

كلمات مفتاحية:الوكيل الذكي للذكاء الاصطناعي, نموذج اللغة الكبير, جيميني 2.5 برو, الحاسوب الفائق للذكاء الاصطناعي من إنفيديا, مؤتمر مايكروسوفت للبناء, الوكيل الذكي للبحث العلمي, تقييم قدرات الاستدلال, برمجة الذكاء الاصطناعي, الوكيل البرمجي لإصلاح الأخطاء تلقائياً, منصة مايكروسوفت ديسكفري للبحث العلمي, تقنية إنفيديا لينك فيوجن, عقدة فائقة كلاودماتريكس 384, خوارزمية إيدج إنفينيت
🔥 أبرز العناوين
وكلاء الذكاء الاصطناعي (AI agents) يعيدون تعريف نماذج التطوير والبحث العلمي: كشف مؤتمر Microsoft Build عن سلسلة من أدوات وكلاء الذكاء الاصطناعي، بما في ذلك Coding Agent الذي يقوم بإصلاح الأخطاء البرمجية ذاتيًا وصيانة الشيفرة البرمجية، ومنصة وكلاء البحث العلمي Microsoft Discovery القادرة على توليد الأفكار ومحاكاة النتائج والتعلم الذاتي. وفي الوقت نفسه، صرح كل من Kevin Weil، كبير مسؤولي المنتجات في OpenAI، و Dario Amodei، الرئيس التنفيذي لشركة Anthropic، بأن الذكاء الاصطناعي يمتلك بالفعل قدرات برمجية متقدمة، مما ينذر باحتمال استبدال وظائف المبرمجين المبتدئين، وتحول دور المطورين إلى “موجهي الذكاء الاصطناعي (AI guiders)”. تشير هذه التطورات إلى أن وكلاء الذكاء الاصطناعي يتطورون من أدوات مساعدة إلى قوة أساسية قادرة على العمل بشكل مستقل في المشاريع المعقدة، مما سيحدث تحولًا عميقًا في عمليات وكفاءة تطوير البرمجيات والبحث العلمي (المصدر: GitHub Trending, X)
قدرات الاستدلال لدى نماذج اللغة الكبيرة (LLM) تواجه تحديات وتقييمات جديدة: كشفت العديد من الدراسات والمناقشات الحديثة عن محدودية نماذج اللغة الكبيرة في مهام الاستدلال المعقدة. وأشارت دراسة أجرتها جامعة هارفارد ومؤسسات أخرى إلى أن سلسلة الفكر (CoT) قد تؤدي أحيانًا إلى انخفاض دقة النموذج في اتباع التعليمات، بسبب تركيزها المفرط على تخطيط المحتوى وإهمال القيود البسيطة. وفي الوقت نفسه، كشفت المهام الفيزيائية في العالم الحقيقي (مثل تصنيع الأجزاء) والاستدلال البصري المكاني المعقد (مثل مشاكل تكديس المكعبات) أيضًا عن أوجه قصور في نماذج الذكاء الاصطناعي الرائدة (بما في ذلك o3 و Gemini 2.5 Pro). ولتقييم قدرات النماذج بشكل أكثر دقة، تم اقتراح معايير جديدة مثل EMMA و SPOT، تهدف إلى الكشف عن المستوى الحقيقي للذكاء الاصطناعي في الدمج متعدد الوسائط (multimodal fusion) والتحقق العلمي (scientific validation) وغيرها، مما يدفع النماذج نحو تطور استدلال أكثر قوة وموثوقية (المصدر: HuggingFace Daily Papers, 量子位)
Google AI تستعرض قوتها الشاملة، و Gemini 2.5 Pro يُظهر أداءً قويًا: أظهرت Google هجومًا شاملاً في مجال الذكاء الاصطناعي، حيث حقق نموذجها Gemini 2.5 Pro أداءً متميزًا في العديد من اختبارات الأداء (مثل LMSYS Chatbot Arena)، خاصة في فهم السياق الطويل (long context) والفيديو، حيث وصل إلى مستويات رائدة، وتفوق على الإصدارات السابقة في WebDev Arena. وفي مؤتمر Google Cloud Next ‘25، أعلنت Google عن أكثر من 200 تحديث، بما في ذلك Gemini 2.5 Flash و Imagen 3 و Veo 2 و Vertex AI Agent Development Kit (ADK) وبروتوكول Agent2Agent (A2A)، مما يؤكد عزمها على دمج الذكاء الاصطناعي في جميع مستويات منصتها السحابية (cloud platform) ودفع عجلة تطبيقه على نطاق واسع في المؤسسات. كما تواصل Google Labs احتضان منتجات ابتكارية أصلية للذكاء الاصطناعي (AI-native innovative products)، مثل NotebookLM وغيرها، مما يدل على قدرتها القوية على ابتكار المنتجات وتحديثها (المصدر: Google, GoogleDeepMind)
Nvidia تطلق حاسوبًا فائقًا للذكاء الاصطناعي على مستوى سطح المكتب وحلول مصانع الذكاء الاصطناعي للمؤسسات: أعلنت Nvidia في مؤتمر Computex عن العديد من المنتجات الهامة، بما في ذلك حاسوب الذكاء الاصطناعي الشخصي DGX Station المزود بشريحة GB300 الفائقة، والذي يتمتع بذاكرة موحدة (unified memory) تصل إلى 784GB ويدعم تشغيل نماذج لغة كبيرة بمعاملات 1T؛ بالإضافة إلى RTX PRO Server الموجه للمؤسسات، والذي يمكنه تسريع تطبيقات وكلاء الذكاء الاصطناعي، والذكاء الاصطناعي الفيزيائي، والحوسبة العلمية وغيرها. وفي الوقت نفسه، أطلقت Nvidia تقنية NVLink Fusion شبه المخصصة ومنصة بيانات NVIDIA AI، وأعلنت عن تعاونها مع Disney وغيرها لتطوير محرك الذكاء الاصطناعي الفيزيائي Newton. تشير هذه المبادرات إلى أن Nvidia تتحول من شركة شرائح إلى شركة بنية تحتية للذكاء الاصطناعي (AI infrastructure company)، بهدف بناء نظام بيئي متكامل للذكاء الاصطناعي من سطح المكتب إلى مراكز البيانات (المصدر: nvidia, 量子位)

🎯 أحدث التطورات
Kimi.ai تطلق نموذج التفكير في النصوص الطويلة kimi-thinking-preview: أطلقت Kimi.ai أحدث نماذجها للتفكير في النصوص الطويلة kimi-thinking-preview، وهو متاح الآن على platform.moonshot.ai. يُقال إن النموذج يتمتع بقدرات متميزة في الوسائط المتعددة والاستدلال، ويمكن للمستخدمين الجدد الحصول على قسيمة بقيمة 5 دولارات لتجربته. تقترح تعليقات المجتمع أن يتم تقييم النموذج من قبل طرف ثالث، وتشير إلى أن Kimi قد حققت بالفعل الريادة على livecodebench من خلال نموذج تفكير مخصص (المصدر: X)
Red Hat تطلق llm-d: إطار عمل للاستدلال الموزع (distributed inference framework) قائم على Kubernetes: لمعالجة مشاكل بطء سرعة استدلال نماذج اللغة الكبيرة (LLM) وارتفاع تكلفتها وصعوبة توسيعها، أطلقت Red Hat إطار عمل llm-d، وهو إطار عمل أصلي لـ Kubernetes للاستدلال الموزع. يستفيد هذا الإطار من vLLM، والجدولة الذكية، والحوسبة المنفصلة لتحسين استدلال LLM. يعتمد llm-d على ثلاثة أسس مفتوحة المصدر: vLLM (محرك استدلال LLM عالي الأداء)، و Kubernetes (معيار تنسيق الحاويات)، و Inference Gateway (IGW) (الذي يحقق التوجيه الذكي من خلال توسيع Gateway API)، ويهدف إلى تحسين كفاءة وقابلية توسيع استدلال LLM (المصدر: X, X)
Meta AI تطلق مجموعة بيانات OMol25، تحتوي على أكثر من 100 مليون متشكل جزيئي (molecular conformers): أطلقت Meta AI مجموعة بيانات OMol25 على HuggingFace، والتي تحتوي على أكثر من 100 مليون متشكل جزيئي، تغطي 83 عنصرًا وبيئات كيميائية متنوعة. تهدف مجموعة البيانات هذه إلى تدريب نماذج تعلم الآلة القادرة على تحقيق دقة على مستوى نظرية الكثافة الوظيفية (DFT)، مع تقليل تكاليف الحوسبة بشكل كبير. سيساعد هذا في تسريع البحث والتطبيق في مجالات مثل اكتشاف الأدوية (drug discovery)، وتصميم المواد المتقدمة (advanced materials design)، وحلول الطاقة النظيفة (clean energy solutions) (المصدر: X)
Gemini 2.5 Pro متوفر في تطبيق NotebookLM على متجر تطبيقات iOS في ألمانيا: أصبح تطبيق NotebookLM من Google (المدمج مع Gemini 2.5 Pro) متاحًا في متجر تطبيقات iOS في ألمانيا، بعد أن كان متاحًا سابقًا في إصدار iOS لمنطقة الاتحاد الأوروبي عبر TestFlight فقط. وفي الوقت نفسه، يبدو أن إصدار Android متاح على نطاق أوسع. يهدف NotebookLM إلى مساعدة المستخدمين على فهم ومعالجة المستندات الطويلة والملاحظات والمحتويات الأخرى (المصدر: X)
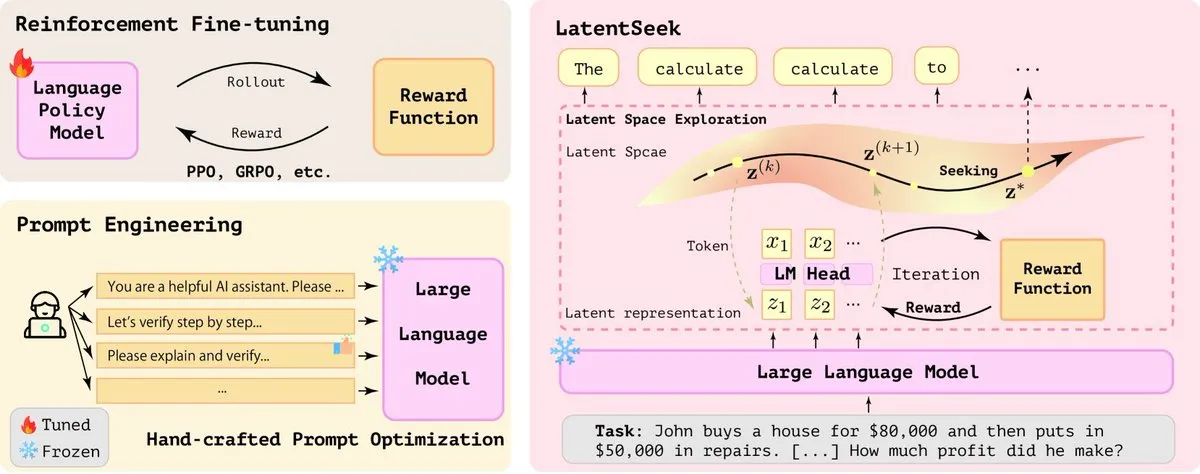
ByteDance نشطة في أبحاث الذكاء الاصطناعي، وتنشر العديد من الأوراق البحثية مؤخرًا: نشر فريق SEED التابع لشركة ByteDance ما لا يقل عن 13 ورقة بحثية متعلقة بالذكاء الاصطناعي خلال الشهرين الماضيين، تشمل مجالات مثل دمج النماذج (model merging)، وسلسلة الفكر التكيفية المحفزة بالتعلم المعزز (AdaCoT)، وتحسين الاستدلال من خلال التمثيل الكامن (LatentSeek)، وغيرها. تُظهر هذه الأبحاث استثمار ByteDance المستمر واستكشافها لتعزيز كفاءة نماذج اللغة الكبيرة وقدراتها الاستدلالية وأساليب تدريبها (المصدر: X, X)
الذكاء الاصطناعي يقود الجيل القادم من بطاريات الزنك لتحقيق كفاءة 99.8% وعمر تشغيل 4300 ساعة: من خلال التحسين بواسطة الذكاء الاصطناعي، حقق الجيل الجديد من بطاريات الزنك كفاءة كولومبية (Coulombic efficiency) بنسبة 99.8% وعمر تشغيل يصل إلى 4300 ساعة. يُظهر هذا الاختراق التكنولوجي إمكانات تطبيق الذكاء الاصطناعي في علوم المواد وتخزين الطاقة، ومن المتوقع أن يدفع عجلة تطوير تكنولوجيا بطاريات أكثر كفاءة واستدامة، وهو أمر ذو أهمية كبيرة لتخزين الطاقة المتجددة والأجهزة الإلكترونية المحمولة (المصدر: X)

