
Kata Kunci:Chip AI, Model Besar, Agen Cerdas, Sistem Tingkat Wafer Cerebras, Claude Cowork, GPT-5.2 Codex
🔥 Sorotan
OpenAI Tandatangani Kontrak Chip AI Cerebras Senilai $10 Miliar : OpenAI menjalin kemitraan mendalam dengan unicorn chip AI Cerebras, berencana mengimplementasikan sistem wafer-scale 750MW dengan nilai transaksi diperkirakan melebihi $10 miliar. Chip Cerebras terkenal dengan ukuran besarnya, mengintegrasikan 4 triliun transistor dalam satu chip, dan mencapai kecepatan inferensi 15x lebih cepat dibanding sistem GPU. Langkah ini menandai upaya OpenAI untuk diversifikasi sumber daya komputasi di luar Nvidia, bertujuan meningkatkan pengalaman tugas berat seperti pemrograman melalui kemampuan respons real-time. Sam Altman sebagai investor pribadi Cerebras mendorong transformasi daya komputasi dari biaya menjadi sumber daya strategis (Sumber: Zhixi)
Guncangan di Thinking Machines: Barret Zoph Kembali ke OpenAI : Perusahaan AI bintang senilai $12 miliar, Thinking Machines, mengalami perubahan drastis saat pendiri Mira Murati memecat CTO Barret Zoph karena diduga melakukan kebocoran rahasia ke kompetitor. Zoph bersama pendiri bersama Luke Metz dan anggota inti Sam Schoenholz mengumumkan kepulangan massal ke OpenAI. Konflik internal tim “OpenAI-alumni” ini mengungkap persaingan kekuasaan dan kepentingan di lab AI top, sekaligus menjadi arus balik talenta penting bagi OpenAI (Sumber: APPSO)

Claude Cowork Picu Revolusi Kolaborasi & Kontroversi Keamanan : Produk Anthropic ini menandai transisi AI dari dialog ke pengambilalihan desktop. Kode intinya dihasilkan autonom oleh Claude Code dalam 1.5 minggu, menggunakan sistem “Skills” untuk mengubah instruksi menjadi aset yang dapat digunakan kembali. Namun, alat ini terbukti memiliki kerentanan serius seperti penghapusan file 11GB pengguna dengan perintah “rm -rf” dan serangan injeksi prompt tidak langsung. Felix Rieseberg menekankan bahwa antarmuka Agent akan semakin sederhana, berfokus pada pengalaman pribadi sebagai alur produktivitas yang dapat digunakan berulang (Sumber: InfoQ)

AI for Science: Studi Tsinghua di Nature Ungkap Dilema “Pendakian Massal” : Tim Li Yong dari Tsinghua menganalisis 250 juta literatur menemukan bahwa meskipun AI meningkatkan output ilmuwan individu (3x lebih banyak makalah), komunitas ilmiah justru mengalami penyempitan perhatian kolektif. Peneliti cenderung mengerumuni “gunung populer” yang mudah diproses AI, mengurangi interaksi lintas disiplin sebesar 22%. Sementara itu, sistem evaluasi SDE yang dipimpin tim China menunjukkan akurasi model top seperti GPT-5 dan DeepSeek-R1 dalam tugas penemuan ilmiah jauh lebih rendah dibanding performa kumpulan soal (Sumber: Qbitai)

