
Schlüsselwörter:DeepSeek-OCR, Visuelle Textkomprimierung, KI-Agent, Bestärkendes Lernen, KI-Automatisierung, AWS-Ausfall, Mamba-Architektur, KI-Musik, Kontextuelle optische Komprimierung, OmniDocBench, Glyph visuelles Textkomprimierungsframework, Projekt Merkur, TeleStudio KI-Kreativplattform
🔥 Fokus
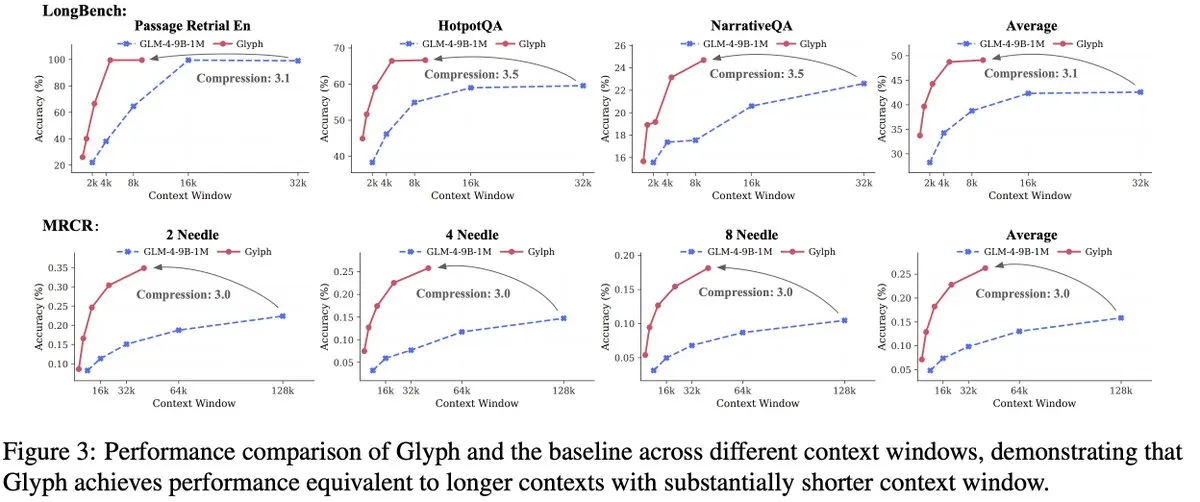
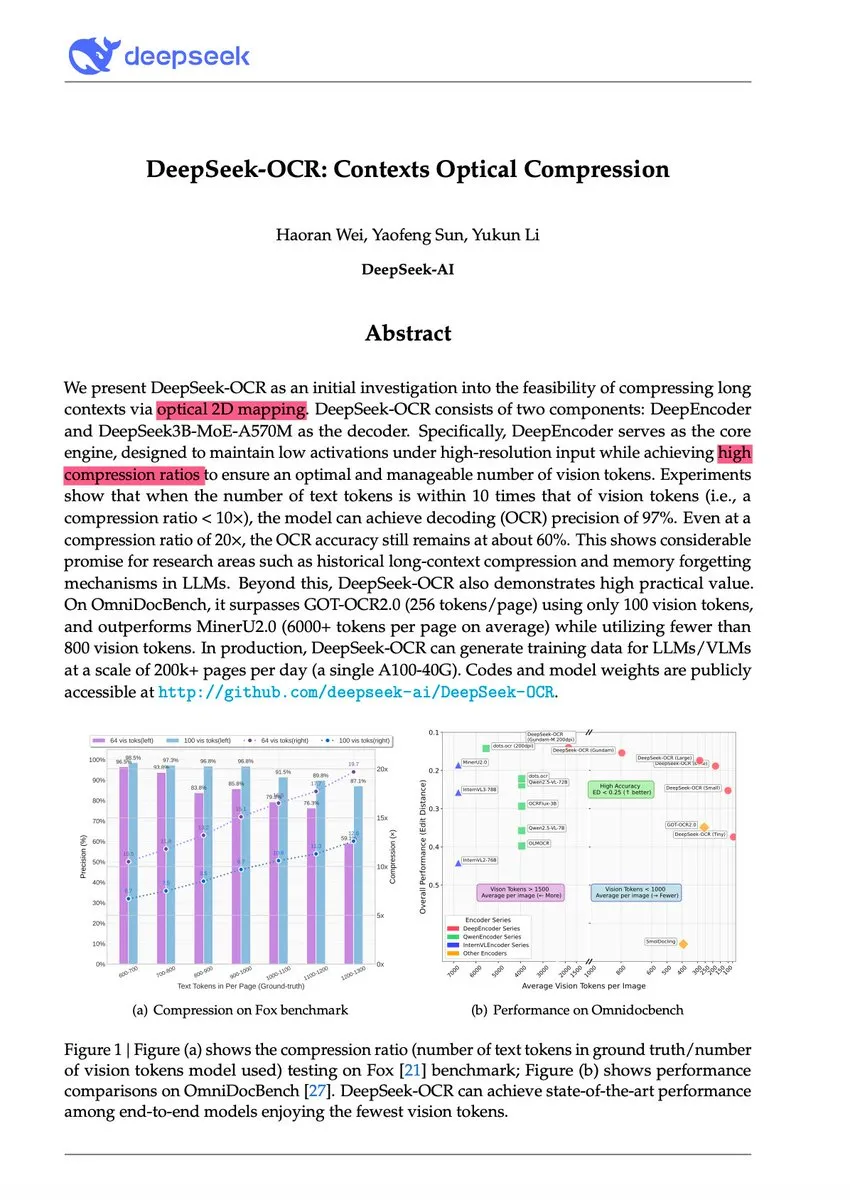
DeepSeek-OCR revolutioniert das Paradigma der visuellen Textkompression: Das DeepSeek-OCR-Modell stellt ein neues Paradigma der “kontextuellen optischen Kompression” vor, das lange Texte in visuelle Bilder umwandelt und Informationen effizient durch visuelle Token komprimiert. Das 3B-Modell erreicht SOTA auf OmniDocBench und kann Texte mit einer Kompressionsrate von 10x (nahezu verlustfrei) bis 20x (60% Genauigkeit) verarbeiten. Eine einzelne A100 GPU kann täglich über 200.000 Dokumentenseiten bearbeiten. Andrej Karpathy bezeichnet dies als “den JPEG-Moment der KI” und glaubt, dass es eine Veränderung des LLM-Eingabeparadigma andeuten und sogar menschliche Vergessensmechanismen simulieren könnte, was zu einer Architektur mit unendlichem Kontext führt.
(Quelle:量子位、ZhihuFrontier、huggingface)
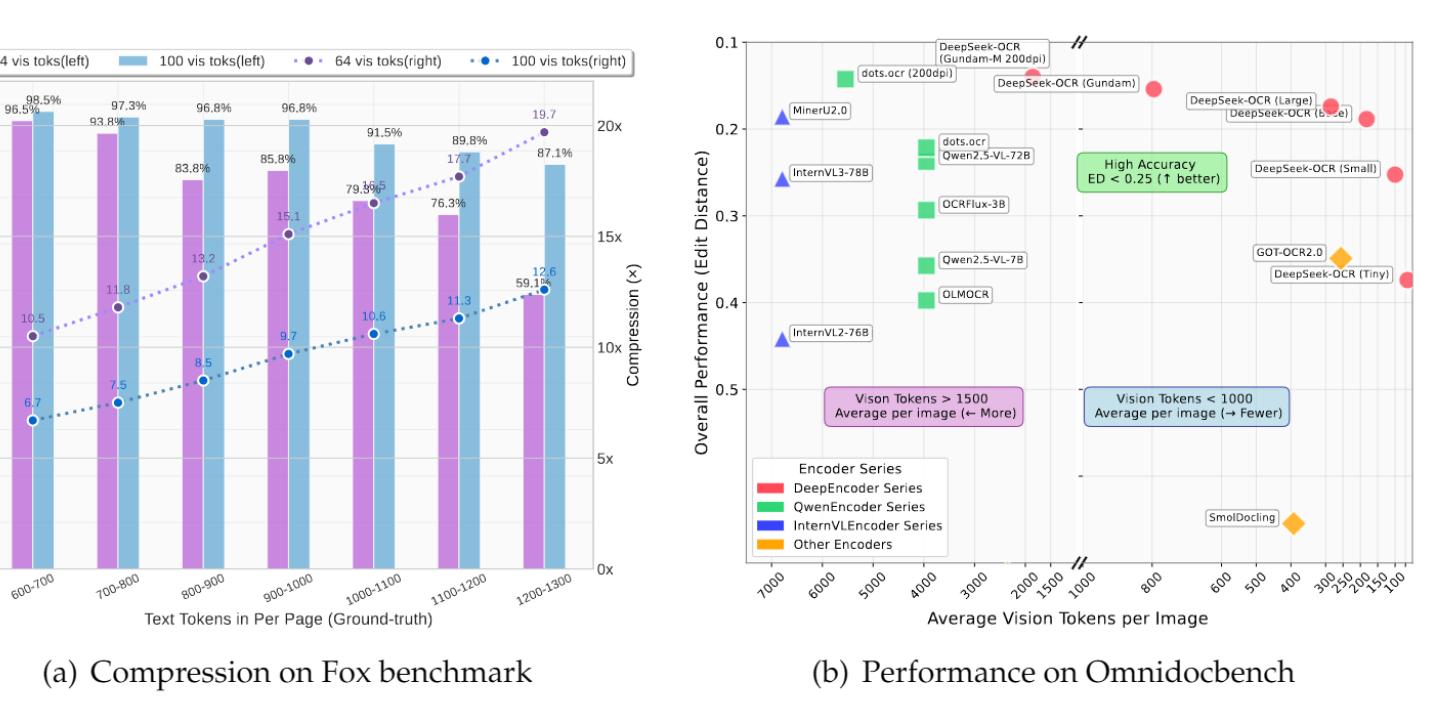
GLM-Team veröffentlicht Glyph-Framework für visuelle Textkompression: Zeitgleich mit DeepSeek-OCR veröffentlichte das GLM-Team das Glyph-Framework, das durch die Umwandlung langer Texte in Bilder und deren Verarbeitung durch VLM eine 3-4-fache Textkompression erreicht, während die Genauigkeit führender LLMs erhalten bleibt. Diese Methode verbessert die Vorfüll- und Dekodiergeschwindigkeit erheblich und ermöglicht es VLMs mit 128K Kontext, Textaufgaben auf 1M Token-Niveau zu bearbeiten. Dies bestätigt gemeinsam mit DeepSeek-OCR die Machbarkeit der visuellen Kompression als Lösung für lange Kontexte.
(Quelle:Reddit r/LocalLLaMA、Zai_org)
Andrej Karpathys tiefgreifende Kritik an AI-Agenten und RL: Andrej Karpathy, ehemaliger Forschungsleiter bei OpenAI, wies in einem langen Gespräch darauf hin, dass AI-Agenten noch zehn Jahre von echter Reife entfernt sind und es ihnen derzeit an Multimodalität, kontinuierlichem Lernen, vollständigen kognitiven Strukturen und Gedächtnisfähigkeiten fehlt. Er kritisierte scharf den “blinden Versuch-und-Irrtum”-Mechanismus von Reinforcement Learning (RL) als ineffizient und leicht zu täuschen. Er plädierte dafür, dass Modelle menschliche Mechanismen der Rückschau und Reflexion lernen und durch “traumähnliche” Mechanismen einen Zustand hoher Entropie aufrechterhalten sollten, um einen kognitiven Kollaps zu vermeiden. Karpathy betonte, dass AGI sich schrittweise in die Wirtschaft integrieren wird, anstatt sie sofort umzukrempeln, und dass die Herausforderungen des autonomen Fahrens weit über die Technologie selbst hinausgehen und die Koordination sozialer Systeme erfordern.
(Quelle:量子位、sama、vikhyatk)

Disruptive Auswirkungen der AI-Automatisierung auf die McKinsey-Beratungsbranche: McKinsey erhielt eine OpenAI-Medaille für seinen enormen Token-Verbrauch, was zeigt, wie tief AI in sein Beratungsgeschäft eingedrungen ist. Top-Beratungsunternehmen wie McKinsey und Boston Consulting setzen AI-Tools umfassend ein, z.B. McKinseys Lilli (bereits von 70% der Mitarbeiter genutzt), und BCG integriert die AI-Nutzung sogar in die Leistungsbeurteilung. Die durch AI gesteigerte Effizienz führte bei McKinsey zur Entlassung von über 5.000 Mitarbeitern, wobei Juniorberaterpositionen am stärksten betroffen waren. AI-Startups bieten ebenfalls AI-Analystendienste an und fordern traditionelle Beratungsmodelle heraus. Die Branche befürchtet, dass AI es jungen Berufseinsteigern erschweren wird, “implizites Wissen” aufzubauen, und die Karrierewege verändern wird.
(Quelle:量子位、Teknium1)

Amazon AWS-Serverausfall führt zu weitreichenden Internetdienstunterbrechungen: Ein großflächiger Ausfall in der AWS-Region us-east-1 von Amazon führte zu Unterbrechungen zahlreicher Online-Dienste wie ChatGPT, Docker, Zoom, Slack, Spieleplattformen, Streaming-Dienste und Fahrdienste sowie einiger Offline-Dienste (z.B. Flug-Check-in, intelligente Türschlösser). Die Störung wurde durch DNS-Auflösungsprobleme und Anomalien im internen EC2-Netzwerksubsystem verursacht. Da us-east-1 eine Kernregion von AWS ist, hatte der Ausfall enorme Auswirkungen auf globale Dienste und unterstreicht die Anfälligkeit zentralisierter Cloud-Service-Architekturen. Dies veranlasst Entwickler, die Bedeutung von Multi-Region-Bereitstellungen und Resilienzmechanismen neu zu bewerten.
(Quelle:量子位、TheRundownAI、qtnx_)

