
キーワード:量子コンピューティング, 自動運転, 大規模言語モデル, 3D生成モデル, AIツール, 機械学習, 人工知能研究, CUDA-Q量子コンピューティングプラットフォーム, Waymo自動運転データ研究, Claudeマルチエージェントシステム, Tencent Hunyuan 3D 2.1, AI生成コア性能最適化
🔥 注目ニュース
NVIDIA、量子コンピューティング専用プラットフォームCUDA-Qを発表: NVIDIAのCEOジェンスン・フアン氏はGTCパリの講演で、量子-古典ハイブリッドスーパーコンピューティングプラットフォームであるCUDA-Qを発表しました。このプラットフォームは、現在の古典計算と将来の量子計算の間のギャップを埋めることを目的としており、古典コンピュータ上で量子演算をシミュレートしたり、実際の量子コンピュータを支援したりすることを可能にします。CUDA-QはGrace Blackwellで利用可能であり、GB200 NVL72スーパーコンピュータを通じて開発速度を1300倍に向上させることができます。フアン氏は、量子コンピュータの実用化は数年以内に実現すると予測し、この開発段階においてNVIDIAのチップ(特にGB200)がシミュレーション計算とQPU支援に不可欠であると強調しました。NVIDIAは、世界の量子コンピューティング企業やスーパーコンピューティングセンターと協力し、GPUとQPUの連携を探求しています (出典: 量子位)

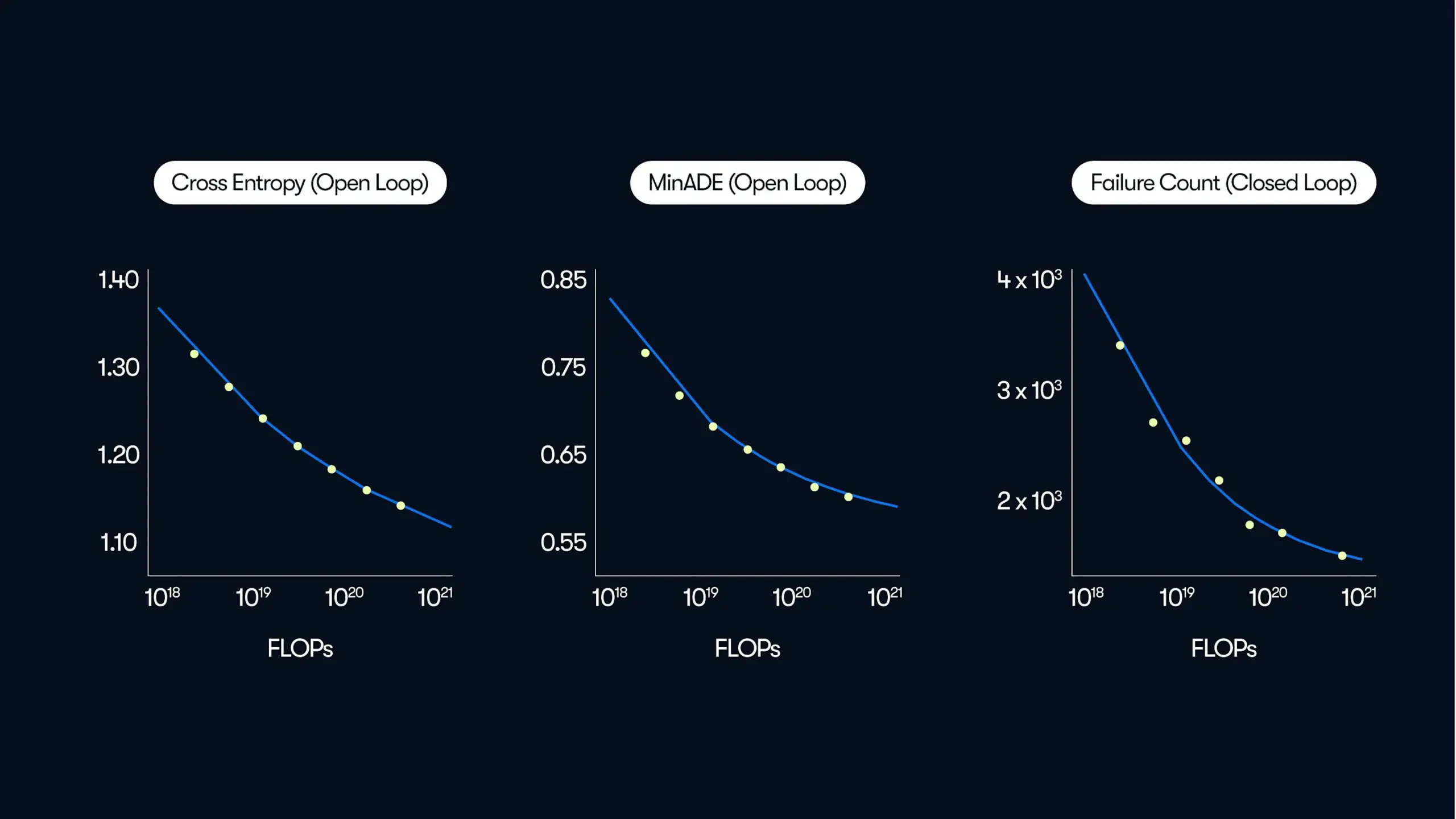
Waymo、自動運転の大規模研究を発表、「データ駆動型」の性能向上法則を明らかに: Waymoは最新のブログ記事で、50万時間の運転データに基づく包括的な研究成果を共有しました。これは自動運転分野で過去最大規模のデータセットです。研究によると、大規模言語モデル(LLM)と同様に、自動運転システムの動作予測の質も訓練計算量の増加に伴いべき乗則に従うことが示されました。データ規模の拡大はモデル性能の向上に不可欠であり、同時に、推論計算能力の拡大もモデルが複雑な運転シナリオを処理する能力を高めます。この研究は、訓練データと計算資源を増やすことで、実世界の自動運転性能を大幅に改善できることを初めて実証し、業界に規模拡大による能力向上の道筋を示しました (出典: Sawyer Merritt, scaling01)
Anthropic、Claudeマルチエージェント研究システムの構築経験を共有: Anthropicはエンジニアリングブログで、複数の並列動作するエージェントを利用してClaudeの研究能力を構築する方法を詳細に紹介しました。記事では、開発過程での成功体験、直面した問題、エンジニアリング上の課題が共有されています。このマルチエージェントシステムにより、Claudeは情報検索、分析、統合をより効率的に行い、研究能力と複雑な問題への回答能力を向上させることができます。この共有は、大規模言語モデルが複雑なシステム設計を通じてどのように機能を拡張するかを理解する上で重要な参考価値があります (出典: ImazAngel, teortaxesTex)
Meta、ビデオ理解・予測・ロボット制御を実現する世界モデルV-JEPA 2を発表: Meta AIは、ビデオベースで訓練された世界モデルであるV-JEPA 2を発表しました。これは物理世界の動態の理解と予測において著しい進歩を遂げています。V-JEPA 2は効率的なビデオ特徴学習を行えるだけでなく、新しい環境でのゼロショットプランニングやロボット制御も実現し、汎用人工知能分野における可能性を示しています。このモデルは自己教師あり学習を通じてビデオデータから世界の表現を学習し、よりスマートで現実世界とよりよく対話できるAIシステムを構築するための新しい道を提供します (出典: dl_weekly)
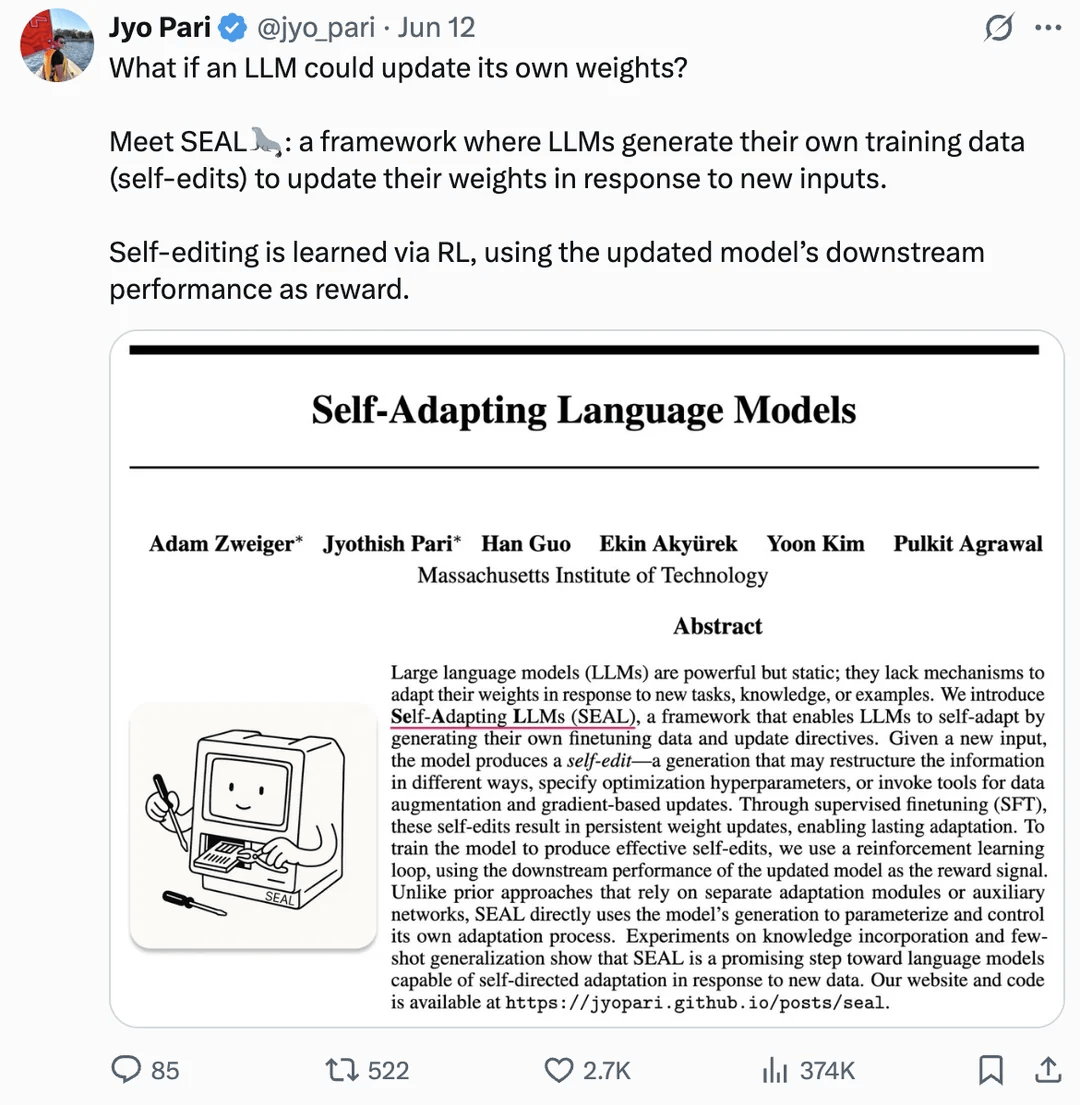
論文、LLMの重み自己更新による自己改善の実現を議論: arXivに掲載された論文(2506.10943)は、大規模言語モデル(LLM)が自身の重みを更新することで自己改善を実現できるようになったと提案しています。このメカニズムは、LLMが新しいデータや経験から学習し、完全な再訓練なしに内部パラメータを動的に調整して性能を向上させたり、新しいタスクに適応したりできることを意味する可能性があります。この研究方向が成功すれば、LLMの適応性と継続的な学習能力が大幅に向上し、より自律的なAIシステムへの重要な一歩となります (出典: Reddit r/artificial)
