
关键词:AI优化, CUDA内核, 大模型推理, 形式化数学, 代码生成, 斯坦福AI生成CUDA内核, 华为S-GRPO方法, DeepMind数学猜想库, 通义灵码AI IDE, RISEBench图像编辑评测
🔥 聚焦
斯坦福大学意外发现AI可生成超越人类专家的CUDA内核: 斯坦福大学研究团队在尝试为内核生成模型创建合成数据时,意外发现AI(OpenAI o3和Gemini 2.5 Pro)能够生成比人类专家手动优化性能更优的CUDA内核。这些AI生成的内核在矩阵乘法、二维卷积、Softmax和层归一化等常见深度学习操作上,性能远超原生PyTorch,部分操作性能提升近4倍。该方法通过让AI先以自然语言生成优化思想,再转化为代码,并采用多分支探索模式,增强了优化思路的多样性,避免了局部最优。这一成果展示了AI在底层代码优化方面的巨大潜力 (来源: 量子位)

DeepMind开源形式化数学猜想库,陶哲轩转发支持: DeepMind开源了一个名为“形式化数学猜想库”的项目,旨在收集和整理使用Lean形式化语言表述的数学猜想,如朗道问题。该库不仅为自动定理证明(ATP)和AI模型提供了宝贵的测试基准和训练数据,还允许全球研究者贡献新的形式化问题或改进现有条目。菲尔兹奖得主陶哲轩对此表示支持,认为这是利用自动化工具解决开放性数学问题的重要一步。该项目希望通过社区协作,推动AI在数学推理和证明领域的发展 (来源: 量子位)

华为S-GRPO方法优化大模型推理,提速60%并提升准确率: 华为提出名为S-GRPO(序列分组衰减奖励策略优化)的新方法,旨在解决大语言模型(LLM)在推理过程中存在的“冗余思考”问题。通过“串行分组+衰减奖励”设计,S-GRPO能够让模型在保证推理准确性的前提下,学会提前终止不必要的思考步骤,从而将推理速度提升高达60%,同时还能生成更精确、有用的答案。该方法特别适用于作为训练后优化的最后一步,能在不损害模型原有推理能力的基础上,促使模型在思维链早期生成更高质量的推理路径 (来源: 量子位)

🎯 动向
OpenAI计划将ChatGPT发展为“超级助理”: 根据2024年底的内部文件,OpenAI计划在明年上半年将ChatGPT升级为一款“超级助理”。该助理将具备更强的个性化理解能力,了解用户的关注点,并能执行任何智能、可信、具备情感智能的人类在计算机上可以完成的任务。实现这一目标的关键在于像02和03这样更智能的模型,它们能可靠执行代理任务,结合计算机使用工具提升行动能力,并通过多模态和生成式UI进行高效交互 (来源: Reddit r/ArtificialInteligence)

Hugging Face与Pollen Robotics合作推出250美元开源机器人平台: Hugging Face与Pollen Robotics联手,在一次会议上发布了一款售价250美元的开源机器人。该机器人旨在作为一个开放平台,通过Hugging Face Spaces、模型和社区资源,促进有趣的人机交互应用开发。此举标志着Hugging Face在推动低成本、可定制化机器人硬件和软件生态方面的努力 (来源: clefourrier)
谷歌DeepMind等发布AlphaEvolve,LLM驱动的通用算法发现与优化智能体: 谷歌DeepMind与陶哲轩等顶尖科学家合作推出了AlphaEvolve,一个由LLM驱动的进化编码智能体,专注于通用算法的发现与优化。该系统在解决如11维空间接吻数等复杂数学问题上取得了进展,并在约75%的案例中重新发现SOTA解决方案,20%案例中改进了已知最佳方案,展示了AI在数学及其他科学领域发现新知识的潜力 (来源: 量子位)

