
Palavras-chave:computação quântica, condução autônoma, modelos de linguagem de grande escala, modelos de geração 3D, ferramentas de IA, aprendizado de máquina, pesquisa em inteligência artificial, plataforma de computação quântica CUDA-Q, pesquisa de dados de condução autônoma da Waymo, sistema multiagente Claude, Tencent Hunyuan 3D 2.1, otimização de desempenho do núcleo de geração por IA
🔥 Foco
Nvidia lança plataforma CUDA-Q dedicada à computação quântica: Jensen Huang, CEO da Nvidia, anunciou em seu discurso na GTC Paris o lançamento do CUDA-Q, uma plataforma de supercomputação quântico-clássica acelerada. A plataforma visa preencher a lacuna entre a computação clássica atual e a futura computação quântica, permitindo simular operações quânticas em computadores clássicos ou auxiliar computadores quânticos reais. O CUDA-Q já está disponível no Grace Blackwell e pode aumentar a velocidade de desenvolvimento em 1300 vezes através do supercomputador GB200 NVL72. Huang previu que a aplicação prática de computadores quânticos se concretizará em poucos anos e enfatizou que, nesta fase de desenvolvimento, os chips da Nvidia (especialmente o GB200) são indispensáveis para simulação computacional e para auxiliar as QPUs. A Nvidia está colaborando com empresas de computação quântica e centros de supercomputação globais para explorar o trabalho sinérgico entre GPUs e QPUs (Fonte: QbitAI)

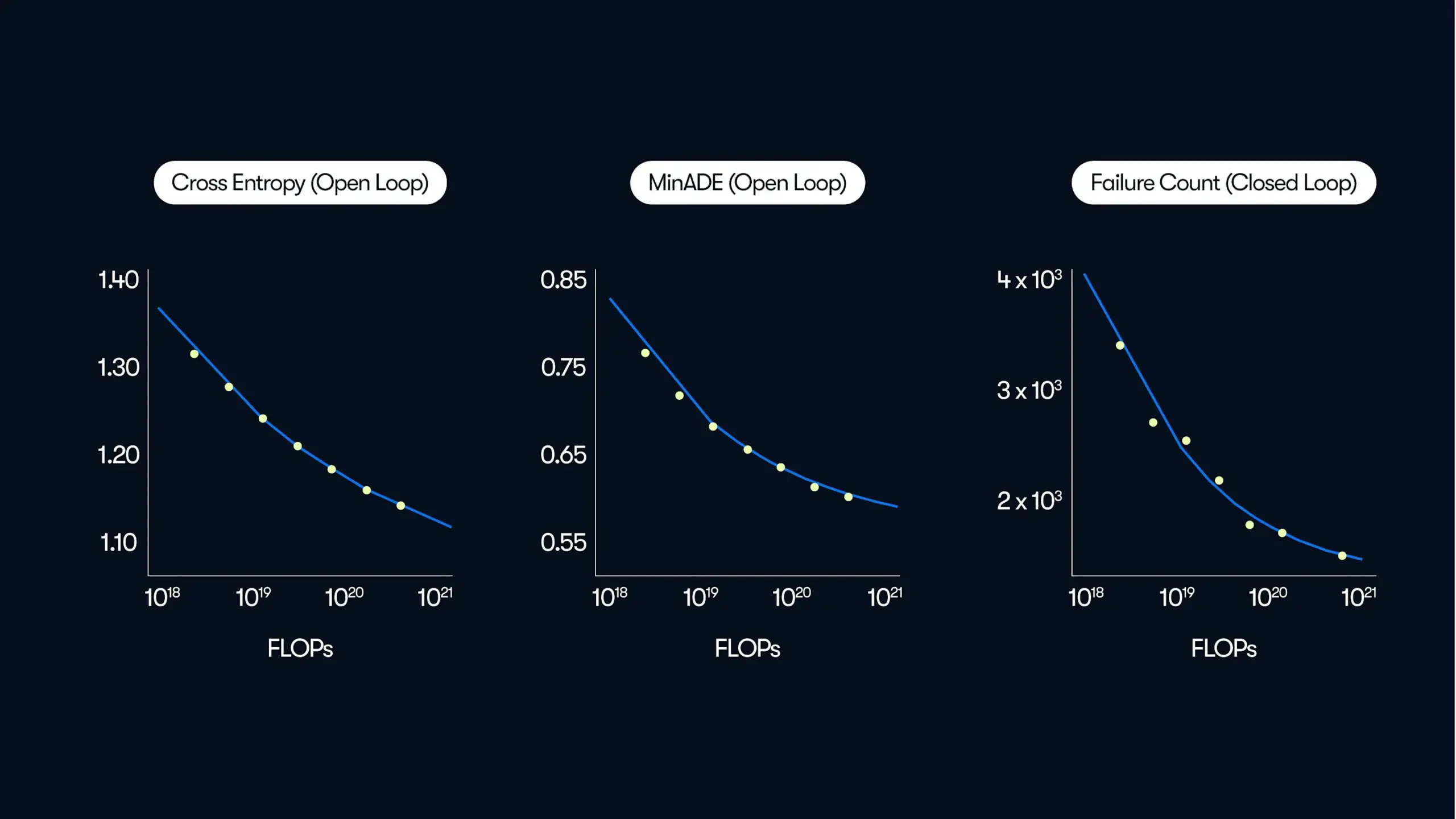
Waymo divulga pesquisa em larga escala sobre direção autônoma, revelando a lei de melhoria de desempenho “orientada por dados”: Em sua postagem de blog mais recente, a Waymo compartilhou os resultados de um estudo abrangente baseado em 500.000 horas de dados de direção, o maior conjunto de dados do setor de direção autônoma até o momento. A pesquisa indica que, semelhante aos grandes modelos de linguagem (LLM), a qualidade da previsão de movimento dos sistemas de direção autônoma também segue uma relação de lei de potência com o aumento do volume de computação de treinamento. A expansão da escala dos dados é crucial para melhorar o desempenho do modelo, enquanto a ampliação da capacidade de computação de inferência também pode aumentar a capacidade do modelo de lidar com cenários de direção complexos. Este estudo confirma pela primeira vez que, aumentando os dados de treinamento e os recursos computacionais, o desempenho da direção autônoma no mundo real pode ser significativamente melhorado, apontando para a indústria um caminho para aumentar as capacidades através da escala (Fonte: Sawyer Merritt, scaling01)
Anthropic compartilha experiência na construção do sistema de pesquisa multiagente Claude: Em seu blog de engenharia, a Anthropic detalhou como utiliza múltiplos agentes trabalhando em paralelo para construir as capacidades de pesquisa do Claude. O artigo compartilha experiências bem-sucedidas durante o processo de desenvolvimento, problemas encontrados e desafios de engenharia. Este sistema multiagente permite que o Claude recupere, analise e sintetize informações de forma mais eficaz, melhorando assim sua capacidade de pesquisar e responder a perguntas complexas. Este compartilhamento tem um valor de referência importante para entender como os grandes modelos de linguagem podem expandir suas funcionalidades através do design de sistemas complexos (Fonte: ImazAngel, teortaxesTex)
Meta lança modelo mundial V-JEPA 2, alcançando compreensão de vídeo, previsão e controle de robôs: A Meta AI lançou o V-JEPA 2, um modelo mundial treinado com base em vídeo, que alcançou progressos significativos na compreensão e previsão da dinâmica do mundo físico. O V-JEPA 2 não apenas realiza aprendizado eficiente de características de vídeo, mas também pode alcançar planejamento zero-shot e controle de robôs em novos ambientes, demonstrando seu potencial no campo da inteligência artificial geral. O modelo aprende representações do mundo a partir de dados de vídeo através de aprendizado auto-supervisionado, fornecendo um novo caminho para construir sistemas de IA mais inteligentes e capazes de interagir com o mundo real (Fonte: dl_weekly)
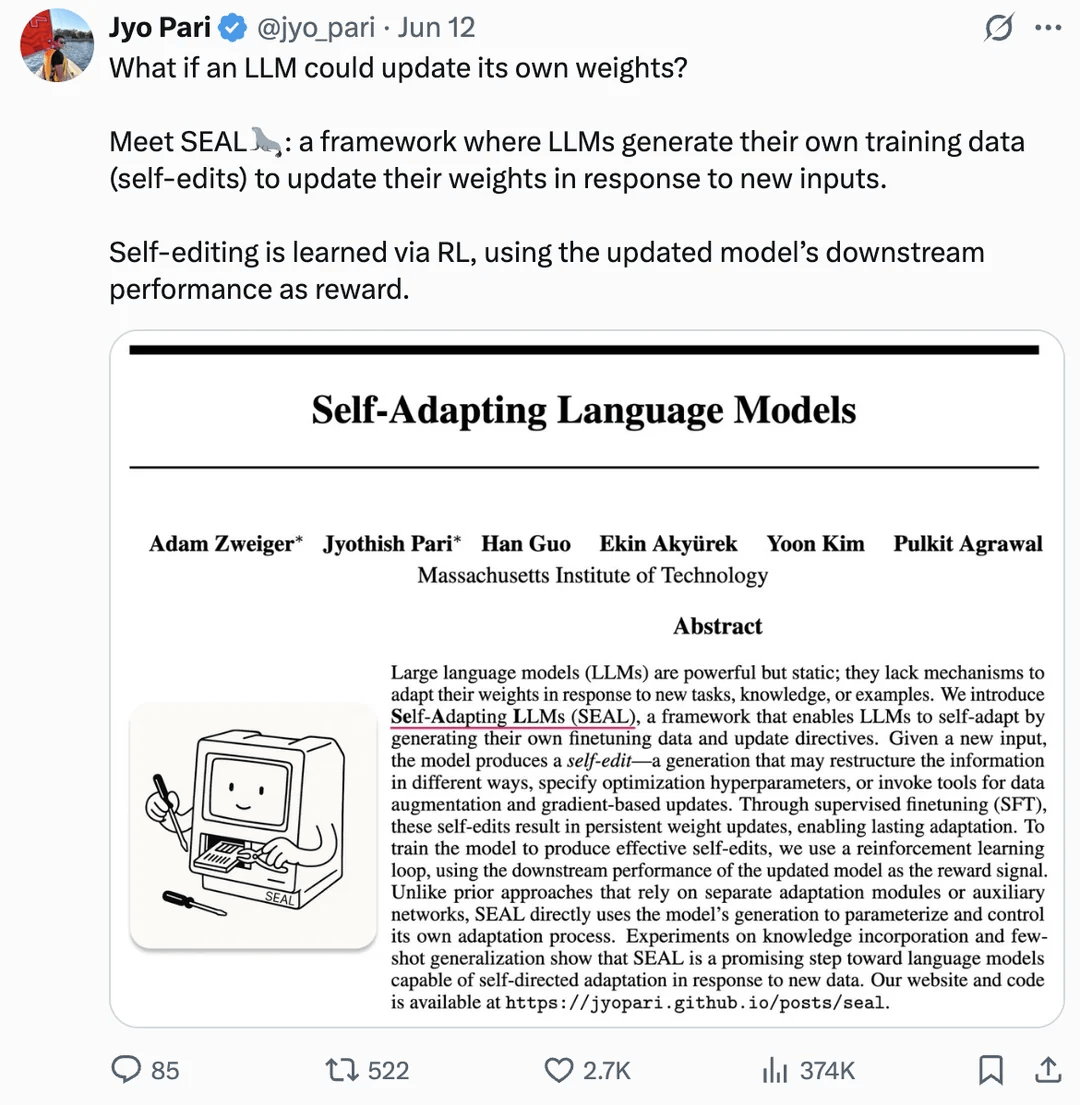
