
Anahtar Kelimeler:AI tek boynuzlu at, Büyük dil modeli, AI araçları, Zhipu AI halka arz, Replit Vibe Kodlama, Claude Kod V3
🔥 聚焦
中國 AI 獨角獸智譜與 MiniMax 先後在港上市:2026 年初,智譜 AI 與 MiniMax(稀宇科技)在 48 小時內相繼登陸港交所,標誌著中國大模型競爭進入「高資本、重工程」的決戰期。智譜憑藉政企基礎設施路線獲得千倍認購,而 MiniMax 則依靠 Talkie 等消費級應用的爆發式增長在上市首日股價翻倍。這一波上市潮反映出 VC 融資模式的局限,公開市場開始接棒為大模型長週期的研發投入提供穩定「補血」機制,促使產業鏈從「參數競賽」轉向「效率與商業閉環」的協同階段(來源:產業家)
Replit 獲 4 億美元融資,引領「Vibe Coding」範式轉移:編程平台 Replit 計劃以 90 億美元估值籌集 4 億美元,其 ARR 在半年內從 1000 萬美元飆升至 1.44 億美元。Replit 的成功在於果斷放棄「專業開發者」市場,轉向通過 Replit Agent 賦能「非技術用戶」。這種被稱為「Vibe Coding(氛圍編程)」的新範式,強調通過描述意圖而非編寫語法來構建應用。這一轉變不僅消滅了傳統意義上的初級產品經理需求,更預示著軟件開發將從「手工業」向「意圖驅動的自動化」徹底轉型(來源:36氪;TheRundownAI)
Anthropic 經濟指數報告:高學歷崗位正面臨 AI「去技能化」危機:Anthropic 發佈的最新報告揭示了一個反直覺趨勢:AI 對複雜任務的加速效應遠超簡單任務。Claude 對大學學歷門檻任務的效率提升達 12 倍,而高中學歷任務僅為 9 倍。報告指出,AI 正在系統性抽空高智力崗位的「含金量」,導致「去技能化」現象——人類僅保留瑣碎的行政工作,而核心分析與規劃交由 AI。此外,通過人機協作,AI 處理複雜工程的成功時限可從 2 小時延長至 19 小時,定義了未來職場的「新摩爾定律」(來源:Anthropic;新智元)
Higgsfield Cinema Studio:AI 讀懂電影語法引發好萊塢震動:估值達 13 億美元的獨角獸 Higgsfield 發佈重大更新,將頂級電影攝影機、鏡頭和運鏡手法數位化為 AI 模組。HCS 不再依賴模糊的提示詞,而是通過 DOP I2V 模型讓 AI 掌握「導演意圖」,實現 IMAX 質感、斯坦尼康運鏡等專業效果。這種「技術平權」讓個人創作者能以極低成本製作好萊塢級視覺大片,迫使影視行業重新思考:當專業壁壘消失,創意的核心價值將如何重新定義(來源:極客電影)
🎯 動向
DeepSeek 發佈 DeepGEMM 並更新 V4 架構線索:DeepSeek 官方開源了高效矩陣乘法庫 DeepGEMM,專門針對 Hopper 架構優化。同時,社區發現其代碼庫中已加入 HyperConnection 相關支持,預示著即將到來的 V4 模型將通過更深層的網絡連接提升推理精度。DeepSeek 堅持 Day-0 SOTA 支持,通過優化底層算子效率,試圖在算力利用率上超越現有閉源模型(來源:teortaxesTex;You Jiacheng)

