
Mots-clés:DeepSeek V4, programmation IA, interface neuronale directe, modèle open source DeepSeek, génération de code par IA, production en série de Neuralink
🔥 À la une
Bilan de l’année de percée de DeepSeek et attentes pour le modèle V4 : DeepSeek prévoit de lancer son modèle de nouvelle génération V4 en février 2026, avec l’ambition de surpasser les séries Claude et GPT dans le domaine de la programmation. En revenant sur l’année écoulée, DeepSeek a brisé le mythe de la “puissance de calcul brute” grâce à des coûts d’entraînement extrêmement bas (environ 294 000 $), propulsant les modèles open-source d’un rôle de suiveur à celui de concurrent direct. Bien que confronté à la concurrence des applications de géants comme Doubao (ByteDance), sa valeur fondamentale s’est déplacée vers la construction d’un écosystème de modèles de base, permettant à l’industrie de développer des applications verticales. Le succès de DeepSeek prouve que l’innovation algorithmique peut percer les barrières de la puissance de calcul (Source : Information, Xin Kedu)
Crise énergétique des Data Centers et enjeux politiques de la transition nucléaire : Avec l’explosion de la demande en calcul AI, les Data Centers géants provoquent une forte indignation publique en Virginie et en Géorgie en raison de leur consommation massive d’électricité et d’eau. L’administration Trump tente d’apaiser la situation en incitant les géants technologiques à partager les coûts d’électricité, Microsoft ayant déjà promis de coopérer. Parallèlement, la nouvelle génération de réacteurs nucléaires est perçue comme la clé pour étancher la soif énergétique de l’AI, visant à rompre avec la lenteur de construction du 20e siècle pour fournir une énergie zéro émission. Cela marque une extension de la compétition AI des puces vers les infrastructures nationales et les politiques énergétiques (Source : MIT Technology Review, WP)

