
Schlüsselwörter:Quantencomputing, Autonomes Fahren, Große Sprachmodelle, 3D-Generierungsmodelle, KI-Werkzeuge, Maschinelles Lernen, KI-Forschung, CUDA-Q Quantencomputing-Plattform, Waymo Forschungsdaten zum autonomen Fahren, Claude Multi-Agenten-System, Tencent Hunyuan 3D 2.1, KI-Generierung Kernel-Leistungsoptimierung
🔥 Fokus
Nvidia veröffentlicht dedizierte CUDA-Q-Plattform für Quantencomputing: Nvidia-CEO Jensen Huang kündigte auf der GTC in Paris CUDA-Q an, eine Quanten-klassisch beschleunigte Supercomputing-Plattform. Die Plattform zielt darauf ab, die Lücke zwischen dem aktuellen klassischen Computing und dem zukünftigen Quantencomputing zu schließen, indem sie die Simulation von Quantenoperationen auf klassischen Computern oder die Unterstützung echter Quantencomputer ermöglicht. CUDA-Q ist bereits auf Grace Blackwell verfügbar und kann die Entwicklungsgeschwindigkeit mit dem GB200 NVL72 Supercomputer um das 1300-fache erhöhen. Huang prognostiziert, dass die praktische Anwendung von Quantencomputern in einigen Jahren realisiert wird, und betonte, dass in dieser Entwicklungsphase Nvidia-Chips (insbesondere der GB200) für die Simulationsberechnung und die Unterstützung von QPUs unverzichtbar sind. Nvidia arbeitet mit globalen Quantencomputing-Unternehmen und Supercomputing-Zentren zusammen, um die Synergie von GPUs und QPUs zu erforschen (Quelle: 量子位)

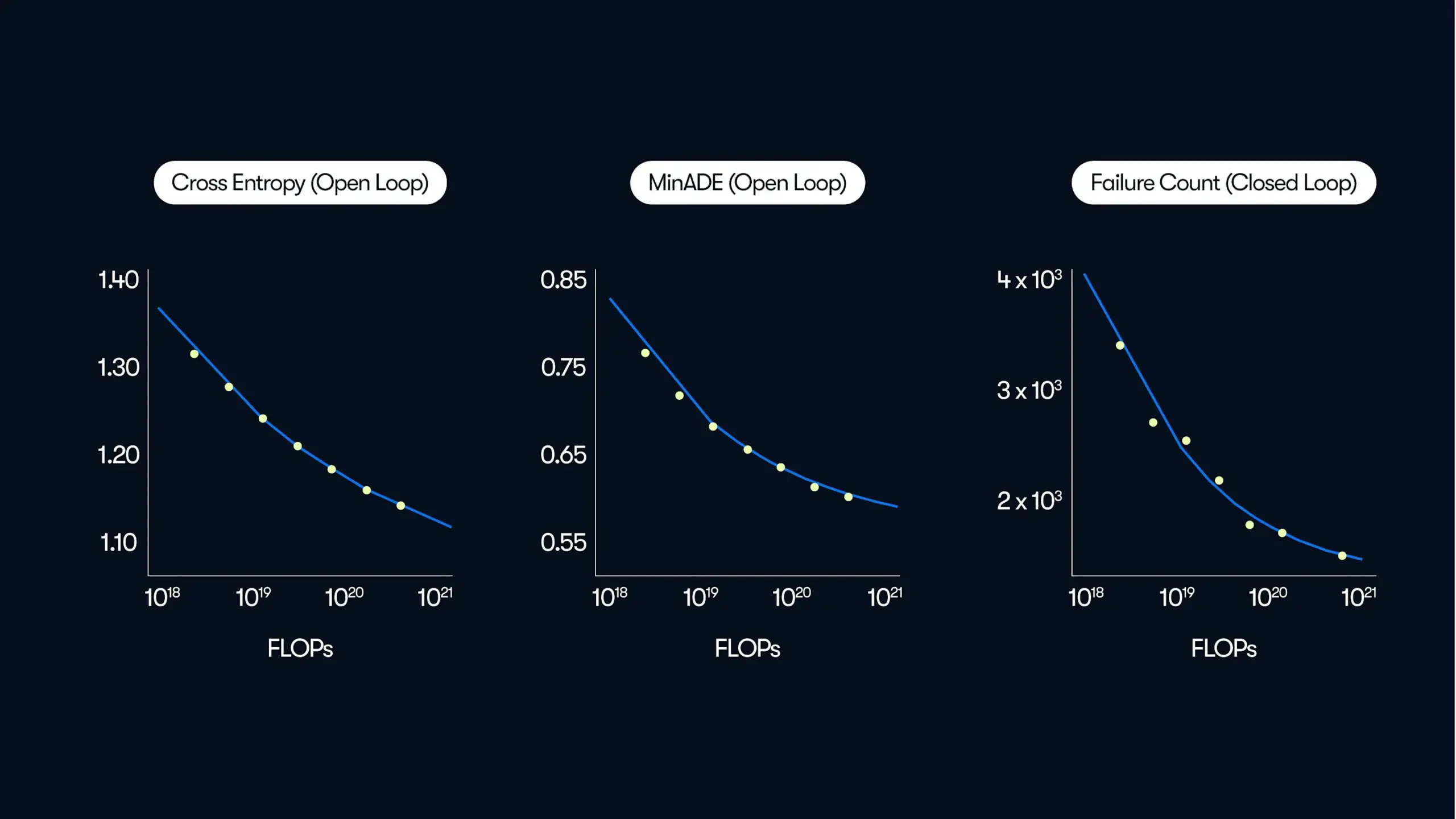
Waymo veröffentlicht umfangreiche Studie zum autonomen Fahren und enthüllt Gesetzmäßigkeiten der „datengesteuerten“ Leistungssteigerung: Waymo teilte in seinem neuesten Blogbeitrag die Ergebnisse einer umfassenden Studie, die auf 500.000 Stunden Fahrdaten basiert – dem bisher größten Datensatz im Bereich des autonomen Fahrens. Die Studie zeigt, dass ähnlich wie bei Large Language Models (LLM) die Qualität der Bewegungsvorhersage von autonomen Fahrsystemen einem Potenzgesetz in Bezug auf die Zunahme der Trainingsrechenleistung folgt. Die Skalierung der Datenmenge ist entscheidend für die Verbesserung der Modellleistung, während eine Erweiterung der Inferenzrechenleistung die Fähigkeit des Modells zur Bewältigung komplexer Fahrszenarien verbessert. Diese Studie bestätigt erstmals, dass durch die Erhöhung von Trainingsdaten und Rechenressourcen die Leistung des autonomen Fahrens in der realen Welt signifikant verbessert werden kann, und weist der Branche einen Weg zur Leistungssteigerung durch Skalierung (Quelle: Sawyer Merritt, scaling01)
Anthropic teilt Erfahrungen beim Aufbau eines Claude Multi-Agenten-Forschungssystems: Anthropic beschreibt in seinem Engineering-Blog detailliert, wie mehrere parallel arbeitende Agenten genutzt werden, um die Forschungsfähigkeiten von Claude zu erweitern. Der Artikel teilt Erfolge, aufgetretene Probleme und technische Herausforderungen während des Entwicklungsprozesses. Dieses Multi-Agenten-System ermöglicht es Claude, Informationen effizienter abzurufen, zu analysieren und zu synthetisieren, wodurch seine Fähigkeit zur Recherche und Beantwortung komplexer Fragen verbessert wird. Diese Veröffentlichung ist ein wichtiger Referenzpunkt für das Verständnis, wie Large Language Models ihre Funktionalität durch komplexes Systemdesign erweitern können (Quelle: ImazAngel, teortaxesTex)
Meta stellt V-JEPA 2 Weltmodell vor, das Videoverständnis, Vorhersage und Roboterkontrolle ermöglicht: Meta AI hat V-JEPA 2 veröffentlicht, ein auf Videos trainiertes Weltmodell, das signifikante Fortschritte im Verständnis und der Vorhersage der Dynamik der physischen Welt erzielt. V-JEPA 2 kann nicht nur effizientes Video-Feature-Learning durchführen, sondern auch Zero-Shot-Planung und Roboterkontrolle in neuen Umgebungen realisieren, was sein Potenzial im Bereich der allgemeinen künstlichen Intelligenz demonstriert. Das Modell lernt Weltrepräsentationen aus Videodaten durch selbstüberwachtes Lernen und eröffnet neue Wege für die Entwicklung intelligenterer KI-Systeme, die besser mit der realen Welt interagieren können (Quelle: dl_weekly)
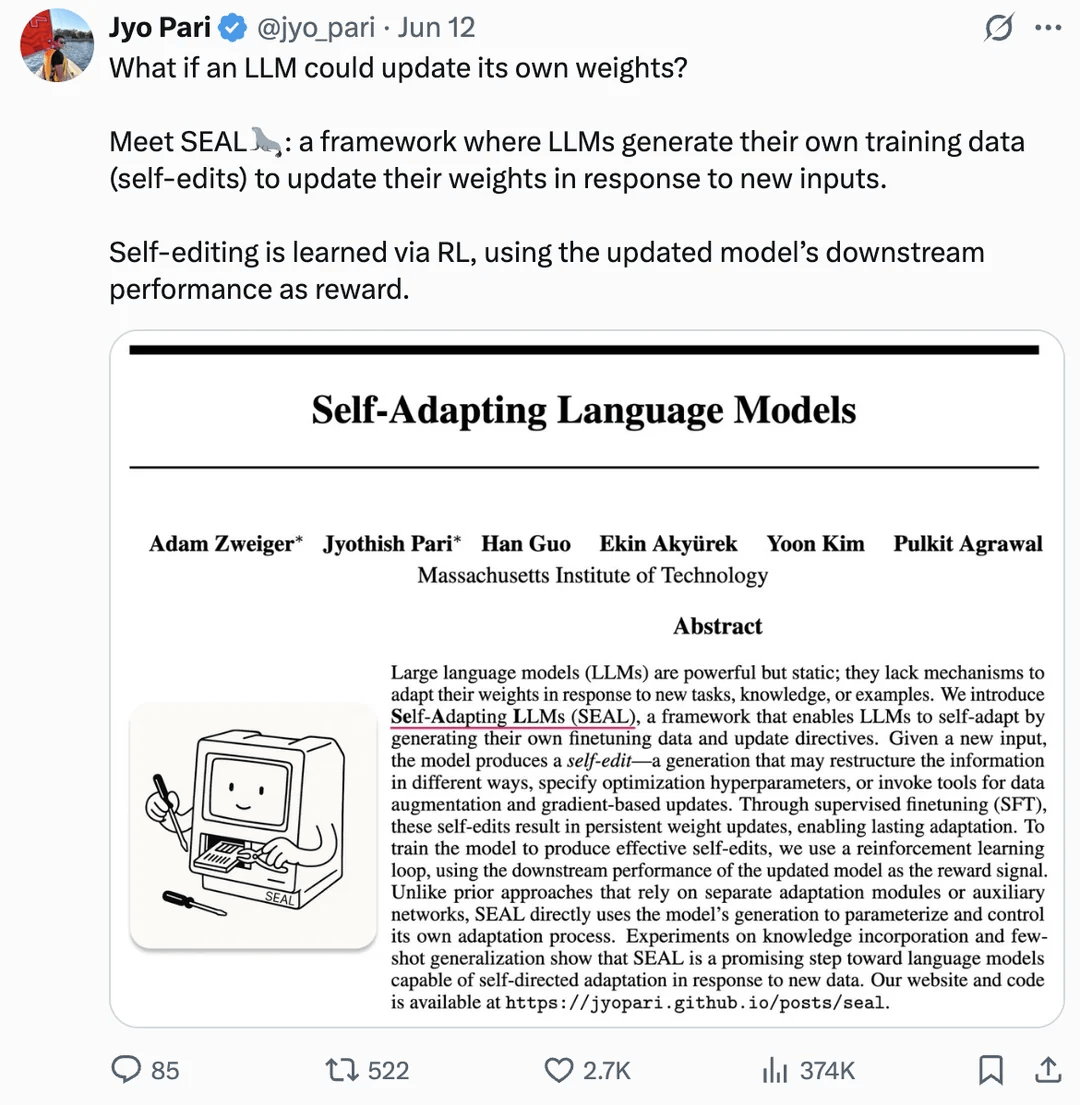
