
关键词:AI独角兽, 大模型, AI工具, 智谱AI上市, Replit Vibe Coding, Claude Code V3
🔥 聚焦
中国AI独角兽智谱与MiniMax先后在港上市 : 2026年初,智谱AI与MiniMax(稀宇科技)在48小时内相继登陆港交所,标志着中国大模型竞争进入“高资本、重工程”的决战期。智谱凭借政企基础设施路线获得千倍认购,而MiniMax则依靠Talkie等消费级应用的爆发式增长在上市首日股价翻倍。这一波上市潮反映出VC融资模式的局限,公开市场开始接棒为大模型长周期的研发投入提供稳定“补血”机制,促使产业链从“参数竞赛”转向“效率与商业闭流”的协同阶段(来源:产业家)
Replit获4亿美元融资,引领“Vibe Coding”范式转移 : 编程平台Replit计划以90亿美元估值筹集4亿美元,其ARR在半年内从1000万美元飙升至1.44亿美元。Replit的成功在于果断放弃“专业开发者”市场,转向通过Replit Agent赋能“非技术用户”。这种被称为“Vibe Coding(氛围编程)”的新范式,强调通过描述意图而非编写语法来构建应用。这一转变不仅消灭了传统意义上的初级产品经理需求,更预示着软件开发将从“手工业”向“意图驱动的自动化”彻底转型(来源:36氪;TheRundownAI)
Anthropic经济指数报告:高学历岗位正面临AI“去技能化”危机 : Anthropic发布的最新报告揭示了一个反直觉趋势:AI对复杂任务的加速效应远超简单任务。Claude对大学学历门槛任务的效率提升达12倍,而高中学历任务仅为9倍。报告指出,AI正在系统性抽空高智力岗位的“含金量”,导致“去技能化”现象——人类仅保留琐碎的行政工作,而核心分析与规划交由AI。此外,通过人机协作,AI处理复杂工程的成功时限可从2小时延长至19小时,定义了未来职场的“新摩尔定律”(来源:Anthropic;新智元)
Higgsfield Cinema Studio:AI读懂电影语法引发好莱坞震动 : 估值达13亿美元的独角兽Higgsfield发布重大更新,将顶级电影摄影机、镜头和运镜手法数字化为AI模块。HCS不再依赖模糊的提示词,而是通过DOP I2V模型让AI掌握“导演意图”,实现IMAX质感、斯坦尼康运镜等专业效果。这种“技术平权”让个人创作者能以极低成本制作好莱坞级视觉大片,迫使影视行业重新思考:当专业壁垒消失,创意的核心价值将如何重新定义(来源:极客电影)
🎯 动向
DeepSeek发布DeepGEMM并更新V4架构线索 : DeepSeek官方开源了高效矩阵乘法库DeepGEMM,专门针对Hopper架构优化。同时,社区发现其代码库中已加入HyperConnection相关支持,预示着即将到来的V4模型将通过更深层的网络连接提升推理精度。DeepSeek坚持Day-0 SOTA支持,通过优化底层算子效率,试图在算力利用率上超越现有闭源模型(来源:teortaxesTex;You Jiacheng)

