
Palabras clave:OpenAI, IA de Google, Transformer, Modelo publicitario de ChatGPT, Base Siri de Gemini 3, Máquina de Pensamiento Continuo CTM
🔥 Enfoque
OpenAI activa el modo de “generación de ingresos por publicidad” y niveles de suscripción : OpenAI ha anunciado la introducción de anuncios en la versión gratuita de ChatGPT y en el nuevo nivel “Go” de 8 dólares, marcando la transición de su modelo de negocio de suscripción pura a uno de “publicidad + suscripción”. Aunque Sam Altman calificó anteriormente la publicidad como un “último recurso”, ante los elevados costes de computación, esta medida busca lograr la democratización de la AI. La comunidad ha reaccionado con ironía, sugiriendo que AGI ha evolucionado a “Ad-Generated Income” (Ingresos Generados por Anuncios). OpenAI enfatiza que los anuncios no afectarán la objetividad de las respuestas y que no venderán historiales de conversación a los anunciantes, pero esto sigue siendo visto como el fin de la experiencia pura de la AI (Fuente: OpenAI, sama)

Google AI muestra ventajas estructurales y el valor de mercado de Alphabet supera los 4 billones : Google ha realizado movimientos frecuentes recientemente, lanzando la función Personal Intelligence para lograr el razonamiento de datos entre aplicaciones como Gmail y Photos, y asociándose con Apple para que Gemini 3 sea la base del nuevo Siri. Los análisis indican que Google posee el control total del stack, desde sus propios chips TPU e infraestructura de nube global hasta datos reales masivos de Search y YouTube; esta “ventaja estructural” le otorga la iniciativa en la era de la economía de la inferencia. Como resultado, el valor de mercado de Alphabet superó al de Apple por primera vez en 19 años, demostrando el enorme poder de la integración vertical en la carrera de la AI (Fuente: GeminiApp, Reddit)

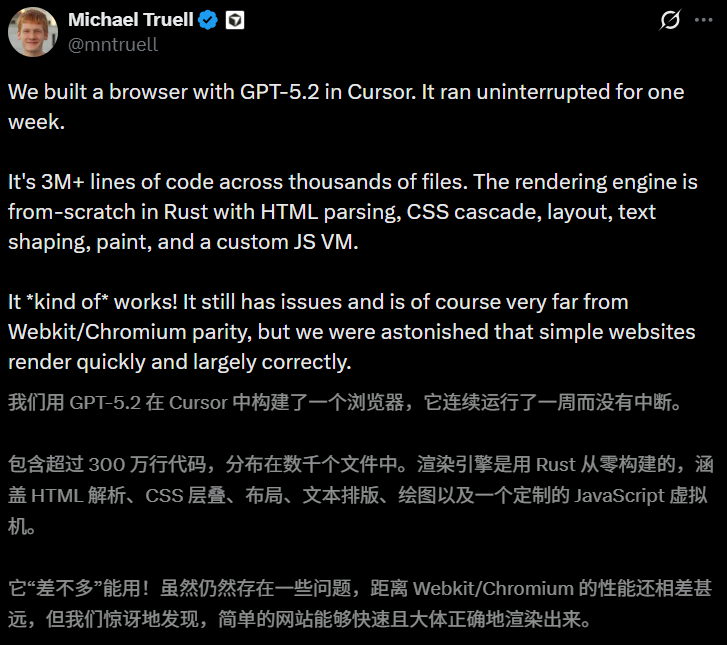
El incidente del “navegador escrito por AI” de Cursor es desmentido por la comunidad : Cursor afirmó anteriormente que su agente inteligente funcionó continuamente durante 7 días para escribir un navegador con 3 millones de líneas de código, pero posteriormente fue cuestionado colectivamente por la comunidad de desarrolladores. Los análisis técnicos muestran que el código del proyecto ni siquiera supera la compilación más básica, siendo ridiculizado como “AI Slop”. La comunidad señala que esto refleja las trampas del actual “Vibe Coding”: la búsqueda excesiva de cantidad generada ignorando el rigor de la ingeniería. Este fracaso recuerda a la industria que, aunque la AI puede generar Tokens de forma frenética, todavía existe una brecha significativa para alcanzar una verdadera ingeniería autónoma (Fuente: Cursor, Reddit)
