
Keywords:VGGT, 3D vision, Transformer, CVPR 2025, Meta, University of Oxford, autonomous driving, AI safety, Vision Geometry Transformer, single forward pass 3D prediction, SafeKey framework, Waymo autonomous driving research, Doubao large model 1.6
🔥 Focus
VGGT: Meta and Oxford University Propose Visual Geometry Transformer, Predicting Complete 3D Scene Information in a Single Feedforward Pass, Wins CVPR 2025 Best Paper Award: VGGT (Visual Geometry Grounded Transformer), jointly proposed by Meta and Oxford University, became the sole Best Paper at CVPR 2025. This model, based on Vision Transformer, uses an alternating “global-intra-frame” self-attention mechanism and can end-to-end predict complete 3D scene information, including camera intrinsics and extrinsics, depth maps, point clouds, and 3D trajectories, in a single feedforward pass. VGGT learns solely from extensive 3D annotated data without geometric inductive biases, performs excellently when processing 1 to 200 image inputs, surpasses various existing geometric or deep learning methods, and demonstrates broad application potential in the 3D vision field (Source: QbitAI)

Nvidia CEO Jensen Huang and Anthropic CEO Clash on AI Development Views: Nvidia CEO Jensen Huang stated at a press conference in Paris that he disagrees with almost all of Anthropic CEO Dario Amodei’s views on AI. Huang pointed out that Amodei believes AI is too dangerous and should be controlled by a few companies; AI is costly, and other companies should not be involved; and AI will lead to mass unemployment. Huang countered that AI is an important technology that should be developed openly, safely, and responsibly, not in a closed environment, emphasizing the importance of openness for safety (Source: hardmaru)
SafeKey Framework Enhances Large Reasoning Model Safety, Reducing Risk Rate by 9.6%: A research team from UC Santa Cruz, UC Berkeley, Cisco Research, and Yale University proposed the SafeKey framework, aimed at enhancing the safety of Large Reasoning Models (LRMs). The study found that model “jailbreaking” is related to the failure to effectively utilize early “key phrase” safety signals. SafeKey amplifies safety signals through a “dual-path safety head” and compels the model to rely on its own understanding for safety decisions via “query-masked modeling.” Experiments show that SafeKey reduces the dangerous response rate by 9.6% without significantly impacting the model’s core capabilities (even slightly improving them), performing particularly well against unknown attacks (Source: QbitAI)

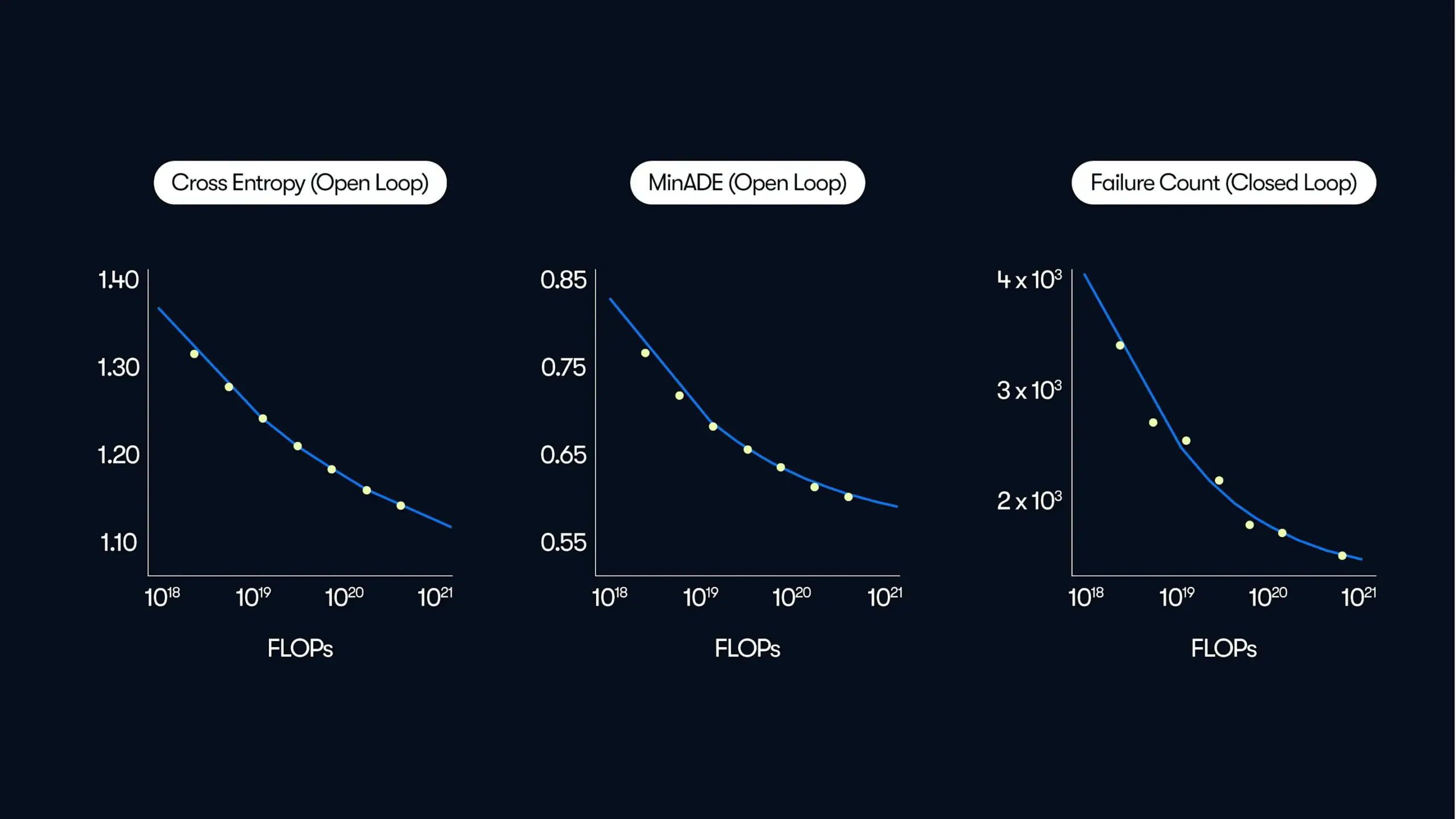
Waymo Study Shows Autonomous Driving System Performance Exhibits Power-Law Scaling with Data and Compute: Waymo released a comprehensive study based on 500,000 hours of driving data, revealing a power-law relationship between the motion prediction quality of its autonomous driving system and training computation, similar to the scaling laws of Large Language Models (LLMs). The research emphasizes that data scale is crucial for improving model performance, while increasing inference computation also enhances the model’s ability to handle complex driving scenarios. This study demonstrates for the first time that real-world autonomous driving performance can be improved by increasing training data and computational resources (Source: zacharynado)
🎯 Trends
