
Palavras-chave:Unicórnio de IA, Modelo de grande escala, Ferramentas de IA, IPO da Zhipu AI, Replit Vibe Coding, Claude Code V3
🔥 Destaques
Unicórnios chineses de AI, Zhipu e MiniMax, estreiam na bolsa de Hong Kong: No início de 2026, a Zhipu AI e a MiniMax (Xiyu Technology) listaram-se na Bolsa de Valores de Hong Kong (HKEX) com um intervalo de 48 horas, marcando a fase decisiva de “alto capital e engenharia pesada” na competição de Large Language Models na China. A Zhipu obteve uma subscrição mil vezes maior graças à sua rota de infraestrutura para governo e empresas, enquanto a MiniMax viu o preço de suas ações dobrar no primeiro dia, impulsionada pelo crescimento explosivo de aplicativos voltados ao consumidor, como o Talkie. Esta onda de IPOs reflete as limitações do modelo de financiamento por VC, com o mercado público começando a assumir o papel de fornecer mecanismos estáveis de “reabastecimento” para o investimento em P&D de longo ciclo de modelos de grande escala, incentivando a cadeia industrial a mudar da “corrida de parâmetros” para uma fase de colaboração em “eficiência e ciclo comercial fechado” (Fonte: 产业家)
Replit levanta US$ 400 milhões, liderando a mudança de paradigma “Vibe Coding”: A plataforma de programação Replit planeja arrecadar US$ 400 milhões com uma avaliação de US$ 9 bilhões, após seu ARR saltar de US$ 10 milhões para US$ 144 milhões em seis meses. O sucesso da Replit reside na decisão decisiva de abandonar o mercado de “desenvolvedores profissionais” para focar em capacitar “usuários não técnicos” através do Replit Agent. Este novo paradigma, chamado de “Vibe Coding”, enfatiza a construção de aplicativos descrevendo intenções em vez de escrever sintaxe. Essa mudança não apenas elimina a necessidade de gerentes de produto juniores no sentido tradicional, mas também sinaliza uma transformação total do desenvolvimento de software de “artesanato” para “automação impulsionada por intenção” (Fonte: 36氪; TheRundownAI)
Relatório do Índice Econômico da Anthropic: cargos de alta escolaridade enfrentam crise de “desqualificação” por AI: O último relatório da Anthropic revela uma tendência contraintuitiva: o efeito de aceleração da AI em tarefas complexas supera de longe o de tarefas simples. O Claude aumentou a eficiência em tarefas que exigem nível universitário em 12 vezes, enquanto para tarefas de nível médio o aumento foi de apenas 9 vezes. O relatório aponta que a AI está sistematicamente esvaziando o “valor agregado” de cargos de alta inteligência, levando ao fenômeno de “desqualificação” (de-skilling) — onde humanos retêm apenas tarefas administrativas triviais, enquanto a análise e o planejamento central são entregues à AI. Além disso, através da colaboração humano-máquina, o tempo de sucesso para lidar com engenharia complexa pode ser estendido de 2 para 19 horas, definindo a “nova Lei de Moore” do ambiente de trabalho futuro (Fonte: Anthropic; 新智元)
