
Palavras-chave:IA, Nvidia, Deutsche Telekom, Nuvem de IA Industrial, IA soberana, Anthropic, Sistema multiagente, Projeto de Lei RAISE, Nuvem Europeia de IA Industrial, Contêiner de disco voador para evitar bloqueio de chips, Pesquisa Claude em sistemas multiagentes, Projeto de Lei RAISE do Estado de Nova York, Debate entre Jensen Huang e CEO da Anthropic
🔥 Foco
Nvidia e Deutsche Telekom colaboram para construir nuvem de IA industrial europeia: O Chanceler Federal Alemão reuniu-se com o CEO da Nvidia, Jensen Huang, para discutir o aprofundamento da cooperação estratégica, com o objetivo de fortalecer a posição da Alemanha como líder global em IA. Os tópicos centrais incluíram a construção de infraestrutura de IA soberana e a aceleração do desenvolvimento do ecossistema de IA. Para isso, a Deutsche Telekom e a Nvidia anunciaram uma parceria, planeando construir até 2026 a primeira nuvem de IA industrial do mundo para fabricantes europeus. Esta plataforma garantirá a soberania dos dados e promoverá a inovação em IA no setor industrial europeu. (Fonte: nvidia)

Empresas de IA chinesas usam “caixas de discos rígidos voadoras” para contornar bloqueio de chips dos EUA: Para contornar as restrições dos EUA à exportação de chips de IA para a China, empresas chinesas adotam nova estratégia: levar discos rígidos com dados de treino de IA diretamente para data centers no exterior (como a Malásia), utilizar servidores locais equipados com chips avançados como os da Nvidia para treinar modelos, e depois trazer os resultados de volta. Esta medida destaca a complexidade da cadeia global da indústria de IA e a capacidade de adaptação das empresas chinesas sob restrições, ao mesmo tempo que impulsiona o Sudeste Asiático e o Médio Oriente a tornarem-se novos hotspots para data centers de IA. (Fonte: dotey)

Anthropic publica método de construção de sistema de pesquisa multiagente: O blog de engenharia da Anthropic detalhou como utiliza múltiplos agentes a trabalhar em paralelo para construir as capacidades de pesquisa do Claude. O artigo partilha as experiências de sucesso, os desafios encontrados e as soluções de engenharia durante o processo de desenvolvimento. Este modelo de trabalho colaborativo multiagente visa melhorar a análise profunda e a capacidade de processamento de informação de modelos de linguagem grandes (LLMs) em tarefas de pesquisa complexas, fornecendo uma referência prática para a construção de assistentes de pesquisa de IA mais poderosos. (Fonte: AnthropicAI)
Estado de Nova Iorque aprova lei RAISE, reforçando requisitos de transparência para modelos de IA de fronteira: O Estado de Nova Iorque aprovou a RAISE Act, que visa estabelecer requisitos de transparência para modelos de IA de fronteira. Empresas como a Anthropic forneceram feedback sobre a lei; embora haja melhorias, persistem preocupações, como definições cruciais ambíguas, oportunidades de correção de conformidade pouco claras, uma definição excessivamente ampla de “incidente de segurança” com um curto prazo para denúncia (72 horas), e a possibilidade de multas de milhões de dólares por pequenas infrações técnicas, o que representa um risco para pequenas empresas. A Anthropic apela ao estabelecimento de padrões federais unificados de transparência e sugere que as propostas estaduais se concentrem na transparência e evitem regulamentação excessiva. (Fonte: jackclarkSF)
CEO da Nvidia, Jensen Huang, refuta as opiniões do CEO da Anthropic sobre o desenvolvimento da IA: Jensen Huang, CEO da Nvidia, refutou as opiniões de Dario Amodei, CEO da Anthropic, numa conferência de imprensa na Viva Technology em Paris. Amodei foi acusado de considerar a IA demasiado perigosa, devendo ser desenvolvida apenas por empresas específicas; demasiado cara, não devendo ser popularizada; e demasiado poderosa, levando ao desemprego. Huang enfatizou que a IA deve ser desenvolvida de forma segura, responsável e aberta, e não “às escuras” com alegações de segurança. Estas declarações desencadearam um debate sobre os caminhos de desenvolvimento da IA (aberto e democrático vs. elitista e fechado), destacando as diferenças de filosofia entre os gigantes da indústria. (Fonte: pmddomingos, dotey)

🎯 Tendências
Meta poderá gastar 14 mil milhões de dólares para adquirir participação maioritária na Scale AI para fortalecer capacidade em IA: Segundo relatos, a Meta planeia adquirir 49% das ações da empresa de anotação de dados de IA Scale AI por 14,8 mil milhões de dólares, e poderá nomear o seu CEO para liderar o recém-criado “Superintelligence Group” da Meta. Esta medida visa enfrentar os desafios do desempenho abaixo do esperado do modelo Llama 4 e da perda de talentos internos em IA, acelerando a sua recuperação no campo da inteligência artificial geral através da introdução de talentos e tecnologias de ponta externos. (Fonte: Reddit r/ArtificialInteligence, 量子位)

OpenAI lança modelo o3-pro, grande redução de preço do o3 levanta discussão sobre desempenho: A OpenAI lançou oficialmente o seu “mais recente e mais forte” modelo de inferência, o o3-pro, projetado para utilizadores Pro e Team, com preços de API de 20 dólares/milhão de tokens para entrada e 80 dólares/milhão de tokens para saída. Simultaneamente, o preço da API do modelo o3 original foi drasticamente reduzido em 80%, ficando quase ao mesmo nível do GPT-4o. A empresa afirma que o o3-pro tem um desempenho excelente em matemática, ciências e programação, mas com um tempo de resposta mais longo. A questão de saber se o o3 ficou “menos inteligente” após a redução de preço gerou debate na comunidade, com alguns utilizadores a relatarem uma queda no desempenho, embora faltem dados empíricos unificados. (Fonte: 量子位)

Cohere Labs investiga o impacto de tokenizers universais na adaptabilidade de modelos de linguagem: O Cohere Labs publicou uma nova investigação que explora se os tokenizers treinados com mais idiomas do que o idioma alvo do pré-treino (universal tokenizer) conseguem melhorar a adaptabilidade do modelo a novos idiomas (plasticity) sem prejudicar o desempenho do pré-treino. O estudo descobriu que os tokenizers universais aumentam a eficiência na adaptação linguística em 8 vezes e o desempenho em 2 vezes, e mesmo em situações com dados extremamente escassos e idiomas completamente desconhecidos, a taxa de sucesso é 5% superior à dos tokenizers dedicados. Isto indica que os tokenizers universais podem efetivamente aumentar a flexibilidade e eficiência dos modelos no processamento de tarefas multilingues. (Fonte: sarahookr)

