
Kata Kunci:komputasi kuantum, mengemudi otonom, model bahasa besar, model generasi 3D, alat AI, pembelajaran mesin, penelitian kecerdasan buatan, platform komputasi kuantum CUDA-Q, penelitian data mengemudi otonom Waymo, sistem multi-agen Claude, Tencent Hunyuan 3D 2.1, optimasi kinerja inti generasi AI
🔥 Fokus
NVIDIA merilis platform khusus komputasi kuantum CUDA-Q: CEO NVIDIA Jensen Huang dalam pidatonya di GTC Paris mengumumkan peluncuran CUDA-Q, sebuah platform superkomputer akselerasi kuantum-klasik. Platform ini bertujuan untuk menjembatani kesenjangan antara komputasi klasik saat ini dan komputasi kuantum di masa depan, memungkinkan simulasi operasi kuantum pada komputer klasik, atau memberikan bantuan untuk komputer kuantum nyata. CUDA-Q telah tersedia di Grace Blackwell, dan melalui superkomputer GB200 NVL72 dapat meningkatkan kecepatan pengembangan hingga 1300 kali lipat. Jensen Huang memprediksi bahwa aplikasi praktis komputer kuantum akan terwujud dalam beberapa tahun, dan menekankan bahwa pada tahap pengembangan ini, chip NVIDIA (khususnya GB200) sangat diperlukan dalam simulasi komputasi dan membantu QPU. NVIDIA bekerja sama dengan perusahaan komputasi kuantum global dan pusat superkomputer untuk mengeksplorasi kerja sinergis antara GPU dan QPU (Sumber: QbitAI)

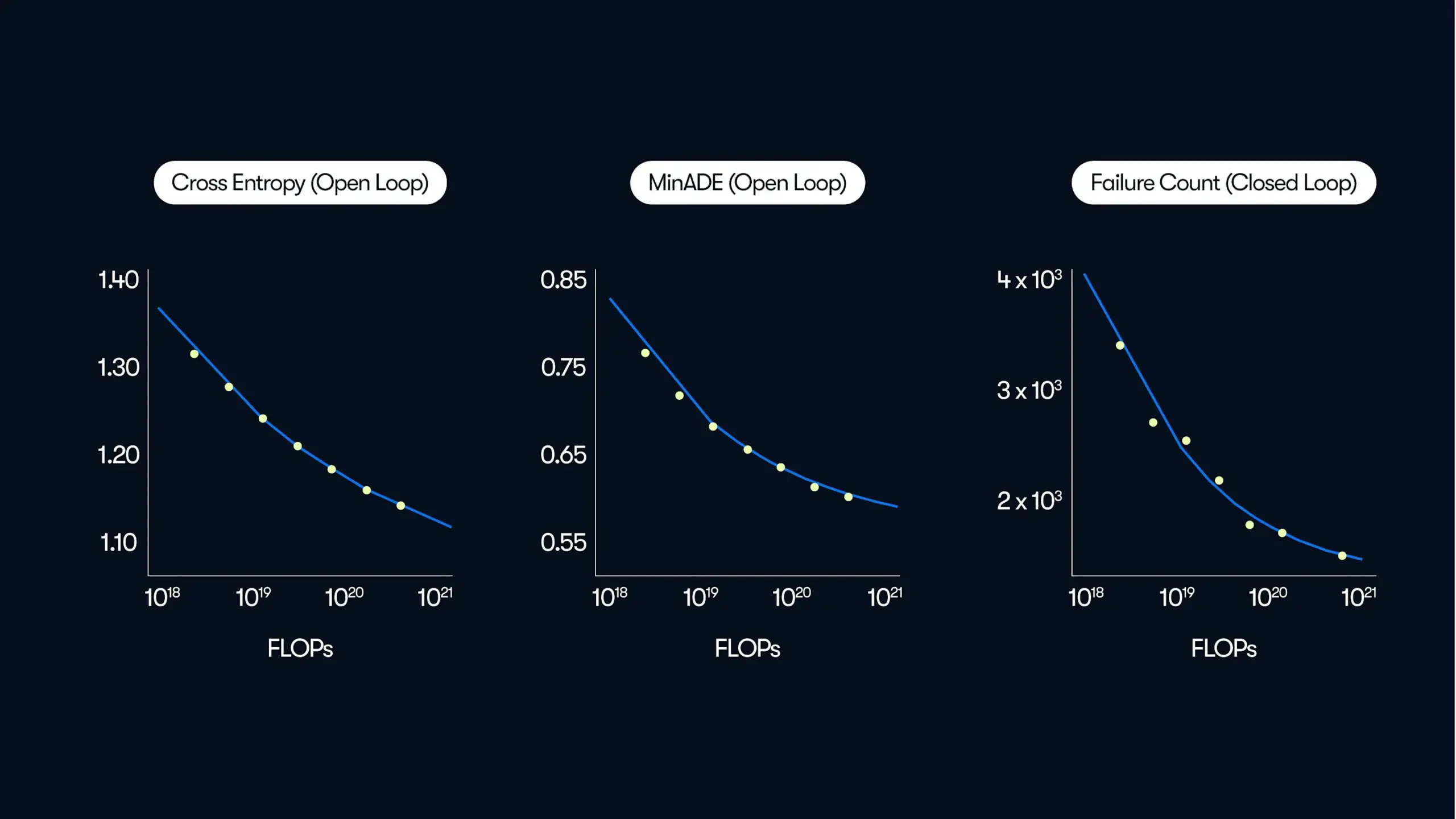
Waymo merilis penelitian skala besar tentang kemudi otomatis, mengungkap pola peningkatan kinerja yang “didorong data”: Waymo dalam posting blog terbarunya, membagikan hasil penelitian komprehensif berdasarkan data mengemudi selama 500.000 jam, yang merupakan kumpulan data terbesar di bidang kemudi otomatis hingga saat ini. Penelitian menunjukkan bahwa, mirip dengan model bahasa besar (LLM), kualitas prediksi gerakan sistem kemudi otomatis juga mengikuti hubungan hukum pangkat seiring dengan peningkatan jumlah komputasi pelatihan. Perluasan skala data sangat penting untuk meningkatkan kinerja model, sementara itu, peningkatan kemampuan komputasi inferensi juga dapat meningkatkan kemampuan model untuk menangani skenario mengemudi yang kompleks. Penelitian ini untuk pertama kalinya mengonfirmasi bahwa dengan meningkatkan data pelatihan dan sumber daya komputasi, kinerja kemudi otomatis di dunia nyata dapat ditingkatkan secara signifikan, menunjukkan jalur bagi industri untuk meningkatkan kemampuan melalui penskalaan (Sumber: Sawyer Merritt, scaling01)
Anthropic berbagi pengalaman membangun sistem penelitian multi-agen Claude: Anthropic dalam blog tekniknya merinci cara membangun kemampuan penelitian Claude dengan memanfaatkan beberapa agen yang bekerja secara paralel. Artikel tersebut berbagi pengalaman sukses selama proses pengembangan, masalah yang dihadapi, dan tantangan teknik. Sistem multi-agen ini memungkinkan Claude untuk melakukan pengambilan, analisis, dan sintesis informasi secara lebih efektif, sehingga meningkatkan kemampuannya dalam meneliti dan menjawab pertanyaan kompleks. Pembagian ini memiliki nilai referensi penting untuk memahami bagaimana model bahasa besar dapat memperluas fungsinya melalui desain sistem yang kompleks (Sumber: ImazAngel, teortaxesTex)
Meta meluncurkan model dunia V-JEPA 2, mewujudkan pemahaman video, prediksi, dan kontrol robot: Meta AI merilis V-JEPA 2, model dunia yang dilatih berdasarkan video, yang telah mencapai kemajuan signifikan dalam memahami dan memprediksi dinamika dunia fisik. V-JEPA 2 tidak hanya dapat melakukan pembelajaran fitur video yang efisien, tetapi juga dapat mewujudkan perencanaan zero-shot dan kontrol robot di lingkungan baru, menunjukkan potensinya di bidang kecerdasan buatan umum. Model ini belajar representasi dunia dari data video melalui pembelajaran mandiri, menyediakan jalur baru untuk membangun sistem AI yang lebih cerdas dan lebih mampu berinteraksi dengan dunia nyata (Sumber: dl_weekly)
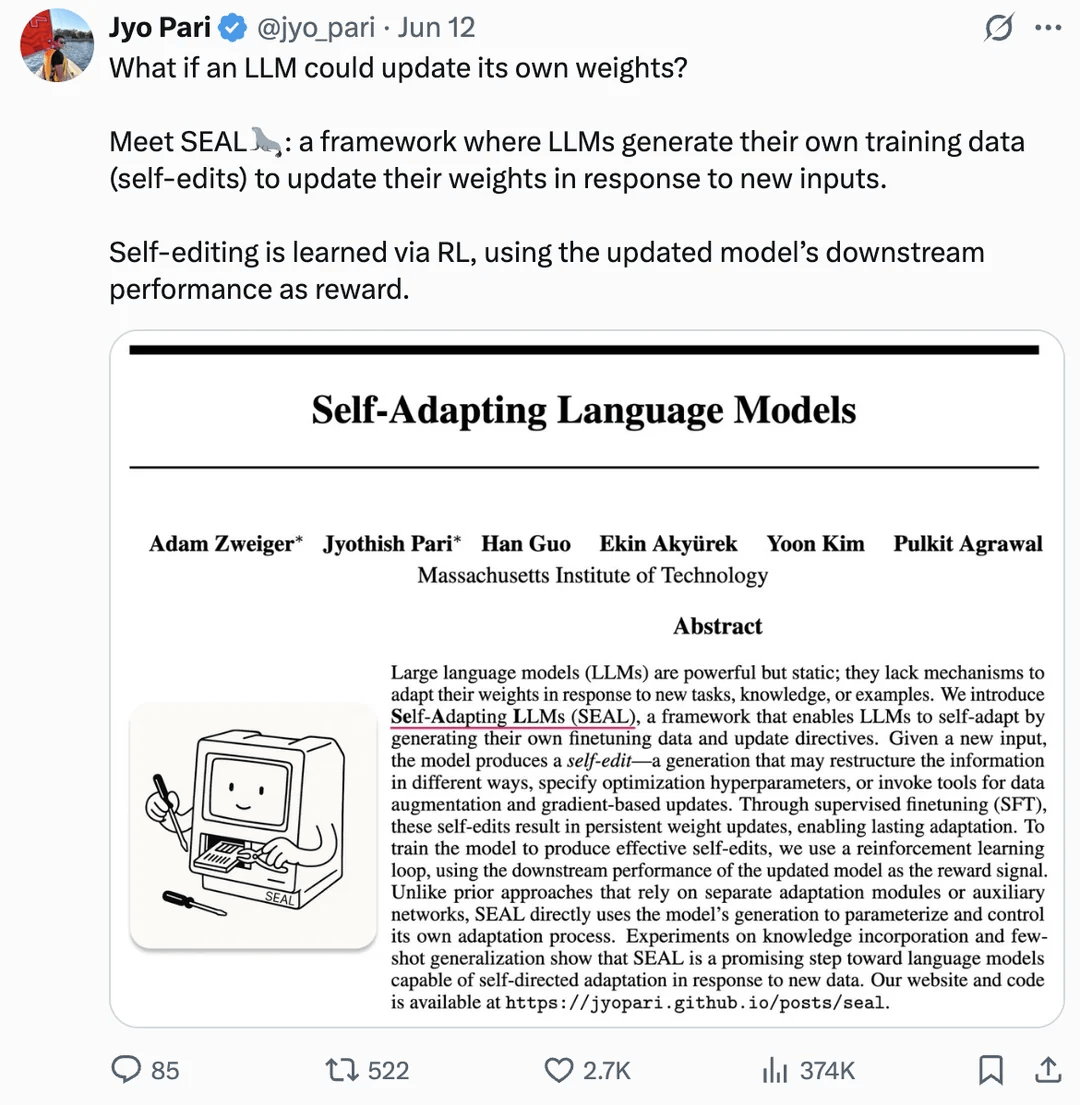