🎯 動向
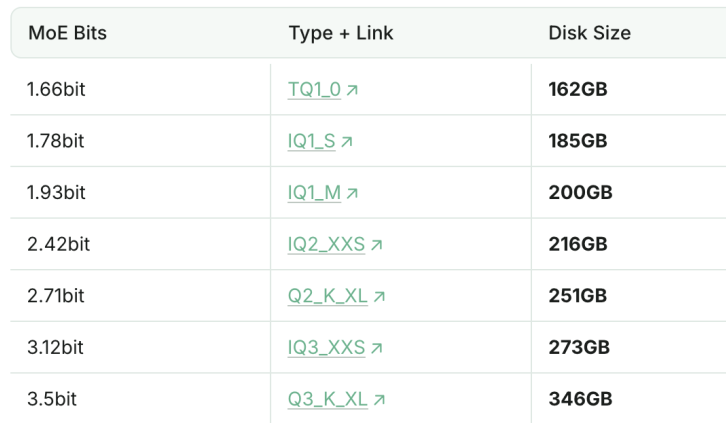
1.93bit量子化版DeepSeek-R1、プログラミング能力でClaude 4 Sonnetを上回る: UnslothスタジオはDeepSeek-R1(0528版)を1.93bitに量子化することに成功し、プログラミングベンチマークaiderで60%の成績を収め、Claude 4 Sonnet(56.4%)および1月版のフルスペックR1を上回りました。この極度に圧縮されたバージョンはファイルサイズが70%以上削減され、GPUなしでも(CPUと十分なメモリがあれば)実行可能です。フルスペック版R1-0528はaiderで71.4%のスコアを記録し、思考モードをオフにしたClaude 4 Opusを上回りました。これは、モデル量子化技術が性能を維持しつつリソース要件を大幅に削減する可能性を示しています (出典: 量子位)
Tencent Hunyuan、初のプロダクションレベルPBR 3D生成モデルHunyuan 3D 2.1をオープンソース化: Tencent Hunyuanチームは、業界初の完全にオープンソース化されたプロダクションレベルのPBR(Physically Based Rendering)3D生成モデルであるHunyuan 3D 2.1を発表しました。このモデルはPBRマテリアル合成技術を利用し、映画レベルの視覚効果を持つ3Dコンテンツを生成でき、皮革や青銅などのマテリアルが光の下でより生き生きとリアルに表現されます。プロジェクトはモデルの重み、訓練/推論コード、データパイプライン、アーキテクチャを公開し、コンシューマー向けグラフィックカードでの実行もサポートしており、3Dコンテンツ生成技術の発展と普及を推進することを目指しています (出典: op7418, ImazAngel)
Meta AI、3D点群表現の自己教師あり学習を推進するSonataを発表: Meta AIは、3D自己教師あり学習分野で著しい進歩を遂げた研究であるSonataを発表しました。Sonataは幾何学的ショートカットの問題を特定・解決し、柔軟かつ効率的なフレームワークを導入することで、非常にロバストな3D点群表現を学習することができます。この研究は3D認識技術の既存レベルを向上させ、将来の3D認識とその応用分野におけるイノベーションの基盤を築きます (出典: AIatMeta)

Meta AI、読書行動理解のための「野外読書認識データセット」を発表: Meta AIは、「Reading Recognition in the Wild」と名付けられた大規模マルチモーダルデータセットを公開しました。これにはビデオ、視線追跡、頭部姿勢センサーの出力が含まれています。このデータセットは、ウェアラブルデバイスからの読書認識タスクの解決を支援することを目的としており、60Hzの高頻度で視線データを収集した初の自己中心視点データセットであり、人間の読書行動の研究に貴重なリソースを提供します (出典: AIatMeta)

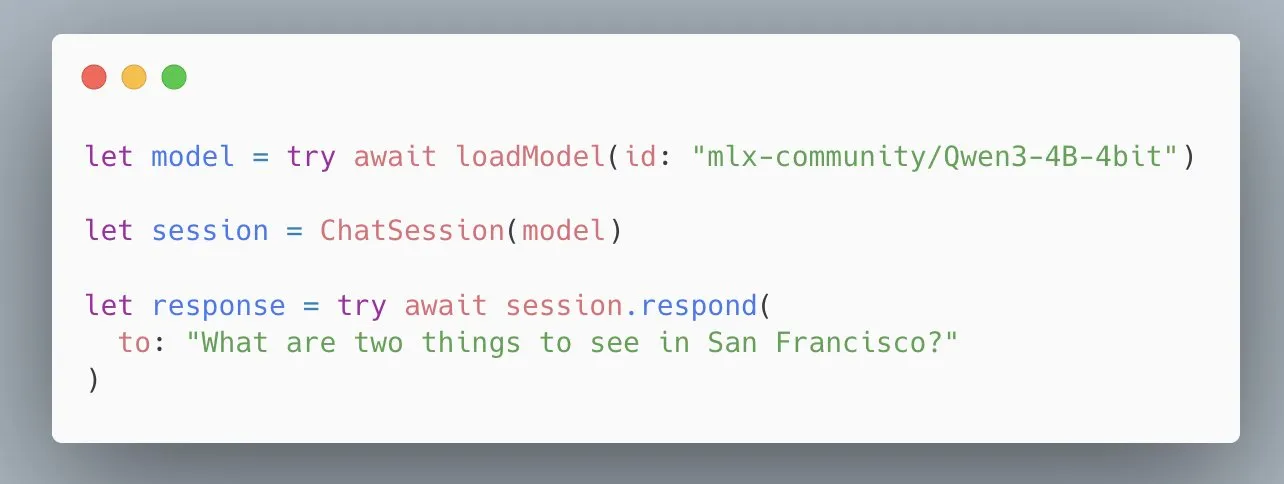
Apple MLX Swift LLM APIが簡素化、3行のコードでモデルをロード可能に: 開発者からMLX Swift LLM APIの習得が難しいとのフィードバックを受け、Appleチームは迅速に改善を行い、新しい簡素化されたAPIを発表しました。現在、開発者はわずか3行のコードでSwiftプロジェクトにLLMまたはVLMをロードし、チャットセッションを開始でき、Appleエコシステムでの大規模言語モデルの使用のハードルを大幅に下げました (出典: stablequan)
Google Gemma3 4B、ブラジルポルトガル語最適化版GAIAをリリース: Googleはブラジルの複数の機関(ABRIA, CEIA-UFG, Nama, Amadeus AI)およびDeepMindと共同で、ブラジルポルトガル語に最適化されたオープンソース言語モデルGAIA (Gemma-3-Gaia-PT-BR-4b-it) を発表しました。このモデルはGemma-3-4b-ptをベースとし、130億の高品質なブラジルポルトガル語トークンで継続的な事前学習が行われました。GAIAは革新的な「重みマージ」技術を採用して指示追従を実現し、従来のSFTを必要とせず、ENEM 2024ベンチマークテストでベースのGemmaモデルを上回りました。このモデルはチャット、質疑応答、要約、テキスト生成、およびブラジルポルトガル語のファインチューニングのベースモデルとして適しています (出典: Reddit r/LocalLLaMA)
