
Schlüsselwörter:KI-Einhorn, Großes Modell, KI-Tools, Zhipu KI Börsengang, Replit Vibe Coding, Claude Code V3
🔥 Fokus
Chinesische AI-Unicorns Zhipu und MiniMax gehen nacheinander in Hongkong an die Börse: Anfang 2026 notierten Zhipu AI und MiniMax (Xiyu Technology) innerhalb von 48 Stunden an der Hongkonger Börse (HKEX). Dies markiert den Eintritt des chinesischen Wettbewerbs um Large Models in eine entscheidende Phase von „hohem Kapital und intensivem Engineering“. Zhipu erzielte durch seine Strategie der Regierungs- und Unternehmensinfrastruktur eine tausendfache Überzeichnung, während MiniMax dank des explosiven Wachstums von Consumer-Anwendungen wie Talkie seinen Aktienkurs am ersten Handelstag verdoppeln konnte. Diese Börsenwelle spiegelt die Grenzen des VC-Finanzierungsmodells wider; der öffentliche Markt übernimmt nun die Rolle, stabile „Blutzufuhr“ für die langfristigen F&E-Investitionen in Large Models bereitzustellen, was die Branche von einem „Parameter-Wettlauf“ in eine Phase der Synergie zwischen „Effizienz und kommerziellem Closed-Loop“ zwingt (Quelle: 产业家)
Replit erhält 400 Mio. USD Finanzierung und führt Paradigmenwechsel zum „Vibe Coding“ an: Die Programmierplattform Replit plant, 400 Millionen USD bei einer Bewertung von 9 Milliarden USD aufzunehmen, nachdem ihr ARR innerhalb eines halben Jahres von 10 Millionen USD auf 144 Millionen USD angestiegen ist. Der Erfolg von Replit liegt in der konsequenten Abkehr vom Markt für „professionelle Entwickler“ hin zur Befähigung von „nicht-technischen Nutzern“ durch den Replit Agent. Dieses neue Paradigma, bekannt als „Vibe Coding“, betont den Aufbau von Anwendungen durch die Beschreibung von Intentionen anstatt durch das Schreiben von Syntax. Dieser Wandel eliminiert nicht nur den Bedarf an traditionellen Junior-Produktmanagern, sondern deutet auch auf eine vollständige Transformation der Softwareentwicklung vom „Handwerk“ hin zur „intent-driven Automation“ hin (Quelle: 36氪; TheRundownAI)
Anthropic Economic Index Report: Hochqualifizierte Berufe stehen vor einer AI-„Deskilling“-Krise: Der neueste Bericht von Anthropic enthüllt einen kontraintuitiven Trend: Der Beschleunigungseffekt von AI auf komplexe Aufgaben übertrifft den bei einfachen Aufgaben bei weitem. Claude steigert die Effizienz bei Aufgaben mit Universitätsabschluss-Niveau um das 12-fache, während es bei Aufgaben auf High-School-Niveau nur das 9-fache ist. Der Bericht weist darauf hin, dass AI systematisch den „Gehalt“ hochintellektueller Positionen aushöhlt, was zu einem „Deskilling“-Phänomen führt – Menschen behalten nur triviale administrative Aufgaben, während Kernanalysen und Planung an die AI delegiert werden. Zudem kann durch Mensch-Maschine-Kollaboration das Zeitfenster für den Erfolg bei komplexen Engineering-Projekten von 2 auf 19 Stunden verlängert werden, was das „neue Mooresche Gesetz“ der zukünftigen Arbeitswelt definiert (Quelle: Anthropic; 新智元)
Higgsfield Cinema Studio: AI versteht Filmsprache und erschüttert Hollywood: Das mit 1,3 Milliarden USD bewertete Unicorn Higgsfield hat ein bedeutendes Update veröffentlicht, das High-End-Filmkameras, Objektive und Kamerabewegungen als AI-Module digitalisiert. HCS verlässt sich nicht mehr auf vage Prompts, sondern lässt die AI durch das DOP I2V-Modell die „Regie-Intention“ verstehen, um professionelle Effekte wie IMAX-Texturen oder Steadicam-Fahrten zu realisieren. Diese „technische Demokratisierung“ ermöglicht es individuellen Schöpfern, visuelle Blockbuster auf Hollywood-Niveau zu extrem niedrigen Kosten zu produzieren, was die Filmindustrie dazu zwingt, neu zu überdenken: Wie wird der Kernwert von Kreativität neu definiert, wenn professionelle Barrieren verschwinden? (Quelle: 极客电影)
🎯 Trends
DeepSeek veröffentlicht DeepGEMM und aktualisiert Hinweise auf V4-Architektur: DeepSeek hat die effiziente Matrix-Multiplikationsbibliothek DeepGEMM als Open Source veröffentlicht, die speziell für die Hopper-Architektur optimiert ist. Gleichzeitig entdeckte die Community im Code-Repository Unterstützung für HyperConnection, was darauf hindeutet, dass das kommende V4-Modell die Inferenzpräzision durch tiefere Netzwerkverbindungen verbessern wird. DeepSeek hält an seinem Day-0 SOTA-Support fest und versucht, durch die Optimierung der Effizienz der zugrunde liegenden Operatoren die Rechenleistungsauslastung bestehender Closed-Source-Modelle zu übertreffen (Quelle: teortaxesTex; You Jiacheng)

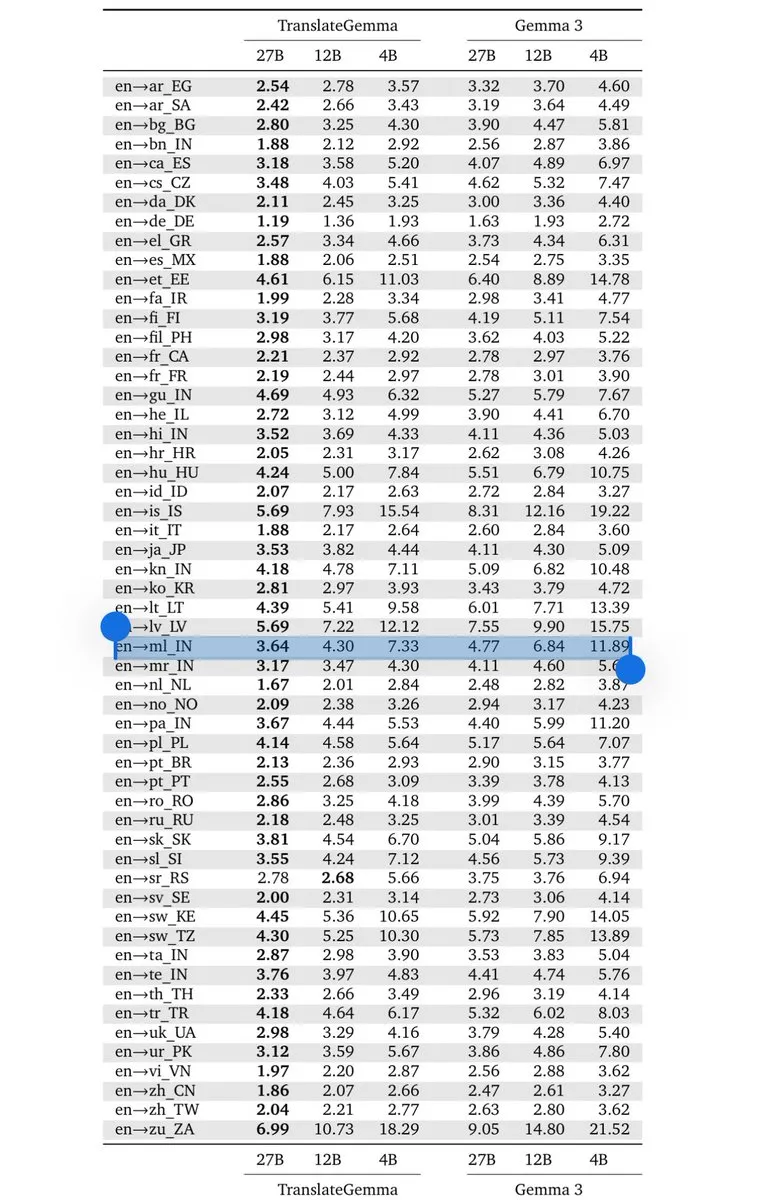
Google DeepMind veröffentlicht TranslateGemma: Neuer Standard für On-Device-Übersetzung: Basierend auf der Gemma 3-Architektur hat Google die TranslateGemma-Modellreihe (4B/12B/27B) veröffentlicht. Durch Knowledge Distillation von Gemini generiert, unterstützt das Modell 55 Sprachen bei gleichzeitiger Leichtgewichtigkeit, was es Entwicklern ermöglicht, vollständig auf dem Gerät laufende Übersetzungstools mit geringer Latenz zu bauen. Dies ist von großer Bedeutung für Märkte wie Indien mit hohem Bedarf an mehrsprachiger Verarbeitung und markiert, dass die Inferenzfähigkeiten von Modellen mit kleinen Parametern in spezifischen vertikalen Bereichen bereits an Frontier-Modelle heranreichen (Quelle: arohan; Google DeepMind)