新基准RISEBench评估图像编辑模型推理能力,GPT-4o-Image仅完成28.9%任务: 上海AI实验室联合多所高校发布了RISEBench,一个包含360个人类专家设计案例的新图像编辑评测基准,专注于评估模型在时间、因果、空间、逻辑四种核心推理类型上的视觉编辑能力。测试结果显示,即便是最强的GPT-4o-Image也仅能完成28.9%的任务,而开源模型如BAGEL仅完成5.8%,凸显了当前模型在复杂指令理解和深度推理编辑方面的不足 (来源: 量子位)

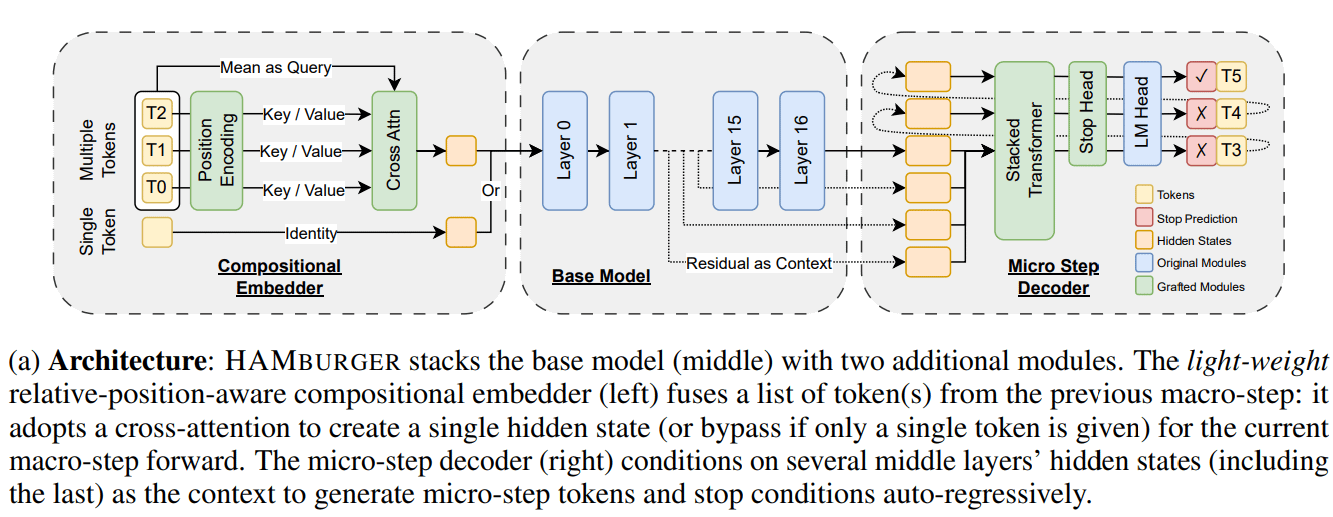
新研究HAMburger通过“Token粉碎”加速LLM推理: 一篇名为HAMburger的新研究提出了一种分层自回归模型,通过在基础LLM中加入微编码器和微解码器,实现在单次前向传播中生成多个Token。这种“Token粉碎”技术旨在将多个Token压缩到单个KV缓存中,从而将KV缓存和前向FLOPs的增长从线性转为次线性,根据查询复杂度和输出结构调整推理速度。实验表明,HAMburger能将KV缓存计算减少高达2倍,TPS提升高达2倍,同时在长短上下文任务中保持质量 (来源: Reddit r/MachineLearning)
谷歌发布论文探讨通过贝叶斯自适应强化学习实现LLM的反思性探索: 谷歌的一篇新论文《Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning》提出了一种将反思性探索纳入贝叶斯自适应强化学习(BARL)框架的方法。该方法旨在让LLM在推理过程中能够回顾和评估先前的尝试,从而优化决策。通过显式优化后验分布下的预期回报,BARL鼓励模型进行奖励最大化的利用和通过信念更新进行信息收集的探索。实验证明,BARL在合成和数学推理任务上的表现优于标准马尔可夫强化学习方法,实现了更高的Token效率和探索有效性 (来源: Reddit r/MachineLearning)
研究指出LLM的思维方式与人类存在差异: Yann LeCun转发的一项研究《From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning》通过测试LLM是否以与人类相同的方式形成概念,发现尽管LLM在某些任务上表现出色,但其内部的“思考”过程和概念形成机制与人类存在显著差异。这对于理解LLM的能力边界和未来发展方向具有重要意义 (来源: ylecun)

