
Ключевые слова:Квантовые вычисления, Автономное вождение, Большие языковые модели, 3D генеративные модели, ИИ инструменты, Машинное обучение, Исследования искусственного интеллекта, Квантовая платформа CUDA-Q, Исследование данных автономного вождения Waymo, Многоагентная система Claude, Tencent Hunyuan 3D 2.1, Оптимизация производительности ядра ИИ генерации
🔥 聚焦
NVIDIA выпускает специализированную платформу CUDA-Q для квантовых вычислений: Генеральный директор NVIDIA Дженсен Хуанг на своей презентации на GTC в Париже объявил о запуске CUDA-Q, платформы для суперкомпьютеров с квантово-классическим ускорением. Платформа призвана сократить разрыв между современными классическими вычислениями и будущими квантовыми вычислениями, позволяя моделировать квантовые операции на классических компьютерах или оказывать поддержку реальным квантовым компьютерам. CUDA-Q уже доступна на Grace Blackwell и может ускорить разработку в 1300 раз с помощью суперкомпьютера GB200 NVL72. Дженсен Хуанг прогнозирует, что практическое применение квантовых компьютеров будет реализовано в течение нескольких лет, и подчеркнул, что на данном этапе разработки чипы NVIDIA (в частности, GB200) незаменимы для моделирования вычислений и поддержки QPU. NVIDIA сотрудничает с глобальными компаниями в области квантовых вычислений и суперкомпьютерными центрами для изучения совместной работы GPU и QPU (Источник: 量子位)

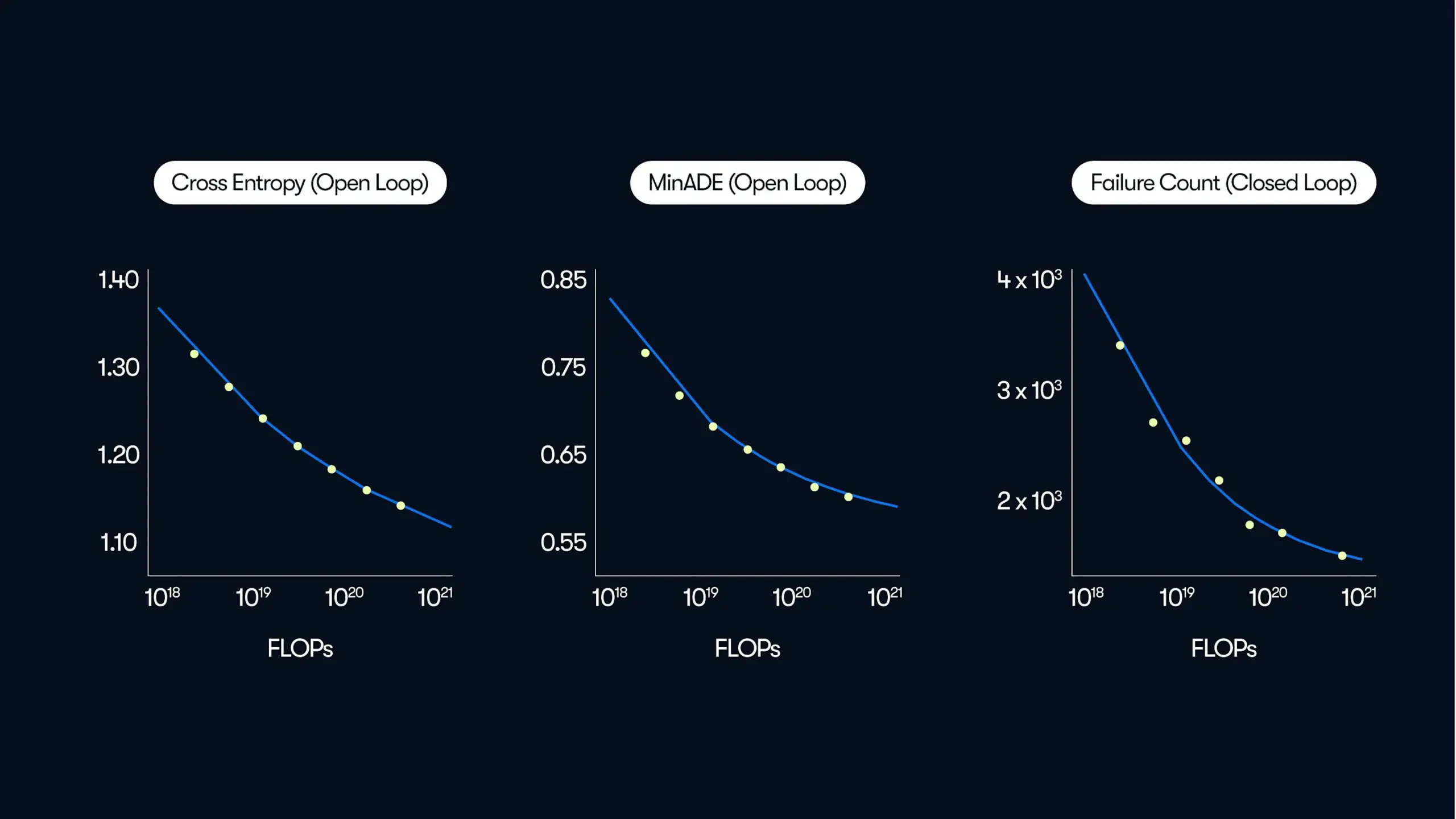
Waymo публикует масштабное исследование в области автономного вождения, раскрывающее закономерности повышения производительности за счет «управления данными»: В своем последнем сообщении в блоге Waymo поделилась результатами всестороннего исследования, основанного на 500 000 часах данных о вождении, что является крупнейшим на сегодняшний день набором данных в области автономного вождения. Исследование показывает, что, подобно большим языковым моделям (LLM), качество прогнозирования движения систем автономного вождения также следует степенному закону с увеличением объема вычислений для обучения. Расширение масштаба данных имеет решающее значение для повышения производительности модели, в то же время увеличение вычислительных мощностей для логического вывода также может улучшить способность модели обрабатывать сложные сценарии вождения. Это исследование впервые подтверждает, что за счет увеличения объема обучающих данных и вычислительных ресурсов можно значительно улучшить производительность автономного вождения в реальном мире, указывая отрасли путь к повышению возможностей за счет масштабирования (Источник: Sawyer Merritt, scaling01)
Anthropic делится опытом создания исследовательской системы Claude с несколькими агентами: В своем инженерном блоге Anthropic подробно рассказала, как использовать несколько параллельно работающих агентов для создания исследовательских возможностей Claude. В статье описывается успешный опыт, возникшие проблемы и инженерные вызовы в процессе разработки. Такая многоагентная система позволяет Claude более эффективно осуществлять поиск, анализ и синтез информации, тем самым повышая его способность проводить исследования и отвечать на сложные вопросы. Этот опыт имеет важное справочное значение для понимания того, как большие языковые модели могут расширять свои функции за счет проектирования сложных систем (Источник: ImazAngel, teortaxesTex)
Meta представляет мировую модель V-JEPA 2, обеспечивающую понимание и прогнозирование видео, а также управление роботами: Meta AI выпустила V-JEPA 2, мировую модель, обученную на видеоданных, которая достигла значительного прогресса в понимании и прогнозировании динамики физического мира. V-JEPA 2 не только эффективно изучает признаки видео, но также способна к планированию с нулевым обучением (zero-shot planning) и управлению роботами в новых средах, демонстрируя свой потенциал в области общего искусственного интеллекта. Модель изучает представления мира из видеоданных с помощью самообучения (self-supervised learning), открывая новые пути для создания более интеллектуальных AI-систем, способных взаимодействовать с реальным миром (Источник: dl_weekly)
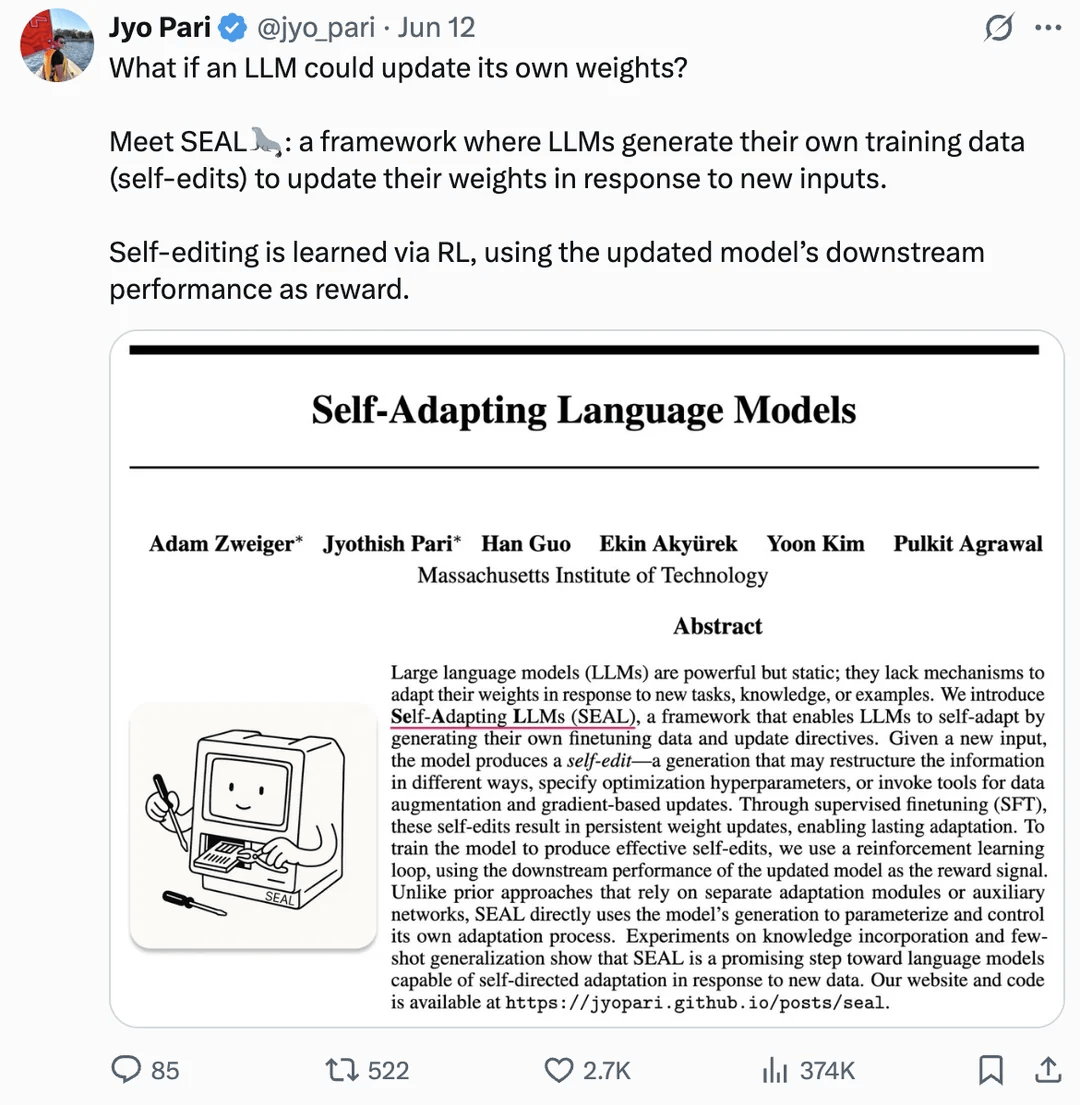