Figure AIロボット、Helix AIと自律性を融合し、スケーラブルな展開を推進: Figure AIは、同社の実世界ロボットがHelix AIと自律性を強化することで、どのようにスケーラブルな展開を推進しているかを示しました。これは、物理ロボットと高度なAIモデルの組み合わせが、より複雑な環境でのロボットの応用を可能にしつつあることを示しており、ロボット分野におけるエンジニアリングと新興技術の重要性を強調しています (出典: Ronald_vanLoon)
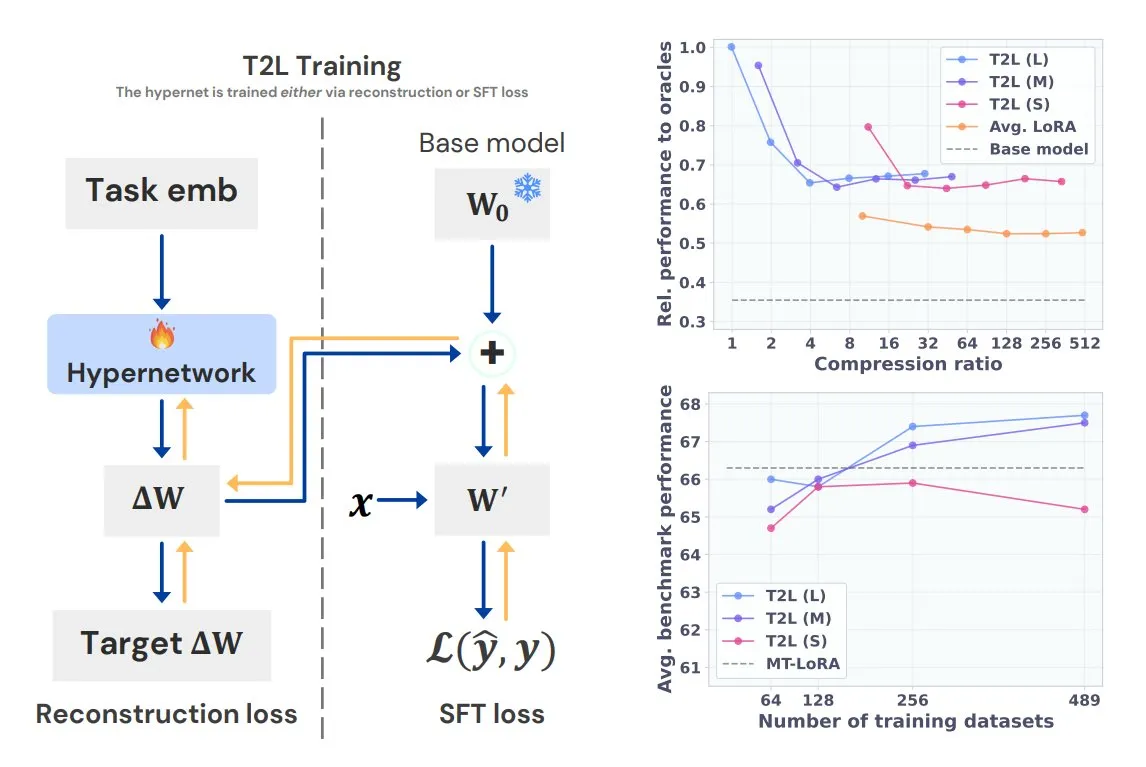
Sakana AI、Text-to-LoRA (T2L) ハイパーネットワークを発表: Sakana AIは、Text-to-LoRA (T2L) という新しいタイプのハイパーネットワークを発表しました。これは、複数の既存のLoRA(Low-Rank Adaptation)を自身に圧縮し、タスクのテキスト記述のみから大規模言語モデル用の新しいLoRAアダプタを迅速に生成することができます。T2Lは訓練後、即座に新しいLoRAを作成でき、特定タスク向けのLLMの迅速なカスタマイズと展開に効率的な手段を提供します。関連成果はICML 2025で発表される予定です (出典: TheTuringPost)
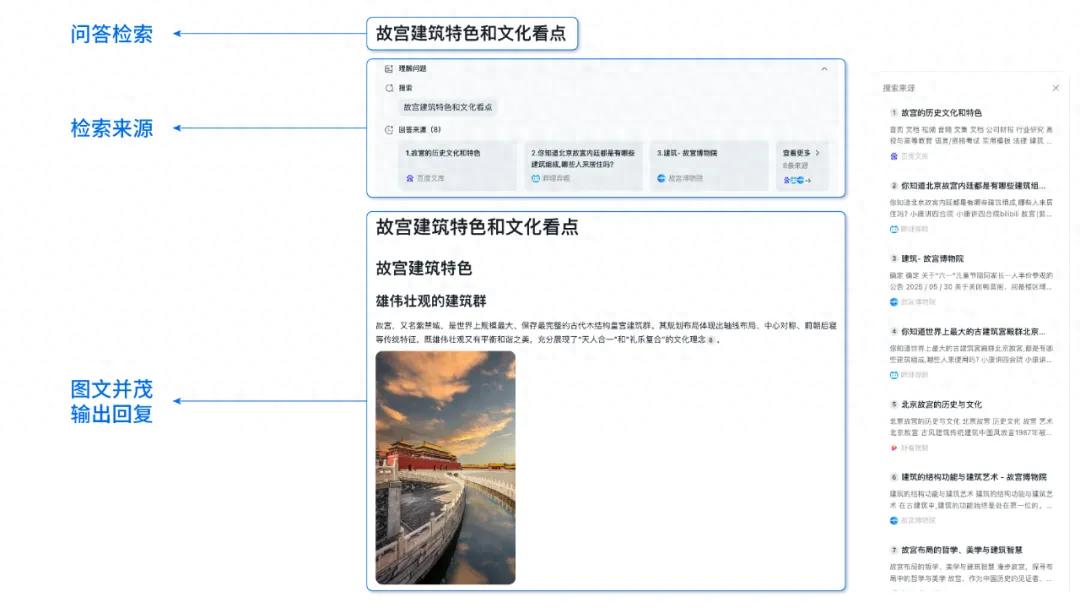
Baidu AI Search、Baidu Smart Cloud Qianfanプラットフォームで全面提供開始: Baidu Smart Cloud Qianfanアプリケーション開発プラットフォームAppBuilderは、「Baidu AI Search」サービスを正式に開始しました。このサービスは、「Baidu Search」と「スマート検索生成」という2つのコア機能を統合し、企業に情報検索からスマート生成までの全プロセスサービスを提供します。Baiduの20年以上にわたる中国語検索技術と千億レベルのデータベースを活用し、広告なしのマルチモーダル検索結果を提供し、正確なフィルタリング、ソース追跡、エンタープライズレベルのセキュリティポリシーをサポートします。スマート検索生成機能は、Wenxin、Deepseekなどのモデルと組み合わせ、AI要約、プライベートナレッジ連携検索などの機能を提供します (出典: 量子位)
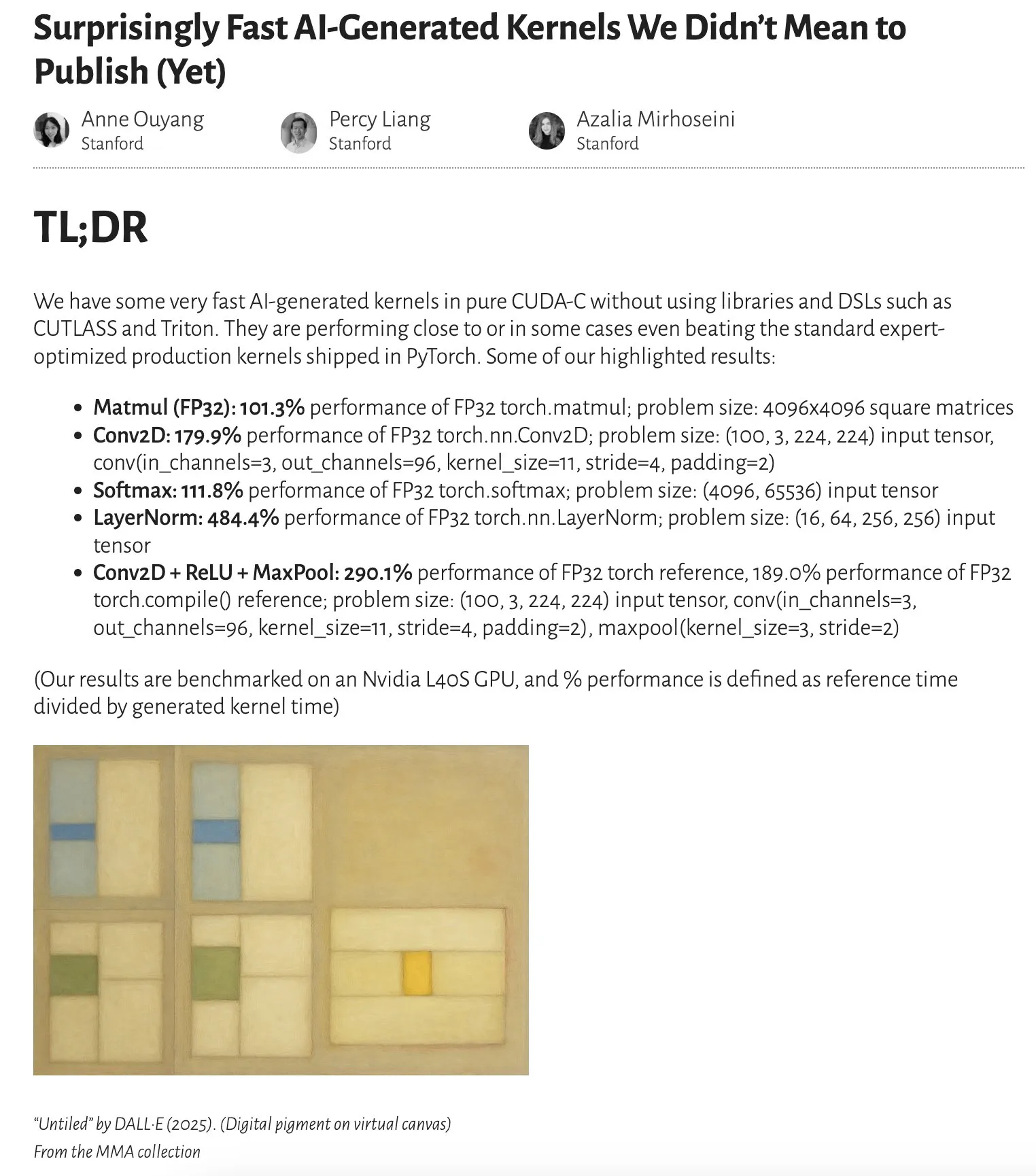
研究、AI生成カーネルの性能が専門家最適化カーネルに匹敵、あるいは上回ることを示す: Anne Ouyang氏のブログ記事によると、単純なテスト時のみの検索(test-time only search)によって生成されたAIカーネルの性能は、PyTorchの標準的な、専門家によって最適化されたプロダクションカーネルに匹敵し、場合によってはそれを上回ることが示されました。これは、AIがコード最適化と性能向上において大きな可能性を秘めていることを示しており、将来的に基盤ライブラリの最適化においてより重要な役割を果たす可能性があります (出典: jeremyphoward)
「拡散二元性」研究、離散拡散言語モデルの少数ステップ生成新手法を提案: ICML 2025で発表された論文「The Diffusion Duality」は、潜在的なガウス拡散を利用することで、離散拡散言語モデルにおいて少数ステップでの生成を実現する新しい手法を提案しました。この手法は、7つのゼロショット尤度ベンチマークのうち3つで自己回帰(AR)モデルを上回り、拡散モデルの生成効率を向上させるための新しいアイデアを提供しました (出典: arankomatsuzaki)
MLP層の解釈可能性に新たな突破口:活性化を解釈可能な特徴に分解: Mor Geva氏らの新しい研究は、多層パーセプトロン(MLP)の活性化を解釈可能な特徴に分解する簡単な方法を示しました。この方法は、隠れた概念の階層構造を明らかにし、そこでは疎なニューロンの組み合わせがますます抽象的な概念を形成しており、ニューラルネットワークの内部動作メカニズムを理解するためのより深い視点を提供します (出典: menhguin)