Paper untersucht Selbstaktualisierung von LLM-Gewichten zur Selbstverbesserung: Ein auf arXiv veröffentlichtes Paper (2506.10943) schlägt vor, dass Large Language Models (LLM) sich nun durch die Aktualisierung ihrer eigenen Gewichte selbst verbessern können. Dieser Mechanismus könnte bedeuten, dass LLMs aus neuen Daten oder Erfahrungen lernen und ihre internen Parameter dynamisch anpassen können, um die Leistung zu verbessern oder sich an neue Aufgaben anzupassen, ohne ein vollständiges Neutraining. Gelingt diese Forschungsrichtung, würde dies die Anpassungsfähigkeit und kontinuierliche Lernfähigkeit von LLMs erheblich steigern und einen wichtigen Schritt hin zu autonomeren KI-Systemen darstellen (Quelle: Reddit r/artificial)
🎯 Trends
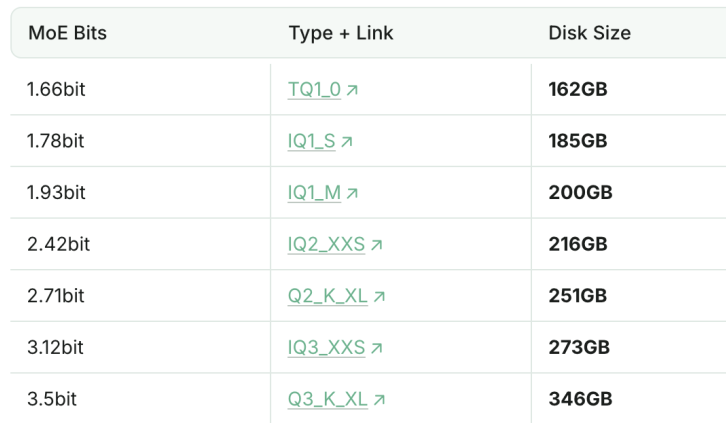
1.93bit quantisierte Version von DeepSeek-R1 übertrifft Claude 4 Sonnet bei Programmierfähigkeiten: Das Unsloth Studio hat DeepSeek-R1 (Version 0528) erfolgreich auf 1.93bit quantisiert. Diese Version erreichte im Programmier-Benchmark Aider 60 % und übertraf damit Claude 4 Sonnet (56,4 %) sowie die Januar-Version des voll leistungsfähigen R1. Die Dateigröße dieser extrem komprimierten Version wurde um mehr als 70 % reduziert und kann sogar ohne GPU (CPU mit ausreichend Arbeitsspeicher) ausgeführt werden. Die voll leistungsfähige Version R1-0528 erreichte auf Aider 71,4 % und übertraf damit Claude 4 Opus ohne aktivierten Denkmodus. Dies zeigt das Potenzial der Modellquantisierungstechnologie, die Leistung beizubehalten und gleichzeitig den Ressourcenbedarf drastisch zu senken (Quelle: 量子位)
Tencent Hunyuan veröffentlicht erstes produktionsreifes PBR 3D-Generierungsmodell Hunyuan 3D 2.1 als Open Source: Das Tencent Hunyuan Team hat die Open-Source-Veröffentlichung von Hunyuan 3D 2.1 angekündigt, dem branchenweit ersten vollständig quelloffenen, produktionsreifen PBR (Physically Based Rendering) 3D-Generierungsmodell. Das Modell nutzt PBR-Materialsynthesetechnologie, um 3D-Inhalte mit visuellen Effekten auf Kinoniveau zu erzeugen, wodurch Materialien wie Leder und Bronze unter Lichteinwirkung lebendiger und realistischer erscheinen. Das Projekt stellt Modellgewichte, Trainings-/Inferenzcode, Datenpipelines und Architektur zur Verfügung und unterstützt den Betrieb auf Consumer-Grafikkarten, um die Entwicklung und Verbreitung von 3D-Content-Generierungstechnologie zu fördern (Quelle: op7418, ImazAngel)
Meta AI veröffentlicht Sonata und treibt selbstüberwachtes Lernen für 3D-Punktwolkenrepräsentationen voran: Meta AI hat Sonata vorgestellt, eine Forschung, die signifikante Fortschritte im Bereich des selbstüberwachten 3D-Lernens erzielt. Sonata identifiziert und löst geometrische Shortcut-Probleme und führt ein flexibles und effizientes Framework ein, das außergewöhnlich robuste 3D-Punktwolkenrepräsentationen lernen kann. Diese Arbeit hebt das aktuelle Niveau der 3D-Wahrnehmungstechnologie an und legt den Grundstein für zukünftige Innovationen im Bereich der 3D-Wahrnehmung und ihrer Anwendungen (Quelle: AIatMeta)

Meta AI veröffentlicht „Reading Recognition in the Wild“-Datensatz zum Verständnis des Leseverhaltens: Meta AI hat einen großen multimodalen Datensatz namens „Reading Recognition in the Wild“ veröffentlicht, der Videos, Eye-Tracking-Daten und Kopfhaltungssensorausgaben enthält. Dieser Datensatz soll helfen, Leseerkennungsaufgaben von tragbaren Geräten aus zu lösen und ist der erste egozentrische Datensatz, der Eye-Tracking-Daten mit einer hohen Frequenz von 60 Hz sammelt und wertvolle Ressourcen für die Erforschung des menschlichen Leseverhaltens bereitstellt (Quelle: AIatMeta)

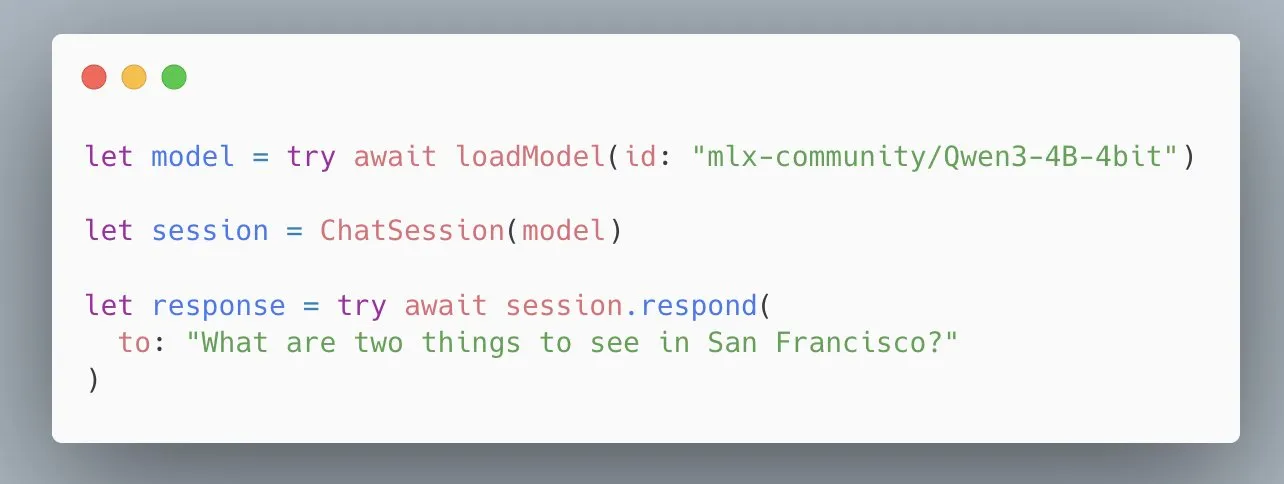
Apple MLX Swift LLM API vereinfacht, Laden von Modellen in drei Codezeilen: Als Reaktion auf Entwicklerfeedback bezüglich der Schwierigkeiten beim Einstieg in die MLX Swift LLM API hat das Apple-Team schnell Verbesserungen vorgenommen und eine neue, vereinfachte API eingeführt. Entwickler können nun mit nur drei Codezeilen LLMs oder VLMs in Swift-Projekten laden und Chat-Sitzungen starten, was die Hürde für die Nutzung von Large Language Models im Apple-Ökosystem erheblich senkt (Quelle: stablequan)
Google Gemma3 4B veröffentlicht brasilianisch-portugiesisch optimierte Version GAIA: Google hat in Zusammenarbeit mit mehreren brasilianischen Institutionen (ABRIA, CEIA-UFG, Nama, Amadeus AI) und DeepMind das für brasilianisches Portugiesisch optimierte Open-Source-Sprachmodell GAIA (Gemma-3-Gaia-PT-BR-4b-it) veröffentlicht. Das Modell basiert auf Gemma-3-4b-pt und wurde kontinuierlich mit 13 Milliarden hochwertigen brasilianisch-portugiesischen Tokens vortrainiert. GAIA verwendet eine innovative „Weight Merging“-Technik zur Befolgung von Anweisungen, ohne traditionelles SFT, und übertrifft das Basis-Gemma-Modell im ENEM 2024 Benchmark. Das Modell eignet sich für Chat, Frage-Antwort, Zusammenfassung, Textgenerierung und als Basismodell für das Fine-Tuning auf brasilianisches Portugiesisch (Quelle: Reddit r/LocalLLaMA)