NVIDIA veröffentlicht KVzap als Open Source: KV Cache Pruning ermöglicht verlustfreie Kompression: NVIDIA AI hat die SOTA-Methode KVzap zum KV Cache Pruning als Open Source bereitgestellt. Diese Technologie ermöglicht eine 2x-4x Kompression des KV Caches bei nahezu verlustfreier Qualität. Da Agent-Langzeitdialoge und komplexe Reasoning-Aufgaben zum Mainstream werden, hat sich der KV Cache zum zentralen Flaschenhals der Inferenzkosten entwickelt. Die Einführung von KVzap wird den Grafikspeicherbedarf und die Antwortlatenz bei Long-Context-Aufgaben erheblich reduzieren und den Durchsatz von Inferenzsystemen steigern (Quelle: Reddit r/artificial; Sudden-Dog2918)
Zhipu und Huawei veröffentlichen GLM-Image: Erstes multimodales Modell, das vollständig auf chinesischen Chips trainiert wurde: Zhipu AI hat gemeinsam mit Huawei GLM-Image vorgestellt, das erste Frontier-Modell, das von der Vorverarbeitung bis zum vollständigen Training komplett auf dem chinesischen Ascend 910-Chip realisiert wurde. Das Modell nutzt eine autoregressive + Diffusion-Decoder-Architektur, erreicht SOTA-Niveau beim Rendern von chinesischem Text und unterstützt die Generierung in beliebigen Seitenverhältnissen bei Auflösungen von 1024-2048. Die Inferenz-Energieeffizienz soll um 60 % höher sein als beim H200, was beweist, dass auch unabhängig vom NVIDIA-Ökosystem multimodale Modelle mit industrieller Wettbewerbsfähigkeit trainiert werden können (Quelle: Reddit r/MachineLearning; karminski3)
Microsoft veröffentlicht FrogMini-14B: Verbesserung der Code-Debugging-Fähigkeiten durch SFT: Microsoft hat FrogMini-14B auf Hugging Face veröffentlicht. Das Modell basiert auf Qwen3 und erzielte im SWE-Bench Verified-Test einen hervorragenden Pass@1-Wert von 45,0 %. Die Kerntechnologie besteht in der Nutzung von erfolgreichen Debugging-Trajektorien, die von starken Teacher-Modellen wie Claude generiert wurden, für das Supervised Fine-Tuning (SFT). Dieser Trend zeigt, dass mittelgroße Modelle der 14B-Klasse durch hochwertige synthetische Daten und gezieltes Aufgabentraining eine exzellente Praxistauglichkeit in spezifischen Software-Engineering-Aufgaben erreichen können (Quelle: NerdyRodent)
🧰 Tools
