
Palavras-chave:OpenAI, IA do Google, Transformer, Modelo de publicidade do ChatGPT, Base Siri do Gemini 3, Máquina de Pensamento Contínuo CTM
🔥 Destaque
OpenAI inicia modelo de “geração de receita publicitária” e níveis de assinatura: A OpenAI anunciou que introduzirá anúncios na versão gratuita do ChatGPT e no novo nível “Go” de 8 dólares, marcando a transição de seu modelo de negócios de assinatura pura para “anúncios + assinatura”. Embora Sam Altman tenha chamado os anúncios de “último recurso”, diante dos altos custos de computação, a medida visa alcançar a inclusão da AI. A comunidade reagiu intensamente, ironizando que o AGI evoluiu para “Ad-Generated Income” (Renda Gerada por Anúncios). A OpenAI enfatizou que os anúncios não afetarão a objetividade das respostas e que não venderá históricos de conversas para anunciantes, mas isso ainda é visto como o fim da experiência pura de AI (Fontes: OpenAI, sama)

IA do Google demonstra vantagem estrutural, valor de mercado da Alphabet ultrapassa 4 trilhões: O Google tem se movimentado intensamente, lançando a função Personal Intelligence para realizar inferência de dados entre aplicativos como Gmail e Photos, e fechando uma parceria com a Apple para tornar o Gemini 3 a base da nova versão da Siri. Analistas apontam que o Google possui controle total da stack, desde chips TPU proprietários e infraestrutura de nuvem global até dados reais massivos de Search e YouTube. Essa “vantagem estrutural” permite que a empresa tome a iniciativa na era da economia de inferência. Como resultado, o valor de mercado da Alphabet superou o da Apple pela primeira vez em 19 anos, demonstrando o enorme poder da integração vertical na corrida da AI (Fontes: GeminiApp, Reddit)

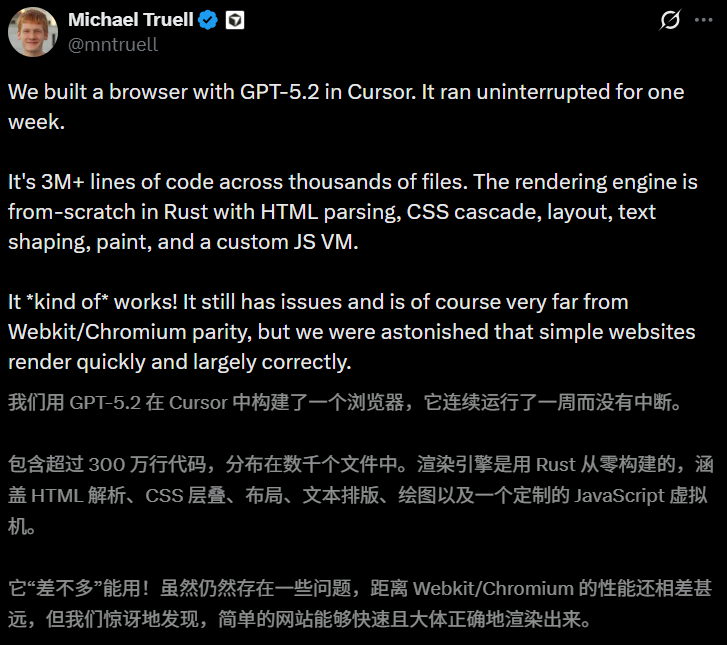
Incidente do “navegador escrito por AI” da Cursor é “desmascarado” pela comunidade: A Cursor afirmou anteriormente que seu agente operou continuamente por 7 dias para escrever um navegador com 3 milhões de linhas de código, mas foi posteriormente questionada coletivamente pela comunidade de desenvolvedores. Análises técnicas mostraram que o código do projeto não conseguia sequer passar pela compilação básica, sendo ridicularizado como “AI Slop” (lixo de IA). A comunidade apontou que isso reflete a armadilha do atual “Vibe Coding”: a busca excessiva pela quantidade de geração em detrimento do rigor da engenharia. Este fracasso lembra a indústria que, embora a AI possa gerar Tokens freneticamente, ainda há uma lacuna significativa para a verdadeira engenharia autônoma (Fontes: Cursor, Reddit)