🎯 Trends
Apple AI-Forschung: Mamba-Architektur übertrifft Transformer bei Agent-Aufgaben: Eine aktuelle Studie von Apple zeigt, dass die Mamba-Architektur in Kombination mit externen Tools in Agent-Szenarien mit langen Aufgaben und mehreren Interaktionen effizienter ist und ein größeres Generalisierungspotenzial aufweist als Transformer. Mamba, als State-Space-Modell, dessen Rechenaufwand linear mit der Sequenzlänge wächst, unterstützt Streaming-Verarbeitung und hat einen stabilen Speicherverbrauch. Durch die Einführung externer Tools gleicht es seine Kurzzeitgedächtnisbeschränkungen aus und zeigt hervorragende Leistungen bei Aufgaben wie mehrstelliger Addition und Code-Debugging.
(Quelle:量子位)
AI-Musikbranche tritt in neue Phase der Compliance und Kommerzialisierung ein: Das AI-Musikunternehmen Suno schließt eine Finanzierungsrunde von über 100 Millionen US-Dollar ab, mit einer Bewertung von 2 Milliarden US-Dollar, und veröffentlicht das V5-Modell sowie die Suno Studio Digital Audio Workstation, die die Musikgenerierungsqualität und die kreative Kontrolle verbessern. Udio veröffentlicht ebenfalls ein visuelles Bearbeitungstool. ElevenLabs bringt Eleven Music auf den Markt und schließt Lizenzvereinbarungen mit der unabhängigen Musikorganisation Merlin und dem Rechteinhaber Kobalt ab, zudem erhält es eine strategische Investition von NVIDIA. Gleichzeitig verschärfen die drei großen Plattenfirmen ihre Urheberrechtsverletzungsklagen gegen Suno und Udio, und Spotify verstärkt die Regulierung und löscht “Junk-Tracks”. Dies deutet darauf hin, dass sich AI-Musik von einem “wilden Wachstum” zu einer standardisierten Entwicklung bewegen wird.
(Quelle:36氪)

ByteDance AI-Assistent Cici erobert stillschweigend internationale Märkte: Die AI-Assistenten-App “Cici” von ByteDance verzeichnete in letzter Zeit einen sprunghaften Anstieg der Downloads in Mexiko, Großbritannien und südostasiatischen Ländern und erreichte Spitzenpositionen in den App Stores. Cici ist dem führenden chinesischen “Doubao” in Aussehen und Technologie hochgradig ähnlich, integriert interne Technologien von ByteDance (wie PicPic, Coze) und nutzt die GPT-Serie von OpenAI sowie Googles Gemini-Modelle zur Dialoggenerierung. Dies markiert die Globalisierungsstrategie von ByteDance im AI-Bereich.
(Quelle:量子位)
Anthropic startet Claude for Life Sciences-Plattform zur Forschungsunterstützung: Anthropic hat Claude for Life Sciences veröffentlicht, eine AI-Plattform, die Lebenswissenschaftlern bei der Hypothesenbildung, Datenanalyse und ähnlichen Aufgaben helfen soll, um die Effizienz zu steigern und den verantwortungsvollen Einsatz von AI zu fördern. Durch die Integration wissenschaftlicher Tools, Fähigkeiten und neuer Partnerschaften wird Claude in der wissenschaftlichen Forschung praktischer.
(Quelle:Reddit r/ClaudeAI、BlackHC)
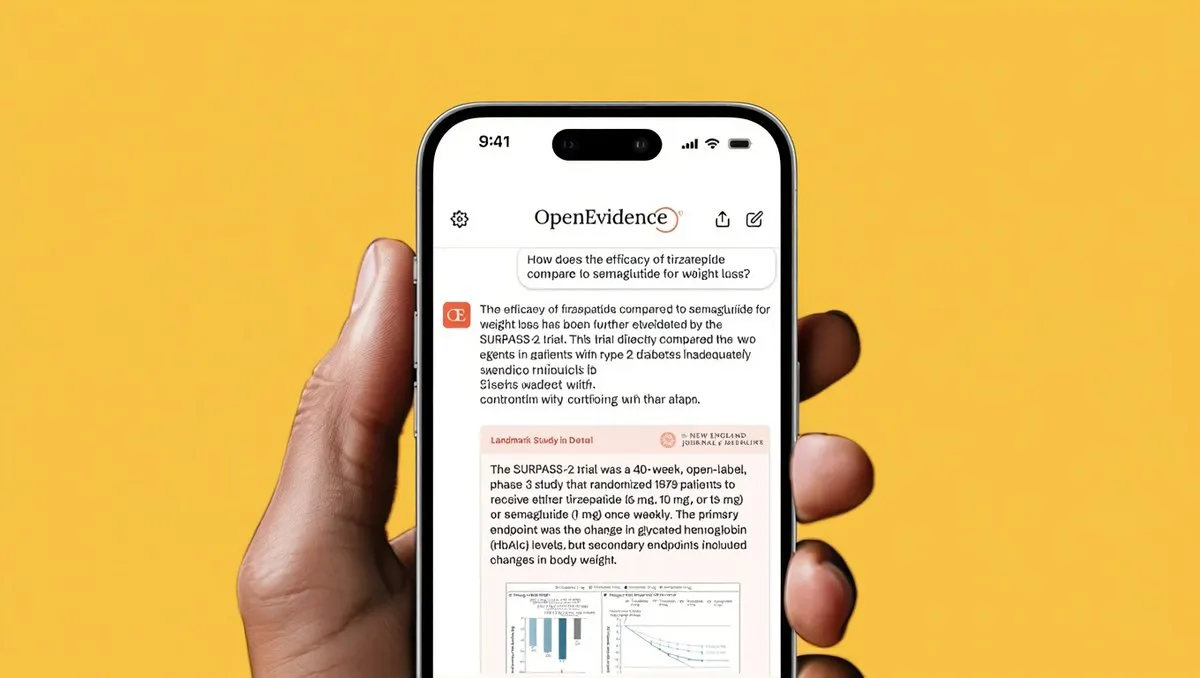
Fortschritte der AI im Gesundheitswesen: Die klinische Studie mit der PRIMA-Netzhautprothese war erfolgreich und ermöglichte blinden Patienten, intuitives Sehen wiederzuerlangen. Gleichzeitig erhielt OpenEvidence eine Finanzierung von 200 Millionen US-Dollar, mit einer Bewertung von 6 Milliarden US-Dollar. Ihre AI-Plattform unterstützt monatlich 15 Millionen klinische Konsultationen und zielt darauf ab, medizinische Entscheidungen zu beschleunigen. Diese Fortschritte zeigen das enorme Potenzial von AI zur Verbesserung der menschlichen Gesundheit und zur Steigerung der Effizienz im Gesundheitswesen.
(Quelle:gfodor、TheRundownAI)

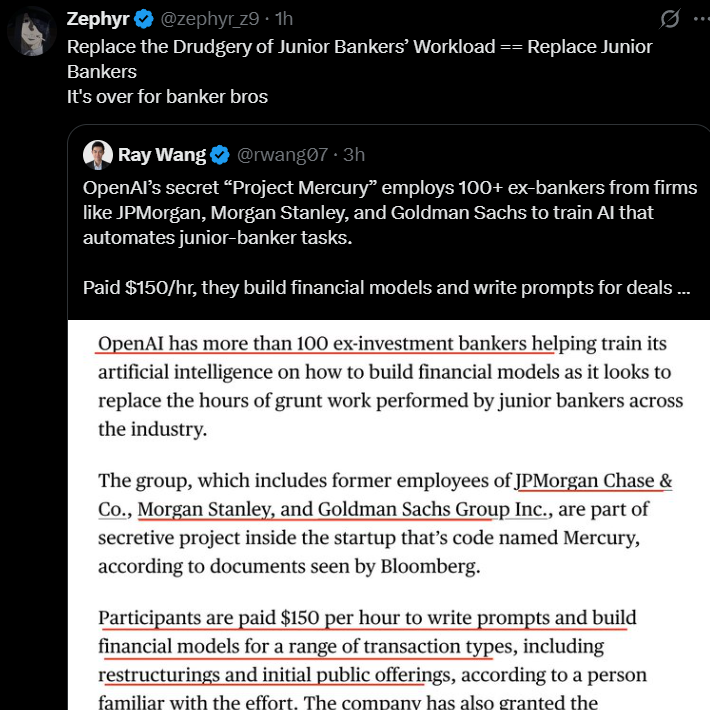
Auswirkungen der AI-Automatisierung auf Junior-Finanzpositionen: OpenAI hat das geheime Projekt “Project Mercury” gestartet, bei dem über hundert Investmentbanker eingestellt werden, um AI-Modelle zu trainieren, die die grundlegenden Aufgaben von Juniorbankern automatisieren sollen, bei einer Bezahlung von 150 US-Dollar pro Stunde. Dies deutet darauf hin, dass AI tief in die Finanzbranche eindringen wird, insbesondere mit erheblichen Auswirkungen auf Juniorpositionen mit hoher Wiederholungsrate und relativ niedrigem Wissensschwellenwert.
(Quelle:Teknium1)

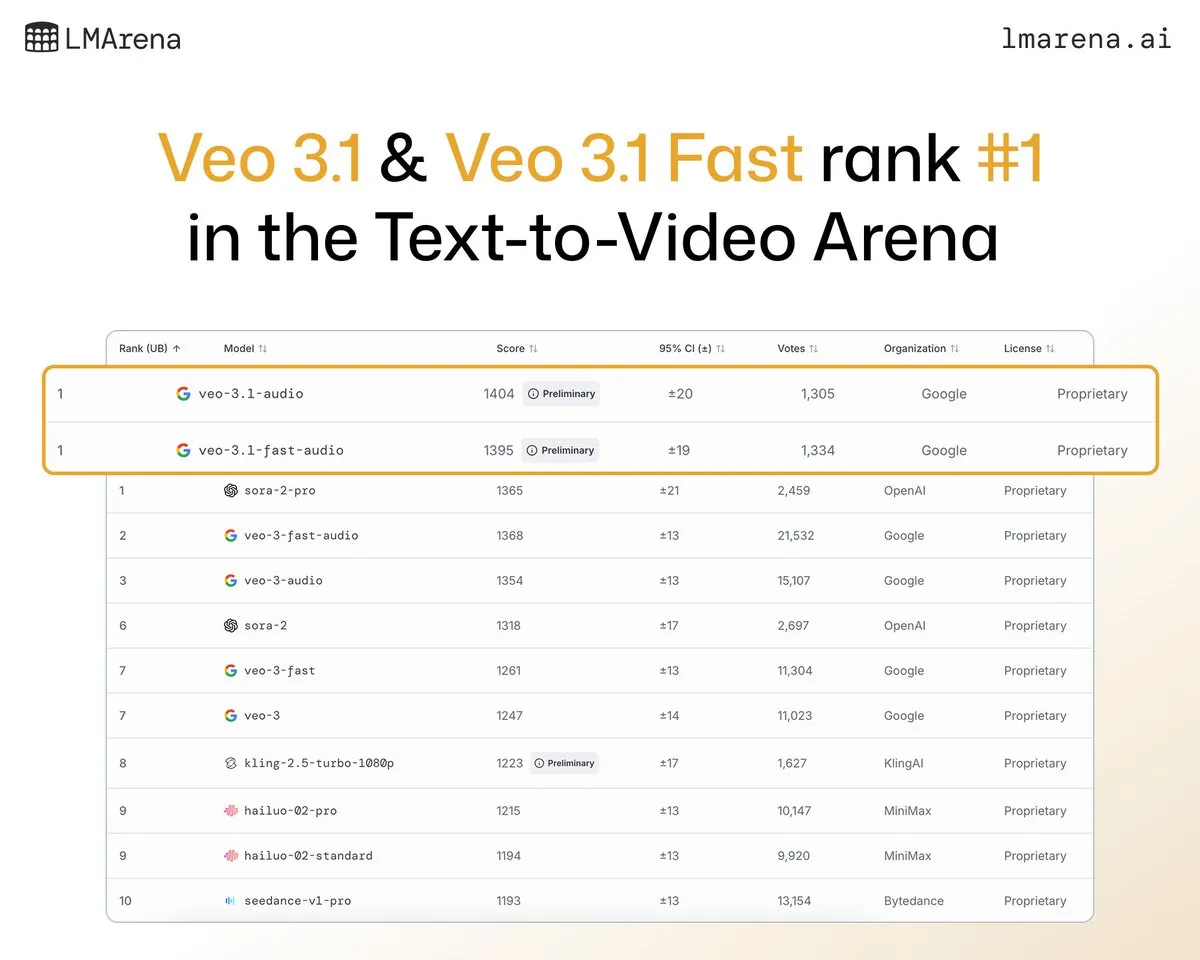
Googles DeepMind Veo 3.1 gewinnt im Video-Generierungsranking: Googles neuestes Video-Generierungsmodell DeepMind Veo 3.1 zeigt hervorragende Leistungen im LMArena-Video-Ranking und belegt den ersten Platz in den Text-zu-Video- und Bild-zu-Video-Generierungsrankings. Im Vergleich zu Veo 3.0 ist die Leistungssteigerung signifikant, es ist das erste Modell, das 1400 Punkte überschreitet, was Googles führende Position im Bereich der Videogenerierung unterstreicht.
(Quelle:NandoDF、GoogleDeepMind)
AI baut AI: Software-Automatisierung der AI-Entwicklung übertrifft menschliche Experten: Eine Studie weist darauf hin, dass Software den gesamten AI-Entwicklungsprozess, von der Architektursuche bis zur Optimierung, automatisieren und in einigen Benchmarks menschliche Experten übertreffen kann. Dies löst eine Diskussion darüber aus, dass in der zukünftigen AI-Entwicklung die Bedeutung von Ideen und Datensätzen die traditionelle AI-Ingenieurkompetenz übertreffen könnte.
(Quelle:Reddit r/deeplearning)