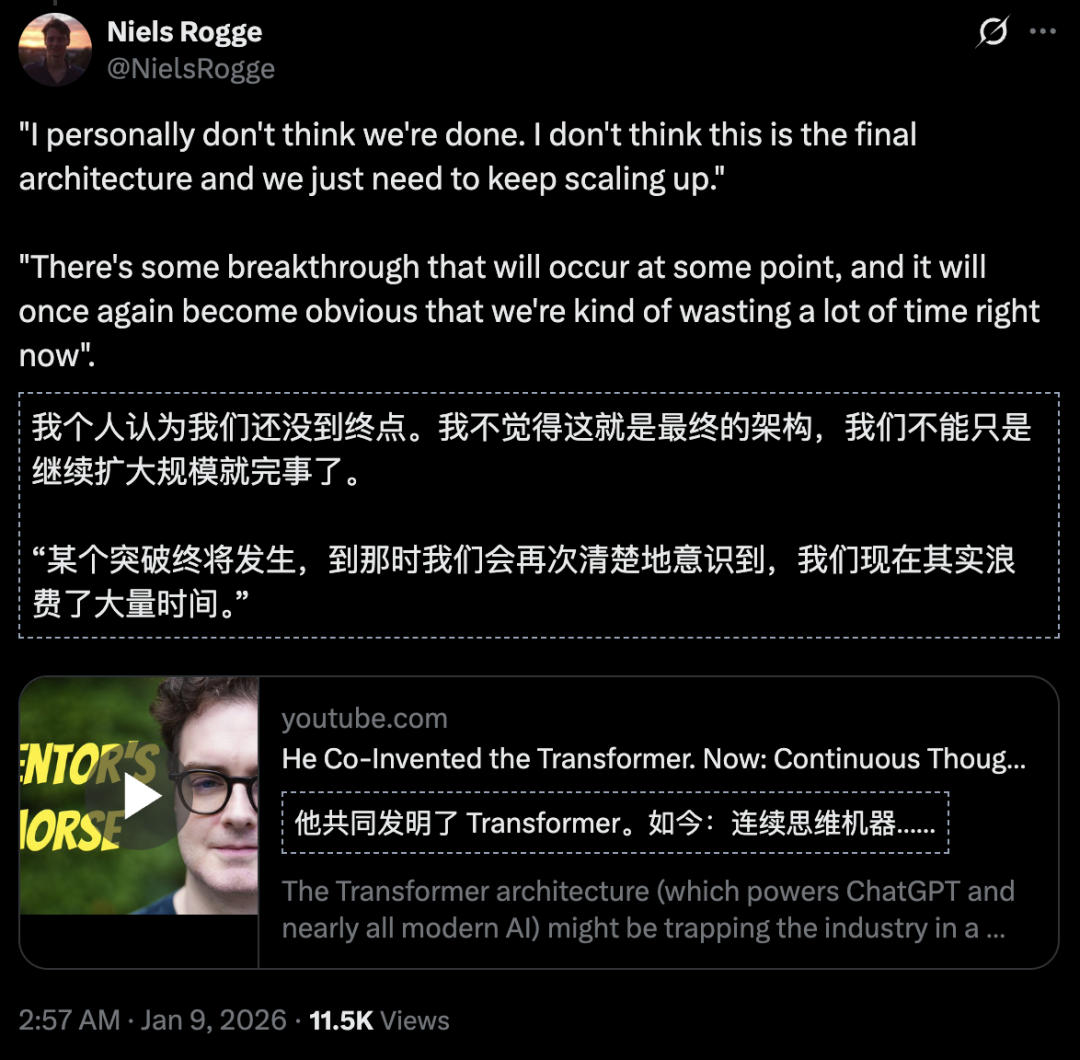
El inventor de Transformer advierte: la investigación actual de AI está en un callejón sin salida : Llion Jones, co-inventor de Transformer, declaró que ha reducido drásticamente su investigación en Transformer porque el campo está saturado de estudios de ajuste fino, convirtiéndose en una “optimización local”. Considera que Transformer es una “lotería de arquitectura” cuyo éxito ha llevado a la industria a un “pozo de gravedad”, ignorando la necesidad de repensar fundamentalmente la representación del conocimiento y las formas de pensar. Actualmente se está orientando hacia una “Continuous Thinking Machine” (CTM) inspirada en la biología, con el objetivo de romper las limitaciones de la “inteligencia dentada” de los LLM actuales. La opinión de Jones ha provocado una profunda discusión sobre si la Scaling Law es el único camino hacia la AGI (Fuente: Sakana AI, 36Kr)
🎯 Tendencias
OpenAI se asocia con Cerebras para lanzar una versión ultra rápida de Codex : Sam Altman confirmó el lanzamiento de una versión ultra rápida de Codex basada en el soporte de hardware de Cerebras. El Wafer-Scale Engine (WSE) de Cerebras es conocido por su altísimo rendimiento de inferencia; se espera que esta colaboración mejore significativamente la velocidad de respuesta de los agentes de programación de AI y su capacidad para manejar tareas largas y complejas. Además, la función de memoria de ChatGPT se ha fortalecido notablemente, permitiendo recordar con mayor fiabilidad detalles de conversaciones pasadas, como recetas o planes de ejercicio, reforzando su atributo de asistente personal (Fuente: sama, Cerebras)

La reproducción de la arquitectura mHC de DeepSeek revela una “bomba de estabilidad” : Un grupo de desarrolladores logró reproducir los experimentos de Hyper-Connections (HC) de DeepSeek-V2/V3 en un clúster de 8xH100. Los resultados muestran que, a una escala de 1.7B de parámetros, la tasa de amplificación de la señal alcanzó las 10,924 veces, superando con creces las 3,000 veces reportadas en el paper. Aunque los optimizadores modernos (AdamW) pueden ocultar temporalmente este problema para evitar que el modelo colapse, esto se considera una “bomba de tiempo” para el entrenamiento a largo plazo. Las verificaciones demuestran que el uso de Manifold Hyper-Connections (mHC) con proyección Sinkhorn resuelve perfectamente este problema de estabilidad sin coste computacional adicional (Fuente: taylorkolasinski, Reddit)