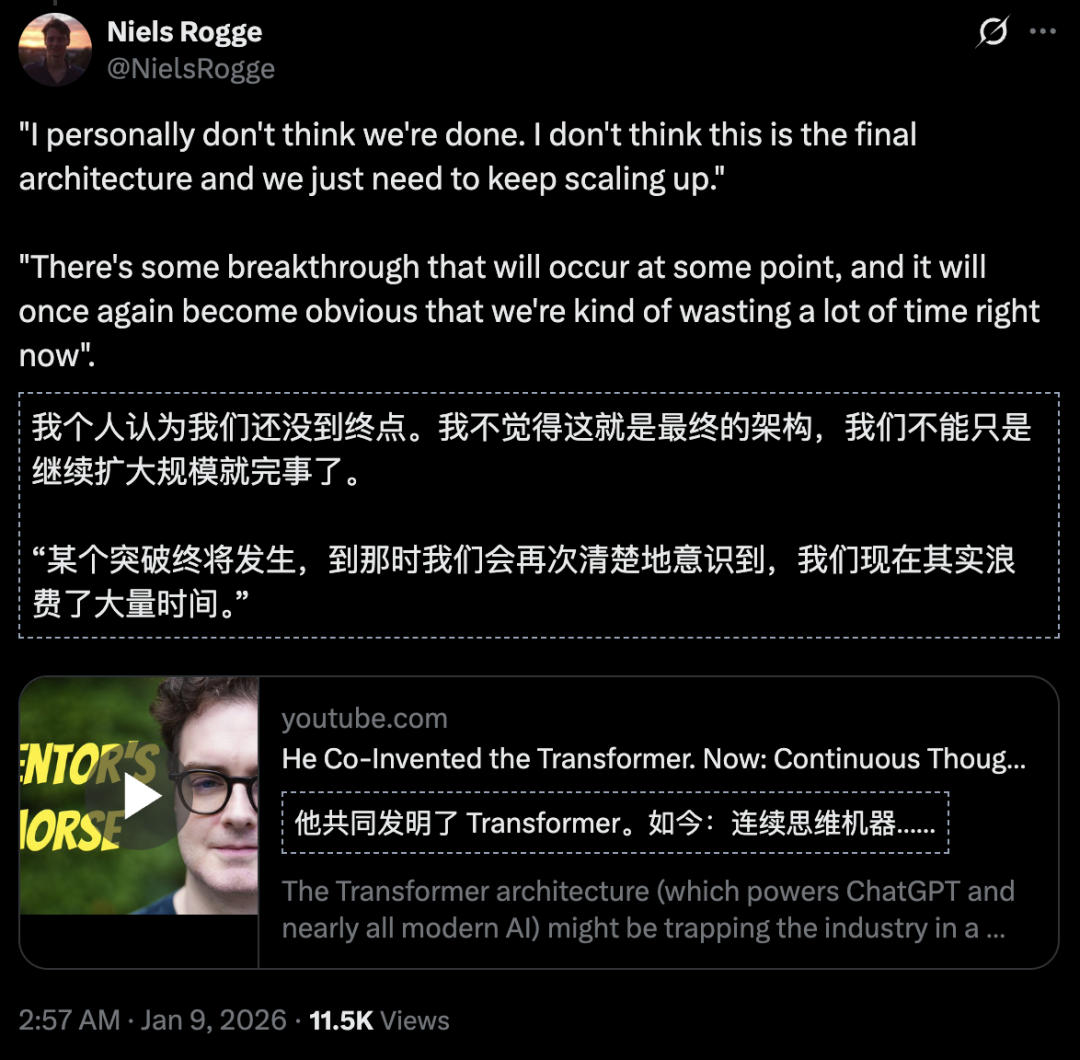
Inventor do Transformer alerta: a pesquisa atual de AI está em um beco sem saída: Llion Jones, co-inventor do Transformer, afirmou que reduziu drasticamente suas pesquisas sobre o Transformer porque a área está saturada de estudos de fine-tuning, tornando-se uma “otimização local”. Ele acredita que o Transformer é uma “loteria de arquitetura” e seu sucesso levou a indústria a um “poço de gravidade”, ignorando a necessidade de repensar fundamentalmente a representação do conhecimento e as formas de pensar. Atualmente, ele está se voltando para a “Continuous Thinking Machine” (CTM), inspirada na biologia, visando quebrar as limitações da “inteligência serrilhada” dos LLM atuais. As opiniões de Jones geraram discussões profundas sobre se a Scaling Law é o único caminho para o AGI (Fontes: Sakana AI, 36Kr)
🎯 Tendências
OpenAI une-se à Cerebras para lançar versão ultra-rápida do Codex: Sam Altman confirmou o lançamento de uma versão ultra-rápida do Codex baseada no hardware da Cerebras. O Wafer Scale Engine (WSE) da Cerebras é conhecido por seu throughput de inferência ultra-alto, e esta colaboração deve aumentar significativamente a velocidade de resposta e a capacidade de lidar com tarefas longas e complexas de agentes de programação de AI. Além disso, a função de memória do ChatGPT foi aprimorada, permitindo lembrar detalhes de conversas passadas, como receitas ou planos de exercícios, reforçando seu papel como assistente pessoal (Fontes: sama, Cerebras)

Reprodução da arquitetura mHC da DeepSeek revela “bomba de estabilidade”: Desenvolvedores reproduziram com sucesso os experimentos de Hyper-Connections (HC) da DeepSeek-V2/V3 em um cluster 8xH100. Os resultados mostraram que, em uma escala de 1.7B de parâmetros, a taxa de amplificação do sinal chegou a 10.924 vezes, superando em muito as 3.000 vezes relatadas no paper. Embora otimizadores modernos (AdamW) possam mascarar temporariamente esse problema para evitar o colapso do modelo, isso é visto como uma “bomba-relógio” para treinamentos de longo prazo. A validação mostrou que a manifold Hyper-Connections (mHC) usando projeção Sinkhorn resolve perfeitamente o problema de estabilidade sem custo computacional adicional (Fontes: taylorkolasinski, Reddit)
