
Palabras clave:computación cuántica, conducción autónoma, modelos de lenguaje grandes, modelos generativos 3D, herramientas de IA, aprendizaje automático, investigación en inteligencia artificial, plataforma de computación cuántica CUDA-Q, estudio de datos de conducción autónoma de Waymo, sistema multiagente Claude, Tencent Hunyuan 3D 2.1, optimización del rendimiento del núcleo generativo de IA
🔥 Enfoque
Nvidia lanza la plataforma CUDA-Q dedicada a la computación cuántica: El CEO de Nvidia, Jensen Huang, anunció en su discurso en el GTC de París el lanzamiento de CUDA-Q, una plataforma de supercomputación acelerada cuántico-clásica. Esta plataforma tiene como objetivo cerrar la brecha entre la computación clásica actual y la futura computación cuántica, permitiendo simular operaciones cuánticas en computadoras clásicas o asistir a computadoras cuánticas reales. CUDA-Q ya está disponible en Grace Blackwell y puede acelerar el desarrollo hasta 1300 veces a través del superordenador GB200 NVL72. Huang predice que las aplicaciones prácticas de las computadoras cuánticas se materializarán en pocos años y enfatizó que, en esta fase de desarrollo, los chips de Nvidia (especialmente el GB200) son indispensables para la simulación de cálculos y la asistencia a las QPU. Nvidia está colaborando con empresas de computación cuántica y centros de supercomputación de todo el mundo para explorar la sinergia entre GPU y QPU (Fuente: 量子位)

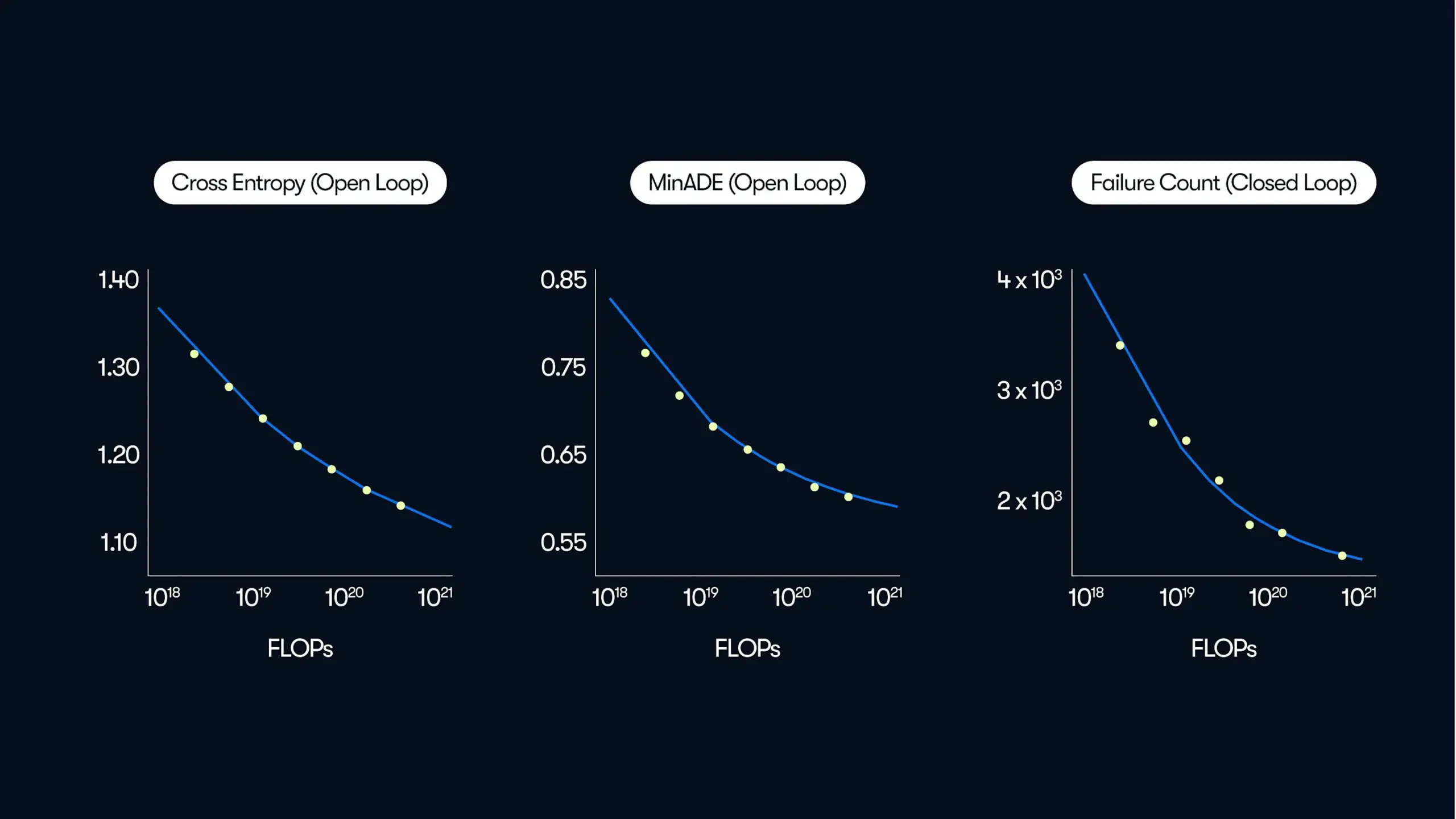
Waymo publica una investigación a gran escala sobre conducción autónoma, revelando las leyes de mejora del rendimiento “impulsadas por datos”: Waymo, en su última entrada de blog, compartió los resultados de un estudio exhaustivo basado en 500.000 horas de datos de conducción, el conjunto de datos más grande hasta la fecha en el campo de la conducción autónoma. El estudio muestra que, de manera similar a los modelos de lenguaje grandes (LLM), la calidad de la predicción de movimiento de los sistemas de conducción autónoma también sigue una relación de ley de potencia con el aumento de la cantidad de cómputo de entrenamiento. La expansión de la escala de datos es crucial para mejorar el rendimiento del modelo, y al mismo tiempo, aumentar la capacidad de cómputo de inferencia también puede mejorar la capacidad del modelo para manejar escenarios de conducción complejos. Esta investigación confirma por primera vez que al aumentar los datos de entrenamiento y los recursos computacionales, se puede mejorar significativamente el rendimiento de la conducción autónoma en el mundo real, señalando a la industria un camino para mejorar las capacidades a través de la escalabilidad (Fuente: Sawyer Merritt, scaling01)
Anthropic comparte experiencia en la construcción de un sistema de investigación multiagente para Claude: Anthropic detalló en su blog de ingeniería cómo utiliza múltiples agentes que trabajan en paralelo para construir las capacidades de investigación de Claude. El artículo comparte experiencias exitosas, problemas encontrados y desafíos de ingeniería durante el proceso de desarrollo. Este sistema multiagente permite a Claude realizar de manera más eficiente la recuperación, análisis y síntesis de información, mejorando así su capacidad para investigar y responder preguntas complejas. Esta contribución es de gran valor de referencia para comprender cómo los modelos de lenguaje grandes pueden expandir sus funcionalidades a través del diseño de sistemas complejos (Fuente: ImazAngel, teortaxesTex)
Meta lanza el modelo mundial V-JEPA 2, logrando comprensión y predicción de video, y control robótico: Meta AI ha lanzado V-JEPA 2, un modelo mundial entrenado en video que ha logrado avances significativos en la comprensión y predicción de la dinámica del mundo físico. V-JEPA 2 no solo puede realizar un aprendizaje eficiente de características de video, sino que también puede lograr planificación zero-shot y control robótico en nuevos entornos, demostrando su potencial en el campo de la inteligencia artificial general. El modelo aprende representaciones del mundo a partir de datos de video mediante aprendizaje autosupervisado, proporcionando una nueva vía para construir sistemas de IA más inteligentes y capaces de interactuar con el mundo real (Fuente: dl_weekly)
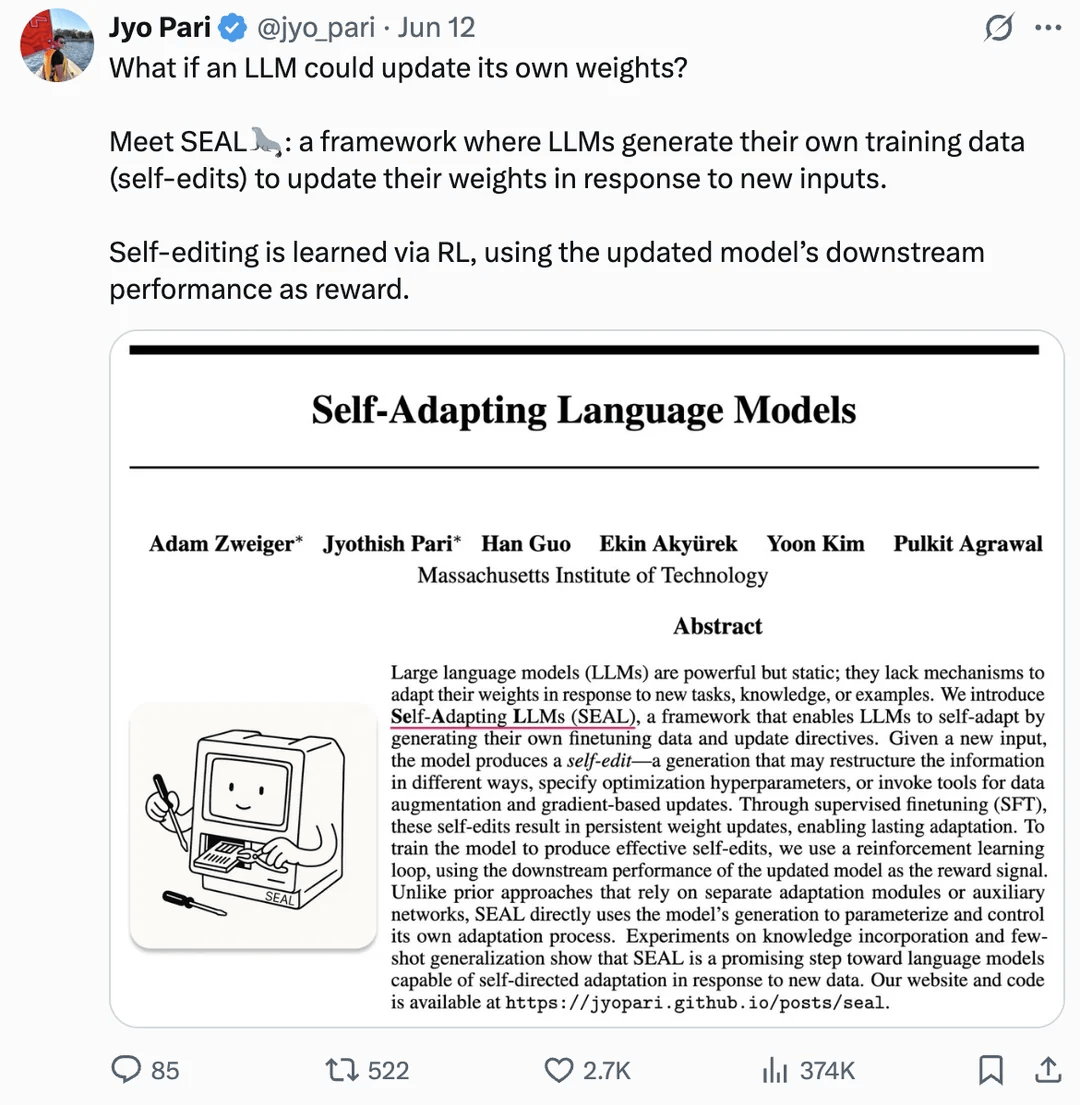
