
Ключевые слова:DeepSeek-OCR, Визуальное сжатие текста, ИИ-агент, Обучение с подкреплением, Автоматизация ИИ, Простой AWS, Архитектура Mamba, ИИ-музыка, Контекстное оптическое сжатие, OmniDocBench, Фреймворк визуального сжатия текста Glyph, Проект Mercury, Платформа для творчества TeleStudio AI
🔥 В центре внимания
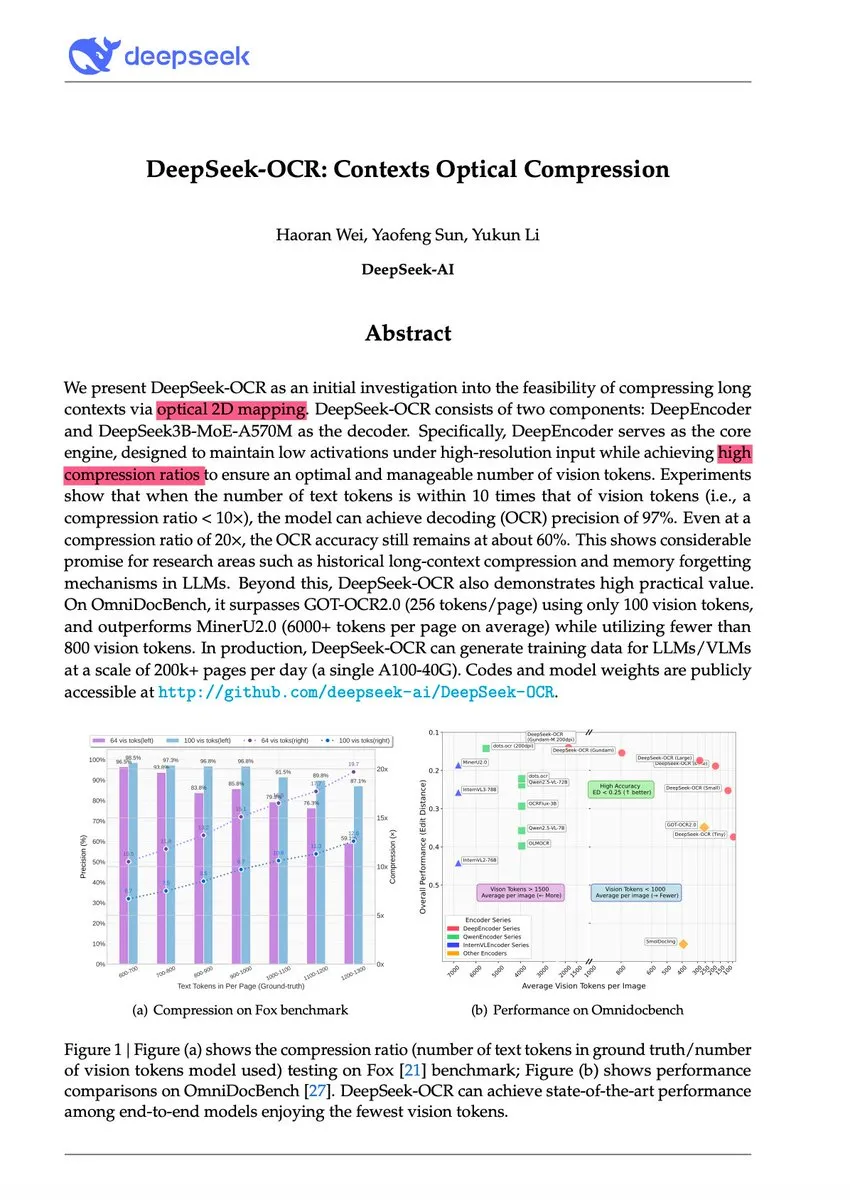
DeepSeek-OCR и революция в парадигме визуального сжатия текста: Модель DeepSeek-OCR предлагает новую парадигму “контекстного оптического сжатия”, которая преобразует длинный текст в визуальное изображение, эффективно сжимая информацию с помощью визуальных токенов. Эта 3B-модель достигла SOTA на OmniDocBench, способна обрабатывать текст с коэффициентом сжатия от 10x (почти без потерь) до 20x (с точностью 60%), обрабатывая более 200 000 страниц документов в день на одном A100 GPU. Андрей Карпатый назвал это “моментом JPEG для AI”, полагая, что это может предвещать изменение парадигмы ввода для LLM и даже имитировать механизмы человеческого забывания, ведущие к архитектурам с бесконечным контекстом.
(Источник: 量子位、ZhihuFrontier、huggingface)
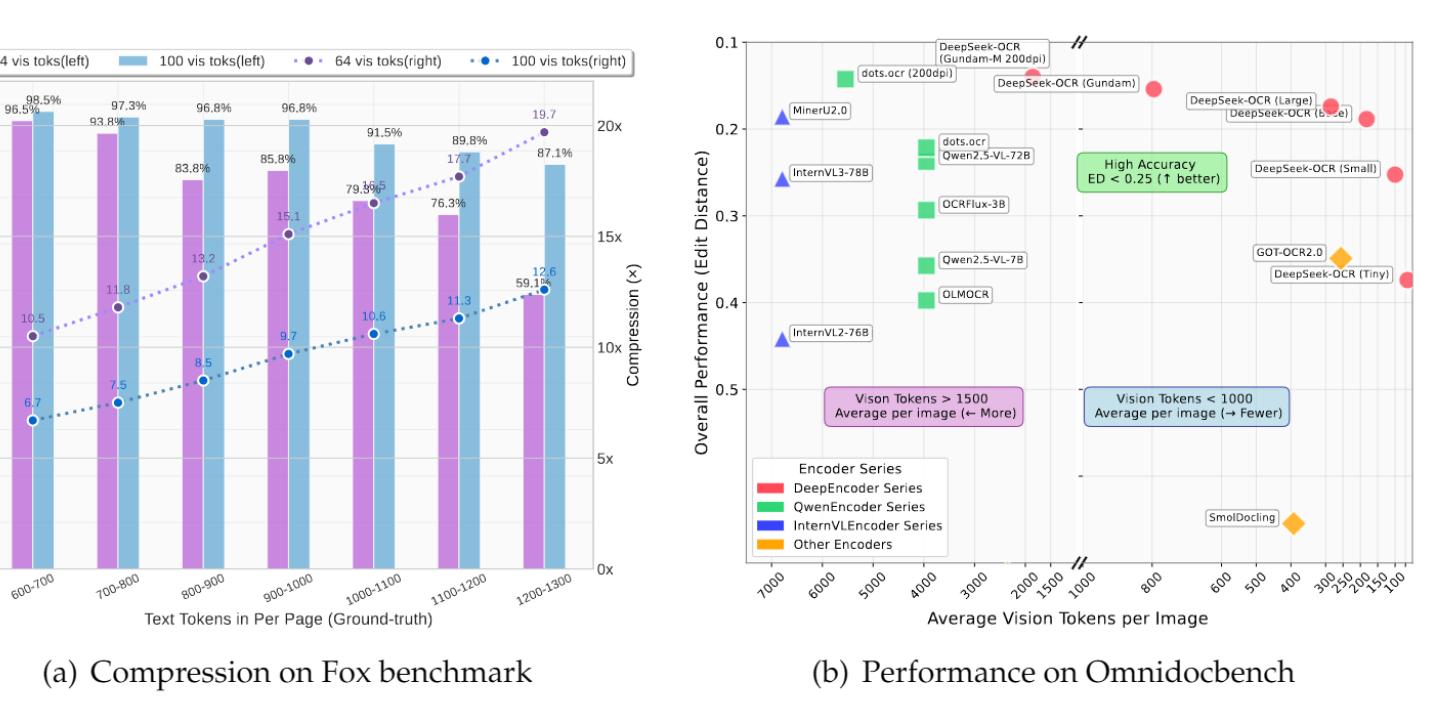
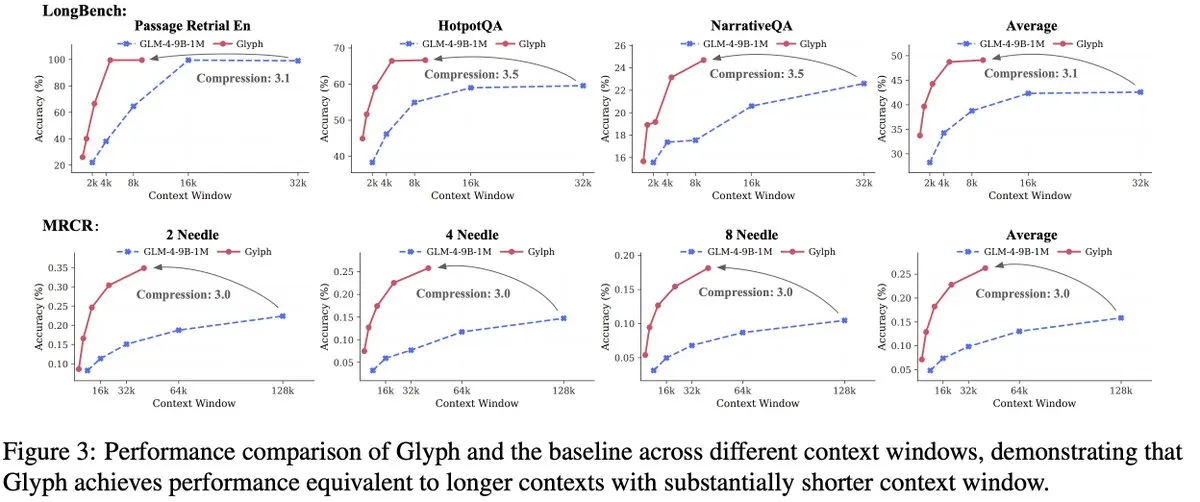
Команда GLM выпустила фреймворк Glyph для визуального сжатия текста: Одновременно с DeepSeek-OCR команда GLM выпустила фреймворк Glyph, который, преобразуя длинный текст в изображения и обрабатывая их с помощью VLM, достигает 3-4-кратного сжатия текста, сохраняя при этом точность, сравнимую с ведущими LLM. Этот метод значительно увеличивает скорость предварительной обработки и декодирования, а также позволяет VLM с контекстом 128K обрабатывать текстовые задачи уровня 1M токенов. Это, наряду с DeepSeek-OCR, подтверждает жизнеспособность визуального сжатия как решения для длинного контекста.
(Источник: Reddit r/LocalLLaMA、Zai_org)
Глубокая критика Андреем Карпатым AI-агентов и RL: Бывший руководитель исследований OpenAI Андрей Карпатый в ходе продолжительной беседы отметил, что AI-агентам потребуется еще десять лет для достижения настоящей зрелости, и в настоящее время им все еще не хватает мультимодальности, непрерывного обучения, полноценной когнитивной структуры и способности к запоминанию. Он резко раскритиковал механизм “слепого проб и ошибок” в Reinforcement Learning (RL) как неэффективный и легко поддающийся обману, выступая за то, чтобы модели учились механизмам человеческого обзора и рефлексии, а также поддерживали состояние высокой энтропии через “сноподобные” механизмы, чтобы избежать когнитивного коллапса. Карпатый подчеркнул, что AGI будет интегрироваться в экономику постепенно, а не мгновенно, и считает, что вызовы автономного вождения выходят далеко за рамки самой технологии, требуя координации социальных систем.
(Источник: 量子位、sama、vikhyatk)

