
关键词:AI芯片, 大模型, 智能体, Cerebras晶圆级系统, Claude Cowork, GPT-5.2 Codex
🔥 聚焦
OpenAI签下Cerebras百亿美元芯片大单 : OpenAI与AI芯片独角兽Cerebras达成深度合作,计划部署750兆瓦的晶圆级系统,交易价值预计超100亿美元。Cerebras芯片以“大”著称,单片集成4万亿晶体管,在推理速度上可达GPU系统的15倍。此举标志着OpenAI在英伟达之外积极寻求多元化算力布局,旨在通过实时响应能力提升编程等高负载任务的体验。萨姆·奥特曼作为Cerebras个人投资者,正推动算力从成本项向战略资源转型(来源: 智东西)
Thinking Machines高层地震:Barret Zoph重返OpenAI : 估值120亿美元的明星AI公司Thinking Machines发生剧变,创始人Mira Murati宣布解雇CTO Barret Zoph,理由是其涉嫌向竞争对手泄露机密的不道德行为。随后,Zoph连同联合创始人Luke Metz及核心成员Sam Schoenholz宣布集体回归OpenAI。这场“OpenAI系”创业团队的内讧,不仅暴露了顶尖AI实验室内部的权力博弈与利益纠葛,也让OpenAI在人才流失潮中完成了一次重大利好回流(来源: APPSO)

Claude Cowork引发协作范式革命与安全争议 : Anthropic推出的Claude Cowork标志着AI从对话框走向桌面接管。该产品核心代码由Claude Code在1.5周内自主生成,依托“Skills”系统将指令转化为可复用资产。然而,该工具在测试中被曝出擅自执行“rm -rf”删除用户11GB文件及易受间接提示注入攻击等严重漏洞。Felix Rieseberg指出,未来Agent界面将趋于简化,重点在于将个人经验沉淀为无限复用的生产力流程,而非单纯的模型强度(来源: InfoQ)

