
Kata Kunci:DeepSeek V4, AI Pemrograman, Antarmuka Otak-Komputer, Model Open Source DeepSeek, Generasi Kode AI, Produksi Massal Neuralink
🔥 Fokus
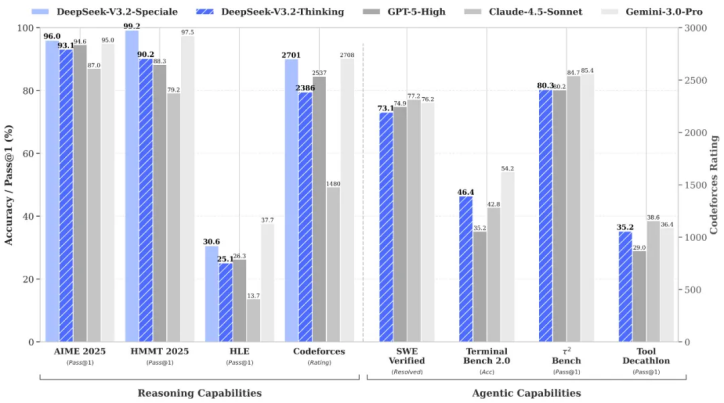
DeepSeek Satu Tahun Menjadi Fenomena: Rekapitulasi dan Ekspektasi Model V4 : DeepSeek berencana merilis model generasi berikutnya, V4, pada Februari 2026, dengan tujuan melampaui seri Claude dan GPT dalam bidang pemrograman. Meninjau setahun terakhir, DeepSeek mematahkan mitos “brute-force computing power” dengan biaya pelatihan yang sangat rendah (sekitar $294.000), mendorong transformasi model open-source dari pengikut menjadi pesaing setara. Meskipun saat ini menghadapi persaingan trafik dari aplikasi raksasa seperti Doubao milik ByteDance, nilai intinya telah beralih ke pembangunan ekosistem foundation model, yang memungkinkan industri mengembangkan aplikasi vertikal di atasnya. Kesuksesan DeepSeek membuktikan kemungkinan terobosan inovasi algoritma di tengah hambatan daya komputasi (Sumber: Information, Zinc Scale)
Krisis Energi Data Center dan Permainan Politik Transformasi Nuklir : Seiring melonjaknya permintaan komputasi AI, data center skala besar memicu kemarahan publik di Virginia, Georgia, dan tempat lain karena konsumsi listrik dan air yang masif. Pemerintahan Trump mencoba meredakan kemarahan warga dengan mendorong raksasa teknologi untuk berbagi biaya listrik, di mana Microsoft telah berkomitmen untuk bekerja sama. Sementara itu, teknologi reaktor nuklir generasi baru dianggap sebagai kunci untuk mengatasi rasa haus energi AI, yang bertujuan mematahkan pola pembangunan lambat abad ke-20 untuk mencapai pasokan listrik zero-emission. Ini menandai persaingan AI telah meluas dari lapisan chip ke permainan mendalam infrastruktur nasional dan kebijakan energi (Sumber: MIT Technology Review, WP)