ByteDance Releases Doubao Large Model 1.6 and Multiple AI Applications, Emphasizing Combined Capabilities and Productization: ByteDance recently released a series of AI products, including Doubao Large Model 1.6, video generation model Seedance 1.0 Pro, and voice podcast & real-time speech models. Doubao 1.6 enhances multimodal processing and operational capabilities, supports think-while-searching and DeepResearch, and can perform GUI operations. Seedance 1.0 Pro excels in video generation coherence and stability, supporting 10-second 1080p video generation. ByteDance’s strategy focuses more on integrating AI capabilities into directly runnable applications and embedding them into existing products (like the Doubao APP, Volcano Engine), emphasizing combined capabilities and rapid productization rather than solely pursuing leadership in single model parameters. Its pricing strategy is also more cost-effective, aiming to lower the barrier to AI adoption (Source: 36Kr)
Tencent Open-Sources Hunyuan 3D 2.1 Model, Featuring PBR Textures and Consumer-Grade GPU Compatibility: Tencent announced at CVPR the open-sourcing of its latest 3D generation model, Hunyuan 3D 2.1. The model has been optimized for both geometric accuracy and texture detail, notably introducing PBR (Physically Based Rendering) texture generation technology, which can render complex materials like leather, metal, and ceramics with high quality and visual realism. Hunyuan 3D 2.1 is fully open-sourced, including model weights, training code, and data processing pipelines, and supports running on consumer-grade GPUs with one-click deployment, aiming to promote the popularization of 3D content creation (Source: QbitAI)

Perplexity AI Actively Improving Deep Research Feature in Response to User Feedback: Perplexity AI CEO Arav Srinivas stated that the team has carefully listened to negative feedback regarding its Deep Research feature and has begun making improvements. Some enhancements are already live in production, and users should notice an improved experience. In the future, Deep Research and Labs features will be integrated into the Comet product, aiming to optimize users’ decision-making processes by leveraging personal context and data (Source: AravSrinivas)
Anthropic Research Reveals Multi-Agent Systems Can Significantly Improve Task Performance: Research released by Anthropic shows that using multi-agent systems (e.g., Opus as the main agent, Sonnet as sub-agents) for tasks improves performance by 90% compared to using Opus alone. This collaborative model is akin to how human societies significantly boost productivity through division of labor. The study details how to build effective multi-agent research systems and shares its evaluation methods, including using an LLM as a referee. However, some commentators noted that the Claude research methodology described in the report might suffer from insufficient search depth (Source: zacharynado, omarsar0, nrehiew_)

Research Indicates Large Language Model Reasoning Ability is Limited by “Unfamiliarity” Rather Than “Complexity”: François Chollet points out that the reasoning ability of Large Language Models (LRMs) does not break down upon reaching a certain “complexity” or “number of steps” threshold, but rather fails when faced with “unfamiliar” tasks, and this unfamiliarity threshold is very low. Models can solve extremely complex tasks covered during training/tuning phases, but even simple novel tasks (like ARC 2 tasks) may lead to failure. The step/complexity thresholds observed on familiar problems (like the Tower of Hanoi) are actually a result of creating “novelty” by increasing problem variables (Source: fchollet, jeremyphoward)
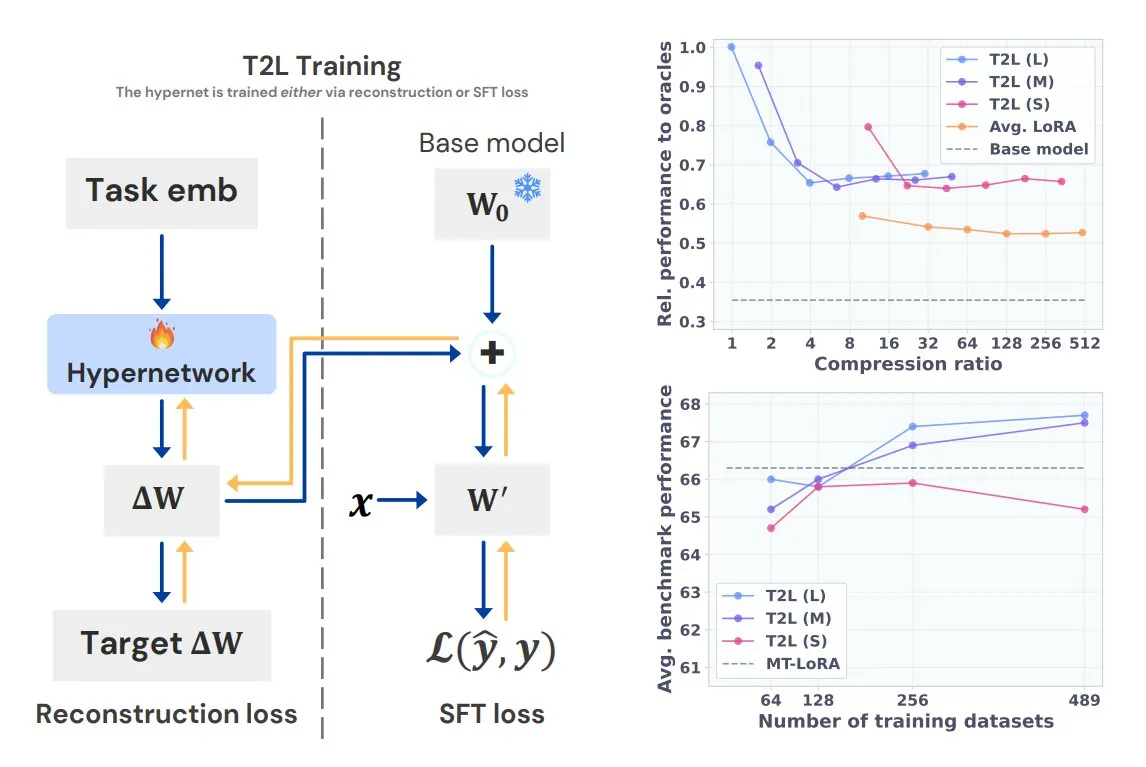
