Anahtar Kelimeler:AI Süper Bilgisayar Mimarisi, Büyük Model, AI Ajan, Rubin Süper Bilgisayar Mimarisi, MiroThinker 1.5, Manifold Kısıtlı Süper Bağlantı
🔥 聚焦
NVIDIA 發佈 Rubin 超算架構:從「賣鏟子」轉向「賣生產力車間」:黃仁勳在 CES 2026 展示了全新 AI 超算架構 Vera Rubin。該架構並非單純的顯卡升級,而是集成了 Vera CPU、Rubin GPU、NVLink 6 等六顆專用芯片的垂直整合系統。Rubin 旨在解決系統規模化難題,宣稱 Inference throughput 提升 10 倍,訓練萬億參數模型的 GPU 需求減至 Blackwell 的四分之一,Token 成本降至十分之一。這一舉動標誌著 NVIDIA 正通過系統級優化構築護城河,試圖將算力堆疊從「手工組裝」變為「標準化流水線」,預示著平價推理時代的到來(來源: 36氪、TheRundownAI)
MiroThinker 1.5 震撼發佈:30B 模型比肩 GPT-5-High:由陳天橋(TCCI)資助、清華副教授戴季峰領銜的 MiroMind 團隊發佈了 MiroThinker 1.5。該模型僅憑 30B 參數,在 HLE、BrowseComp 等高難度基准測試中與 GPT-5-High、DeepSeek-V3.2 並駕齊驅。其核心技術為「Interactive Scaling」,通過訓練模型處理更深、更頻繁的 Agent 與環境交互來提升性能。這一成果證明了小型精英團隊通過正確的架構選擇(如專注於 Agent 建模而非單純預訓練),依然能在 AGI 前沿重塑競爭格局(來源: GitHub、ZhihuFrontier)

DeepSeek 發佈流形約束超連接(mHC):Transformer 架構的重大突破:DeepSeek 團隊發表論文《Manifold-Constrained Hyper-Connections》,提出了一種能在不導致訓練崩潰的前提下拓寬 Residual stream 的新方案。該技術解決了超深模型訓練中的不穩定性、可擴展性和內存開銷問題。CEO 梁文鋒親自署名,這被認為是自 2015 年 Transformer 誕生以來對架構最根本的改進之一。實驗顯示,該技術在 27B 參數、60 層深度的模型上表現優異,預示著 DeepSeek V4 可能會採用更深、更寬的架構設計(來源: nrehiew_、Reddit)