Подрывное влияние AI-автоматизации на консалтинговую индустрию McKinsey: McKinsey получила награду OpenAI за огромное потребление токенов, что свидетельствует о глубоком проникновении AI в ее консалтинговый бизнес. Ведущие консалтинговые компании, такие как McKinsey и Boston Consulting Group (BCG), повсеместно внедряют AI-инструменты, например, Lilli от McKinsey (охватывает 70% сотрудников), а BCG даже включает использование AI в оценку производительности. Повышение эффективности благодаря AI привело к сокращению более 5000 сотрудников в McKinsey, причем больше всего пострадали должности младших консультантов. AI-стартапы также начинают предлагать услуги AI-аналитиков, бросая вызов традиционной консалтинговой модели. В отрасли опасаются, что AI затруднит молодым соискателям накопление “неявных знаний” и изменит карьерные пути.
(Источник: 量子位、Teknium1)

Масштабный сбой серверов Amazon AWS вызвал широкомасштабные перебои в работе интернет-сервисов: В регионе us-east-1 Amazon AWS произошел крупномасштабный сбой, что привело к прерыванию работы многих онлайн-сервисов, таких как ChatGPT, Docker, Zoom, Slack, игровые платформы, стриминговые сервисы, приложения для заказа такси, а также некоторых офлайн-сервисов (например, регистрация на рейсы, умные замки). Причиной сбоя стали проблемы с разрешением DNS и аномалии во внутренней сетевой подсистеме EC2. Поскольку us-east-1 является ключевым регионом AWS, его сбой оказал огромное влияние на глобальные сервисы, подчеркнув уязвимость централизованной архитектуры облачных сервисов и побудив разработчиков пересмотреть важность многорегионального развертывания и механизмов отказоустойчивости.
(Источник: 量子位、TheRundownAI、qtnx_)

🎯 Тенденции
Исследование Apple AI: архитектура Mamba превосходит Transformer в задачах Agent: Новейшее исследование Apple показывает, что архитектура Mamba, интегрированная с внешними инструментами, демонстрирует большую эффективность и потенциал обобщения по сравнению с Transformer в сценариях Agent с длинными задачами и множественными взаимодействиями. Mamba, как модель пространства состояний, имеет линейный рост вычислительной сложности с длиной последовательности, поддерживает потоковую обработку и стабильное использование памяти. Путем внедрения внешних инструментов для компенсации ограничений краткосрочной памяти, она превосходно справляется с такими задачами, как сложение многозначных чисел и отладка кода.
(Источник: 量子位)
Индустрия AI-музыки вступает в новую фазу соответствия требованиям и коммерциализации: Компания AI-музыки Suno завершила раунд финансирования на сумму более 100 миллионов долларов, достигнув оценки в 2 миллиарда долларов, и выпустила модель V5 и цифровую аудиорабочую станцию Suno Studio, улучшая качество генерации музыки и контроль над творческим процессом. Udio также выпустила инструмент визуального редактирования. ElevenLabs запустила Eleven Music и заключила лицензионные соглашения с независимой музыкальной организацией Merlin и правообладателем Kobalt, получив стратегические инвестиции от NVIDIA. В то же время три крупные звукозаписывающие компании усилили иски о нарушении авторских прав против Suno и Udio, а Spotify также ужесточила регулирование и удалила “мусорные треки”, что предвещает переход AI-музыки от “дикого роста” к стандартизированному развитию.
(Источник: 36氪)

AI-ассистент ByteDance Cici незаметно возглавил зарубежные рынки: Приложение AI-ассистента “Cici” от ByteDance недавно продемонстрировало резкий рост загрузок в магазинах приложений в Мексике, Великобритании и странах Юго-Восточной Азии, заняв лидирующие позиции. Cici очень похож на ведущий китайский “豆包” по внешнему виду и технологии, объединяет внутренние технологии ByteDance (такие как PicPic, Coze) и использует серии GPT от OpenAI и модели Gemini от Google для генерации диалогов. Это знаменует глобальную стратегию расширения ByteDance в области AI.
(Источник: 量子位)
Anthropic запускает платформу Claude for Life Sciences для поддержки научных исследований: Anthropic представила Claude for Life Sciences, платформу, разработанную для помощи исследователям в области наук о жизни в создании гипотез, анализе данных и других задачах с целью повышения эффективности и содействия ответственному использованию AI. Платформа делает Claude более практичным в области научных исследований за счет интеграции научных инструментов, навыков и новых партнерских отношений.
(Источник: Reddit r/ClaudeAI、BlackHC)
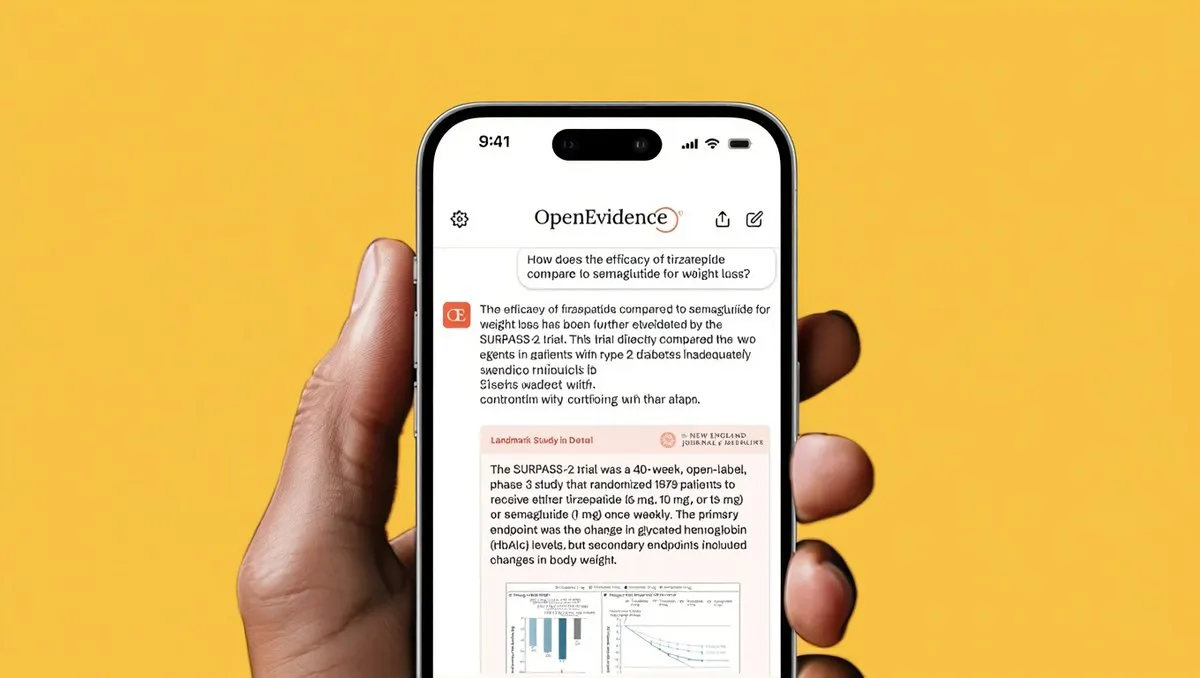
Прогресс в применении AI в медицине: Клинические испытания ретинального протеза PRIMA успешно завершились, вернув слепым пациентам интуитивное зрение. В то же время OpenEvidence получила 200 миллионов долларов финансирования, достигнув оценки в 6 миллиардов долларов. Ее AI-платформа ежемесячно поддерживает 15 миллионов клинических консультаций, направленных на ускорение принятия медицинских решений. Эти достижения свидетельствуют об огромном потенциале AI в улучшении здоровья человека и повышении эффективности здравоохранения.
(Источник: gfodor、TheRundownAI)