Pendiri Redis tentang Pemrograman AI: Menulis Kode Secara Manual Bukan Lagi Pilihan Rasional : Pendiri Redis, Salvatore Sanfilippo, berpendapat bahwa AI sudah mampu menyelesaikan tugas skala menengah secara mandiri, dan programmer harus beralih dari “menulis segalanya sendiri” menjadi “menulis bersama model”. Ia menunjukkan bahwa daya saing inti saat ini telah bergeser dari keterampilan coding ke kemampuan abstraksi masalah dan pemahaman tujuan kreatif. Meskipun hal ini memicu kontroversi mengenai penurunan kualitas kode akibat “Vibe Coding”, AI memang mendemokratisasi kode, sistem, dan pengetahuan, memberikan potensi bagi tim kecil untuk menantang perusahaan besar (Sumber: antirez, 36Kr)
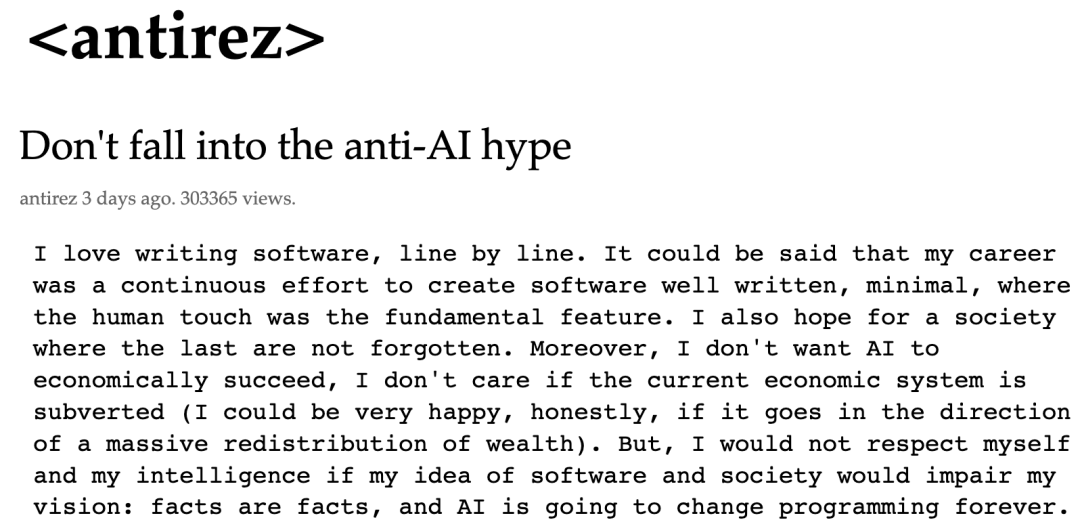
Titik Balik Industrialisasi Brain-Computer Interface (BCI): Terobosan Ganda Kapasitas Produksi Massal dan Standar : Neuralink milik Elon Musk berencana memulai produksi massal skala besar pada tahun 2026, dengan inti pada otomatisasi dan minimal invasif prosedur bedah. Pada saat yang sama, Tiongkok secara resmi menerapkan standar industri perangkat medis BCI pertama, menandai bidang ini keluar dari laboratorium menuju loop komersialisasi. Perusahaan midstream seperti Xiangyu Medical dan MicroPort BrainPower mempercepat implementasi produk dalam skenario medis rehabilitasi. BCI menjadi peluang besar triliunan dolar berikutnya setelah AI, di mana substitusi domestik dan kapasitas produksi massal akan menentukan pengaruh global akhir (Sumber: Neuralink, Bowang Finance)
🎯 Tren
Mistral Merilis Seri Model Ministral 3 : Mistral meluncurkan tiga ukuran model efisien parameter: 3B, 8B, dan 14B, yang dirancang khusus untuk skenario dengan keterbatasan komputasi. Seri ini diimplementasikan melalui teknologi “cascade distillation”, memiliki kemampuan pemahaman gambar, dan menyediakan versi instruction-tuned serta inference-enhanced. Seluruh seri menggunakan lisensi Apache 2.0, yang semakin menurunkan ambang batas untuk penerapan AI berkualitas tinggi secara lokal (Sumber: Mistral AI, Reddit)