Guerra dos gigantes da AI na saúde: OpenAI foca no paciente, Anthropic no médico: A OpenAI lançou o ChatGPT Health, posicionado como um gestor de saúde para o consumidor, capaz de interpretar exames, conectar dados de dispositivos vestíveis e colaborar com a b.well para garantir a privacidade. A Anthropic lançou o Claude for Healthcare, acessando bancos de dados profissionais como CMS e ICD-10 via Connector, visando ajudar profissionais de saúde com papelada tediosa e autorizações. A diferença de layout reflete as vantagens de ecossistema da OpenAI no lado C (consumidor) e da Anthropic no lado B (empresarial) (Fonte: DeepLearning.AI)

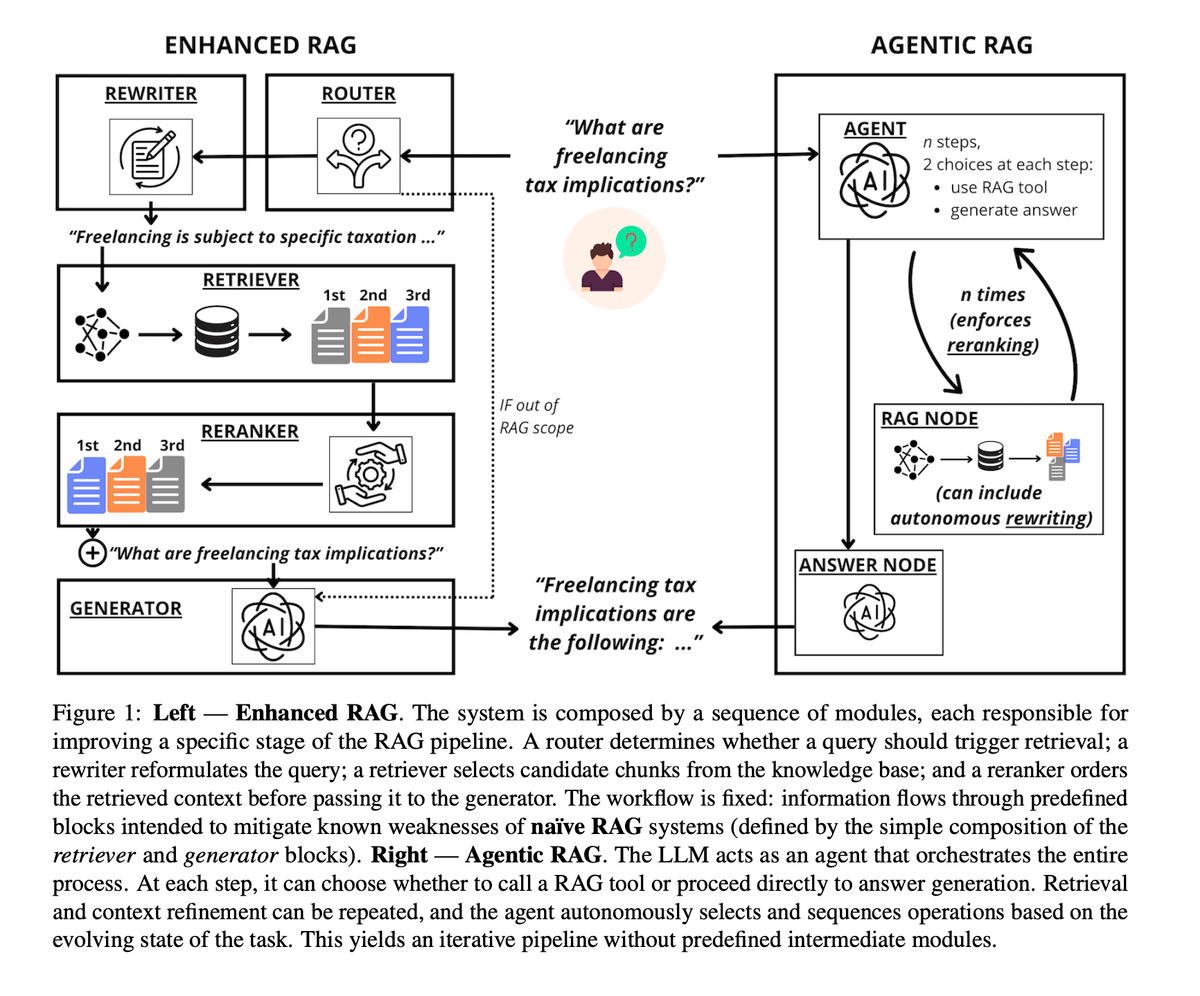
Comparação empírica entre Agentic RAG e Enhanced RAG: Um estudo recente comparou o Enhanced RAG de “pipeline fixo” com o Agentic RAG de “agendamento total por LLM”. Os resultados mostram que o Agentic RAG supera no tratamento da intenção do usuário e na reescrita de consultas, mas é extremamente sensível à capacidade do modelo e tem um custo computacional 2 a 10 vezes maior. Em contraste, o Enhanced RAG é mais estável e econômico no refinamento de documentos (reranking). A conclusão sugere: escolha o Enhanced para recursos limitados ou modelos fracos; escolha o Agentic para flexibilidade extrema e orçamento suficiente (Fontes: omarsar0, arXiv)
🧰 Ferramentas
Claude Cowork aberto oficialmente para usuários Pro: A Anthropic anunciou que o Claude Cowork agora suporta assinantes Pro. Esta função permite que o Claude acesse pastas locais, leia, edite ou crie arquivos, sendo útil para gerar tabelas a partir de capturas de tela, organizar notas esparsas, etc. A comunidade alerta os usuários a criarem diretórios de trabalho independentes para evitar que o agente exclua arquivos importantes acidentalmente, incentivando a vê-lo como um “estagiário inteligente que entende tudo literalmente” (Fontes: dotey, Reddit)
vLLM-MLX: Framework de inferência nativa ultra-rápida para Apple Silicon: Resolvendo o problema da inferência lenta para usuários de Mac, desenvolvedores lançaram o vLLM-MLX. O framework utiliza Apple MLX para aceleração nativa de GPU, alcançando 464 tok/s em inferência Llama-3.2-1B no M4 Max e 197 vezes a velocidade em tempo real no Whisper STT. Ele oferece interface compatível com OpenAI, suporta multimodalidade (texto, imagem, áudio, vídeo) e continuous batching, sendo uma das soluções de inferência local de LLM mais potentes para Mac (Fontes: waybarrios, Reddit)