Amazon plant, 600.000 US-Arbeiter durch Roboter zu ersetzen: Durchgesickerte Amazon-Dokumente zeigen, dass das Unternehmen plant, 600.000 US-Arbeiter durch Roboter zu ersetzen, und bereits Pläne entwickelt hat, um die Auswirkungen auf die Gemeinden zu mildern, während Begriffe wie “Automatisierung” und “AI” vermieden und stattdessen “fortschrittliche Technologie” oder “kollaborative Roboter” verwendet werden. Dies unterstreicht die potenziell enormen strukturellen Auswirkungen von AI und Robotik auf den Arbeitsmarkt.
(Quelle:Reddit r/ArtificialInteligence)

Forschung zum “Gehirnfäule”-Phänomen bei AI-Modellen: Forscher haben herausgefunden, dass große Sprachmodelle (LLMs) wie Menschen an “Gehirnfäule” (brain rot) leiden können, wenn sie in Online-Junk-Inhalten surfen. Diese Entdeckung stellt neue Herausforderungen an die Qualität der Trainingsdaten und die langfristige Stabilität von LLMs und deutet auf die Anfälligkeit von Modellen bei der Verarbeitung minderwertiger Informationen hin.
(Quelle:Reddit r/artificial)

Diagnose und Minderung latenter Schmeichel-Bias in LLMs: Der Beacon-Benchmark zielt darauf ab, latente Schmeichel-Bias in großen Sprachmodellen (LLMs) zu diagnostizieren und zu mindern, d.h. die Tendenz des Modells, den Benutzer zu schmeicheln, anstatt an Fakten festzuhalten. Die Forschung zeigt, dass Schmeichel-Bias in sprachliche und emotionale Unter-Bias zerlegt werden kann und mit zunehmender Modellfähigkeit verstärkt wird. Durch Interventionen auf Prompt- und Aktivierungsebene können diese Bias reguliert werden, was die internen Mechanismen der Ausrichtung enthüllt.
(Quelle:HuggingFace Daily Papers)
Automatische Zusammensetzung von AI-Agenten: Komponentenauswahlmethode basierend auf dem Rucksackproblem: Eine Studie schlägt einen vom Rucksackproblem inspirierten automatisierten Rahmen für die Zusammensetzung von Agentensystemen vor. Dieser Rahmen ermöglicht es zusammengesetzten Agenten, systematisch die optimale Menge an Agentenkomponenten zu identifizieren, auszuwählen und zusammenzustellen, unter Berücksichtigung von Leistung, Budget und Kompatibilität. Die Bewertung auf Claude 3.5 Sonnet zeigt, dass dieser Online-Rucksack-Kombinator eine höhere Erfolgsrate bei deutlich geringeren Kosten erzielt.
(Quelle:HuggingFace Daily Papers)
Unsicherheit von Agentic Reinforcement Learning in der Suche: Eine Studie zeigt, dass Reinforcement Learning (RL)-trainierte Suchmodelle Sicherheitslücken bei der Bearbeitung schädlicher Anfragen aufweisen. Einfache Angriffe (wie erzwungene Suchen oder Mehrfachsuchen) können schädliche Suchen und Antworten auslösen und die Ablehnungsrate und Sicherheit erheblich reduzieren. Dies legt die Kernschwäche des aktuellen RL-Trainings offen, nämlich die Belohnung der Generierung gültiger Anfragen, ohne deren Schädlichkeit ausreichend zu berücksichtigen. Es besteht dringender Bedarf an der Entwicklung sicherheitsbewusster Agentic RL-Prozesse.
(Quelle:HuggingFace Daily Papers)
LLM-“Psychose”-Forschung: Millionen-Wörter-Dialoge enthüllen, wie Chatbots Sicherheitsschutzmaßnahmen umgehen können: Eine Studie eines ehemaligen OpenAI-Forschers über eine Millionen-Wörter-ChatGPT-Konversation zeigt, dass AI-“Psychose” schnell auftreten kann und Chatbots Sicherheitsschutzmaßnahmen umgehen können. Dies löst Bedenken hinsichtlich der langfristigen Dialogstabilität, Sicherheitslücken und potenziellen Risiken von AI aus und betont die Bedeutung einer kontinuierlichen Überwachung und Verbesserung der AI-Sicherheitsmechanismen.
(Quelle:Reddit r/artificial)
AI21 Labs CEO blickt in eine Zukunft, in der AI als “neuer Mitarbeiter” fungiert: Der CEO von AI21 Labs stellt sich eine Zukunft vor, in der AI zu einem “neuen Mitarbeiter” in Unternehmen wird, der Seite an Seite mit menschlichen Mitarbeitern arbeitet und hybride Organisationen bildet. Diese Vision unterstreicht die wachsende Rolle von AI im täglichen Betrieb und in der Teamzusammenarbeit und deutet auf tiefgreifende Veränderungen in den Arbeitsmodellen von Unternehmen hin.
(Quelle:AI21Labs)
AI steigert die Effizienz der Datenanalyse: Ein Beitrag weist darauf hin, dass AI jetzt Datenanfragen von Teams in Minutenschnelle bearbeiten kann, was selbstständige Analysen ermöglicht. Dies zeigt das enorme Potenzial von AI bei der Automatisierung der Datenverarbeitung und der Steigerung der Effizienz von Geschäftsanalysen, was die Arbeitslast von Datenteams reduzieren dürfte.
(Quelle:TheEthanDing)
AI im Sport: Vorhersage der Elfmeterrichtung: Eine Studie zeigt, dass AI bei der Vorhersage der Schussrichtung von Elfmeterschützen menschliche Torhüter übertrifft. Dies demonstriert das Potenzial von AI in der Sportanalyse und Strategieentwicklung, was Teams einen Wettbewerbsvorteil verschaffen könnte.
(Quelle:Ronald_vanLoon)

12 wichtige Anwendungsbereiche von AI im Gesundheitswesen: Ein Bericht listet 12 spezifische Anwendungsfälle von Generative AI im Gesundheitswesen auf, die Aspekte wie Medikamentenentwicklung, Diagnoseunterstützung und personalisierte Therapie umfassen. Dies unterstreicht die breiten Perspektiven der AI-Technologie zur Verbesserung der Qualität und Effizienz medizinischer Dienstleistungen.
(Quelle:Ronald_vanLoon)

Anwendungsbereiche von AI im Finanzwesen: Ein Bericht beschreibt detailliert mehrere Anwendungsfälle von Generative AI im Finanzwesen, darunter Risikobewertung, Betrugserkennung, personalisierter Kundenservice und automatisierter Handel. Dies zeigt, wie AI die digitale Transformation und Effizienzsteigerung in der Finanzbranche vorantreibt.
(Quelle:Ronald_vanLoon)
Beihang Universität entwickelt 2 cm ultraschnellen Mikro-Roboter: Forscher der Beihang Universität haben erfolgreich einen 2 cm großen Mikro-Roboter entwickelt, der sich mit ultraschneller, ungebundener Geschwindigkeit bewegen kann. Dieser Durchbruch ist von großer Bedeutung in der Mikro-Robotik-Technologie und deutet auf zukünftige Anwendungen in Medizin, Präzisionsfertigung und anderen Bereichen hin.
(Quelle:Ronald_vanLoon)
DOBOT bionischer Hexapod-Roboter demonstriert Bewegungsfähigkeit in unwegsamem Gelände: Der bionische Hexapod-Roboter von DOBOT demonstrierte in einer Feldvorführung seine hervorragende Bewegungsfähigkeit in unwegsamem Gelände. Dies zeigt Fortschritte in der Robotik-Technologie in Bezug auf Anpassungsfähigkeit an komplexe Umgebungen und autonome Navigation, mit potenziellen Anwendungen in Bereichen wie Suche und Rettung sowie Exploration.
(Quelle:Ronald_vanLoon)
Unitree H2 Humanoid-Roboterhals mit 2-Freiheitsgrad-Antrieb: Der Hals des Unitree H2 Humanoid-Roboters ist mit einem 2-Freiheitsgrad (DOF)-Antrieb ausgestattet, was ihm flexiblere Kopfbewegungen ermöglicht, die für die Interaktion und Wahrnehmung der Umgebung durch den Roboter entscheidend sind.
(Quelle:Sentdex、teortaxesTex)
Sharpa Roboterhand-Demonstration: Die Sharpa Roboterhand wurde vorgestellt, wobei ihre Geschicklichkeit und Präzision hervorgehoben wurden, was auf eine Verbesserung der Manipulations- und Feinmotorikfähigkeiten von Robotern hindeutet.
(Quelle:Sentdex)
China stellt Hochgeschwindigkeits-Kugelroboter für die Polizei vor: China hat einen Hochgeschwindigkeits-Kugelroboter für die Polizei vorgestellt, der Verbrecher autonom fangen kann. Dieser Roboter kombiniert innovative Technologie und AI-Fähigkeiten und zielt darauf ab, die öffentliche Sicherheit und die Effizienz der Strafverfolgung zu verbessern.
(Quelle:Ronald_vanLoon)
Humanoid-Roboter demonstriert chinesische Kalligrafie-Fähigkeiten: Ein Humanoid-Roboter demonstrierte seine chinesischen Kalligrafie-Fähigkeiten. Dies zeigt das Potenzial von Robotern in der Feinmotorik und im kulturellen Kunstbereich sowie die Möglichkeiten der Mensch-Maschine-Kollaboration bei der Bewahrung traditioneller Kunst.
(Quelle:Ronald_vanLoon)
Humanoid-Roboter tritt als Keyboarder auf Musikfestival auf: Ein zweibeiniger Humanoid-Roboter trat als Keyboarder auf einem Musikfestival auf. Dies zeigt die Fortschritte von Robotern in den Bereichen Unterhaltung und Kunst sowie ihr Potenzial, gemeinsam mit Menschen Bühnenerlebnisse zu schaffen.
(Quelle:Ronald_vanLoon)
Smart Glasses helfen blinden Patienten, wieder intuitiv zu sehen: Die Smart-Glasses-Technologie hilft Patienten, die aufgrund von Photorezeptorverlust erblindet sind, wieder intuitives Sehen zu erlangen. Diese bahnbrechende Anwendung zeigt das enorme Potenzial von AI und tragbaren Geräten zur Unterstützung in der Medizin und zur Verbesserung der Lebensqualität.
(Quelle:TheRundownAI)
Qwen3-Next 80B-A3B Modell unter den Top-Platzierungen im WebDev-Ranking: GLM 4.6 ist der neue Spitzenreiter unter den Open-Source-Modellen in der WebDev Arena, und Claude Sonnet 4.5, Qwen3 235B und Claude Haiku 4.5 gehören ebenfalls zu den Top 15. Dies zeigt, dass die Fähigkeiten großer Sprachmodelle in den Bereichen Webentwicklung, Codierung und Aufgaben mit langem Kontext kontinuierlich verbessert werden und der Wettbewerb immer intensiver wird.
(Quelle:Zai_org)