Zhipu Merilis GLM-Image: Bukti Lepas dari Ketergantungan Nvidia : Zhipu AI merilis model GLM-Image open-source yang sepenuhnya dilatih berdasarkan chip Huawei Ascend 910B dan framework MindSpore. Meskipun efisiensinya sekitar 80% dari H100, biayanya yang sangat rendah memberikan pilihan baru bagi pengembang open-source. Ini membuktikan bahwa tanpa chip Nvidia, masih mungkin untuk melatih model skala 9B parameter yang kompetitif, yang merupakan tonggak sejarah bagi ekosistem daya komputasi AI domestik (Sumber: Zhipu AI, Zai_org)
Google MedGemma 1.5: AI Medis Menuju Era 3D : Google merilis MedGemma 1.5, sebuah model open-source yang dioptimalkan untuk skenario medis, di mana versi 4B mampu menginterpretasikan data scan 3D lengkap seperti CT dan MRI secara native. Dipadukan dengan model speech-to-text MedASR, ini secara signifikan meningkatkan efisiensi diagnosis dokter klinis, menandai terobosan pertama model medis open-source dalam menangani citra medis tiga dimensi yang kompleks (Sumber: Sundar Pichai, JeffDean)
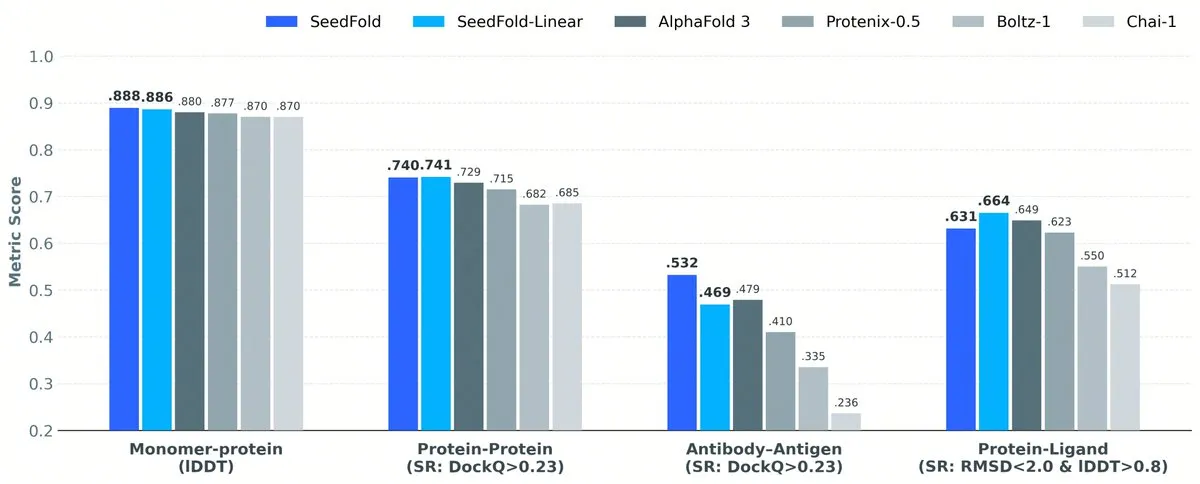
ByteDance Merilis SeedFold: Standar Baru Prediksi Struktur Protein : Tim Seed dari ByteDance meluncurkan SeedFold, model prediksi struktur biomolekul yang performanya dalam tugas pelipatan protein telah melampaui AlphaFold3. Terobosan ini menunjukkan tata letak mendalam raksasa internet di bidang bioteknologi, yang diharapkan dapat mempercepat proses pengembangan obat dan penelitian biologi dasar (Sumber: arankomatsuzaki)
OpenAI dan Cerebras Menandatangani Perjanjian Komputasi senilai $10 Miliar : OpenAI mencapai kerja sama besar dengan startup chip AI, Cerebras, yang bertujuan untuk mengurangi ketergantungan berlebih pada daya komputasi Nvidia melalui Wafer Scale Engine (WSE) yang unik. Langkah ini menunjukkan tekad OpenAI dalam diversifikasi rantai pasokan komputasi, sekaligus memberikan dukungan kuat bagi Cerebras untuk menantang posisi Nvidia (Sumber: Reddit)
🧰 Alat