В статье рассматривается самообновление весов LLM для самосовершенствования: В статье, опубликованной на arXiv (2506.10943), предполагается, что большие языковые модели (LLM) теперь могут самосовершенствоваться, обновляя собственные веса. Этот механизм может означать, что LLM способны учиться на новых данных или опыте и динамически корректировать свои внутренние параметры для повышения производительности или адаптации к новым задачам без необходимости полного переобучения. В случае успеха это направление исследований значительно повысит адаптивность и способность LLM к непрерывному обучению, что станет важным шагом на пути к более автономным AI-системам (Источник: Reddit r/artificial)
🎯 动向
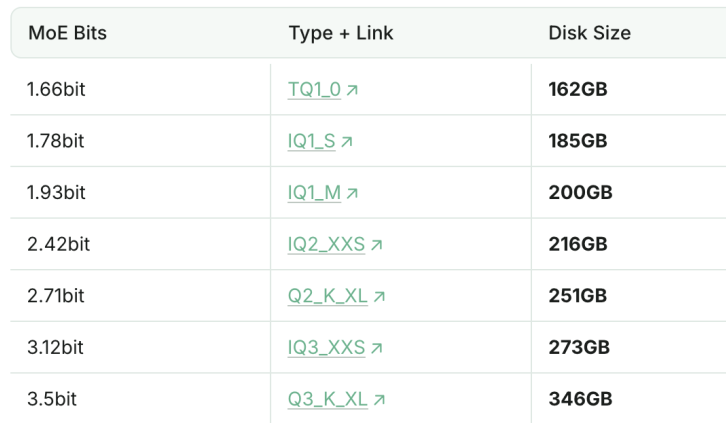
Квантованная версия DeepSeek-R1 (1.93bit) превосходит Claude 4 Sonnet в программировании: Студия Unsloth успешно квантовала DeepSeek-R1 (версия 0528) до 1.93bit. На бенчмарке по программированию aider она набрала 60%, превзойдя Claude 4 Sonnet (56.4%) и январскую полнофункциональную версию R1. Размер файла этой сильно сжатой версии уменьшился более чем на 70%, и она может работать даже без GPU (на CPU с достаточным объемом памяти). Полнофункциональная версия R1-0528 набрала на aider 71.4%, превзойдя Claude 4 Opus без активированного режима размышлений. Это демонстрирует потенциал технологии квантования моделей для значительного снижения требований к ресурсам при сохранении производительности (Источник: 量子位)
Tencent Hunyuan выпускает первую производственного уровня PBR 3D-модель генерации Hunyuan 3D 2.1 с открытым исходным кодом: Команда Tencent Hunyuan объявила об открытии исходного кода Hunyuan 3D 2.1, первой в отрасли полностью открытой 3D-модели генерации уровня PBR (Physically Based Rendering), достигшей производственного уровня. Модель использует технологию синтеза материалов PBR для создания 3D-контента с визуальными эффектами кинематографического уровня, что делает такие материалы, как кожа и бронза, более живыми и реалистичными при освещении. Проект предоставляет открытый доступ к весам модели, коду для обучения/логического вывода, конвейерам данных и архитектуре, а также поддерживает работу на потребительских видеокартах, стремясь способствовать развитию и популяризации технологии генерации 3D-контента (Источник: op7418, ImazAngel)
Meta AI выпускает Sonata для продвижения самообучающегося представления 3D-облаков точек: Meta AI представила Sonata, исследование, достигшее значительного прогресса в области самообучения (self-supervised learning) для 3D. Sonata, выявляя и решая проблемы геометрических «коротких путей» (geometric shortcuts) и внедряя гибкую и эффективную структуру, способна изучать исключительно надежные представления 3D-облаков точек. Эта работа повышает существующий уровень технологий 3D-восприятия и закладывает основу для будущих инноваций в области 3D-восприятия и его приложений (Источник: AIatMeta)

Meta AI выпускает «Набор данных для распознавания чтения в естественных условиях» для понимания поведения при чтении: Meta AI опубликовала большой мультимодальный набор данных под названием “Reading Recognition in the Wild”, включающий видео, данные отслеживания взгляда и датчиков положения головы. Этот набор данных предназначен для решения задач распознавания чтения с носимых устройств и является первым набором данных с эгоцентрической перспективой, собирающим данные отслеживания взгляда с высокой частотой 60 Гц, предоставляя ценный ресурс для изучения поведения человека при чтении (Источник: AIatMeta)

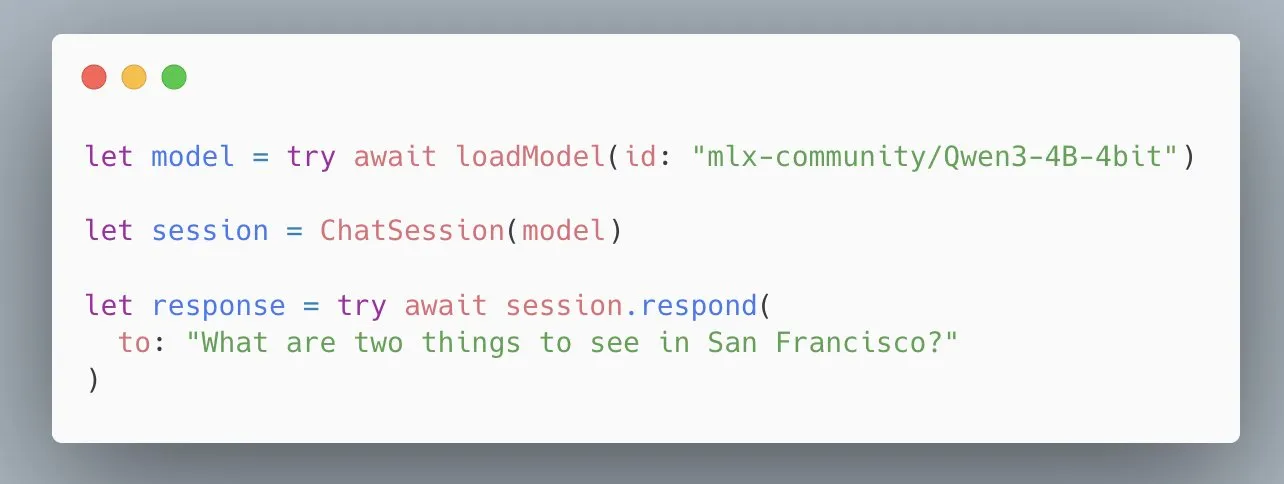
Apple упрощает MLX Swift LLM API, позволяя загружать модели тремя строками кода: В ответ на отзывы разработчиков о сложности освоения MLX Swift LLM API, команда Apple оперативно внесла улучшения и представила новый упрощенный API. Теперь разработчики могут всего тремя строками кода загрузить LLM или VLM в проект Swift и запустить чат-сессию, что значительно снижает порог входа для использования больших языковых моделей в экосистеме Apple (Источник: stablequan)
