关键词:AI超算架构, 大模型, AI Agent, Rubin超算架构, MiroThinker 1.5, 流形约束超连接
🔥 聚焦
英伟达发布Rubin超算架构:从“卖铲子”转向“卖生产力车间” : 黄仁勋在CES 2026展示了全新AI超算架构Vera Rubin。该架构并非单纯的显卡升级,而是集成了Vera CPU、Rubin GPU、NVLink 6等六颗专用芯片的垂直整合系统。Rubin旨在解决系统规模化难题,宣称推理吞吐量提升10倍,训练万亿参数模型的GPU需求减至Blackwell的四分之一,Token成本降至十分之一。这一举动标志着英伟达正通过系统级优化构筑护城河,试图将算力堆叠从“手工组装”变为“标准化流水线”,预示着平价推理时代的到来(来源: 36氪、TheRundownAI)
MiroThinker 1.5震撼发布:30B模型比肩GPT-5-High : 由陈天桥(TCCI)资助、清华副教授戴季峰领衔的MiroMind团队发布了MiroThinker 1.5。该模型仅凭30B参数,在HLE、BrowseComp等高难度基准测试中与GPT-5-High、DeepSeek-V3.2并驾齐驱。其核心技术为“交互式缩放”(Interactive Scaling),通过训练模型处理更深、更频繁的智能体与环境交互来提升性能。这一成果证明了小型精英团队通过正确的架构选择(如专注于Agent建模而非单纯预训练),依然能在AGI前沿重塑竞争格局(来源: GitHub、ZhihuFrontier)

DeepSeek发布流形约束超连接(mHC):Transformer架构的重大突破 : DeepSeek团队发表论文《Manifold-Constrained Hyper-Connections》,提出了一种能在不导致训练崩溃的前提下拓宽残差流的新方案。该技术解决了超深模型训练中的不稳定性、可扩展性和内存开销问题。CEO梁文锋亲自署名,这被认为是自2015年Transformer诞生以来对架构最根本的改进之一。实验显示,该技术在27B参数、60层深度的模型上表现优异,预示着DeepSeek V4可能会采用更深、更宽的架构设计(来源: nrehiew_、Reddit)