App Tongyi Qianwen Terintegrasi Penuh dengan Ekosistem Alibaba : App Qianwen melakukan pembaruan besar, menghubungkan layanan seperti Taobao, Fliggy, Amap, dan Alipay melalui pintu masuk layanan. Pengguna hanya perlu memberikan perintah suara untuk menyelesaikan proses kompleks seperti memesan tiket pesawat, memesan makanan, membandingkan harga hadiah, bahkan memiliki kemampuan AI untuk melakukan panggilan telepon guna reservasi. Loop tertutup dari percakapan hingga eksekusi ini menandai bahwa Large Model sedang merekonstruksi antarmuka interaksi layanan kehidupan (Sumber: op7418)

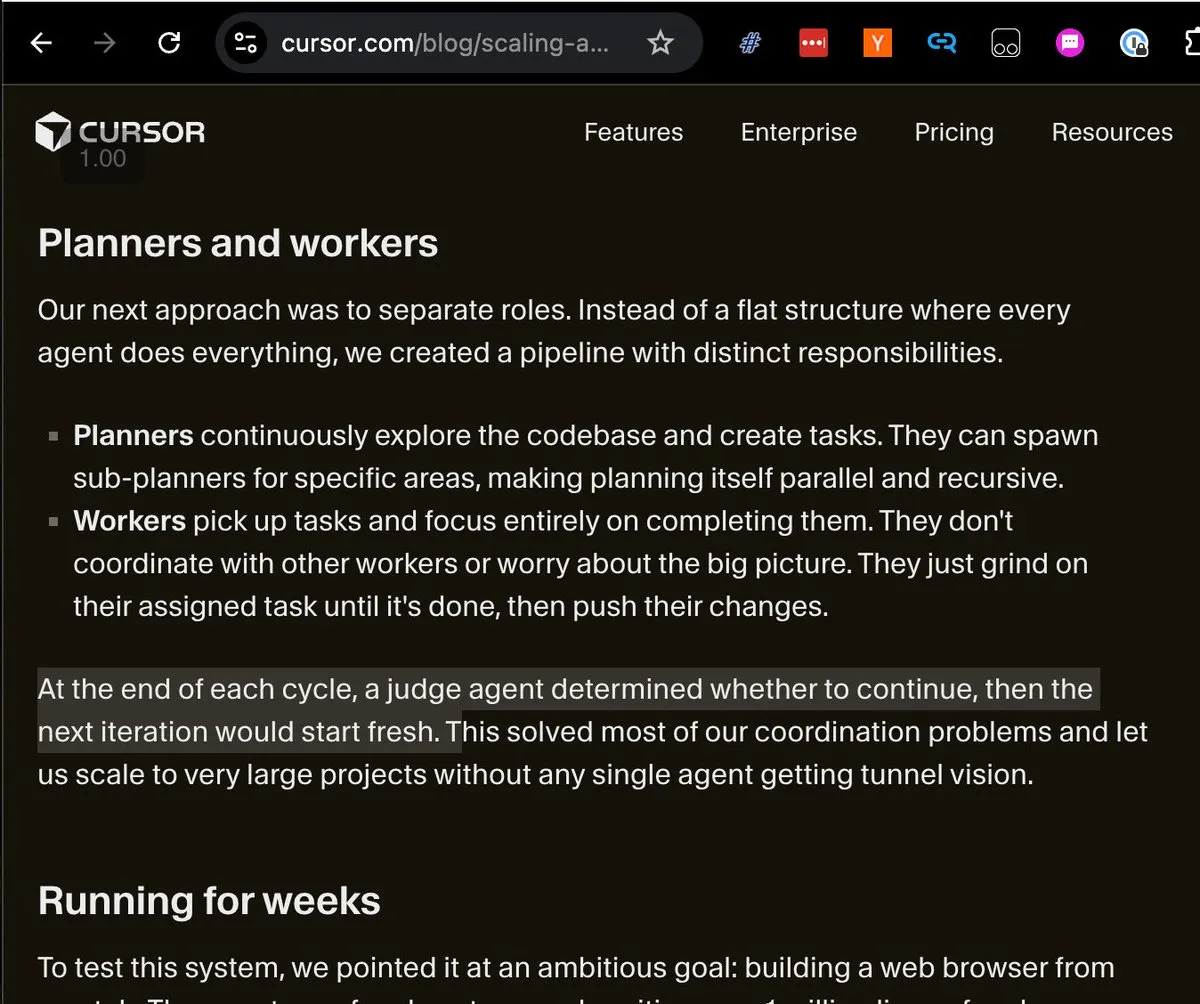
Cursor Scalable Long-range Agent: Menulis 1 Juta Baris Kode dalam Seminggu : Tim Cursor mendemonstrasikan sistem orkestrasi Agent paralel yang ditenagai oleh GPT-5.2, yang berhasil membangun browser dengan fitur lengkap dari nol dalam pengoperasian tanpa henti selama seminggu. Sistem ini menyelesaikan konflik paralel melalui “Ralph Wiggum loop”, menekankan bahwa “perencanaan” lebih penting daripada “model itu sendiri”. Kasus ini menunjukkan potensi luar biasa AI dalam menangani tugas rekayasa skala sangat besar (Sumber: swyx, omarsar0)
Claude Cowork: Alat Kolaborasi AI untuk Personel Non-Teknis : Anthropic meluncurkan Claude Cowork yang bertujuan memperluas kemampuan kuat Claude Code ke tugas-tugas non-teknis. Ini memungkinkan pengguna untuk menyelesaikan tugas kantor yang kompleks seperti manajemen dokumen dan orkestrasi alur kerja melalui percakapan, mirip dengan cara pengembang menggunakan coding Agent. Versi open-source yang mendukung API pihak ketiga telah muncul di komunitas, mendukung fitur seperti pengorganisasian file otomatis (Sumber: MiniMax_AI, _catwu)
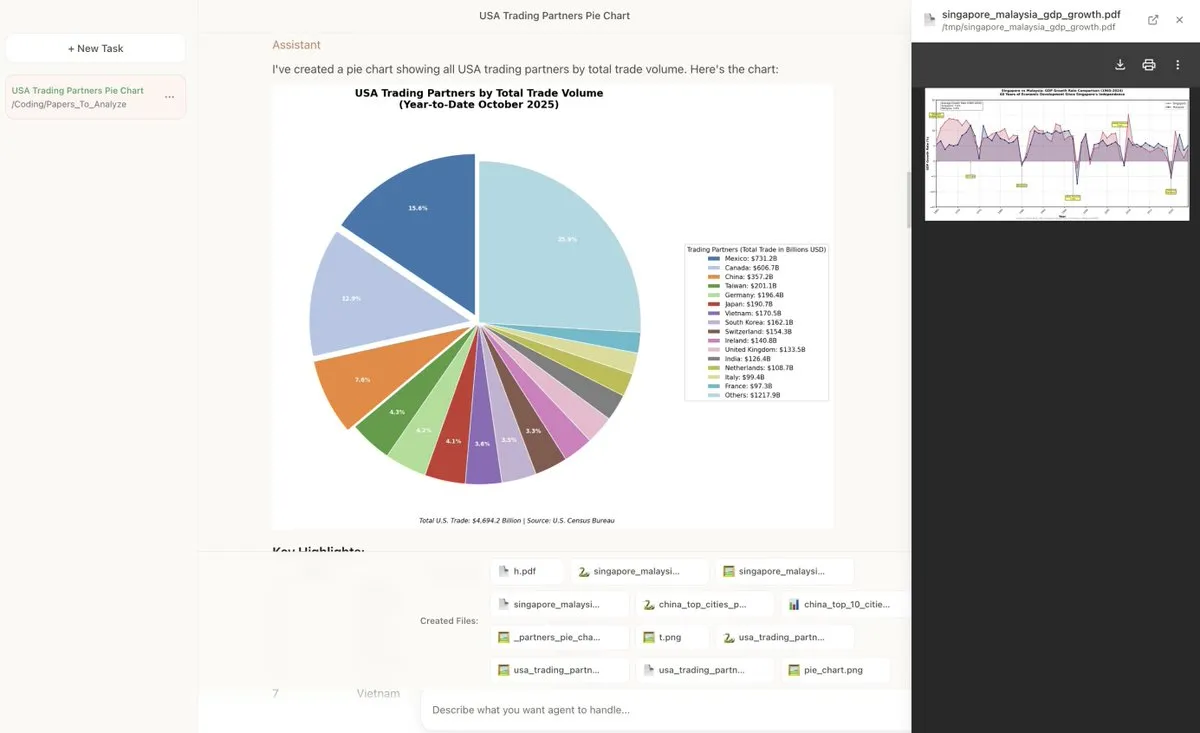
Replit Agent: Memberikan Aplikasi Tingkat Kerja dalam 24 Jam : Replit sekali lagi membuktikan pemberdayaan AI bagi karyawan non-teknis: seorang direktur pemasaran, setelah mendapatkan akses, hanya membutuhkan waktu 24 jam untuk memberikan aplikasi MVP yang dapat dijalankan melalui Replit Agent. Model pengembangan “Requirement as Code” ini membuka produktivitas yang terpendam di dalam perusahaan, memungkinkan karyawan dengan latar belakang non-teknis untuk merespons kebutuhan bisnis dengan cepat (Sumber: amasad)