Higgsfield Cinema Studio: AI entende a gramática cinematográfica e abala Hollywood: O unicórnio Higgsfield, avaliado em US$ 1,3 bilhão, lançou uma atualização importante que digitaliza câmeras de cinema, lentes e técnicas de movimento de câmera de alto nível em módulos de AI. O HCS não depende mais de prompts vagos; em vez disso, através do modelo DOP I2V, permite que a AI domine a “intenção do diretor”, alcançando efeitos profissionais como textura IMAX e movimentos de Steadicam. Essa “democratização tecnológica” permite que criadores individuais produzam blockbusters visuais de nível Hollywood a um custo baixíssimo, forçando a indústria cinematográfica a repensar como o valor central da criatividade será redefinido quando as barreiras profissionais desaparecerem (Fonte: 极客电影)
🎯 Tendências
DeepSeek lança DeepGEMM e atualiza pistas da arquitetura V4: A DeepSeek lançou oficialmente em código aberto a DeepGEMM, uma biblioteca eficiente de multiplicação de matrizes otimizada especificamente para a arquitetura Hopper. Simultaneamente, a comunidade descobriu que o suporte para HyperConnection foi adicionado ao seu repositório de código, indicando que o próximo modelo V4 melhorará a precisão da inferência através de conexões de rede mais profundas. A DeepSeek mantém seu suporte SOTA Day-0, tentando superar os modelos de código fechado existentes em termos de utilização de poder computacional através da otimização da eficiência dos operadores de baixo nível (Fonte: teortaxesTex; You Jiacheng)

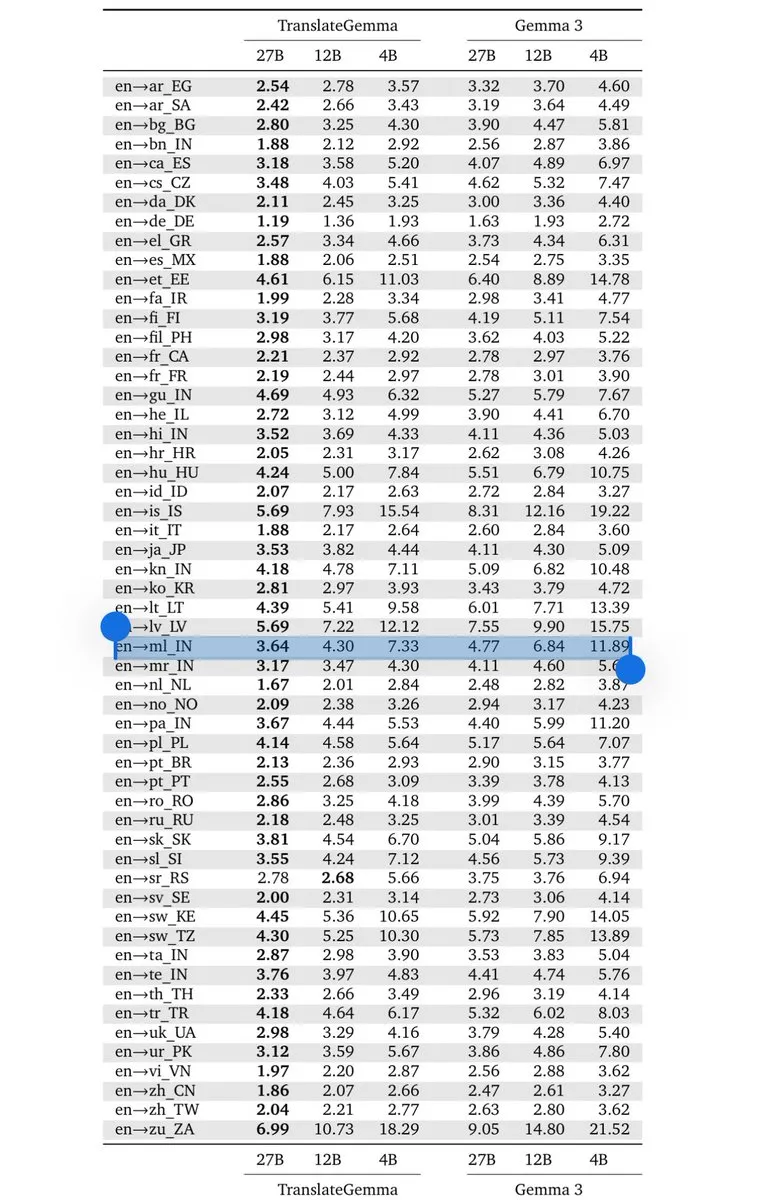
Google DeepMind lança TranslateGemma: novo padrão para tradução on-device: Baseado na arquitetura Gemma 3, o Google lançou a série de modelos TranslateGemma (4B/12B/27B). Através da destilação de conhecimento gerada pelo Gemini, o modelo mantém a leveza enquanto suporta 55 idiomas, permitindo que desenvolvedores construam ferramentas de tradução de baixa latência que rodam inteiramente no dispositivo. Isso é de grande importância para mercados com forte demanda por processamento multilíngue, como a Índia, marcando que a capacidade de inferência de modelos de parâmetros pequenos em domínios verticais específicos já se aproxima dos modelos de fronteira (Fonte: arohan; Google DeepMind)
NVIDIA abre o código do KVzap: técnica de poda de KV Cache alcança compressão sem perdas: A NVIDIA AI lançou em código aberto o KVzap, um método SOTA de poda de KV Cache. Esta tecnologia é capaz de alcançar uma compressão de 2x-4x no cache KV quase sem perdas. À medida que diálogos longos de Agentes e tarefas de raciocínio complexo se tornam dominantes, o KV Cache tornou-se o principal gargalo no custo de inferência. O lançamento do KVzap reduzirá significativamente a ocupação de memória de vídeo e a latência de resposta em tarefas de contexto longo, aumentando o throughput dos sistemas de inferência (Fonte: Reddit r/artificial; Sudden-Dog2918)