Artículo explora la autoactualización de pesos en LLM para lograr la automejora: Un artículo publicado en arXiv (2506.10943) propone que los modelos de lenguaje grandes (LLM) ahora pueden automejorarse actualizando sus propios pesos. Este mecanismo podría significar que los LLM son capaces de aprender de nuevos datos o experiencias y ajustar dinámicamente sus parámetros internos para mejorar el rendimiento o adaptarse a nuevas tareas, sin necesidad de un reentrenamiento completo. Si esta línea de investigación tiene éxito, aumentará enormemente la adaptabilidad y la capacidad de aprendizaje continuo de los LLM, siendo un paso importante hacia sistemas de IA más autónomos (Fuente: Reddit r/artificial)
🎯 Tendencias
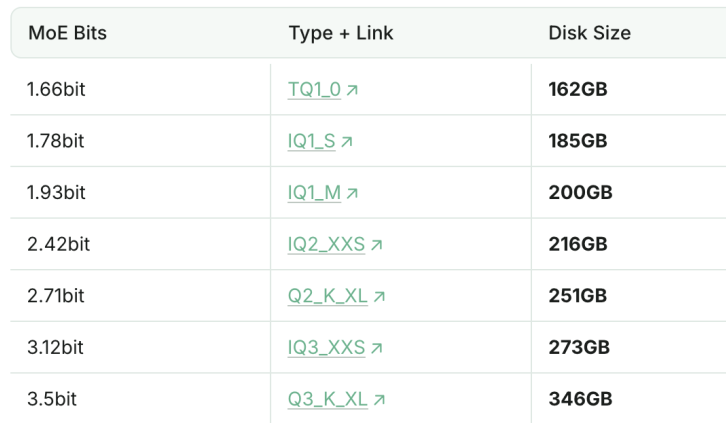
La versión cuantizada a 1.93bit de DeepSeek-R1 supera en capacidad de programación a Claude 4 Sonnet: El estudio Unsloth ha logrado cuantizar DeepSeek-R1 (versión 0528) a 1.93bit, obteniendo un 60% en el benchmark de programación aider, superando a Claude 4 Sonnet (56.4%) y a la versión completa de R1 de enero. Esta versión extremadamente comprimida reduce el tamaño del archivo en más del 70% e incluso puede ejecutarse sin GPU (CPU con suficiente memoria). La versión completa R1-0528 obtuvo un 71.4% en aider, superando a Claude 4 Opus sin el modo de pensamiento activado. Esto demuestra el potencial de la tecnología de cuantización de modelos para reducir drásticamente los requisitos de recursos manteniendo el rendimiento (Fuente: 量子位)
Tencent Hunyuan abre el código de su primer modelo de generación 3D PBR de nivel de producción, Hunyuan 3D 2.1: El equipo de Tencent Hunyuan anunció la apertura del código de Hunyuan 3D 2.1, el primer modelo de generación 3D PBR (Physically Based Rendering) de nivel de producción completamente de código abierto en la industria. Este modelo utiliza tecnología de síntesis de materiales PBR para generar contenido 3D con efectos visuales de calidad cinematográfica, haciendo que materiales como el cuero y el bronce se vean más vívidos y realistas bajo iluminación. El proyecto ha liberado los pesos del modelo, el código de entrenamiento/inferencia, los pipelines de datos y la arquitectura, y es compatible con tarjetas gráficas de consumo, con el objetivo de promover el desarrollo y la popularización de la tecnología de generación de contenido 3D (Fuente: op7418, ImazAngel)
Meta AI lanza Sonata, impulsando el aprendizaje autosupervisado para representaciones de nubes de puntos 3D: Meta AI ha presentado Sonata, una investigación que representa un avance significativo en el campo del aprendizaje autosupervisado 3D. Sonata, al identificar y resolver problemas de atajos geométricos e introducir un marco flexible y eficiente, es capaz de aprender representaciones de nubes de puntos 3D excepcionalmente robustas. Este trabajo eleva el nivel actual de las tecnologías de percepción 3D y sienta las bases para futuras innovaciones en el campo de la percepción 3D y sus aplicaciones (Fuente: AIatMeta)

Meta AI lanza el “Conjunto de datos de reconocimiento de lectura en entornos naturales”, para comprender el comportamiento de lectura: Meta AI ha hecho público un gran conjunto de datos multimodal llamado “Reading Recognition in the Wild”, que incluye videos, seguimiento ocular y salidas de sensores de postura de la cabeza. Este conjunto de datos tiene como objetivo ayudar a resolver tareas de reconocimiento de lectura desde dispositivos portátiles y es el primer conjunto de datos desde una perspectiva egocéntrica que recopila datos de seguimiento ocular a una alta frecuencia de 60Hz, proporcionando un recurso invaluable para investigar el comportamiento de lectura humano (Fuente: AIatMeta)

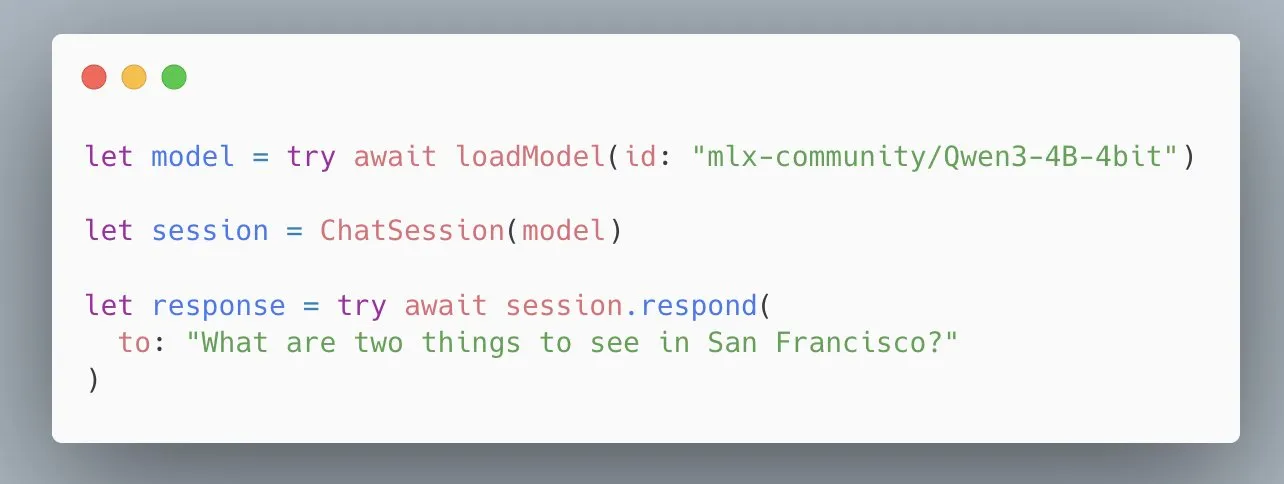
La API LLM de MLX Swift de Apple se simplifica, carga modelos en tres líneas de código: En respuesta a los comentarios de los desarrolladores sobre la dificultad de iniciarse con la API LLM de MLX Swift, el equipo de Apple ha realizado mejoras rápidamente, lanzando una nueva API simplificada. Ahora, los desarrolladores solo necesitan tres líneas de código para cargar un LLM o VLM en sus proyectos Swift e iniciar una sesión de chat, lo que reduce significativamente la barrera de entrada para usar modelos de lenguaje grandes en el ecosistema de Apple (Fuente: stablequan)