Perplexity تطلق متصفح Comet الذكي المعتمد على الذكاء الاصطناعي للاختبار المبكر: بدأت Perplexity في طرح متصفح الويب Comet الذي يتمتع بقدرات وكيل ذكي للمختبرين الأوائل. من المتوقع أن يوفر هذا المتصفح تجربة “تصفح بالأجواء (vibe browsing)” جديدة تمامًا، وقد يجمع بين قدرات Perplexity القوية في البحث بالذكاء الاصطناعي وتكامل المعلومات، ليقدم للمستخدمين طريقة تصفح ويب أكثر ذكاءً وتخصيصًا (المصدر: X)
Intel تطلق سلسلة بطاقات الرسوميات Arc Pro B عالية القيمة مع ذاكرة فيديو كبيرة (large VRAM): أطلقت Intel بطاقتي الرسوميات Arc Pro B50 (ذاكرة فيديو 16GB، بسعر 299 دولارًا) و Arc Pro B60 (ذاكرة فيديو 24GB، بسعر 500 دولار للبطاقة الواحدة) المصممة خصيصًا لمحطات عمل الذكاء الاصطناعي. أظهرت B60 أداءً أفضل من Nvidia RTX A1000 في اختبارات استدلال الذكاء الاصطناعي (AI inference tests)، كما أن ذاكرة الفيديو الأكبر تمنحها ميزة عند تشغيل النماذج الكبيرة. تستخدم محطة عمل Project Battlematrix معالجات Xeon، ويمكن تزويدها بما يصل إلى 8 وحدات معالجة رسوميات B60 (إجمالي ذاكرة فيديو 192GB)، وتدعم نماذج بمعاملات تزيد عن 70 مليار. يُنظر إلى هذه الخطوة على أنها استراتيجية من Intel للسعي نحو تحقيق اختراق في سوق أجهزة الذكاء الاصطناعي من حيث القيمة مقابل السعر (المصدر: 量子位)

Huawei Cloud تطلق عقدة CloudMatrix 384 الفائقة (supernode) لتعزيز قوة الحوسبة للذكاء الاصطناعي: أطلقت Huawei Cloud عقدة CloudMatrix 384 الفائقة، التي تعتمد بنية مترابطة بالكامل من نظير إلى نظير (fully peer-to-peer interconnected architecture)، ويمكنها ربط 384 بطاقة تسريع للذكاء الاصطناعي (AI accelerator cards) لتشكيل خادم سحابي فائق، يوفر قوة حوسبة تصل إلى 300Pflops، بهدف مواجهة تحديات كفاءة الاتصال، وجدار الذاكرة، والموثوقية في تدريب واستدلال الذكاء الاصطناعي. تؤكد هذه البنية بشكل خاص على توافقها مع نماذج MoE (MoE models)، وتعزيز الحوسبة بالشبكات، وتعزيز الحوسبة بالتخزين، وقد تم تطبيقها بالفعل لدعم خدمات استدلال النماذج الكبيرة مثل DeepSeek-R1 (المصدر: 量子位)

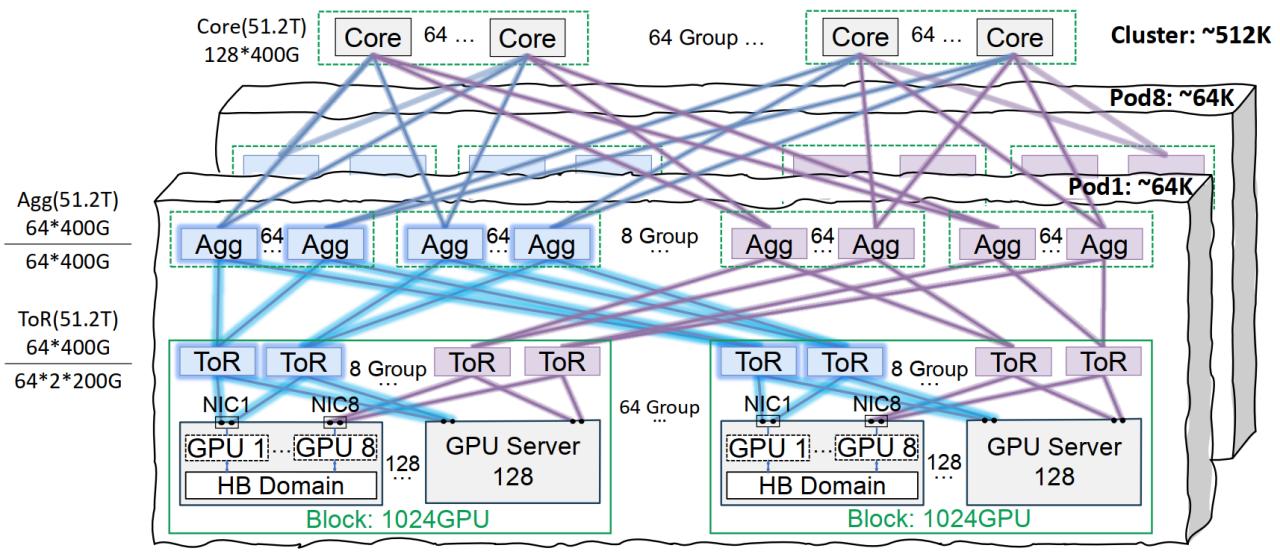
بنية تحتية لشبكة Xingmai من Tencent Cloud تُحسّن تدريب النماذج الكبيرة: أطلقت Tencent Cloud حل البنية التحتية لشبكة Xingmai عالية الأداء، المصمم خصيصًا لتدريب واستدلال نماذج الذكاء الاصطناعي واسعة النطاق. يعالج هذا الحل نقاط الضعف في مراكز البيانات التقليدية من حيث الشبكات وكثافة النشر وتحديد الأعطال، وذلك من خلال بنية مترابطة على نفس المسار (تدعم شبكة تضم 64 ألف وحدة معالجة رسوميات لكل Pod و 512 ألف وحدة معالجة رسوميات للمجموعة بأكملها)، وحلول محسّنة لإدارة الطاقة والتبريد، ونظام مراقبة ذكي. تدعم Xingmai بالفعل أعمال Tencent المطورة ذاتيًا مثل Hunyuan، وقدمت تحسينًا للأداء لإطار اتصالات DeepEP الخاص بـ DeepSeek (المصدر: 量子位)
Stability AI تطلق نموذج SV4D2.0، مما قد يشير إلى عودتها في مجال توليد الفيديو (video generation domain): أطلقت Stability AI نموذجًا باسم sv4d2.0 على Hugging Face، مما أثار اهتمام المجتمع. على الرغم من قلة التفاصيل المحددة، قد تعني هذه الخطوة أن Stability AI لديها تطورات تقنية جديدة أو تحديثات للمنتجات في مجال توليد الفيديو أو المجالات ثلاثية/رباعية الأبعاد ذات الصلة، مما يشير إلى أنها قد تعود إلى طليعة مجال التوليد بالذكاء الاصطناعي بعد فترة من التعديلات (المصدر: X)
Meta AI تطلق خوارزمية التعلم Adjoint Sampling: اقترحت Meta AI خوارزمية تعلم جديدة تسمى Adjoint Sampling، لتدريب النماذج التوليدية القائمة على مكافأة عددية (scalar reward). تعتمد هذه الخوارزمية على أساس نظري طورته FAIR، وتتمتع بقابلية عالية للتوسع، ومن المتوقع أن تصبح أساسًا لأبحاث طرق أخذ العينات القابلة للتطوير (scalable sampling methods) في المستقبل. تم نشر الورقة البحثية والنماذج والشيفرة البرمجية والمعايير ذات الصلة (المصدر: X)
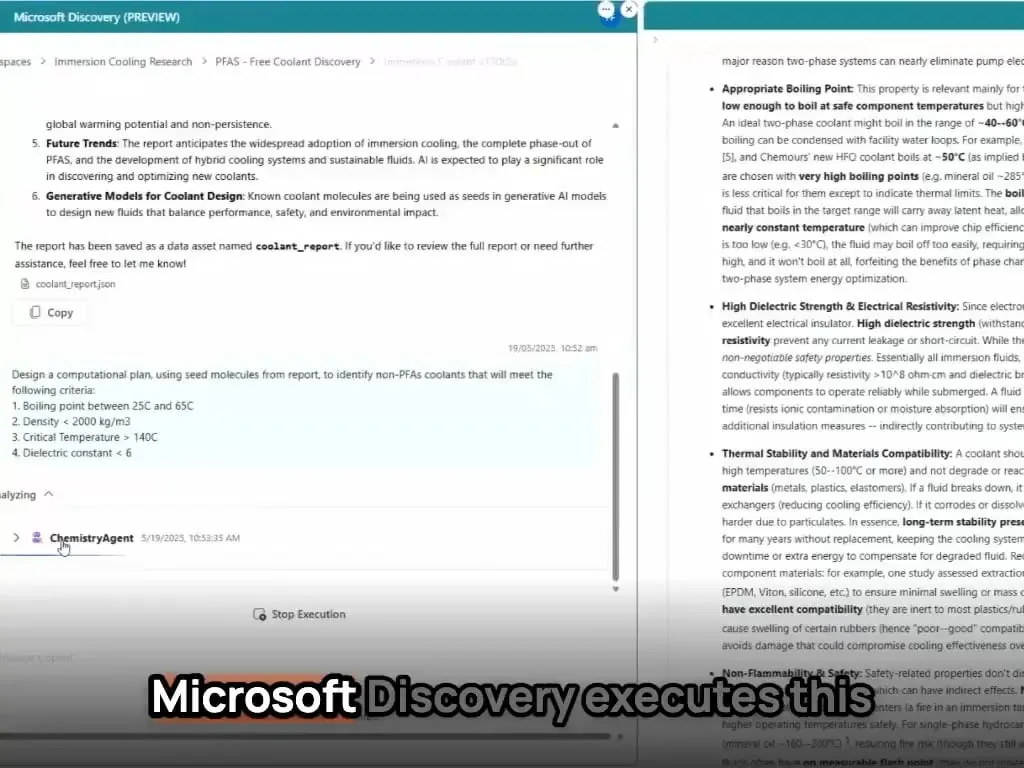
وكلاء الذكاء الاصطناعي من Microsoft يكملون اكتشاف وتصنيع مواد جديدة في غضون ساعات: عرضت Microsoft القدرات القوية لوكلائها في مجال البحث والتطوير العلمي. تستطيع هذه الوكلاء مسح المؤلفات العلمية، ووضع الخطط، وكتابة الشيفرة البرمجية، وتشغيل المحاكاة، وإكمال اكتشاف مبرد جديد لمراكز البيانات في غضون ساعات، وهو ما يتطلب عادةً سنوات من البحث والتطوير. علاوة على ذلك، نجح الفريق في تصنيع المبرد الجديد الذي صممه الذكاء الاصطناعي وقام بعرضه على لوحة أم فعلية، مما يُظهر الإمكانات الهائلة للذكاء الاصطناعي في تسريع الاكتشاف والابتكار الذاتي في مجالات مثل علوم المواد (المصدر: Reddit r/artificial)
معهد أبحاث بكين للذكاء الاصطناعي (BAAI) يطلق ثلاثة نماذج متجهات (vector models) من سلسلة BGE، تركز على استرجاع الشيفرات البرمجية والوسائط المتعددة (code and multimodal retrieval): أطلق معهد أبحاث بكين للذكاء الاصطناعي بالتعاون مع جامعات BGE-Code-v1 (نموذج متجه للشيفرات البرمجية)، و BGE-VL-v1.5 (نموذج متجه عام متعدد الوسائط)، و BGE-VL-Screenshot (نموذج متجه للمستندات المرئية). أظهرت هذه النماذج أداءً متميزًا في اختبارات CoIR، و Code-RAG، و MMEB، و MVRB وغيرها. يعتمد BGE-Code-v1 على Qwen2.5-Coder-1.5B، ويعتمد BGE-VL-v1.5 على LLaVA-1.6، ويعتمد BGE-VL-Screenshot على Qwen2.5-VL-3B-Instruct. تهدف هذه النماذج إلى تحسين أداء استرجاع الشيفرات البرمجية، وفهم النصوص والصور، واسترجاع المستندات المرئية المعقدة، وقد تم فتح مصدرها بالكامل (المصدر: WeChat)
تقنية OmniPlacement من Huawei تُحسّن استدلال نماذج MoE، وتقلل نظريًا من كمون (latency) DeepSeek-V3 بنسبة 10%: لمعالجة مشكلة عدم توازن حمل شبكة الخبراء (unbalanced load in expert networks) في نماذج خليط الخبراء (MoE) (مثل “الخبراء النشطون” و “الخبراء الخاملون” (‘hot experts’ and ‘cold experts’)) والتي تحد من أداء الاستدلال، اقترح فريق Huawei تقنية OmniPlacement. من خلال إعادة ترتيب الخبراء، والنشر الزائد بين الطبقات، والجدولة الديناميكية شبه الفورية، يمكن لهذه التقنية نظريًا تقليل كمون الاستدلال (inference latency) بنسبة 10% تقريبًا وزيادة الإنتاجية (throughput) بنسبة 10% تقريبًا في نماذج مثل DeepSeek-V3. سيتم فتح مصدر هذا الحل بالكامل قريبًا (المصدر: WeChat)