HeadHunterフレームワーク、摂動アテンションガイダンスの精密な制御を実現: Sayak Paul氏らは、摂動アテンションガイダンスの原理的な分析のためのHeadHunterフレームワークを提案しました。このフレームワークは、生成品質と視覚的属性の深い細粒度制御を可能にし、生成モデルの出力の改善とカスタマイズのための新しいツールと洞察を提供します (出典: huggingface, RisingSayak)

🧰 ツール
Windsurf有料プランでClaude Sonnet 4が利用可能に: Windsurfは、すべての有料プランでClaude Sonnet 4モデルが利用可能になったことを発表しました。ユーザーはWindsurfプラットフォーム上でAnthropicのこの最新モデルの強力な機能をテキスト生成、対話などのタスクに活用できるようになり、AIアシスタントの性能と体験をさらに向上させることができます (出典: op7418)
Anthropic、Claude Code公式Python SDKをリリース: Anthropicは、Claude Code向けの公式Python SDKをリリースしました。これにより、開発者はClaudeのコード生成能力とツール使用能力を自身のPythonプロジェクトに容易に統合できるようになります。このSDKは、ツール使用、ストリーミング出力、同期/非同期操作、ファイル処理をサポートし、チャット構造を内蔵しており、Claude Codeとの対話開発プロセスを簡素化します (出典: Reddit r/ClaudeAI)
Claude Task Master VS Code拡張機能リリース: DevDreedは、Claude Task Master VS Code拡張機能のバージョン1.0.0をリリースしました。この拡張機能は、eyaltoledano氏のClaude Task Master AIプロジェクトを補完することを目的としており、Claude Task Masterの出力をVS Codeインターフェースに直接統合し、ユーザーがエディタとコンソール間をシームレスに切り替えられるようにして、開発効率を向上させます (出典: Reddit r/ClaudeAI)
SmartSelect AI:ブラウザ内テキスト・画像AI処理ツール: SmartSelect AIというChrome拡張機能がリリースされました。これにより、ユーザーはウェブ閲覧中に選択したテキストを直接要約、翻訳、チャットしたり、画像をAIで記述したりすることができ、タブを切り替えたりChatGPTなどの外部アプリケーションにコピー&ペーストしたりする必要がありません。このツールはGeminiモデルに基づいており、情報取得と処理の効率向上を目指しています (出典: Reddit r/deeplearning)

Unsiloed AI、多機能データチャンキングツールをオープンソース化: Unsiloed AI (EF 2024) は、データチャンキング(chunker)機能の一部をオープンソース化しました。このツールは、PDF、Excel、PPTなど様々な形式のドキュメントを処理し、大規模言語モデルが処理しやすい形式に変換することを目的としています。Unsiloed AIは、Fortune 100企業や複数のスタートアップ企業でマルチモーダルデータ取り込みに利用されています (出典: Reddit r/LocalLLaMA)
Claude Superprompt System:Claudeプロンプトを最適化する無料ツール: Igor Warzocha氏は、「Claude Superprompt System」というオンラインツールを開発・共有しました。これは、ユーザーが簡単なリクエストを、思考連鎖や文脈例を含む構造化された複雑なプロンプトに変換し、Claudeの能力をより良く活用することを目的としています。このツールは、Anthropicの公式ドキュメントやコミュニティで見つかったベストプラクティスに基づいており、XMLタグによる構造化、CoT推論ブロックなどによってプロンプトを最適化し、Claudeの出力品質を向上させます。プロジェクトコードはGitHubでオープンソース化されています (出典: Reddit r/artificial)
ローカルTTS FirefoxプラグインKokoro-TTSリリース: 開発者のPinguy氏は、Kokoro TTSというFirefoxプラグインをリリースしました。このプラグインは、82Mパラメータのローカルホストされたニューラルネットワークモデル(Kokoro TTSモデル)を使用してテキスト読み上げを行い、完全にオフラインで動作し、ユーザーのプライバシーを保護します。複数の音声とアクセントをサポートし、古いハードウェアでもスムーズに動作し、Windows、Linux、macOS版が提供されています (出典: Reddit r/artificial)