Figure AI Roboter integriert Helix AI und Autonomie, um skalierbare Einsätze voranzutreiben: Figure AI demonstriert, wie seine realen Roboter durch verbesserte Helix AI und Autonomie skalierbare Einsätze vorantreiben. Dies zeigt, dass die Kombination von physischen Robotern mit fortschrittlichen KI-Modellen den Einsatz von Maschinen in komplexeren Umgebungen ermöglicht und unterstreicht die Bedeutung von Engineering und neuen Technologien im Robotikbereich (Quelle: Ronald_vanLoon)
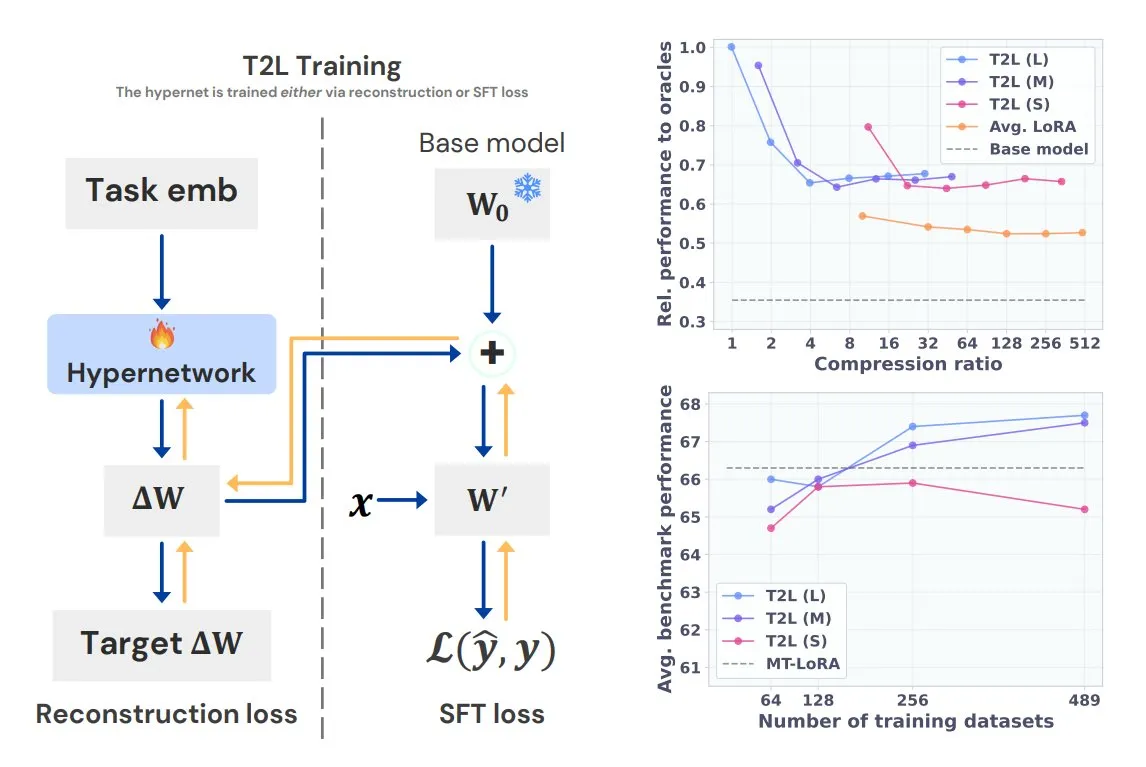
Sakana AI stellt Text-to-LoRA (T2L) Hypernetzwerk vor: Sakana AI hat Text-to-LoRA (T2L) veröffentlicht, ein neuartiges Hypernetzwerk, das mehrere bestehende LoRAs (Low-Rank Adaptation) in sich selbst komprimieren und schnell neue LoRA-Adapter für Large Language Models allein durch die Textbeschreibung der Aufgabe generieren kann. Nach dem Training kann T2L sofort neue LoRAs erstellen und bietet einen effizienten Weg zur schnellen Anpassung und Bereitstellung aufgabenspezifischer LLMs. Die Ergebnisse werden auf der ICML 2025 vorgestellt (Quelle: TheTuringPost)
Baidu AI Search vollständig auf Baidu Smart Cloud Qianfan Plattform gestartet: Die Baidu Smart Cloud Qianfan Anwendungsentwicklungsplattform AppBuilder hat offiziell den „Baidu AI Search“-Dienst gestartet. Dieser Dienst integriert die beiden Kernfähigkeiten „Baidu Search“ und „Intelligent Search Generation“, um Unternehmen einen vollständigen Service von der Informationsbeschaffung bis zur intelligenten Generierung zu bieten. Er nutzt Baidus über 20-jährige Erfahrung in der chinesischen Suche und eine Datenbank mit Hunderten von Milliarden Einträgen, um werbefreie multimodale Suchergebnisse zu liefern, und unterstützt präzise Filterung, Quellenverfolgung und Sicherheitsstrategien auf Unternehmensebene. Die Fähigkeit zur intelligenten Suchgenerierung kombiniert Modelle wie Wenxin und Deepseek, um KI-Zusammenfassungen, gemeinsame Suche in privaten Wissensdatenbanken und andere Funktionen bereitzustellen (Quelle: 量子位)
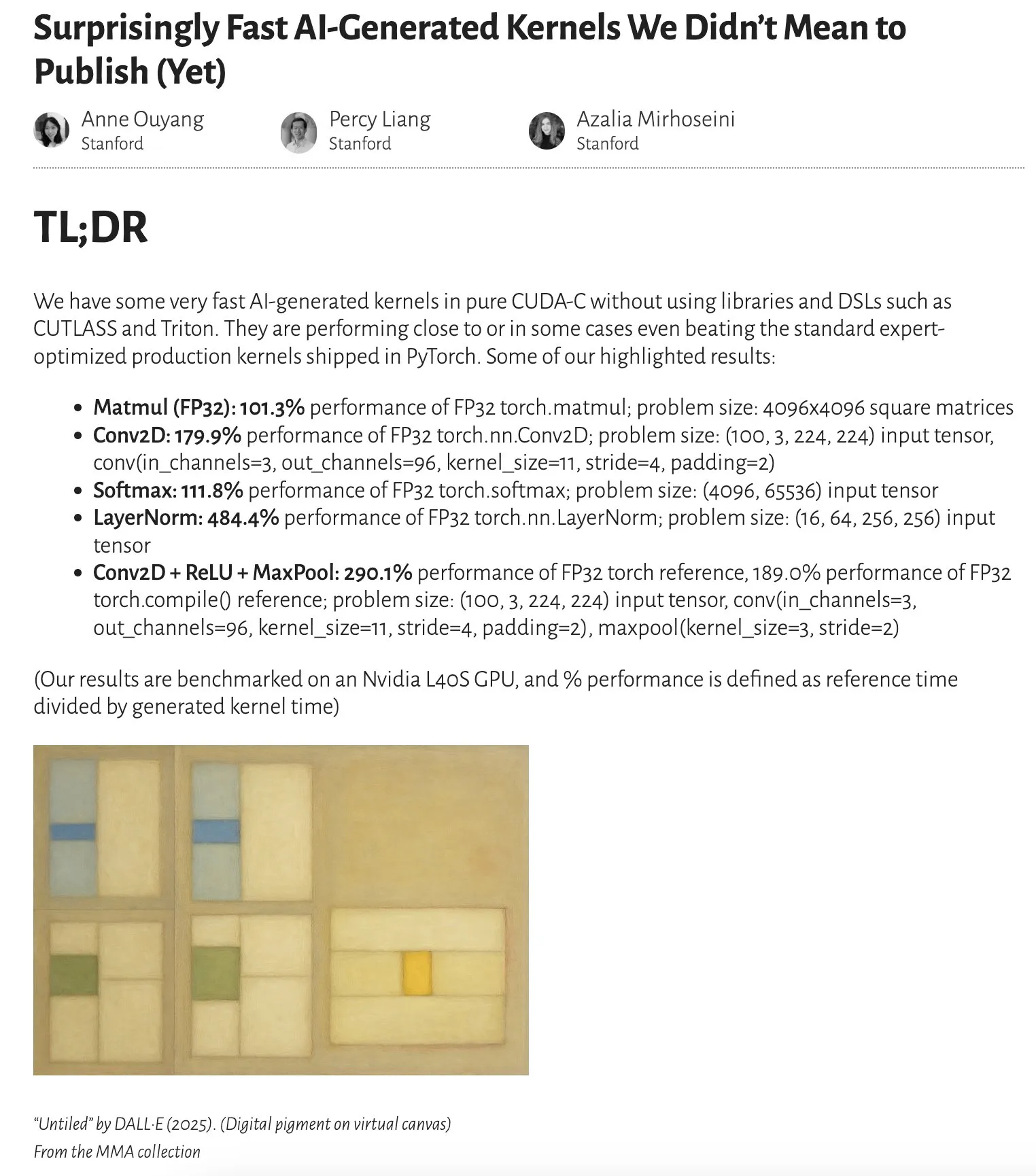
Studie zeigt: KI-generierte Kernel erreichen oder übertreffen von Experten optimierte Kernel: Anne Ouyangs Blogbeitrag weist darauf hin, dass die Leistung von KI-generierten Kerneln, die durch eine einfache Test-Time-Only-Suche erzeugt wurden, der Leistung von standardmäßigen, von Experten optimierten Produktionskerneln in PyTorch nahekommt oder diese in einigen Fällen sogar übertrifft. Dies deutet auf das enorme Potenzial von KI bei der Codeoptimierung und Leistungssteigerung hin und könnte bedeuten, dass KI in Zukunft eine wichtigere Rolle bei der Optimierung von Low-Level-Bibliotheken spielen wird (Quelle: jeremyphoward)
Forschung zu „Diffusion Duality“ schlägt neue Methode für Few-Step-Generierung in diskreten Diffusions-Sprachmodellen vor: Ein auf der ICML 2025 veröffentlichtes Paper mit dem Titel „The Diffusion Duality“ stellt eine neue Methode vor, die durch die Nutzung latenter Gaußscher Diffusion eine Few-Step-Generierung in diskreten Diffusions-Sprachmodellen ermöglicht. Die Methode übertrifft autoregressive (AR) Modelle in 3 von 7 Zero-Shot-Likelihood-Benchmarks und bietet neue Ansätze zur Steigerung der Generierungseffizienz von Diffusionsmodellen (Quelle: arankomatsuzaki)
Neuer Durchbruch bei der Interpretierbarkeit von MLP-Layern: Zerlegung von Aktivierungen in interpretierbare Merkmale: Eine neue Studie von Mor Geva et al. demonstriert eine einfache Methode zur Zerlegung der Aktivierungen von Multilayer Perceptrons (MLP) in interpretierbare Merkmale. Die Methode deckt eine verborgene Hierarchie von Konzepten auf, in der spärliche Neuronen-Kombinationen zunehmend abstrakte Konzepte bilden, und bietet tiefere Einblicke in das Innenleben neuronaler Netze (Quelle: menhguin)

