
키워드:오픈AI, 구글 AI, 트랜스포머, ChatGPT 광고 모델, 제미니 3 시리 베이스, 연속 사고 기계 CTM
🔥 포커스
OpenAI, ‘광고 수익 창출’ 모드 및 구독 등급 도입 : OpenAI가 ChatGPT 무료 버전과 새롭게 추가된 8달러 상당의 ‘Go’ 등급에 광고를 도입한다고 발표하며, 비즈니스 모델을 순수 구독제에서 ‘광고+구독’ 형태로 전환하기 시작했습니다. Sam Altman은 과거 광고를 “최후의 수단”이라고 언급한 바 있으나, 막대한 컴퓨팅 비용에 직면하여 AI 보편화를 실현하기 위한 조치로 풀이됩니다. 커뮤니티에서는 AGI가 ‘광고 생성 수익’(Ad-Generated Income)으로 진화했다는 풍자가 나오는 등 반응이 격렬합니다. OpenAI는 광고가 답변의 객관성에 영향을 미치지 않으며 대화 기록을 광고주에게 판매하지 않을 것이라고 강조했지만, 이는 여전히 AI의 순수한 사용자 경험이 끝난 것으로 간주되고 있습니다 (출처: OpenAI, sama)

구글 AI의 구조적 우위 입증, Alphabet 시가총액 4조 달러 돌파 : 구글은 최근 Gmail, Photos 등 앱 전반에서 데이터 추론을 구현하는 Personal Intelligence 기능을 발표하고, Apple과 협력하여 Gemini 3를 차세대 Siri의 기반으로 제공하는 등 활발한 행보를 보이고 있습니다. 분석가들은 구글이 자체 개발한 TPU 칩, 글로벌 클라우드 인프라부터 Search, YouTube 등 방대한 실데이터에 이르기까지 풀스택 제어권을 보유하고 있으며, 이러한 ‘구조적 우위’가 추론 경제학 시대에 주도권을 쥐게 한다고 지적합니다. 이에 따라 Alphabet의 시가총액은 19년 만에 처음으로 Apple을 추월하며 AI 경쟁에서 수직 계열화의 강력한 위력을 보여주었습니다 (출처: GeminiApp, Reddit)

Cursor ‘AI 브라우저 개발’ 사건, 커뮤니티의 ‘가짜 뉴스’ 판정 : Cursor는 자사의 에이전트가 7일간 연속 가동되어 300만 라인의 코드로 구성된 브라우저를 개발했다고 주장했으나, 이후 개발자 커뮤니티로부터 집단적인 의구심을 샀습니다. 기술 분석 결과, 해당 프로젝트의 코드는 기본적인 컴파일조차 통과하지 못해 ‘AI Slop’(AI 쓰레기)이라는 조롱을 받았습니다. 커뮤니티는 이것이 현재 ‘Vibe Coding’(분위기 코딩)의 함정을 반영한다고 지적했습니다. 즉, 생성된 양에만 과도하게 집착하고 엔지니어링의 엄격함을 간과했다는 것입니다. 이번 사건은 AI가 Token을 미친 듯이 쏟아낼 수는 있지만, 진정한 자율 엔지니어링까지는 여전히 상당한 격차가 있음을 업계에 상기시켰습니다 (출처: Cursor, Reddit)
Transformer 발명자의 경고: 현재 AI 연구는 막다른 골목에 다다랐다 : Transformer의 공동 발명자인 Llion Jones는 해당 분야가 미세 조정 연구로 가득 차 ‘국소 최적화’에 빠졌기 때문에 Transformer 연구를 대폭 줄였다고 밝혔습니다. 그는 Transformer를 ‘아키텍처 복권’이라고 부르며, 그 성공이 업계를 ‘중력 우물’에 빠뜨려 지식 표현과 사고 방식에 대한 근본적인 재고를 방해하고 있다고 주장했습니다. 그는 현재 생물학에서 영감을 받은 ‘Continuous Thinking Machine’(CTM)으로 방향을 틀어 현재 LLM의 ‘톱니형 지능’ 한계를 깨고자 합니다. Jones의 관점은 Scaling Law가 AGI로 가는 유일한 경로인지에 대한 심도 있는 논의를 불러일으켰습니다 (출처: Sakana AI, 36Kr)
🎯 동향
OpenAI, Cerebras와 손잡고 초고속 버전 Codex 출시 : Sam Altman은 Cerebras 하드웨어 기반의 초고속 버전 Codex를 출시할 것이라고 확인했습니다. Cerebras의 Wafer Scale Engine(WSE)은 초고속 추론 처리량으로 유명하며, 이번 협력은 AI 프로그래밍 에이전트의 응답 속도와 복잡한 장기 작업 처리 능력을 대폭 향상시킬 것으로 기대됩니다. 또한, ChatGPT의 기억 기능도 크게 강화되어 레시피나 운동 계획 등 과거 대화의 세부 사항을 더 확실하게 기억함으로써 개인 비서로서의 속성을 더욱 강화했습니다 (출처: sama, Cerebras)