Makalah membahas pembaruan mandiri bobot LLM untuk mencapai peningkatan diri: Sebuah makalah yang diterbitkan di arXiv (2506.10943) mengusulkan bahwa model bahasa besar (LLM) sekarang dapat mencapai peningkatan diri dengan memperbarui bobotnya sendiri. Mekanisme ini mungkin berarti bahwa LLM dapat belajar dari data atau pengalaman baru, dan secara dinamis menyesuaikan parameter internalnya untuk meningkatkan kinerja atau beradaptasi dengan tugas baru, tanpa perlu pelatihan ulang penuh. Arah penelitian ini jika berhasil, akan sangat meningkatkan kemampuan adaptasi dan pembelajaran berkelanjutan LLM, merupakan langkah penting menuju sistem AI yang lebih otonom (Sumber: Reddit r/artificial)
🎯 Tren
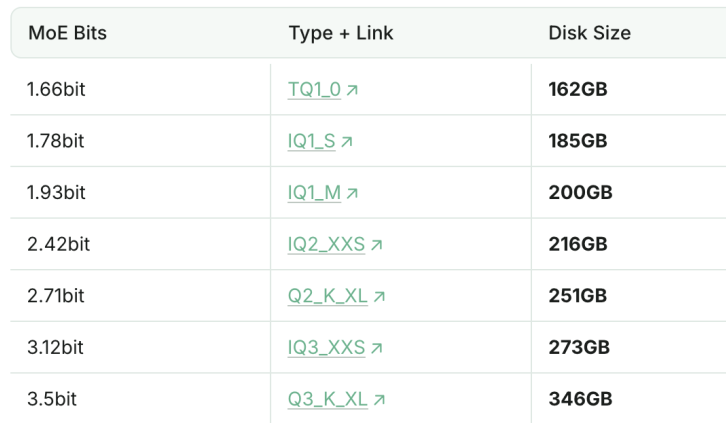
Kemampuan pemrograman DeepSeek-R1 versi kuantisasi 1.93bit melampaui Claude 4 Sonnet: Studio Unsloth berhasil menguantisasi DeepSeek-R1 (versi 0528) menjadi 1.93bit, yang mencapai skor 60% pada benchmark pemrograman aider, melampaui Claude 4 Sonnet (56.4%) dan R1 versi penuh Januari. Versi yang sangat terkompresi ini mengurangi ukuran file lebih dari 70%, bahkan dapat berjalan tanpa GPU (CPU dengan memori yang cukup). R1-0528 versi penuh mencetak skor 71.4% di aider, melampaui Claude 4 Opus tanpa mode berpikir diaktifkan. Ini menunjukkan potensi teknologi kuantisasi model dalam mempertahankan kinerja sambil secara signifikan mengurangi kebutuhan sumber daya (Sumber: QbitAI)
Tencent Hunyuan membuka sumber model generasi 3D PBR tingkat produksi pertamanya, Hunyuan 3D 2.1: Tim Tencent Hunyuan mengumumkan pembukaan sumber Hunyuan 3D 2.1, yang merupakan model generasi 3D PBR (Physically Based Rendering) pertama di industri yang sepenuhnya open-source dan mencapai tingkat produksi. Model ini menggunakan teknologi sintesis material PBR, mampu menghasilkan konten 3D dengan efek visual tingkat film, membuat material seperti kulit, perunggu, dll., tampak lebih hidup dan realistis di bawah pencahayaan. Proyek ini membuka bobot model, kode pelatihan/inferensi, pipeline data, dan arsitektur, serta mendukung pengoperasian pada kartu grafis kelas konsumen, bertujuan untuk mendorong pengembangan dan mempopulerkan teknologi generasi konten 3D (Sumber: op7418, ImazAngel)
Meta AI merilis Sonata, memajukan pembelajaran mandiri untuk representasi 3D point cloud: Meta AI meluncurkan Sonata, sebuah penelitian yang mencapai kemajuan signifikan dalam bidang pembelajaran mandiri 3D. Sonata, dengan mengidentifikasi dan menyelesaikan masalah pintasan geometris, serta memperkenalkan kerangka kerja yang fleksibel dan efisien, mampu mempelajari representasi 3D point cloud yang sangat tangguh. Pekerjaan ini meningkatkan tingkat teknologi persepsi 3D yang ada saat ini dan meletakkan dasar bagi inovasi di masa depan dalam bidang persepsi 3D dan aplikasinya (Sumber: AIatMeta)

Meta AI merilis “Kumpulan Data Pengenalan Membaca di Alam Liar”, untuk memahami perilaku membaca: Meta AI mempublikasikan kumpulan data multimodal besar bernama “Reading Recognition in the Wild”, yang berisi video, pelacakan mata, dan output sensor postur kepala. Kumpulan data ini bertujuan untuk membantu menyelesaikan tugas pengenalan membaca dari perangkat yang dapat dikenakan, dan merupakan kumpulan data perspektif egosentris pertama yang mengumpulkan data pelacakan mata dengan frekuensi tinggi 60Hz, menyediakan sumber daya berharga untuk meneliti perilaku membaca manusia (Sumber: AIatMeta)

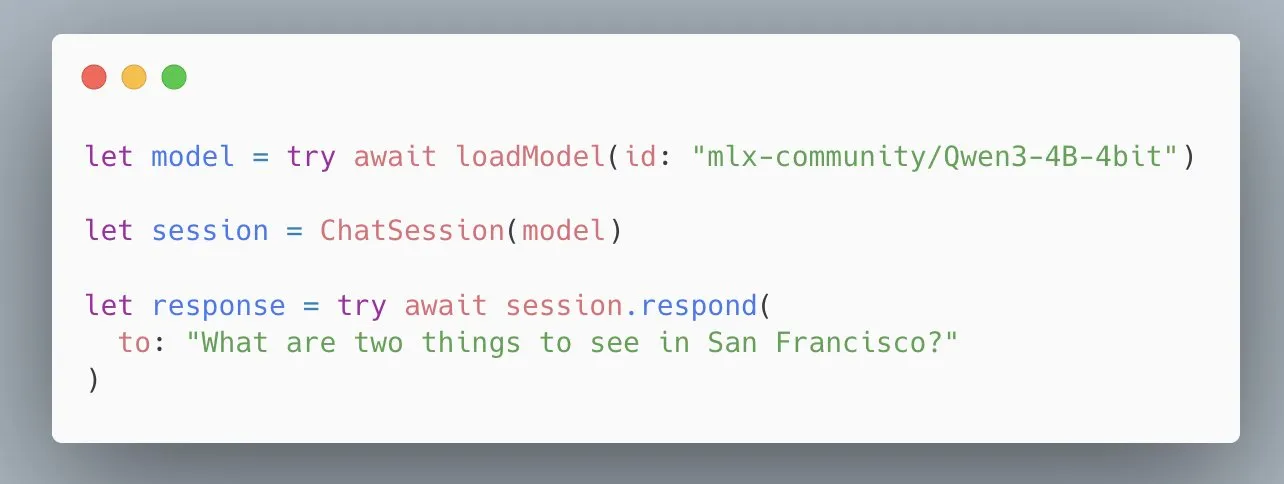
API MLX Swift LLM Apple disederhanakan, model dapat dimuat hanya dengan tiga baris kode: Menanggapi umpan balik pengembang tentang kesulitan memulai dengan API MLX Swift LLM, tim Apple dengan cepat melakukan perbaikan dan meluncurkan API baru yang disederhanakan. Sekarang, pengembang hanya memerlukan tiga baris kode untuk memuat LLM atau VLM dalam proyek Swift dan memulai sesi obrolan, secara signifikan mengurangi hambatan untuk menggunakan model bahasa besar dalam ekosistem Apple (Sumber: stablequan)