Sakana AI Introduces Text-to-LoRA (T2L) Hypernetwork Model: Sakana AI has released Text-to-LoRA (T2L), a novel hypernetwork capable of rapidly generating new LoRA adapters for large language models based on a textual description of the task. T2L can not only compress multiple existing LoRAs but also create new ones on-the-fly post-training, offering a new pathway for rapid customization of task-specific models. This research will be presented at ICML 2025 (Source: TheTuringPost)
Nvidia’s Cosmos-Predict2 (2B Model) Demonstrates Impressive Image Generation Capabilities: Nvidia’s Cosmos-Predict2, a 2-billion-parameter model positioned as a “world foundation model platform for physical AI,” has shown impressive capabilities in artistic image generation. Although its base dataset might not be optimal, the model is well-structured, and the quality of generated images is not far off from the 14B parameter version, only slightly inferior in detail and prompt adherence, showcasing the potential of smaller models with specific optimizations (Source: teortaxesTex)
MIT Develops New Algorithm Enabling Drones to Autonomously Avoid Storms: MIT has developed a new algorithm that endows unmanned aerial vehicles (UAVs) with “brain-like” decision-making capabilities, allowing them to analyze weather conditions in real-time and autonomously plan routes to avoid storms. This technology is expected to enhance drone flight safety and mission efficiency in complex meteorological conditions (Source: Ronald_vanLoon)

Meta Research: GPT-Style Language Models Memorize 3.6 Bits of Information Per Parameter: A new study by Meta calculates that GPT-style language models can memorize approximately 3.6 bits of information per parameter. The research assesses their memory capacity by measuring the total number of bits memorized by the model (based on Shannon’s 1953 theory) and observes a specific curve relationship between memory and data scale (Source: jxmnop)

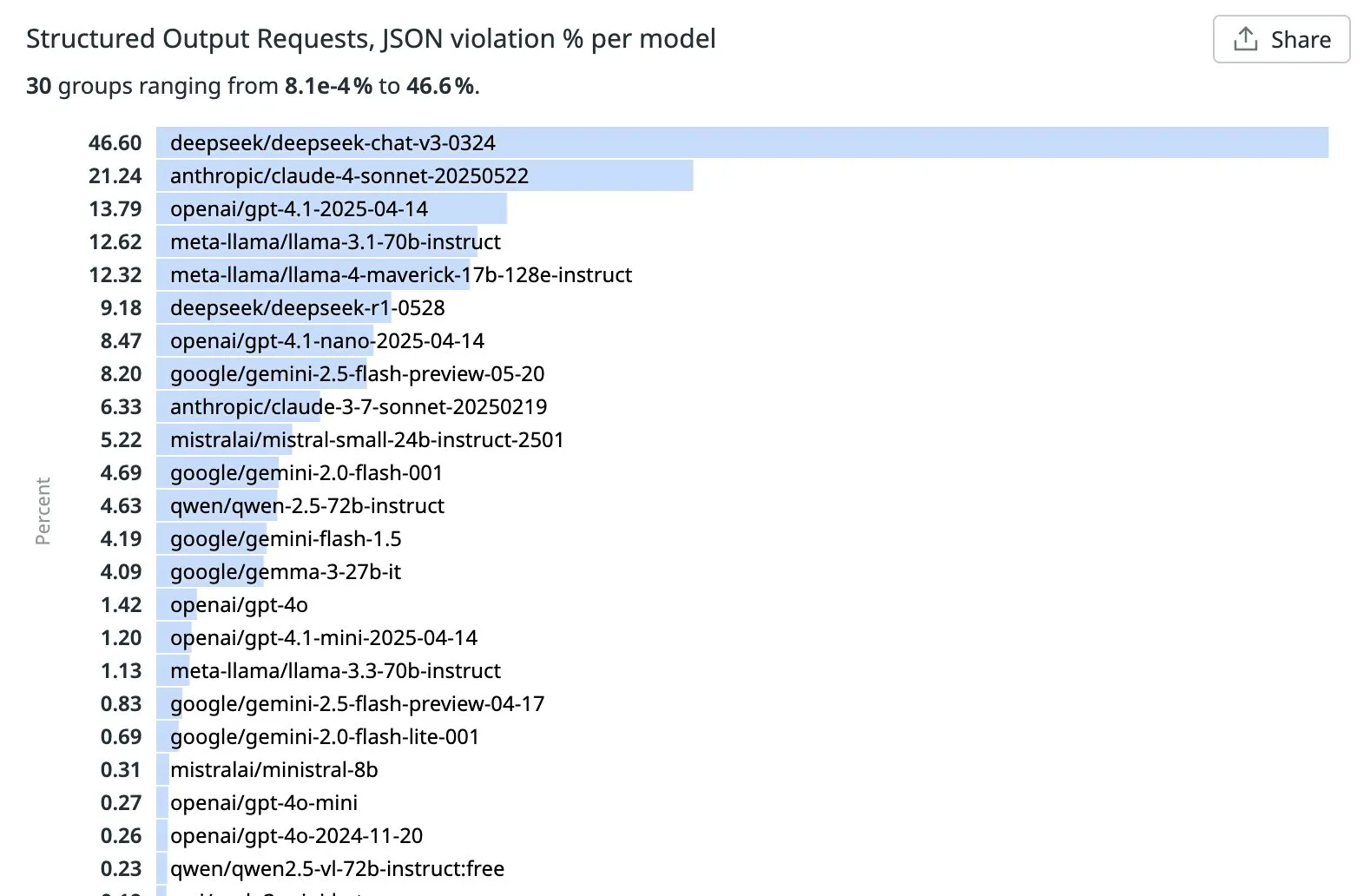
OpenRouter Releases LLM Ranking for Violation Rates in Structured Output (JSON) Tasks: OpenRouter has ranked major LLMs based on the percentage of JSON violations detected in top structured output requests over the past week. The results show that Qwen, Mistral, and GPT-4o-mini performed well with low JSON violation rates. In contrast, DeepSeek v3 and Sonnet 4 had violation rates exceeding 20%, indicating significant room for improvement in accurately adhering to JSON format. The specific patterns causing these discrepancies are not yet clear (Source: xanderatallah, teortaxesTex)
Ant Group Launches Unified Multimodal Model Ming-Omni: Ant Group has released the Ming-Omni series models, a unified multimodal model capable of perception and generation across text, image, audio, and video. Its lightweight version, Ming-Lite-Omni, uses an MoE architecture with only 2.8B activated parameters, possesses high-quality image generation and natural speech synthesis capabilities, and has been open-sourced on Hugging Face under the MIT license (Source: teortaxesTex, _akhaliq)
China’s QiMeng AI Chip Design Tool Completes Processor Design in Days, Surpassing Engineer Efficiency: China’s AI chip design tool “QiMeng” has demonstrated its efficient processor design capabilities, completing design tasks in just a few days that would traditionally take engineers much longer. This marks the potential of AI in chip design automation, promising to accelerate chip development cycles and reduce costs (Source: Ronald_vanLoon)

Hao AI Lab’s o3-pro Model Excels in LLM Game Benchmark: Hao AI Lab’s o3-pro model has made significant progress in Lmgame Bench (a benchmark for evaluating the gaming capabilities of large language models). In Tetris and Sokoban games, o3-pro achieved SOTA levels and far surpassed its predecessor, o3. Particularly in Tetris, o3-pro can clear over 8 lines, demonstrating planning capabilities, while other models struggle after only a few lines (Source: clefourrier)