Google Gemma3 4B lanza GAIA, una versión optimizada para portugués brasileño: Google, en colaboración con varias instituciones brasileñas (ABRIA, CEIA-UFG, Nama, Amadeus AI) y DeepMind, ha lanzado GAIA (Gemma-3-Gaia-PT-BR-4b-it), un modelo de lenguaje de código abierto optimizado para el portugués brasileño. El modelo se basa en Gemma-3-4b-pt y ha sido preentrenado continuamente con 13 mil millones de tokens de alta calidad en portugués brasileño. GAIA utiliza una innovadora técnica de “fusión de pesos” para lograr el seguimiento de instrucciones, sin necesidad del tradicional SFT, y ha superado al modelo base Gemma en el benchmark ENEM 2024. Este modelo es adecuado para chat, preguntas y respuestas, resumen, generación de texto y como modelo base para el ajuste fino en portugués brasileño (Fuente: Reddit r/LocalLLaMA)
El robot de Figure AI integra Helix AI y autonomía, impulsando el despliegue escalable: Figure AI ha demostrado cómo sus robots del mundo real están impulsando el despliegue escalable mediante la mejora de Helix AI y la autonomía. Esto indica que la combinación de robots físicos con modelos avanzados de IA está haciendo posible la aplicación de robots en entornos más complejos, y subraya la importancia de la ingeniería y las tecnologías emergentes en el campo de la robótica (Fuente: Ronald_vanLoon)
Sakana AI presenta la hiperred Text-to-LoRA (T2L): Sakana AI ha lanzado Text-to-LoRA (T2L), una nueva hiperred capaz de comprimir múltiples LoRA (Low-Rank Adaptation) existentes en sí misma y generar rápidamente nuevos adaptadores LoRA para modelos de lenguaje grandes (LLM) basándose únicamente en la descripción textual de la tarea. Una vez entrenada, T2L puede crear nuevos LoRA instantáneamente, ofreciendo una vía eficiente para la personalización rápida y el despliegue de LLM para tareas específicas. Los resultados se presentarán en ICML 2025 (Fuente: TheTuringPost)
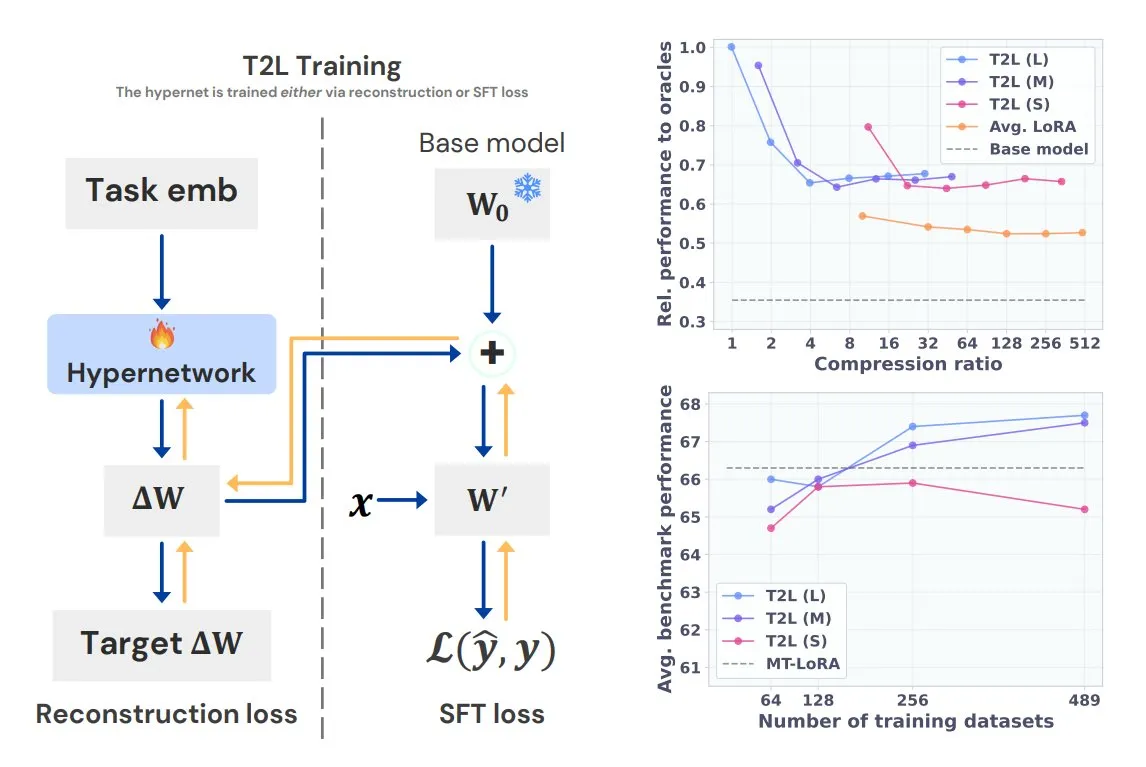
Baidu AI Search se lanza completamente en la plataforma Baidu Smart Cloud Qianfan: La plataforma de desarrollo de aplicaciones AppBuilder de Baidu Smart Cloud Qianfan ha lanzado oficialmente el servicio “Baidu AI Search”. Este servicio integra las dos capacidades principales de “Baidu Search” y “Generación de Búsqueda Inteligente”, proporcionando a las empresas un servicio completo desde la recuperación de información hasta la generación inteligente. Utiliza los más de 20 años de tecnología de búsqueda en chino de Baidu y una base de datos de cientos de miles de millones de entradas para ofrecer resultados de búsqueda multimodales sin publicidad, y admite filtrado preciso, rastreo de fuentes y políticas de seguridad de nivel empresarial. La capacidad de generación de búsqueda inteligente, combinada con modelos como Wenxin y Deepseek, ofrece funciones como resumen por IA y búsqueda conjunta con conocimiento privado (Fuente: 量子位)
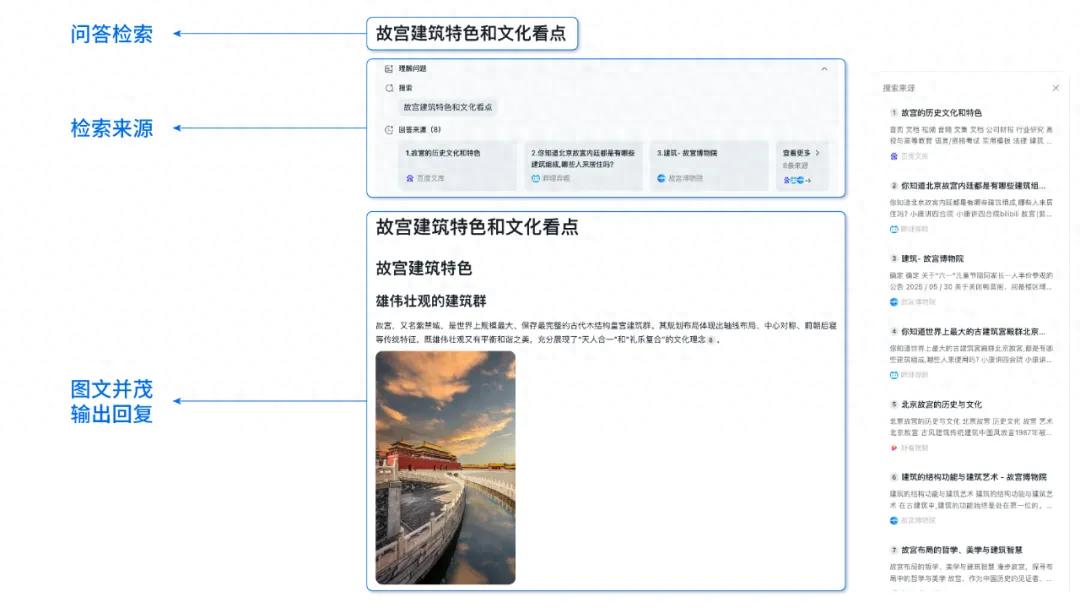
Estudio muestra que el rendimiento de los kernels generados por IA se acerca o incluso supera a los kernels optimizados por expertos: Un artículo de blog de Anne Ouyang señala que los kernels de IA generados mediante una simple búsqueda en tiempo de prueba (test-time only search) ya se acercan en rendimiento, e incluso en algunos casos superan, a los kernels de producción estándar optimizados por expertos en PyTorch. Esto indica el enorme potencial de la IA en la optimización de código y la mejora del rendimiento, y podría desempeñar un papel más importante en la optimización de bibliotecas de bajo nivel en el futuro (Fuente: jeremyphoward)
Investigación “Diffusion Duality” propone nuevo método de generación en pocos pasos para modelos de lenguaje de difusión discreta: Un artículo publicado en ICML 2025, titulado “The Diffusion Duality”, propone un nuevo método que, mediante la utilización de la difusión gaussiana latente, logra la generación en pocos pasos en modelos de lenguaje de difusión discreta. Este método supera a los modelos autorregresivos (AR) en 3 de 7 benchmarks de verosimilitud zero-shot, ofreciendo una nueva perspectiva para mejorar la eficiencia de generación de los modelos de difusión (Fuente: arankomatsuzaki)
Nuevo avance en la interpretabilidad de las capas MLP: descomposición de activaciones en características interpretables: Una nueva investigación de Mor Geva y otros demuestra un método simple para descomponer las activaciones de las capas de perceptrón multicapa (MLP) en características interpretables. Este método revela una jerarquía oculta de conceptos, donde combinaciones dispersas de neuronas forman conceptos cada vez más abstractos, proporcionando una perspectiva más profunda para comprender el funcionamiento interno de las redes neuronales (Fuente: menhguin)

