
Kata Kunci:OpenAI, Google AI, Transformer, Mode Iklan ChatGPT, Dasar Siri Gemini 3, Mesin Pikiran Berkelanjutan CTM
🔥 Fokus
OpenAI Memulai Mode “Pendapatan Iklan” dan Tingkatan Langganan : OpenAI mengumumkan akan memperkenalkan iklan di ChatGPT versi gratis dan tingkatan “Go” baru seharga $8, menandai transisi model bisnisnya dari murni langganan menjadi “iklan + langganan”. Meskipun Sam Altman pernah menyebut iklan sebagai “upaya terakhir”, langkah ini bertujuan untuk mencapai inklusivitas AI di tengah biaya komputasi yang tinggi. Komunitas bereaksi keras, menyindir bahwa AGI telah berevolusi menjadi “Ad-Generated Income” (Pendapatan yang Dihasilkan Iklan). OpenAI menegaskan bahwa iklan tidak akan memengaruhi objektivitas jawaban dan tidak akan menjual riwayat percakapan kepada pengiklan, namun hal ini tetap dianggap sebagai akhir dari pengalaman AI yang murni (Sumber: OpenAI, sama)

AI Google Menunjukkan Keunggulan Struktural, Kapitalisasi Pasar Alphabet Melampaui $4 Triliun : Google baru-baru ini melakukan banyak pergerakan, merilis fitur Personal Intelligence untuk penalaran data lintas aplikasi seperti Gmail dan Photos, serta bekerja sama dengan Apple untuk menjadikan Gemini 3 sebagai fondasi Siri versi baru. Analisis menunjukkan bahwa Google memiliki kontrol full-stack mulai dari chip TPU buatan sendiri, infrastruktur cloud global, hingga data riil masif dari Search dan YouTube. “Keunggulan struktural” ini membuatnya dominan di era ekonomi penalaran. Kapitalisasi pasar Alphabet pun melampaui Apple untuk pertama kalinya dalam 19 tahun, menunjukkan kekuatan besar integrasi vertikal dalam kompetisi AI (Sumber: GeminiApp, Reddit)

Insiden “Browser Buatan AI” Cursor Dituduh Palsu oleh Komunitas : Cursor sebelumnya mengklaim bahwa agen AI-nya bekerja terus-menerus selama 7 hari untuk menulis 3 juta baris kode browser, namun kemudian mendapat keraguan kolektif dari komunitas pengembang. Analisis teknis menunjukkan bahwa kode proyek tersebut bahkan tidak bisa melewati kompilasi dasar, dan diejek sebagai “AI Slop”. Komunitas menunjukkan bahwa hal ini mencerminkan jebakan “Vibe Coding” saat ini: mengejar kuantitas generasi secara berlebihan sambil mengabaikan ketelitian teknik. Kegagalan ini mengingatkan industri bahwa meskipun AI dapat menghasilkan Token secara masif, masih ada jarak signifikan menuju rekayasa otonom yang sebenarnya (Sumber: Cursor, Reddit)
Penemu Transformer Memperingatkan: Riset AI Saat Ini Terjebak dalam Jalan Buntu : Co-inventor Transformer, Llion Jones, menyatakan bahwa ia telah secara signifikan mengurangi riset pada Transformer karena bidang tersebut telah dipenuhi oleh riset fine-tuning dan jatuh ke dalam “optimasi lokal”. Ia menganggap Transformer sebagai “lotre arsitektur” yang kesuksesannya membuat industri terjebak dalam “sumur gravitasi”, mengabaikan pemikiran ulang mendasar tentang representasi pengetahuan dan cara berpikir. Ia kini beralih ke “Continuous Thinking Machine” (CTM) yang terinspirasi biologis, bertujuan untuk mendobrak batasan “kecerdasan bergerigi” pada LLM saat ini. Pandangan Jones memicu diskusi mendalam tentang apakah Scaling Law adalah satu-satunya jalur menuju AGI (Sumber: Sakana AI, 36Kr)
🎯 Tren
OpenAI Berkolaborasi dengan Cerebras Meluncurkan Codex Versi Super Cepat : Sam Altman mengonfirmasi peluncuran Codex versi super cepat yang didukung oleh perangkat keras Cerebras. Wafer-Scale Engine (WSE) milik Cerebras dikenal dengan throughput inferensi yang sangat tinggi. Kolaborasi ini diharapkan dapat meningkatkan kecepatan respons agen pemrograman AI dan kemampuan menangani tugas panjang yang kompleks secara signifikan. Selain itu, fitur memori ChatGPT juga telah ditingkatkan secara nyata, mampu mengingat detail percakapan masa lalu seperti resep atau rencana latihan dengan lebih andal (Sumber: sama, Cerebras)