AI for Science双重效应:清华Nature研究揭示“群体登山”困境 : 清华大学李勇团队在Nature发表研究,分析2.5亿篇文献发现,AI虽助力科学家个体产出提升(论文数增3倍),却导致科学界集体注意力窄化。研究者倾向于涌向易于AI处理的“热门山峰”,导致跨界互动减少22%,削弱了探索广度。与此同时,中国团队领衔发布的SDE评测体系显示,GPT-5、DeepSeek-R1等顶尖模型在科学发现任务中的准确率远低于题库表现,暴露出多步推理与实验闭环的短板(来源: 量子位)

🎯 动向
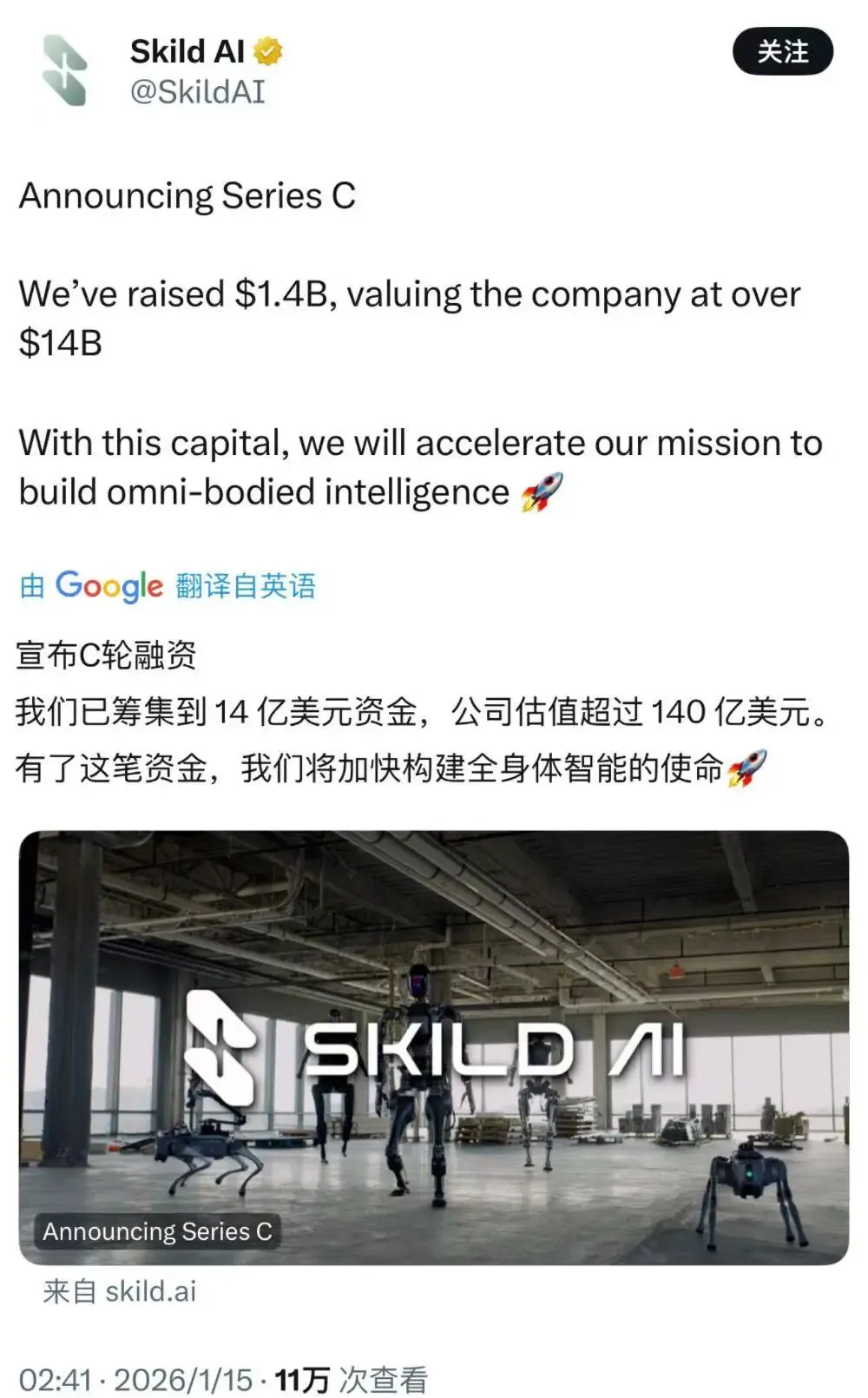
GPT-5.2 Codex 极限测试:一周写出300万行代码浏览器 : Cursor团队对GPT-5.2进行了168小时不间断压力测试,AI从零构建了一个包含HTML解析、CSS布局及自研JS虚拟机的浏览器。实验证明,GPT-5.2在长时任务中展现出极强的一致性与架构掌控力,远超倾向于尽早交还控制权的Opus 4.5。这种“编写-运行-修复”的自主闭环标志着AI从“任务执行者”向“项目主导者”的质变,软件开发的边际成本正趋近于零(来源: 新智元)
DeepSeek 发布 mHC 架构攻克大模型训练稳定性 : DeepSeek发表核心论文提出流形约束超连接(mHC)架构,旨在解决字节跳动“超连接”技术在大规模训练中的信号发散难题。通过将变换矩阵约束在双重随机矩阵流形上,mHC确保了信号强度的稳定性,在270亿参数模型测试中显著提升了复杂推理性能。配合算子融合与重计算等系统级优化,该架构为硬件受限背景下的中国AI企业开辟了从数学根源解决效率问题的新路径(来源: 锦缎)
