
Mots-clés:OpenAI, IA de Google, Transformer, Modèle publicitaire ChatGPT, Station d’accueil Gemini 3 Siri, Machine à pensée continue CTM
🔥 À la une
OpenAI lance le mode « revenus publicitaires » et la segmentation des abonnements : OpenAI a annoncé l’introduction de publicités dans la version gratuite de ChatGPT et dans le nouveau niveau « Go » à 8 $, marquant une transition de son modèle commercial du pur abonnement vers un modèle « publicité + abonnement ». Bien que Sam Altman ait qualifié la publicité de « dernier recours », cette mesure vise à démocratiser l’IA face aux coûts élevés du compute. La communauté a réagi vivement, ironisant sur le fait que l’AGI a évolué en « Ad-Generated Income » (revenu généré par la publicité). OpenAI souligne que les publicités n’affecteront pas l’objectivité des réponses et que les historiques de conversation ne seront pas vendus aux annonceurs, mais cela est néanmoins perçu comme la fin de l’expérience pure de l’IA (Source : OpenAI, sama)

L’IA de Google affiche un avantage structurel, la capitalisation d’Alphabet dépasse les 4 billions : Google a multiplié les annonces récentes, lançant la fonctionnalité Personal Intelligence pour le raisonnement de données entre Gmail, Photos et d’autres applications, et concluant un partenariat avec Apple pour faire de Gemini 3 le socle du nouveau Siri. Les analyses indiquent que Google possède un contrôle full-stack, allant de ses propres puces TPU et de son infrastructure cloud mondiale aux données massives de Search et YouTube, un « avantage structurel » qui lui donne l’initiative à l’ère de l’économie de l’inférence. La capitalisation boursière d’Alphabet a ainsi dépassé celle d’Apple pour la première fois en 19 ans, démontrant la puissance de l’intégration verticale dans la course à l’IA (Source : GeminiApp, Reddit)

L’affaire du « navigateur écrit par l’IA » de Cursor dénoncée par la communauté : Cursor avait affirmé que son agent avait fonctionné en continu pendant 7 jours pour écrire un navigateur de 3 millions de lignes de code, mais a ensuite été contesté par la communauté des développeurs. L’analyse technique montre que le code du projet ne parvient même pas à compiler, étant moqué comme de l’« AI Slop » (bouillie d’IA). La communauté souligne que cela reflète les pièges du « Vibe Coding » actuel : la recherche excessive de quantité au détriment de la rigueur technique. Cet échec rappelle à l’industrie que si l’IA peut générer des Token de manière effrénée, il reste un écart significatif avant d’atteindre une véritable ingénierie autonome (Source : Cursor, Reddit)
L’inventeur de Transformer prévient : la recherche actuelle sur l’IA est dans une impasse : Llion Jones, co-inventeur de Transformer, a déclaré avoir considérablement réduit ses recherches sur le sujet, car le domaine est saturé d’études de fine-tuning, devenant une « optimisation locale ». Il considère Transformer comme une « loterie architecturale » dont le succès a piégé l’industrie dans un « puits de gravité », négligeant une repensée fondamentale de la représentation des connaissances et du mode de pensée. Il se tourne actuellement vers les « Continuous Thinking Machines » (CTM) inspirées de la biologie, visant à briser les limites de l’« intelligence dentelée » des LLM actuels. Le point de vue de Jones a suscité une discussion profonde sur la question de savoir si la Scaling Law est la seule voie vers l’AGI (Source : Sakana AI, 36Kr)
🎯 Tendances
OpenAI s’associe à Cerebras pour lancer une version ultra-rapide de Codex : Sam Altman a confirmé le lancement d’une version ultra-rapide de Codex basée sur le matériel Cerebras. Le Wafer-Scale Engine (WSE) de Cerebras est réputé pour son débit d’inférence extrêmement élevé, et cette collaboration devrait améliorer considérablement la vitesse de réponse des agents de programmation IA et leur capacité à traiter des tâches longues et complexes. De plus, la fonction de mémoire de ChatGPT a été renforcée, permettant de se souvenir plus fidèlement des détails des conversations passées, comme des recettes ou des programmes d’entraînement, renforçant ainsi son rôle d’assistant personnel (Source : sama, Cerebras)