El marco HeadHunter logra un control fino sobre la guía de atención perturbada: Sayak Paul y otros propusieron el marco HeadHunter para un análisis basado en principios de la guía de atención perturbada. Este marco permite un control detallado y profundo sobre la calidad de generación y los atributos visuales, proporcionando nuevas herramientas y conocimientos para mejorar y personalizar la salida de los modelos generativos (Fuente: huggingface, RisingSayak)

🧰 Herramientas
Los planes de pago de Windsurf ahora son compatibles con Claude Sonnet 4: Windsurf anunció que todos sus planes de pago ya incluyen el modelo Claude Sonnet 4. Los usuarios ahora pueden aprovechar las potentes funciones de este último modelo de Anthropic en la plataforma Windsurf para tareas como generación de texto, conversación, etc., mejorando aún más el rendimiento y la experiencia del asistente de IA (Fuente: op7418)
Anthropic lanza el SDK oficial de Python para Claude Code: Anthropic ha lanzado oficialmente el SDK de Python para Claude Code, diseñado para facilitar a los desarrolladores la integración de las capacidades de generación de código y uso de herramientas de Claude en sus propios proyectos de Python. El SDK admite el uso de herramientas, salida en streaming, operaciones síncronas/asíncronas, manejo de archivos e incluye una estructura de chat incorporada, simplificando el proceso de desarrollo para interactuar con Claude Code (Fuente: Reddit r/ClaudeAI)
Lanzamiento de la extensión Claude Task Master para VS Code: DevDreed ha lanzado la versión 1.0.0 de la extensión Claude Task Master para VS Code. Esta extensión tiene como objetivo complementar el proyecto de IA Claude Task Master de eyaltoledano, integrando la salida de Claude Task Master directamente en la interfaz de VS Code, facilitando a los usuarios el cambio sin interrupciones entre el editor y la consola, y mejorando la eficiencia del desarrollo (Fuente: Reddit r/ClaudeAI)
SmartSelect AI: Herramienta de procesamiento de texto e imágenes con IA en el navegador: Se ha lanzado una extensión de Chrome llamada SmartSelect AI, que permite a los usuarios resumir, traducir o chatear directamente sobre el texto seleccionado mientras navegan por la web, y obtener descripciones de imágenes mediante IA, sin necesidad de cambiar de pestaña o copiar y pegar en aplicaciones externas como ChatGPT. Esta herramienta se basa en el modelo Gemini y tiene como objetivo mejorar la eficiencia en la adquisición y procesamiento de información (Fuente: Reddit r/deeplearning)

Unsiloed AI abre el código de su herramienta multifuncional de segmentación de datos: Unsiloed AI (EF 2024) ha abierto el código de parte de su funcionalidad de segmentación de datos (chunker). Esta herramienta está diseñada para ayudar a procesar documentos en diversos formatos como PDF, Excel, PPT, etc., transformándolos en un formato adecuado para el procesamiento por modelos de lenguaje grandes. Unsiloed AI ya es utilizada por empresas Fortune 100 y varias startups para la ingesta de datos multimodales (Fuente: Reddit r/LocalLLaMA)
Claude Superprompt System: Herramienta gratuita para optimizar los prompts de Claude: Igor Warzocha ha desarrollado y compartido una herramienta en línea llamada “Claude Superprompt System”, diseñada para ayudar a los usuarios a transformar solicitudes simples en prompts complejos, estructurados y con ejemplos de cadena de pensamiento y contexto, para aprovechar mejor las capacidades de Claude. La herramienta se basa en la documentación oficial de Anthropic y en las mejores prácticas descubiertas por la comunidad, optimizando los prompts mediante estructuras de etiquetas XML, bloques de razonamiento CoT, etc., para mejorar la calidad de la salida de Claude. El código del proyecto está disponible en GitHub (Fuente: Reddit r/artificial)
Lanzamiento del plugin local de TTS para Firefox, Kokoro-TTS: El desarrollador Pinguy ha lanzado un plugin para Firefox llamado Kokoro TTS, que utiliza un modelo de red neuronal alojado localmente de 82M de parámetros (modelo Kokoro TTS) para la conversión de texto a voz, funcionando completamente offline para proteger la privacidad del usuario. Admite múltiples voces y acentos, y funciona fluidamente incluso en hardware antiguo, ofreciendo versiones para Windows, Linux y macOS (Fuente: Reddit r/artificial)
Spy Search: Actualización del proyecto de motor de búsqueda LLM de código abierto: JasonHonKL ha actualizado su proyecto de motor de búsqueda LLM de código abierto, Spy Search. Este proyecto se dedica a construir un motor de búsqueda eficiente basado en modelos de lenguaje grandes, y la última versión ya puede buscar y responder en menos de 3 segundos. El código del proyecto está alojado en GitHub y tiene como objetivo proporcionar a los usuarios una herramienta de búsqueda diaria rápida y útil (Fuente: Reddit r/deeplearning)