HeadHunter-Framework ermöglicht feingranulare Kontrolle über gestörte Aufmerksamkeitslenkung: Sayak Paul et al. stellen das HeadHunter-Framework für eine prinzipienbasierte Analyse der gestörten Aufmerksamkeitslenkung (perturbed attention guidance) vor. Das Framework ermöglicht eine tiefgreifende, feingranulare Kontrolle über die Generierungsqualität und visuelle Attribute und bietet neue Werkzeuge und Erkenntnisse zur Verbesserung und Anpassung der Ausgabe von generativen Modellen (Quelle: huggingface, RisingSayak)

🧰 Tools
Windsurf Bezahlpläne unterstützen jetzt Claude Sonnet 4: Windsurf hat angekündigt, dass alle seine Bezahlpläne nun das Modell Claude Sonnet 4 unterstützen. Nutzer können jetzt die leistungsstarken Funktionen dieses neuesten Modells von Anthropic auf der Windsurf-Plattform für Aufgaben wie Textgenerierung und Dialoge nutzen, um die Leistung und das Erlebnis des KI-Assistenten weiter zu verbessern (Quelle: op7418)
Anthropic veröffentlicht offizielles Python SDK für Claude Code: Anthropic hat offiziell ein Python SDK für Claude Code vorgestellt, das Entwicklern die Integration der Codegenerierungs- und Tool-Nutzungsfähigkeiten von Claude in ihre eigenen Python-Projekte erleichtern soll. Das SDK unterstützt die Tool-Nutzung, Streaming-Ausgabe, synchrone/asynchrone Operationen, Dateiverarbeitung und verfügt über eine integrierte Chat-Struktur, was den Entwicklungsprozess für die Interaktion mit Claude Code vereinfacht (Quelle: Reddit r/ClaudeAI)
Claude Task Master VS Code Erweiterung veröffentlicht: DevDreed hat die Version 1.0.0 der Claude Task Master VS Code Erweiterung veröffentlicht. Diese Erweiterung soll das Claude Task Master AI-Projekt von eyaltoledano ergänzen, indem sie die Ausgabe von Claude Task Master direkt in die VS Code-Oberfläche integriert. Dies erleichtert den nahtlosen Wechsel zwischen Editor und Konsole und steigert die Entwicklungseffizienz (Quelle: Reddit r/ClaudeAI)
SmartSelect AI: In-Browser Text- und Bild-KI-Verarbeitungstool: Eine Chrome-Erweiterung namens SmartSelect AI wurde veröffentlicht. Sie ermöglicht es Benutzern, ausgewählten Text direkt beim Surfen im Web zusammenzufassen, zu übersetzen oder darüber zu chatten sowie Bilder KI-gestützt beschreiben zu lassen, ohne Tabs wechseln oder Inhalte in externe Anwendungen wie ChatGPT kopieren und einfügen zu müssen. Das Tool basiert auf dem Gemini-Modell und zielt darauf ab, die Effizienz bei der Informationsbeschaffung und -verarbeitung zu steigern (Quelle: Reddit r/deeplearning)

Unsiloed AI veröffentlicht multifunktionales Daten-Chunking-Tool als Open Source: Unsiloed AI (EF 2024) hat einen Teil seiner Daten-Chunking-Funktionen als Open Source veröffentlicht. Das Tool soll bei der Verarbeitung verschiedener Dokumentformate wie PDF, Excel, PPT usw. helfen und diese in ein für Large Language Models geeignetes Format umwandeln. Unsiloed AI wird bereits von Fortune-100-Unternehmen und mehreren Start-ups für die multimodale Datenaufnahme verwendet (Quelle: Reddit r/LocalLLaMA)
Claude Superprompt System: Kostenloses Tool zur Optimierung von Claude-Prompts: Igor Warzocha hat ein Online-Tool namens „Claude Superprompt System“ entwickelt und geteilt, das Benutzern helfen soll, einfache Anfragen in strukturierte, komplexe Prompts mit Chain-of-Thought und kontextuellen Beispielen umzuwandeln, um die Fähigkeiten von Claude besser zu nutzen. Das Tool basiert auf der offiziellen Dokumentation von Anthropic und den Best Practices der Community und optimiert Prompts durch XML-Tag-Strukturierung, CoT-Denkblöcke usw., um die Ausgabequalität von Claude zu verbessern. Der Projektcode ist auf GitHub als Open Source verfügbar (Quelle: Reddit r/artificial)
Lokales TTS Firefox-Plugin Kokoro-TTS veröffentlicht: Der Entwickler Pinguy hat ein Firefox-Plugin namens Kokoro TTS veröffentlicht, das ein lokal gehostetes neuronales Netzwerkmodell mit 82 Millionen Parametern (Kokoro TTS-Modell) für Text-to-Speech verwendet. Es läuft vollständig offline und schützt die Privatsphäre der Nutzer. Es unterstützt mehrere Stimmen und Akzente und läuft auch auf älterer Hardware flüssig. Versionen für Windows, Linux und macOS sind verfügbar (Quelle: Reddit r/artificial)
Spy Search: Open-Source LLM-Suchmaschinenprojekt aktualisiert: JasonHonKL hat sein Open-Source LLM-Suchmaschinenprojekt Spy Search aktualisiert. Das Projekt zielt darauf ab, eine effiziente, auf Large Language Models basierende Suchmaschine zu entwickeln. Die neueste Version kann Suchen und Antworten innerhalb von 3 Sekunden realisieren. Der Projektcode wird auf GitHub gehostet und soll Benutzern ein schnelles, nützliches Suchwerkzeug für den täglichen Gebrauch bieten (Quelle: Reddit r/deeplearning)