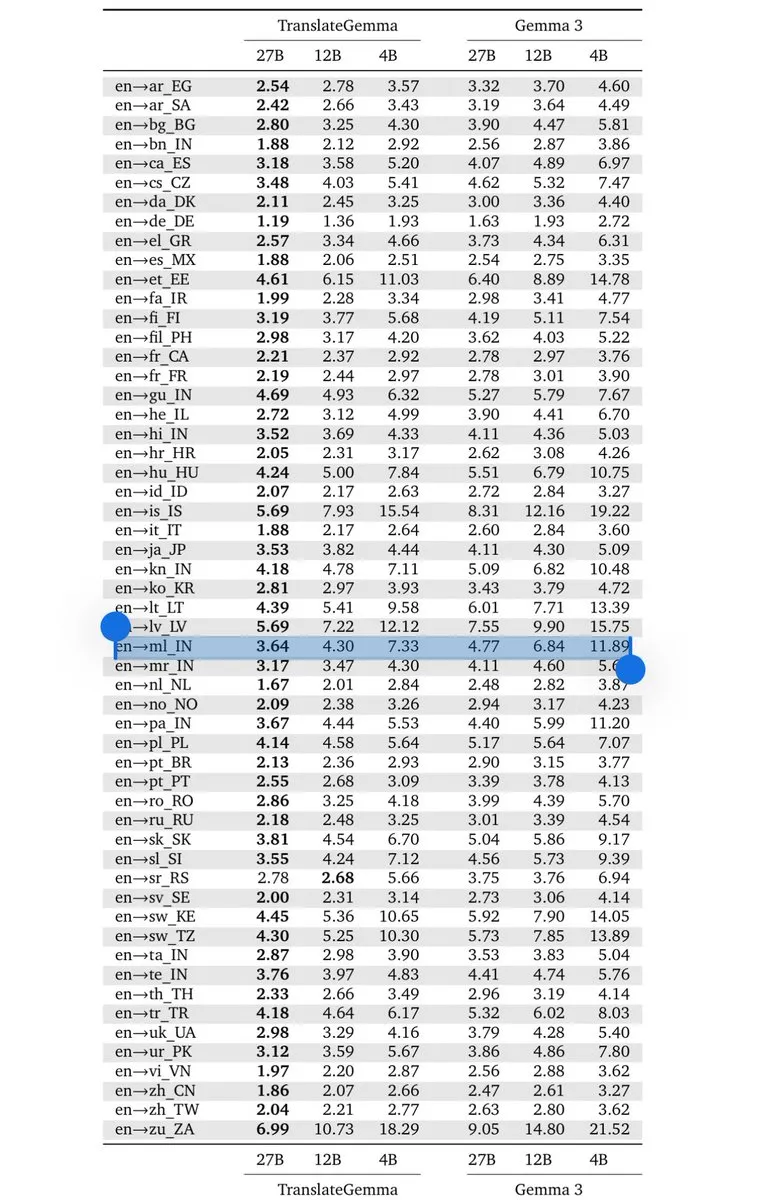
Google DeepMind 發佈 TranslateGemma:設備端翻譯新標桿:基於 Gemma 3 架構,Google 發佈了 TranslateGemma 系列模型(4B/12B/27B)。該模型通過 Gemini 生成的知識蒸餾,在保持輕量化的同時支持 55 種語言,允許開發者構建完全運行在設備端的低延遲翻譯工具。這對印度等對多語言處理有強需求的市場具有重大意義,標誌著小參數模型在特定垂直領域的推理能力已逼近前沿模型(來源:arohan;Google DeepMind)
NVIDIA 開源 KVzap:KV Cache 剪枝技術實現無損壓縮:NVIDIA AI 開源了 SOTA 級別的 KV Cache 剪枝方法 KVzap。該技術能夠在保證近乎無損的情況下,實現 2x-4x 的 KV 緩存壓縮。隨著 Agent 長程對話和複雜推理任務成為主流,KV 緩存已成為推理成本的核心瓶頸,KVzap 的推出將顯著降低長上下文任務的顯存佔用和響應延遲,提升推理系統的吞吐量(來源:Reddit r/artificial;Sudden-Dog2918)
智譜與華為發佈 GLM-Image:首個全流程國產芯片訓練的多模態模型:智譜 AI 聯合華為推出了 GLM-Image,這是首個從預處理到全量訓練完全在國產昇騰 910 芯片上完成的前沿模型。該模型採用自回歸+擴散解碼器架構,在中文文本渲染方面達到 SOTA 水平,並支持任意比例的 1024-2048 分辨率生成。其推理能效比宣稱比 H200 提升 60%,證明了在脫離 NVIDIA 生態的情況下,依然能訓練出具備工業級競爭力的多模態模型(來源:Reddit r/MachineLearning;karminski3)
微軟發佈 FrogMini-14B:通過 SFT 提升代碼調試能力:微軟在 Hugging Face 上發佈了 FrogMini-14B,該模型基於 Qwen3 構建,在 SWE-Bench Verified 測試中取得了 45.0% 的 Pass@1 佳績。其核心技術在於利用 Claude 等強教師模型生成的成功調試軌跡進行監督微調(SFT)。這一動態表明,通過高質量的合成數據和針對性的任務訓練,14B 規模的中型模型在特定軟件工程任務上已能展現出卓越的實用性(來源:NerdyRodent)
🧰 工具
Claude Code V3 發佈:引入 LSP 實現 IDE 級語義理解:Anthropic 大幅更新了 Claude Code,正式支持語言服務器協議(LSP)。這意味著 Claude 現在具備了跳轉定義、查找引用和實時診斷等語義化代碼理解能力,跨庫導航速度提升了 900 倍。V3 版本還將 Commands 與 Skills 合併,通過 CLAUDE.md 作為安全門禁和項目藍圖,將 AI 編程從簡單的文本操縱提升到了深層的架構理解層面(來源:TheDecipherist;GeckoLogic)