Le créateur de Redis sur la programmation AI : écrire du code à la main n’est plus un choix rationnel : Salvatore Sanfilippo, fondateur de Redis, estime que l’AI est désormais capable d’accomplir seule des tâches de taille moyenne, et que les programmeurs doivent passer de “tout écrire à la main” à “co-écrire avec le modèle”. Il souligne que la compétitivité ne réside plus dans les compétences de codage, mais dans la capacité d’abstraction des problèmes et la compréhension des objectifs créatifs. Bien que cela alimente le débat sur la baisse de qualité du code liée au “Vibe Coding”, l’AI démocratise effectivement le code, les systèmes et la connaissance, permettant à de petites équipes de défier de grandes entreprises (Source : antirez, 36Kr)
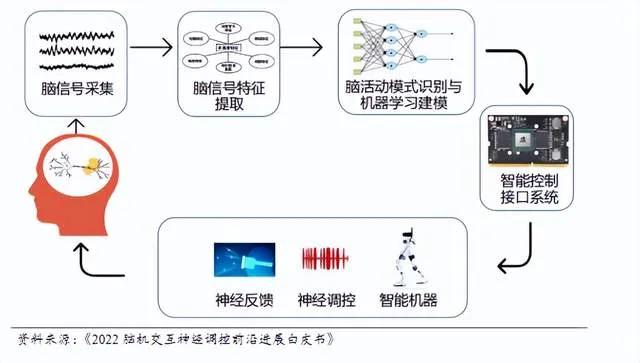
Point d’inflexion de l’industrialisation des BCI : percées dans la production de masse et les standards : Neuralink d’Elon Musk prévoit de lancer une production à grande échelle en 2026, misant sur l’automatisation et le caractère mini-invasif des procédures chirurgicales. Parallèlement, la Chine a officiellement mis en œuvre sa première norme industrielle pour les dispositifs médicaux d’interface cerveau-machine (BCI), marquant le passage du laboratoire à une boucle commerciale fermée. Des entreprises comme Xiangyu Medical et MicroPort BrainScience accélèrent le déploiement de produits dans la rééducation médicale. Le BCI devient le prochain secteur à mille milliards de dollars après l’AI, où la substitution locale et la capacité de production détermineront le leadership mondial (Source : Neuralink, Bowang Finance)
🎯 Tendances
Mistral publie la série de modèles Ministral 3 : Mistral lance trois tailles de modèles (3B, 8B et 14B) optimisés pour l’efficacité des paramètres, conçus pour des scénarios à calcul limité. Cette série, réalisée via la technique de “distillation en cascade”, possède des capacités de compréhension d’image et propose des versions avec fine-tuning d’instructions et amélioration du raisonnement. Toute la gamme adopte la licence Apache 2.0, abaissant encore le seuil de déploiement local d’AI de haute qualité (Source : Mistral AI, Reddit)
Zhipu publie GLM-Image : la preuve de l’indépendance vis-à-vis de Nvidia : Zhipu AI a rendu open-source le modèle GLM-Image, entièrement entraîné sur des puces Huawei Ascend 910B et le framework MindSpore. Bien que son efficacité soit d’environ 80 % par rapport à un H100, son coût extrêmement bas offre une nouvelle option aux développeurs open-source. Cela prouve qu’il est possible d’entraîner des modèles compétitifs de 9B paramètres sans puces Nvidia, une étape historique pour l’écosystème de calcul AI chinois (Source : Zhipu AI, Zai_org)