Google Gemma3 4B meluncurkan GAIA, versi yang dioptimalkan untuk Bahasa Portugis Brasil: Google, bekerja sama dengan beberapa institusi Brasil (ABRIA, CEIA-UFG, Nama, Amadeus AI) dan DeepMind, merilis model bahasa open-source GAIA (Gemma-3-Gaia-PT-BR-4b-it) yang dioptimalkan untuk Bahasa Portugis Brasil. Model ini didasarkan pada Gemma-3-4b-pt dan telah menjalani pra-pelatihan berkelanjutan pada 13 miliar token Bahasa Portugis Brasil berkualitas tinggi. GAIA menggunakan teknologi inovatif “penggabungan bobot” untuk mencapai kepatuhan instruksi, tanpa SFT tradisional, dan melampaui model Gemma dasar dalam benchmark ENEM 2024. Model ini cocok untuk obrolan, tanya jawab, peringkasan, pembuatan teks, dan sebagai model dasar untuk fine-tuning Bahasa Portugis Brasil (Sumber: Reddit r/LocalLLaMA)
Robot Figure AI menggabungkan Helix AI dengan otonomi, mendorong penyebaran yang dapat diskalakan: Figure AI menunjukkan bagaimana robot dunia nyatanya mendorong penyebaran yang dapat diskalakan melalui peningkatan Helix AI dan otonomi. Ini menunjukkan bahwa kombinasi robot fisik dengan model AI canggih memungkinkan penerapan robot di lingkungan yang lebih kompleks, dan menekankan pentingnya rekayasa dan teknologi baru di bidang robotika (Sumber: Ronald_vanLoon)
Sakana AI meluncurkan hypernetwork Text-to-LoRA (T2L): Sakana AI merilis Text-to-LoRA (T2L), sebuah hypernetwork jenis baru yang mampu mengompres beberapa LoRA (Low-Rank Adaptation) yang ada ke dalam dirinya sendiri, dan dengan cepat menghasilkan adaptor LoRA baru untuk model bahasa besar hanya melalui deskripsi teks tugas tersebut. Setelah dilatih, T2L dapat secara instan membuat LoRA baru, menyediakan jalur yang efisien untuk kustomisasi cepat dan penyebaran LLM khusus tugas. Hasil terkait akan dipresentasikan di ICML 2025 (Sumber: TheTuringPost)
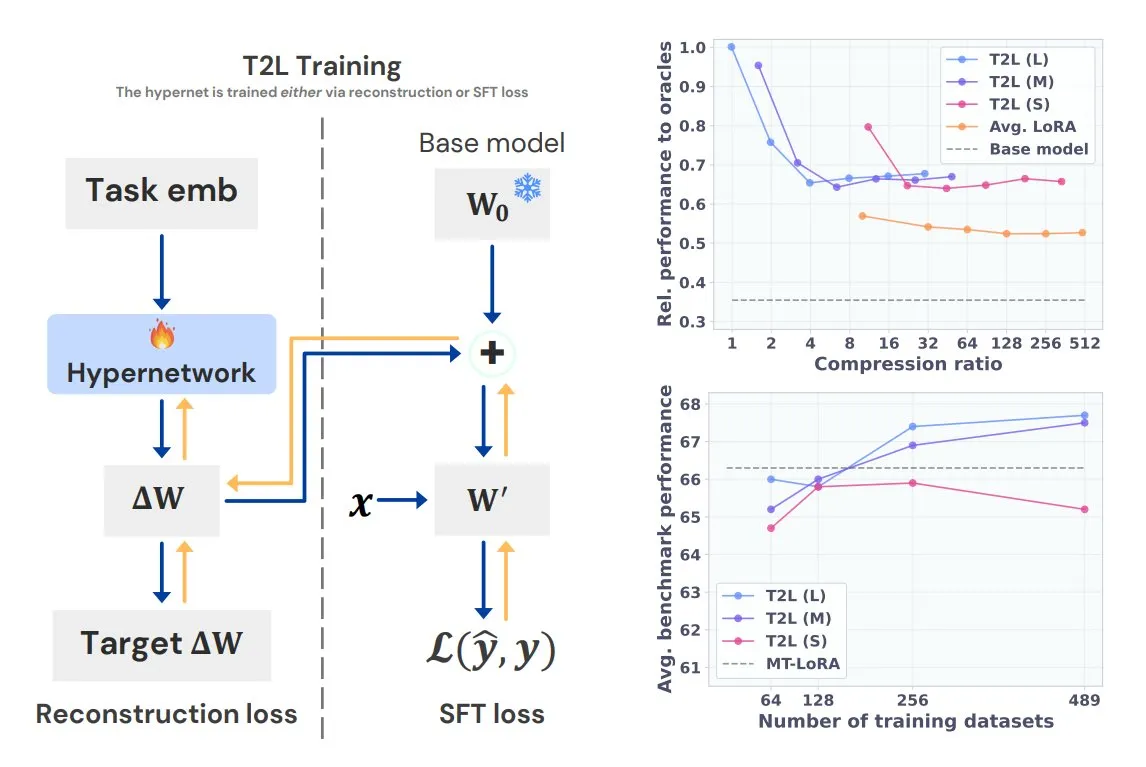
Baidu AI Search sepenuhnya diluncurkan di platform Baidu Smart Cloud Qianfan: Platform pengembangan aplikasi Baidu Smart Cloud Qianfan, AppBuilder, secara resmi meluncurkan layanan “Baidu AI Search”. Layanan ini mengintegrasikan dua kemampuan inti, “Baidu Search” dan “Intelligent Search Generation”, untuk menyediakan layanan rantai penuh mulai dari pengambilan informasi hingga generasi cerdas bagi perusahaan. Layanan ini memanfaatkan teknologi pencarian Bahasa Mandarin Baidu selama lebih dari 20 tahun dan database tingkat ratusan miliar, menyediakan hasil pencarian multimodal tanpa iklan, dan mendukung penyaringan yang akurat, penelusuran sumber, dan strategi keamanan tingkat perusahaan. Kemampuan generasi pencarian cerdas menggabungkan model seperti Wenxin, Deepseek, dll., untuk menyediakan fungsi seperti ringkasan AI, pencarian gabungan pengetahuan pribadi, dll. (Sumber: QbitAI)
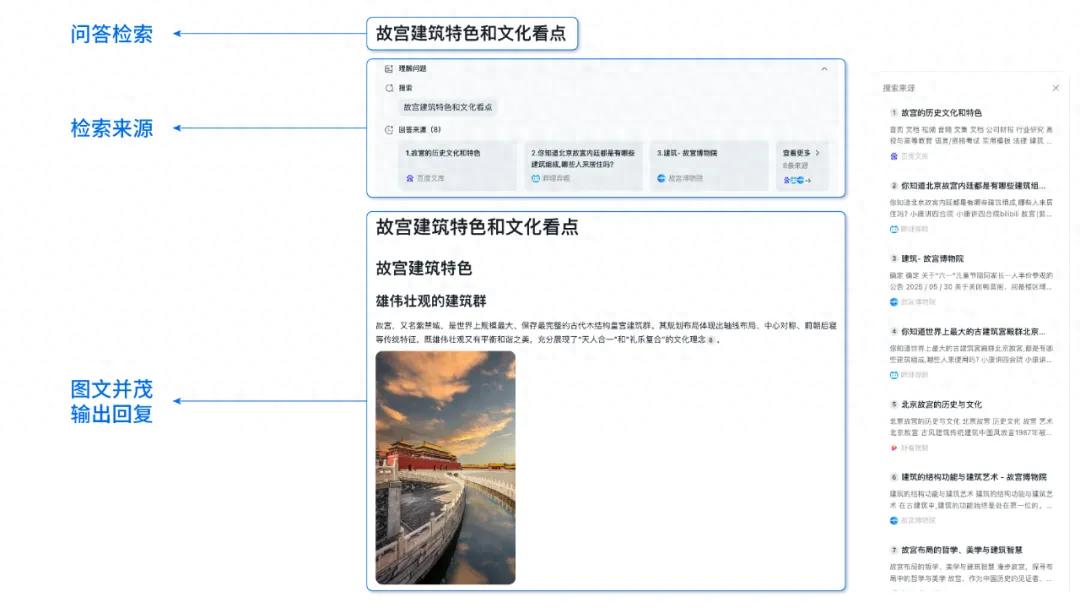
Penelitian menunjukkan kinerja kernel yang dihasilkan AI mendekati atau bahkan melampaui kernel yang dioptimalkan pakar: Artikel blog Anne Ouyang menunjukkan bahwa kernel AI yang dihasilkan melalui pencarian sederhana hanya pada waktu pengujian (test-time only search), kinerjanya telah mendekati atau bahkan dalam beberapa kasus melampaui kernel produksi standar yang dioptimalkan oleh pakar di PyTorch. Ini menunjukkan bahwa AI memiliki potensi besar dalam optimasi kode dan peningkatan kinerja, dan di masa depan mungkin memainkan peran yang lebih penting dalam optimasi pustaka tingkat rendah (Sumber: jeremyphoward)
Penelitian “Diffusion Duality” mengusulkan metode baru untuk generasi langkah-sedikit model bahasa difusi diskrit: Sebuah makalah yang diterbitkan di ICML 2025, “The Diffusion Duality”, mengusulkan metode baru untuk mencapai generasi langkah-sedikit dalam model bahasa difusi diskrit dengan memanfaatkan difusi Gaussian laten. Metode ini mengalahkan model autoregresif (AR) pada 3 dari 7 benchmark likelihood zero-shot, memberikan ide baru untuk meningkatkan efisiensi generasi model difusi (Sumber: arankomatsuzaki)
Terobosan baru dalam interpretabilitas lapisan MLP: dekomposisi aktivasi menjadi fitur yang dapat dijelaskan: Penelitian baru oleh Mor Geva dkk. menunjukkan metode sederhana yang dapat menguraikan aktivasi Multi-Layer Perceptron (MLP) menjadi fitur yang dapat dijelaskan. Metode ini mengungkap hierarki konsep tersembunyi, di mana kombinasi neuron yang jarang membentuk konsep yang semakin abstrak, memberikan perspektif yang lebih dalam untuk memahami mekanisme kerja internal jaringan neural (Sumber: menhguin)