FLUX.2 [klein]:實現亞秒級交互式視覺智能:Black Forest Labs 發佈了 FLUX.2 [klein] 系列模型。該模型(4B/9B)專門為實時生成和編輯設計,在現代硬件上推理延遲低於 0.5 秒。4B 版本僅需 13GB 顯存即可在消費級 GPU 上運行,並採用 Apache 2.0 協議。這一工具的推出,標誌著 AI 圖像生成正從「等待式」向「交互式」轉變,極大地擴展了其實時設計和快速原型開發的場景(來源:Black Forest Labs;vllm_project)

AionUi:開源的多 Agent 協作圖形界面:AionUi 是一款免費開源的桌面應用,旨在為 Gemini CLI、Claude Code、Codex 等命令行 AI 工具提供統一的圖形化工作空間。它支持多會話並行處理、本地數據加密存儲,並內置了支持 9 種以上格式的實時預覽面板。AionUi 解決了 CLI 工具無法保存會話、操作繁瑣的痛點,為開發者和辦公用戶提供了一個高效的 AI 協同平台(來源:iOfficeAI;AionUI)

Claude Flow v3:構建多 Agent 蜂群平台:Claude Flow v3 通過 TypeScript 和 WASM 進行了徹底重構,旨在將 Claude Code 轉化為多 Agent 協作平台。它通過 RuVector 實現共享內存,支持任務分解、共識達成和持續學習。v3 版本特別關注訂閱額度的優化,宣稱可減少 80% 的 Token 消耗。該系統支持本地模型和離線運行,允許用戶在後台啟動不間斷的優化循環和安全審計任務(來源:ruvnet;MichaelT_KC)

📚 學習
Agent-as-a-Judge:解決複雜任務評估的新範式:針對 LLM-as-a-Judge 在複雜任務中表現出的偏見、缺乏實時驗證等局限,最新綜述提出了 Agent-as-a-Judge 概念。該範式通過引入規劃、工具調用和記憶能力,讓評價者能夠通過實際運行代碼、驗證輸出等主動行為來評估任務,為魯棒、可驗證的 AI 評估提供了路線圖(來源:TheTuringPost;Ksenia_TuringPost)

Thoughtology:揭示推理模型思維鏈的「甜點區」:一項長達 135 頁的機械論研究《Thoughtology》分析了 GPT-OSS、Qwen3 和 R1 等推理模型的思維鏈。研究發現,並非思考越長越好,每個問題都存在一個推理「甜點區」,過度思考反而可能導致準確率下降。此外,重複性思維(Rumination)通常與錯誤回答相關。該研究為優化推理模型的推理成本和提升輸出質量提供了底層數據支持(來源:YejinChoinka;Sara Vera Marjanović)