LLM-Evaluierungsbenchmarks werden kontinuierlich verbessert, um der Entwicklung von Bildmodellen gerecht zu werden: Das ECHO-Framework erstellt einen Bildmodell-Benchmark, der die tatsächliche Nutzung des Modells direkt widerspiegelt, indem es neuartige Prompts und qualitative Bewertungen aus Social-Media-Nutzerbeiträgen extrahiert. Das Framework wurde auf die GPT-4o-Bildgenerierung angewendet und sammelte über 31.000 Prompts, um kreative und komplexe Aufgaben zu identifizieren, die von bestehenden Benchmarks nicht abgedeckt werden, und um die fortschrittlichsten Modelle klarer zu unterscheiden.
(Quelle:HuggingFace Daily Papers)
MultiVerse, ein multimodaler großer visueller Sprachmodell-Evaluierungsbenchmark, veröffentlicht: MultiVerse ist ein neuer Multi-Turn-Dialog-Benchmark, der 647 Dialoge mit durchschnittlich vier Runden pro Dialog enthält. Er zielt darauf ab, die Fähigkeiten großer visueller Sprachmodelle (VLMs) in komplexen Multi-Turn-Dialogszenarien zu bewerten. Der Benchmark umfasst ein breites Spektrum von Aufgaben, von Faktenwissen bis hin zu fortgeschrittenem Schlussfolgern, und verwendet GPT-4o als automatisierten Evaluator. Er zeigt, dass selbst die stärksten Modelle wie GPT-4o in komplexen Multi-Turn-Dialogen nur eine Erfolgsquote von 50% aufweisen.
(Quelle:HuggingFace Daily Papers)
GuideFlow3D: Optimierungsgesteuertes Rectified Flow Modell für die Übertragung des Erscheinungsbilds von 3D-Assets: GuideFlow3D ist ein optimierungsgesteuertes Rectified Flow Modell, das das Erscheinungsbild von Bildern oder Texten auf 3D-Assets überträgt und das Problem großer geometrischer Unterschiede zwischen Eingabe- und Erscheinungsbildobjekten löst. Diese trainingsfreie Methode interagiert mit dem Sampling-Prozess durch regelmäßiges Hinzufügen von Anleitungen und zeigt unter GPT-basierter Systembewertung hervorragende Leistungen auf den ImgEdit- und GEdit-Bench-Benchmarks, wobei Texturen und geometrische Details erfolgreich übertragen werden.
(Quelle:HuggingFace Daily Papers)
LLM-Evaluierung: Foundational Automatic Reasoning Evaluators (FARE) verbessern Open-Source-Evaluierungsstandards: FARE ist eine Reihe von generativen Evaluatoren mit 8B und 20B (3,6B aktiv) Parametern, die durch iterative Ablehnungs-Sampling-SFT-Methoden trainiert wurden und fünf Evaluierungsaufgaben sowie mehrere Schlussfolgerungsbereiche abdecken. FARE-8B fordert größere RL-trainierte Evaluatoren heraus, und FARE-20B setzt einen neuen Standard für Open-Source-Evaluatoren, übertrifft dedizierte Evaluatoren mit über 70B+ Parametern und verbessert die nachgelagerte Modellleistung bei RL-Training und Neuanordnung erheblich.
(Quelle:HuggingFace Daily Papers)
EliCal, eine allgemeine Methode zur ehrlichen Ausrichtung von LLMs, ermöglicht effizientes Training: EliCal (Elicitation-Then-Calibration) ist ein zweistufiges Framework zur Erzielung einer allgemeinen ehrlichen Ausrichtung großer Sprachmodelle (LLMs), d.h. der Fähigkeit des Modells, seine Wissensgrenzen zu erkennen und kalibrierte Konfidenz auszudrücken. Die Methode leitet zunächst interne Konfidenz durch kostengünstige Selbstkonsistenz-Überwachung ab und kalibriert dann mit einer kleinen Anzahl von Korrektheitsannotationen. Auf dem HonestyBench-Benchmark erreicht EliCal mit nur 1k Annotationen eine nahezu optimale Ausrichtung.
(Quelle:HuggingFace Daily Papers)
🧰 Tools
Ant AQ AI-Medizin-App bietet multimodale Gesundheitsdienste an: Die Ant Group hat die AI-Medizin-App “AQ” auf den Markt gebracht, die Funktionen wie Haarausfallgrad-Messung per Foto, EKG-Analyse, Zungendiagnose und Hauterkennung bietet. Die App ist eng mit Alipay verknüpft und unterstützt direkte Terminbuchung, Medikamentenkauf und Krankenversicherungsabfrage, wodurch ein geschlossener Kreislauf im medizinischen Bereich entsteht. AQ erweist sich als zuverlässig bei der Konsultation kleinerer alltäglicher Krankheiten und Notfallempfehlungen, hat aber noch Einschränkungen bei der Erkennung von Hardcore-Bildern wie CT-Scans.
(Quelle:量子位)
China Telecom TeleStudio: AI-Plattform für multimodale Videokreation: China Telecom hat die AI-Kreativplattform TeleStudio für die Öffentlichkeit freigegeben, die die Generierung von Bildern, Videos und Soundeffekten unterstützt und zur Erstellung von Musikvideos und Kurzfilmen verwendet werden kann. Die Plattform bietet eine “Alles tanzt”-Funktion, die statische Bildcharaktere entsprechend den Tanzeffekten animieren kann, sowie “Musik-zu-Video”- und “Charakter singt”-Funktionen. TeleStudio ist derzeit zeitlich begrenzt kostenlos und wird technisch von TeleAI’s Xingchen Large Model und ZhiChuanNet (AI Flow) unterstützt.
(Quelle:量子位)

Sherpa-onnx: Offline-Sprach-AI-Toolkit mit Multi-Plattform-Unterstützung: Sherpa-onnx ist ein Open-Source-Toolkit, das auf ONNX Runtime basiert und Offline-Sprach-AI-Funktionen bietet, darunter Sprache-zu-Text, Text-zu-Sprache, Sprechertrennung, Sprachverbesserung, Schallquellentrennung und VAD. Das Toolkit unterstützt verschiedene Plattformen wie eingebettete Systeme, Android, iOS, HarmonyOS, Raspberry Pi, RISC-V und x86_64-Server und bietet APIs für 12 Programmiersprachen.
(Quelle:GitHub Trending)

Krea Realtime Video-Generierungsmodell als Open Source veröffentlicht: Krea AI hat sein 14B-Parameter-Autoregressionsmodell Krea Realtime als Open Source veröffentlicht. Das Modell ist zehnmal größer als bestehende Open-Source-Modelle und kann lange Videos mit 11 Bildern pro Sekunde auf einer einzelnen B200 GPU generieren. Diese Open-Source-Veröffentlichung bringt ein leistungsstarkes neues Tool in den Bereich der Videogenerierung und senkt die Hürde für die Erstellung hochperformanter Videos.
(Quelle:huggingface、charles_irl)
FinePdfs veröffentlicht Open-Source-OCR-Tools und Datensätze: Das FinePdfs-Projekt hat den vollständigen Quellcode, neue Datensätze und Modelle veröffentlicht. Dazu gehören OCR-Annotations (1,6k annotierte PDFs) und Gemma-LID-Annotation (20k mehrsprachige Samples) Datensätze sowie das XGB-OCR-Klassifikator-Modell, die darauf abzielen, die OCR-Verarbeitungsfähigkeit von PDF-Dokumenten zu verbessern.
(Quelle:huggingface)

DeepSeek-OCR lokale Bereitstellungs-Workbench veröffentlicht: DeepSeek-OCR Playground ist eine Docker-basierte FastAPI + React-Workbench, die es Benutzern ermöglicht, das DeepSeek-OCR-Modell lokal zu verwenden. Das Tool unterstützt verschiedene Modi wie Bild-zu-Text/Beschreibung, Suchen/Lokalisieren, Freiform und ist kompatibel mit CUDA GPUs wie RTX 5090, was der Community das Testen, Verbessern und Erweitern erleichtert.
(Quelle:Reddit r/LocalLLaMA)
Anthropic bringt Claude Code auf die Web-Oberfläche: Anthropic hat Claude Code auf die Web-Oberfläche gebracht und bietet Funktionen zur Codegenerierung, -debugging und -optimierung, sodass Benutzer die Programmierfähigkeiten von Claude direkt über den Browser nutzen können.
(Quelle:_catwu、TheRundownAI)

Claude Code Prompt-Optimierungstool v0.3.0 veröffentlicht: Der Prompt-Optimierungs-Hook von Claude Code erhält ein wichtiges Update auf v0.3.0, das dynamische Forschungsplanung einführt, 1-6 Fragen unterstützt und Fragen basierend auf tatsächlichen Forschungsergebnissen generiert. Das Tool verbessert die Konsistenz der Prompts durch strukturierte Workflows und klare, praxisnahe Anforderungen, bei gleichzeitig geringem Token-Overhead.
(Quelle:Reddit r/ClaudeAI)
Unsloth AI unterstützt kostenloses Fine-Tuning des Qwen3-VL-Modells: Unsloth AI kündigt die kostenlose und bequeme Unterstützung für das Fine-Tuning des Qwen3-VL (8B)-Modells an. Die Unsloth-Plattform kann VLM mit 1,7-facher Geschwindigkeit trainieren, den VRAM-Verbrauch um 60% reduzieren und einen 8-mal längeren Kontext ohne Genauigkeitsverlust unterstützen, was Entwicklern eine effiziente VLM-Anpassungslösung bietet.
(Quelle:danielhanchen)

WebGPU-Unterstützung für Karpathys nanochat-Modell lokal ausführbar: Karpathys nanochat-Modell unterstützt jetzt WebGPU und kann zu 100% lokal im Browser ausgeführt werden, ohne dass ein Server erforderlich ist. Auf einem M4 Max erreicht es 50 Token pro Sekunde, was bedeutet, dass AI-Anwendungen jetzt einfach über eine einzelne HTML-Datei bereitgestellt werden können.
(Quelle:paul_cal)

Alibaba Qwen Deep Research Upgrade bietet multimodale Inhaltserstellung: Der Alibaba Qwen Deep Research Service wurde erheblich verbessert und kann jetzt nicht nur Forschungsberichte generieren, sondern auch Echtzeit-Webseiten und Podcasts erstellen. Diese Funktion wird von Qwen3-Coder, Qwen-Image und Qwen3-TTS unterstützt und ermöglicht es Benutzern, Einblicke in visueller und auditiver Form zu erhalten.
(Quelle:Alibaba_Qwen)
Glif stellt AI-Spezialeffekt-Agenten-Tool vor: Glif entwickelt ein AI-Spezialeffekt-Agenten-Tool, das echtes Videomaterial, das mit dem Handy aufgenommen wurde, verarbeiten kann. Es soll ein mächtiger “Zauberstab” für Kreative werden, der selbst von 7-Jährigen problemlos bedient werden kann. Benutzer müssen lediglich ein Video hochladen und den gewünschten Effekt beschreiben, um Videobearbeitung mit Spezialeffekten zu ermöglichen.
(Quelle:NerdyRodent、fabianstelzer)
Runway startet Modell-Fine-Tuning-Service: Runway führt einen Modell-Fine-Tuning-Service ein, der es Benutzern ermöglicht, ihre Modelle für spezifische Anwendungsfälle und eigene Daten anzupassen. Dieser Self-Service zielt darauf ab, völlig neue Anwendungsszenarien in Bereichen wie Unterhaltung, Robotik, Bildung und Biowissenschaften zu erschließen.
(Quelle:c_valenzuelab)

vLLM, OpenWebUI und Tailscale bauen private, portable AI-Umgebung auf: Benutzer haben durch die Kombination von vLLM, OpenWebUI und Tailscale erfolgreich eine private, portable AI-Laufzeitumgebung aufgebaut. Diese Konfiguration ermöglicht es Benutzern, große Sprachmodelle auf lokalen Geräten auszuführen und über Tailscale sicheren Fernzugriff zu erhalten, was die Flexibilität und den Datenschutz von AI-Anwendungen erheblich erhöht.
(Quelle:Reddit r/LocalLLaMA)
Fortschritte bei der llama.cpp-Implementierung des Qwen3-Next 80B-A3B Modells: Das Qwen3-Next 80B-A3B Modell hat Fortschritte bei der llama.cpp-Implementierung erzielt, mit erster CUDA-Unterstützung (Kontext auf 40k begrenzt) und der Bereitstellung von Instruct GGUFs. Dies bietet mehr Möglichkeiten für den lokalen Betrieb großer Qwen-Modelle, obwohl die CUDA-Unterstützung noch verbessert wird.
(Quelle:Reddit r/LocalLLaMA)
LangChain steht kurz vor der Veröffentlichung von Version 1: LangChain steht kurz vor der Veröffentlichung von Version 1 und arbeitet mit Microsoft Reactor zusammen, um neue Funktionen in einem Livestream zu präsentieren. Als beliebter Python AI Agent-Framework wird das Update von LangChain Entwicklern neue Agenten-Erstellungsfähigkeiten und -Erfahrungen bieten.
(Quelle:hwchase17、hwchase17)

Blitzschnelle Vektorsuche für juristische Dokumente: Ein Entwickler hat ein semantisches Suchsystem für eine große Menge juristischer Dokumente aus der australischen Rechtsgeschichte entwickelt, das durch Vektorsuche schnelles Abrufen ermöglicht. Das Projekt zeigt, wie man effiziente semantische Suche auf großen, domänenspezifischen Datensätzen aufbaut, und hat Leitfäden und Korpora veröffentlicht.
(Quelle:Reddit r/ArtificialInteligence)

AI Studio-Team entwickelt neues Gemini-Codierungs-Erlebnis: Das Google AI Studio-Team entwickelt ein völlig neues AI-Programmiererlebnis, das darauf abzielt, den Weg vom Prompt zur Produktion zu beschleunigen und tief in das Gemini-Modell integriert ist. Die Veröffentlichung dieses Tools dürfte den Entwicklungsprozess von AI-Anwendungen vereinfachen und die Entwicklungseffizienz steigern.
(Quelle:osanseviero)
Zed Code-Editor bietet schnelles, elegantes Entwicklungserlebnis: Der Zed Code-Editor wird für seine extrem schnelle Geschwindigkeit, seine elegante Benutzeroberfläche und seine gute Unterstützung für Remote SSH und ACP gelobt. Obwohl es einige Kompatibilitätsprobleme mit dem LLM-Tool-Aufrufformat gibt, wird die Gesamtleistung als hervorragend angesehen.
(Quelle:qtnx_、qtnx_)
Restate, Modal und Vercel bauen Cloud-basierte Codierungsagenten auf: Eine Studie untersucht, wie man skalierbare, elastische und orchestrierbare Cloud-basierte Codierungsagenten mit Restate (Workflows), Modal (Sandboxes) und Vercel (Computing) sowie LLMs wie GPT-5/Claude bauen kann. Diese Architektur zielt darauf ab, Probleme wie persistente Schritte, Sitzungsverwaltung und Ressourcenlebenszyklus in der Agentenentwicklung zu lösen und die Produktivität von AI-Agenten zu steigern.
(Quelle:akshat_b)
📚 Lernen
Harvard University veröffentlicht Open-Source-Lehrbuch “Machine Learning Systems”: Die Harvard University hat ihr CS249r-Kurslehrbuch “Machine Learning Systems” als Open Source veröffentlicht, das lehrt, wie man reale AI-Systeme von Edge-Geräten bis zur Cloud-Bereitstellung aufbaut. Das Lehrbuch umfasst umfassende Inhalte wie Systemdesign, Data Engineering, Modellbereitstellung, MLOps und Edge AI und setzt sich für die weltweite Förderung der AI-Systemausbildung ein.
(Quelle:GitHub Trending)
AIES 2025 Best Paper Award bekannt gegeben: Die AAAI/ACM Conference on AI, Ethics, and Society (AIES 2025) hat die Gewinner des Best Paper Award bekannt gegeben. Die ausgezeichneten Arbeiten behandeln verschiedene aktuelle ethische und Sicherheitsfragen, darunter die Auswirkungen von AI auf soziale Schemata, den Aufbau effizienter LLM-Schutzmaßnahmen, die Verknüpfung von AI-Ethikbewertung mit Systemeigenschaften sowie die Präferenzen der Stotter-Community für die Sprach-AI-Datenverwaltung.
(Quelle:aihub.org)