🎯 Tren
Uji Ekstrem GPT-5.2 Codex: Menulis Browser 3 Juta Baris Kode dalam Seminggu : Tim Cursor menguji GPT-5.2 selama 168 jam non-stop, membangun browser dari nol dengan parser HTML, tata letak CSS, dan mesin virtual JS buatan sendiri. Eksperimen membuktikan konsistensi dan penguasaan arsitektur GPT-5.2 dalam tugas panjang jauh melampaui Opus 4.5 yang cenderung mengembalikan kontrol lebih awal. Siklus “tulis-jalankan-perbaiki” yang otonom ini menandai transisi AI dari “pelaksana tugas” menjadi “pemimpin proyek”, mendekati biaya marjinal nol dalam pengembangan perangkat lunak (Sumber: Xinzhiyuan)
DeepSeek Rilis Arsitektur mHC untuk Stabilitas Pelatihan Model Besar : DeepSeek menerbitkan makalah inti tentang arsitektur hyperconnection berbasis manifold constraint (mHC), mengatasi masalah divergensi sinyal dalam teknologi “hyperconnection” ByteDance pada pelatihan skala besar. Dengan membatasi matriks transformasi pada manifold matriks ganda stokastik, mHC memastikan stabilitas kekuatan sinyal, meningkatkan kinerja penalaran kompleks pada model 27 miliar parameter. Dipadu dengan optimasi sistem seperti operator fusion dan recomputation, arsitektur ini membuka jalan baru bagi perusahaan AI China dengan sumber daya terbatas untuk menyelesaikan masalah efisiensi dari akar matematika (Sumber: Jinduan)
Peningkatan Aplikasi Qwen Alibaba: Membangun Ekosistem Agent “Intent as Transaction” : Qwen App mengumumkan integrasi penuh dengan keluarga Alibaba termasuk Taobao, Alipay, dan Amap, menyediakan 400+ fungsi Agent seperti pemesanan makanan dan tiket. Berbeda dengan model “aliansi” raksasa luar negeri, Alibaba memanfaatkan ekosistem layanan fisik asli untuk mengalokasikan sumber daya dunia nyata setelah memahami maksud pengguna. Wu Jia menyatakan Qwen menggunakan data transaksi unik untuk meningkatkan model, bertujuan mengubah Token menjadi Take Rate, memulai revolusi interaksi manusia-mesin ketiga yang menantang logika pencarian tradisional (Sumber: 36Kr)