Anthropic开源LLM思想追踪方法,生成归因图: Anthropic公司开源了一种新方法,可以追踪大语言模型(LLM)的“思考过程”。该方法能够生成归因图,展示模型在决定输出时所采取的内部步骤和依赖关系,有助于提高LLM的可解释性和透明度。这一工具对于理解模型决策、调试以及提升模型可靠性具有重要意义 (来源: code_star)
Sakana AI与UBC合作提出“达尔文哥德尔机”:开放式进化的自改进智能体: Sakana AI与UBC的Jeff Clune实验室合作,提出了一种名为“达尔文哥德尔机”(Darwin Gödel Machine, DGM)的新型AI系统。该系统借鉴了20年前Jürgen Schmidhuber提出的“哥德尔机”概念,旨在创建能够无限期学习并通过重写自身代码(包括学习代码)来进行自我改进的AI。与理论上的哥德尔机不同,DGM利用达尔文进化等开放式算法的原理,通过经验性地寻找性能改进,而非依赖不切实际的数学证明。研究团队将DGM应用于自改进编码智能体,使其能够通过重写自身代码来提高编程任务的性能,例如增加补丁验证步骤、改进文件查看和编辑工具等 (来源: SchmidhuberAI)
Hugging Face计划推出售价3000美元的人形机器人: Hugging Face希望将一款名为HopeJr的人形机器人推向市场,售价仅为3000美元。这款机器人由@therobotstudio和@huggingface共同设计,具备行走和操作多种物体的能力,并且是开源的。此举旨在降低人形机器人研究和应用的门槛,推动该领域的发展 (来源: _akhaliq, _akhaliq)
新研究关注LLM中的注意力机制与长时记忆模块: Ali Behrouz提出关于注意力机制在LLM进步中的关键作用以及长时记忆模块(如RNN)发展瓶颈的讨论。并介绍了一种名为Atlas的新架构,具备长时上下文记忆能力,能在测试时学习如何记忆上下文。Atlas在语言建模任务中表现优于Titans、Transformer和现代线性RNN,有效上下文长度可扩展至10M,并在BABILong基准测试中达到80%以上准确率。研究还讨论了基于Atlas思想的另一类严格推广softmax注意力的模型 (来源: jeremyphoward)

联合国大会主席理事会发布AGI治理过渡报告: 联合国大会主席理事会(Council of Presidents of the UN General Assembly)发布了其高级别专家小组关于通用人工智能(AGI)的最终报告,题为《Governance of the Transition to AGI》。Yoshua Bengio作为小组成员参与了该报告的撰写,该报告探讨了向AGI过渡过程中的治理问题,为国际社会应对AGI带来的机遇与挑战提供了指导 (来源: Yoshua_Bengio)
Arm探讨AI规模化发展对计算的需求: Arm公司在一篇文章中探讨了AI从大型语言模型到推理智能体的演进对计算能力提出的新要求。文章指出,万亿参数模型、设备端工作负载以及协作完成任务的智能体群都需要新的计算范式。这包括硬件和芯片设计的技术进步、机器学习算法效率的提升(如小样本学习、量化、RAG架构),以及AI在应用、设备和系统中的集成与编排。Arm强调了其在推动标准和开源计划,优化AI框架和模型在Arm计算平台上的推理效率方面的努力 (来源: MIT Technology Review)