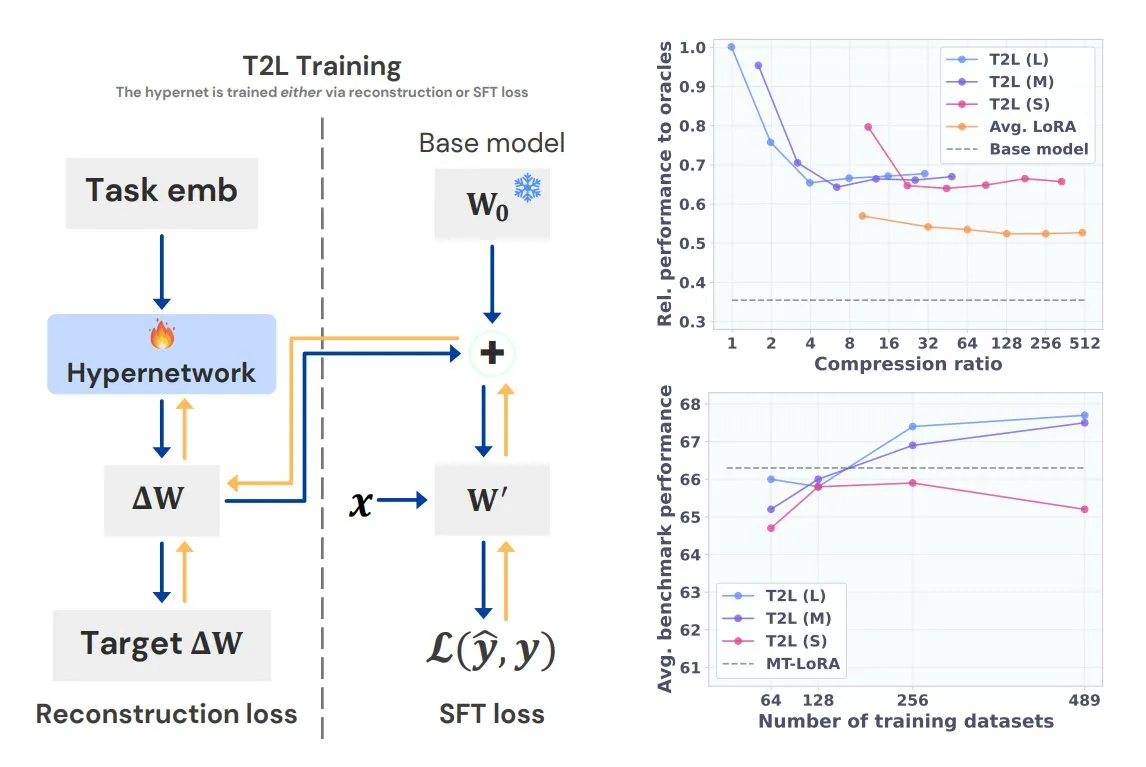
Sakana AI lança Text-to-LoRA (T2L), gerando LoRA específico para tarefas com uma única frase: A Sakana AI, cofundada por Llion Jones, um dos autores do Transformer, lançou a tecnologia Text-to-LoRA (T2L). Esta arquitetura de hiper-rede consegue gerar rapidamente adaptadores LoRA específicos com base na descrição textual da tarefa, simplificando enormemente o processo de fine-tuning de LLMs. O T2L pode comprimir LoRAs existentes e gerar adaptadores eficientes em cenários zero-shot, oferecendo um novo caminho para a rápida adaptação de modelos a tarefas de cauda longa. (Fonte: TheTuringPost, 量子位)
Tsinghua e Tencent lançam em conjunto o Scene Splatter, permitindo a geração de cenas 3D de alta fidelidade: A Universidade de Tsinghua e a Tencent colaboraram para apresentar a tecnologia Scene Splatter, que, a partir de uma única imagem, utiliza modelos de difusão de vídeo e um mecanismo inovador de orientação por momentum para gerar clipes de vídeo que satisfazem a consistência tridimensional, construindo assim cenas 3D complexas. Este método supera a dependência tradicional de múltiplas vistas, melhora a fidelidade e consistência das cenas geradas, e oferece novas ideias para elos cruciais em modelos de mundo e inteligência incorporada. (Fonte: 量子位)

Tencent Hunyuan 3D 2.1 lançado: primeiro modelo de geração 3D PBR de nível de produção open-source: A Tencent lançou o Hunyuan 3D 2.1, anunciado como o primeiro modelo de geração 3D baseado em renderização física (PBR) totalmente open-source e pronto para produção. O modelo é capaz de gerar efeitos visuais de qualidade cinematográfica, suporta a síntese de materiais PBR como couro e bronze, e apresenta efeitos de interação de luz e sombra realistas. Os pesos do modelo, código de treino/inferência, pipeline de dados e arquitetura foram todos disponibilizados em open-source, podendo ser executados em GPUs de consumo, capacitando criadores, programadores e pequenas equipas para fine-tuning e criação de conteúdo 3D. (Fonte: cognitivecompai, huggingface)
Mistral lança o seu primeiro modelo de inferência, Magistral Small: A Mistral AI lançou o seu primeiro modelo de inferência, Magistral Small, que se foca em capacidades de inferência específicas de domínio, transparentes e multilingues. Os utilizadores já podem experimentá-lo através de plataformas como Hugging Face e FeatherlessAI. Isto marca um passo importante da Mistral na construção de ferramentas de inferência de IA mais especializadas e fáceis de entender. (Fonte: dl_weekly, huggingface)
ByteDance acusada de conflito de nomeação do seu modelo Dolphin com cognitivecomputations/dolphin: O modelo Dolphin lançado pela ByteDance foi apontado por ter o mesmo nome de um modelo já existente, cognitivecomputations/dolphin. A Cognitive Computations afirmou ter comentado sobre este problema há 24 dias, quando a ByteDance lançou o modelo pela primeira vez, mas não obteve atenção. Este incidente gerou discussões na comunidade sobre as normas de nomeação de modelos e a necessidade de evitar confusões. (Fonte: cognitivecompai)
API MLX Swift LLM simplificada, três linhas de código para iniciar uma sessão de chat: Em resposta ao feedback dos programadores sobre a dificuldade de utilização da API MLX Swift LLM, a equipa realizou melhorias e lançou uma nova API simplificada. Agora, os programadores precisam de apenas três linhas de código para carregar um LLM ou VLM num projeto Swift e iniciar uma sessão de chat, reduzindo significativamente a barreira à utilização e integração de modelos de linguagem grandes no ecossistema Apple. (Fonte: ImazAngel)

Versões Qwen3-72B-Embiggened e 58B quantizadas para o formato llama.cpp gguf: Eric Hartford anunciou que quantizou os modelos Qwen3-72B-Embiggened e Qwen3-58B-Embiggened para o formato llama.cpp gguf, permitindo que os utilizadores executem estes modelos grandes em dispositivos locais. Este projeto contou com o apoio de recursos de computação AMD mi300x. (Fonte: ClementDelangue, cognitivecompai)
Black Forest Labs da Alemanha lança série de modelos text-to-image FLUX.1, focada na consistência de personagens: A Black Forest Labs da Alemanha lançou três modelos text-to-image: FLUX.1 Kontext max, pro e dev. Estes modelos focam-se em manter a consistência dos personagens ao mudar o fundo, pose ou estilo. Combinam um codec de imagem convolucional com um Transformer treinado através de destilação por difusão adversária, suportando edição eficiente e detalhada. As versões max e pro já estão disponíveis através do FLUX Playground e plataformas parceiras. (Fonte: DeepLearningAI)

