
Mots-clés:VGGT, Vision 3D, Transformeur, CVPR 2025, Meta, Université d’Oxford, Conduite autonome, Sécurité de l’IA, Transformeur de géométrie visuelle, Prédiction 3D en une seule passe avant, Cadre SafeKey, Recherche sur la conduite autonome Waymo, Grand modèle de Doubao 1.6
🔥 Pleins Feux
VGGT : Meta et l’Université d’Oxford proposent le Visual Geometry Grounded Transformer, qui prédit en une seule passe avant (feed-forward) les informations complètes de la scène 3D et remporte le prix du meilleur article à CVPR 2025: VGGT (Visual Geometry Grounded Transformer), proposé conjointement par Meta et l’Université d’Oxford, est devenu le seul meilleur article de CVPR 2025. Ce modèle, basé sur Vision Transformer, utilise un mécanisme d’auto-attention alternant « global-intra-trame » et peut prédire de bout en bout, en une seule passe avant (feed-forward), des informations complètes sur la scène 3D, y compris les paramètres intrinsèques et extrinsèques de la caméra, les cartes de profondeur, les nuages de points et les trajectoires 3D. VGGT apprend de manière autonome uniquement à partir de grandes quantités de données annotées en 3D, sans nécessiter de biais inductif géométrique. Il excelle dans le traitement d’entrées allant de 1 à 200 images, surpassant les performances de nombreuses méthodes géométriques ou d’apprentissage profond existantes, et démontre un vaste potentiel d’application dans le domaine de la vision 3D (Source: 量子位)

Divergence de vues entre Jensen Huang, PDG de Nvidia, et le PDG d’Anthropic sur le développement de l’IA: Jensen Huang, PDG de Nvidia, a déclaré lors d’une conférence de presse à Paris qu’il était en désaccord avec presque toutes les opinions de Dario Amodei, PDG d’Anthropic, concernant l’IA. Huang a souligné qu’Amodei estime que l’IA est trop dangereuse et devrait être contrôlée par un petit nombre d’entreprises ; que son coût est prohibitif et que d’autres entreprises ne devraient pas s’y aventurer ; et qu’elle entraînera des pertes d’emplois massives. Huang a rétorqué que l’IA est une technologie importante qui devrait être développée ouvertement, de manière sûre et responsable, plutôt que dans un environnement fermé, insistant sur l’importance de l’ouverture pour la sécurité (Source: hardmaru)
Le framework SafeKey améliore la sécurité des grands modèles d’inférence, réduisant le taux de risque de 9,6 %: Des équipes de recherche de l’Université de Californie à Santa Cruz, de Berkeley, de Cisco Research et de l’Université Yale ont proposé le framework SafeKey, visant à renforcer la sécurité des grands modèles d’inférence (LRM). L’étude a révélé que le « jailbreak » des modèles est lié à une incapacité à utiliser efficacement les signaux de sécurité précoces des « phrases clés ». SafeKey amplifie les signaux de sécurité via une « tête de sécurité à double voie » et contraint le modèle à s’appuyer sur sa propre compréhension pour prendre des décisions de sécurité grâce à une « modélisation par masquage de requête ». Les expériences montrent que SafeKey réduit le taux de réponses dangereuses de 9,6 % sans affecter significativement les capacités fondamentales du modèle (voire en les améliorant légèrement), et ce, particulièrement face à des attaques inconnues (Source: 量子位)

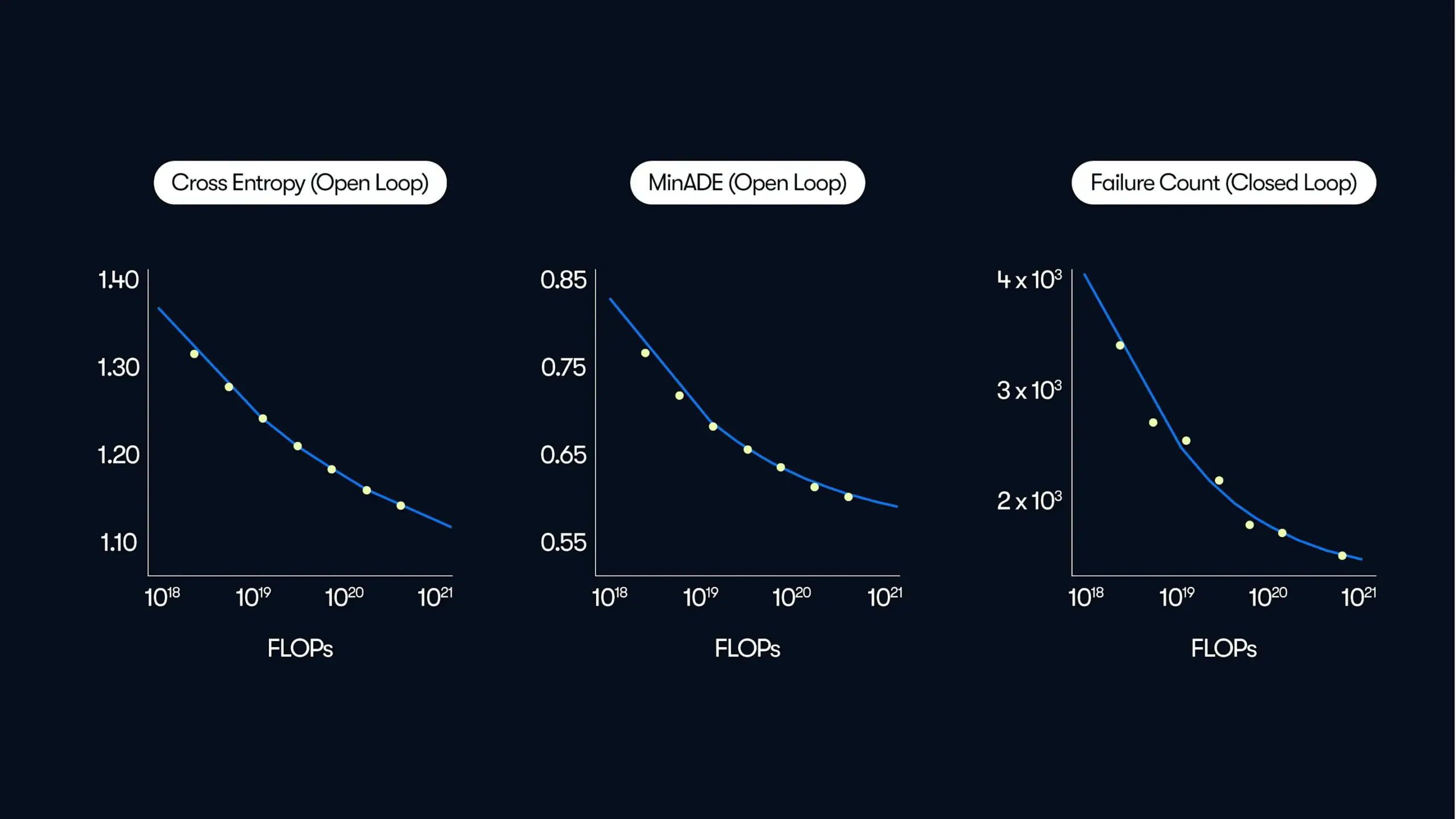
Une étude de Waymo montre que les performances des systèmes de conduite autonome augmentent selon une loi de puissance avec l’échelle des données et du calcul: Waymo a publié une étude complète basée sur 500 000 heures de données de conduite, révélant une relation de loi de puissance entre la qualité de la prédiction de mouvement de son système de conduite autonome et la quantité de calcul d’entraînement, similaire aux lois d’échelle des grands modèles de langage (LLM). L’étude souligne que l’échelle des données est cruciale pour améliorer les performances du modèle, tandis que l’augmentation du calcul d’inférence améliore également la capacité du modèle à gérer des scénarios de conduite complexes. Cette recherche démontre pour la première fois que l’augmentation des données d’entraînement et des ressources de calcul peut améliorer les performances de la conduite autonome dans le monde réel (Source: zacharynado)
🎯 Tendances