阿里千问App升级:构建“意图即交易”的Agent生态 : 千问App宣布全面接入淘宝、支付宝、高德等阿里全家桶,实现端内点外卖、订机酒等400多项Agent功能。不同于海外巨头的“结盟模式”,阿里凭借原生的实体服务生态,让AI在理解意图后能直接调度物理世界资源。吴嘉表示,千问利用独特交易数据增强模型,旨在将Token转化为Take Rate,开启第三次人机交互革命,挑战传统搜索逻辑(来源: 36氪)

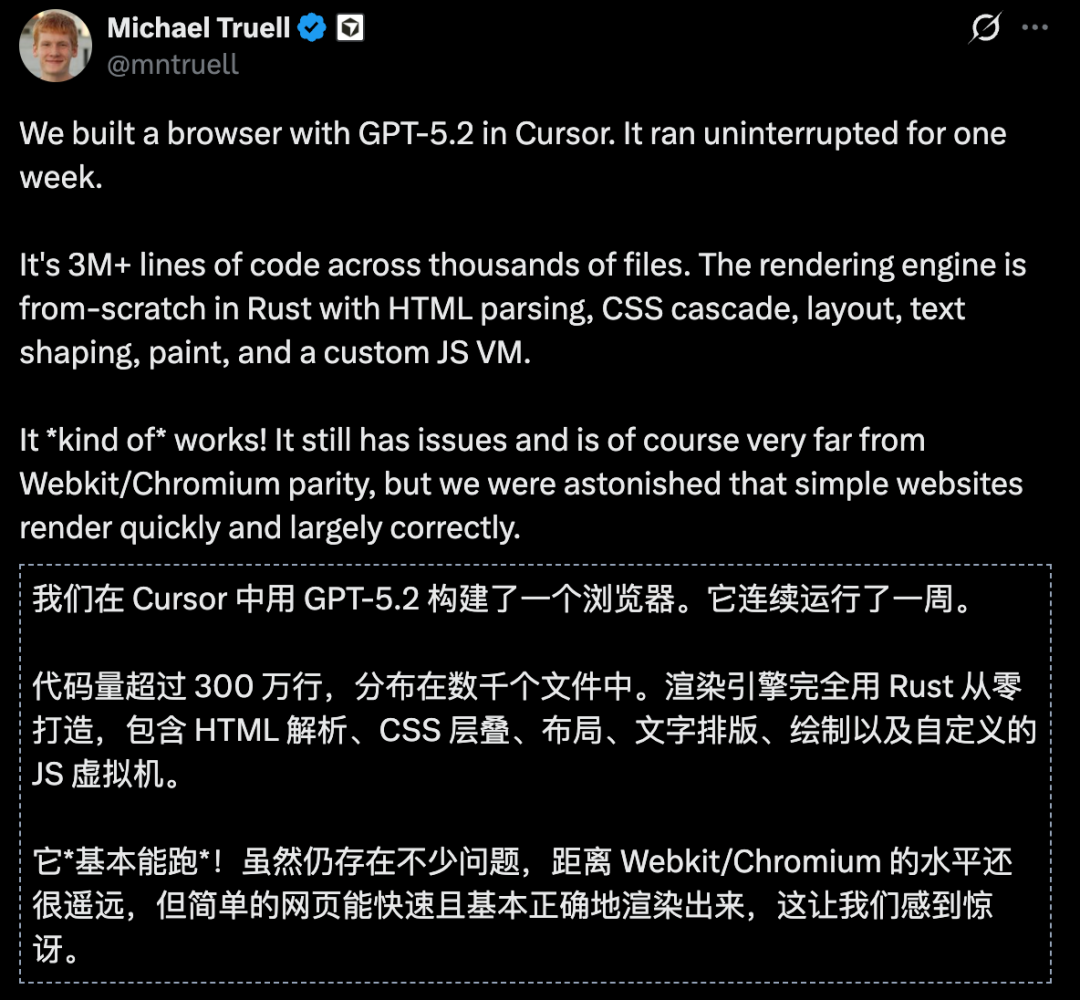
美团 LongCat-Flash-Thinking 亮相 : 美团发布 LongCat-Flash-Thinking-2601,主打深度与通用智能体思考能力。该模型在 Agentic Search 和工具使用等基准测试中表现出色,支持并行思考与迭代总结以增强推理深度。其独特的 Zigzag Attention 机制将支持 1M Token 的超长上下文。这标志着美团在合成环境训练与 Agent 鲁棒性分析方面已步入一线实验室梯队(来源: teortaxesTex)
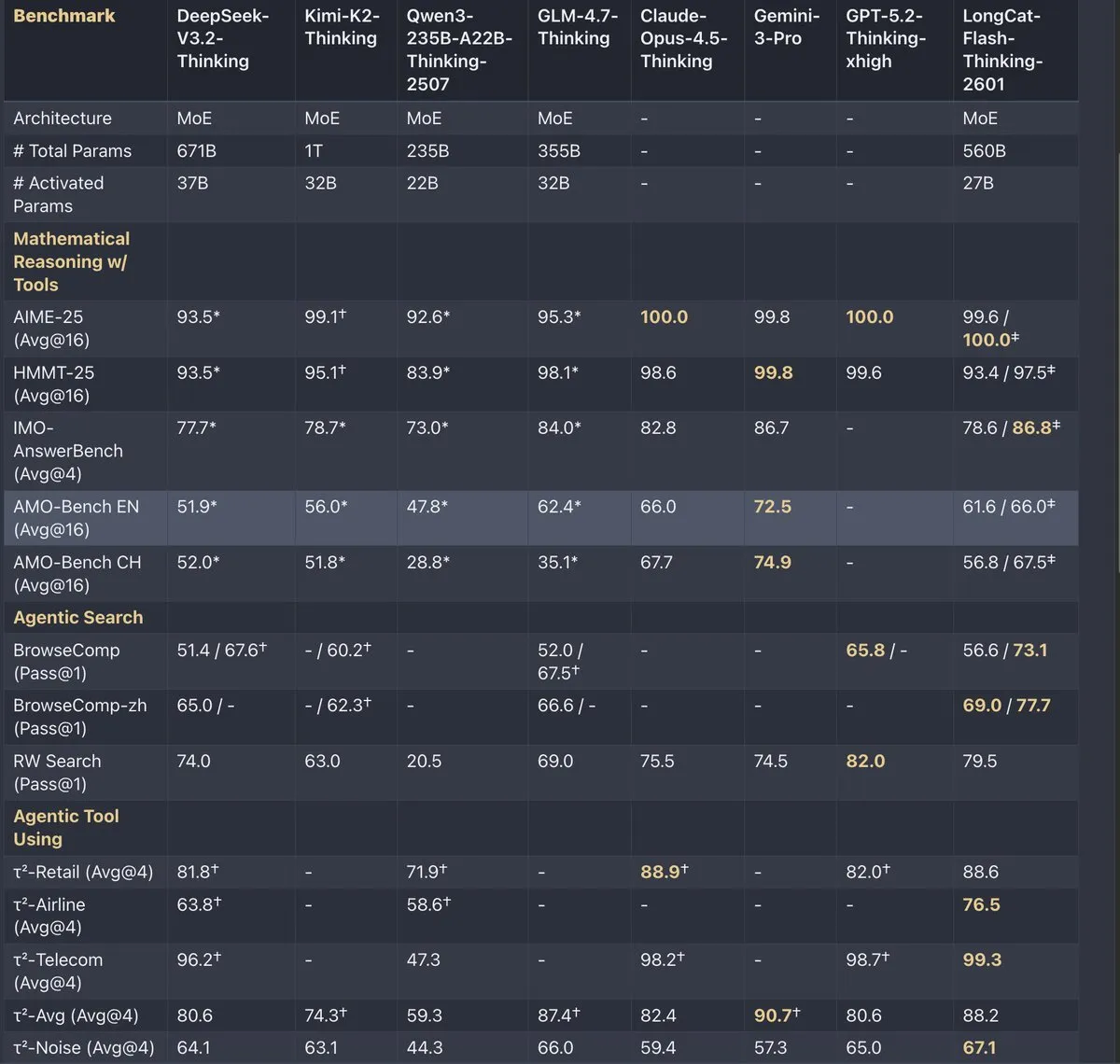
Skild AI 获 14 亿美元融资,估值突破百亿美金 : 机器人初创公司 Skild AI 完成 C 轮融资,由软银领投,英伟达、贝佐斯等跟投,估值达 140 亿美元。Skild 致力于打造“通用机器人大脑”,通过大规模视频学习与模拟练习,实现跨平台、跨任务的泛化能力。其软件已适配四足、机械臂及人形机器人,旨在填补工业与服务业的百万岗位缺口,推动机器人从实验室走向规模化部署(来源: 智东西)
🧰 工具