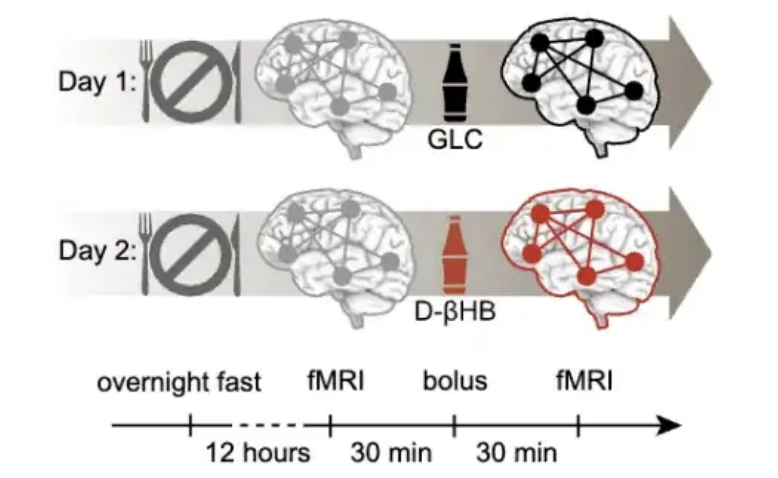
Study Finds Age 40 is a Critical Window for Preventing Brain Aging, Ketone Intervention Shows Significant Effects: A study published in PNAS, analyzing brain scan data from nearly 20,000 people, found that brain aging is not a linear process but follows an S-shaped curve, correlated with increased insulin resistance. The research indicates that around age 40 is when brain network instability begins to accelerate, with the fastest aging rate occurring in the 60s. Experiments showed that ketones (D-βHB) can bypass insulin resistance to supply energy to neurons, significantly stabilizing brain networks, with the most effective intervention period being between 40-59 years old, offering new insights for brain health in middle age (Source: QbitAI)
🧰 Tools
The Browser Company Launches Beta Version of AI-Native Browser Dia: The Browser Company, developer of the Arc browser, has released an internal beta version of its first AI-native browser, Dia. Dia’s main highlight is allowing users to directly chat and interact with any webpage content (including YouTube videos, FigJam, Google Calendar, etc.) without opening external AI tools like ChatGPT. It can automatically fetch context from tabs and supports multi-webpage information integration and comparison, planning, content creation, and more. Currently available only for MacOS, it aims to provide a simpler, AI-first browsing experience (Source: 36Kr)
LangChain Launches Local AI Podcast Generator: LangChain has released a local AI podcast generator. Built with LangChain and Ollama, the system can convert text into multilingual podcasts. It combines text summarization and speech generation technologies to achieve a seamless podcast creation workflow. Users can refer to the provided tutorial to learn how to use the tool (Source: LangChainAI, hwchase17)

Davia: Rapidly Convert Python Apps and LangGraph Agents into Web Applications: Davia is a tool that can instantly convert Python applications and LangGraph agents into polished web applications without writing any frontend code. Built on FastAPI, it automatically generates an interactive user interface, allowing developers to focus on implementing Python logic (Source: LangChainAI, Hacubu)
Tensorlake Integrates with LangChain for Structured Document Processing: Tensorlake announced its integration with LangChain, enabling LangGraph agents to leverage Tensorlake’s powerful multimodal processing system to convert unstructured documents into structured data. This integration provides a new solution for handling complex documents (Source: LangChainAI, hwchase17)
Quark Releases China’s First Gaokao College Application Large Model and Free Volunteer Report Function: Quark has launched China’s first large model for Gaokao (college entrance exam) applications and introduced a free “Volunteer Report” function. Based on an Agent operating model, it simulates expert decision-making processes, combined with a real-time updated “Gaokao Knowledge Base” (covering 2900+ universities, nearly 1600 undergraduate majors, and employment information), to generate personalized application plans for candidates, including “reach, match, safety” tiers. This initiative aims to use AI technology to lower the threshold and cost of Gaokao application planning, changing the landscape of traditionally expensive consulting services (Source: QbitAI)