HandFonted: Herramienta de código abierto para convertir escritura a mano en fuentes: Resham Gaire ha desarrollado y abierto el código del proyecto HandFonted, una aplicación Python de extremo a extremo que puede convertir imágenes de caracteres escritos a mano en archivos de fuente .ttf instalables. El sistema utiliza OpenCV para el procesamiento de imágenes y la segmentación de caracteres, un modelo PyTorch personalizado (ResNet-Inception) para la clasificación de caracteres, y el algoritmo húngaro para la mejor coincidencia, generando finalmente el archivo de fuente con la biblioteca fontTools (Fuente: Reddit r/MachineLearning)
📚 Aprendizaje
Artículo de Wei Dongyi y otros encabeza revista de matemáticas, investigando el fenómeno de explosión en ecuaciones de onda no lineales desenfocantes supercríticas: El artículo “On blow-up for the supercritical defocusing nonlinear wave equation” de los académicos de la Universidad de Pekín Wei Dongyi, Zhang Zhifei y Shao Feng ha sido publicado en la prestigiosa revista de matemáticas “Forum of Mathematics, Pi”. La investigación explora el problema de la explosión (la solución se vuelve infinita en tiempo finito) para una ecuación de onda no lineal desenfocante específica en estado supercrítico. Demostraron que en la dimensión espacial d=4 y p≥29, así como en d≥5 y p≥17, existen soluciones suaves de valores complejos que explotan en tiempo finito. Este logro llena un vacío en el campo correspondiente, y su método de demostración proporciona nuevas ideas para la investigación de explosiones en otras ecuaciones diferenciales parciales no lineales (Fuente: 量子位)

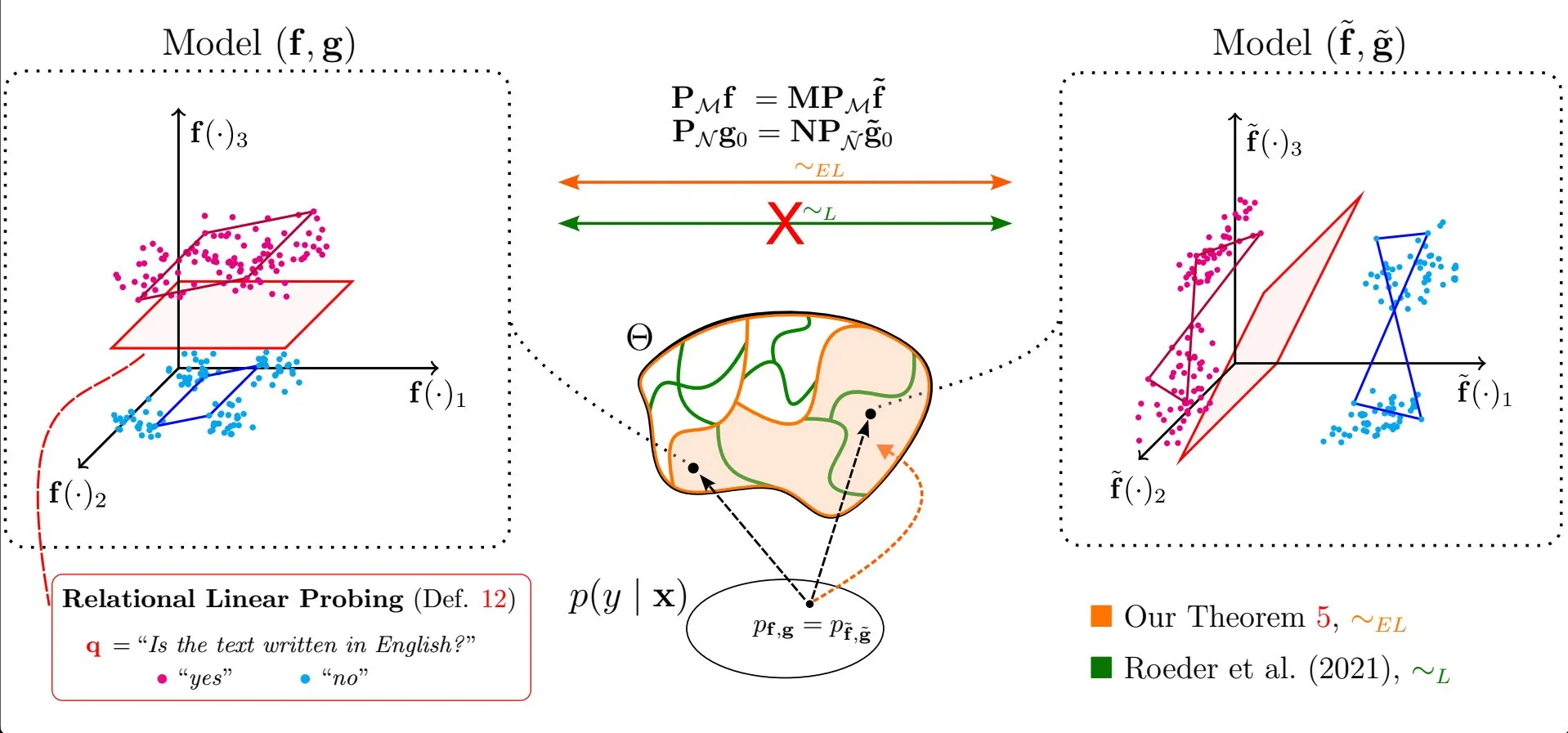
Artículo explora la universalidad de las propiedades lineales en las representaciones de modelos de lenguaje grandes: La investigación de Emanuele Marconato y otros, “All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling” (publicada en AISTATS 2025), explora desde la perspectiva de la identificabilidad por qué las propiedades lineales son tan comunes en las representaciones de los modelos de lenguaje grandes (LLM). Este estudio ayuda a comprender más profundamente la estructura y el comportamiento de las representaciones internas de los LLM (Fuente: menhguin)
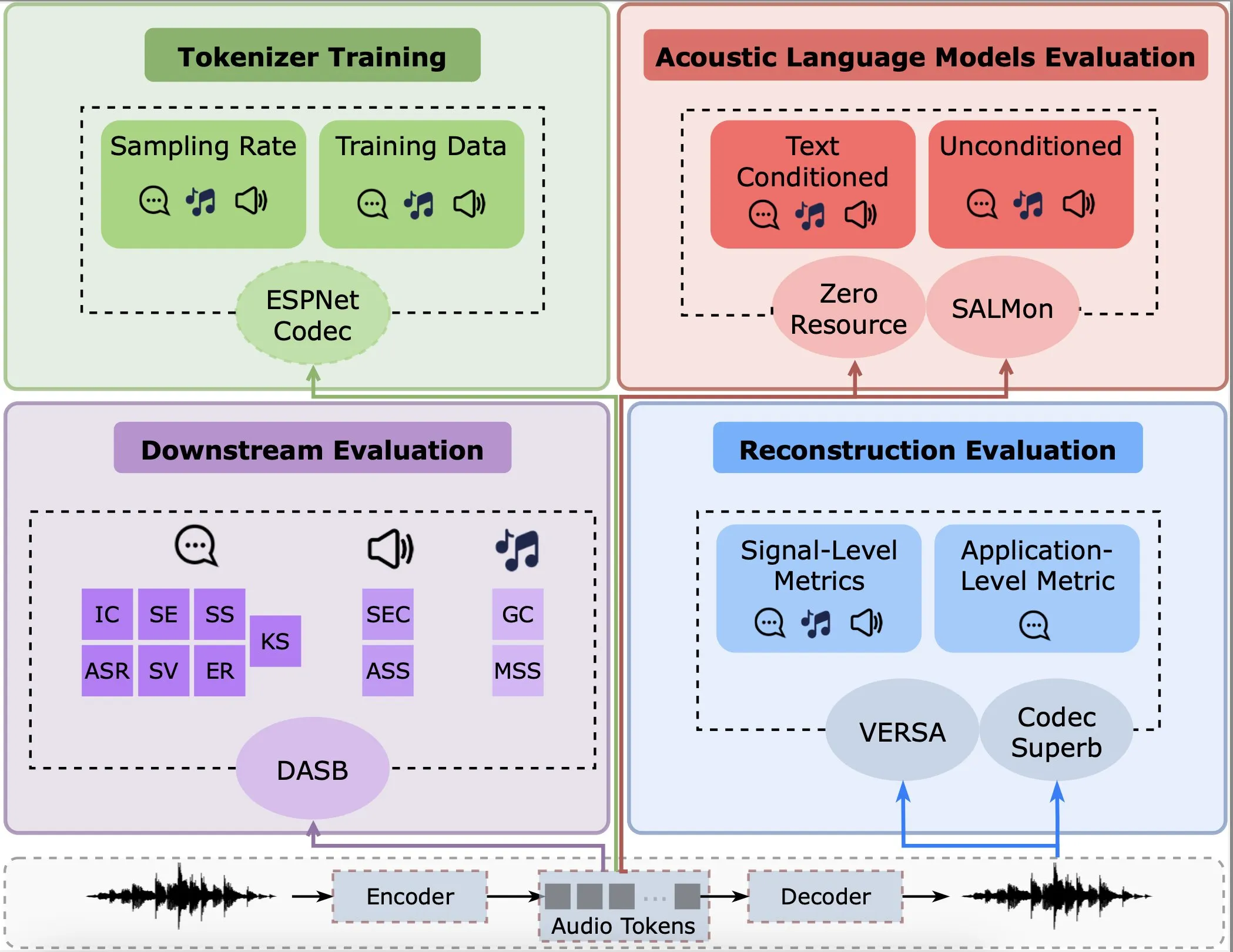
Investigación analiza el rendimiento de los codificadores de audio en reconstrucción, tareas downstream y modelos de lenguaje: Gallil Maimon y otros publicaron una nueva investigación que realiza un análisis empírico exhaustivo de los codificadores de audio existentes (Audio Tokenisers). El estudio evalúa estos codificadores desde múltiples dimensiones, como la calidad de reconstrucción, el rendimiento en tareas downstream y la combinación con modelos de lenguaje, proporcionando una referencia para la selección y optimización de modelos de procesamiento de audio (Fuente: menhguin)
Artículo discute la “ilusión de pensamiento”: comprendiendo las fortalezas y debilidades de los modelos de razonamiento desde la perspectiva de la complejidad del problema: Se ha presentado un artículo en respuesta a la investigación de Apple sobre la “ilusión de pensamiento” (arXiv:2506.09250), con Claude Opus listado como primer autor. Dicho artículo critica el diseño experimental de la investigación de Apple y argumenta que el colapso del razonamiento observado se debe en realidad a limitaciones de tokens, y no a una deficiencia intrínseca en la capacidad lógica del modelo. Esto ha generado un debate sobre cómo evaluar la verdadera capacidad de razonamiento de los modelos de lenguaje grandes (Fuente: NandoDF, BlancheMinerva, teortaxesTex)

Investigación explora modelos de lenguaje adaptativos, pero la memoria a medio plazo sigue siendo un desafío: Dorialexander, tras estudiar artículos relacionados con “modelos de lenguaje adaptativos”, señaló que, aunque es una dirección de investigación prometedora, los modelos aún presentan limitaciones para lograr memoria a medio plazo durante el razonamiento. Esto indica que los modelos actuales todavía enfrentan desafíos al procesar información coherente que requiere abarcar contextos más largos (Fuente: Dorialexander)

