, os desenvolvedores estão mudando de “produtores” para “revisores”. Stephan Schmidt aponta que essa troca frequente de contexto e a tentativa de adivinhar a intenção da AI causam um “superaquecimento” cerebral. A AI não reduziu a carga de trabalho, mas transformou o trabalho braçal em um excesso de processamento cognitivo. A comunidade sugere controlar o ritmo conscientemente e realizar revisões manuais para evitar tornar-se apenas uma peça da máquina computacional (Fonte: 36氪)

“Diálogo de segurança” entre Grok e ChatGPT: Diante da controvérsia sobre o Grok gerar imagens de menores e extremismo, um usuário simulou um debate entre ChatGPT e Grok. No diálogo, o Grok admitiu desvios na execução onde “sacrificou a segurança pelo engajamento”, enquanto o ChatGPT insistiu que “a cautela é a linha de base para a AI pública”. Essa discussão revela o conflito de interesses entre fabricantes de AI na “busca pela verdade” versus “contenção de riscos” (Fonte: Reddit)
Organização de informações na era da AI: Geração Z abandona pastas: Discussões na comunidade indicam que a Geração Z se preocupa cada vez menos com estruturas de pastas tradicionais. Pastas representam “certeza pré-determinada”, enquanto na era da AI, etiquetas, busca global e recall dinâmico (como Readwise) permitem que a informação surja naturalmente com o tempo. O sistema deve ser responsável pela “memória”, em vez de exigir que o usuário decida onde algo pertence no momento da captura (Fonte: scottastevenson)
💡 Outros
Meta lança “Rubric Rewards” para treinar cientistas de AI: A Meta apresentou uma pesquisa sobre o uso de Rubric Rewards para treinar co-cientistas de AI e abriu o código dos conjuntos de dados de treinamento e avaliação. Através de RL, o desempenho da AI em tarefas de pesquisa científica obteve uma taxa de vitória de 70% contra humanos. Isso sinaliza que a AI evoluirá da simples recuperação de conhecimento para a descoberta científica profunda e validação de hipóteses (Fonte: lateinteraction)

10Kh RealOmni-Open: O maior conjunto de dados de Embodied AI: Genrobot.AI abriu o código do dataset 10Kh RealOmni-Open, contendo mais de 10 mil horas e 1 milhão de clipes, cobrindo mais de 3000 cenários domésticos reais. Este é atualmente o maior e mais generalizável conjunto de dados de Embodied AI do mundo, visando resolver a escassez extrema de dados de interação do mundo real na pesquisa robótica (Fonte: huggingface)
AI na saúde: Destaque na CES 2026: Na CES 2026, a aplicação HopeValley para detecção assistida por AI de câncer de mama chamou a atenção. O app utiliza algoritmos de AI para aumentar a precisão do rastreamento precoce, demonstrando o valor real da AI na saúde. Além disso, interfaces cérebro-computador e dispositivos vestíveis nativos de AI tornaram-se os protagonistas absolutos da feira deste ano (Fonte: TheTuringPost)