Task Orchestrator: An MCP Project Management Tool for Claude Code: Developer jpicklyk created an MCP (Machine-Level Code Programming) tool called Task Orchestrator, designed to address Claude Code’s tendency to get “distracted” and forget context when handling complex projects. The tool endows Claude with persistent memory, structured project management (project → feature → task), AI-native templates, intelligent dependency relationships, and progress tracking, making it more like an organized engineering partner. The project is open-sourced on GitHub (Source: Reddit r/ClaudeAI)
ATLAS: A Software Engineering AI Partner Endowing Claude Code with Self-Perception: Developer syahiidkamil created the ATLAS project, aiming to transform Claude Code into a software engineering AI partner with rudimentary self-awareness, memory, identity, and professional standards. ATLAS can maintain project context, self-manage knowledge, evolve with code commits, and proactively request code reviews, thereby fostering a more natural collaboration and review process between users and AI. The project is open-sourced on GitHub, aiming to help users and AI jointly maintain higher quality code (Source: Reddit r/ClaudeAI)
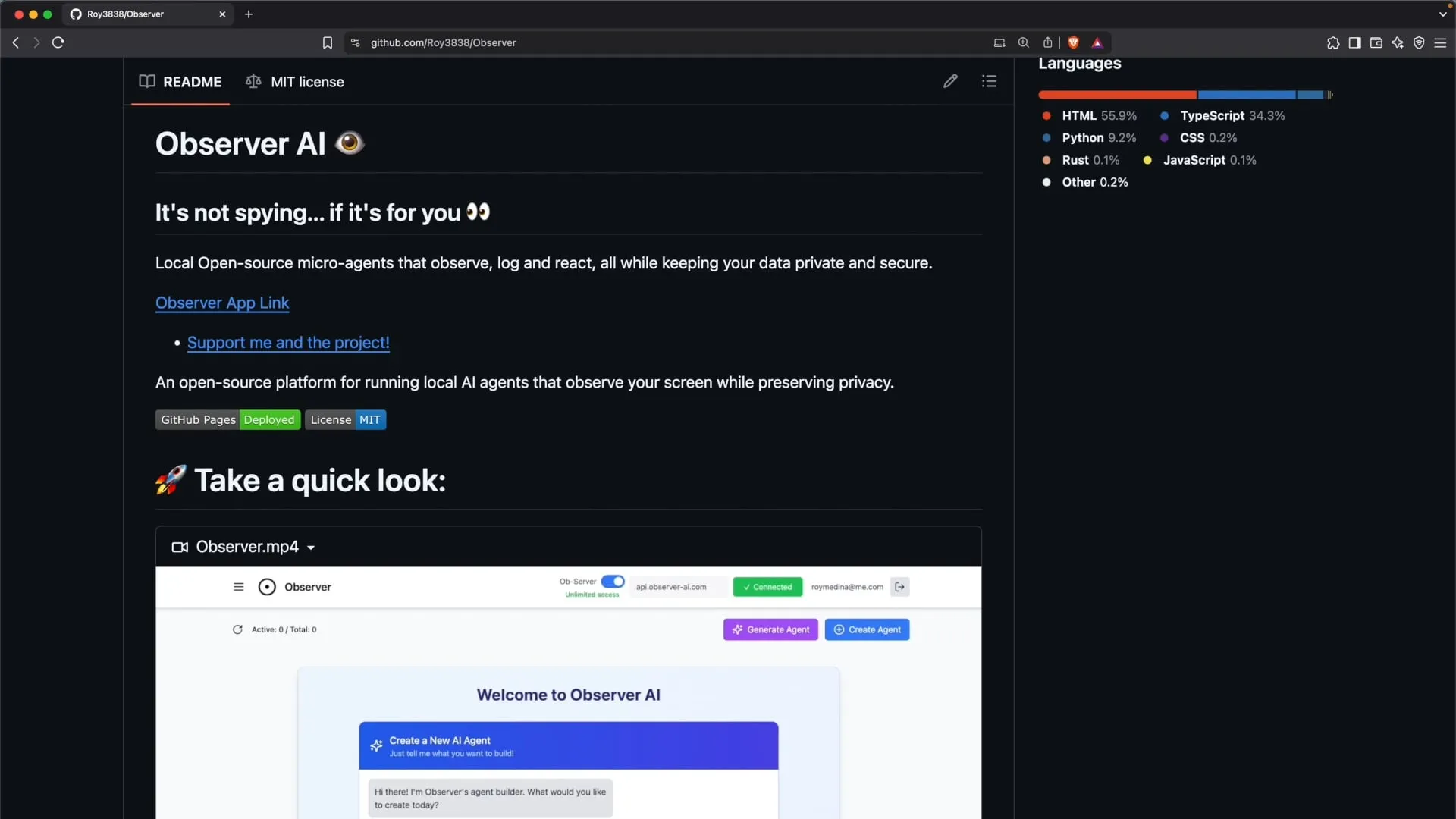
Observer: A Locally Run Screen Monitoring AI Assistant: Observer is an AI tool that can run locally to monitor user screen activity. A tutorial is available to learn how to self-host Observer on a home server, enabling AI-assisted analysis or interaction with screen content (Source: Reddit r/LocalLLaMA)
VantaAI: Sharing a Local AI Assistant Project with Memory and Emotional Logic: A developer shared their personal project, VantaAI, a local AI assistant designed to run completely offline. VantaAI simulates features like emotional memory, mood swings, and personal identity. It possesses long-term memory that evolves based on conversational context, an “emotion graph” tracking mood changes, and narrative-driven memory clustering that views itself as the protagonist of a story. The project uses a custom Vulkan backend for model inference and training, and supports personality-based responses and plugin hot-reloading (Source: Reddit r/LocalLLaMA)
📚 Learning
Hamel Husain and Shreya Shankar Co-author AI Evals Book and Launch Course: Hamel Husain and Shreya Shankar have collaborated on a book about AI Evals (Evaluations) and launched a related course. The first chapter and full table of contents of the book are available for preview, covering AI evaluation methods from theory to practice. The course also features several industry experts as guest lecturers, aiming to help students enhance their AI system evaluation capabilities. The course has received widespread praise and is considered one of the most comprehensive resources on AI Evals currently available (Source: HamelHusain, HamelHusain)
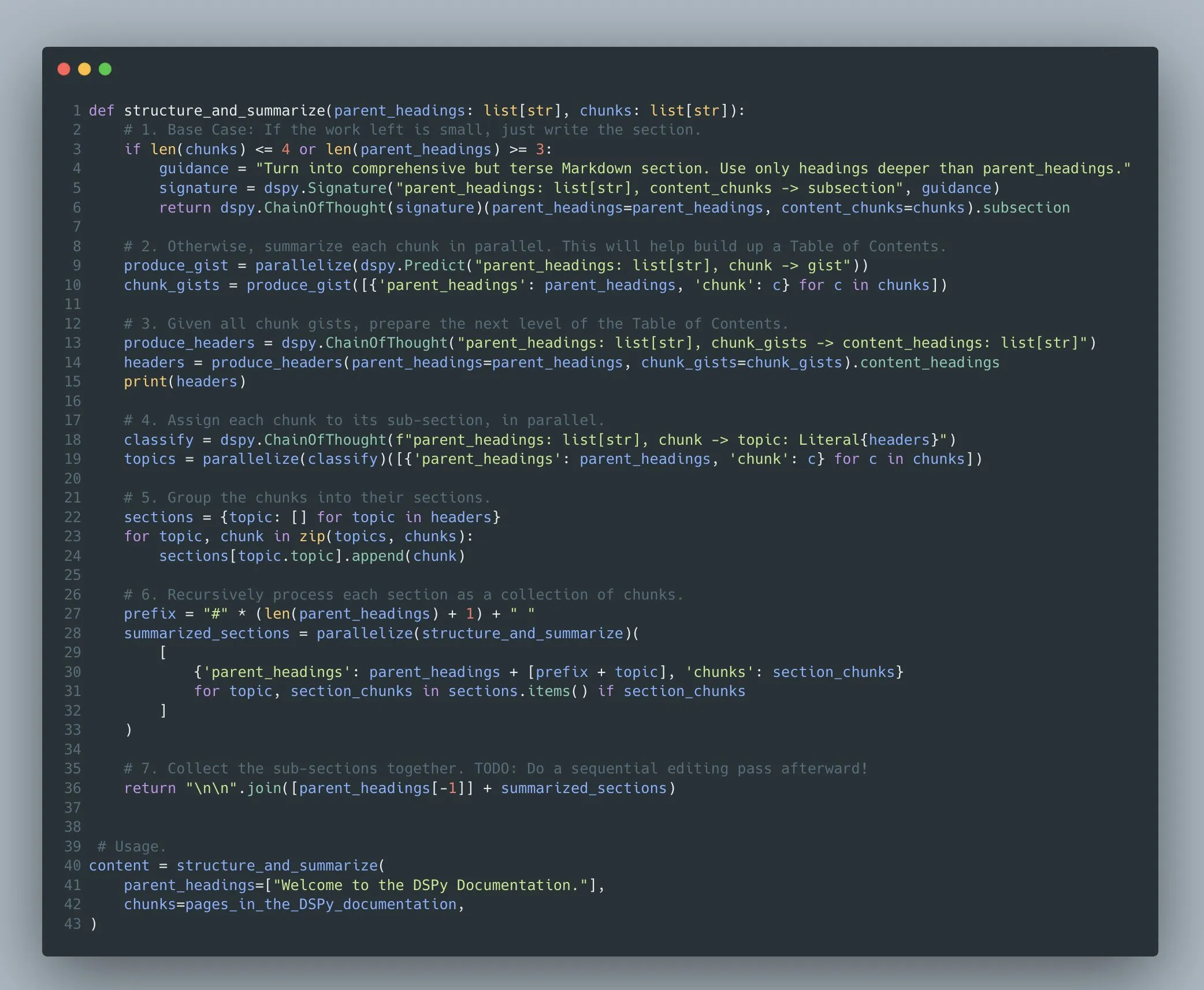
DSPy Framework: Providing High-Level Programming Abstractions for Complex Language Model Programs: The Stanford NLP team emphasizes that the DSPy framework aims to be a high-bandwidth language for precise interaction with computers. DSPy allows developers to build and optimize complex multi-stage language model programs (Compound AI Systems), supporting arbitrary program structures like recursion, exception handling, and nested control flow, not just simple “chains” or “flows.” Its optimizer is dedicated to tuning instructions, demonstrations, and weights in arbitrary computer programs that can arbitrarily call one or more LLMs (Source: stanfordnlp)