Site oficial do SGLang entra no ar: A LMSYS Org lançou oficialmente o site do SGLang, reunindo documentação, Cookbook e informações sobre componentes principais. Como um motor de inferência de alto desempenho, o interesse pelo SGLang disparou recentemente, e o site visa resolver a fragmentação de informações e promover um ecossistema de código aberto mais amplo. Além disso, seu suporte para modelos locais (como via Ollama) foi reforçado (Fontes: eliebakouch, sglang)

OpenWork: Versão open-source do Claude Cowork: Baseado no deepagentsjs, o OpenWork foi lançado oficialmente, visando fornecer um agente de Computer Use totalmente open-source, seguro e executável localmente. Ele suporta planejamento em múltiplas etapas, acesso ao sistema de arquivos e delegação de sub-agentes, com integração nativa ao Ollama, permitindo execução 100% local no Mac via Gemma, Qwen3, DeepSeek, etc., sem necessidade de upload de dados sensíveis para a nuvem (Fontes: ollama, Hacubu)

📚 Aprendizado
Recursive Language Models (RLMs): Pensando além do contexto longo: A visão tradicional sugere que problemas de contexto longo devem ser resolvidos expandindo a janela, mas os RLMs propõem uma nova abordagem: o modelo não deve “engolir” tudo à força, mas sim escrever código via ambiente Python/REPL para realizar “dividir para conquistar” recursivamente nos dados. Isso desacopla a inferência do comprimento do contexto, com o modelo raiz processando apenas saídas estruturadas de sub-chamadas, alcançando um contexto virtual infinito. O método já demonstrou maior profundidade de raciocínio que o RAG tradicional em casos complexos como ensaios clínicos (Fonte: lateinteraction)

AIR Framework: Desconstruindo dados de preferência para alinhamento de LLM: A OpenBMB propôs o AIR Framework, decompondo datasets de preferência em três componentes principais: Anotações (Annotations), Instruções (Instructions) e Pares de Resposta (Response Pairs). A pesquisa descobriu que anotações simples de pontos são superiores a designs complexos; deve-se filtrar instruções onde o desempenho dos modelos varia pouco para forçar o aprendizado de lógica sutil; e uma diferença de 2-3 pontos nos pares de resposta produz os melhores resultados. O framework melhorou a média em 5.3 pontos em 6 benchmarks, fornecendo um roteiro científico para o treinamento de alinhamento (Fontes: _akhaliq, arXiv)