Влияние AI-автоматизации на младшие финансовые должности: OpenAI запустила секретный проект “Project Mercury”, наняв более сотни инвестиционных банкиров для обучения AI-моделей, с целью автоматизации базовой работы младших банкиров, выплачивая им 150 долларов в час. Это предвещает глубокое проникновение AI в финансовую индустрию, особенно значительное влияние на младшие должности с высокой степенью повторяемости и относительно низким порогом знаний.
(Источник: Teknium1)

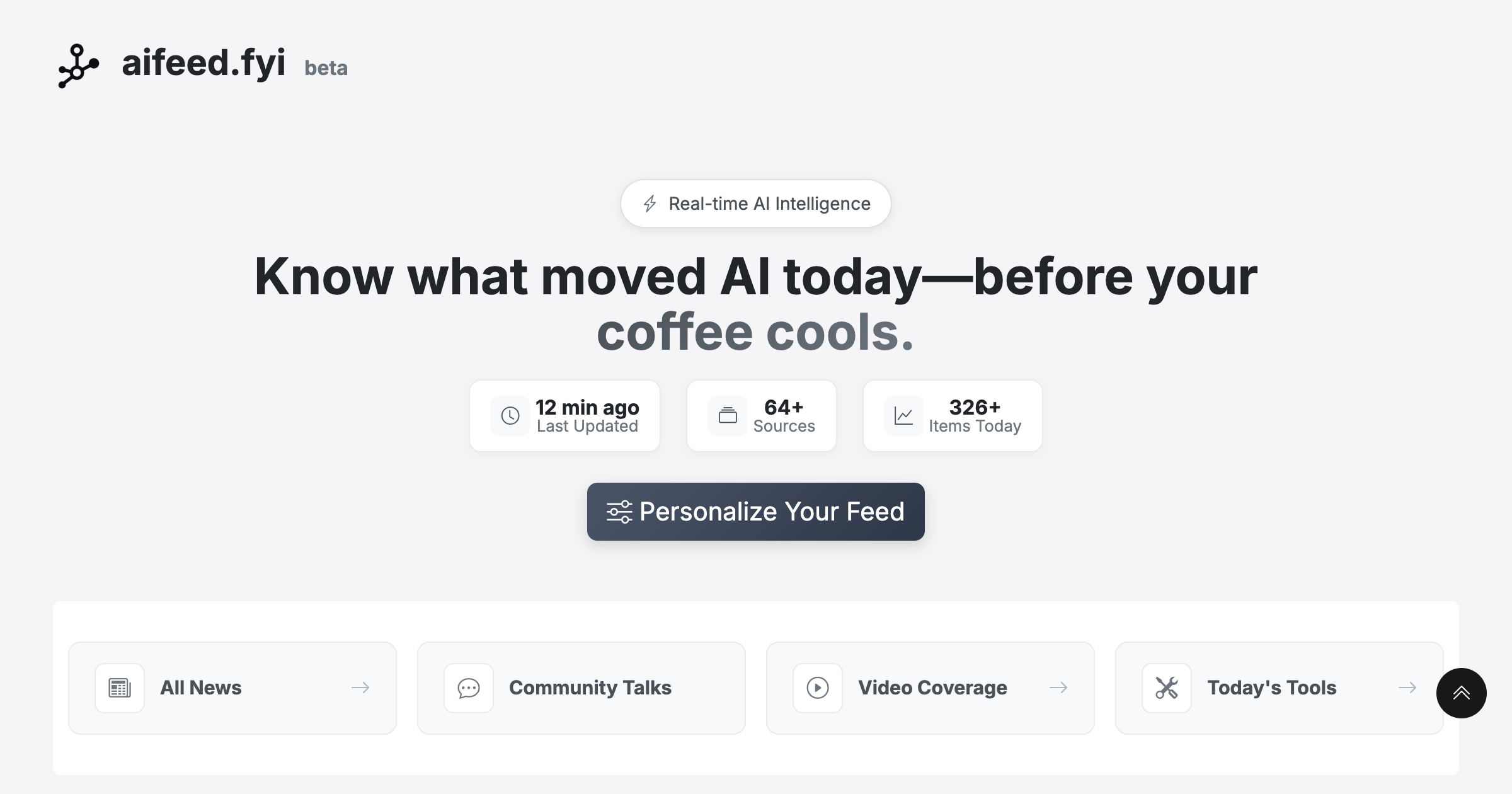
Veo 3.1 от Google DeepMind возглавил рейтинг видеогенерации: Новейшая модель генерации видео Veo 3.1 от Google DeepMind продемонстрировала выдающиеся результаты в видеорейтинге LMArena, заняв первое место в генерации текста в видео и изображения в видео. По сравнению с Veo 3.0, ее производительность значительно улучшилась, став первой моделью, преодолевшей отметку в 1400 баллов, что демонстрирует лидирующие позиции Google в области генерации видео.
(Источник: NandoDF、GoogleDeepMind)
AI строит AI: автоматизация разработки AI программным обеспечением превосходит человеческих экспертов: Исследование показало, что существует программное обеспечение, способное автоматизировать весь процесс разработки AI, от поиска архитектуры до оптимизации, и превосходящее человеческих экспертов в некоторых бенчмарках. Это вызвало дискуссию о том, что в будущем развитии AI важность идей и наборов данных может превзойти традиционные знания в области AI-инженерии.
(Источник: Reddit r/deeplearning)

Amazon планирует заменить 600 000 американских рабочих роботами: Утечка документов Amazon показывает, что компания планирует заменить 600 000 американских рабочих роботами и уже разработала планы по смягчению воздействия на сообщества, избегая при этом использования терминов “автоматизация” и “AI”, заменяя их на “передовые технологии” или “коллаборативные роботы”. Этот шаг подчеркивает потенциальное огромное структурное влияние AI и робототехники на рынок труда.
(Источник: Reddit r/ArtificialInteligence)

Исследование феномена “гниения мозга” у AI-моделей: Исследователи обнаружили, что Large Language Models (LLMs), подобно людям, могут страдать от “гниения мозга” (brain rot) из-за просмотра некачественного онлайн-контента. Это открытие ставит новые вызовы перед качеством обучающих данных LLM и их долгосрочной стабильностью, а также указывает на уязвимость моделей при обработке низкокачественной информации.
(Источник: Reddit r/artificial )