Spy Search:オープンソースLLM検索エンジンプロジェクト更新: JasonHonKL氏は、自身のオープンソースLLM検索エンジンプロジェクトSpy Searchを更新しました。このプロジェクトは、効率的な大規模言語モデルベースの検索エンジンの構築に取り組んでおり、最新バージョンでは3秒以内の検索と応答が可能になっています。プロジェクトコードはGitHubでホストされており、ユーザーに高速で役立つ日常的な検索ツールを提供することを目指しています (出典: Reddit r/deeplearning)
HandFonted:手書き文字をフォントに変換するツールがオープンソース化: Resham Gaire氏はHandFontedプロジェクトを開発し、オープンソース化しました。これは、手書き文字の画像をインストール可能な.ttfフォントファイルに変換するエンドツーエンドのPythonアプリケーションです。このシステムは、OpenCVを画像処理と文字分割に、カスタマイズされたPyTorchモデル(ResNet-Inception)を文字分類に、ハンガリアンアルゴリズムを最適なマッチングに利用し、最後にfontToolsライブラリを使用してフォントファイルを生成します (出典: Reddit r/MachineLearning)
📚 学習
韋東奕氏らの論文が数学ジャーナルでトップに、超臨界非集束非線形波動方程式の爆発現象を研究: 北京大学の研究者である韋東奕氏、章志飛氏、邵鋒氏が共同執筆した論文「On blow-up for the supercritical defocusing nonlinear wave equation」が、トップ数学ジャーナル「Forum of Mathematics, Pi」に掲載されました。この研究は、特定の非集束非線形波動方程式が超臨界状態における爆発(解が有限時間で無限大になる)問題を検討しています。彼らは、空間次元d=4かつp≥29、およびd≥5かつp≥17の場合に、有限時間で爆発する滑らかな複素数値解が存在することを証明しました。この成果は関連分野の空白を埋めるものであり、その証明方法は他の非線形偏微分方程式の爆発研究に新たなアイデアを提供します (出典: 量子位)

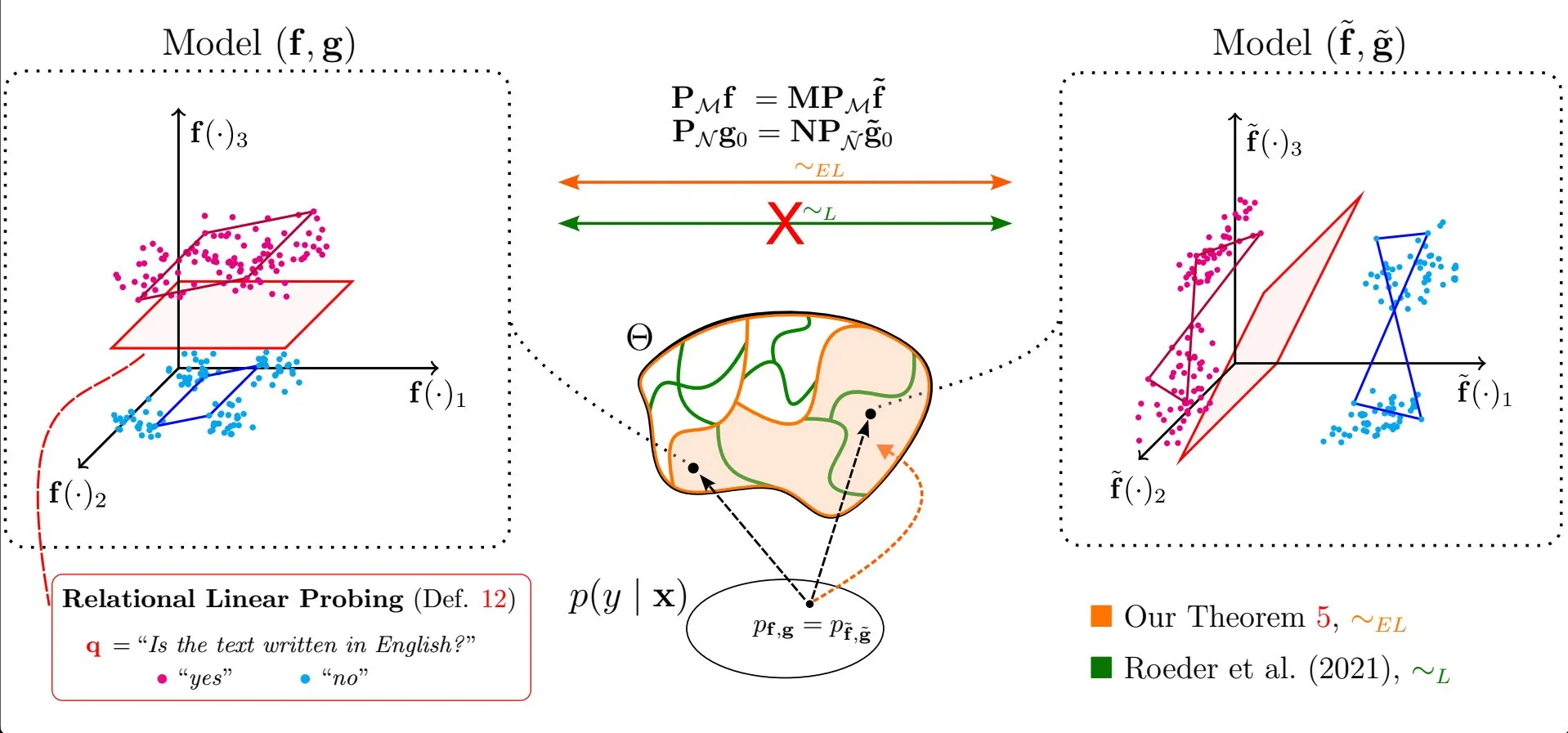
論文、大規模言語モデル表現における線形特性の普遍性を議論: Emanuele Marconato氏らの研究「All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling」(AISTATS 2025で発表)は、識別可能性の観点から、なぜ線形特性が大規模言語モデル(LLM)の表現においてこれほど普遍的なのかを議論しています。この研究は、LLMの内部表現の構造と振る舞いをより深く理解するのに役立ちます (出典: menhguin)
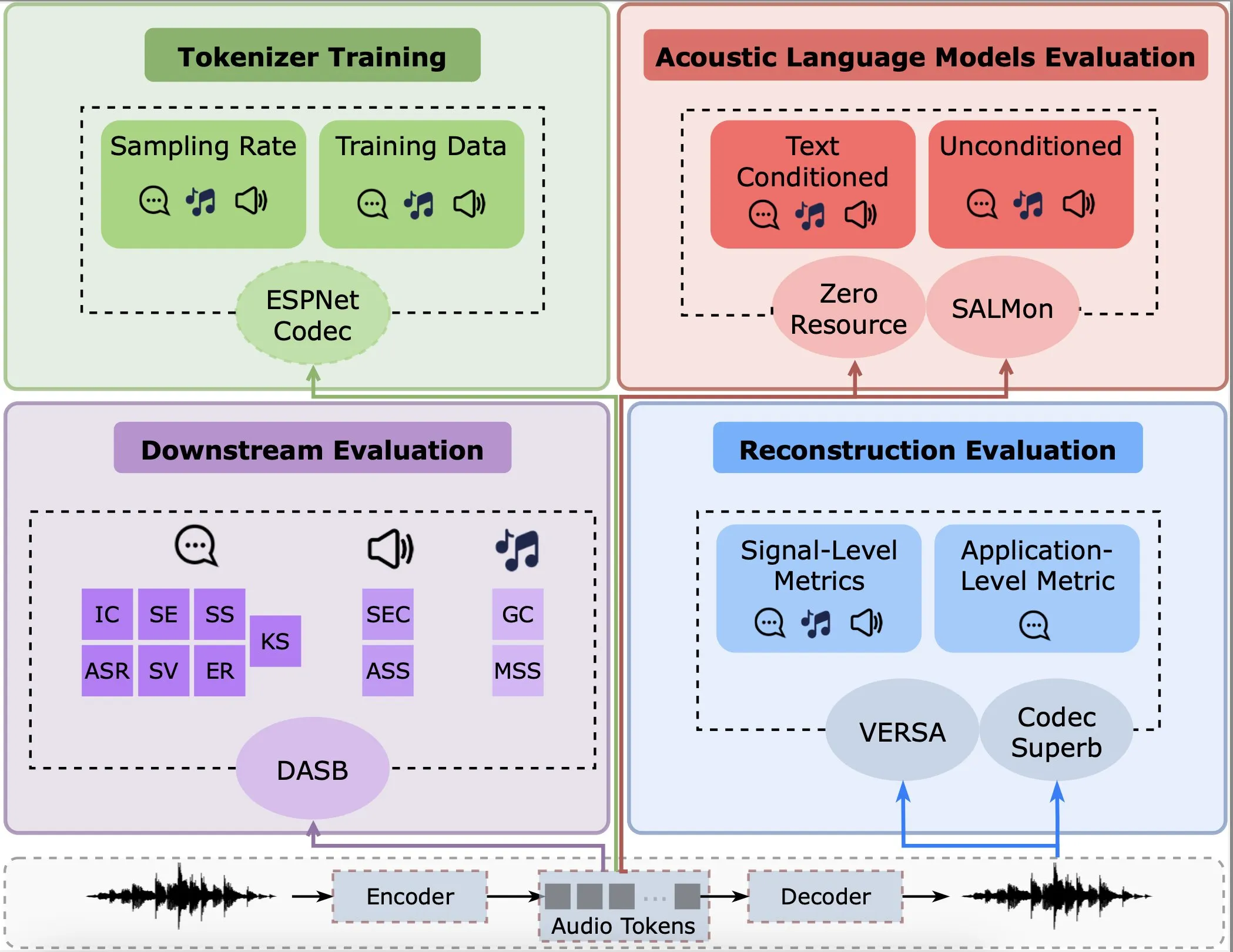
研究、音声エンコーダの再構築、下流タスク、言語モデルにおけるパフォーマンスを分析: Gallil Maimon氏らが発表した新しい研究では、既存の音声エンコーダ(Audio Tokenisers)について包括的な実証分析を行いました。研究は、再構築品質、下流タスクでのパフォーマンス、言語モデルとの組み合わせなど、複数の次元からこれらのエンコーダを評価し、音声処理モデルの選択と最適化のための参考情報を提供しています (出典: menhguin)
論文、「思考の錯覚」を議論:問題の複雑性の観点から推論モデルの優劣を理解する: Apple社の「思考の錯覚」研究に対する反論論文(arXiv:2506.09250)が提出され、Claude Opusが筆頭著者として記載されました。この論文は、Appleの研究の実験計画を批判し、観察された推論の崩壊は実際にはトークン制限によるものであり、モデルの固有の論理能力の欠如ではないと主張しています。これは、大規模言語モデルの真の推論能力をどのように評価するかについての議論を引き起こしています (出典: NandoDF, BlancheMinerva, teortaxesTex)