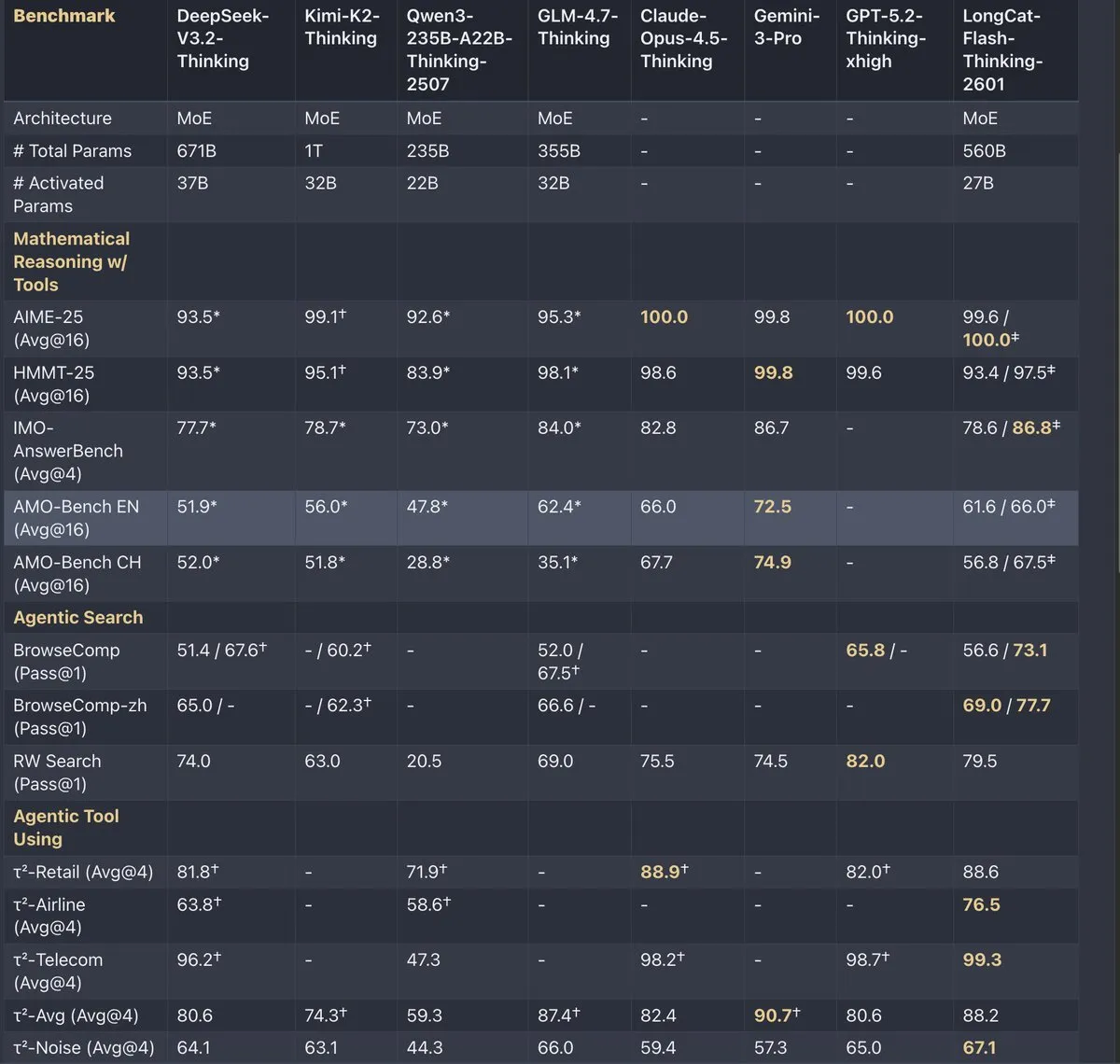
Meituan Luncurkan LongCat-Flash-Thinking : Meituan merilis LongCat-Flash-Thinking-2601 dengan fokus pada kedalaman dan kemampuan berpikir agen cerdas umum. Model ini unggul dalam benchmark seperti Agentic Search dan penggunaan alat, mendukung pemikiran paralel dan ringkasan iteratif untuk meningkatkan kedalaman penalaran. Mekanisme Zigzag Attention-nya mendukung konteks ultra-panjang hingga 1 juta Token. Ini menandakan Meituan telah memasuki jajaran lab top dalam pelatihan lingkungan sintetis dan analisis ketangguhan Agent (Sumber: teortaxesTex)
Skild AI Raup Pendanaan $1.4 Miliar, Valuasi Tembus $10 Miliar : Startup robotika Skild AI menyelesaikan pendanaan Seri C yang dipimpin SoftBank dengan partisipasi Nvidia dan Bezos, mencapai valuasi $14 miliar. Skild berfokus pada pembuatan “otak robot universal” melalui pembelajaran video skala besar dan latihan simulasi untuk kemampuan generalisasi lintas platform dan tugas. Perangkat lunaknya telah diadaptasi untuk robot berkaki empat, lengan mekanik, dan humanoid, bertujuan mengisi kekurangan jutaan lapangan kerja di industri dan layanan (Sumber: Zhixi)
🧰 Alat
Atoms (ex MetaGPT-X): Coding Agent Full-Stack Siap Komersil : DeepWisdom meluncurkan Atoms generasi baru yang menawarkan “situs web operasional dalam 5 menit”. Atoms dilengkapi database, otentikasi pengguna, dan sistem pembayaran Stripe, mengatasi masalah kode generasi AI yang hanya menjadi “mainan”. Arsitektur multi-agentnya mencakup peran riset, SEO, dan analisis data, mampu memperoleh lalu lintas pencarian secara otomatis. Resmi diklaim mencapai 45%+ efektivitas pesaing dengan biaya 20%, memungkinkan pengguna non-programmer memonetisasi melalui AI (Sumber: Zhinengyongxian)

