
Mots-clés:Licorne IA, Grand modèle, Outils d’IA, Introduction en bourse de Zhipu AI, Replit Vibe Coding, Claude Code V3
🔥 À la une
Les licornes chinoises de l’IA Zhipu et MiniMax entrent en bourse à Hong Kong l’une après l’autre : Début 2026, Zhipu AI et MiniMax (Yanxi Technology) ont fait leur entrée à la bourse de Hong Kong (HKEX) à 48 heures d’intervalle, marquant le passage de la compétition des grands modèles en Chine vers une phase décisive de « capital élevé et ingénierie lourde ». Zhipu a obtenu une souscription mille fois supérieure grâce à sa stratégie d’infrastructure pour les gouvernements et entreprises, tandis que MiniMax a vu le cours de son action doubler dès le premier jour, porté par la croissance explosive d’applications grand public comme Talkie. Cette vague d’introductions en bourse reflète les limites du modèle de financement par VC ; les marchés publics prennent désormais le relais pour fournir un mécanisme de « refinancement » stable aux investissements R&D à long terme, poussant l’industrie à passer d’une « course aux paramètres » à une phase de synergie entre « efficacité et boucle commerciale fermée » (Source : 产业家)
Replit lève 400 millions de dollars et mène le changement de paradigme du « Vibe Coding » : La plateforme de programmation Replit prévoit de lever 400 millions de dollars sur une valorisation de 9 milliards de dollars, son ARR ayant bondi de 10 millions à 144 millions de dollars en six mois. Le succès de Replit réside dans l’abandon du marché des « développeurs professionnels » pour se tourner vers les « utilisateurs non techniques » via Replit Agent. Ce nouveau paradigme, baptisé « Vibe Coding », met l’accent sur la construction d’applications par la description de l’intention plutôt que par l’écriture de la syntaxe. Ce changement élimine non seulement le besoin de chefs de produit juniors au sens traditionnel, mais annonce également une transformation radicale du développement logiciel, passant de l’artisanat à l’automatisation pilotée par l’intention (Source : 36氪 ; TheRundownAI)
Rapport de l’indice économique d’Anthropic : les postes hautement qualifiés face à une crise de « déqualification » par l’IA : Le dernier rapport d’Anthropic révèle une tendance contre-intuitive : l’effet d’accélération de l’IA sur les tâches complexes dépasse de loin celui sur les tâches simples. Claude améliore l’efficacité des tâches de niveau universitaire de 12 fois, contre seulement 9 fois pour les tâches de niveau lycée. Le rapport souligne que l’IA vide systématiquement la « valeur ajoutée » des postes à haute intelligence, entraînant un phénomène de « déqualification » (deskilling) — les humains ne conservant que les tâches administratives triviales tandis que l’analyse et la planification stratégiques sont confiées à l’IA. De plus, via la collaboration homme-machine, le délai de réussite de l’IA pour traiter des projets d’ingénierie complexes peut passer de 2 à 19 heures, définissant une « nouvelle loi de Moore » pour le futur du travail (Source : Anthropic ; 新智元)