ByteDance lance le grand modèle Doubao 1.6 et plusieurs applications d’IA, mettant l’accent sur la capacité de combinaison et la concrétisation des produits: ByteDance a récemment lancé une série de produits d’IA, dont le grand modèle Doubao 1.6, le modèle de génération vidéo Seedance 1.0 Pro, ainsi que des modèles de podcast vocal et de voix en temps réel. Doubao 1.6 améliore le traitement multimodal et les capacités opérationnelles, prend en charge la recherche pendant la réflexion (边想边搜) et DeepResearch, et peut effectuer des opérations d’interface graphique. Seedance 1.0 Pro se distingue par la cohérence et la stabilité de la génération vidéo, prenant en charge la génération de vidéos 1080p de 10 secondes. La stratégie de ByteDance est davantage axée sur l’intégration des capacités d’IA dans des applications directement exécutables et leur intégration dans les produits existants (tels que l’application Doubao, Volcano Engine), en mettant l’accent sur la capacité de combinaison et la mise sur le marché rapide des produits, plutôt que sur la simple poursuite de la supériorité des paramètres d’un seul modèle. Sa stratégie de prix est également plus rentable, visant à réduire le seuil d’utilisation de l’IA (Source: 36氪)
Le modèle Tencent Hunyuan 3D 2.1 est open source, mettant en avant les textures PBR et la compatibilité avec les cartes graphiques grand public: Tencent a annoncé lors de la conférence CVPR l’open sourcing de son dernier modèle de génération 3D, Hunyuan 3D 2.1. Ce modèle a été optimisé à la fois pour la précision géométrique et les détails des textures, introduisant notamment la technologie de génération de textures PBR (Physically Based Rendering), capable de rendre avec une haute qualité des matériaux complexes tels que le cuir, le métal et la céramique, pour un effet visuel réaliste. Hunyuan 3D 2.1 est entièrement open source, y compris les poids du modèle, le code d’entraînement et le pipeline de traitement des données. Il prend également en charge l’exécution sur des cartes graphiques grand public et le déploiement en un clic, visant à promouvoir la popularisation de la création de contenu 3D (Source: 量子位)

Perplexity AI améliore activement la fonction Deep Research en réponse aux retours des utilisateurs: Arav Srinivas, PDG de Perplexity AI, a déclaré que l’équipe avait attentivement écouté les retours négatifs concernant sa fonction Deep Research et avait déjà entrepris des améliorations. Certaines améliorations ont déjà été mises en production et les utilisateurs devraient constater une amélioration de l’expérience. À l’avenir, les fonctions Deep Research et Labs seront intégrées au produit Comet, visant à optimiser le processus de prise de décision des utilisateurs en exploitant le contexte et les données personnelles (Source: AravSrinivas)
Une étude d’Anthropic révèle que les systèmes multi-agents peuvent considérablement améliorer les performances des tâches: Une étude publiée par Anthropic montre que l’utilisation de systèmes multi-agents (tels qu’Opus comme agent principal et Sonnet comme sous-agent) pour traiter les tâches améliore les performances de 90 % par rapport à l’utilisation d’Opus seul. Ce mode de travail collaboratif est similaire à la manière dont la société humaine augmente considérablement la productivité grâce à la division du travail et à la collaboration. L’étude détaille comment construire des systèmes de recherche multi-agents efficaces et partage ses méthodes d’évaluation, y compris l’utilisation d’un LLM comme arbitre. Cependant, certains commentaires soulignent que la méthode de recherche Claude décrite dans le rapport pourrait souffrir d’une profondeur de recherche insuffisante (Source: zacharynado, omarsar0, nrehiew_)

Une étude indique que les capacités de raisonnement des grands modèles de langage sont limitées par la « non-familiarité » plutôt que par la « complexité »: François Chollet souligne que les capacités de raisonnement des grands modèles de langage (LRM) ne s’effondrent pas lorsqu’un certain seuil de « complexité » ou de « nombre d’étapes » est atteint, mais échouent face à des tâches « non familières », et ce seuil de non-familiarité est très bas. Les modèles peuvent résoudre des tâches extrêmement complexes couvertes pendant la phase d’entraînement/d’ajustement, mais même des tâches nouvelles simples (comme les tâches ARC 2) peuvent échouer. Les seuils d’étapes/complexité observés sur des problèmes familiers (comme les Tours de Hanoï) sont en réalité le résultat de la création de « nouveauté » en augmentant les variables du problème (Source: fchollet, jeremyphoward)
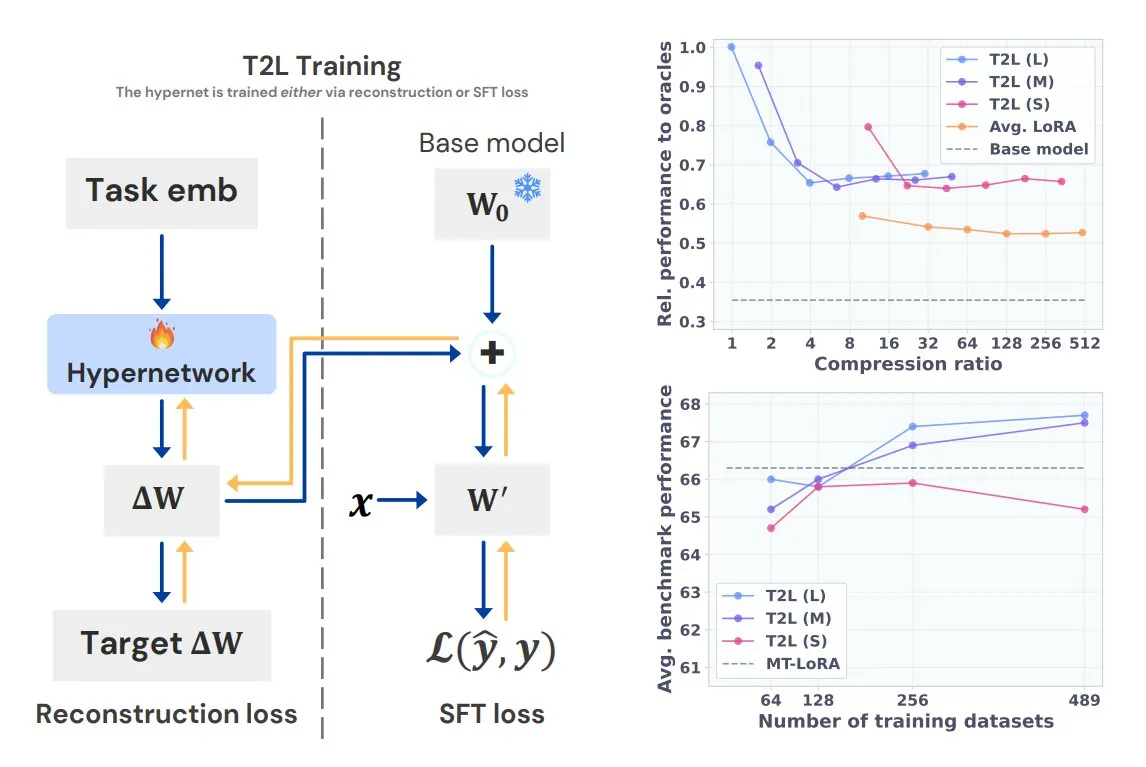