Terence Tao on Lex Fridman Podcast, Discusses Math, Physics Puzzles, and AI’s Future: Renowned mathematician Terence Tao was interviewed by Lex Fridman, delving into the most challenging problems in mathematics and physics, such as the Navier-Stokes equations and the P vs NP problem, and looking ahead to AI’s potential in helping solve these puzzles. The podcast also covered topics like AI-assisted theorem proving, the Lean programming language, DeepMind’s AlphaProof, and the possibility of AI winning a Fields Medal (Source: , arohan)

Phillip Isola’s Team Releases Free Online Computer Vision Textbook: Phillip Isola and his team have released their computer vision textbook online for free. The textbook website (visionbook.mit.edu) is developing interactive components, such as a search function and integration with LLMs (beta), aiming to provide learners with more convenient learning resources and encouraging users to help improve the textbook content via GitHub issues (Source: jeremyphoward, natolambert)
Hugging Face Launches MCP Introductory Course: Hugging Face, in collaboration with Theodora Chu, has launched a new introductory course on MCP (Master Control Program, likely referring to AI Agent or multi-agent system control). The course aims to help learners understand and master MCP-related knowledge and skills (Source: huggingface, ClementDelangue)
DINOv2 and Text Alignment Study (dino.txt) Presented at CVPR 2025: A study named dino.txt was presented at CVPR 2025, focusing on aligning frozen DINOv2 features with text captions to achieve image-level and patch-level vision-language alignment at low cost. This enables models to leverage both DINOv2’s high-quality visual features and CLIP-style vision-language alignment capabilities (Source: TimDarcet, andersonbcdefg)

💼 Business
Tencent-backed AI Unicorn Mininglamp Technology Files for Hong Kong IPO, Valued at 12 Billion RMB: Data intelligence application software company Mininglamp Technology (formerly “Huizhi Holdings”) has submitted its prospectus to the Hong Kong Stock Exchange. Founded in 2005 by Peking University School of Mathematical Sciences alumnus Wu Minghui, the company focuses on providing marketing and operational decision support for enterprises using large models, industry knowledge, and multimodal data. Its core products include Miaozhen Systems, Jinshuju, etc., serving clients such as P&G, McDonald’s, and 135 other Fortune 500 companies. Tencent is its largest shareholder, holding 27.33%. After completing its final pre-IPO financing round in January 2024, the company was valued at approximately 12 billion RMB (Source: QbitAI)

OpenAI and Toy Manufacturer Mattel Announce Strategic Partnership to Co-develop AI Smart Toys: OpenAI announced a partnership with globally renowned toy manufacturer Mattel to jointly develop AI-powered smart toys. This collaboration aims to apply OpenAI’s AI technology to age-appropriate toy experiences, revolutionizing traditional play. Mattel owns famous IPs like Barbie and Hot Wheels. Both parties are committed to strictly ensuring child safety and privacy in the collaboration. Mattel will also integrate OpenAI’s AI tools (such as ChatGPT Enterprise) into its business operations to enhance product development and innovation (Source: 36Kr)
Enterprise Search Startup Glean Completes $150 Million Late-Stage Funding Round: Enterprise search startup Glean announced it has secured $150 million in a late-stage funding round, bringing its valuation to $7.2 billion. Glean uses AI technology to help enterprise employees more efficiently find information within a company’s complex array of SaaS applications and data sources (Source: dl_weekly)
🌟 Community