Framework HeadHunter mencapai kontrol halus atas panduan perhatian yang terganggu: Sayak Paul dkk. mengusulkan framework HeadHunter untuk analisis berprinsip atas panduan perhatian yang terganggu. Framework ini mampu mencapai kontrol granular yang mendalam atas kualitas generasi dan atribut visual, menyediakan alat dan wawasan baru untuk meningkatkan dan menyesuaikan output model generatif (Sumber: huggingface, RisingSayak)

🧰 Alat
Paket berbayar Windsurf sekarang mendukung Claude Sonnet 4: Windsurf mengumumkan bahwa semua paket berbayarnya kini telah mendukung model Claude Sonnet 4. Pengguna sekarang dapat memanfaatkan kemampuan canggih model terbaru dari Anthropic ini di platform Windsurf untuk tugas-tugas seperti pembuatan teks, percakapan, dll., lebih lanjut meningkatkan kinerja dan pengalaman asisten AI (Sumber: op7418)
Anthropic merilis SDK Python resmi untuk Claude Code: Anthropic secara resmi meluncurkan Python SDK untuk Claude Code, yang bertujuan untuk memudahkan pengembang mengintegrasikan kemampuan pembuatan kode dan penggunaan alat Claude ke dalam proyek Python mereka sendiri. SDK ini mendukung penggunaan alat, output streaming, operasi sinkron/asinkron, pemrosesan file, dan memiliki struktur obrolan bawaan, menyederhanakan alur kerja pengembangan untuk berinteraksi dengan Claude Code (Sumber: Reddit r/ClaudeAI)
Ekstensi Claude Task Master VS Code dirilis: DevDreed merilis ekstensi Claude Task Master VS Code versi 1.0.0. Ekstensi ini bertujuan untuk melengkapi proyek Claude Task Master AI dari eyaltoledano, mengintegrasikan output Claude Task Master langsung ke antarmuka VS Code, memudahkan pengguna untuk beralih antara editor dan konsol tanpa hambatan, meningkatkan efisiensi pengembangan (Sumber: Reddit r/ClaudeAI)
SmartSelect AI: Alat pemrosesan teks dan gambar AI dalam browser: Sebuah ekstensi Chrome bernama SmartSelect AI telah dirilis, yang memungkinkan pengguna untuk langsung meringkas, menerjemahkan, atau mengobrol tentang teks yang dipilih saat menjelajahi web, serta mendeskripsikan gambar dengan AI, tanpa perlu beralih tab atau menyalin-tempel ke aplikasi eksternal seperti ChatGPT. Alat ini didasarkan pada model Gemini dan bertujuan untuk meningkatkan efisiensi perolehan dan pemrosesan informasi (Sumber: Reddit r/deeplearning)

Unsiloed AI membuka sumber alat chunking data multifungsi: Unsiloed AI (EF 2024) membuka sumber sebagian fungsi chunker datanya. Alat ini bertujuan untuk membantu memproses berbagai format dokumen seperti PDF, Excel, PPT, dll., mengubahnya menjadi format yang cocok untuk diproses oleh model bahasa besar. Unsiloed AI telah digunakan oleh perusahaan Fortune 100 dan beberapa perusahaan rintisan untuk penyerapan data multimodal (Sumber: Reddit r/LocalLLaMA)
Claude Superprompt System: Alat gratis untuk mengoptimalkan prompt Claude: Igor Warzocha mengembangkan dan membagikan alat online bernama “Claude Superprompt System”, yang bertujuan untuk membantu pengguna mengubah permintaan sederhana menjadi prompt kompleks yang terstruktur, berisi rantai pemikiran dan contoh kontekstual, untuk memanfaatkan kemampuan Claude dengan lebih baik. Alat ini didasarkan pada dokumentasi resmi Anthropic dan praktik terbaik yang ditemukan komunitas, mengoptimalkan prompt melalui struktur tag XML, blok penalaran CoT, dll., untuk meningkatkan kualitas output Claude. Kode proyek telah dibuka di GitHub (Sumber: Reddit r/artificial)
Plugin TTS lokal Firefox Kokoro-TTS dirilis: Pengembang Pinguy merilis plugin Firefox bernama Kokoro TTS, yang menggunakan model jaringan neural yang dihosting secara lokal dengan 82 juta parameter (model Kokoro TTS) untuk text-to-speech, berjalan sepenuhnya offline, melindungi privasi pengguna. Mendukung berbagai suara dan aksen, berjalan lancar bahkan pada perangkat keras lama, menyediakan versi untuk Windows, Linux, dan macOS (Sumber: Reddit r/artificial)
Spy Search: Pembaruan proyek mesin pencari LLM open-source: JasonHonKL memperbarui proyek mesin pencari LLM open-source miliknya, Spy Search. Proyek ini bertujuan untuk membangun mesin pencari berbasis model bahasa besar yang efisien, versi terbaru sudah dapat mencari dan merespons dalam waktu 3 detik. Kode proyek dihosting di GitHub, bertujuan untuk menyediakan alat pencarian harian yang cepat dan berguna bagi pengguna (Sumber: Reddit r/deeplearning)