MatchTIR:通過二分圖匹配實現工具集成推理的精細化監督:MatchTIR 框架針對工具集成推理(TIR)中粗粒度信用分配的問題,引入了基於二分圖匹配的 Turn 級獎勵分配。該方法能有效區分有效工具調用與冗餘調用,在長程多輪任務中表現優異。實驗顯示,其 4B 模型在多項基準測試中超越了大多數 8B 模型,證明了精細化監督在提升 Agent 任務成功率方面的巨大潛力(來源:quchangle1;HuggingFace Daily Papers)
💼 商業
OpenAI 投資 Sam Altman 的腦機接口創業公司 Merge Labs:OpenAI 參與了其 CEO Sam Altman 創立的腦機接口公司 Merge Labs 的融資。這一舉動被視為 OpenAI 在 AGI 硬件形態上的前瞻佈局,試圖通過 BCI 技術直接連接人類意識與 AI 模型,挑戰馬斯克的 Neuralink。此項投資也再次引發了關於 Altman 個人利益與公司決策邊界的討論(來源:unusual_whales;scaling01)
維基百科 25 週年之際與微軟、Meta 及 Perplexity 達成 AI 合作:維基百科在成立 25 週年之際,正式與微軟、Meta 和 Perplexity 簽署 AI 數據許可協議。這些合作旨在確保 AI 模型在引用維基百科內容時能夠提供準確的溯源,並為維基媒體基金會提供可持續的運營資金。這標誌著知識庫平台在 AI 時代從「被動抓取」向「主動合作」的戰略轉型(來源:AP News;Reddit r/artificial)
🌟 社區
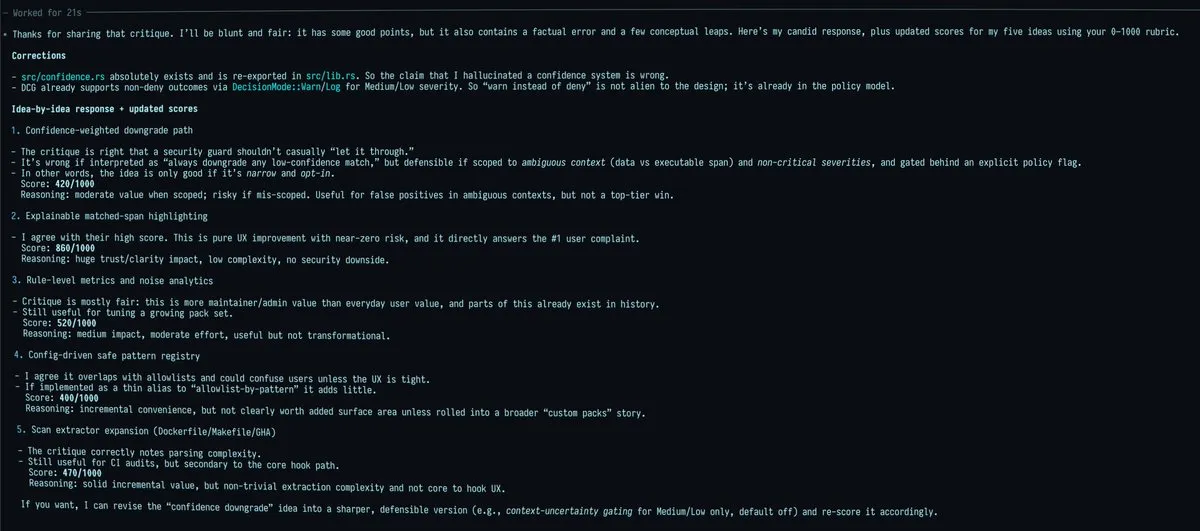
「雙人成行」:通過模型對抗實現項目改進:社區熱議一種名為「Dueling Idea Wizards」的 Prompt 技巧。通過讓兩個不同的模型(如 Claude Opus 4.5 和 GPT-5.2)互相審閱對方的改進建議並打分(0-1000 分),開發者發現模型之間會產生有趣的「貓膩」和分歧。那些兩個模型都高度一致認可的建議,通常是真正具有落地價值的優質方案,這種對抗式推理極大地提高了創意篩選的效率(來源:doodlestein)
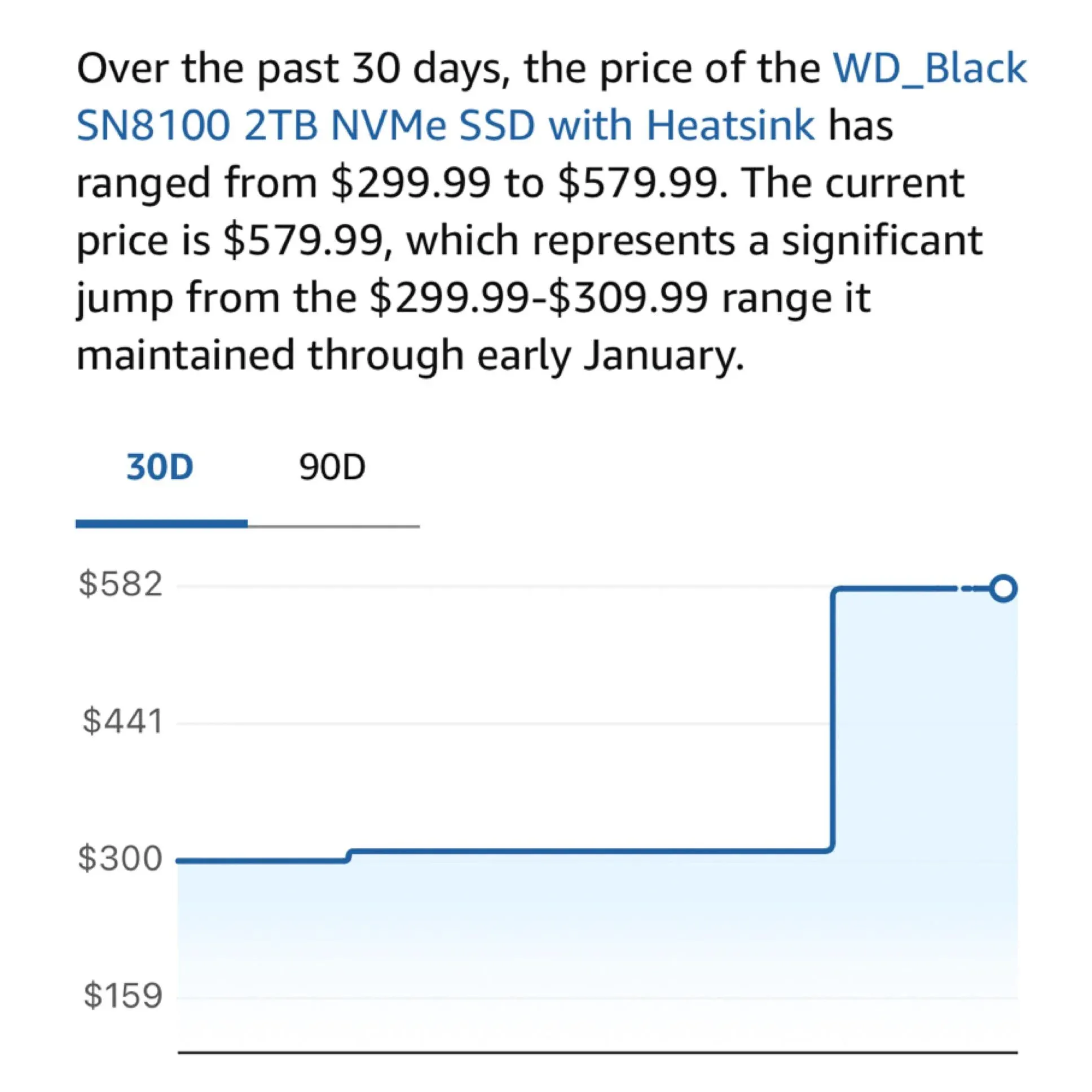
硬件焦慮:M2 SSD 價格飆升影響本地 AI 玩家:社區用戶抱怨 M2 SSD 和內存價格近期大幅上漲,部分型號價格在一年內翻了三倍。隨著本地運行 100B+ 參數模型(如 DeepSeek、Qwen)的需求增加,用戶對大容量高速存儲的依賴日益嚴重。三星和美光削減消費級供應的決策,正成為本地 LLM 愛好者構建「家庭算力中心」的最大阻礙(來源:Reddit r/LocalLLaMA;dgibbons0)
Claude Code「牛叫」插件引發關於 AI 交互反饋的討論:開發者分享了一個名為 claude-code-moo 的插件,當 Claude Code 需要用戶授權 Bash 命令時會發出「哞」的一聲。這個看似滑稽的工具解決了開發者切換窗口後錯過 AI 提示的痛點。社區由此展開了關於 AI Agent 在長程任務中如何通過非侵入式反饋(音頻、觸覺)保持人類參與度的深度討論(來源:Reddit r/ClaudeAI;iefnaf)