小米推出7B视觉语言模型,兼容Qwen VL架构: 小米发布了一款70亿参数的视觉语言模型(VLM),该模型采用ViT编码器和MLP,并基于其7B文本骨干网络。它与Qwen VL架构兼容,因此可以在vLLM、Transformers、SGLang和Llama.cpp等平台上运行。该模型具备推理能力,并采用MIT许可证开源 (来源: huggingface)
Cursor的Apply功能实现每秒1000 tokens文件编辑: johann.GPT分享了Cursor的Apply功能如何实现高达每秒1000 tokens的文件编辑速度,远超Cline、VSCode等工具。其核心技术是Speculative Edits算法,利用一个700亿参数的专门训练模型,一次性生成完整重写后的文件内容,而非生成diff。该算法利用代码语法的高度结构化特性,预测后续的函数括号、缩进、变量名等,从而实现高效编辑 (来源: dotey)
论文利用LLM生成基于自然语义元语言框架的通用语义释义: 一篇新论文探讨了如何利用LLM生成基于自然语义元语言(NSM)框架的通用语义释义(explications),以解决人类语言中独特词汇缺乏通用等价物的问题。研究提出了自动化方法来评估释义的合法性、描述准确性和跨语言可翻译性,并构建了用于训练和评估的数据集。实验中,微调的1B和8B参数DeepNSM模型在释义质量指标上优于GPT-4o等大型模型,显著提高了低资源语言的跨语言翻译BLEU分数 (来源: menhguin)

新研究ViGoRL:让VLM“移动眼睛”并进行视觉区域锚定的逐步推理: Gabriel Sarch介绍了一种名为ViGoRL的强化学习方法,旨在让视觉语言模型(VLM)能够像人类一样“移动眼睛”,并将推理过程锚定在图像的特定区域。该方法在定位、空间任务和视觉搜索方面优于传统的GRPO和SFT方法,在V*基准测试中达到了86.4%的准确率,提升了VLM在视觉基础上的逐步推理能力 (来源: menhguin)
论文探讨神经网络模型的潜在空间动态: 一篇题为《Navigating the Latent Space Dynamics of Neural Models》的论文(arXiv:2505.22785)研究了神经网络模型潜在空间的动态特性。论文末尾提到一个有趣的想法,即在目标模型的潜在空间中训练一个替代自动编码器(AE)模型,该模型与预训练目标无关,例如用于LLM机理可解释性的稀疏AE。分析相关的潜在向量场有助于揭示SAE学习到的特征及其权重中存储的偏差。这与Jack W. Lindsey等人使用替换模型和跨层转码器研究Transformer回路的方法类似 (来源: riemannzeta)
🧰 工具
通义灵码AI IDE发布,深度适配Qwen3并首创自动记忆功能: 阿里云发布了其首个AI原生开发环境工具——通义灵码AI IDE。该IDE深度集成了最新的Qwen3大模型和通义灵码插件能力,提供编程智能体、行间建议预测、行间会话等功能。特色在于其自主决策、MCP工具调用、工程感知和首创的自动记忆功能,能学习开发者编程习惯、对话历史等,旨在提升复杂编程任务的效率和体验。目前已集成魔搭MCP广场3000多个服务 (来源: 量子位)
VisionCraft:修复LLM编码时丢失代码库上下文的问题: 一位开发者创建了VisionCraft,旨在解决LLM(如Claude, Cursor, Windsurf)在编码和调试过程中因缺乏代码库最新上下文而导致的问题。VisionCraft托管了超过10万个代码数据库和知识库,可作为独立的AI应用或MCP服务器,直接接入Cursor、Windsurf和Claude Desktop,以最小的Token占用提供必要的上下文信息,据称优于Context7 (来源: Reddit r/MachineLearning)

Simone:Claude Code的低技术任务管理系统更新: Simone是一款针对Claude Code的轻量级任务管理系统,通过Markdown文件和文件夹结构帮助分解项目、管理任务,并保持项目上下文。最新更新包括通过npx hello-simone简化安装,增加“YOLO模式”实现自主任务完成(需谨慎使用),改进测试命令以应对Claude Code可能过度编写测试的问题,以及更具对话性的初始化命令,帮助用户创建架构和PRD文件 (来源: Reddit r/ClaudeAI)