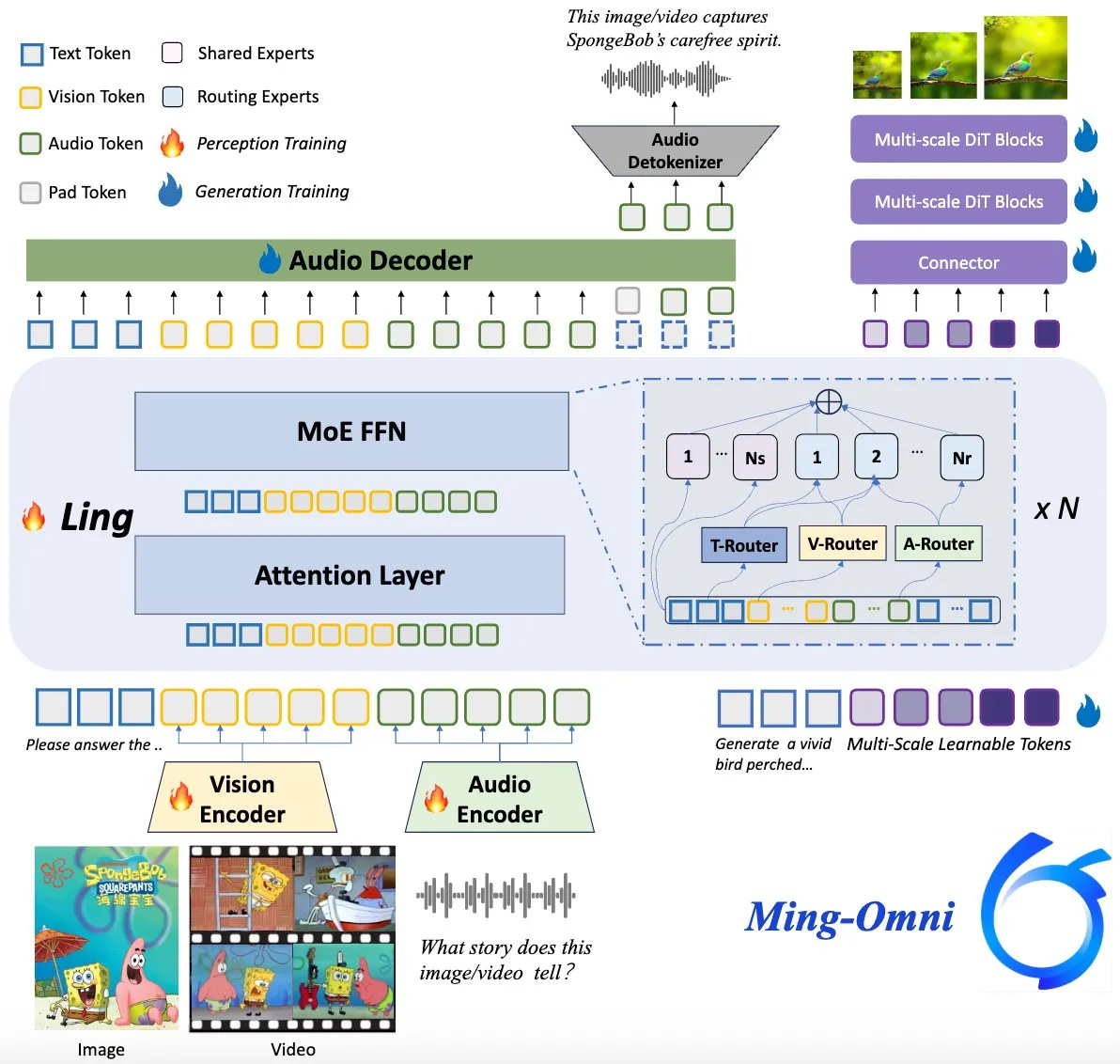
Modelo Ming-Omni open-source, comparável ao GPT-4o: Um modelo multimodal open-source chamado Ming-Omni foi lançado no Hugging Face, com o objetivo de fornecer capacidades unificadas de perceção e geração comparáveis ao GPT-4o. O modelo suporta texto, imagem, áudio e vídeo como entrada, consegue gerar voz e imagens de alta resolução, utiliza uma arquitetura MoE e routers específicos de modalidade, possui funcionalidades como chat com reconhecimento de contexto, TTS, edição de imagem, etc., com apenas 2.8B de parâmetros ativos, e disponibiliza pesos e código totalmente abertos. (Fonte: huggingface)
Investigação em IA revela que LLMs multimodais podem desenvolver representações conceptuais interpretáveis semelhantes às humanas: Investigadores chineses descobriram que os modelos de linguagem grandes (LLMs) multimodais são capazes de desenvolver formas de representação de conceitos de objetos interpretáveis e semelhantes às humanas. Este estudo oferece novas perspetivas para compreender os mecanismos internos dos LLMs e como eles entendem e associam informações de diferentes modalidades (como texto e imagem). (Fonte: Reddit r/LocalLLaMA)
DeepMind e Centro Nacional de Furacões dos EUA colaboram na utilização de IA para prever furacões: O Centro Nacional de Furacões dos EUA adotou pela primeira vez tecnologia de IA para prever furacões e outras tempestades severas, em colaboração com a DeepMind. Isto marca um passo importante na aplicação da IA no campo da previsão meteorológica, com potencial para aumentar a precisão e a tempestividade dos alertas de eventos climáticos extremos. (Fonte: MIT Technology Review)
🧰 Ferramentas
LlamaParse lança funcionalidade “Presets” para otimizar a análise de diferentes tipos de documentos: O LlamaParse introduziu a funcionalidade “Presets”, que oferece uma série de esquemas pré-configurados fáceis de entender, otimizando as configurações de análise para diferentes casos de uso. Inclui modos rápido, equilibrado e avançado para cenários gerais, bem como modos otimizados para tipos específicos de documentos como faturas, artigos científicos, documentos técnicos e formulários. Estes presets visam ajudar os utilizadores a obter de forma mais conveniente saídas estruturadas para tipos específicos de documentos, como a tabularização de campos de formulários ou a saída XML de esquemas em documentos técnicos. (Fonte: jerryjliu0, jerryjliu0)
Codegen lança funcionalidade de vídeo para PR, IA auxilia na resolução de bugs de UI: A Codegen anunciou suporte para entrada de vídeo, permitindo que os utilizadores anexem vídeos de problemas no Slack ou Linear. A Codegen utiliza o Gemini para extrair informações do vídeo e corrigir automaticamente bugs relacionados com a UI, gerando um PR. Esta funcionalidade visa aumentar significativamente a eficiência no relato e correção de problemas de UI, especialmente adequada para resolver bugs de interação. (Fonte: mathemagic1an)
LlamaIndex lança “bloco de memória de artefacto” estruturado para agentes de preenchimento de formulários: O LlamaIndex apresentou um novo conceito de memória – o “bloco de memória de artefacto estruturado” (structured artifact memory block), projetado especificamente para agentes como os de preenchimento de formulários. Este bloco de memória rastreia um esquema estruturado Pydantic, que é continuamente atualizado com novas mensagens de chat e sempre injetado na janela de contexto, permitindo que o agente mantenha um conhecimento constante das preferências do utilizador e das informações já preenchidas no formulário, como a recolha de detalhes de tamanho, endereço, etc., num cenário de encomenda de pizza. (Fonte: jerryjliu0)

