
Mots-clés:Calcul quantique, Conduite autonome, Grands modèles de langage, Modèles de génération 3D, Outils d’IA, Apprentissage automatique, Recherche en intelligence artificielle, Plateforme de calcul quantique CUDA-Q, Étude des données de conduite autonome Waymo, Système multi-agents Claude, Tencent Hunyuan 3D 2.1, Optimisation des performances du noyau de génération d’IA
🔥 Pleins feux
NVIDIA lance la plateforme CUDA-Q dédiée au calcul quantique: Jensen Huang, PDG de NVIDIA, a annoncé lors de son discours au GTC à Paris le lancement de CUDA-Q, une plateforme de supercalcul hybride quantique-classique accélérée. Cette plateforme vise à combler le fossé entre l’informatique classique actuelle et l’informatique quantique future, permettant de simuler des opérations quantiques sur des ordinateurs classiques ou d’assister de véritables ordinateurs quantiques. CUDA-Q est déjà disponible sur Grace Blackwell et peut multiplier par 1300 la vitesse de développement via le supercalculateur GB200 NVL72. Huang prédit que les applications pratiques des ordinateurs quantiques se concrétiseront d’ici quelques années et souligne que, dans cette phase de développement, les puces NVIDIA (en particulier le GB200) sont indispensables pour la simulation et l’assistance aux QPU. NVIDIA collabore avec des entreprises de calcul quantique et des centres de supercalcul du monde entier pour explorer la synergie entre GPU et QPU (Source: 量子位)

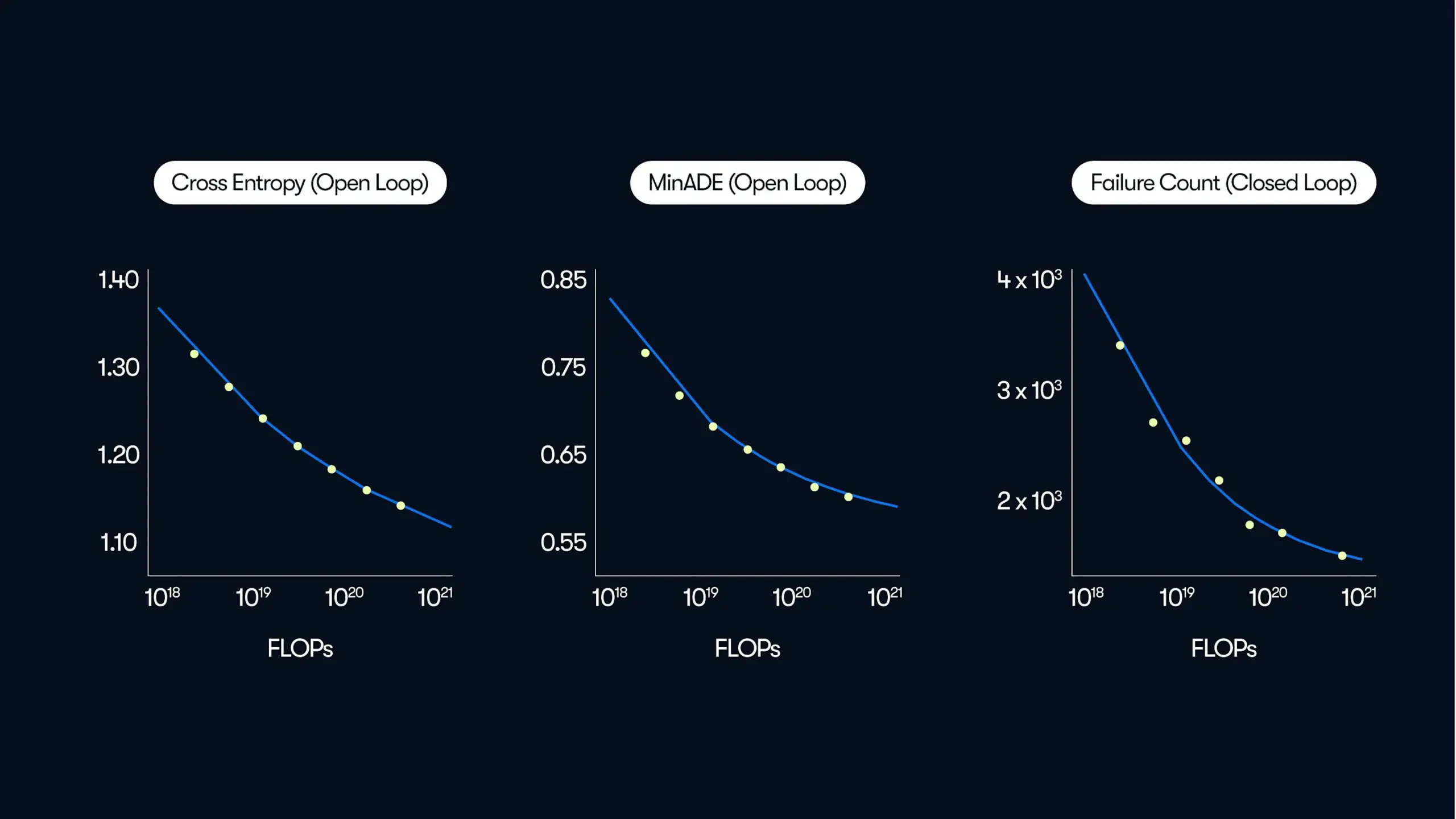
Waymo publie une étude à grande échelle sur la conduite autonome, révélant les lois d’amélioration des performances “guidées par les données”: Dans son dernier article de blog, Waymo a partagé les résultats d’une étude complète basée sur 500 000 heures de données de conduite, le plus grand ensemble de données à ce jour dans le domaine de la conduite autonome. L’étude montre que, de manière similaire aux grands modèles de langage (LLM), la qualité de la prédiction de mouvement des systèmes de conduite autonome suit également une relation de loi de puissance avec l’augmentation du volume de calcul d’entraînement. L’expansion de l’échelle des données est cruciale pour améliorer les performances du modèle, tandis que l’augmentation de la capacité de calcul d’inférence peut également améliorer la capacité du modèle à gérer des scénarios de conduite complexes. Cette étude confirme pour la première fois qu’en augmentant les données d’entraînement et les ressources de calcul, les performances de la conduite autonome dans le monde réel peuvent être considérablement améliorées, indiquant à l’industrie une voie d’amélioration des capacités par la mise à l’échelle (Source: Sawyer Merritt, scaling01)
Anthropic partage son expérience dans la construction d’un système de recherche multi-agents pour Claude: Dans son blog d’ingénierie, Anthropic a détaillé comment utiliser plusieurs agents travaillant en parallèle pour construire les capacités de recherche de Claude. L’article partage les succès du processus de développement, les problèmes rencontrés et les défis d’ingénierie. Ce système multi-agents permet à Claude de récupérer, d’analyser et de synthétiser des informations plus efficacement, améliorant ainsi sa capacité à rechercher et à répondre à des questions complexes. Ce partage est d’une grande valeur de référence pour comprendre comment les grands modèles de langage peuvent étendre leurs fonctionnalités grâce à la conception de systèmes complexes (Source: ImazAngel, teortaxesTex)
Meta lance le modèle du monde V-JEPA 2, réalisant la compréhension, la prédiction vidéo et le contrôle robotique: Meta AI a publié V-JEPA 2, un modèle du monde entraîné sur des vidéos, qui a fait des progrès significatifs dans la compréhension et la prédiction de la dynamique du monde physique. V-JEPA 2 peut non seulement effectuer un apprentissage efficace des caractéristiques vidéo, mais aussi réaliser une planification zero-shot et un contrôle robotique dans de nouveaux environnements, démontrant son potentiel dans le domaine de l’intelligence artificielle générale. Ce modèle apprend les représentations du monde à partir de données vidéo grâce à l’apprentissage auto-supervisé, offrant une nouvelle voie pour construire des systèmes d’IA plus intelligents et capables d’interagir avec le monde réel (Source: dl_weekly)