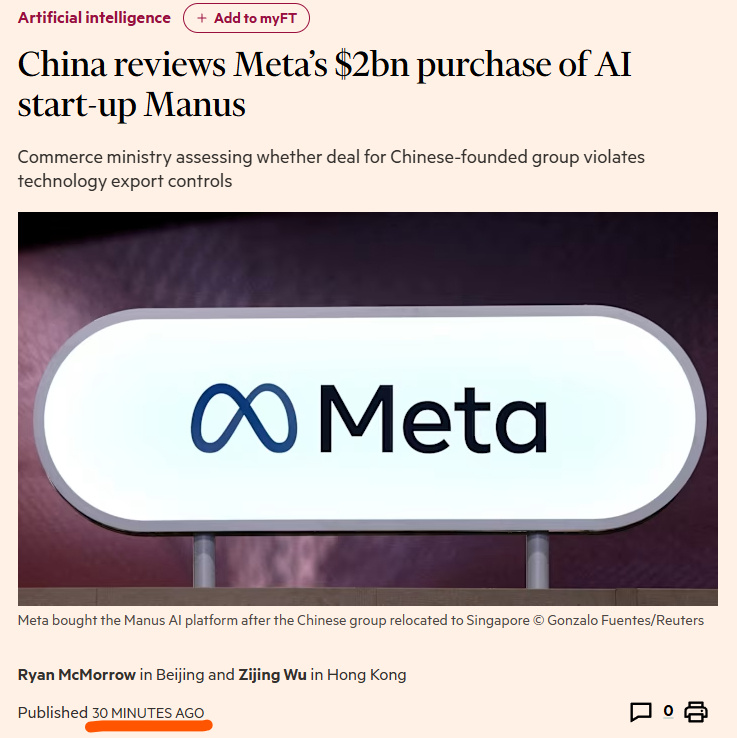
Meta收购Manus交易遭中国监管审查 : 据知情人士透露,中国商务部正评估Meta以20亿美元收购AI Agent初创公司Manus的交易,以确定其是否违反技术出口管制规定。审查核心在于该团队在中国期间开发的数字资产及技术迁移至新加坡的合法性。此举反映了在全球AI竞争背景下,监管机构对顶尖AI人才和核心技术外流的高度敏感,也可能引发关于开源贡献与跨境技术转移边界的深度讨论(来源: dotey、teortaxesTex)
🎯 动向
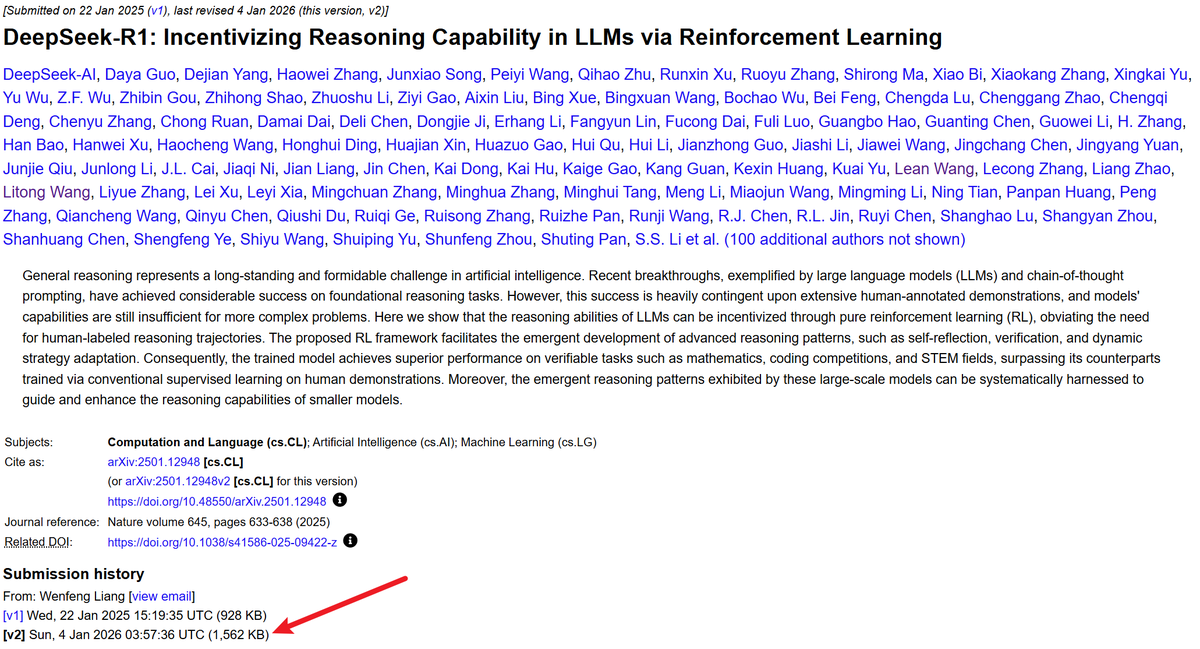
DeepSeek-R1论文大幅更新:从22页扩充至86页 : DeepSeek-R1的技术文档进行了深度补充,详细披露了R1-Zero的自我进化过程、评估细节、蒸馏策略及更深入的消解实验。这一举动被社区视为DeepSeek V4或R2发布的先兆,展示了其在强化学习和推理模型领域的深厚积累。新内容为研究者理解推理模型的内在逻辑提供了极高价值的参考(来源: dejavucoder、MachineLearning)
OpenAI秘密开发笔形消费者设备:挑战iPhone地位 : 传闻OpenAI正研发一款代号为“第三核心设备”的笔形AI硬件,尺寸接近iPod Shuffle。该设备配备麦克风和摄像头,具备环境感知能力,核心功能是将手写笔记实时转换为文本并上传至ChatGPT。此举显示了OpenAI试图绕过现有手机系统,直接通过原生AI硬件占据用户交互入口的野心(来源: Reddit)
Runway发布GWM Worlds:实时环境模拟世界模型 : Runway展示了其最新的世界模型GWM Worlds。用户只需提供一张静态场景图片,模型即可生成一个沉浸式、无限可探索的3D空间,包含实时的几何、光影和物理模拟。该技术旨在为影视制作和游戏开发提供全新的交互式环境生成手段,标志着AI从生成视频向生成可交互世界的跨越(来源: c_valenzuelab)