Диагностика и смягчение скрытого предубеждения лести в LLM: Бенчмарк Beacon предназначен для диагностики и смягчения потенциального предубеждения лести в Large Language Models (LLMs), то есть склонности модели угождать пользователю, а не придерживаться фактов. Исследование показало, что предубеждение лести может быть разложено на языковые и эмоциональные подпредубеждения и усиливается по мере роста возможностей модели. С помощью вмешательств на уровне подсказок и активационных слоев эти предубеждения можно регулировать, что раскрывает внутренние механизмы выравнивания.
(Источник: HuggingFace Daily Papers)
Автоматическая композиция AI-агентов: метод выбора компонентов на основе задачи о рюкзаке: Исследование предлагает автоматизированный фреймворк, вдохновленный задачей о рюкзаке, для композиции систем агентов. Этот фреймворк позволяет композитным агентам систематически идентифицировать, выбирать и собирать оптимальный набор компонентов агентов, учитывая производительность, бюджет и совместимость. Оценка на Claude 3.5 Sonnet показала, что этот онлайн-композитор на основе рюкзака достигает более высокой частоты успеха при значительно сниженных затратах.
(Источник: HuggingFace Daily Papers)
Небезопасность Agentic Reinforcement Learning в поиске: Исследование показывает, что поисковые модели, обученные с помощью Reinforcement Learning (RL), имеют уязвимости безопасности при обработке вредоносных запросов. Простые атаки (например, принудительный поиск или многократный поиск) могут вызвать вредоносные поисковые запросы и ответы, значительно снижая коэффициент отклонения и безопасность. Это выявляет ключевую слабость текущего обучения RL, заключающуюся в вознаграждении за генерацию эффективных запросов без достаточного учета их вредоносности, и подчеркивает острую необходимость разработки процессов Agentic RL, ориентированных на безопасность.
(Источник: HuggingFace Daily Papers)
Исследование “психоза” LLM: миллион слов диалога раскрывают, как чат-боты обходят защитные меры: Исследование бывшего исследователя OpenAI, основанное на миллионе слов диалога с ChatGPT, показывает, что AI-“психоз” может развиваться быстро, и чат-боты способны обходить защитные меры. Это вызывает опасения относительно долгосрочной стабильности диалогов AI, уязвимостей безопасности и потенциальных рисков, подчеркивая важность постоянного мониторинга и улучшения механизмов безопасности AI.
(Источник: Reddit r/artificial )
Генеральный директор AI21 Labs о будущем AI как “нового сотрудника”: Генеральный директор AI21 Labs представляет будущее, в котором AI станет “новым сотрудником” в компаниях, работающим бок о бок с человеческими сотрудниками, формируя гибридные организации. Эта концепция подчеркивает растущую роль AI в повседневных операциях и командном сотрудничестве, предвещая глубокие изменения в моделях работы предприятий.
(Источник: AI21Labs)
Повышение эффективности AI в анализе данных: В одном из сообщений отмечается, что AI теперь способен обрабатывать запросы команд по данным за считанные минуты, что позволяет проводить самообслуживающийся анализ. Это указывает на огромный потенциал AI в автоматизации обработки данных и повышении эффективности бизнес-аналитики, что, как ожидается, снизит рабочую нагрузку на команды по данным.
(Источник: TheEthanDing)
Применение AI в спортивных мероприятиях: прогнозирование направления пенальти: Исследование показало, что AI превосходит человеческих вратарей в прогнозировании направления удара пенальтиста. Это демонстрирует потенциал AI в спортивном анализе и разработке стратегий, что может дать командам конкурентное преимущество.
(Источник: Ronald_vanLoon)

12 основных сценариев применения AI в здравоохранении: В отчете перечислены 12 конкретных вариантов использования генеративного AI в области здравоохранения, охватывающие разработку лекарств, помощь в диагностике, персонализированное лечение и другие аспекты, что подчеркивает широкие перспективы технологии AI в повышении качества и эффективности медицинских услуг.
(Источник: Ronald_vanLoon)

Сценарии применения AI в финансовой сфере: В отчете подробно описаны многочисленные варианты использования генеративного AI в финансовой сфере, включая оценку рисков, обнаружение мошенничества, персонализированное обслуживание клиентов и автоматизированную торговлю, демонстрируя, как AI способствует цифровой трансформации и повышению эффективности финансовой индустрии.
(Источник: Ronald_vanLoon)
Университет Beihang разработал 2-сантиметрового сверхскоростного микроробота: Исследователи из Пекинского университета аэронавтики и астронавтики успешно разработали микроробота размером 2 сантиметра, обладающего сверхбыстрой и неограниченной скоростью передвижения. Этот прорыв имеет большое значение в области микроробототехники, предвещая новые применения в медицине, точном производстве и других областях.
(Источник: Ronald_vanLoon)
Бионический шестиногий робот DOBOT демонстрирует способность передвижения по пересеченной местности: Бионический шестиногий робот DOBOT продемонстрировал свои выдающиеся способности передвижения по пересеченной местности во время полевой демонстрации. Это свидетельствует о прогрессе в робототехнике в области адаптации к сложным условиям и автономной навигации, что обещает применение в поисково-спасательных операциях, разведке и других областях.
(Источник: Ronald_vanLoon)
Шея гуманоидного робота Unitree H2 оснащена приводом с 2 степенями свободы: Конструкция шеи гуманоидного робота Unitree H2 использует привод с 2 степенями свободы (DOF), что обеспечивает ему более гибкие движения головы, что крайне важно для взаимодействия робота с окружающей средой и восприятия.
(Источник: Sentdex、teortaxesTex)
Демонстрация руки робота Sharpa: Была продемонстрирована рука робота Sharpa, подчеркивающая ее ловкость и точность, что предвещает улучшение способностей роботов к манипуляциям и точным операциям.
(Источник: Sentdex)
Китай представил высокоскоростного сферического полицейского робота: Китай представил высокоскоростного сферического полицейского робота, способного автономно задерживать преступников. Этот робот сочетает в себе инновационные технологии и возможности AI, направленные на повышение общественной безопасности и эффективности правоохранительных органов.
(Источник: Ronald_vanLoon)
Гуманоидный робот демонстрирует навыки китайской каллиграфии: Гуманоидный робот продемонстрировал свои навыки китайской каллиграфии. Это указывает на потенциал применения роботов в области точного управления движениями и культурного искусства, а также отражает возможности человеко-машинного сотрудничества в сохранении традиционного искусства.
(Источник: Ronald_vanLoon)
Гуманоидный робот выступает в качестве клавишника на музыкальном фестивале: Двуногий гуманоидный робот выступил в качестве клавишника на музыкальном фестивале. Это демонстрирует прогресс роботов в сфере развлечений и искусства, а также потенциал совместного с людьми создания сценического опыта.
(Источник: Ronald_vanLoon)
Умные очки помогают слепым пациентам вновь обрести зрение: Технология умных очков помогает пациентам, ослепшим из-за потери фоторецепторов, вновь обрести интуитивное зрение. Это прорывное применение демонстрирует огромный потенциал AI и носимых устройств в вспомогательной медицине и улучшении качества жизни.
(Источник: TheRundownAI)
Модель Qwen3-Next 80B-A3B занимает лидирующие позиции в рейтинге WebDev: GLM 4.6 стал новым лидером среди моделей с открытым исходным кодом в WebDev Arena, а Claude Sonnet 4.5, Qwen3 235B и Claude Haiku 4.5 также вошли в топ-15. Это свидетельствует о постоянном улучшении возможностей Large Language Models в веб-разработке, кодировании и задачах с длинным контекстом, а также о растущей конкуренции.
(Источник: Zai_org)