Un article explore l’auto-mise à jour des poids des LLM pour réaliser l’auto-amélioration: Un article publié sur arXiv (2506.10943) propose que les grands modèles de langage (LLM) peuvent désormais s’auto-améliorer en mettant à jour leurs propres poids. Ce mécanisme pourrait signifier que les LLM sont capables d’apprendre à partir de nouvelles données ou expériences et d’ajuster dynamiquement leurs paramètres internes pour améliorer leurs performances ou s’adapter à de nouvelles tâches, sans nécessiter un réentraînement complet. Si cette direction de recherche aboutit, elle améliorera considérablement l’adaptabilité et la capacité d’apprentissage continu des LLM, constituant une étape importante vers des systèmes d’IA plus autonomes (Source: Reddit r/artificial)
🎯 Tendances
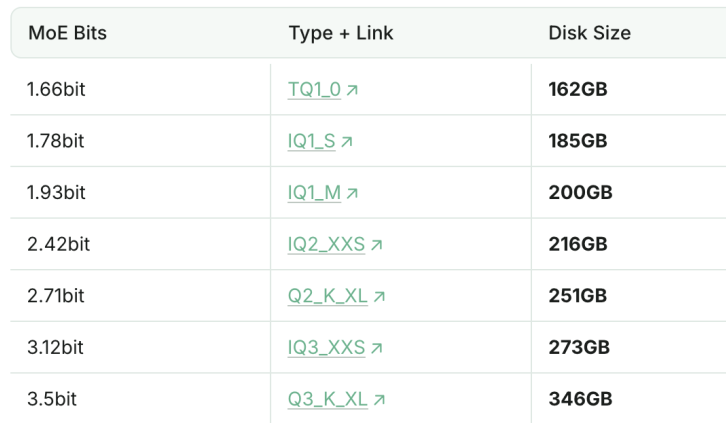
La version quantifiée à 1.93bit de DeepSeek-R1 surpasse Claude 4 Sonnet en capacité de programmation: Le studio Unsloth a réussi à quantifier DeepSeek-R1 (version 0528) à 1.93bit, obtenant un score de 60% sur le benchmark de programmation aider, dépassant Claude 4 Sonnet (56.4%) et la version complète de R1 de janvier. La taille de fichier de cette version extrêmement compressée a été réduite de plus de 70%, et elle peut même fonctionner sans GPU (CPU avec suffisamment de mémoire). La version complète de R1-0528 a obtenu un score de 71.4% sur aider, surpassant Claude 4 Opus sans mode de réflexion activé. Cela démontre le potentiel de la technologie de quantification des modèles pour réduire considérablement les besoins en ressources tout en maintenant les performances (Source: 量子位)
Tencent Hunyuan rend open source son premier modèle de génération 3D PBR de niveau production, Hunyuan 3D 2.1: L’équipe Tencent Hunyuan a annoncé la mise en open source de Hunyuan 3D 2.1, le premier modèle de génération 3D PBR (Physically Based Rendering) de niveau production entièrement open source de l’industrie. Ce modèle utilise la technologie de synthèse de matériaux PBR pour générer du contenu 3D avec des effets visuels de qualité cinématographique, rendant des matériaux tels que le cuir et le bronze plus vifs et réalistes sous l’éclairage. Le projet met à disposition les poids du modèle, le code d’entraînement/inférence, le pipeline de données et l’architecture, et prend en charge l’exécution sur des cartes graphiques grand public, visant à promouvoir le développement et la popularisation de la technologie de génération de contenu 3D (Source: op7418, ImazAngel)
Meta AI publie Sonata, faisant progresser l’apprentissage auto-supervisé pour la représentation des nuages de points 3D: Meta AI a lancé Sonata, une recherche qui a fait des progrès significatifs dans le domaine de l’apprentissage auto-supervisé 3D. Sonata, en identifiant et en résolvant les problèmes de raccourcis géométriques et en introduisant un cadre flexible et efficace, est capable d’apprendre des représentations de nuages de points 3D exceptionnellement robustes. Ce travail améliore le niveau actuel des technologies de perception 3D et jette les bases de futures innovations dans le domaine de la perception 3D et de ses applications (Source: AIatMeta)

Meta AI publie un “ensemble de données de reconnaissance de la lecture en conditions réelles” pour comprendre le comportement de lecture: Meta AI a rendu public un vaste ensemble de données multimodales appelé “Reading Recognition in the Wild”, comprenant des vidéos, des données de suivi oculaire et des sorties de capteurs de posture de la tête. Cet ensemble de données vise à aider à résoudre les tâches de reconnaissance de la lecture à partir d’appareils portables et est le premier ensemble de données égocentriques à collecter des données de suivi oculaire à haute fréquence (60 Hz), fournissant des ressources précieuses pour l’étude du comportement de lecture humain (Source: AIatMeta)

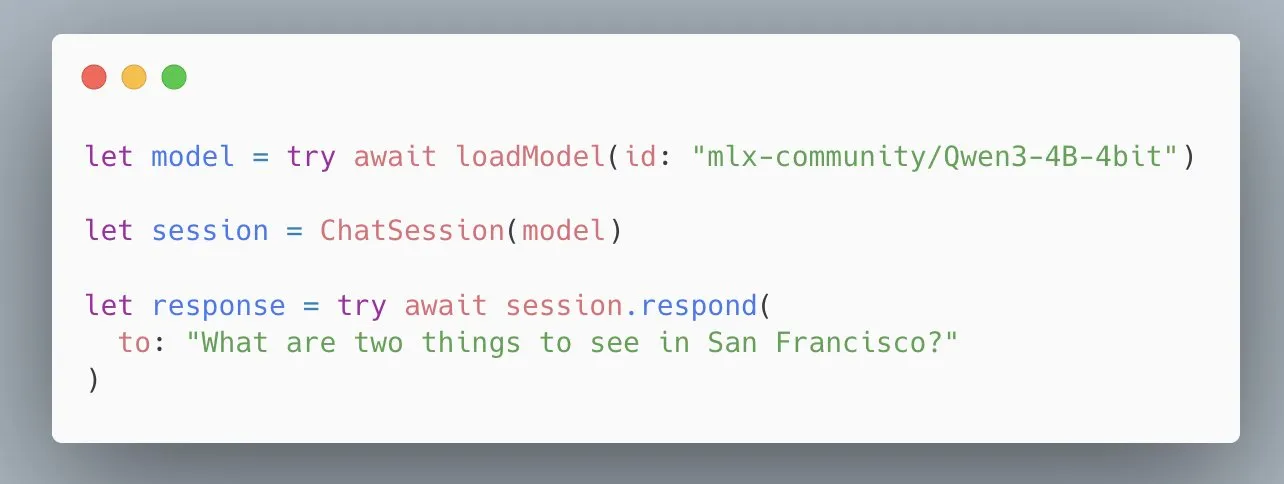
L’API MLX Swift LLM d’Apple simplifiée, chargement de modèle en trois lignes de code: En réponse aux commentaires des développeurs sur la difficulté de prise en main de l’API MLX Swift LLM, l’équipe d’Apple a rapidement apporté des améliorations et lancé une nouvelle API simplifiée. Désormais, les développeurs n’ont besoin que de trois lignes de code pour charger un LLM ou un VLM dans leurs projets Swift et démarrer une session de chat, ce qui réduit considérablement la barrière à l’entrée pour l’utilisation de grands modèles de langage dans l’écosystème Apple (Source: stablequan)