Claude Code V3 veröffentlicht: Einführung von LSP für semantisches Verständnis auf IDE-Niveau: Anthropic hat Claude Code umfassend aktualisiert und unterstützt nun offiziell das Language Server Protocol (LSP). Dies bedeutet, dass Claude nun über semantische Code-Verständnisfähigkeiten wie „Jump to Definition“, „Find References“ und Echtzeit-Diagnose verfügt, wobei die Geschwindigkeit der Navigation über Bibliotheken hinweg um das 900-fache gesteigert wurde. In der V3-Version wurden zudem Commands und Skills zusammengeführt, wobei CLAUDE.md als Sicherheits-Gatekeeper und Projekt-Blueprint dient, was AI-Programmierung von einfacher Textmanipulation auf eine tiefe architektonische Ebene hebt (Quelle: TheDecipherist; GeckoLogic)

FLUX.2 [klein]: Interaktive visuelle Intelligenz im Sub-Sekunden-Bereich: Black Forest Labs hat die Modellreihe FLUX.2 [klein] veröffentlicht. Diese Modelle (4B/9B) sind speziell für Echtzeit-Generierung und -Editierung konzipiert, mit einer Inferenzlatenz von weniger als 0,5 Sekunden auf moderner Hardware. Die 4B-Version benötigt nur 13 GB Grafikspeicher, um auf Consumer-GPUs zu laufen, und nutzt die Apache 2.0-Lizenz. Die Einführung dieses Tools markiert den Übergang der AI-Bildgenerierung von „wartend“ zu „interaktiv“ und erweitert die Szenarien für Echtzeit-Design und Rapid Prototyping erheblich (Quelle: Black Forest Labs; vllm_project)

AionUi: Open-Source-Grafikoberfläche für die Zusammenarbeit mehrerer Agents: AionUi ist eine kostenlose Open-Source-Desktop-Anwendung, die einen einheitlichen grafischen Arbeitsbereich für Kommandozeilen-AI-Tools wie Gemini CLI, Claude Code und Codex bietet. Sie unterstützt die parallele Verarbeitung mehrerer Sessions, lokale verschlüsselte Datenspeicherung und verfügt über ein integriertes Echtzeit-Vorschau-Panel für über 9 Formate. AionUi löst die Probleme von CLI-Tools, wie das Unvermögen, Sessions zu speichern und die umständliche Bedienung, und bietet Entwicklern sowie Büroanwendern eine effiziente AI-Kollaborationsplattform (Quelle: iOfficeAI; AionUI)

Claude Flow v3: Aufbau einer Multi-Agent-Swarm-Plattform: Claude Flow v3 wurde mit TypeScript und WASM vollständig neu aufgebaut, um Claude Code in eine Plattform für die Zusammenarbeit mehrerer Agents zu verwandeln. Durch RuVector wird Shared Memory realisiert, was Aufgabenzerlegung, Konsensfindung und kontinuierliches Lernen unterstützt. Die V3-Version konzentriert sich besonders auf die Optimierung des Abonnement-Kontingents und verspricht eine Reduzierung des Token-Verbrauchs um 80 %. Das System unterstützt lokale Modelle und Offline-Betrieb, sodass Benutzer im Hintergrund ununterbrochene Optimierungsschleifen und Sicherheitsaudit-Aufgaben ausführen können (Quelle: ruvnet; MichaelT_KC)