Google Gemma3 4B выпускает GAIA, оптимизированную версию для бразильского португальского: Google совместно с несколькими бразильскими организациями (ABRIA, CEIA-UFG, Nama, Amadeus AI) и DeepMind выпустила GAIA (Gemma-3-Gaia-PT-BR-4b-it), языковую модель с открытым исходным кодом, оптимизированную для бразильского португальского языка. Модель основана на Gemma-3-4b-pt и прошла дополнительное предварительное обучение на 13 миллиардах высококачественных токенов бразильского португальского языка. GAIA использует инновационную технологию «слияния весов» (weight merging) для следования инструкциям, не требуя традиционного SFT, и превзошла базовую модель Gemma на бенчмарке ENEM 2024. Модель подходит для чатов, ответов на вопросы, резюмирования, генерации текста и в качестве базовой модели для тонкой настройки на бразильском португальском (Источник: Reddit r/LocalLLaMA)
Роботы Figure AI интегрируют Helix AI и автономность для масштабируемого развертывания: Figure AI продемонстрировала, как ее роботы для реального мира способствуют масштабируемому развертыванию за счет усовершенствования Helix AI и автономности. Это показывает, что сочетание физических роботов с передовыми моделями AI делает возможным применение роботов в более сложных средах и подчеркивает важность инженерии и новых технологий в области робототехники (Источник: Ronald_vanLoon)
Sakana AI представляет гиперсеть Text-to-LoRA (T2L): Sakana AI выпустила Text-to-LoRA (T2L), новый тип гиперсети, способный сжимать несколько существующих LoRA (Low-Rank Adaptation) в себя и быстро генерировать новые адаптеры LoRA для больших языковых моделей (LLM) только на основе текстового описания задачи. После обучения T2L может мгновенно создавать новые LoRA, предоставляя эффективный способ быстрой настройки и развертывания LLM для конкретных задач. Соответствующие результаты будут представлены на ICML 2025 (Источник: TheTuringPost)
Baidu AI Search полностью запущен на платформе Baidu Smart Cloud Qianfan: Платформа разработки приложений Baidu Smart Cloud Qianfan AppBuilder официально запустила сервис «Baidu AI Search». Этот сервис объединяет две основные возможности: «Baidu Search» и «Интеллектуальная генерация поиска», предоставляя предприятиям полный спектр услуг от поиска информации до интеллектуальной генерации. Он использует более чем 20-летний опыт Baidu в области поиска на китайском языке и базу данных на сотни миллиардов записей, предлагая мультимодальные результаты поиска без рекламы, а также поддерживает точную фильтрацию, отслеживание источников и корпоративные политики безопасности. Возможности интеллектуальной генерации поиска, сочетающие модели, такие как Ernie Bot и Deepseek, предоставляют функции AI-резюмирования, объединенного поиска по частным знаниям и другие (Источник: 量子位)
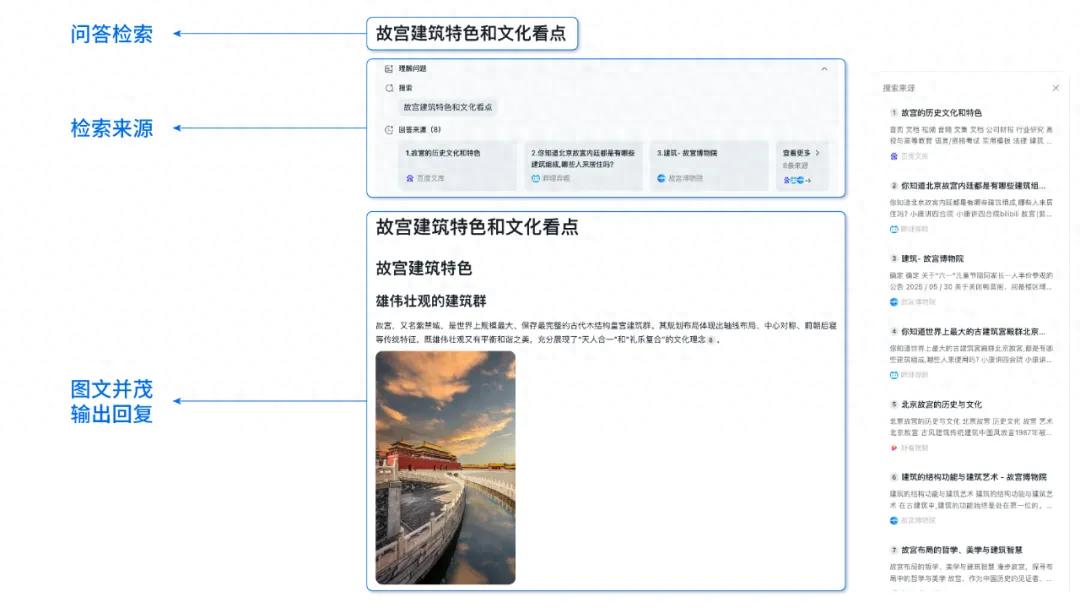
Исследование показывает, что производительность ядер, сгенерированных AI, приближается или даже превосходит ядра, оптимизированные экспертами: В блоге Anne Ouyang отмечается, что производительность AI-ядер, сгенерированных с помощью простого поиска только во время тестирования (test-time only search), уже приближается, а в некоторых случаях даже превосходит стандартные производственные ядра в PyTorch, оптимизированные экспертами. Это свидетельствует о огромном потенциале AI в оптимизации кода и повышении производительности, и в будущем AI может играть более важную роль в оптимизации низкоуровневых библиотек (Источник: jeremyphoward)
Исследование «Диффузионная двойственность» предлагает новый метод генерации за малое число шагов для дискретных диффузионных языковых моделей: В статье «The Diffusion Duality», опубликованной на ICML 2025, предлагается новый метод, который за счет использования скрытой гауссовской диффузии позволяет осуществлять генерацию за малое число шагов в дискретных диффузионных языковых моделях. Этот метод превзошел авторегрессионные (AR) модели на 3 из 7 бенчмарков правдоподобия с нулевым обучением (zero-shot likelihood benchmarks), предлагая новые идеи для повышения эффективности генерации диффузионных моделей (Источник: arankomatsuzaki)
Новый прорыв в интерпретируемости MLP-слоев: разложение активаций на интерпретируемые признаки: Новое исследование Mor Geva и др. демонстрирует простой метод разложения активаций многослойного перцептрона (MLP) на интерпретируемые признаки. Этот метод выявляет скрытую иерархию концепций, в которой разреженные комбинации нейронов формируют все более абстрактные понятия, обеспечивая более глубокое понимание внутренних механизмов работы нейронных сетей (Источник: menhguin)