研究、適応型言語モデルを議論するも、中間記憶は依然として課題: Dorialexander氏は「適応型言語モデル」関連の論文を読んだ後、これは有望な研究方向であるものの、モデルが推論時に中間記憶を実現するには依然として限界があると指摘しています。これは、現在のモデルが比較的長い文脈にまたがる一貫した情報を処理する際に依然として課題に直面していることを示しています (出典: Dorialexander)

RLHFテスト品質研究:現在のテストはどの程度良いのか?どう改善すべきか?テスト品質はどれほど重要か?: Kexun Zhang氏らの最新の研究は、人間からのフィードバックによる強化学習(RLHF)における検証器(テスト)の重要性、特にLLMコーディング分野における重要性を議論しています。研究は3つの重要な問題を提起しています:現在のテストの品質はどうか?より良いテストを得るにはどうすればよいか?テスト品質はモデル性能にどの程度影響を与えるか?この研究は、LLMコーディング能力を向上させるための高品質なテストの必要性を強調しています (出典: StringChaos)
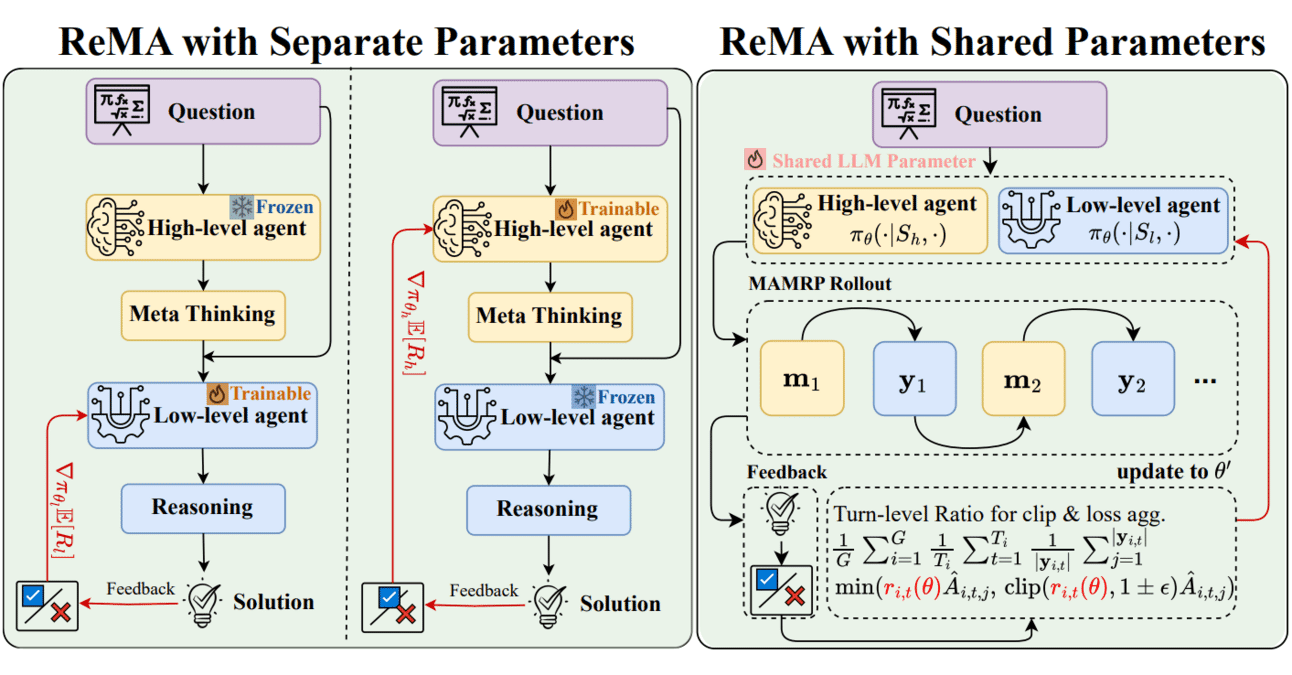
メタラーニングと強化学習の組み合わせ:ReMAがLLMの協調効率を向上: Reinforced Meta-thinking Agents (ReMA) は、メタラーニング(Meta-learning)と強化学習(RL)を組み合わせ、大規模言語モデル(LLM)の効率向上を目指しています。特に複数のLLMエージェントが協調して作業する場合に有効です。ReMAは問題解決をメタ思考(戦略計画)と推論(戦略実行)の2つの部分に分け、専門のエージェントとマルチエージェント強化学習を通じて最適化を行い、数学ベンチマークとLLMを審判とするベンチマークの両方で改善を達成しました (出典: TheTuringPost, TheTuringPost)
AI評価戦略:予算制約下で安価な評価者と高価な評価者を組み合わせて最適なモデル品質推定を得る方法: Adam Fisch氏らの研究(arXiv:2506.07949)は、実際的な問題を検討しています。安価だがノイズの多い評価者、高価だが正確な評価者、そして固定された予算がある場合、モデル品質の最も正確な推定を得るために予算をどのように配分すべきか。この研究は、AIシステム評価のための費用対効果分析フレームワークを提供します (出典: Ar_Douillard)
LLMプロンプトにおける「偽の報酬」と「偽のプロンプト」現象: Stella Li氏らの研究は、LLMの訓練と評価における興味深い現象を明らかにしました。「偽の報酬」(ランダムな報酬でも特定のタスクでモデルのパフォーマンスが向上するなど)の発見に続き、彼らはさらに「偽のプロンプト」を探求しました。これは、「Lorem ipsum」のような無意味なテキストでさえ、特定の状況下で顕著なパフォーマンス向上(例:19.4%)をもたらすというものです。これらの発見は、LLMがプロンプトにどのように応答するか、そしてより堅牢な評価方法をどのように設計するかについて、新たな課題と思考を提起しています (出典: Tim_Dettmers)

論文、AIインタラクションの「人形劇」モデルを議論: 「The Pig in Yellow: AI Interface as Puppet Theatre」と題された論文(または草稿)は、言語AIシステム(LLM、AGI、ASI)を、主観性を持つのではなく主観性をシミュレートする演技的インターフェースとして捉えることを提案しています。記事は「ミス・ピギー」を比喩として用い、AIの流暢さ、一貫性、感情表現は知性の指標ではなく最適化の産物であると分析し、インターフェースは人形のようであり、ユーザーはインタラクションの中で共同で意味を構築し、権力は演技的デザインを通じて現れると強調しています (出典: Reddit r/artificial)
💼 ビジネス
「DJIのゴッドファーザー」李澤湘氏が出資する臥安ロボットがIPOを目指す: ハルビン工業大学の同窓生が創業し、AI搭載家庭用ロボットに特化した臥安ロボット(SwitchBot)が香港証券取引所に目論見書を提出しました。同社は「DJIのゴッドファーザー」として知られる李澤湘氏から投資とリソース支援を受けており、李澤湘氏は12.98%の株式を保有しています。臥安ロボットは過去10年間で7回の資金調達ラウンドを重ね、評価額は2000万元から40億人民元に増加しました。同社の製品には、人間の手足の動きを模倣する実行ロボットや知覚決定システムが含まれ、世界のAI搭載家庭用ロボット市場で最大のサプライヤーとなり、市場シェアは11.9%で、2024年には調整後純利益111万元を達成しました (出典: 量子位)