📚 Lernen
Agent-as-a-Judge: Ein neues Paradigma zur Bewertung komplexer Aufgaben: Angesichts der Grenzen von LLM-as-a-Judge, wie Bias und mangelnde Echtzeit-Verifizierung bei komplexen Aufgaben, schlägt ein neuer Review das Konzept Agent-as-a-Judge vor. Dieses Paradigma führt Planungs-, Tool-Calling- und Gedächtnisfähigkeiten ein, sodass der Bewerter Aufgaben durch aktives Handeln – wie das Ausführen von Code und das Verifizieren von Outputs – evaluieren kann. Dies bietet eine Roadmap für robuste und verifizierbare AI-Evaluierung (Quelle: TheTuringPost; Ksenia_TuringPost)

Thoughtology: Den „Sweet Spot“ der Chain-of-Thought bei Reasoning-Modellen aufdecken: Eine 135-seitige mechanistische Studie namens „Thoughtology“ analysierte die Chain-of-Thought von Reasoning-Modellen wie GPT-OSS, Qwen3 und R1. Die Forschung ergab, dass längeres Nachdenken nicht immer besser ist; für jedes Problem gibt es einen Reasoning-„Sweet Spot“, wobei übermäßiges Nachdenken sogar zu einer sinkenden Genauigkeit führen kann. Zudem ist repetitives Denken (Rumination) oft mit falschen Antworten korreliert. Die Studie liefert grundlegende Daten zur Optimierung der Inferenzkosten und zur Steigerung der Output-Qualität von Reasoning-Modellen (Quelle: YejinChoinka; Sara Vera Marjanović)

MatchTIR: Verfeinerte Überwachung des Tool-Integrated Reasoning durch Bipartite Graph Matching: Das MatchTIR-Framework adressiert das Problem der grobkörnigen Credit Assignment im Tool-Integrated Reasoning (TIR) durch die Einführung einer Turn-basierten Belohnungszuweisung auf Basis von Bipartite Graph Matching. Diese Methode kann effektiv zwischen validen und redundanten Tool-Aufrufen unterscheiden und zeigt in langwierigen Multi-Turn-Aufgaben eine hervorragende Leistung. Experimente zeigen, dass sein 4B-Modell in mehreren Benchmarks die meisten 8B-Modelle übertrifft, was das enorme Potenzial verfeinerter Überwachung zur Steigerung der Erfolgsrate von Agent-Aufgaben beweist (Quelle: quchangle1; HuggingFace Daily Papers)
💼 Business