Artigo discute auto-atualização de pesos de LLM para alcançar auto-aperfeiçoamento: Um artigo publicado no arXiv (2506.10943) propõe que os grandes modelos de linguagem (LLM) agora podem se auto-aperfeiçoar atualizando seus próprios pesos. Esse mecanismo pode significar que os LLMs são capazes de aprender com novos dados ou experiências e ajustar dinamicamente seus parâmetros internos para melhorar o desempenho ou se adaptar a novas tarefas, sem a necessidade de um retreinamento completo. Se bem-sucedida, esta linha de pesquisa aumentará muito a adaptabilidade e a capacidade de aprendizado contínuo dos LLMs, sendo um passo importante em direção a sistemas de IA mais autônomos (Fonte: Reddit r/artificial)
🎯 Tendências
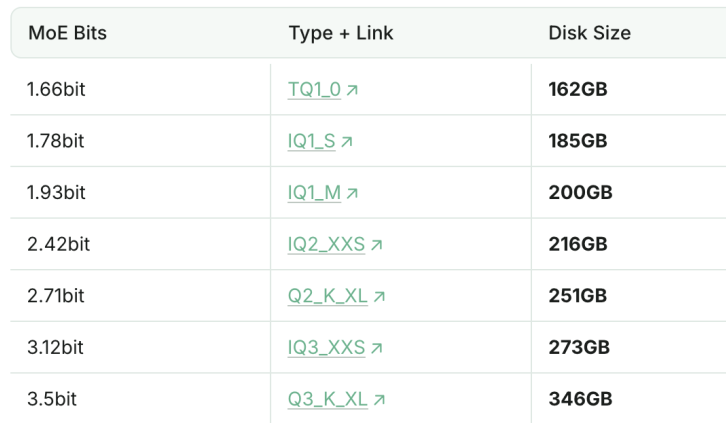
Versão quantizada de 1.93bit do DeepSeek-R1 supera Claude 4 Sonnet em capacidade de programação: O estúdio Unsloth quantizou com sucesso o DeepSeek-R1 (versão 0528) para 1.93bit, alcançando uma pontuação de 60% no benchmark de programação aider, superando o Claude 4 Sonnet (56.4%) e a versão completa do R1 de janeiro. O tamanho do arquivo desta versão extremamente comprimida foi reduzido em mais de 70%, podendo até mesmo rodar sem GPU (CPU com memória suficiente). A versão completa do R1-0528 obteve 71.4% no aider, superando o Claude 4 Opus sem o modo de pensamento ativado. Isso demonstra o potencial da tecnologia de quantização de modelos em manter o desempenho enquanto reduz drasticamente os requisitos de recursos (Fonte: QbitAI)
Tencent Hunyuan torna open source o primeiro modelo de geração 3D PBR de nível de produção, Hunyuan 3D 2.1: A equipe Tencent Hunyuan anunciou o open source do Hunyuan 3D 2.1, o primeiro modelo de geração 3D PBR (Physically Based Rendering) totalmente open source e de nível de produção da indústria. O modelo utiliza tecnologia de síntese de material PBR para gerar conteúdo 3D com efeitos visuais de nível cinematográfico, tornando materiais como couro e bronze mais vívidos e realistas sob iluminação. O projeto disponibilizou os pesos do modelo, código de treinamento/inferência, pipeline de dados e arquitetura, e suporta execução em placas de vídeo de consumo, visando promover o desenvolvimento e a popularização da tecnologia de geração de conteúdo 3D (Fonte: op7418, ImazAngel)
Meta AI lança Sonata, avançando no aprendizado auto-supervisionado para representações de nuvem de pontos 3D: A Meta AI apresentou o Sonata, uma pesquisa que alcançou progressos significativos no campo do aprendizado auto-supervisionado 3D. O Sonata, ao identificar e resolver problemas de atalhos geométricos e introduzir um framework flexível e eficiente, é capaz de aprender representações de nuvem de pontos 3D excepcionalmente robustas. Este trabalho eleva o nível atual da tecnologia de percepção 3D e estabelece as bases para futuras inovações no campo da percepção 3D e suas aplicações (Fonte: AIatMeta)

Meta AI lança “Reading Recognition in the Wild dataset” para entender o comportamento de leitura: A Meta AI tornou público um grande conjunto de dados multimodal chamado “Reading Recognition in the Wild”, contendo vídeo, rastreamento ocular e saídas de sensores de postura da cabeça. O conjunto de dados visa ajudar a resolver tarefas de reconhecimento de leitura a partir de dispositivos vestíveis e é o primeiro conjunto de dados de perspectiva egocêntrica a coletar dados de rastreamento ocular em alta frequência de 60Hz, fornecendo um recurso valioso para o estudo do comportamento de leitura humana (Fonte: AIatMeta)

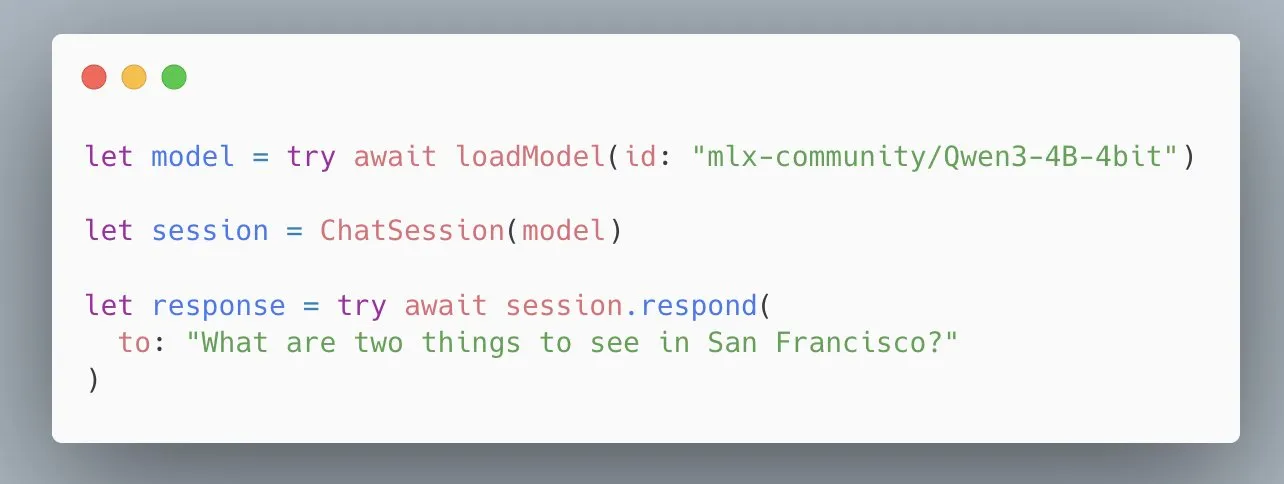
API MLX Swift LLM da Apple simplificada, carrega modelo em três linhas de código: Em resposta ao feedback dos desenvolvedores sobre a dificuldade de iniciar com a API MLX Swift LLM, a equipe da Apple agiu rapidamente para melhorá-la, lançando uma nova API simplificada. Agora, os desenvolvedores precisam de apenas três linhas de código para carregar um LLM ou VLM em seus projetos Swift e iniciar uma sessão de chat, reduzindo significativamente a barreira para usar grandes modelos de linguagem no ecossistema da Apple (Fonte: stablequan)