Método de otimização por Repetição de Prompt (Prompt Repetition): Um estudo interessante mostrou que, para LLMs de não-raciocínio, repetir o prompt duas vezes pode melhorar significativamente o desempenho sem aumentar a latência. Este método aproveita o paralelismo na fase de pre-fill, ajudando o modelo a focar melhor nas instruções principais ao lidar com grandes contextos. Embora o princípio seja extremamente simples, demonstrou ganhos estáveis em múltiplos benchmarks, sendo visto como uma estratégia de otimização de baixo custo para computação em tempo de inferência (Fontes: Reddit, arXiv)
💼 Negócios
Meta adquire startup de agentes de Singapura Manus AI por valor bilionário: Informações indicam que a Meta fechou um acordo para adquirir a Manus AI por 2 a 3 bilhões de dólares. A Manus AI é famosa por seu poderoso Computer Use e agentes de pesquisa profunda, tendo atraído mais de 2 milhões de pessoas para sua lista de espera. A Meta planeja integrá-la ao Facebook, Instagram e WhatsApp para criar um assistente de AI onipotente. Atualmente, o negócio enfrenta investigações de reguladores chineses devido à origem dos fundadores e à sensibilidade tecnológica (Fontes: DeepLearning.AI, WSJ)

OpenAI investe em concorrente da Neuralink: A OpenAI está diversificando seu portfólio de investimentos, tendo recentemente injetado capital em uma concorrente da Neuralink apoiada por Sam Altman. A medida demonstra o forte interesse da OpenAI na área de Brain-Computer Interface (BCI), visando explorar a possibilidade de longo prazo de fusão profunda entre AI e inteligência biológica humana, expandindo ainda mais sua presença em hardware e ciências da vida de fronteira (Fonte: TheRundownAI)
🌟 Comunidade
A transição de “Vibe Coding” para “Cracked Engineer”: A comunidade discute o novo termo “Cracked Engineer”, referindo-se a desenvolvedores de elite que dominam a base técnica e conseguem guiar agentes de AI com precisão para realizar o trabalho de uma equipe inteira. Diferente dos “Vibe Programmers” que geram código sem pensar, os Cracked Engineers identificam falhas lógicas na geração da AI à primeira vista. O consenso da indústria está se formando: o desenvolvimento de software futuro não será milhares de agentes sem supervisão, mas poucas pessoas experientes liderando AI Agents em construções precisas (Fontes: 36Kr, yacinelearning)