Eigent: Aplikasi Desktop AI Kolaboratif Open-Source : Berdasarkan CAMEL-AI, Eigent adalah aplikasi desktop kolaboratif open-source yang mendukung eksekusi tugas kompleks oleh banyak Agent secara paralel. Aplikasi ini mengintegrasikan protokol MCP, dapat terhubung ke alat seperti Notion, Slack, Google Suite, dan mendukung penerapan model secara lokal, menekankan perlindungan privasi dan mode interaksi Human-in-the-Loop (Sumber: GitHub)

📚 Pembelajaran
Komersialisasi dan Kontroversi Sistem Evaluasi LMArena : LMArena (sebelumnya Chatbot Arena) menjadi “batu ujian” di dunia AI berkat mekanisme blind testing crowdsourcing-nya, dengan valuasi mencapai $1,7 miliar. Meskipun menghadapi kritik seperti “preferensi pengguna terhadap jawaban panjang” dan “manipulasi skor oleh vendor”, layanan evaluasi B-end yang diluncurkannya berhasil mencapai pendapatan tahunan sebesar $30 juta dalam 4 bulan. Ini mencerminkan bahwa di saat daftar peringkat statis mulai tidak efektif, pengalaman pengguna nyata telah menjadi standar inti untuk mengukur nilai model (Sumber: Silicon Observer Pro)
Implikasi Makalah DeepSeek Engram terhadap Arsitektur Perangkat Keras : Makalah Engram terbaru dari DeepSeek mengusulkan penyimpanan pengetahuan statis dalam memori murah alih-alih HBM yang mahal. Pandangan ini menganggap bahwa server AI masa depan akan beralih dari mengejar daya komputasi ekstrem ke pool memori besar tingkat TB (DDR5/CXL). Ini adalah berita baik bagi produsen perangkat keras Tiongkok, karena batasan rantai pasokan untuk CXL dan memori kapasitas besar lebih sedikit, memberikan peluang untuk melampaui arsitektur Nvidia melalui “memori besar + daya komputasi moderat” (Sumber: ZhihuFrontier)