DeepSeek mHC 아키텍처 재현으로 ‘안정성 폭탄’ 노출 : 개발자들이 8xH100 클러스터에서 DeepSeek-V2/V3의 Hyper-Connections(HC) 실험을 재현하는 데 성공했습니다. 결과에 따르면 1.7B 파라미터 규모에서 신호 증폭률이 논문에서 보고된 3,000배를 훨씬 초과하는 10,924배에 달했습니다. 현대적인 옵티마이저(AdamW)가 이 문제를 일시적으로 가려 모델이 붕괴되지 않게 할 수는 있지만, 이는 장기 훈련의 ‘시한폭탄’으로 간주됩니다. 검증 결과, Sinkhorn 투영을 적용한 Manifold Hyper-Connections(mHC)가 추가 계산 비용 없이 이 안정성 문제를 완벽하게 해결할 수 있음이 밝혀졌습니다 (출처: taylorkolasinski, Reddit)
의료 AI 거물들의 전쟁: OpenAI는 환자 중심, Anthropic은 의사 중심 : OpenAI는 소비자용 건강 관리자로 포지셔닝된 ChatGPT Health를 발표했습니다. 검사 결과지 해석, 웨어러블 기기 데이터 연결 기능을 갖추었으며 b.well과 협력하여 프라이버시를 보장합니다. 반면 Anthropic은 Connector를 통해 CMS 및 ICD-10 등 전문 데이터베이스에 접속하는 Claude for Healthcare를 출시하여, 의료진의 번거로운 서류 작업과 승인 업무를 돕는 데 주력하고 있습니다. 이러한 차별화된 행보는 OpenAI의 C단(소비자), Anthropic의 B단(기업) 생태계 우위를 반영합니다 (출처: DeepLearning.AI)