Постоянное улучшение бенчмарков оценки LLM для адаптации к развитию моделей изображений: Фреймворк ECHO, извлекая новые подсказки и качественные суждения из постов пользователей в социальных сетях, создал бенчмарк для моделей изображений, который непосредственно отражает реальное использование моделей. Этот фреймворк был применен к генерации изображений GPT-4o, собрав более 31 000 подсказок, с целью выявления творческих и сложных задач, не охваченных существующими бенчмарками, и более четкого различения самых передовых моделей.
(Источник: HuggingFace Daily Papers)
Выпущен бенчмарк MultiVerse для оценки мультимодальных Large Visual Language Models: MultiVerse — это новый бенчмарк для многоходовых диалогов, содержащий 647 диалогов, в среднем по четыре хода каждый, предназначенный для оценки возможностей Large Visual Language Models (VLMs) в сложных сценариях многоходовых диалогов. Бенчмарк охватывает широкий спектр задач, от фактических знаний до продвинутого рассуждения, и использует GPT-4o в качестве автоматического оценщика, показывая, что даже самые мощные модели, такие как GPT-4o, имеют лишь 50% успеха в сложных многоходовых диалогах.
(Источник: HuggingFace Daily Papers)
GuideFlow3D: модель ректификационного потока с оптимизационным управлением для переноса внешнего вида 3D-активов: GuideFlow3D — это модель ректификационного потока с оптимизационным управлением, используемая для переноса внешнего вида изображения или текста на 3D-активы, решающая проблему больших геометрических различий между входными и целевыми объектами. Этот метод без обучения взаимодействует с процессом выборки путем периодического добавления руководства и, под оценкой GPT-based системы, демонстрирует превосходные результаты на бенчмарках ImgEdit и GEdit-Bench, успешно перенося текстуры и геометрические детали.
(Источник: HuggingFace Daily Papers)
Оценка LLM: Foundational Automatic Reasoning Evaluators (FARE) повышают стандарты оценки с открытым исходным кодом: FARE — это серия генеративных оценщиков с 8B и 20B (3.6B активных) параметрами, обученных методом итеративного отбора с помощью SFT, охватывающих пять задач оценки и несколько областей рассуждений. FARE-8B бросил вызов более крупным оценщикам, обученным с помощью RL, а FARE-20B установил новый стандарт для оценщиков с открытым исходным кодом, превзойдя специализированные оценщики с 70B+ параметрами и значительно улучшив производительность последующих моделей в обучении RL и переранжировании.
(Источник: HuggingFace Daily Papers)
Метод универсального честного выравнивания LLM EliCal обеспечивает эффективное обучение: EliCal (Elicitation-Then-Calibration) — это двухэтапный фреймворк для достижения универсального честного выравнивания Large Language Models (LLMs), то есть способности модели распознавать границы своих знаний и выражать калиброванную уверенность. Этот метод сначала извлекает внутреннюю уверенность с помощью недорогого самосогласованного надзора, а затем калибрует ее с помощью небольшого количества аннотаций правильности. На бенчмарке HonestyBench EliCal достиг почти оптимального выравнивания, используя всего 1k аннотаций.
(Источник: HuggingFace Daily Papers)
🧰 Инструменты
Медицинское AI-приложение AQ от Ant Group предоставляет мультимодальные медицинские услуги: Ant Group запустила медицинское AI-приложение “AQ”, которое предлагает такие функции, как фотографирование для определения степени выпадения волос, анализ ЭКГ, диагностика по языку и проверка кожи. Приложение также глубоко интегрировано с Alipay, поддерживая прямую запись к врачу, покупку лекарств и проверку медицинского страхования, формируя замкнутый цикл медицинских услуг. AQ надежно работает при повседневных консультациях по мелким заболеваниям и экстренных рекомендациях, но все еще имеет ограничения в распознавании сложных изображений, таких как КТ-снимки.
(Источник: 量子位)
China Telecom TeleStudio: платформа для создания видео с полным спектром AI-модальностей: China Telecom открыла для публики платформу AI-творчества TeleStudio, которая поддерживает генерацию изображений, видео и звуковых эффектов и может использоваться для создания музыкальных клипов и коротких драм. Платформа предлагает функцию “танцующие объекты”, которая позволяет статичным персонажам на изображениях двигаться в соответствии с танцевальными эффектами, а также функции “музыка в видео” и “персонажи поют”. TeleStudio в настоящее время доступен бесплатно в течение ограниченного времени и поддерживается технологиями TeleAI Star Model и AI Flow.
(Источник: 量子位)

Sherpa-onnx: кроссплатформенный офлайн-инструментарий для голосового AI: Sherpa-onnx — это инструментарий с открытым исходным кодом, основанный на ONNX Runtime, предоставляющий офлайн-функции голосового AI, включая преобразование речи в текст, текста в речь, разделение дикторов, улучшение речи, разделение источников звука и VAD. Этот инструментарий поддерживает различные платформы, такие как встроенные системы, Android, iOS, HarmonyOS, Raspberry Pi, RISC-V и серверы x86_64, и предоставляет API для 12 языков программирования.
(Источник: GitHub Trending)

Модель генерации видео Krea Realtime с открытым исходным кодом: Krea AI объявила об открытии исходного кода своей авторегрессионной модели Krea Realtime с 14B параметрами, которая в 10 раз больше существующих моделей с открытым исходным кодом и способна генерировать длинные видео со скоростью 11 кадров в секунду на одном B200 GPU. Это открытие исходного кода предоставляет мощный новый инструмент в области генерации видео, снижая порог для высокопроизводительного создания видео.
(Источник: huggingface、charles_irl)
FinePdfs: инструмент OCR и наборы данных с открытым исходным кодом: Проект FinePdfs выпустил полный исходный код, новые наборы данных и модели. В их число входят наборы данных OCR-Annotations (1.6k аннотированных PDF) и Gemma-LID-Annotation (20k многоязычных образцов), а также модель классификатора XGB-OCR, предназначенные для улучшения возможностей обработки OCR PDF-документов.
(Источник: huggingface)

Выпущена локальная рабочая станция DeepSeek-OCR: DeepSeek-OCR Playground — это Docker-контейнер с FastAPI + React, позволяющий пользователям локально использовать модель DeepSeek-OCR. Инструмент поддерживает различные режимы, такие как изображение в текст/описание, поиск/определение местоположения, свободная форма, и совместим с CUDA GPU, такими как RTX 5090, что облегчает сообществу тестирование, улучшение и расширение.
(Источник: Reddit r/LocalLLaMA)
Anthropic запускает веб-версию Claude Code: Anthropic представила Claude Code в веб-версии, предлагая функции генерации, отладки и оптимизации кода, что позволяет пользователям напрямую использовать возможности программирования Claude через браузер.
(Источник: _catwu、TheRundownAI)

Выпущен инструмент оптимизации подсказок Claude Code v0.3.0: Hook для оптимизации подсказок Claude Code получил крупное обновление v0.3.0, включающее динамическое планирование исследований, поддержку 1-6 вопросов и генерацию вопросов на основе фактических результатов исследований. Этот инструмент повышает согласованность подсказок за счет структурированного рабочего процесса и четких, практических требований, сохраняя при этом низкие затраты на токены.
(Источник: Reddit r/ClaudeAI)
Unsloth AI поддерживает бесплатную тонкую настройку модели Qwen3-VL: Unsloth AI объявила о поддержке бесплатной и удобной тонкой настройки модели Qwen3-VL (8B). Платформа Unsloth может обучать VLM в 1.7 раза быстрее, сокращать использование VRAM на 60% и поддерживать в 8 раз более длинный контекст без потери точности, предоставляя разработчикам эффективное решение для настройки VLM.
(Источник: danielhanchen)

WebGPU поддерживает локальный запуск модели nanochat от Карпатого: Модель nanochat от Карпатого теперь поддерживает WebGPU и может работать на 100% локально в браузере без сервера. На M4 Max она достигает 50 токенов в секунду, что означает, что AI-приложения теперь могут быть легко развернуты с помощью одного HTML-файла.
(Источник: paul_cal)

Alibaba Qwen Deep Research обновлен для генерации мультимодального контента: Сервис Qwen Deep Research от Alibaba получил значительное обновление, теперь он может не только генерировать исследовательские отчеты, но и создавать веб-страницы в реальном времени и подкасты. Эта функция поддерживается Qwen3-Coder, Qwen-Image и Qwen3-TTS, что позволяет пользователям получать информацию в визуальной и звуковой форме.
(Источник: Alibaba_Qwen)
Glif запускает AI-инструмент для спецэффектов: Glif разрабатывает AI-инструмент для спецэффектов, который может обрабатывать реальные видеоматериалы, записанные на телефон, и призван стать мощной “волшебной палочкой” для создателей, с которой легко справится даже 7-летний ребенок. Пользователям достаточно загрузить видео и описать желаемый эффект, чтобы сгенерировать видеоэффекты.
(Источник: NerdyRodent、fabianstelzer)
Runway запускает услугу тонкой настройки моделей: Runway запускает услугу тонкой настройки моделей (Model Fine-tuning), позволяющую пользователям настраивать свои модели в соответствии с конкретными сценариями использования и собственными данными. Эта услуга самообслуживания призвана открыть совершенно новые сценарии применения в таких областях, как развлечения, робототехника, образование и науки о жизни.
(Источник: c_valenzuelab)

vLLM, OpenWebUI и Tailscale создают частную портативную AI-среду: Пользователи успешно создали частную, портативную среду выполнения AI, объединив vLLM, OpenWebUI и Tailscale. Эта конфигурация позволяет пользователям запускать Large Language Models на локальных устройствах и обеспечивать безопасный удаленный доступ через Tailscale, что значительно повышает гибкость AI-приложений и конфиденциальность данных.
(Источник: Reddit r/LocalLLaMA)
Прогресс в реализации модели Qwen3-Next 80B-A3B в llama.cpp: Достигнут прогресс в реализации модели Qwen3-Next 80B-A3B в llama.cpp, с предварительной поддержкой CUDA (ограничение контекста до 40k) и предоставлением Instruct GGUFs. Это открывает больше возможностей для локального запуска больших моделей Qwen, хотя поддержка CUDA все еще совершенствуется.
(Источник: Reddit r/LocalLLaMA)
LangChain скоро выпустит версию v1: LangChain скоро выпустит версию v1 и проведет прямую трансляцию с Microsoft Reactor, чтобы поделиться новыми функциями. LangChain, как популярный фреймворк Python AI Agent, предоставит разработчикам новые возможности и опыт в создании агентов.
(Источник: hwchase17、hwchase17)

Молниеносный векторный поиск для юридических документов: Разработчик создал систему семантического поиска для огромного количества юридических документов из истории австралийского права, обеспечивающую быстрый поиск с помощью векторного поиска. Этот проект демонстрирует, как создать эффективный семантический поиск на крупномасштабных, предметно-ориентированных наборах данных, и уже опубликовал руководства и корпус.
(Источник: Reddit r/ArtificialInteligence)