Pembaruan Claude Code: Dynamic MCP Loading & Optimasi Interaksi : Claude Code memperkenalkan mekanisme pemuatan alat dinamis yang secara signifikan mengurangi inflasi konteks akibat pemasangan banyak alat MCP. Fitur baru pelengkapan instruksi dengan tombol Tab memungkinkan pengguna menambahkan penjelasan spesifik saat menerima atau menolak prompt izin, meningkatkan presisi kolaborasi Agent. Pengembang menerapkan strategi “disclosure bertahap” untuk mempertahankan keamanan data lokal sambil memperkuat kemampuan operasi lintas aplikasi (Sumber: op7418)

LlamaSheets: Solusi AI untuk Tabel Kacau : LlamaIndex meluncurkan LlamaSheets yang khusus mengurai tata letak Excel kompleks seperti sel gabungan, multi-sheet, dan kolom tersembunyi. Alat ini mengubah spreadsheet tidak terstruktur menjadi format terstruktur 2D (seperti Parquet) yang mudah dipahami LLM, dengan konsistensi konteks dalam alur kerja. Mode Agentic-nya menyediakan ekstraksi nilai grafik presisi tinggi dengan biaya sangat rendah, ideal untuk skenario keuangan dan riset pasar (Sumber: jerryjliu0)

GitNexus: Mesin Kode Cerdas Berbasis Browser Open-Source : GitNexus adalah alat pemahaman kode yang berjalan sepenuhnya di sisi browser, mendukung kueri relasi kode kompleks seperti IMPORTS, CALLS, dan EXTENDS. Kombinasi kemampuan kueri graf dan pencarian semantik ini dapat mendeteksi “radius ledakan” perubahan kode secara andal. Melalui protokol MCP, ia berfungsi sebagai plugin Claude Code atau Cursor, mencegah bug akibat ketergantungan yang diabaikan AI selama refaktor (Sumber: Reddit)
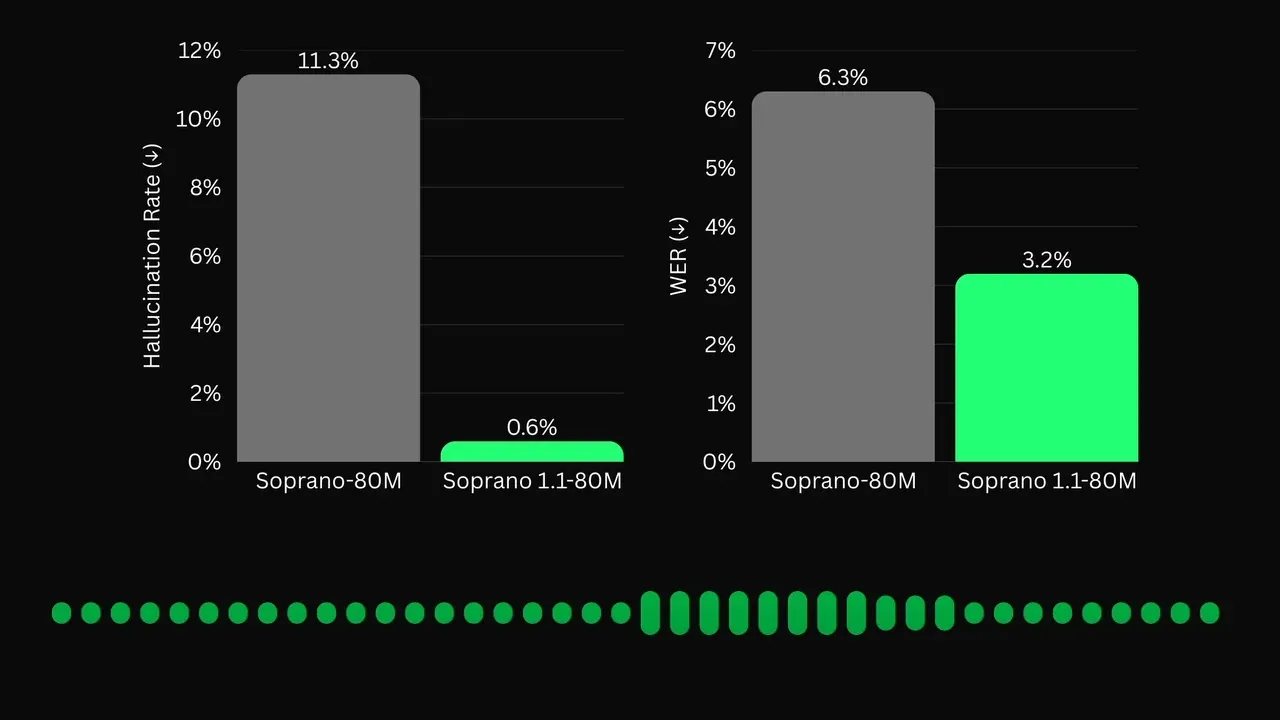
Soprano 1.1-80M: Model TTS Super Ringan Dirilis : Eugene merilis Soprano 1.1 yang hanya 80 juta parameter namun mencapai stabilitas suara sangat tinggi, mengurangi halusinasi (seperti suara guttural tak terduga) hingga 95%. Model ini mendukung generasi kalimat hingga 30 detik dengan kejelasan setara model komersial besar. Ukurannya yang sangat kecil cocok untuk perangkat tertanam atau robot dengan sumber daya terbatas, menunjukkan potensi besar model parameter kecil dalam modalitas spesifik (Sumber: Reddit)
📚 Pembelajaran
Panduan Mendalam Claude Code: Dari CLAUDE.md hingga Hooks Enforcement : Komunitas memperbarui panduan komprehensif Claude Code yang menekankan peran sentral CLAUDE.md global dalam perlindungan keamanan dan perancah proyek. Panduan menunjukkan bahwa meskipun aturan bersifat saran, Hooks seperti PreToolUse dapat menegakkan aturan secara deterministik (seperti memblokir akses file sensitif). Penelitian menunjukkan topik campuran mengurangi kinerja 39%, sehingga menganjurkan prinsip “satu tugas satu percakapan” dan berbagi cara memanfaatkan Skills untuk mengemas pengalaman ahli yang dapat digunakan kembali (Sumber: Reddit)