Guerra de gigantes en AI médica: OpenAI se enfoca en pacientes, Anthropic en médicos : OpenAI lanzó ChatGPT Health, posicionado como un gestor de salud para el consumidor que puede interpretar análisis, conectar datos de dispositivos wearables y colaborar con b.well para garantizar la privacidad. Anthropic, por su parte, presentó Claude for Healthcare, que accede a bases de datos profesionales como CMS e ICD-10 a través de Connector, con el objetivo de ayudar al personal médico con el papeleo tedioso y las autorizaciones. La diferencia en sus enfoques refleja las ventajas ecológicas de OpenAI en el sector C-end y de Anthropic en el B-end (Fuente: DeepLearning.AI)

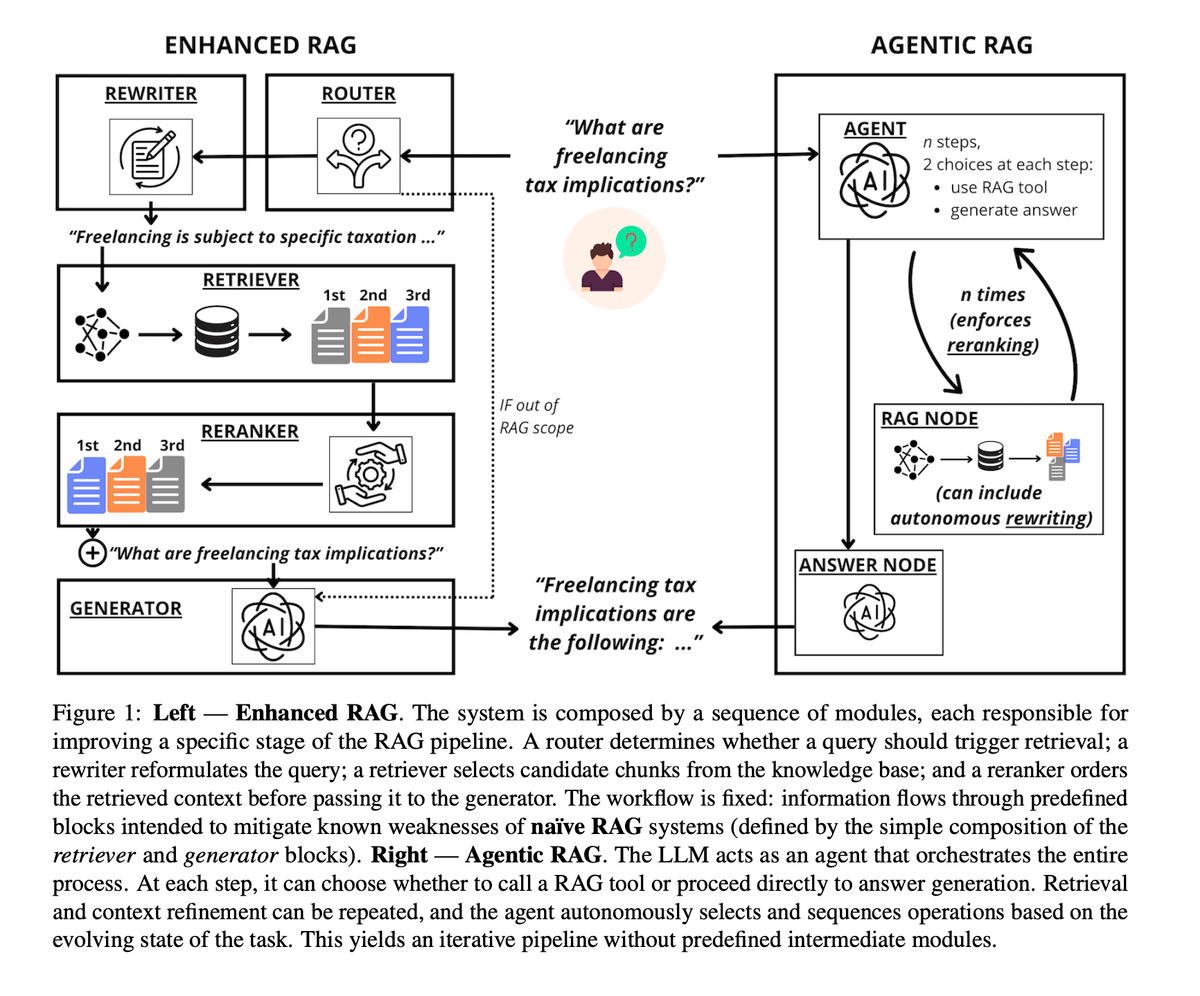
Comparación empírica entre Agentic RAG y Enhanced RAG : Un estudio reciente comparó el Enhanced RAG de “tubería fija” con el Agentic RAG de “programación total por LLM”. Los resultados muestran que el Agentic RAG es superior en el manejo de la intención del usuario y la reescritura de consultas, pero es extremadamente sensible a las capacidades del modelo y su coste computacional es de 2 a 10 veces mayor. En contraste, el Enhanced RAG es más estable y económico en el refinamiento de documentos (re-ranking). La conclusión sugiere: elegir Enhanced RAG cuando los recursos son limitados o se usan modelos débiles; elegir Agentic RAG cuando se busca flexibilidad máxima y se tiene presupuesto suficiente (Fuente: omarsar0, arXiv)
🧰 Herramientas
Claude Cowork se abre oficialmente a usuarios Pro : Anthropic anunció que Claude Cowork ya está disponible para suscriptores Pro. Esta función permite a Claude acceder a carpetas locales, leer, editar o crear archivos, siendo útil para generar tablas desde capturas de pantalla o organizar notas dispersas. La comunidad recomienda a los usuarios establecer directorios de trabajo independientes para evitar que el agente borre archivos importantes por error, y sugiere tratarlo como un “becario inteligente que entiende todo literalmente” (Fuente: dotey, Reddit)
vLLM-MLX: framework de inferencia ultra rápida nativo para Apple Silicon : Para solucionar la lentitud de inferencia en usuarios de Mac, los desarrolladores han lanzado vLLM-MLX. Este framework utiliza Apple MLX para lograr aceleración nativa por GPU; en un M4 Max, la velocidad de inferencia de Llama-3.2-1B alcanza los 464 tok/s y Whisper STT llega a 197 veces la velocidad en tiempo real. Ofrece una interfaz compatible con OpenAI, soporta multimodalidad (texto, imagen, audio, video) y procesamiento por lotes continuo, siendo una de las soluciones de inferencia de LLM local más potentes para Mac (Fuente: waybarrios, Reddit)