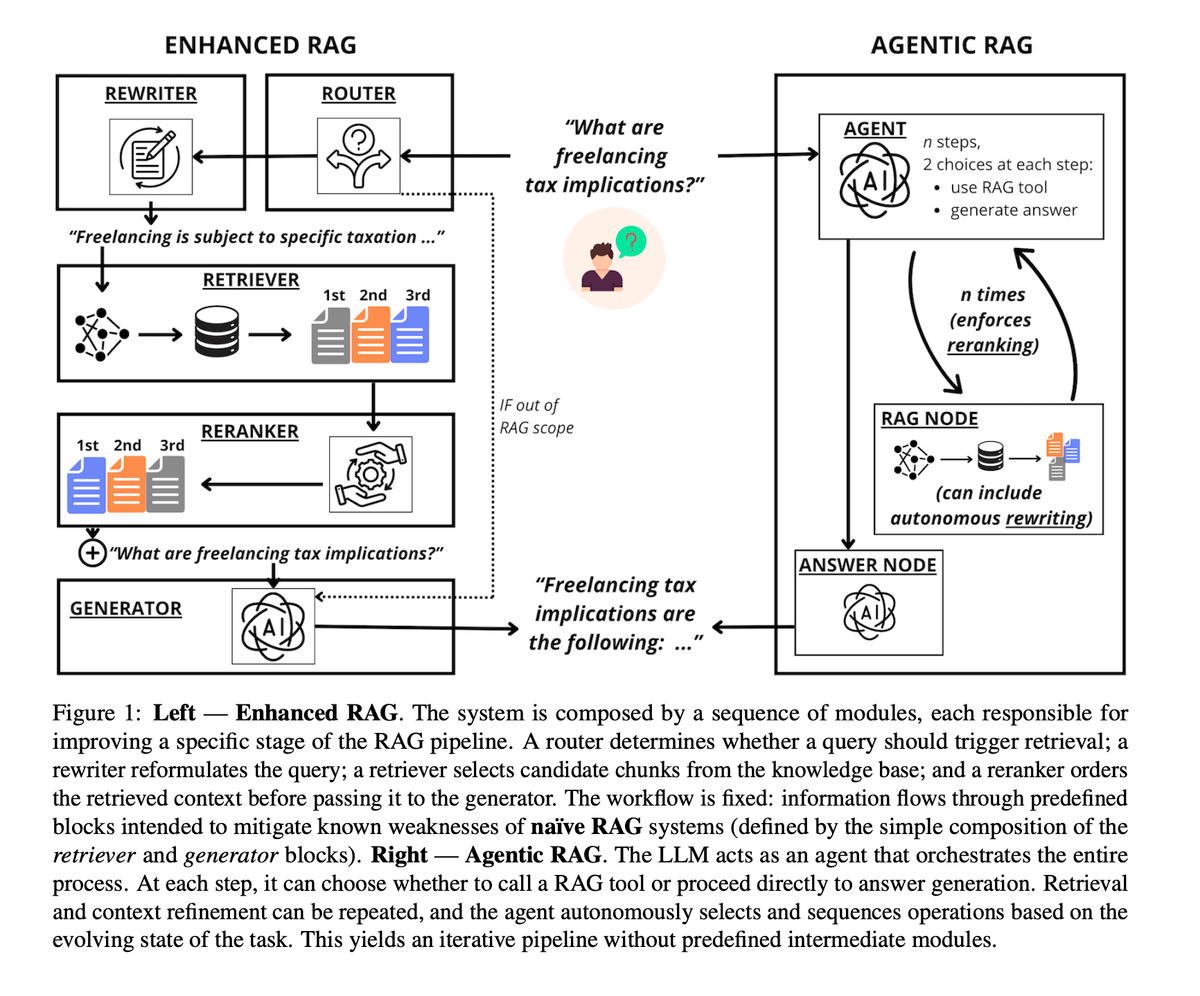
에이전트 RAG와 강화된 RAG의 실증 비교 : 최신 연구에서 ‘고정 파이프라인’ 방식의 강화된 RAG와 ‘LLM 전체 스케줄링’ 방식의 에이전트 RAG를 비교했습니다. 결과적으로 에이전트 RAG는 사용자 의도 처리 및 쿼리 재작성에서 우수한 성능을 보였으나, 모델 능력에 극도로 민감하며 계산 비용이 2~10배 더 높았습니다. 반면 강화된 RAG는 문서 정제(리랭킹)에서 더 안정적이고 경제적이었습니다. 결론적으로 자원이 제한되거나 약한 모델을 사용할 때는 강화된 방식을, 극강의 유연성을 추구하며 예산이 충분할 때는 에이전트 방식을 추천합니다 (출처: omarsar0, arXiv)
🧰 도구
Claude Cowork, Pro 사용자에게 정식 개방 : Anthropic은 Claude Cowork를 이제 Pro 구독자도 사용할 수 있다고 발표했습니다. 이 기능은 Claude가 로컬 폴더에 접근하여 파일을 읽고, 편집하거나 생성할 수 있게 해주며, 스크린샷으로 표를 만들거나 흩어진 노트를 정리하는 등의 시나리오에 적합합니다. 커뮤니티에서는 에이전트가 중요 파일을 실수로 삭제하는 것을 방지하기 위해 독립적인 작업 디렉토리를 생성할 것을 권장하며, 이를 “말귀를 잘 알아듣는 똑똑한 인턴”으로 간주할 것을 제안합니다 (출처: dotey, Reddit)
vLLM-MLX: Apple Silicon 네이티브 초고속 추론 프레임워크 : Mac 사용자의 느린 추론 속도 문제를 해결하기 위해 개발자들이 vLLM-MLX를 출시했습니다. 이 프레임워크는 Apple MLX를 활용하여 네이티브 GPU 가속을 구현하며, M4 Max에서 Llama-3.2-1B 추론 속도가 464 tok/s에 달하고 Whisper STT는 실시간 대비 197배의 속도를 보여줍니다. OpenAI 호환 인터페이스를 제공하며 멀티모달(텍스트, 이미지, 오디오, 비디오) 및 지속적 배칭을 지원하여, 현재 Mac 플랫폼에서 가장 강력한 로컬 LLM 추론 솔루션 중 하나로 꼽힙니다 (출처: waybarrios, Reddit)
SGLang 공식 웹사이트 오픈 : LMSYS Org가 SGLang 공식 웹사이트를 정식으로 개설하여 문서, Cookbook 및 핵심 컴포넌트 정보를 통합했습니다. 고성능 추론 엔진인 SGLang에 대한 관심이 최근 급증함에 따라, 공식 사이트 구축을 통해 정보 파편화 문제를 해결하고 더 넓은 오픈 소스 생태계 구축을 추진하고자 합니다. 또한, Ollama 등을 통한 로컬 모델 지원도 더욱 강화되었습니다 (출처: eliebakouch, sglang)