Higgsfield Cinema Studio : l’IA comprend la grammaire cinématographique et secoue Hollywood : La licorne Higgsfield, valorisée à 1,3 milliard de dollars, a publié une mise à jour majeure numérisant les caméras, objectifs et techniques de mouvement de caméra de haut niveau en modules IA. HCS ne dépend plus de prompts flous, mais permet à l’IA de maîtriser « l’intention du réalisateur » via le modèle DOP I2V, réalisant des effets professionnels tels que la texture IMAX ou les mouvements Steadicam. Cette « égalité technologique » permet aux créateurs individuels de produire des blockbusters visuels de qualité Hollywood à un coût extrêmement bas, forçant l’industrie cinématographique à repenser la définition de la valeur créative une fois les barrières techniques disparues (Source : 极客电影)
🎯 Tendances
DeepSeek publie DeepGEMM et met à jour les indices de l’architecture V4 : DeepSeek a officiellement rendu open-source DeepGEMM, une bibliothèque de multiplication de matrices efficace optimisée spécifiquement pour l’architecture Hopper. Parallèlement, la communauté a découvert l’ajout du support HyperConnection dans sa base de code, prédisant que le futur modèle V4 améliorera la précision de l’inférence via des connexions réseau plus profondes. DeepSeek maintient son support Day-0 SOTA en optimisant l’efficacité des opérateurs de bas niveau pour surpasser les modèles fermés existants en termes d’utilisation de la puissance de calcul (Source : teortaxesTex ; You Jiacheng)

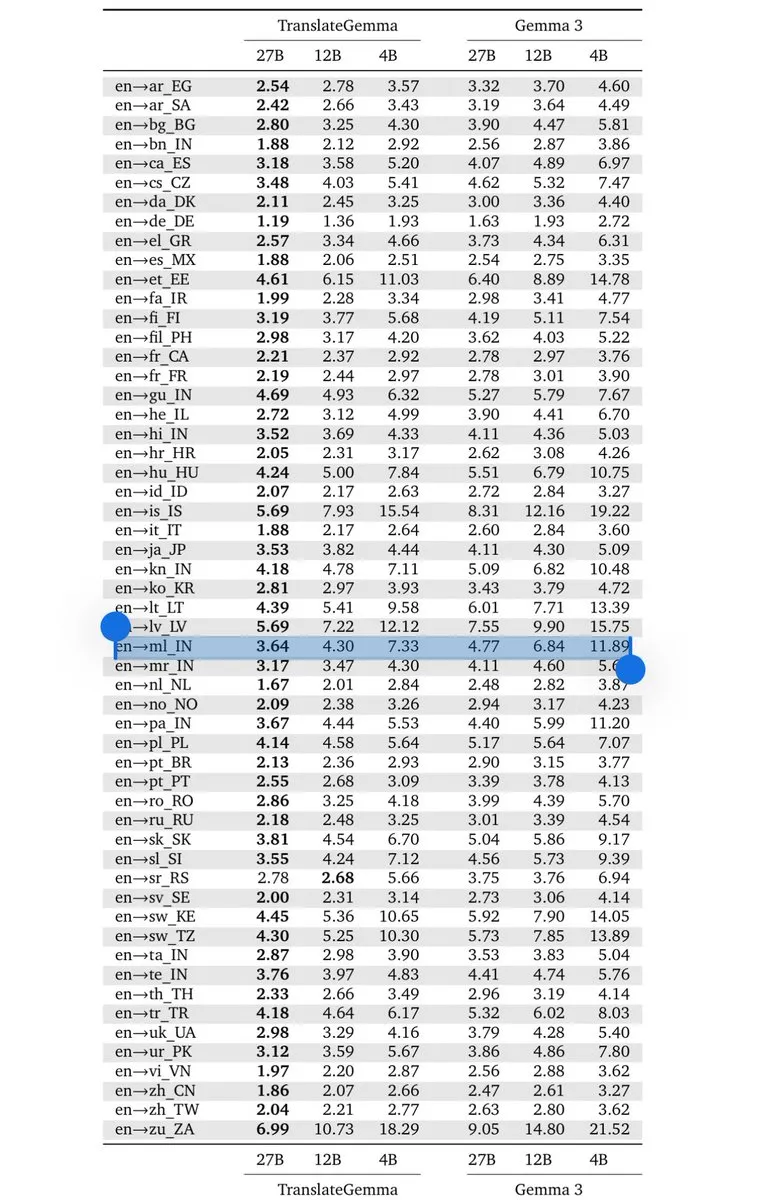
Google DeepMind publie TranslateGemma : nouveau standard pour la traduction on-device : Basée sur l’architecture Gemma 3, Google a publié la série de modèles TranslateGemma (4B/12B/27B). Grâce à la distillation de connaissances générée par Gemini, ces modèles supportent 55 langues tout en restant légers, permettant aux développeurs de construire des outils de traduction à faible latence fonctionnant entièrement sur l’appareil. Cela revêt une importance majeure pour des marchés comme l’Inde ayant de forts besoins en traitement multilingue, marquant une étape où les capacités d’inférence des modèles à petits paramètres dans des domaines verticaux approchent celles des modèles de pointe (Source : arohan ; Google DeepMind)
NVIDIA open-source KVzap : technique d’élagage KV Cache pour une compression sans perte : NVIDIA AI a rendu open-source KVzap, une méthode d’élagage de KV Cache de niveau SOTA. Cette technologie permet une compression du cache KV de 2x à 4x tout en garantissant une qualité quasi sans perte. Alors que les dialogues longs des Agents et les tâches de raisonnement complexe deviennent la norme, le cache KV est devenu le goulot d’étranglement central des coûts d’inférence. Le lancement de KVzap réduira considérablement l’occupation de la mémoire vidéo et la latence de réponse pour les tâches à long contexte, augmentant ainsi le débit des systèmes d’inférence (Source : Reddit r/artificial ; Sudden-Dog2918)