Zhipu e Huawei lançam GLM-Image: primeiro modelo multimodal treinado inteiramente em chips chineses: A Zhipu AI, em colaboração com a Huawei, lançou o GLM-Image, o primeiro modelo de fronteira treinado inteiramente em chips chineses Ascend 910, desde o pré-processamento até o treinamento total. O modelo adota uma arquitetura de autorregressão + decodificador de difusão, atingindo o nível SOTA em renderização de texto em chinês e suportando geração em qualquer proporção com resolução de 1024-2048. Sua eficiência energética de inferência é declarada como 60% superior à do H200, provando que é possível treinar modelos multimodais com competitividade industrial mesmo fora do ecossistema NVIDIA (Fonte: Reddit r/MachineLearning; karminski3)
Microsoft lança FrogMini-14B: aprimorando a capacidade de depuração de código via SFT: A Microsoft lançou no Hugging Face o FrogMini-14B, baseado no Qwen3, que alcançou uma excelente pontuação de 45,0% no Pass@1 no teste SWE-Bench Verified. Sua tecnologia principal reside no uso de trajetórias de depuração bem-sucedidas geradas por modelos “professores” fortes, como o Claude, para ajuste fino supervisionado (SFT). Essa dinâmica demonstra que, através de dados sintéticos de alta qualidade e treinamento de tarefas direcionadas, modelos de tamanho médio de 14B já podem exibir utilidade excepcional em tarefas específicas de engenharia de software (Fonte: NerdyRodent)
🧰 Ferramentas
Lançamento do Claude Code V3: introdução de LSP para compreensão semântica de nível IDE: A Anthropic atualizou significativamente o Claude Code, agora suportando oficialmente o Language Server Protocol (LSP). Isso significa que o Claude agora possui capacidades de compreensão de código semântico, como “ir para definição”, “encontrar referências” e diagnósticos em tempo real, com a velocidade de navegação entre bibliotecas aumentada em 900 vezes. A versão V3 também funde Commands com Skills, usando o CLAUDE.md como um portão de segurança e blueprint do projeto, elevando a programação por AI de simples manipulação de texto para uma compreensão arquitetônica profunda (Fonte: TheDecipherist; GeckoLogic)

FLUX.2 [klein]: inteligência visual interativa em subsegundos: A Black Forest Labs lançou a série de modelos FLUX.2 [klein]. Estes modelos (4B/9B) foram projetados especificamente para geração e edição em tempo real, com latência de inferência inferior a 0,5 segundos em hardware moderno. A versão 4B requer apenas 13GB de VRAM para rodar em GPUs de consumo e utiliza a licença Apache 2.0. O lançamento desta ferramenta marca a transição da geração de imagens por AI de um modelo de “espera” para um “interativo”, expandindo enormemente os cenários de design em tempo real e prototipagem rápida (Fonte: Black Forest Labs; vllm_project)