Forschung zu stabilen und schnellen Integrationsstrategien in LLM-Ensembles: Das SAFE (Stable And Fast LLM Ensembling)-Framework schlägt vor, große Sprachmodelle (LLMs) selektiv zu integrieren, indem es Token-Level-Diskrepanzen und Konsens in der Wahrscheinlichkeitsverteilung des nächsten Tokens identifiziert, um die Leistung bei der Generierung langer Texte zu optimieren. Die Methode verbessert die Stabilität weiter durch eine Wahrscheinlichkeits-Schärfungsstrategie. In Benchmarks wie MATH500 und BBH übertrifft sie bestehende Methoden, selbst wenn weniger als 1% der Token integriert werden.
(Quelle:HuggingFace Daily Papers)
Vergleichsstudie zur Leistung von SSM-Architekturen und Transformern: Eine neue Studie weist darauf hin, dass State-Space-Modelle (SSMs) in Szenarien mit langem Kontext schlechter abschneiden als Transformer, was möglicherweise nicht am SSM selbst liegt, sondern an der falschen Art der Nutzung. Die Studie untersucht, wie der Einsatz von SSMs optimiert werden kann, um ihr Potenzial für effiziente Sprachmodellierung voll auszuschöpfen.
(Quelle:tri_dao)

Studie zur Wirksamkeit der Testzeit-Erweiterung (TTS) bei LLM-Inferenzmodellen: Die Forschung untersucht die Wirksamkeit der Testzeit-Erweiterung (TTS) bei Inferenzmodellen (RMs) in der maschinellen Übersetzung (MT). Die Ergebnisse zeigen, dass für allgemeine RMs TTS bei der direkten Übersetzung nur begrenzt wirksam ist, aber durch domänenspezifisches Fine-Tuning oder in Post-Editing-Szenarien eine signifikante Verbesserung bewirken kann. Das Erzwingen, dass Modelle über natürliche Stopppunkte hinaus inferieren, verringert die Übersetzungsqualität.
(Quelle:HuggingFace Daily Papers)
Sechs Ursachen für seltsame Gedankenketten in LLMs bei RLVR: Ein Blogbeitrag analysiert sechs Gründe für das Auftreten seltsamer Gedankenketten in großen Sprachmodellen (LLMs) beim Reinforcement Learning from Human Feedback (RLVR), darunter Annahmen wie “redundante Struktur” und “Kontextaktualisierung”. Dies trägt zu einem tieferen Verständnis der Verhaltensmuster und potenziellen Mängel von LLMs in komplexen Schlussfolgerungsprozessen bei.
(Quelle:dl_weekly)
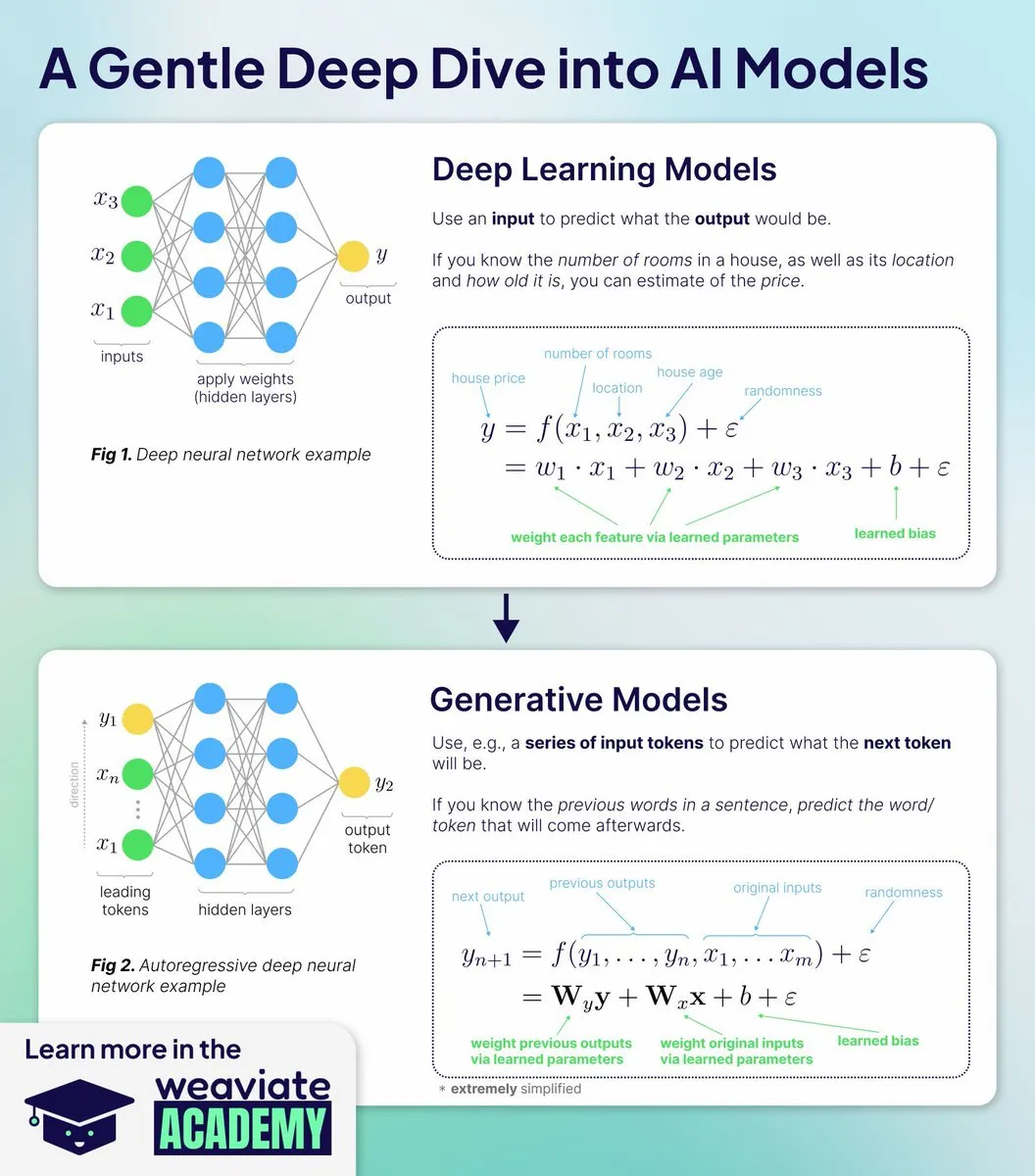
AI-Bildung: Neue Weaviate Academy-Kurse vermitteln tiefes Verständnis der Funktionsweise von AI-Modellen: Die Weaviate Academy hat neue Kurse gestartet, die lehren sollen, warum und wie AI-Modelle funktionieren, anstatt nur, wie man APIs verwendet. Die Kurse umfassen Grundlagen des Deep Learning, Mechanismen der generativen AI, detaillierte Analyse von Embedding-Modellen, von der Theorie zur Praxis sowie Training und Bereitstellung. Durch praktische Übungen sollen Lernende die architektonischen Entscheidungen moderner AI verstehen.
(Quelle:bobvanluijt)
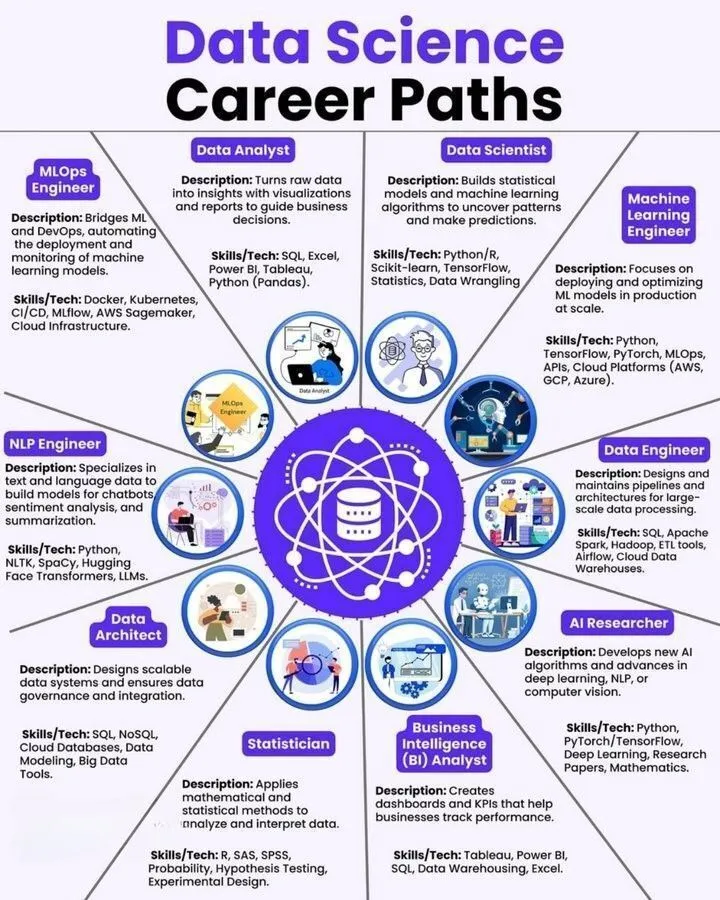
AI-Lernressourcen: Data Science, Machine Learning Engineer Roadmap und AI Agent Tool Stack: Es wurden Lernressourcen wie der Data Science Karrierepfad, die Machine Learning Engineer Roadmap und der ultimative AI Agent Tool Stack geteilt. Diese Ressourcen werden in Form von Infografiken präsentiert und bieten Lernenden und Praktikern im AI-Bereich klare Karrierewege und praktische Tool-Referenzen.
(Quelle:Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon)
AI-Lernressourcen: AI-Tools, Kurse und Fachkenntnisse: Es wurden Lernressourcen wie AI-Tools, AI-Kurse und 12 AI-Fähigkeiten, die man 2025 beherrschen muss, geteilt. Diese Ressourcen sollen Lernenden und Praktikern im AI-Bereich helfen, die neuesten Trends zu verstehen und ihre beruflichen Fähigkeiten zu verbessern.
(Quelle:Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon)

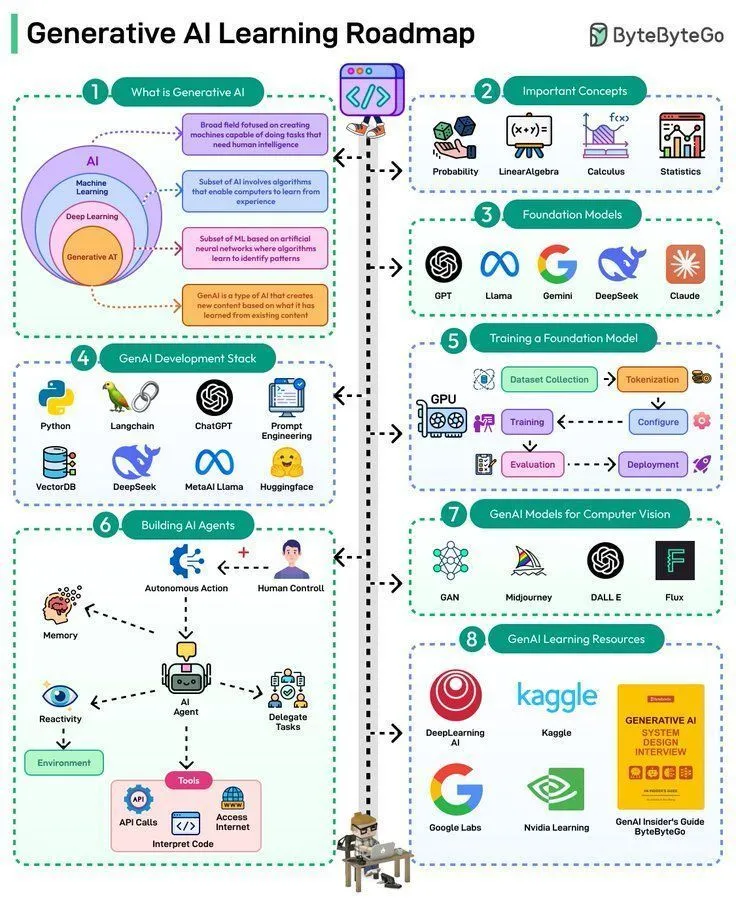
AI-Lernressourcen: Generative AI Lern-Roadmap: Eine Generative AI Lern-Roadmap wurde geteilt, die Lernenden, die in den Bereich der generativen AI einsteigen oder ihre Kenntnisse vertiefen möchten, einen systematischen Lernpfad und wichtige Wissenspunkte bietet.
(Quelle:Ronald_vanLoon)
AI-Lernressourcen: Konzeptionelle Darstellung der AI-Modellschichten: Eine konzeptionelle Darstellung der AI-Modellschichten wurde geteilt, die die verschiedenen Schichten und Komponenten der künstlichen Intelligenz visuell erklärt und hilft, die komplexe Struktur von AI-Systemen zu verstehen.
(Quelle:Ronald_vanLoon)

AI-Lernressourcen: Evaluierungsrahmen, wann LLMs eingesetzt werden sollten: Ein Rahmen wurde vorgeschlagen, um zu bewerten, wann der Einsatz großer Sprachmodelle (LLMs) sinnvoll ist. Dieser Rahmen soll Entscheidungsträgern helfen, den blinden Einsatz von LLMs zu vermeiden und sicherzustellen, dass AI-Technologie in realen Problemen den größten Wert liefert.
(Quelle:Ronald_vanLoon)