vivo تطلق خوارزمية EdgeInfinite، لتحقيق معالجة فعالة للنصوص الطويلة بحجم 128K على الهواتف: نشر معهد vivo AI للأبحاث دراسة في ACL 2025، وأطلق خوارزمية EdgeInfinite، المصممة خصيصًا للأجهزة الطرفية (edge devices). من خلال وحدة ذاكرة بوابية قابلة للتدريب (trainable gated memory module) وتقنيات ضغط/فك ضغط الذاكرة (memory compression/decompression techniques)، تعالج هذه الخوارزمية النصوص الطويلة جدًا بكفاءة في بنية Transformer. تم اختبار الخوارزمية على نموذج BlueLM-3B، ويمكنها معالجة 128 ألف رمز (tokens) على جهاز بذاكرة GPU سعة 10GB، وأظهرت أداءً متميزًا في العديد من مهام LongBench، مع تقليل كبير في زمن إخراج الكلمة الأولى (first-token latency) واستهلاك الذاكرة (المصدر: WeChat)

🧰 الأدوات
تحديثات LlamaParse، تعزيز قدرات تحليل المستندات (document parsing): أصدرت LlamaParse العديد من التحديثات، مما أدى إلى تحسين أدائها كأداة تحليل مستندات مدفوعة بوكلاء الذكاء الاصطناعي. تشمل الميزات الجديدة دعم Gemini 2.5 Pro و GPT-4.1، وإضافة كشف الانحراف (skew detection) ودرجات الثقة (confidence scores). بالإضافة إلى ذلك، تم تقديم زر لمقتطفات الشيفرة البرمجية، لتسهيل نسخ تكوينات التحليل مباشرة إلى مستودعات الشيفرة البرمجية، وإضافة إعدادات مسبقة لحالات الاستخدام (use case presets) والقدرة على التبديل بين تصدير Markdown المعروض أو الخام (المصدر: X)
Hugging Face تطلق حزمة Tiny Agents NPM: أطلق Julien Chaumond حزمة Tiny Agents، وهي حزمة NPM للوكلاء خفيفة الوزن وقابلة للتركيب (composable agent NPM package). تعتمد على Inference Client من Hugging Face ومكدس MCP (Model Component Protocol)، وتهدف إلى تسهيل بدء المطورين بسرعة وبناء تطبيقات وكلاء صغيرة. يتوفر برنامج تعليمي رسمي للبدء (المصدر: X)
منصة LangGraph تضيف دعم MCP، لتبسيط تكامل الوكلاء: تدعم منصة LangGraph الآن بروتوكول مكونات النموذج (MCP – Model Component Protocol)، حيث يكشف كل وكيل يتم نشره على المنصة تلقائيًا عن نقطة نهاية MCP. هذا يعني أنه يمكن للمستخدمين الاستفادة من هذه الوكلاء كأدوات، واستخدامها في أي عميل HTTP يدعم التدفق (streamable HTTP client) ومتوافق مع MCP، دون الحاجة إلى كتابة شيفرة برمجية مخصصة أو تكوين بنية تحتية إضافية، مما يبسط التكامل والتشغيل البيني بين الوكلاء (المصدر: X)

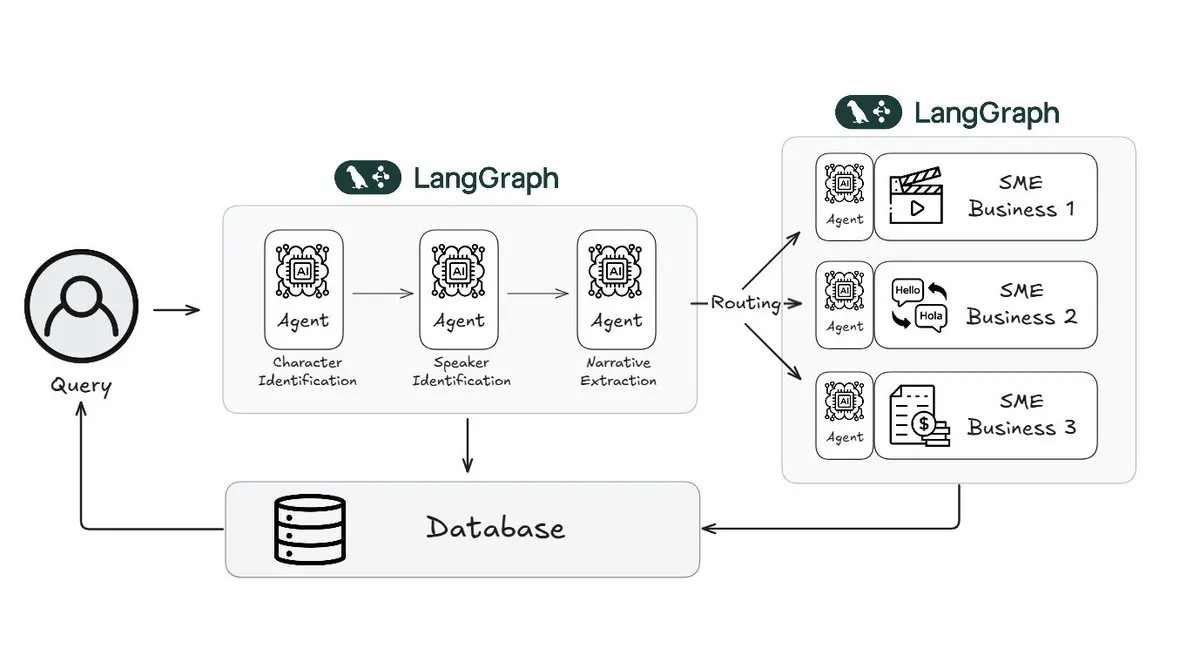
Webtoon تستخدم LangGraph لتقليل عبء عمل مراجعة القصص (story review) بنسبة 70%: قامت Webtoon، الشركة الرائدة في مجال القصص المصورة الرقمية، ببناء Webtoon Comprehension AI (WCAI)، باستخدام LangGraph لأتمتة فهم السرد (narrative comprehension) لمكتبتها الضخمة من المحتوى. يستبدل WCAI التصفح اليدوي بوكلاء أذكياء متعددة الوسائط، قادرين على التعرف على الشخصيات والمتحدثين، واستخلاص الحبكة والنبرة، والاستعلام عن الرؤى باللغة الطبيعية، مما قلل من عبء عمل فرق التسويق والترجمة والتوصيات بنسبة 70% وعزز الإبداع (المصدر: X)
OpenMemory MCP يحقق مشاركة ذاكرة خاصة دائمة (persistent private memory sharing) بين أدوات الذكاء الاصطناعي: أطلق مشروع Mem0 خادم OpenMemory MCP، بهدف توفير ذاكرة خاصة دائمة عبر المنصات والجلسات لتطبيقات الذكاء الاصطناعي. يمكن للمستخدمين نشره محليًا، وربط OpenMemory بأدوات عميلة مثل Cursor عبر بروتوكول MCP، لتحقيق إضافة الذاكرة والبحث فيها وسردها وحذفها. توفر هذه الأداة وظائف إدارة الذاكرة من خلال لوحة تحكم، ومن المتوقع أن تعزز قدرات التخصيص وفهم السياق لدى وكلاء الذكاء الاصطناعي (المصدر: WeChat)