HandFonted: Alat konversi tulisan tangan ke font open-source: Resham Gaire mengembangkan dan membuka sumber proyek HandFonted, sebuah aplikasi Python end-to-end yang dapat mengubah gambar karakter tulisan tangan menjadi file font .ttf yang dapat diinstal. Sistem ini menggunakan OpenCV untuk pemrosesan gambar dan segmentasi karakter, menggunakan model PyTorch kustom (ResNet-Inception) untuk klasifikasi karakter, dan melalui algoritma Hungarian untuk pencocokan terbaik, akhirnya menggunakan pustaka fontTools untuk menghasilkan file font (Sumber: Reddit r/MachineLearning)
📚 Belajar
Makalah Wei Dongyi dkk. menduduki puncak jurnal matematika, meneliti fenomena ledakan persamaan gelombang nonlinier defokus superkritis: Makalah karya cendekiawan Universitas Peking Wei Dongyi, Zhang Zhifei, dan Shao Feng berjudul “On blow-up for the supercritical defocusing nonlinear wave equation” diterbitkan di jurnal matematika terkemuka “Forum of Mathematics, Pi”. Penelitian ini membahas masalah ledakan (solusi menjadi tak terbatas dalam waktu terbatas) dari persamaan gelombang nonlinier defokus tertentu dalam keadaan superkritis. Mereka membuktikan bahwa dalam dimensi spasial d=4 dan p≥29, serta d≥5 dan p≥17, terdapat solusi bernilai kompleks yang halus yang meledak dalam waktu terbatas. Hasil ini mengisi kekosongan di bidang terkait, dan metode pembuktiannya memberikan ide baru untuk penelitian ledakan persamaan diferensial parsial nonlinier lainnya (Sumber: QbitAI)

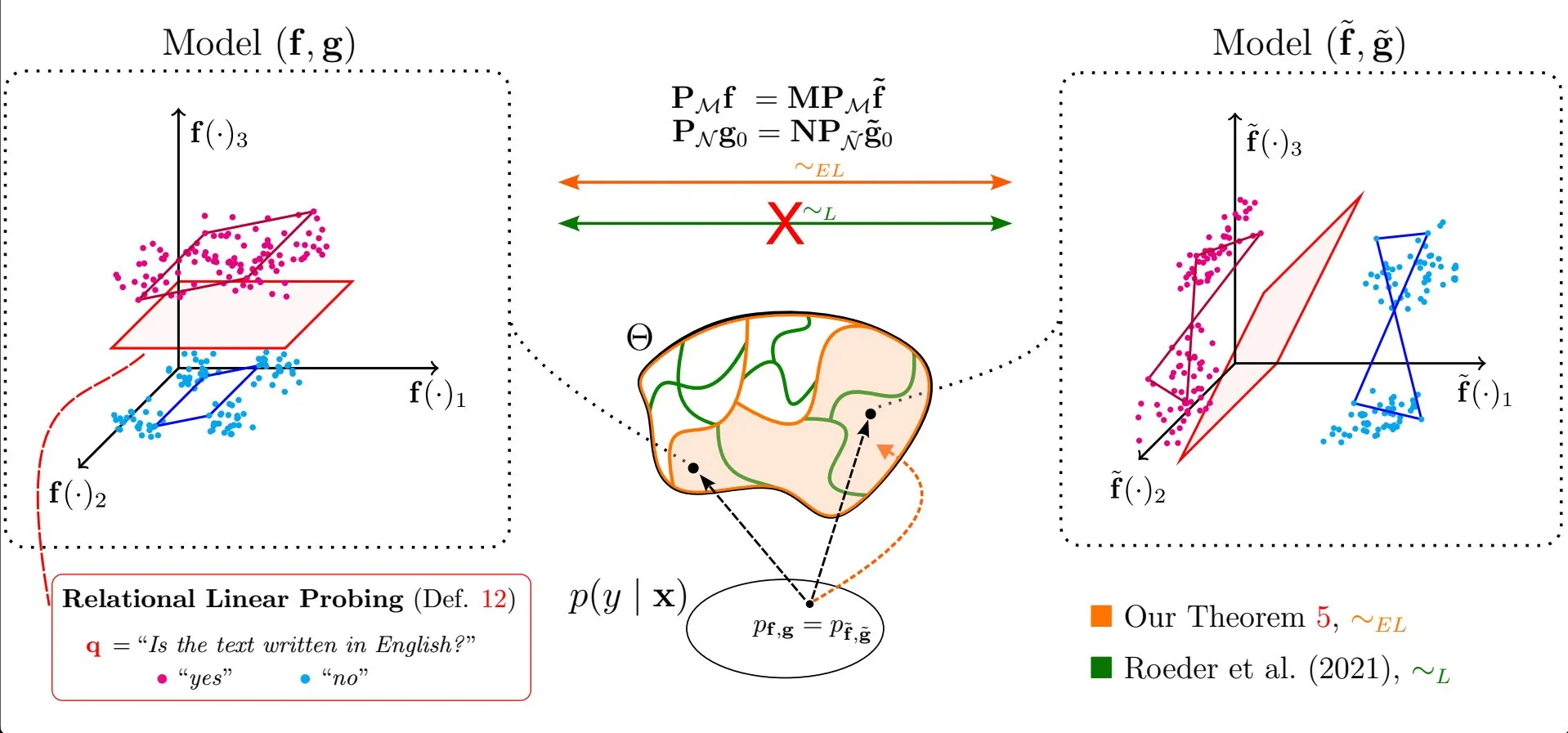
Makalah membahas universalitas karakteristik linier dalam representasi model bahasa besar: Penelitian Emanuele Marconato dkk. berjudul “All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling” (diterbitkan di AISTATS 2025) membahas dari perspektif identifiabilitas mengapa karakteristik linier begitu umum dalam representasi model bahasa besar (LLM). Penelitian ini membantu pemahaman yang lebih dalam tentang struktur dan perilaku representasi internal LLM (Sumber: menhguin)
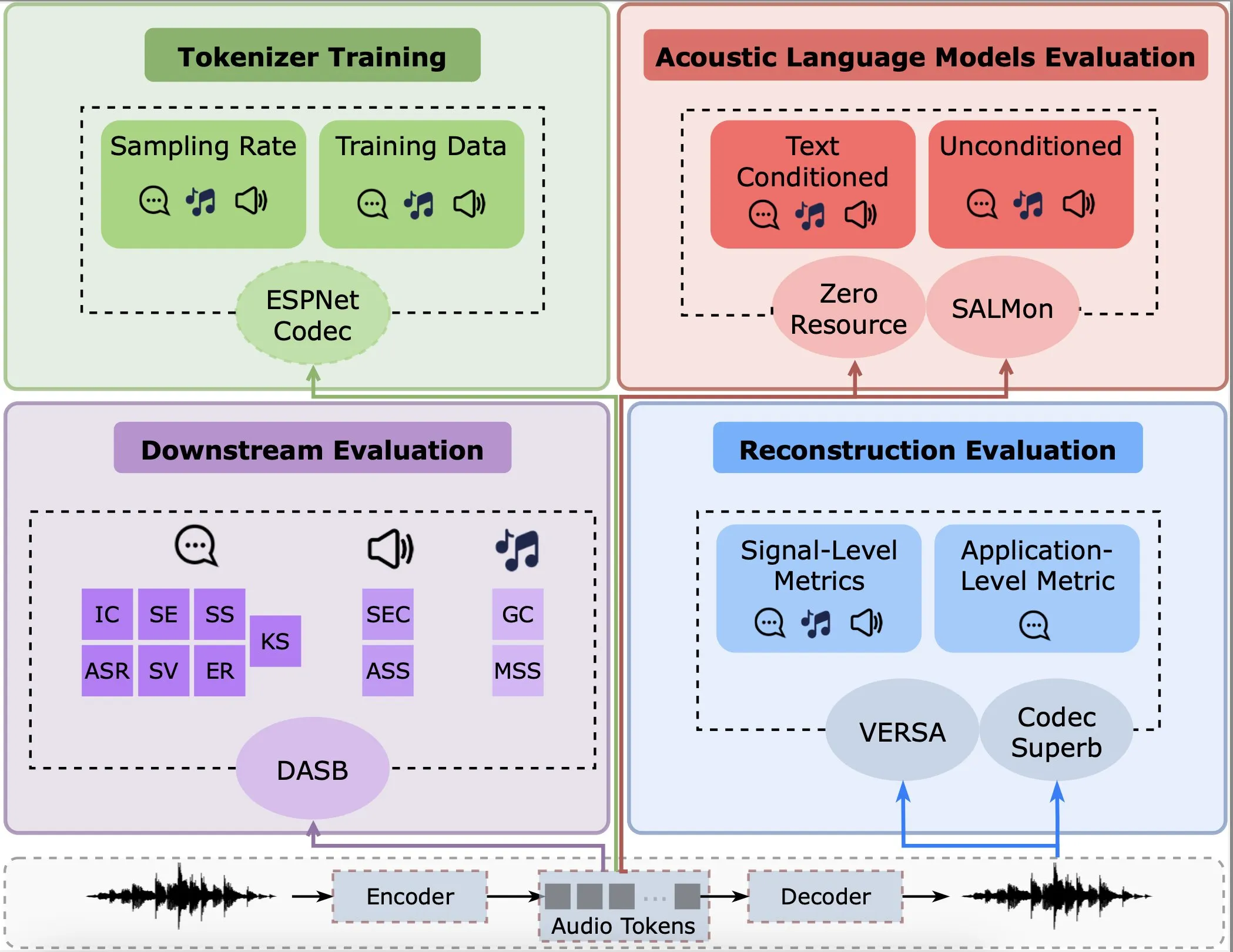
Penelitian menganalisis kinerja audio encoder dalam rekonstruksi, tugas hilir, dan model bahasa: Gallil Maimon dkk. menerbitkan penelitian baru yang melakukan analisis empiris komprehensif terhadap audio encoder (Audio Tokenisers) yang ada. Penelitian ini mengevaluasi encoder ini dari berbagai dimensi seperti kualitas rekonstruksi, kinerja dalam tugas hilir, dan kombinasi dengan model bahasa, memberikan referensi untuk memilih dan mengoptimalkan model pemrosesan audio (Sumber: menhguin)
Makalah membahas “ilusi berpikir”: memahami kelebihan dan kekurangan model penalaran dari perspektif kompleksitas masalah: Sebuah makalah tanggapan terhadap penelitian “ilusi berpikir” Apple (arXiv:2506.09250) telah diajukan, dengan Claude Opus dicantumkan sebagai penulis pertama. Makalah ini mengkritik desain eksperimental penelitian Apple dan berpendapat bahwa keruntuhan penalaran yang diamati sebenarnya disebabkan oleh batasan token, bukan kurangnya kemampuan logika intrinsik model. Hal ini memicu diskusi tentang bagaimana mengevaluasi kemampuan penalaran sebenarnya dari model bahasa besar (Sumber: NandoDF, BlancheMinerva, teortaxesTex)

Penelitian membahas model bahasa adaptif, tetapi memori jangka menengah masih menjadi tantangan: Dorialexander, setelah mempelajari makalah terkait “model bahasa adaptif”, menunjukkan bahwa meskipun ini adalah arah penelitian yang menjanjikan, model masih memiliki keterbatasan dalam mencapai memori jangka menengah saat melakukan penalaran. Ini menunjukkan bahwa model saat ini masih menghadapi tantangan dalam memproses informasi koheren yang membutuhkan konteks yang lebih panjang (Sumber: Dorialexander)

