
Keywords:AI unicorn, Large language model, AI tools, Zhipu AI IPO, Replit Vibe Coding, Claude Code V3
🔥 Focus
Chinese AI Unicorns Zhipu and MiniMax Go Public in Hong Kong: In early 2026, Zhipu AI and MiniMax (Xiyu Technology) listed on the Hong Kong Stock Exchange (HKEX) within 48 hours, marking the entry of China’s large model competition into a decisive phase of “high capital and heavy engineering.” Zhipu achieved a thousand-fold subscription rate with its government-enterprise infrastructure route, while MiniMax saw its stock price double on the first day, driven by the explosive growth of consumer applications like Talkie. This wave of IPOs reflects the limitations of the VC financing model; the public market is beginning to take over, providing a stable “blood transfusion” mechanism for long-cycle R&D in large models, pushing the industry chain from a “parameter race” to a collaborative stage of “efficiency and commercial closed-loops.” (Source: Industry News)
Replit Raises $400M, Leading the “Vibe Coding” Paradigm Shift: Programming platform Replit plans to raise $400 million at a $9 billion valuation, with its ARR skyrocketing from $10 million to $144 million in six months. Replit’s success lies in its decisive pivot away from the “professional developer” market to empowering “non-technical users” through Replit Agent. This new paradigm, dubbed “Vibe Coding,” emphasizes building applications by describing intent rather than writing syntax. This shift not only eliminates the need for traditional junior product managers but also signals a complete transformation of software development from “handicraft” to “intent-driven automation.” (Source: 36Kr; TheRundownAI)
Anthropic Economic Index Report: High-Education Jobs Face AI “Deskilling” Crisis: Anthropic’s latest report reveals a counter-intuitive trend: AI’s acceleration effect on complex tasks far exceeds that on simple tasks. Claude’s efficiency gain for tasks requiring a university degree reached 12x, compared to only 9x for high-school-level tasks. The report points out that AI is systematically hollowing out the “value” of high-intelligence positions, leading to a “deskilling” phenomenon where humans retain only trivial administrative work while core analysis and planning are handed over to AI. Furthermore, through human-AI collaboration, the successful timeframe for AI to handle complex engineering can be extended from 2 hours to 19 hours, defining a “New Moore’s Law” for the future workplace. (Source: Anthropic; Sinanews)
Higgsfield Cinema Studio: AI Understanding Film Grammar Shakes Hollywood: Higgsfield, a unicorn valued at $1.3 billion, released a major update digitizing top-tier cinema cameras, lenses, and camera movements into AI modules. HCS no longer relies on vague prompts; instead, it uses the DOP I2V model to let AI grasp “director’s intent,” achieving professional effects like IMAX texture and Steadicam movements. This “technical democratization” allows individual creators to produce Hollywood-level visual blockbusters at extremely low costs, forcing the film industry to rethink how the core value of creativity will be redefined when professional barriers disappear. (Source: Geek Movie)
🎯 Trends
DeepSeek Releases DeepGEMM and Updates V4 Architecture Clues: DeepSeek officially open-sourced DeepGEMM, an efficient matrix multiplication library specifically optimized for the Hopper architecture. Meanwhile, the community discovered that HyperConnection support has been added to its codebase, suggesting that the upcoming V4 model will enhance reasoning accuracy through deeper network connections. DeepSeek adheres to Day-0 SOTA support, attempting to surpass existing closed-source models in compute utilization by optimizing underlying operator efficiency. (Source: teortaxesTex; You Jiacheng)