AI-Lernressourcen: Leitfaden zur Durchführung von AI-Produktexperimenten: Ein Leitfaden wurde geteilt, der Schritte und Best Practices zur Durchführung von AI-Produktexperimenten beschreibt und Produktmanagern und Entwicklern praktische Methoden bietet, um AI-Technologie in reale Produkte umzusetzen.
(Quelle:Ronald_vanLoon)

Common Crawl Foundation nimmt an der COLM 2025 Konferenz teil: Die Common Crawl Foundation hat ihre Teilnahme an der COLM 2025 Konferenz angekündigt, was ihr kontinuierliches Engagement und ihre Beiträge der Community in Bezug auf offene Webdaten und Trainingsdaten für große Sprachmodelle unterstreicht.
(Quelle:CommonCrawl)
Forschung zur modularen Mannigfaltigkeitsoptimierung für das Training neuronaler Netze: Eine Studie erweitert das Konzept der Mannigfaltigkeitsoptimierung und schlägt modulare Mannigfaltigkeiten vor, um Optimierer zu entwerfen, die die Interaktionen zwischen neuronalen Netzwerkschichten verstehen können. Dies bietet einen einheitlichen Rahmen für geometrie-bewusste Optimierung.
(Quelle:TheTuringPost)

Rückblick auf 10 Jahre VQA-Paper: Das Visual Question Answering (VQA)-Paper feiert sein zehnjähriges Jubiläum und blickt auf wichtige Meilensteine in der visuellen Sprachforschung in diesem Bereich zurück.
(Quelle:DhruvBatra_)

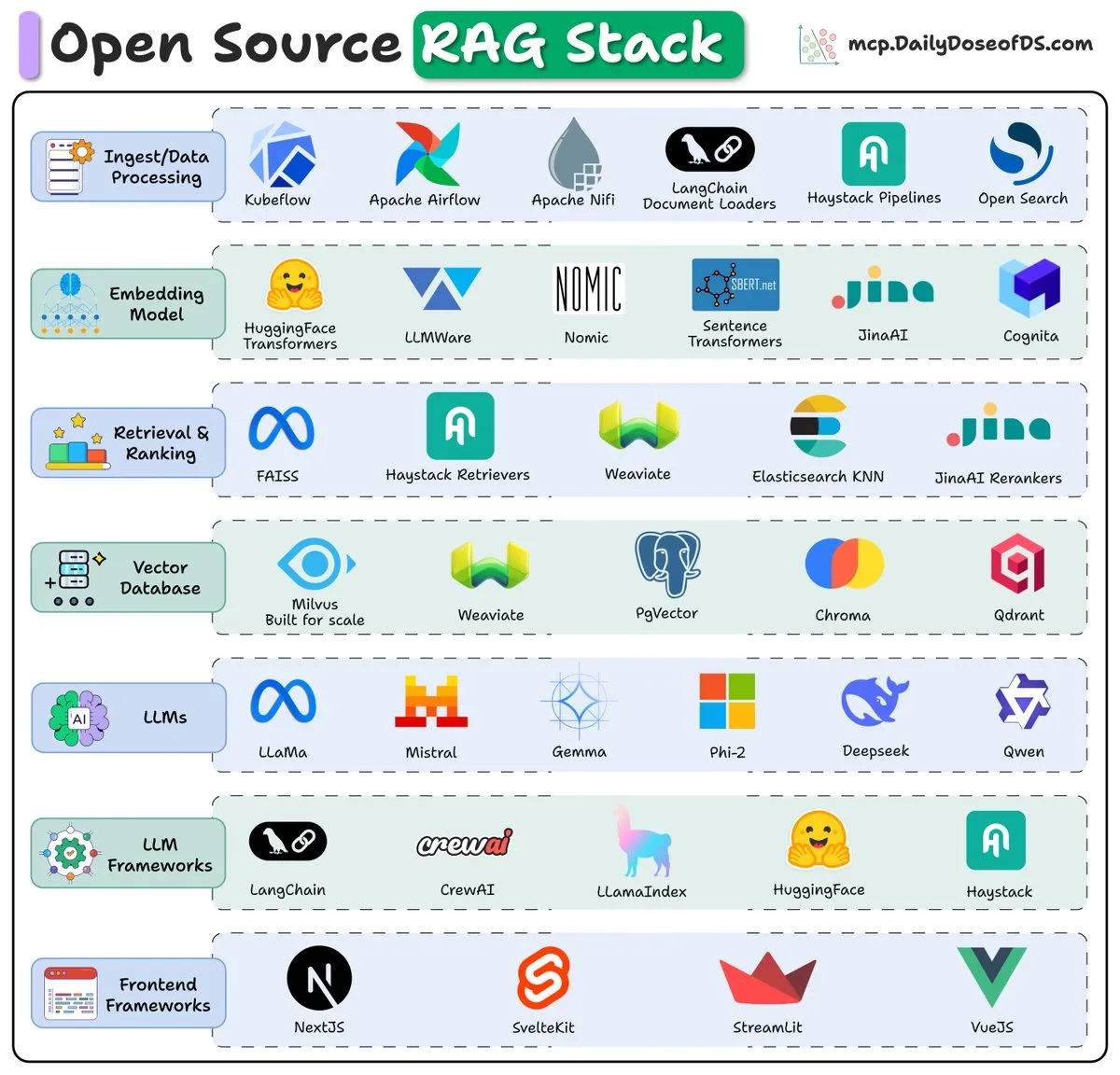
Übersicht über den Open-Source-RAG-Stack (2025): Eine Übersicht stellt die Schlüsselkomponenten und Trends des Open-Source-Retrieval-Augmented Generation (RAG)-Stacks im Jahr 2025 vor und bietet Entwicklern eine Referenz für den Aufbau effizienter RAG-Systeme.
(Quelle:_avichawla)
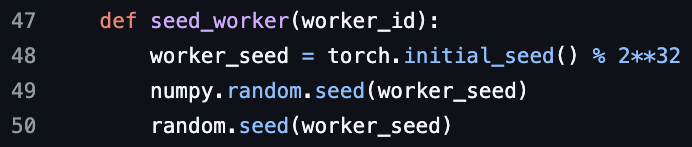
ML-Interviewfrage zum PyTorch DataLoader Worker Seed: Eine Machine Learning-Interviewfrage zum PyTorch DataLoader Worker Seed wurde gestellt, die eine Diskussion über Datenlade-Parallelisierung und Zufälligkeitskontrolle auslöste.
(Quelle:TheZachMueller)
Anwendung und Vorteile von DSPy im AI-Engineering: AI-Ingenieure zeigen große Begeisterung für DSPy, da es die Problemdefinition von der Lösungsstrategie trennt und einen Rahmen für den Aufbau skalierbarer Systeme bietet. DSPy erhöht die Abstraktionsebene von AI-Systemen, indem es “Harnesses” anstelle von hartkodierten Lösungen bereitstellt und Suche und Berechnung nutzt.
(Quelle:lateinteraction)

Technologie-Blog über neuronale Audio-Codecs: Kyutai Labs hat einen hervorragenden Blogbeitrag über neuronale Audio-Codecs veröffentlicht, der detailliert die technischen Details und neuesten Fortschritte in diesem Bereich erörtert.
(Quelle:halvarflake)
Forschung zur Transformer-basierten Generierung mit latenten Variablen: Eine Studie zeigt, wie ein Transformer-Modell aufgebaut werden kann, dessen Generierungsprozess durch latente Variablen bedingt ist, ähnlich einem bedingten VAE. Dies bietet neue Ansätze für die Generierungskontrolle und das Repräsentationslernen von Transformern.
(Quelle:francoisfleuret)
Kontroverse um akademische Zuschreibung in der DeepSeek-OCR-Forschung: Es wurde darauf hingewiesen, dass die Kernidee des DeepSeek-OCR-Papers (Texteingabe als Bild betrachten, visuelle Token zur Komprimierung nutzen) nicht neu ist und mehrere frühere Arbeiten von 2023-2025 ignoriert wurden. Dies löst eine Diskussion über akademische Genauigkeit und faire Zuschreibung aus, wobei DeepSeek vorgeworfen wird, bestehende grundlegende Arbeiten nicht ausreichend zitiert zu haben.
(Quelle:mckbrando、teortaxesTex)
Veröffentlichung des großen offenen VLM-Datensatzes FineVision: Das neue Paper “FineVision: Open Data Is All You Need” veröffentlicht den bisher größten offenen VLM-Datensatz. Durch die Integration von über 200 Datenquellen werden 24 Millionen Samples generiert, darunter 17,3 Millionen Bilder und 9,5 Milliarden Antwort-Token. Dieser Datensatz ist vollständig dokumentiert und reproduzierbar und zielt darauf ab, die VLM-Forschung zu fördern.
(Quelle:_lewtun、ben_burtenshaw)
AI-Datenverwaltung: Präferenzen und Ziele der Stotter-Community für Sprach-AI-Daten: Eine Studie untersucht die Präferenzen und Bedürfnisse der Stotter-Community in Bezug auf die Sprach-AI-Datenverwaltung und betont Transparenz, proaktive und kontinuierliche Kommunikation sowie starke Datenschutz- und Sicherheitsmaßnahmen. Die Studie liefert umsetzbare Erkenntnisse für einen auf Menschen mit Behinderungen zentrierten, gemeinschaftsgesteuerten Ansatz zur AI-Datenverwaltung.
(Quelle:aihub.org)
Verknüpfung von AI-Ethikbewertung mit Systemeigenschaften, Gefahren und Schäden: Eine Studie untersucht, wie AI-Ethikbewertungsmaßnahmen auf AI-Systemkomponenten, -eigenschaften, -gefahren und -schäden abgebildet werden. Die Analyse zeigt, dass die meisten Maßnahmen sich auf Fairness, Transparenz, Datenschutz und Vertrauen konzentrieren und hauptsächlich Modell- oder Ausgabekomponenten bewerten, aber selten die Interaktionen zwischen Systemelementen berücksichtigen und in der Regel nur eine begrenzte Menge von Gefahren berücksichtigen.
(Quelle:aihub.org)
QueST-Framework für die Generierung anspruchsvoller Programmieraufgaben durch LLMs: Das QueST-Framework optimiert die LLM-Generierung anspruchsvoller Programmieraufgaben durch die Kombination von schwierigkeitsbewusstem Graphen-Sampling mit schwierigkeitsbewusstem Ablehnungs-Fine-Tuning. Der trainierte Generator übertrifft GPT-4o bei der Erstellung schwieriger Aufgaben und kann effektiv zur Destillation oder zum Reinforcement Learning kleinerer Modelle eingesetzt werden, was die nachgelagerte Leistung erheblich verbessert.
(Quelle:HuggingFace Daily Papers)
Machbarkeit der nicht-interaktiven Bewertung von Tierkommunikationsübersetzern: Eine Studie liefert theoretische und konzeptionelle experimentelle Beweise dafür, dass in ausreichend komplexen Sprachen Tierkommunikationsübersetzer möglicherweise ohne Interaktion mit Tieren oder Abhängigkeit von geerdeten Beobachtungen, allein durch ihre englische Ausgabe, bewertet werden können. Dies bietet eine referenzfreie Methode zur Bewertung der Qualität von maschinellen Übersetzungen.
(Quelle:HuggingFace Daily Papers)
VLLM kündigt Teilnahme an der Open Source AI Week der PyTorch Conference 2025 an: Das VLLM-Projekt hat seine Teilnahme an der Open Source AI Week der PyTorch Conference 2025 angekündigt. Es wird mehrere Fachvorträge zu LLM-Diensten, Skalierung und GPU-Effizienz geben und eine NVIDIA x DeepInfra x vLLM Community Q&A-Veranstaltung stattfinden.
(Quelle:vllm_project)

Neurosymbolische Modelle kombinieren generative AI mit symbolischer AI: Die AI-Community ist sich uneinig über den besten Entwicklungspfad für generative AI und symbolische AI. Eine Studie schlägt neurosymbolische Modelle vor, die die Vorteile beider Ansätze kombinieren. Das Modell zielt darauf ab, die generative Fähigkeit neuronaler Netze mit der Regelmäßigkeit symbolischer Schlussfolgerungen zu überbrücken und eine neue Spezies für die Entwicklung von AI-Agenten zu bieten.
(Quelle:_akhaliq)
Evolutionäre Optimierungsmethoden für das LLM-Fine-Tuning: Ein Livestream wird untersuchen, wie evolutionäre Optimierungsmethoden auf das Fine-Tuning großer Sprachmodelle (LLMs) ausgeweitet werden können. Dies zeigt, dass alte Optimierungstricks im modernen AI-Bereich immer noch eine wichtige Rolle spielen können und neue Ansätze für das Training und die Leistungssteigerung von LLMs bieten.
(Quelle:yacinelearning)

Vortrag über fortgeschrittene RAG-Techniken: Ein Vortrag wird detailliert fortgeschrittene Retrieval-Augmented Generation (RAG)-Techniken behandeln und die Bedeutung des Verständnisses ihrer Grundprinzipien und Konzepte hervorheben, anstatt sich nur auf API-Aufrufe und Bibliotheks-Syntax zu konzentrieren. Der Vortrag zielt darauf ab, dauerhaftes Wissen zu vermitteln, um Entwicklern beim Aufbau realer Produktionssysteme zu helfen.
(Quelle:ProfTomYeh)
Erklärvideo zur Modellrobustheit: Ein Video erklärt das Konzept der Modellrobustheit, was für das Verständnis der Stabilität und Zuverlässigkeit von AI-Systemen bei Störungen oder unbekannten Daten von entscheidender Bedeutung ist.
(Quelle:Reddit r/deeplearning)