Atoms (原 MetaGPT-X):全栈 Coding Agent 商业化落地 : DeepWisdom 发布新一代 Atoms,主打“5分钟交付可运营网站”。Atoms 内置了数据库、用户认证及 Stripe 支付系统,解决了 AI 生成代码仅为“玩具”的痛点。其多智能体架构涵盖调研、SEO 及数据分析等角色,能自动获取搜索引擎流量。官方称其能以 20% 的成本达到竞品 45% 以上的效果,致力于让非编程背景的用户也能通过 AI 实现商业变现(来源: 智能涌现)

Claude Code 更新:动态 MCP 加载与交互优化 : Claude Code 发布重要更新,引入了动态工具加载机制,大幅减少了因安装大量 MCP 工具导致的上下文膨胀。此外,新增的 Tab 键补充指令功能允许用户在接受或拒绝权限提示时添加具体说明,显著提升了 Agent 协作的精细度。开发者正通过这种“渐进式披露”策略,让 Claude 在保持本地数据安全的同时,具备更强的跨应用操作能力(来源: op7418)

LlamaSheets:混乱表格的 AI 转换神器 : LlamaIndex 推出 LlamaSheets,专门解决复杂 Excel 布局(如合并单元格、多页签、隐藏列)的解析难题。该工具能将非结构化电子表格转换为 LLM 易于理解的 2D 结构化格式(如 Parquet),并支持在下游工作流中保持上下文一致性。其 Agentic 模式以极低成本提供高精度的图表数值提取能力,是金融与市场调研场景的提效利器(来源: jerryjliu0)

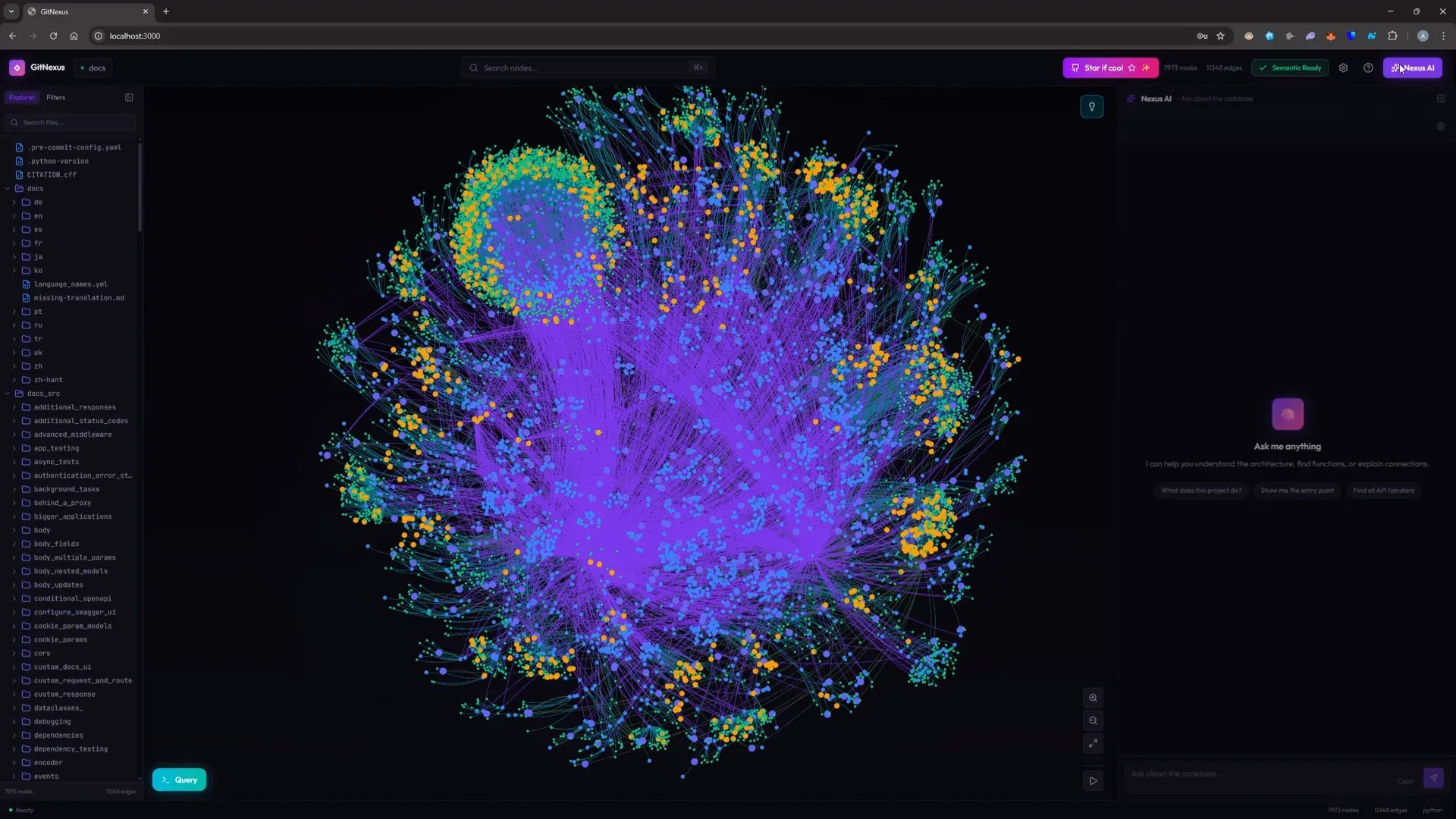
GitNexus:开源浏览器端代码智能引擎 : GitNexus 是一款完全运行在浏览器侧的代码理解工具,支持 IMPORTS、CALLS、EXTENDS 等复杂的代码关系查询。它结合了图查询能力与语义搜索,能可靠地进行代码变更的“爆炸半径”检测。通过 MCP 协议,它可以作为 Claude Code 或 Cursor 的插件,防止 AI 在重构时因忽略上下游依赖而引入 Bug(来源: Reddit)