DFlash: speculative decoding技术让Qwen3加速6.2倍 : Zhijian Liu团队推出DFlash,利用块扩散(block diffusion)进行投机采样。在Qwen3-8B上实现了6.2倍的无损加速,比EAGLE-3快2.5倍。该技术的核心逻辑是“扩散模型负责草拟,自回归模型负责验证”,巧妙解决了LLM推理速度慢的痛点,展示了扩散模型与自回归架构协同工作的巨大潜力(来源: jeremyphoward)
特斯拉FSD完成首次100%自主横跨美国挑战 : 驾驶员David Moss使用特斯拉FSD完成了从洛杉矶到默特尔比奇共2732英里的行程,全程零人工干预,包括在超级充电站的自动泊车。这标志着基于端到端神经网络的自动驾驶技术已具备极高的鲁棒性,正在接近完全无人驾驶的临界点(来源: Reddit)
🧰 工具
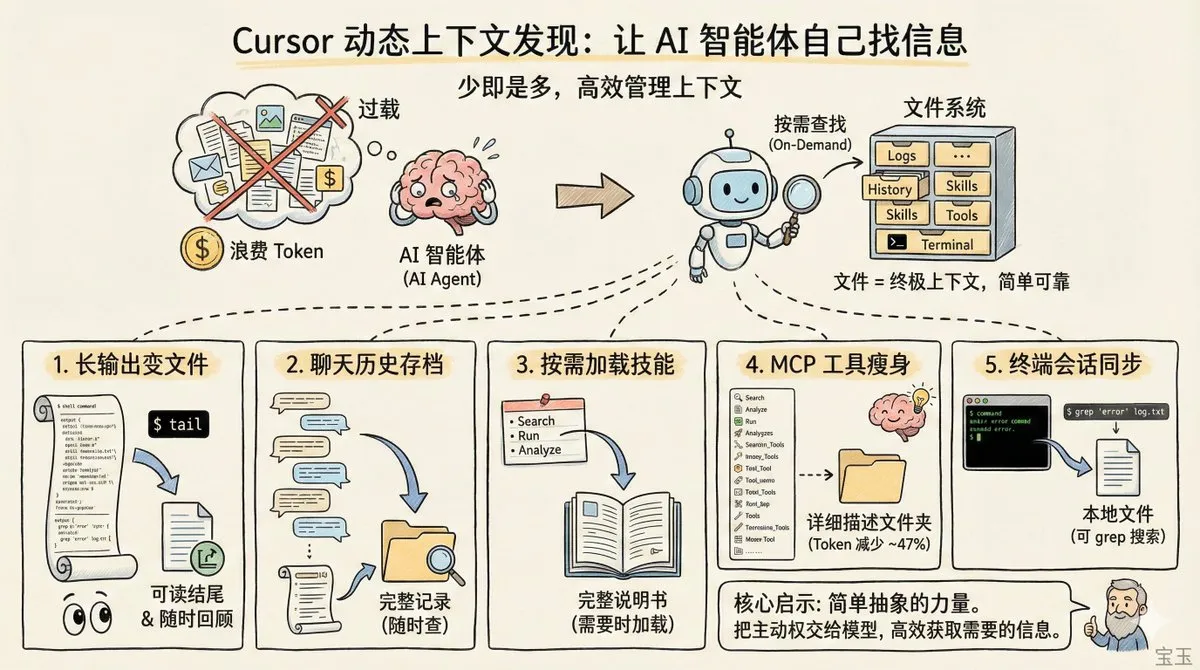
Cursor揭秘“动态上下文发现”:文件系统是Agent的终极记忆 : Cursor发布技术博客,阐述了其通过文件系统管理上下文的策略。通过将长输出转为文件、按需加载技能(Agent Skills)以及优化MCP工具描述,Cursor在保持质量的同时减少了46.9%的Token消耗。其核心观点是:与其预先塞入海量信息干扰模型,不如让模型在需要时通过文件系统主动检索。这与Manus的“文件系统即上下文”理念不谋而合(来源: dotey、swyx)
Claude Desktop集成本地Claude Code界面 : Anthropic更新了其桌面端应用,内置了带图形界面的Claude Code。用户只需在侧边栏切换至“Code”模式并选择本地文件夹,即可在非终端环境下使用Claude进行代码编写和文件管理。这极大地降低了AI编程工具的使用门槛,让不熟悉命令行操作的开发者也能高效利用Claude的Agent能力(来源: op7418)

Skywork上线视频Agent:全流程AI视频编辑能力 : Skywork Videos Agent支持从分镜生成到素材编辑的完整流。用户可以通过文生、图生或首尾帧生成视频素材,并直接在右侧编辑器中合成音乐和语音。其推出的特效模板支持一键复用,展示了AI Agent从单一内容生成向复杂创意工作流管理的进化(来源: op7418)