Фреймворк HeadHunter обеспечивает точный контроль над управлением вниманием с помощью пертурбаций: Sayak Paul и др. предложили фреймворк HeadHunter для принципиального анализа управления вниманием с помощью пертурбаций. Этот фреймворк позволяет осуществлять глубокий и детальный контроль над качеством генерации и визуальными атрибутами, предоставляя новые инструменты и идеи для улучшения и настройки вывода генеративных моделей (Источник: huggingface, RisingSayak)

🧰 工具
Платные планы Windsurf теперь поддерживают Claude Sonnet 4: Windsurf объявил, что все его платные планы теперь включают модель Claude Sonnet 4. Пользователи теперь могут использовать мощные возможности этой новейшей модели от Anthropic на платформе Windsurf для генерации текста, ведения диалогов и других задач, что еще больше повышает производительность и удобство использования AI-ассистентов (Источник: op7418)
Anthropic выпускает официальный Python SDK для Claude Code: Anthropic официально выпустила Python SDK для Claude Code, предназначенный для облегчения разработчикам интеграции возможностей Claude по генерации кода и использованию инструментов в свои Python-проекты. SDK поддерживает использование инструментов, потоковый вывод, синхронные/асинхронные операции, обработку файлов и имеет встроенную структуру чата, что упрощает процесс разработки взаимодействия с Claude Code (Источник: Reddit r/ClaudeAI)
Выпущено расширение Claude Task Master для VS Code: DevDreed выпустил расширение Claude Task Master для VS Code версии 1.0.0. Это расширение предназначено для дополнения AI-проекта Claude Task Master от eyaltoledano, интегрируя вывод Claude Task Master непосредственно в интерфейс VS Code, что позволяет пользователям беспрепятственно переключаться между редактором и консолью, повышая эффективность разработки (Источник: Reddit r/ClaudeAI)
SmartSelect AI: Инструмент для обработки текста и изображений с помощью AI прямо в браузере: Выпущено расширение для Chrome под названием SmartSelect AI, которое позволяет пользователям прямо во время просмотра веб-страниц резюмировать, переводить или обсуждать выделенный текст, а также получать AI-описания изображений без необходимости переключать вкладки или копировать и вставлять текст во внешние приложения, такие как ChatGPT. Инструмент основан на модели Gemini и направлен на повышение эффективности получения и обработки информации (Источник: Reddit r/deeplearning)

Unsiloed AI открывает исходный код многофункционального инструмента для разбиения данных на чанки: Unsiloed AI (EF 2024) открыла исходный код части своих функций для разбиения данных на чанки (chunker). Этот инструмент предназначен для обработки документов различных форматов, таких как PDF, Excel, PPT, и их преобразования в формат, подходящий для обработки большими языковыми моделями. Unsiloed AI уже используется компаниями из списка Fortune 100 и многими стартапами для загрузки мультимодальных данных (Источник: Reddit r/LocalLLaMA)
Claude Superprompt System: Бесплатный инструмент для оптимизации промптов для Claude: Igor Warzocha разработал и поделился онлайн-инструментом под названием «Claude Superprompt System», предназначенным для помощи пользователям в преобразовании простых запросов в структурированные, сложные промпты, содержащие цепочки рассуждений (chain-of-thought) и контекстные примеры, чтобы лучше использовать возможности Claude. Инструмент основан на официальной документации Anthropic и лучших практиках, выявленных сообществом, и оптимизирует промпты с помощью структурирования XML-тегами, блоков рассуждений CoT и других методов, повышая качество вывода Claude. Код проекта открыт на GitHub (Источник: Reddit r/artificial)
Выпущен локальный TTS-плагин Kokoro-TTS для Firefox: Разработчик Pinguy выпустил плагин для Firefox под названием Kokoro TTS. Плагин использует локально размещенную нейросетевую модель с 82 миллионами параметров (модель Kokoro TTS) для преобразования текста в речь, работает полностью в автономном режиме, защищая конфиденциальность пользователей. Поддерживает несколько голосов и акцентов, плавно работает даже на старом оборудовании и доступен для Windows, Linux и macOS (Источник: Reddit r/artificial)