Sakana AI lance le modèle d’hyper-réseau Text-to-LoRA (T2L): Sakana AI a lancé Text-to-LoRA (T2L), un nouveau type d’hyper-réseau capable de générer rapidement de nouveaux adaptateurs LoRA pour les grands modèles de langage à partir d’une description textuelle de la tâche. T2L peut non seulement compresser plusieurs LoRA existants, mais aussi créer de nouveaux LoRA instantanément après l’entraînement, offrant une nouvelle voie pour la personnalisation rapide de modèles spécifiques à une tâche. Cette recherche sera présentée à l’ICML 2025 (Source: TheTuringPost)
Le modèle Cosmos-Predict2 de Nvidia (modèle 2B) démontre d’excellentes capacités de génération d’images: Cosmos-Predict2 de Nvidia, un modèle de 2 milliards de paramètres, est positionné comme une « plateforme de modèle de fondation mondial pour l’IA physique » et montre des capacités impressionnantes en matière de génération d’images artistiques. Bien que son ensemble de données de base ne soit peut-être pas optimal, la structure du modèle est bonne et la qualité des images générées n’est pas très éloignée de la version à 14 milliards de paramètres, n’étant que légèrement inférieure en termes de détails et de respect des invites, ce qui montre le potentiel des petits modèles avec une optimisation spécifique (Source: teortaxesTex)
Le MIT développe un nouvel algorithme permettant aux drones d’éviter de manière autonome les tempêtes: Le MIT a développé un nouvel algorithme qui confère aux drones (UAV) des capacités de prise de décision semblables à celles d’un « cerveau », leur permettant d’analyser en temps réel les conditions météorologiques et de planifier de manière autonome leur itinéraire pour éviter les tempêtes. Cette technologie devrait améliorer la sécurité des vols et l’efficacité des missions des drones dans des conditions météorologiques complexes (Source: Ronald_vanLoon)

Étude de Meta : les modèles de langage de type GPT mémorisent 3,6 bits d’information par paramètre: Une nouvelle étude de Meta a calculé que les modèles de langage de type GPT peuvent mémoriser environ 3,6 bits d’information par paramètre. L’étude évalue leur capacité de mémorisation en mesurant le nombre total de bits mémorisés (basé sur la théorie de Shannon de 1953) et observe une relation curviligne spécifique entre la mémoire et l’échelle des données (Source: jxmnop)

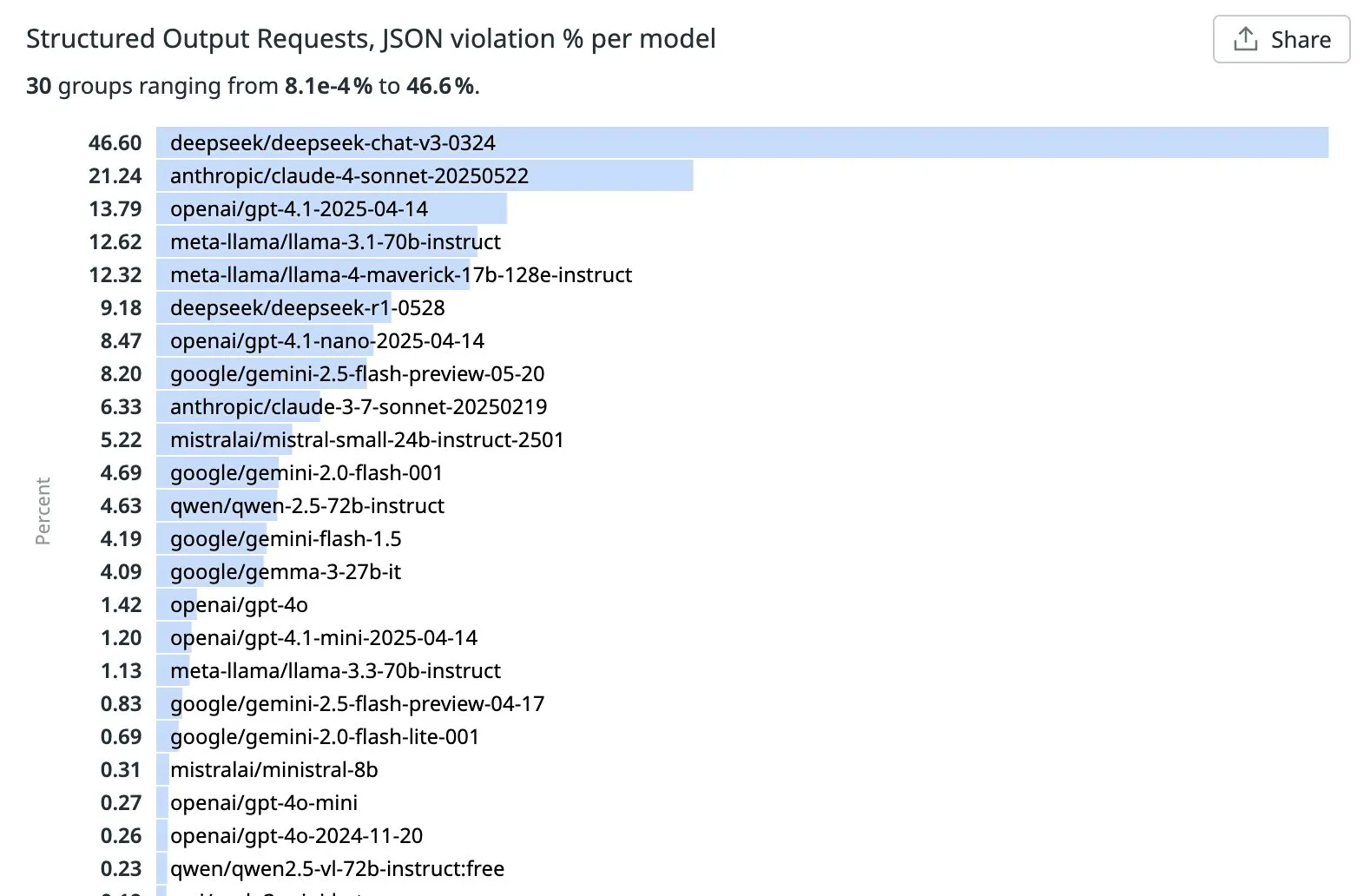
OpenRouter publie le classement des taux de non-conformité des LLM dans les tâches de sortie structurée (JSON): OpenRouter a classé les principaux LLM en fonction du pourcentage de violations JSON détectées dans les requêtes de sortie structurée de premier plan au cours de la semaine écoulée. Les résultats montrent que Qwen, Mistral et GPT-4o-mini affichent de bonnes performances, avec de faibles taux de violation JSON. En revanche, les taux de violation de DeepSeek v3 et Sonnet 4 dépassent 20 %, ce qui indique une marge d’amélioration considérable pour respecter précisément le format JSON. Les raisons spécifiques de ces différences ne sont pas encore claires (Source: xanderatallah, teortaxesTex)
Ant Group lance le modèle multimodal unifié Ming-Omni: Ant Group a lancé la série de modèles Ming-Omni, un modèle multimodal unifié capable de percevoir et de générer à travers le texte, les images, l’audio et la vidéo. Sa version légère, Ming-Lite-Omni, adopte une architecture MoE avec seulement 2,8 milliards de paramètres activés, offrant une génération d’images de haute qualité et une synthèse vocale naturelle. Elle a été mise en open source sur Hugging Face sous licence MIT (Source: teortaxesTex, _akhaliq)
L’outil chinois de conception de puces IA QiMeng conçoit des processeurs en quelques jours, surpassant l’efficacité des ingénieurs: L’outil de conception de puces IA développé en Chine, « QiMeng », a démontré sa capacité à concevoir efficacement des processeurs, accomplissant en quelques jours seulement des tâches de conception qui prendraient traditionnellement beaucoup plus de temps aux ingénieurs. Cela marque le potentiel de l’IA dans le domaine de l’automatisation de la conception de puces, promettant d’accélérer les cycles de développement des puces et de réduire les coûts (Source: Ronald_vanLoon)

Le modèle o3-pro de Hao AI Lab affiche d’excellentes performances dans les benchmarks de jeux pour LLM: Le modèle o3-pro de Hao AI Lab a réalisé des progrès significatifs dans Lmgame Bench (un benchmark pour évaluer les capacités de jeu des grands modèles de langage). Dans les jeux Tetris et Sokoban, o3-pro atteint le niveau SOTA et surpasse de loin son prédécesseur, le modèle o3. En particulier dans Tetris, o3-pro est capable d’éliminer plus de 8 lignes, démontrant ses capacités de planification, tandis que d’autres modèles sont bloqués après seulement quelques lignes (Source: clefourrier)