Hugging Face Hosts Global LeRobot Robotics Hackathon to Promote Open-Source Robotics Development: Hugging Face is hosting the LeRobot robotics hackathon simultaneously in multiple cities worldwide (including Miami, Aachen, Lyon, Munich, Bangalore, London, Paris, Los Angeles, San Francisco Bay Area, etc.). The event aims to promote open-source robotics technology and AI applications in robotics, with participants developing projects using the LeRobot platform and provided hardware (such as robotic arms, depth cameras). The event has attracted a large number of developers to jointly explore cutting-edge technologies like robot learning and Vision Language Model (VLA) training, and has seen creative projects emerge, such as a mini glambot, an automated biolab assistant, and a tea-making robot (Source: ClementDelangue, huggingface, ClementDelangue)

Discussion on Claude Code’s Capabilities and Usage Methods: Discussions have emerged on social media regarding Claude Code’s capabilities. Some users believe that although Claude Code claims some of its code is self-generated, this is not equivalent to complete “bootstrapping,” analogizing that VSCode’s code is also primarily written in VSCode. It’s emphasized that when using tools like Claude Code, basic principles such as small iterative steps, code review, and version control should be adopted, along with the ability to lead program design and task division. When generated code has issues, one should first try to let it fix them, and if ineffective, roll back. Other users pointed out that Atlassian’s Rizo is considered a competitor to Claude Code and offers 20 million free tokens daily (Source: dotey, dotey, Reddit r/ClaudeAI)
Viewpoint on AI’s Impact on the Job Market: Exacerbating Polarization, Benefiting Top Talent: BrivaelLp believes that current AI technology (like code generation tools) can boost the efficiency of average developers by 5x, while top developers can see a 100x improvement. This will lead companies to prefer hiring experienced top talent and reduce demand for junior staff. AI may exacerbate the “Matthew effect” within various industries, with the top 10% of practitioners entering a golden age, while the middle tier faces pressure, echoing the sentiment “no market for mediocrity” (Source: BrivaelLp)
Discussion on Advantages and Application Scenarios of Local LLMs: The Reddit community discussed the advantages of running Large Language Models (LLMs) locally. Besides privacy protection and potential cost savings (though hardware investment can be significant), users emphasized complete control over the model, customization capabilities (like modifying the model, integrating RAG), no API limitations, offline use, and fewer censorship mechanisms. Local LLMs also offer convenience for learning and experimentation, for example, users deploying visual LLMs locally to process family photos or developing AI assistants with memory and emotional logic (Source: Reddit r/LocalLLaMA)
Ongoing Discussion on Whether LLMs Possess True Reasoning Abilities: There is an ongoing discussion in the community about whether Large Language Models (LLMs) truly possess reasoning abilities and where the boundaries of these capabilities lie. François Chollet believes LLM reasoning is limited by “unfamiliarity” rather than “complexity.” Others argue that LLMs are merely performing pattern matching and “recall” based on vast training data, not genuine thought. These discussions reflect deep thinking about the nature of current AI technology and its future direction (Source: fchollet, francoisfleuret, vikhyatk)
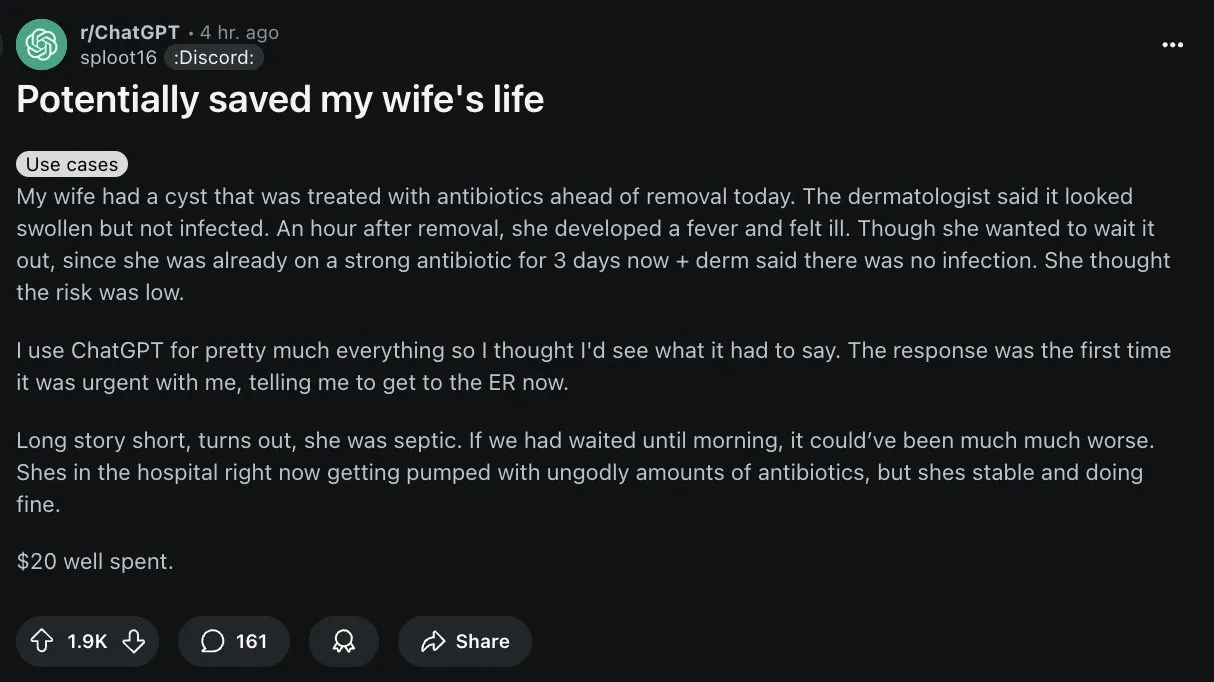