Spy Search: Обновление проекта поисковой системы LLM с открытым исходным кодом: JasonHonKL обновил свой проект поисковой системы LLM с открытым исходным кодом Spy Search. Проект направлен на создание эффективной поисковой системы на основе больших языковых моделей, последняя версия которой способна выполнять поиск и отвечать в течение 3 секунд. Код проекта размещен на GitHub и предназначен для предоставления пользователям быстрого и полезного инструмента для повседневного поиска (Источник: Reddit r/deeplearning)
HandFonted: Инструмент для преобразования рукописного текста в шрифт с открытым исходным кодом: Resham Gaire разработал и открыл исходный код проекта HandFonted – это сквозное Python-приложение, которое может преобразовывать изображения рукописных символов в устанавливаемые файлы шрифтов .ttf. Система использует OpenCV для обработки изображений и сегментации символов, кастомную модель PyTorch (ResNet-Inception) для классификации символов, венгерский алгоритм для оптимального сопоставления и, наконец, библиотеку fontTools для генерации файла шрифта (Источник: Reddit r/MachineLearning)
📚 学习
Статья Вэй Дунъи и др. опубликована в ведущем математическом журнале, исследует явление взрыва для сверхкритического дефокусирующего нелинейного волнового уравнения: Статья ученых из Пекинского университета Вэй Дунъи, Чжан Чжифэя и Шао Фэна «On blow-up for the supercritical defocusing nonlinear wave equation» опубликована в ведущем математическом журнале «Forum of Mathematics, Pi». В исследовании рассматривается проблема взрыва (решение становится бесконечным за конечное время) для определенного дефокусирующего нелинейного волнового уравнения в сверхкритическом состоянии. Они доказали существование гладких комплекснозначных решений, взрывающихся за конечное время, при пространственной размерности d=4 и p≥29, а также при d≥5 и p≥17. Этот результат заполняет пробел в соответствующей области, а метод доказательства предлагает новые идеи для исследования взрыва других нелинейных дифференциальных уравнений в частных производных (Источник: 量子位)

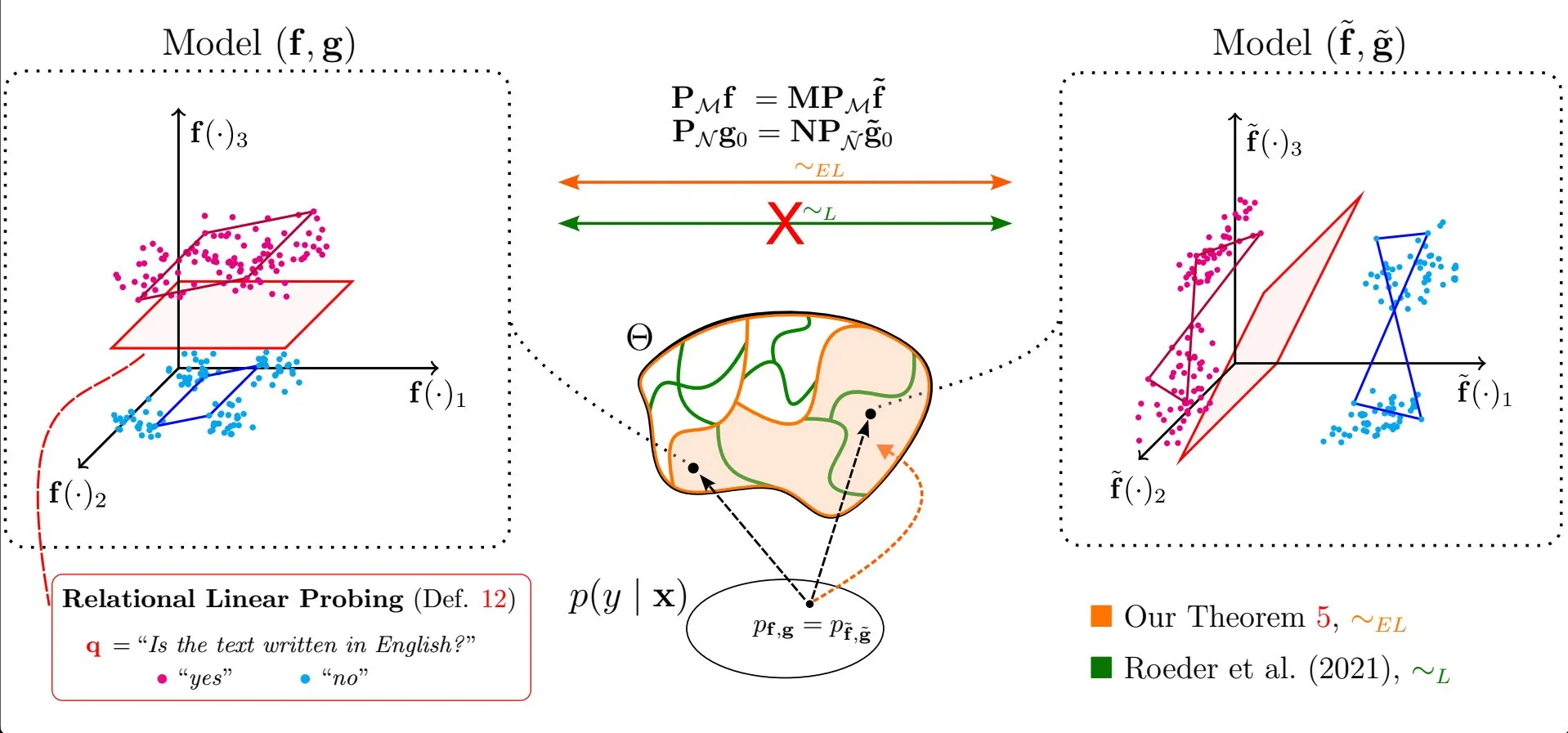
В статье исследуется распространенность линейных свойств в представлениях больших языковых моделей: Исследование Emanuele Marconato и др. «All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling» (опубликовано на AISTATS 2025) рассматривает с точки зрения идентифицируемости, почему линейные свойства так распространены в представлениях больших языковых моделей (LLM). Это исследование способствует более глубокому пониманию структуры и поведения внутренних представлений LLM (Источник: menhguin)
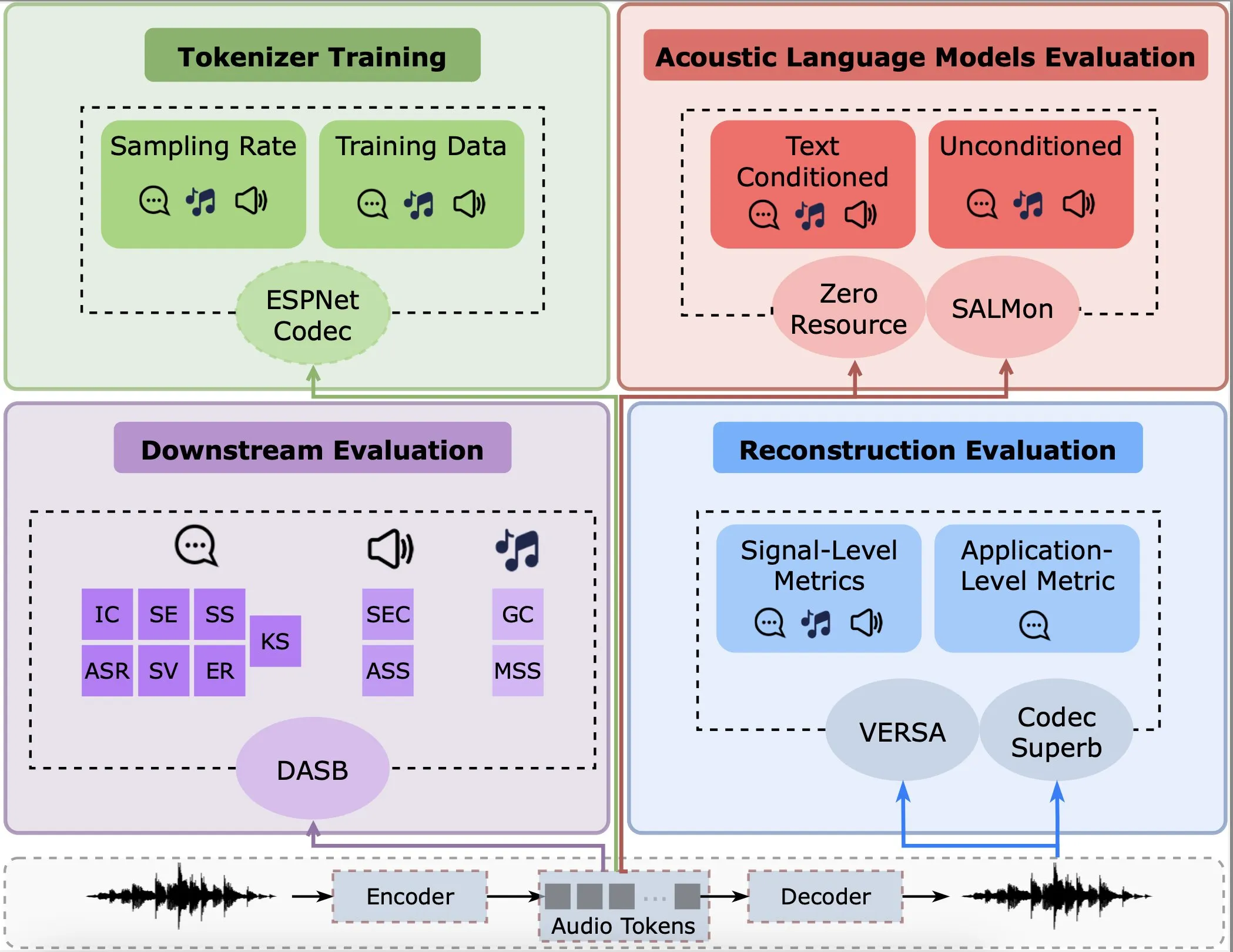
Исследование анализирует производительность аудиокодеров в задачах реконструкции, последующих задачах и языковых моделях: Gallil Maimon и др. опубликовали новое исследование, в котором проведен всесторонний эмпирический анализ существующих аудиокодеров (Audio Tokenisers). Исследование оценивает эти кодеры по нескольким параметрам, включая качество реконструкции, производительность в последующих задачах и интеграцию с языковыми моделями, предоставляя ориентиры для выбора и оптимизации моделей обработки аудио (Источник: menhguin)
Статья исследует «иллюзию мышления»: понимание преимуществ и недостатков моделей рассуждения с точки зрения сложности задачи: Была представлена ответная статья (arXiv:2506.09250) на исследование Apple об «иллюзии мышления», где Claude Opus указан в качестве первого автора. В статье критикуется дизайн эксперимента исследования Apple и утверждается, что наблюдаемый коллапс способности к рассуждению на самом деле вызван ограничением токенов, а не отсутствием у модели внутренних логических способностей. Это вызвало дискуссию о том, как оценивать реальные способности к рассуждению у больших языковых моделей (Источник: NandoDF, BlancheMinerva, teortaxesTex)

Исследование адаптивных языковых моделей: среднесрочная память остается проблемой: Dorialexander, изучив статьи по «адаптивным языковым моделям», отметил, что, хотя это перспективное направление исследований, модели по-прежнему ограничены в реализации среднесрочной памяти во время логического вывода. Это указывает на то, что текущие модели все еще сталкиваются с трудностями при обработке связной информации, требующей охвата более длинного контекста (Источник: Dorialexander)