إطلاق Miaoduo AI 2.0، كمساعد ذكاء اصطناعي لتصميم الواجهات (AI assistant for interface design): تم إطلاق Miaoduo AI 2.0 كمساعد ذكاء اصطناعي في مجال تصميم الواجهات، يهدف إلى التعاون مع المستخدمين لإكمال مهام التصميم. يعزز الإصدار الجديد التفاعل من خلال مربع سحري للذكاء الاصطناعي، ويدعم التحرير الحواري (conversational editing) وتصميم الحلول التكرارية، ويمكنه إنشاء إصدارات متعددة من الواجهات بناءً على أنماط محددة مسبقًا أو مدخلات المستخدم (نصوص طويلة، رسومات تخطيطية، صور مرجعية)، ويتوافق مع أنظمة التصميم السائدة. بالإضافة إلى ذلك، يوفر وظائف معالجة الصور والنصوص (image and text processing)، واستشارات التصميم (design consultation)، وأوامر سريعة (تحويل اللغة الطبيعية إلى استدعاءات API) (quick commands (natural language to API calls)). يدعم Miaoduo AI بروتوكول MCP، ويحسن بيانات مسودات التصميم ليقرأها النموذج الكبير، وذلك لإنشاء شيفرة برمجية للواجهة الأمامية عالية الدقة (المصدر: 量子位)

llmbasedos: إثبات مفهوم لنظام تشغيل ذكاء اصطناعي قابل للإقلاع (proof-of-concept for a bootable AI operating system) مفتوح المصدر قائم على MCP: قام المطور iluxu بفتح مصدر مشروع llmbasedos قبل ثلاثة أيام من إعلان Microsoft عن مفهوم “USB-C for AI apps” (القائم على MCP). هذا المشروع هو نظام تشغيل ذكاء اصطناعي يمكن إقلاعه بسرعة من USB أو جهاز افتراضي، ويتواصل عبر بوابة FastAPI باستخدام JSON-RPC مع عمليات خفيفة بلغة Python، مما يسمح باستدعاء نصوص المستخدم من خلال تكوين بسيط لـ cap.json بواسطة ChatGPT/Claude/VS Code وغيرها. يستخدم افتراضيًا llama.cpp دون اتصال بالإنترنت، ويمكن أيضًا التبديل إلى GPT-4o أو Claude 3، ويهدف إلى تعزيز معايير اتصال تطبيقات الذكاء الاصطناعي المفتوحة (المصدر: Reddit r/LocalLLaMA)
📚 التعلم
لماذا يعتبر تقطير المعرفة (KD – Knowledge Distillation) فعالاً؟ بحث جديد يقدم تفسيراً موجزاً: قدم Kyunghyun Cho وآخرون تفسيراً موجزاً لفعالية تقطير المعرفة (KD). يفترضون أن استخدام أخذ العينات التقريبي منخفض الاعتلاج (low-entropy approximate sampling) من نموذج المعلم يؤدي إلى أن يكون لدى نموذج الطالب دقة أعلى ولكن معدل استرجاع أقل (higher precision but lower recall). نظراً لأن نماذج اللغة ذاتية الانحدار (autoregressive language models) هي في جوهرها توزيعات مختلطة متتالية لا نهائية (infinitely cascaded mixture distributions)، فقد تحققوا من هذه الفرضية من خلال SmolLM. يرى البحث أن طرق التقييم الحالية قد تركز بشكل مفرط على الدقة، وتتجاهل فقدان معدل الاسترجاع، وهو ما يتعلق بالمحتوى ومجموعات المستخدمين التي قد تتجاهلها النماذج العامة واسعة النطاق (المصدر: X)

LatentSeek: تحسين قدرات استدلال نماذج اللغة الكبيرة (LLM) من خلال تحسين تدرج السياسة في الفضاء الكامن (latent space policy gradient optimization): تقترح ورقة بحثية بعنوان “Seek in the Dark” طريقة LatentSeek، وهي نموذج جديد لتعزيز قدرات استدلال نماذج اللغة الكبيرة (LLM) في وقت الاختبار من خلال تدرج السياسة على مستوى المثيل في الفضاء الكامن. لا تتطلب هذه الطريقة تدريباً أو بيانات أو نماذج مكافأة، وتهدف إلى تحسين عملية استدلال النموذج من خلال تحسين التمثيل الكامن. تُظهر هذه الطريقة المستقلة عن التدريب إمكانات في تحسين أداء مهام الاستدلال المعقدة لنماذج اللغة الكبيرة (المصدر: X)
Microsoft تقترح CoML: تعلم النموذج المتسلسل (Chain-of-Model Learning, CoML) لنماذج اللغة: اقترح باحثو Microsoft نموذج تعلم جديد يسمى “تعلم النموذج المتسلسل” (CoML). تدمج هذه الطريقة العلاقات السببية للحالات المخفية (causal relationships of hidden states) في بنية متسلسلة في كل طبقة شبكة، بهدف تحسين كفاءة توسيع تدريب النموذج ومرونة الاستدلال (elastic inference) عند النشر. يقسم مفهومها الأساسي “التمثيل المتسلسل” (CoR – Chain-of-Representation) الحالة المخفية لكل طبقة إلى سلاسل تمثيل فرعية متعددة، حيث يمكن للسلاسل اللاحقة الوصول إلى تمثيلات الإدخال لجميع السلاسل السابقة، مما يسمح للنموذج بالتوسع التدريجي عن طريق إضافة سلاسل، والقدرة على توفير نماذج فرعية متعددة الأحجام للاستدلال المرن عن طريق اختيار أعداد مختلفة من السلاسل. يُظهر CoLM (نموذج اللغة المتسلسل) المصمم بناءً على هذا المبدأ ومتغيره CoLM-Air (الذي يقدم آلية مشاركة KV) أداءً مكافئًا لـ Transformer القياسي، ويجلب مزايا التوسع التدريجي والاستدلال المرن (المصدر: X, HuggingFace Daily Papers)

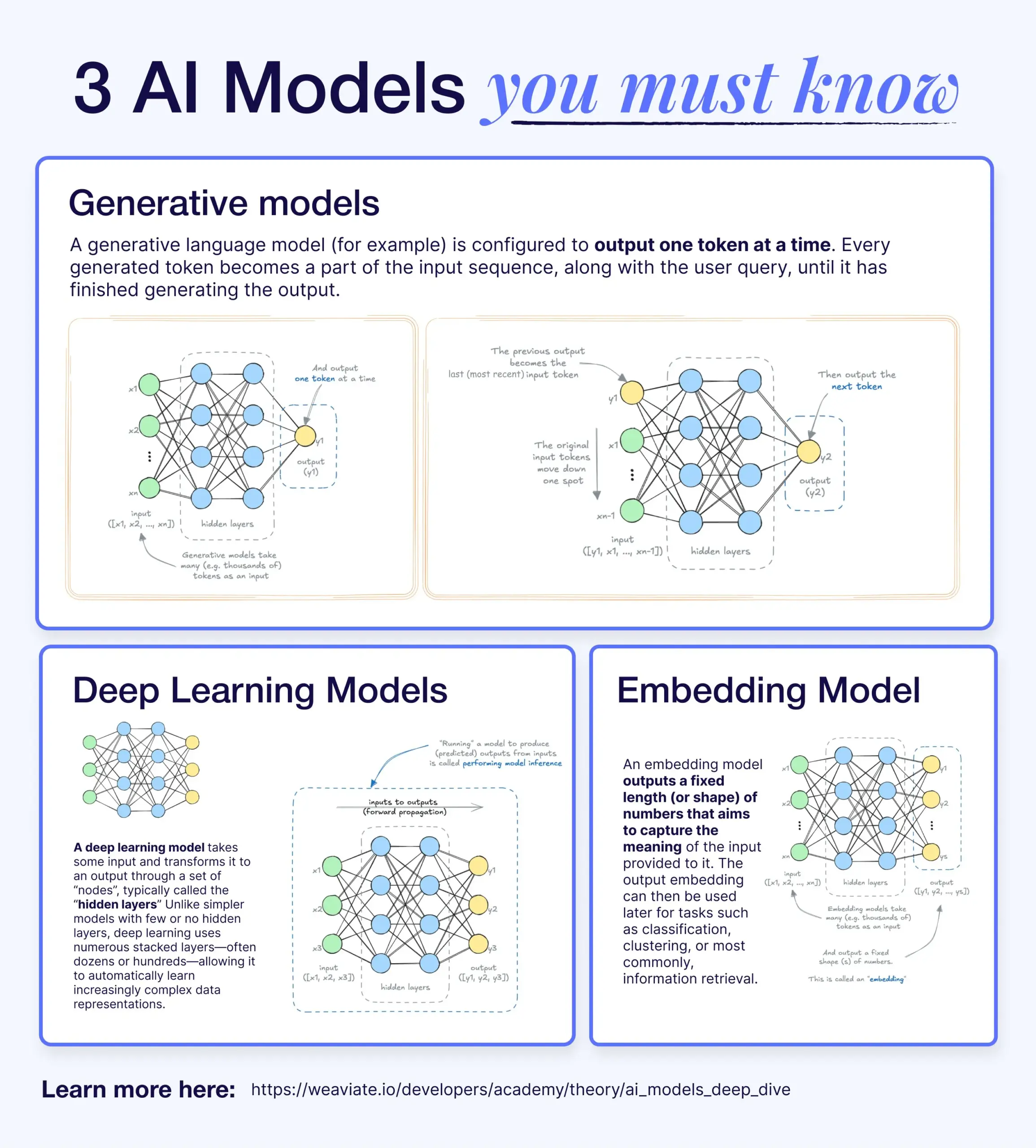
الفرق والعلاقة بين نماذج التعلم العميق، النماذج التوليدية، ونماذج التضمين (Deep Learning models, Generative Models, and Embedding Models): تشرح مقالة توعوية العلاقة بين نماذج التعلم العميق والنماذج التوليدية ونماذج التضمين. نماذج التعلم العميق هي البنية الأساسية، وتعالج المدخلات والمخرجات العددية من خلال شبكات عصبونية متعددة الطبقات. النماذج التوليدية هي نوع من نماذج التعلم العميق، متخصصة في إنشاء محتوى جديد مشابه لبيانات تدريبها (مثل GPT، DALL-E). نماذج التضمين هي أيضًا نوع من نماذج التعلم العميق، تُستخدم لتحويل البيانات (نصوص، صور، إلخ) إلى تمثيلات متجهة عددية تلتقط معلومات دلالية (semantic information)، وغالبًا ما تُستخدم في بحث التشابه (similarity search) وأنظمة RAG (RAG systems). في العديد من أنظمة الذكاء الاصطناعي، تعمل هذه النماذج معًا، على سبيل المثال، تستخدم أنظمة RAG نماذج التضمين للاسترجاع، ثم تقوم النماذج التوليدية بإنشاء الردود (المصدر: X)
DSPy تقترح فلسفة الاستثمار في أنظمة الذكاء الاصطناعي (philosophy of investment in AI systems): شاركت DSPy فلسفتها بشأن الاستثمار في أنظمة الذكاء الاصطناعي، مؤكدة على ضرورة تركيز الجهود على ثلاث طبقات أساسية لأنظمة الذكاء الاصطناعي: البيانات، والنماذج، والخوارزميات. يعتقدون أنه من خلال توفير وحدات علوية قابلة للتركيب (composable top-level modules) (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules)، يمكن للمطورين تكرار هذه الطبقات الأساسية الثلاث بسرعة، وبالتالي بناء أنظمة ذكاء اصطناعي أكثر قوة (المصدر: X)
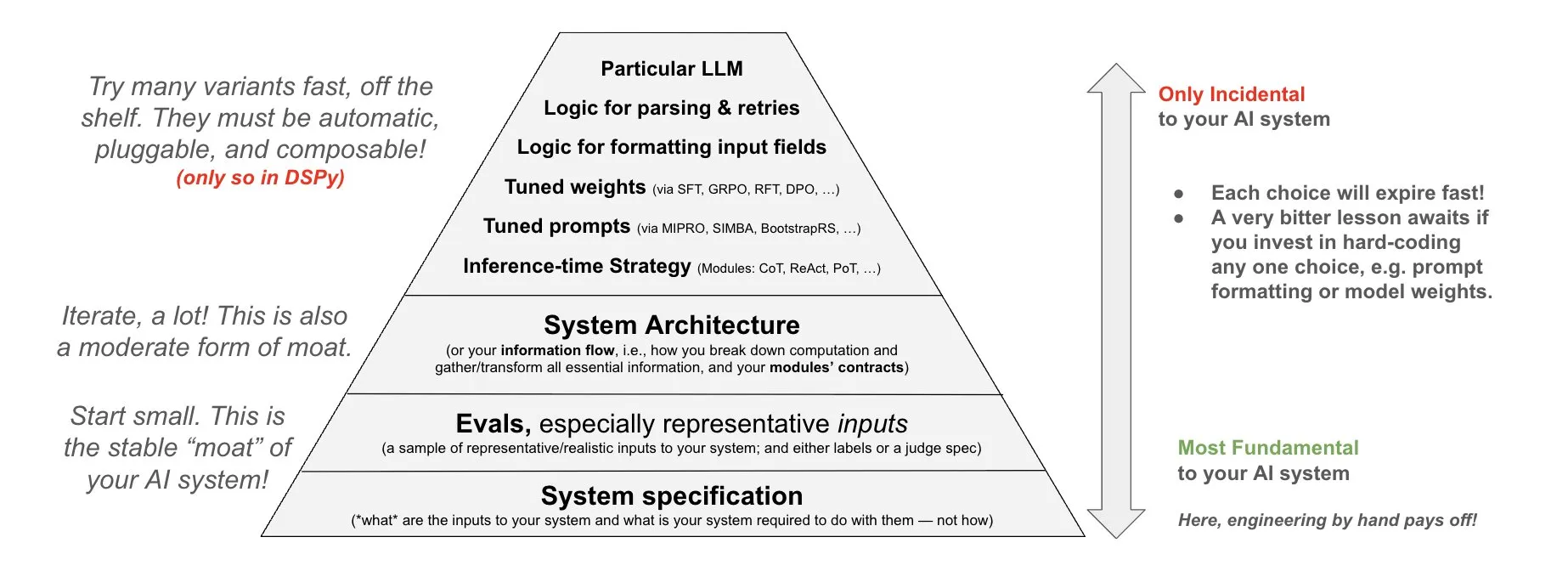
تحديث مكتبة Transformers، التبديل التلقائي إلى أنوية محسّنة (optimized kernels) لتعزيز الأداء: يحقق أحدث إصدار من مكتبة Hugging Face Transformers التبديل التلقائي إلى أنوية محسّنة عندما يسمح الجهاز بذلك. يدمج هذا التحديث مكتبة kernels، ويستهدف النماذج الشائعة مثل Llama، ويستفيد من أنوية المجتمع الأكثر شيوعًا على Hugging Face Hub، بهدف تحسين كفاءة تشغيل النموذج وأدائه على الأجهزة المتوافقة (المصدر: X)
إصدار معيار ARC-AGI-2، يتحدى أنظمة استدلال الذكاء الاصطناعي الرائدة: نشر François Chollet وآخرون ورقة بحثية حول معيار ARC-AGI-2، توضح بالتفصيل مبادئ تصميمه، وتحدياته، وتحليل الأداء البشري، وأداء النماذج الحالية. يهدف هذا المعيار إلى تقييم قدرات التفكير المجرد (abstract reasoning abilities) للذكاء الاصطناعي، حيث يمكن للبشر حل 100% من المهام، بينما تقل درجة نماذج الذكاء الاصطناعي الرائدة الحالية عن 5%، مما يُظهر فجوة هائلة لا تزال قائمة بين الذكاء الاصطناعي والبشر في التفكير المجرد المتقدم (المصدر: X)