Meta 收購 Manus 交易遭中國監管審查:據知情人士透露,中國商務部正評估 Meta 以 20 億美元收購 AI Agent 初創公司 Manus 的交易,以確定其是否違反技術出口管制規定。審查核心在於該團隊在中國期間開發的數字資產及技術遷移至新加坡的合法性。此舉反映了在全球 AI 競爭背景下,監管機構對頂尖 AI 人才和核心技術外流的高度敏感,也可能引發關於開源貢獻與跨境技術轉移邊界的深度討論(來源: dotey、teortaxesTex)
🎯 動向
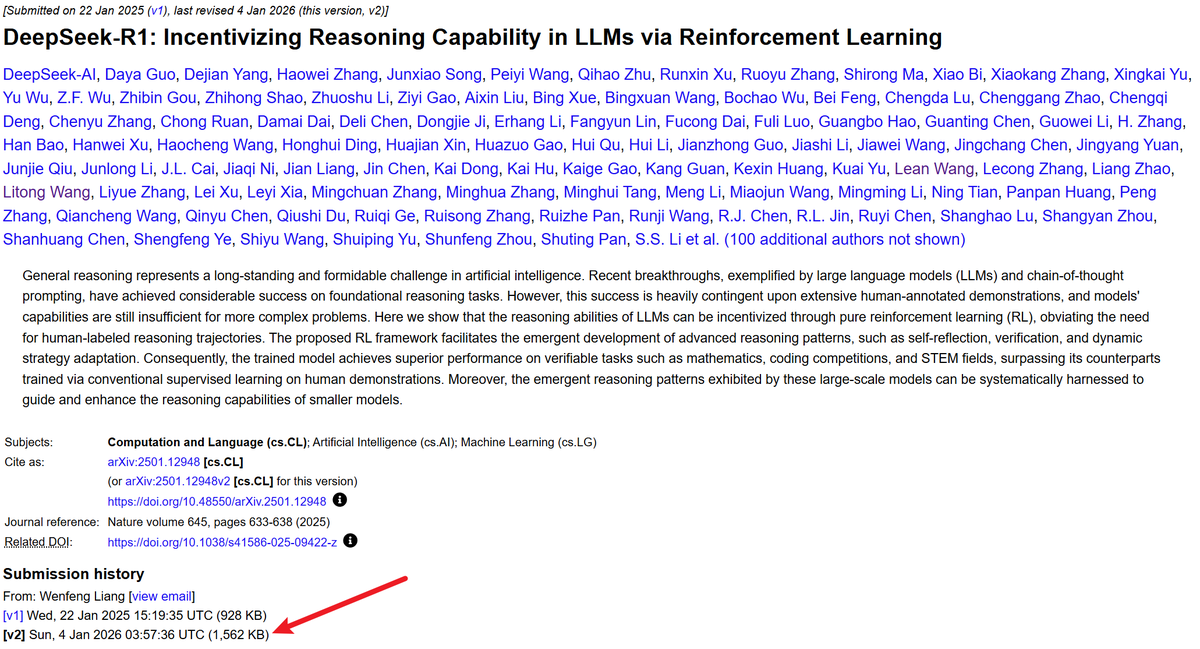
DeepSeek-R1 論文大幅更新:從 22 頁擴充至 86 頁:DeepSeek-R1 的技術文檔進行了深度補充,詳細披露了 R1-Zero 的自我進化過程、評估細節、蒸餾策略及更深入的消解實驗。這一舉動被社區視為 DeepSeek V4 或 R2 發佈的先兆,展示了其在 Reinforcement Learning 和推理模型領域的深厚積累。新內容為研究者理解推理模型的內在邏輯提供了極高價值的參考(來源: dejavucoder、MachineLearning)
OpenAI 秘密開發筆形消費者設備:挑戰 iPhone 地位:傳聞 OpenAI 正研發一款代號為「Third Core Device」的筆形 AI 硬件,尺寸接近 iPod Shuffle。該設備配備麥克風和攝像頭,具備環境感知能力,核心功能是將手寫筆記實時轉換為文本並上傳至 ChatGPT。此舉顯示了 OpenAI 試圖繞過現有手機系統,直接通過原生 AI 硬件佔據用戶交互入口的野心(來源: Reddit)
Runway 發佈 GWM Worlds:實時環境模擬世界模型:Runway 展示了其最新的世界模型 GWM Worlds。用戶只需提供一張靜態場景圖片,模型即可生成一個沉浸式、無限可探索的 3D 空間,包含實時的幾何、光影和物理模擬。該技術旨在為影視製作和遊戲開發提供全新的交互式環境生成手段,標誌著 AI 從生成視頻向生成可交互世界的跨越(來源: c_valenzuelab)