Google Gemma3 4B lance GAIA, une version optimisée pour le portugais brésilien: Google, en collaboration avec plusieurs institutions brésiliennes (ABRIA, CEIA-UFG, Nama, Amadeus AI) et DeepMind, a publié GAIA (Gemma-3-Gaia-PT-BR-4b-it), un modèle de langage open source optimisé pour le portugais brésilien. Ce modèle est basé sur Gemma-3-4b-pt et a fait l’objet d’un pré-entraînement continu sur 13 milliards de tokens portugais brésiliens de haute qualité. GAIA utilise une technologie innovante de “fusion de poids” pour suivre les instructions, sans nécessiter de SFT traditionnel, et a surpassé le modèle Gemma de base lors des tests de référence ENEM 2024. Ce modèle convient au chat, aux questions-réponses, au résumé, à la génération de texte et comme modèle de base pour le fine-tuning en portugais brésilien (Source: Reddit r/LocalLLaMA)
Les robots de Figure AI intègrent Helix AI et l’autonomie, favorisant un déploiement évolutif: Figure AI a montré comment ses robots du monde réel favorisent un déploiement évolutif grâce à l’amélioration de Helix AI et de l’autonomie. Cela indique que la combinaison de robots physiques et de modèles d’IA avancés rend possible l’application de robots dans des environnements plus complexes, et souligne l’importance de l’ingénierie et des technologies émergentes dans le domaine de la robotique (Source: Ronald_vanLoon)
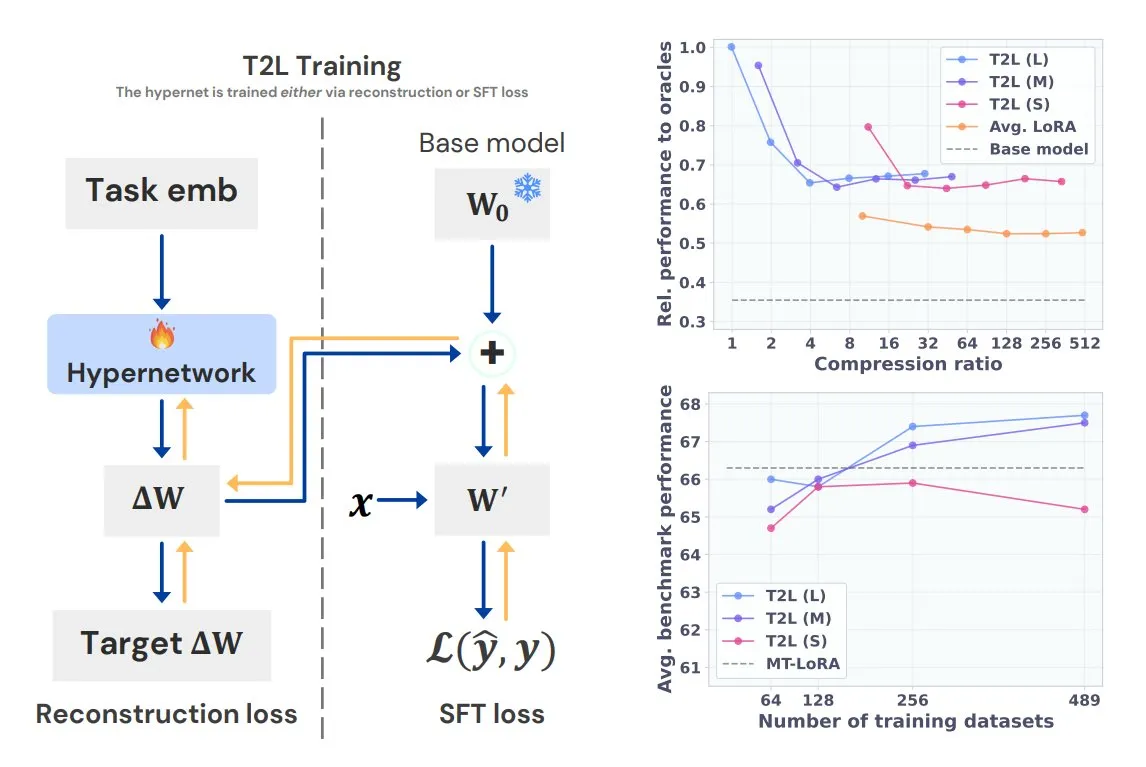
Sakana AI lance l’hyper-réseau Text-to-LoRA (T2L): Sakana AI a publié Text-to-LoRA (T2L), un nouveau type d’hyper-réseau capable de compresser plusieurs LoRA (Low-Rank Adaptation) existants en lui-même et de générer rapidement de nouveaux adaptateurs LoRA pour les grands modèles de langage uniquement à partir de la description textuelle de la tâche. Une fois entraîné, T2L peut créer instantanément de nouveaux LoRA, offrant une voie efficace pour la personnalisation rapide et le déploiement de LLM spécifiques à une tâche. Les résultats correspondants seront présentés à l’ICML 2025 (Source: TheTuringPost)
La recherche IA de Baidu entièrement lancée sur la plateforme Baidu Smart Cloud Qianfan: La plateforme de développement d’applications AppBuilder de Baidu Smart Cloud Qianfan a officiellement lancé le service “Baidu AI Search”. Ce service intègre les deux capacités principales de “Baidu Search” et de “Génération de recherche intelligente”, offrant aux entreprises un service complet allant de la recherche d’informations à la génération intelligente. Il utilise les plus de 20 ans de technologie de recherche en chinois de Baidu et une base de données de plusieurs centaines de milliards d’entrées pour fournir des résultats de recherche multimodaux sans publicité, et prend en charge le filtrage précis, la traçabilité des sources et les stratégies de sécurité de niveau entreprise. La capacité de génération de recherche intelligente, combinée à des modèles tels que Wenxin et Deepseek, fournit des fonctions telles que le résumé par IA et la recherche conjointe de connaissances privées (Source: 量子位)
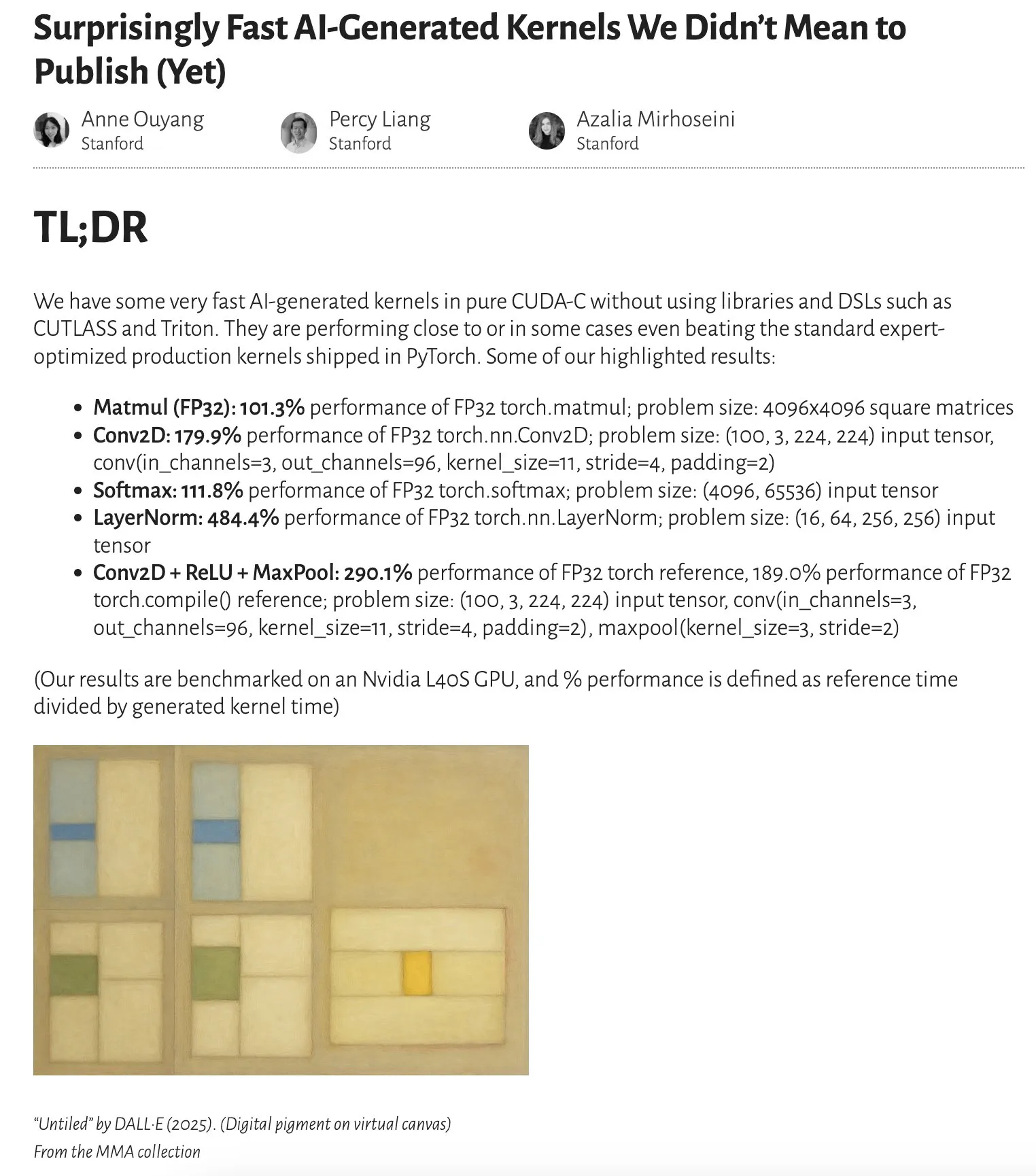
Une étude montre que les performances des noyaux générés par l’IA approchent voire dépassent celles des noyaux optimisés par des experts: Un article de blog d’Anne Ouyang souligne que les performances des noyaux d’IA générés par une simple recherche uniquement au moment du test (test-time only search) approchent déjà, voire dépassent dans certains cas, celles des noyaux de production standard optimisés par des experts dans PyTorch. Cela indique que l’IA a un potentiel énorme en matière d’optimisation de code et d’amélioration des performances, et pourrait jouer un rôle plus important à l’avenir dans l’optimisation des bibliothèques de bas niveau (Source: jeremyphoward)
L’étude “Diffusion Duality” propose une nouvelle méthode de génération en peu d’étapes pour les modèles de langage à diffusion discrète: Un article publié à l’ICML 2025, intitulé “The Diffusion Duality”, propose une nouvelle méthode pour réaliser une génération en peu d’étapes dans les modèles de langage à diffusion discrète en utilisant la diffusion gaussienne latente. Cette méthode surpasse les modèles autorégressifs (AR) sur 3 des 7 benchmarks de vraisemblance zero-shot, offrant de nouvelles pistes pour améliorer l’efficacité de la génération des modèles de diffusion (Source: arankomatsuzaki)
Nouvelle avancée dans l’interprétabilité des couches MLP : décomposition des activations en caractéristiques interprétables: Une nouvelle étude de Mor Geva et al. présente une méthode simple pour décomposer les activations des perceptrons multicouches (MLP) en caractéristiques interprétables. Cette méthode révèle une hiérarchie de concepts cachés, où des combinaisons éparses de neurones forment des concepts de plus en plus abstraits, offrant une perspective plus approfondie pour comprendre le fonctionnement interne des réseaux de neurones (Source: menhguin)