AionUi: interface gráfica de código aberto para colaboração multi-Agent: AionUi é um aplicativo de desktop gratuito e de código aberto projetado para fornecer um espaço de trabalho gráfico unificado para ferramentas de AI de linha de comando, como Gemini CLI, Claude Code e Codex. Ele suporta processamento paralelo de múltiplas sessões, armazenamento de dados local criptografado e possui um painel de visualização em tempo real integrado que suporta mais de 9 formatos. O AionUi resolve as dores de cabeça das ferramentas CLI, como a incapacidade de salvar sessões e operações complicadas, oferecendo uma plataforma de colaboração de AI eficiente para desenvolvedores e usuários de escritório (Fonte: iOfficeAI; AionUI)

Claude Flow v3: construindo uma plataforma de enxame (Swarm) multi-Agent: O Claude Flow v3 foi completamente reconstruído usando TypeScript e WASM, com o objetivo de transformar o Claude Code em uma plataforma de colaboração multi-Agent. Ele utiliza RuVector para memória compartilhada, suportando decomposição de tarefas, consenso e aprendizado contínuo. A versão v3 foca especialmente na otimização de cotas de assinatura, alegando reduzir o consumo de Tokens em 80%. O sistema suporta modelos locais e execução offline, permitindo que os usuários iniciem loops de otimização ininterruptos e tarefas de auditoria de segurança em segundo plano (Fonte: ruvnet; MichaelT_KC)

📚 Aprendizado
Agent-as-a-Judge: um novo paradigma para avaliação de tarefas complexas: Visando as limitações do LLM-as-a-Judge, como viés e falta de verificação em tempo real em tarefas complexas, uma nova revisão propõe o conceito de Agent-as-a-Judge. Este paradigma introduz planejamento, chamadas de ferramentas e capacidades de memória, permitindo que o avaliador avalie tarefas através de comportamentos ativos, como execução de código e verificação de saídas, fornecendo um roteiro para uma avaliação de AI robusta e verificável (Fonte: TheTuringPost; Ksenia_TuringPost)

Thoughtology: revelando o “sweet spot” da Chain of Thought em modelos de raciocínio: Um estudo mecanicista de 135 páginas intitulado “Thoughtology” analisou a Chain of Thought de modelos de raciocínio como GPT-OSS, Qwen3 e R1. A pesquisa descobriu que pensar por mais tempo nem sempre é melhor; existe um “sweet spot” de raciocínio para cada problema, e o excesso de pensamento pode levar a uma queda na precisão. Além disso, o pensamento repetitivo (Rumination) geralmente está associado a respostas incorretas. O estudo fornece dados fundamentais para otimizar os custos de raciocínio e melhorar a qualidade da saída dos modelos (Fonte: YejinChoinka; Sara Vera Marjanović)