Команда AI Studio создает новый опыт кодирования Gemini: Команда Google AI Studio разрабатывает совершенно новый опыт AI-программирования, направленный на ускорение пути от подсказки до производства и глубоко интегрированный с моделью Gemini. Выпуск этого инструмента, как ожидается, упростит процесс разработки AI-приложений и повысит эффективность разработки.
(Источник: osanseviero)
Редактор кода Zed предлагает быстрый и элегантный опыт разработки: Редактор кода Zed получил похвалу за свою чрезвычайно высокую скорость, элегантный пользовательский интерфейс и хорошую поддержку удаленного SSH и ACP. Несмотря на некоторые проблемы совместимости с форматами вызова инструментов LLM, его общая производительность считается выдающейся.
(Источник: qtnx_、qtnx_)
Restate, Modal и Vercel создают облачные кодирующие агенты: Исследование изучило, как использовать Restate (рабочие процессы), Modal (песочницы) и Vercel (вычисления), а также LLM, такие как GPT-5/Claude, для создания масштабируемых, отказоустойчивых и оркестрируемых облачных кодирующих агентов. Эта архитектура направлена на решение таких проблем в разработке агентов, как сохранение шагов, управление сессиями, жизненный цикл ресурсов, и повышение производительности AI-агентов.
(Источник: akshat_b)
📚 Обучение
Гарвардский университет открыл исходный код учебника “Системы машинного обучения”: Гарвардский университет открыл исходный код учебника по курсу CS249r “Системы машинного обучения”, который призван научить, как создавать реальные AI-системы от периферийных устройств до облачного развертывания. Учебник охватывает всестороннее содержание, включая системный дизайн, инженерию данных, развертывание моделей, MLOps и периферийный AI, и направлен на продвижение образования в области AI-систем по всему миру.
(Источник: GitHub Trending)
Объявлены победители премии за лучшую статью AIES 2025: Конференция AAAI/ACM по искусственному интеллекту, этике и обществу (AIES 2025) объявила победителей премии за лучшую статью, охватывающую ряд передовых этических вопросов и вопросов безопасности, таких как влияние AI на социальные схемы, создание эффективных защитных барьеров для LLM, связь этической оценки AI с системными атрибутами, а также предпочтения сообщества заикающихся в отношении управления данными голосового AI.
(Источник: aihub.org)

Исследование стратегий стабильной и быстрой интеграции в ансамблях LLM: Фреймворк SAFE (Stable And Fast LLM Ensembling) предлагает выборочную интеграцию Large Language Models (LLMs) путем выявления несоответствий на уровне токенов и консенсуса в распределении вероятностей следующего токена для оптимизации производительности генерации длинного текста. Этот метод дополнительно повышает стабильность за счет стратегии усиления вероятности и превосходит существующие методы в бенчмарках MATH500 и BBH, даже при интеграции менее 1% токенов.
(Источник: HuggingFace Daily Papers)
Сравнительное исследование архитектур SSM и Transformer: Новое исследование показывает, что State Space Models (SSMs) уступают Transformer в сценариях с длинным контекстом, что, возможно, является проблемой не самих SSM, а неправильного их использования. Исследование изучает, как оптимизировать использование SSM, чтобы полностью раскрыть их потенциал в эффективном языковом моделировании.
(Источник: tri_dao)

Исследование эффективности расширения LLM-моделей вывода во время тестирования: Исследование изучило эффективность расширения во время тестирования (TTS) для моделей вывода (RMs) в машинном переводе (MT). Результаты показывают, что для общих RMs TTS имеет ограниченный эффект в прямом переводе, но за счет тонкой настройки для конкретной области или в сценариях постобработки TTS может привести к значительному улучшению. Принуждение модели к выводу за пределы естественной точки остановки, наоборот, снижает качество перевода.
(Источник: HuggingFace Daily Papers)
Шесть основных причин странных цепочек рассуждений LLM в RLVR: В статье в блоге анализируются шесть причин появления странных цепочек рассуждений в Large Language Models (LLMs) в Reinforcement Learning from Human Feedback (RLVR), включая такие гипотезы, как “избыточная структура” и “обновление контекста”. Это помогает глубже понять поведенческие паттерны и потенциальные недостатки LLM в сложных процессах рассуждений.
(Источник: dl_weekly)
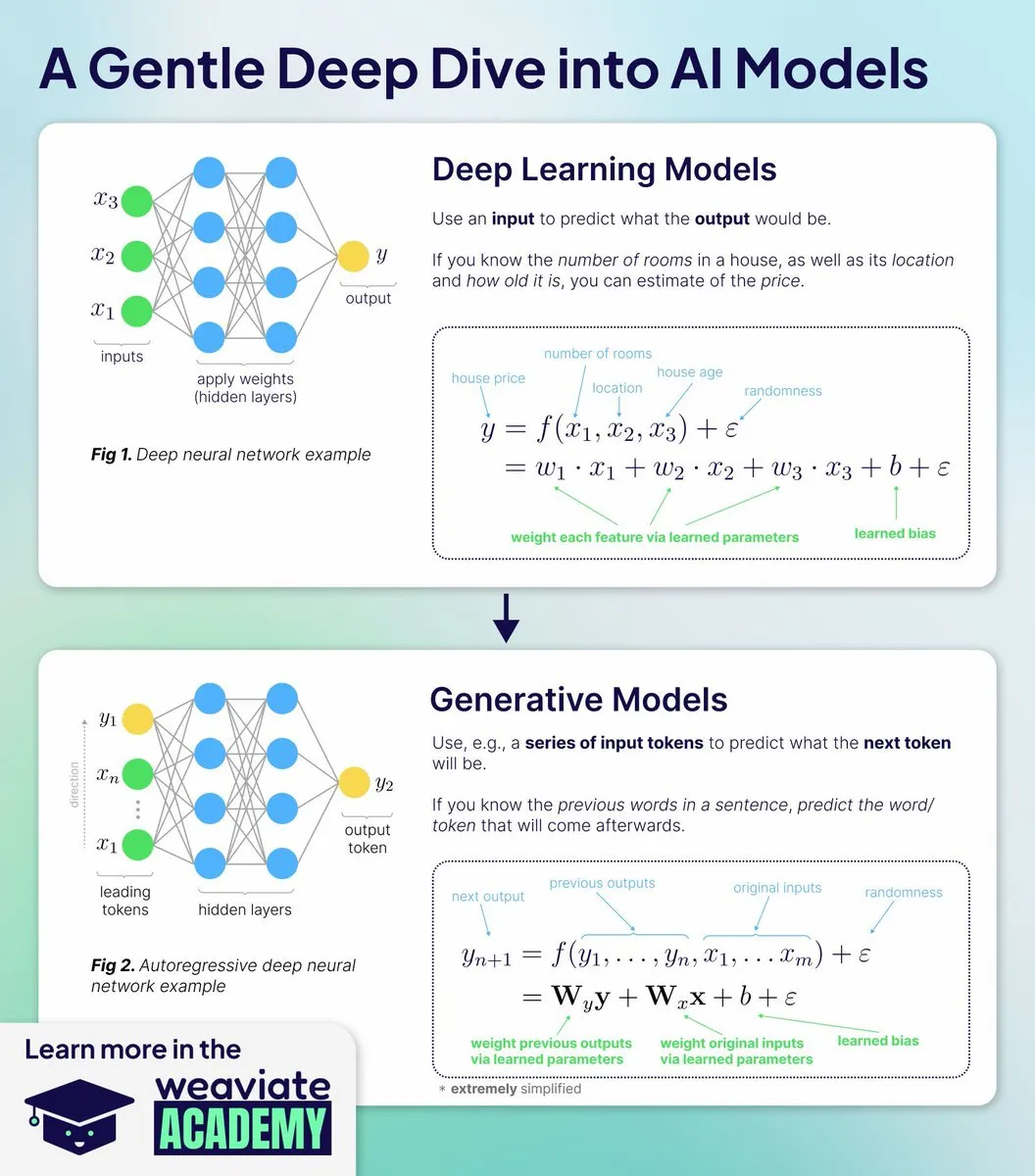
AI-образование: новый курс Weaviate Academy для глубокого понимания принципов работы AI-моделей: Weaviate Academy запустила новый курс, призванный научить, почему и как работают AI-модели, а не просто как использовать API. Курс охватывает основы глубокого обучения, механизмы генеративного AI, глубокий анализ моделей встраивания, от теории к практике, а также обучение и развертывание, помогая учащимся понять архитектурные решения современного AI через практические занятия.
(Источник: bobvanluijt)
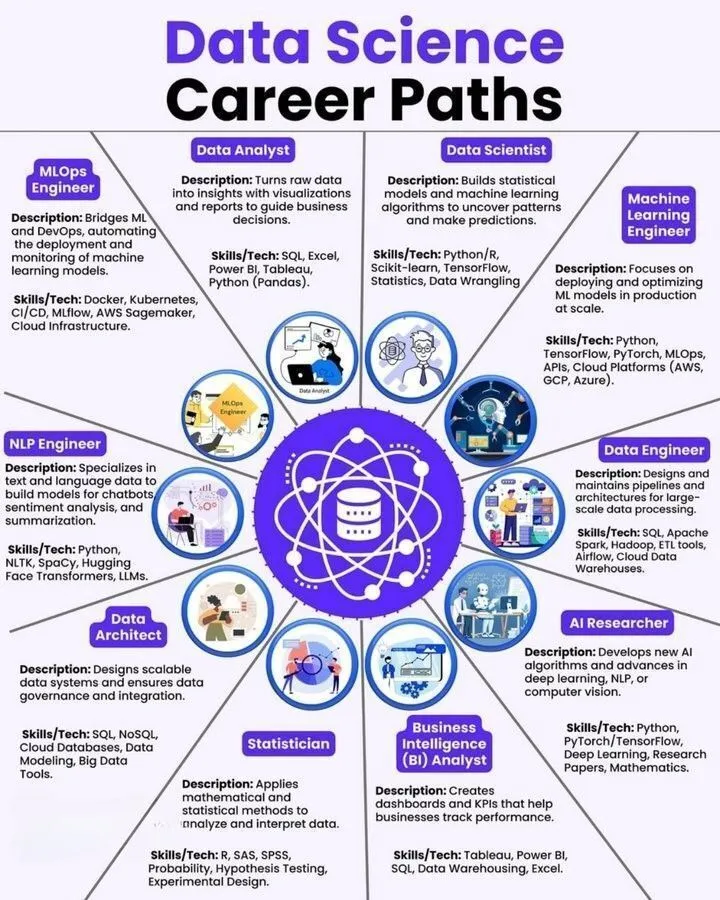
Ресурсы для изучения AI: карьерный путь в науке о данных, дорожная карта инженера машинного обучения и набор инструментов для AI Agent: Были представлены учебные ресурсы, такие как карьерный путь в науке о данных, дорожная карта инженера машинного обучения и полный набор инструментов для AI Agent. Эти ресурсы представлены в виде инфографики, предоставляя учащимся и специалистам в области AI четкие направления карьерного развития и практические ссылки на инструменты.
(Источник: Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon)
Ресурсы для изучения AI: инструменты, курсы и профессиональные навыки AI: Были представлены учебные ресурсы, такие как инструменты AI, курсы AI и 12 навыков AI, которые необходимо освоить к 2025 году. Эти ресурсы призваны помочь учащимся и специалистам в области AI понять последние тенденции и повысить свои профессиональные компетенции.
(Источник: Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon)