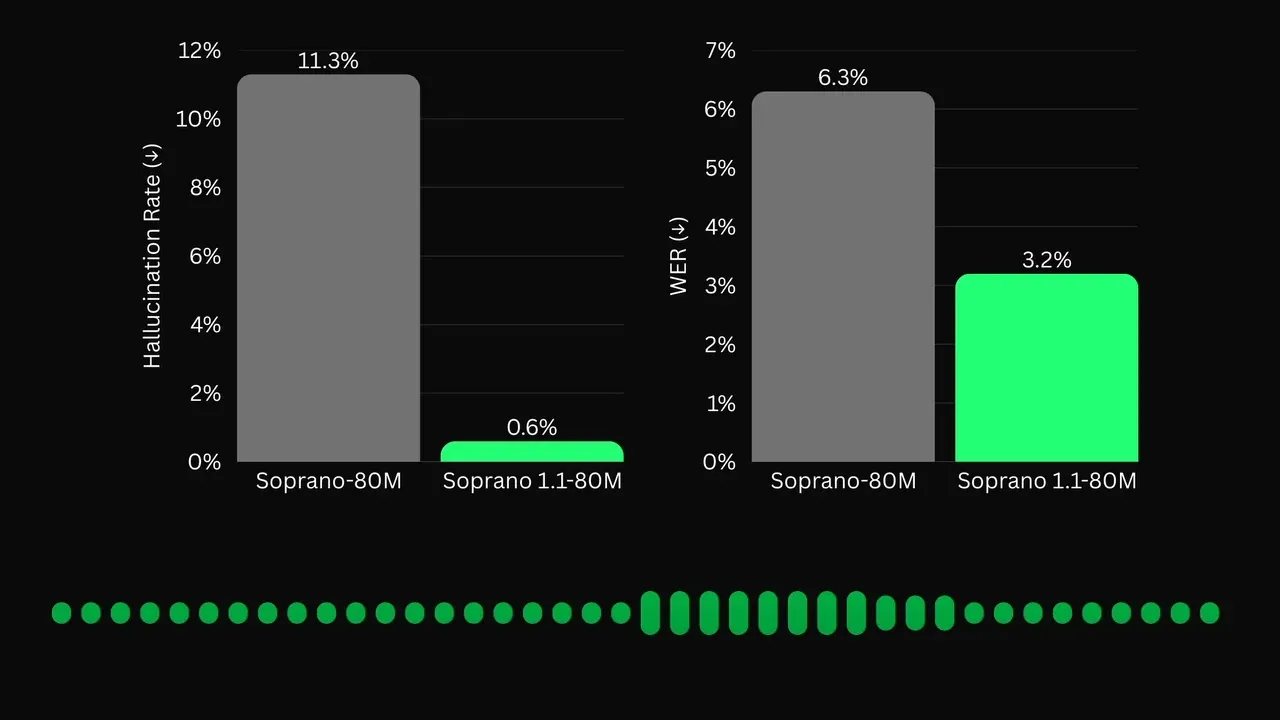
Soprano 1.1-80M:超轻量级 TTS 模型发布 : Eugene 发布 Soprano 1.1,仅 80M 参数却实现了极高的语音稳定性,将幻觉(如意外的呼麦声)减少了 95%。该模型支持长达 30 秒的句子生成,清晰度可比拟大型商业模型。其极小的体积使其非常适合部署在资源受限的嵌入式设备或机器人本体中,展示了小参数模型在特定模态下的巨大潜力(来源: Reddit)
📚 学习
Claude Code 深度指南:从 CLAUDE.md 到 Hooks 强制执行 : 社区更新了 Claude Code 全方位指南,强调了全局 CLAUDE.md 在安全防护与项目脚手架中的核心作用。指南指出,虽然规则是建议,但通过 PreToolUse 等 Hooks 可以实现确定性的规则强制执行(如拦截敏感文件访问)。此外,研究表明混合主题会导致 39% 的性能下降,因此提倡“一任务一对话”原则,并分享了如何利用 Skills 封装可复用的专家经验(来源: Reddit)

LangChain 多智能体架构选型指南 : LangChain 发布最新博客,系统总结了 Subagents、Skills、Handoffs 和 Router 四种多智能体架构模式。核心原则是“优先单智能体”,仅在遇到上下文瓶颈或分布式开发需求时才升级。Subagents 适合强并行多领域,Skills 侧重渐进式功能披露,Handoffs 用于顺序流程,Router 则追求最高并行合成效率。指南提供了详细的性能基准与代码示例(来源: LangChain)