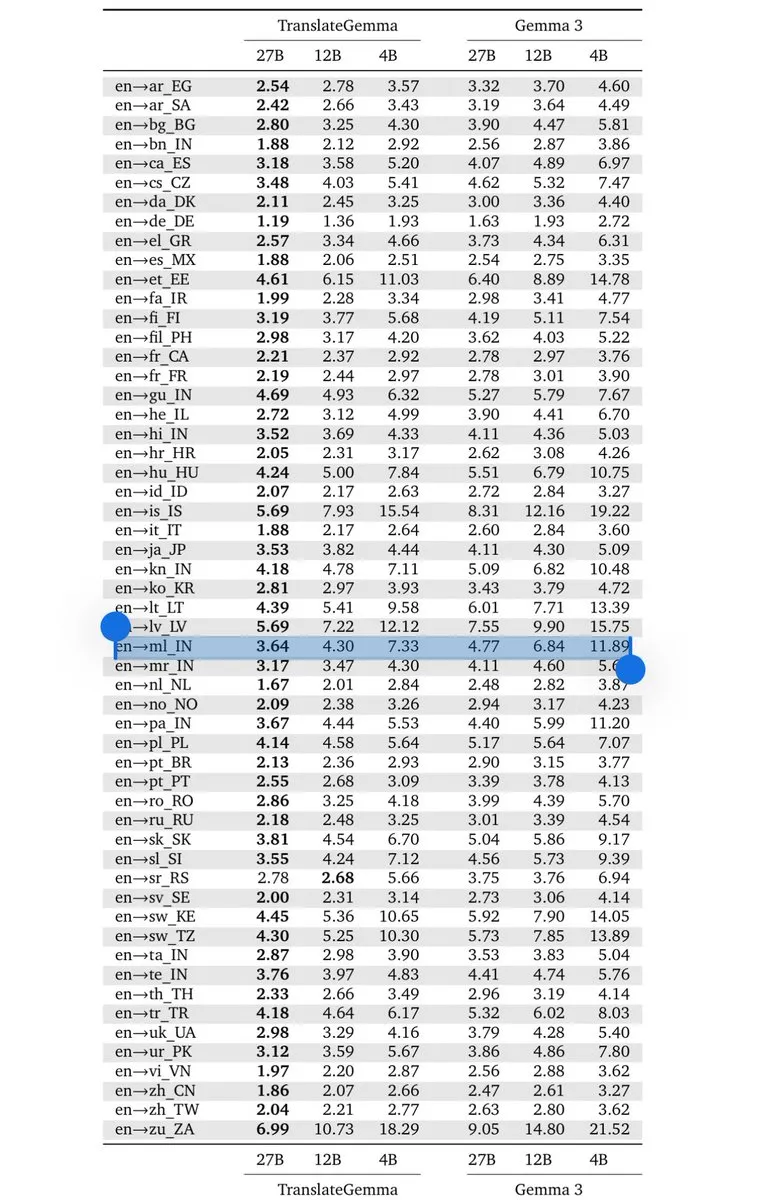
Google DeepMind发布TranslateGemma:设备端翻译新标杆 : 基于Gemma 3架构,Google发布了TranslateGemma系列模型(4B/12B/27B)。该模型通过Gemini生成的知识蒸馏,在保持轻量化的同时支持55种语言,允许开发者构建完全运行在设备端的低延迟翻译工具。这对印度等对多语言处理有强需求的市场具有重大意义,标志着小参数模型在特定垂直领域的推理能力已逼近前沿模型(来源:arohan;Google DeepMind)
NVIDIA开源KVzap:KV Cache剪枝技术实现无损压缩 : NVIDIA AI开源了SOTA级别的KV Cache剪枝方法KVzap。该技术能够在保证近乎无损的情况下,实现2x-4x的KV缓存压缩。随着Agent长程对话和复杂推理任务成为主流,KV缓存已成为推理成本的核心瓶颈,KVzap的推出将显著降低长上下文任务的显存占用和响应延迟,提升推理系统的吞吐量(来源:Reddit r/artificial;Sudden-Dog2918)
智谱与华为发布GLM-Image:首个全流程国产芯片训练的多模态模型 : 智谱AI联合华为推出了GLM-Image,这是首个从预处理到全量训练完全在国产昇腾910芯片上完成的前沿模型。该模型采用自回归+扩散解码器架构,在中文文本渲染方面达到SOTA水平,并支持任意比例的1024-2048分辨率生成。其推理能效比宣称比H200提升60%,证明了在脱离NVIDIA生态的情况下,依然能训练出具备工业级竞争力的多模态模型(来源:Reddit r/MachineLearning;karminski3)
微软发布FrogMini-14B:通过SFT提升代码调试能力 : 微软在Hugging Face上发布了FrogMini-14B,该模型基于Qwen3构建,在SWE-Bench Verified测试中取得了45.0%的Pass@1佳绩。其核心技术在于利用Claude等强教师模型生成的成功调试轨迹进行监督微调(SFT)。这一动态表明,通过高质量的合成数据和针对性的任务训练,14B规模的中型模型在特定软件工程任务上已能展现出卓越的实用性(来源:NerdyRodent)
🧰 工具
Claude Code V3发布:引入LSP实现IDE级语义理解 : Anthropic大幅更新了Claude Code,正式支持语言服务器协议(LSP)。这意味着Claude现在具备了跳转定义、查找引用和实时诊断等语义化代码理解能力,跨库导航速度提升了900倍。V3版本还将Commands与Skills合并,通过CLAUDE.md作为安全门禁和项目蓝图,将AI编程从简单的文本操纵提升到了深层的架构理解层面(来源:TheDecipherist;GeckoLogic)