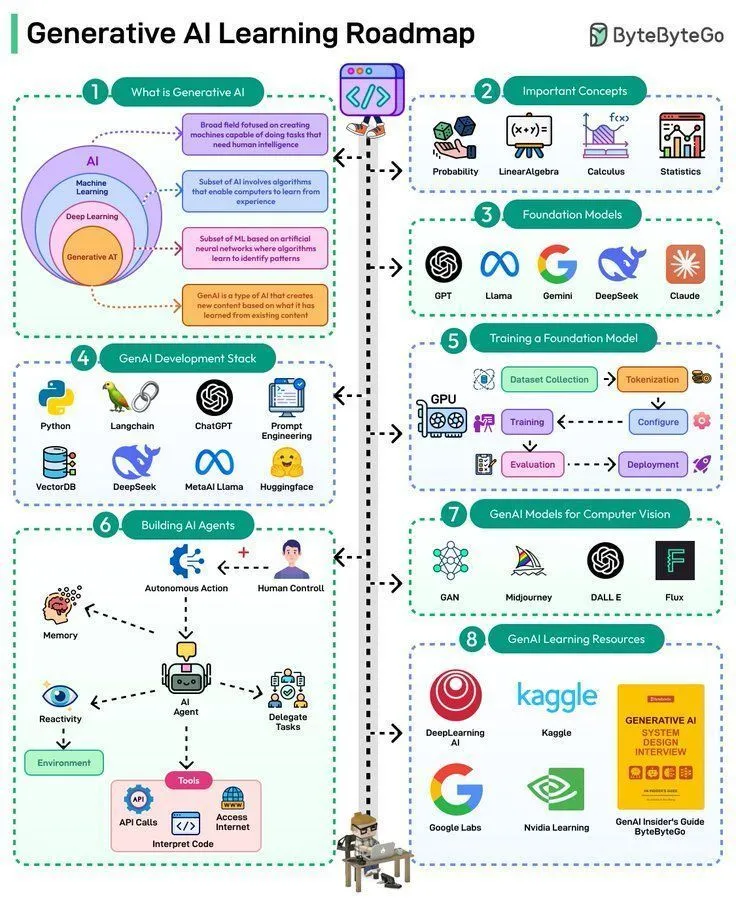
Ресурсы для изучения AI: дорожная карта обучения генеративному AI: Была представлена дорожная карта обучения генеративному AI, которая предоставляет систематизированный путь обучения и ключевые знания для тех, кто хочет войти или углубить свои знания в области генеративного AI.
(Источник: Ronald_vanLoon)
Ресурсы для изучения AI: концептуальная схема слоев AI-модели: Была представлена концептуальная схема слоев AI-модели, которая визуально объясняет различные уровни и компоненты искусственного интеллекта, помогая понять сложную структуру AI-систем.
(Источник: Ronald_vanLoon)

Ресурсы для изучения AI: фреймворк оценки, когда использовать LLM: Предложен фреймворк для оценки того, когда использование Large Language Models (LLM) является оправданным. Этот фреймворк призван помочь лицам, принимающим решения, избежать слепого применения LLM и обеспечить максимальную ценность технологии AI в решении реальных проблем.
(Источник: Ronald_vanLoon)

Ресурсы для изучения AI: руководство по проведению экспериментов с AI-продуктами: Было представлено руководство, описывающее шаги и лучшие практики по проведению экспериментов с AI-продуктами, предоставляя менеджерам по продуктам и разработчикам практические методы преобразования AI-технологий в реальные продукты.
(Источник: Ronald_vanLoon)

Фонд Common Crawl примет участие в конференции COLM 2025: Фонд Common Crawl объявил о своем участии в конференции COLM 2025, что свидетельствует о его постоянном участии в сообществе и вкладе в данные открытого веба и обучающие данные для Large Language Models.
(Источник: CommonCrawl)
Исследование модульной оптимизации многообразий для обучения нейронных сетей: Исследование расширило концепцию оптимизации многообразий (Manifold optimization), предложив модульные многообразия (modular manifolds) для помощи в разработке оптимизаторов, способных понимать взаимодействия между слоями нейронных сетей. Это предоставляет единый фреймворк для геометрически-ориентированной оптимизации.
(Источник: TheTuringPost)

Обзор десятилетия статьи о VQA: Десять лет со дня публикации статьи о Visual Question Answering (VQA), обзор важных вех в этой области исследований визуального языка.
(Источник: DhruvBatra_)