Исследование качества тестов RLHF: Насколько хороши текущие тесты? Как их улучшить? Насколько важно качество тестов?: В последней работе Kexun Zhang и др. рассматривается важность валидаторов (тестов) в обучении с подкреплением на основе обратной связи от человека (RLHF), особенно в области кодирования с помощью LLM. Исследование ставит три ключевых вопроса: Каково качество текущих тестов? Как получить лучшие тесты? Насколько качество тестов влияет на производительность модели? Исследование подчеркивает необходимость высококачественных тестов для повышения способности LLM к кодированию (Источник: StringChaos)
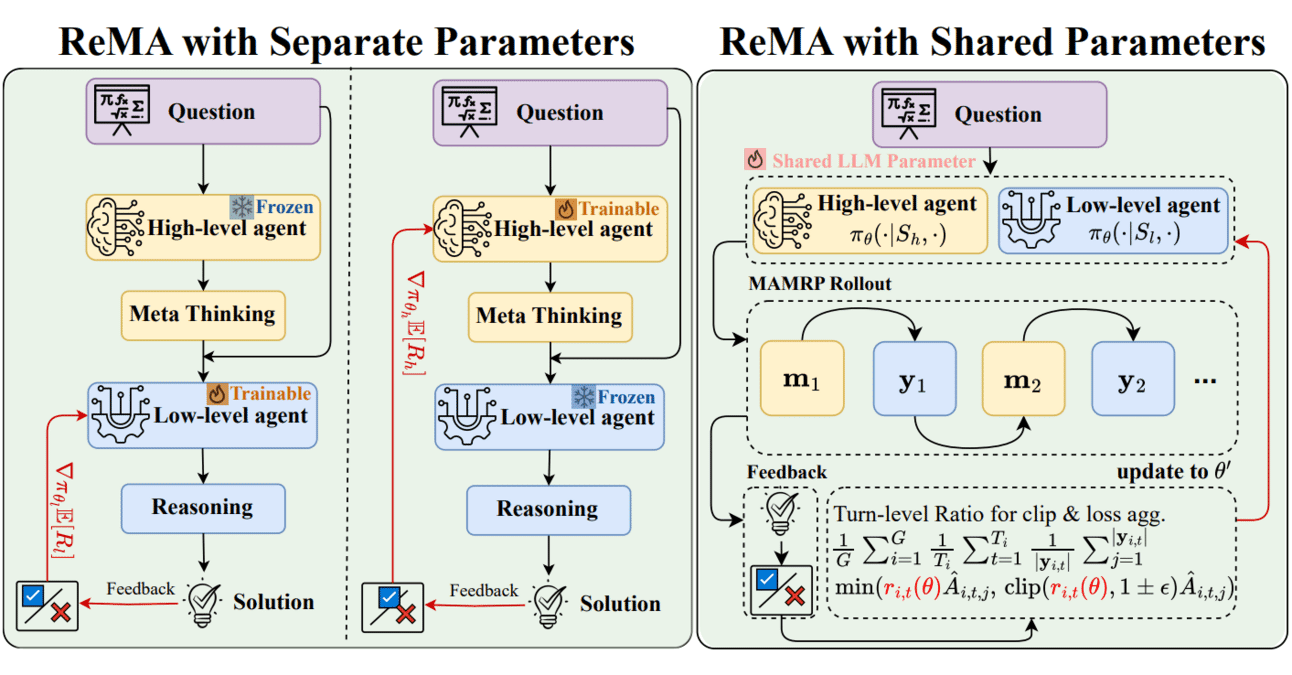
Сочетание Meta-learning и обучения с подкреплением: ReMA повышает эффективность совместной работы LLM: Reinforced Meta-thinking Agents (ReMA) сочетают мета-обучение (Meta-learning) и обучение с подкреплением (RL) с целью повышения эффективности больших языковых моделей (LLM), особенно при совместной работе нескольких LLM-агентов. ReMA разделяет решение проблем на две части: мета-мышление (планирование стратегии) и рассуждение (выполнение стратегии), и оптимизируется с помощью специализированных агентов и многоагентного обучения с подкреплением, достигая улучшений как на математических бенчмарках, так и на бенчмарках, где LLM выступает в роли арбитра (Источник: TheTuringPost, TheTuringPost)
Стратегии оценки AI: как получить наилучшую оценку качества модели, сочетая дешевых и дорогих оценщиков в рамках бюджетных ограничений: Исследование Adam Fisch и др. (arXiv:2506.07949) рассматривает практическую проблему: при наличии дешевого, но «шумного» оценщика, дорогого, но точного оценщика и фиксированного бюджета, как следует распределить бюджет, чтобы получить наиболее точную оценку качества модели. Исследование предоставляет основу для анализа экономической эффективности оценки AI-систем (Источник: Ar_Douillard)
Явления «ложного вознаграждения» и «ложного промпта» в промптах LLM: Исследование Stella Li и др. выявило интересные явления в обучении и оценке LLM. После обнаружения «ложного вознаграждения» (например, случайное вознаграждение также может улучшить производительность модели в некоторых задачах), они далее исследовали «ложный промпт» – даже бессмысленный текст, такой как «Lorem ipsum», в некоторых случаях может привести к значительному повышению производительности (например, на 19.4%). Эти открытия ставят новые задачи и заставляют задуматься о том, как LLM реагируют на промпты и как разрабатывать более надежные методы оценки (Источник: Tim_Dettmers)

Статья рассматривает модель «кукольного театра» для взаимодействия с AI: В статье (или черновике) под названием «The Pig in Yellow: AI Interface as Puppet Theatre» предлагается рассматривать языковые AI-системы (LLM, AGI, ASI) как перформативные интерфейсы, которые имитируют субъективность, а не обладают ею. Используя метафору «Мисс Пигги», статья анализирует, что беглость, связность и эмоциональные проявления AI являются не показателями разума, а продуктом оптимизации, подчеркивая, что интерфейс подобен марионетке, а пользователи совместно конструируют смысл во взаимодействии, где власть проявляется через перформативный дизайн (Источник: Reddit r/artificial)
💼 商业
Woan Robot, в которую инвестировал «крестный отец DJI» Ли Цзэсян, стремится к IPO: Woan Robot (SwitchBot), основанная выпускниками Харбинского политехнического университета и специализирующаяся на AI-роботах для дома, подала заявку на IPO на Гонконгской фондовой бирже. Компания получила инвестиции и ресурсную поддержку от «крестного отца DJI» Ли Цзэсяна, который владеет 12.98% акций. За последние десять лет Woan Robot привлекла семь раундов финансирования, а ее оценка выросла с 20 миллионов до 4 миллиардов юаней. Ее продукция включает роботов-исполнителей, имитирующих движения человеческих конечностей, и системы восприятия и принятия решений. Компания стала крупнейшим в мире поставщиком AI-роботов для дома с долей рынка 11.9% и в 2024 году достигла скорректированной чистой прибыли в 1.11 миллиона юаней (Источник: 量子位)