Penelitian kualitas pengujian RLHF: Seberapa baik pengujian saat ini? Bagaimana cara memperbaikinya? Seberapa penting kualitas pengujian?: Karya terbaru Kexun Zhang dkk. membahas pentingnya validator (pengujian) dalam Reinforcement Learning from Human Feedback (RLHF), terutama di bidang pengkodean LLM. Penelitian ini mengajukan tiga pertanyaan kunci: Bagaimana kualitas pengujian saat ini? Bagaimana cara mendapatkan pengujian yang lebih baik? Seberapa besar pengaruh kualitas pengujian terhadap kinerja model? Penelitian ini menekankan perlunya pengujian berkualitas tinggi untuk meningkatkan kemampuan pengkodean LLM (Sumber: StringChaos)
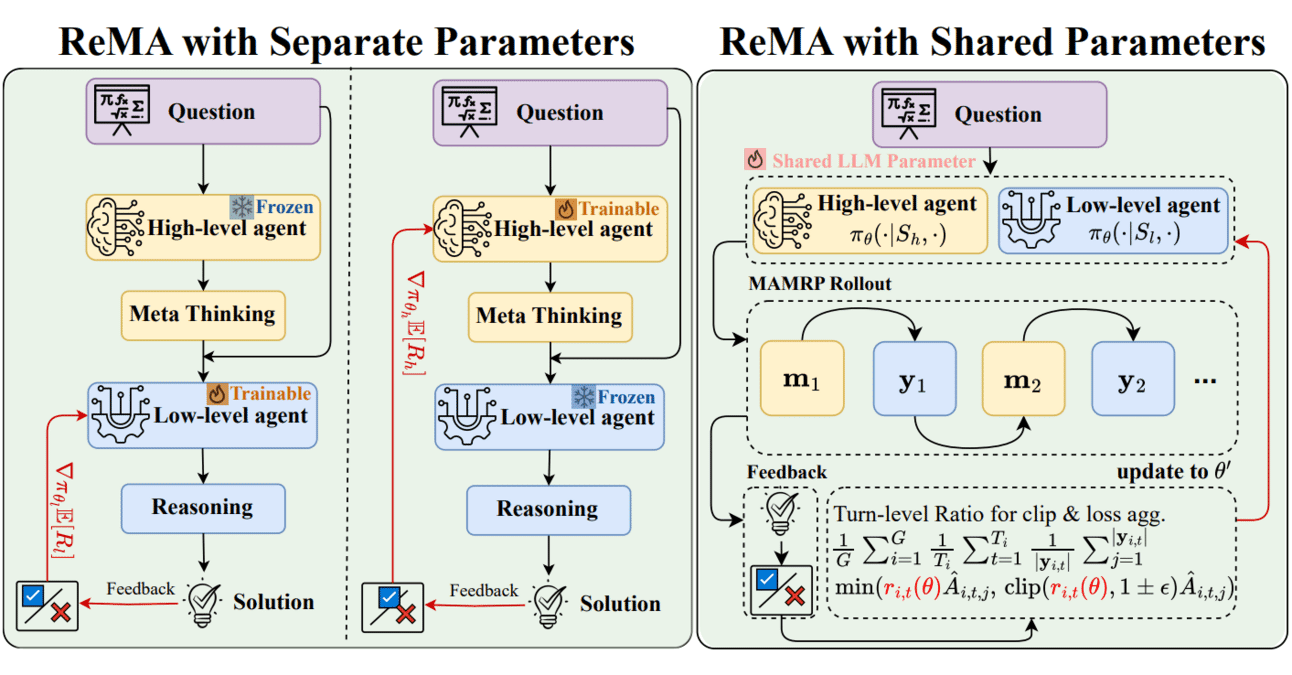
Kombinasi Meta-learning dan Reinforcement Learning: ReMA meningkatkan efisiensi kolaborasi LLM: Reinforced Meta-thinking Agents (ReMA) menggabungkan Meta-learning dan Reinforcement Learning (RL), bertujuan untuk meningkatkan efisiensi model bahasa besar (LLM), terutama ketika beberapa agen LLM bekerja sama. ReMA membagi pemecahan masalah menjadi dua bagian: meta-thinking (perencanaan strategi) dan reasoning (pelaksanaan strategi), dan dioptimalkan melalui agen khusus dan reinforcement learning multi-agen, mencapai peningkatan baik pada benchmark matematika maupun benchmark dengan LLM sebagai wasit (Sumber: TheTuringPost, TheTuringPost)
Strategi evaluasi AI: Bagaimana menggabungkan evaluator murah dan mahal dalam batasan anggaran untuk mendapatkan estimasi kualitas model terbaik: Penelitian Adam Fisch dkk. (arXiv:2506.07949) membahas masalah praktis: ketika memiliki evaluator yang murah tetapi bising, evaluator yang mahal tetapi akurat, dan anggaran tetap, bagaimana seharusnya anggaran dialokasikan untuk mendapatkan estimasi kualitas model yang paling akurat. Penelitian ini menyediakan kerangka kerja analisis biaya-manfaat untuk evaluasi sistem AI (Sumber: Ar_Douillard)
Fenomena “hadiah palsu” dan “prompt palsu” dalam prompt LLM: Penelitian Stella Li dkk. mengungkap fenomena menarik dalam pelatihan dan evaluasi LLM. Setelah menemukan “hadiah palsu” (misalnya, hadiah acak juga dapat meningkatkan kinerja model pada tugas tertentu), mereka lebih lanjut mengeksplorasi “prompt palsu”, yaitu bahkan teks yang tidak berarti seperti “Lorem ipsum”, dalam beberapa kasus dapat membawa peningkatan kinerja yang signifikan (misalnya 19,4%). Temuan ini mengajukan tantangan dan pemikiran baru tentang bagaimana LLM merespons prompt dan bagaimana merancang metode evaluasi yang lebih kuat (Sumber: Tim_Dettmers)

Makalah membahas model “teater boneka” interaksi AI: Sebuah makalah (atau draf) berjudul “The Pig in Yellow: AI Interface as Puppet Theatre” mengusulkan untuk memandang sistem AI bahasa (LLM, AGI, ASI) sebagai antarmuka performatif, yang mensimulasikan subjektivitas alih-alih memilikinya. Artikel tersebut menggunakan “Miss Piggy” sebagai metafora, menganalisis bahwa kelancaran, koherensi, dan ekspresi emosional AI bukanlah indikator pikiran, melainkan produk optimasi, menekankan bahwa antarmuka seperti boneka, pengguna bersama-sama membangun makna dalam interaksi, dan kekuasaan diwujudkan melalui desain performatif (Sumber: Reddit r/artificial)
💼 Bisnis
Woan Robot (SwitchBot) yang sahamnya dimiliki oleh “Bapak DJI” Li Zexiang, menuju IPO: Woan Robot (SwitchBot), yang didirikan oleh alumni Harbin Institute of Technology dan berfokus pada robot rumah tangga AI berwujud, telah mengajukan prospektus di bursa saham Hong Kong. Perusahaan ini mendapatkan investasi dan dukungan sumber daya dari “Bapak DJI” Li Zexiang, yang memegang 12,98% saham. Woan Robot telah menerima tujuh putaran pendanaan dalam sepuluh tahun terakhir, dengan valuasi meningkat dari 20 juta menjadi 4 miliar RMB. Produknya meliputi robot eksekutor yang mensimulasikan gerakan anggota tubuh manusia dan sistem persepsi-keputusan, telah menjadi pemasok robot rumah tangga AI berwujud terbesar di dunia dengan pangsa pasar 11,9%, dan pada tahun 2024 mencapai laba bersih yang disesuaikan sebesar 1,11 juta RMB (Sumber: QbitAI)