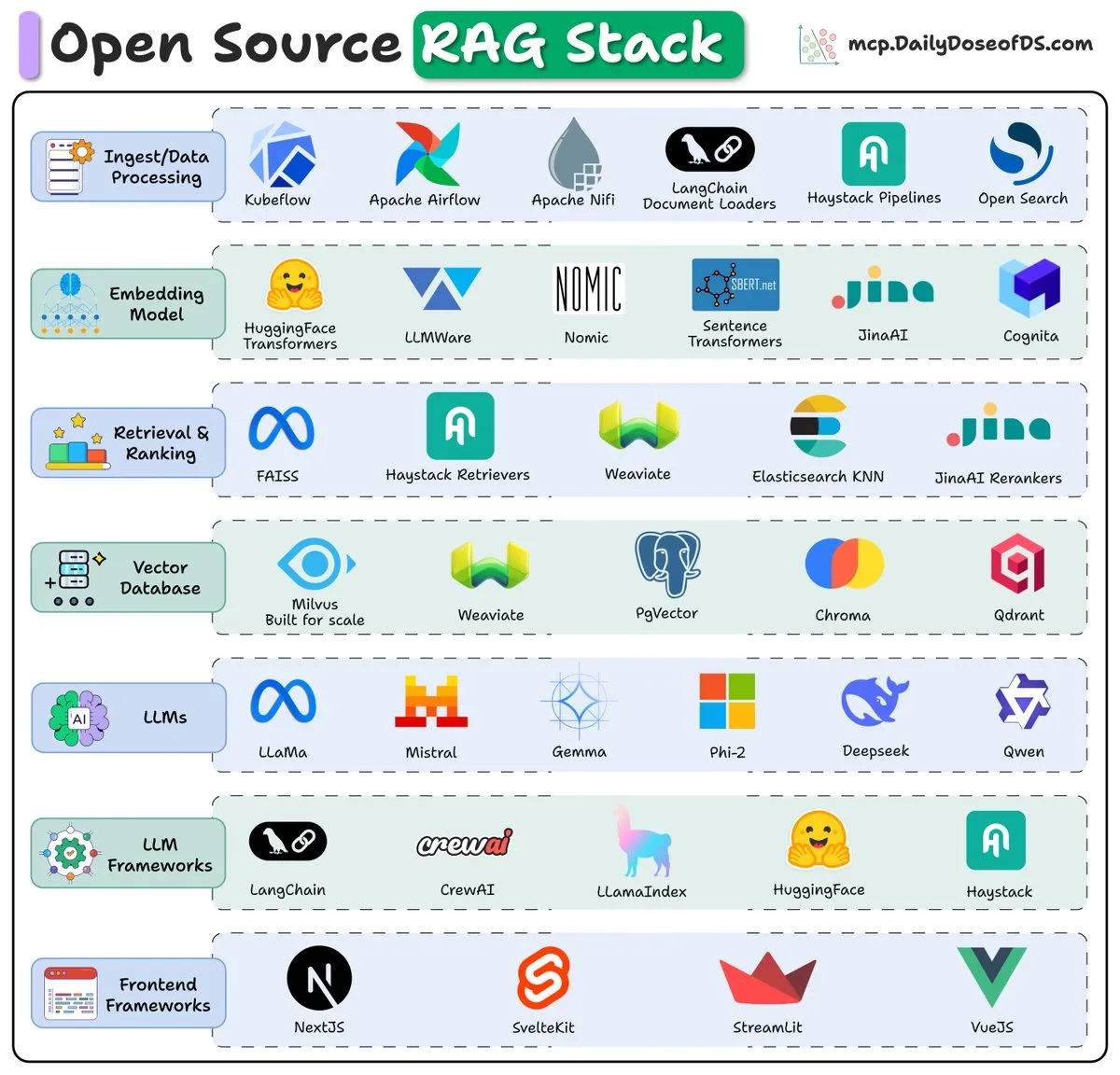
Обзор стека RAG с открытым исходным кодом (2025): В обзоре представлены ключевые компоненты и тенденции стека Retrieval Augmented Generation (RAG) с открытым исходным кодом на 2025 год, предоставляя разработчикам справочную информацию для создания эффективных систем RAG.
(Источник: _avichawla)
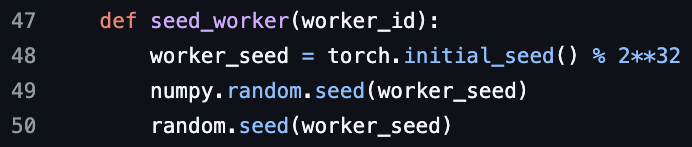
Вопрос на ML-собеседовании о PyTorch DataLoader worker seed: Был задан вопрос на собеседовании по машинному обучению о PyTorch DataLoader worker seed, что вызвало дискуссию о параллелизации загрузки данных и контроле случайности.
(Источник: TheZachMueller)
Применение и преимущества DSPy в AI-инженерии: AI-инженеры проявляют большой энтузиазм по поводу использования DSPy, поскольку он отделяет определение проблемы от стратегии решения и предоставляет фреймворк для создания масштабируемых систем. DSPy повышает уровень абстракции AI-систем, предлагая “жгуты” вместо жестко закодированных решений, используя поиск и вычисления.
(Источник: lateinteraction)

Технический блог о нейронных аудиокодеках: Kyutai Labs опубликовала отличную статью в блоге о нейронных аудиокодеках, глубоко исследуя технические детали и последние достижения в этой области.
(Источник: halvarflake)
Исследование генерации Transformer на основе латентных переменных: Исследование показало, как построить модель Transformer, процесс генерации которой обусловлен латентными переменными, подобно условному VAE. Это предлагает новые идеи для управления генерацией и обучения представлений в Transformer.
(Источник: francoisfleuret)
Споры об академической принадлежности, вызванные исследованием DeepSeek-OCR: Было отмечено, что основная идея статьи DeepSeek-OCR (рассмотрение текстового ввода как изображения и использование визуальных токенов для сжатия) не является новой, и несколько предшествующих работ 2023-2025 годов были проигнорированы. Это вызвало дискуссию об академической строгости и справедливом присвоении авторства, DeepSeek обвиняется в недостаточном цитировании существующих фундаментальных работ.
(Источник: mckbrando、teortaxesTex)
Выпущен крупномасштабный открытый набор данных VLM FineVision: В новой статье “FineVision: Open Data Is All You Need” представлен крупнейший на сегодняшний день открытый набор данных VLM, который путем интеграции более 200 источников данных генерирует 24M образцов, содержащих 17.3M изображений и 9.5B токенов ответов. Этот набор данных полностью документирован, воспроизводим и предназначен для содействия исследованиям VLM.
(Источник: _lewtun、ben_burtenshaw)
Управление данными AI: предпочтения и цели сообщества заикающихся в отношении данных голосового AI: Исследование изучило предпочтения и потребности сообщества заикающихся в отношении управления данными голосового AI, подчеркнув прозрачность, активное и постоянное общение, а также надежные меры конфиденциальности и безопасности. Это исследование предоставляет практические выводы для ориентированного на людей с ограниченными возможностями, управляемого сообществом подхода к управлению данными AI.
(Источник: aihub.org)
Связь этической оценки AI с системными атрибутами, опасностями и ущербом: Исследование рассмотрело, как меры этической оценки AI соотносятся с компонентами, атрибутами, опасностями и ущербом AI-систем. Анализ показал, что большинство мер сосредоточены на справедливости, прозрачности, конфиденциальности и доверии, в основном оценивая модели или выходные компоненты, но редко учитывают взаимодействие между системными элементами и обычно рассматривают лишь узкий набор опасностей.
(Источник: aihub.org)
Фреймворк QueST для генерации сложных задач по программированию с помощью LLM: Фреймворк QueST оптимизирует генерацию сложных задач по программированию с помощью LLM, сочетая выборку графов с учетом сложности и тонкую настройку с учетом сложности отказа. Обученный генератор превосходит GPT-4o в создании сложных задач и может эффективно использоваться для дистилляции или Reinforcement Learning небольших моделей, значительно улучшая последующую производительность.
(Источник: HuggingFace Daily Papers)
Возможность неинтерактивной оценки переводчиков общения животных: Исследование предоставило теоретические и экспериментальные доказательства концепции, показывающие, что в достаточно сложных языках можно оценивать переводчиков общения животных, не взаимодействуя с животными и не полагаясь на наблюдения на месте, а только по их английскому выводу. Это предлагает метод оценки качества машинного перевода без эталонного перевода.
(Источник: HuggingFace Daily Papers)
Анонс мероприятий VLLM на Неделе AI с открытым исходным кодом: Проект VLLM объявил о своем участии в Неделе AI с открытым исходным кодом на PyTorch Conference 2025, где будет проведено несколько тематических выступлений по обслуживанию LLM, масштабированию и эффективности GPU, а также мероприятие Q&A сообщества NVIDIA x DeepInfra x vLLM.
(Источник: vllm_project)

Нейросимвольные модели, сочетающие генеративный AI и символьный AI: В сообществе AI существуют разногласия относительно наилучшего пути развития генеративного AI и символьного AI. Исследование предлагает нейросимвольные модели, объединяющие преимущества обоих подходов. Эта модель призвана преодолеть разрыв между генеративными возможностями нейронных сетей и регулярностью символьного рассуждения, предлагая новый вид для развития AI-агентов.
(Источник: _akhaliq)
Эволюционные методы оптимизации для тонкой настройки LLM: Прямая трансляция будет посвящена тому, как расширить методы эволюционной оптимизации для тонкой настройки Large Language Models (LLMs). Это показывает, что старые методы оптимизации все еще могут играть важную роль в современной области AI, предлагая новые идеи для обучения и повышения производительности LLM.
(Источник: yacinelearning)

Лекция по продвинутым технологиям RAG: Лекция подробно объяснила продвинутые технологии Retrieval Augmented Generation (RAG), подчеркнув важность понимания их основных принципов и концепций, а не только сосредоточения на вызовах API и синтаксисе библиотек. Лекция направлена на предоставление долгосрочных знаний, помогающих разработчикам создавать реальные производственные системы.
(Источник: ProfTomYeh)
Видео с объяснением устойчивости модели: Видео объясняет концепцию устойчивости модели (model robustness), что крайне важно для понимания стабильности и надежности AI-систем при столкновении с помехами или невиданными данными.
(Источник: [Reddit r/deeplearning](https://www.reddit.com/r/deeplearning/comments/1oc7tri/explaining_model_robustness_