OpenAI investiert in Sam Altmans Brain-Computer-Interface-Startup Merge Labs: OpenAI hat sich an einer Finanzierungsrunde für Merge Labs beteiligt, ein von seinem CEO Sam Altman gegründetes Unternehmen für Brain-Computer-Interfaces (BCI). Dieser Schritt wird als vorausschauende Positionierung von OpenAI im Bereich AGI-Hardwareformen angesehen, mit dem Ziel, das menschliche Bewusstsein über BCI-Technologie direkt mit AI-Modellen zu verbinden und Elon Musks Neuralink herauszufordern. Diese Investition hat erneut Diskussionen über die Grenzen zwischen Altmans persönlichen Interessen und Unternehmensentscheidungen entfacht (Quelle: unusual_whales; scaling01)
Wikipedia schließt zum 25. Jubiläum AI-Kooperationen mit Microsoft, Meta und Perplexity ab: Anlässlich seines 25-jährigen Bestehens hat Wikipedia offizielle AI-Datenlizenzvereinbarungen mit Microsoft, Meta und Perplexity unterzeichnet. Diese Kooperationen sollen sicherstellen, dass AI-Modelle bei der Zitierung von Wikipedia-Inhalten eine genaue Quellenangabe liefern, und gleichzeitig nachhaltige Betriebsmittel für die Wikimedia Foundation bereitstellen. Dies markiert eine strategische Transformation von Wissensdatenbank-Plattformen im AI-Zeitalter vom „passiven Scraping“ hin zur „aktiven Kooperation“ (Quelle: AP News; Reddit r/artificial)
🌟 Community
„It Takes Two“: Projektverbesserung durch Modell-Adversarialismus: In der Community wird eine Prompt-Technik namens „Dueling Idea Wizards“ heiß diskutiert. Indem zwei verschiedene Modelle (z. B. Claude Opus 4.5 und GPT-5.2) die Verbesserungsvorschläge des jeweils anderen bewerten und bepunkten (0-1000 Punkte), entdecken Entwickler interessante Nuancen und Meinungsverschiedenheiten zwischen den Modellen. Vorschläge, die von beiden Modellen gleichermaßen hoch bewertet werden, sind oft diejenigen mit echtem praktischem Wert. Dieses adversarielle Reasoning steigert die Effizienz der Ideenselektion erheblich (Quelle: doodlestein)
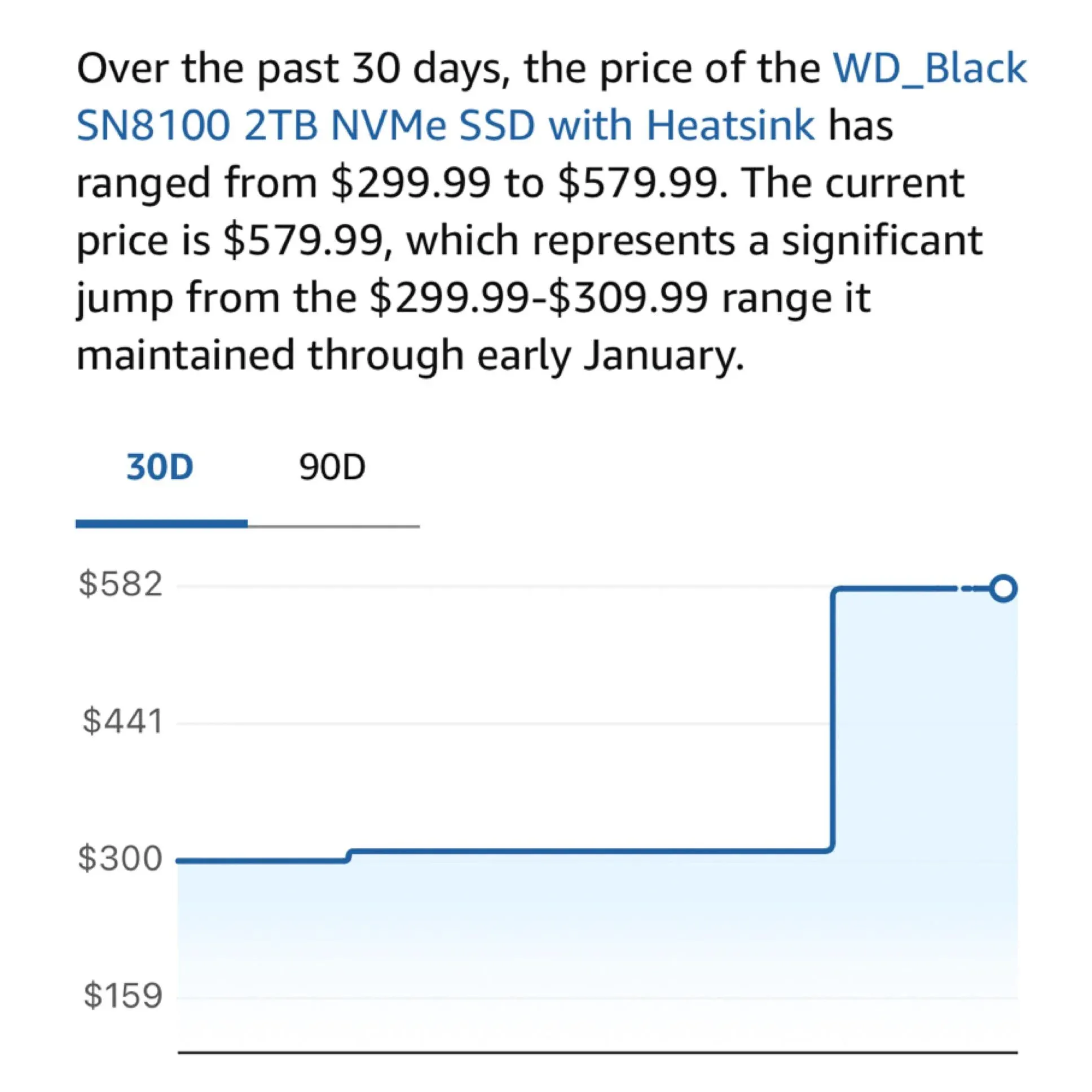
Hardware-Angst: Explodierende M.2 SSD-Preise treffen lokale AI-Nutzer: Community-Nutzer beklagen, dass die Preise für M.2 SSDs und Arbeitsspeicher kürzlich massiv gestiegen sind, wobei sich die Preise für einige Modelle innerhalb eines Jahres verdreifacht haben. Mit dem steigenden Bedarf, Modelle mit über 100B Parametern (wie DeepSeek, Qwen) lokal auszuführen, wächst die Abhängigkeit der Nutzer von schnellen Speichern mit hoher Kapazität. Die Entscheidung von Samsung und Micron, das Angebot für den Consumer-Markt zu kürzen, wird zum größten Hindernis für lokale LLM-Enthusiasten beim Aufbau von „Home Compute Centern“ (Quelle: Reddit r/LocalLLaMA; dgibbons0)