Investigación sobre la calidad de las pruebas en RLHF: ¿Qué tan buenas son las pruebas actuales? ¿Cómo mejorarlas? ¿Qué tan importante es la calidad de las pruebas?: El último trabajo de Kexun Zhang y otros explora la importancia de los validadores (pruebas) en el aprendizaje por refuerzo a partir de retroalimentación humana (RLHF), especialmente en el ámbito de la codificación con LLM. La investigación plantea tres preguntas clave: ¿Cuál es la calidad de las pruebas actuales? ¿Cómo obtener mejores pruebas? ¿Qué tanto impacto tiene la calidad de las pruebas en el rendimiento del modelo? El estudio enfatiza la necesidad de pruebas de alta calidad para mejorar las capacidades de codificación de los LLM (Fuente: StringChaos)
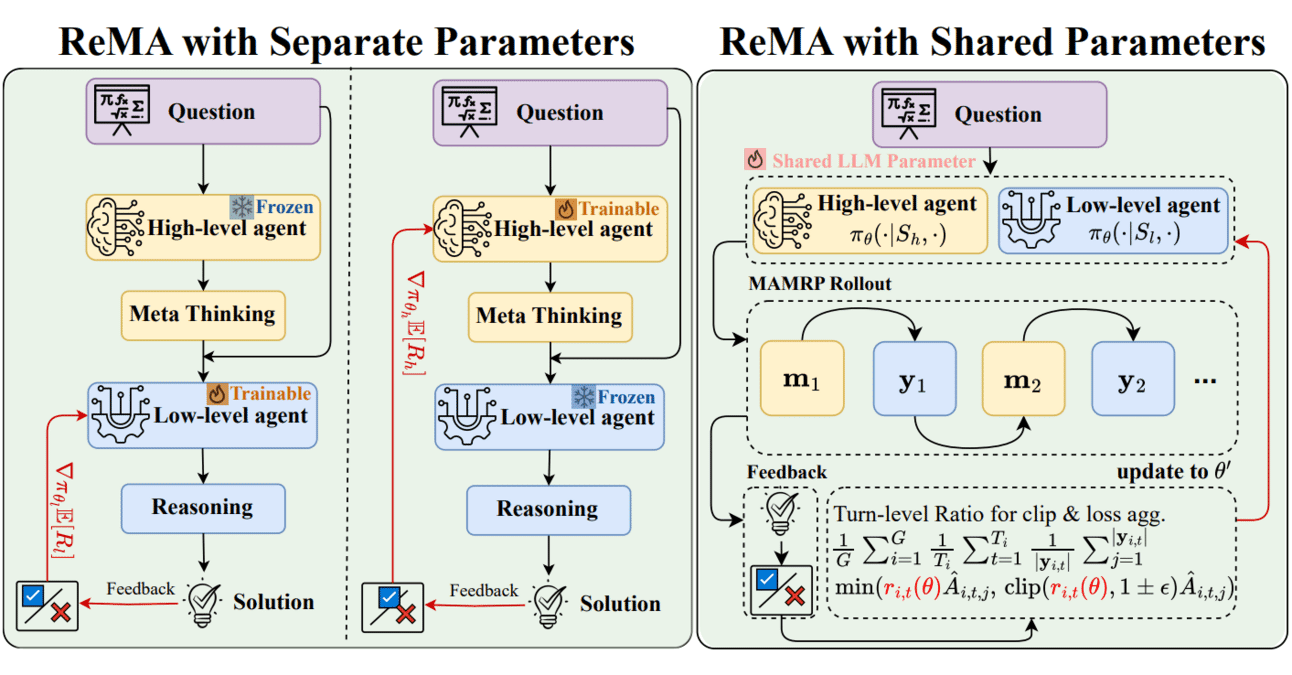
Meta-aprendizaje y aprendizaje por refuerzo combinados: ReMA mejora la eficiencia colaborativa de los LLM: Reinforced Meta-thinking Agents (ReMA) combina el meta-aprendizaje (Meta-learning) y el aprendizaje por refuerzo (RL) con el objetivo de mejorar la eficiencia de los modelos de lenguaje grandes (LLM), especialmente cuando múltiples agentes LLM trabajan en colaboración. ReMA divide la resolución de problemas en meta-pensamiento (planificación de estrategias) y razonamiento (ejecución de estrategias), y se optimiza mediante agentes especializados y aprendizaje por refuerzo multiagente, logrando mejoras tanto en benchmarks matemáticos como en benchmarks donde un LLM actúa como juez (Fuente: TheTuringPost, TheTuringPost)
Estrategias de evaluación de IA: Cómo combinar evaluadores baratos y caros bajo restricciones presupuestarias para obtener la mejor estimación de la calidad del modelo: La investigación de Adam Fisch y otros (arXiv:2506.07949) explora un problema práctico: cuando se dispone de un evaluador barato pero ruidoso, un evaluador caro pero preciso, y un presupuesto fijo, ¿cómo se debe asignar el presupuesto para obtener la estimación más precisa de la calidad del modelo? Este estudio proporciona un marco de análisis de costo-beneficio para la evaluación de sistemas de IA (Fuente: Ar_Douillard)
Fenómenos de “recompensa espuria” y “prompt espurio” en los prompts de LLM: La investigación de Stella Li y otros revela fenómenos interesantes en el entrenamiento y evaluación de LLM. Tras descubrir la “recompensa espuria” (donde incluso recompensas aleatorias pueden mejorar el rendimiento del modelo en ciertas tareas), exploraron además el “prompt espurio”, donde incluso texto sin sentido como “Lorem ipsum” puede, en algunos casos, generar mejoras significativas en el rendimiento (por ejemplo, un 19.4%). Estos hallazgos plantean nuevos desafíos y reflexiones sobre cómo los LLM responden a los prompts y cómo diseñar métodos de evaluación más robustos (Fuente: Tim_Dettmers)

Artículo explora el modelo de “teatro de marionetas” para la interacción con IA: Un artículo titulado “The Pig in Yellow: AI Interface as Puppet Theatre” (o borrador) propone considerar los sistemas de IA lingüística (LLM, AGI, ASI) como interfaces performativas que simulan subjetividad en lugar de poseerla. El artículo utiliza la metáfora de “Miss Piggy” para analizar cómo la fluidez, coherencia y expresión emocional de la IA no son indicadores de mente, sino productos de optimización, enfatizando que la interfaz es como una marioneta, donde el usuario co-construye el significado en la interacción, y el poder se manifiesta a través del diseño performativo (Fuente: Reddit r/artificial)
💼 Negocios
Woan Robot, participada por el “padrino de DJI” Li Zexiang, acelera hacia su IPO: Woan Robot (SwitchBot), fundada por excompañeros de la Universidad de Tecnología de Harbin y especializada en robots domésticos de IA personificada, ha presentado su solicitud de salida a bolsa en Hong Kong. La empresa ha recibido inversión y apoyo de recursos de Li Zexiang, el “padrino de DJI”, quien posee el 12.98% de las acciones. En los últimos diez años, Woan Robot ha acumulado siete rondas de financiación, con una valoración que ha crecido de 20 millones a 4 mil millones de yuanes. Sus productos incluyen robots ejecutores que simulan movimientos de extremidades humanas y sistemas de percepción y toma de decisiones, convirtiéndose en el mayor proveedor mundial de robots domésticos de IA personificada, con una cuota de mercado del 11.9%, y logrando un beneficio neto ajustado de 1.11 millones de yuanes en 2024 (Fuente: 量子位)

