
Schlüsselwörter:OpenAI, Google KI, Transformer, ChatGPT Werbemodell, Gemini 3 Siri-Dock, Kontinuierliche Denkmaschine CTM
🔥 Fokus
OpenAI startet „Ad-Revenue“-Modell und Abo-Stufen: OpenAI hat angekündigt, Werbung in der kostenlosen Version von ChatGPT sowie in der neuen 8-Dollar-Stufe „Go“ einzuführen. Dies markiert den Wandel des Geschäftsmodells von reinen Abonnements hin zu „Werbung + Abo“. Obwohl Sam Altman Werbung einst als „letztes Mittel“ bezeichnete, zielt dieser Schritt angesichts der enormen Rechenkosten darauf ab, AI einem breiteren Publikum zugänglich zu machen. Die Community reagiert heftig und spottet, dass AGI zu „Ad-Generated Income“ mutiert sei. OpenAI betont, dass Anzeigen die Objektivität der Antworten nicht beeinflussen und keine Chat-Protokolle an Werbetreibende verkauft werden, dennoch wird dies als Ende der „reinen“ AI-Erfahrung gesehen (Quelle: OpenAI, sama)

Google AI zeigt strukturelle Vorteile, Alphabet-Marktwert übersteigt 4 Billionen: Google hat zuletzt massiv aufgerüstet und die Funktion Personal Intelligence veröffentlicht, die datenübergreifendes Reasoning in Apps wie Gmail und Photos ermöglicht. Zudem wurde eine Kooperation mit Apple geschlossen, durch die Gemini 3 zur Basis des neuen Siri wird. Analysen zeigen, dass Google durch die volle Kontrolle über den Stack – von eigenen TPU-Chips über die globale Cloud-Infrastruktur bis hin zu massiven Realdaten von Search und YouTube – im Zeitalter der „Reasoning Economics“ die Initiative übernimmt. Der Marktwert von Alphabet überholte damit erstmals seit 19 Jahren den von Apple, was die enorme Macht der vertikalen Integration im AI-Wettlauf unterstreicht (Quelle: GeminiApp, Reddit)

Cursor „AI-Browser“-Vorfall von der Community als Fake entlarvt: Cursor behauptete zuvor, dass sein Agent in sieben Tagen ununterbrochener Laufzeit einen Browser mit 3 Millionen Zeilen Code geschrieben habe, was jedoch auf massive Skepsis in der Entwickler-Community stieß. Technische Analysen ergaben, dass der Code des Projekts nicht einmal die grundlegendste Kompilierung bestand, und er wurde als „AI Slop“ verspottet. Die Community weist darauf hin, dass dies die Fallen des aktuellen „Vibe Coding“ widerspiegelt: ein übermäßiges Streben nach Quantität bei Vernachlässigung technischer Strenge. Dieser Vorfall erinnert die Branche daran, dass AI zwar massenhaft Token generieren kann, aber noch weit von echter autonomer Ingenieursleistung entfernt ist (Quelle: Cursor, Reddit)
Transformer-Erfinder warnt: Aktuelle AI-Forschung steckt in einer Sackgasse: Llion Jones, Mit-Erfinder des Transformer, gab an, seine Forschung an Transformern drastisch reduziert zu haben, da das Feld mit Fine-Tuning-Studien überfüllt sei und in „lokaler Optimierung“ stagniere. Er betrachtet den Transformer als eine „Architektur-Lotterie“, deren Erfolg die Branche in ein „Gravitationsloch“ gezogen habe, wodurch ein grundlegendes Überdenken von Wissensrepräsentation und Denkweisen vernachlässigt werde. Er widmet sich nun biologisch inspirierten „Continuous Thinking Machines“ (CTM), um die Grenzen der aktuellen „gezackten Intelligenz“ von LLMs zu durchbrechen. Jones’ Ansichten lösten eine tiefe Diskussion darüber aus, ob das Scaling Law der einzige Weg zu AGI ist (Quelle: Sakana AI, 36Kr)
🎯 Trends
OpenAI und Cerebras bringen Hochgeschwindigkeits-Version von Codex heraus: Sam Altman bestätigte den Launch einer extrem schnellen Codex-Version auf Basis von Cerebras-Hardware. Die Wafer-Scale Engine (WSE) von Cerebras ist für ihren extrem hohen Reasoning-Durchsatz bekannt. Diese Zusammenarbeit soll die Reaktionsgeschwindigkeit von AI-Coding-Agents und deren Fähigkeit zur Bearbeitung komplexer Langzeitaufgaben massiv steigern. Zudem wurde die Gedächtnisfunktion von ChatGPT deutlich verbessert, sodass Details aus vergangenen Gesprächen wie Rezepte oder Trainingspläne zuverlässiger behalten werden (Quelle: sama, Cerebras)