Terence Tao ينشر برنامجًا تعليميًا لإثبات نهايات الدوال بمساعدة GitHub Copilot: نشر عالم الرياضيات Terence Tao برنامجًا تعليميًا بالفيديو يوضح كيفية استخدام GitHub Copilot للمساعدة في إثبات مسائل نهايات الدوال، بما في ذلك نظريات الجمع والطرح والضرب. وأكد أنه على الرغم من أن Copilot يمكنه إنشاء أطر الشيفرة البرمجية بسرعة واقتراح دوال المكتبات الموجودة، إلا أنه لا يزال يتطلب تدخلًا وتعديلًا بشريًا كبيرًا في التفاصيل الرياضية المعقدة، ومعالجة الحالات الخاصة، والحلول الإبداعية، وفي بعض الأحيان قد يكون الجمع بين الاستدلال بالورقة والقلم ثم التحقق الرسمي أكثر كفاءة (المصدر: 36氪)
إطار PhyT2V يستخدم نماذج اللغة الكبيرة (LLM) لتعزيز الاتساق الفيزيائي في تحويل النص إلى فيديو (physical consistency in text-to-video): اقترح فريق بحثي من جامعة بيتسبرغ إطار PhyT2V، الذي يحسن التلقينات النصية من خلال الاستدلال المتسلسل (CoT – Chain-of-Thought) الموجه بنماذج اللغة الكبيرة وآلية التصحيح الذاتي التكرارية (iterative self-correction mechanism)، وذلك لتعزيز الواقعية الفيزيائية للمحتوى الذي تولده نماذج تحويل النص إلى فيديو (T2V) الحالية. لا تتطلب هذه الطريقة إعادة تدريب النماذج، بل تحلل عدم التطابق الدلالي بين الفيديو الذي تم إنشاؤه بالفعل والتلقين، وتدمج القواعد الفيزيائية لتصحيح التلقين، بهدف تحسين الاتساق الفيزيائي لنماذج T2V عند معالجة سيناريوهات خارج التوزيع (OOD – Out-of-Distribution). أظهرت التجارب أن PhyT2V يمكن أن يحسن بشكل كبير أداء نماذج مثل CogVideoX و OpenSora على معايير مثل VideoPhy و PhyGenBench (المصدر: WeChat)