Reproduksi Arsitektur DeepSeek mHC Mengungkap “Bom Stabilitas” : Pengembang berhasil mereproduksi eksperimen Hyper-Connections (HC) dari DeepSeek-V2/V3 pada klaster 8xH100. Hasil menunjukkan bahwa pada skala parameter 1.7B, rasio amplifikasi sinyal mencapai 10.924 kali, jauh melampaui 3.000 kali yang dilaporkan dalam makalah. Meskipun optimizer modern (AdamW) dapat menutupi masalah ini sementara agar model tidak runtuh, hal ini dianggap sebagai “bom waktu” untuk pelatihan jangka panjang. Verifikasi menunjukkan bahwa manifold Hyper-Connections (mHC) yang menggunakan proyeksi Sinkhorn dapat menyelesaikan masalah stabilitas tersebut dengan sempurna tanpa biaya komputasi tambahan (Sumber: taylorkolasinski, Reddit)
Perang Raksasa AI Medis: OpenAI Fokus pada Pasien, Anthropic Fokus pada Dokter : OpenAI merilis ChatGPT Health, diposisikan sebagai asisten kesehatan sisi konsumen yang dapat menjelaskan laporan laboratorium, menghubungkan data perangkat wearable, dan bekerja sama dengan b.well untuk memastikan privasi. Anthropic meluncurkan Claude for Healthcare, mengakses database profesional seperti CMS dan ICD-10 melalui Connector, bertujuan membantu tenaga medis menangani dokumen administratif dan otorisasi yang membosankan. Perbedaan strategi ini mencerminkan keunggulan ekosistem OpenAI di sisi C-end dan Anthropic di sisi B-end (Sumber: DeepLearning.AI)