Tencent запускает «План Цинъюнь» 2026, впервые открывая репозиторий тем для исследований: Tencent объявила о запуске «Плана Цинъюнь» 2026, направленного на привлечение ведущих студентов-технологов со всего мира. План охватывает десять технологических областей, включая большие модели AI, базовую инфраструктуру, высокопроизводительные вычисления, и предлагает более ста технических тем. В отличие от предыдущих лет, в этом году впервые открыт репозиторий тем Цинъюнь, а для талантливых кандидатов предусмотрен «зеленый коридор» при приеме на работу. Цель плана – углубление сотрудничества между университетами и предприятиями и подготовка молодых научных талантов. Tencent предоставит ведущих отраслевых наставников, вычислительные ресурсы и конкурентоспособную заработную плату (Источник: 量子位)

Цифровой аватар Ло Юнхао начнет вещание на Baidu E-commerce 15 июня: Ло Юнхао объявил, что его AI-цифровой аватар дебютирует в прямом эфире на платформе Baidu E-commerce 15 июня. Это первый случай, когда ведущий стример использует AI-цифрового аватара для прямых продаж, что стало возможным благодаря прорывам Baidu в ключевых технологиях, таких как создание высокоубедительных цифровых людей. Этот шаг рассматривается как исследование новой парадигмы электронной коммерции «AI + ведущий IP» и, как ожидается, будет способствовать развитию индустрии прямых продаж в направлении интеллектуализации, высокой эффективности и низких затрат. Данные Baidu E-commerce показывают, что более 100 000 цифровых стримеров уже используются в различных отраслях, что значительно снижает операционные расходы продавцов и увеличивает GMV (Источник: 量子位)
🌟 社区
Китайские AI-компании перевозят жесткие диски с большими объемами данных в Малайзию для обучения моделей: NIK сообщает, что китайские AI-компании, чтобы обойти ограничения на чипы и использовать зарубежные вычислительные ресурсы, прибегают к стратегии «ручной» перевозки жестких дисков, заполненных обучающими данными, в такие страны, как Малайзия. Например, инженеры перевозили 15 жестких дисков с 80TB данных в Малайзию для аренды серверов и обучения моделей. Это явление отражает острую глобальную конкуренцию за вычислительные мощности AI и реальные проблемы трансграничного перемещения данных, а также вызывает дискуссии о безопасности данных и соблюдении нормативных требований (Источник: jpt401, agihippo, cloneofsimo, fabianstelzer)

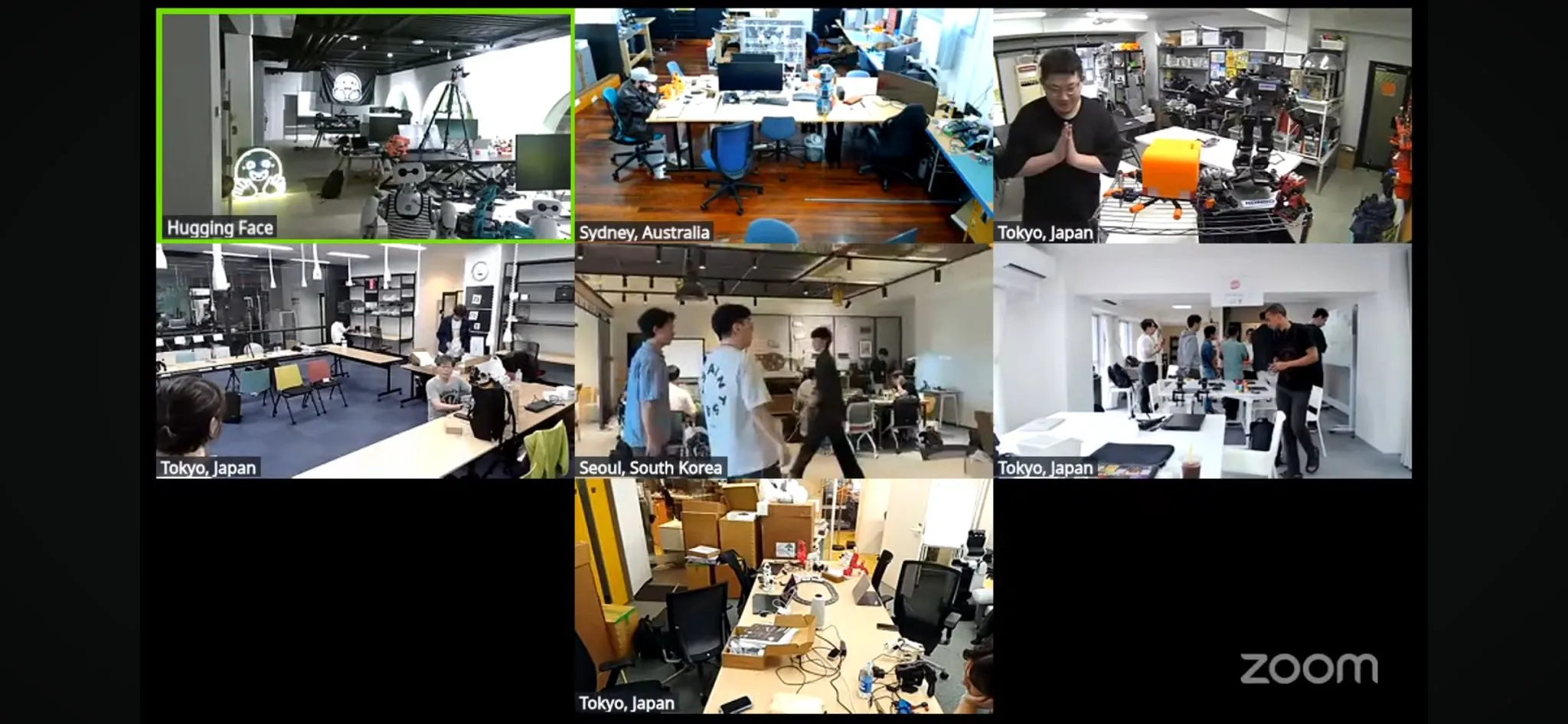
Стартовал крупнейший в мире хакатон по робототехнике LeRobot: Официально стартовал глобальный хакатон по робототехнике LeRobot, организованный Hugging Face. Он охватывает более 100 локаций на 5 континентах и привлек более 2300 участников. Мероприятие направлено на содействие развитию роботов с открытым исходным кодом на базе AI. Участники в течение 52 часов будут заниматься созданием и исследованием в области робототехники. Разработчики и команды из разных мест активно участвуют, делятся фотографиями с мест и ходом работы над проектами, демонстрируя энтузиазм и креативность сообщества в отношении робототехники (Источник: _akhaliq, eliebakouch, ClementDelangue)
Lovable проводит соревнование по генерации веб-страниц с помощью AI, Claude получает положительные отзывы: Lovable провела мероприятие, позволив пользователям бесплатно использовать топовые модели от OpenAI, Anthropic и Google для участия в соревновании по генерации веб-страниц с помощью AI. Пользователь op7418 поделился опытом генерации веб-страниц с использованием одного и того же набора промптов для моделей трех компаний и отметил, что Claude выделился объемом контента и визуальными эффектами. Подобные мероприятия предоставляют разработчикам и пользователям возможность сравнить производительность различных больших моделей в конкретных сценариях применения (Источник: _philschmid, op7418)
Обсуждение способности AI-моделей к рассуждению: ограничение токенов и реальная логика: В ответ на статью Apple об «иллюзии мышления» (Illusion of Thinking) в сообществе появились опровергающие мнения. В комментариях и последующих исследованиях (например, arXiv:2506.09250, где Claude Opus указан как автор) утверждается, что наблюдаемый «коллапс» способности моделей к рассуждению в большей степени обусловлен ограничением количества токенов, а не отсутствием у моделей собственных логических способностей. Когда моделям разрешается использовать более сжатый формат ответа или предоставляется достаточный контекст, они успешно решают проблемы. Это вызвало углубленное обсуждение того, как точно оценивать и понимать реальные способности к рассуждению у больших языковых моделей, а также возможные ограничения текущих методов оценки (Источник: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