NousCoder-14b:开源竞赛级编程模型 : Nous Research发布了基于Qwen3-14B后调优的NousCoder-14b。该模型在Atropos框架下使用48张B200训练4天,通过可验证执行奖励(verifiable execution rewards)将Pass@1准确率提升至67.87%。团队同时开源了完整的RL环境、基准测试和训练堆栈,推动了开源社区在复杂逻辑编程领域的能力边界(来源: tokenbender、huggingface)
Memvid:AI Agent的单文件无服务器存储层 : Memvid是一款用Rust编写的便携式AI记忆系统。它借鉴视频编码逻辑,将数据、嵌入和搜索结构打包进单个.mv2文件中,提供亚5毫秒的本地检索速度。这种设计让AI Agent能够像携带硬盘一样携带长期记忆,无需复杂的RAG管线或服务器端向量数据库,是构建离线优先Agent的理想选择(来源: GitHub)

📚 学习
Rust老兵Steve Klabnik联手Claude,11天打造新语言Rue : 《Rust权威指南》作者Steve Klabnik利用Claude辅助,在11天内编写了约10万行Rust代码,创建了实验性系统级语言Rue。该项目展示了AI如何大幅降低语言设计的实验成本,让开发者从繁重的代码编写中解放,转而关注抽象设计与约束定义。这一案例引发了关于“AI时代是否还需要新编程语言”的社区大讨论(来源: 36氪)

CogFlow框架:模拟人类认知解决视觉数学难题 : 论文提出CogFlow框架,通过“感知-内化-推理”三阶段模拟人类解决数学问题的逻辑。其引入的“知识内化奖励模型”确保模型能真实整合视觉线索而非寻找捷径。随论文发布的MathCog数据集包含12万条高质量感知-推理对齐标注,为多模态数学推理研究提供了重要资源(来源: HuggingFace)