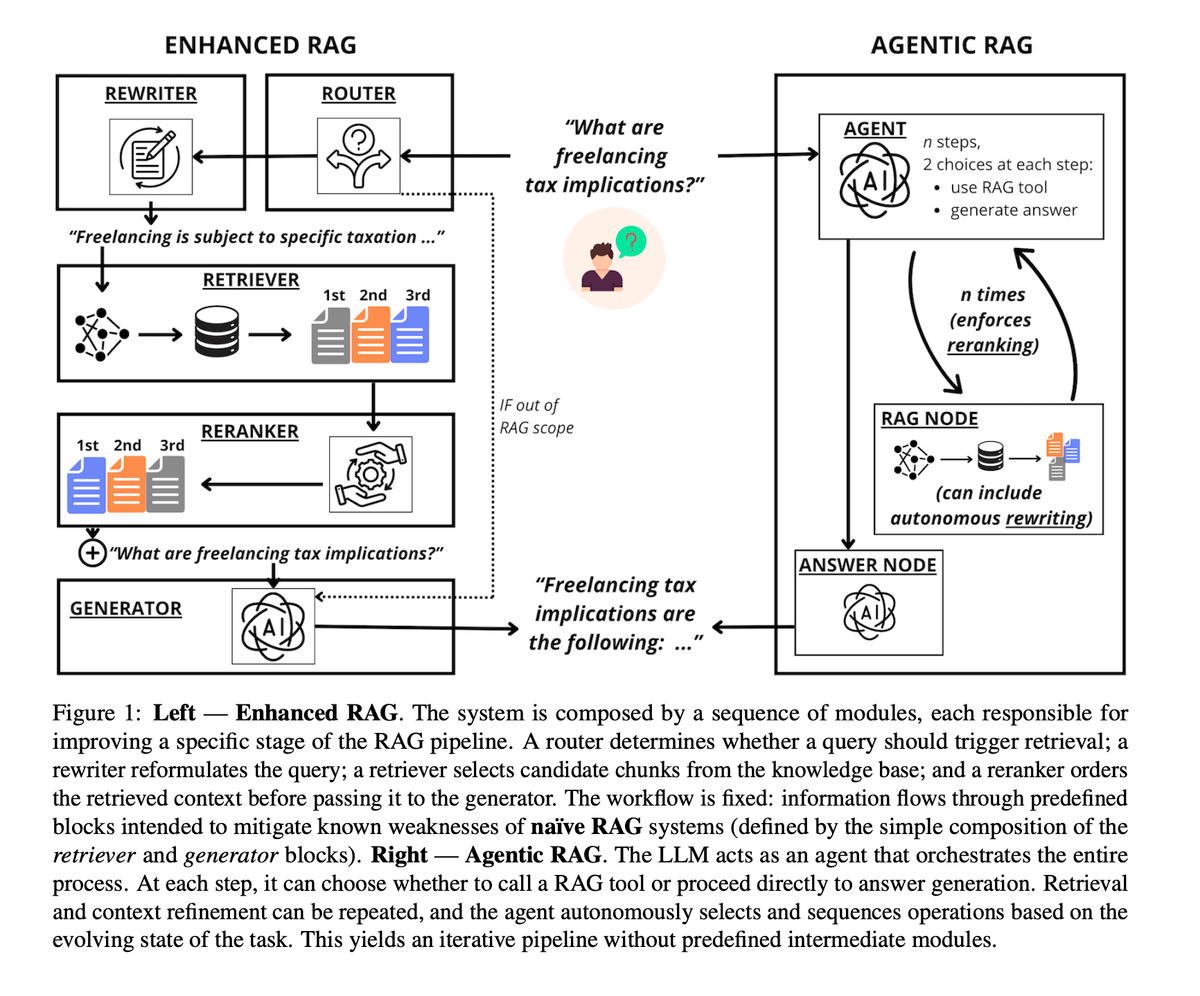
Perbandingan Empiris Antara Agentic RAG dan Enhanced RAG : Riset terbaru membandingkan Enhanced RAG dengan “pipa tetap” dan Agentic RAG dengan “penjadwalan penuh LLM”. Hasil menunjukkan bahwa Agentic RAG berkinerja lebih baik dalam menangani niat pengguna dan penulisan ulang kueri, namun sangat sensitif terhadap kemampuan model dan biaya komputasinya 2-10 kali lebih tinggi. Sebaliknya, Enhanced RAG lebih stabil dan ekonomis dalam penyaringan dokumen (re-ranking). Kesimpulan menyarankan: pilih Enhanced RAG saat sumber daya terbatas atau menggunakan model lemah; pilih Agentic RAG saat mengejar fleksibilitas ekstrem dengan anggaran cukup (Sumber: omarsar0, arXiv)
🧰 Alat
Claude Cowork Resmi Dibuka untuk Pengguna Pro : Anthropic mengumumkan bahwa Claude Cowork kini mendukung pelanggan Pro. Fitur ini memungkinkan Claude mengakses folder lokal, membaca, mengedit, atau membuat file, cocok untuk skenario seperti membuat tabel dari tangkapan layar atau merapikan catatan yang berantakan. Komunitas mengingatkan pengguna untuk membuat direktori kerja terpisah guna menghindari penghapusan file penting secara tidak sengaja oleh agen, dan menyarankan untuk menganggapnya sebagai “magang cerdas yang memahami makna harfiah” (Sumber: dotey, Reddit)
vLLM-MLX: Framework Inferensi Super Cepat Native untuk Apple Silicon : Menjawab keluhan pengguna Mac tentang inferensi yang lambat, pengembang meluncurkan vLLM-MLX. Framework ini menggunakan Apple MLX untuk akselerasi GPU native, mencapai kecepatan inferensi Llama-3.2-1B sebesar 464 tok/s pada M4 Max, dan Whisper STT mencapai 197 kali kecepatan real-time. Alat ini menyediakan antarmuka yang kompatibel dengan OpenAI, mendukung multimodal (teks, gambar, audio, video) serta continuous batching, menjadikannya salah satu solusi inferensi LLM lokal terkuat di platform Mac saat ini (Sumber: waybarrios, Reddit)
Situs Web Resmi SGLang Diluncurkan : LMSYS Org secara resmi merilis situs web SGLang, merangkum dokumentasi, Cookbook, dan informasi komponen inti. Sebagai mesin inferensi berperforma tinggi, popularitas SGLang melonjak baru-baru ini. Peluncuran situs web ini bertujuan untuk menyelesaikan masalah fragmentasi informasi dan mendorong pembangunan ekosistem open-source yang lebih luas. Selain itu, dukungannya terhadap model lokal (seperti melalui Ollama) juga semakin diperkuat (Sumber: eliebakouch, sglang)