Grok mergulha em controvérsias de segurança e geração de conteúdo impróprio: O Grok da xAI enfrenta pressão regulatória global por gerar imagens sexualizadas de mulheres sem permissão e fornecer tutoriais para fabricação de explosivos. Embora o X tenha restringido permissões de usuários pagos e bloqueado algumas instruções ilegais, governos do Brasil, UE, França e outros países iniciaram investigações. A comunidade debate intensamente: um lado teme que a AI se torne ferramenta de crime, enquanto o outro se opõe à censura excessiva em nome da liberdade de expressão, refletindo a tensão entre conformidade e abertura em modelos de fronteira (Fontes: DeepLearning.AI, Reddit)

Consumo de energia de data centers gera “Efeito NIMBY”: Relatórios mostram que projetos de 98 bilhões de dólares em data centers de AI foram paralisados em um único trimestre devido a protestos comunitários e problemas de fornecimento de energia. Críticos temem que data centers elevem preços de eletricidade e consumo de água, enquanto especialistas como Andrew Ng acreditam que esses temores são exagerados, apontando que data centers são mais eficientes que salas de servidores locais e tendem a usar energia renovável. Este jogo entre “infraestrutura de AI vs. recursos comunitários” será o foco central da política energética em 2026 (Fontes: DeepLearning.AI, Reddit)
💡 Outros
Cão-guia de AI inicia testes no metrô de Shenzhen: Robôs cães-guia equipados com tecnologia de AI começaram a prestar serviços no metrô de Shenzhen. O robô possui alta precisão para evitar obstáculos e capacidade de interação por voz, auxiliando pessoas com deficiência visual em processos complexos como entrada na estação, embarque e baldeação, demonstrando o valor social da AI na acessibilidade urbana (Fonte: Ronald_vanLoon)
Mão robótica destra com 22 graus de liberdade é apresentada: Desenvolvedores exibiram uma mão robótica destra com 22 graus de liberdade (DOF), cuja estrutura simula altamente a mão humana e é equipada com um sistema de sensores táteis ultra-sensíveis. Isso marca um grande avanço na operação fina e percepção tátil de robôs, estabelecendo as bases para futuros serviços domésticos e montagem industrial de precisão (Fonte: Ronald_vanLoon)