SOP系统:视觉-语言-动作(VLA)模型的在线后训练方案 : SOP系统实现了机器人在物理世界中的分布式、多任务在线训练。通过闭环架构,机器人集群将经验流实时传回云端学习器,并异步接收策略更新。实验显示,通过数小时的真实交互即可显著提升模型在折叠衣服、货物上架等复杂任务中的表现,且性能随机器人数量线性扩展(来源: HuggingFace)
💼 商业
智谱AI与MiniMax拟于香港IPO:中国大模型独角兽开启上市潮 : 智谱AI与MiniMax计划于2026年1月在香港上市,预计融资额约5.5亿美元,估值约65亿美元。智谱2024年营收约4470万美元,MiniMax约为3050万美元。尽管面临贸易紧张局势,两家公司凭借扎实的技术模型和用户基础(MiniMax用户达2.2亿),被认为估值仍具吸引力,标志着中国AI产业进入资本回报期(来源: bookwormengr、36氪)
xAI完成200亿美元融资:估值飙升至2300亿美元 : 马斯克旗下的xAI再次筹集200亿美元资金,用于购买算力和扩展其在X平台上的AI能力。xAI的独特优势在于拥有X平台的实时数据和2.5亿日活用户。马斯克的策略是“以AI构建注意力”,通过Grok的幽默与反传统风格,在OpenAI和Anthropic的包围圈中走出差异化路线(来源: TheRundownAI、Yuchenj_UW)
李开复总结2025:从“世界工厂”进化为“Agent工厂” : 01.AI CEO李开复指出,2025年是推理AI Agent的元年,DeepSeek时刻重塑了ToB市场。他预测2026年将进入“一人一AI团队”时代,多智能体系统将像流水线重塑工业一样重塑组织。中国凭借强大的开源模型和制造根基,有望成为全球Agent工厂,将组织能力模块化并24/7部署(来源: ZhihuFrontier)

🌟 社区
Noam Brown实验反思:AI尚无法完全替代领域专家 : 顶级AI研究员Noam Brown尝试用Codex和Claude Code编写扑克求解器。虽然AI能加速开发,但在算法逻辑、前端GUI实现及创新算法研发上仍频繁出错甚至“误导”用户。他认为AI目前更像是一个“不稳定的编译器”,在需要深厚领域背景的科研任务中,人类专家的验证和纠偏依然不可或缺(来源: polynoamial、SebastienBubeck)