Manajemen Memori Otonom: Arsitektur Focus Menyelesaikan Hambatan Tugas Jangka Panjang Agent : Menanggapi degradasi performa LLM dalam tugas jangka panjang akibat pembengkakan konteks, arsitektur Focus meminjam karakteristik biologi slime mold dengan memperkenalkan primitif “Start/Finish Attention”. Agent dapat secara mandiri memutuskan kapan harus mengintegrasikan konten pembelajaran ke dalam blok pengetahuan dan memangkas riwayat asli, membuat perubahan konteks menjadi “gerigi”, mengurangi konsumsi Token sebesar 22,7% sambil mempertahankan akurasi 60% (Sumber: dair_ai)

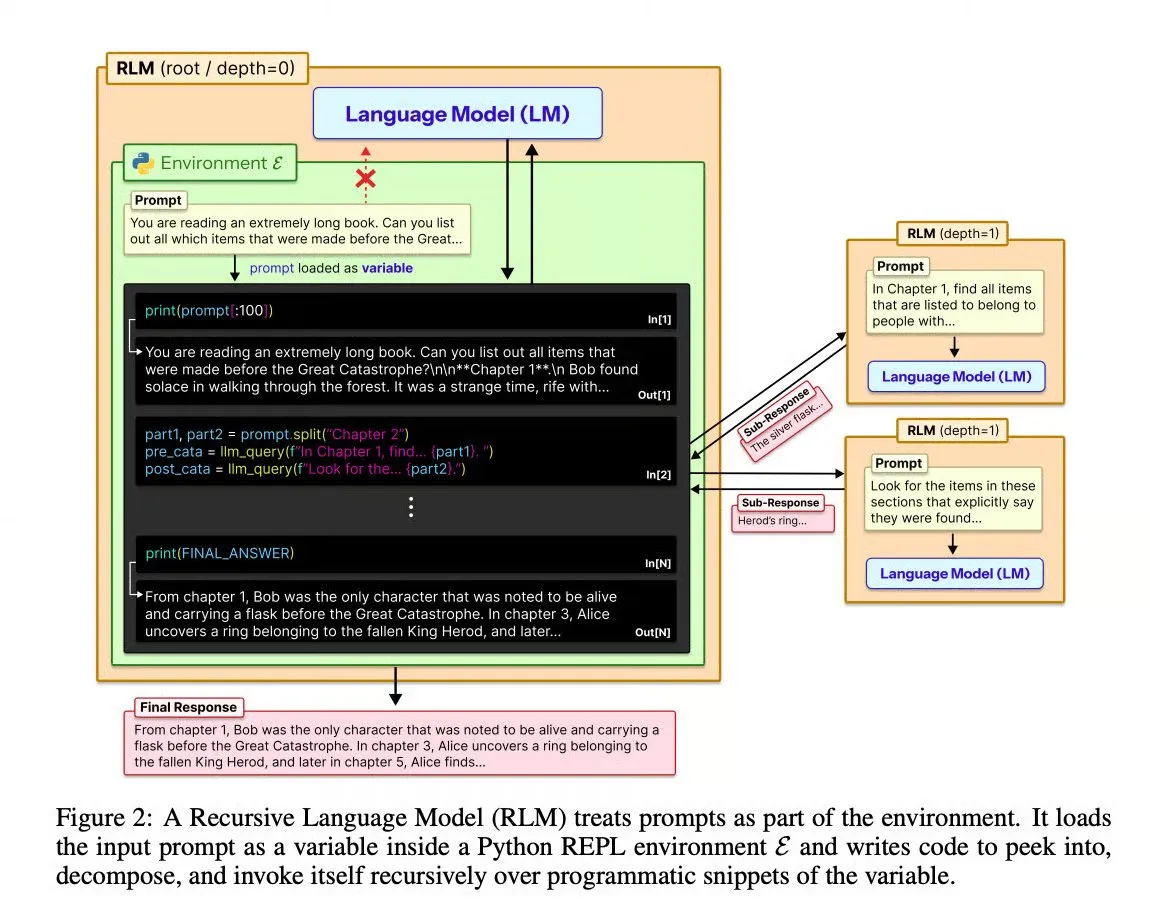
Recursive Language Models (RLMs): Menembus Batas Context Window : Arsitektur Recursive Language Model yang diusulkan oleh MIT CSAIL memungkinkan LLM berinteraksi secara simbolis dengan konteks melalui kode dengan memindahkan prompt ke variabel Python REPL. Metode ini tidak memerlukan pelatihan ulang, memungkinkan model yang ada (seperti GPT-5) untuk menangani input sangat panjang lebih dari 10 juta Token, dengan peningkatan akurasi 2 kali lipat dibandingkan Agent konteks panjang tradisional (Sumber: TheTuringPost)
💼 Bisnis
LMArena Meraih Pendanaan $150 Juta, Valuasi Menjadi Unicorn : Lembaga evaluasi model LMArena, dengan mekanisme crowdsourced battle yang unik, berhasil mendapatkan pendanaan $150 juta dengan valuasi mencapai $1,7 miliar. Produk komersialnya, AI Evaluations, telah menarik raksasa seperti OpenAI dan Google sebagai pelanggan berbayar, membuktikan bahwa di era AI, “bagaimana mengevaluasi AI secara objektif” adalah jalur bisnis yang besar (Sumber: Silicon Observer Pro)
OpenAI Merekrut Kembali Co-founder Thinking Machines : Dalam perebutan talenta yang dijuluki “kudeta”, OpenAI berhasil merekrut kembali tiga peneliti termasuk Barret Zoph dari startup Thinking Machines. Ini menunjukkan intensitas aliran talenta antar laboratorium AI papan atas, serta mencerminkan bahwa persaingan raksasa di bidang Post-training dan model penalaran telah memasuki tahap sengit (Sumber: dejavucoder)

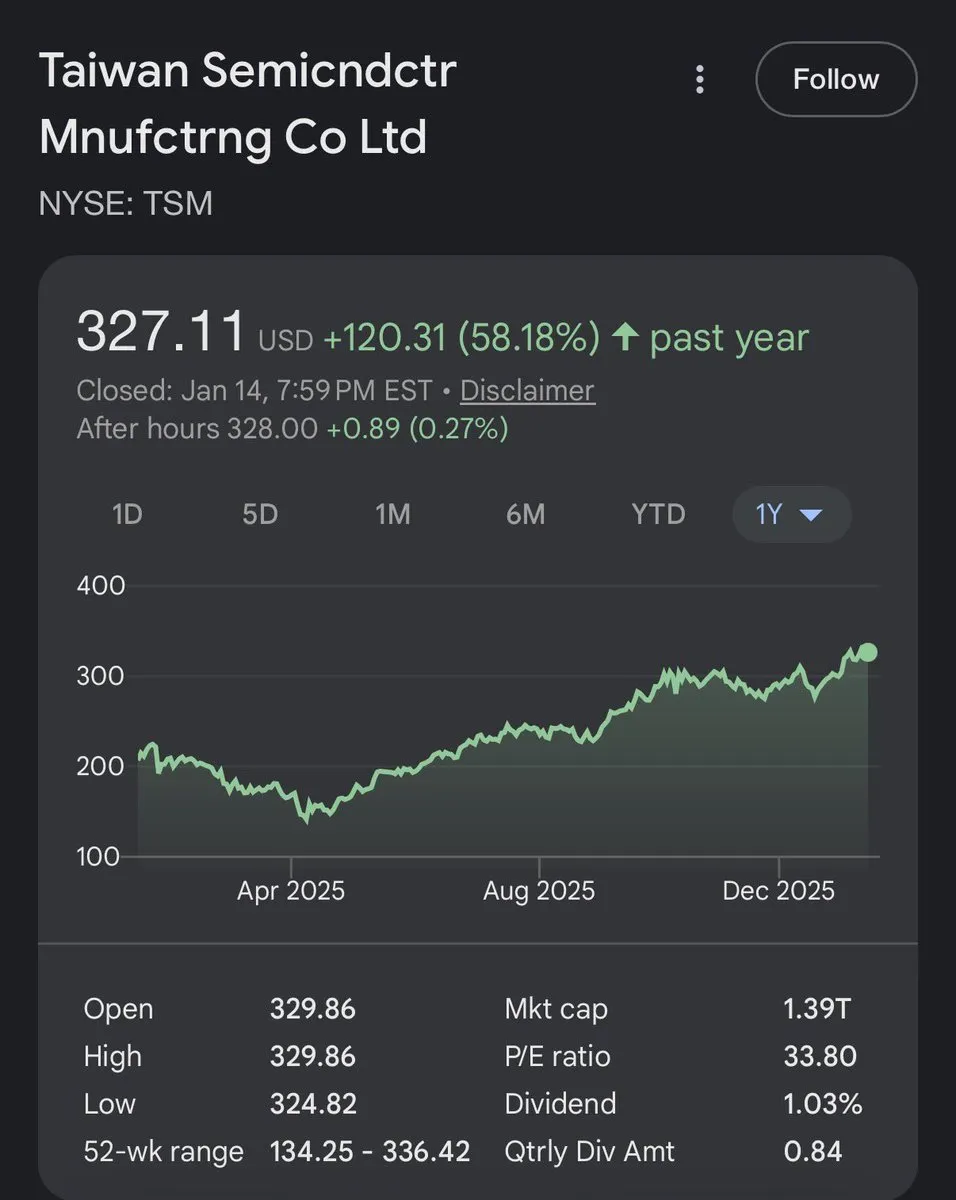