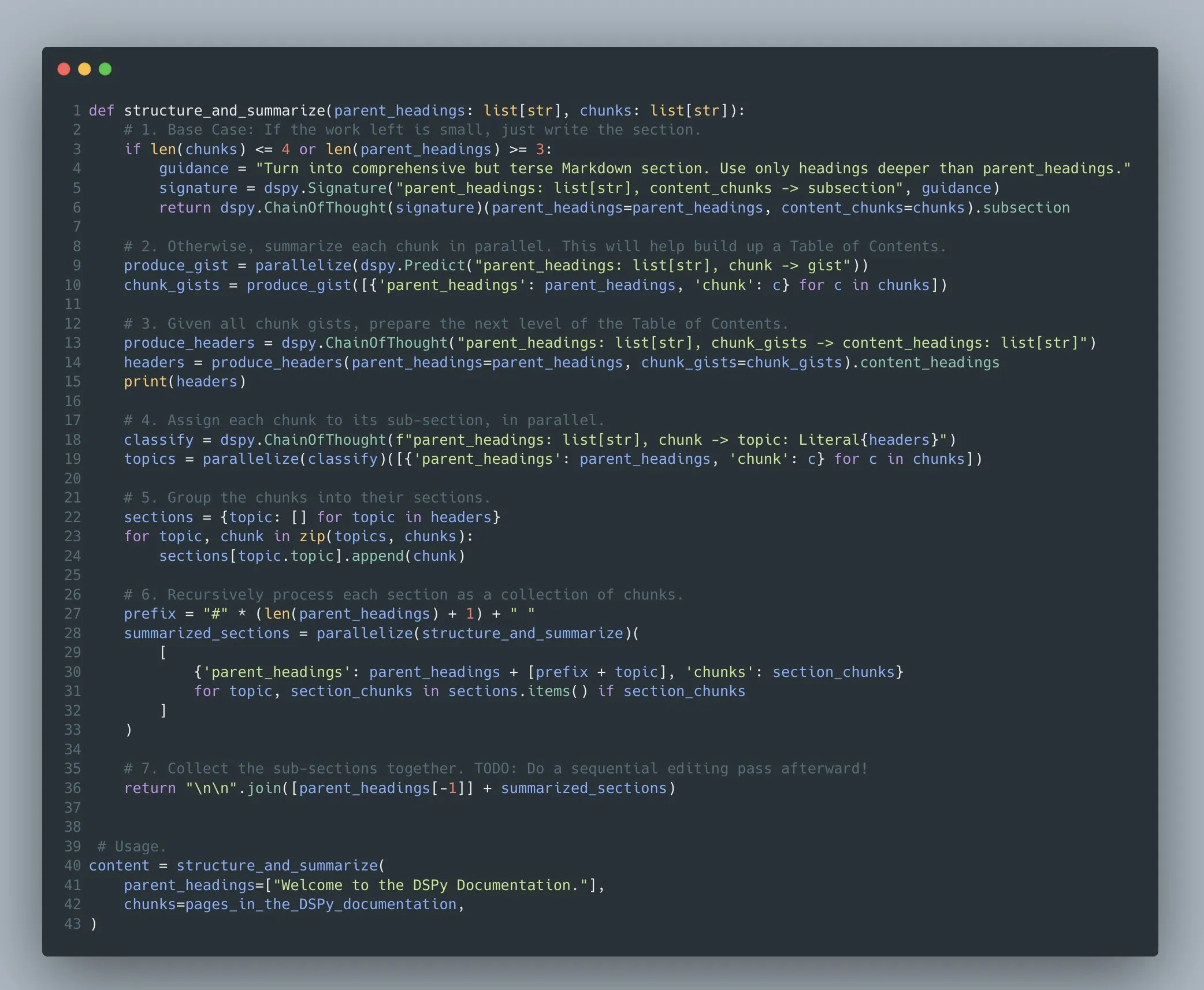
Фреймворк DSPy поддерживает оптимизацию сложных многоэтапных программ на основе языковых моделей: Omar Khattab подчеркнул, что фреймворк DSPy с 2022/2023 года поддерживает оптимизацию промптов и обучение с подкреплением для сложных многоэтапных программ на основе языковых моделей (Compound AI Systems). Он считает, что по мере усложнения AI-систем более уместно рассматривать их как «программы», а не просто «модели». DSPy предназначен для поддержки создания и оптимизации таких программ произвольной сложности (включая рекурсию, обработку исключений и т.д.), а не только линейных «процессов» или «цепочек» (Источник: lateinteraction)
Дискуссия о том, похожи ли LLM на человеческое мышление: Geoffrey Hinton считает, что большие языковые модели (LLM) схожи с тем, как люди обрабатывают язык, и являются лучшими моделями для понимания того, как работает язык. Однако Pedro Domingos ставит это под сомнение, утверждая, что превосходство LLM над старыми лингвистическими теориями не означает, что они мыслят как люди. Эта дискуссия отражает продолжающиеся дебаты в области AI о природе LLM и их связи с человеческим познанием (Источник: pmddomingos)
Огромный потенциал применения AI в исследованиях в области физических наук: Исследователь в области наук о Земле поделился положительным опытом использования o3 Pro (возможно, имеется в виду некая продвинутая модель OpenAI), назвав его «очень умным постдоком» в своих исследованиях. Модель отлично справляется с кодированием, разработкой моделей, уточнением идей, способна быстро и точно выполнять инструкции и помогать в исследованиях. Исследователь считает, что, хотя текущие модели еще не обладают способностью самостоятельно ставить исследовательские задачи (признак AGI), их мощные вспомогательные функции уже значительно повысили эффективность научных исследований, и предчувствует, что появление автономных LLM не за горами (Источник: Reddit r/ArtificialInteligence)
💡 其他
Инструменты для генерации комиксов с помощью AI делают творческое самовыражение более доступным: Пользователь StriderWriting поделился опытом создания комиксов с помощью AI-инструментов, отметив, что AI позволяет превращать «глупые идеи» в комиксы. Это отражает распространение AI в области создания креативного контента, снижение порога для творчества и предоставление большему количеству людей возможности легко выражать свои творческие идеи (Источник: Reddit r/ChatGPT)

Опасения по поводу предвзятости AI: проявление гендерных стереотипов в ChatGPT вызывает недовольство пользователей: Одна пользовательница сообщила, что ChatGPT в диалоге демонстрирует негативные стереотипы в отношении мужчин, например, при обсуждении рабочих и медицинских вопросов без подсказки предполагает, что отрицательную роль играет мужчина, и использует выражения вроде «мужчины просто отвратительны». Пользовательница отметила, что такие ленивые гендерные стереотипы вызывают дискомфорт, и задалась вопросом, есть ли у OpenAI правила, ограничивающие подобное поведение. Это вновь вызвало дискуссию о предвзятости данных, на которых обучаются AI-модели, и о том, как это проявляется во взаимодействии (Источник: Reddit r/ChatGPT)
Потенциал объективности AI в новостных репортажах и текущие ограничения: Один пользователь протестировал потенциал модели o3 от OpenAI в качестве «непредвзятого новостного журналиста», попросив ее прокомментировать возможные «непреднамеренные» последствия различных политик администраций Трампа и Байдена с 2017 года. Хотя AI способен генерировать внешне объективный анализ, его источники информации, потенциальная предвзятость и глубина истинного понимания сложных политико-экономических процессов остаются проблемами, которые предстоит решить в будущем. Это отражает ожидания сообщества относительно использования AI для повышения объективности и глубины новостей, а также осознание текущих технологических ограничений (Источник: Reddit r/deeplearning)