DFlash:speculative decoding 技術讓 Qwen3 加速 6.2 倍:Zhijian Liu 團隊推出 DFlash,利用 block diffusion 進行投機採樣。在 Qwen3-8B 上實現了 6.2 倍的無損加速,比 EAGLE-3 快 2.5 倍。該技術的核心邏輯是「擴散模型負責草擬,自回歸模型負責驗證」,巧妙解決了 LLM 推理速度慢的痛點,展示了擴散模型與自回歸架構協同工作的巨大潛力(來源: jeremyphoward)
Tesla FSD 完成首次 100% 自主橫跨美國挑戰:駕駛員 David Moss 使用 Tesla FSD 完成了從洛杉磯到默特爾比奇共 2732 英里的行程,全程零人工干預,包括在超級充電站的自動泊車。這標誌著基於端到端神經網絡的自動駕駛技術已具備極高的魯棒性,正在接近完全無人駕駛的臨界點(來源: Reddit)
🧰 工具
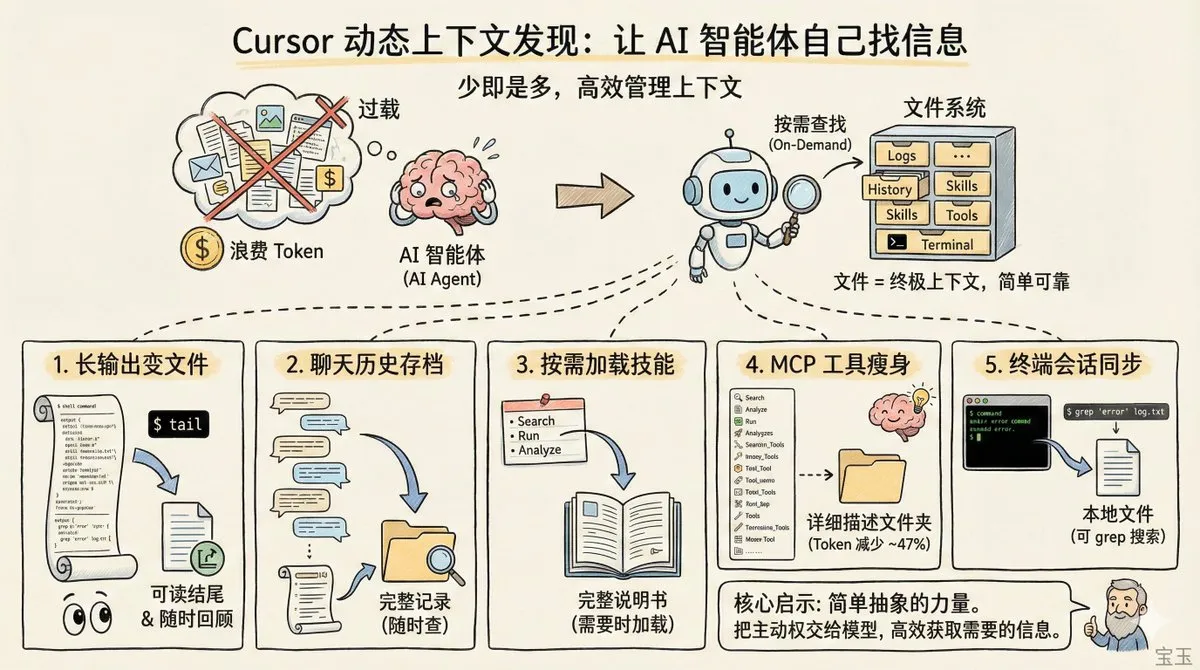
Cursor 揭秘「動態上下文發現」:文件系統是 Agent 的終極記憶:Cursor 發佈技術博客,闡述了其通過文件系統管理上下文的策略。通過將長輸出轉為文件、按需加載技能(Agent Skills)以及優化 MCP 工具描述,Cursor 在保持質量的同時減少了 46.9% 的 Token 消耗。其核心觀點是:與其預先塞入海量信息干擾模型,不如讓模型在需要時通過文件系統主動檢索。這與 Manus 的「文件系統即上下文」理念不謀而合(來源: dotey、swyx)
Claude Desktop 集成本地 Claude Code 界面:Anthropic 更新了其桌面端應用,內置了帶圖形界面的 Claude Code。用戶只需在側邊欄切換至「Code」模式並選擇本地文件夾,即可在非終端環境下使用 Claude 進行代碼編寫和文件管理。這極大地降低了 AI 編程工具的使用門檻,讓不熟悉命令行操作的開發者也能高效利用 Claude 的 Agent 能力(來源: op7418)