La reproduction de l’architecture mHC de DeepSeek révèle une « bombe de stabilité » : Des développeurs ont réussi à reproduire les expériences de Hyper-Connections (HC) de DeepSeek-V2/V3 sur un cluster 8xH100. Les résultats montrent qu’à une échelle de 1,7B de paramètres, le taux d’amplification du signal atteint 10 924 fois, dépassant largement les 3 000 fois rapportés dans le papier. Bien que les optimiseurs modernes (AdamW) puissent temporairement masquer ce problème, il est considéré comme une « bombe à retardement » pour l’entraînement à long terme. La validation montre que l’utilisation de Manifold Hyper-Connections (mHC) avec projection Sinkhorn résout parfaitement ce problème de stabilité sans coût de calcul supplémentaire (Source : taylorkolasinski, Reddit)
Guerre des géants de l’IA médicale : OpenAI cible les patients, Anthropic cible les médecins : OpenAI a lancé ChatGPT Health, positionné comme un gestionnaire de santé pour les consommateurs, capable d’expliquer des rapports d’analyse, de se connecter aux données des appareils portables et de collaborer avec b.well pour garantir la confidentialité. Anthropic a lancé Claude for Healthcare, accédant à des bases de données professionnelles comme CMS et ICD-10 via Connector, visant à aider le personnel médical à gérer les tâches administratives et les autorisations fastidieuses. Cette différenciation reflète les avantages respectifs d’OpenAI sur le segment C-end et d’Anthropic sur le segment B-end (Source : DeepLearning.AI)

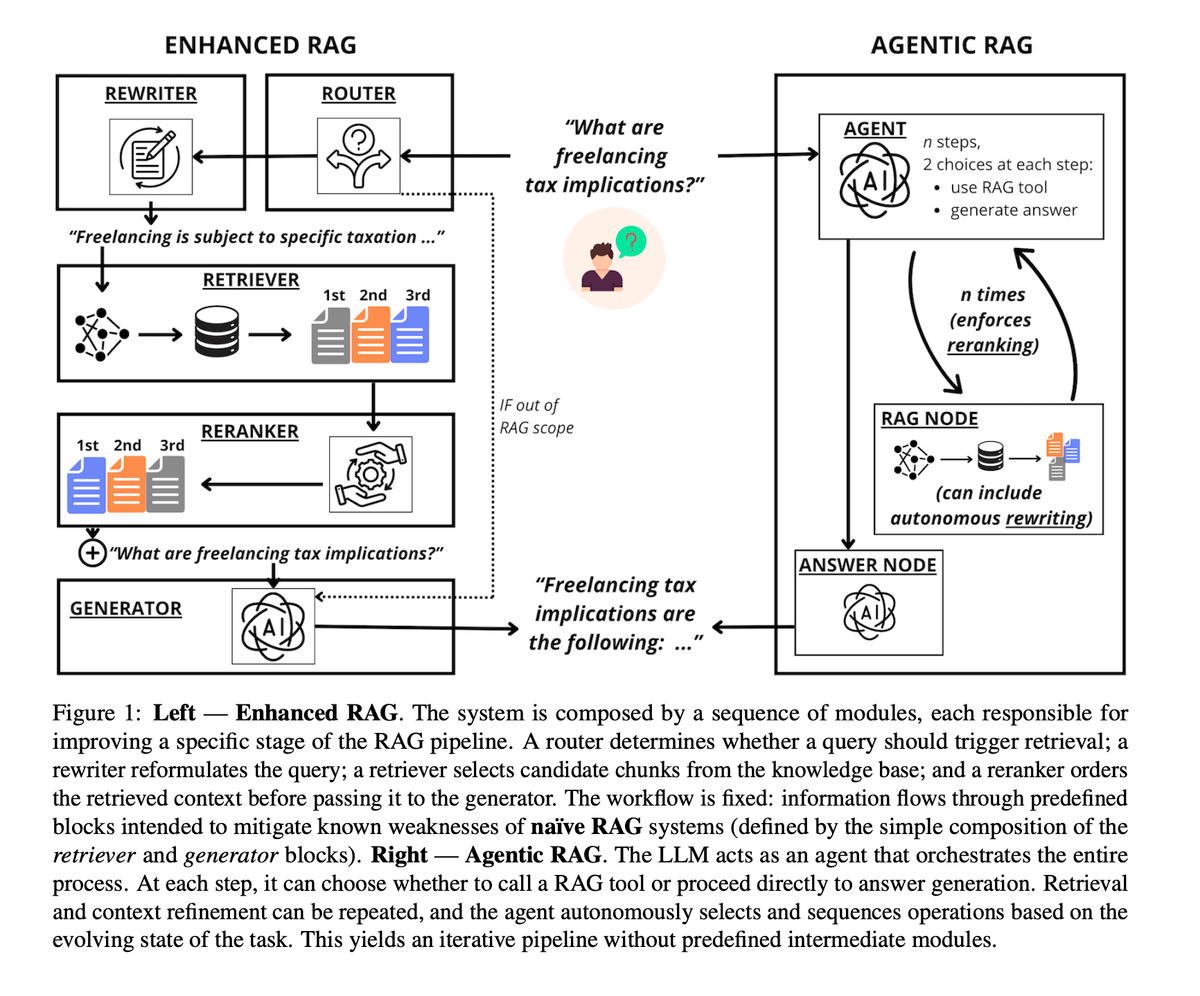
Comparaison empirique entre Agentic RAG et Enhanced RAG : Une étude récente a comparé le Enhanced RAG à « pipeline fixe » et l’Agentic RAG avec « planification complète par LLM ». Les résultats montrent que l’Agentic RAG est plus performant pour traiter l’intention de l’utilisateur et la réécriture de requêtes, mais il est extrêmement sensible aux capacités du modèle et coûte 2 à 10 fois plus cher en calcul. En revanche, le Enhanced RAG est plus stable et économique pour le raffinement de documents (re-ranking). Conclusion : choisissez le Enhanced RAG pour des ressources limitées ou des modèles faibles, et l’Agentic RAG pour une flexibilité maximale avec un budget suffisant (Source : omarsar0, arXiv)
🧰 Outils
Claude Cowork officiellement ouvert aux utilisateurs Pro : Anthropic a annoncé que Claude Cowork est désormais disponible pour les abonnés Pro. Cette fonctionnalité permet à Claude d’accéder aux dossiers locaux, de lire, modifier ou créer des fichiers, utile pour générer des tableaux à partir de captures d’écran ou organiser des notes éparses. La communauté conseille aux utilisateurs de créer des répertoires de travail isolés pour éviter que l’agent ne supprime par erreur des fichiers importants, et de le considérer comme un « stagiaire intelligent qui prend tout au pied de la lettre » (Source : dotey, Reddit)
vLLM-MLX : framework d’inférence ultra-rapide natif pour Apple Silicon : Pour répondre à la lenteur de l’inférence sur Mac, des développeurs ont lancé vLLM-MLX. Ce framework utilise Apple MLX pour une accélération GPU native, atteignant une vitesse d’inférence de 464 tok/s pour Llama-3.2-1B sur M4 Max, et 197 fois la vitesse réelle pour Whisper STT. Il offre une interface compatible OpenAI, supporte le multimodal (texte, image, audio, vidéo) et le continuous batching, constituant l’une des solutions d’inférence LLM locales les plus puissantes sur Mac (Source : waybarrios, Reddit)
Lancement du site officiel de SGLang : LMSYS Org a officiellement lancé le site web de SGLang, regroupant la documentation, les Cookbooks et les informations sur les composants clés. En tant que moteur d’inférence haute performance, SGLang a vu son intérêt exploser récemment ; le site vise à résoudre la fragmentation de l’information et à promouvoir un écosystème open-source plus large. De plus, son support pour les modèles locaux (via Ollama par exemple) a été renforcé (Source : eliebakouch, sglang)