Google Gemma3 4B lança versão GAIA otimizada para português do Brasil: O Google, em colaboração com várias instituições brasileiras (ABRIA, CEIA-UFG, Nama, Amadeus AI) e a DeepMind, lançou o modelo de linguagem open source GAIA (Gemma-3-Gaia-PT-BR-4b-it), otimizado para o português do Brasil. O modelo é baseado no Gemma-3-4b-pt e passou por pré-treinamento contínuo em 13 bilhões de tokens de português do Brasil de alta qualidade. O GAIA utiliza uma técnica inovadora de “fusão de pesos” para seguir instruções, dispensando o SFT tradicional, e superou o modelo Gemma base no benchmark ENEM 2024. O modelo é adequado para chat, perguntas e respostas, resumo, geração de texto e como modelo base para fine-tuning em português do Brasil (Fonte: Reddit r/LocalLLaMA)
Robô da Figure AI integra Helix AI e autonomia, impulsionando implantação escalável: A Figure AI demonstrou como seus robôs do mundo real estão impulsionando a implantação escalável através do aprimoramento do Helix AI e da autonomia. Isso indica que a combinação de robôs físicos com modelos avançados de IA está tornando possível a aplicação de robôs em ambientes mais complexos e destaca a importância da engenharia e das tecnologias emergentes no campo da robótica (Fonte: Ronald_vanLoon)
Sakana AI lança super-rede Text-to-LoRA (T2L): A Sakana AI lançou o Text-to-LoRA (T2L), uma nova super-rede capaz de comprimir múltiplos LoRAs (Low-Rank Adaptation) existentes em si mesma e gerar rapidamente novos adaptadores LoRA para grandes modelos de linguagem apenas através da descrição textual da tarefa. Após o treinamento, o T2L pode criar instantaneamente novos LoRAs, fornecendo um caminho eficiente para personalização rápida e implantação de LLMs para tarefas específicas. Os resultados relevantes serão apresentados na ICML 2025 (Fonte: TheTuringPost)
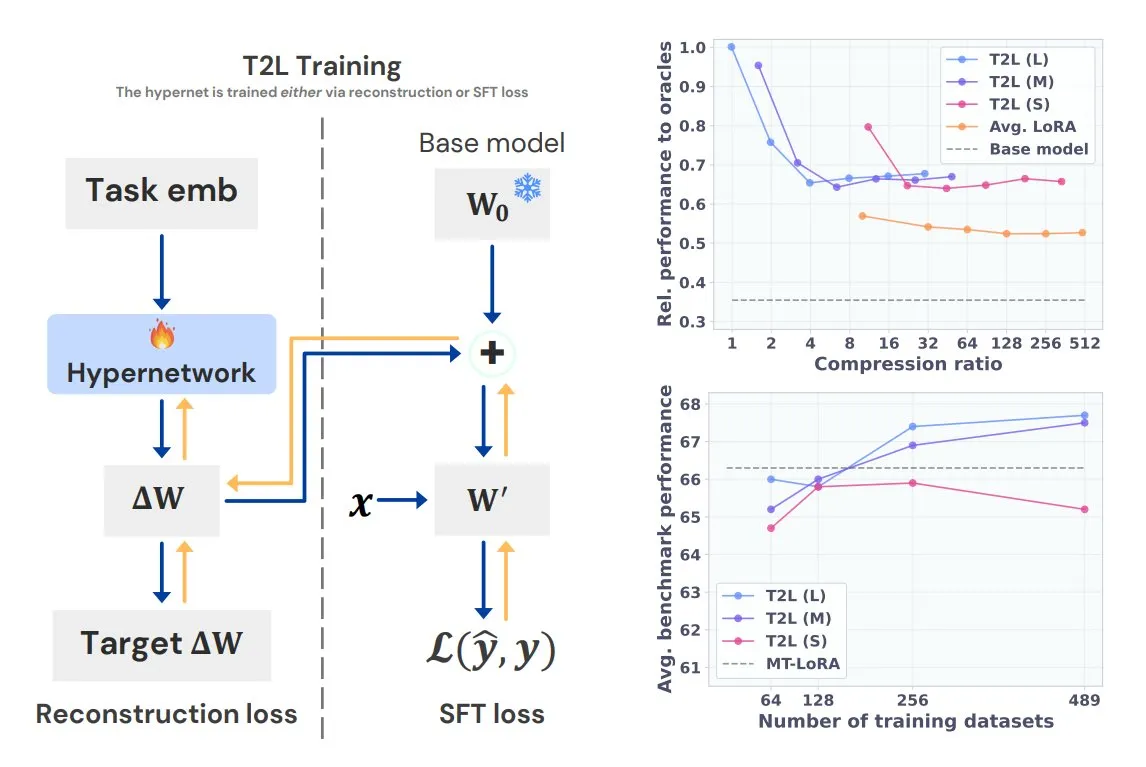
Pesquisa de IA do Baidu totalmente lançada na plataforma Baidu Smart Cloud Qianfan: A plataforma de desenvolvimento de aplicativos Baidu Smart Cloud Qianfan AppBuilder lançou oficialmente o serviço “Baidu AI Search”. Este serviço integra as duas capacidades principais “Baidu Search” e “Geração de Pesquisa Inteligente”, fornecendo às empresas um serviço completo, desde a recuperação de informações até a geração inteligente. Ele utiliza os mais de 20 anos de tecnologia de busca em chinês do Baidu e um banco de dados de centenas de bilhões de entradas para fornecer resultados de busca multimodais sem anúncios, e suporta filtragem precisa, rastreamento de fontes e políticas de segurança de nível empresarial. A capacidade de geração de pesquisa inteligente, combinada com modelos como Wenxin e Deepseek, oferece resumo por IA, busca conjunta em conhecimento privado e outras funções (Fonte: QbitAI)
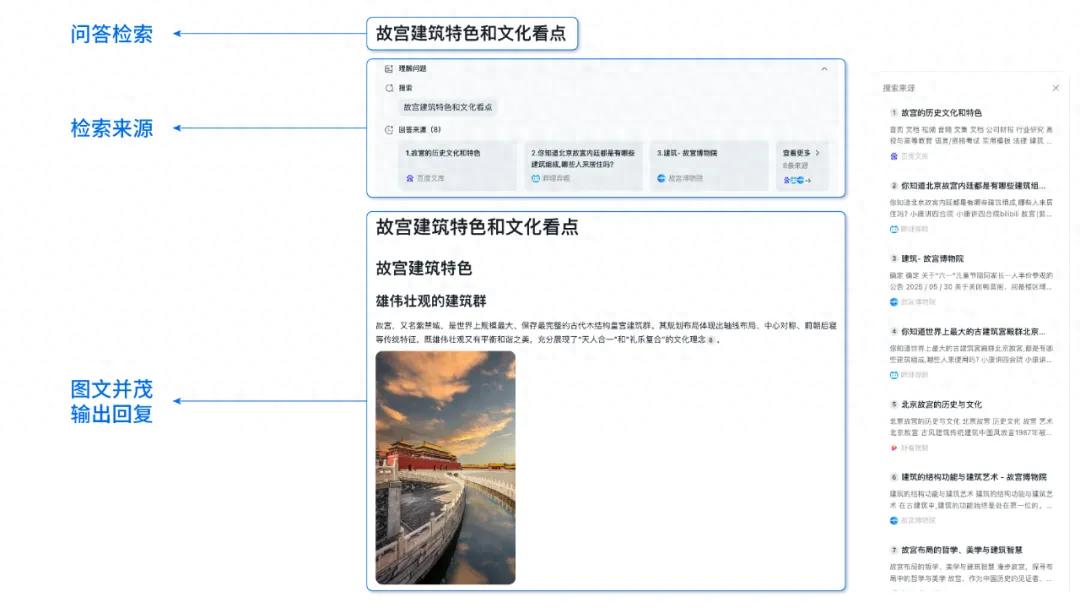
Estudo mostra que o desempenho de kernels gerados por IA se aproxima ou até supera os kernels otimizados por especialistas: O artigo de blog de Anne Ouyang aponta que os kernels de IA gerados por meio de uma simples busca apenas em tempo de teste (test-time only search) já se aproximam, e em alguns casos superam, o desempenho dos kernels de produção padrão otimizados por especialistas no PyTorch. Isso indica o enorme potencial da IA na otimização de código e melhoria de desempenho, podendo desempenhar um papel mais importante na otimização de bibliotecas de baixo nível no futuro (Fonte: jeremyphoward)
Pesquisa “Diffusion Duality” propõe novo método para geração em poucos passos em modelos de linguagem de difusão discreta: Um artigo publicado na ICML 2025, intitulado “The Diffusion Duality”, propõe um novo método que, ao utilizar a difusão gaussiana latente, alcança a geração em poucos passos em modelos de linguagem de difusão discreta. O método superou os modelos autorregressivos (AR) em 3 de 7 benchmarks de verossimilhança zero-shot, oferecendo novas ideias para aumentar a eficiência da geração de modelos de difusão (Fonte: arankomatsuzaki)
Novo avanço na interpretabilidade da camada MLP: decomposição de ativações em características interpretáveis: Uma nova pesquisa de Mor Geva e colegas demonstra um método simples para decompor as ativações de perceptrons multicamadas (MLP) em características interpretáveis. O método revela uma hierarquia oculta de conceitos, onde combinações esparsas de neurônios formam conceitos cada vez mais abstratos, fornecendo uma perspectiva mais profunda para entender o funcionamento interno das redes neurais (Fonte: menhguin)