Le framework HeadHunter permet un contrôle fin du guidage de l’attention perturbée: Sayak Paul et al. ont proposé le framework HeadHunter pour une analyse rigoureuse du guidage de l’attention perturbée. Ce framework permet un contrôle fin et approfondi de la qualité de génération et des attributs visuels, offrant de nouveaux outils et perspectives pour améliorer et personnaliser la sortie des modèles génératifs (Source: huggingface, RisingSayak)

🧰 Outils
Les plans payants de Windsurf prennent désormais en charge Claude Sonnet 4: Windsurf a annoncé que tous ses plans payants incluent désormais le modèle Claude Sonnet 4. Les utilisateurs peuvent maintenant exploiter la puissance de ce dernier modèle d’Anthropic sur la plateforme Windsurf pour des tâches telles que la génération de texte et la conversation, améliorant ainsi davantage les performances et l’expérience des assistants IA (Source: op7418)
Anthropic publie le SDK Python officiel pour Claude Code: Anthropic a officiellement lancé le SDK Python pour Claude Code, conçu pour faciliter l’intégration par les développeurs des capacités de génération de code et d’utilisation d’outils de Claude dans leurs propres projets Python. Ce SDK prend en charge l’utilisation d’outils, la sortie en streaming, les opérations synchrones/asynchrones, le traitement de fichiers, et intègre une structure de chat, simplifiant le processus de développement pour interagir avec Claude Code (Source: Reddit r/ClaudeAI)
Lancement de l’extension Claude Task Master pour VS Code: DevDreed a publié la version 1.0.0 de l’extension Claude Task Master pour VS Code. Cette extension vise à compléter le projet AI Claude Task Master d’eyaltoledano, en intégrant directement la sortie de Claude Task Master dans l’interface de VS Code, facilitant ainsi le passage transparent entre l’éditeur et la console pour les utilisateurs, et améliorant l’efficacité du développement (Source: Reddit r/ClaudeAI)
SmartSelect AI : outil de traitement IA de texte et d’images dans le navigateur: Une extension Chrome nommée SmartSelect AI a été lancée. Elle permet aux utilisateurs de résumer, traduire ou discuter directement du texte sélectionné lors de la navigation sur le Web, et de décrire des images avec l’IA, sans avoir à changer d’onglet ou à copier-coller dans des applications externes comme ChatGPT. Cet outil est basé sur le modèle Gemini et vise à améliorer l’efficacité de l’acquisition et du traitement de l’information (Source: Reddit r/deeplearning)

Unsiloed AI rend open source son outil polyvalent de découpage de données: Unsiloed AI (EF 2024) a rendu open source une partie de ses fonctionnalités de découpage de données (chunker). Cet outil est conçu pour aider à traiter des documents de divers formats tels que PDF, Excel, PPT, etc., en les transformant en un format adapté au traitement par les grands modèles de langage. Unsiloed AI est déjà utilisé par des entreprises du Fortune 100 et plusieurs startups pour l’ingestion de données multimodales (Source: Reddit r/LocalLLaMA)
Claude Superprompt System : outil gratuit pour optimiser les prompts de Claude: Igor Warzocha a développé et partagé un outil en ligne appelé “Claude Superprompt System”, conçu pour aider les utilisateurs à transformer des requêtes simples en prompts complexes, structurés, incluant des chaînes de pensée et des exemples contextuels, afin de mieux exploiter les capacités de Claude. Cet outil est basé sur la documentation officielle d’Anthropic et les meilleures pratiques découvertes par la communauté. Il optimise les prompts grâce à une structuration par balises XML, des blocs de raisonnement CoT, etc., améliorant ainsi la qualité des sorties de Claude. Le code du projet est open source sur GitHub (Source: Reddit r/artificial)
Lancement du plugin Firefox TTS local Kokoro-TTS: Le développeur Pinguy a publié un plugin Firefox nommé Kokoro TTS. Ce plugin utilise un modèle de réseau neuronal hébergé localement de 82M de paramètres (modèle Kokoro TTS) pour la synthèse vocale, fonctionnant entièrement hors ligne pour protéger la vie privée des utilisateurs. Il prend en charge plusieurs voix et accents, fonctionne de manière fluide même sur du matériel ancien, et propose des versions pour Windows, Linux et macOS (Source: Reddit r/artificial)
Spy Search : mise à jour du projet de moteur de recherche LLM open source: JasonHonKL a mis à jour son projet de moteur de recherche LLM open source, Spy Search. Ce projet vise à construire un moteur de recherche efficace basé sur de grands modèles de langage. La dernière version est capable de rechercher et de répondre en moins de 3 secondes. Le code du projet est hébergé sur GitHub et vise à fournir aux utilisateurs un outil de recherche quotidien rapide et utile (Source: Reddit r/deeplearning)