MatchTIR: supervisão refinada de raciocínio integrado a ferramentas via correspondência de grafo bipartido: O framework MatchTIR aborda o problema da atribuição de crédito de granulação grossa em Tool-Integrated Reasoning (TIR), introduzindo uma atribuição de recompensa em nível de turno baseada em correspondência de grafo bipartido. Este método distingue efetivamente chamadas de ferramentas válidas de redundantes, apresentando desempenho superior em tarefas de múltiplas rodadas de longo alcance. Experimentos mostram que seu modelo 4B superou a maioria dos modelos 8B em vários benchmarks, demonstrando o enorme potencial da supervisão refinada para aumentar a taxa de sucesso de tarefas de Agentes (Fonte: quchangle1; HuggingFace Daily Papers)
💼 Negócios
OpenAI investe na Merge Labs, startup de interface cérebro-computador de Sam Altman: A OpenAI participou de uma rodada de financiamento para a Merge Labs, uma empresa de interface cérebro-computador (BCI) fundada por seu CEO, Sam Altman. Este movimento é visto como um posicionamento estratégico da OpenAI no hardware para AGI, tentando conectar diretamente a consciência humana a modelos de AI via tecnologia BCI, desafiando a Neuralink de Elon Musk. O investimento também reacendeu discussões sobre os limites entre os interesses pessoais de Altman e as decisões da empresa (Fonte: unusual_whales; scaling01)
Wikipedia celebra 25 anos com acordos de licenciamento de dados de AI com Microsoft, Meta e Perplexity: No seu 25º aniversário, a Wikipedia assinou formalmente acordos de licenciamento de dados de AI com a Microsoft, Meta e Perplexity. Estas parcerias visam garantir que os modelos de AI forneçam atribuições precisas ao citar conteúdo da Wikipedia e ofereçam financiamento operacional sustentável para a Wikimedia Foundation. Isso marca uma transição estratégica das plataformas de base de conhecimento da “captura passiva” para a “colaboração ativa” na era da AI (Fonte: AP News; Reddit r/artificial)
🌟 Comunidade
“It Takes Two”: melhoria de projetos através do confronto entre modelos: A comunidade está discutindo uma técnica de Prompt chamada “Dueling Idea Wizards”. Ao fazer com que dois modelos diferentes (como Claude Opus 4.5 e GPT-5.2) revisem as sugestões de melhoria um do outro e atribuam notas (0-1000), desenvolvedores descobriram que surgem divergências e nuances interessantes entre os modelos. Sugestões aprovadas com alta consistência por ambos os modelos costumam ser soluções de alta qualidade com valor real de implementação. Esse raciocínio adversarial aumenta drasticamente a eficiência da triagem de ideias (Fonte: doodlestein)
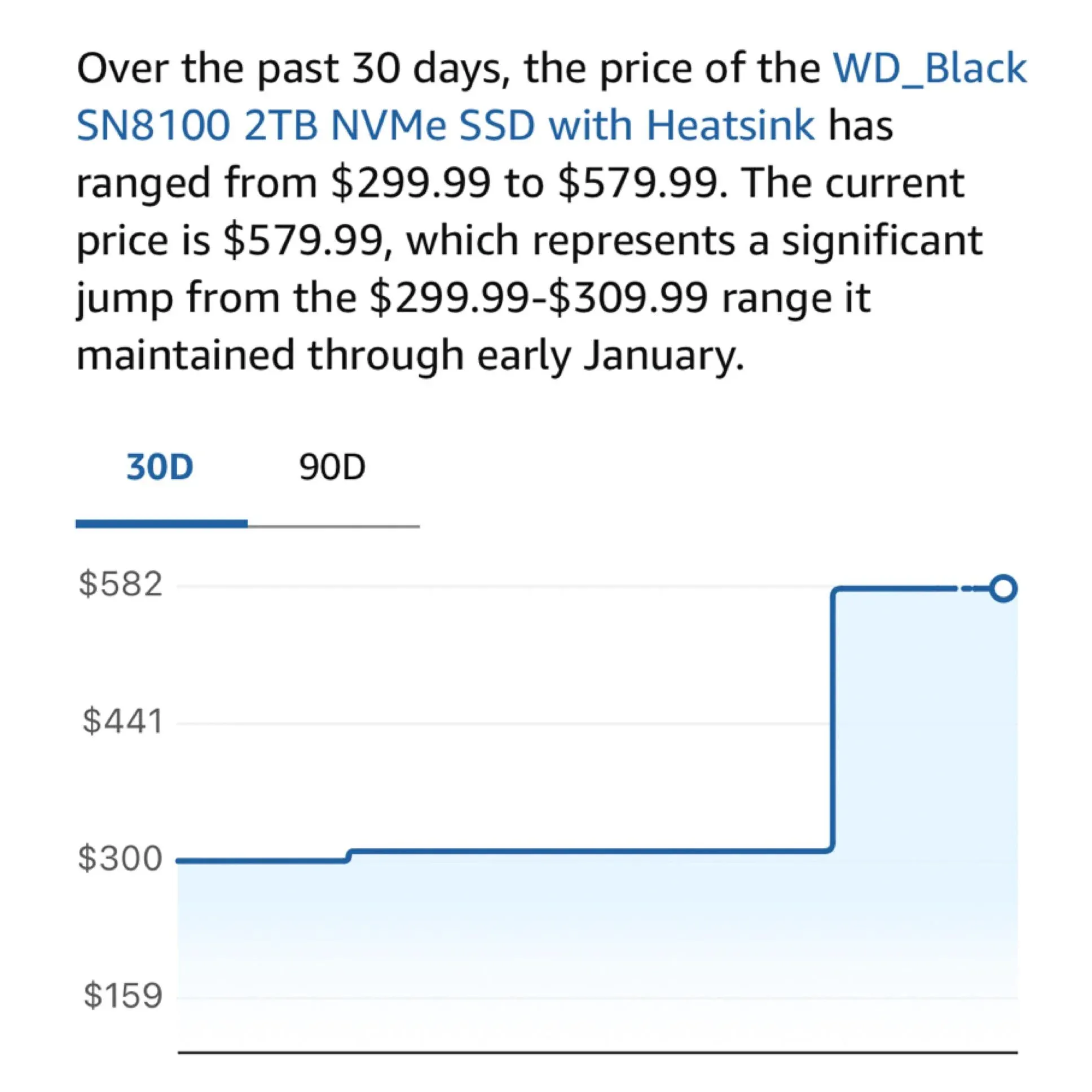
Ansiedade de hardware: aumento nos preços de SSDs M2 afeta entusiastas de AI local: Usuários da comunidade reclamam que os preços de SSDs M2 e memórias subiram drasticamente recentemente, com alguns modelos triplicando de preço em um ano. Com a crescente demanda para rodar modelos de mais de 100B de parâmetros localmente (como DeepSeek e Qwen), a dependência de armazenamento de alta velocidade e grande capacidade tornou-se crítica. A decisão da Samsung e Micron de reduzir a oferta para o mercado de consumo está se tornando o maior obstáculo para entusiastas de LLM local construírem seus “centros de computação domésticos” (Fonte: Reddit r/LocalLLaMA; dgibbons0)