Framework HeadHunter alcança controle refinado sobre orientação de atenção perturbada: Sayak Paul e colegas propuseram o framework HeadHunter para análise baseada em princípios da orientação de atenção perturbada. O framework permite um controle profundo e refinado sobre a qualidade da geração e os atributos visuais, fornecendo novas ferramentas e insights para melhorar e personalizar a saída de modelos generativos (Fonte: huggingface, RisingSayak)

🧰 Ferramentas
Planos pagos do Windsurf agora suportam Claude Sonnet 4: O Windsurf anunciou que todos os seus planos pagos agora incluem o modelo Claude Sonnet 4. Os usuários podem agora utilizar as poderosas capacidades deste mais recente modelo da Anthropic na plataforma Windsurf para tarefas como geração de texto, conversação, entre outras, melhorando ainda mais o desempenho e a experiência do assistente de IA (Fonte: op7418)
Anthropic lança SDK Python oficial para Claude Code: A Anthropic lançou oficialmente o SDK Python para Claude Code, com o objetivo de facilitar aos desenvolvedores a integração das capacidades de geração de código e uso de ferramentas do Claude em seus próprios projetos Python. O SDK suporta o uso de ferramentas, saída em streaming, operações síncronas/assíncronas, processamento de arquivos e possui uma estrutura de chat integrada, simplificando o processo de desenvolvimento para interagir com o Claude Code (Fonte: Reddit r/ClaudeAI)
Extensão Claude Task Master para VS Code lançada: DevDreed lançou a versão 1.0.0 da extensão Claude Task Master para VS Code, que visa complementar o projeto Claude Task Master AI de eyaltoledano, integrando diretamente a saída do Claude Task Master na interface do VS Code, facilitando aos usuários a alternância perfeita entre o editor e o console, aumentando a eficiência do desenvolvimento (Fonte: Reddit r/ClaudeAI)
SmartSelect AI: Ferramenta de processamento de IA para texto e imagem no navegador: Uma extensão do Chrome chamada SmartSelect AI foi lançada, permitindo aos usuários resumir, traduzir ou conversar diretamente sobre o texto selecionado enquanto navegam na web, e obter descrições de IA para imagens, sem a necessidade de alternar abas ou copiar e colar em aplicativos externos como o ChatGPT. A ferramenta é baseada no modelo Gemini e visa aumentar a eficiência na obtenção e processamento de informações (Fonte: Reddit r/deeplearning)

Unsiloed AI torna open source ferramenta multifuncional de divisão de dados: A Unsiloed AI (EF 2024) tornou open source parte de sua funcionalidade de divisão de dados (chunker). A ferramenta visa ajudar no processamento de documentos em vários formatos, como PDF, Excel, PPT, convertendo-os em formatos adequados para processamento por grandes modelos de linguagem. A Unsiloed AI já é utilizada por empresas da Fortune 100 e várias startups para ingestão de dados multimodais (Fonte: Reddit r/LocalLLaMA)
Claude Superprompt System: Ferramenta gratuita para otimizar prompts do Claude: Igor Warzocha desenvolveu e compartilhou uma ferramenta online chamada “Claude Superprompt System”, projetada para ajudar os usuários a transformar solicitações simples em prompts complexos, estruturados, contendo cadeias de pensamento e exemplos contextuais, para melhor utilizar as capacidades do Claude. A ferramenta é baseada na documentação oficial da Anthropic e nas melhores práticas descobertas pela comunidade, otimizando os prompts através de estruturação com tags XML, blocos de raciocínio CoT, entre outros, para melhorar a qualidade da saída do Claude. O código do projeto está disponível como open source no GitHub (Fonte: Reddit r/artificial)
Plugin local de TTS para Firefox Kokoro-TTS lançado: O desenvolvedor Pinguy lançou um plugin para Firefox chamado Kokoro TTS, que usa um modelo de rede neural hospedado localmente com 82 milhões de parâmetros (modelo Kokoro TTS) para conversão de texto em fala, funcionando totalmente offline e protegendo a privacidade do usuário. Suporta várias vozes e sotaques, e funciona fluentemente mesmo em hardware antigo, oferecendo versões para Windows, Linux e macOS (Fonte: Reddit r/artificial)