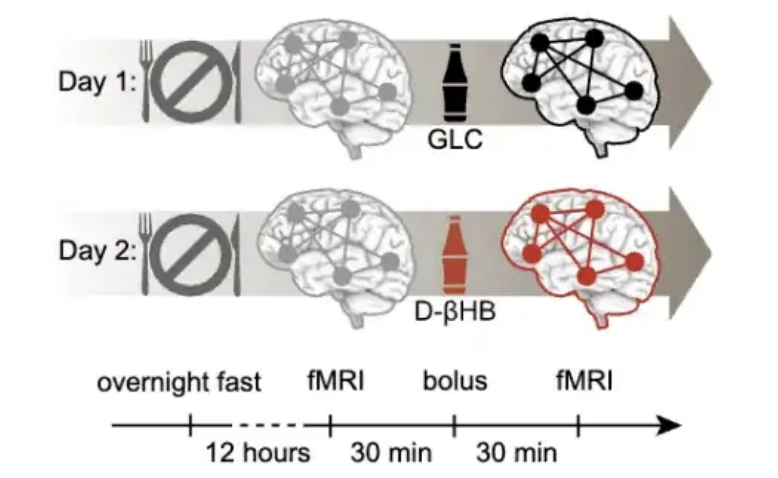
Une étude révèle que 40 ans est une fenêtre critique pour prévenir le vieillissement cérébral, l’intervention par corps cétoniques étant significativement efficace: Une étude publiée dans PNAS, analysant près de 20 000 scanners cérébraux, a révélé que le vieillissement cérébral n’est pas un processus linéaire mais suit une courbe en S, corrélée à une augmentation de la résistance à l’insuline. L’étude indique quenviron 40 ans est la période où l’instabilité du réseau cérébral commence à s’accélérer, le vieillissement étant le plus rapide dans la soixantaine. Les expériences montrent que les corps cétoniques (D-βHB) peuvent contourner la résistance à l’insuline pour fournir de l’énergie aux neurones, ayant un effet significatif sur la stabilisation du réseau cérébral, particulièrement efficace pour une intervention dans la tranche d’âge 40-59 ans, offrant de nouvelles perspectives pour la santé cérébrale à mi-vie (Source: 量子位)
🧰 Outils
The Browser Company lance la version bêta de Dia, son navigateur natif IA: The Browser Company, développeur du navigateur Arc, a lancé la version bêta interne de Dia, son premier navigateur natif IA. Le principal atout de Dia est de permettre aux utilisateurs d’interagir directement par chat avec le contenu de n’importe quelle page web (y compris les vidéos YouTube, FigJam, Google Agenda, etc.), sans avoir à ouvrir des outils d’IA externes comme ChatGPT. Il peut automatiquement extraire le contexte des onglets, prendre en charge l’intégration et la comparaison d’informations multi-pages, la planification, la création de contenu, etc. Actuellement disponible uniquement sur MacOS, il vise à offrir une expérience de navigation plus épurée et axée sur l’IA (Source: 36氪)
LangChain lance un générateur de podcasts IA local: LangChain a lancé un générateur de podcasts IA local. Ce système, construit avec LangChain et Ollama, est capable de convertir du texte en podcasts multilingues. Il combine des technologies de résumé de texte et de génération vocale pour un processus de création de podcasts fluide. Les utilisateurs peuvent consulter le tutoriel fourni pour apprendre à utiliser cet outil (Source: LangChainAI, hwchase17)

Davia : convertit rapidement les applications Python et les agents LangGraph en applications Web: Davia est un outil capable de transformer instantanément les applications Python et les agents LangGraph en applications Web élégantes, sans écrire une seule ligne de code frontal. Basé sur FastAPI, il génère automatiquement des interfaces utilisateur interactives, permettant aux développeurs de se concentrer sur la logique Python (Source: LangChainAI, Hacubu)
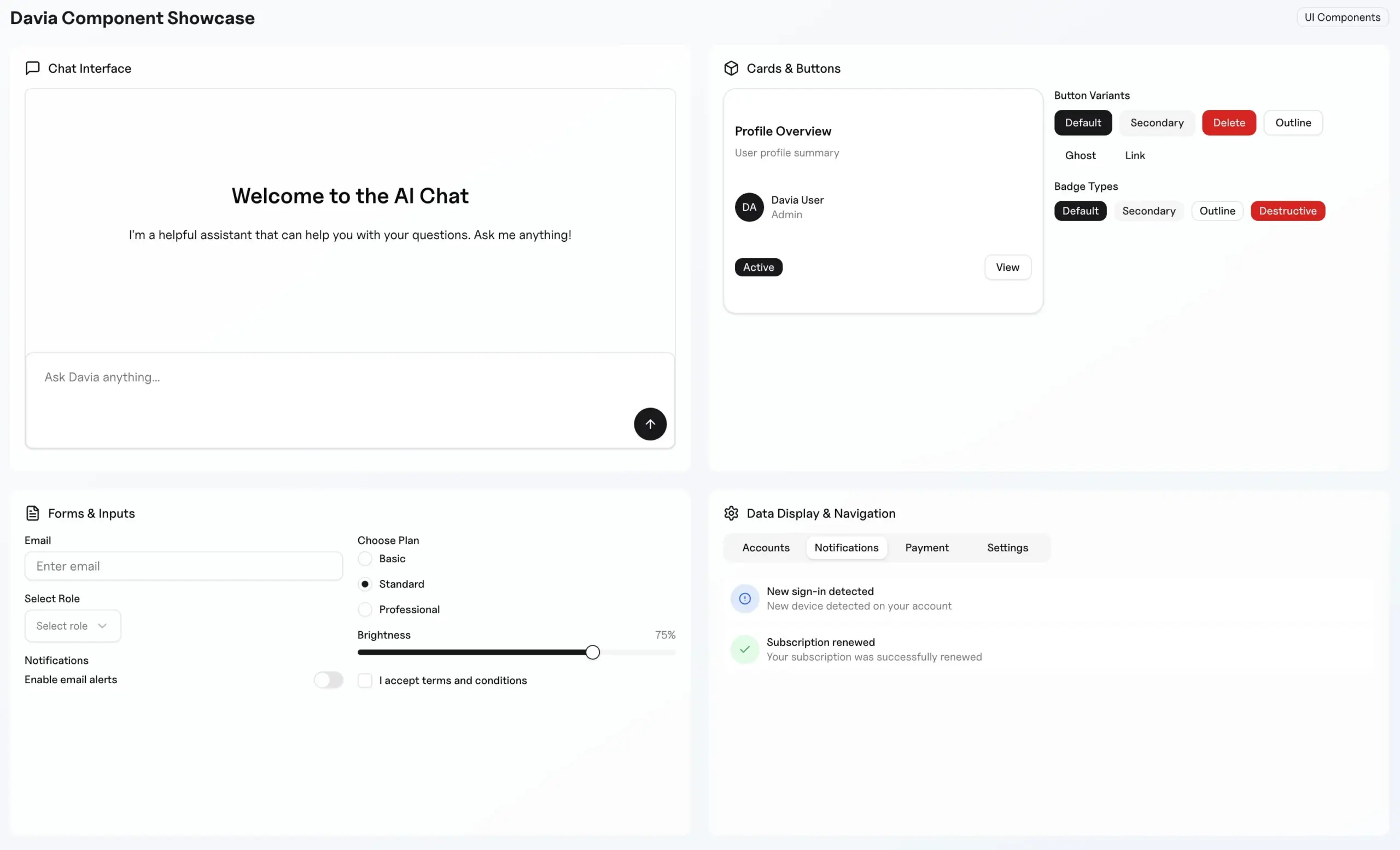
Intégration de Tensorlake avec LangChain pour le traitement structuré de documents: Tensorlake a annoncé son intégration avec LangChain, permettant aux agents LangGraph d’utiliser le puissant système de traitement multimodal de Tensorlake pour convertir des documents non structurés en données structurées. Cette intégration offre de nouvelles solutions pour le traitement de documents complexes (Source: LangChainAI, hwchase17)
Kuake lance le premier grand modèle chinois pour l’orientation post-bac et une fonction gratuite de rapport d’orientation: Kuake a lancé le premier grand modèle chinois pour l’orientation post-bac (高考志愿大模型) et a mis en ligne une fonction gratuite de « rapport d’orientation ». Ce modèle, basé sur un mode de fonctionnement Agent, peut simuler le processus de décision d’experts. Combiné à une « base de connaissances sur le高考 » mise à jour en temps réel (couvrant plus de 2900 établissements d’enseignement supérieur, près de 1600 spécialisations de premier cycle et des informations sur l’emploi), il génère pour les candidats des propositions d’orientation personnalisées comprenant trois niveaux : « ambitieux », « réaliste », « sécurité ». Cette initiative vise à utiliser la technologie de l’IA pour réduire les obstacles et les coûts liés à l’orientation post-bac, et à changer la situation des consultations traditionnelles coûteuses (Source: 量子位)