Claude Code „Moo“-Plugin löst Diskussion über AI-Interaktionsfeedback aus: Ein Entwickler teilte ein Plugin namens claude-code-moo, das ein „Muh“-Geräusch von sich gibt, wenn Claude Code eine Benutzerautorisierung für Bash-Befehle benötigt. Dieses scheinbar alberne Tool löst das Problem, dass Entwickler AI-Prompts verpassen, nachdem sie das Fenster gewechselt haben. Die Community startete daraufhin eine tiefgehende Diskussion darüber, wie AI Agents in Langzeitaufgaben durch nicht-intrusives Feedback (Audio, Haptik) die menschliche Einbindung aufrechterhalten können (Quelle: Reddit r/ClaudeAI; iefnaf)

💡 Sonstiges
Galbot S1 von Galbot: Durchbrechen der Lastgrenzen für Embodied AI Roboter: Galbot hat den Schwerlastroboter Galbot S1 vorgestellt, dessen Doppelarme eine maximale Last von 50 kg tragen können; bei voll ausgestreckten Armen kann er 32 kg bewegen, was den Branchendurchschnitt weit übertrifft. Der Roboter wird bereits in Fabriken von CATL eingesetzt und realisiert durch ein Embodied-Transportmodell einen vollautonomen Betrieb ohne Fernsteuerung. Dies signalisiert, dass Embodied AI die Demo-Phase des „Kaffeekochens“ verlässt und in die Kernbereiche der industriellen Produktion mit hoher Intensität und langen Zyklen eintritt (Quelle: 银河通用; 36氪)

Visualisierung von AI-Halluzinationen: Negative Auswirkungen der Aufgabengröße auf die Konsistenz: Ein Community-Nutzer demonstrierte durch die Generierung von Bildern mit 10, 50 und 100 Charakteren, wie sich AI-Halluzinationen mit zunehmender Aufgabengröße verschlimmern. Das Experiment ergab, dass die AI bei steigender Charakteranzahl deutliche Einbrüche bei Nationalitätsmerkmalen, Rechtschreibung und Körperstrukturen zeigt. Dies erinnert Entwickler daran, dass beim Aufbau komplexer Agent-Aufgaben die kognitive Last eines einzelnen Prompts durch Aufgabenzerlegung (Decomposition) reduziert werden muss (Quelle: Reddit r/ChatGPT; haneke86)
Raspberry Pi AI HAT+ 2 veröffentlicht: Inference-Maschine für 1B-Modelle am Edge: Raspberry Pi hat das AI HAT+ 2 für 130 USD auf den Markt gebracht, ausgestattet mit einem Hailo-10H-Beschleuniger und 8 GB Grafikspeicher. Die Hardware ist speziell für die lokale Ausführung von LLMs und VLMs konzipiert und erreicht eine Rechenleistung von 40 TOPS ohne Cloud-Abhängigkeit. Die Community sieht darin die perfekte Wahl für den Bau kleiner lokaler Agent-Inference-Maschinen, die quantisierte Modelle der 1B-Klasse flüssig ausführen können, was die Verbreitung von AI in IoT- und datenschutzsensiblen Szenarien vorantreibt (Quelle: ben_burtenshaw; Raspberry Pi)