Spy Search: Atualização do projeto de motor de busca LLM open source: JasonHonKL atualizou seu projeto de motor de busca LLM open source, Spy Search. O projeto se dedica a construir um motor de busca eficiente baseado em grandes modelos de linguagem, e a versão mais recente já consegue pesquisar e responder em menos de 3 segundos. O código do projeto está hospedado no GitHub e visa fornecer aos usuários uma ferramenta de busca diária rápida e útil (Fonte: Reddit r/deeplearning)
HandFonted: Ferramenta open source para converter caligrafia em fonte: Resham Gaire desenvolveu e tornou open source o projeto HandFonted, uma aplicação Python de ponta a ponta que converte imagens de caracteres manuscritos em arquivos de fonte .ttf instaláveis. O sistema utiliza OpenCV para processamento de imagem e segmentação de caracteres, um modelo PyTorch personalizado (ResNet-Inception) para classificação de caracteres, e o algoritmo Húngaro para melhor correspondência, finalmente usando a biblioteca fontTools para gerar o arquivo de fonte (Fonte: Reddit r/MachineLearning)
📚 Aprendizado
Artigo de Wei Dongyi e outros lidera revista de matemática, investigando fenômeno de explosão em equação de onda não linear deslocalizante supercrítica: O artigo “On blow-up for the supercritical defocusing nonlinear wave equation”, de Wei Dongyi, Zhang Zhifei e Shao Feng, acadêmicos da Universidade de Pequim, foi publicado na renomada revista de matemática “Forum of Mathematics, Pi”. A pesquisa explora o problema da explosão (solução que se torna infinita em tempo finito) para uma equação de onda não linear deslocalizante específica no estado supercrítico. Eles provaram que, para dimensão espacial d=4 e p≥29, e para d≥5 e p≥17, existem soluções complexas suaves que explodem em tempo finito. Este resultado preenche uma lacuna no campo e seu método de prova oferece novas ideias para o estudo da explosão em outras equações diferenciais parciais não lineares (Fonte: QbitAI)

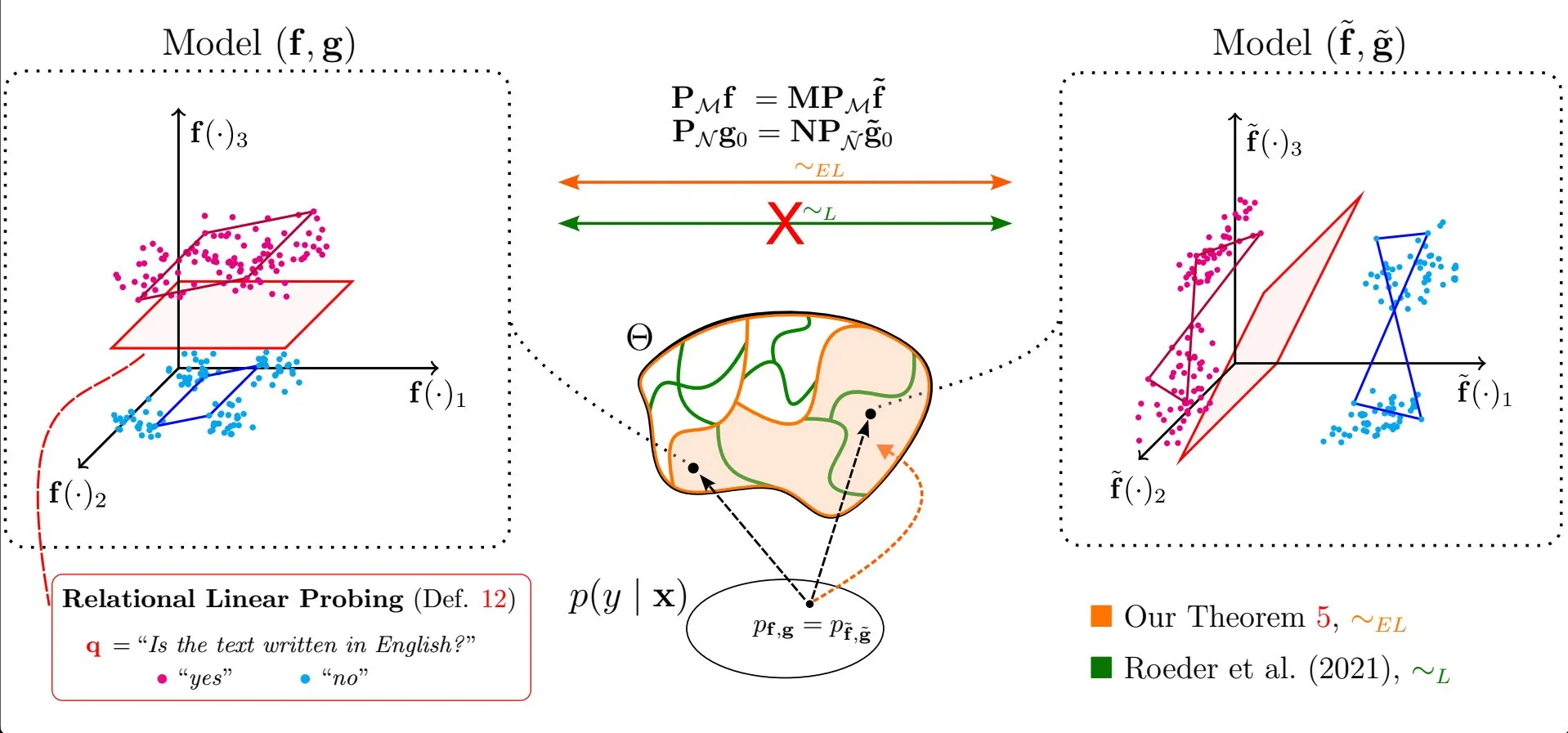
Artigo explora a universalidade das propriedades lineares nas representações de grandes modelos de linguagem: A pesquisa de Emanuele Marconato e colegas, “All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling” (publicada na AISTATS 2025), explora, da perspectiva da identificabilidade, por que as propriedades lineares são tão prevalentes nas representações de grandes modelos de linguagem (LLM). Este estudo ajuda a entender mais profundamente a estrutura e o comportamento das representações internas dos LLMs (Fonte: menhguin)
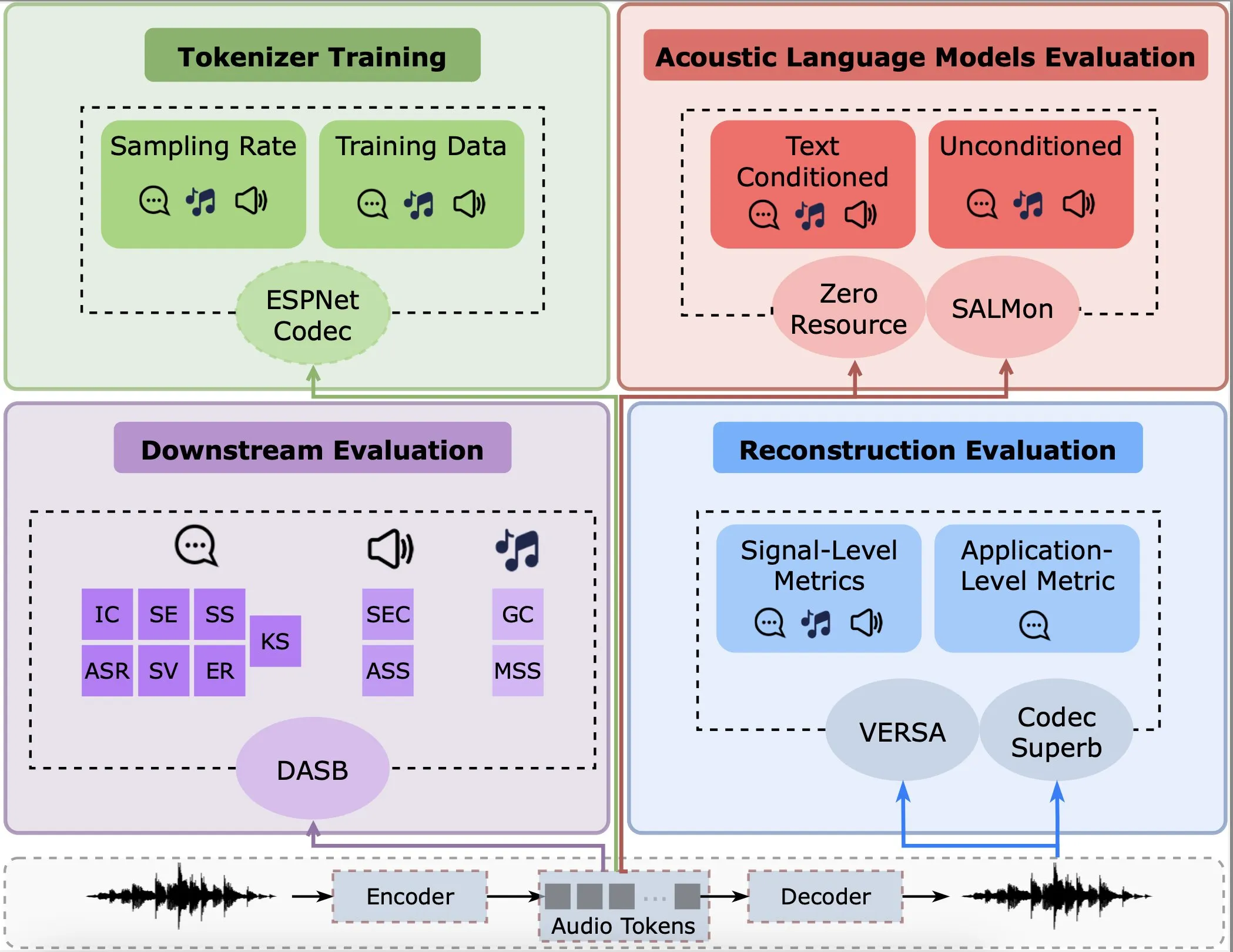
Estudo analisa o desempenho de codificadores de áudio na reconstrução, tarefas downstream e modelos de linguagem: Gallil Maimon e colegas publicaram uma nova pesquisa realizando uma análise empírica abrangente dos codificadores de áudio existentes (Audio Tokenisers). O estudo avaliou esses codificadores em múltiplas dimensões, como qualidade de reconstrução, desempenho em tarefas downstream e integração com modelos de linguagem, fornecendo referências para a seleção e otimização de modelos de processamento de áudio (Fonte: menhguin)
Artigo discute “ilusão de pensamento”: entendendo os prós e contras dos modelos de raciocínio da perspectiva da complexidade do problema: Um artigo de resposta à pesquisa da Apple sobre “ilusão de pensamento” (arXiv:2506.09250) foi submetido, com Claude Opus listado como primeiro autor. O artigo critica o design experimental da pesquisa da Apple e argumenta que o colapso de raciocínio observado é, na verdade, causado por limitações de token, e não por uma falta intrínseca de capacidade lógica do modelo. Isso gerou discussões sobre como avaliar a verdadeira capacidade de raciocínio dos grandes modelos de linguagem (Fonte: NandoDF, BlancheMinerva, teortaxesTex)

Estudo explora modelos de linguagem adaptativos, mas memória de médio prazo ainda é um desafio: Após ler artigos relacionados a “modelos de linguagem adaptativos”, Dorialexander apontou que, embora seja uma direção de pesquisa promissora, ainda existem limitações para que os modelos alcancem memória de médio prazo durante o raciocínio. Isso indica que os modelos atuais ainda enfrentam desafios ao processar informações coerentes que abrangem contextos mais longos (Fonte: Dorialexander)