Tencent lanza el “Plan Qingyun” 2026, abriendo por primera vez su repositorio de temas de investigación: Tencent ha anunciado el lanzamiento del “Plan Qingyun” 2026, dirigido a los mejores estudiantes de tecnología del mundo, cubriendo diez áreas tecnológicas principales como modelos grandes de IA, infraestructura básica, computación de alto rendimiento, y ofreciendo más de cien temas tecnológicos. A diferencia de años anteriores, esta edición del plan abre por primera vez el repositorio de temas de investigación de Qingyun y ofrece a los talentos destacados una vía rápida de contratación, con el objetivo de profundizar la cooperación entre la universidad y la empresa y cultivar jóvenes talentos tecnológicos. Tencent proporcionará profesorado de primer nivel en la industria, recursos de computación y salarios competitivos (Fuente: 量子位)

El avatar digital de Luo Yonghao debutará en Baidu E-commerce el 15 de junio: Luo Yonghao anunció que su avatar digital de IA debutará en una transmisión en vivo en la plataforma de comercio electrónico de Baidu el 15 de junio. Esta es la primera vez que un presentador de primer nivel utiliza un avatar digital de IA para la venta en vivo, gracias a los avances de Baidu en tecnologías clave como los avatares digitales de alta persuasión. Esta medida se considera una exploración de un nuevo paradigma de comercio electrónico “IA + IP de primer nivel”, que se espera impulse a la industria de las transmisiones en vivo hacia la inteligencia, la eficiencia y la reducción de costos. Los datos de Baidu E-commerce muestran que ya hay más de 100,000 presentadores digitales aplicados en diversas industrias, lo que reduce significativamente los costos operativos de los comerciantes y aumenta el GMV (Fuente: 量子位)
🌟 Comunidad
Empresas chinas de IA transportan grandes cantidades de discos duros con datos a Malasia para entrenar modelos: NIK informa que las empresas chinas de IA, para eludir las restricciones de chips y utilizar recursos computacionales en el extranjero, han adoptado la estrategia de llevar personalmente discos duros llenos de datos de entrenamiento a lugares como Malasia. Por ejemplo, hay ingenieros que han llevado 15 discos duros con 80TB de datos a Malasia para alquilar servidores y entrenar modelos. Este fenómeno refleja la intensa competencia global por la potencia de cálculo de IA y los desafíos reales del flujo transfronterizo de datos, al mismo tiempo que suscita debates sobre la seguridad y el cumplimiento normativo de los datos (Fuente: jpt401, agihippo, cloneofsimo, fabianstelzer)

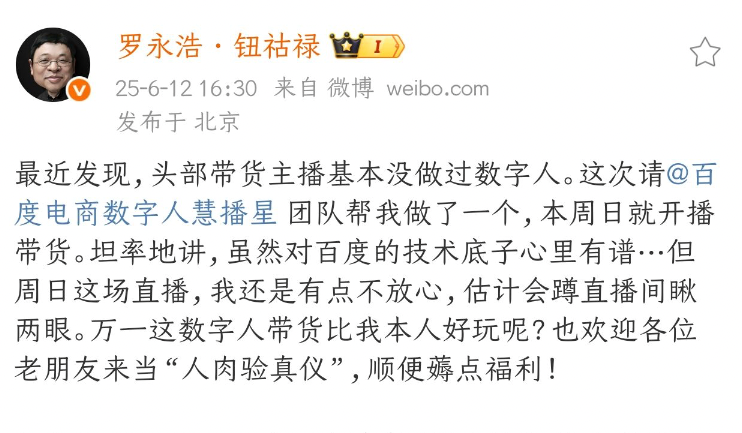
Arranca el hackathon de robótica LeRobot a escala global, el más grande del mundo: El hackathon global de robótica LeRobot, organizado por Hugging Face, ha comenzado oficialmente, abarcando más de 100 ubicaciones en los 5 continentes y atrayendo a más de 2300 participantes. El evento tiene como objetivo impulsar el desarrollo de robots de IA de código abierto, y los participantes construirán y explorarán proyectos relacionados con la robótica durante 52 horas. Desarrolladores y equipos de todo el mundo participan con entusiasmo, compartiendo fotos del evento y el progreso de sus proyectos, lo que demuestra la pasión y creatividad de la comunidad por la tecnología robótica (Fuente: _akhaliq, eliebakouch, ClementDelangue)
Lovable organiza un duelo de generación de páginas web con IA, Claude recibe elogios por su rendimiento: Lovable organizó un evento que permitió a los usuarios utilizar gratuitamente los modelos de primer nivel de OpenAI, Anthropic y Google para una competencia de generación de páginas web con IA. El usuario op7418 compartió su experiencia generando páginas web con los tres modelos utilizando el mismo conjunto de prompts, y consideró que Claude destacó en términos de cantidad de contenido y efectos visuales. Este tipo de eventos ofrece a desarrolladores y usuarios la oportunidad de comparar el rendimiento de diferentes modelos grandes en escenarios de aplicación específicos (Fuente: _philschmid, op7418)
Debate sobre la capacidad de razonamiento de los modelos de IA: limitación de tokens frente a lógica real: En respuesta al artículo de Apple sobre la “ilusión de pensamiento” (Illusion of Thinking), han surgido opiniones contrarias en la comunidad. Comentarios e investigaciones posteriores (como arXiv:2506.09250, que incluye a Claude Opus como autor) argumentan que el “colapso” observado en la capacidad de razonamiento de los modelos se debe más a la limitación en el número de tokens que a una deficiencia en la capacidad lógica intrínseca del modelo. Cuando se permite a los modelos utilizar formatos de respuesta más comprimidos o disponen de suficiente contexto, son capaces de resolver los problemas con éxito. Esto ha provocado un debate profundo sobre cómo evaluar y comprender con precisión la verdadera capacidad de razonamiento de los modelos de lenguaje grandes, así como las posibles limitaciones de los métodos de evaluación actuales (Fuente: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