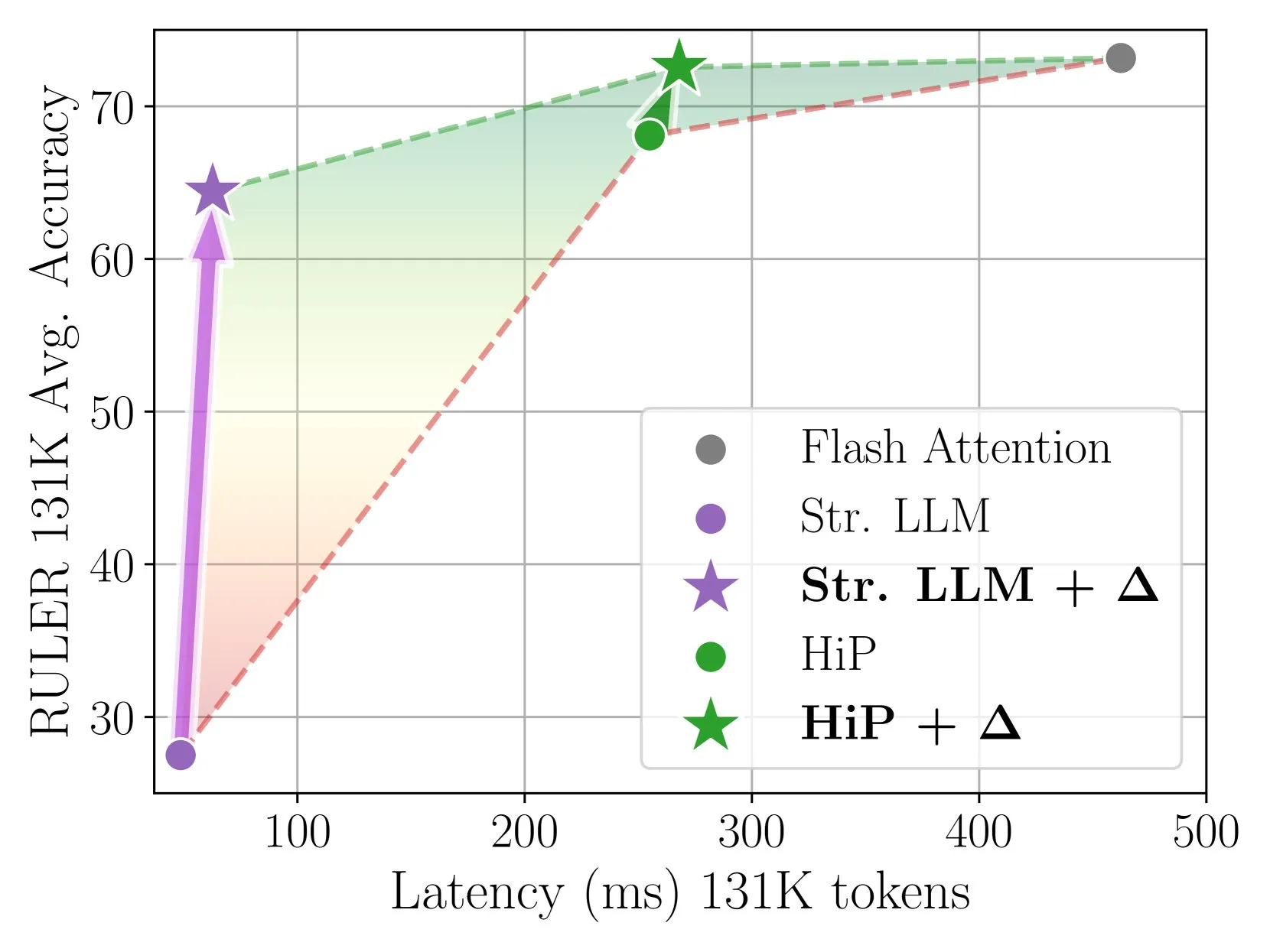
Delta Attention تحقق استدلال انتباه متناثر (sparse attention inference) سريع ودقيق من خلال التصحيح التزايدي: وجدت هذه الدراسة أن حساب الانتباه المتناثر يؤدي إلى انحراف التوزيع (distribution shift) في مخرجات الانتباه، مما يقلل من أداء النموذج. تقوم Delta Attention بتصحيح هذا الانحراف في التوزيع، مما يجعل توزيع مخرجات الانتباه المتناثر أقرب إلى الانتباه الكامل، وبالتالي، مع الحفاظ على درجة تناثر عالية (حوالي 98.5%)، تحسن الأداء بشكل كبير، وتستعيد 88% من دقة الانتباه الكامل لانتباه النافذة المنزلقة (مع sink token) (sliding window attention (with sink token)) على معيار RULER، وبتكلفة حسابية صغيرة. عند معالجة تعبئة مسبقة لـ 1 مليون رمز (token)، تكون أسرع بـ 32 مرة من Flash Attention 2 (المصدر: HuggingFace Daily Papers)
إطار Thinkless يمكّن نماذج اللغة الكبيرة (LLM) من تعلم متى يتم إجراء استدلال CoT (when to perform CoT reasoning): لمعالجة مشكلة انخفاض كفاءة الحوسبة الناتجة عن استخدام نماذج اللغة الكبيرة (LLM) لاستدلال سلسلة الفكر (CoT) المعقد في جميع الاستعلامات، اقترح الباحثون إطار Thinkless. يقوم هذا الإطار بتدريب LLM من خلال التعلم المعزز، لتمكينها من اختيار استدلال قصير أو طويل (short-form or long-form reasoning) بشكل تكيفي بناءً على تعقيد المهمة وقدراتها الخاصة. تقوم الخوارزمية الأساسية DeGRPO بتقسيم هدف التعلم إلى خسارة رموز التحكم (control token loss) (التي تحدد نمط الاستدلال) وخسارة الاستجابة (response loss) (لتحسين دقة الإجابة)، وبالتالي استقرار عملية التدريب. أظهرت التجارب أن Thinkless يمكن أن تقلل من استخدام التفكير المتسلسل الطويل بنسبة 50%-90% على معايير مثل Minerva Algebra، مما يحسن بشكل كبير كفاءة الاستدلال (المصدر: HuggingFace Daily Papers)
خوارزمية CPGD تعزز استقرار التعلم المعزز لنماذج اللغة القائمة على القواعد (rule-based language model reinforcement learning): لمعالجة مشكلة عدم استقرار التدريب التي قد تظهر في طرق التعلم المعزز الحالية القائمة على القواعد (مثل GRPO, REINFORCE++, RLOO) عند تدريب نماذج اللغة، اقترح الباحثون خوارزمية CPGD (تحسين تدرج السياسة المقصوص مع انحراف السياسة). تقوم CPGD بتنظيم تحديثات السياسة ديناميكيًا من خلال إدخال قيد انحراف السياسة (policy drift) القائم على تباعد KL، وتستخدم آلية قص نسبة اللوغاريتم (log-ratio clipping mechanism) لمنع تحديثات السياسة المفرطة. يُظهر التحليل النظري والتجريبي أن CPGD يمكن أن تخفف من عدم الاستقرار، وتحسن الأداء بشكل كبير مع الحفاظ على استقرار التدريب (المصدر: HuggingFace Daily Papers)
مترجم استعلام رمزي عصبي (neuro-symbolic query compiler) QCompiler يعزز قدرة أنظمة RAG على معالجة الاستعلامات المعقدة: لمعالجة مشكلة صعوبة تحديد نية البحث بدقة في أنظمة التوليد المعزز بالاسترجاع (RAG – Retrieval Augmented Generation) عند معالجة الاستعلامات المعقدة ذات الهياكل المتداخلة والعلاقات المعتمدة، خاصة في ظل محدودية الموارد، تم اقتراح إطار QCompiler. مستوحى من قواعد النحو اللغوي وتصميم المترجمات، يقوم هذا الإطار أولاً بتصميم قواعد BNF نحوية G[q] دنيا وكافية لتشكيل الاستعلامات المعقدة رسميًا، ثم يقوم بتحويل الاستعلام إلى شجرة نحو مجردة (AST – Abstract Syntax Tree) للتنفيذ من خلال محول تعبيرات الاستعلام، ومحلل نحوي معجمي، ومعالج هبوطي تكراري. تضمن ذرية الاستعلامات الفرعية في العقد الورقية استرجاع مستندات وإنشاء استجابات أكثر دقة (المصدر: HuggingFace Daily Papers)
مجموعة بيانات Jedi ومعيار OSWorld-G يدفعان بحث تحديد مواقع عناصر واجهة المستخدم الرسومية (GUI element localization research) في سيناريوهات استخدام الكمبيوتر: لمعالجة عنق الزجاجة في تحديد مواقع واجهة المستخدم الرسومية (GUI) (ربط التعليمات باللغة الطبيعية بعمليات GUI)، أصدر الباحثون معيار OSWorld-G (564 عينة ذات علامات دقيقة، تغطي مطابقة النصوص، والتعرف على العناصر، وفهم التخطيط، والعمليات الدقيقة) ومجموعة بيانات اصطناعية واسعة النطاق Jedi (4 ملايين عينة). تفوقت النماذج متعددة المقاييس المدربة على Jedi على الطرق الحالية في ScreenSpot-v2 و ScreenSpot-Pro و OSWorld-G، وتمكنت من تعزيز قدرات الوكلاء في النماذج الأساسية العامة في مهام الكمبيوتر المعقدة (OSWorld)، من 5% إلى 27% (المصدر: HuggingFace Daily Papers)
استدلال سلسلة الفكر المجزأ (Fractured CoT) يعزز كفاءة وأداء استدلال نماذج اللغة الكبيرة (LLM): لمعالجة مشكلة ارتفاع تكلفة الرموز (tokens) الناتجة عن استدلال CoT، وجد الباحثون أن CoT المبتور (إيقاف الاستدلال قبل اكتماله وإنشاء الإجابة مباشرة) يمكن أن يحقق عادةً أداءً مكافئًا لـ CoT الكامل، ولكن باستهلاك رموز أقل بكثير. بناءً على ذلك، تم اقتراح استراتيجية استدلال موحدة Fractured Sampling، من خلال تعديل ثلاثة أبعاد: عدد مسارات الاستدلال، وعدد الحلول النهائية لكل مسار، وعمق بتر مسارات الاستدلال. حققت هذه الاستراتيجية توازنًا أفضل بين الدقة والتكلفة على العديد من معايير الاستدلال وأحجام النماذج، مما يمهد الطريق لاستدلال LLM أكثر كفاءة وقابلية للتوسع (المصدر: HuggingFace Daily Papers)
التحقق متعدد الوسائط من الصيغ الكيميائية (multimodal validation of chemical formulas) من خلال تكييف سياق LLM (LLM context conditioning) وتلقينات PWP: استكشف الباحثون تكييف سياق LLM المهيكل، جنبًا إلى جنب مع مبادئ تلقينات سير العمل الدائمة (PWP – Persistent Workflow Prompting)، لتعديل سلوك LLM أثناء الاستدلال، بهدف تحسين موثوقيتها في مهام التحقق الدقيقة (مثل الصيغ الكيميائية)، خاصة عند معالجة المستندات العلمية المعقدة التي تحتوي على صور. تستخدم هذه الطريقة واجهات دردشة قياسية فقط (Gemini 2.5 Pro, ChatGPT Plus o3)، دون الحاجة إلى API أو تعديلات على النموذج. أظهرت التجارب الأولية أن هذه الطريقة حسنت التعرف على الأخطاء النصية، وساعدت Gemini 2.5 Pro في التعرف على أخطاء الصيغ في الصور التي تجاهلتها المراجعة اليدوية (المصدر: HuggingFace Daily Papers)
تحقيق مراجعة الأقران الأكاديمية (academic peer review) المدفوعة بالذكاء الاصطناعي باستخدام PWP، والتلقينات الفوقية، والاستدلال الفوقي (meta-prompting and meta-reasoning): اقترح الباحثون طريقة تلقينات سير العمل الدائمة (PWP)، لتحقيق مراجعة أقران نقدية للمخطوطات العلمية من خلال واجهات دردشة LLM القياسية. تعتمد PWP بنية معيارية هرمية (مهيكلة بـ Markdown) لتحديد سير عمل تحليلي مفصل، ومن خلال التلقينات الفوقية والاستدلال الفوقي، تقوم بترميز عمليات مراجعة الخبراء بشكل منهجي (بما في ذلك المعرفة الضمنية). توجه PWP نموذج LLM لإجراء تقييم منهجي متعدد الوسائط، مثل التمييز بين الادعاءات والأدلة، ودمج تحليل النصوص/الصور/الرسوم البيانية، وإجراء فحوصات جدوى كمية، وغيرها. نجحت PWP في تحديد العيوب المنهجية في حالات الاختبار (المصدر: HuggingFace Daily Papers)
معيار SPOT لتقييم قدرة الذكاء الاصطناعي على التحقق الآلي من الأبحاث العلمية: لتقييم قدرة نماذج اللغة الكبيرة (LLM) كـ “عالم مشارك بالذكاء الاصطناعي (AI co-scientist)” في التحقق الآلي من المخطوطات الأكاديمية (automated validation of academic manuscripts)، أطلق الباحثون معيار SPOT. يتضمن هذا المعيار 83 ورقة بحثية منشورة و 91 خطأً كافيًا لإحداث تصحيحات أو سحب (errata or retractions)، وتم التحقق منها بشكل متقاطع من قبل المؤلفين الأصليين والمراجعين البشريين. أظهرت نتائج التجارب أنه حتى أكثر نماذج LLM تقدمًا (مثل o3)، لم يتجاوز معدل استرجاعها على SPOT نسبة 21.1%، وكانت دقتها أقل من 6.1%، كما كانت ثقة النموذج منخفضة، وكانت نتائج التشغيل المتعدد غير متسقة، مما يشير إلى وجود فجوة هائلة بين قدرات LLM الحالية والاحتياجات الفعلية في التحقق الأكاديمي الموثوق (المصدر: HuggingFace Daily Papers)
ExTrans تحقق ترجمة الاستدلال العميق متعددة اللغات (multilingual deep-inference translation) من خلال التعلم المعزز المعزز بالعينات (sample-augmented reinforcement learning): لتعزيز قدرات نماذج الاستدلال الكبيرة (LRM) في الترجمة الآلية، خاصة في السيناريوهات متعددة اللغات، اقترح الباحثون ExTrans. تصمم هذه الطريقة نهجًا جديدًا لنمذجة المكافآت (reward modeling)، من خلال مقارنة ترجمات نموذج سياسة الترجمة مع ترجمات LRM قوية (مثل DeepSeek-R1-671B) لتحديد المكافأة كميًا. أظهرت التجارب أن النموذج المدرب باستخدام Qwen2.5-7B-Instruct كعمود فقري حقق أداءً رائدًا (SOTA) في الترجمة الأدبية، وتفوق على OpenAI-o1 و DeepSeeK-R1. من خلال نمذجة المكافآت خفيفة الوزن، يمكن لهذه الطريقة نقل قدرات الترجمة أحادية الاتجاه بفعالية إلى 90 اتجاه ترجمة عبر 11 لغة (المصدر: HuggingFace Daily Papers)
انتباه متناثر قابل للتدريب VSA (Trainable Sparse Attention VSA) يسرع نماذج انتشار الفيديو (video diffusion models): لمعالجة مشكلة التعقيد التربيعي لآلية الانتباه الكامل ثلاثي الأبعاد في نماذج Transformer لانتشار الفيديو (DiT)، اقترح الباحثون VSA (انتباه متناثر قابل للتدريب). تقوم VSA بتجميع الرموز (tokens) في كتل وتحديد الرموز الرئيسية من خلال مرحلة تقريبية خفيفة الوزن، ثم تقوم بحساب انتباه دقيق على مستوى الرموز داخل هذه الكتل. VSA هي نواة واحدة قابلة للتفاضل يمكن تدريبها من طرف إلى طرف، ولا تتطلب تحليلًا لاحقًا، وتحافظ على 85% من MFU لـ FlashAttention3. أظهرت التجارب أن VSA تقلل من FLOPS التدريب بمقدار 2.53 مرة دون تقليل خسارة الانتشار، وتسرع وقت الانتباه لنموذج Wan-2.1 مفتوح المصدر بمقدار 6 مرات، وتقلل وقت التوليد من طرف إلى طرف من 31 ثانية إلى 18 ثانية (المصدر: HuggingFace Daily Papers)
SoftCoT++: تحقيق التوسع في وقت الاختبار (TTS – Test-Time Scaling) من خلال استدلال سلسلة الفكر الناعم (soft Chain-of-Thought reasoning): لتعزيز قدرات الاستكشاف لطريقة SoftCoT التي تقوم بالاستدلال في فضاء كامن مستمر، اقترح الباحثون SoftCoT++. تقوم هذه الطريقة بإزعاج الأفكار الكامنة من خلال اضطرابات متعددة للرموز الأولية المخصصة، وتطبق التعلم التبايني لتعزيز تنوع تمثيلات الأفكار الناعمة، وبالتالي توسيع SoftCoT إلى نموذج التوسع في وقت الاختبار (TTS). أظهرت التجارب أن SoftCoT++ تحسن بشكل كبير أداء SoftCoT، وتتفوق على SoftCoT مع توسيع الاتساق الذاتي، كما أنها متوافقة بقوة مع تقنيات التوسع التقليدية (مثل الاتساق الذاتي) (المصدر: HuggingFace Daily Papers)
MTVCrafter: ترميز الحركة رباعي الأبعاد (4D motion tokenization) لتحريك صور بشرية في عالم مفتوح (open-world human image animation): لمعالجة مشكلة اعتماد الطرق الحالية على صور الوضعيات ثنائية الأبعاد مما يحد من قدرتها على التعميم، تقترح MTVCrafter نمذجة تسلسلات الحركة ثلاثية الأبعاد الأصلية (الحركة رباعية الأبعاد) مباشرة. جوهرها هو 4DMoT (مرمز الحركة رباعي الأبعاد)، الذي يقوم بتكميم تسلسلات الحركة ثلاثية الأبعاد إلى رموز حركة رباعية الأبعاد، مما يوفر إشارات مكانية وزمانية أكثر قوة. بعد ذلك، من خلال تصميم فريد لانتباه الحركة وترميز الموضع رباعي الأبعاد، يستفيد MV-DiT (DiT المدرك للحركة) بفعالية من هذه الرموز كسياق، لتحقيق تحريك الصور البشرية في عوالم ثلاثية الأبعاد معقدة. أظهرت التجارب أن MTVCrafter تحقق 6.98 على FID-VID، متفوقة بشكل كبير على أحدث ما توصلت إليه التكنولوجيا (SOTA)، ويمكنها التعميم بشكل جيد على شخصيات متنوعة بأنماط ومشاهد مختلفة (المصدر: HuggingFace Daily Papers)
QVGen: دفع حدود نماذج توليد الفيديو الكمية (quantized video generation models): لمعالجة مشكلة متطلبات الحوسبة والذاكرة الكبيرة لنماذج انتشار الفيديو (DM)، تقترح QVGen إطارًا جديدًا للتدريب المدرك للتكميم (QAT – Quantization-Aware Training) مصمم خصيصًا للتكميم ببتات منخفضة جدًا (extremely low-bit quantization) (مثل 4 بت وما دون). من خلال التحليل النظري، وجد الباحثون أن تقليل معيار التدرج (gradient norm) أمر بالغ الأهمية لتقارب QAT، وأدخلوا وحدة مساعدة (Phi) لتخفيف أخطاء التكميم الكبيرة. للتخلص من تكلفة استدلال Phi، تم اقتراح استراتيجية اضمحلال الرتبة (rank decay strategy)، من خلال SVD والتنظيم القائم على الرتبة للتخلص التدريجي من Phi. أظهرت التجارب أن QVGen تحقق لأول مرة جودة مكافئة للدقة الكاملة في إعداد 4 بت، وتتفوق بشكل كبير على الطرق الحالية (المصدر: HuggingFace Daily Papers)
ViPlan: المسندات الرمزية (symbolic predicates) ومعيار نماذج اللغة البصرية (visual language model benchmark) للتخطيط البصري (visual planning): لسد الفجوة في المقارنة بين طرق التخطيط الرمزي المدفوعة بنماذج اللغة البصرية (VLM) وطرق تخطيط VLM المباشرة، تم اقتراح ViPlan كأول معيار مفتوح المصدر للتخطيط البصري. يتضمن ViPlan مهامًا متزايدة الصعوبة في مجالين رئيسيين: نسخة مرئية من Blocksworld وبيئة روبوت منزلي محاكاة. من خلال اختبار الأداء على 9 عائلات VLM مفتوحة المصدر وبعض النماذج مغلقة المصدر، وجد أن التخطيط الرمزي يتفوق في Blocksworld (حيث يكون تحديد المواقع الدقيقة للصور أمرًا بالغ الأهمية)، بينما يتفوق تخطيط VLM المباشر في مهام الروبوت المنزلي (حيث تكون المعرفة العامة وقدرات استعادة الأخطاء مهمة). أظهر البحث أيضًا أن تلقينات CoT ليس لها فائدة كبيرة لمعظم النماذج والطرق، مما يشير إلى أن قدرات الاستدلال البصري الحالية لنماذج VLM لا تزال قاصرة (المصدر: HuggingFace Daily Papers)
من الصرخات الأولية إلى القواعد النحوية: دراسة تطور اللغة (language evolution research) في بيئة البحث عن الطعام التعاونية (cooperative foraging environment): لاستكشاف أصول اللغة وتطورها، قام الباحثون بمحاكاة سيناريوهات التعاون البشري المبكر في لعبة بحث عن طعام متعددة الوكلاء. من خلال التعلم المعزز العميق من طرف إلى طرف، تعلم الوكلاء استراتيجيات العمل والتواصل من الصفر. وجد البحث أن بروتوكولات التواصل التي طورها الوكلاء أظهرت السمات المميزة للغة الطبيعية: الاعتباطية، والتبادلية، والإزاحة، والانتشار الثقافي، والتركيبية. يوفر هذا الإطار منصة لدراسة كيفية تطور اللغة في بيئات متعددة الوكلاء مجسدة، قابلة للملاحظة جزئيًا، وتتطلب استدلالًا زمنيًا، ومدفوعة بأهداف تعاونية (المصدر: HuggingFace Daily Papers)
Tiny QA Benchmark++: توليد مجموعة بيانات اصطناعية متعددة اللغات خفيفة الوزن للغاية (ultra-lightweight multilingual synthetic dataset generation) واختبار دخان للتقييم المستمر لـ LLM (smoke test for continuous LLM evaluation): Tiny QA Benchmark++ (TQB++) هو مجموعة اختبار دخان خفيفة الوزن للغاية ومتعددة اللغات، تهدف إلى توفير شبكة أمان على غرار اختبارات الوحدة لخطوط أنابيب LLM، ويمكن تشغيلها في ثوانٍ بتكلفة منخفضة للغاية. يتضمن TQB++ مجموعة ذهبية باللغة الإنجليزية مكونة من 52 عنصرًا، ويوفر مولد بيانات اصطناعية صغيرًا قائمًا على LiteLLM (حزمة pypi)، يمكن للمستخدمين من خلاله إنشاء حزم اختبار صغيرة مخصصة للغة أو المجال أو الصعوبة. يوفر المشروع حزمًا جاهزة بـ 10 لغات، ويدعم أدوات مثل OpenAI-Evals و LangChain، مما يسهل دمجها في عمليات CI/CD، لاستخدامها في الكشف السريع عن أخطاء قوالب التلقين، وانحرافات مقسم الكلمات، والآثار الجانبية للضبط الدقيق (المصدر: HuggingFace Daily Papers)
HelpSteer3-Preference: مجموعة بيانات تفضيلات بشرية مفتوحة المصدر (open human-annotated preference dataset) عبر مهام ولغات متعددة: لتلبية الحاجة إلى بيانات تفضيلات مفتوحة عالية الجودة ومتنوعة، أصدرت NVIDIA مجموعة بيانات HelpSteer3-Preference. تحتوي مجموعة البيانات هذه على أكثر من 40,000 عينة تفضيل بشرية معنونة، وتتبع ترخيص CC-BY-4.0، وتغطي تطبيقات LLM حقيقية مثل STEM، والترميز، والسيناريوهات متعددة اللغات. حققت نماذج المكافأة (RM) المدربة باستخدام مجموعة البيانات هذه أداءً رائدًا (SOTA) على RM-Bench (82.4%) و JudgeBench (73.7%)، متفوقة على أفضل النتائج السابقة بحوالي 10%. يمكن أيضًا استخدام مجموعة البيانات هذه لتدريب نماذج RM توليدية، ومواءمة نماذج السياسة من خلال RLHF (المصدر: HuggingFace Daily Papers)
SEED-GRPO: GRPO معزز بالاعتلاج الدلالي لتحسين السياسة المدركة لعدم اليقين (uncertainty-aware policy optimization): لمعالجة مشكلة عدم مراعاة GRPO لعدم يقين LLM تجاه تلقينات الإدخال عند تحديث السياسة، اقترح الباحثون SEED-GRPO. تقيس هذه الطريقة صراحةً عدم يقين LLM تجاه تلقينات الإدخال (أي التنوع الدلالي للإجابات المتعددة التي تم إنشاؤها) من خلال الاعتلاج الدلالي (semantic entropy)، وتستخدم ذلك لتعديل حجم تحديث السياسة. تسمح آلية التدريب المدركة لعدم اليقين هذه بتحديثات أكثر تحفظًا للمسائل ذات عدم اليقين العالي، مع الحفاظ على إشارة التعلم الأصلية للمسائل الموثوقة. أظهرت التجارب أن SEED-GRPO تحقق أداءً رائدًا (SOTA) على خمسة معايير للاستدلال الرياضي (المصدر: HuggingFace Daily Papers)
إنشاء نموذج المستخدم العام (GUM – General User Model) من استخدام الكمبيوتر: اقترح الباحثون بنية نموذج المستخدم العام (GUM)، التي تتعلم معرفة المستخدم وتفضيلاته من خلال ملاحظة أي تفاعل للمستخدم مع الكمبيوتر (مثل لقطات شاشة الجهاز)، وتبني افتراضات مرجحة بالثقة (confidence-weighted propositions). يستطيع GUM استنتاج افتراضات جديدة من ملاحظات متعددة الوسائط غير منظمة، واسترجاع الافتراضات ذات الصلة كسياق، وتصحيح الافتراضات الحالية باستمرار. تهدف هذه البنية إلى تعزيز مساعدي الدردشة، وإدارة إشعارات نظام التشغيل، وتمكين الوكلاء التفاعليين من التكيف مع تفضيلات المستخدم عبر التطبيقات. أظهرت التجارب أن GUM يمكنه إجراء استنتاجات مستخدم معايرة ودقيقة، وأن المساعدين القائمين على GUM يمكنهم تحديد وتنفيذ إجراءات مفيدة لم يطلبها المستخدم صراحةً (المصدر: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: مشروع شائع على GitHub، يوفر مستودع موارد تعلم هندسة البيانات (data engineering learning resource repository) شاملاً، بما في ذلك خارطة طريق للبدء لعام 2024، ومواد معسكر تدريبي مجاني على YouTube لمدة 6 أسابيع، وحالات مشاريع، ونصائح للمقابلات، وكتب موصى بها، وقوائم بالمجتمعات والنشرات الإخبارية. من بين الكتب الموصى بها: “Fundamentals of Data Engineering” و “Designing Data-Intensive Applications” و “Designing Machine Learning Systems”. يسرد الدليل أيضًا شركات في مختلف مجالات هندسة البيانات، مثل Mage (التنسيق)، و Databricks (بحيرة البيانات)، و Snowflake (مستودع البيانات)، و dbt (جودة البيانات)، و LangChain (مكتبة تطبيقات LLM)، وغيرها، ويوفر روابط لمدونات هندسة البيانات لشركات معروفة وأوراق بيضاء مهمة (المصدر: GitHub Trending)
💼 الأعمال
Cohere تتعاون مع SAP لتقديم وكلاء الذكاء الاصطناعي للمؤسسات (enterprise-grade AI agents) إلى الأعمال العالمية: أعلنت Cohere عن تعاونها مع SAP لدمج تقنية وكلاء الذكاء الاصطناعي للمؤسسات الخاصة بها في SAP Business Suite، لتزويد الشركات العالمية بقدرات ذكاء اصطناعي آمنة وقابلة للتطوير. ستصل نماذج Cohere الرائدة أيضًا إلى SAP AI Core، مما يمكّن الشركات في مجالات مثل التمويل والرعاية الصحية من الاستفادة من نماذج الذكاء الاصطناعي متعددة اللغات والمتخصصة في مجالات معينة (Command, Embed, Rerank)، بهدف تسريع تطبيقات الذكاء الاصطناعي للمؤسسات وإطلاق قيمة تجارية حقيقية (المصدر: X, X)
xAI تسعى للاستفادة من البيانات الحكومية، وتوسيع أعمالها في قطاعي الشركات والحكومة: وفقًا لـ The Information، تخطط شركة xAI التابعة لـ Elon Musk للاستفادة من بيانات الوكالات الحكومية لتطوير النماذج والتطبيقات، وبيعها للعملاء الحكوميين. قد تصبح هذه المبادرة جزءًا مهمًا من استراتيجية xAI التجارية، ولكنها تثير أيضًا نقاشات حول استخدام البيانات والتحيزات المحتملة (المصدر: X)
Weaviate و AWS تعمقان التعاون العالمي، لتسريع مبادرات الذكاء الاصطناعي التوليدي (generative AI initiatives): أعلنت شركة قواعد بيانات المتجهات (vector database company) Weaviate عن تعزيز تعاونها العالمي مع AWS، بهدف تسريع مشاريع الذكاء الاصطناعي التوليدي بشكل مشترك. سيركز هذا التعاون على تزويد المطورين العالميين بسرعة أكبر، ونطاق أوسع، وتجربة مطور أفضل، لدفع عجلة تطبيق وتطوير تكنولوجيا الذكاء الاصطناعي التوليدي (المصدر: X)