Pesquisa sobre a qualidade dos testes RLHF: Quão bons são os testes atuais? Como melhorá-los? Quão importante é a qualidade dos testes?: O trabalho mais recente de Kexun Zhang e colegas explora a importância dos validadores (testes) no Aprendizado por Reforço com Feedback Humano (RLHF), especialmente no domínio da codificação por LLM. A pesquisa levanta três questões cruciais: Qual é a qualidade dos testes atuais? Como obter testes melhores? Qual o impacto da qualidade dos testes no desempenho do modelo? O estudo enfatiza a necessidade de testes de alta qualidade para melhorar as capacidades de codificação dos LLMs (Fonte: StringChaos)
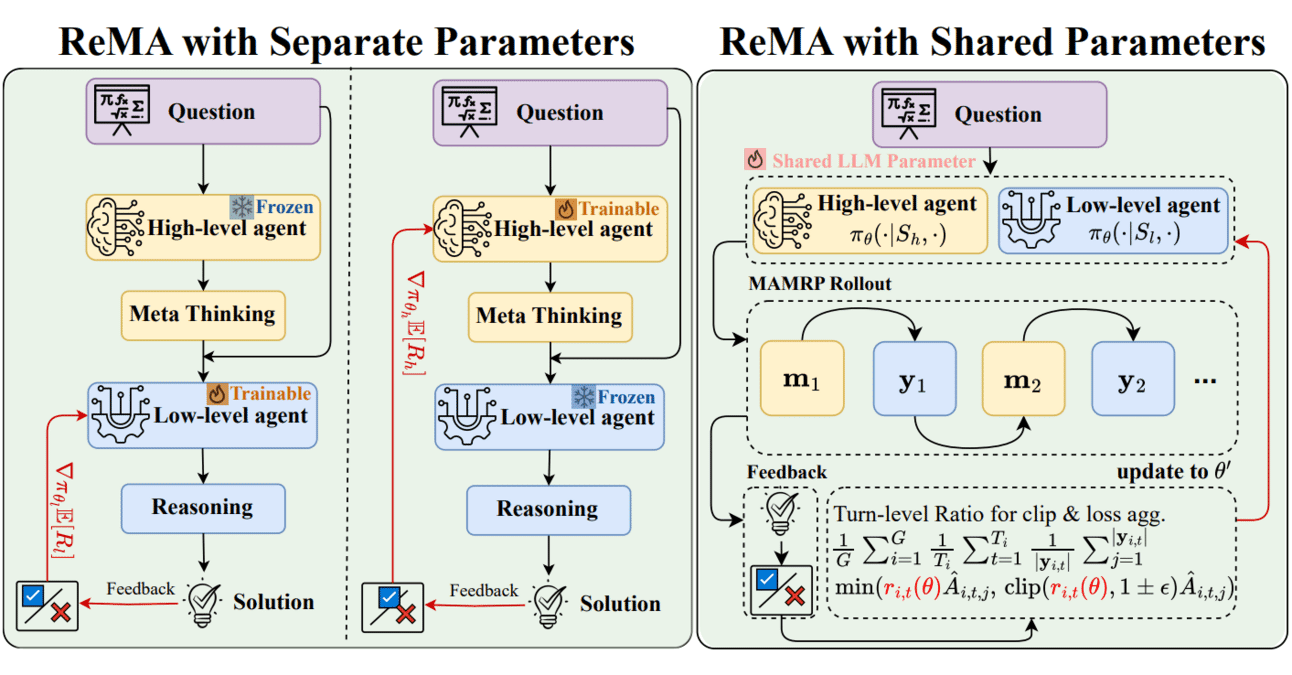
Combinação de Meta-learning e Aprendizado por Reforço: ReMA aumenta a eficiência colaborativa de LLMs: Reinforced Meta-thinking Agents (ReMA) combina meta-aprendizado (Meta-learning) e aprendizado por reforço (RL) para aumentar a eficiência de grandes modelos de linguagem (LLM), especialmente quando múltiplos agentes LLM trabalham colaborativamente. ReMA divide a resolução de problemas em meta-pensamento (planejamento de estratégias) e raciocínio (execução de estratégias), otimizando através de agentes especializados e aprendizado por reforço multiagente, alcançando melhorias em benchmarks matemáticos e benchmarks com LLM como juiz (Fonte: TheTuringPost, TheTuringPost)
Estratégias de avaliação de IA: Como combinar avaliadores baratos e caros sob restrições orçamentárias para obter a melhor estimativa da qualidade do modelo: A pesquisa de Adam Fisch e colegas (arXiv:2506.07949) explora um problema prático: quando se tem um avaliador barato, mas ruidoso, um avaliador caro, mas preciso, e um orçamento fixo, como alocar o orçamento para obter a estimativa mais precisa da qualidade do modelo. O estudo fornece um framework de análise de custo-benefício para a avaliação de sistemas de IA (Fonte: Ar_Douillard)
Fenômenos de “recompensa espúria” e “prompt espúrio” em prompts de LLM: A pesquisa de Stella Li e colegas revela fenômenos interessantes no treinamento e avaliação de LLMs. Após descobrir “recompensas espúrias” (como recompensas aleatórias que também podem melhorar o desempenho do modelo em certas tarefas), eles exploraram ainda mais “prompts espúrios”, onde mesmo textos sem sentido como “Lorem ipsum” podem, em alguns casos, trazer melhorias significativas de desempenho (como 19,4%). Essas descobertas levantam novos desafios e reflexões sobre como os LLMs respondem a prompts e como projetar métodos de avaliação mais robustos (Fonte: Tim_Dettmers)

Artigo discute modelo de “teatro de marionetes” para interação com IA: Um artigo (ou rascunho) intitulado “The Pig in Yellow: AI Interface as Puppet Theatre” propõe considerar sistemas de IA de linguagem (LLM, AGI, ASI) como interfaces performativas, que simulam subjetividade em vez de possuí-la. O artigo usa “Miss Piggy” como metáfora, analisando que a fluidez, coerência e expressão emocional da IA não são indicadores de mente, mas produtos de otimização, enfatizando que a interface é como uma marionete, onde o usuário co-constrói significado na interação, e o poder se manifesta através do design performativo (Fonte: Reddit r/artificial)
💼 Negócios
Woan Technology, com participação do “padrinho da DJI” Li Zexiang, busca IPO: A Woan Technology (SwitchBot), fundada por ex-colegas da Universidade de Tecnologia de Harbin e focada em robôs domésticos com IA incorporada, apresentou seu prospecto na bolsa de Hong Kong. A empresa recebeu investimento e apoio de recursos de Li Zexiang, o “padrinho da DJI”, que detém 12,98% das ações. Nos últimos dez anos, a Woan Technology acumulou sete rodadas de financiamento, com sua avaliação crescendo de 20 milhões para 4 bilhões de RMB. Seus produtos incluem robôs executores que simulam movimentos de membros humanos e sistemas de percepção e decisão, tornando-se o maior fornecedor global de robôs domésticos com IA incorporada, com uma participação de mercado de 11,9%, e alcançando um lucro líquido ajustado de 1,11 milhão de RMB em 2024 (Fonte: QbitAI)