Zhipu et Huawei publient GLM-Image : premier modèle multimodal entraîné intégralement sur puces chinoises : Zhipu AI, en collaboration avec Huawei, a lancé GLM-Image, le premier modèle de pointe dont le processus complet, du prétraitement à l’entraînement total, a été réalisé sur des puces chinoises Ascend 910. Le modèle utilise une architecture auto-régressive + décodeur de diffusion, atteignant le niveau SOTA pour le rendu de texte chinois et supportant la génération de résolutions 1024-2048 à n’importe quel ratio. Son efficacité énergétique d’inférence serait 60 % supérieure à celle du H200, prouvant qu’il est possible d’entraîner des modèles multimodaux compétitifs au niveau industriel en dehors de l’écosystème NVIDIA (Source : Reddit r/MachineLearning ; karminski3)
Microsoft publie FrogMini-14B : amélioration du débogage de code via SFT : Microsoft a publié FrogMini-14B sur Hugging Face, un modèle basé sur Qwen3 ayant obtenu un score Pass@1 de 45,0 % sur le benchmark SWE-Bench Verified. Sa technologie clé repose sur l’utilisation de trajectoires de débogage réussies générées par des modèles « enseignants » puissants comme Claude pour le réglage fin supervisé (SFT). Cette dynamique montre que grâce à des données synthétiques de haute qualité et un entraînement ciblé, des modèles de taille moyenne (14B) peuvent faire preuve d’une utilité exceptionnelle sur des tâches d’ingénierie logicielle spécifiques (Source : NerdyRodent)
🧰 Outils
Sortie de Claude Code V3 : introduction du LSP pour une compréhension sémantique de niveau IDE : Anthropic a considérablement mis à jour Claude Code, supportant désormais officiellement le Language Server Protocol (LSP). Cela signifie que Claude possède désormais des capacités de compréhension sémantique du code telles que le saut vers la définition, la recherche de références et le diagnostic en temps réel, avec une vitesse de navigation inter-bibliothèques multipliée par 900. La version V3 fusionne également Commands et Skills, utilisant CLAUDE.md comme contrôle de sécurité et plan de projet, élevant la programmation par IA de la simple manipulation de texte à une compréhension architecturale profonde (Source : TheDecipherist ; GeckoLogic)

FLUX.2 [klein] : intelligence visuelle interactive en moins d’une seconde : Black Forest Labs a publié la série de modèles FLUX.2 [klein]. Ces modèles (4B/9B) sont conçus spécifiquement pour la génération et l’édition en temps réel, avec une latence d’inférence inférieure à 0,5 seconde sur du matériel moderne. La version 4B ne nécessite que 13 Go de VRAM pour fonctionner sur des GPU grand public et utilise la licence Apache 2.0. Le lancement de cet outil marque le passage de la génération d’images par IA d’un mode « attente » à un mode « interactif », élargissant considérablement les scénarios de design en temps réel et de prototypage rapide (Source : Black Forest Labs ; vllm_project)