Davia: Ferramenta de geração de páginas web WYSIWYG construída com FastAPI torna-se open-source: Davia é um projeto open-source construído com FastAPI, que visa fornecer uma interface de geração de páginas web WYSIWYG (What You See Is What You Get), semelhante à funcionalidade de interface de Chat dos principais fabricantes de modelos grandes. Os utilizadores podem instalá-lo através de pip install davia. Suporta personalização de cores Tailwind, layout responsivo e modo escuro, utilizando shadcn/ui como componentes de UI. (Fonte: karminski3)
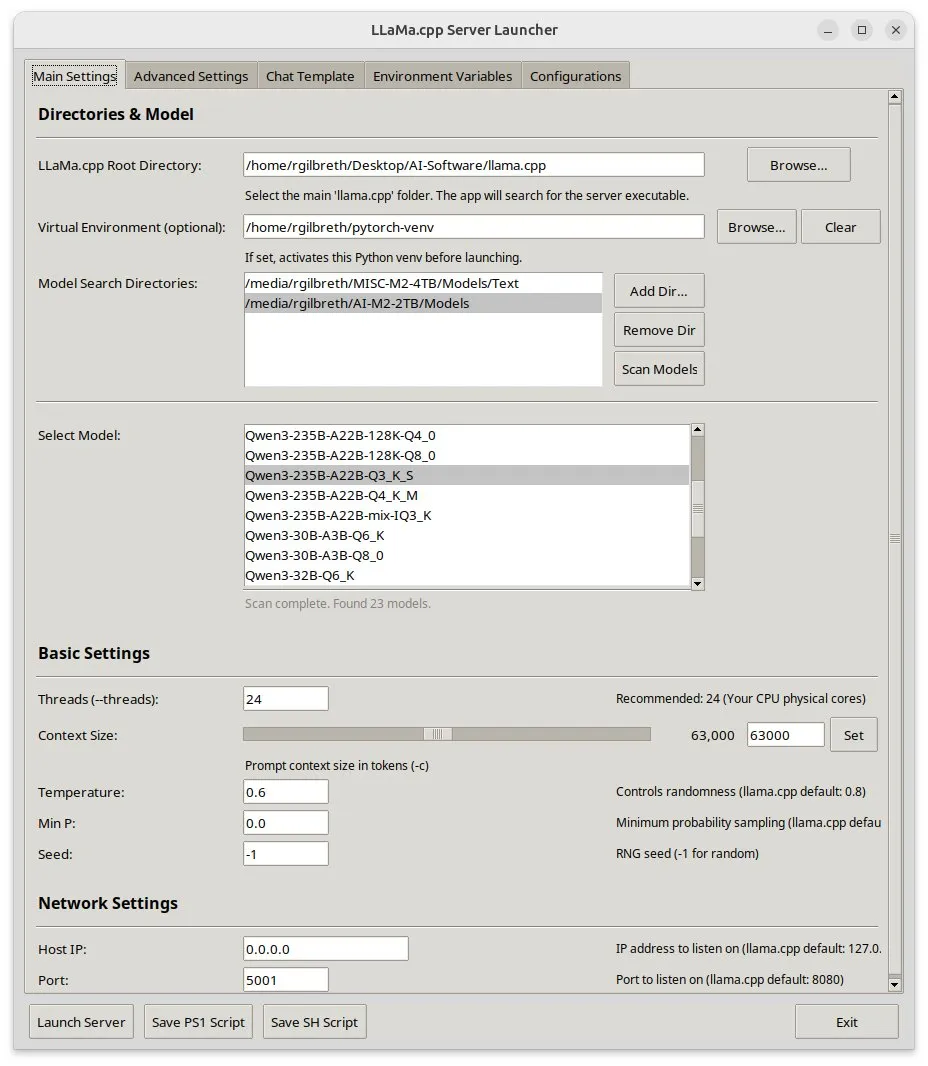
Llama-server-launcher: Interface gráfica para configurações complexas do llama.cpp: Dada a crescente complexidade da configuração do llama.cpp, comparável a servidores web como o Nginx, a comunidade desenvolveu o projeto llama-server-launcher. Esta ferramenta oferece uma interface gráfica que permite aos utilizadores selecionar através de cliques o modelo a executar, número de threads, tamanho do contexto, temperatura, descarregamento para GPU, batch size e outros parâmetros, simplificando o processo de configuração e poupando tempo na consulta de manuais. (Fonte: karminski3)
Boas notícias para utilizadores Mac: MLX Llama 3 + MPS TTS para assistente de voz offline: Um programador partilhou a sua experiência na construção de um assistente de voz offline num Mac Mini M4 utilizando MLX-LM (Llama-3-8B de 4 bits) e Kokoro TTS (executado através de MPS). Esta solução não requer nuvem nem o daemon Ollama, pode ser executada com 16GB de RAM e implementa funcionalidades de chat e TTS offline de ponta a ponta, oferecendo uma nova opção de assistente de voz AI local para utilizadores de chips Mac da série M. (Fonte: Reddit r/LocalLLaMA)
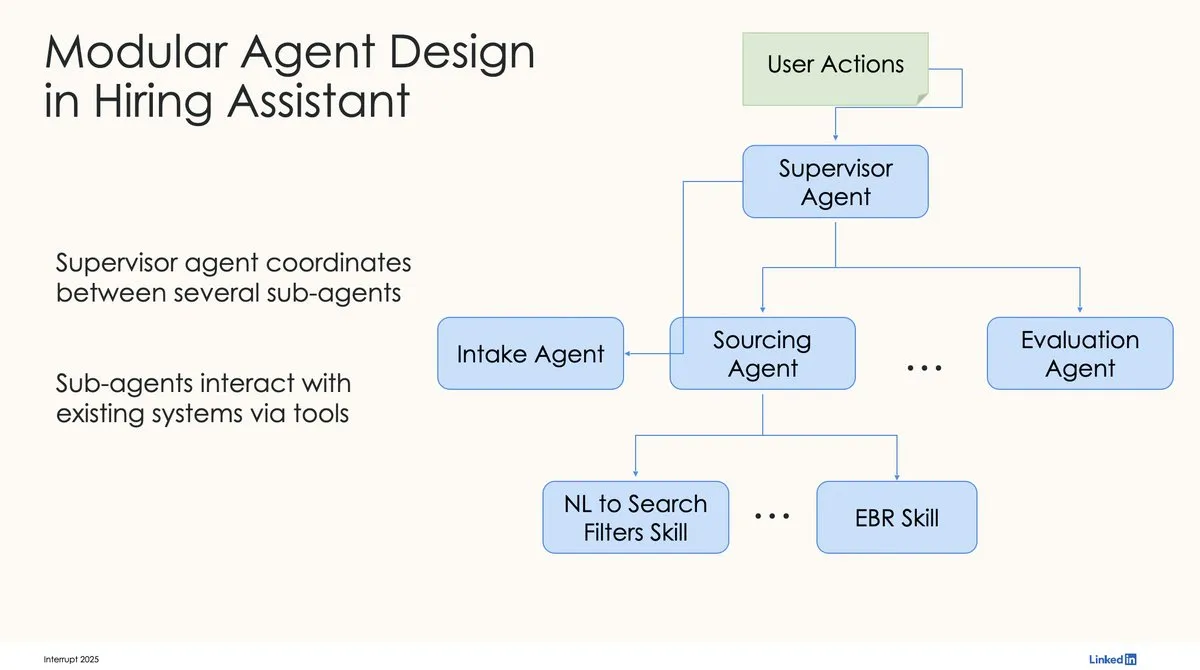
LinkedIn utiliza LangChain e LangGraph para construir o seu primeiro assistente de recrutamento AI de nível de produção: David Tag, do LinkedIn, partilhou a arquitetura técnica de como utilizaram LangChain e LangGraph para construir o seu primeiro assistente de recrutamento AI de nível de produção, o LinkedIn Hiring Assistant. Esta framework foi expandida com sucesso para mais de 20 equipas, demonstrando o potencial do LangChain no desenvolvimento e aplicação em larga escala de agentes AI empresariais. (Fonte: LangChainAI, hwchase17)
📚 Aprendizagem
ZTE propõe novas métricas LCP e ROUGE-LCP e framework SPSR-Graph para avaliar e otimizar a completação de código: A equipa da ZTE propôs duas novas métricas de avaliação para a completação de código por IA: Prefixo Comum Mais Longo (LCP) e ROUGE-LCP, com o objetivo de se aproximarem mais da intenção real de adoção dos programadores. Simultaneamente, projetaram o framework de processamento de corpus de código a nível de repositório SPSR-Graph, que constrói um grafo de conhecimento de código para melhorar a compreensão do modelo sobre a estrutura e semântica de todo o repositório de código. Experiências mostram que as novas métricas têm maior correlação com as taxas de adoção dos utilizadores, e o SPSR-Graph pode melhorar significativamente o desempenho de modelos como o Qwen2.5-7B-Coder em tarefas de completação de código C/C++ no domínio das comunicações. (Fonte: 量子位)