Google MedGemma 1.5 : l’AI médicale passe à la 3D : Google a publié MedGemma 1.5, un modèle open-source optimisé pour le secteur médical. Sa version 4B peut interpréter nativement des données de scans 3D complets tels que CT et MRI. Couplé au modèle de reconnaissance vocale MedASR, il améliore considérablement l’efficacité des diagnostics cliniques, marquant une première pour un modèle médical open-source dans le traitement d’imagerie médicale tridimensionnelle complexe (Source : Sundar Pichai, JeffDean)
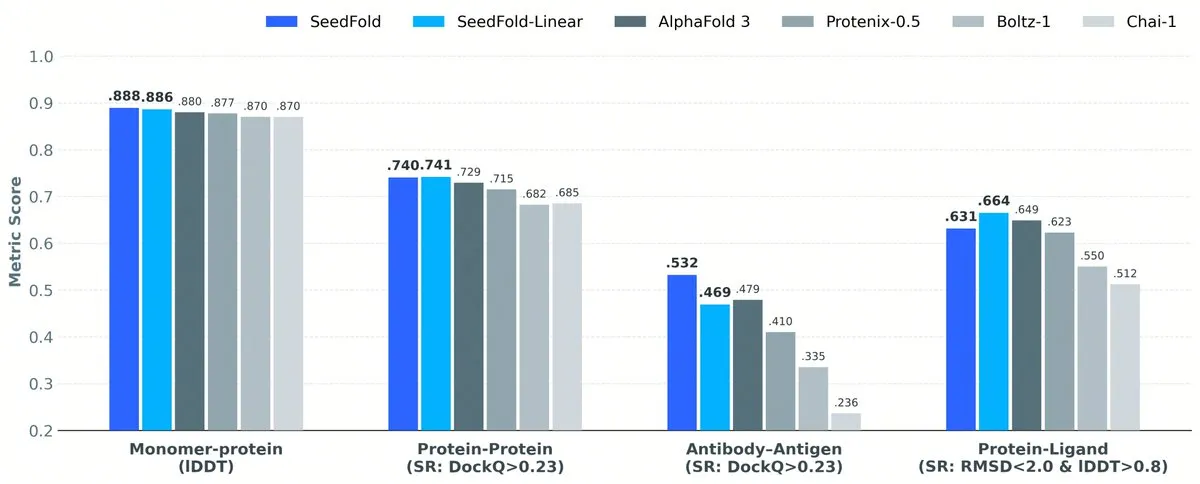
ByteDance publie SeedFold : nouveaux sommets dans la prédiction de structures protéiques : L’équipe Seed de ByteDance a lancé SeedFold, un modèle de prédiction de structures biomoléculaires dont les performances sur le repliement des protéines surpassent déjà AlphaFold3. Cette percée montre l’investissement profond des géants de l’Internet dans la biotechnologie, promettant d’accélérer la recherche de médicaments et la biologie fondamentale (Source : arankomatsuzaki)
OpenAI et Cerebras signent un accord de calcul de 10 milliards de dollars : OpenAI a conclu un partenariat massif avec la startup de puces AI Cerebras, visant à réduire sa dépendance excessive envers Nvidia grâce à leur moteur unique Wafer Scale Engine (WSE). Ce mouvement démontre la détermination d’OpenAI à diversifier sa chaîne d’approvisionnement en calcul, tout en offrant un soutien majeur à Cerebras pour défier la position de Nvidia (Source : Reddit)
🧰 Outils
L’application Qwen (Tongyi Qianwen) s’intègre pleinement à l’écosystème Alibaba : L’application Qwen a bénéficié d’une mise à jour majeure, connectant via son entrée “Services” des plateformes comme Taobao, Fliggy, Amap et Alipay. Les utilisateurs peuvent désormais réserver des billets d’avion, commander des repas ou comparer des cadeaux via des commandes vocales, l’AI étant même capable de passer des appels pour des réservations. Ce passage de la conversation à l’exécution marque une restructuration des services de la vie quotidienne par les grands modèles (Source : op7418)