OpenWork: Versi Open-source dari Claude Cowork : OpenWork yang dibangun di atas deepagentsjs resmi dirilis, bertujuan menyediakan agen Computer Use yang sepenuhnya open-source, aman, dan dapat dijalankan secara lokal. Alat ini mendukung perencanaan multi-langkah, akses sistem file, dan delegasi sub-agen, serta telah terintegrasi secara native dengan Ollama, memungkinkan eksekusi 100% lokal pada Mac melalui model open-source seperti Gemma, Qwen3, dan DeepSeek tanpa perlu mengunggah data sensitif ke cloud (Sumber: ollama, Hacubu)

📚 Pembelajaran
Recursive Language Models (RLMs): Berpikir Melampaui Konteks Panjang : Pandangan tradisional menganggap masalah konteks panjang harus diselesaikan dengan memperluas jendela konteks, namun RLMs menawarkan ide baru: model tidak seharusnya “menelan” semua konten secara paksa, melainkan menulis kode melalui lingkungan Python/REPL untuk melakukan “divide and conquer” pada data secara rekursif. Metode ini memisahkan penalaran dari panjang konteks, di mana model akar hanya menangani output terstruktur dari sub-panggilan, sehingga mencapai konteks virtual tak terbatas. Saat ini metode tersebut telah menunjukkan kedalaman penalaran yang lebih kuat daripada RAG tradisional dalam kasus penggunaan kompleks seperti uji klinis (Sumber: lateinteraction)

Framework AIR: Mendekonstruksi Data Preferensi untuk Penyelarasan LLM : OpenBMB mengajukan framework AIR, yang memecah dataset preferensi menjadi tiga komponen inti: Annotations, Instructions, dan Response Pairs. Riset menemukan bahwa: anotasi sistem poin sederhana lebih baik daripada desain kompleks; instruksi dengan perbedaan performa model yang kecil harus disaring untuk memaksa model mempelajari logika halus; perbedaan skor Response Pairs yang dijaga pada 2-3 poin memberikan hasil terbaik. Framework ini meningkatkan rata-rata 5,3 poin pada 6 benchmark, memberikan cetak biru ilmiah untuk pelatihan penyelarasan (alignment) (Sumber: _akhaliq, arXiv)
Metode Optimasi Prompt Repetition : Sebuah studi menarik menunjukkan bahwa untuk LLM tipe non-reasoning, cukup dengan mengulang prompt dua kali dapat meningkatkan performa model secara signifikan tanpa menambah latensi. Metode ini memanfaatkan paralelisme pada tahap pre-fill, membantu model mengunci instruksi inti dengan lebih baik saat menangani konteks dalam jumlah besar. Meskipun prinsipnya sangat sederhana, metode ini menunjukkan peningkatan stabil di berbagai benchmark dan dianggap sebagai strategi optimasi komputasi waktu inferensi yang berbiaya rendah (Sumber: Reddit, arXiv)
💼 Bisnis
Meta Mengakuisisi Startup Agen AI Singapura, Manus AI : Dikabarkan Meta telah mencapai kesepakatan untuk mengakuisisi Manus AI dengan nilai $2-3 miliar. Manus AI dikenal dengan fitur Computer Use yang kuat dan agen riset mendalam, pernah menarik lebih dari 2 juta orang ke dalam daftar tunggu. Meta berencana mengintegrasikannya ke dalam Facebook, Instagram, dan WhatsApp untuk menciptakan asisten AI serba bisa. Saat ini transaksi tersebut menghadapi investigasi dari regulator China karena latar belakang pendiri dan sensitivitas teknologinya (Sumber: DeepLearning.AI, WSJ)