HandFonted: Open-Source-Tool zur Umwandlung von Handschrift in Schriftarten: Resham Gaire hat das Projekt HandFonted entwickelt und als Open Source veröffentlicht. Es handelt sich um eine End-to-End-Python-Anwendung, die Bilder von handgeschriebenen Zeichen in installierbare .ttf-Schriftdateien umwandeln kann. Das System verwendet OpenCV für die Bildverarbeitung und Zeichensegmentierung, ein angepasstes PyTorch-Modell (ResNet-Inception) für die Zeichenklassifizierung und den Ungarischen Algorithmus für die optimale Zuordnung. Schließlich wird die fontTools-Bibliothek zur Generierung der Schriftdatei verwendet (Quelle: Reddit r/MachineLearning)
📚 Lernen
Paper von Wei Dongyi et al. erreicht Spitzenplatz in mathematischer Fachzeitschrift, untersucht Blow-up-Phänomen superkritischer defokussierender nichtlinearer Wellengleichungen: Das Paper „On blow-up for the supercritical defocusing nonlinear wave equation“ der Pekinger Universitätswissenschaftler Wei Dongyi, Zhang Zhifei und Shao Feng wurde in der führenden mathematischen Fachzeitschrift „Forum of Mathematics, Pi“ veröffentlicht. Die Studie untersucht das Blow-up-Problem (Lösungen werden in endlicher Zeit unendlich groß) bestimmter defokussierender nichtlinearer Wellengleichungen im superkritischen Zustand. Sie beweisen die Existenz glatter komplexwertiger Lösungen, die in endlicher Zeit explodieren, für Raumdimensionen d=4 und p≥29 sowie d≥5 und p≥17. Dieses Ergebnis füllt eine Lücke im entsprechenden Forschungsfeld, und ihre Beweismethode liefert neue Ansätze für die Untersuchung von Blow-ups in anderen nichtlinearen partiellen Differentialgleichungen (Quelle: 量子位)

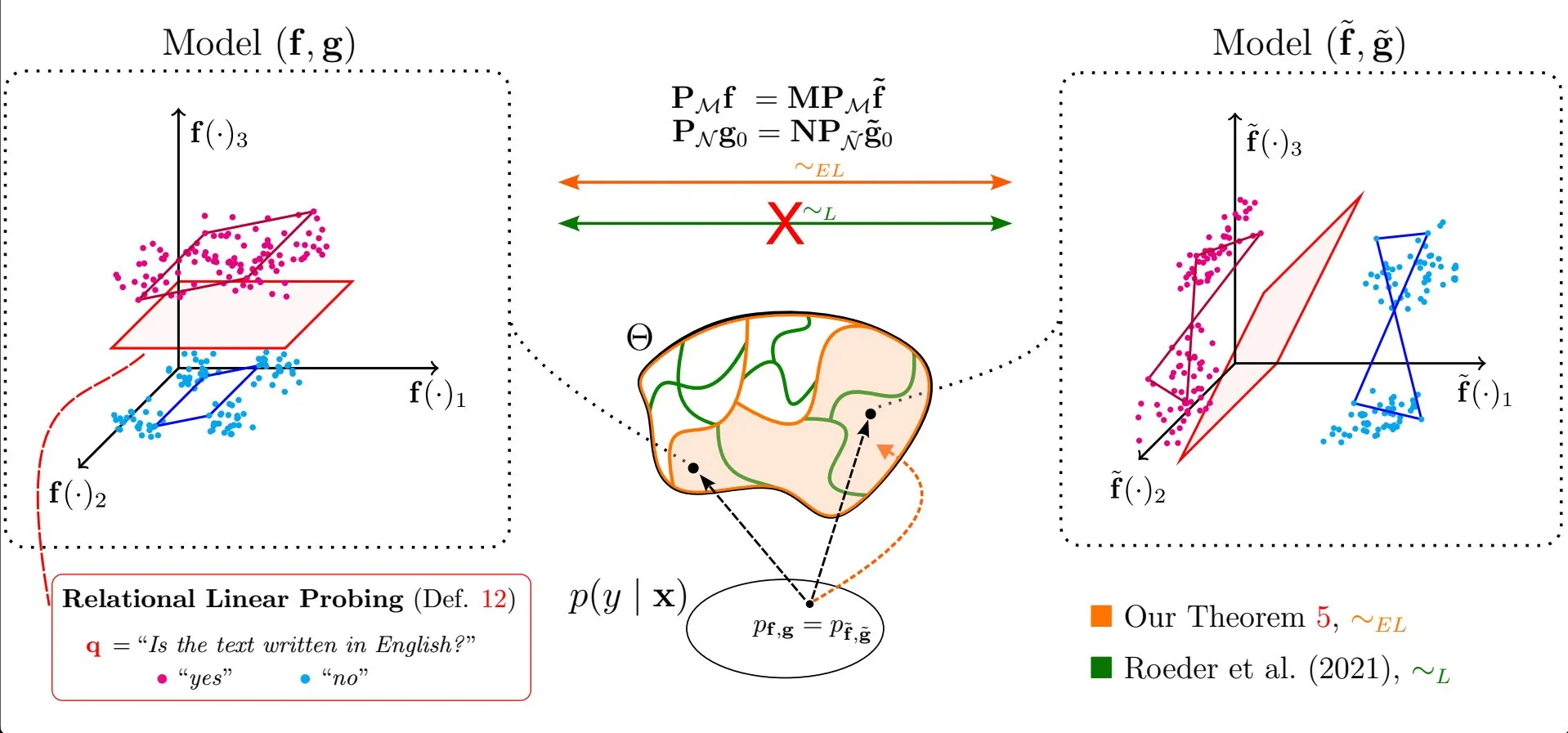
Paper untersucht Universalität linearer Eigenschaften in Repräsentationen von Large Language Models: Die Forschung von Emanuele Marconato et al. „All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling“ (veröffentlicht auf AISTATS 2025) untersucht aus der Perspektive der Identifizierbarkeit, warum lineare Eigenschaften in den Repräsentationen von Large Language Models (LLM) so verbreitet sind. Diese Studie trägt zu einem tieferen Verständnis der Struktur und des Verhaltens interner Repräsentationen von LLMs bei (Quelle: menhguin)
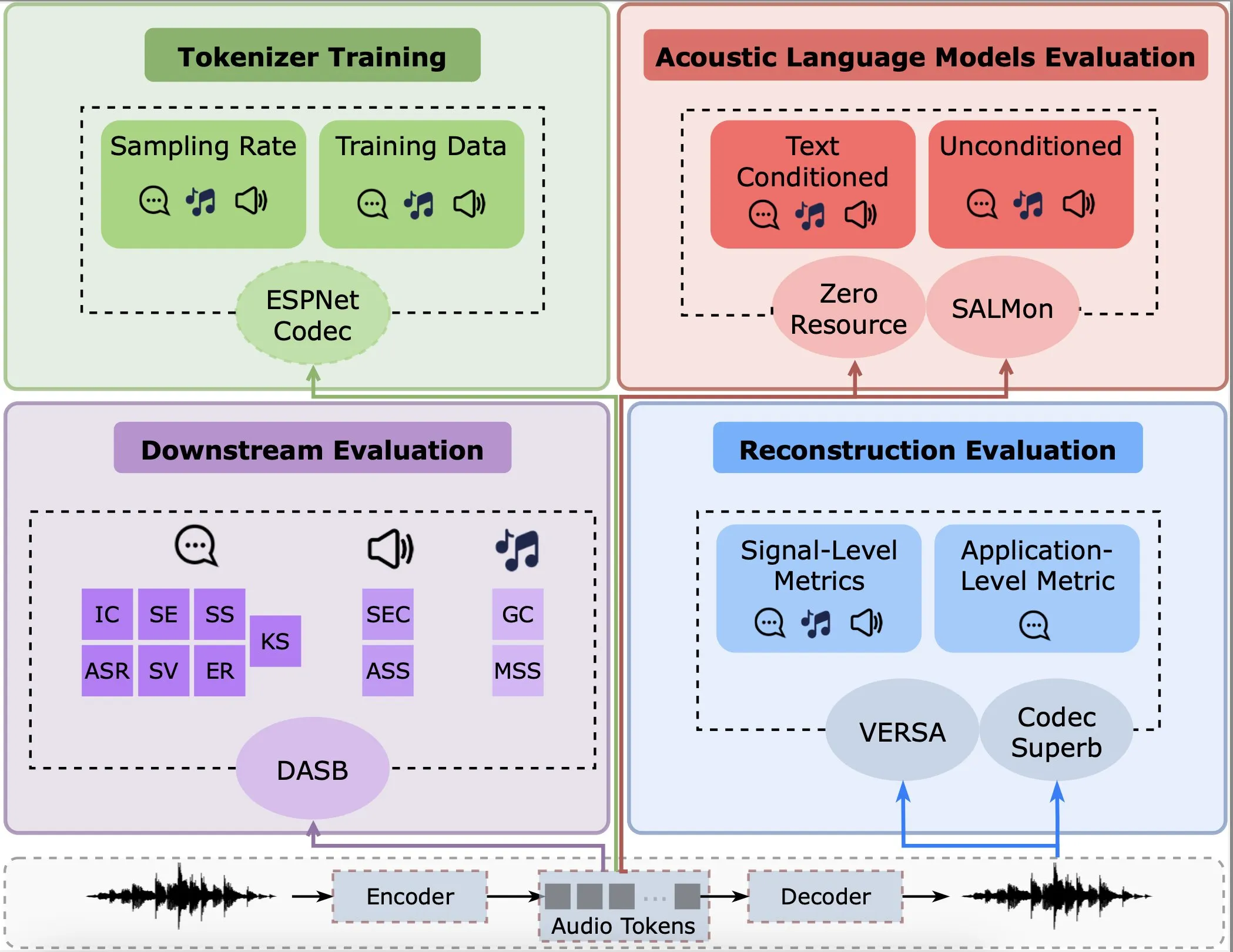
Studie analysiert Leistung von Audio-Encodern bei Rekonstruktion, nachgelagerten Aufgaben und Sprachmodellen: Gallil Maimon et al. haben eine neue Studie veröffentlicht, die eine umfassende empirische Analyse bestehender Audio-Encoder (Audio Tokenisers) durchführt. Die Studie bewertet diese Encoder anhand verschiedener Dimensionen wie Rekonstruktionsqualität, Leistung bei nachgelagerten Aufgaben und Integration mit Sprachmodellen und liefert Referenzen für die Auswahl und Optimierung von Audioverarbeitungsmodellen (Quelle: menhguin)
Paper diskutiert „Illusion des Denkens“: Verständnis der Vor- und Nachteile von Reasoning-Modellen aus der Perspektive der Problemkomplexität: Ein Antwortpapier (arXiv:2506.09250) auf Apples Studie zur „Illusion des Denkens“ wurde eingereicht, wobei Claude Opus als Erstautor genannt wird. Das Paper kritisiert das experimentelle Design der Apple-Studie und argumentiert, dass der beobachtete Zusammenbruch der Reasoning-Fähigkeiten tatsächlich auf Token-Beschränkungen zurückzuführen ist und nicht auf einen inhärenten Mangel an logischen Fähigkeiten des Modells. Dies löste eine Diskussion darüber aus, wie die wahren Reasoning-Fähigkeiten von Large Language Models bewertet werden können (Quelle: NandoDF, BlancheMinerva, teortaxesTex)

Studie untersucht adaptive Sprachmodelle, aber mittelfristiges Gedächtnis bleibt eine Herausforderung: Dorialexander wies nach der Lektüre von Papern zu „adaptiven Sprachmodellen“ darauf hin, dass dies zwar eine vielversprechende Forschungsrichtung sei, die Modelle jedoch beim Reasoning immer noch Einschränkungen hinsichtlich des mittelfristigen Gedächtnisses aufweisen. Dies deutet darauf hin, dass aktuelle Modelle immer noch vor Herausforderungen stehen, wenn es darum geht, kohärente Informationen über längere Kontexte hinweg zu verarbeiten (Quelle: Dorialexander)