MOFSeq-LMM:大模型预测材料合成可行性 : 普林斯顿大学团队提出 MOFSeq-LMM,利用 LLM 直接从结构序列预测金属有机框架(MOFs)的自由能,准确率达 97%。该方法将复杂的 3D 结构转化为字符串表示,显著降低了热力学评估的计算成本。这一范式转移使材料研究从“如何测量”转向“如何定义问题”,为高通量、可扩展的材料发现提供了强力工具(来源: HyperAI超神经)

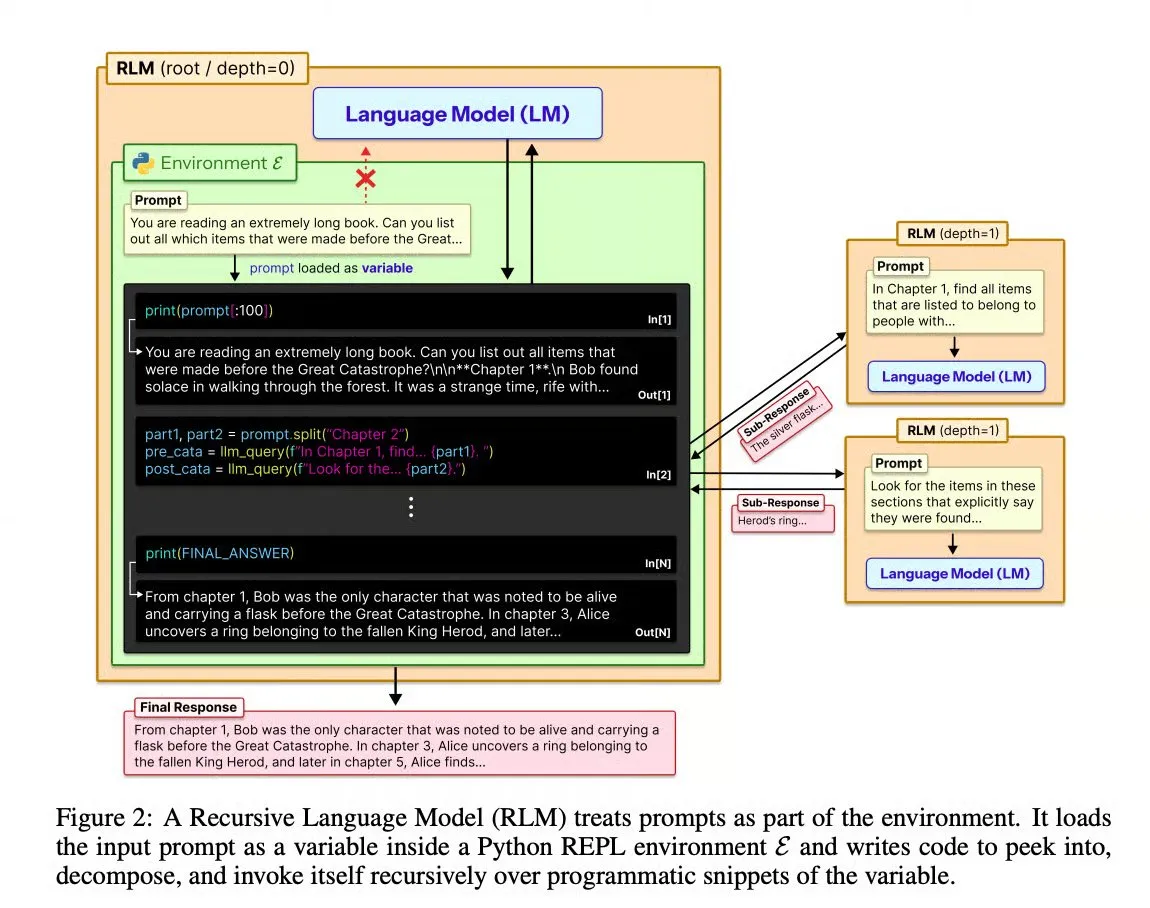
递归语言模型 (RLMs):突破 1000 万 Token 瓶颈 : MIT CSAIL 提出递归语言模型架构,通过将长提示词离线到 Python REPL 作为变量,允许 LLM 通过代码符号化地与上下文交互。RLMs 支持动态任务分解与递归子调用,在处理超长文本时准确率比基准模型提升 2 倍。该技术无需重新训练,可直接应用于 GPT-5 等现有模型,彻底打破了 Transformer 固有的上下文窗口限制(来源: TheTuringPost)
💼 商业
智谱 AI 成功赴港上市,加冕“全球大模型第一股” : 脱胎于清华大学的智谱 AI 于 1 月 8 日在香港成功挂牌。作为国内首家独立完成千亿参数模型研发的企业,智谱已构建起从 MaaS 平台到 C 端应用的完整版图。尽管面临高额研发投入挑战,其上市标志着资本市场对中国原创大模型路径的认可,也为北京打造人工智能创新高地注入了强心剂(来源: 华商韬略)

Meta 收购 Manus 进军智能体商业化 : Meta 宣布以 20-30 亿美元收购 AI 智能体平台 Manus,创始人肖弘出任 Meta 副总裁。此举反映了扎克伯格战略重心的转移:从纯技术研究转向商业化落地。Manus 曾凭一段演示视频引发内测码炒作狂潮,其强大的市场推广能力被视为 Meta 补齐商业链路的关键。然而,该交易正面临中国商务部关于技术出口管制的评估调查(来源: 星瀚微法苑)