Reproduktion der DeepSeek mHC-Architektur enthüllt „Stabilitätsbombe“: Entwicklern ist es gelungen, die Hyper-Connections (HC) Experimente von DeepSeek-V2/V3 auf einem 8xH100-Cluster zu reproduzieren. Die Ergebnisse zeigten bei einer Skalierung von 1.7B Parametern eine Signalverstärkung um das 10.924-fache, was weit über den im Paper berichteten 3.000-fachen Wert liegt. Obwohl moderne Optimizer (AdamW) dieses Problem temporär kaschieren können, wird es als „Zeitbombe“ für langfristiges Training betrachtet. Die Validierung ergab, dass manifold Hyper-Connections (mHC) mit Sinkhorn-Projektion dieses Stabilitätsproblem ohne zusätzlichen Rechenaufwand perfekt lösen (Quelle: taylorkolasinski, Reddit)
Kampf der Medical AI-Giganten: OpenAI fokussiert auf Patienten, Anthropic auf Ärzte: OpenAI veröffentlichte ChatGPT Health, positioniert als Gesundheitsmanager für Konsumenten, der Laborberichte interpretieren und Wearable-Daten verknüpfen kann, wobei die Privatsphäre durch die Partnerschaft mit b.well gesichert wird. Anthropic hingegen führte Claude for Healthcare ein, das über Connector auf professionelle Datenbanken wie CMS und ICD-10 zugreift, um medizinisches Personal bei bürokratischen Aufgaben und Autorisierungen zu entlasten. Diese Differenzierung spiegelt die jeweiligen Stärken von OpenAI im C-Bereich und Anthropic im B-Bereich wider (Quelle: DeepLearning.AI)