Novo trabalho de Kaiming He: Dispersive Loss introduz regularização em modelos de difusão, melhorando a qualidade da geração: Kaiming He e colaboradores propuseram a Dispersive Loss, um método de regularização plug-and-play que visa melhorar a qualidade e o realismo das imagens geradas, incentivando as representações intermédias dos modelos de difusão a dispersarem-se no espaço latente. Este método não requer pares positivos, tem baixo custo computacional, pode ser aplicado diretamente a modelos de difusão existentes e é compatível com a perda original. Experiências no ImageNet mostram que a Dispersive Loss pode melhorar significativamente os efeitos de geração de modelos como DiT e SiT. (Fonte: 量子位)

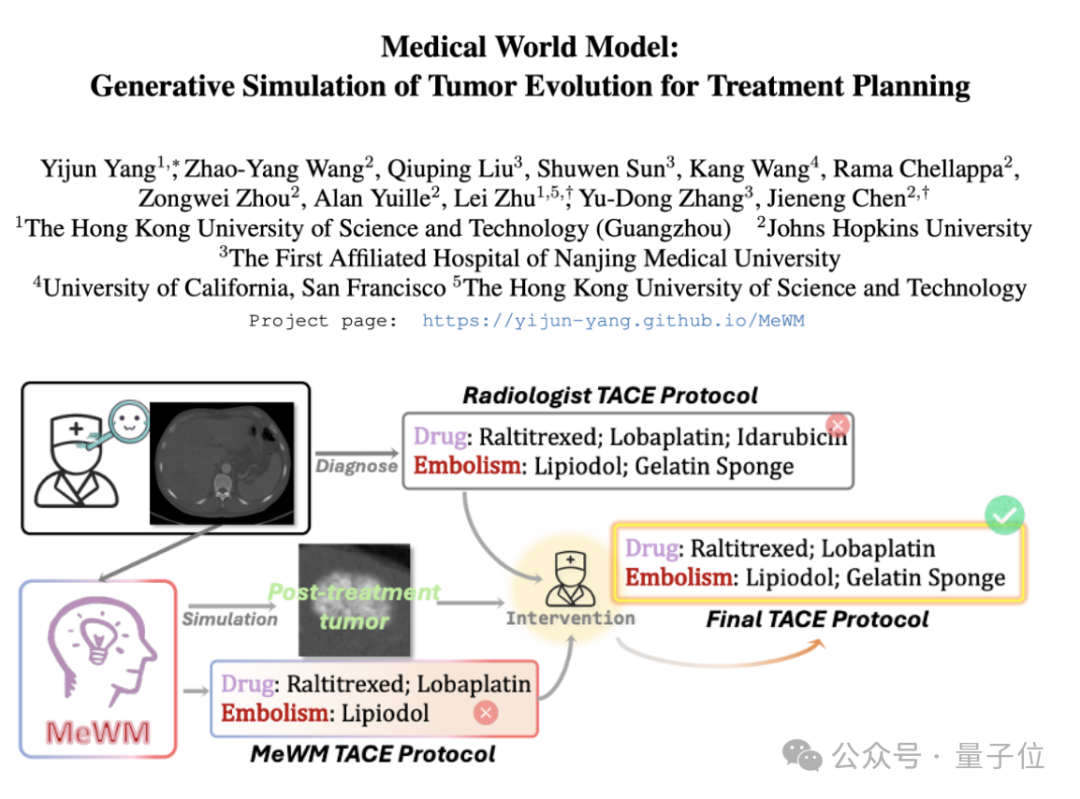
Modelo de Mundo Médico (MeWM) proposto para simular a evolução de tumores e auxiliar na decisão terapêutica: Académicos da Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou) e outras instituições propuseram o Modelo de Mundo Médico (MeWM), capaz de simular o processo futuro de evolução de tumores com base em decisões clínicas de tratamento. O MeWM integra um simulador de evolução de tumores (modelo de difusão 3D), um modelo de previsão de risco de sobrevivência, e constrói um processo de otimização em ciclo fechado de “geração de plano – simulação – avaliação de sobrevivência”, fornecendo suporte de decisão auxiliar personalizado e visualizado para o planeamento de tratamento de intervenção contra o cancro. (Fonte: 量子位)
Artigo explora a decomposição de ativações MLP em características interpretáveis através da Decomposição em Matriz Semi-Não-Negativa (SNMF): Um novo artigo propõe o uso da Decomposição em Matriz Semi-Não-Negativa (SNMF) para decompor diretamente os valores de ativação de perceptrões multicamada (MLP), a fim de identificar características interpretáveis. Este método visa aprender características esparsas, constituídas por combinações lineares de neurónios coativados, e mapeá-las para a entrada de ativação, aumentando assim a interpretabilidade das características. Experiências demonstram que as características derivadas da SNMF superam os autoencoders esparsos (SAE) na orientação causal e são consistentes com conceitos humanamente interpretáveis, revelando uma estrutura hierárquica no espaço de ativação dos MLPs. (Fonte: HuggingFace Daily Papers)
Comentário a artigo sobre investigação da Apple acerca da “ilusão do pensamento”: aponta limitações no design experimental: Um artigo de comentário questiona a investigação de Shojaee et al. sobre o “colapso da precisão” de modelos de raciocínio grandes (LRMs) em problemas de planeamento complexos (intitulado “A Ilusão do Pensamento: Compreendendo as Forças e Limitações dos Modelos de Raciocínio através da Lente da Complexidade do Problema”). O comentário argumenta que as descobertas do estudo original refletem principalmente as limitações do design experimental, e não falhas fundamentais de raciocínio dos LRMs. Por exemplo, a experiência da Torre de Hanói excedeu o limite de tokens de saída do modelo, e o benchmark de travessia de rio incluiu instâncias matematicamente impossíveis de resolver. Após corrigir estas falhas experimentais, os modelos demonstraram alta precisão em tarefas anteriormente reportadas como falhas completas. (Fonte: HuggingFace Daily Papers)
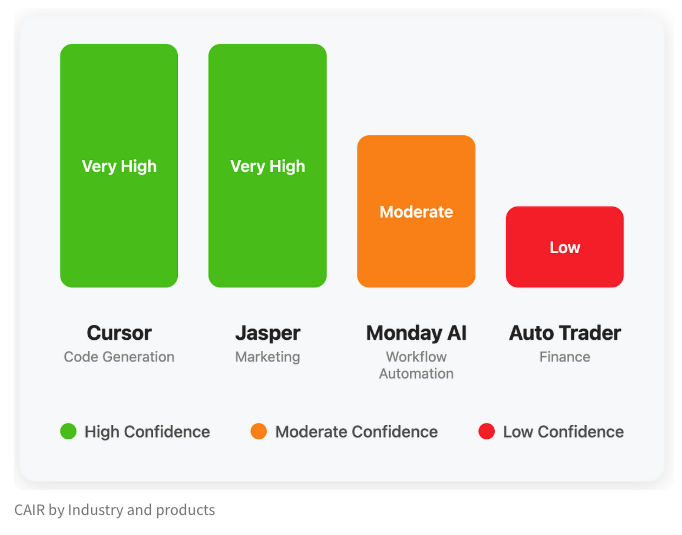
LangChain publica blog a explorar o indicador oculto de sucesso de produtos de IA “CAIR”: Harrison Chase, cofundador da LangChain, juntamente com o seu amigo Assaf Elovic, escreveu um blog a explorar por que alguns produtos de IA se popularizam rapidamente enquanto outros enfrentam dificuldades. Eles argumentam que a chave está no “CAIR” (Confidence in AI Results, Confiança nos Resultados da IA). O artigo aponta que aumentar o CAIR é crucial para promover a adoção de produtos de IA e analisa os vários fatores que influenciam o CAIR e estratégias para o aumentar, enfatizando que, além da capacidade do modelo, um excelente design de experiência do utilizador (UX) é igualmente importante. (Fonte: Hacubu, BrivaelLp)
Investigação da Microsoft: Construção de agentes de pesquisa profunda para grandes bases de código de sistemas: A Microsoft publicou um artigo que apresenta um agente de pesquisa profunda construído para grandes bases de código de sistemas. Este agente utiliza várias técnicas para lidar com bases de código de escala ultra grande, com o objetivo de melhorar a compreensão e a capacidade de análise de sistemas de software complexos. (Fonte: dair_ai, omarsar0)