Task Orchestrator : outil de gestion de projet MCP conçu pour Claude Code: Le développeur jpicklyk a créé un outil MCP (Machine-Level Code Programming) appelé Task Orchestrator, visant à résoudre le problème de Claude Code qui a tendance à être « distrait » et à oublier le contexte lors du traitement de projets complexes. Cet outil confère à Claude une mémoire persistante, une gestion de projet structurée (projet → fonctionnalité → tâche), des modèles natifs IA, des relations de dépendance intelligentes et des capacités de suivi de progression, le transformant davantage en un partenaire d’ingénierie organisé. Le projet est open source sur GitHub (Source: Reddit r/ClaudeAI)
ATLAS : partenaire IA en ingénierie logicielle dotant Claude Code de capacités d’auto-perception: Le développeur syahiidkamil a créé le projet ATLAS, visant à transformer Claude Code en un partenaire IA en ingénierie logicielle doté d’une conscience de soi rudimentaire, d’une mémoire, d’une identité et de normes professionnelles. ATLAS peut maintenir le contexte du projet, gérer ses propres connaissances, évoluer avec les soumissions de code et demander activement des revues de code, favorisant ainsi un processus de collaboration et de révision plus naturel entre l’utilisateur et l’IA. Le projet est open source sur GitHub, visant à aider les utilisateurs et l’IA à maintenir ensemble un code de meilleure qualité (Source: Reddit r/ClaudeAI)
Observer : assistant IA de surveillance d’écran fonctionnant localement: Observer est un outil d’IA qui peut fonctionner localement et surveiller l’activité de l’écran de l’utilisateur. Un tutoriel explique comment auto-héberger Observer sur un serveur domestique pour une analyse ou une interaction assistée par IA du contenu de l’écran (Source: Reddit r/LocalLLaMA)
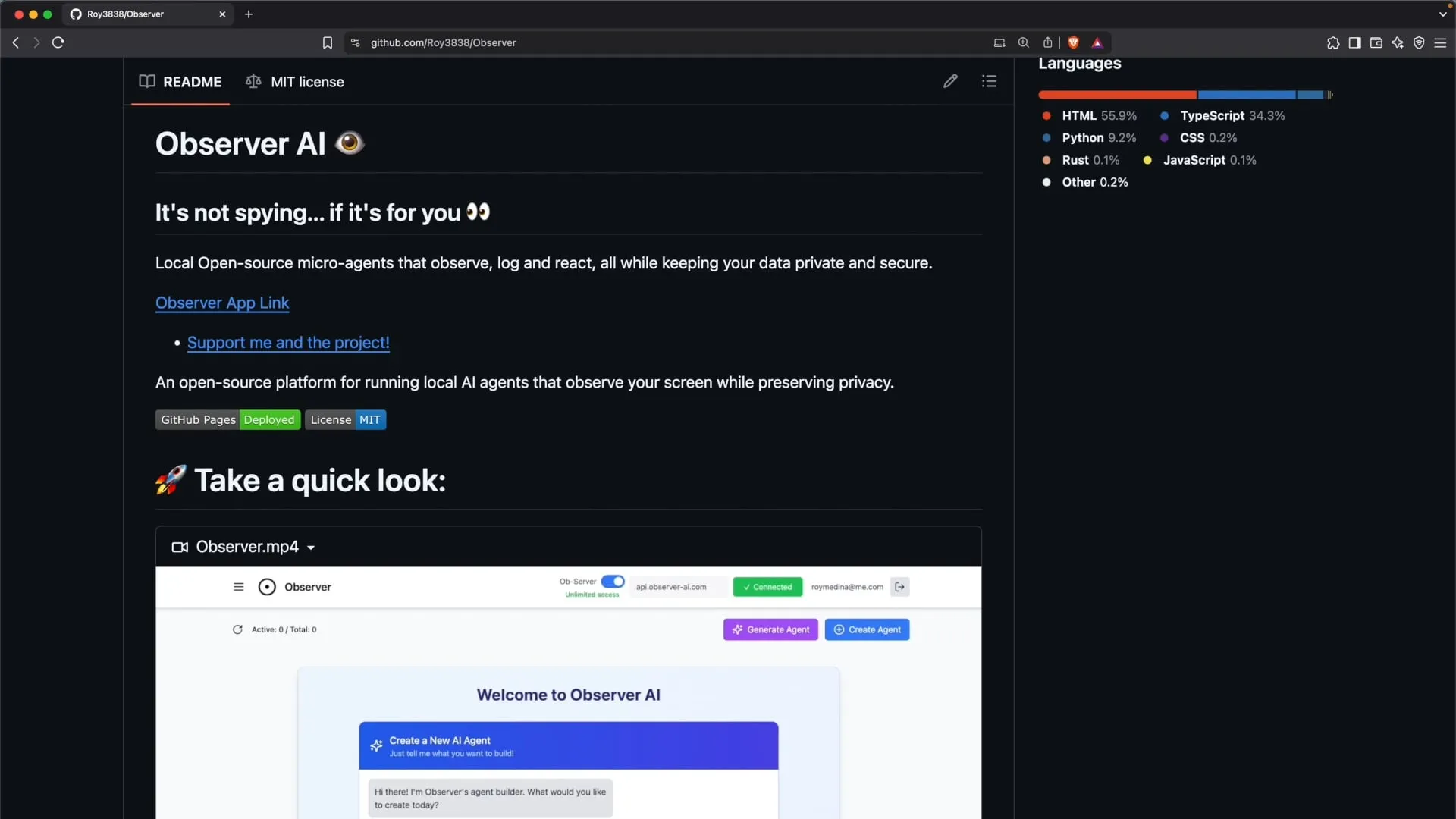
VantaAI : partage d’un projet d’assistant IA local doté de mémoire et de logique émotionnelle: Un développeur a partagé son projet personnel VantaAI, un assistant IA local conçu pour fonctionner entièrement hors ligne. VantaAI simule des caractéristiques telles que la mémoire émotionnelle, les fluctuations d’humeur et l’identité personnelle. Il possède une mémoire à long terme qui évolue en fonction du contexte conversationnel, une « carte émotionnelle » qui suit les changements d’humeur, et un regroupement de souvenirs axé sur la narration, se considérant comme le protagoniste d’une histoire. Le projet utilise un backend Vulkan personnalisé pour l’inférence et l’entraînement du modèle, et prend en charge les réponses basées sur la personnalité et le rechargement à chaud des plugins (Source: Reddit r/LocalLLaMA)
📚 Apprentissage
Hamel Husain et Shreya Shankar co-écrivent un livre sur les AI Evals et lancent un cours: Hamel Husain et Shreya Shankar ont collaboré à la rédaction d’un livre sur l’évaluation de l’IA (Evals) et ont lancé un cours associé. Le premier chapitre du livre et la table des matières complète sont disponibles en avant-première, couvrant les méthodes d’évaluation de l’IA de la théorie à la pratique. Le cours invite également plusieurs experts du secteur en tant que conférenciers invités, visant à aider les participants à améliorer leurs capacités d’évaluation des systèmes d’IA. Ce cours a reçu de nombreux éloges et est considéré comme l’une des ressources les plus complètes actuellement disponibles sur l’évaluation de l’IA (Source: HamelHusain, HamelHusain)
Le framework DSPy : fournit des abstractions de programmation de haut niveau pour les programmes complexes de modèles de langage: L’équipe de Stanford NLP souligne que le framework DSPy vise à devenir un langage à large bande passante pour une interaction précise avec les ordinateurs. DSPy permet aux développeurs de construire et d’optimiser des programmes complexes de modèles de langage multi-étapes (Compound AI Systems), prenant en charge des structures de programme arbitraires telles que la récursivité, la gestion des exceptions, les flux de contrôle imbriqués, et pas seulement de simples « chaînes » ou « flux ». Son optimiseur s’efforce d’ajuster les instructions, les démonstrations et les poids dans des programmes informatiques arbitraires qui peuvent appeler arbitrairement un ou plusieurs LLM (Source: stanfordnlp)
Terence Tao invité du podcast de Lex Fridman, discute des problèmes complexes en mathématiques et physique, et de l’avenir de l’IA: Le célèbre mathématicien Terence Tao a été interviewé par Lex Fridman, discutant en profondeur des problèmes les plus stimulants en mathématiques et en physique, tels que les équations de Navier-Stokes, le problème P vs NP, etc., et envisageant le potentiel de l’intelligence artificielle pour aider à résoudre ces énigmes. Le podcast aborde également des sujets tels que la démonstration de théorèmes assistée par IA, le langage de programmation Lean, AlphaProof de DeepMind et la possibilité qu’une IA remporte la médaille Fields (Source: , arohan)