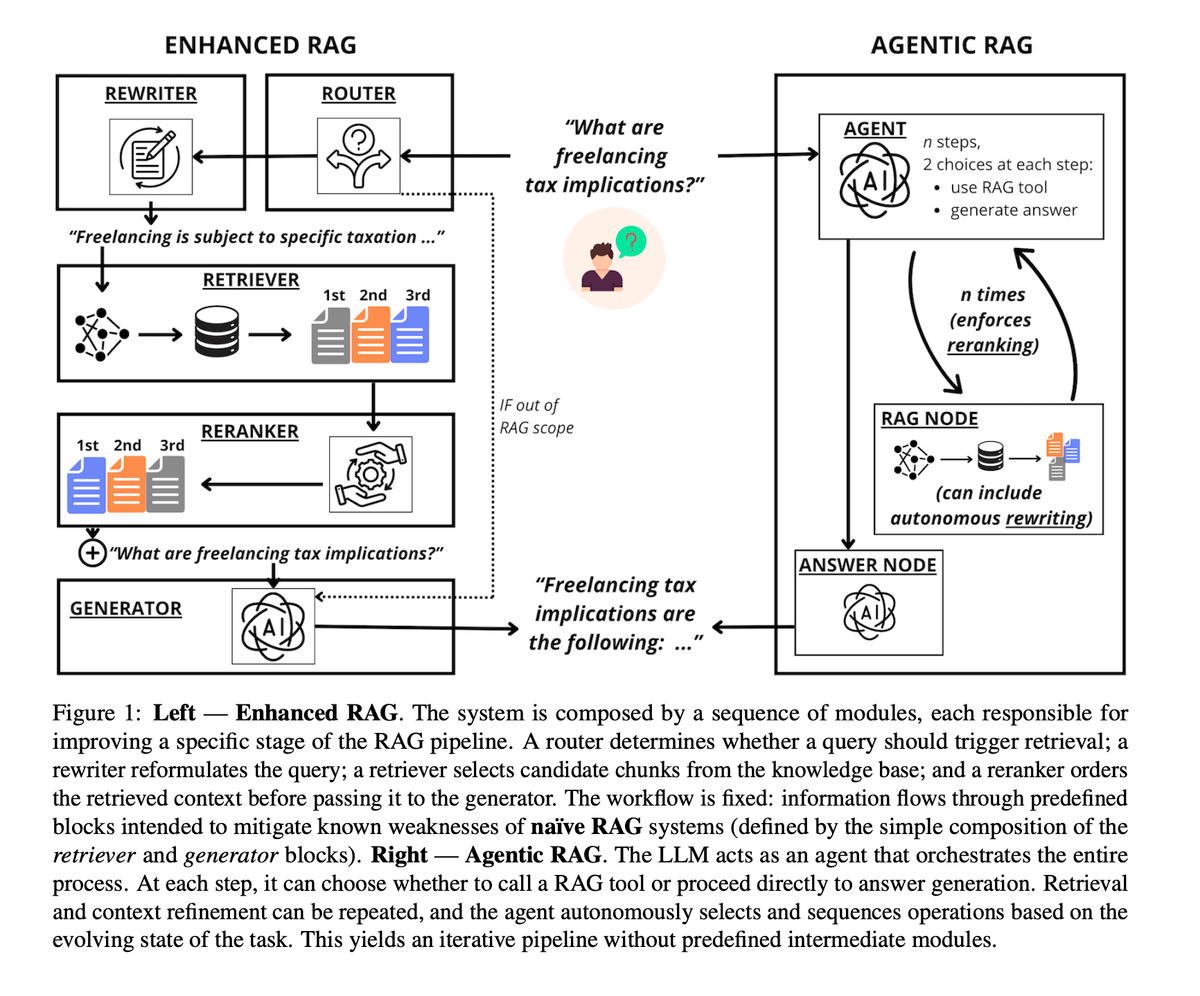
Empirischer Vergleich zwischen Agentic RAG und Enhanced RAG: Eine aktuelle Studie verglich Enhanced RAG mit „fester Pipeline“ und Agentic RAG mit „durchgehendem LLM-Scheduling“. Die Ergebnisse zeigen, dass Agentic RAG bei der Verarbeitung von Nutzerintentionen und Query-Rewriting besser abschneidet, jedoch extrem sensibel auf die Modellfähigkeiten reagiert und 2- bis 10-mal höhere Rechenkosten verursacht. Im Gegensatz dazu ist Enhanced RAG bei der Dokumenten-Verfeinerung (Reranking) stabiler und wirtschaftlicher. Empfehlung: Bei Ressourcenmangel oder schwachen Modellen Enhanced RAG wählen; bei maximaler Flexibilität und ausreichendem Budget Agentic RAG (Quelle: omarsar0, arXiv)
🧰 Tools
Claude Cowork offiziell für Pro-Nutzer verfügbar: Anthropic gab bekannt, dass Claude Cowork nun für Pro-Abonnenten freigeschaltet ist. Diese Funktion erlaubt Claude den Zugriff auf lokale Ordner, um Dateien zu lesen, zu bearbeiten oder zu erstellen – ideal für Aufgaben wie das Erstellen von Tabellen aus Screenshots oder das Organisieren loser Notizen. Die Community rät Nutzern, separate Arbeitsverzeichnisse zu verwenden, um das versehentliche Löschen wichtiger Dateien durch den Agent zu vermeiden, und ihn als „intelligenten Praktikanten, der alles wörtlich nimmt“ zu betrachten (Quelle: dotey, Reddit)
vLLM-MLX: Natives Framework für extrem schnelles Inference auf Apple Silicon: Um das Problem langsamer Inference für Mac-Nutzer zu lösen, haben Entwickler vLLM-MLX veröffentlicht. Das Framework nutzt Apple MLX für native GPU-Beschleunigung und erreicht auf einem M4 Max bei Llama-3.2-1B eine Geschwindigkeit von 464 tok/s sowie bei Whisper STT die 197-fache Echtzeitgeschwindigkeit. Es bietet eine OpenAI-kompatible Schnittstelle, unterstützt Multimodalität (Text, Bild, Audio, Video) sowie Continuous Batching und ist derzeit eine der leistungsstärksten lokalen LLM-Inference-Lösungen für den Mac (Quelle: waybarrios, Reddit)
Offizielle SGLang-Website gestartet: LMSYS Org hat die offizielle Website für SGLang veröffentlicht, die Dokumentationen, Cookbooks und Informationen zu Kernkomponenten bündelt. Als Hochleistungs-Inference-Engine hat SGLang zuletzt stark an Aufmerksamkeit gewonnen. Die Website soll die Informationsfragmentierung beheben und den Aufbau eines breiteren Open-Source-Ökosystems fördern. Zudem wurde die Unterstützung für lokale Modelle (z. B. via Ollama) weiter ausgebaut (Quelle: eliebakouch, sglang)