AionUi : interface graphique open-source pour la collaboration multi-agents : AionUi est une application de bureau gratuite et open-source conçue pour fournir un espace de travail graphique unifié aux outils d’IA en ligne de commande tels que Gemini CLI, Claude Code et Codex. Elle supporte le traitement parallèle multi-sessions, le stockage local crypté des données et intègre un panneau de prévisualisation en temps réel supportant plus de 9 formats. AionUi résout les points de friction des outils CLI, comme l’impossibilité de sauvegarder les sessions, offrant une plateforme de collaboration IA efficace pour les développeurs et les utilisateurs de bureau (Source : iOfficeAI ; AionUI)

Claude Flow v3 : construire une plateforme d’essaim multi-agents : Claude Flow v3 a été entièrement réécrit en TypeScript et WASM pour transformer Claude Code en une plateforme de collaboration multi-agents. Il utilise RuVector pour la mémoire partagée et supporte la décomposition des tâches, l’établissement de consensus et l’apprentissage continu. La version v3 se concentre particulièrement sur l’optimisation des quotas d’abonnement, affirmant réduire la consommation de tokens de 80 %. Le système supporte les modèles locaux et le fonctionnement hors ligne, permettant aux utilisateurs de lancer des boucles d’optimisation et des tâches d’audit de sécurité ininterrompues en arrière-plan (Source : ruvnet ; MichaelT_KC)

📚 Apprentissage
Agent-as-a-Judge : un nouveau paradigme pour l’évaluation de tâches complexes : Face aux limites de LLM-as-a-Judge (biais, manque de vérification en temps réel), une nouvelle revue propose le concept d’Agent-as-a-Judge. Ce paradigme introduit des capacités de planification, d’appel d’outils et de mémoire, permettant à l’évaluateur d’apprécier une tâche par des actions actives (exécution de code, vérification de sortie), offrant ainsi une feuille de route pour une évaluation de l’IA robuste et vérifiable (Source : TheTuringPost ; Ksenia_TuringPost)

Thoughtology : révéler la « zone idéale » de la chaîne de pensée des modèles de raisonnement : Une étude mécaniste de 135 pages intitulée « Thoughtology » a analysé la Chain of Thought de modèles comme GPT-OSS, Qwen3 et R1. L’étude révèle que plus de réflexion n’est pas forcément synonyme de meilleurs résultats ; il existe une « zone idéale » (sweet spot) de raisonnement pour chaque question, au-delà de laquelle la précision peut chuter. De plus, la rumination (pensée répétitive) est souvent liée à des réponses erronées. Cette recherche fournit des données fondamentales pour optimiser les coûts de raisonnement et améliorer la qualité des sorties (Source : YejinChoinka ; Sara Vera Marjanović)