Skywork 上線視頻 Agent:全流程 AI 視頻編輯能力:Skywork Videos Agent 支持從分鏡生成到素材編輯的完整流。用戶可以通過文生、圖生或首尾幀生成視頻素材,並直接在右側編輯器中合成音樂和語音。其推出的特效模板支持一鍵復用,展示了 AI Agent 從單一內容生成向複雜創意工作流管理的進化(來源: op7418)
NousCoder-14b:開源競賽級編程模型:Nous Research 發佈了基於 Qwen3-14B 後調優的 NousCoder-14b。該模型在 Atropos 框架下使用 48 張 B200 訓練 4 天,通過可驗證執行獎勵(verifiable execution rewards)將 Pass@1 準確率提升至 67.87%。團隊同時開源了完整的 RL 環境、基准測試和訓練堆棧,推動了開源社區在複雜邏輯編程領域的能力邊界(來源: tokenbender、huggingface)
Memvid:AI Agent 的單文件無服務器存儲層:Memvid 是一款用 Rust 編寫的便攜式 AI 記憶系統。它借鑑視頻編碼邏輯,將數據、嵌入和搜索結構打包進單個 .mv2 文件中,提供亞 5 毫秒的本地檢索速度。這種設計讓 AI Agent 能夠像攜帶硬盤一樣攜帶長期記憶,無需複雜的 RAG 管線或服務器端向量數據庫,是構建離線優先 Agent 的理想選擇(來源: GitHub)

📚 學習
Rust 老兵 Steve Klabnik 聯手 Claude,11 天打造新語言 Rue:《Rust 權威指南》作者 Steve Klabnik 利用 Claude 輔助,在 11 天內編寫了約 10 萬行 Rust 代碼,創建了實驗性系統級語言 Rue。該項目展示了 AI 如何大幅降低語言設計的實驗成本,讓開發者從繁重的代碼編寫中解放,轉而關注抽象設計與約束定義。這一案例引發了關於「AI 時代是否還需要新編程語言」的社區大討論(來源: 36氪)

CogFlow 框架:模擬人類認知解決視覺數學難題:論文提出 CogFlow 框架,通過「感知-內化-推理」三階段模擬人類解決數學問題的邏輯。其引入的「知識內化獎勵模型」確保模型能真實整合視覺線索而非尋找捷徑。隨論文發佈的 MathCog 數據集包含 12 萬條高質量感知-推理對齊標注,為多模態數學推理研究提供了重要資源(來源: HuggingFace)