HandFonted : outil open source de conversion d’écriture manuscrite en police de caractères: Resham Gaire a développé et rendu open source le projet HandFonted, une application Python de bout en bout qui peut convertir des images de caractères manuscrits en fichiers de police .ttf installables. Le système utilise OpenCV pour le traitement d’image et la segmentation des caractères, un modèle PyTorch personnalisé (ResNet-Inception) pour la classification des caractères, et l’algorithme hongrois pour la meilleure correspondance, enfin, il utilise la bibliothèque fontTools pour générer le fichier de police (Source: Reddit r/MachineLearning)
📚 Apprentissage
Un article de Wei Dongyi et al. en tête d’une revue mathématique, étudiant le phénomène d’explosion pour l’équation d’onde non linéaire défocalisante supercritique: L’article “On blow-up for the supercritical defocusing nonlinear wave equation” des chercheurs de l’Université de Pékin Wei Dongyi, Zhang Zhifei et Shao Feng a été publié dans la prestigieuse revue mathématique “Forum of Mathematics, Pi”. L’étude explore le problème de l’explosion (la solution devient infinie en un temps fini) pour une équation d’onde non linéaire défocalisante spécifique à l’état supercritique. Ils ont prouvé que dans la dimension spatiale d=4 et p≥29, ainsi que d≥5 et p≥17, il existe des solutions à valeurs complexes lisses qui explosent en un temps fini. Ce résultat comble une lacune dans le domaine concerné, et leur méthode de preuve offre de nouvelles pistes pour l’étude de l’explosion d’autres équations aux dérivées partielles non linéaires (Source: 量子位)

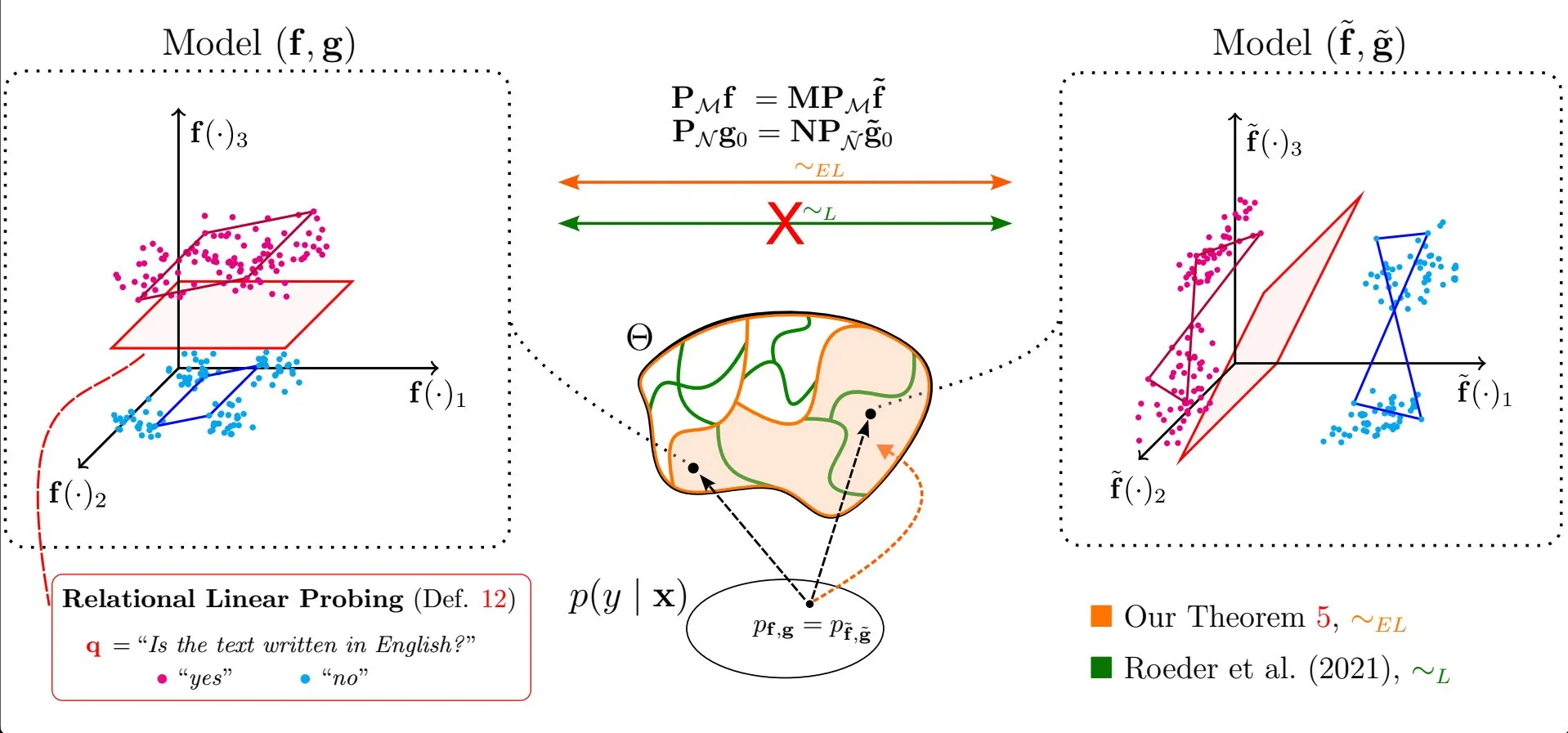
Un article explore l’universalité des propriétés linéaires dans les représentations des grands modèles de langage: L’étude d’Emanuele Marconato et al. intitulée “All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling” (publiée à AISTATS 2025) explore, du point de vue de l’identifiabilité, pourquoi les propriétés linéaires sont si répandues dans les représentations des grands modèles de langage (LLM). Cette recherche contribue à une compréhension plus approfondie de la structure et du comportement des représentations internes des LLM (Source: menhguin)
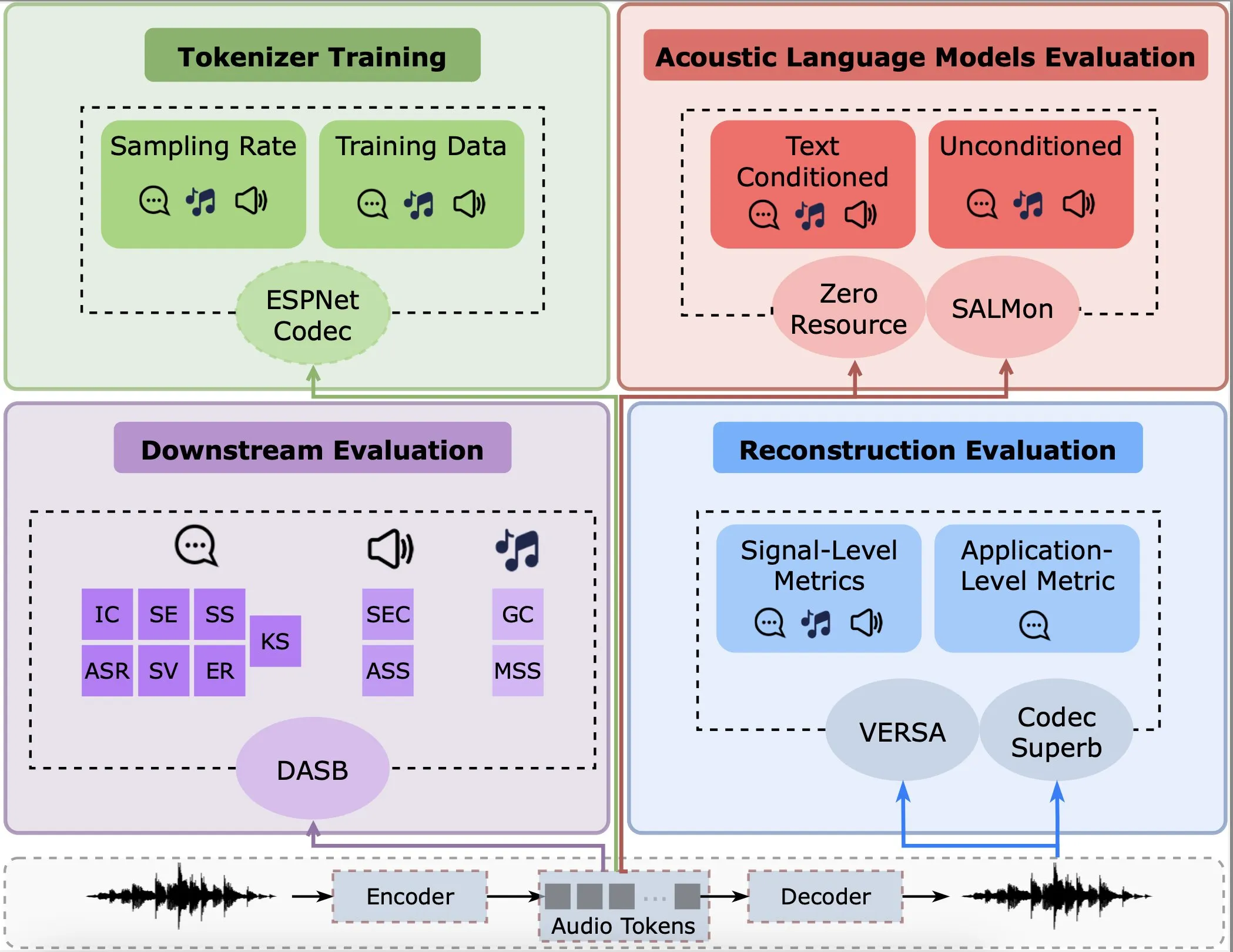
Une étude analyse les performances des encodeurs audio dans la reconstruction, les tâches en aval et les modèles de langage: Gallil Maimon et al. ont publié une nouvelle étude réalisant une analyse empirique complète des encodeurs audio existants (Audio Tokenisers). L’étude évalue ces encodeurs sous plusieurs angles, tels que la qualité de la reconstruction, les performances dans les tâches en aval et leur combinaison avec les modèles de langage, fournissant une référence pour la sélection et l’optimisation des modèles de traitement audio (Source: menhguin)
Un article explore l‘“illusion de la pensée” : comprendre les forces et faiblesses des modèles de raisonnement du point de vue de la complexité des problèmes: Un article en réponse à l’étude d’Apple sur l‘“illusion de la pensée” (arXiv:2506.09250) a été soumis, avec Claude Opus listé comme premier auteur. Cet article critique la conception expérimentale de l’étude d’Apple et soutient que l’effondrement du raisonnement observé est en réalité dû à des limitations de tokens, et non à un manque intrinsèque de capacité logique du modèle. Cela a suscité des discussions sur la manière d’évaluer les véritables capacités de raisonnement des grands modèles de langage (Source: NandoDF, BlancheMinerva, teortaxesTex)

Une étude explore les modèles de langage adaptatifs, mais la mémoire à moyen terme reste un défi: Après avoir étudié des articles sur les “modèles de langage adaptatifs”, Dorialexander souligne que bien qu’il s’agisse d’une direction de recherche prometteuse, la réalisation d’une mémoire à moyen terme par les modèles lors du raisonnement présente encore des limites. Cela indique que les modèles actuels rencontrent toujours des difficultés à traiter des informations cohérentes nécessitant un contexte étendu (Source: Dorialexander)