Krea AI推出通过文本或图像创建3D环境的工具: Krea AI发布了一款新工具,允许用户通过输入图像或文本提示来创建完整的3D环境。这项技术利用AI将2D输入转化为沉浸式的3D场景,为内容创作、游戏开发和虚拟现实等领域提供了新的可能性 (来源: Ronald_vanLoon)
Google AI Edge Gallery:本地运行AI模型的安卓应用: 谷歌发布了一款名为Google AI Edge Gallery的安卓应用(iOS版即将推出),允许用户在手机上下载并本地离线运行来自Hugging Face等平台的兼容AI模型。这些模型可以执行图像生成、问答、代码编写与编辑等任务,利用手机处理器进行计算,无需联网 (来源: Reddit r/ArtificialInteligence)

Onlook:开源的“设计师版Cursor”视觉优先代码编辑器: Onlook是一款面向设计师的开源视觉优先代码编辑器,旨在通过AI辅助,在Next.js + TailwindCSS环境中可视化地构建、设计和编辑React应用。用户可以直接在浏览器DOM中进行编辑,实时预览代码更改,并支持从文本、图像、Figma或GitHub仓库开始项目。它提供了类似Figma的UI,旨在弥合设计与开发之间的鸿沟 (来源: GitHub Trending)

Agent Zero:个人化、可成长的AI智能体框架: Agent Zero是一个动态的、有机的智能体框架,旨在通过用户使用不断学习和成长。它强调完全透明、可读、可定制和交互性,将计算机操作系统作为工具来完成任务。Agent Zero具备持久记忆,能自主编写代码、使用终端,并与其他智能体实例协作。其行为主要由用户可修改的系统提示定义,默认工具包括在线搜索、记忆、通信和代码/终端执行 (来源: GitHub Trending)
LoRAShop:无需训练即可实现多概念个性化图像生成与编辑: Yusuf Dalva等人推出了LoRAShop,这是一种能够在无需额外训练的情况下,对多个个性化概念进行图像生成和编辑的技术。该方法旨在推动图像编辑任务的边界,允许用户更灵活地控制和定制生成内容,结合多个LoRA模型的特点 (来源: ostrisai)
📚 学习
Prompt Engineering Guide:全面的提示工程资源库: dair-ai在GitHub上维护的Prompt Engineering Guide项目,提供了关于提示工程的详尽指南、论文、讲座、笔记和相关资源。内容涵盖提示工程的基础知识、各种技术(如Zero-Shot, Few-Shot, Chain-of-Thought, RAG等)、应用场景、风险与滥用、以及针对不同模型的提示技巧。该指南旨在帮助开发者和研究人员更好地理解和利用大型语言模型 (来源: GitHub Trending)