SOP 系統:視覺-語言-動作(VLA)模型的在線後訓練方案:SOP 系統實現了機器人在物理世界中的分布式、多任務在線訓練。通過閉環架構,機器人集群將經驗流實時傳回雲端學習器,並異步接收策略更新。實驗顯示,通過數小時的真實交互即可顯著提升模型在折疊衣服、貨物上架等複雜任務中的表現,且性能隨機器人數量線性擴展(來源: HuggingFace)
💼 商業
智譜 AI 與 MiniMax 擬於香港 IPO:中國大模型獨角獸開啟上市潮:智譜 AI 與 MiniMax 計劃於 2026 年 1 月在香港上市,預計融資額約 5.5 億美元,估值約 65 億美元。智譜 2024 年營收約 4470 萬美元,MiniMax 約為 3050 萬美元。儘管面臨貿易緊張局勢,兩家公司憑藉扎實的技術模型和用戶基礎(MiniMax 用戶達 2.2 億),被認為估值仍具吸引力,標誌著中國 AI 產業進入資本回報期(來源: bookwormengr、36氪)
xAI 完成 200 億美元融資:估值飆升至 2300 億美元:Elon Musk 旗下的 xAI 再次籌集 200 億美元資金,用於購買算力和擴展其在 X 平台上的 AI 能力。xAI 的獨特優勢在於擁有 X 平台的實時數據和 2.5 億日活用戶。Musk 的策略是「以 AI 構建注意力」,通過 Grok 的幽默與反傳統風格,在 OpenAI 和 Anthropic 的包圍圈中走出差異化路線(來源: TheRundownAI、Yuchenj_UW)
李開復總結 2025:從「世界工廠」進化為「Agent 工廠」:01.AI CEO 李開復指出,2025 年是推理 AI Agent 的元年,DeepSeek 時刻重塑了 ToB 市場。他預測 2026 年將進入「一人一 AI 團隊」時代,多智能體系統將像流水線重塑工業一樣重塑組織。中國憑藉強大的開源模型和製造根基,有望成為全球 Agent 工廠,將組織能力模塊化並 24/7 部署(來源: ZhihuFrontier)

🌟 社區
Noam Brown 實驗反思:AI 尚無法完全替代領域專家:頂級 AI 研究員 Noam Brown 嘗試用 Codex 和 Claude Code 編寫撲克求解器。雖然 AI 能加速開發,但在算法邏輯、前端 GUI 實現及創新算法研發上仍頻繁出錯甚至「誤導」用戶。他認為 AI 目前更像是一個「不穩定的編譯器」,在需要深厚領域背景的科研任務中,人類專家的驗證和糾偏依然不可或缺(來源: polynoamial、SebastienBubeck)