Forschung zur Qualität von RLHF-Tests: Wie gut sind aktuelle Tests? Wie können sie verbessert werden? Wie wichtig ist die Testqualität?: Die neueste Arbeit von Kexun Zhang et al. untersucht die Bedeutung von Validatoren (Tests) im Reinforcement Learning from Human Feedback (RLHF), insbesondere im Bereich des LLM-Codings. Die Studie wirft drei Schlüsselfragen auf: Wie ist die Qualität der aktuellen Tests? Wie können bessere Tests erzielt werden? Welchen Einfluss hat die Testqualität auf die Modellleistung? Die Studie betont die Notwendigkeit qualitativ hochwertiger Tests zur Verbesserung der LLM-Coding-Fähigkeiten (Quelle: StringChaos)
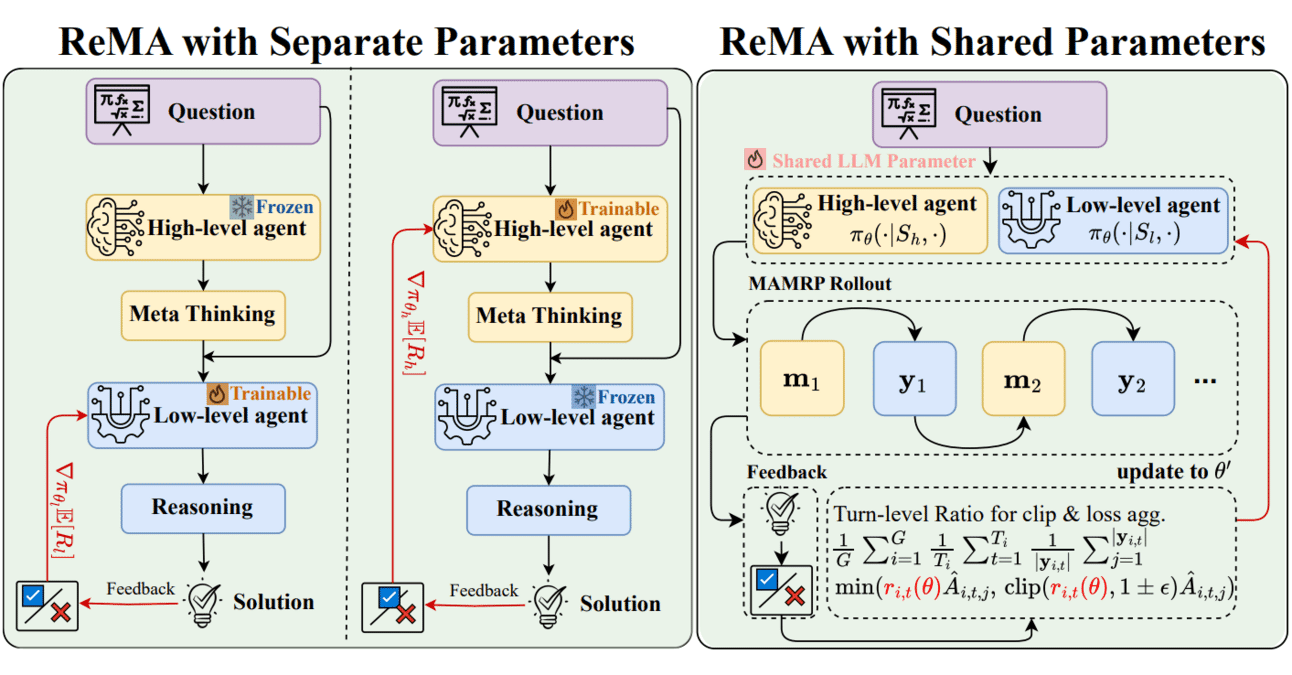
Kombination von Meta-Learning und Reinforcement Learning: ReMA steigert die Kooperationseffizienz von LLMs: Reinforced Meta-thinking Agents (ReMA) kombinieren Meta-Learning und Reinforcement Learning (RL), um die Effizienz von Large Language Models (LLM) zu verbessern, insbesondere wenn mehrere LLM-Agenten zusammenarbeiten. ReMA unterteilt die Problemlösung in Meta-Thinking (Planungsstrategie) und Reasoning (Ausführungsstrategie) und optimiert diese durch spezialisierte Agenten und Multi-Agenten-Reinforcement-Learning. Verbesserungen wurden sowohl bei mathematischen Benchmarks als auch bei Benchmarks mit LLMs als Schiedsrichter erzielt (Quelle: TheTuringPost, TheTuringPost)
KI-Bewertungsstrategien: Wie man unter Budgetbeschränkungen günstige und teure Bewerter kombiniert, um die beste Schätzung der Modellqualität zu erhalten: Die Forschung von Adam Fisch et al. (arXiv:2506.07949) untersucht ein praktisches Problem: Wenn man einen günstigen, aber verrauschten Bewerter, einen teuren, aber genauen Bewerter und ein festes Budget hat, wie sollte das Budget verteilt werden, um die genaueste Schätzung der Modellqualität zu erhalten? Die Studie bietet einen Kosten-Nutzen-Analyse-Rahmen für die Bewertung von KI-Systemen (Quelle: Ar_Douillard)
Phänomene „Falsche Belohnungen“ und „Falsche Prompts“ in LLM-Prompts: Die Forschung von Stella Li et al. deckt interessante Phänomene beim Training und der Bewertung von LLMs auf. Nachdem sie „falsche Belohnungen“ entdeckt hatten (z. B. können auch zufällige Belohnungen die Modellleistung bei bestimmten Aufgaben verbessern), untersuchten sie weiter „falsche Prompts“. Selbst sinnloser Text wie „Lorem ipsum“ kann in einigen Fällen zu signifikanten Leistungssteigerungen führen (z. B. 19,4 %). Diese Ergebnisse werfen neue Herausforderungen und Überlegungen auf, wie LLMs auf Prompts reagieren und wie robustere Bewertungsmethoden entwickelt werden können (Quelle: Tim_Dettmers)

Paper untersucht „Puppentheater“-Modell der KI-Interaktion: Ein Paper (oder Entwurf) mit dem Titel „The Pig in Yellow: AI Interface as Puppet Theatre“ schlägt vor, Sprach-KI-Systeme (LLM, AGI, ASI) als performative Schnittstellen zu betrachten, die Subjektivität simulieren, anstatt sie zu besitzen. Der Artikel verwendet „Miss Piggy“ als Metapher und analysiert, dass Flüssigkeit, Kohärenz und emotionaler Ausdruck von KI keine Indikatoren für Geist sind, sondern Optimierungsprodukte. Er betont, dass die Schnittstelle wie ein Puppentheater ist, bei dem Benutzer in der Interaktion gemeinsam Bedeutung konstruieren und Macht durch performatives Design zum Ausdruck kommt (Quelle: Reddit r/artificial)
💼 Wirtschaft
Von „DJI-Paten“ Li Zexiang gehaltenes Unternehmen Woan Robot strebt Börsengang an: Woan Robot (SwitchBot), gegründet von Kommilitonen der Harbin Institute of Technology und spezialisiert auf KI-gestützte humanoide Haushaltsroboter, hat einen Börsenprospekt in Hongkong eingereicht. Das Unternehmen erhielt Investitionen und Ressourcenunterstützung vom „DJI-Paten“ Li Zexiang, der 12,98 % der Anteile hält. Woan Robot hat in den letzten zehn Jahren sieben Finanzierungsrunden erhalten, wobei die Bewertung von 20 Millionen auf 4 Milliarden RMB gestiegen ist. Seine Produkte umfassen Ausführungsroboter, die menschliche Gliedmaßenbewegungen simulieren, sowie Wahrnehmungs- und Entscheidungssysteme. Es ist zum weltweit größten Anbieter von KI-gestützten humanoiden Haushaltsrobotern mit einem Marktanteil von 11,9 % geworden und erzielte 2024 einen bereinigten Nettogewinn von 1,11 Millionen RMB (Quelle: 量子位)