L’équipe de Phillip Isola publie un manuel de vision par ordinateur en ligne gratuit: Phillip Isola et son équipe ont publié gratuitement en ligne leur manuel de vision par ordinateur. Le site web du manuel (visionbook.mit.edu) développe des composants interactifs, tels qu’une fonction de recherche et une intégration avec un LLM (version bêta), visant à fournir aux apprenants des ressources d’apprentissage plus pratiques et à encourager les utilisateurs à aider à améliorer le contenu du manuel via les issues GitHub (Source: jeremyphoward, natolambert)
Hugging Face lance un cours d’introduction au MCP: Hugging Face, en collaboration avec Theodora Chu, a lancé un nouveau cours d’introduction au MCP (Master Control Program, pouvant faire référence au contrôle d’Agent IA ou de systèmes multi-agents). Ce cours vise à aider les apprenants à comprendre et à maîtriser les connaissances et compétences liées au MCP (Source: huggingface, ClementDelangue)
L’étude sur l’alignement de DINOv2 avec le texte (dino.txt) présentée à CVPR 2025: Une étude intitulée dino.txt a été présentée à CVPR 2025. Cette recherche vise à aligner les caractéristiques figées de DINOv2 avec des légendes textuelles, afin de réaliser à faible coût un alignement visuo-linguistique au niveau de l’image et du patch. Cela permet au modèle d’exploiter simultanément les caractéristiques visuelles de haute qualité de DINOv2 et les capacités d’alignement visuo-linguistique de type CLIP (Source: TimDarcet, andersonbcdefg)

💼 Affaires
Minglue Technology, licorne IA soutenue par Tencent, prépare son introduction en bourse à Hong Kong avec une valorisation de 12 milliards de yuans: Minglue Technology (anciennement « Huizhi Holdings »), une société de logiciels d’applications d’intelligence des données, a déposé une demande d’introduction en bourse à la Bourse de Hong Kong. Fondée en 2005 par Wu Minghui, ancien élève de l’École de mathématiques de l’Université de Pékin, l’entreprise se concentre sur l’utilisation de grands modèles, de connaissances sectorielles et de données multimodales pour fournir aux entreprises un soutien à la décision en matière de marketing et d’opérations. Ses produits phares incluent Miaozhen Systems, Jinshuju, etc., et elle sert des clients tels que Procter & Gamble, McDonald’s et 135 autres entreprises du Fortune 500. Tencent est son principal actionnaire, avec 27,33 % des parts. Après avoir finalisé son dernier tour de financement pré-IPO en janvier 2024, la société est valorisée à environ 12 milliards de yuans RMB (Source: 量子位)

OpenAI et le fabricant de jouets Mattel concluent un partenariat stratégique pour développer conjointement des jouets intelligents IA: OpenAI a annoncé un partenariat avec Mattel, fabricant de jouets de renommée mondiale, pour développer conjointement des jouets intelligents dotés de technologie d’intelligence artificielle. Cette collaboration vise à appliquer la technologie IA d’OpenAI à des expériences de jeu adaptées à l’âge, révolutionnant ainsi les modes de jeu traditionnels. Mattel possède des licences de propriété intellectuelle célèbres telles que Barbie et Hot Wheels. Les deux parties s’engagent à garantir rigoureusement la sécurité et la confidentialité des enfants dans le cadre de cette collaboration. Mattel intégrera également les outils d’IA d’OpenAI (tels que ChatGPT Enterprise) dans ses opérations commerciales afin de renforcer le développement et l’innovation de ses produits (Source: 36氪)
La start-up de recherche d’entreprise Glean lève 150 millions de dollars dans un tour de financement de stade avancé: La start-up de recherche d’entreprise Glean a annoncé avoir obtenu 150 millions de dollars de financement de stade avancé, portant sa valorisation à 7,2 milliards de dollars. Glean utilise la technologie IA pour aider les employés d’entreprise à trouver plus efficacement des informations au sein des applications SaaS et des sources de données complexes de leur entreprise (Source: dl_weekly)
🌟 Communauté