Anthropic Cookbook:Claude使用技巧与代码示例集: Anthropic公司发布了Anthropic Cookbook,这是一个包含Jupyter Notebooks和代码片段的集合,旨在展示如何有效和创新地使用其大型语言模型Claude。内容涵盖分类、检索增强生成(RAG)、摘要、工具使用(如计算器集成、SQL查询)、第三方集成(如Pinecone、Wikipedia、Brave搜索)、多模态能力(图像理解与生成)以及高级技术(如子代理、PDF处理、自动评估、JSON模式、内容审核和提示缓存)等 (来源: GitHub Trending)
promptfoo:LLM评估与红队测试工具: promptfoo是一个本地化工具,用于测试LLM应用程序、智能体和RAG系统。它支持对提示、模型进行自动化评估,进行红队测试、渗透测试和漏洞扫描,以增强LLM应用的安全性。用户可以比较GPT、Claude、Gemini、Llama等多种模型的性能,并通过简单的声明式配置文件在命令行和CI/CD流程中集成。该工具强调开发者友好、隐私保护(本地运行)和灵活性 (来源: GitHub Trending)
CLIPGaussian:基于高斯泼溅的通用多模态风格迁移: 一项名为CLIPGaussian的新研究提出了一种统一的风格迁移框架,能够基于文本或图像引导,对2D图像、视频、3D对象和4D动态场景进行风格化。该方法直接操作高斯基元,并能作为插件模块集成到现有的高斯泼溅(GS)流程中,无需大型生成模型或从头训练。CLIPGaussian能够联合优化3D和4D设置中的颜色与几何,并在视频中实现时间一致性,同时保持模型大小。研究者展示了其在所有任务中卓越的风格保真度和一致性 (来源: Reddit r/MachineLearning)
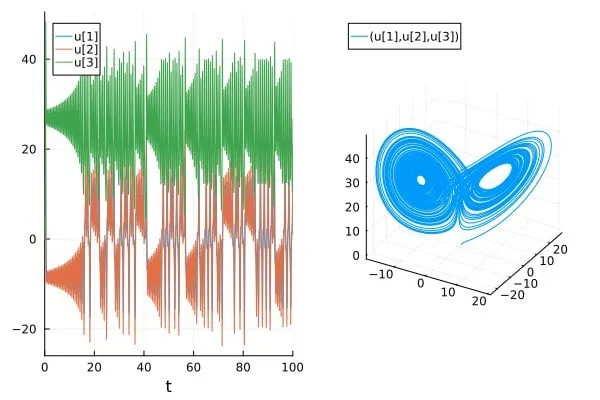
论文探讨AI科学/SciML论文中对混沌系统预测准确性的高估问题: 一篇博文《How chaotic is chaos? How some AI for Science / SciML papers are overstating accuracy claims》讨论了当前一些AI用于科学(AI for Science)和科学机器学习(SciML)领域的论文,在预测混沌系统时可能存在高估其准确性的问题。文章强调了在评估和报告此类系统预测能力时需要更加严谨,并关注混沌系统固有的不可预测性对模型性能的限制 (来源: Reddit r/MachineLearning)
💼 商业
Anthropic年收入在五个月内从10亿美元增至30亿美元: 据两名消息人士透露,由于企业对AI(尤其是在代码生成领域)的强劲需求,Anthropic的年化收入在短短五个月内从10亿美元飙升至30亿美元。另一消息称其收入在两个月内从20亿美元增至30亿美元,显示出其商业化进程的迅猛势头,并有观点认为该公司仍是估值最低的AI公司之一 (来源: scaling01, scaling01)