硬件价格预警:GPU、DRAM和NAND将迎来暴涨 : 社区讨论指出,受数据中心需求激增和OpenAI等巨头产能争夺影响,2026年Q1内存合同价预计上涨55-60%,SSD价格已翻倍。英伟达RTX 5090价格或将攀升至5000美元。这促使开发者转向更高效的量化模型(如FLUX.2 quantized)和 llama.cpp 等轻量化推理框架(来源: Reddit)

提示词工程的终结?“Scratchpad”法则走红 : 社区发现,与其花费数周撰写复杂的Persona和约束,不如简单要求AI在回答前使用<scratchpad>进行头脑风暴和自我批判。这种“强制思考”模式在逻辑问题上胜过大多数复杂提示词。观点认为,Prompt Engineering的核心其实只是在想方设法让模型“慢下来”去思考(来源: Reddit)
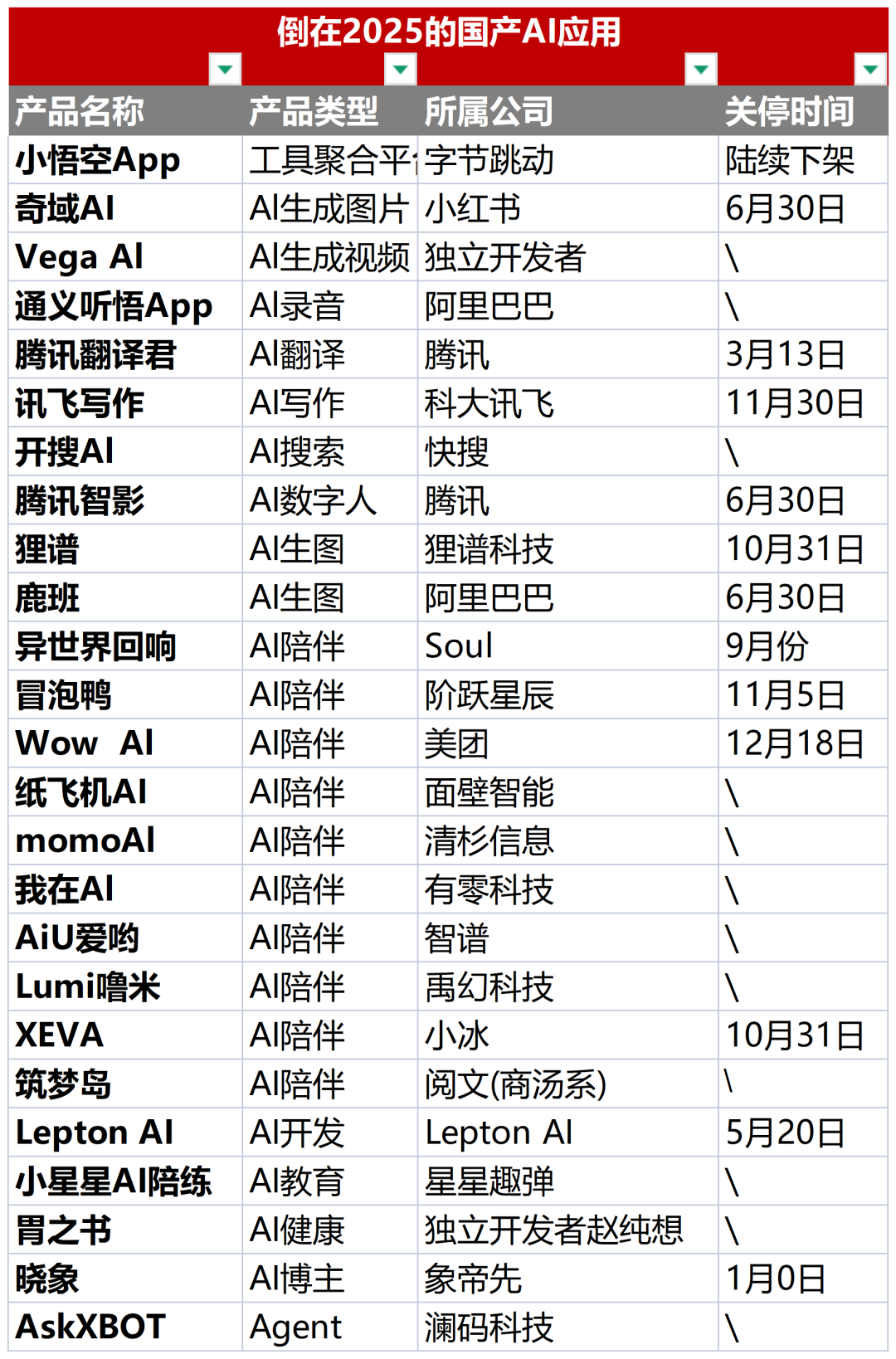
AI应用“猝死潮”:2025年平均每天倒下一个AI工具 : 统计显示,2025年全球已有近400个AI工具停服,国内包括冒泡鸭、Wow AI等知名陪伴类应用集体下架。失败主因在于:缺乏造血能力的虚胖流量、单点功能的“裸奔”创新以及触碰合规生死线。这标志着AI创业正从“炫技时代”回归商业常识,只有解决真实痛点的产品才能存活(来源: 36氪)
💡 其他
Agibot Genie Sim 3.0:具身智能开源仿真平台发布 : 灵足机器人(AGIBOT)在CES 2026推出Genie Sim 3.0,集成NVIDIA Isaac Sim,提供超1万小时的真实机器人操作合成数据集。该平台支持分钟级生成大规模仿真场景,旨在通过高质量3D重建和视觉生成技术,降低具身智能对物理硬件的依赖,加速模型迭代(来源: ziran_pu)
AI创造病毒风险引发安全忧虑 : 社区热议AI从零开始设计病毒的能力,认为这距离“完美生物武器”仅一步之遥。讨论呼吁加强对生物领域大模型的监管和护栏建设,防止技术被滥用于制造新型病原体,凸显了AI治理在非数字领域的紧迫性(来源: Reddit)