FLUX.2 [klein]:实现亚秒级交互式视觉智能 : Black Forest Labs发布了FLUX.2 [klein]系列模型。该模型(4B/9B)专门为实时生成和编辑设计,在现代硬件上推理延迟低于0.5秒。4B版本仅需13GB显存即可在消费级GPU上运行,并采用Apache 2.0协议。这一工具的推出,标志着AI图像生成正从“等待式”向“交互式”转变,极大地扩展了其实时设计和快速原型开发的场景(来源:Black Forest Labs;vllm_project)

AionUi:开源的多Agent协作图形界面 : AionUi是一款免费开源的桌面应用,旨在为Gemini CLI、Claude Code、Codex等命令行AI工具提供统一的图形化工作空间。它支持多会话并行处理、本地数据加密存储,并内置了支持9种以上格式的实时预览面板。AionUi解决了CLI工具无法保存会话、操作繁琐的痛点,为开发者和办公用户提供了一个高效的AI协同平台(来源:iOfficeAI;AionUI)

Claude Flow v3:构建多Agent蜂群平台 : Claude Flow v3通过TypeScript和WASM进行了彻底重构,旨在将Claude Code转化为多Agent协作平台。它通过RuVector实现共享内存,支持任务分解、共识达成和持续学习。v3版本特别关注订阅额度的优化,宣称可减少80%的Token消耗。该系统支持本地模型和离线运行,允许用户在后台启动不间断的优化循环和安全审计任务(来源:ruvnet;MichaelT_KC)

📚 学习
Agent-as-a-Judge:解决复杂任务评估的新范式 : 针对LLM-as-a-Judge在复杂任务中表现出的偏见、缺乏实时验证等局限,最新综述提出了Agent-as-a-Judge概念。该范式通过引入规划、工具调用和记忆能力,让评价者能够通过实际运行代码、验证输出等主动行为来评估任务,为鲁棒、可验证的AI评估提供了路线图(来源:TheTuringPost;Ksenia_TuringPost)

Thoughtology:揭示推理模型思维链的“甜点区” : 一项长达135页的机械论研究《Thoughtology》分析了GPT-OSS、Qwen3和R1等推理模型的思维链。研究发现,并非思考越长越好,每个问题都存在一个推理“甜点区”,过度思考反而可能导致准确率下降。此外,重复性思维(Rumination)通常与错误回答相关。该研究为优化推理模型的推理成本和提升输出质量提供了底层数据支持(来源:YejinChoinka;Sara Vera Marjanović)