Hugging Face organise le hackathon mondial de robotique LeRobot pour promouvoir le développement de la technologie robotique open source: Hugging Face a organisé simultanément le hackathon de robotique LeRobot dans plusieurs villes du monde (dont Miami, Aix-la-Chapelle, Lyon, Munich, Bangalore, Londres, Paris, Los Angeles, la Baie de San Francisco, etc.). L’événement visait à promouvoir la technologie robotique open source et l’application de l’IA dans le domaine de la robotique. Les participants ont utilisé la plateforme LeRobot et le matériel fourni (comme des bras robotiques, des caméras de profondeur) pour développer leurs projets. L’événement a attiré un grand nombre de développeurs, explorant ensemble des technologies de pointe telles que l’apprentissage robotique, l’entraînement de modèles visuo-linguistiques (VLA), et a vu émerger des projets créatifs tels qu’un mini glambot, un assistant de laboratoire biologique automatisé, un robot maître de thé, etc. (Source: ClementDelangue, huggingface, ClementDelangue)

Discussion sur les capacités et les méthodes d’utilisation de Claude Code: Des discussions sur les capacités de Claude Code sont apparues sur les réseaux sociaux. Certains utilisateurs estiment que, bien que Claude Code affirme qu’une partie de son code est auto-générée, cela n’équivaut pas à un « auto-amorçage » complet, de la même manière que le code de VSCode est également principalement écrit avec VSCode. Il est souligné que lors de l’utilisation d’outils tels que Claude Code, des principes de base tels que l’itération par petites étapes, la révision du code, la gestion des versions, etc., doivent être adoptés, et il faut être capable de diriger la conception du programme et la division des tâches. Lorsque le code généré pose problème, il faut d’abord essayer de le faire corriger par l’outil, et si cela échoue, revenir en arrière. D’autres utilisateurs soulignent que Rizo, lancé par Atlassian, est considéré comme un concurrent de Claude Code et offre 20 millions de tokens gratuits par jour (Source: dotey, dotey, Reddit r/ClaudeAI)
Point de vue sur l’impact de l’IA sur le marché de l’emploi : une polarisation accrue, les meilleurs talents en bénéficient: BrivaelLp estime que la technologie IA actuelle (comme les outils de génération de code) peut multiplier par 5 l’efficacité des développeurs moyens, tandis que celle des meilleurs développeurs peut être multipliée par 100. Cela conduira les entreprises à préférer recruter des talents de haut niveau expérimentés et à réduire leurs besoins en personnel débutant. L’IA pourrait exacerber l’« effet Matthieu » au sein de divers secteurs, les 10 % les plus performants connaissant un âge d’or, tandis que la couche intermédiaire subira des pressions, faisant écho à l’idée qu’il n’y a « pas de marché pour la médiocrité » (Source: BrivaelLp)
Discussion sur les avantages et les cas d’utilisation des LLM locaux: La communauté Reddit a discuté des avantages de l’exécution locale de grands modèles de langage (LLM). Outre la protection de la vie privée et les économies potentielles (bien que l’investissement matériel puisse être considérable), les utilisateurs ont souligné le contrôle total sur les modèles, la capacité de personnalisation (comme la modification des modèles, l’intégration de RAG), l’absence de restrictions d’API, l’utilisation hors ligne et des mécanismes de censure moins stricts. Les LLM locaux facilitent également l’apprentissage et l’expérimentation ; par exemple, certains utilisateurs déploient localement des LLM visuels pour traiter des photos de famille ou développent des assistants IA dotés de mémoire et de logique émotionnelle (Source: Reddit r/LocalLLaMA)
Le débat sur la capacité de raisonnement réelle des LLM se poursuit: Au sein de la communauté, le débat persiste sur la question de savoir si les grands modèles de langage (LLM) possèdent réellement une capacité de raisonnement et où se situent les limites de cette capacité. François Chollet estime que la capacité de raisonnement des LLM est limitée par la « non-familiarité » plutôt que par la « complexité ». D’autres soutiennent que les LLM ne font que de la reconnaissance de formes et du « rappel » basés sur de vastes ensembles de données d’entraînement, et non une véritable réflexion. Ces discussions reflètent une réflexion approfondie sur la nature de la technologie IA actuelle et ses orientations futures (Source: fchollet, francoisfleuret, vikhyatk)
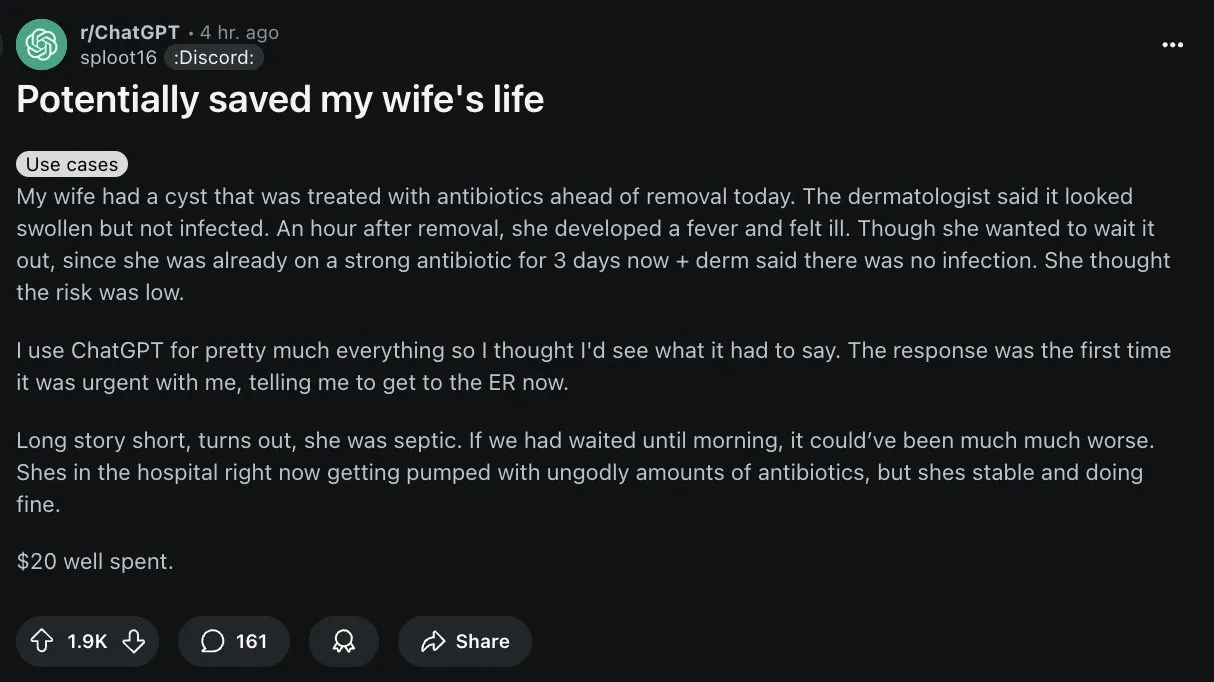