Agent Cursor à long terme : 1 million de lignes de code en une semaine : L’équipe Cursor a présenté un système d’orchestration d’Agents parallèles propulsé par GPT-5.2, capable de construire un navigateur complet à partir de zéro en tournant sans interruption pendant une semaine. Le système utilise une “boucle Ralph Wiggum” pour résoudre les conflits parallèles, soulignant que la “planification” est plus cruciale que le “modèle lui-même”. Ce cas démontre le potentiel phénoménal de l’AI pour gérer des tâches d’ingénierie à très grande échelle (Source : swyx, omarsar0)
Claude Cowork : l’outil de collaboration AI pour les non-techniciens : Anthropic a lancé Claude Cowork, visant à étendre les capacités de Claude Code aux tâches non techniques. Il permet aux utilisateurs d’accomplir des tâches de bureau complexes (gestion de documents, orchestration de flux) par simple dialogue, à l’instar des développeurs utilisant des Agents de programmation. Des versions open-source supportant des API tierces sont déjà apparues dans la communauté (Source : MiniMax_AI, _catwu)
Replit Agent : livrer une application professionnelle en 24 heures : Replit prouve une fois de plus l’autonomisation des employés non techniciens par l’AI : un directeur marketing a pu livrer un MVP fonctionnel en seulement 24 heures après avoir obtenu l’accès à Replit Agent. Ce mode de développement “le besoin devient le code” libère la productivité latente au sein des entreprises (Source : amasad)
Eigent : application de bureau AI collaborative open-source : Basée sur CAMEL-AI, Eigent est une application de bureau collaborative supportant l’exécution parallèle de tâches complexes par plusieurs Agents. Elle intègre le protocole MCP pour se connecter à Notion, Slack, Google Suite, etc., et supporte le déploiement local, mettant l’accent sur la confidentialité et l’interaction Human-in-the-Loop (Source : GitHub)

📚 Apprentissage