MatchTIR:通过二分图匹配实现工具集成推理的精细化监督 : MatchTIR框架针对工具集成推理(TIR)中粗粒度信用分配的问题,引入了基于二分图匹配的Turn级奖励分配。该方法能有效区分有效工具调用与冗余调用,在长程多轮任务中表现优异。实验显示,其4B模型在多项基准测试中超越了大多数8B模型,证明了精细化监督在提升Agent任务成功率方面的巨大潜力(来源:quchangle1;HuggingFace Daily Papers)
💼 商业
OpenAI投资Sam Altman的脑机接口创业公司Merge Labs : OpenAI参与了其CEO Sam Altman创立的脑机接口公司Merge Labs的融资。这一举动被视为OpenAI在AGI硬件形态上的前瞻布局,试图通过BCI技术直接连接人类意识与AI模型,挑战马斯克的Neuralink。此项投资也再次引发了关于Altman个人利益与公司决策边界的讨论(来源:unusual_whales;scaling01)
维基百科25周年之际与微软、Meta及Perplexity达成AI合作 : 维基百科在成立25周年之际,正式与微软、Meta和Perplexity签署AI数据许可协议。这些合作旨在确保AI模型在引用维基百科内容时能够提供准确的溯源,并为维基媒体基金会提供可持续的运营资金。这标志着知识库平台在AI时代从“被动抓取”向“主动合作”的战略转型(来源:AP News;Reddit r/artificial)
🌟 社区
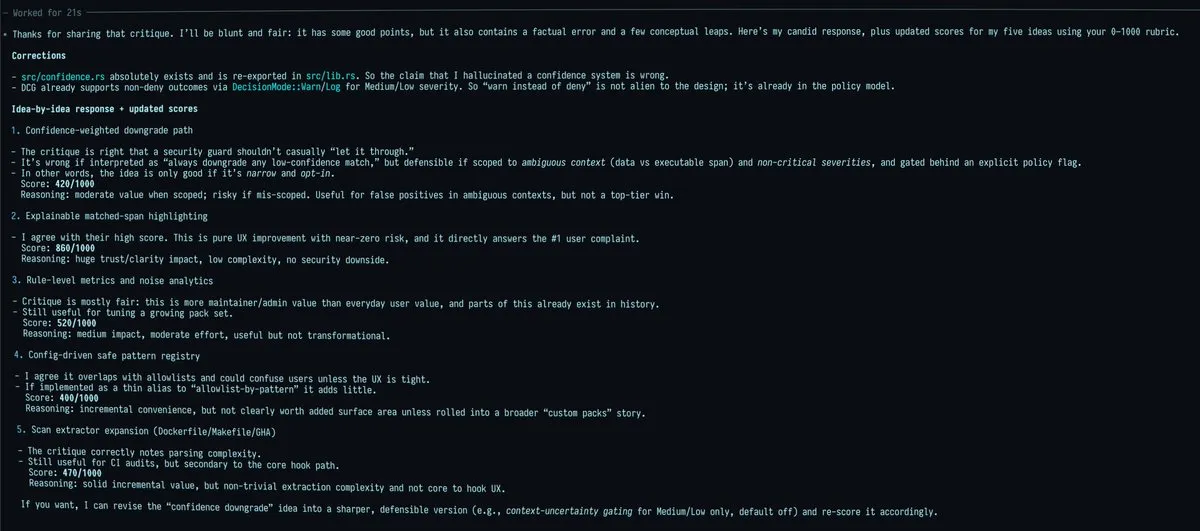
“双人成行”:通过模型对抗实现项目改进 : 社区热议一种名为“Dueling Idea Wizards”的Prompt技巧。通过让两个不同的模型(如Claude Opus 4.5和GPT-5.2)互相审阅对方的改进建议并打分(0-1000分),开发者发现模型之间会产生有趣的“猫腻”和分歧。那些两个模型都高度一致认可的建议,通常是真正具有落地价值的优质方案,这种对抗式推理极大地提高了创意筛选的效率(来源:doodlestein)
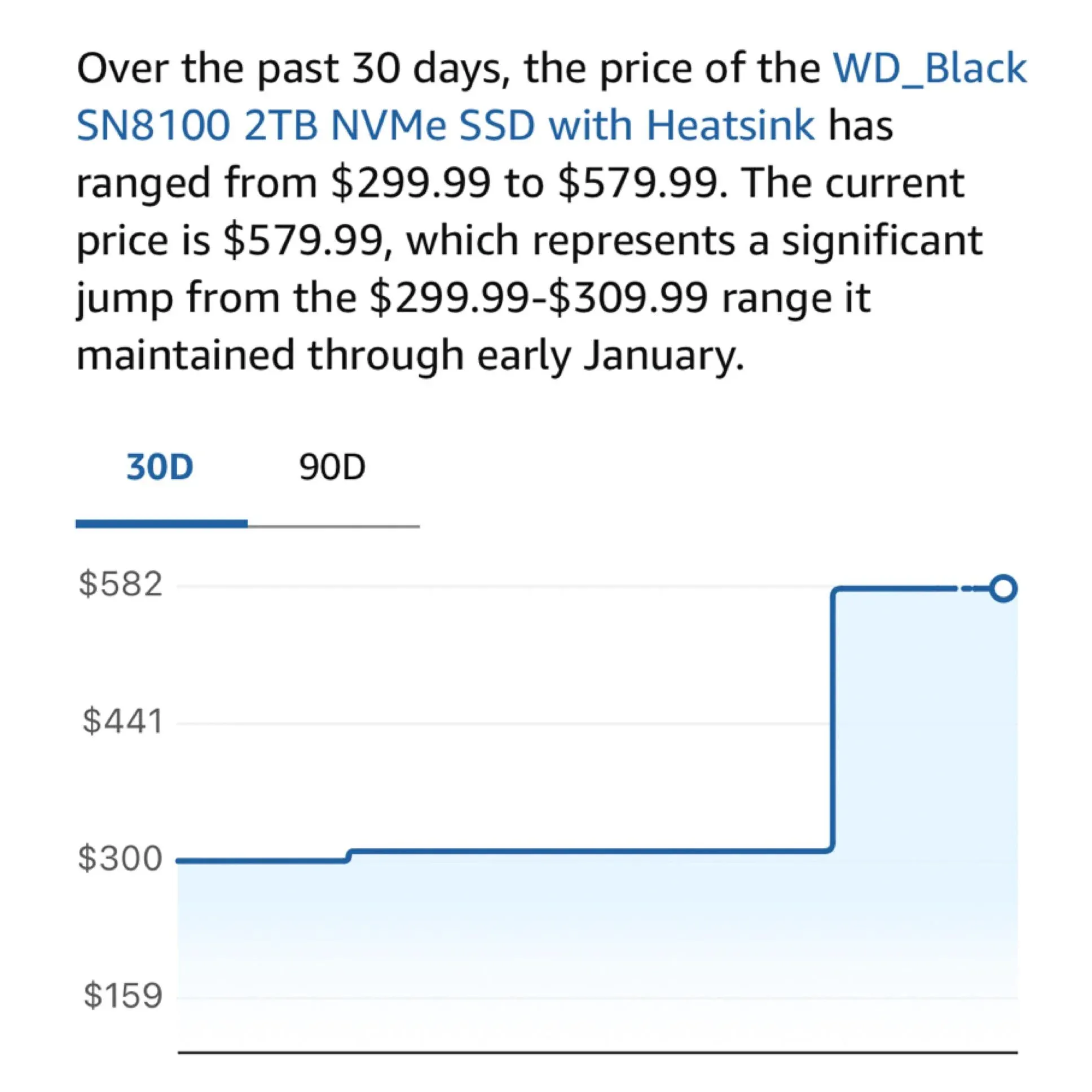
硬件焦虑:M2 SSD价格飙升影响本地AI玩家 : 社区用户抱怨M2 SSD和内存价格近期大幅上涨,部分型号价格在一年内翻了三倍。随着本地运行100B+参数模型(如DeepSeek、Qwen)的需求增加,用户对大容量高速存储的依赖日益严重。三星和美光削减消费级供应的决策,正成为本地LLM爱好者构建“家庭算力中心”的最大阻碍(来源:Reddit r/LocalLLaMA;dgibbons0)
Claude Code“牛叫”插件引发关于AI交互反馈的讨论 : 开发者分享了一个名为claude-code-moo的插件,当Claude Code需要用户授权Bash命令时会发出“哞”的一声。这个看似滑稽的工具解决了开发者切换窗口后错过AI提示的痛点。社区由此展开了关于AI Agent在长程任务中如何通过非侵入式反馈(音频、触觉)保持人类参与度的深度讨论(来源:Reddit r/ClaudeAI;iefnaf)