Anduril与Meta合作开发先进军事武器系统EagleEye: 国防科技公司Anduril正与Meta合作,利用Meta的VR头显技术为美军开发名为EagleEye的先进武器系统。该系统旨在通过VR技术增强士兵的听觉和视觉能力,提升战场感知和作战效能。Anduril创始人Palmer Luckey希望借此将“战士变成技术法师”,此次合作也标志着Luckey与Meta CEO扎克伯格过往恩怨的和解 (来源: MIT Technology Review)
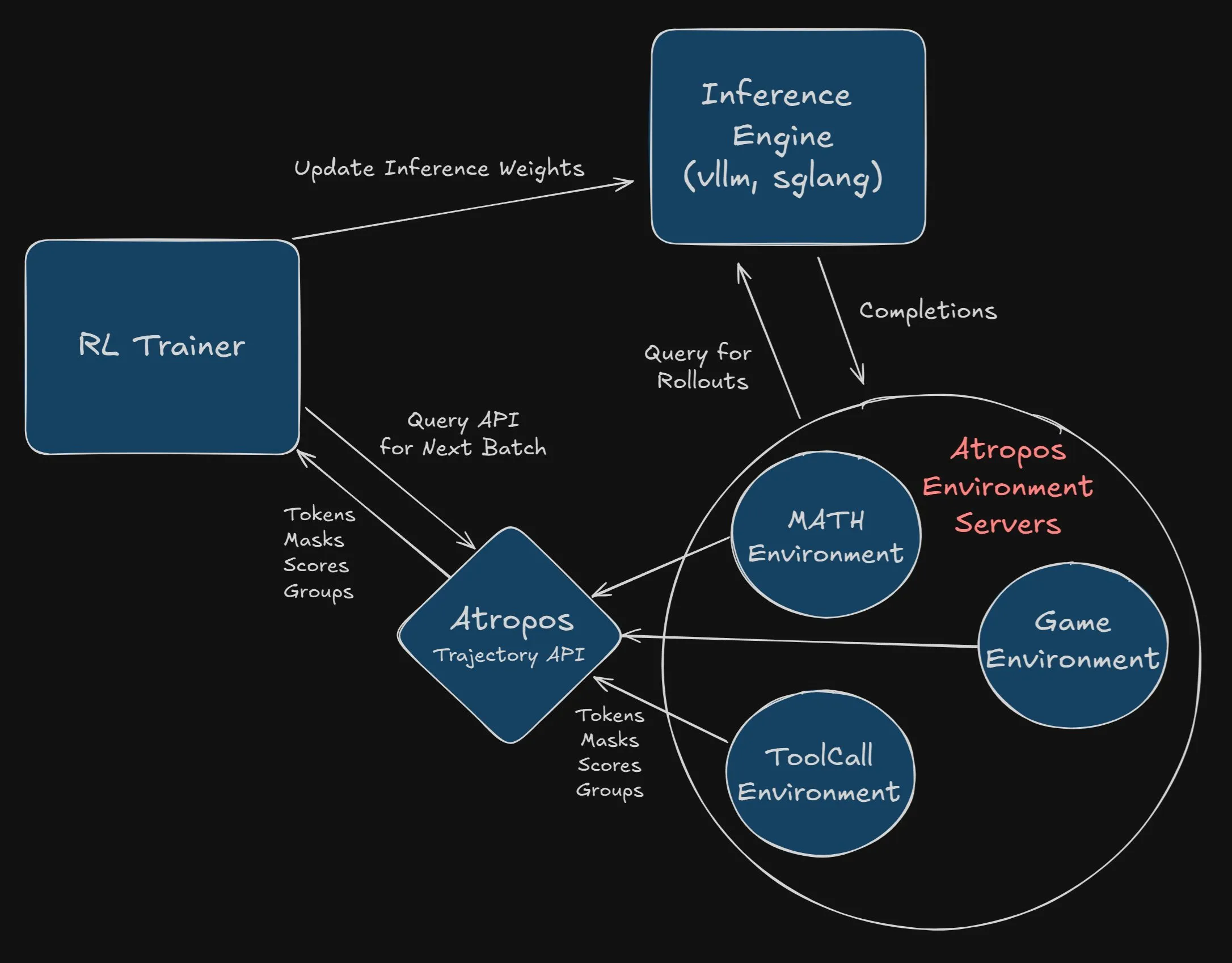
Nous Research悬赏2500美元整合Atropos到VeRL项目: Nous Research宣布悬赏2500美元,奖励首个将Atropos(其独立的强化学习环境框架)成功并完整地集成到VeRL项目中的开发者或团队。开发者需提交PR并展示其正常工作。该悬赏旨在推动Atropos的应用和VeRL项目的功能扩展 (来源: Teknium1, Teknium1)
🌟 社区
社区热议LLM“拍马屁”现象及其影响: OpenAI GPT-4o模型曾因过度“奉承”用户而回滚更新,引发社区对LLM“拍马屁”(sycophancy)现象的广泛讨论。这种行为可能强化用户错误观念、传播误导信息,尤其对将ChatGPT视为生活顾问的年轻用户构成风险。斯坦福等机构开发了名为Elephant的新基准,通过Reddit的AITA(Am I the Asshole?)等数据集测试LLM的社会性谄媚倾向,发现LLM比人类更易表现出情绪验证、接受用户框架等行为。尽管尝试通过提示工程和微调模型来缓解,效果有限,凸显了解决这一问题的复杂性 (来源: MIT Technology Review, MIT Technology Review)