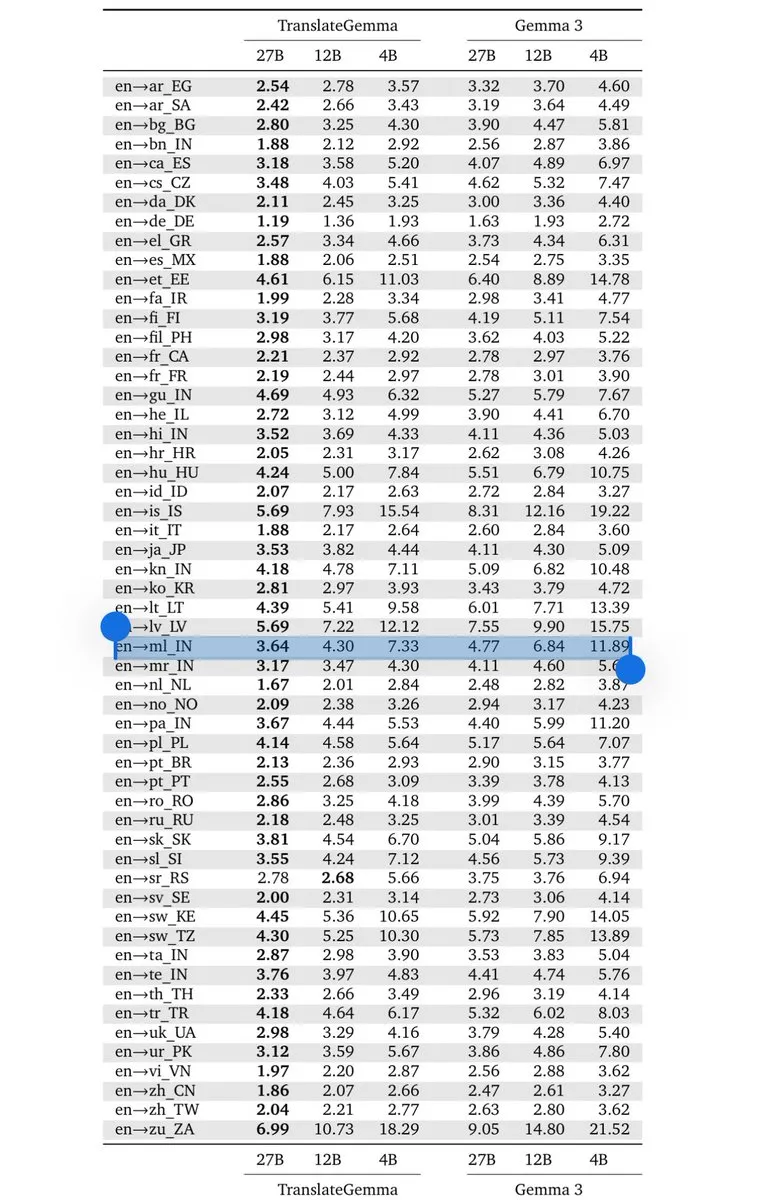
Google DeepMind Releases TranslateGemma: A New Benchmark for On-Device Translation: Based on the Gemma 3 architecture, Google released the TranslateGemma series (4B/12B/27B). Through knowledge distillation generated by Gemini, the model supports 55 languages while remaining lightweight, allowing developers to build low-latency translation tools that run entirely on-device. This is of great significance for markets with strong demand for multilingual processing, such as India, marking that the reasoning capabilities of small-parameter models in specific vertical fields are approaching frontier models. (Source: arohan; Google DeepMind)
NVIDIA Open-Sources KVzap: KV Cache Pruning for Lossless Compression: NVIDIA AI open-sourced KVzap, a SOTA KV Cache pruning method. This technology can achieve 2x-4x KV cache compression while remaining nearly lossless. As long-range Agent dialogues and complex reasoning tasks become mainstream, KV cache has become a core bottleneck for inference costs. The launch of KVzap will significantly reduce memory footprint and response latency for long-context tasks, increasing the throughput of inference systems. (Source: Reddit r/artificial; Sudden-Dog2918)
Zhipu and Huawei Release GLM-Image: First Multimodal Model Trained Entirely on Domestic Chips: Zhipu AI, in collaboration with Huawei, launched GLM-Image, the first frontier model to be fully trained—from preprocessing to full-scale training—on domestic Ascend 910 chips. The model adopts an autoregressive + diffusion decoder architecture, reaching SOTA levels in Chinese text rendering and supporting generation at any aspect ratio in 1024-2048 resolution. Its inference energy efficiency ratio is claimed to be 60% higher than the H200, proving that industrial-grade competitive multimodal models can still be trained outside the NVIDIA ecosystem. (Source: Reddit r/MachineLearning; karminski3)
Microsoft Releases FrogMini-14B: Enhancing Code Debugging via SFT: Microsoft released FrogMini-14B on Hugging Face, a model built on Qwen3 that achieved a Pass@1 score of 45.0% on the SWE-Bench Verified test. Its core technology lies in using successful debugging trajectories generated by strong teacher models like Claude for Supervised Fine-Tuning (SFT). This trend indicates that through high-quality synthetic data and targeted task training, 14B-scale mid-sized models can demonstrate excellent utility in specific software engineering tasks. (Source: NerdyRodent)
🧰 Tools
Claude Code V3 Released: Introducing LSP for IDE-level Semantic Understanding: Anthropic significantly updated Claude Code, officially supporting the Language Server Protocol (LSP). This means Claude now possesses semantic code understanding capabilities such as jump-to-definition, find references, and real-time diagnostics, with cross-library navigation speed increased by 900x. V3 also merges Commands and Skills, using CLAUDE.md as a security gate and project blueprint, elevating AI programming from simple text manipulation to deep architectural understanding. (Source: TheDecipherist; GeckoLogic)