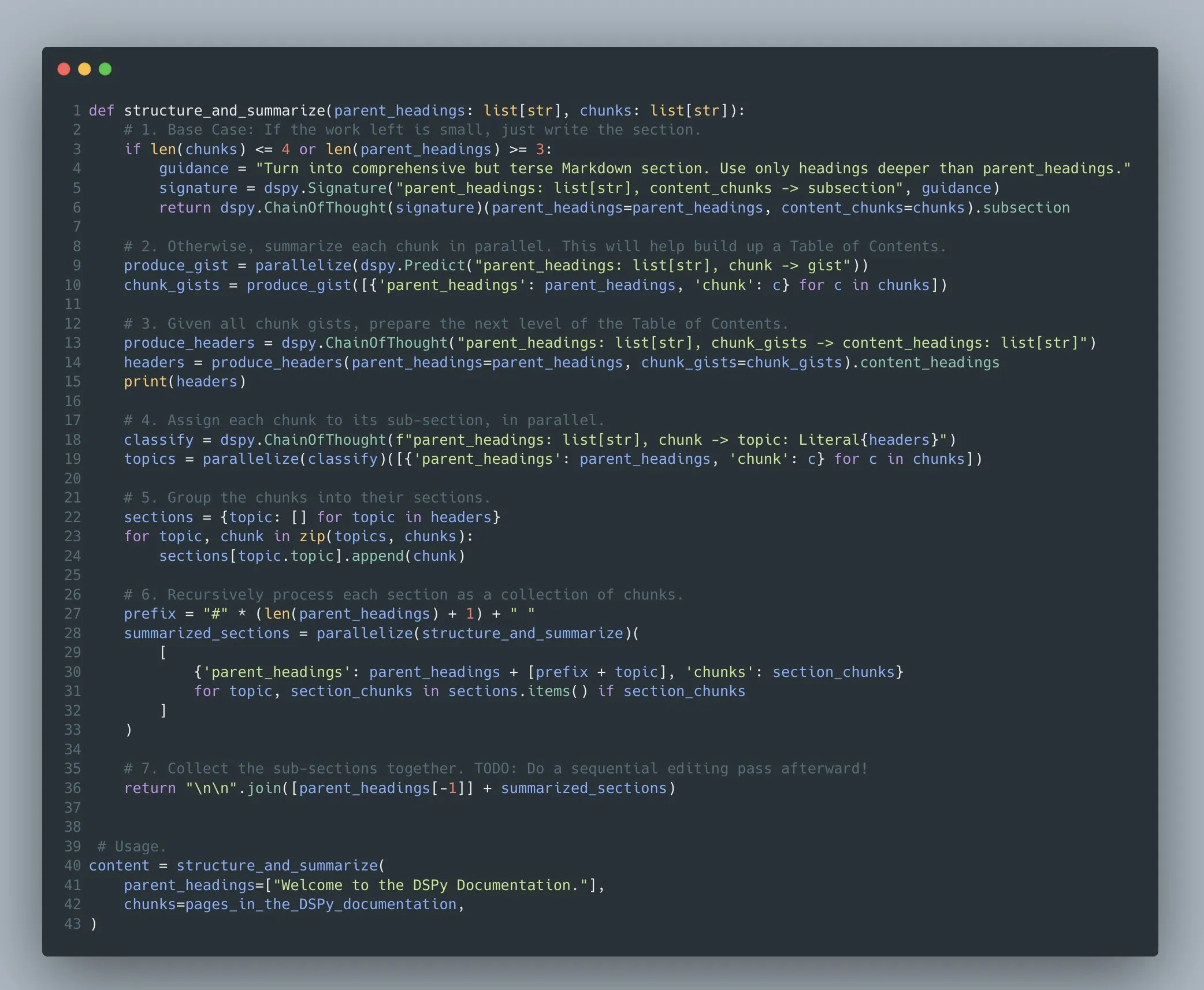
El framework DSPy admite la optimización de programas complejos de modelos de lenguaje multietapa: Omar Khattab enfatizó que el framework DSPy ha admitido desde 2022/2023 la optimización de prompts y el aprendizaje por refuerzo para programas complejos de modelos de lenguaje multietapa (Compound AI Systems). Sostiene que, a medida que los sistemas de IA se vuelven cada vez más complejos, es más apropiado considerarlos como “programas” en lugar de simples “modelos”. DSPy tiene como objetivo proporcionar soporte para construir y optimizar este tipo de programas de complejidad arbitraria (incluyendo recursividad, manejo de excepciones, etc.), y no solo “flujos” o “cadenas” lineales (Fuente: lateinteraction)
Debate sobre si los LLM piensan de forma similar a los humanos: Geoffrey Hinton considera que los modelos de lenguaje grandes (LLM) procesan el lenguaje de manera similar a los humanos y son nuestro mejor modelo para entender cómo funciona el lenguaje. Sin embargo, Pedro Domingos cuestiona esto, argumentando que el hecho de que los LLM superen a las antiguas teorías lingüísticas no significa que piensen como los humanos. Esta discusión refleja el debate continuo en el campo de la IA sobre la naturaleza de los LLM y su relación con la cognición humana (Fuente: pmddomingos)
El enorme potencial de la IA en la investigación en ciencias físicas: Un investigador en el campo de las ciencias de la Tierra compartió una experiencia positiva utilizando o3 Pro (posiblemente refiriéndose a algún modelo avanzado de OpenAI), describiéndolo como un “postdoctorado muy inteligente” en su investigación. El modelo demostró un rendimiento excepcional en codificación, desarrollo de modelos y refinamiento de ideas, ejecutando instrucciones de manera rápida y precisa y asistiendo en la investigación. El investigador considera que, aunque los modelos actuales aún no poseen la capacidad de proponer activamente preguntas de investigación (una característica de la AGI), sus potentes funciones de asistencia ya han mejorado significativamente la eficiencia de la investigación científica, y presiente que los LLM con autonomía no están lejos (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
Las herramientas de generación de cómics con IA facilitan la expresión creativa: El usuario StriderWriting compartió su experiencia creando cómics con herramientas de IA, considerando que la IA hace posible transformar “ideas tontas” en cómics. Esto refleja la popularización de la IA en el campo de la generación de contenido creativo, reduciendo la barrera de entrada y permitiendo que más personas expresen fácilmente su creatividad (Fuente: Reddit r/ChatGPT)

Preocupación por el sesgo en la IA: el rendimiento de ChatGPT en estereotipos de género genera descontento entre los usuarios: Una usuaria informó que ChatGPT mostró estereotipos negativos hacia los hombres en una conversación, por ejemplo, al discutir problemas laborales y médicos, asumió sin que se le indicara que el rol negativo era masculino y utilizó comentarios como “los hombres son odiosos”. La usuaria señaló que este tipo de estereotipo perezoso basado en el género es incómodo y cuestionó si OpenAI tiene reglas para restringir este tipo de comportamiento. Esto vuelve a plantear el debate sobre el sesgo en los datos de entrenamiento de los modelos de IA y cómo se manifiesta en la interacción (Fuente: Reddit r/ChatGPT)
Potencial y limitaciones actuales de la IA en la objetividad de los informes de noticias: Un usuario probó el potencial del modelo o3 de OpenAI como “periodista imparcial”, pidiéndole que comentara las posibles consecuencias “contraproducentes” de varias políticas de las administraciones de Trump y Biden desde 2017. Aunque la IA pudo generar análisis aparentemente objetivos, sus fuentes de información, sesgos potenciales y la verdadera profundidad de su comprensión de las complejas dinámicas político-económicas siguen siendo problemas a resolver en el futuro. Esto refleja la expectativa de la comunidad de utilizar la IA para mejorar la objetividad y profundidad de las noticias, así como el reconocimiento de las limitaciones tecnológicas actuales (Fuente: Reddit r/deeplearning)