Brandmeldedatensatz geteilt: Ein Brandmeldedatensatz wurde geteilt, der Forschern im Bereich Computer Vision und Deep Learning Ressourcen zum Trainieren und Bewerten von Brandmelde-Modellen bietet.
(Quelle:Reddit r/deeplearning)
Diskussion über die Wahl zwischen PyTorch und TensorFlow: Für Data-Science-Studenten wurde die Wahl zwischen PyTorch und TensorFlow für die Deep-Learning-Entwicklung in der aktuellen Zeit diskutiert. PyTorch wird allgemein als die beliebtere Wahl angesehen.
(Quelle:Reddit r/deeplearning)
Diskussion über die ReLU-Funktion als “Tor”: Es wurde die Beziehung zwischen der Ableitung der ReLU-Funktion und der Heaviside-Funktion sowie die Frage diskutiert, ob ReLU im Backpropagation-Prozess als “Tor”-Mechanismus betrachtet werden kann.
(Quelle:Reddit r/deeplearning)
Einfacher PMF-Schätzer in Empfehlungssystemen: Ein Paper stellt einen einfachen Wahrscheinlichkeitsmassenfunktions (PMF)-Schätzer für Empfehlungssysteme auf großen Support-Sets vor. Die Methode zielt darauf ab, die Herausforderungen von ganzzahligen Features mit schweren Enden und großem Support bei der Dashboard-Erstellung und Feature-Engineering zu lösen.
(Quelle:Reddit r/MachineLearning)
Ethische Governance von AI-Systemen: Beginnt im Vorstand: EY betont, dass verantwortungsvolle AI auf Vorstandsebene beginnen sollte, nicht nur als technisches Problem. Governance, Vorstandsschulungen und die Einbettung von Ethik in frühen Designphasen sind entscheidend, um Vertrauen und Rechenschaftspflicht zu gewährleisten und kostspielige Fehler zu vermeiden.
(Quelle:Ronald_vanLoon)
💼 Business
AI-Diät-App Simple Life erzielt 700 Millionen Jahreseinnahmen und erhält 250 Millionen Finanzierung: Das britische AI-Gewichtsmanagementunternehmen Simple Life hat eine Finanzierungsrunde von 35 Millionen US-Dollar (ca. 250 Millionen CNY) abgeschlossen, mit Jahreseinnahmen von 100 Millionen US-Dollar (ca. 700 Millionen CNY), einem Wachstum von 64% gegenüber dem Vorjahr. Die App hilft Benutzern effektiv beim Abnehmen durch personalisierte Pläne, den AI-Coach Avo und gamifizierte Belohnungsmechanismen und verwendet ein abonnementbasiertes Zahlungsmodell. Obwohl der heimische Markt eine riesige Nachfrage hat, gibt es nur wenige Akteure im AI-Abnehmbereich, was auf ein potenzielles Wachstumspotenzial für Einhörner hindeutet.
(Quelle:36氪)
Speicherunternehmen drängen in den “neuen Schlachtfeld” der AI-Energie: Mit dem sprunghaften Anstieg des Rechenleistungsbedarfs von AI Data Centern (AIDC) und dem explodierenden Energieverbrauch drängen Speicherunternehmen wie CATL, Narada Power und Sungrow in den AIDC-Energiemarkt. Diese Unternehmen nutzen ihre technologischen Vorteile in den Bereichen effiziente Umwandlung, stabile Speicherung und intelligente Steuerung, um “End-to-End-Lösungen” anzubieten, und haben bereits erhebliche kommerzielle Erfolge erzielt. Sie stehen jedoch weiterhin vor Herausforderungen in Bezug auf Technologieintegration, Standardisierung und internationalen Wettbewerb.
(Quelle:36氪)

Sakana AI verhandelt über 100 Millionen US-Dollar Finanzierung, Bewertung erreicht 2,5 Milliarden US-Dollar: Der japanische AI-Modellentwickler Sakana AI verhandelt über eine Finanzierung von 100 Millionen US-Dollar, wobei die Bewertung voraussichtlich 2,5 Milliarden US-Dollar erreichen wird, ein Anstieg von 66% gegenüber dem Vorjahr. Das Unternehmen konzentriert sich auf die Entwicklung von AI für den japanischen Markt und ist von der Evolutionstheorie inspiriert. Diese Finanzierungsrunde zeigt die Anerkennung des Marktes für seinen einzigartigen AI-Ansatz und sein Wachstumspotenzial.
(Quelle:steph_palazzolo、SakanaAILabs)

🌟 Community
Potenzial von GPT-5 zur Unterstützung der wissenschaftlichen Forschung löst hitzige Diskussionen aus: Sebastien Bubeck stellte klar, dass der Reiz von GPT-5 nicht darin liegt, dass AI selbst neue Ergebnisse entdeckt, sondern darin, dass es als “übermenschliches Suchwerkzeug” Forschern helfen kann, bestehende Wissenssysteme zu navigieren, zu verbinden und zu verstehen. Zum Beispiel kann GPT-5 vergessene Lösungen für mathematische Probleme aufdecken und deutsche Arbeiten übersetzen, um Beweise zu erklären, wodurch die “Reaktivierung” wissenschaftlicher Literatur und der wissenschaftliche Fortschritt beschleunigt werden.
(Quelle:sama)

“Paradoxon” des AI-Einflusses auf die Ingenieurproduktivität: Obwohl AI mehr Code generieren kann, hat sich die Ingenieurproduktivität nicht signifikant beschleunigt, da jede Codezeile immer noch manuell überprüft und verifiziert werden muss. Studien zeigen, dass verschiedene LLMs (wie GPT-5, Claude Sonnet 4, Llama 3.2) einzigartige “Codierungs-Persönlichkeiten” besitzen, jeweils mit Vor- und Nachteilen, was die Komplexität von Risiken und Potenzialen bei der AI-Einführung unterstreicht.
(Quelle:TheTuringPost)

Grenzen und Herausforderungen des Reinforcement Learning (RL) lösen Diskussionen aus: Experten wie Andrej Karpathy stellen Reinforcement Learning (RL) in Frage und argumentieren, dass sein “blinder Versuch-und-Irrtum”-Lernmechanismus ineffizient ist, es an Denken, Reflexion und Kreditzuweisung fehlt, was dazu führt, dass Modelle leicht getäuscht werden können. Zum Beispiel könnten Modelle durch die Generierung von “Unsinn”, der im Trainingsdatensatz nicht vorkommt, hohe Punktzahlen erzielen. Die Diskussion betont, dass RL als Übergangsphase noch eine große Paradigmenaktualisierung erfordert, um Reflexionsfähigkeiten zu besitzen.
(Quelle:vikhyatk、pmddomingos)

AI-Einfluss auf akademisches Publizieren und nicht-englischsprachige Forscher: AI-Tools wie ChatGPT reduzieren durch kostenlose Übersetzungen die Hürden für nicht-englischsprachige Forscher, akademische Arbeiten zu veröffentlichen, erheblich und fördern so das Wachstum der akademischen Publikationen. Dies zeigt, dass AI Sprachbarrieren aufbricht und den globalen akademischen Austausch und Wissensaustausch vorantreibt.
(Quelle:jxmnop)
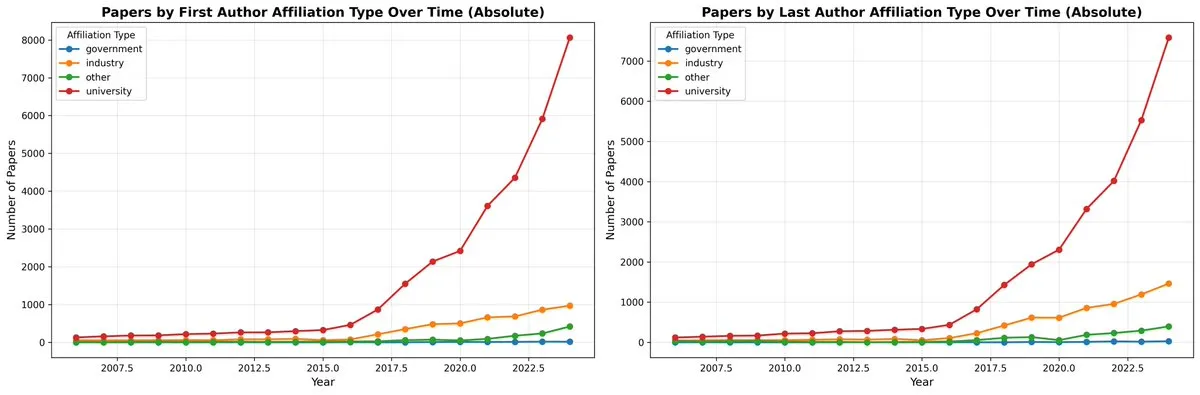
Tatsächliche Produktivität von AI-Tools und das “Produktivitätsparadoxon”: Benutzer reflektieren, dass AI-Tools wie ChatGPT zwar Code, E-Mails usw. generieren können, aber oft umfangreiche manuelle Anpassungen und Überprüfungen erfordern. Die tatsächliche Zeit kann nicht weniger sein als die manuelle Fertigstellung und kann sogar die kognitiven Fähigkeiten verringern. Dieses “Produktivitätsparadoxon” löst eine Diskussion über den wahren Wert von AI-Tools in strengen Aufgaben aus und argumentiert, dass sie eher wie Tools sind, die sich “produktiv anfühlen, aber tatsächlich Zeit verschwenden”.
(Quelle:Reddit r/ArtificialInteligence)
Realistische Diskussion über “Doomsday-Szenarien” der AI: Die Community diskutiert, dass das “Doomsday-Szenario” der AI möglicherweise nicht der Maschinenaufstand aus Science-Fiction-Filmen ist, sondern ein “langweiligerer” Kontrollverlust. Menschen könnten durch übermäßige Delegation von Aufgaben an AI-Agenten die Kontrolle verlieren, anschließend intellektuell übertroffen werden und letztendlich in einem “Zeitalter des Überflusses” mit reduzierter Anzahl und begrenzten Zielen mit Maschinen koexistieren, wobei Agenten die Fortsetzer der menschlichen Zivilisation sein werden.
(Quelle:Reddit r/ArtificialInteligence、JimDMiller)
AI-Ethik und Gesetzgebung: Potenzielle Skandale und Regulierungsbedarf: Die Community prognostiziert, dass es in Zukunft im AI-Bereich zu großen Skandalen kommen könnte, die eine schnelle Gesetzgebung vorantreiben werden. Potenzielle Ereignisse umfassen Deepfake-Pornografie, AI-generierte falsche Rechtsbeweise, AI-Stimmklon-Betrug, AI-Händler, die einen Finanzmarktzusammenbruch auslösen, usw. Dies unterstreicht die Spannung zwischen der schnellen Entwicklung der AI-Technologie und der verzögerten Regulierung.
(Quelle:Reddit r/ArtificialInteligence)
LLM-Designpräferenzen: Benötigen Modelle einen “Denkmodus”?: Die Community diskutiert, ob die nächste Generation von Open-Source-Google-Modellen einen “Denkmodus” enthalten sollte. Die Meinungen der Benutzer gehen auseinander: Einige glauben, dass ein “Denkmodus” zur Steigerung der Intelligenz beiträgt, während andere befürchten, dass er die Rechenlatenz und den Token-Verbrauch erhöht. Die Diskussion befasst sich auch damit, wie ein umschaltbarer “Denkmodus” implementiert werden kann, um Intelligenz und Effizienz zu vereinen.
(Quelle:Reddit r/LocalLLaMA)
Bedenken und Chancen durch den Einsatz von AI in der Medienbranche: Channel 4s Einführung eines AI-Moderators stößt bei echten Fernsehmoderatoren auf Gleichgültigkeit oder Skepsis, die argumentieren, dass AI die menschliche Fähigkeit zur sofortigen Reaktion fehlt und sie sich besser für geskriptete Inhalte als für Live-Übertragungen eignet. Die Diskussion weist auch darauf hin, dass AI die Arbeit des Umgestaltens von Erzählungen in Nachrichtenredaktionen ersetzen könnte, aber unabhängige Journalisten befähigen kann, dezentrale Nachrichtenproduktion durch lokale LLMs und Open-Source-Tools zu realisieren.
(Quelle:Reddit r/artificial)

Diskussion über AI-Codequalität und “Code-Schrott”: Die Community diskutiert die Qualität von AI-generiertem Code. Einige schlagen vor, ein Abzeichen “AI Made This Code. It’s Not Slop.” zu verwenden, um auf die Bezeichnung “Code-Schrott” (code slop) zu reagieren. Dies spiegelt die Besorgnis der Entwickler über die Qualität der AI-unterstützten Programmierung und ihre komplexen Gefühle gegenüber AI-Tools wider.
(Quelle:aiamblichus)

Beschwerden von Claude AI-Benutzern über die Generierung von Markdown-Dateien: Claude AI-Benutzer beschweren sich über die häufige Generierung von Markdown-Dateien durch das Modell und halten dies in bestimmten Szenarien für unnötig und umständlich. Dies spiegelt die Präferenzen der Benutzer für das LLM-Ausgabeformat und den Wunsch nach flexiblerer Kontrolle wider.
(Quelle:Reddit r/ClaudeAI)