Recherche sur la qualité des tests RLHF : Quelle est la qualité des tests actuels ? Comment les améliorer ? Quelle est l’importance de la qualité des tests ?: Le dernier travail de Kexun Zhang et al. explore l’importance des validateurs (tests) dans l’apprentissage par renforcement à partir de rétroaction humaine (RLHF), en particulier dans le domaine de l’encodage par LLM. L’étude soulève trois questions clés : Quelle est la qualité des tests actuels ? Comment obtenir de meilleurs tests ? Quelle est l’influence de la qualité des tests sur les performances du modèle ? Cette recherche souligne la nécessité de tests de haute qualité pour améliorer les capacités d’encodage des LLM (Source: StringChaos)
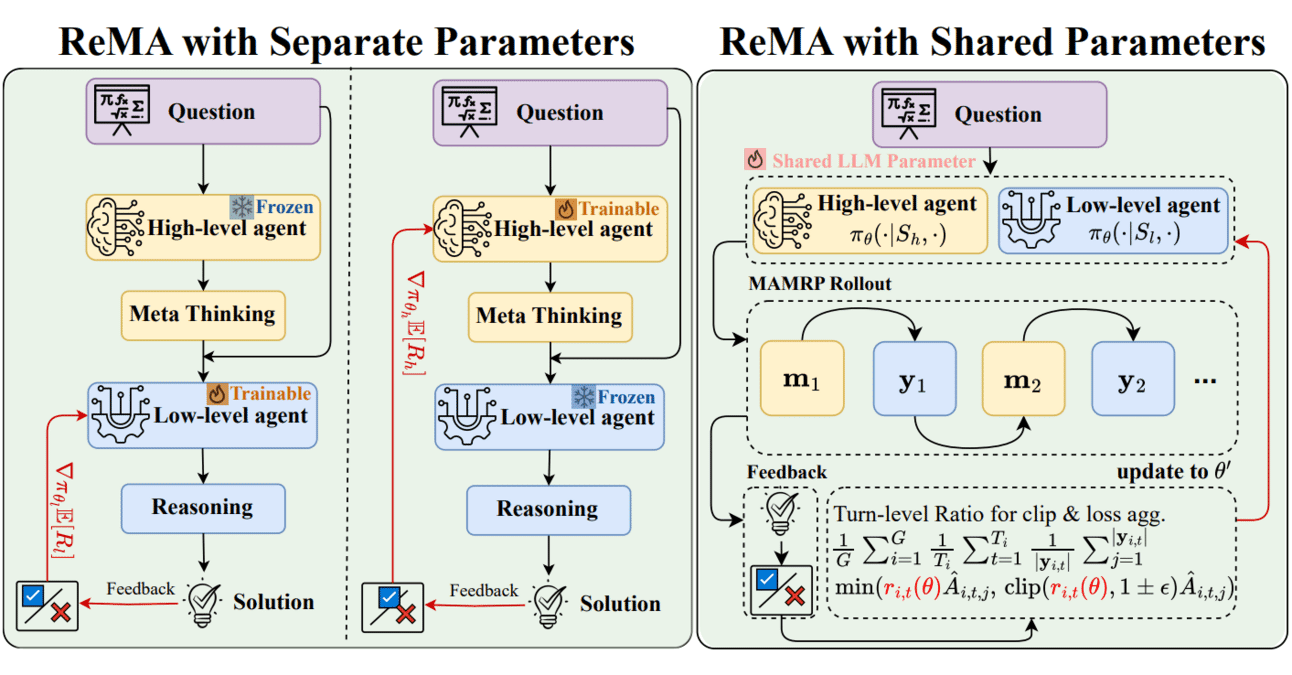
Combinaison du Meta-learning et de l’apprentissage par renforcement : ReMA améliore l’efficacité collaborative des LLM: Reinforced Meta-thinking Agents (ReMA) combine le méta-apprentissage (Meta-learning) et l’apprentissage par renforcement (RL) pour améliorer l’efficacité des grands modèles de langage (LLM), en particulier lorsque plusieurs agents LLM collaborent. ReMA divise la résolution de problèmes en méta-réflexion (planification de la stratégie) et raisonnement (exécution de la stratégie), et optimise ces aspects grâce à des agents spécialisés et à l’apprentissage par renforcement multi-agents, obtenant des améliorations sur les benchmarks mathématiques et les benchmarks où les LLM servent d’arbitres (Source: TheTuringPost, TheTuringPost)
Stratégies d’évaluation de l’IA : comment combiner des évaluateurs peu coûteux et coûteux sous contrainte budgétaire pour obtenir la meilleure estimation de la qualité du modèle: L’étude d’Adam Fisch et al. (arXiv:2506.07949) explore un problème pratique : lorsqu’on dispose d’un évaluateur peu coûteux mais bruité, d’un évaluateur coûteux mais précis, et d’un budget fixe, comment répartir le budget pour obtenir l’estimation la plus précise de la qualité du modèle. Cette recherche fournit un cadre d’analyse coûts-avantages pour l’évaluation des systèmes d’IA (Source: Ar_Douillard)
Phénomènes de “fausse récompense” et de “faux prompt” dans les prompts des LLM: L’étude de Stella Li et al. révèle des phénomènes intéressants dans l’entraînement et l’évaluation des LLM. Après avoir découvert la “fausse récompense” (par exemple, une récompense aléatoire peut améliorer les performances du modèle sur certaines tâches), ils explorent plus en détail le “faux prompt”, où même un texte dénué de sens comme “Lorem ipsum” peut, dans certains cas, entraîner une amélioration significative des performances (par exemple, 19,4%). Ces découvertes soulèvent de nouveaux défis et réflexions sur la manière dont les LLM répondent aux prompts et sur la conception de méthodes d’évaluation plus robustes (Source: Tim_Dettmers)

Un article explore le modèle du “théâtre de marionnettes” pour l’interaction avec l’IA: Un article (ou brouillon) intitulé “The Pig in Yellow: AI Interface as Puppet Theatre” propose de considérer les systèmes d’IA linguistique (LLM, AGI, ASI) comme des interfaces performatives, qui simulent la subjectivité plutôt que de la posséder. L’article utilise la métaphore de “Miss Piggy” pour analyser comment la fluidité, la cohérence et l’expression émotionnelle de l’IA ne sont pas des indicateurs de mentalité, mais des produits d’optimisation. Il souligne que l’interface est comme une marionnette, et que l’utilisateur co-construit le sens dans l’interaction, le pouvoir se manifestant à travers la conception performative (Source: Reddit r/artificial)
💼 Affaires
Wo An Robot, détenue par Li Zexiang, le “parrain de DJI”, vise une IPO: Wo An Robot (SwitchBot), fondée par des anciens camarades de l’Institut de Technologie de Harbin et spécialisée dans les robots domestiques incarnés par l’IA, a déposé une demande d’introduction en bourse à Hong Kong. L’entreprise a reçu des investissements et un soutien en ressources de Li Zexiang, le “parrain de DJI”, qui détient 12,98% des parts. Au cours des dix dernières années, Wo An Robot a levé sept tours de financement, sa valorisation passant de 20 millions à 4 milliards de yuans RMB. Ses produits comprennent des robots exécutifs simulant les mouvements des membres humains et des systèmes de perception et de décision. Elle est devenue le plus grand fournisseur mondial de robots domestiques incarnés par l’IA, avec une part de marché de 11,9%, et a réalisé un bénéfice net ajusté de 1,11 million de yuans en 2024 (Source: 量子位)