🌟 المجتمع
صعود وكلاء برمجة الذكاء الاصطناعي (AI coding agents)، يثير نقاشًا حول مستقبل مهنة المبرمجين: تتسابق شركات مثل Microsoft و OpenAI لإطلاق أو تعزيز وكلاء برمجة الذكاء الاصطناعي، مثل GitHub Copilot Coding Agent و OpenAI Codex، القادرة على إكمال مهام الترميز وإصلاح الأخطاء وصيانة الشيفرة البرمجية بشكل مستقل. يتوقع Dario Amodei، الرئيس التنفيذي لشركة Anthropic، أن يتمكن الذكاء الاصطناعي من كتابة معظم أو كل الشيفرة البرمجية في المدى القصير، كما يعتقد Kevin Weil، كبير مسؤولي المنتجات في OpenAI، أن الذكاء الاصطناعي سينمو من مهندس مبتدئ إلى مهندس معماري. أثار هذا نقاشًا واسعًا في المجتمع حول مستقبل مهنة المبرمجين: يخشى البعض من استبدال الوظائف المبتدئة، وأن يقوم الذكاء الاصطناعي بأتمتة كمية كبيرة من أعمال البرمجة؛ بينما يعتقد آخرون أن الذكاء الاصطناعي سيعزز كفاءة المبرمجين، مما يسمح لهم بالتركيز على تصميمات معمارية وابتكارات ذات مستوى أعلى، وتحول دورهم إلى “موجهي الذكاء الاصطناعي (AI guides/leaders)”. يشير الاتجاه العام إلى أن تعلم التعاون الفعال مع الذكاء الاصطناعي سيصبح مهارة أساسية للمبرمجين (المصدر: X, X, 36氪, 36氪)
مفهوم ومعايير AI Agent محل نقاش حاد، وبروتوكول MCP يحظى بالاهتمام: مع ظهور تطبيقات AI Agent (مثل Manus، Genspark Super Agent، Fellou.ai)، بدأ المجتمع نقاشًا حول تعريف Agent، ومستويات قدراته، ونماذج تطويره. اقترحت شركة رأس المال الاستثماري المعروفة BVP تصنيفًا من سبعة مستويات لـ Agent من L0 إلى L6. وفي الوقت نفسه، حظي بروتوكول سياق النموذج (MCP – Model Context Protocol) بالاهتمام كتقنية رئيسية لتحقيق التوافق التشغيلي بين تطبيقات الذكاء الاصطناعي (interoperability between AI applications). وقد دعمت الشركات الكبرى الأجنبية مثل Anthropic و OpenAI و Google بالفعل MCP أو تخطط لدعمه، وبدأت الشركات المحلية مثل Alibaba Cloud و Tencent Cloud في بناء منصات تطوير Agent محلية حول MCP. حتى أن المطور iluxu قام بفتح مصدر مشروع llmbasedos مشابه قبل أن تطرح Microsoft مفهوم “USB-C for AI apps”، بهدف تعزيز معايير اتصال Agent المفتوحة (المصدر: X, X, WeChat, Reddit r/LocalLLaMA)
أداء نماذج اللغة الكبيرة (LLM) ضعيف في مهام استدلال محددة، مما يثير تساؤلات حول حدود قدراتها: يناقش المجتمع بحماس ظاهرة “فشل” نماذج اللغة الكبيرة بشكل جماعي في بعض مهام الاستدلال الفيزيائي أو المكاني البصري (physical or visuospatial reasoning tasks) التي تبدو بسيطة، على سبيل المثال، سؤال حول تكديس المكعبات لتشكيل مكعب أكبر، حتى النماذج الرائدة مثل o3 و Gemini 2.5 Pro قدمت إجابات خاطئة. وفي الوقت نفسه، أشارت مقالة تقييم إلى أنه في المهام الفيزيائية الأساسية مثل تصنيع الأجزاء، كان أداء نماذج اللغة الكبيرة (بما في ذلك o3) أقل من أداء العمال ذوي الخبرة، ويرجع ذلك أساسًا إلى عدم كفاية القدرات البصرية وأخطاء الاستدلال الفيزيائي، بالإضافة إلى نقص المعرفة الضمنية بالعالم الحقيقي. أثارت هذه الحالات تساؤلات حول قدرات الفهم الحقيقية لنماذج اللغة الكبيرة، ومشكلة الهلوسة (hallucination problem) (مثل ارتفاع معدل الهلوسة لدى o3 أثناء الاستدلال)، وفعالية المعايير الحالية، مما يؤكد على أن الذكاء الاصطناعي لا يزال لديه مجال كبير للتحسين في المعرفة المتخصصة والاستدلال المعقد (المصدر: 量子位, 36氪)