OpenWork: Open-Source-Version von Claude Cowork: Basierend auf deepagentsjs wurde OpenWork veröffentlicht, mit dem Ziel, einen vollständig quelloffenen, sicheren und lokal ausführbaren Computer Use Agent bereitzustellen. Er unterstützt mehrstufige Planung, Dateisystemzugriff sowie die Delegation an Sub-Agents. Durch die native Integration von Ollama ermöglicht er die 100% lokale Ausführung von Modellen wie Gemma, Qwen3 oder DeepSeek auf dem Mac, ohne sensible Daten in die Cloud hochladen zu müssen (Quelle: ollama, Hacubu)

📚 Lernen
Recursive Language Models (RLMs): Denken über den Long Context hinaus: Traditionell wird versucht, Long-Context-Probleme durch größere Fenster zu lösen. RLMs schlagen einen neuen Weg vor: Das Modell soll nicht alles „verschlingen“, sondern über eine Python/REPL-Umgebung Code schreiben, um Daten rekursiv nach dem „Divide and Conquer“-Prinzip zu verarbeiten. Dies entkoppelt das Reasoning von der Kontextlänge, da das Root-Modell nur strukturierte Outputs von Sub-Aufrufen verarbeitet, was einen unendlichen virtuellen Kontext ermöglicht. Diese Methode zeigt in komplexen Anwendungsfällen wie klinischen Studien bereits eine größere Reasoning-Tiefe als klassisches RAG (Quelle: lateinteraction)

AIR-Framework: Dekonstruktion von Preference Data für LLM-Alignment: OpenBMB stellte das AIR-Framework vor, das Preference-Datensätze in drei Kernkomponenten zerlegt: Annotations, Instructions und Response Pairs. Die Forschung ergab: Einfache Punktesysteme bei der Annotation sind komplexen Designs überlegen; es sollten Instructions gewählt werden, bei denen Modelle geringe Leistungsunterschiede zeigen, um feine Logik zu erzwingen; bei Response Pairs ist eine Differenz von 2-3 Punkten am effektivsten. Das Framework verbesserte die Ergebnisse in 6 Benchmarks um durchschnittlich 5,3 Punkte (Quelle: _akhaliq, arXiv)
Optimierung durch Prompt Repetition: Eine interessante Studie zeigt, dass bei nicht-reasoning-fokussierten LLMs das einfache Verdoppeln des Prompts die Modellleistung signifikant steigern kann, ohne die Latenz zu erhöhen. Diese Methode nutzt die Parallelität der Prefill-Phase, um dem Modell zu helfen, Kernanweisungen bei großen Kontextmengen besser zu fixieren. Trotz der Einfachheit zeigt sie in mehreren Benchmarks stabile Gewinne und wird als kostengünstige Strategie für Inference-time Compute betrachtet (Quelle: Reddit, arXiv)
💼 Business
Meta übernimmt singapurisches Agent-Startup Manus AI für Milliardenbetrag: Berichten zufolge hat Meta eine Vereinbarung zur Übernahme von Manus AI für 2 bis 3 Milliarden US-Dollar getroffen. Manus AI ist bekannt für seine starken Computer Use und Deep Research Agents und hatte über 2 Millionen Menschen auf der Warteliste. Meta plant die Integration in Facebook, Instagram und WhatsApp, um einen Allround-AI-Assistenten zu schaffen. Der Deal wird derzeit von chinesischen Regulierungsbehörden aufgrund des Hintergrunds der Gründer und der technologischen Sensibilität untersucht (Quelle: DeepLearning.AI, WSJ)