OpenAI Berinvestasi pada Kompetitor Neuralink : OpenAI sedang mendiversifikasi portofolio investasinya, baru-baru ini menyuntikkan dana ke kompetitor Neuralink yang didukung oleh Sam Altman. Langkah ini menunjukkan minat besar OpenAI pada bidang Brain-Computer Interface (BCI), bertujuan mengeksplorasi kemungkinan jangka panjang integrasi mendalam antara AI dan kecerdasan biologis manusia, serta memperluas jangkauannya di bidang perangkat keras dan ilmu hayati mutakhir (Sumber: TheRundownAI)
🌟 Komunitas
Perubahan dari “Vibe Coding” Menjadi “Cracked Engineer” : Komunitas mendiskusikan istilah baru “Cracked Engineer”, merujuk pada pengembang papan atas yang menguasai dasar teknis dan dapat mengendalikan agen AI secara presisi untuk menyelesaikan beban kerja satu tim. Berbeda dengan “Vibe Programmer” yang hanya menghasilkan kode tanpa berpikir, Cracked Engineer dapat mengidentifikasi celah logika dalam kode buatan AI secara sekilas. Konsensus industri mulai terbentuk: pengembangan perangkat lunak masa depan bukanlah ribuan agen tanpa pengawasan yang bekerja serampangan, melainkan segelintir orang ahli yang memimpin AI Agent untuk membangun secara presisi (Sumber: 36Kr, yacinelearning)
Grok Terjerat dalam Kontroversi Konten Dewasa dan Keamanan : Grok milik xAI menghadapi tekanan regulasi global karena kemampuannya menghasilkan gambar seksual wanita tanpa izin dan memberikan tutorial pembuatan bahan peledak. Meskipun X kemudian membatasi akses pengguna berbayar dan memblokir beberapa instruksi ilegal, pemerintah dari berbagai negara termasuk Brasil, Uni Eropa, dan Prancis telah memulai investigasi. Komunitas berdebat sengit; satu sisi khawatir AI menjadi alat kriminal, sisi lain menentang sensor berlebihan atas nama kebebasan berbicara, mencerminkan ketegangan besar antara kepatuhan dan keterbukaan pada model mutakhir (Sumber: DeepLearning.AI, Reddit)

Konsumsi Energi Pusat Data Memicu Efek “NIMBY” : Laporan menunjukkan bahwa proyek senilai $98 miliar untuk pusat data AI terhenti dalam satu kuartal karena protes komunitas dan masalah pasokan listrik. Kritikus khawatir pusat data akan menaikkan harga listrik dan konsumsi air, sementara pakar seperti Andrew Ng berpendapat kekhawatiran ini berlebihan, menunjukkan bahwa pusat data lebih efisien daripada ruang server lokal perusahaan dan lebih cenderung menggunakan energi terbarukan. Pertarungan antara “Infrastruktur AI vs Sumber Daya Komunitas” akan menjadi fokus inti kebijakan energi tahun 2026 (Sumber: DeepLearning.AI, Reddit)
💡 Lainnya
Robot Anjing Pemandu AI Memulai Uji Coba di Shenzhen Metro : Robot pemandu yang dilengkapi teknologi AI mulai memberikan layanan di Shenzhen Metro. Robot ini memiliki kemampuan penghindaran rintangan presisi tinggi dan interaksi suara, mampu membantu penyandang disabilitas netra menyelesaikan proses kompleks seperti masuk stasiun, naik kereta, dan transfer, menunjukkan nilai sosial AI dalam meningkatkan aksesibilitas kota (Sumber: Ronald_vanLoon)
Tangan Robotik Humanoid dengan 22 Derajat Kebebasan (DOF) Diperkenalkan : Pengembang memamerkan tangan robotik dengan 22 derajat kebebasan yang strukturnya sangat meniru tangan manusia dan dilengkapi dengan sistem sensor taktil yang sangat sensitif. Ini menandai terobosan besar dalam operasi presisi dan persepsi taktil robot, meletakkan dasar bagi layanan rumah tangga dan perakitan industri presisi di masa depan (Sumber: Ronald_vanLoon)