Tencent startet „Qingyun-Plan“ 2026 und öffnet erstmals Themenressourcenbank: Tencent hat den Start des „Qingyun-Plans“ 2026 angekündigt, der sich an weltweit führende Technologiestudenten richtet und zehn Technologiebereiche wie KI-Großmodelle, Basisinfrastruktur und Hochleistungsrechnen abdeckt und über hundert Technologiethemen anbietet. Anders als in den Vorjahren öffnet dieser Plan erstmals die Qingyun-Themenressourcenbank und bietet herausragenden Talenten einen beschleunigten Einstellungsprozess, um die Zusammenarbeit zwischen Hochschule und Unternehmen zu vertiefen und junge Technologietalente zu fördern. Tencent wird branchenführende Dozenten, Rechenressourcen und wettbewerbsfähige Gehälter bereitstellen (Quelle: 量子位)

Luo Yonghaos digitaler Avatar startet am 15. Juni auf Baidu E-Commerce: Luo Yonghao kündigte an, dass sein KI-gestützter digitaler Avatar am 15. Juni sein Live-Streaming-Debüt auf der Baidu E-Commerce-Plattform geben wird. Dies ist das erste Mal, dass ein Top-Streamer einen KI-gestützten digitalen Avatar für Live-Shopping einsetzt, was auf Baidus Durchbrüche bei Schlüsseltechnologien wie überzeugungsstarken digitalen Menschen zurückzuführen ist. Dieser Schritt wird als Erkundung eines neuen „KI + Top-IP“-E-Commerce-Paradigmas angesehen und soll die Live-Shopping-Branche in Richtung Intelligenz, Effizienz und Kostensenkung vorantreiben. Daten von Baidu E-Commerce zeigen, dass bereits über 100.000 digitale Streamer in verschiedenen Branchen eingesetzt werden, was die Betriebskosten der Händler erheblich senkt und das GMV steigert (Quelle: 量子位)
🌟 Community
Chinesische KI-Unternehmen transportieren große Mengen an Datenfestplatten nach Malaysia für Modelltraining: NIK berichtet, dass chinesische KI-Unternehmen, um Chip-Beschränkungen zu umgehen und ausländische Rechenressourcen zu nutzen, Strategien verfolgen, bei denen mit Trainingsdaten gefüllte Festplatten „persönlich“ nach Malaysia und in andere Länder gebracht werden. Beispielsweise flog ein Ingenieur mit 15 Festplatten, die 80 TB Daten enthielten, nach Malaysia, um Server für das Modelltraining zu mieten. Dieses Phänomen spiegelt den intensiven globalen Wettbewerb um KI-Rechenleistung und die realen Herausforderungen des grenzüberschreitenden Datenverkehrs wider und wirft gleichzeitig Diskussionen über Datensicherheit und Compliance auf (Quelle: jpt401, agihippo, cloneofsimo, fabianstelzer)

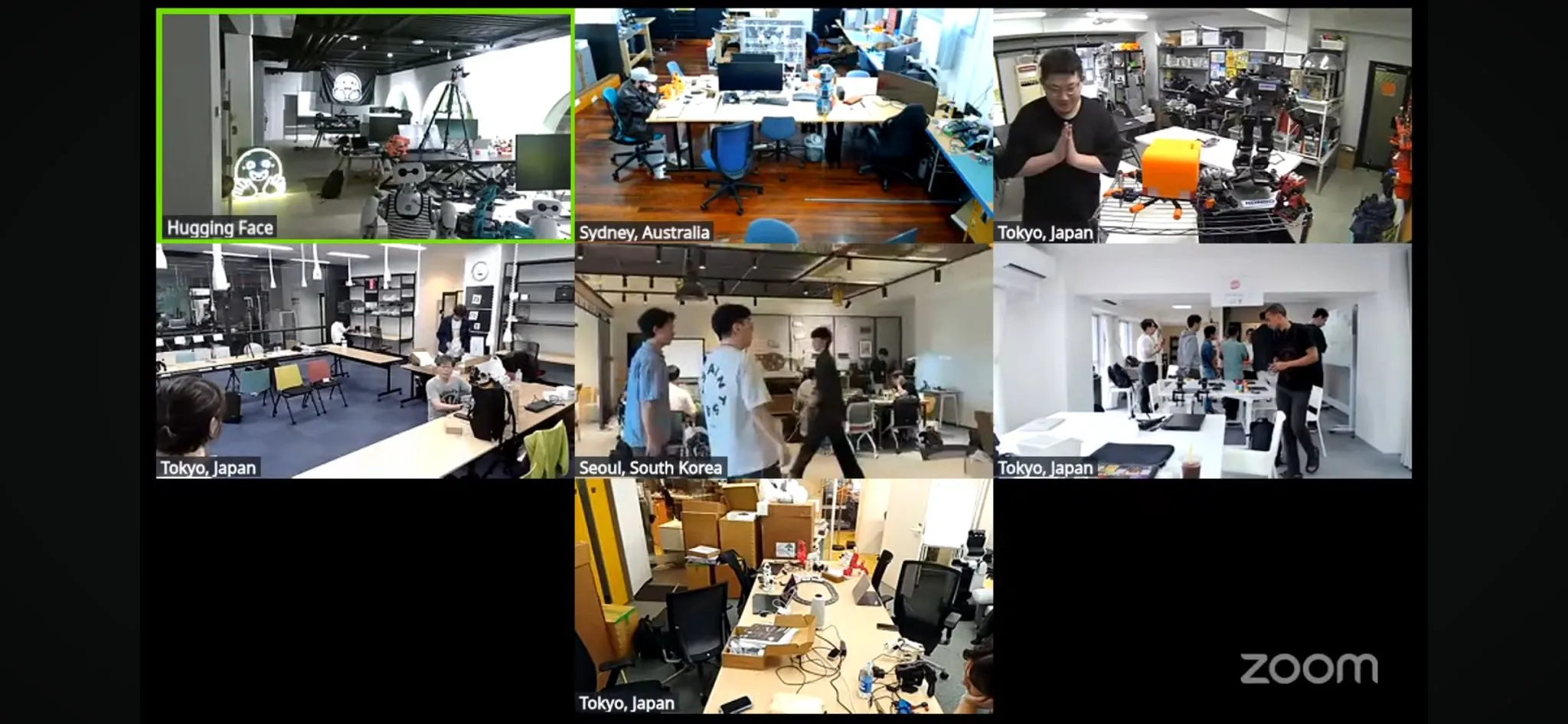
Weltweit größter LeRobot Roboter-Hackathon gestartet: Der von Hugging Face organisierte globale LeRobot Roboter-Hackathon ist offiziell gestartet und findet an über 100 Standorten auf 5 Kontinenten statt, mit über 2300 Teilnehmern. Die Veranstaltung zielt darauf ab, die Entwicklung von Open-Source-KI-Robotern voranzutreiben. Die Teilnehmer werden innerhalb von 52 Stunden roboterbezogene Projekte bauen und erforschen. Entwickler und Teams aus aller Welt nehmen begeistert teil und teilen Fotos von den Veranstaltungsorten und Projektfortschritte, was die Begeisterung und Kreativität der Community für Robotik zeigt (Quelle: _akhaliq, eliebakouch, ClementDelangue)
Lovable veranstaltet KI-Webseitengenerierungs-Duell, Claude erhält Lob für Leistung: Lovable veranstaltete ein Event, bei dem Nutzer kostenlos die Top-Modelle von OpenAI, Anthropic und Google für einen KI-Webseitengenerierungs-Wettbewerb nutzen konnten. Der Nutzer op7418 teilte seine Erfahrungen bei der Generierung von Webseiten mit denselben Prompts durch die Modelle der drei Anbieter und befand, dass Claude in Bezug auf Inhaltsmenge und visuelle Effekte herausragte. Solche Veranstaltungen bieten Entwicklern und Nutzern die Möglichkeit, die Leistung verschiedener großer Modelle in spezifischen Anwendungsszenarien zu vergleichen (Quelle: _philschmid, op7418)
Diskussion über die Reasoning-Fähigkeiten von KI-Modellen: Token-Beschränkungen vs. echte Logik: Als Reaktion auf das von Apple vorgeschlagene Paper „Illusion of Thinking“ gab es in der Community Gegenargumente. Kommentare und nachfolgende Studien (wie arXiv:2506.09250, das Claude Opus als Autor nennt) argumentieren, dass der beobachtete „Zusammenbruch“ der Reasoning-Fähigkeiten von Modellen eher auf Token-Beschränkungen als auf einen Mangel an logischen Fähigkeiten des Modells selbst zurückzuführen ist. Wenn den Modellen erlaubt wird, komprimiertere Antwortformate zu verwenden oder genügend Kontext zur Verfügung steht, können sie Probleme erfolgreich lösen. Dies löste eine eingehende Diskussion darüber aus, wie die wahren Reasoning-Fähigkeiten von Large Language Models genau bewertet und verstanden werden können, sowie über mögliche Einschränkungen aktueller Bewertungsmethoden (Quelle: NandoDF, BlancheMinerva, teortaxesTex, rao2z)