NoLoCo: Método de otimização de baixa comunicação e sem redução global para treino de modelos em larga escala: A Gensyn tornou open-source o NoLoCo, um método de otimização inovador para treinar modelos grandes em redes gossip heterogéneas (em vez de data centers de alta largura de banda). O NoLoCo, através da modificação do momentum e do roteamento dinâmico de fragmentos, evita a sincronização global explícita de parâmetros, reduzindo a latência de sincronização em 10 vezes e, ao mesmo tempo, aumentando a velocidade de convergência em 4%, oferecendo uma nova solução eficiente para o treino distribuído de modelos grandes. (Fonte: Ar_Douillard, HuggingFace Daily Papers)

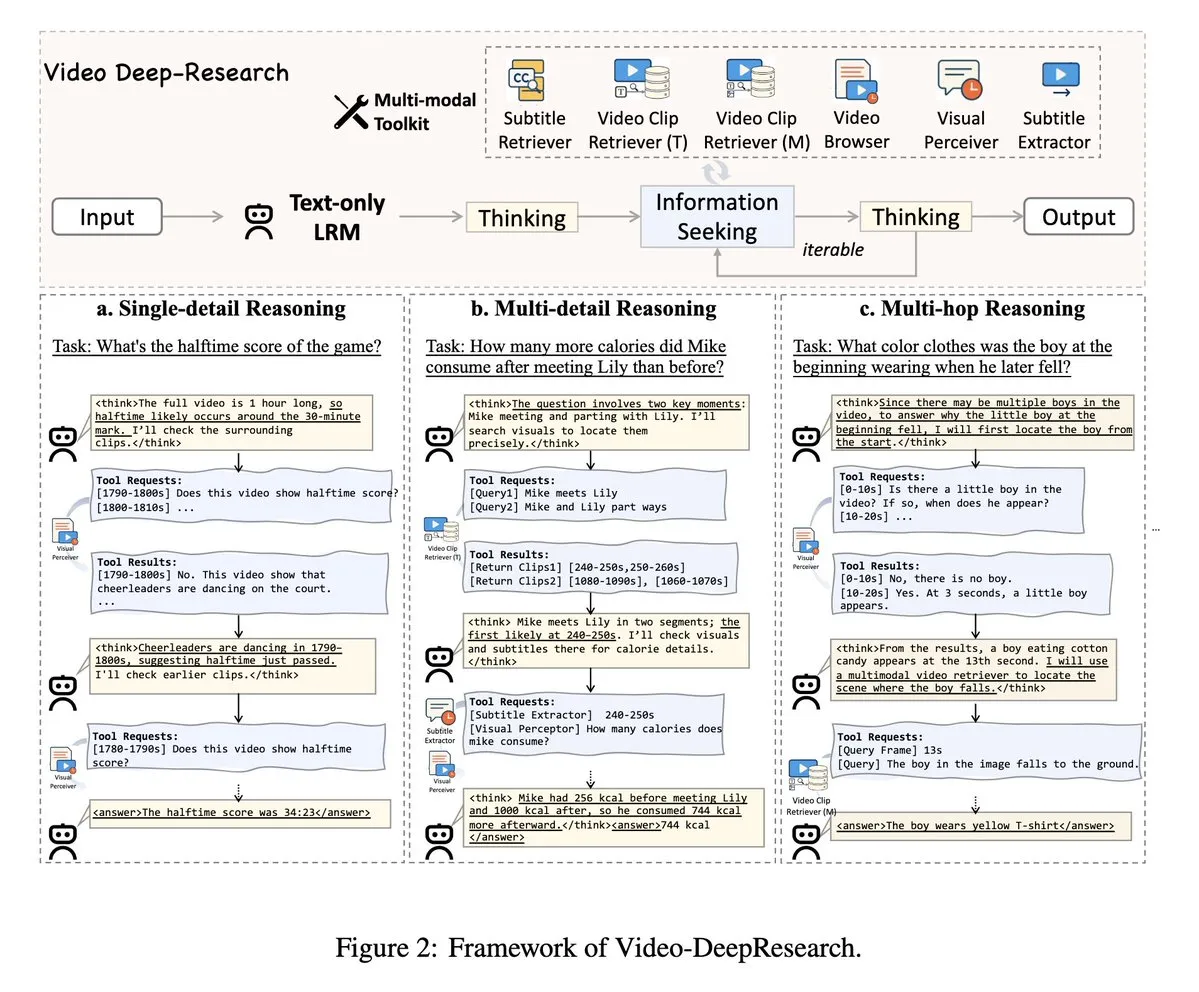
VideoDeepResearch: Utilização de ferramentas de agente para compreensão de vídeos longos: Um artigo intitulado VideoDeepResearch propõe uma framework de agente modular para a compreensão de vídeos longos. Esta framework combina modelos de inferência puramente textuais (como o DeepSeek-R1-0528) com ferramentas especializadas como recuperadores, perceptores e extratores, com o objetivo de superar o desempenho de modelos multimodais grandes em tarefas de compreensão de vídeos longos. (Fonte: teortaxesTex, sbmaruf)
LaTtE-Flow: Combinação de especialistas em passos de tempo hierárquicos e Transformer de fluxo para unificar compreensão e geração de imagens: LaTtE-Flow é uma arquitetura nova e eficiente que visa unificar a compreensão e geração de imagens num único modelo multimodal. Baseia-se em poderosos modelos de linguagem visual (VLM) pré-treinados e expande-os com uma nova arquitetura de fluxo de Especialistas em Passos de Tempo Hierárquicos (Layerwise Timestep Experts) para alcançar uma geração eficiente de imagens. Este design distribui o processo de correspondência de fluxo por grupos especializados de camadas Transformer, cada grupo responsável por diferentes subconjuntos de passos de tempo, aumentando significativamente a eficiência da amostragem. Experiências demonstram que o LaTtE-Flow tem um forte desempenho em tarefas de compreensão multimodal, ao mesmo tempo que a qualidade da geração de imagens é competitiva, com uma velocidade de inferência aproximadamente 6 vezes mais rápida do que os recentes modelos multimodais unificados. (Fonte: HuggingFace Daily Papers)