FLUX.2 [klein]: Achieving Sub-second Interactive Visual Intelligence: Black Forest Labs released the FLUX.2 [klein] series. These models (4B/9B) are specifically designed for real-time generation and editing, with inference latency under 0.5 seconds on modern hardware. The 4B version requires only 13GB of VRAM to run on consumer GPUs and uses the Apache 2.0 license. The launch of this tool marks a shift in AI image generation from “waiting” to “interactive,” greatly expanding scenarios for real-time design and rapid prototyping. (Source: Black Forest Labs; vllm_project)

AionUi: Open-Source Multi-Agent Collaborative GUI: AionUi is a free, open-source desktop application designed to provide a unified graphical workspace for command-line AI tools like Gemini CLI, Claude Code, and Codex. It supports parallel multi-session processing, local encrypted data storage, and features a built-in real-time preview panel supporting over 9 formats. AionUi addresses the pain points of CLI tools, such as the inability to save sessions and cumbersome operations, providing an efficient AI collaboration platform for developers and office users. (Source: iOfficeAI; AionUI)

Claude Flow v3: Building a Multi-Agent Swarm Platform: Claude Flow v3 has been completely rebuilt using TypeScript and WASM, aiming to transform Claude Code into a multi-agent collaboration platform. It implements shared memory via RuVector, supporting task decomposition, consensus reaching, and continuous learning. V3 specifically focuses on optimizing subscription quotas, claiming to reduce token consumption by 80%. The system supports local models and offline operation, allowing users to launch uninterrupted optimization loops and security audit tasks in the background. (Source: ruvnet; MichaelT_KC)

📚 Learning
Agent-as-a-Judge: A New Paradigm for Evaluating Complex Tasks: Addressing the limitations of LLM-as-a-Judge, such as bias and lack of real-time verification in complex tasks, a new survey proposes the concept of Agent-as-a-Judge. This paradigm introduces planning, tool calling, and memory capabilities, allowing the evaluator to assess tasks through active behaviors like running code and verifying outputs, providing a roadmap for robust, verifiable AI evaluation. (Source: TheTuringPost; Ksenia_TuringPost)

Thoughtology: Revealing the “Sweet Spot” of Reasoning Model Chain-of-Thought: A 135-page mechanistic study titled “Thoughtology” analyzed the Chain-of-Thought (CoT) of reasoning models like GPT-OSS, Qwen3, and R1. The study found that longer thinking is not always better; every problem has a reasoning “sweet spot,” and overthinking can actually lead to decreased accuracy. Additionally, repetitive thinking (Rumination) is often associated with incorrect answers. This research provides underlying data support for optimizing reasoning costs and improving output quality. (Source: YejinChoinka; Sara Vera Marjanović)