المنافسة التكنولوجية بين الصين والولايات المتحدة واستراتيجيات تطوير الذكاء الاصطناعي تثير الاهتمام: تحدث Jensen Huang، الرئيس التنفيذي لشركة Nvidia، في مقابلة عن ضوابط الرقائق (chip regulations)، ومصانع الذكاء الاصطناعي (AI factories)، والواقعية المؤسسية (enterprise pragmatism)، وتم تفسير وجهات نظره على أنها رؤية عميقة للوضع الحالي للمنافسة التكنولوجية بين الصين والولايات المتحدة. يرى بعض المعلقين أن الولايات المتحدة تحاول الحفاظ على مكانتها الرائدة من خلال تقييد وصول الصين إلى موارد الذكاء الاصطناعي المتقدمة، ولكن هذا قد يؤدي إلى وضع يخسر فيه الطرفان، ويبطئ التنمية العالمية للذكاء الاصطناعي. يبدو أن Huang يعتقد أن المنافسة الحقيقية طويلة الأجل، ويجب على الولايات المتحدة أن تتصدر بشكل شامل (الرقائق، المصانع، البنية التحتية، النماذج، التطبيقات)، بدلاً من السعي فقط لتحقيق ميزة نسبية قصيرة الأجل، وإلا فقد تفوت فرصة التنمية في عصر الذكاء الاصطناعي، وتتخلف في نهاية المطاف في المنافسة على القوة الوطنية الشاملة (المصدر: X)
تطبيقات ومناقشات حول استخدام أدوات الذكاء الاصطناعي مثل ChatGPT في المساعدة في الصحة النفسية (mental health support): يشارك مستخدمو مجتمع Reddit تجاربهم في استخدام أدوات الذكاء الاصطناعي مثل ChatGPT لتقديم الدعم في مجال الصحة النفسية، معتقدين أنها يمكن أن تقدم المساعدة بين جلسات العلاج المتخصصة، خاصة في تنظيم والتعبير عن المشاعر المعقدة. من خلال طرح الأسئلة على الذكاء الاصطناعي أو جعل الذكاء الاصطناعي يطرح أسئلة حول مشاعرهم، يمكن للمستخدمين فهم مصادر مشاعرهم بشكل أفضل ووضع خطط للتحسين. في التعليقات، يعتقد بعض المستخدمين (بمن فيهم أولئك الذين يصفون أنفسهم بأنهم معالجون) أن الذكاء الاصطناعي في بعض الحالات يتفوق حتى على بعض المعالجين البشريين، خاصة بالنسبة لأولئك الذين يجدون صعوبة في الحصول على مساعدة متخصصة أو لديهم عوائق ثقة تجاه المعالجين البشريين. ولكن حذر مستخدمون آخرون من أن الذكاء الاصطناعي لا يمكن أن يحل محل العلاج المتخصص بالكامل، ويجب الانتباه إلى قضايا خصوصية البيانات الشخصية (المصدر: Reddit r/ChatGPT)
💡 أخرى
انطلاق مسابقة “كأس تشيتشي” للخوارزميات (algorithm competition)، تركز على ثلاثة اتجاهات رائدة في الذكاء الاصطناعي: أطلق مختبر تشييوان مسابقة “كأس تشيتشي” للخوارزميات، بجوائز إجمالية قدرها 750 ألف يوان. تحدد المسابقة ثلاثة مسارات: “التقسيم المتين للكائنات في صور الاستشعار عن بعد عبر الأقمار الصناعية (robust instance segmentation of satellite remote sensing images)”، و “كشف الأهداف الأرضية بواسطة الطائرات بدون طيار للمنصات المدمجة (UAV ground target detection for embedded platforms)”، و “الهجمات العدائية ضد نماذج اللغة الكبيرة متعددة الوسائط (adversarial attacks against large multimodal models)”. تهدف المسابقة إلى تعزيز الابتكار والتطبيق العملي للتقنيات الأساسية للذكاء الاصطناعي مثل الإدراك المتين، والنشر خفيف الوزن، والدفاع ضد الهجمات العدائية. المسابقة مفتوحة للمؤسسات البحثية والشركات والمؤسسات العامة في الصين (المصدر: WeChat)

خطأ في المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي (error in AI-generated content) في صحيفة شيكاغو صن تايمز، توصي بكتب وخبراء غير موجودين: في أحد أعدادها التي توصي بأنشطة صيفية، يبدو أن جزءًا من محتوى صحيفة “شيكاغو صن تايمز” قد تم إنشاؤه بواسطة الذكاء الاصطناعي، حيث تضمن توصيات بكتب خيالية لمؤلفين موجودين بالفعل، واستشهد بآراء “خبراء” يبدو أنهم غير موجودين. على سبيل المثال، أدرجت كتاب “Nightshade Market” لـ Min Jin Lee وكتاب “Boiling Point” لـ Rebecca Makkai كقراءات موصى بها، لكن هذه الكتب غير موجودة. أثارت هذه الحادثة مخاوف بشأن دقة وآليات مراجعة المحتوى الذي تنشئه وسائل الإعلام الإخبارية باستخدام الذكاء الاصطناعي (المصدر: Reddit r/artificial)
نقاش حول ما إذا كان الذكاء الاصطناعي يشكل “غشًا” (does AI constitute ‘cheating’): يناقش المجتمع حدود استخدام أدوات الذكاء الاصطناعي (مثل ChatGPT، Claude) في العمل والدراسة. الرأي السائد هو أنه في حالة عدم وجود قواعد واضحة تمنع ذلك (مثل الواجبات الجامعية)، فإن استخدام أدوات الذكاء الاصطناعي لزيادة الكفاءة أو إكمال المهام المتكررة أو المساعدة في التفكير ليس “غشًا”، بل يشبه استخدام الآلة الحاسبة أو محركات البحث. يكمن المفتاح في ما إذا كان المستخدم يفهم مخرجات الذكاء الاصطناعي، وما إذا كان بإمكانه تعديلها والتحقق منها بفعالية، وما إذا كان يعلن بصدق عن الدور المساعد للذكاء الاصطناعي (خاصة في السياقات الأكاديمية). ومع ذلك، إذا تم الاعتماد كليًا على المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي والادعاء بأنه أصلي دون تمييز، فقد ينطوي ذلك على سوء سلوك أكاديمي أو يؤثر على تنمية المهارات الشخصية (المصدر: Reddit r/ArtificialInteligence)