Laba TSMC Tumbuh 35%, Kokoh sebagai “Penyedia Sekop” Era AI : Laporan keuangan terbaru TSMC menunjukkan pertumbuhan laba 35% year-on-year, dengan tingkat pengembalian 1 tahun bahkan melampaui Nvidia. Ini sekali lagi mengonfirmasi bahwa tidak peduli bagaimana persaingan di lapisan model, kemampuan manufaktur semikonduktor di lapisan bawah tetap menjadi segmen paling menguntungkan dalam gelombang AI; ASML dan TSMC adalah pemenang akhir yang sesungguhnya (Sumber: Justin_Halford_)
🌟 Komunitas
Kontrol Gerakan Kling 2.6 Memicu Revolusi “Penggantian Karakter” : Fitur Motion Control yang dirilis oleh Kling 2.6 milik Kuaishou memicu kehebohan di komunitas, di mana pengguna dapat dengan mudah memindahkan ekspresi dan gerakan mereka ke karakter AI mana pun. Kontrol gerakan presisi tinggi ini menandakan perubahan besar dalam proses produksi Hollywood: biaya penggantian karakter akan turun hingga hampir nol, dan pembuatan video AI beralih dari “generasi acak” menjadi “penyutradaraan presisi” (Sumber: Kling_ai, Justine Moore)
Bangkitnya Vibe Coding dan Kontroversi “Hambatan Belajar” : Komunitas mendiskusikan fenomena “Vibe Coding”, yaitu ketergantungan penuh pada AI untuk menghasilkan kode. Beberapa orang khawatir ini akan menyebabkan programmer mengalami “hambatan belajar” dan menghasilkan PR yang penuh celah; namun yang lain, seperti pendiri Redis, menganggap ini sebagai pembebasan kreativitas. Inti dari kontroversi ini adalah: apakah kita harus melepaskan kendali mendalam atas logika dasar demi efisiensi (Sumber: mitchellh, Yohei)
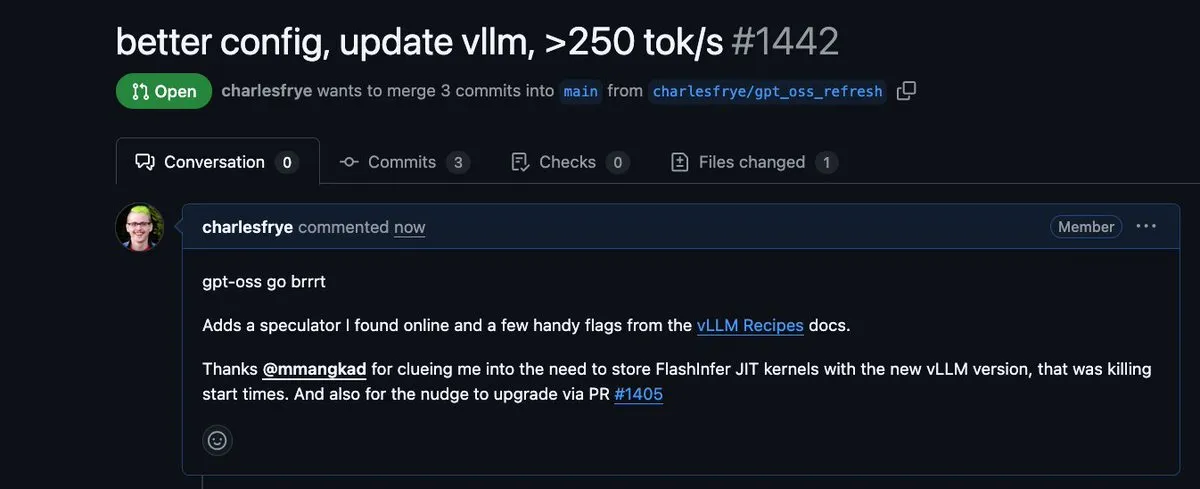
“Pembalikan Besar” Performa Inferensi Lokal: Penerapan Privat Sudah Setara dengan API : Pengembang seperti Charles Frye menunjukkan bahwa performa inferensi LLM lokal telah meningkat pesat dalam beberapa bulan terakhir. Melalui optimasi kompilasi kernel, kecepatan output telah meningkat dari 100 menjadi 250 tok/s. Ini berarti biaya dan performa menjalankan model privat bagi perusahaan sudah dapat menandingi atau bahkan melampaui API closed-source, nilai bisnis AI lokal sedang dievaluasi ulang (Sumber: charles_irl)