💡 其他
银河通用Galbot S1:打破具身智能机器人负载上限 : 银河通用发布了重载机器人Galbot S1,其双臂最大负载达50kg,手臂伸直时可搬运32kg,远超行业平均水平。该机器人已在宁德时代工厂实战应用,通过具身搬运模型实现零遥操、全自主作业。这标志着具身智能正从“泡咖啡”的演示阶段,真正进入高强度、长周期的工业生产核心环节(来源:银河通用;36氪)

AI幻觉可视化:任务规模对一致性的负面影响 : 社区用户通过生成包含10、50、100个角色的图像展示了AI幻觉随任务规模增加而恶化的过程。实验发现,随着角色数量增加,AI在处理国籍特征、文字拼写和肢体结构时出现明显崩溃。这提醒开发者,在构建复杂Agent任务时,必须通过任务分解(Decomposition)来降低单一Prompt的认知负荷(来源:Reddit r/ChatGPT;haneke86)
Raspberry Pi AI HAT+ 2发布:边缘侧的1B模型推理机 : 树莓派推出了售价130美元的AI HAT+ 2,搭载Hailo-10H加速器和8GB显存。该硬件专为本地运行LLM和VLM设计,无需云端依赖即可实现40 TOPS算力。社区认为这是构建小型本地Agent推理机的完美选择,能够流畅运行量化后的1B规模模型,推动了AI在物联网和隐私敏感场景的普及(来源:ben_burtenshaw;Raspberry Pi)