MatchTIR : supervision fine du raisonnement intégré aux outils via l’appariement de graphes bipartis : Le framework MatchTIR s’attaque au problème de l’attribution de crédit à gros grain dans le Tool-Integrated Reasoning (TIR) en introduisant une distribution de récompense au niveau du tour (Turn-level) basée sur l’appariement de graphes bipartis. Cette méthode distingue efficacement les appels d’outils valides des appels redondants, excellant dans les tâches multi-tours à long terme. Les expériences montrent que son modèle 4B surpasse la plupart des modèles 8B sur plusieurs benchmarks, prouvant le potentiel de la supervision fine pour augmenter le taux de réussite des Agents (Source : quchangle1 ; HuggingFace Daily Papers)
💼 Business
OpenAI investit dans Merge Labs, la startup d’interface cerveau-machine de Sam Altman : OpenAI a participé au financement de Merge Labs, une société d’interface cerveau-machine (BCI) fondée par son CEO Sam Altman. Ce mouvement est perçu comme un positionnement prospectif d’OpenAI sur les formes matérielles de l’AGI, tentant de connecter directement la conscience humaine aux modèles d’IA via la technologie BCI, défiant ainsi Neuralink d’Elon Musk. Cet investissement relance également les discussions sur les frontières entre les intérêts personnels d’Altman et les décisions de l’entreprise (Source : unusual_whales ; scaling01)
Wikipédia fête ses 25 ans et conclut des accords IA avec Microsoft, Meta et Perplexity : À l’occasion de son 25e anniversaire, Wikipédia a officiellement signé des accords de licence de données IA avec Microsoft, Meta et Perplexity. Ces partenariats visent à garantir que les modèles d’IA fournissent des sources précises lorsqu’ils citent le contenu de Wikipédia, tout en assurant un financement opérationnel durable pour la Fondation Wikimedia. Cela marque une transition stratégique pour les plateformes de connaissances, passant du « scraping passif » à la « collaboration active » à l’ère de l’IA (Source : AP News ; Reddit r/artificial)
🌟 Communauté
« It Takes Two » : amélioration de projet via la confrontation de modèles : La communauté discute vivement d’une technique de Prompt nommée « Dueling Idea Wizards ». En demandant à deux modèles différents (ex: Claude Opus 4.5 et GPT-5.2) de réviser mutuellement leurs suggestions d’amélioration et de les noter (0-1000), les développeurs ont découvert des divergences et des « astuces » intéressantes entre les modèles. Les suggestions validées avec un score élevé par les deux modèles sont généralement celles ayant la plus grande valeur pratique, cette méthode de raisonnement contradictoire améliorant considérablement l’efficacité du filtrage créatif (Source : doodlestein)
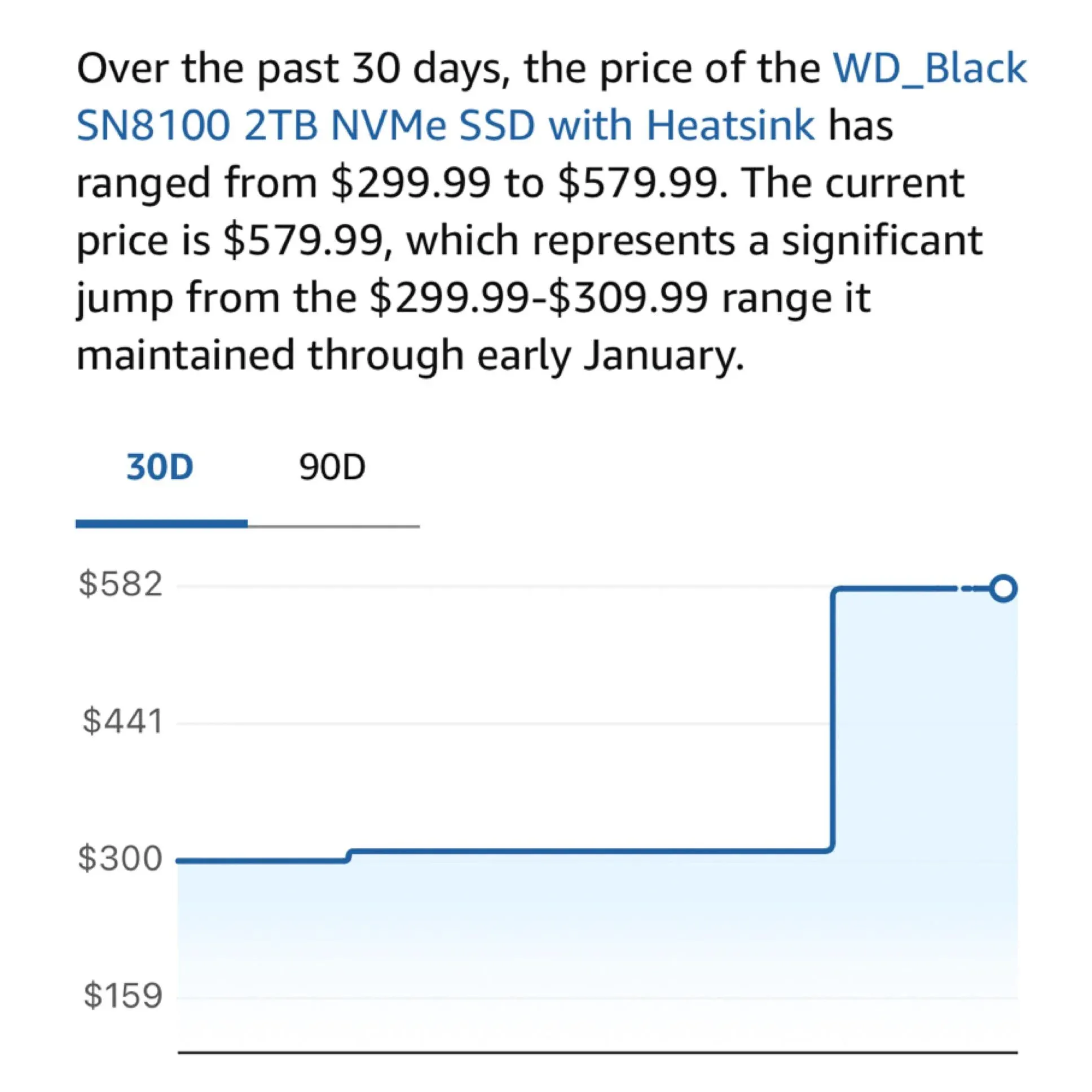