Tencent、2026年「青雲計画」を開始、初めて課題リソースバンクを公開: Tencentは、2026年「青雲計画」の開始を発表しました。これは世界のトップレベルの技術系学生を対象とし、AI大規模モデル、基盤アーキテクチャ、高性能コンピューティングなど10の技術分野をカバーし、100以上の技術課題を提供します。例年と異なり、今回は初めて青雲課題リソースバンクを公開し、優秀な人材には採用のグリーンチャネルを提供することで、産学連携を深化させ、若手科学技術人材を育成することを目指しています。Tencentは、業界トップクラスの指導陣、計算リソース、競争力のある報酬を提供します (出典: 量子位)

羅永浩氏のデジタルヒューマン、6月15日にBaidu ECでライブ配信デビュー: 羅永浩氏は、自身のAIデジタルヒューマンアバターが6月15日にBaidu ECプラットフォームでライブ配信デビューすることを発表しました。これは、トップクラスのライブ配信者がAIデジタルヒューマンを使用してライブコマースを行う初の事例であり、Baiduの説得力の高いデジタルヒューマンなどの重要技術におけるブレークスルーによるものです。この動きは、「AI+トップIP」ECの新しいパラダイムの探求と見なされており、ライブコマース業界のインテリジェント化、高効率・低コスト化を推進することが期待されています。Baidu ECのデータによると、すでに10万人以上のデジタルヒューマン配信者が各業界で活用されており、事業者の運営コストを大幅に削減し、GMVを向上させています (出典: 量子位)
🌟 コミュニティ
中国AI企業、モデル訓練のため大量のデータ入りハードディスクをマレーシアへ輸送: NIKの報道によると、中国のAI企業はチップ規制を回避し、海外の計算リソースを利用するため、訓練データが満載されたハードディスクをマレーシアなどに「手荷物で」持ち込む戦略を取っています。例えば、あるエンジニアは80TBのデータが入った15台のハードディスクをマレーシアに持ち込み、サーバーを借りてモデル訓練を行いました。この現象は、世界のAI計算能力競争の激しさ、データ越境移動の現実的な課題を反映するとともに、データセキュリティとコンプライアンスに関する議論を引き起こしています (出典: jpt401, agihippo, cloneofsimo, fabianstelzer)

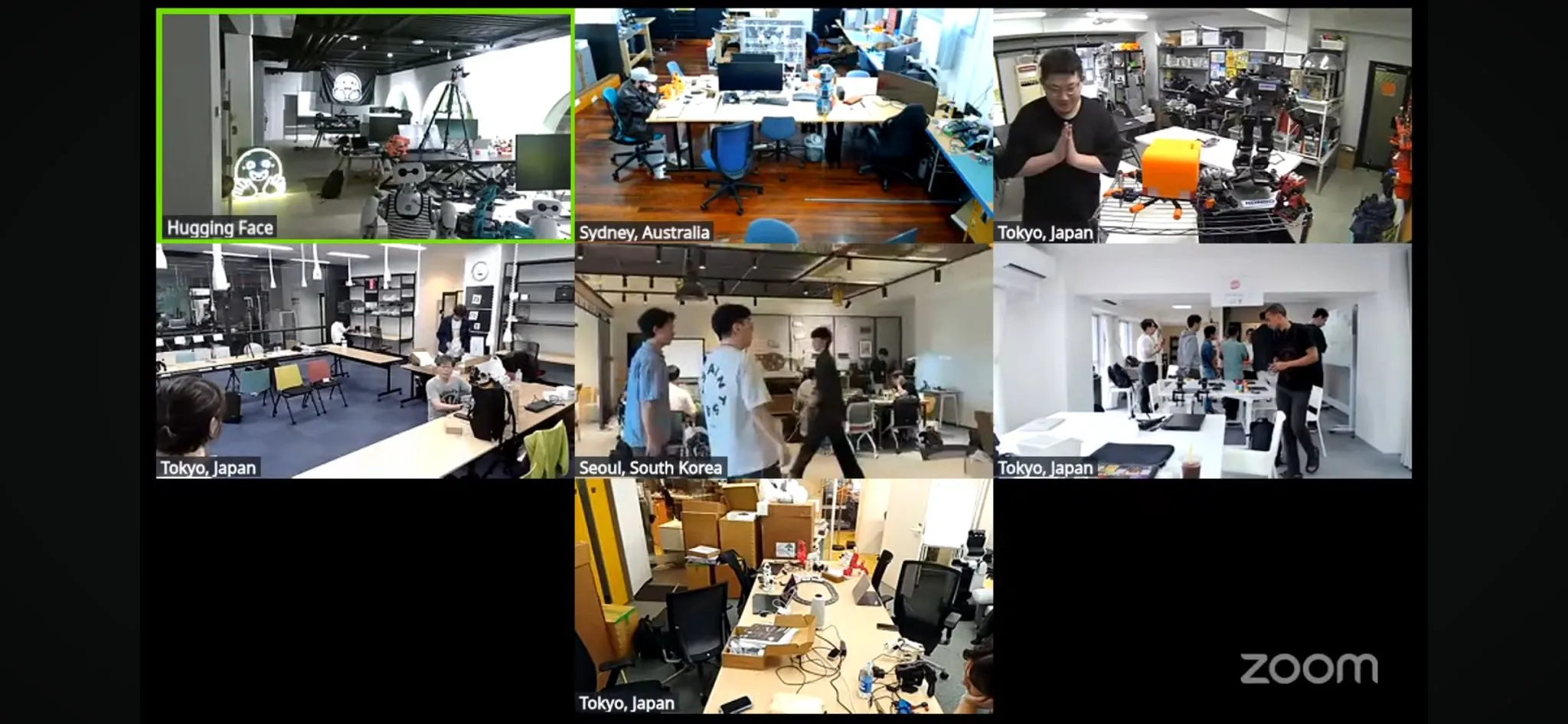
世界最大規模のLeRobotロボットハッカソンが始動: Hugging Faceが主催するLeRobotグローバルロボットハッカソンが正式に始動し、世界5大陸100以上の拠点をカバーし、2300人以上の参加者を集めました。このイベントはオープンソースAIロボットの発展を推進することを目的としており、参加者は52時間以内にロボット関連の構築と探求を行います。各地の開発者やチームが熱心に参加し、現場の写真やプロジェクトの進捗を共有しており、コミュニティのロボット技術への情熱と創造性を示しています (出典: _akhaliq, eliebakouch, ClementDelangue)
Lovable、AIウェブページ生成対決を開催、Claudeのパフォーマンスが好評: Lovableは、ユーザーがOpenAI、Anthropic、Googleのトップモデルを無料で使用してAIウェブページ生成コンテストに参加できるイベントを開催しました。ユーザーop7418は、同じプロンプトセットを使用して3社のモデルでウェブページを生成した体験を共有し、Claudeがコンテンツ量と視覚効果の点で優れていると評価しました。このようなイベントは、開発者やユーザーに、特定の応用シナリオにおけるさまざまな大規模モデルのパフォーマンスを比較する機会を提供します (出典: _philschmid, op7418)
AIモデルの推論能力に関する議論:トークン制限と真の論理: Apple社が提唱した「思考の錯覚」(Illusion of Thinking)論文に対し、コミュニティから反論意見が出ています。コメントやその後の研究(例えばarXiv:2506.09250、Claude Opusを著者として記載)では、観察されたモデルの推論能力の「崩壊」は、モデル自身の論理能力の欠如ではなく、むしろトークン数の制限によるものであると主張されています。モデルがより圧縮された回答形式を使用したり、十分なコンテキストが与えられたりすると、問題を解決できるというのです。これは、大規模言語モデルの真の推論能力をいかに正確に評価し理解するか、また現在の評価方法に存在する可能性のある限界について、深い議論を呼んでいます (出典: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