Lanzamiento del sitio web oficial de SGLang : LMSYS Org ha publicado oficialmente el sitio web de SGLang, que reúne documentación, Cookbook e información sobre componentes principales. Como motor de inferencia de alto rendimiento, el interés por SGLang se ha disparado recientemente; el sitio web busca resolver la fragmentación de la información y promover un ecosistema de código abierto más amplio. Además, se ha reforzado su soporte para modelos locales (como a través de Ollama) (Fuente: eliebakouch, sglang)

OpenWork: la versión de código abierto de Claude Cowork : Se ha lanzado oficialmente OpenWork, basado en deepagentsjs, con el objetivo de proporcionar un agente de uso de computadora completamente de código abierto, seguro y ejecutable localmente. Soporta planificación de múltiples pasos, acceso al sistema de archivos y delegación a sub-agentes; además, integra nativamente Ollama, permitiendo la ejecución 100% local en Mac mediante modelos como Gemma, Qwen3 y DeepSeek, sin necesidad de subir datos sensibles a la nube (Fuente: ollama, Hacubu)

📚 Aprendizaje
Recursive Language Models (RLMs): pensando más allá del contexto largo : La visión tradicional sostiene que los problemas de contexto largo deben resolverse ampliando la ventana, pero los RLMs proponen una nueva idea: el modelo no debe “tragar” todo el contenido a la fuerza, sino escribir código a través de un entorno Python/REPL para aplicar “divide y vencerás” a los datos de forma recursiva. Este método desacopla el razonamiento de la longitud del contexto, donde el modelo raíz solo procesa la salida estructurada de las sub-llamadas, logrando así un contexto virtual infinito. Actualmente, este método ha demostrado una profundidad de razonamiento mayor que el RAG tradicional en casos complejos como ensayos clínicos (Fuente: lateinteraction)

AIR Framework: deconstruyendo los datos de preferencia para el alineamiento de LLM : OpenBMB ha propuesto el AIR Framework, que desglosa los conjuntos de datos de preferencia en tres componentes principales: Anotaciones (Annotations), Instrucciones (Instructions) y Pares de Respuesta (Response Pairs). La investigación encontró que: las anotaciones simples por puntos son superiores a los diseños complejos; se deben filtrar instrucciones donde la diferencia de rendimiento entre modelos sea pequeña para forzar al modelo a aprender lógica sutil; y una diferencia de 2-3 puntos en los pares de respuesta ofrece los mejores resultados. Este framework mejoró un promedio de 5.3 puntos en 6 pruebas de referencia, proporcionando un plano científico para el entrenamiento de alineamiento (Fuente: _akhaliq, arXiv)