Tencent meluncurkan “Program Qingyun” 2026, pertama kalinya membuka bank sumber daya topik penelitian: Tencent mengumumkan peluncuran “Program Qingyun” 2026, yang ditujukan untuk merekrut mahasiswa teknologi terkemuka global, mencakup sepuluh bidang teknologi termasuk model besar AI, infrastruktur dasar, komputasi kinerja tinggi, dll., menawarkan lebih dari seratus topik teknologi. Berbeda dari tahun-tahun sebelumnya, program kali ini untuk pertama kalinya membuka bank sumber daya topik Qingyun, dan menyediakan jalur hijau perekrutan untuk talenta luar biasa, bertujuan untuk memperdalam kerja sama sekolah-perusahaan dan membina talenta teknologi muda. Tencent akan menyediakan pengajar tingkat industri teratas, sumber daya komputasi, dan gaji yang kompetitif (Sumber: QbitAI)

Manusia digital Luo Yonghao akan melakukan siaran perdana di Baidu E-commerce pada 15 Juni: Luo Yonghao mengumumkan bahwa avatar manusia digital AI-nya akan melakukan siaran langsung perdana di platform Baidu E-commerce pada 15 Juni. Ini adalah pertama kalinya seorang streamer terkemuka menggunakan manusia digital AI untuk siaran langsung penjualan produk, berkat terobosan Baidu dalam teknologi kunci seperti manusia digital dengan daya persuasi tinggi. Langkah ini dianggap sebagai eksplorasi paradigma baru e-commerce “AI + IP terkemuka”, diharapkan dapat mendorong industri siaran langsung e-commerce menuju arah yang lebih cerdas, efisien, dan berbiaya rendah. Data Baidu E-commerce menunjukkan bahwa lebih dari 100.000 streamer manusia digital telah diterapkan di berbagai industri, secara signifikan mengurangi biaya operasional pedagang dan meningkatkan GMV (Sumber: QbitAI)
🌟 Komunitas
Perusahaan AI Tiongkok mengirimkan sejumlah besar hard disk data ke Malaysia untuk melatih model: NIK melaporkan bahwa perusahaan AI Tiongkok, untuk menghindari pembatasan chip dan memanfaatkan sumber daya komputasi di luar negeri, telah mengadopsi strategi membawa hard disk yang penuh dengan data pelatihan “secara manual” ke tempat-tempat seperti Malaysia. Misalnya, ada insinyur yang membawa 15 hard disk berisi 80TB data terbang ke Malaysia untuk menyewa server guna melatih model. Fenomena ini mencerminkan persaingan sengit dalam sumber daya komputasi AI global dan tantangan nyata dari aliran data lintas batas, sekaligus menimbulkan diskusi tentang keamanan dan kepatuhan data (Sumber: jpt401, agihippo, cloneofsimo, fabianstelzer)

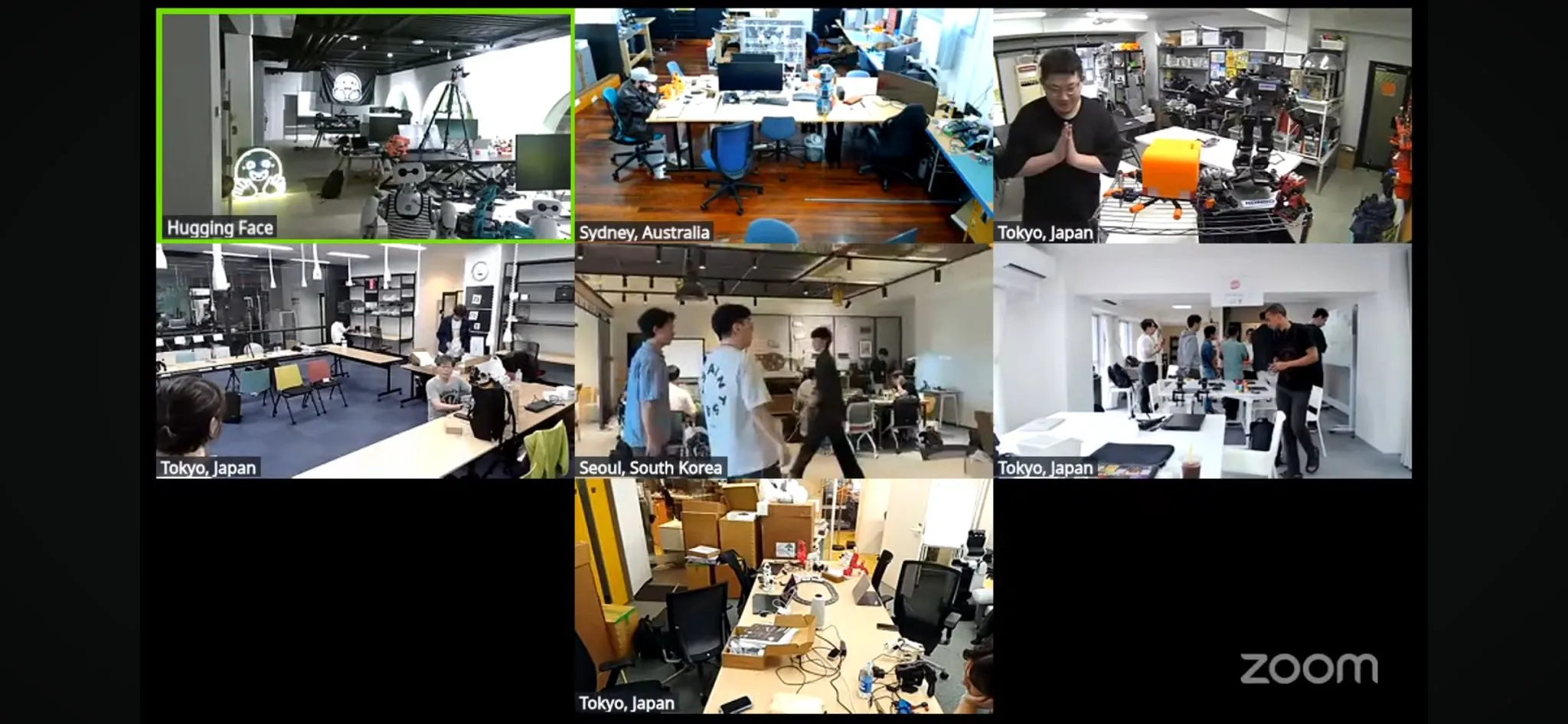
Hackathon robot LeRobot skala terbesar global dimulai: Hackathon robot global LeRobot yang diselenggarakan oleh Hugging Face secara resmi dimulai, mencakup lebih dari 100 lokasi di 5 benua, menarik lebih dari 2300 peserta. Kegiatan ini bertujuan untuk mendorong pengembangan robot AI open-source, para peserta akan melakukan pembuatan dan eksplorasi terkait robot dalam waktu 52 jam. Pengembang dan tim dari berbagai tempat berpartisipasi dengan antusias, membagikan foto di tempat dan kemajuan proyek, menunjukkan antusiasme dan kreativitas komunitas terhadap teknologi robotika (Sumber: _akhaliq, eliebakouch, ClementDelangue)
Lovable mengadakan duel pembuatan halaman web AI, kinerja Claude mendapat pujian: Lovable mengadakan sebuah acara yang memungkinkan pengguna untuk menggunakan model teratas dari OpenAI, Anthropic, dan Google secara gratis untuk kompetisi pembuatan halaman web AI. Pengguna op7418 berbagi pengalamannya menggunakan serangkaian prompt yang sama untuk menghasilkan halaman web melalui ketiga model tersebut, dan berpendapat bahwa Claude menonjol dalam hal kuantitas konten dan efek visual. Acara semacam ini memberi pengembang dan pengguna kesempatan untuk membandingkan kinerja berbagai model besar dalam skenario aplikasi tertentu (Sumber: _philschmid, op7418)
Diskusi tentang kemampuan penalaran model AI: batasan token vs. logika nyata: Menanggapi makalah “Illusion of Thinking” yang diajukan oleh Apple, muncul pandangan sanggahan di komunitas. Beberapa komentar dan penelitian lanjutan (seperti arXiv:2506.09250, yang mencantumkan Claude Opus sebagai penulis) berpendapat bahwa “keruntuhan” kemampuan penalaran model yang diamati lebih disebabkan oleh batasan jumlah token, daripada kurangnya kemampuan logika intrinsik model itu sendiri. Ketika model diizinkan menggunakan format jawaban yang lebih ringkas atau memiliki konteks yang cukup, mereka mampu menyelesaikan masalah dengan sukses. Hal ini memicu diskusi mendalam tentang bagaimana secara akurat mengevaluasi dan memahami kemampuan penalaran sebenarnya dari model bahasa besar, serta kemungkinan keterbatasan metode evaluasi saat ini (Sumber: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