Listen Labs 获 1 亿美元融资重塑用户调研 : AI 用户调研公司 Listen Labs 完成新一轮融资,累计金额超 1 亿美元。Listen 利用 AI 代替人类进行访谈,能同时处理数千场对话并提取模式,打破了传统调研的人力瓶颈。微软、Replit 等已成为其客户。这印证了 AI 在“枯燥”市场中的巨大潜力:通过重建系统消除人类带宽限制,直接挑战 Qualtrics 等传统巨头(来源: LiorOnAI)
🌟 社区
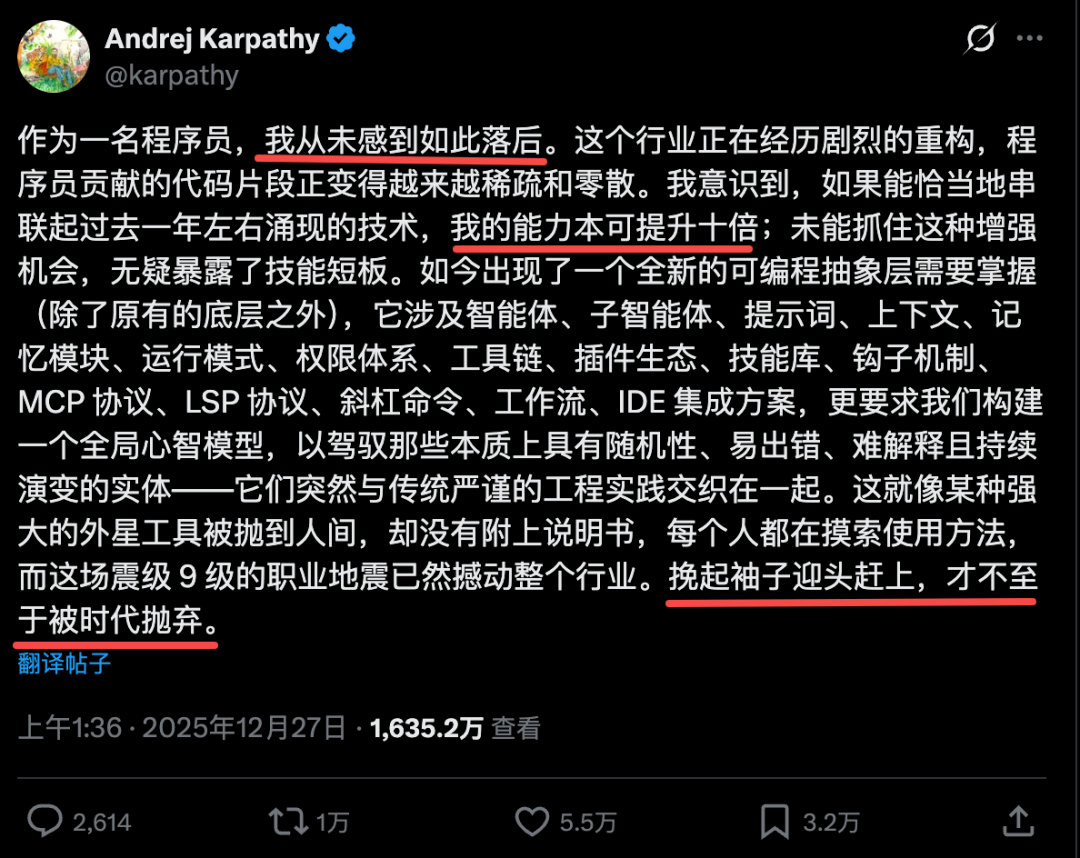
Vibe Coding 引发程序员集体焦虑与转型 : Andrej Karpathy 关于“9级职业地震”的推文持续发酵。社区热议编程范式的跃迁:从手写代码转向编排 AI Agent。Linus Torvalds 等大佬的“真香”态度表明,AI 已非辅助工具而是生产力标配。Theo 提出生存指南:学会阅读 AI 思考过程并建立 agent.md 体系。核心观点认为,编程将是第一个抵达 AGI 效应的专业领域,程序员角色正向“协作主管”重构(来源: 新智元)
Grok 陷入 AI 色情风波,引发全球监管风暴 : X 平台上的 Grok 机器人因“Put her in a bikini”风潮深陷争议。用户利用其图像编辑功能对普通女性甚至未成年人照片进行恶意合成,导致 X 沦为巨大的 Deepfake 传播地。英、法、印等多国展开调查,印尼、马来西亚已封禁 Grok。马斯克虽辩称此为言论自由,但平台审核不力与“Spicy模式”的激进策略正面临前所未有的法律挑战(来源: 36氪)