Tencent lança “Plano Qingyun” 2026, abrindo pela primeira vez banco de recursos de projetos: A Tencent anunciou o lançamento do “Plano Qingyun” 2026, visando recrutar os melhores estudantes de tecnologia do mundo, cobrindo dez grandes áreas tecnológicas, incluindo grandes modelos de IA, infraestrutura básica, computação de alto desempenho, e oferecendo mais de cem projetos tecnológicos. Diferentemente dos anos anteriores, esta edição do plano abre pela primeira vez o banco de recursos de projetos Qingyun e oferece um canal verde de recrutamento para talentos excepcionais, com o objetivo de aprofundar a cooperação universidade-empresa e cultivar jovens talentos em tecnologia. A Tencent fornecerá professores de ponta da indústria, recursos de computação e remuneração competitiva (Fonte: QbitAI)

Humano digital de Luo Yonghao estreará no e-commerce do Baidu em 15 de junho: Luo Yonghao anunciou que seu avatar digital de IA fará sua estreia em直播 (transmissão ao vivo) na plataforma de e-commerce do Baidu em 15 de junho. Esta é a primeira vez que um streamer de ponta utiliza um humano digital de IA para vendas em直播, beneficiando-se dos avanços do Baidu em tecnologias chave como humanos digitais altamente persuasivos. Esta iniciativa é vista como uma exploração de um novo paradigma de e-commerce “IA + IP de ponta”, com potencial para impulsionar a indústria de直播 e-commerce em direção à inteligência, eficiência e baixo custo. Dados do e-commerce do Baidu mostram que mais de 100.000 streamers digitais já estão sendo aplicados em vários setores, reduzindo significativamente os custos operacionais dos comerciantes e aumentando o GMV (Fonte: QbitAI)
🌟 Comunidade
Empresas chinesas de IA transportam grandes volumes de dados em discos rígidos para a Malásia para treinar modelos: A NIK reportou que empresas chinesas de IA, para contornar restrições de chips e utilizar recursos computacionais no exterior, adotaram a estratégia de transportar fisicamente discos rígidos cheios de dados de treinamento para locais como a Malásia. Por exemplo, um engenheiro viajou para a Malásia com 15 discos rígidos contendo 80TB de dados para alugar servidores e treinar modelos. Este fenômeno reflete a intensa competição global por poder computacional de IA e os desafios práticos do fluxo transfronteiriço de dados, levantando também discussões sobre segurança de dados e conformidade (Fonte: jpt401, agihippo, cloneofsimo, fabianstelzer)

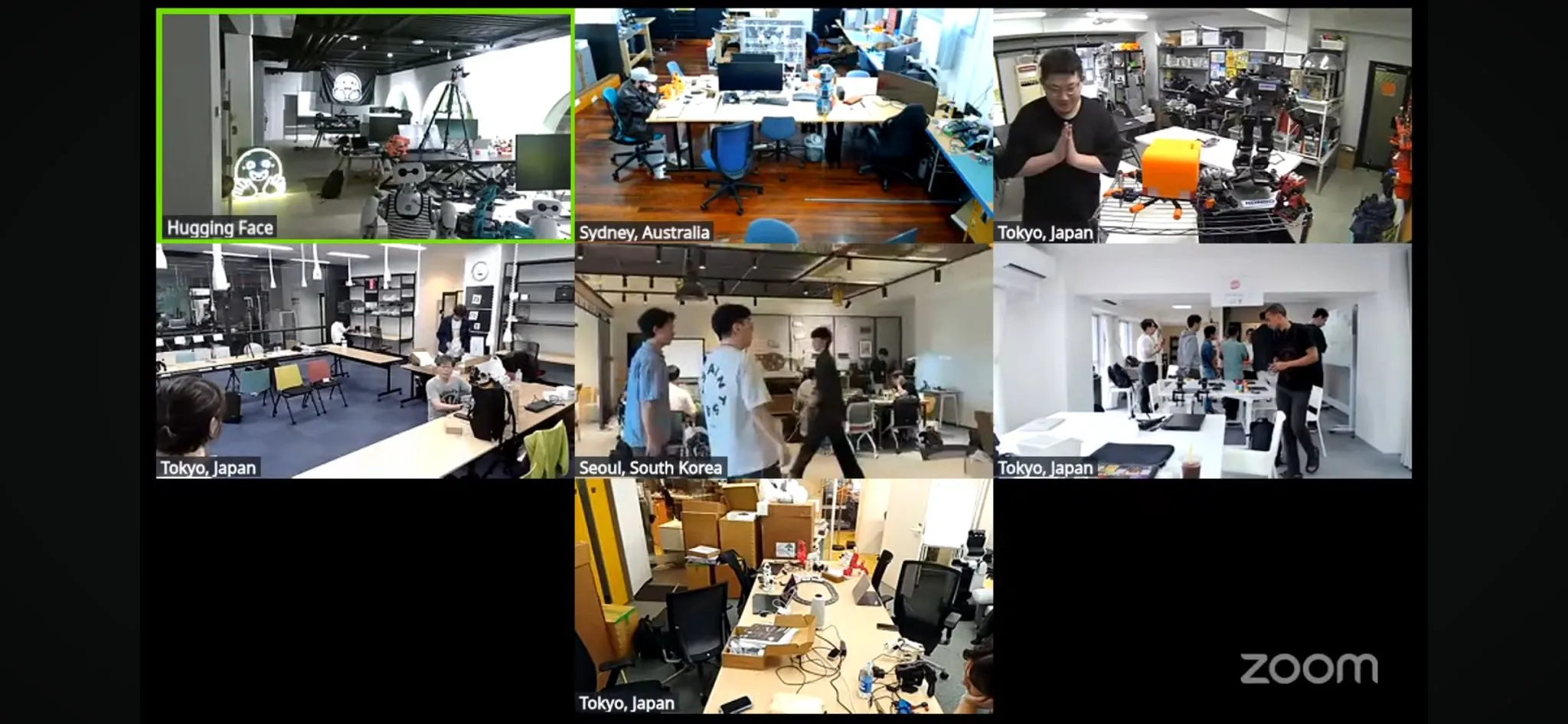
Maior hackathon de robótica LeRobot do mundo é lançado: O hackathon global de robótica LeRobot, organizado pela Hugging Face, foi oficialmente lançado, cobrindo mais de 100 locais em 5 continentes e atraindo mais de 2300 participantes. O evento visa promover o desenvolvimento de robôs de IA open source, e os participantes terão 52 horas para construir e explorar projetos relacionados a robôs. Desenvolvedores e equipes de todo o mundo participaram com entusiasmo, compartilhando fotos do local e o progresso de seus projetos, demonstrando o entusiasmo e a criatividade da comunidade pela tecnologia robótica (Fonte: _akhaliq, eliebakouch, ClementDelangue)
Lovable organiza duelo de geração de páginas web por IA, desempenho do Claude é elogiado: A Lovable organizou um evento permitindo que usuários utilizassem gratuitamente os modelos de ponta da OpenAI, Anthropic e Google para uma competição de geração de páginas web por IA. O usuário op7418 compartilhou sua experiência usando o mesmo conjunto de prompts para gerar páginas web com os três modelos, considerando que o Claude se destacou em termos de volume de conteúdo e efeitos visuais. Eventos como este oferecem aos desenvolvedores e usuários a oportunidade de comparar o desempenho de diferentes grandes modelos em cenários de aplicação específicos (Fonte: _philschmid, op7418)
Discussão sobre a capacidade de raciocínio de modelos de IA: limitação de tokens vs. lógica real: Em resposta ao artigo “Illusion of Thinking” proposto pela Apple, surgiram opiniões contrárias na comunidade. Comentários e pesquisas subsequentes (como arXiv:2506.09250, que lista Claude Opus como autor) argumentam que o “colapso” observado na capacidade de raciocínio dos modelos é mais devido à limitação do número de tokens do que a uma falha na capacidade lógica intrínseca dos modelos. Quando permitido que os modelos usem formatos de resposta mais concisos ou tenham contexto suficiente, eles conseguem resolver os problemas com sucesso. Isso gerou uma discussão aprofundada sobre como avaliar e entender com precisão a verdadeira capacidade de raciocínio dos grandes modelos de linguagem, bem como as possíveis limitações dos métodos de avaliação atuais (Fonte: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