Commercialisation et controverses du système d’évaluation LMArena : LMArena (anciennement Chatbot Arena) est devenu la référence de l’AI grâce à son mécanisme de test à l’aveugle participatif, avec une valorisation atteignant 1,7 milliard de dollars. Malgré les critiques sur la préférence des utilisateurs pour les réponses longues, son service d’évaluation B2B a généré 30 millions de dollars de revenus annualisés en 4 mois. Cela montre que l’expérience utilisateur réelle est devenue le critère central de valeur des modèles (Source : Silicon Observer Pro)
Implications du papier DeepSeek Engram sur l’architecture matérielle : Le dernier papier Engram de DeepSeek propose de stocker les connaissances statiques dans de la mémoire bon marché plutôt que dans la coûteuse HBM. Cette vision suggère que les futurs serveurs AI passeront de la recherche de puissance de calcul extrême vers des pools de mémoire massifs (DDR5/CXL) de l’ordre du téraoctet. C’est une excellente nouvelle pour les fabricants de matériel chinois, car les contraintes sur la chaîne d’approvisionnement CXL et mémoire haute capacité sont moindres (Source : ZhihuFrontier)

Gestion autonome de la mémoire : l’architecture Focus résout les goulots d’étranglement des Agents : Pour contrer la dégradation des performances des LLM dans les tâches longues due à l’explosion du contexte, l’architecture Focus s’inspire de la biologie des myxomycètes en introduisant des primitives “start/finish attention”. L’Agent décide quand intégrer le contenu appris dans des blocs de connaissances et élaguer l’historique original, créant un contexte en “dents de scie” qui réduit la consommation de Token de 22,7 % tout en maintenant 60 % de précision (Source : dair_ai)

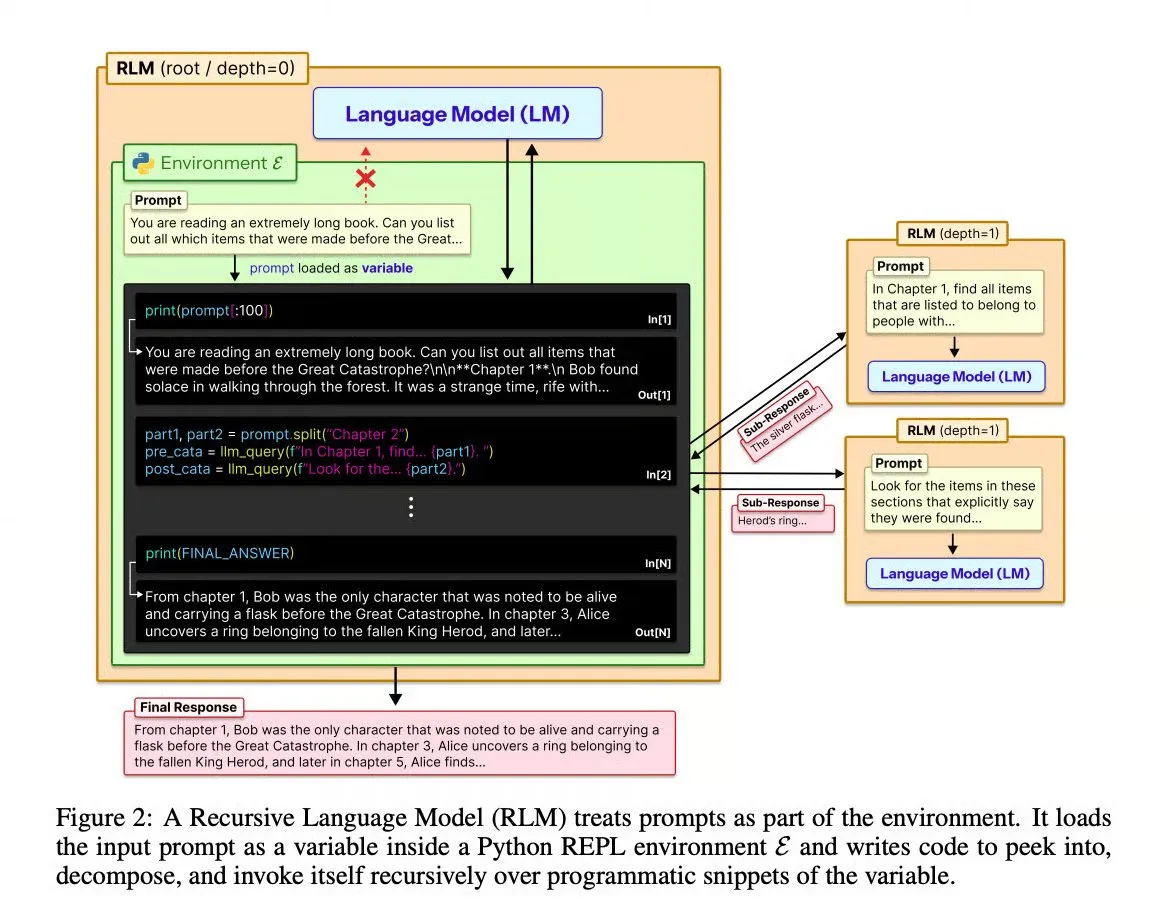
Recursive Language Models (RLMs) : dépasser les limites de la fenêtre de contexte : L’architecture RLMs proposée par le MIT CSAIL permet aux LLM d’interagir symboliquement avec le contexte via du code, en déchargeant les prompts dans des variables Python REPL. Cette méthode permet aux modèles existants (comme GPT-5) de traiter des entrées dépassant 10 millions de Tokens sans réentraînement, avec une précision deux fois supérieure aux Agents à long contexte traditionnels (Source : TheTuringPost)
💼 Business