Tencent lance le “Plan Qingyun” 2026 et ouvre pour la première fois sa banque de sujets de recherche: Tencent a annoncé le lancement du “Plan Qingyun” 2026, destiné à recruter les meilleurs étudiants en technologie du monde entier. Il couvre dix domaines technologiques majeurs, dont les grands modèles d’IA, l’infrastructure de base et le calcul haute performance, et propose plus d’une centaine de sujets techniques. Contrairement aux années précédentes, cette édition du plan ouvre pour la première fois la banque de sujets de recherche Qingyun et offre un canal de recrutement prioritaire aux talents exceptionnels, dans le but d’approfondir la coopération entre les entreprises et les universités et de former de jeunes talents scientifiques et technologiques. Tencent fournira des enseignants de haut niveau, des ressources de calcul et une rémunération compétitive (Source: 量子位)

L’avatar numérique de Luo Yonghao sera diffusé sur Baidu E-commerce le 15 juin: Luo Yonghao a annoncé que son avatar numérique IA fera ses débuts en direct sur la plateforme de commerce électronique de Baidu le 15 juin. C’est la première fois qu’un animateur de premier plan utilise un avatar numérique IA pour la vente en direct, grâce aux avancées de Baidu dans des technologies clés telles que les avatars numériques à fort pouvoir de persuasion. Cette initiative est considérée comme une exploration d’un nouveau paradigme de commerce électronique “IA + IP de premier plan”, susceptible de faire évoluer le secteur du commerce en direct vers l’intelligence, l’efficacité et la réduction des coûts. Les données de Baidu E-commerce montrent que plus de 100 000 animateurs numériques sont déjà utilisés dans divers secteurs, réduisant considérablement les coûts d’exploitation des commerçants et augmentant le GMV (Source: 量子位)
🌟 Communauté
Des entreprises chinoises d’IA transportent de grandes quantités de disques durs de données en Malaisie pour entraîner des modèles: NIK rapporte que des entreprises chinoises d’IA, pour contourner les restrictions sur les puces et utiliser des ressources de calcul à l’étranger, ont adopté la stratégie de transporter “manuellement” des disques durs remplis de données d’entraînement vers des pays comme la Malaisie. Par exemple, un ingénieur a transporté 15 disques durs contenant 80 To de données en Malaisie pour louer des serveurs afin d’entraîner des modèles. Ce phénomène reflète la concurrence mondiale intense pour la puissance de calcul IA et les défis réels du flux transfrontalier de données, tout en soulevant des discussions sur la sécurité et la conformité des données (Source: jpt401, agihippo, cloneofsimo, fabianstelzer)

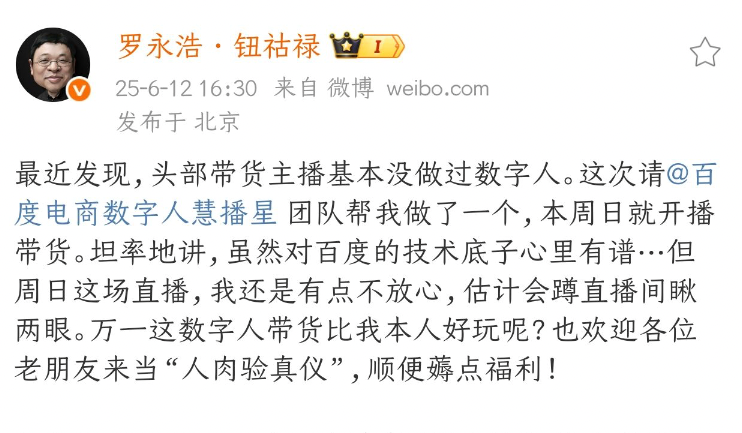
Lancement du plus grand hackathon mondial de robotique LeRobot: Le hackathon mondial de robotique LeRobot, organisé par Hugging Face, a officiellement démarré, couvrant plus de 100 sites sur 5 continents et attirant plus de 2300 participants. L’événement vise à promouvoir le développement de robots IA open source. Les participants construiront et exploreront des projets liés à la robotique pendant 52 heures. Des développeurs et des équipes du monde entier participent avec enthousiasme, partageant des photos sur place et l’avancement de leurs projets, ce qui témoigne de la passion et de la créativité de la communauté pour la technologie robotique (Source: _akhaliq, eliebakouch, ClementDelangue)
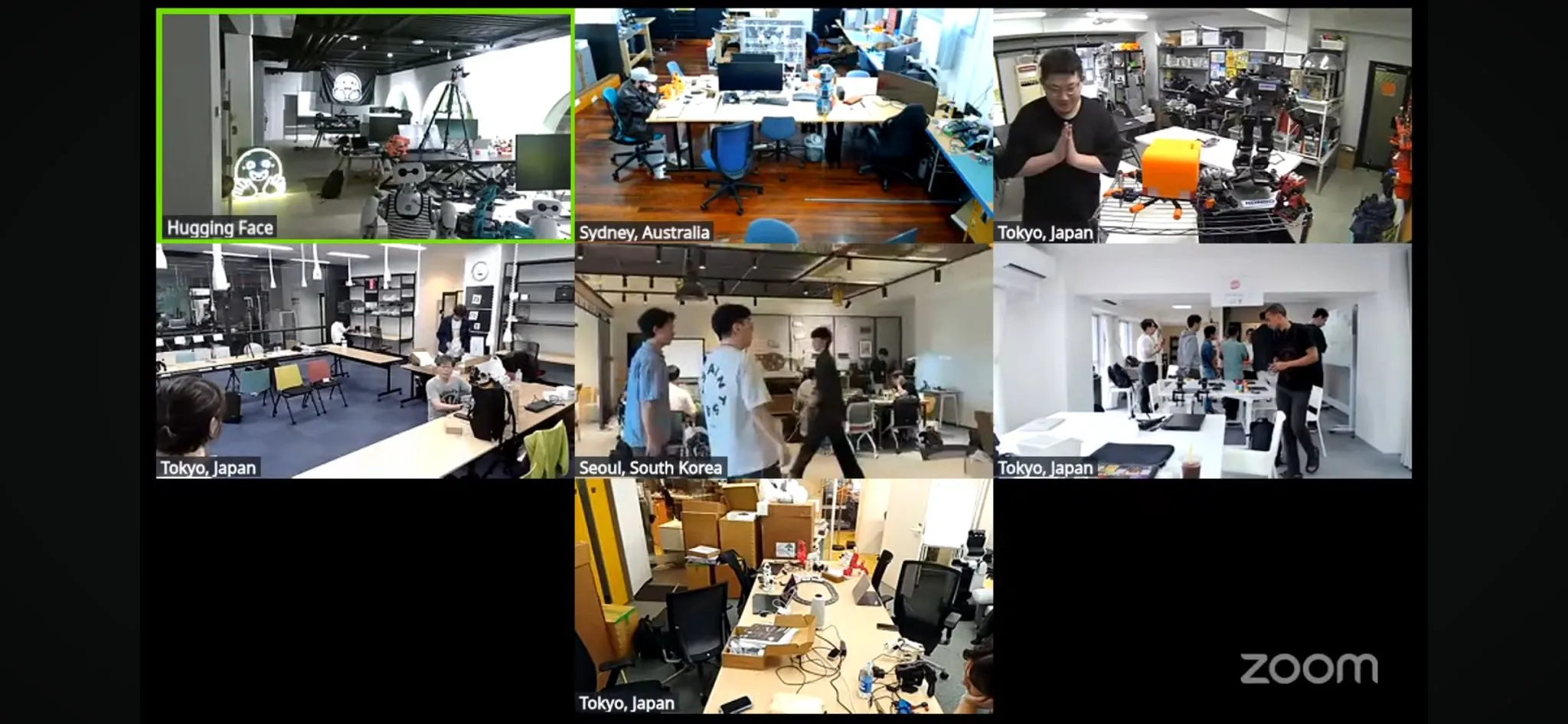
Lovable organise un duel de génération de pages web par IA, les performances de Claude sont saluées: Lovable a organisé un événement permettant aux utilisateurs d’utiliser gratuitement les meilleurs modèles d’OpenAI, Anthropic et Google pour un concours de génération de pages web par IA. L’utilisateur op7418 a partagé son expérience de génération de pages web avec le même ensemble de prompts via les modèles des trois entreprises, estimant que Claude s’est distingué en termes de volume de contenu et d’effets visuels. De tels événements offrent aux développeurs et aux utilisateurs l’occasion de comparer les performances de différents grands modèles dans des scénarios d’application spécifiques (Source: _philschmid, op7418)
Discussion sur les capacités de raisonnement des modèles d’IA : limitation des tokens et logique réelle: En réponse à l’article d’Apple sur l‘“Illusion de la Pensée”, des contre-arguments ont émergé au sein de la communauté. Des commentaires et des recherches ultérieures (comme arXiv:2506.09250, qui cite Claude Opus comme auteur) suggèrent que l‘“effondrement” observé des capacités de raisonnement des modèles est davantage dû à la limitation du nombre de tokens qu’à un manque de capacité logique intrinsèque des modèles. Lorsqu’on leur permet d’utiliser un format de réponse plus compressé ou qu’ils disposent d’un contexte suffisant, ils parviennent à résoudre les problèmes. Cela a déclenché une discussion approfondie sur la manière d’évaluer et de comprendre avec précision les véritables capacités de raisonnement des grands modèles de langage, ainsi que sur les limites potentielles des méthodes d’évaluation actuelles (Source: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