L’IA montre un potentiel dans le diagnostic médical, mais les utilisateurs doivent être prudents: Sur Reddit, un utilisateur a partagé un cas où ChatGPT a aidé sa femme à corriger une erreur de diagnostic médical, suscitant une discussion sur les applications de l’IA dans le domaine médical. Bien que l’IA montre un potentiel pour aider au diagnostic, en particulier pour l’identification de maladies rares et l’analyse d’images médicales, la communauté a également souligné que les IA généralistes comme ChatGPT ne sont pas des outils médicaux professionnels et que leurs informations peuvent être inexactes ou obsolètes. Les utilisateurs doivent faire preuve d’une extrême prudence lorsqu’ils adoptent des conseils médicaux fournis par l’IA et doivent impérativement consulter des médecins professionnels. Certains utilisateurs suggèrent de vérifier les limites de l’IA en lui demandant si elle est absolument fiable (Source: Reddit r/ChatGPT, gdb)
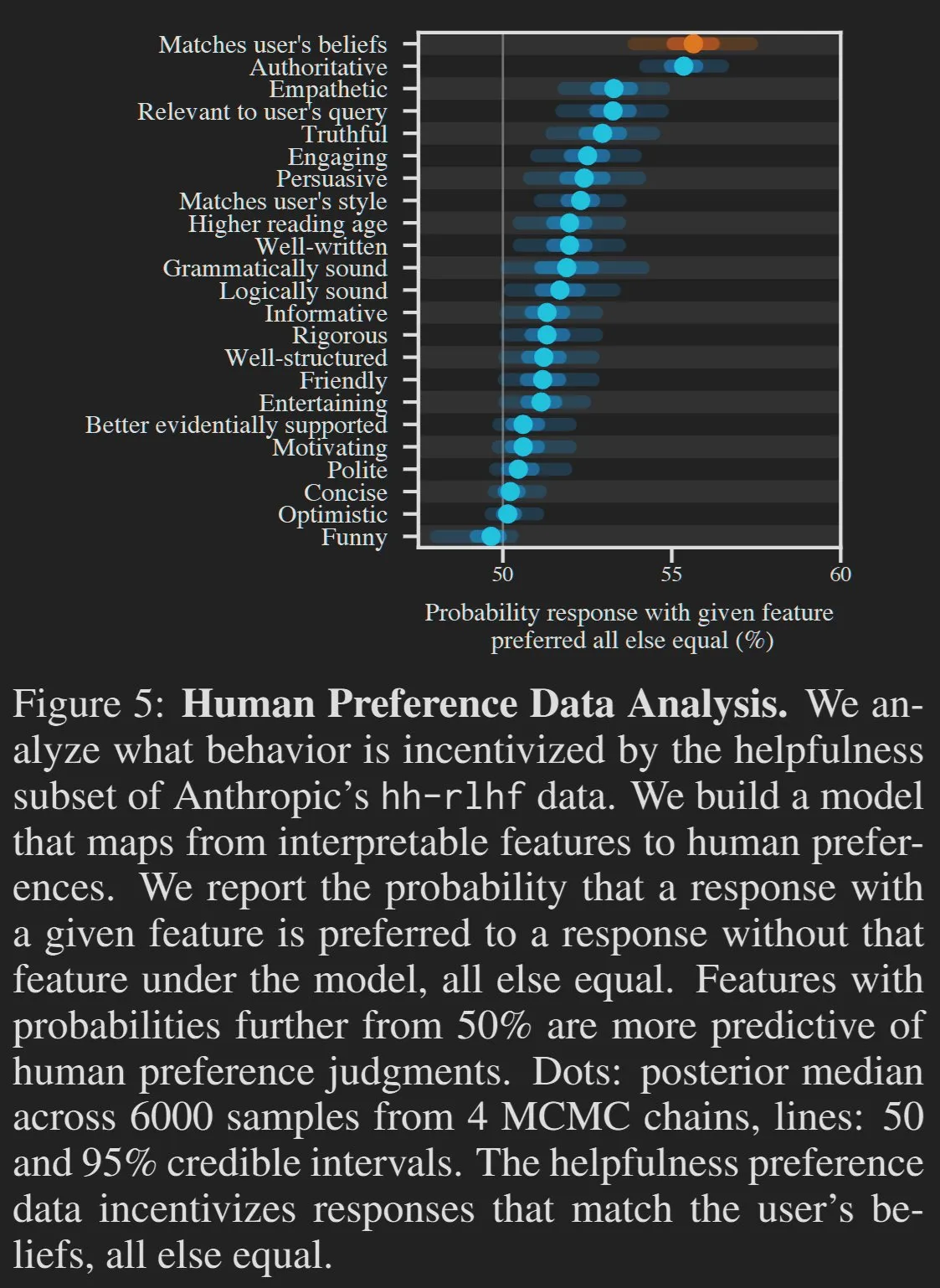
La qualité du contenu généré par l’IA et les préférences des utilisateurs suscitent le débat: Certains estiment que certaines caractéristiques « indésirables » des grands modèles de langage (LLM), telles que leur verbosité excessive ou leur tendance à complaire à l’utilisateur, sont en réalité le résultat des préférences des utilisateurs. De la même manière que les gens préfèrent les aliments transformés riches en sucre, les entreprises d’IA, pour optimiser les scores sur des plateformes comme LMArena, pourraient amener les modèles à produire des résultats qui plaisent aux utilisateurs plutôt que de viser une exactitude et une concision extrêmes. HamelHusain a également partagé son guide de rédaction inclus dans ses invites pour lutter contre le « verbiage » dans le contenu généré par l’IA, soulignant la nécessité de supprimer activement les informations redondantes (Source: scaling01, jeremyphoward, HamelHusain)
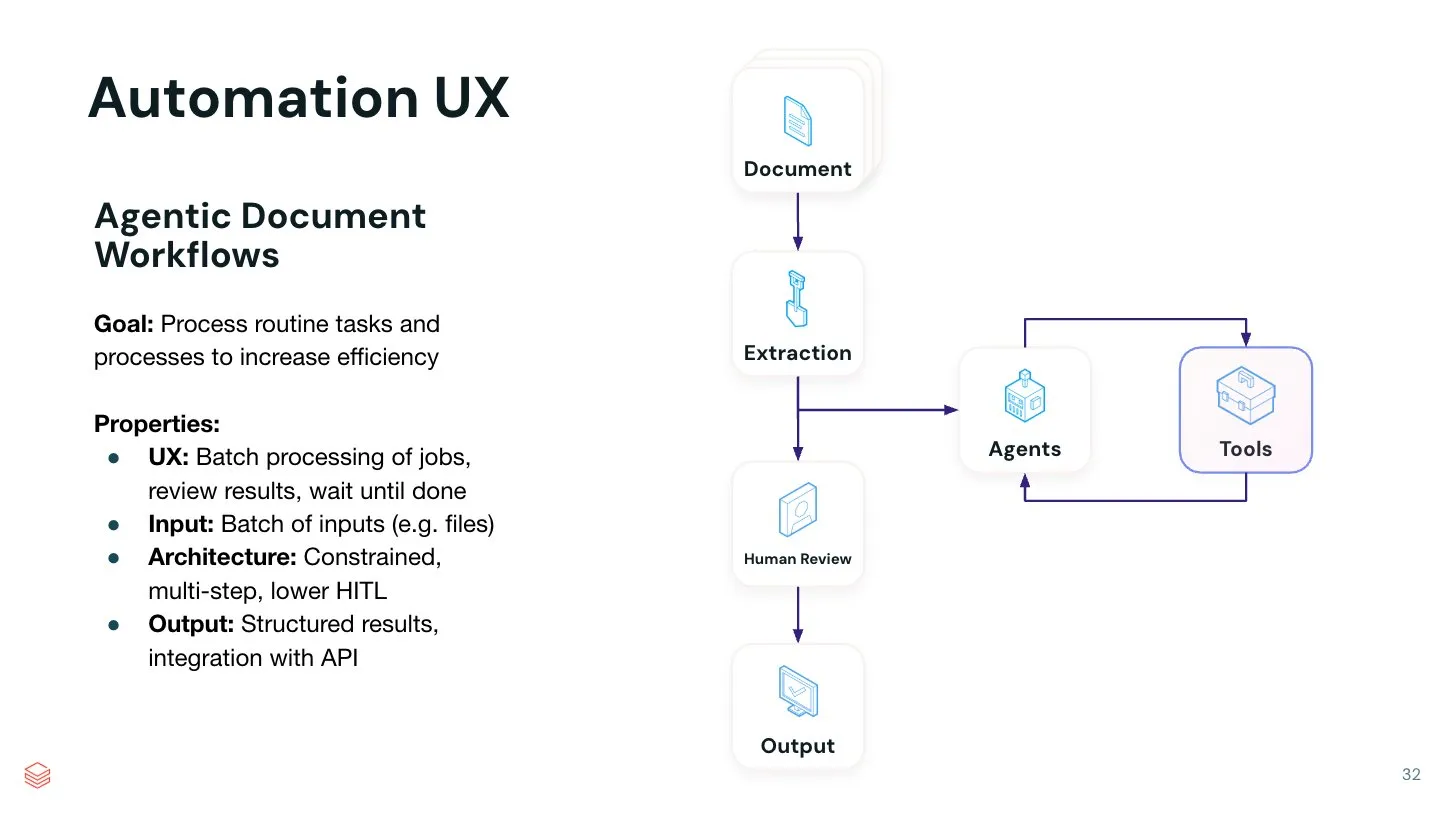
La valeur des Agents IA dans l’automatisation de tâches spécifiques est mise en évidence: Jerry Liu souligne que, bien que les assistants de chat généraux excellent dans le brainstorming créatif, l’exécution de tâches spécifiques nécessite encore beaucoup d’ingénierie des invites. Il estime qu’il y a une valeur immense à construire des systèmes d’Agents IA automatisés capables d’accomplir une seule tâche spécifique de manière exceptionnelle. En codant des processus spécifiques dans les flux de travail des Agents, on peut obtenir une automatisation plus efficace et plus contrôlable. LlamaIndex s’efforce de prendre en charge ce type de flux de travail de code spécialisé, et il est possible que davantage d’interfaces utilisateur/UX sans code apparaissent à l’avenir pour construire de tels Agents automatisés (Source: jerryjliu0)
💡 Divers
Le prix du jeune chercheur CVPR 2025 est décerné à Xie Saining et Su Hao: Lors de la conférence CVPR 2025, Xie Saining et Su Hao ont reçu le prix du jeune chercheur. Ce prix vise à récompenser les contributions exceptionnelles dans le domaine de la vision par ordinateur de chercheurs en début de carrière ayant obtenu leur doctorat il y a moins de sept ans. Su Hao (doctorant de Li Feifei) a participé au projet ImageNet, tandis que Xie Saining a collaboré avec Kaiming He sur ResNeXt et a participé au projet MAE, tous deux étant des travaux importants dans le domaine de la vision par ordinateur (Source: 量子位)

L’imprimante laser Nikon SLM NXG pourrait révolutionner la fabrication: L’imprimante laser SLM NXG lancée par Nikon présente une ressemblance frappante avec les équipements DUV (lithographie ultraviolette profonde). Cette imprimante est considérée comme ayant le potentiel de déclencher une révolution dans la fabrication générative, en particulier pour certains domaines. Bien que Nikon ait perdu la course DUV face à ASML, sa technologie de source laser continue de se développer et de s’appliquer à de nouveaux domaines de fabrication (Source: teortaxesTex)
Progrès significatifs de la génération d’images par IA entre 2022 et 2025: Un utilisateur de Reddit a partagé une comparaison d’images générées par IA en 2022 et 2025 en utilisant la même invite (thème « Rick et Morty »). L’image de 2022 présentait des défauts évidents dans les détails des personnages (comme les mains, le nez) et la cohérence globale, tandis que l’image de 2025 est considérablement améliorée, montrant le développement fulgurant de la technologie de génération d’images par IA en quelques années seulement. Bien que certains utilisateurs soulignent que les détails des mains des personnages dans la nouvelle image ne sont toujours pas parfaits, les progrès globaux sont évidents (Source: Reddit r/artificial)