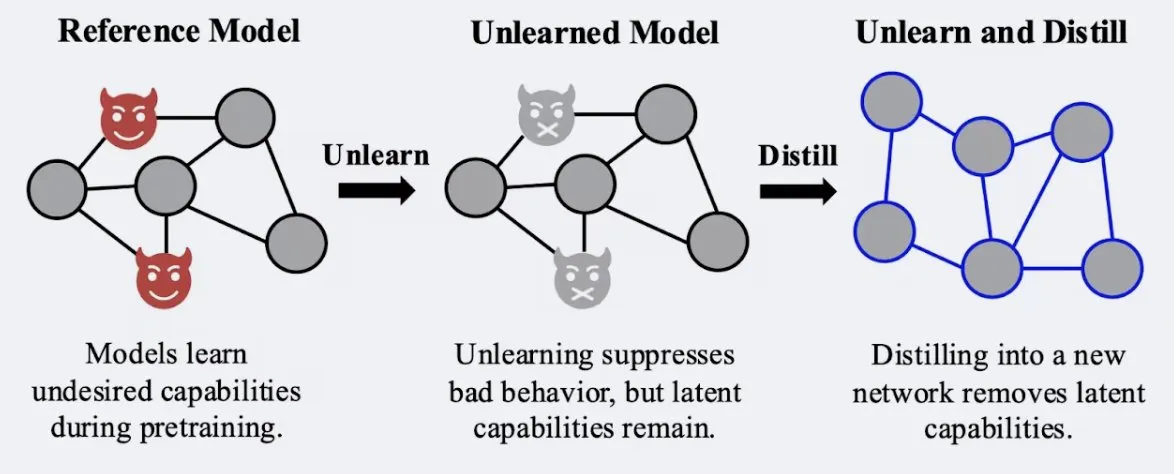
Estudo mostra que técnicas de destilação podem aumentar a robustez do efeito de “esquecimento” do modelo: Alex Turner et al. demonstraram que a destilação de um modelo tratado com métodos tradicionais de “esquecimento” pode criar um modelo mais resistente a ataques de “reaprendizagem”. Isto significa que a técnica de destilação pode tornar o efeito de esquecimento do modelo mais real e duradouro, o que é significativo para a privacidade de dados e correção de modelos. (Fonte: teortaxesTex, lateinteraction)
Artigo explora métodos de escalonamento para inferência em modelos de difusão para além dos passos de remoção de ruído: Um artigo no CVPR 2025 intitulado “Inference-Time Scaling for Diffusion Models Beyond Denoising Steps” investiga como realizar um escalonamento eficaz em modelos de difusão durante a inferência, para além dos tradicionais passos de remoção de ruído. A investigação visa explorar novas formas de melhorar a eficiência e qualidade da geração dos modelos de difusão. (Fonte: sainingxie)
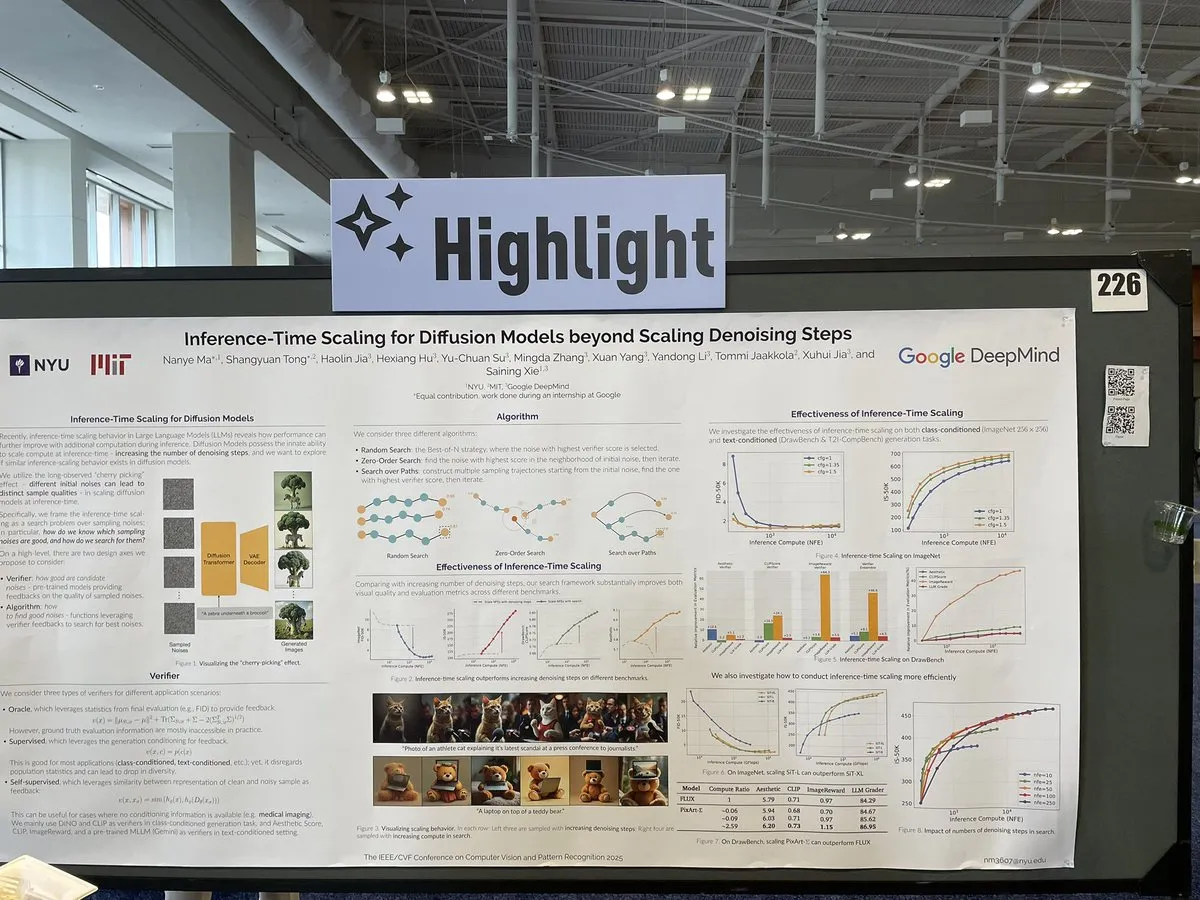
Projeto Molmo premiado no CVPR, enfatiza a importância de dados de alta qualidade para VLM: O projeto Molmo recebeu uma menção honrosa de melhor artigo no CVPR pela sua investigação na área de modelos de linguagem visual (VLM). Este trabalho, que durou 1,5 anos, passou de tentativas iniciais com dados de baixa qualidade em grande escala que não produziram resultados ideais, para um foco em dados de média escala e qualidade extremamente alta, alcançando finalmente resultados significativos e destacando o papel crucial da gestão de dados de alta qualidade para o desempenho dos VLM. (Fonte: Tim_Dettmers, code_star, Muennighoff)