Plugin de “mugido” do Claude Code gera discussão sobre feedback na interação com AI: Um desenvolvedor compartilhou um plugin chamado claude-code-moo, que emite um “muuu” quando o Claude Code precisa de autorização do usuário para comandos Bash. Esta ferramenta aparentemente cômica resolve o problema de desenvolvedores que perdem os avisos da AI após trocar de janela. A comunidade iniciou uma discussão profunda sobre como Agentes de AI em tarefas de longo prazo podem manter o engajamento humano através de feedback não intrusivo (áudio, tátil) (Fonte: Reddit r/ClaudeAI; iefnaf)

💡 Outros
Galbot S1 da Galbot: quebrando o limite de carga de robôs com inteligência incorporada: A Galbot lançou o robô de carga pesada Galbot S1, com uma carga máxima de braço duplo de 50kg e capacidade de carregar 32kg com os braços estendidos, superando em muito a média da indústria. O robô já está em uso prático na fábrica da CATL, realizando operações totalmente autônomas sem teleoperação através de modelos de transporte incorporados (Embodied AI). Isso marca a transição da inteligência incorporada de demonstrações de “fazer café” para o núcleo da produção industrial de alta intensidade e longo ciclo (Fonte: 银河通用; 36氪)

Visualização de alucinações de AI: o impacto negativo da escala da tarefa na consistência: Um usuário da comunidade demonstrou como as alucinações de AI pioram com o aumento da escala da tarefa ao gerar imagens contendo 10, 50 e 100 personagens. O experimento descobriu que, à medida que o número de personagens aumenta, a AI apresenta falhas óbvias ao lidar com características nacionais, ortografia de palavras e estruturas corporais. Isso serve como um lembrete para desenvolvedores de que, ao construir tarefas complexas de Agentes, é necessário reduzir a carga cognitiva de um único Prompt através da decomposição de tarefas (Decomposition) (Fonte: Reddit r/ChatGPT; haneke86)
Lançamento do Raspberry Pi AI HAT+ 2: máquina de inferência para modelos 1B na borda: O Raspberry Pi lançou o AI HAT+ 2 por US$ 130, equipado com o acelerador Hailo-10H e 8GB de VRAM. O hardware foi projetado especificamente para rodar LLMs e VLMs localmente, alcançando 40 TOPS de poder computacional sem dependência da nuvem. A comunidade considera esta a escolha perfeita para construir pequenas máquinas de inferência de Agentes locais, capazes de rodar suavemente modelos quantizados de escala 1B, impulsionando a popularização da AI em IoT e cenários sensíveis à privacidade (Fonte: ben_burtenshaw; Raspberry Pi)