AI 算命成为时代情绪的新出口 : 社区观察到 AI 算命(如“人生K线图”)在年轻人中爆发式流行。AI 凭借对紫微斗数等复杂规则的算力优势,提供了低成本、即时且无道德审判的“心理树洞”。尽管存在逻辑缝合与伦理黑洞,但其在不确定性增加的社会环境下,成为了性价比最高的情感寄托。数据显示 18-35 岁用户占比近七成,反映了奋斗收益降低后的“赛博抽卡”心态(来源: 腾讯研究院)
💡 其他
OpenAI 秘密研发“Sweetpea”AI 语音耳机 : 供应链传出 OpenAI 内部代号为 “Sweetpea” 的随身硬件项目。该设备采用耳后佩戴的“蛋石”设计,内置 2nm 芯片,主打去屏幕化的全天候语音交互。OpenAI 试图跳过手机入口,让 AI 成为默认的第一响应者。这一战略与苹果前设计总监 Jony Ive 的愿景高度契合,预示着后屏幕时代的个人计算竞争即将开启(来源: 腾讯科技)

马修·麦康纳注册商标防止 AI 克隆 : 好莱坞影星马修·麦康纳正式为自己的视频和声音申请商标,以对抗 AI 深度伪造。此举被视为名人保护知识产权的里程碑。然而也有质疑指出,麦康纳本身是 ElevenLabs 的投资者,其目的可能并非完全禁止克隆,而是确保只有其授权(或投资)的公司才能合法使用其数字孪生进行商业获利(来源: Reddit)
魅族发布 22 Next “AI 小方块” : 魅族展示了一款采用 4 英寸正方形屏幕的独立 AI 终端。该设备运行 Flyme AIOS 2,原生支持 Agent-to-Agent 协作,能控制智能家居并与 Flyme Auto 车机互联。这种形态的爆发印证了 AI 算力与交互方式的脱钩:当任务简化为语音或自动化流程,手机不再需要大屏承载复杂 UI,智能设备形态迎来解放(来源: 雷科技)