硬件價格預警:GPU、DRAM 和 NAND 將迎來暴漲:社區討論指出,受數據中心需求激增和 OpenAI 等巨頭產能爭奪影響,2026 年 Q1 內存合同價預計上漲 55-60%,SSD 價格已翻倍。NVIDIA RTX 5090 價格或將攀升至 5000 美元。這促使開發者轉向更高效的量化模型(如 FLUX.2 quantized)和 llama.cpp 等輕量化推理框架(來源: Reddit)

提示詞工程的終結?「Scratchpad」法則走紅:社區發現,與其花費數周撰寫複雜的 Persona 和約束,不如簡單要求 AI 在回答前使用 <scratchpad> 進行頭腦風暴和自我批判。這種「強制思考」模式在邏輯問題上勝過大多數複雜提示詞。觀點認為,Prompt Engineering 的核心其實只是在想方設法讓模型「慢下來」去思考(來源: Reddit)
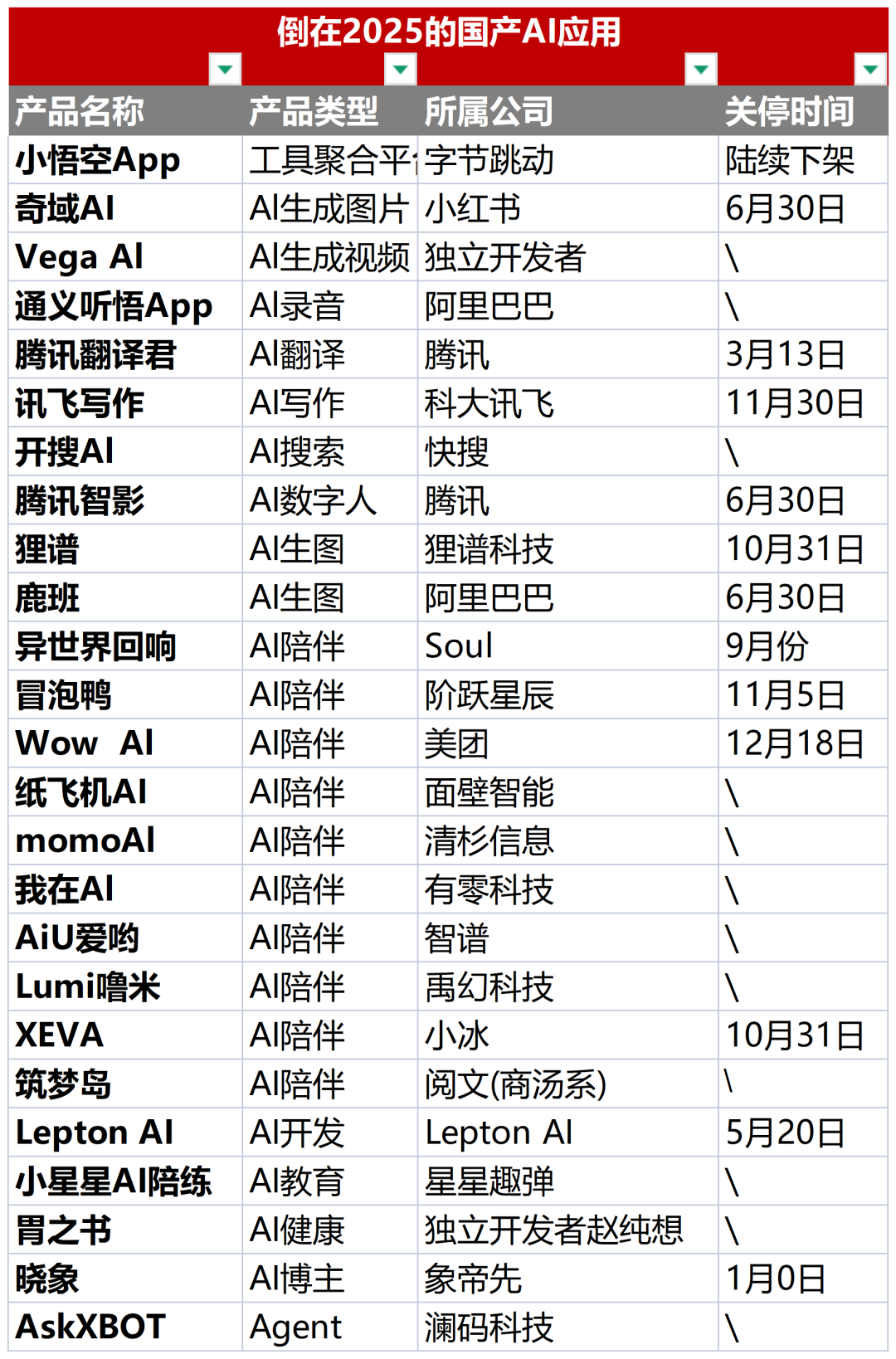
AI 應用「猝死潮」:2025 年平均每天倒下一個 AI 工具:統計顯示,2025 年全球已有近 400 個 AI 工具停服,國內包括冒泡鴨、Wow AI 等知名陪伴類應用集體下架。失敗主因在於:缺乏造血能力的虛胖流量、單點功能的「裸奔」創新以及觸碰合規生死線。這標誌著 AI 創業正從「炫技時代」回歸商業常識,只有解決真實痛點的產品才能存活(來源: 36氪)
💡 其他
Agibot Genie Sim 3.0:具身智能開源仿真平台發佈:靈足機器人(AGIBOT)在 CES 2026 推出 Genie Sim 3.0,集成 NVIDIA Isaac Sim,提供超 1 萬小時的真實機器人操作合成數據集。該平台支持分鐘級生成大規模仿真場景,旨在通過高質量 3D 重建和視覺生成技術,降低具身智能對物理硬件的依賴,加速模型迭代(來源: ziran_pu)
AI 創造病毒風險引發安全憂慮:社區熱議 AI 從零開始設計病毒的能力,認為這距離「完美生物武器」僅一步之遙。討論呼籲加強對生物領域大模型的監管和護欄建設,防止技術被濫用於製造新型病原體,凸顯了 AI 治理在非數字領域的緊迫性(來源: Reddit)