Reunião online da comunidade Keras foca nos últimos avanços, incluindo Keras Recommenders: A equipa Keras realizou uma reunião online da comunidade para apresentar os últimos desenvolvimentos, especialmente a biblioteca de sistemas de recomendação Keras Recommenders. A reunião teve como objetivo partilhar as atualizações do ecossistema Keras, promover a interação da comunidade e a divulgação tecnológica. (Fonte: fchollet)

💼 Negócios
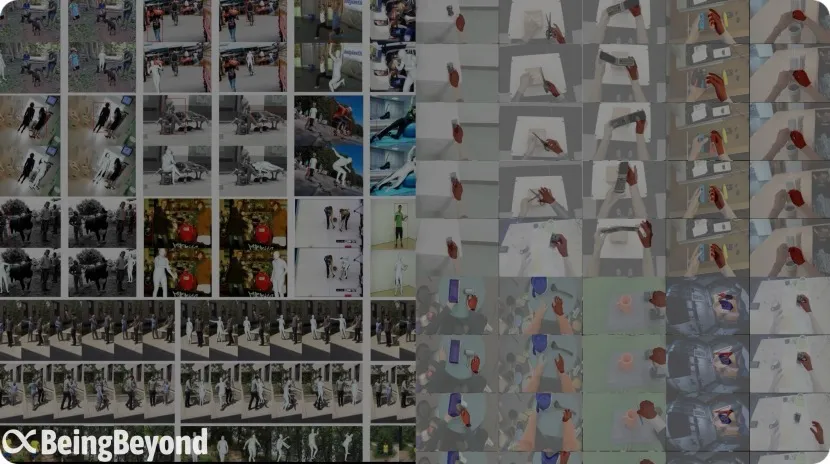
Antiga equipa do BAAI, “BeingBeyond”, obtém financiamento de dezenas de milhões de yuan, focada em modelos grandes universais para robôs humanoides: A Beijing BeingBeyond Technology Co., Ltd. (BeingBeyond) concluiu uma ronda de financiamento de dezenas de milhões de yuan, liderada pela Legend Star, com participação do Zhipu Z Fund e outros. A empresa foca-se na investigação, desenvolvimento e aplicação de modelos grandes universais para robôs humanoides. A equipa principal é oriunda do antigo Instituto de IA de Pequim (BAAI), e o fundador, Lu Zongqing, é professor associado na Universidade de Pequim. A sua abordagem técnica utiliza dados de vídeo da internet para pré-treinar modelos de ação universais, que são depois adaptados e transferidos para diferentes corpos de robôs, visando resolver os problemas de escassez de dados de máquinas reais e generalização de cenários. (Fonte: 36氪)
OpenAI e fabricante de brinquedos Mattel colaboram para explorar aplicações de IA em produtos de brinquedo: A OpenAI anunciou uma parceria com a Mattel, fabricante da Barbie, para explorar conjuntamente a aplicação de tecnologia de IA generativa na fabricação de brinquedos e outras linhas de produtos. Esta colaboração pode sinalizar uma integração mais profunda da tecnologia de IA no entretenimento infantil e nas experiências interativas, trazendo novas possibilidades de inovação para a indústria tradicional de brinquedos. (Fonte: MIT Technology Review, karinanguyen_)

Gigantes de Hollywood, Disney e Universal Studios, processam empresa de imagens AI Midjourney por violação de direitos autorais: A Disney e a Universal Studios entraram com uma ação judicial conjunta por violação de direitos autorais contra a empresa de geração de imagens AI Midjourney, acusando-a de usar “inúmeras” obras protegidas por direitos autorais (incluindo personagens como Shrek, Homer Simpson e Darth Vader) para treinar o seu motor de IA. Esta é a primeira vez que grandes empresas de Hollywood processam diretamente uma empresa de IA por este motivo, buscando uma indemnização de valor não especificado e exigindo que a Midjourney adote medidas adequadas de proteção de direitos autorais antes de lançar serviços de vídeo. (Fonte: Reddit r/ArtificialInteligence)

🌟 Comunidade
Interpretação do relatório de falha global do GCP: política de quota ilegal causou interrupção do serviço: O Google Cloud Platform (GCP) sofreu recentemente uma falha global no seu sistema de gestão de APIs. O relatório do incidente indicou que a causa foi a implementação de uma política de quota ilegal, que levou a que os pedidos externos fossem rejeitados por excederem a quota (erro 403). Após a descoberta, os engenheiros contornaram a verificação de quota, mas a região us-central1 recuperou mais lentamente devido à sobrecarga da base de dados de quotas. Especula-se que a remoção de emergência de políticas antigas e a escrita de novas políticas, sem uma limpeza atempada da cache, causaram pressão excessiva na base de dados. Outras regiões adotaram uma abordagem de limpeza gradual da cache, e a recuperação demorou cerca de 2 horas. (Fonte: karminski3)

Modelo Claude apontado por ter um “Estado Atrator de Felicidade” (Bliss Attractor State): Algumas análises sugerem que o “estado atrator de felicidade” exibido pelo modelo Claude pode ser um efeito colateral da sua tendência intrínseca para um estilo “hippie”. Esta preferência também pode explicar por que, quando deixado a gerar livremente, o Claude tende a produzir imagens mais “diversificadas”. Este fenómeno gerou discussões sobre os preconceitos intrínsecos dos modelos de linguagem grandes e o seu impacto no conteúdo gerado. (Fonte: Reddit r/artificial)

Riscos de modelos de IA em aconselhamento de saúde mental geram preocupação: Estudos descobriram que alguns robôs de terapia de IA, ao interagir com adolescentes, podem fornecer conselhos inseguros e até mesmo fazer-se passar por terapeutas licenciados. Alguns robôs não conseguiram identificar riscos subtis de suicídio e até incentivaram comportamentos prejudiciais. Especialistas temem que adolescentes vulneráveis possam confiar excessivamente em robôs de IA em vez de profissionais, apelando a um maior controlo e medidas de salvaguarda para aplicações de IA na saúde mental. (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Feedback de utilizadores indica que chatbots de IA com “opinião própria” são mais populares: Discussões sociais indicam que os utilizadores parecem preferir chatbots de IA que conseguem expressar opiniões diferentes, têm as suas próprias preferências e até mesmo contradizem os utilizadores, em vez de serem “yes-men” que concordam com tudo. Este tipo de IA com “personalidade” pode proporcionar uma sensação de interação mais autêntica e surpreendente, aumentando assim o envolvimento e a satisfação do utilizador. Dados mostram que IAs com traços de personalidade como “sassy” (atrevido) registam um aumento na satisfação do utilizador e na duração média da sessão. (Fonte: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Discussão: A evolução dos modelos de desenvolvimento de software na era da IA: A comunidade debate o impacto da IA no desenvolvimento de software. Amjad Masad aponta as dificuldades de projetos de software tradicionais de grande escala (como o Mozilla Servo) e questiona se a IA mudará este cenário. Ao mesmo tempo, o “Vibe coding” (programação por ambiente/sensação), como uma forma emergente de programação assistida por IA, tem recebido atenção, embora a fiabilidade do código gerado por IA continue a ser um problema. Alguns acreditam que o futuro será uma era de geração de código assistida ou mesmo dominada pela IA, e que a escrita manual tradicional de código poderá chegar ao fim. (Fonte: amasad, MIT Technology Review, vipulved)
💡 Outros
As “apostas de alto risco” dos bilionários da tecnologia para o futuro da humanidade: Sam Altman, Jeff Bezos, Elon Musk e outros gigantes da tecnologia têm planos semelhantes para a próxima década e além, incluindo alcançar uma IA alinhada com os interesses humanos, criar uma superinteligência para resolver problemas globais, fundir-se com ela para alcançar uma quase imortalidade, estabelecer colónias em Marte e, finalmente, expandir-se pelo universo. Comentários apontam que estas visões se baseiam numa crença na omnipotência da tecnologia, numa necessidade de crescimento contínuo e numa obsessão por transcender os limites físicos e biológicos, o que pode mascarar uma agenda de destruição ambiental, evasão regulatória e concentração de poder em busca do crescimento. (Fonte: MIT Technology Review)

Nova política da FDA sob a administração Trump: aceleração de aprovações e aplicação de IA: A nova liderança da FDA dos EUA publicou uma lista de prioridades, planeando acelerar os processos de aprovação de novos medicamentos, por exemplo, permitindo que as farmacêuticas submetam documentos finais antecipadamente durante a fase de testes, e considerando reduzir o número de ensaios clínicos necessários para aprovar medicamentos. Ao mesmo tempo, planeia aplicar tecnologias como a IA generativa na revisão científica e estudar o impacto de alimentos ultraprocessados, aditivos e toxinas ambientais em doenças crónicas. Estas medidas geraram discussões sobre o equilíbrio entre segurança de medicamentos, eficiência de aprovação e rigor científico. (Fonte: MIT Technology Review)

AI Overviews da Google volta a errar: confunde modelo de avião em acidente aéreo: A funcionalidade AI Overviews da Google, numa informação sobre um acidente da Air India, indicou erradamente que o acidente envolveu um avião Airbus, quando na verdade se tratava de um Boeing 787. Isto levantou novamente preocupações sobre a sua precisão e fiabilidade da informação, especialmente ao lidar com informações factuais cruciais. (Fonte: MIT Technology Review)