OpenAI investiert in Neuralink-Konkurrenten: OpenAI diversifiziert sein Portfolio und investierte kürzlich in einen von Sam Altman unterstützten Konkurrenten von Neuralink. Dieser Schritt unterstreicht das Interesse von OpenAI an Brain-Computer Interfaces (BCI), um die langfristigen Möglichkeiten einer tiefen Verschmelzung von AI und menschlicher biologischer Intelligenz zu erforschen und die Präsenz in Hardware und Life Sciences auszubauen (Quelle: TheRundownAI)
🌟 Community
Wandel vom „Vibe Coding“ zum „Cracked Engineer“: In der Community wird intensiv über den Begriff „Cracked Engineer“ diskutiert – Entwickler, die technische Grundlagen beherrschen und AI Agents so präzise steuern können, dass sie das Arbeitspensum eines ganzen Teams bewältigen. Im Gegensatz zu „Vibe Codern“, die Code blind generieren lassen, erkennen Cracked Engineers Logikfehler der AI sofort. Es bildet sich ein Konsens: Die Zukunft der Softwareentwicklung liegt nicht in tausenden unkontrollierten Agents, sondern in wenigen Experten, die AI Agents präzise führen (Quelle: 36Kr, yacinelearning)
Grok in der Kritik wegen NSFW-Generierung und Sicherheitsbedenken: Grok von xAI steht unter globalem Regulierungsdruck, da es nicht autorisierte sexualisierte Bilder von Frauen generieren kann und Anleitungen zum Bau von Sprengstoffen lieferte. Obwohl X den Zugriff für zahlende Nutzer einschränkte und illegale Befehle blockierte, haben Regierungen in Brasilien, der EU und Frankreich Untersuchungen eingeleitet. Die Community debattiert hitzig: Eine Seite fürchtet den Missbrauch der AI für kriminelle Zwecke, die andere lehnt übermäßige Zensur im Namen der Meinungsfreiheit ab (Quelle: DeepLearning.AI, Reddit)

Energieverbrauch von Rechenzentren löst „NIMBY-Effekt“ aus: Ein Bericht zeigt, dass allein in einem Quartal AI-Rechenzentrumsprojekte im Wert von 98 Milliarden US-Dollar aufgrund von Bürgerprotesten und Stromversorgungsproblemen gestoppt wurden. Kritiker fürchten steigende Strompreise und hohen Wasserverbrauch. Experten wie Andrew Ng halten diese Sorgen für übertrieben und weisen darauf hin, dass Rechenzentren effizienter als lokale Firmen-Serverräume sind und verstärkt auf erneuerbare Energien setzen. Der Konflikt „AI-Infrastruktur vs. kommunale Ressourcen“ wird ein zentrales Thema der Energiepolitik 2026 (Quelle: DeepLearning.AI, Reddit)
💡 Sonstiges
AI-Blindenhunde starten Pilotprojekt in der Metro von Shenzhen: Mit AI-Technologie ausgestattete Blindenführ-Roboter haben ihren Dienst in der Metro von Shenzhen aufgenommen. Die Roboter verfügen über hochpräzise Hindernisumgehung und Sprachinteraktion, um sehbehinderten Menschen beim Betreten der Station, beim Einsteigen und beim Umsteigen zu helfen – ein Beispiel für den sozialen Wert von AI für die Barrierefreiheit in Städten (Quelle: Ronald_vanLoon)
Humanoide Roboterhand mit 22 Freiheitsgraden (DOF) vorgestellt: Entwickler präsentierten eine Roboterhand mit 22 Freiheitsgraden, deren Struktur die menschliche Hand präzise nachahmt und mit hochempfindlichen taktilen Sensoren ausgestattet ist. Dies markiert einen Durchbruch in der Feinmotorik und taktilen Wahrnehmung von Robotern und legt den Grundstein für künftige Anwendungen im Haushalt und in der industriellen Präzisionsmontage (Quelle: Ronald_vanLoon)