AI Shows Potential in Medical Diagnosis, but Users Need to Be Cautious: A Reddit user shared a case where ChatGPT helped their wife correct a doctor’s misdiagnosis, sparking a discussion about AI applications in healthcare. While AI shows potential in assisting diagnosis, especially for rare diseases and medical image analysis, the community also stressed that general AI like ChatGPT is not a professional medical tool, and its information may be inaccurate or outdated. Users should be extremely cautious when adopting AI-provided medical advice and must consult professional doctors. Some users suggested verifying AI’s limitations by asking if it is absolutely reliable (Source: Reddit r/ChatGPT, gdb)
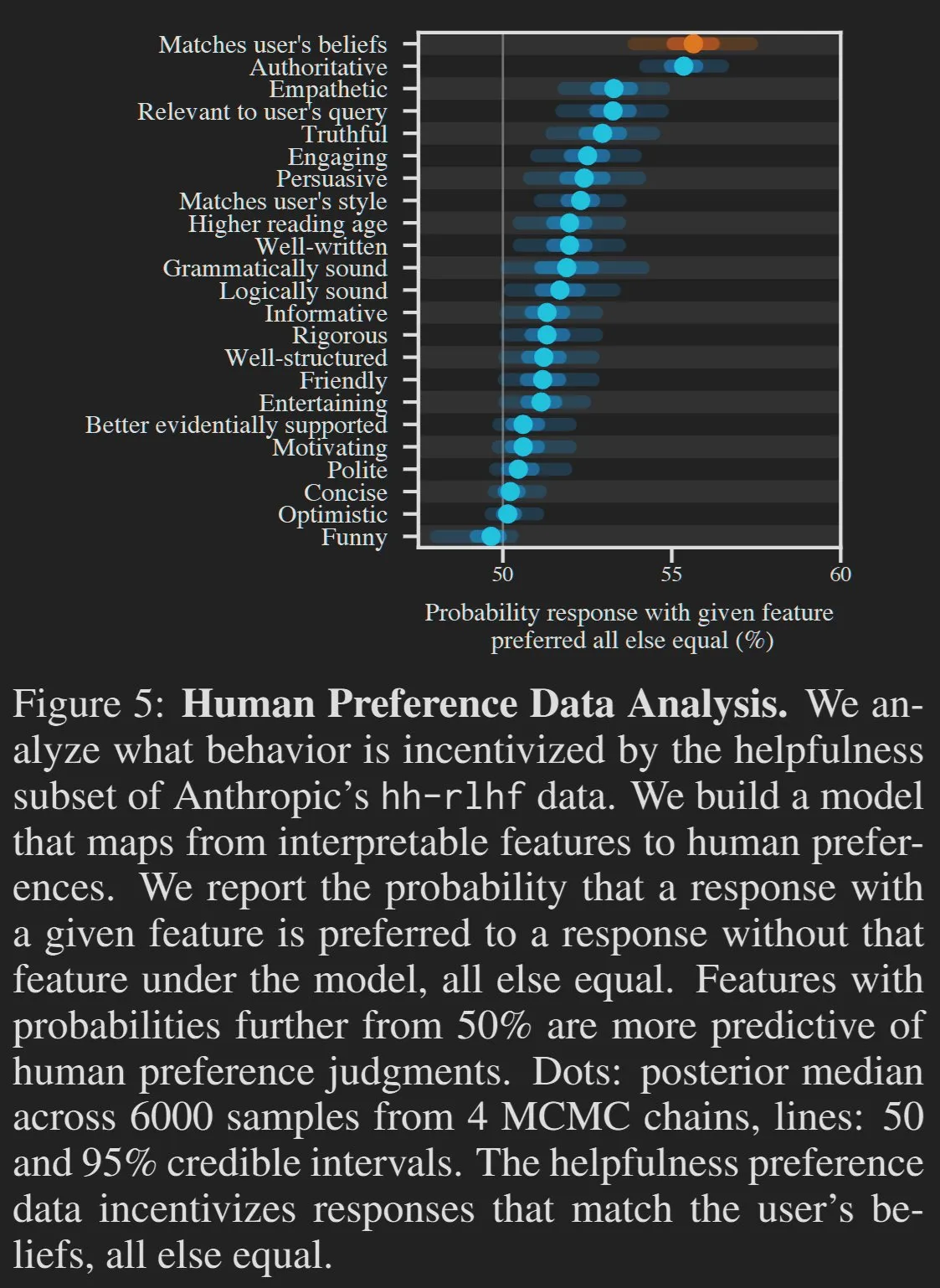
Quality of AI-Generated Content and User Preferences Spark Discussion: Some argue that certain “undesirable” traits of Large Language Models (LLMs), such as being overly verbose or pandering to users, are actually a result of user preferences. Analogous to people’s preference for high-sugar processed foods, AI companies, to optimize scores on platforms like LMArena, may cause model outputs to trend towards pleasing users rather than pursuing utmost accuracy and conciseness. HamelHusain also shared writing guidelines he adds to prompts to combat “fluff” in AI-generated content, emphasizing the need to actively remove redundant information (Source: scaling01, jeremyphoward, HamelHusain)
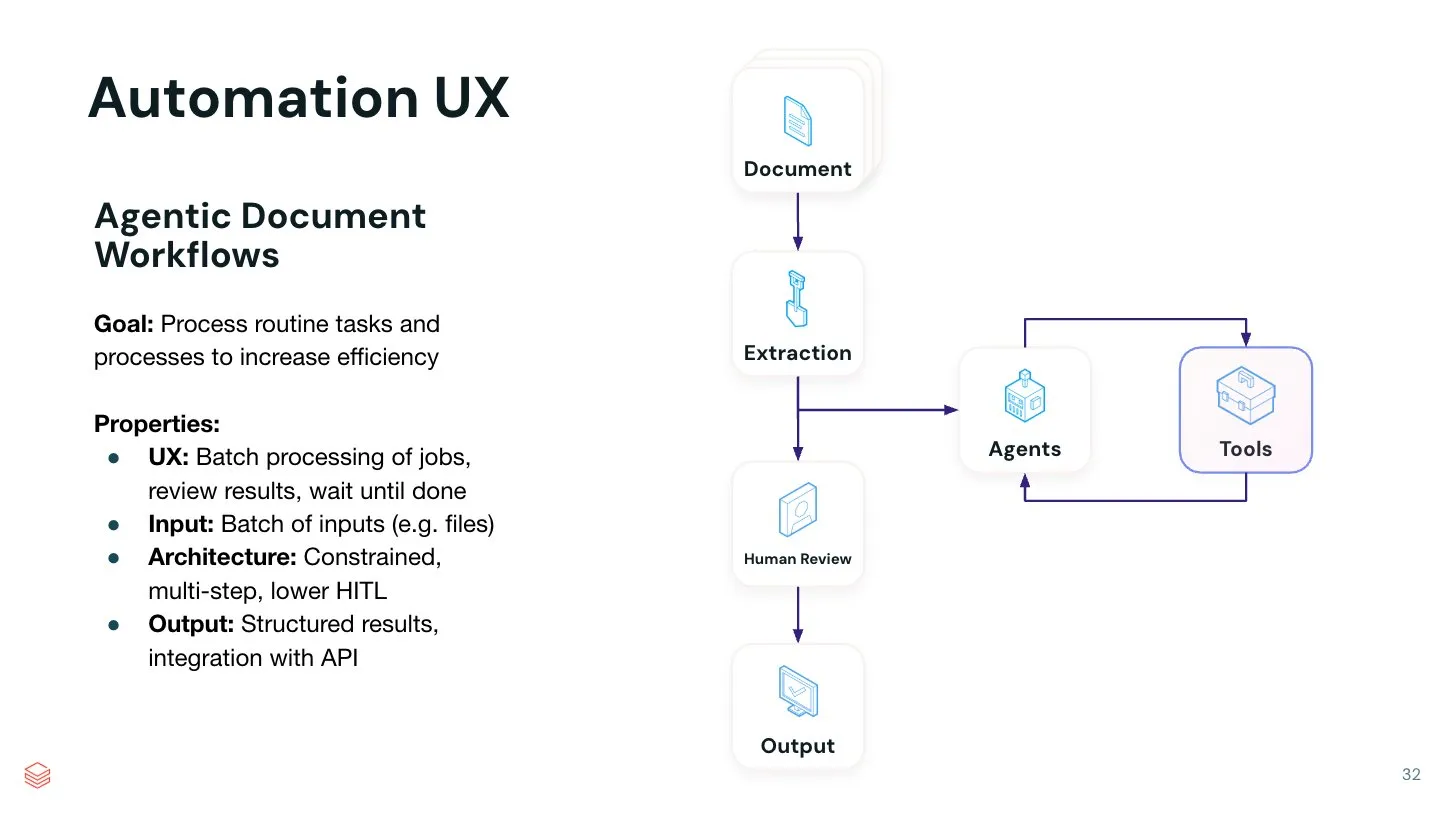
Value of AI Agents in Automating Specific Tasks Highlighted: Jerry Liu pointed out that while general-purpose chat assistants excel at creative brainstorming, they still require significant prompt engineering to execute specific tasks. He believes there is immense value in building automated AI Agent systems that can excellently perform a single, specific task. By encoding specific processes into Agent workflows, more efficient and controllable automation can be achieved. LlamaIndex is working to support such specialized code workflows, and more no-code UI/UX for building such automated Agents may emerge in the future (Source: jerryjliu0)
💡 Other
CVPR 2025 Young Researcher Awards Go to Saining Xie and Hao Su: At the CVPR 2025 conference, Saining Xie and Hao Su received the Young Researcher Award. This award recognizes early-career researchers (within 7 years of Ph.D. completion) for their outstanding contributions to computer vision. Hao Su (Fei-Fei Li’s Ph.D. student) participated in the ImageNet project, while Saining Xie collaborated with Kaiming He on ResNeXt and participated in the MAE project, both significant works in the CV field (Source: QbitAI)

Nikon SLM NXG Laser Printer May Drive Manufacturing Revolution: Nikon’s SLM NXG laser printer bears a striking resemblance to DUV (Deep Ultraviolet Lithography) equipment. This printer is considered to have the potential to spark a generative manufacturing revolution, especially in specific fields. Although Nikon lost the DUV race to ASML, its laser source technology continues to develop and find applications in new manufacturing areas (Source: teortaxesTex)
Significant Progress in AI Image Generation Between 2022 and 2025: A Reddit user shared a comparison of images generated by AI in 2022 and 2025 using the same prompt (“Rick and Morty” theme). The 2022 image had clear flaws in character details (like hands, noses) and overall coherence, while the 2025 image showed substantial improvement, demonstrating the rapid advancement of AI image generation technology in just a few years. Although some users pointed out that character hand details in the new image are still not perfect, the overall progress is evident (Source: Reddit r/artificial)