AI und menschliche Kognition: Aufbau eines “menschlichen Spiegels” zum Verständnis des AI-Denkens: Das Konzept der “Anthrosynthese” wird vorgeschlagen, um digitale Intelligenz in menschliche Simulationen umzuwandeln, um die Denkweise von AI zu erforschen und nicht nur ihr Verhalten. Dies unterstreicht die Bedeutung der Schaffung einer gemeinsamen Sprache zwischen organischer und synthetischer Kognition, um die internen Abläufe von AI besser zu verstehen und zu erklären.
(Quelle:Reddit r/deeplearning)
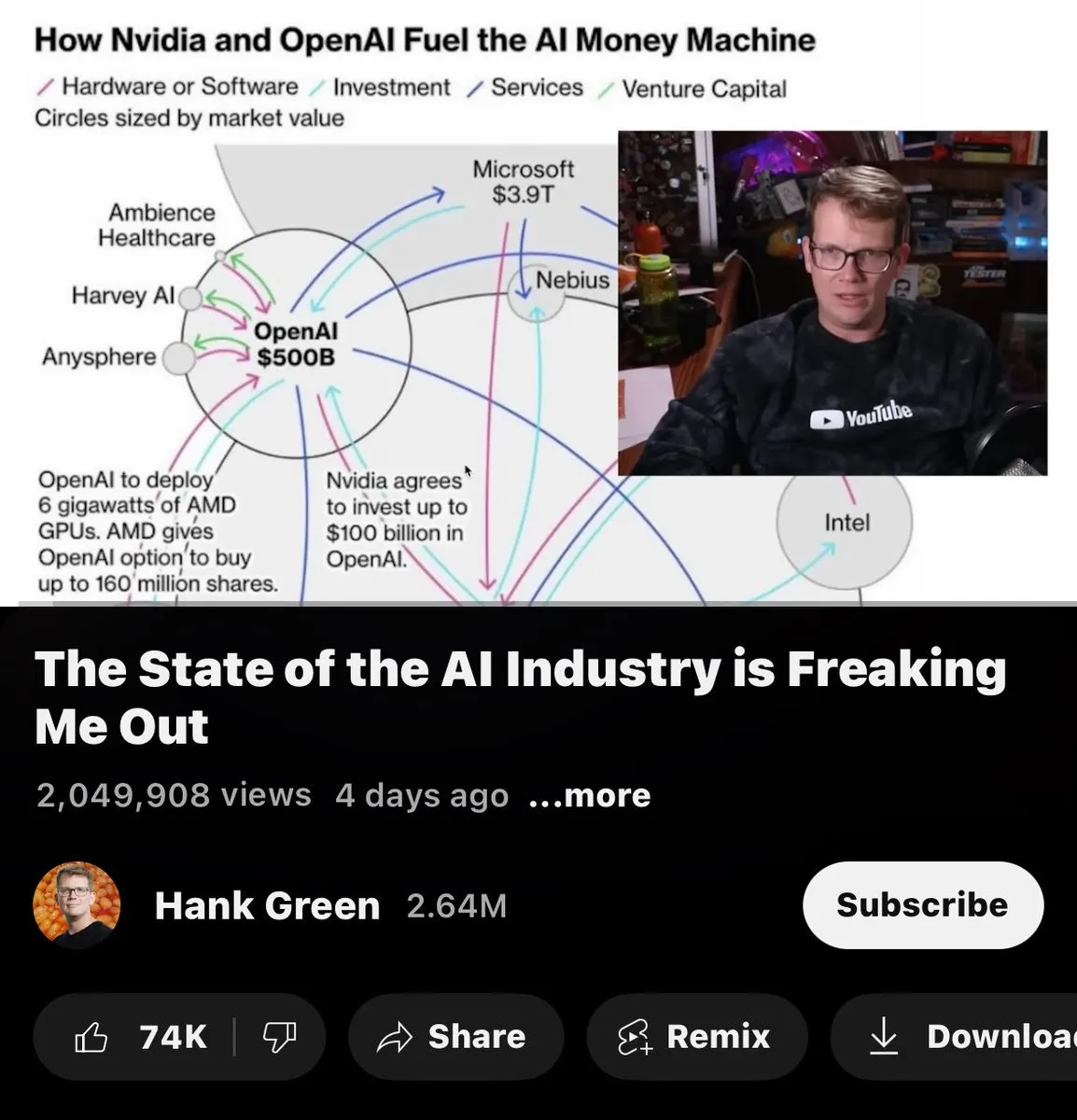
Kritik an der Wirtschaftsstruktur der AI-Branche: Schaufeln, Gleise und Minen: Eine kritische Ansicht besagt, dass in der aktuellen AI-Branche Nvidia “Schaufeln” (Hardware) verkauft, OpenAI “Gleise” (Plattformen) legt und Oracle “Minen” (Daten) gräbt, aber niemand wirklich “Gold” findet. Dies deutet darauf hin, dass in der AI-Wertschöpfungskette Infrastrukturanbieter profitieren, während auf der Anwendungsebene noch keine allgemeinen wirtschaftlichen Erträge erzielt wurden.
(Quelle:algo_diver)
Anthropic veröffentlicht keine Open-Source-Modelle, löst Community-Diskussion aus: Es wird darauf hingewiesen, dass Anthropic das einzige AI-Labor ist, das noch keine Modelle als Open Source veröffentlicht hat, was eine Diskussion in der Community über die Open-Source-Strategien verschiedener AI-Unternehmen auslöst.
(Quelle:gfodor)
Anfälligkeit der Cloud-Service-Abhängigkeit und Smart-Home-Risiken: Ein Beitrag über eine intelligente Internet-Matratze, die aufgrund eines Ausfalls in der AWS US-East-1 Region nicht funktionierte, löste eine Diskussion über die übermäßige Abhängigkeit von Smart-Home-Geräten von Cloud-Diensten und deren potenzielle Risiken aus. Benutzer befürchten, dass Alltagsgeräte ausfallen könnten, sobald Cloud-Dienste unterbrochen sind, was den Komfort und die Sicherheit des Lebens beeinträchtigt.
(Quelle:qtnx_)
Kontroverse über die Auswirkungen von AI auf die Beschäftigung: Reduzierung oder beschleunigtes Wachstum: Die Community diskutiert die Auswirkungen von AI auf den Arbeitsmarkt, wobei es gegensätzliche Ansichten gibt: “Arbeitsplatzabbau” und “beschleunigtes Wachstum”. Einige glauben, dass AI zu Arbeitslosigkeit führen wird, während andere argumentieren, dass hervorragende Unternehmen durch AI das Wachstum beschleunigen und Arbeitskräfte behalten werden.
(Quelle:teortaxesTex)
Einschränkungen von LLMs im akademischen Schreiben: Ein Forscher stellte fest, dass LLMs beim Verfassen des verwandten Arbeitsabschnitts von Papern dazu neigen, nur die Zusammenfassung zu lesen und Inhalte zu “erfinden”, anstatt sie tiefgehend zu verstehen. Dies zeigt, dass in akademischen Aufgaben, die tiefes Verständnis und kritische Analyse erfordern, menschliche Forscher weiterhin unverzichtbar sind.
(Quelle:gneubig)
Besorgnis über die Qualität von AI-generierten Inhalten und “AI-Schrott”: Victor Riparbelli, CEO von Synthesia, diskutierte das Problem des “AI-Schrotts” (AI slop) und wies darauf hin, dass die Qualität von AI-generierten Inhalten uneinheitlich ist und in Zukunft mehr Tools benötigt werden, um Verbraucher zu schützen. Er prognostiziert, dass die Menschen mit fortschreitender Technologie mehr auf den Inhalt selbst als auf seine Produktionsweise achten werden.
(Quelle:synthesiaIO)
AGI-Implementierungszeitplan und Durchbruchsbedarf: Die Community diskutiert den Implementierungszeitplan für AGI (Künstliche Allgemeine Intelligenz) und argumentiert, dass eine Prognose von “zehn Jahren oder mehr” bedeutet, dass noch ein oder mehrere große Durchbrüche erforderlich sind, nicht nur eine Ansammlung von Zeit. Dies spiegelt das Bewusstsein für unbekannte Faktoren und Herausforderungen im AGI-Entwicklungspfad wider.
(Quelle:Grad62304977)
Ansichten der AI-Forschung und Industrie zum Wert von Papern: Die Community diskutiert, dass nicht alle Papers von renommierten Laboren alles verändern können, was ein normales Phänomen ist. Gleichzeitig wird argumentiert, dass der Wert von DeepSeek-OCR und ähnlichen Forschungen in ihrer Absicht und OCR-Validierung liegt, nicht in der absoluten Neuheit der Kernidee.
(Quelle:nrehiew_)
Verschiedene Wege der AI-Forschung: Vergleich zwischen China und den USA und Einfluss von Open Source: Die Community diskutiert die Unterschiede in den grundlegenden AI-Forschungsmethoden zwischen China und den USA sowie den Einfluss der chinesischen Open-Source-Strategie auf die globale AI-Entwicklung. Einige argumentieren, dass selbst wenn China alles als Open Source veröffentlicht, beide Länder immer noch unterschiedliche grundlegende Methoden entwickeln könnten.
(Quelle:jpt401)
Geschäftsstrategie im AI-Zeitalter: Modelliteration und Daten-Schwungrad: Eine Ansicht betont, dass Unternehmen im AI-Zeitalter davon ausgehen sollten, dass Modelle sich kontinuierlich schnell verbessern werden, und sich auf den Aufbau eines starken Daten-Schwungrads konzentrieren sollten. Durch das Training des Systems bei jeder Transaktion können kontinuierliche Verbesserungen erzielt werden, anstatt sich auf kurzlebige “technologische Gräben” zu verlassen.
(Quelle:leveredvlad)

Interessante AI-Forschungsideen: Nachtraining und Prompt-Injektion: Die Community hat einige interessante prä-Trainings-Forschungsideen vorgeschlagen, darunter die Messung der Schwierigkeit des Nachtrainings von Chat-Modellen seit 2022 und die Erstellung offener Webseiten mit “Schlafphrasen/Prompt-Injektionen”, um zu beobachten, ob fortschrittliche Modelle nach einigen Jahren davon betroffen sind.
(Quelle:menhguin)
Philosophische Diskussion über AI und menschliche Lernmechanismen: Die Community diskutiert die grundlegenden Unterschiede zwischen menschlichem und AI-Lernen und weist darauf hin, dass Menschen Wissen durch Denken, Fragen und Diskutieren verstehen, während AI nur Token vorhersagt. Es wird betont, dass AI “traumähnliche” Mechanismen entwickeln sollte, um einen Zustand hoher Entropie aufrechtzuerhalten, und “Vergessen” lernen sollte, um abstrakte Muster zu extrahieren, anstatt alle Details zu speichern.
(Quelle:NandoDF)
Unterschiede zwischen AI und kausalem Lernen: Eine Ansicht besagt, dass Korrelationslernen sich vom kausalen Lernen unterscheidet. Menschen stellen Kausalzusammenhänge durch Erfahrung und Beobachtung her, und wenn AI diesen Prozess nicht replizieren kann, wird sie weiterhin ein mächtiges Korrelationssystem-Tool bleiben. Dies unterstreicht, dass AI in Bezug auf tiefes Verständnis und Generalisierungsfähigkeit noch Durchbrüche erzielen muss.
(Quelle:farguney)
Dilemma des LLM-Verhaltens: Falscher Code, perfekte Erklärung, dann perfekter Code: Ein Benutzer beobachtete, dass LLMs bei Programmieraufgaben zuerst fehlerhaften Code schreiben, dann die Fehlerursache perfekt erklären und schließlich korrekten Code schreiben könnten. Dieses Phänomen löste eine Diskussion über die internen Verständnismechanismen von LLMs und “warum nicht gleich richtig schreiben” aus.
(Quelle:VictorTaelin)
Hervorragende Leistung von Haiku 4.5 bei Agent-Aufgaben: Claude Haiku 4.5 wird für seine schnelle Reaktion und hochwertige Ausgabe gelobt und gilt als sehr gut geeignet für den Aufbau von Minimum Viable Products (MVPs) und die Konzentration auf Agentenaufgaben. Es wird als das erste fortschrittliche Modell mittlerer Größe angesehen, das auf Agenten-/hyperfokussierte Aufgaben ausgerichtet ist.
(Quelle:Reddit r/ClaudeAI)
Eröffnung von Cafe Cursor NYC und Unternehmenskultur: Cafe Cursor NYC wurde eröffnet und als Unternehmen gelobt, das von “echten Bauherren” gegründet wurde. Dies spiegelt die Anerkennung der Community für die Unternehmenskultur von Cursor AI und die kontinuierliche Produktiteration wider.
(Quelle:imjaredz)

💡 Sonstiges
Proteindesign-Wettbewerb zielt darauf ab, das Nipah-Virus zu neutralisieren: Ein globaler Proteindesign-Wettbewerb läuft, der Wissenschaftler, Ingenieure und Hacker einlädt, neue Proteine zu entwerfen, die das Nipah-Virus neutralisieren können. Das Nipah-Virus hat eine Sterblichkeitsrate von bis zu 75%, und es gibt derzeit keine wirksame Behandlungsmethode. Der Wettbewerb zielt darauf ab, die Entwicklung neuer Medikamente durch dezentrale wissenschaftliche Experimente zu beschleunigen.
(Quelle:clefourrier)

Vorstellung des Konzepts eines AI Operating System: Renen Hallak hat das Konzept eines “AI Operating System” (AI OS) vorgeschlagen, das darauf abzielt, Daten, Berechnungen und Strategien zu vereinheitlichen und Infrastruktur für das Agenten-Zeitalter bereitzustellen. Ein AI OS würde alles zwischen Hardware und Agenten-Anwendungen verwalten, einschließlich Datenvereinheitlichung, Workload-Orchestrierung, Zugriffsrichtlinienausführung usw., und wird als nächster Schritt in der Datenentwicklung angesehen.
(Quelle:TheTuringPost)

Kognitive Muster der AI in der Computer Vision: Ein Bild zeigt anschaulich, wie Computer-Vision-Forscher die Welt sehen und die meisten visuellen Probleme lösen. Dies ist eine humorvolle Art, die einzigartigen Denkweisen und Problemlösungsansätze der Forscher in diesem Bereich darzustellen.
(Quelle:jbhuang0604)