OpenWork: 오픈 소스 버전 Claude Cowork : deepagentsjs를 기반으로 구축된 OpenWork가 정식 출시되었습니다. 이는 완전히 오픈 소스이며 안전하고 로컬에서 실행 가능한 Computer Use 에이전트를 제공하는 것을 목표로 합니다. 다단계 계획 수립, 파일 시스템 접근, 하위 에이전트 위임을 지원하며 Ollama와 네이티브로 통합되어 Mac에서 Gemma, Qwen3, DeepSeek 등 오픈 소스 모델을 통해 민감한 데이터를 클라우드에 업로드하지 않고 100% 로컬에서 실행할 수 있습니다 (출처: ollama, Hacubu)

📚 학습
재귀 언어 모델(RLMs): 긴 컨텍스트를 넘어선 사고 : 기존에는 긴 컨텍스트 문제를 윈도우 크기 확장으로 해결하려 했으나, RLMs는 새로운 아이디어를 제시합니다. 모델이 모든 내용을 강제로 ‘삼키는’ 대신, Python/REPL 환경을 통해 코드를 작성하고 데이터를 재귀적으로 ‘분할 정복’해야 한다는 것입니다. 이 방식은 추론과 컨텍스트 길이를 분리하며, 루트 모델은 하위 호출의 구조화된 출력만 처리하여 무한한 가상 컨텍스트를 구현합니다. 현재 이 방법은 임상 시험과 같은 복잡한 사례에서 전통적인 RAG보다 강력한 추론 깊이를 보여주고 있습니다 (출처: lateinteraction)

AIR 프레임워크: LLM 정렬을 위한 선호도 데이터 해체 : OpenBMB는 선호도 데이터셋을 주석(Annotations), 지시어(Instructions), 응답 쌍(Response Pairs)의 세 가지 핵심 요소로 해체하는 AIR 프레임워크를 제안했습니다. 연구 결과, 단순한 점수제 주석이 복잡한 설계보다 우수하며, 모델이 미세한 논리를 학습하도록 각 모델 간 성능 차이가 적은 지시어를 선별해야 하고, 응답 쌍의 점수 차이는 2~3점일 때 효과가 가장 좋다는 사실을 발견했습니다. 이 프레임워크는 6개 벤치마크에서 평균 5.3점의 성능 향상을 이끌어내며 정렬 훈련의 과학적 청사진을 제시했습니다 (출처: _akhaliq, arXiv)
프롬프트 반복(Prompt Repetition) 최적화 기법 : 비추론형 LLM의 경우 프롬프트를 단순히 두 번 반복하는 것만으로도 지연 시간 증가 없이 모델 성능을 현저히 높일 수 있다는 흥미로운 연구 결과가 나왔습니다. 이 방법은 프리필(pre-fill) 단계의 병렬성을 활용하여 모델이 방대한 컨텍스트를 처리할 때 핵심 지시어를 더 잘 고정할 수 있도록 돕습니다. 원리는 매우 간단하지만 여러 벤치마크에서 안정적인 이득을 보여주어, 저비용 추론 시 계산 최적화 전략으로 간주됩니다 (출처: Reddit, arXiv)
💼 비즈니스
Meta, 싱가포르 에이전트 스타트업 Manus AI 거액 인수 : Meta가 Manus AI를 20~30억 달러에 인수하기로 합의한 것으로 알려졌습니다. Manus AI는 강력한 Computer Use 및 심층 연구 에이전트로 유명하며, 200만 명 이상의 대기 명단을 확보한 바 있습니다. Meta는 이를 Facebook, Instagram, WhatsApp에 통합하여 만능 AI 비서를 구축할 계획입니다. 현재 이 거래는 창업자의 배경 및 기술적 민감성으로 인해 중국 규제 당국의 조사를 받고 있어 귀추가 주목됩니다 (출처: DeepLearning.AI, WSJ)