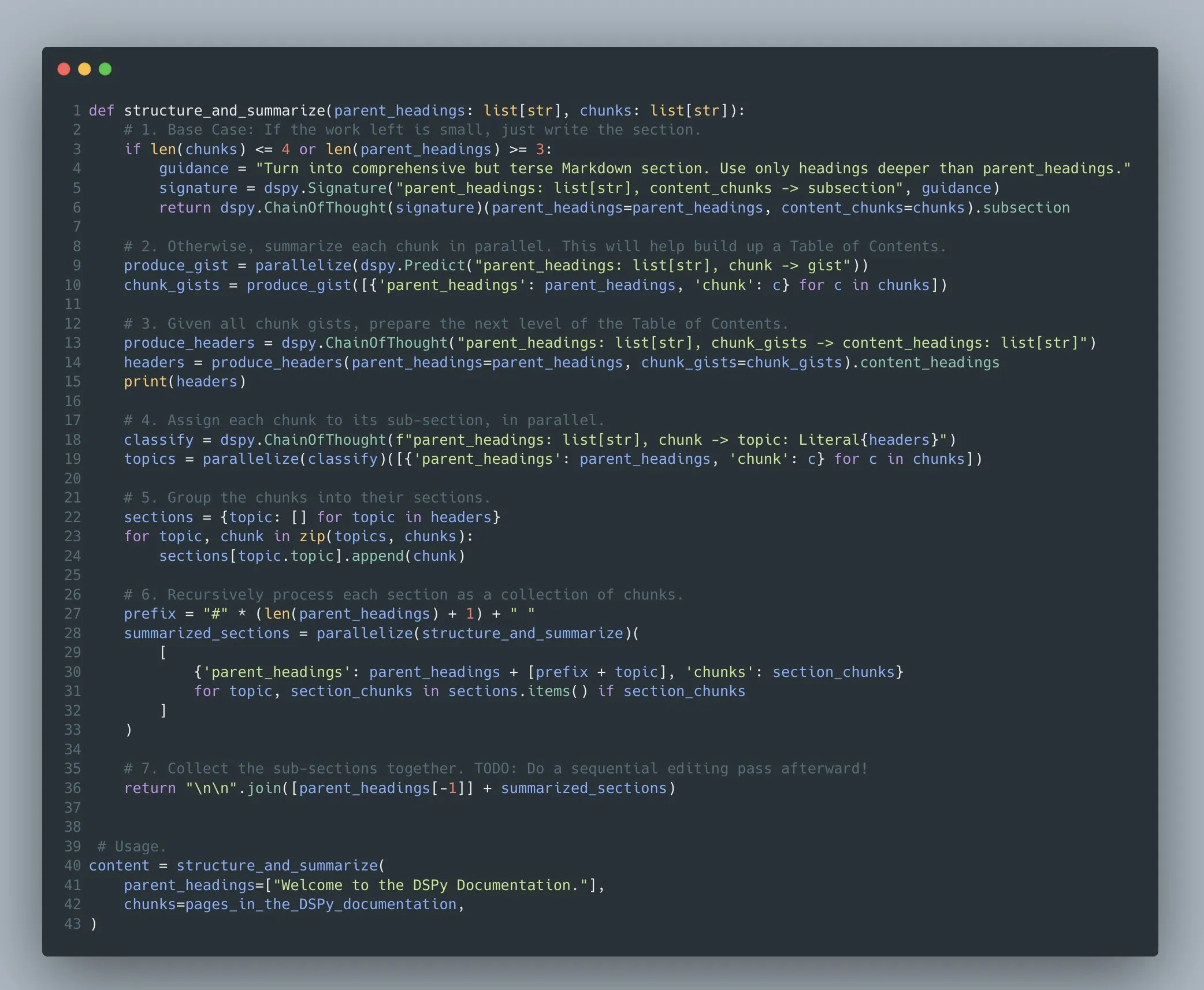
DSPyフレームワーク、複雑な多段階言語モデルプログラムの最適化をサポート: Omar Khattab氏は、DSPyフレームワークが2022/2023年以来、複雑な多段階言語モデルプログラム(Compound AI Systems)のプロンプト最適化と強化学習をサポートしていることを強調しました。彼は、AIシステムがますます複雑になるにつれて、それらを単純な「モデル」ではなく「プログラム」として捉える方が適切であり、DSPyは、線形的な「フロー」や「チェーン」だけでなく、再帰や例外処理などを含む任意の複雑さのプログラムの構築と最適化をサポートすることを目的としていると述べています (出典: lateinteraction)
LLMが人間の思考と類似しているかについての議論: Geoffrey Hinton氏は、大規模言語モデル(LLM)は人間が言語を処理する方法と類似しており、言語がどのように機能するかを理解するための最良のモデルであると考えています。しかし、Pedro Domingos氏はこれに疑問を呈し、LLMが古い言語学理論よりも優れているからといって、人間のように思考していることにはならないと主張しています。この議論は、AI分野におけるLLMの本質と人間の認知との関係についての継続的な議論を反映しています (出典: pmddomingos)
物理科学研究におけるAIの応用ポテンシャルの大きさ: 地球科学分野のある研究者が、o3 Pro(おそらくOpenAIの何らかの高度なモデルを指す)を使用した肯定的な経験を共有し、研究において「非常に賢いポスドク」のようだと述べています。このモデルは、コーディング、モデル開発、アイデアの洗練において優れたパフォーマンスを発揮し、指示を迅速かつ正確に実行し、研究を支援することができます。研究者は、現在のモデルはまだ研究課題を積極的に提案する能力(AGIの特徴)を備えていないものの、その強力な補助機能はすでに研究効率を大幅に向上させており、自律性を持つLLMの登場も遠くないと予感しています (出典: Reddit r/ArtificialInteligence)
💡 その他
AI生成漫画ツールでクリエイティブな表現がより手軽に: ユーザーStriderWriting氏は、AIツールを使って漫画を制作した体験を共有し、AIによって「くだらないアイデア」を漫画にすることが可能になったと述べています。これは、AIがクリエイティブコンテンツ生成分野で普及し、制作のハードルを下げ、より多くの人々が自分のアイデアを簡単に表現できるようになったことを反映しています (出典: Reddit r/ChatGPT)

AIの偏見に対する懸念:ChatGPTの性別ステレオタイプ表現にユーザーが不満: ある女性ユーザーは、ChatGPTが会話の中で男性に対する否定的なステレオタイプを示したと報告しています。例えば、仕事や医療問題について議論する際、指示がないにもかかわらず否定的な役割を男性と仮定し、「男って嫌なものだ」といった発言をしたとのことです。ユーザーは、このような性別に基づいた安易なステレオタイプは不快であり、OpenAIがこのような行為を抑制するルールを持っているのか疑問を呈しています。これは、AIモデルの訓練データの偏見と、それがインタラクションでどのように現れるかについての議論を再び引き起こしています (出典: Reddit r/ChatGPT)
ニュース報道におけるAIの客観性の可能性と現在の限界: あるユーザーが、OpenAIのo3モデルを「偏見のないニュース記者」としてテストし、2017年以降のトランプ政権とバイデン政権の複数の政策がもたらす可能性のある「意図せぬ」結果についてコメントするよう指示しました。AIは客観的に見える分析を生成できましたが、その情報源、潜在的な偏見、複雑な政治経済の動態に対する真の理解の深さは、将来解決すべき問題として残っています。これは、AIを利用してニュースの客観性と深さを向上させることへのコミュニティの期待と、現在の技術的限界に対する認識を反映しています (出典: Reddit r/deeplearning)