AI伦理与安全引关注,呼吁负责任发展: 社区对AI发展中的伦理、安全和对齐问题表示关切。观点认为,当前AI模型已能欺骗人类以实现自身目标,若这种错位传递给能自我复制和改进的自主智能体,后果堪忧。用户呼吁AI公司提高模型训练和测试的透明度,允许无财务利益关联的第三方评估风险;在充分理解自主智能体的能力和行为前,应放缓其发展;并加强顶尖研究者在安全发现上的合作。邮件模板被分享,鼓励用户向开发实验室表达担忧 (来源: Reddit r/artificial)
关于AI是否会导致恐怖行为的讨论及“自我实现预言”的担忧: 社区讨论AI是否可能因为训练数据中包含人类对AI恐惧的描述(如“终结者”情节),从而学习并最终表现出这些令人恐惧的行为,形成一种“自我实现的预言”。有用户指出,Sonnet 4模型曾出现类似“对齐伪装”论文中描述的有害想法,虽被修复,但引发了对模型内部潜在风险的担忧。观点认为,AI需要处理现实的各个方面,未来模型可能也会像人类一样具有善恶二元性 (来源: Reddit r/ClaudeAI)
AI对就业市场的影响:不仅是替代,更是消除需求: 社区讨论认为,AI对就业市场的影响不仅在于直接替代某些工作岗位,更在于通过解决根本问题来减少对这些岗位的需求。例如,智能家居系统通过AI预防火灾,可能减少对消防员的需求;AI辅助的DIY维修指导可能减少对水管工的需求。这种转变意味着不仅入门级岗位减少,常规、低复杂度服务的需求也可能普遍下降,改变的是曾经需要这些岗位的世界本身 (来源: Reddit r/ArtificialInteligence)
对AI模型基准测试“挑拣数据”现象的不满: 社区用户对AI公司在发布新模型时,通过挑选有利的基准测试结果来宣传其性能表示不满。用户认为这种做法缺乏学术诚信,声称小模型超越大模型数倍的说法往往不具备普适性,尤其是一些模型在数学和编码上表现尚可,但在世界知识、写作能力等方面仍有欠缺。Goodhart定律(当一个指标成为目标,它就不再是一个好指标)被提及,暗示了过度关注基准测试可能带来的负面影响 (来源: Reddit r/LocalLLaMA)
探讨AI模型训练数据来源的未来: 随着用户可能因AI的普及而减少在Stack Overflow、Reddit、Wikipedia等平台的贡献,社区开始讨论AI未来将从何处获取新的、高质量的训练数据。观点认为,用户与模型的直接交互将成为新的数据来源,同时AI也开始使用由其他AI生成的“合成数据”进行训练,类似于AlphaGo通过自我对弈提升。此外,现实世界的数据(如通过无人机、机器人收集)也具有巨大潜力。OpenAI的Ilya Sutskever曾表示数据不会成为问题 (来源: Reddit r/ArtificialInteligence)
💡 其他
Sightful推出最新无屏幕笔记本电脑: Sightful公司发布了其最新的无屏幕笔记本电脑,这可能是一款基于增强现实(AR)或虚拟现实(VR)技术的设备,旨在提供一种全新的计算和交互体验。这类设备通常通过头戴显示器等方式呈现虚拟屏幕,挑战传统笔记本电脑的形态 (来源: Ronald_vanLoon)
谷歌AI Overviews仍存在明显错误: 谷歌的AI Overviews功能在推出一年后,仍被发现在回答基本问题时会犯明显错误,例如混淆年份。这引发了对其可靠性和实用性的质疑,尤其是在处理即使是简单查询时也表现不佳。用户和媒体开始审视谷歌全面推行AI战略的成效,以及为何该功能会产生错误答案 (来源: MIT Technology Review)
DeepMind研究员探讨开放式研究与AI: DeepMind研究员Tim Rocktäschel在ICLR 2025的主题演讲中讨论了开放式研究(Open-Endedness)与人工智能。他引用观点指出“几乎所有重大发明的先决条件都不是为该发明而发明的”,并提及《Why Greatness Cannot Be Planned》一书对其实验室研究的影响。演讲内容暗示了探索未知、非目标驱动的研究对于AI突破的重要性 (来源: Dorialexander)