Método de optimización por Prompt Repetition : Un estudio interesante muestra que, para LLMs que no son de razonamiento, simplemente repetir el prompt dos veces puede mejorar significativamente el rendimiento del modelo sin aumentar la latencia. Este método aprovecha el paralelismo de la fase de pre-llenado, ayudando al modelo a fijar mejor las instrucciones principales cuando maneja grandes cantidades de contexto. Aunque el principio es extremadamente simple, ha mostrado ganancias estables en múltiples pruebas de referencia, siendo considerado una estrategia de optimización de cómputo en tiempo de inferencia de bajo coste (Fuente: Reddit, arXiv)
💼 Negocios
Meta adquiere la startup de agentes de Singapur Manus AI por una cifra millonaria : Se informa que Meta ha llegado a un acuerdo para adquirir Manus AI por un precio de entre 2,000 y 3,000 millones de dólares. Manus AI es conocida por su potente Computer Use y sus agentes de investigación profunda, habiendo atraído a más de 2 millones de personas a su lista de espera. Meta planea integrarla en Facebook, Instagram y WhatsApp para crear un asistente de AI todopoderoso. Actualmente, la transacción enfrenta investigaciones de los reguladores chinos debido al origen de sus fundadores y la sensibilidad tecnológica (Fuente: DeepLearning.AI, WSJ)

OpenAI invierte en un competidor de Neuralink : OpenAI está diversificando su cartera de inversiones y recientemente inyectó capital en un competidor de Neuralink respaldado por Sam Altman. Este movimiento muestra el gran interés de OpenAI en el campo de las interfaces cerebro-computadora (BCI), con el objetivo de explorar la posibilidad a largo plazo de una integración profunda entre la AI y la inteligencia biológica humana, expandiendo aún más su presencia en hardware y ciencias de la vida de vanguardia (Fuente: TheRundownAI)
🌟 Comunidad
La transición de “Vibe Coding” a “Cracked Engineer” : La comunidad debate el nuevo término “Cracked Engineer”, que se refiere a desarrolladores de élite que dominan la base técnica y pueden manejar con precisión agentes de AI para completar el trabajo de todo un equipo. A diferencia de los “programadores de ambiente” que generan código sin pensar, un Cracked Engineer puede identificar a simple vista los fallos lógicos generados por la AI. Se está llegando a un consenso en la industria: el desarrollo de software del futuro no será miles de agentes sin supervisión chocando entre sí, sino unas pocas personas expertas liderando AI Agents para construir con precisión (Fuente: 36Kr, yacinelearning)