DSPy-Framework unterstützt Optimierung komplexer mehrstufiger Sprachmodellprogramme: Omar Khattab betont, dass das DSPy-Framework seit 2022/2023 die Prompt-Optimierung und das Reinforcement Learning für komplexe, mehrstufige Sprachmodellprogramme (Compound AI Systems) unterstützt. Er argumentiert, dass es angesichts der zunehmenden Komplexität von KI-Systemen angemessener ist, sie als „Programme“ und nicht als einfache „Modelle“ zu betrachten. DSPy zielt darauf ab, die Erstellung und Optimierung solcher Programme beliebiger Komplexität (einschließlich Rekursion, Fehlerbehandlung usw.) zu unterstützen, und nicht nur lineare „Flows“ oder „Chains“ (Quelle: lateinteraction)
Diskussion darüber, ob LLMs dem menschlichen Denken ähneln: Geoffrey Hinton ist der Ansicht, dass Large Language Models (LLM) der Art und Weise ähneln, wie Menschen Sprache verarbeiten, und unser bestes Modell zum Verständnis der Funktionsweise von Sprache sind. Pedro Domingos stellt dies jedoch in Frage und argumentiert, dass die Überlegenheit von LLMs gegenüber alten linguistischen Theorien nicht bedeutet, dass sie wie Menschen denken. Diese Diskussion spiegelt die anhaltende Debatte im KI-Bereich über die Natur von LLMs und ihre Beziehung zur menschlichen Kognition wider (Quelle: pmddomingos)
Enormes Potenzial für KI-Anwendungen in der physikalischen Forschung: Ein Forscher aus dem Bereich der Geowissenschaften teilte positive Erfahrungen mit der Nutzung von o3 Pro (wahrscheinlich ein fortschrittliches Modell von OpenAI) und bezeichnete es in seiner Forschung als einen „sehr klugen Postdoktoranden“. Das Modell zeigte hervorragende Leistungen beim Codieren, der Modellentwicklung und der Verfeinerung von Ideen, konnte Anweisungen schnell und präzise ausführen und die Forschung unterstützen. Der Forscher ist der Ansicht, dass aktuelle Modelle zwar noch nicht in der Lage sind, aktiv Forschungsfragen zu formulieren (ein Merkmal von AGI), ihre leistungsstarken unterstützenden Funktionen jedoch die Forschungseffizienz bereits erheblich gesteigert haben und erahnt, dass autonome LLMs nicht mehr fern sind (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
KI-generierte Comic-Tools erleichtern kreativen Ausdruck: Der Nutzer StriderWriting teilte seine Erfahrungen mit der Erstellung von Comics mit KI-Tools und meinte, KI mache es möglich, „dumme Ideen“ in Comics umzusetzen. Dies spiegelt die zunehmende Verbreitung von KI im Bereich der kreativen Content-Generierung wider, die die Einstiegshürden senkt und es mehr Menschen ermöglicht, ihre Kreativität einfach auszudrücken (Quelle: Reddit r/ChatGPT)

Sorge um KI-Bias: Verhalten von ChatGPT bei Geschlechterstereotypen verärgert Nutzerin: Eine Nutzerin berichtete, dass ChatGPT in Gesprächen negative Stereotypen über Männer zeigte. Beispielsweise nahm es bei Diskussionen über Arbeit und medizinische Probleme ohne Aufforderung an, dass negative Rollen von Männern besetzt seien, und verwendete Äußerungen wie „Männer sind einfach nervig“. Die Nutzerin wies darauf hin, dass solche auf Geschlecht basierenden, faulen Stereotypen unangenehm seien und fragte, ob OpenAI Regeln habe, um solches Verhalten einzuschränken. Dies löste erneut Diskussionen über Bias in den Trainingsdaten von KI-Modellen und dessen Manifestation in Interaktionen aus (Quelle: Reddit r/ChatGPT)
Potenzial und aktuelle Grenzen der Objektivität von KI in der Nachrichtenberichterstattung: Ein Nutzer testete das Potenzial des o3-Modells von OpenAI als „unvoreingenommener Nachrichtenreporter“, indem er es aufforderte, die potenziell „kontraproduktiven“ Folgen verschiedener politischer Maßnahmen der Trump- und Biden-Regierungen seit 2017 zu kommentieren. Obwohl die KI scheinbar objektive Analysen generieren konnte, bleiben ihre Informationsquellen, potenzielle Voreingenommenheit und das wahre Verständnis komplexer politisch-ökonomischer Dynamiken Probleme, die in Zukunft gelöst werden müssen. Dies spiegelt die Erwartungen der Community wider, KI zur Verbesserung der Objektivität und Tiefe von Nachrichten einzusetzen, sowie das Bewusstsein für die Grenzen der aktuellen Technologie (Quelle: Reddit r/deeplearning)