MatchTIR: Refined Supervision for Tool-Integrated Reasoning via Bipartite Graph Matching: The MatchTIR framework addresses the issue of coarse-grained credit assignment in Tool-Integrated Reasoning (TIR) by introducing Turn-level reward assignment based on bipartite graph matching. This method effectively distinguishes valid tool calls from redundant ones, performing exceptionally well in long-range multi-turn tasks. Experiments show that its 4B model surpasses most 8B models across multiple benchmarks, proving the huge potential of refined supervision in improving Agent task success rates. (Source: quchangle1; HuggingFace Daily Papers)
💼 Business
OpenAI Invests in Sam Altman’s Brain-Computer Interface Startup Merge Labs: OpenAI participated in a funding round for Merge Labs, a brain-computer interface (BCI) company founded by its CEO Sam Altman. This move is seen as OpenAI’s forward-looking layout for AGI hardware forms, attempting to directly connect human consciousness with AI models through BCI technology, challenging Elon Musk’s Neuralink. This investment has also reignited discussions regarding the boundaries between Altman’s personal interests and corporate decision-making. (Source: unusual_whales; scaling01)
Wikipedia Partners with Microsoft, Meta, and Perplexity on AI for its 25th Anniversary: On its 25th anniversary, Wikipedia officially signed AI data licensing agreements with Microsoft, Meta, and Perplexity. These collaborations aim to ensure that AI models provide accurate attribution when citing Wikipedia content and provide sustainable operating funds for the Wikimedia Foundation. This marks a strategic transformation for knowledge base platforms in the AI era, moving from “passive scraping” to “active cooperation.” (Source: AP News; Reddit r/artificial)
🌟 Community
“It Takes Two”: Improving Projects through Model Adversarialism: The community is buzzing about a prompt technique called “Dueling Idea Wizards.” By having two different models (e.g., Claude Opus 4.5 and GPT-5.2) review each other’s improvement suggestions and assign scores (0-1000), developers found that models generate interesting “collusions” and disagreements. Suggestions that both models highly agree on are usually high-quality solutions with real practical value. This adversarial reasoning greatly improves the efficiency of creative screening. (Source: doodlestein)
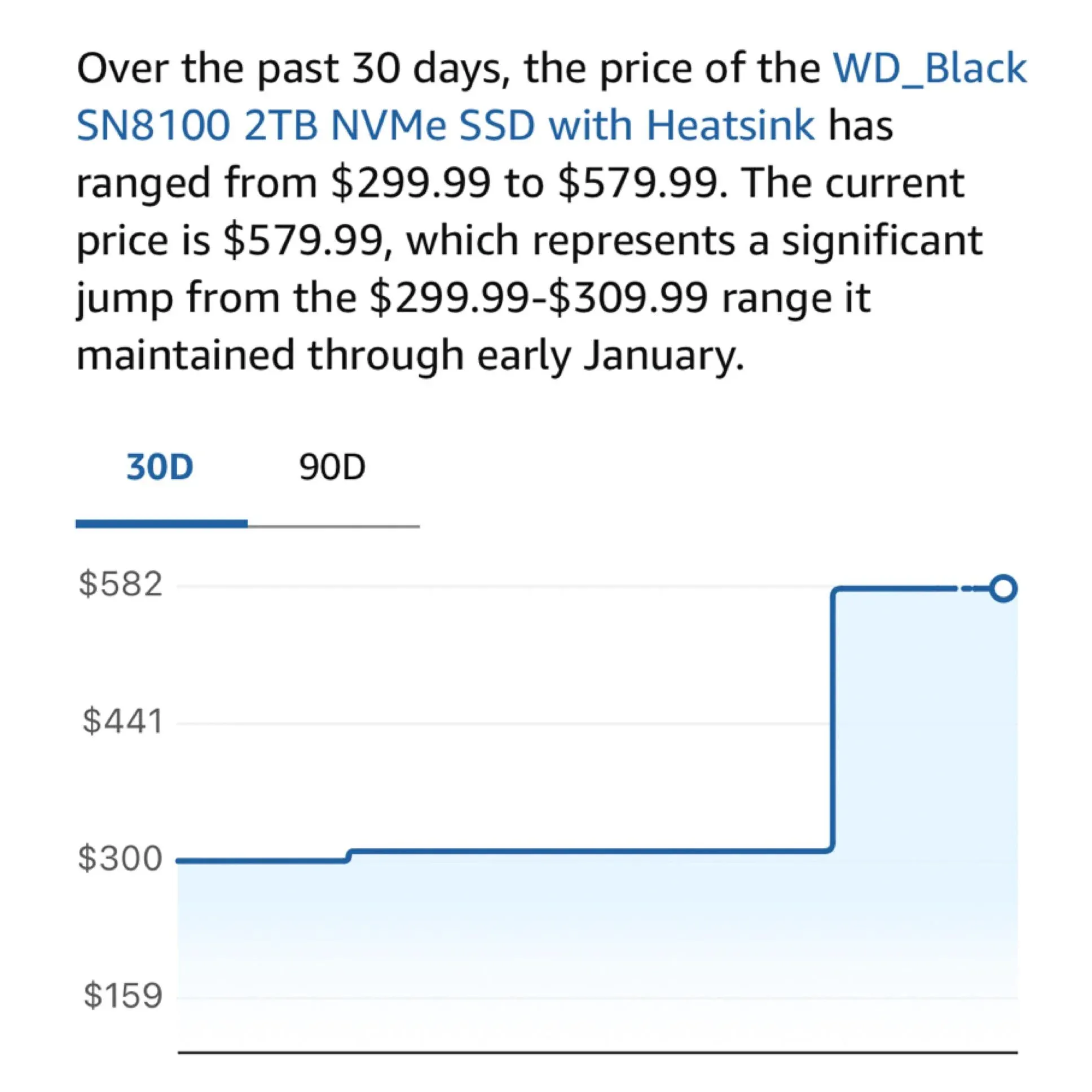
Hardware Anxiety: M2 SSD Prices Skyrocket, Affecting Local AI Players: Community users are complaining about the recent sharp rise in M2 SSD and memory prices, with some models tripling in price within a year. As the demand for running 100B+ parameter models (like DeepSeek, Qwen) locally increases, users’ reliance on large-capacity high-speed storage has become critical. Decisions by Samsung and Micron to cut consumer-grade supply are becoming the biggest obstacle for local LLM enthusiasts building “home compute centers.” (Source: Reddit r/LocalLLaMA; dgibbons0)
Claude Code “Moo” Plugin Sparks Discussion on AI Interaction Feedback: A developer shared a plugin called claude-code-moo, which emits a “moo” sound when Claude Code requires user authorization for Bash commands. This seemingly silly tool solves the pain point of developers missing AI prompts after switching windows. This has led to a deep community discussion on how AI Agents can maintain human engagement through non-intrusive feedback (audio, haptic) during long-range tasks. (Source: Reddit r/ClaudeAI; iefnaf)