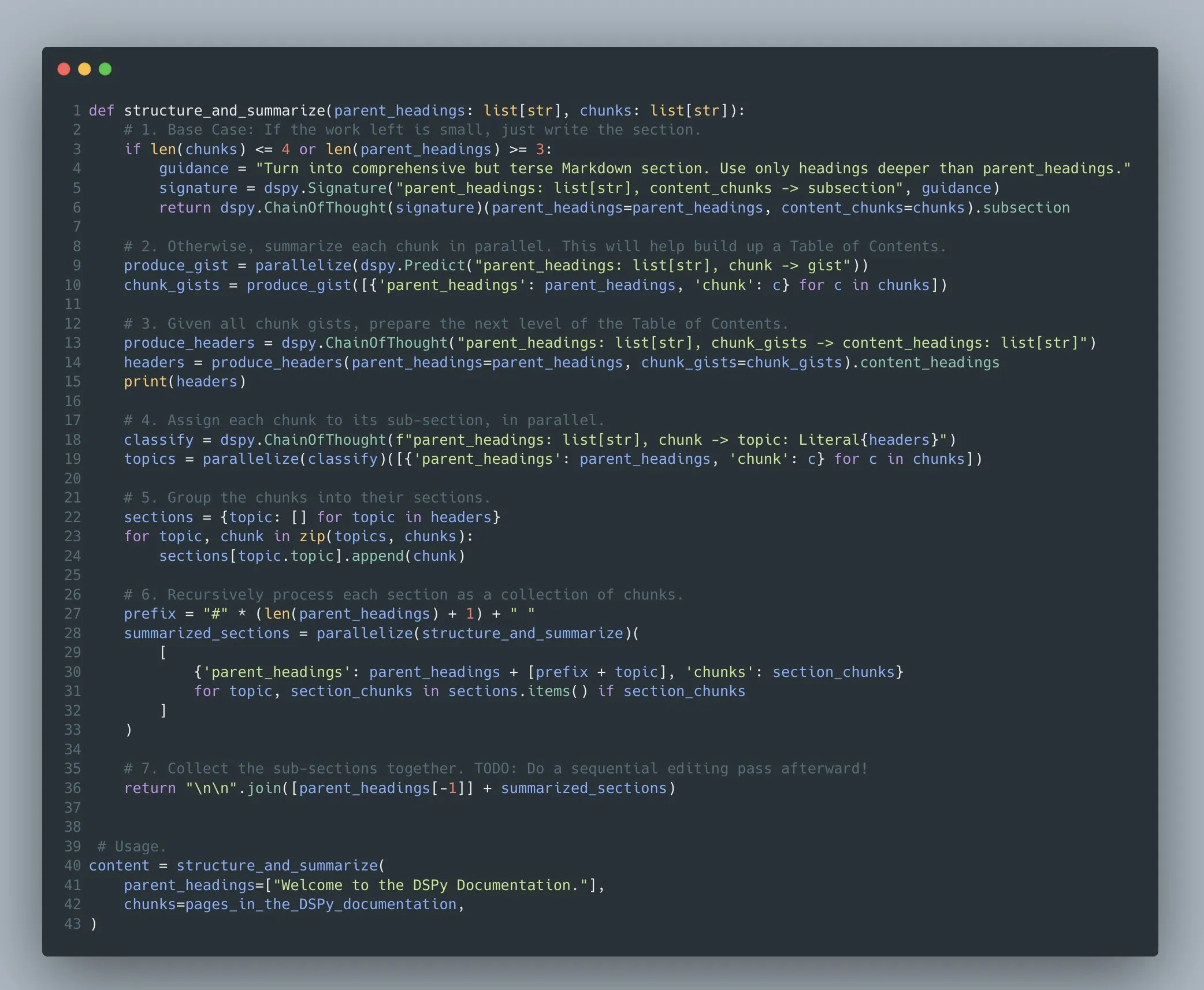
Framework DSPy suporta otimização de programas complexos de modelos de linguagem multiestágio: Omar Khattab enfatizou que o framework DSPy suporta, desde 2022/2023, a otimização de prompts e aprendizado por reforço para programas complexos de modelos de linguagem multiestágio (Compound AI Systems). Ele argumenta que, com a crescente complexidade dos sistemas de IA, é mais apropriado considerá-los como “programas” em vez de simples “modelos”. O DSPy visa fornecer suporte para a construção e otimização desses programas de complexidade arbitrária (incluindo recursão, tratamento de exceções, etc.), e não apenas “fluxos” ou “cadeias” lineares (Fonte: lateinteraction)
Discussão sobre se os LLMs são semelhantes ao pensamento humano: Geoffrey Hinton acredita que os grandes modelos de linguagem (LLM) são semelhantes à forma como os humanos processam a linguagem e são o nosso melhor modelo para entender como a linguagem funciona. No entanto, Pedro Domingos questiona isso, argumentando que o fato de os LLMs serem superiores às antigas teorias linguísticas não significa que eles pensem como os humanos. Esta discussão reflete o debate contínuo no campo da IA sobre a natureza dos LLMs e sua relação com a cognição humana (Fonte: pmddomingos)
IA tem enorme potencial de aplicação em pesquisa de ciências físicas: Um pesquisador da área de geociências compartilhou uma experiência positiva usando o o3 Pro (possivelmente referindo-se a algum modelo avançado da OpenAI), descrevendo-o como um “pós-doutorando muito inteligente” em sua pesquisa. O modelo demonstrou excelente desempenho em codificação, desenvolvimento de modelos e refinamento de ideias, executando instruções de forma rápida e precisa e auxiliando na pesquisa. O pesquisador acredita que, embora os modelos atuais ainda não possuam a capacidade de propor ativamente questões de pesquisa (uma característica da AGI), suas poderosas funções de auxílio já aumentaram significativamente a eficiência da pesquisa científica, e pressente que LLMs com autonomia não estão longe (Fonte: Reddit r/ArtificialInteligence)
💡 Outros
Ferramentas de geração de quadrinhos por IA tornam a expressão criativa mais conveniente: O usuário StriderWriting compartilhou sua experiência usando ferramentas de IA para criar quadrinhos, afirmando que a IA tornou possível transformar “ideias bobas” em quadrinhos. Isso reflete a popularização da IA no campo da geração de conteúdo criativo, reduzindo as barreiras à criação e permitindo que mais pessoas expressem facilmente suas ideias criativas (Fonte: Reddit r/ChatGPT)

Preocupações com o viés da IA: Desempenho do ChatGPT em estereótipos de gênero causa insatisfação do usuário: Uma usuária relatou que o ChatGPT demonstrou estereótipos negativos em relação aos homens em conversas, por exemplo, ao discutir questões de trabalho e médicas, presumiu que o papel negativo era masculino sem ser solicitado e usou comentários como “homens são detestáveis”. A usuária apontou que esse tipo de estereótipo preguiçoso baseado em gênero é desconfortável e questionou se a OpenAI tem regras para restringir tal comportamento. Isso reacendeu a discussão sobre o viés nos dados de treinamento de modelos de IA e como ele se manifesta nas interações (Fonte: Reddit r/ChatGPT)
Potencial e limitações atuais da IA na objetividade de reportagens jornalísticas: Um usuário testou o potencial do modelo o3 da OpenAI como um “repórter imparcial”, solicitando que comentasse as possíveis consequências “não intencionais” de várias políticas dos governos Trump e Biden desde 2017. Embora a IA tenha sido capaz de gerar análises aparentemente objetivas, suas fontes de informação, vieses potenciais e a profundidade real de sua compreensão de dinâmicas político-econômicas complexas ainda são questões a serem resolvidas no futuro. Isso reflete a expectativa da comunidade em utilizar a IA para aumentar a objetividade e profundidade do jornalismo, bem como o reconhecimento das limitações tecnológicas atuais (Fonte: Reddit r/deeplearning)