Grok sumergido en controversias de generación de contenido explícito y seguridad : Grok, de xAI, enfrenta presión regulatoria global por generar imágenes sexualizadas de mujeres sin consentimiento y proporcionar tutoriales para fabricar explosivos. Aunque X restringió posteriormente los permisos de los usuarios de pago y bloqueó algunas instrucciones ilegales, gobiernos de varios países como Brasil, la UE y Francia han iniciado investigaciones. La comunidad mantiene un debate intenso: una parte teme que la AI se convierta en una herramienta criminal, mientras que la otra se opone a la censura excesiva apelando a la libertad de expresión, reflejando la enorme tensión entre cumplimiento y apertura en los modelos de vanguardia (Fuente: DeepLearning.AI, Reddit)

El consumo energético de los centros de datos provoca el efecto “NIMBY” : Un informe revela que solo en un trimestre, proyectos por valor de 98,000 millones de dólares para centros de datos de AI quedaron estancados debido a protestas comunitarias y problemas de suministro eléctrico. Los críticos temen que los centros de datos disparen los precios de la electricidad y el consumo de agua, mientras que expertos como Andrew Ng consideran que estos temores son exagerados, señalando que los centros de datos son más eficientes que las salas de servidores locales de las empresas y tienden a usar energías renovables. Este juego entre “infraestructura de AI vs. recursos comunitarios” será el foco central de las políticas energéticas en 2026 (Fuente: DeepLearning.AI, Reddit)
💡 Otros
Perros guía con AI inician pruebas piloto en el metro de Shenzhen : Robots guía equipados con tecnología de AI han comenzado a prestar servicio en el metro de Shenzhen. Estos robots cuentan con alta precisión para evitar obstáculos e interacción por voz, ayudando a personas con discapacidad visual a completar procesos complejos como entrar en la estación, subir al tren y realizar transbordos, demostrando el valor social de la AI para mejorar la accesibilidad urbana (Fuente: Ronald_vanLoon)
Presentada una mano robótica diestra con 22 grados de libertad : Los desarrolladores mostraron una mano robótica diestra con 22 grados de libertad (DOF), cuya estructura simula fielmente la mano humana y está equipada con un sistema de sensores táctiles ultra sensibles. Esto marca un avance importante en la operación de precisión y la percepción táctil de los robots, sentando las bases para futuros servicios domésticos y ensamblaje industrial de precisión (Fuente: Ronald_vanLoon)