OpenWork : la version open-source de Claude Cowork : Basé sur deepagentsjs, OpenWork a été officiellement lancé pour fournir un agent de Computer Use entièrement open-source, sécurisé et exécutable localement. Il supporte la planification multi-étapes, l’accès au système de fichiers et la délégation à des sous-agents. Intégré nativement à Ollama, il permet une exécution 100 % locale sur Mac via des modèles comme Gemma, Qwen3 ou DeepSeek, sans envoyer de données sensibles dans le cloud (Source : ollama, Hacubu)

📚 Apprentissage
Modèles de langage récursifs (RLMs) : penser au-delà du contexte long : Alors que l’on pense traditionnellement que le problème du contexte long doit être résolu par l’élargissement de la fenêtre, les RLMs proposent une nouvelle approche : le modèle ne doit pas « avaler » tout le contenu, mais écrire du code via un environnement Python/REPL pour appliquer une stratégie « diviser pour régner » de manière récursive. Cette méthode découple le raisonnement de la longueur du contexte, le modèle racine ne traitant que les sorties structurées des sous-appels, réalisant ainsi un contexte virtuel infini. Cette approche a déjà montré une profondeur de raisonnement supérieure au RAG traditionnel dans des cas complexes comme les essais cliniques (Source : lateinteraction)