Anxiété matérielle : la flambée des prix des SSD M.2 impacte les utilisateurs d’IA locale : Les utilisateurs de la communauté se plaignent de la hausse massive des prix des SSD M.2 et de la RAM, certains modèles ayant triplé de prix en un an. Avec le besoin croissant de faire tourner localement des modèles de plus de 100B paramètres (comme DeepSeek ou Qwen), la dépendance au stockage haute vitesse de grande capacité s’accentue. La décision de Samsung et Micron de réduire l’offre grand public devient l’obstacle majeur pour les passionnés de LLM locaux souhaitant construire leur propre « centre de calcul domestique » (Source : Reddit r/LocalLLaMA ; dgibbons0)
Le plugin « Meuglement » de Claude Code lance un débat sur le feedback des interactions IA : Un développeur a partagé un plugin nommé claude-code-moo qui émet un « meuglement » lorsque Claude Code nécessite une autorisation de l’utilisateur pour une commande Bash. Cet outil, d’apparence comique, résout le problème des développeurs qui manquent les notifications de l’IA après avoir changé de fenêtre. La communauté a entamé une discussion profonde sur la manière dont les Agents IA peuvent maintenir l’engagement humain via des feedbacks non intrusifs (audio, haptique) lors de tâches de longue durée (Source : Reddit r/ClaudeAI ; iefnaf)

💡 Autre
Galbot S1 de Galbot : briser la limite de charge des robots intelligents incarnés : Galbot a lancé le robot de charge lourde Galbot S1, dont la charge maximale des deux bras atteint 50 kg (32 kg bras tendus), dépassant de loin la moyenne de l’industrie. Ce robot est déjà utilisé dans les usines de CATL, réalisant des opérations de manutention totalement autonomes sans téléopération via un modèle de manipulation incarnée. Cela marque le passage de l’IA incarnée du stade de démonstration (« faire du café ») à une intégration réelle dans les processus de production industrielle à haute intensité (Source : 银河通用 ; 36氪)

Visualisation des hallucinations de l’IA : l’impact négatif de l’échelle des tâches sur la cohérence : Un utilisateur a démontré, via la génération d’images contenant 10, 50 et 100 personnages, comment les hallucinations de l’IA s’aggravent avec l’ampleur de la tâche. L’expérience montre qu’à mesure que le nombre de personnages augmente, l’IA échoue visiblement sur les traits nationaux, l’orthographe et les structures corporelles. Cela rappelle aux développeurs que lors de la construction de tâches complexes pour des Agents, il est impératif de réduire la charge cognitive d’un prompt unique par la décomposition des tâches (Decomposition) (Source : Reddit r/ChatGPT ; haneke86)
Sortie du Raspberry Pi AI HAT+ 2 : une machine d’inférence pour modèles 1B en périphérie : Raspberry Pi a lancé l’AI HAT+ 2 au prix de 130 $, équipé de l’accélérateur Hailo-10H et de 8 Go de VRAM. Ce matériel est conçu spécifiquement pour faire tourner localement des LLM et VLM sans dépendance au cloud, avec une puissance de calcul de 40 TOPS. La communauté y voit le choix parfait pour construire de petits moteurs d’inférence d’Agents locaux capables de faire tourner fluidement des modèles 1B quantifiés, favorisant l’adoption de l’IA dans l’IoT et les scénarios sensibles à la confidentialité (Source : ben_burtenshaw ; Raspberry Pi)