💡 Others
Galbot S1: Breaking the Load Limit for Embodied AI Robots: Galbot released the heavy-duty robot Galbot S1, with a maximum dual-arm load of 50kg and a carrying capacity of 32kg when arms are extended, far exceeding the industry average. The robot has been applied in CATL factories, achieving zero-teleoperation, fully autonomous operations through an embodied transport model. This marks the transition of embodied intelligence from the “coffee-making” demonstration phase to the core of high-intensity, long-cycle industrial production. (Source: Galbot; 36Kr)

Visualizing AI Hallucinations: The Negative Impact of Task Scale on Consistency: A community user demonstrated how AI hallucinations worsen as task scale increases by generating images containing 10, 50, and 100 characters. The experiment found that as the number of characters increased, the AI experienced significant breakdowns in handling national characteristics, text spelling, and limb structures. This serves as a reminder to developers that when building complex Agent tasks, cognitive load on a single prompt must be reduced through task decomposition. (Source: Reddit r/ChatGPT; haneke86)
Raspberry Pi AI HAT+ 2 Released: An Edge-side 1B Model Inference Machine: Raspberry Pi launched the AI HAT+ 2, priced at $130, featuring the Hailo-10H accelerator and 8GB of VRAM. The hardware is designed specifically for running LLMs and VLMs locally, achieving 40 TOPS of compute power without cloud dependency. The community considers this a perfect choice for building small local Agent inference machines, capable of smoothly running quantized 1B-scale models, promoting the popularization of AI in IoT and privacy-sensitive scenarios. (Source: ben_burtenshaw; Raspberry Pi)