OpenAI, Neuralink 경쟁사에 투자 : OpenAI가 투자 포트폴리오를 다각화하며 최근 Sam Altman이 지원하는 Neuralink의 경쟁사에 자금을 투입했습니다. 이는 OpenAI가 뇌-컴퓨터 인터페이스(BCI) 분야에 깊은 관심을 가지고 있음을 보여주며, AI와 인간의 생물학적 지능이 심층적으로 융합될 장기적 가능성을 탐색하고 하드웨어 및 첨단 생명 과학 분야로 영역을 확장하려는 의도로 풀이됩니다 (출처: TheRundownAI)
🌟 커뮤니티
‘Vibe Coding’에서 ‘Cracked Engineer’로의 전환 : 커뮤니티에서는 기술적 근간에 정통하고 AI 에이전트를 정교하게 다루어 한 팀의 업무량을 혼자 해내는 최상위 개발자를 뜻하는 ‘Cracked Engineer’라는 신조어가 화제입니다. 생각 없이 코드를 생성하기만 하는 ‘Vibe Programmer’와 달리, 이들은 AI가 생성한 논리적 허점을 즉각 식별해냅니다. 미래의 소프트웨어 개발은 수천 개의 관리되지 않는 에이전트가 충돌하는 것이 아니라, 소수의 숙련된 전문가가 AI Agent를 이끌고 정밀하게 구축하는 형태가 될 것이라는 공감대가 형성되고 있습니다 (출처: 36Kr, yacinelearning)
Grok, 딥페이크 생성 및 안전성 논란 : xAI의 Grok이 허가되지 않은 여성 성적 대상화 이미지 생성 및 폭발물 제조 튜토리얼 제공으로 인해 글로벌 규제 압박에 직면했습니다. X는 이후 유료 사용자 권한을 제한하고 일부 불법 지시어를 차단했으나, 브라질, EU, 프랑스 등 여러 국가 정부가 조사에 착수했습니다. 커뮤니티에서는 AI가 범죄 도구로 전락할 것을 우려하는 쪽과 표현의 자유를 이유로 과도한 검열에 반대하는 쪽이 격렬하게 대립하며, 첨단 모델의 규제 준수와 개방성 사이의 거대한 긴장감을 보여주고 있습니다 (출처: DeepLearning.AI, Reddit)

데이터 센터 에너지 소비가 불러온 ‘님비 현상’ : 보고서에 따르면 AI 데이터 센터 프로젝트 중 단일 분기에만 980억 달러 규모가 커뮤니티의 항의와 전력 공급 문제로 중단되었습니다. 비판론자들은 데이터 센터가 전기료와 물 소비를 높인다고 우려하는 반면, Andrew Ng 등 전문가들은 이러한 우려가 과장되었다고 보며 데이터 센터가 기업의 로컬 서버실보다 효율적이고 재생 에너지를 사용하는 경향이 있다고 지적합니다. ‘AI 인프라 vs 지역 사회 자원’에 대한 이 갈등은 2026년 에너지 정책의 핵심 쟁점이 될 전망입니다 (출처: DeepLearning.AI, Reddit)
💡 기타
AI 안내견, 선전 지하철에서 시범 운영 시작 : AI 기술을 탑재한 안내 로봇이 선전 지하철에서 서비스를 시작했습니다. 이 로봇은 고정밀 장애물 회피 및 음성 상호작용 능력을 갖추어 시각 장애인의 개찰구 통과, 열차 탑승 및 환승 등 복잡한 과정을 지원하며, 도시 무장애 수준 향상에 있어 AI의 사회적 가치를 보여주고 있습니다 (출처: Ronald_vanLoon)
22자유도 휴머노이드 로봇 손 공개 : 연구진이 인간의 손 구조를 고도로 모방하고 초민감 촉각 센서 시스템을 갖춘 22자유도 로봇 손을 선보였습니다. 이는 로봇의 정밀 조작과 촉각 인지 분야에서 중대한 돌파구를 마련한 것으로, 미래의 가사 서비스 및 산업용 정밀 조립을 위한 토대를 닦았습니다 (출처: Ronald_vanLoon)