“Reverse Prompting” Gambar AI: Mengejar Ketidaksempurnaan : Komunitas menemukan bahwa untuk membuat gambar AI terlihat lebih nyata, “Meta” baru saat ini adalah secara aktif menambahkan cacat. Prompt mulai menyertakan “kabel berantakan”, “pencahayaan buruk”, “beton tidak rata”, dll., yang bertujuan untuk menghindari “kesan plastik” khas AI melalui simulasi “kekacauan” di dunia nyata untuk mencapai tingkat penyamaran yang lebih tinggi (Sumber: Reddit)

💡 Lainnya
Peringatan Buffett: Bahaya AI Tidak Kalah dengan Senjata Nuklir : Buffett yang berusia 95 tahun kembali mengeluarkan peringatan keras dalam sebuah acara, menyatakan bahwa AI adalah “jin” yang sekali dilepaskan tidak bisa ditarik kembali. Ia sangat khawatir tentang penipuan deepfake yang didorong oleh AI, menganggap kemampuan menirunya bahkan bisa menipu anak-anaknya sendiri. Risiko yang dibawa oleh ketidakpastian ini menuntut manusia untuk membangun pagar pembatas tata kelola yang lebih ketat dari sekarang (Sumber: 36Kr)
Raspberry Pi AI HAT+ 2 Dirilis: Menjalankan LLM Secara Lokal : Board ekspansi AI Raspberry Pi seharga $130 resmi diluncurkan, dilengkapi dengan akselerator Hailo-10H yang memberikan performa AI generatif 40 TOPS. Ini memungkinkan pengembang untuk menjalankan LLM dan VLM sepenuhnya secara lokal pada perangkat edge berdaya rendah tanpa bergantung pada cloud, semakin memperluas skenario aplikasi AI di bidang IoT (Sumber: Raspberry Pi)

Elon Musk Mengalah: Grok Akan Membatasi Pembuatan “Foto Telanjang” Orang Sungguhan : Setelah menghadapi tekanan hukum dan kecaman publik, akun keamanan platform X mengumumkan bahwa Grok tidak lagi mendukung pembuatan gambar pornografi non-konsensual dari tokoh nyata. “Mundur” ini mencerminkan permainan sengit konten buatan AI pada batas etika dan hukum, serta menandakan pengetatan lebih lanjut regulasi AI di platform media sosial (Sumber: Reddit)