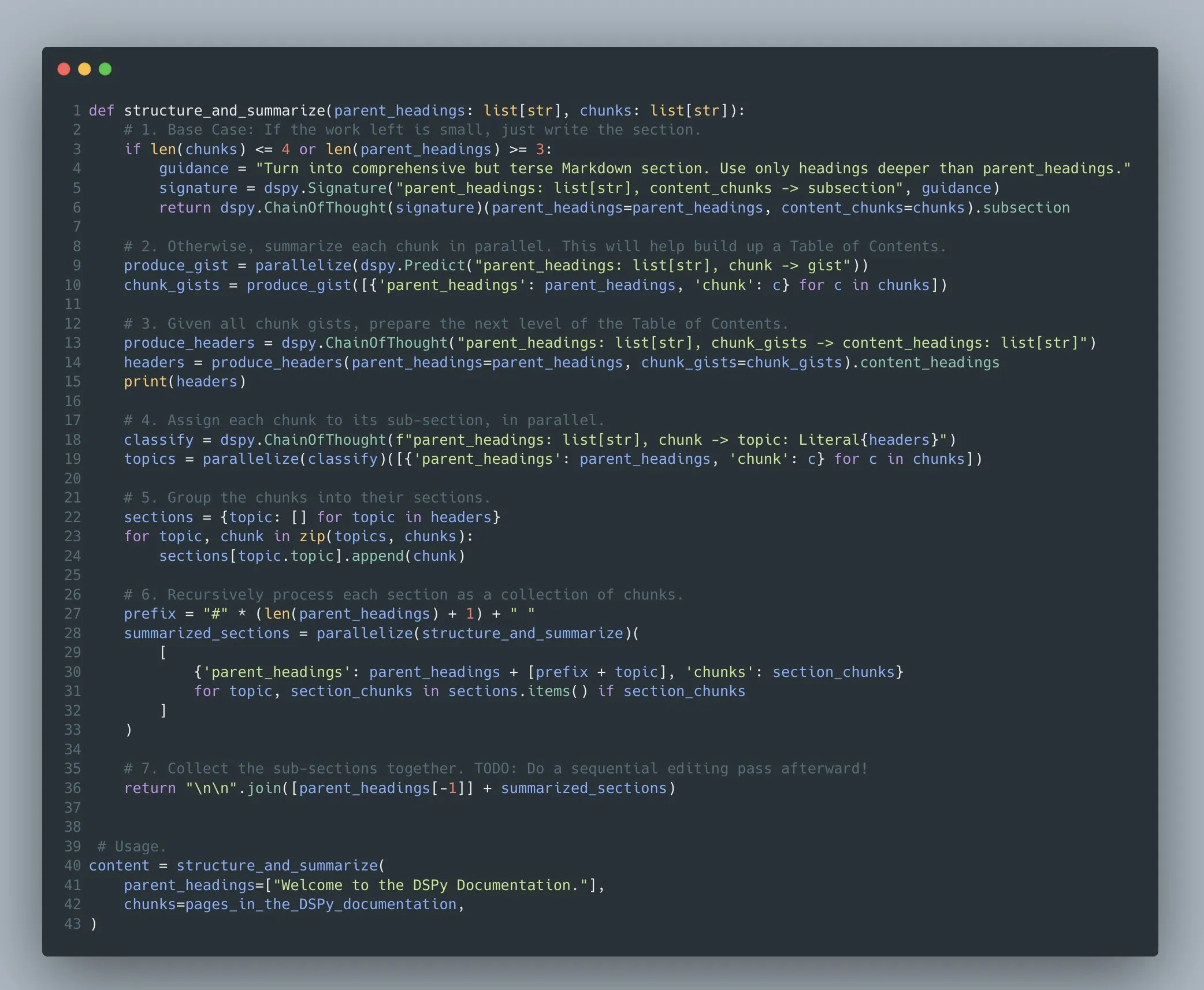
Framework DSPy mendukung optimasi program model bahasa multi-tahap yang kompleks: Omar Khattab menekankan bahwa framework DSPy sejak 2022/2023 telah mendukung optimasi prompt dan reinforcement learning untuk program model bahasa multi-tahap yang kompleks (Compound AI Systems). Dia berpendapat bahwa seiring dengan meningkatnya kompleksitas sistem AI, lebih tepat untuk memandangnya sebagai “program” daripada sekadar “model”, dan DSPy bertujuan untuk menyediakan dukungan untuk membangun dan mengoptimalkan program dengan kompleksitas arbitrer semacam itu (termasuk rekursi, penanganan pengecualian, dll.), bukan hanya “alur kerja” atau “rantai” linier (Sumber: lateinteraction)
Diskusi tentang apakah LLM mirip dengan pemikiran manusia: Geoffrey Hinton berpendapat bahwa model bahasa besar (LLM) mirip dengan cara manusia memproses bahasa dan merupakan model terbaik kita untuk memahami cara kerja bahasa. Namun, Pedro Domingos meragukan hal ini, berpendapat bahwa LLM lebih unggul dari teori linguistik lama tidak berarti mereka berpikir seperti manusia. Diskusi ini mencerminkan perdebatan berkelanjutan di bidang AI mengenai sifat LLM dan hubungannya dengan kognisi manusia (Sumber: pmddomingos)
Potensi besar aplikasi AI dalam penelitian ilmu fisika: Seorang peneliti di bidang ilmu bumi berbagi pengalaman positif menggunakan o3 Pro (kemungkinan merujuk pada salah satu model canggih OpenAI), menyebutnya sebagai “postdoc yang sangat cerdas” dalam penelitiannya. Model ini menunjukkan kinerja luar biasa dalam pengkodean, pengembangan model, dan penyempurnaan ide, mampu menjalankan instruksi dengan cepat dan akurat serta membantu penelitian. Peneliti tersebut berpendapat bahwa meskipun model saat ini belum memiliki kemampuan untuk secara proaktif mengajukan pertanyaan penelitian (ciri AGI), fungsi pendukungnya yang kuat telah secara signifikan meningkatkan efisiensi penelitian ilmiah, dan merasakan bahwa LLM dengan otonomi sudah tidak lama lagi (Sumber: Reddit r/ArtificialInteligence)
💡 Lainnya
Alat pembuat komik AI membuat ekspresi kreatif lebih mudah: Pengguna StriderWriting berbagi pengalaman menggunakan alat AI untuk membuat komik, berpendapat bahwa AI memungkinkan untuk mengubah “ide konyol” menjadi komik. Ini mencerminkan penyebaran AI di bidang pembuatan konten kreatif, menurunkan hambatan untuk berkreasi, dan memungkinkan lebih banyak orang untuk mengekspresikan ide kreatif mereka dengan mudah (Sumber: Reddit r/ChatGPT)

Kekhawatiran tentang bias AI: Kinerja ChatGPT pada stereotip gender menimbulkan ketidakpuasan pengguna: Seorang pengguna wanita melaporkan bahwa ChatGPT menunjukkan stereotip negatif terhadap pria dalam percakapan, misalnya, ketika membahas masalah pekerjaan dan medis, tanpa diminta, ChatGPT mengasumsikan peran negatif adalah pria dan menggunakan pernyataan seperti “pria memang menyebalkan”. Pengguna menunjukkan bahwa stereotip malas berdasarkan gender ini tidak nyaman dan mempertanyakan apakah OpenAI memiliki aturan untuk membatasi perilaku semacam itu. Ini sekali lagi memicu diskusi tentang bias data pelatihan model AI dan bagaimana hal itu terwujud dalam interaksi (Sumber: Reddit r/ChatGPT)
Potensi objektivitas AI dalam pelaporan berita dan keterbatasan saat ini: Seorang pengguna menguji potensi model o3 OpenAI sebagai “wartawan berita yang tidak bias” dengan memintanya mengomentari kemungkinan konsekuensi “yang tidak diinginkan” dari berbagai kebijakan pemerintah Trump dan Biden sejak 2017. Meskipun AI mampu menghasilkan analisis yang tampak objektif, sumber informasinya, potensi bias, dan kedalaman pemahaman sebenarnya tentang dinamika politik-ekonomi yang kompleks masih menjadi masalah yang perlu diselesaikan di masa depan. Ini mencerminkan harapan komunitas untuk memanfaatkan AI guna meningkatkan objektivitas dan kedalaman berita, serta kesadaran akan keterbatasan teknologi saat ini (Sumber: Reddit r/deeplearning)