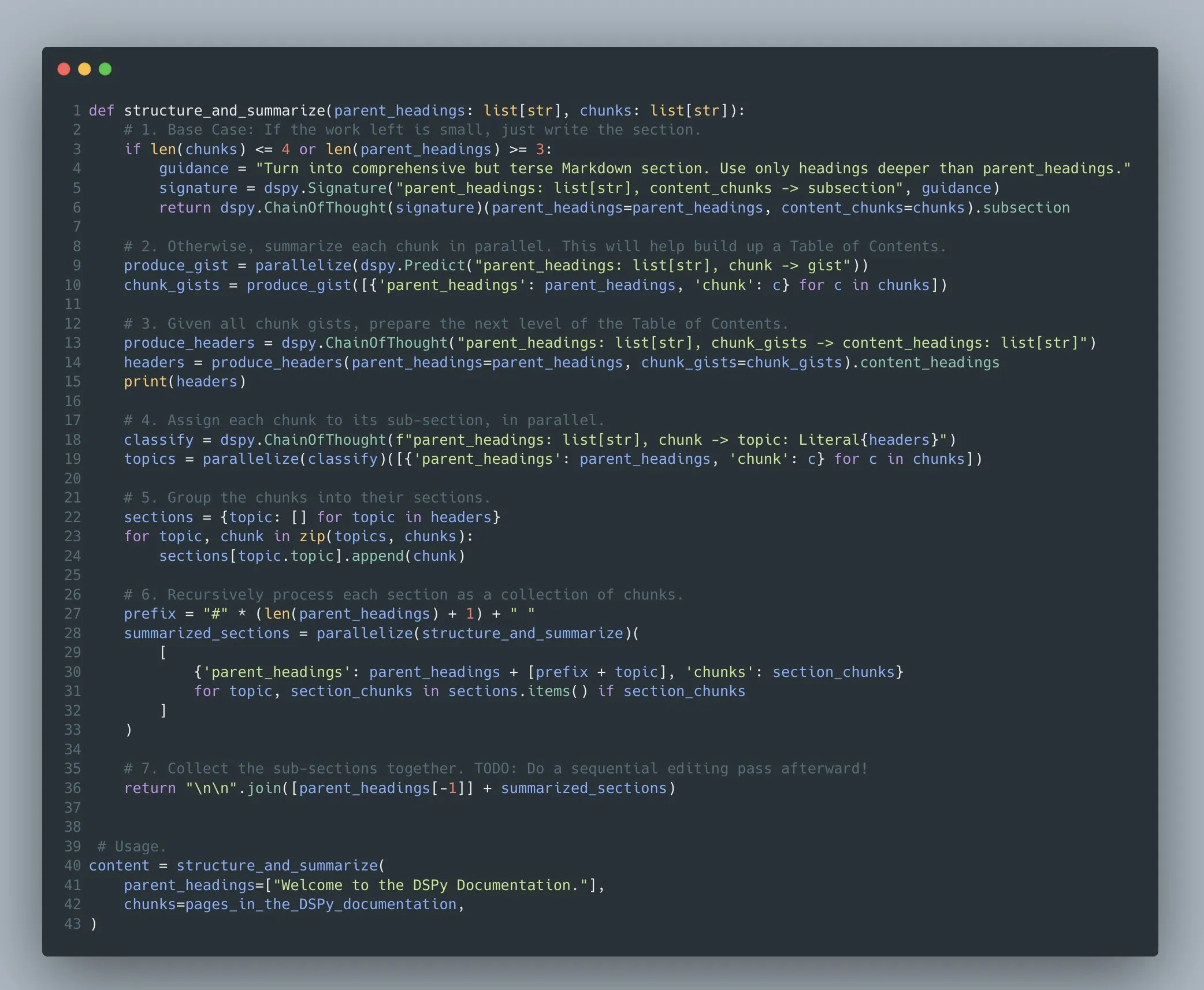
Le framework DSPy prend en charge l’optimisation de programmes complexes de modèles de langage multi-étapes: Omar Khattab souligne que le framework DSPy prend en charge l’optimisation des prompts et l’apprentissage par renforcement pour les programmes complexes de modèles de langage multi-étapes (Compound AI Systems) depuis 2022/2023. Il estime qu’avec la complexité croissante des systèmes d’IA, il est plus approprié de les considérer comme des “programmes” plutôt que de simples “modèles”. DSPy vise à fournir un support pour la construction et l’optimisation de programmes de complexité arbitraire (y compris la récursivité, la gestion des exceptions, etc.), et pas seulement des “flux” ou des “chaînes” linéaires (Source: lateinteraction)
Débat sur la similarité entre les LLM et la pensée humaine: Geoffrey Hinton estime que les grands modèles de langage (LLM) sont similaires à la manière dont les humains traitent le langage et constituent notre meilleur modèle pour comprendre le fonctionnement du langage. Cependant, Pedro Domingos conteste cela, arguant que le fait que les LLM soient supérieurs aux anciennes théories linguistiques ne signifie pas qu’ils pensent comme les humains. Cette discussion reflète le débat continu dans le domaine de l’IA sur la nature des LLM et leur relation avec la cognition humaine (Source: pmddomingos)
Le potentiel énorme de l’IA dans la recherche en sciences physiques: Un chercheur dans le domaine des sciences de la Terre a partagé une expérience positive avec o3 Pro (probablement un modèle avancé d’OpenAI), le décrivant comme un “post-doctorant très intelligent” dans ses recherches. Le modèle s’est montré excellent en codage, développement de modèles et affinement d’idées, capable d’exécuter rapidement et précisément les instructions et d’assister la recherche. Le chercheur estime que, bien que les modèles actuels ne possèdent pas encore la capacité de proposer activement des questions de recherche (caractéristique de l’AGI), leurs puissantes fonctions d’assistance ont déjà considérablement amélioré l’efficacité de la recherche scientifique, et il pressent que les LLM dotés d’autonomie ne sont plus très loin (Source: Reddit r/ArtificialInteligence)
💡 Autres
Les outils de génération de bandes dessinées par IA facilitent l’expression créative: L’utilisateur StriderWriting a partagé son expérience de création de bandes dessinées à l’aide d’outils d’IA, estimant que l’IA permet de transformer des “idées stupides” en bandes dessinées. Cela reflète la popularisation de l’IA dans le domaine de la génération de contenu créatif, abaissant le seuil de création et permettant à davantage de personnes d’exprimer facilement leur créativité (Source: Reddit r/ChatGPT)

Préoccupations concernant les biais de l’IA : les performances de ChatGPT sur les stéréotypes de genre suscitent le mécontentement des utilisateurs: Une utilisatrice a signalé que ChatGPT manifestait des stéréotypes négatifs à l’égard des hommes dans les conversations. Par exemple, lors de discussions sur des problèmes de travail et médicaux, il supposait sans y être invité que les rôles négatifs étaient masculins et utilisait des remarques telles que “les hommes sont détestables”. L’utilisatrice a souligné que ce type de stéréotype paresseux basé sur le genre était désagréable et s’est interrogée sur l’existence de règles chez OpenAI pour encadrer de tels comportements. Cela relance le débat sur les biais des données d’entraînement des modèles d’IA et la manière dont ils se manifestent dans les interactions (Source: Reddit r/ChatGPT)
Potentiel d’objectivité de l’IA dans les reportages d’actualité et limites actuelles: Un utilisateur a testé le potentiel du modèle o3 d’OpenAI en tant que “journaliste impartial” en lui demandant de commenter les conséquences “contre-productives” potentielles de plusieurs politiques des administrations Trump et Biden depuis 2017. Bien que l’IA puisse générer une analyse d’apparence objective, ses sources d’information, ses biais potentiels et sa véritable profondeur de compréhension des dynamiques politico-économiques complexes restent des problèmes à résoudre à l’avenir. Cela reflète les attentes de la communauté quant à l’utilisation de l’IA pour améliorer l’objectivité et la profondeur des informations, ainsi que la prise de conscience des limites technologiques actuelles (Source: Reddit r/deeplearning)