LMArena lève 150 millions de dollars et devient une licorne : L’organisme d’évaluation de modèles LMArena a réussi une levée de fonds de 150 millions de dollars, portant sa valorisation à 1,7 milliard. Son produit commercial AI Evaluations a déjà attiré des géants comme OpenAI et Google, prouvant qu’à l’ère de l’AI, “comment évaluer l’AI objectivement” est en soi un marché colossal (Source : Silicon Observer Pro)
OpenAI débauche le co-fondateur de Thinking Machines : Dans une guerre des talents qualifiée de “coup d’État”, OpenAI a réussi à réintégrer Barret Zoph et deux autres chercheurs de la startup Thinking Machines. Cela illustre l’intensité de la circulation des talents entre les laboratoires d’élite et reflète la compétition acharnée dans les domaines du Post-training et des modèles de raisonnement (Source : dejavucoder)

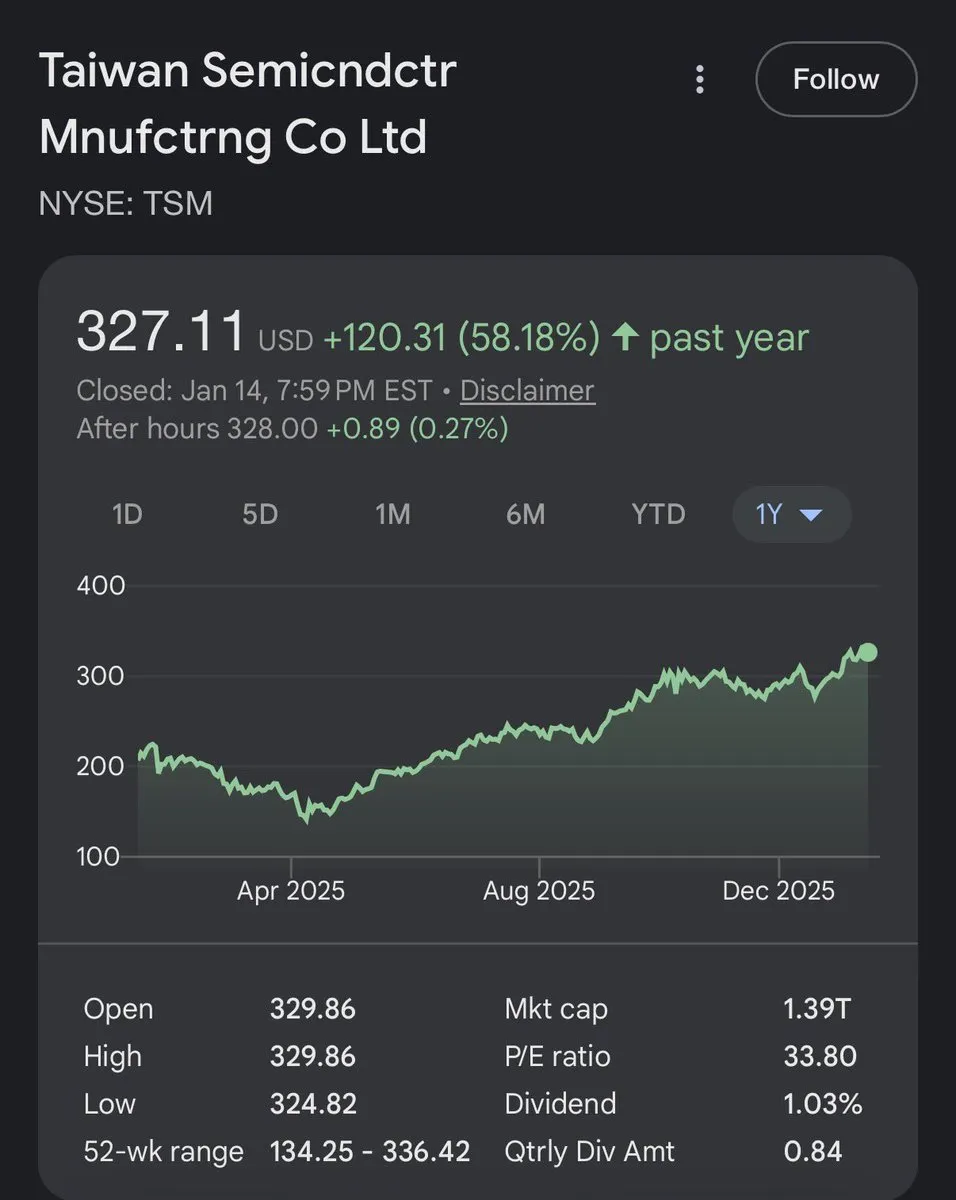
TSMC : bénéfice en hausse de 35 %, le “vendeur de pelles” de l’ère AI : Les derniers résultats financiers de TSMC montrent une croissance du bénéfice de 35 % sur un an, avec un rendement annuel surpassant même celui de Nvidia. Cela confirme que, quelle que soit la compétition au niveau des modèles, la capacité de fabrication de semi-conducteurs reste le segment le plus stable et lucratif de la vague AI (Source : Justin_Halford_)
🌟 Communauté
Kling 2.6 : le Motion Control déclenche une révolution du “remplacement de personnage” : La fonction Motion Control de Kling 2.6 (Kuaishou) a fait sensation, permettant aux utilisateurs de transférer facilement leurs expressions et mouvements sur n’importe quel personnage AI. Ce contrôle de haute précision annonce un changement majeur pour Hollywood : le coût du remplacement de personnage devient négligeable, et la génération vidéo AI passe de la “génération aléatoire” à la “réalisation précise” (Source : Kling_ai, Justine Moore)
L’essor du Vibe Coding et le débat sur les “troubles de l’apprentissage” : La communauté discute du phénomène “Vibe Coding”, qui consiste à s’appuyer entièrement sur l’AI pour générer du code. Certains craignent que cela n’entraîne des lacunes d’apprentissage chez les programmeurs, produisant des PR truffées de failles ; d’autres, comme le créateur de Redis, y voient une libération de la créativité. Le cœur du débat : doit-on sacrifier la maîtrise de la logique profonde au profit de l’efficacité ? (Source : mitchellh, Yohei)
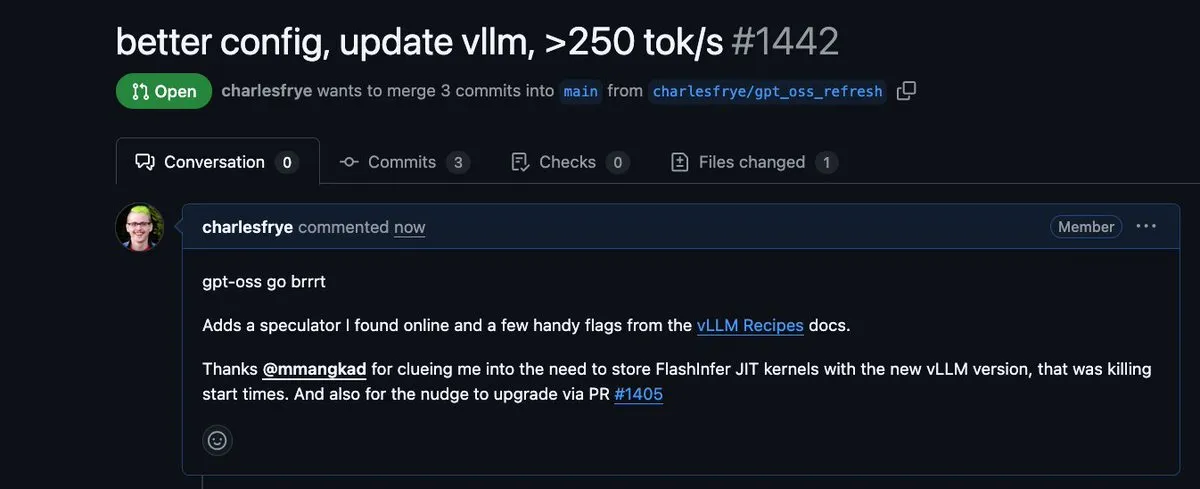