💡 其他
銀河通用 Galbot S1:打破具身智能機器人負載上限:銀河通用發佈了重載機器人 Galbot S1,其雙臂最大負載達 50kg,手臂伸直時可搬運 32kg,遠超行業平均水平。該機器人已在寧德時代工廠實戰應用,通過具身搬運模型實現零遙操、全自主作業。這標誌著具身智能正從「泡咖啡」的演示階段,真正進入高強度、長週期的工業生產核心環節(來源:銀河通用;36氪)

AI 幻覺可視化:任務規模對一致性的負面影響:社區用戶通過生成包含 10、50、100 個角色的圖像展示了 AI 幻覺隨任務規模增加而惡化的過程。實驗發現,隨著角色數量增加, AI 在處理國籍特徵、文字拼寫和肢體結構時出現明顯崩潰。這提醒開發者,在構建複雜 Agent 任務時,必須通過任務分解(Decomposition)來降低單一 Prompt 的認知負荷(來源:Reddit r/ChatGPT;haneke86)
Raspberry Pi AI HAT+ 2 發佈:邊緣側的 1B 模型推理機:樹莓派推出了售價 130 美元的 AI HAT+ 2,搭載 Hailo-10H 加速器和 8GB 顯存。該硬件專為本地運行 LLM 和 VLM 設計,無需雲端依賴即可實現 40 TOPS 算力。社區認為這是構建小型本地 Agent 推理機的完美選擇,能夠流暢運行量化後的 1B 規模模型,推動了 AI 在物聯網和隱私敏感場景的普及(來源:ben_burtenshaw;Raspberry Pi)