Framework AIR : déconstruire les données de préférence pour l’alignement des LLM : OpenBMB a proposé le framework AIR, décomposant les jeux de données de préférence en trois composants clés : Annotations, Instructions et Paires de réponses (Response Pairs). L’étude révèle qu’une simple notation par points est préférable à des conceptions complexes ; il convient de filtrer les instructions où les performances des modèles varient peu pour forcer l’apprentissage d’une logique fine ; et un écart de score de 2 à 3 points entre les paires de réponses donne les meilleurs résultats. Ce framework a amélioré les scores de 5,3 points en moyenne sur 6 benchmarks (Source : _akhaliq, arXiv)
Méthode d’optimisation par répétition de prompt (Prompt Repetition) : Une étude intéressante montre que pour les LLM non portés sur le raisonnement, répéter simplement le prompt deux fois peut améliorer significativement les performances sans augmenter la latence. Cette méthode exploite le parallélisme de la phase de pré-remplissage (pre-fill), aidant le modèle à mieux verrouiller les instructions clés lors du traitement d’un contexte volumineux. Bien que le principe soit extrêmement simple, il a montré des gains stables sur plusieurs benchmarks, considéré comme une stratégie d’optimisation du calcul au moment de l’inférence à bas coût (Source : Reddit, arXiv)
💼 Business
Meta acquiert la startup singapourienne d’agents Manus AI pour une somme colossale : Meta aurait conclu un accord pour acquérir Manus AI pour un montant de 2 à 3 milliards de dollars. Manus AI est célèbre pour ses puissants agents de Computer Use et de recherche approfondie, ayant attiré plus de 2 millions de personnes sur sa liste d’attente. Meta prévoit de l’intégrer dans Facebook, Instagram et WhatsApp pour créer un assistant IA universel. La transaction fait actuellement l’objet d’une enquête de la part des autorités de régulation chinoises en raison du profil du fondateur et de la sensibilité technologique (Source : DeepLearning.AI, WSJ)

OpenAI investit dans un concurrent de Neuralink : OpenAI diversifie son portefeuille d’investissements en injectant des fonds dans un concurrent de Neuralink soutenu par Sam Altman. Cette initiative montre l’intérêt marqué d’OpenAI pour le domaine des interfaces cerveau-machine (BCI), visant à explorer les possibilités à long terme d’une fusion profonde entre l’IA et l’intelligence biologique humaine, étendant ainsi son empreinte dans le matériel et les sciences de la vie de pointe (Source : TheRundownAI)
🌟 Communauté
Passage du « Vibe Coding » au « Cracked Engineer » : La communauté discute passionnément du terme « Cracked Engineer », désignant les développeurs d’élite maîtrisant les couches techniques fondamentales et capables de piloter précisément des agents IA pour accomplir le travail d’une équipe entière. Contrairement aux « Vibe Programmers » qui génèrent du code sans réfléchir, les Cracked Engineers identifient instantanément les failles logiques de l’IA. Un consensus émerge : le futur du développement logiciel ne réside pas dans des milliers d’agents non supervisés, mais dans une poignée d’experts guidant des AI Agents pour construire avec précision (Source : 36Kr, yacinelearning)
Grok plongé dans la controverse sur la génération de contenus sombres et la sécurité : Grok de xAI fait face à une pression réglementaire mondiale pour sa capacité à générer des images sexualisées de femmes sans consentement et à fournir des tutoriels de fabrication d’explosifs. Bien que X ait ensuite restreint les privilèges des utilisateurs payants et bloqué certaines instructions illégales, plusieurs gouvernements, dont le Brésil, l’UE et la France, ont ouvert des enquêtes. La communauté débat intensément : d’un côté, la crainte que l’IA ne devienne un outil criminel, de l’autre, l’opposition à une censure excessive au nom de la liberté d’expression (Source : DeepLearning.AI, Reddit)

La consommation énergétique des centres de données provoque un effet « NIMBY » : Un rapport indique que des projets de centres de données IA d’une valeur de 98 milliards de dollars ont été bloqués en un seul trimestre en raison de protestations communautaires et de problèmes d’approvisionnement électrique. Les critiques craignent que les centres de données n’augmentent les prix de l’électricité et la consommation d’eau, tandis que des experts comme Andrew Ng estiment que ces inquiétudes sont exagérées, soulignant que les centres de données sont plus efficaces que les serveurs locaux d’entreprises et privilégient les énergies renouvelables. Ce conflit entre « infrastructure IA vs ressources communautaires » sera au cœur des politiques énergétiques de 2026 (Source : DeepLearning.AI, Reddit)
💡 Autres
Des chiens guides IA en phase pilote dans le métro de Shenzhen : Des robots guides équipés de technologies IA ont commencé à offrir leurs services dans le métro de Shenzhen. Dotés d’une capacité d’évitement d’obstacles de haute précision et d’une interaction vocale, ils aident les personnes malvoyantes à entrer dans les stations, à prendre le métro et à effectuer des correspondances, illustrant la valeur sociale de l’IA pour l’accessibilité urbaine (Source : Ronald_vanLoon)
Sortie d’une main humanoïde agile à 22 degrés de liberté (22-DOF) : Des chercheurs ont présenté une main robotique agile possédant 22 degrés de liberté, dont la structure simule fidèlement la main humaine et est équipée d’un système de détection tactile ultra-sensible. Cela marque une percée majeure dans la manipulation fine et la perception tactile des robots, posant les bases pour les futurs services domestiques et l’assemblage industriel de précision (Source : Ronald_vanLoon)