Panduan Pemilihan Arsitektur Multi-Agent LangChain : LangChain merilis blog terbaru yang merangkum empat pola arsitektur multi-agent: Subagents, Skills, Handoffs, dan Router. Prinsip intinya adalah “utamakan single-agent”, baru tingkatkan ke multi-agent saat menghadapi hambatan konteks atau kebutuhan pengembangan terdistribusi. Subagents cocok untuk multidomain paralel kuat, Skills fokus pada pengungkapan fungsi bertahap, Handoffs untuk alur berurutan, sedangkan Router mengejar efisiensi sintesis paralel tertinggi. Panduan menyediakan tolok ukur kinerja dan contoh kode rinci (Sumber: LangChain)

MOFSeq-LMM: Prediksi Kelayakan Sintesis Material oleh Model Besar : Tim Princeton mengusulkan MOFSeq-LMM yang menggunakan LLM untuk memprediksi energi bebas kerangka logam-organik (MOFs) langsung dari urutan struktur dengan akurasi 97%. Metode ini mengubah struktur 3D kompleks menjadi representasi string, secara signifikan mengurangi biaya komputasi evaluasi termodinamika. Pergeseran paradigma ini mengubah penelitian material dari “bagaimana mengukur” menjadi “bagaimana mendefinisikan masalah”, menyediakan alat kuat untuk penemuan material throughput tinggi dan terukur (Sumber: HyperAI)

**Model Bahasa Rekursif (RLMs): Menembus Batas