Inversion des performances de raisonnement local : le déploiement privé égale désormais les API : Des développeurs comme Charles Frye soulignent que les performances des LLM locaux ont bondi ces derniers mois. Grâce à l’optimisation de la compilation des kernels, la vitesse de sortie est passée de 100 à 250 tok/s. Cela signifie que le coût et les performances des modèles privés pour les entreprises peuvent désormais égaler, voire surpasser, les API propriétaires (Source : charles_irl)
Le “Reverse Prompting” des images AI : la quête de l’imperfection : Pour rendre les images AI plus réalistes, la nouvelle tendance (Meta) consiste à ajouter délibérément des défauts. Les prompts incluent désormais des “câbles emmêlés”, un “mauvais éclairage” ou du “béton irrégulier”, visant à simuler le “chaos” du monde réel pour éviter l’aspect “plastique” typique de l’AI (Source : Reddit)

💡 Autre
Warren Buffett prévient : l’AI est aussi dangereuse que l’arme nucléaire : À 95 ans, Buffett a de nouveau lancé un avertissement sévère, affirmant que le “génie” de l’AI, une fois sorti de sa bouteille, ne pourra plus y retourner. Il s’inquiète particulièrement des arnaques deepfake, estimant que leur capacité d’imitation pourrait tromper ses propres enfants. Ces risques exigent la mise en place de garde-fous plus stricts (Source : 36Kr)
Sortie du Raspberry Pi AI HAT+ 2 : faire tourner des LLM localement : La nouvelle carte d’extension AI pour Raspberry Pi, vendue 130 $, est équipée de l’accélérateur Hailo-10H offrant 40 TOPS de performance AI générative. Elle permet aux développeurs de faire tourner des LLM et VLM de manière totalement locale sur des appareils Edge à basse consommation, sans dépendre du cloud (Source : Raspberry Pi)

Concession de Musk : Grok limitera la génération de nus de personnes réelles : Face à la pression juridique et à la condamnation publique, le compte de sécurité de la plateforme X a annoncé que Grok ne supporterait plus la génération d’images pornographiques non consensuelles de personnes réelles. Ce recul reflète les tensions éthiques et juridiques liées aux contenus générés par AI et présage un durcissement de la régulation sur les réseaux sociaux (Source : Reddit)